30 KiB
5. LLMアーキテクチャ
LLMアーキテクチャ
{% hint style="success" %} この第5段階の目標は非常にシンプルです:完全なLLMのアーキテクチャを開発すること。すべてをまとめ、すべてのレイヤーを適用し、テキストを生成したり、テキストをIDに変換したり、その逆を行うためのすべての機能を作成します。
このアーキテクチャは、トレーニング後のテキストの予測とトレーニングの両方に使用されます。 {% endhint %}
LLMアーキテクチャの例はhttps://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynbから取得できます:
高レベルの表現は以下のように観察できます:

- 入力(トークン化されたテキスト):プロセスはトークン化されたテキストから始まり、数値表現に変換されます。
- トークン埋め込みおよび位置埋め込みレイヤー:トークン化されたテキストは、トークン埋め込みレイヤーと位置埋め込みレイヤーを通過し、シーケンス内のトークンの位置をキャプチャします。これは単語の順序を理解するために重要です。
- トランスフォーマーブロック:モデルには12のトランスフォーマーブロックが含まれており、それぞれに複数のレイヤーがあります。これらのブロックは以下のシーケンスを繰り返します:
- マスク付きマルチヘッドアテンション:モデルが入力テキストの異なる部分に同時に焦点を合わせることを可能にします。
- レイヤー正規化:トレーニングを安定させ、改善するための正規化ステップです。
- フィードフォワードレイヤー:アテンションレイヤーからの情報を処理し、次のトークンについての予測を行う役割を担います。
- ドロップアウトレイヤー:これらのレイヤーは、トレーニング中にユニットをランダムにドロップすることで過学習を防ぎます。
- 最終出力レイヤー:モデルは4x50,257次元のテンソルを出力します。ここで50,257は語彙のサイズを表します。このテンソルの各行は、モデルがシーケンス内の次の単語を予測するために使用するベクトルに対応します。
- 目標:目的は、これらの埋め込みを取得し、再びテキストに変換することです。具体的には、出力の最後の行が次の単語を生成するために使用され、この図では「forward」として表されています。
コード表現
import torch
import torch.nn as nn
import tiktoken
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
# Shortcut connection for feed forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
GELU活性化関数
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
目的と機能
- GELU (ガウス誤差線形ユニット): モデルに非線形性を導入する活性化関数。
- スムーズな活性化: 負の入力をゼロにするReLUとは異なり、GELUは入力を出力にスムーズにマッピングし、負の入力に対して小さな非ゼロ値を許可します。
- 数学的定義:
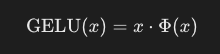
{% hint style="info" %} FeedForward層内の線形層の後にこの関数を使用する目的は、線形データを非線形に変換し、モデルが複雑で非線形な関係を学習できるようにすることです。 {% endhint %}
フィードフォワードニューラルネットワーク
行列の形状をよりよく理解するために、形状がコメントとして追加されています:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
x = self.layers[0](x)# x shape: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[1](x) # x shape remains: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[2](x) # x shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
目的と機能
- 位置ごとのフィードフォワードネットワーク: 各位置に対して別々に、かつ同一に二層の完全接続ネットワークを適用します。
- 層の詳細:
- 最初の線形層: 次元を
emb_dimから4 * emb_dimに拡張します。 - GELU活性化: 非線形性を適用します。
- 第二の線形層: 次元を再び
emb_dimに減少させます。
{% hint style="info" %} ご覧の通り、フィードフォワードネットワークは3層を使用しています。最初の層は線形層で、線形重み(モデル内でトレーニングするパラメータ)を使用して次元を4倍にします。その後、GELU関数がすべての次元に適用され、より豊かな表現を捉えるための非線形変化が行われ、最後にもう一つの線形層が元の次元サイズに戻します。 {% endhint %}
マルチヘッドアテンションメカニズム
これは以前のセクションで説明されました。
目的と機能
- マルチヘッド自己注意: トークンをエンコードする際に、モデルが入力シーケンス内の異なる位置に焦点を当てることを可能にします。
- 主要コンポーネント:
- クエリ、キー、値: 入力の線形射影で、注意スコアを計算するために使用されます。
- ヘッド: 複数の注意メカニズムが並行して実行されます(
num_heads)、それぞれが縮小された次元(head_dim)を持ちます。 - 注意スコア: クエリとキーのドット積として計算され、スケーリングとマスキングが行われます。
- マスキング: 将来のトークンにモデルが注意を向けないようにする因果マスクが適用されます(GPTのような自己回帰モデルにとって重要です)。
- 注意重み: マスクされたスケーリングされた注意スコアのソフトマックス。
- コンテキストベクター: 注意重みに従った値の加重和。
- 出力射影: すべてのヘッドの出力を組み合わせるための線形層。
{% hint style="info" %} このネットワークの目標は、同じコンテキスト内のトークン間の関係を見つけることです。さらに、トークンは異なるヘッドに分割され、最終的に見つかった関係はこのネットワークの最後で結合されるため、過学習を防ぎます。
さらに、トレーニング中に因果マスクが適用され、特定のトークンに対する関係を見ているときに後のトークンが考慮されないようにし、ドロップアウトも適用されて過学習を防ぎます。 {% endhint %}
層 正規化
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # Prevent division by zero during normalization.
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
目的と機能
- レイヤー正規化: バッチ内の各個別の例に対して、特徴(埋め込み次元)全体で入力を正規化するために使用される技術。
- コンポーネント:
eps: 正規化中のゼロ除算を防ぐために分散に追加される小さな定数(1e-5)。scaleとshift: 正規化された出力をスケールおよびシフトするためにモデルが学習可能なパラメータ(nn.Parameter)。それぞれ、初期値は1と0。- 正規化プロセス:
- 平均の計算(
mean): 埋め込み次元(dim=-1)に沿って入力xの平均を計算し、ブロードキャストのために次元を保持する(keepdim=True)。 - 分散の計算(
var): 埋め込み次元に沿ってxの分散を計算し、同様に次元を保持する。unbiased=Falseパラメータは、バイアス推定量を使用して分散が計算されることを保証する(N-1ではなくNで割る)。これは、サンプルではなく特徴に対して正規化する際に適切。 - 正規化(
norm_x):xから平均を引き、分散にepsを加えた平方根で割る。 - スケールとシフト: 正規化された出力に学習可能な
scaleとshiftパラメータを適用する。
{% hint style="info" %} 目標は、同じトークンのすべての次元で平均0、分散1を確保することです。これにより、深層ニューラルネットワークのトレーニングを安定させることが目的であり、これはトレーニング中のパラメータの更新によるネットワークの活性化の分布の変化を指す内部共変量シフトを減少させることに関連しています。 {% endhint %}
トランスフォーマーブロック
形状を理解するために、行列の形状をコメントとして追加しました:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for attention block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm1(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.att(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for feedforward block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm2(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.ff(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
目的と機能
- 層の構成: マルチヘッドアテンション、フィードフォワードネットワーク、レイヤーノーマライゼーション、残差接続を組み合わせる。
- レイヤーノーマライゼーション: 安定したトレーニングのためにアテンションとフィードフォワード層の前に適用される。
- 残差接続(ショートカット): 層の入力を出力に加えて勾配の流れを改善し、深いネットワークのトレーニングを可能にする。
- ドロップアウト: 正則化のためにアテンションとフィードフォワード層の後に適用される。
ステップバイステップの機能
- 最初の残差パス(自己アテンション):
- 入力(
shortcut): 残差接続のために元の入力を保存する。 - レイヤーノーム(
norm1): 入力を正規化する。 - マルチヘッドアテンション(
att): 自己アテンションを適用する。 - ドロップアウト(
drop_shortcut): 正則化のためにドロップアウトを適用する。 - 残差を加える(
x + shortcut): 元の入力と結合する。
- 2番目の残差パス(フィードフォワード):
- 入力(
shortcut): 次の残差接続のために更新された入力を保存する。 - レイヤーノーム(
norm2): 入力を正規化する。 - フィードフォワードネットワーク(
ff): フィードフォワード変換を適用する。 - ドロップアウト(
drop_shortcut): ドロップアウトを適用する。 - 残差を加える(
x + shortcut): 最初の残差パスからの入力と結合する。
{% hint style="info" %}
トランスフォーマーブロックはすべてのネットワークをグループ化し、トレーニングの安定性と結果を改善するためにいくつかの正規化とドロップアウトを適用します。
ドロップアウトは各ネットワークの使用後に行われ、正規化は前に適用されることに注意してください。
さらに、ショートカットを使用しており、これはネットワークの出力をその入力に加えることから成ります。これにより、初期層が最後の層と「同じくらい」貢献することを確実にすることで、消失勾配問題を防ぐのに役立ちます。 {% endhint %}
GPTModel
形状は行列の形状をよりよく理解するためにコメントとして追加されています:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# shape: (vocab_size, emb_dim)
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# shape: (context_length, emb_dim)
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# Stack of TransformerBlocks
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
# shape: (emb_dim, vocab_size)
def forward(self, in_idx):
# in_idx shape: (batch_size, seq_len)
batch_size, seq_len = in_idx.shape
# Token embeddings
tok_embeds = self.tok_emb(in_idx)
# shape: (batch_size, seq_len, emb_dim)
# Positional embeddings
pos_indices = torch.arange(seq_len, device=in_idx.device)
# shape: (seq_len,)
pos_embeds = self.pos_emb(pos_indices)
# shape: (seq_len, emb_dim)
# Add token and positional embeddings
x = tok_embeds + pos_embeds # Broadcasting over batch dimension
# x shape: (batch_size, seq_len, emb_dim)
x = self.drop_emb(x) # Dropout applied
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.trf_blocks(x) # Pass through Transformer blocks
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.final_norm(x) # Final LayerNorm
# x shape remains: (batch_size, seq_len, emb_dim)
logits = self.out_head(x) # Project to vocabulary size
# logits shape: (batch_size, seq_len, vocab_size)
return logits # Output shape: (batch_size, seq_len, vocab_size)
目的と機能
- 埋め込み層:
- トークン埋め込み (
tok_emb): トークンインデックスを埋め込みに変換します。リマインダーとして、これは語彙内の各トークンの各次元に与えられる重みです。 - 位置埋め込み (
pos_emb): 埋め込みに位置情報を追加してトークンの順序を捉えます。リマインダーとして、これはテキスト内の位置に応じてトークンに与えられる重みです。 - ドロップアウト (
drop_emb): 正則化のために埋め込みに適用されます。 - トランスフォーマーブロック (
trf_blocks): 埋め込みを処理するためのn_layersトランスフォーマーブロックのスタックです。 - 最終正規化 (
final_norm): 出力層の前の層正規化です。 - 出力層 (
out_head): 最終的な隠れ状態を語彙サイズに投影して予測のためのロジットを生成します。
{% hint style="info" %} このクラスの目的は、シーケンス内の次のトークンを予測するために、他のすべてのネットワークを使用することです。これはテキスト生成のようなタスクにとって基本的です。
どのようにして指定された数のトランスフォーマーブロックを使用するかに注意してください。また、各トランスフォーマーブロックは1つのマルチヘッドアテンションネット、1つのフィードフォワードネット、およびいくつかの正規化を使用しています。したがって、12のトランスフォーマーブロックが使用される場合は、これを12倍します。
さらに、出力の前に正規化層が追加され、最後に適切な次元で結果を得るために最終線形層が適用されます。各最終ベクトルが使用される語彙のサイズを持つことに注意してください。これは、語彙内の可能なトークンごとに確率を得ようとしているためです。 {% endhint %}
トレーニングするパラメータの数
GPT構造が定義されると、トレーニングするパラメータの数を見つけることが可能です:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
model = GPTModel(GPT_CONFIG_124M)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# Total number of parameters: 163,009,536
ステップバイステップ計算
1. 埋め込み層: トークン埋め込み & 位置埋め込み
- 層:
nn.Embedding(vocab_size, emb_dim) - パラメータ:
vocab_size * emb_dim
token_embedding_params = 50257 * 768 = 38,597,376
- レイヤー:
nn.Embedding(context_length, emb_dim) - パラメータ:
context_length * emb_dim
position_embedding_params = 1024 * 768 = 786,432
総埋め込みパラメータ
embedding_params = token_embedding_params + position_embedding_params
embedding_params = 38,597,376 + 786,432 = 39,383,808
2. トランスフォーマーブロック
トランスフォーマーブロックは12個あるので、1つのブロックのパラメータを計算し、それを12倍します。
トランスフォーマーブロックごとのパラメータ
a. マルチヘッドアテンション
- コンポーネント:
- クエリ線形層 (
W_query):nn.Linear(emb_dim, emb_dim, bias=False) - キー線形層 (
W_key):nn.Linear(emb_dim, emb_dim, bias=False) - バリュー線形層 (
W_value):nn.Linear(emb_dim, emb_dim, bias=False) - 出力プロジェクション (
out_proj):nn.Linear(emb_dim, emb_dim) - 計算:
W_query,W_key,W_valueのそれぞれ:
qkv_params = emb_dim * emb_dim = 768 * 768 = 589,824
このような層が3つあるので:
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472
- 出力プロジェクション (
out_proj):
out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592
- マルチヘッドアテンションの総パラメータ:
mha_params = total_qkv_params + out_proj_params
mha_params = 1,769,472 + 590,592 = 2,360,064
b. フィードフォワードネットワーク
- コンポーネント:
- 最初の線形層:
nn.Linear(emb_dim, 4 * emb_dim) - 2番目の線形層:
nn.Linear(4 * emb_dim, emb_dim) - 計算:
- 最初の線形層:
ff_first_layer_params = (emb_dim * 4 * emb_dim) + (4 * emb_dim)
ff_first_layer_params = (768 * 3072) + 3072 = 2,359,296 + 3,072 = 2,362,368
- 2番目の線形層:
ff_second_layer_params = (4 * emb_dim * emb_dim) + emb_dim
ff_second_layer_params = (3072 * 768) + 768 = 2,359,296 + 768 = 2,360,064
- フィードフォワードの総パラメータ:
ff_params = ff_first_layer_params + ff_second_layer_params
ff_params = 2,362,368 + 2,360,064 = 4,722,432
c. レイヤーノーマライゼーション
- コンポーネント:
- 各ブロックに2つの
LayerNormインスタンス。 - 各
LayerNormは2 * emb_dimのパラメータ(スケールとシフト)を持つ。 - 計算:
layer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
d. トランスフォーマーブロックごとの総パラメータ
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
すべてのトランスフォーマーブロックの合計パラメータ
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
3. 最終層
a. 最終層正規化
- パラメータ:
2 * emb_dim(スケールとシフト)
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
b. 出力投影層 (out_head)
- 層:
nn.Linear(emb_dim, vocab_size, bias=False) - パラメータ:
emb_dim * vocab_size
pythonCopy codeoutput_projection_params = 768 * 50257 = 38,597,376
4. すべてのパラメータの要約
pythonCopy codetotal_params = (
embedding_params +
total_transformer_blocks_params +
final_layer_norm_params +
output_projection_params
)
total_params = (
39,383,808 +
85,026,816 +
1,536 +
38,597,376
)
total_params = 163,009,536
テキスト生成
前のトークンのように次のトークンを予測するモデルがあれば、出力から最後のトークンの値を取得するだけで済みます(それが予測されたトークンの値になります)。これは語彙内の各エントリごとの値となり、次にsoftmax関数を使用して次元を正規化し、合計が1になる確率に変換し、最大のエントリのインデックスを取得します。これが語彙内の単語のインデックスになります。
Code from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))