29 KiB
5. LLM Architecture
LLM Architecture
{% hint style="success" %} The goal of this fifth phase is very simple: Develop the architecture of the full LLM. Put everything together, apply all the layers and create all the functions to generate text or transform text to IDs and backwards.
This architecture will be used for both, training and predicting text after it was trained. {% endhint %}
LLM architecture example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
A high level representation can be observed in:
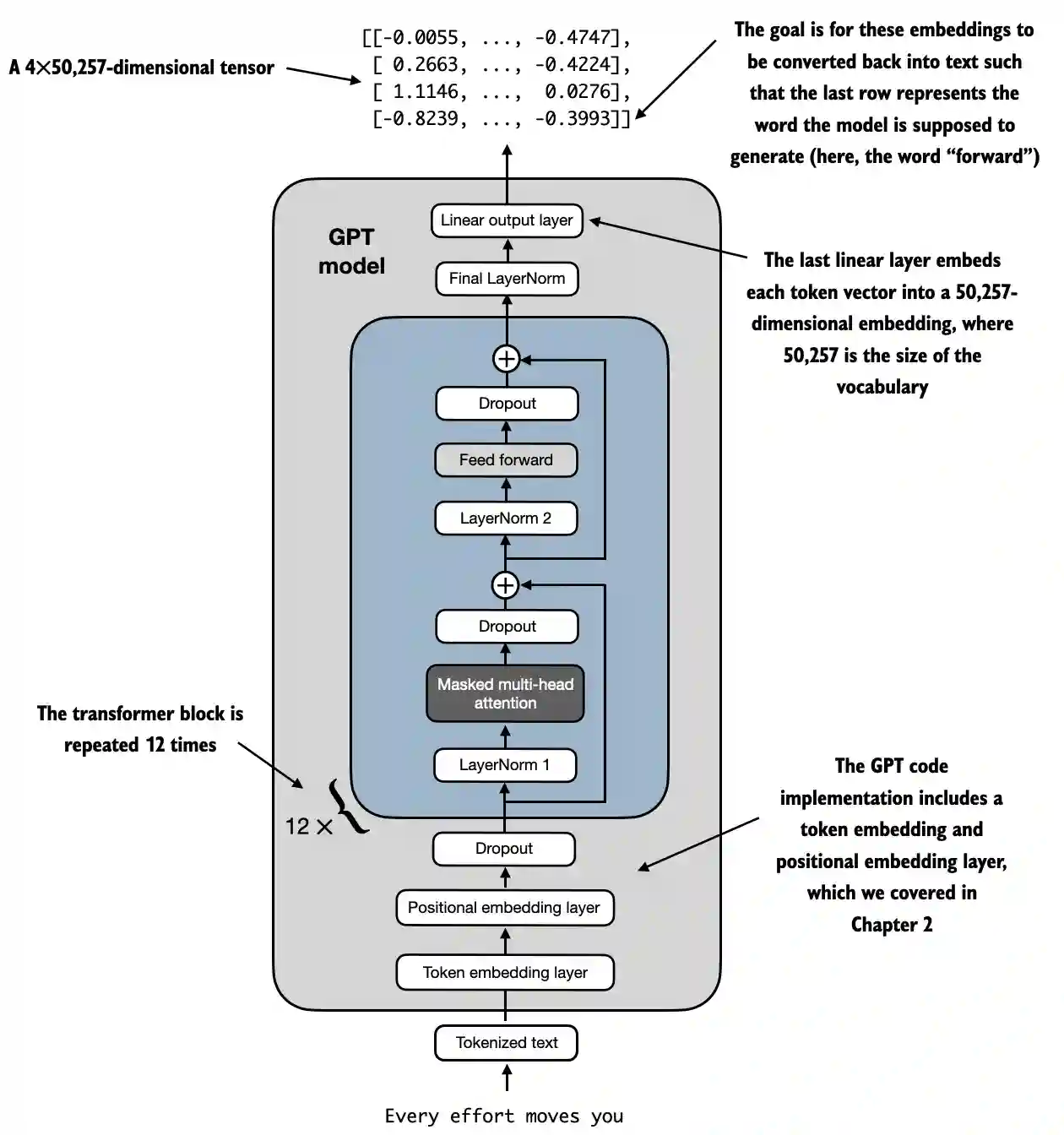
- Input (Tokenized Text): The process begins with tokenized text, which is converted into numerical representations.
- Token Embedding and Positional Embedding Layer: The tokenized text is passed through a token embedding layer and a positional embedding layer, which captures the position of tokens in a sequence, critical for understanding word order.
- Transformer Blocks: The model contains 12 transformer blocks, each with multiple layers. These blocks repeat the following sequence:
- Masked Multi-Head Attention: Allows the model to focus on different parts of the input text at once.
- Layer Normalization: A normalization step to stabilize and improve training.
- Feed Forward Layer: Responsible for processing the information from the attention layer and making predictions about the next token.
- Dropout Layers: These layers prevent overfitting by randomly dropping units during training.
- Final Output Layer: The model outputs a 4x50,257-dimensional tensor, where 50,257 represents the size of the vocabulary. Each row in this tensor corresponds to a vector that the model uses to predict the next word in the sequence.
- Goal: The objective is to take these embeddings and convert them back into text. Specifically, the last row of the output is used to generate the next word, represented as "forward" in this diagram.
Code representation
import torch
import torch.nn as nn
import tiktoken
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
# Shortcut connection for feed forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
Let's explain it step by step:
GELU Activation Function
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
Purpose and Functionality
- GELU (Gaussian Error Linear Unit): An activation function that introduces non-linearity into the model.
- Smooth Activation: Unlike ReLU, which zeroes out negative inputs, GELU smoothly maps inputs to outputs, allowing for small, non-zero values for negative inputs.
- Mathematical Definition:
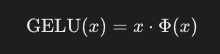
{% hint style="info" %} The goal of the use of this function after linear layers inside the FeedForward layer is to change the linear data to be none linear to allow the model to learn complex, non-linear relationships. {% endhint %}
FeedForward Neural Network
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
x = self.layers[0](x)# x shape: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[1](x) # x shape remains: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[2](x) # x shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Purpose and Functionality
- Position-wise FeedForward Network: Applies a two-layer fully connected network to each position separately and identically.
- Layer Details:
- First Linear Layer: Expands the dimensionality from
emb_dimto4 * emb_dim. - GELU Activation: Applies non-linearity.
- Second Linear Layer: Reduces the dimensionality back to
emb_dim.
- First Linear Layer: Expands the dimensionality from
{% hint style="info" %} As you can see, the Feed Forward network uses 3 layers. The first one is a linear layer that will multiply the dimensions by 4 using linear weights (parameters to train inside the model). Then, the GELU function is used in all those dimensions to apply none-linear variations to capture richer representations and finally another linear layer is used to get back to the original size of dimensions. {% endhint %}
Multi-Head Attention Mechanism
This was already explained in an earlier section.
Purpose and Functionality
- Multi-Head Self-Attention: Allows the model to focus on different positions within the input sequence when encoding a token.
- Key Components:
- Queries, Keys, Values: Linear projections of the input, used to compute attention scores.
- Heads: Multiple attention mechanisms running in parallel (
num_heads), each with a reduced dimension (head_dim). - Attention Scores: Computed as the dot product of queries and keys, scaled and masked.
- Masking: A causal mask is applied to prevent the model from attending to future tokens (important for autoregressive models like GPT).
- Attention Weights: Softmax of the masked and scaled attention scores.
- Context Vector: Weighted sum of the values, according to attention weights.
- Output Projection: Linear layer to combine the outputs of all heads.
{% hint style="info" %} The goal of this network is to find the relations between tokens in the same context. Moreover, the tokens are divided in different heads in order to prevent overfitting although the final relations found per head are combined at the end of this network.
Moreover, during training a causal mask is applied so later tokens are not taken into account when looking the specific relations to a token and some dropout is also applied to prevent overfitting. {% endhint %}
Layer Normalization
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # Prevent division by zero during normalization.
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
Purpose and Functionality
- Layer Normalization: A technique used to normalize the inputs across the features (embedding dimensions) for each individual example in a batch.
- Components:
eps: A small constant (1e-5) added to the variance to prevent division by zero during normalization.scaleandshift: Learnable parameters (nn.Parameter) that allow the model to scale and shift the normalized output. They are initialized to ones and zeros, respectively.
- Normalization Process:
- Compute Mean (
mean): Calculates the mean of the inputxacross the embedding dimension (dim=-1), keeping the dimension for broadcasting (keepdim=True). - Compute Variance (
var): Calculates the variance ofxacross the embedding dimension, also keeping the dimension. Theunbiased=Falseparameter ensures that the variance is calculated using the biased estimator (dividing byNinstead ofN-1), which is appropriate when normalizing over features rather than samples. - Normalize (
norm_x): Subtracts the mean fromxand divides by the square root of the variance pluseps. - Scale and Shift: Applies the learnable
scaleandshiftparameters to the normalized output.
- Compute Mean (
{% hint style="info" %} The goal is to ensure a mean of 0 with a variance of 1 across all dimensions of the same token . The goal of this is to stabilize the training of deep neural networks by reducing the internal covariate shift, which refers to the change in the distribution of network activations due to the updating of parameters during training. {% endhint %}
Transformer Block
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for attention block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm1(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.att(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for feedforward block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm2(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.ff(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Purpose and Functionality
- Composition of Layers: Combines multi-head attention, feedforward network, layer normalization, and residual connections.
- Layer Normalization: Applied before the attention and feedforward layers for stable training.
- Residual Connections (Shortcuts): Add the input of a layer to its output to improve gradient flow and enable training of deep networks.
- Dropout: Applied after attention and feedforward layers for regularization.
Step-by-Step Functionality
- First Residual Path (Self-Attention):
- Input (
shortcut): Save the original input for the residual connection. - Layer Norm (
norm1): Normalize the input. - Multi-Head Attention (
att): Apply self-attention. - Dropout (
drop_shortcut): Apply dropout for regularization. - Add Residual (
x + shortcut): Combine with the original input.
- Input (
- Second Residual Path (FeedForward):
- Input (
shortcut): Save the updated input for the next residual connection. - Layer Norm (
norm2): Normalize the input. - FeedForward Network (
ff): Apply the feedforward transformation. - Dropout (
drop_shortcut): Apply dropout. - Add Residual (
x + shortcut): Combine with the input from the first residual path.
- Input (
{% hint style="info" %}
The transformer block groups all the networks together and applies some normalization and dropouts to improve the training stability and results.
Note how dropouts are done after the use of each network while normalization is applied before.
Moreover, it also uses shortcuts which consists on adding the output of a network with its input. This helps to prevent the vanishing gradient problem by making sure that initial layers contribute "as much" as the last ones. {% endhint %}
GPTModel
Shapes have been added as comments to understand better the shapes of matrices:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# shape: (vocab_size, emb_dim)
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# shape: (context_length, emb_dim)
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# Stack of TransformerBlocks
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
# shape: (emb_dim, vocab_size)
def forward(self, in_idx):
# in_idx shape: (batch_size, seq_len)
batch_size, seq_len = in_idx.shape
# Token embeddings
tok_embeds = self.tok_emb(in_idx)
# shape: (batch_size, seq_len, emb_dim)
# Positional embeddings
pos_indices = torch.arange(seq_len, device=in_idx.device)
# shape: (seq_len,)
pos_embeds = self.pos_emb(pos_indices)
# shape: (seq_len, emb_dim)
# Add token and positional embeddings
x = tok_embeds + pos_embeds # Broadcasting over batch dimension
# x shape: (batch_size, seq_len, emb_dim)
x = self.drop_emb(x) # Dropout applied
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.trf_blocks(x) # Pass through Transformer blocks
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.final_norm(x) # Final LayerNorm
# x shape remains: (batch_size, seq_len, emb_dim)
logits = self.out_head(x) # Project to vocabulary size
# logits shape: (batch_size, seq_len, vocab_size)
return logits # Output shape: (batch_size, seq_len, vocab_size)
Purpose and Functionality
- Embedding Layers:
- Token Embeddings (
tok_emb): Converts token indices into embeddings. As reminder, these are the weights given to each dimension of each token in the vocabulary. - Positional Embeddings (
pos_emb): Adds positional information to the embeddings to capture the order of tokens. As reminder, these are the weights given to token according to it's position in the text.
- Token Embeddings (
- Dropout (
drop_emb): Applied to embeddings for regularisation. - Transformer Blocks (
trf_blocks): Stack ofn_layerstransformer blocks to process embeddings. - Final Normalization (
final_norm): Layer normalization before the output layer. - Output Layer (
out_head): Projects the final hidden states to the vocabulary size to produce logits for prediction.
{% hint style="info" %} The goal of this class is to use all the other mentioned networks to predict the next token in a sequence, which is fundamental for tasks like text generation.
Note how it will use as many transformer blocks as indicated and that each transformer block is using one multi-head attestation net, one feed forward net and several normalizations. So if 12 transformer blocks are used, multiply this by 12.
Moreover, a normalization layer is added before the output and a final linear layer is applied a the end to get the results with the proper dimensions. Note how each final vector has the size of the used vocabulary. This is because it's trying to get a probability per possible token inside the vocabulary. {% endhint %}
Number of Parameters to train
Having the GPT structure defined it's possible to find out the number of parameters to train:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
model = GPTModel(GPT_CONFIG_124M)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# Total number of parameters: 163,009,536
Step-by-Step Calculation
1. Embedding Layers: Token Embedding & Position Embedding
- Layer:
nn.Embedding(vocab_size, emb_dim) - Parameters:
vocab_size * emb_dim
token_embedding_params = 50257 * 768 = 38,597,376
- Layer:
nn.Embedding(context_length, emb_dim) - Parameters:
context_length * emb_dim
position_embedding_params = 1024 * 768 = 786,432
Total Embedding Parameters
embedding_params = token_embedding_params + position_embedding_params
embedding_params = 38,597,376 + 786,432 = 39,383,808
2. Transformer Blocks
There are 12 transformer blocks, so we'll calculate the parameters for one block and then multiply by 12.
Parameters per Transformer Block
a. Multi-Head Attention
- Components:
- Query Linear Layer (
W_query):nn.Linear(emb_dim, emb_dim, bias=False) - Key Linear Layer (
W_key):nn.Linear(emb_dim, emb_dim, bias=False) - Value Linear Layer (
W_value):nn.Linear(emb_dim, emb_dim, bias=False) - Output Projection (
out_proj):nn.Linear(emb_dim, emb_dim)
- Query Linear Layer (
- Calculations:
-
Each of
W_query,W_key,W_value:qkv_params = emb_dim * emb_dim = 768 * 768 = 589,824Since there are three such layers:
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472 -
Output Projection (
out_proj):out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592 -
Total Multi-Head Attention Parameters:
mha_params = total_qkv_params + out_proj_params mha_params = 1,769,472 + 590,592 = 2,360,064
-
b. FeedForward Network
- Components:
- First Linear Layer:
nn.Linear(emb_dim, 4 * emb_dim) - Second Linear Layer:
nn.Linear(4 * emb_dim, emb_dim)
- First Linear Layer:
- Calculations:
-
First Linear Layer:
ff_first_layer_params = (emb_dim * 4 * emb_dim) + (4 * emb_dim) ff_first_layer_params = (768 * 3072) + 3072 = 2,359,296 + 3,072 = 2,362,368 -
Second Linear Layer:
ff_second_layer_params = (4 * emb_dim * emb_dim) + emb_dim ff_second_layer_params = (3072 * 768) + 768 = 2,359,296 + 768 = 2,360,064 -
Total FeedForward Parameters:
ff_params = ff_first_layer_params + ff_second_layer_params ff_params = 2,362,368 + 2,360,064 = 4,722,432
-
c. Layer Normalizations
-
Components:
- Two
LayerNorminstances per block. - Each
LayerNormhas2 * emb_dimparameters (scale and shift).
- Two
-
Calculations:
pythonCopy codelayer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
d. Total Parameters per Transformer Block
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
Total Parameters for All Transformer Blocks
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
3. Final Layers
a. Final Layer Normalization
- Parameters:
2 * emb_dim(scale and shift)
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
b. Output Projection Layer (out_head)
- Layer:
nn.Linear(emb_dim, vocab_size, bias=False) - Parameters:
emb_dim * vocab_size
pythonCopy codeoutput_projection_params = 768 * 50257 = 38,597,376
4. Summing Up All Parameters
pythonCopy codetotal_params = (
embedding_params +
total_transformer_blocks_params +
final_layer_norm_params +
output_projection_params
)
total_params = (
39,383,808 +
85,026,816 +
1,536 +
38,597,376
)
total_params = 163,009,536
Generate Text
Having a model that predicts the next token like the one before, it's just needed to take the last token values from the output (as they will be the ones of the predicted token), which will be a value per entry in the vocabulary and then use the softmax function to normalize the dimensions into probabilities that sums 1 and then get the index of the of the biggest entry, which will be the index of the word inside the vocabulary.
Code from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))