28 KiB
5. Arquitetura LLM
Arquitetura LLM
{% hint style="success" %} O objetivo desta quinta fase é muito simples: Desenvolver a arquitetura do LLM completo. Junte tudo, aplique todas as camadas e crie todas as funções para gerar texto ou transformar texto em IDs e vice-versa.
Esta arquitetura será usada tanto para treinar quanto para prever texto após ter sido treinada. {% endhint %}
Exemplo de arquitetura LLM de https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
Uma representação de alto nível pode ser observada em:
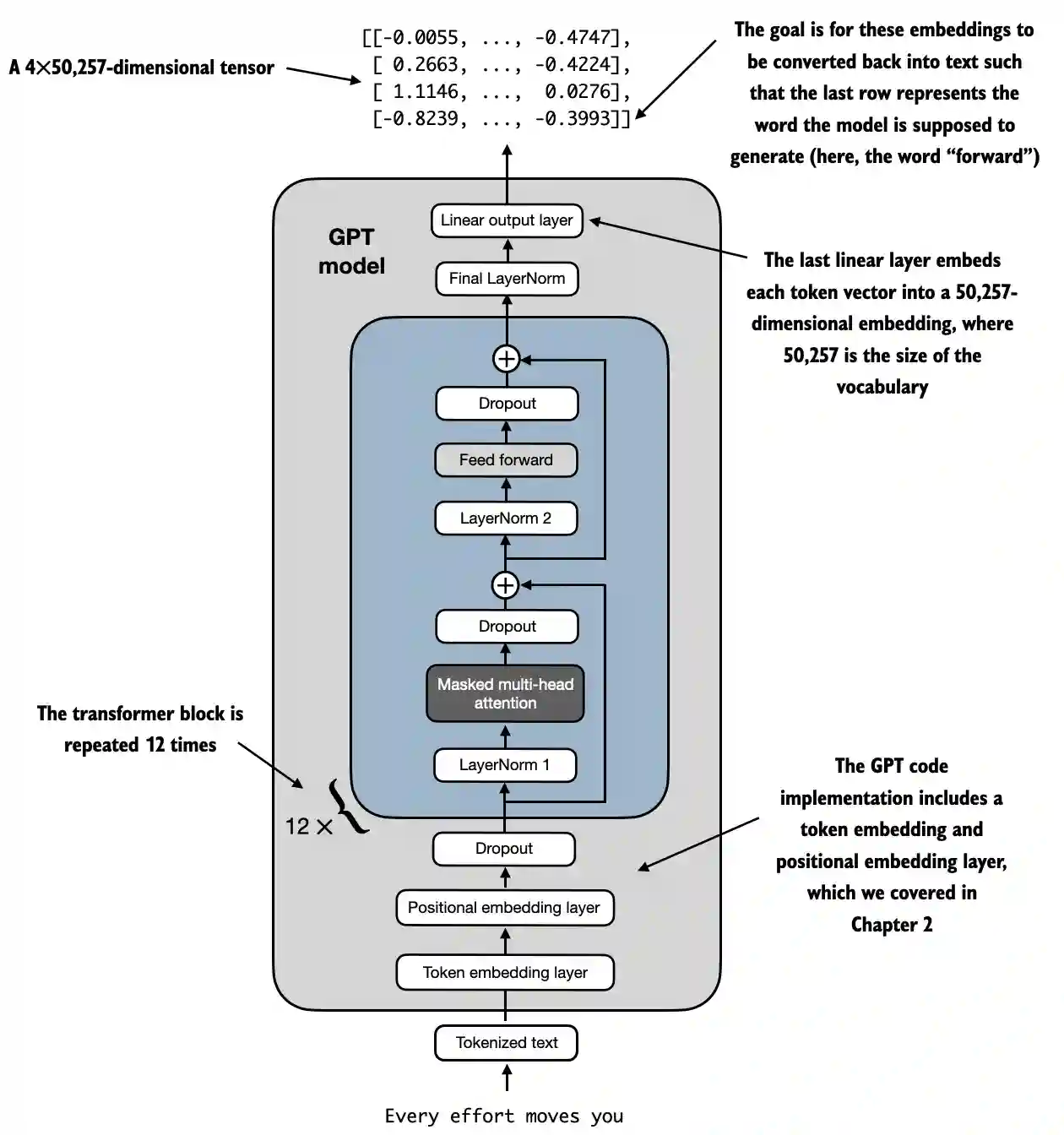
- Entrada (Texto Tokenizado): O processo começa com texto tokenizado, que é convertido em representações numéricas.
- Camada de Embedding de Token e Camada de Embedding Posicional: O texto tokenizado é passado por uma camada de embedding de token e uma camada de embedding posicional, que captura a posição dos tokens em uma sequência, crítica para entender a ordem das palavras.
- Blocos Transformer: O modelo contém 12 blocos transformer, cada um com várias camadas. Esses blocos repetem a seguinte sequência:
- Atenção Multi-Cabeça Mascarada: Permite que o modelo se concentre em diferentes partes do texto de entrada ao mesmo tempo.
- Normalização de Camada: Um passo de normalização para estabilizar e melhorar o treinamento.
- Camada Feed Forward: Responsável por processar as informações da camada de atenção e fazer previsões sobre o próximo token.
- Camadas de Dropout: Essas camadas previnem overfitting ao descartar unidades aleatoriamente durante o treinamento.
- Camada de Saída Final: O modelo produz um tensor de 4x50.257 dimensões, onde 50.257 representa o tamanho do vocabulário. Cada linha neste tensor corresponde a um vetor que o modelo usa para prever a próxima palavra na sequência.
- Objetivo: O objetivo é pegar esses embeddings e convertê-los de volta em texto. Especificamente, a última linha da saída é usada para gerar a próxima palavra, representada como "forward" neste diagrama.
Representação de Código
import torch
import torch.nn as nn
import tiktoken
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
# Shortcut connection for feed forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
Função de Ativação GELU
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
Propósito e Funcionalidade
- GELU (Unidade Linear de Erro Gaussiano): Uma função de ativação que introduz não-linearidade no modelo.
- Ativação Suave: Ao contrário do ReLU, que zera entradas negativas, o GELU mapeia suavemente entradas para saídas, permitindo pequenos valores não nulos para entradas negativas.
- Definição Matemática:
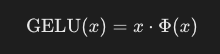
{% hint style="info" %} O objetivo do uso desta função após camadas lineares dentro da camada FeedForward é mudar os dados lineares para não lineares, permitindo que o modelo aprenda relações complexas e não lineares. {% endhint %}
Rede Neural FeedForward
Formas foram adicionadas como comentários para entender melhor as formas das matrizes:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
x = self.layers[0](x)# x shape: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[1](x) # x shape remains: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[2](x) # x shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Propósito e Funcionalidade
- Rede FeedForward por Posição: Aplica uma rede totalmente conectada de duas camadas a cada posição separadamente e de forma idêntica.
- Detalhes da Camada:
- Primeira Camada Linear: Expande a dimensionalidade de
emb_dimpara4 * emb_dim. - Ativação GELU: Aplica não-linearidade.
- Segunda Camada Linear: Reduz a dimensionalidade de volta para
emb_dim.
{% hint style="info" %} Como você pode ver, a rede Feed Forward usa 3 camadas. A primeira é uma camada linear que multiplicará as dimensões por 4 usando pesos lineares (parâmetros a serem treinados dentro do modelo). Em seguida, a função GELU é usada em todas essas dimensões para aplicar variações não-lineares para capturar representações mais ricas e, finalmente, outra camada linear é usada para retornar ao tamanho original das dimensões. {% endhint %}
Mecanismo de Atenção Multi-Cabeça
Isso já foi explicado em uma seção anterior.
Propósito e Funcionalidade
- Auto-Atenção Multi-Cabeça: Permite que o modelo se concentre em diferentes posições dentro da sequência de entrada ao codificar um token.
- Componentes Chave:
- Consultas, Chaves, Valores: Projeções lineares da entrada, usadas para calcular pontuações de atenção.
- Cabeças: Múltiplos mecanismos de atenção funcionando em paralelo (
num_heads), cada um com uma dimensão reduzida (head_dim). - Pontuações de Atenção: Calculadas como o produto escalar de consultas e chaves, escaladas e mascaradas.
- Mascaramento: Uma máscara causal é aplicada para evitar que o modelo preste atenção a tokens futuros (importante para modelos autoregressivos como o GPT).
- Pesos de Atenção: Softmax das pontuações de atenção mascaradas e escaladas.
- Vetor de Contexto: Soma ponderada dos valores, de acordo com os pesos de atenção.
- Projeção de Saída: Camada linear para combinar as saídas de todas as cabeças.
{% hint style="info" %} O objetivo desta rede é encontrar as relações entre tokens no mesmo contexto. Além disso, os tokens são divididos em diferentes cabeças para evitar overfitting, embora as relações finais encontradas por cabeça sejam combinadas no final desta rede.
Além disso, durante o treinamento, uma máscara causal é aplicada para que tokens posteriores não sejam levados em conta ao buscar as relações específicas de um token e algum dropout também é aplicado para prevenir overfitting. {% endhint %}
Normalização da Camada
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # Prevent division by zero during normalization.
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
Propósito e Funcionalidade
- Normalização de Camada: Uma técnica usada para normalizar as entradas entre as características (dimensões de incorporação) para cada exemplo individual em um lote.
- Componentes:
eps: Uma constante pequena (1e-5) adicionada à variância para evitar divisão por zero durante a normalização.scaleeshift: Parâmetros aprendíveis (nn.Parameter) que permitem ao modelo escalar e deslocar a saída normalizada. Eles são inicializados como uns e zeros, respectivamente.- Processo de Normalização:
- Calcular Média (
mean): Calcula a média da entradaxao longo da dimensão de incorporação (dim=-1), mantendo a dimensão para broadcasting (keepdim=True). - Calcular Variância (
var): Calcula a variância dexao longo da dimensão de incorporação, também mantendo a dimensão. O parâmetrounbiased=Falsegarante que a variância seja calculada usando o estimador enviesado (dividindo porNem vez deN-1), o que é apropriado ao normalizar sobre características em vez de amostras. - Normalizar (
norm_x): Subtrai a média dexe divide pela raiz quadrada da variância maiseps. - Escalar e Deslocar: Aplica os parâmetros aprendíveis
scaleeshiftà saída normalizada.
{% hint style="info" %} O objetivo é garantir uma média de 0 com uma variância de 1 em todas as dimensões do mesmo token. O objetivo disso é estabilizar o treinamento de redes neurais profundas reduzindo a mudança de covariáveis internas, que se refere à mudança na distribuição das ativações da rede devido à atualização de parâmetros durante o treinamento. {% endhint %}
Bloco Transformer
Formats foram adicionados como comentários para entender melhor os formatos das matrizes:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for attention block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm1(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.att(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for feedforward block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm2(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.ff(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
Propósito e Funcionalidade
- Composição de Camadas: Combina atenção multi-cabeça, rede feedforward, normalização de camada e conexões residuais.
- Normalização de Camada: Aplicada antes das camadas de atenção e feedforward para treinamento estável.
- Conexões Residuais (Atalhos): Adiciona a entrada de uma camada à sua saída para melhorar o fluxo de gradiente e permitir o treinamento de redes profundas.
- Dropout: Aplicado após as camadas de atenção e feedforward para regularização.
Funcionalidade Passo a Passo
- Primeiro Caminho Residual (Auto-Atenção):
- Entrada (
shortcut): Salvar a entrada original para a conexão residual. - Norma de Camada (
norm1): Normalizar a entrada. - Atenção Multi-Cabeça (
att): Aplicar auto-atendimento. - Dropout (
drop_shortcut): Aplicar dropout para regularização. - Adicionar Residual (
x + shortcut): Combinar com a entrada original.
- Segundo Caminho Residual (FeedForward):
- Entrada (
shortcut): Salvar a entrada atualizada para a próxima conexão residual. - Norma de Camada (
norm2): Normalizar a entrada. - Rede FeedForward (
ff): Aplicar a transformação feedforward. - Dropout (
drop_shortcut): Aplicar dropout. - Adicionar Residual (
x + shortcut): Combinar com a entrada do primeiro caminho residual.
{% hint style="info" %}
O bloco transformer agrupa todas as redes e aplica algumas normalizações e dropouts para melhorar a estabilidade e os resultados do treinamento.
Note como os dropouts são feitos após o uso de cada rede, enquanto a normalização é aplicada antes.
Além disso, também utiliza atalhos que consistem em adicionar a saída de uma rede com sua entrada. Isso ajuda a prevenir o problema do gradiente que desaparece, garantindo que as camadas iniciais contribuam "tanto" quanto as últimas. {% endhint %}
GPTModel
As formas foram adicionadas como comentários para entender melhor as formas das matrizes:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# shape: (vocab_size, emb_dim)
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# shape: (context_length, emb_dim)
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# Stack of TransformerBlocks
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
# shape: (emb_dim, vocab_size)
def forward(self, in_idx):
# in_idx shape: (batch_size, seq_len)
batch_size, seq_len = in_idx.shape
# Token embeddings
tok_embeds = self.tok_emb(in_idx)
# shape: (batch_size, seq_len, emb_dim)
# Positional embeddings
pos_indices = torch.arange(seq_len, device=in_idx.device)
# shape: (seq_len,)
pos_embeds = self.pos_emb(pos_indices)
# shape: (seq_len, emb_dim)
# Add token and positional embeddings
x = tok_embeds + pos_embeds # Broadcasting over batch dimension
# x shape: (batch_size, seq_len, emb_dim)
x = self.drop_emb(x) # Dropout applied
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.trf_blocks(x) # Pass through Transformer blocks
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.final_norm(x) # Final LayerNorm
# x shape remains: (batch_size, seq_len, emb_dim)
logits = self.out_head(x) # Project to vocabulary size
# logits shape: (batch_size, seq_len, vocab_size)
return logits # Output shape: (batch_size, seq_len, vocab_size)
Propósito e Funcionalidade
- Camadas de Embedding:
- Token Embeddings (
tok_emb): Converte índices de tokens em embeddings. Como lembrete, estes são os pesos dados a cada dimensão de cada token no vocabulário. - Positional Embeddings (
pos_emb): Adiciona informações de posição aos embeddings para capturar a ordem dos tokens. Como lembrete, estes são os pesos dados ao token de acordo com sua posição no texto. - Dropout (
drop_emb): Aplicado aos embeddings para regularização. - Blocos Transformer (
trf_blocks): Pilha den_layersblocos transformer para processar embeddings. - Normalização Final (
final_norm): Normalização de camada antes da camada de saída. - Camada de Saída (
out_head): Projeta os estados ocultos finais para o tamanho do vocabulário para produzir logits para previsão.
{% hint style="info" %} O objetivo desta classe é usar todas as outras redes mencionadas para prever o próximo token em uma sequência, o que é fundamental para tarefas como geração de texto.
Note como ela usará tantos blocos transformer quanto indicado e que cada bloco transformer está usando uma rede de atenção multi-head, uma rede feed forward e várias normalizações. Portanto, se 12 blocos transformer forem usados, multiplique isso por 12.
Além disso, uma camada de normalização é adicionada antes da saída e uma camada linear final é aplicada no final para obter os resultados com as dimensões adequadas. Note como cada vetor final tem o tamanho do vocabulário utilizado. Isso ocorre porque está tentando obter uma probabilidade por token possível dentro do vocabulário. {% endhint %}
Número de Parâmetros a treinar
Tendo a estrutura do GPT definida, é possível descobrir o número de parâmetros a treinar:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
model = GPTModel(GPT_CONFIG_124M)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# Total number of parameters: 163,009,536
Cálculo Passo a Passo
1. Camadas de Embedding: Token Embedding & Position Embedding
- Camada:
nn.Embedding(vocab_size, emb_dim) - Parâmetros:
vocab_size * emb_dim
token_embedding_params = 50257 * 768 = 38,597,376
- Camada:
nn.Embedding(context_length, emb_dim) - Parâmetros:
context_length * emb_dim
position_embedding_params = 1024 * 768 = 786,432
Total de Parâmetros de Embedding
embedding_params = token_embedding_params + position_embedding_params
embedding_params = 38,597,376 + 786,432 = 39,383,808
2. Blocos Transformer
Existem 12 blocos transformer, então vamos calcular os parâmetros para um bloco e depois multiplicar por 12.
Parâmetros por Bloco Transformer
a. Atenção Multi-Cabeça
- Componentes:
- Camada Linear de Consulta (
W_query):nn.Linear(emb_dim, emb_dim, bias=False) - Camada Linear de Chave (
W_key):nn.Linear(emb_dim, emb_dim, bias=False) - Camada Linear de Valor (
W_value):nn.Linear(emb_dim, emb_dim, bias=False) - Projeção de Saída (
out_proj):nn.Linear(emb_dim, emb_dim) - Cálculos:
- Cada um de
W_query,W_key,W_value:
qkv_params = emb_dim * emb_dim = 768 * 768 = 589,824
Como existem três dessas camadas:
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472
- Projeção de Saída (
out_proj):
out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592
- Total de Parâmetros de Atenção Multi-Cabeça:
mha_params = total_qkv_params + out_proj_params
mha_params = 1,769,472 + 590,592 = 2,360,064
b. Rede FeedForward
- Componentes:
- Primeira Camada Linear:
nn.Linear(emb_dim, 4 * emb_dim) - Segunda Camada Linear:
nn.Linear(4 * emb_dim, emb_dim) - Cálculos:
- Primeira Camada Linear:
ff_first_layer_params = (emb_dim * 4 * emb_dim) + (4 * emb_dim)
ff_first_layer_params = (768 * 3072) + 3072 = 2,359,296 + 3,072 = 2,362,368
- Segunda Camada Linear:
ff_second_layer_params = (4 * emb_dim * emb_dim) + emb_dim
ff_second_layer_params = (3072 * 768) + 768 = 2,359,296 + 768 = 2,360,064
- Total de Parâmetros FeedForward:
ff_params = ff_first_layer_params + ff_second_layer_params
ff_params = 2,362,368 + 2,360,064 = 4,722,432
c. Normalizações de Camada
- Componentes:
- Duas instâncias de
LayerNormpor bloco. - Cada
LayerNormtem2 * emb_dimparâmetros (escala e deslocamento). - Cálculos:
layer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
d. Total de Parâmetros por Bloco Transformer
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
Total de Parâmetros para Todos os Blocos Transformer
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
3. Camadas Finais
a. Normalização da Camada Final
- Parâmetros:
2 * emb_dim(escala e deslocamento)
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
b. Camada de Projeção de Saída (out_head)
- Camada:
nn.Linear(emb_dim, vocab_size, bias=False) - Parâmetros:
emb_dim * vocab_size
pythonCopy codeoutput_projection_params = 768 * 50257 = 38,597,376
4. Resumindo Todos os Parâmetros
pythonCopy codetotal_params = (
embedding_params +
total_transformer_blocks_params +
final_layer_norm_params +
output_projection_params
)
total_params = (
39,383,808 +
85,026,816 +
1,536 +
38,597,376
)
total_params = 163,009,536
Gerar Texto
Tendo um modelo que prevê o próximo token como o anterior, é necessário apenas pegar os últimos valores de token da saída (já que serão os do token previsto), que será um valor por entrada no vocabulário e então usar a função softmax para normalizar as dimensões em probabilidades que somam 1 e então obter o índice da maior entrada, que será o índice da palavra dentro do vocabulário.
Código de https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))