19 KiB
4. Attention Mechanisms
Attention Mechanisms and Self-Attention in Neural Networks
Attention mechanisms allow neural networks to focus on specific parts of the input when generating each part of the output. They assign different weights to different inputs, helping the model decide which inputs are most relevant to the task at hand. This is crucial in tasks like machine translation, where understanding the context of the entire sentence is necessary for accurate translation.
{% hint style="success" %}
이 네 번째 단계의 목표는 매우 간단합니다: 일부 주의 메커니즘을 적용합니다. 이는 어휘의 단어와 현재 LLM을 훈련하는 데 사용되는 문장에서의 이웃 간의 관계를 포착하는 많은 반복 레이어가 될 것입니다.
이를 위해 많은 레이어가 사용되므로 많은 학습 가능한 매개변수가 이 정보를 포착하게 됩니다.
{% endhint %}
Understanding Attention Mechanisms
In traditional sequence-to-sequence models used for language translation, the model encodes an input sequence into a fixed-size context vector. However, this approach struggles with long sentences because the fixed-size context vector may not capture all necessary information. Attention mechanisms address this limitation by allowing the model to consider all input tokens when generating each output token.
Example: Machine Translation
Consider translating the German sentence "Kannst du mir helfen diesen Satz zu übersetzen" into English. A word-by-word translation would not produce a grammatically correct English sentence due to differences in grammatical structures between languages. An attention mechanism enables the model to focus on relevant parts of the input sentence when generating each word of the output sentence, leading to a more accurate and coherent translation.
Introduction to Self-Attention
Self-attention, or intra-attention, is a mechanism where attention is applied within a single sequence to compute a representation of that sequence. It allows each token in the sequence to attend to all other tokens, helping the model capture dependencies between tokens regardless of their distance in the sequence.
Key Concepts
- Tokens: 입력 시퀀스의 개별 요소(예: 문장의 단어).
- Embeddings: 의미 정보를 포착하는 토큰의 벡터 표현.
- Attention Weights: 다른 토큰에 대한 각 토큰의 중요성을 결정하는 값.
Calculating Attention Weights: A Step-by-Step Example
Let's consider the sentence "Hello shiny sun!" and represent each word with a 3-dimensional embedding:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Our goal is to compute the context vector for the word "shiny" using self-attention.
Step 1: Compute Attention Scores
{% hint style="success" %} 각 차원 값을 쿼리와 관련된 각 토큰의 값과 곱하고 결과를 더합니다. 각 토큰 쌍에 대해 1개의 값을 얻습니다. {% endhint %}
For each word in the sentence, compute the attention score with respect to "shiny" by calculating the dot product of their embeddings.
Attention Score between "Hello" and "shiny"

Attention Score between "shiny" and "shiny"

Attention Score between "sun" and "shiny"

Step 2: Normalize Attention Scores to Obtain Attention Weights
{% hint style="success" %} 수학적 용어에 혼란스러워하지 마세요. 이 함수의 목표는 간단합니다. 모든 가중치를 정규화하여 총합이 1이 되도록 합니다.
또한, softmax 함수는 지수 부분으로 인해 차이를 강조하므로 유용한 값을 감지하기 쉽게 만듭니다. {% endhint %}
Apply the softmax function to the attention scores to convert them into attention weights that sum to 1.

Calculating the exponentials:

Calculating the sum:
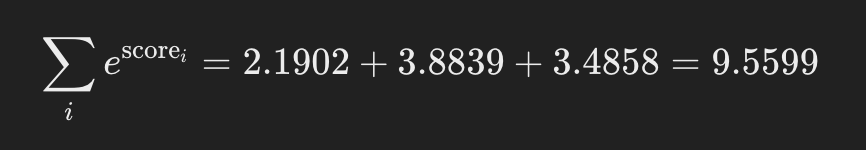
Calculating attention weights:

Step 3: Compute the Context Vector
{% hint style="success" %} 각 주의 가중치를 가져와 관련된 토큰 차원에 곱한 다음 모든 차원을 더하여 단 하나의 벡터(컨텍스트 벡터)를 얻습니다. {% endhint %}
The context vector is computed as the weighted sum of the embeddings of all words, using the attention weights.
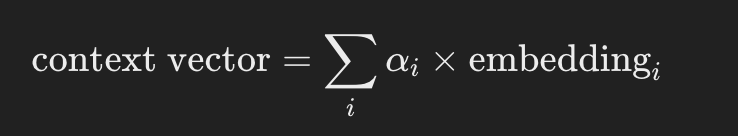
Calculating each component:
- Weighted Embedding of "Hello":



Summing the weighted embeddings:
context vector=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
이 컨텍스트 벡터는 "shiny"라는 단어에 대한 풍부한 임베딩을 나타내며, 문장의 모든 단어에서 정보를 통합합니다.
Summary of the Process
- Compute Attention Scores: Use the dot product between the embedding of the target word and the embeddings of all words in the sequence.
- Normalize Scores to Get Attention Weights: Apply the softmax function to the attention scores to obtain weights that sum to 1.
- Compute Context Vector: Multiply each word's embedding by its attention weight and sum the results.
Self-Attention with Trainable Weights
In practice, self-attention mechanisms use trainable weights to learn the best representations for queries, keys, and values. This involves introducing three weight matrices:

The query is the data to use like before, while the keys and values matrices are just random-trainable matrices.
Step 1: Compute Queries, Keys, and Values
Each token will have its own query, key and value matrix by multiplying its dimension values by the defined matrices:
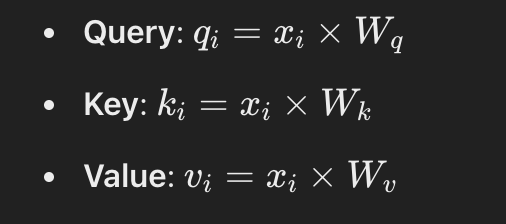
These matrices transform the original embeddings into a new space suitable for computing attention.
Example
Assuming:
- Input dimension
din=3(embedding size) - Output dimension
dout=2(desired dimension for queries, keys, and values)
Initialize the weight matrices:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
쿼리, 키, 값 계산:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Step 2: Compute Scaled Dot-Product Attention
Compute Attention Scores
이전 예제와 유사하지만, 이번에는 토큰의 차원 값 대신 토큰의 키 행렬을 사용합니다(이미 차원을 사용하여 계산됨). 따라서 각 쿼리 qi와 키 kj에 대해:
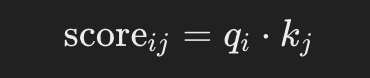
Scale the Scores
내적이 너무 커지는 것을 방지하기 위해, 키 차원 dk의 제곱근으로 점수를 조정합니다:
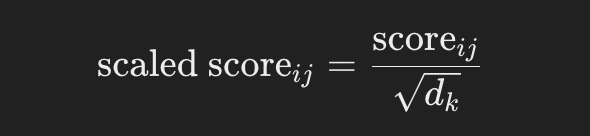
{% hint style="success" %} 점수는 차원의 제곱근으로 나누어지는데, 이는 내적이 매우 커질 수 있기 때문에 이를 조절하는 데 도움이 됩니다. {% endhint %}
Apply Softmax to Obtain Attention Weights: 초기 예제와 같이 모든 값을 정규화하여 합이 1이 되도록 합니다.
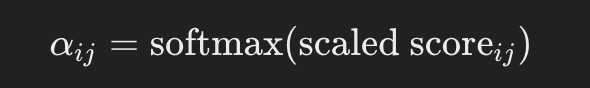
Step 3: Compute Context Vectors
초기 예제와 같이, 각 값을 해당 주의 가중치로 곱한 후 모든 값 행렬을 합산합니다:
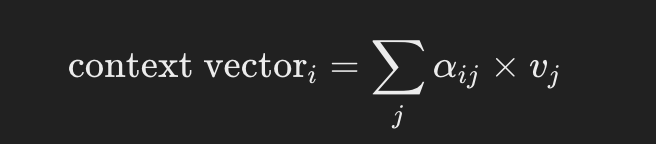
Code Example
https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb에서 예제를 가져와서 우리가 이야기한 자기 주의 기능을 구현하는 이 클래스를 확인할 수 있습니다:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
행렬을 임의의 값으로 초기화하는 대신, nn.Linear를 사용하여 모든 가중치를 학습할 매개변수로 표시합니다.
{% endhint %}
인과적 주의: 미래 단어 숨기기
LLM에서는 모델이 다음 토큰을 예측하기 위해 현재 위치 이전에 나타나는 토큰만 고려하도록 하고자 합니다. 인과적 주의는 마스킹된 주의라고도 하며, 주의 메커니즘을 수정하여 미래 토큰에 대한 접근을 방지함으로써 이를 달성합니다.
인과적 주의 마스크 적용
인과적 주의를 구현하기 위해, 우리는 소프트맥스 연산 이전에 주의 점수에 마스크를 적용하여 나머지 점수가 여전히 1이 되도록 합니다. 이 마스크는 미래 토큰의 주의 점수를 음의 무한대로 설정하여 소프트맥스 이후에 그들의 주의 가중치가 0이 되도록 보장합니다.
단계
- 주의 점수 계산: 이전과 동일합니다.
- 마스크 적용: 대각선 위에 음의 무한대로 채워진 상삼각 행렬을 사용합니다.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf')
masked_scores = attention_scores + mask
- 소프트맥스 적용: 마스킹된 점수를 사용하여 주의 가중치를 계산합니다.
attention_weights = torch.softmax(masked_scores, dim=-1)
드롭아웃으로 추가 주의 가중치 마스킹
과적합을 방지하기 위해, 소프트맥스 연산 후 주의 가중치에 드롭아웃을 적용할 수 있습니다. 드롭아웃은 훈련 중 일부 주의 가중치를 무작위로 0으로 만듭니다.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
정기적인 드롭아웃은 약 10-20%입니다.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Single-Head Attention을 Multi-Head Attention으로 확장하기
Multi-head attention은 실질적으로 자기 주의 함수의 여러 인스턴스를 실행하는 것으로, 각 인스턴스는 자신의 가중치를 가지고 있어 서로 다른 최종 벡터가 계산됩니다.
코드 예제
이전 코드를 재사용하고 여러 번 실행하는 래퍼를 추가하는 것이 가능할 수 있지만, https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb에서 제공하는 이 최적화된 버전은 모든 헤드를 동시에 처리하여(비용이 많이 드는 for 루프의 수를 줄임) 더 효율적입니다. 코드에서 볼 수 있듯이, 각 토큰의 차원은 헤드 수에 따라 서로 다른 차원으로 나뉩니다. 이렇게 하면 토큰이 8차원을 가지고 있고 3개의 헤드를 사용하고자 할 경우, 차원은 4차원의 2개의 배열로 나뉘고 각 헤드는 그 중 하나를 사용하게 됩니다:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
다른 간결하고 효율적인 구현을 위해 PyTorch의 torch.nn.MultiheadAttention 클래스를 사용할 수 있습니다.
{% hint style="success" %} ChatGPT의 짧은 답변: 각 헤드가 모든 토큰의 모든 차원을 확인하는 대신 토큰의 차원을 헤드 간에 나누는 것이 더 나은 이유:
각 헤드가 모든 임베딩 차원을 처리할 수 있도록 하는 것이 유리해 보일 수 있지만, 표준 관행은 임베딩 차원을 헤드 간에 나누는 것입니다. 이 접근 방식은 계산 효율성과 모델 성능의 균형을 맞추고 각 헤드가 다양한 표현을 학습하도록 장려합니다. 따라서 임베딩 차원을 나누는 것이 일반적으로 각 헤드가 모든 차원을 확인하는 것보다 선호됩니다. {% endhint %}