32 KiB
Pentesting Kubernetes
The original author of this page is Jorge (read his original post here)
Architecture & Basics
What does Kubernetes do?
- Allows running container/s in a container engine.
- Schedule allows containers mission efficient.
- Keep containers alive.
- Allows container communications.
- Allows deployment techniques.
- Handle volumes of information.
Architecture
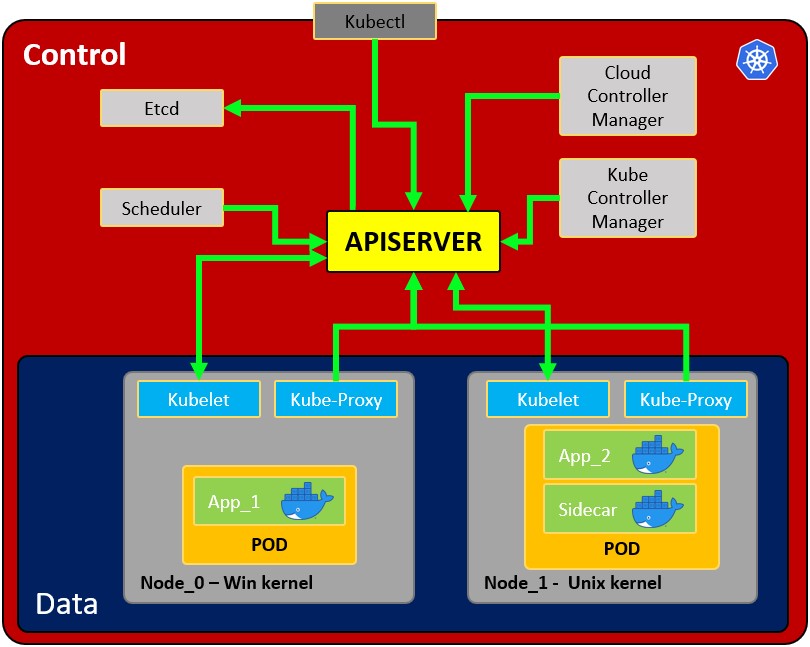
- Node: operating system with pod or pods.
- Pod: Wrapper around a container or multiple containers with. A pod should only contain one application
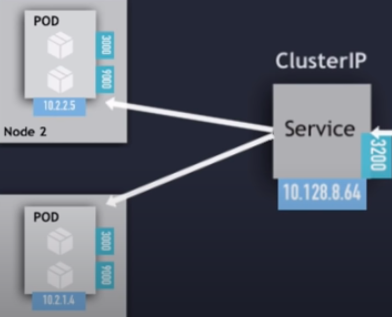
so usually, a pod run just 1 container. The pod is the way kubernetes abstracts the container technology running.- Service: Each pod has 1 internal IP address from the internal range of the node. However, it can be also exposed via a service. The service has also an IP address and its goal is to maintain the communication between pods so if one dies the new replacement
with a different internal IPwill be accessible exposed in the same IP of the service. It can be configured as internal or external. The service also actuates as a load balancer when 2 pods are connected to the same service. When a service is created you can find the endpoints of each service runningkubectl get endpoints
- Service: Each pod has 1 internal IP address from the internal range of the node. However, it can be also exposed via a service. The service has also an IP address and its goal is to maintain the communication between pods so if one dies the new replacement
- Pod: Wrapper around a container or multiple containers with. A pod should only contain one application
- Kubelet: Primary node agent. The component that establishes communication between node and kubectl, and only can run pods
through API server. The kubelet doesn’t manage containers that were not created by Kubernetes. - Kube-proxy: is the service in charge of the communications
servicesbetween the apiserver and the node. The base is an IPtables for nodes. Most experienced users could install other kube-proxies from other vendors. - Sidecar container: Sidecar containers are the containers that should run along with the main container in the pod. This sidecar pattern extends and enhances the functionality of current containers without changing them. Nowadays, We know that we use container technology to wrap all the dependencies for the application to run anywhere. A container does only one thing and does that thing very well.
- Master process:
- Api Server: Is the way the users and the pods use to communicate with the master process. Only authenticated request should be allowed.
- Scheduler: Scheduling refers to making sure that Pods are matched to Nodes so that Kubelet can run them. It has enough intelligence to decide which node has more available resources the assign the new pod to it. Note that the scheduler doesn't start new pods, it just communicate with the Kubelet process running inside the node, which will launch the new pod.
- Kube Controller manager: It checks resources like replica sets or deployments to check if, for example, the correct number of pods or nodes are running. In case a pod is missing, it will communicate with the scheduler to start a new one. It controls replication, tokens, and account services to the API.
- etcd: Data storage, persistent, consistent, and distributed. Is Kubernetes’s database and the key-value storage where it keeps the complete state of the clusters
each change is logged here. Components like the Scheduler or the Controller manager depends on this date to know which changes have occurredavailable resourced of the nodes, number of pods running...
- Cloud controller manager: Is the specific controller for flow controls and applications, i.e: if you have clusters in AWS or OpenStack.
Note that as the might be several nodes running several pods, there might also be several master processes which their access to the Api server load balanced and their etcd synchronized.
Volumes:
When a pod creates data that shouldn't be lost when the pod disappear it should be stored in a physical volume. Kubernetes allow to attach a volume to a pod to persist the data. The volume can be in the local machine or in a remote storage. If you are running pods in different physical nodes you should use a remote storage so all the pods can access it.
Other configurations:
- ConfigMap: You can configure URLs to access services. The pod will obtain data from here to know how to communicate with the rest of the services
pods. Note that this is not the recommended place to save credentials! - Secret: This is the place to store secret data like passwords, API keys... encoded in B64. The pod will be able to access this data to use the required credentials.
- Deployments: This is where the components to be run by kubernetes are indicated. A user usually won't work directly with pods, pods are abstracted in ReplicaSets
number of same pods replicated, which are run via deployments. Note that deployments are for stateless applications. The minimum configuration for a deployment is the name and the image to run. - StatefulSet: This component is meant specifically for applications like databases which needs to access the same storage.
- Ingress: This is the configuration that is use to expose the application publicly with an URL. Note that this can also be done using external services, but this is the correct way to expose the application.
- If you implement an Ingress you will need to create Ingress Controllers. The Ingress Controller is a pod that will be the endpoint that will receive the requests and check and will load balance them to the services. the ingress controller will send the request based on the ingress rules configured. Note that the ingress rules can point to different paths or even subdomains to different internal kubernetes services.
- A better security practice would be to use a cloud load balancer or a proxy server as entrypoint to don't have any part of the Kubernetes cluster exposed.
- When request that doesn't match any ingress rule is received, the ingress controller will direct it to the "Default backend". You can
describethe ingress controller to get the address of this parameter. minikube addons enable ingress
- If you implement an Ingress you will need to create Ingress Controllers. The Ingress Controller is a pod that will be the endpoint that will receive the requests and check and will load balance them to the services. the ingress controller will send the request based on the ingress rules configured. Note that the ingress rules can point to different paths or even subdomains to different internal kubernetes services.
PKI infrastructure - Certificate Authority CA:
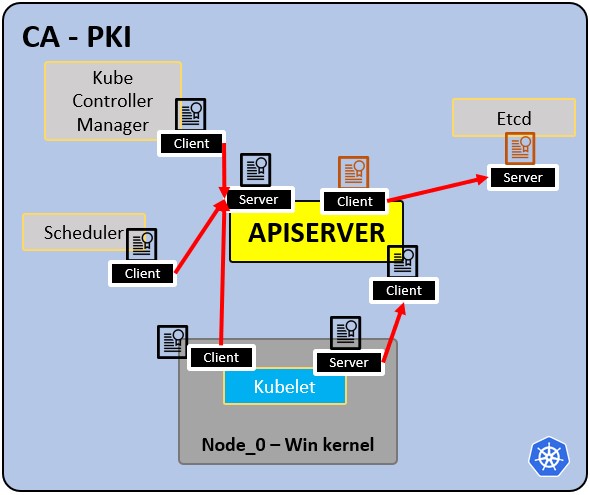
- CA is the trusted root for all certificates inside the cluster.
- Allows components to validate to each other.
- All cluster certificates are signed by the CA.
- ETCd has its own certificate.
- types:
- apiserver cert.
- kubelet cert.
- scheduler cert.
Minikube
Minikube can be used to perform some quick tests on kubernetes without needing to deploy a whole kubernetes environment. It will run the master and node processes in one machine. Minikube will use virtualbox to run the node. See here how to install it.
$ minikube start
😄 minikube v1.19.0 on Ubuntu 20.04
✨ Automatically selected the virtualbox driver. Other choices: none, ssh
💿 Downloading VM boot image ...
> minikube-v1.19.0.iso.sha256: 65 B / 65 B [-------------] 100.00% ? p/s 0s
> minikube-v1.19.0.iso: 244.49 MiB / 244.49 MiB 100.00% 1.78 MiB p/s 2m17.
👍 Starting control plane node minikube in cluster minikube
💾 Downloading Kubernetes v1.20.2 preload ...
> preloaded-images-k8s-v10-v1...: 491.71 MiB / 491.71 MiB 100.00% 2.59 MiB
🔥 Creating virtualbox VM (CPUs=2, Memory=3900MB, Disk=20000MB) ...
🐳 Preparing Kubernetes v1.20.2 on Docker 20.10.4 ...
▪ Generating certificates and keys ...
▪ Booting up control plane ...
▪ Configuring RBAC rules ...
🔎 Verifying Kubernetes components...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 Enabled addons: storage-provisioner, default-storageclass
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by defaul
$ minikube status
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
---- ONCE YOU HAVE A K8 SERVICE RUNNING WITH AN EXTERNAL SERVICE -----
$ minikube service mongo-express-service
(This will open your browser to access the service exposed port)
$ minikube delete
🔥 Deleting "minikube" in virtualbox ...
💀 Removed all traces of the "minikube" cluster
Kubectl Basics
Kubectl is the command line tool fro kubernetes clusters. It communicates with the Api server of the master process to perform actions in kubernetes or to ask for data.
kubectl version #Get client and server version
kubectl get pod
kubectl get services
kubectl get deployment
kubectl get replicaset
kubectl get secret
kubectl get all
kubectl get ingress
kubectl get endpoints
#kubectl create deployment <deployment-name> --image=<docker image>
kubectl create deployment nginx-deployment --image=nginx
#Access the configuration of the deployment and modify it
#kubectl edit deployment <deployment-name>
kubectl edit deployment nginx-deployment
#Get the logs of the pod for debbugging (the output of the docker container running)
#kubectl logs <replicaset-id/pod-id>
kubectl logs nginx-deployment-84cd76b964
#kubectl describe pod <pod-id>
kubectl describe pod mongo-depl-5fd6b7d4b4-kkt9q
#kubectl exec -it <pod-id> -- bash
kubectl exec -it mongo-depl-5fd6b7d4b4-kkt9q -- bash
#kubectl describe service <service-name>
kubectl describe service mongodb-service
#kubectl delete deployment <deployment-name>
kubectl delete deployment mongo-depl
#Deploy from config file
kubectl apply -f deployment.yml
YAML configuration files examples
Each configuration file has 3 parts: metadata, specification what need to be launch, status desired state.
Inside the specification of the deployment configuration file you can find the template defined with a new configuration structure defining the image to run:

Example of Deployment + Service declared in the same configuration file from [here](https://gitlab.com/nanuchi/youtube-tutorial-series/-/blob/master/demo-kubernetes-components/mongo.yaml)
As a service usually is related to one deployment it's possible to declare both in the same configuration file the service declared in this config is only accessible internally:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongodb-deployment
labels:
app: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb
image: mongo
ports:
- containerPort: 27017
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongodb-secret
key: mongo-root-password
---
apiVersion: v1
kind: Service
metadata:
name: mongodb-service
spec:
selector:
app: mongodb
ports:
- protocol: TCP
port: 27017
targetPort: 27017
Example of external service config
This service will be accessible externally check the `nodePort` and `type: LoadBlancer` attributes:
---
apiVersion: v1
kind: Service
metadata:
name: mongo-express-service
spec:
selector:
app: mongo-express
type: LoadBalancer
ports:
- protocol: TCP
port: 8081
targetPort: 8081
nodePort: 30000
{% hint style="info" %} This is useful for testing but for production you should have only internal services and an Ingress to expose the application. {% endhint %}
Example of Ingress config file
This will expose the application in http://dashboard.com.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
spec:
rules:
- host: dashboard.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80
Example of secrets config file
Note how the password are encoded in B64 which isn't secure!
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
mongo-root-username: dXNlcm5hbWU=
mongo-root-password: cGFzc3dvcmQ=
Example of ConfigMap
A ConfigMap is the configuration that is given to the pods so they know how to locate and access other services. In this case, each pod will know that the name mongodb-service is the address of a pod that they can communicate with this pod will be executing a mongodb:
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
data:
database_url: mongodb-service
Then, inside a deployment config this address can be specified in the following way so it's loaded inside the env of the pod:
[...]
spec:
[...]
template:
[...]
spec:
containers:
- name: mongo-express
image: mongo-express
ports:
- containerPort: 8081
env:
- name: ME_CONFIG_MONGODB_SERVER
valueFrom:
configMapKeyRef:
name: mongodb-configmap
key: database_url
[...]
Example of volume config
You can find different example of storage configuration yaml files in https://gitlab.com/nanuchi/youtube-tutorial-series/-/tree/master/kubernetes-volumes.
Note that volumes aren't inside namespaces
Namespaces
Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces. These are intended for use in environments with many users spread across multiple teams, or projects. For clusters with a few to tens of users, you should not need to create or think about namespaces at all. You only should start using namespaces to have a better control and organization of each part of the application deployed in kubernetes.
Namespaces provide a scope for names. Names of resources need to be unique within a namespace, but not across namespaces. Namespaces cannot be nested inside one another and each Kubernetes resource can only be in one namespace.
There are 4 namespaces by default if you are using minikube:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-public Active 1d
kube-system Active 1d
- kube-system: It's not meant or the users use and you shouldn't touch it. It's for master and kubectl processes.
- kube-public: Publicly accessible date. Contains a configmap which contains cluster information
- kube-node-lease: Determines the availability of a node
- default: The namespace the user will use to create resources
#Create namespace
kubectl create namespace my-namespace
{% hint style="info" %}
Note that most Kubernetes resources e.g. pods, services, replication controllers, and others are in some namespaces. However, other resources like namespace resources and low-level resources, such as nodes and persistenVolumes are not in a namespace. To see which Kubernetes resources are and aren’t in a namespace:
kubectl api-resources --namespaced=true #In a namespace
kubectl api-resources --namespaced=false #Not in a namespace
{% endhint %}
You can save the namespace for all subsequent kubectl commands in that context.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
Helm
Helm is the package manager for Kubernetes. It allows to package YAML files and distribute them in public and private repositories. These packages are called Helm Charts.
helm search <keyword>
Helm is also a template engine that allows to generate config files with variables:

Pentesting Kubernetes from the outside
{% page-ref page="pentesting-kubernetes-from-the-outside.md" %}
Vulnerabilities and misconfigurations
Enumeration inside a Pod
If you manage to compromise a Pod read the following page to learn how to enumerate and try to escalate privileges/escape:
{% page-ref page="enumeration-from-a-pod.md" %}
Kubernetes secrets
A Secret is an object that contains sensitive data such as a password, a token or a key. Such information might otherwise be put in a Pod specification or in an image. Users can create Secrets and the system also creates Secrets. The name of a Secret object must be a valid DNS subdomain name. Read here the official documentation.
Secrets might be things like:
- API, SSH Keys.
- OAuth tokens.
- Credentials, Passwords
plain text or b64 + encryption. - Information or comments.
- Database connection code, strings… .
There are different types of secrets in Kubernetes
| Builtin Type | Usage |
|---|---|
| Opaque | arbitrary user-defined data (Default) |
| kubernetes.io/service-account-token | service account token |
| kubernetes.io/dockercfg | serialized ~/.dockercfg file |
| kubernetes.io/dockerconfigjson | serialized ~/.docker/config.json file |
| kubernetes.io/basic-auth | credentials for basic authentication |
| kubernetes.io/ssh-auth | credentials for SSH authentication |
| kubernetes.io/tls | data for a TLS client or server |
| bootstrap.kubernetes.io/token | bootstrap token data |
{% hint style="info" %} The Opaque type is the default one, the typical key-value pair defined by users. {% endhint %}
How secrets works:
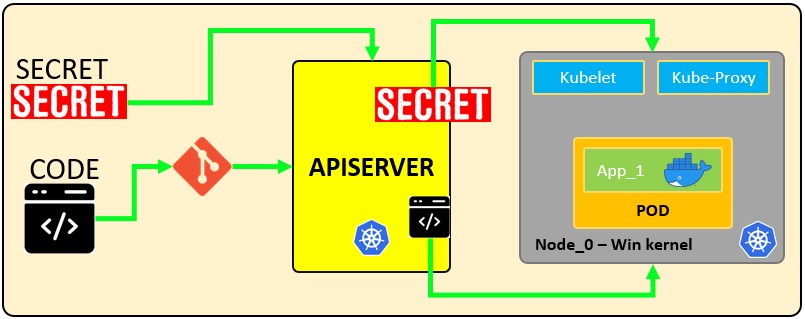
The following configuration file defines a secret called mysecret with 2 key-value pairs username: YWRtaW4= and password: MWYyZDFlMmU2N2Rm. It also defines a pod called secretpod that will have the username and password defined in mysecret exposed in the environment variables SECRET_USERNAME __and __SECRET_PASSWOR. It will also mount the username secret inside mysecret in the path /etc/foo/my-group/my-username with 0640 permissions.
{% code title="secretpod.yaml" %}
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
---
apiVersion: v1
kind: Pod
metadata:
name: secretpod
spec:
containers:
- name: secretpod
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
volumeMounts:
- name: foo
mountPath: "/etc/foo"
restartPolicy: Never
volumes:
- name: foo
secret:
secretName: mysecret
items:
- key: username
path: my-group/my-username
mode: 0640
{% endcode %}
kubectl apply -f <secretpod.yaml>
kubectl get pods #Wait until the pod secretpod is running
kubectl exec -it secretpod -- bash
env | grep SECRET && cat /etc/foo/my-group/my-username && echo
Secrets in etcd
etcd is a consistent and highly-available key-value store used as Kubernetes backing store for all cluster data. Let’s access to the secrets stored in etcd:
cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
You will see certs, keys and url’s were are located in the FS. Once you get it, you would be able to connect to etcd.
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] health
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] health
Once you achieve establish communication you would be able to get the secrets:
#ETCDCTL_API=3 etcdctl --cert <path to client.crt> --key <path to client.ket> --cacert <path to CA.cert> endpoint=[<ip:port>] get <path/to/secret>
ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/etcd/ca.cert endpoint=[127.0.0.1:1234] get /registry/secrets/default/secret_02
Adding encryption to the ETCD
By default all the secrets are stored in plain text inside etcd unless you apply an encryption layer. The following example is based on https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
{% code title="encryption.yaml" %}
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: cjjPMcWpTPKhAdieVtd+KhG4NN+N6e3NmBPMXJvbfrY= #Any random key
- identity: {}
{% endcode %}
After that, you need to set the --encryption-provider-config flag on the kube-apiserver to point to the location of the created config file. You can modify /etc/kubernetes/manifest/kube-apiserver.yaml and add the following lines:
containers:
- command:
- kube-apiserver
- --encriyption-provider-config=/etc/kubernetes/etcd/<configFile.yaml>
Scroll down in the volumeMounts:
- mountPath: /etc/kubernetes/etcd
name: etcd
readOnly: true
Scroll down in the volumeMounts to hostPath:
- hostPath:
path: /etc/kubernetes/etcd
type: DirectoryOrCreate
name: etcd
Verifying that data is encrypted
Data is encrypted when written to etcd. After restarting your kube-apiserver, any newly created or updated secret should be encrypted when stored. To check, you can use the etcdctl command line program to retrieve the contents of your secret.
-
Create a new secret called
secret1in thedefaultnamespace:kubectl create secret generic secret1 -n default --from-literal=mykey=mydata -
Using the etcdctl commandline, read that secret out of etcd:
ETCDCTL_API=3 etcdctl get /registry/secrets/default/secret1 [...] | hexdump -Cwhere
[...]must be the additional arguments for connecting to the etcd server. -
Verify the stored secret is prefixed with
k8s:enc:aescbc:v1:which indicates theaescbcprovider has encrypted the resulting data. -
Verify the secret is correctly decrypted when retrieved via the API:
kubectl describe secret secret1 -n defaultshould match
mykey: bXlkYXRh, mydata is encoded, check decoding a secret to completely decode the secret.
Since secrets are encrypted on write, performing an update on a secret will encrypt that content:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
Final tips:
- Try not to keep secrets in the FS, get them from other places.
- Check out https://www.vaultproject.io/ for add more protection to your secrets.
- https://kubernetes.io/docs/concepts/configuration/secret/#risks
- https://docs.cyberark.com/Product-Doc/OnlineHelp/AAM-DAP/11.2/en/Content/Integrations/Kubernetes_deployApplicationsConjur-k8s-Secrets.htm
RBAC Hardening
Kubernetes has an authorization module named Role-Based Access Control [**RBAC**](https://kubernetes.io/docs/reference/access-authn-authz/rbac/) that helps to set utilization permissions to the API server.
The RBAC table is constructed from “Roles” and “ClusterRoles.” The difference between them is just where the role will be applied – a “Role” will grant access to only one specific namespace, while a “ClusterRole” can be used in all namespaces in the cluster. Moreover, ClusterRoles can also grant access to:
- cluster-scoped resources
like nodes. - non-resource endpoints
like /healthz. - namespaced resources
like Pods, across all namespaces.
Example of Role configuration:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: defaultGreen
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list", "watch"]
Example of ClusterRole configuration:
For example you can use a ClusterRole to allow a particular user to run:
kubectl get pods --all-namespaces
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
Role and ClusterRole Binding concept
A role binding grants the permissions defined in a role to a user or set of users. It holds a list of subjects users, groups, or service accounts, and a reference to the role being granted. A RoleBinding grants permissions within a specific namespace whereas a ClusterRoleBinding grants that access cluster-wide.
RoleBinding example:
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows "jane" to read pods in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# You can specify more than one "subject"
- kind: User
name: jane # "name" is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role #this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io
ClusterRoleBinding example:
apiVersion: rbac.authorization.k8s.io/v1
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager # Name is case sensitive
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
Permissions are additive so if you have a clusterRole with “list” and “delete” secrets you can add it with a Role with “get”. So be aware and test always your roles and permissions and specify what is ALLOWED, because everything is DENIED by default.
RBAC Structure
RBAC’s permission is built from three individual parts:
- Role\ClusterRole – The actual permission. It contains rules that represent a set of permissions. Each rule contains resources and verbs. The verb is the action that will apply on the resource.
- Subject
User, Group or ServiceAccount– The object that will receive the permissions. - RoleBinding\ClusterRoleBinding – The connection between Role\ClusterRole and the subject.
This is what it will look like in a real cluster:
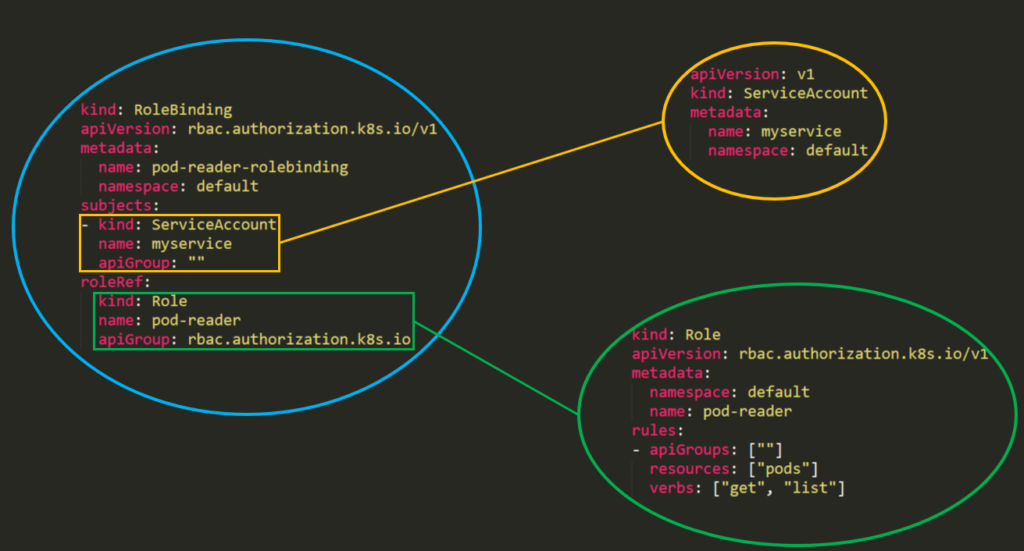
“Fine-grained role bindings provide greater security, but require more effort to administrate."
From Kubernetes 1.6 onwards, RBAC policies are enabled by default. ****But to enable RBAC you can use something like:
kube-apiserver --authorization-mode=Example,RBAC --other-options --more-options
This is enabled by default. RBAC functions:
- Restrict the access to the resources to users or ServiceAccounts.
- An RBAC Role or ClusterRole contains rules that represent a set of permissions.
- Permissions are purely additive
there are no “deny” rules. - RBAC works with Roles and Bindings
{% hint style="info" %} When configuring roles and permissions it's highly important to always follow the principle of Least Privileges {% endhint %}
Service Accounts Hardening
To learn about Service Accounts Hardenig read the page:
{% page-ref page="enumeration-from-a-pod.md" %}
Kubernetes API Hardening
It's very important to protect the access to the Kubernetes Api Server as a malicious actor with enough privileges could be able to abuse it and damage in a lot of way the environment.
It's important to secure both the access **whitelist** origins to access the API Server and deny any otehr connection and the authentication following the principle of **least** **privilege**. And definitely never allow anonymous requests.
Common Request process:
User or K8s ServiceAccount –> Authentication –> Authorization –> Admission Control.
Tips:
- Close ports.
- Avoid Anonymous access.
- NodeRestriction; No access from specific nodes to the API.
- https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#noderestriction
- Basically prevents kubelets from adding/removing/updating labels with a node-restriction.kubernetes.io/ prefix. This label prefix is reserved for administrators to label their Node objects for workload isolation purposes, and kubelets will not be allowed to modify labels with that prefix.
- And also, allows kubelets to add/remove/update these labels and label prefixes.
- Ensure with labels the secure workload isolation.
- Avoid specific pods from API access.
- Avoid ApiServer exposure to the internet.
- Avoid unauthorized access RBAC.
- ApiServer port with firewall and IP whitelisting.
SecurityContext Hardening
By default root user will be used when a Pod is started if no other user is specified. You can run your application inside a more secure context using a template similar to the following one:
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumes:
- name: sec-ctx-vol
emptyDir: {}
containers:
- name: sec-ctx-demo
image: busybox
command: [ "sh", "-c", "sleep 1h" ]
securityContext:
runAsNonRoot: true
volumeMounts:
- name: sec-ctx-vol
mountPath: /data/demo
securityContext:
allowPrivilegeEscalation: true
- https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
- https://kubernetes.io/docs/concepts/policy/pod-security-policy/
General Hardening
You should update your Kubernetes environment as frequently as necessary to have:
- Dependencies up to date.
- Bug and security patches.
****Release cycles: Each 3 months there is a new minor release -- 1.20.3 = 1(Major).20(Minor).3(patch)
The best way to update a Kubernetes Cluster is from** [**here**](https://kubernetes.io/docs/tasks/administer-cluster/cluster-upgrade/)**:
- Upgrade the Master Node components following this sequence:
- etcd
all instances. - kube-apiserver
all control plane hosts. - kube-controller-manager.
- kube-scheduler.
- cloud controller manager, if you use one.
- etcd
- Upgrade the Worker Node components such as kube-proxy, kubelet.
References
{% embed url="https://sickrov.github.io/" %}
{% embed url="https://www.youtube.com/watch?v=X48VuDVv0do" %}