19 KiB
4. Meccanismi di Attenzione
Meccanismi di Attenzione e Auto-Attenzione nelle Reti Neurali
I meccanismi di attenzione consentono alle reti neurali di concentrarsi su parti specifiche dell'input durante la generazione di ciascuna parte dell'output. Assegnano pesi diversi a diversi input, aiutando il modello a decidere quali input sono più rilevanti per il compito in questione. Questo è cruciale in compiti come la traduzione automatica, dove comprendere il contesto dell'intera frase è necessario per una traduzione accurata.
{% hint style="success" %}
L'obiettivo di questa quarta fase è molto semplice: Applicare alcuni meccanismi di attenzione. Questi saranno molti strati ripetuti che andranno a catturare la relazione di una parola nel vocabolario con i suoi vicini nella frase attuale utilizzata per addestrare il LLM.
Vengono utilizzati molti strati per questo, quindi molti parametri addestrabili andranno a catturare queste informazioni.
{% endhint %}
Comprendere i Meccanismi di Attenzione
Nei modelli tradizionali sequenza-a-sequenza utilizzati per la traduzione linguistica, il modello codifica una sequenza di input in un vettore di contesto di dimensione fissa. Tuttavia, questo approccio ha difficoltà con frasi lunghe perché il vettore di contesto di dimensione fissa potrebbe non catturare tutte le informazioni necessarie. I meccanismi di attenzione affrontano questa limitazione consentendo al modello di considerare tutti i token di input durante la generazione di ciascun token di output.
Esempio: Traduzione Automatica
Considera la traduzione della frase tedesca "Kannst du mir helfen diesen Satz zu übersetzen" in inglese. Una traduzione parola per parola non produrrebbe una frase inglese grammaticalmente corretta a causa delle differenze nelle strutture grammaticali tra le lingue. Un meccanismo di attenzione consente al modello di concentrarsi su parti rilevanti della frase di input durante la generazione di ciascuna parola della frase di output, portando a una traduzione più accurata e coerente.
Introduzione all'Auto-Attenzione
L'auto-attenzione, o intra-attention, è un meccanismo in cui l'attenzione viene applicata all'interno di una singola sequenza per calcolare una rappresentazione di quella sequenza. Consente a ciascun token nella sequenza di prestare attenzione a tutti gli altri token, aiutando il modello a catturare le dipendenze tra i token indipendentemente dalla loro distanza nella sequenza.
Concetti Chiave
- Token: Elementi individuali della sequenza di input (ad es., parole in una frase).
- Embeddings: Rappresentazioni vettoriali dei token, che catturano informazioni semantiche.
- Pesi di Attenzione: Valori che determinano l'importanza di ciascun token rispetto agli altri.
Calcolo dei Pesi di Attenzione: Un Esempio Passo-Passo
Consideriamo la frase "Hello shiny sun!" e rappresentiamo ciascuna parola con un embedding a 3 dimensioni:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Il nostro obiettivo è calcolare il vettore di contesto per la parola "shiny" utilizzando l'auto-attenzione.
Passo 1: Calcolare i Punteggi di Attenzione
{% hint style="success" %} Basta moltiplicare ciascun valore dimensionale della query con quello pertinente di ciascun token e sommare i risultati. Ottieni 1 valore per coppia di token. {% endhint %}
Per ciascuna parola nella frase, calcola il punteggio di attenzione rispetto a "shiny" calcolando il prodotto scalare dei loro embeddings.
Punteggio di Attenzione tra "Hello" e "shiny"

Punteggio di Attenzione tra "shiny" e "shiny"

Punteggio di Attenzione tra "sun" e "shiny"

Passo 2: Normalizzare i Punteggi di Attenzione per Ottenere i Pesi di Attenzione
{% hint style="success" %} Non perderti nei termini matematici, l'obiettivo di questa funzione è semplice, normalizzare tutti i pesi affinché sommati diano 1 in totale.
Inoltre, la funzione softmax è utilizzata perché accentua le differenze grazie alla parte esponenziale, rendendo più facile rilevare valori utili. {% endhint %}
Applica la funzione softmax ai punteggi di attenzione per convertirli in pesi di attenzione che sommano a 1.

Calcolando gli esponenziali:

Calcolando la somma:

Calcolando i pesi di attenzione:

Passo 3: Calcolare il Vettore di Contesto
{% hint style="success" %} Basta prendere ciascun peso di attenzione e moltiplicarlo per le dimensioni del token correlato e poi sommare tutte le dimensioni per ottenere un solo vettore (il vettore di contesto) {% endhint %}
Il vettore di contesto è calcolato come la somma pesata degli embeddings di tutte le parole, utilizzando i pesi di attenzione.

Calcolando ciascun componente:
- Embedding Pesato di "Hello":



Sommando gli embeddings pesati:
context vector=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
Questo vettore di contesto rappresenta l'embedding arricchito per la parola "shiny", incorporando informazioni da tutte le parole nella frase.
Riepilogo del Processo
- Calcolare i Punteggi di Attenzione: Utilizzare il prodotto scalare tra l'embedding della parola target e gli embeddings di tutte le parole nella sequenza.
- Normalizzare i Punteggi per Ottenere i Pesi di Attenzione: Applicare la funzione softmax ai punteggi di attenzione per ottenere pesi che sommano a 1.
- Calcolare il Vettore di Contesto: Moltiplicare l'embedding di ciascuna parola per il suo peso di attenzione e sommare i risultati.
Auto-Attenzione con Pesi Addestrabili
In pratica, i meccanismi di auto-attenzione utilizzano pesi addestrabili per apprendere le migliori rappresentazioni per query, chiavi e valori. Questo comporta l'introduzione di tre matrici di peso:

La query è i dati da utilizzare come prima, mentre le matrici di chiavi e valori sono semplicemente matrici casuali-addestrabili.
Passo 1: Calcolare Query, Chiavi e Valori
Ogni token avrà la propria matrice di query, chiave e valore moltiplicando i suoi valori dimensionale per le matrici definite:
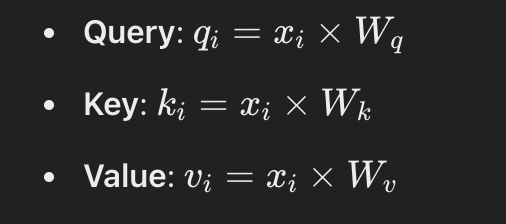
Queste matrici trasformano gli embeddings originali in uno spazio nuovo adatto per il calcolo dell'attenzione.
Esempio
Assumendo:
- Dimensione di input
din=3(dimensione dell'embedding) - Dimensione di output
dout=2(dimensione desiderata per query, chiavi e valori)
Inizializza le matrici di peso:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
Calcola le query, le chiavi e i valori:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Step 2: Calcola l'Attenzione a Prodotto Scalato
Calcola i Punteggi di Attenzione
Simile all'esempio precedente, ma questa volta, invece di utilizzare i valori delle dimensioni dei token, utilizziamo la matrice chiave del token (già calcolata utilizzando le dimensioni):. Quindi, per ogni query qi e chiave kj:

Scala i Punteggi
Per evitare che i prodotti scalari diventino troppo grandi, scalali per la radice quadrata della dimensione della chiave dk:

{% hint style="success" %} Il punteggio è diviso per la radice quadrata delle dimensioni perché i prodotti scalari potrebbero diventare molto grandi e questo aiuta a regolarli. {% endhint %}
Applica Softmax per Ottenere i Pesi di Attenzione: Come nell'esempio iniziale, normalizza tutti i valori in modo che sommino 1.

Step 3: Calcola i Vettori di Contesto
Come nell'esempio iniziale, somma semplicemente tutte le matrici di valori moltiplicando ciascuna per il suo peso di attenzione:

Esempio di Codice
Prendendo un esempio da https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb puoi controllare questa classe che implementa la funzionalità di auto-attention di cui abbiamo parlato:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
Nota che invece di inizializzare le matrici con valori casuali, nn.Linear viene utilizzato per contrassegnare tutti i pesi come parametri da addestrare.
{% endhint %}
Attenzione Causale: Nascondere Parole Future
Per i LLM vogliamo che il modello consideri solo i token che appaiono prima della posizione attuale per prevedere il prossimo token. L'attenzione causale, nota anche come attenzione mascherata, raggiunge questo obiettivo modificando il meccanismo di attenzione per impedire l'accesso ai token futuri.
Applicare una Maschera di Attenzione Causale
Per implementare l'attenzione causale, applichiamo una maschera ai punteggi di attenzione prima dell'operazione softmax in modo che quelli rimanenti sommino ancora 1. Questa maschera imposta i punteggi di attenzione dei token futuri a meno infinito, garantendo che dopo il softmax, i loro pesi di attenzione siano zero.
Passaggi
- Calcolare i Punteggi di Attenzione: Stesso di prima.
- Applicare la Maschera: Utilizzare una matrice triangolare superiore riempita con meno infinito sopra la diagonale.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf')
masked_scores = attention_scores + mask
- Applicare Softmax: Calcolare i pesi di attenzione utilizzando i punteggi mascherati.
attention_weights = torch.softmax(masked_scores, dim=-1)
Mascherare Ulteriori Pesi di Attenzione con Dropout
Per prevenire l'overfitting, possiamo applicare dropout ai pesi di attenzione dopo l'operazione softmax. Il dropout annulla casualmente alcuni dei pesi di attenzione durante l'addestramento.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
Un dropout regolare è di circa il 10-20%.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Estensione dell'Attenzione a Testa Singola all'Attenzione a Testa Multipla
L'attenzione a testa multipla in termini pratici consiste nell'eseguire più istanze della funzione di auto-attenzione, ognuna con i propri pesi, in modo che vengano calcolati vettori finali diversi.
Esempio di Codice
Potrebbe essere possibile riutilizzare il codice precedente e aggiungere solo un wrapper che lo lancia più volte, ma questa è una versione più ottimizzata da https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb che elabora tutte le teste contemporaneamente (riducendo il numero di costose iterazioni for). Come puoi vedere nel codice, le dimensioni di ciascun token sono suddivise in diverse dimensioni in base al numero di teste. In questo modo, se un token ha 8 dimensioni e vogliamo utilizzare 3 teste, le dimensioni saranno suddivise in 2 array di 4 dimensioni e ciascuna testa utilizzerà uno di essi:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Per un'altra implementazione compatta ed efficiente, puoi utilizzare la torch.nn.MultiheadAttention classe in PyTorch.
{% hint style="success" %} Risposta breve di ChatGPT sul perché sia meglio dividere le dimensioni dei token tra le teste invece di far controllare a ciascuna testa tutte le dimensioni di tutti i token:
Sebbene consentire a ciascuna testa di elaborare tutte le dimensioni di embedding possa sembrare vantaggioso perché ogni testa avrebbe accesso a tutte le informazioni, la pratica standard è dividere le dimensioni di embedding tra le teste. Questo approccio bilancia l'efficienza computazionale con le prestazioni del modello e incoraggia ciascuna testa a imparare rappresentazioni diverse. Pertanto, dividere le dimensioni di embedding è generalmente preferito rispetto a far controllare a ciascuna testa tutte le dimensioni. {% endhint %}