19 KiB
4. Mecanismos de Atenção
Mecanismos de Atenção e Auto-Atenção em Redes Neurais
Os mecanismos de atenção permitem que redes neurais focalizem partes específicas da entrada ao gerar cada parte da saída. Eles atribuem pesos diferentes a diferentes entradas, ajudando o modelo a decidir quais entradas são mais relevantes para a tarefa em questão. Isso é crucial em tarefas como tradução automática, onde entender o contexto de toda a frase é necessário para uma tradução precisa.
{% hint style="success" %}
O objetivo desta quarta fase é muito simples: Aplicar alguns mecanismos de atenção. Estes serão muitos níveis repetidos que vão capturar a relação de uma palavra no vocabulário com seus vizinhos na frase atual sendo usada para treinar o LLM.
Muitos níveis são usados para isso, então muitos parâmetros treináveis vão capturar essas informações.
{% endhint %}
Entendendo os Mecanismos de Atenção
Em modelos tradicionais de sequência para sequência usados para tradução de idiomas, o modelo codifica uma sequência de entrada em um vetor de contexto de tamanho fixo. No entanto, essa abordagem tem dificuldades com frases longas porque o vetor de contexto de tamanho fixo pode não capturar todas as informações necessárias. Os mecanismos de atenção abordam essa limitação permitindo que o modelo considere todos os tokens de entrada ao gerar cada token de saída.
Exemplo: Tradução Automática
Considere traduzir a frase em alemão "Kannst du mir helfen diesen Satz zu übersetzen" para o inglês. Uma tradução palavra por palavra não produziria uma frase em inglês gramaticalmente correta devido a diferenças nas estruturas gramaticais entre os idiomas. Um mecanismo de atenção permite que o modelo se concentre nas partes relevantes da frase de entrada ao gerar cada palavra da frase de saída, levando a uma tradução mais precisa e coerente.
Introdução à Auto-Atenção
A auto-atensão, ou intra-atensão, é um mecanismo onde a atenção é aplicada dentro de uma única sequência para calcular uma representação dessa sequência. Ela permite que cada token na sequência preste atenção a todos os outros tokens, ajudando o modelo a capturar dependências entre tokens, independentemente da distância entre eles na sequência.
Conceitos Chave
- Tokens: Elementos individuais da sequência de entrada (por exemplo, palavras em uma frase).
- Embeddings: Representações vetoriais de tokens, capturando informações semânticas.
- Pesos de Atenção: Valores que determinam a importância de cada token em relação aos outros.
Calculando Pesos de Atenção: Um Exemplo Passo a Passo
Vamos considerar a frase "Hello shiny sun!" e representar cada palavra com um embedding de 3 dimensões:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Nosso objetivo é calcular o vetor de contexto para a palavra "shiny" usando auto-atensão.
Passo 1: Calcular Pontuações de Atenção
{% hint style="success" %} Basta multiplicar cada valor de dimensão da consulta pelo correspondente de cada token e somar os resultados. Você obtém 1 valor por par de tokens. {% endhint %}
Para cada palavra na frase, calcule a pontuação de atenção em relação a "shiny" calculando o produto escalar de seus embeddings.
Pontuação de Atenção entre "Hello" e "shiny"

Pontuação de Atenção entre "shiny" e "shiny"

Pontuação de Atenção entre "sun" e "shiny"

Passo 2: Normalizar Pontuações de Atenção para Obter Pesos de Atenção
{% hint style="success" %} Não se perca nos termos matemáticos, o objetivo desta função é simples, normalizar todos os pesos para que eles somem 1 no total.
Além disso, a função softmax é usada porque acentua diferenças devido à parte exponencial, facilitando a detecção de valores úteis. {% endhint %}
Aplique a função softmax às pontuações de atenção para convertê-las em pesos de atenção que somam 1.
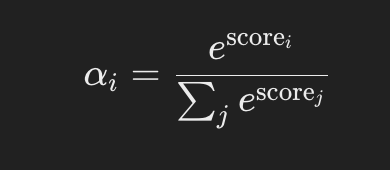
Calculando os exponenciais:

Calculando a soma:
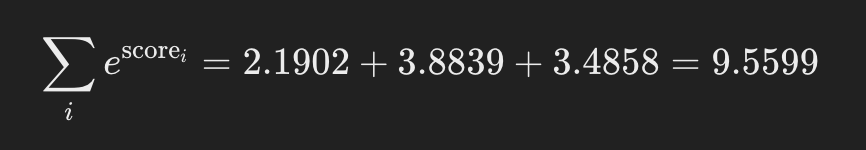
Calculando pesos de atenção:

Passo 3: Calcular o Vetor de Contexto
{% hint style="success" %} Basta pegar cada peso de atenção e multiplicá-lo pelas dimensões do token relacionado e, em seguida, somar todas as dimensões para obter apenas 1 vetor (o vetor de contexto) {% endhint %}
O vetor de contexto é calculado como a soma ponderada dos embeddings de todas as palavras, usando os pesos de atenção.
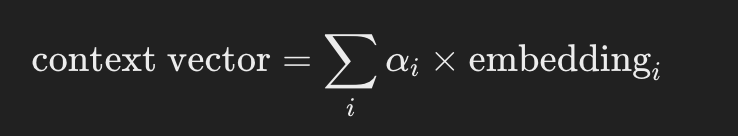
Calculando cada componente:
- Embedding Ponderado de "Hello":



Somando os embeddings ponderados:
context vector=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
Este vetor de contexto representa o embedding enriquecido para a palavra "shiny", incorporando informações de todas as palavras na frase.
Resumo do Processo
- Calcular Pontuações de Atenção: Use o produto escalar entre o embedding da palavra-alvo e os embeddings de todas as palavras na sequência.
- Normalizar Pontuações para Obter Pesos de Atenção: Aplique a função softmax às pontuações de atenção para obter pesos que somem 1.
- Calcular Vetor de Contexto: Multiplique o embedding de cada palavra pelo seu peso de atenção e some os resultados.
Auto-Atenção com Pesos Treináveis
Na prática, os mecanismos de auto-atensão usam pesos treináveis para aprender as melhores representações para consultas, chaves e valores. Isso envolve a introdução de três matrizes de peso:

A consulta é os dados a serem usados como antes, enquanto as matrizes de chaves e valores são apenas matrizes aleatórias e treináveis.
Passo 1: Calcular Consultas, Chaves e Valores
Cada token terá sua própria matriz de consulta, chave e valor multiplicando seus valores de dimensão pelas matrizes definidas:
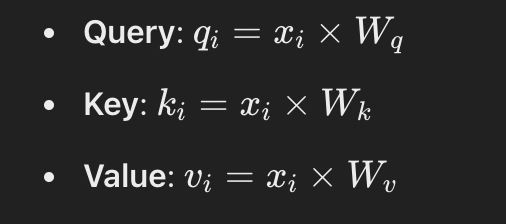
Essas matrizes transformam os embeddings originais em um novo espaço adequado para calcular a atenção.
Exemplo
Assumindo:
- Dimensão de entrada
din=3(tamanho do embedding) - Dimensão de saída
dout=2(dimensão desejada para consultas, chaves e valores)
Inicialize as matrizes de peso:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
Calcule consultas, chaves e valores:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Passo 2: Calcular Atenção de Produto Escalonado
Calcular Pontuações de Atenção
Semelhante ao exemplo anterior, mas desta vez, em vez de usar os valores das dimensões dos tokens, usamos a matriz de chave do token (já calculada usando as dimensões):. Assim, para cada consulta qi e chave kj:
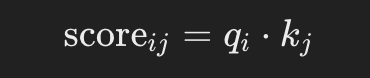
Escalonar as Pontuações
Para evitar que os produtos escalares se tornem muito grandes, escalone-os pela raiz quadrada da dimensão da chave dk:
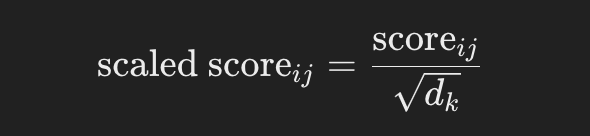
{% hint style="success" %} A pontuação é dividida pela raiz quadrada das dimensões porque os produtos escalares podem se tornar muito grandes e isso ajuda a regulá-los. {% endhint %}
Aplicar Softmax para Obter Pesos de Atenção: Como no exemplo inicial, normalize todos os valores para que somem 1.
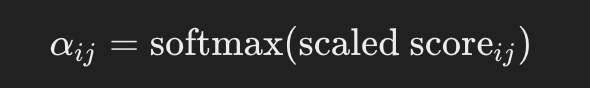
Passo 3: Calcular Vetores de Contexto
Como no exemplo inicial, basta somar todas as matrizes de valores multiplicando cada uma pelo seu peso de atenção:
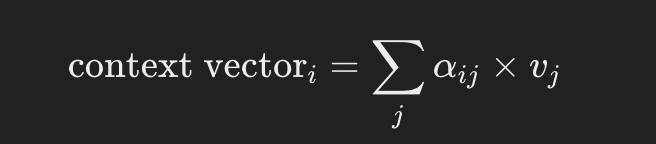
Exemplo de Código
Pegando um exemplo de https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb você pode conferir esta classe que implementa a funcionalidade de auto-atenção que discutimos:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
Observe que, em vez de inicializar as matrizes com valores aleatórios, nn.Linear é usado para marcar todos os pesos como parâmetros a serem treinados.
{% endhint %}
Atenção Causal: Ocultando Palavras Futuras
Para LLMs, queremos que o modelo considere apenas os tokens que aparecem antes da posição atual para prever o próximo token. Atenção causal, também conhecida como atenção mascarada, alcança isso modificando o mecanismo de atenção para impedir o acesso a tokens futuros.
Aplicando uma Máscara de Atenção Causal
Para implementar a atenção causal, aplicamos uma máscara aos scores de atenção antes da operação softmax para que os restantes ainda somem 1. Essa máscara define os scores de atenção dos tokens futuros como negativo infinito, garantindo que, após o softmax, seus pesos de atenção sejam zero.
Passos
- Calcular Scores de Atenção: Igual ao anterior.
- Aplicar Máscara: Use uma matriz triangular superior preenchida com negativo infinito acima da diagonal.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf')
masked_scores = attention_scores + mask
- Aplicar Softmax: Calcule os pesos de atenção usando os scores mascarados.
attention_weights = torch.softmax(masked_scores, dim=-1)
Mascarando Pesos de Atenção Adicionais com Dropout
Para prevenir overfitting, podemos aplicar dropout aos pesos de atenção após a operação softmax. O dropout zera aleatoriamente alguns dos pesos de atenção durante o treinamento.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
Um dropout regular é de cerca de 10-20%.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Estendendo a Atenção de Cabeça Única para Atenção de Múltiplas Cabeças
Atenção de múltiplas cabeças em termos práticos consiste em executar várias instâncias da função de autoatenção, cada uma com seus próprios pesos, de modo que vetores finais diferentes sejam calculados.
Exemplo de Código
Pode ser possível reutilizar o código anterior e apenas adicionar um wrapper que o execute várias vezes, mas esta é uma versão mais otimizada de https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb que processa todas as cabeças ao mesmo tempo (reduzindo o número de loops for caros). Como você pode ver no código, as dimensões de cada token são divididas em diferentes dimensões de acordo com o número de cabeças. Dessa forma, se o token tiver 8 dimensões e quisermos usar 3 cabeças, as dimensões serão divididas em 2 arrays de 4 dimensões e cada cabeça usará uma delas:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Para uma implementação compacta e eficiente, você pode usar a torch.nn.MultiheadAttention classe no PyTorch.
{% hint style="success" %} Resposta curta do ChatGPT sobre por que é melhor dividir as dimensões dos tokens entre as cabeças em vez de fazer com que cada cabeça verifique todas as dimensões de todos os tokens:
Embora permitir que cada cabeça processe todas as dimensões de embedding possa parecer vantajoso porque cada cabeça teria acesso a todas as informações, a prática padrão é dividir as dimensões de embedding entre as cabeças. Essa abordagem equilibra a eficiência computacional com o desempenho do modelo e incentiva cada cabeça a aprender representações diversas. Portanto, dividir as dimensões de embedding é geralmente preferido em vez de fazer com que cada cabeça verifique todas as dimensões. {% endhint %}