28 KiB
Docker Security
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access to the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
- Discover The PEASS Family, our collection of exclusive NFTs
- Get the official PEASS & HackTricks swag
- Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
- Share your hacking tricks by submitting PRs to the hacktricks repo and hacktricks-cloud repo.

Use Trickest to easily build and automate workflows powered by the world's most advanced community tools.
Get Access Today:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Basic Docker Engine Security
Docker engine does the heavy lifting of running and managing Containers. Docker engine uses Linux kernel features like Namespaces and Cgroups to provide basic isolation across Containers. It also uses features like Capabilities dropping, Seccomp, SELinux/AppArmor to achieve a better isolation.
Finally, an auth plugin can be used to limit the actions users can perform.
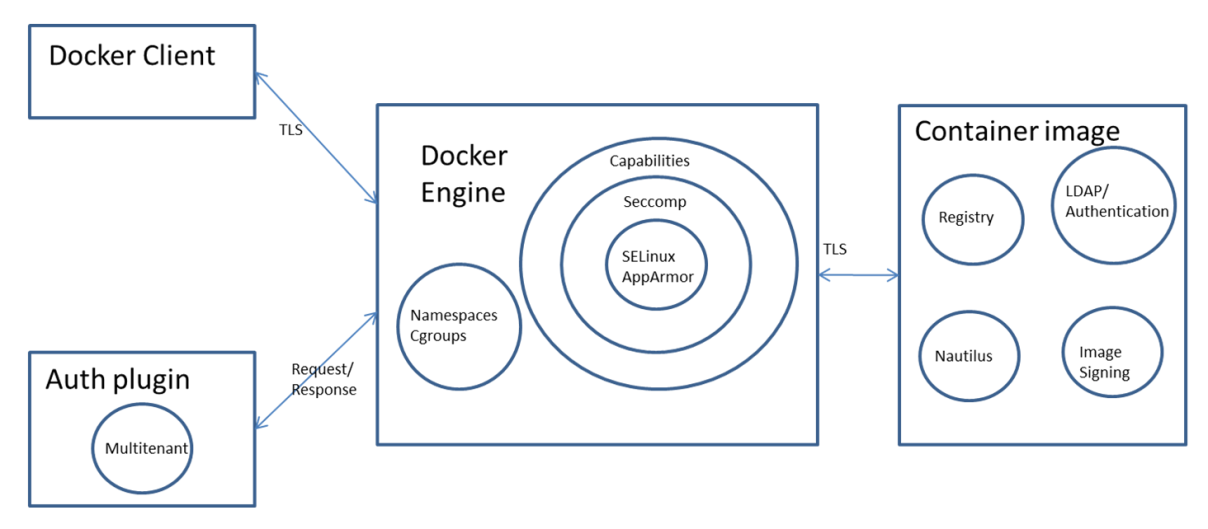
Docker engine secure access
Docker client can access Docker engine locally using Unix socket or remotely using http mechanism. To use it remotely, it is needed to use https and TLS so that confidentiality, integrity and authentication can be ensured.
By default listens on the Unix socket unix:///var/
run/docker.sock and in Ubuntu distributions, Docker start options are specified in /etc/default/docker. To allow Docker API and client to access Docker engine remotely, we need to expose Docker daemon using http socket. This can be done by:
DOCKER_OPTS="-D -H unix:///var/run/docker.sock -H
tcp://192.168.56.101:2376" -> add this to /etc/default/docker
Sudo service docker restart -> Restart Docker daemon
Exposing Docker daemon using http is not a good practice and it is needed to secure the connection using https. There are two options: first option is for client to verify server identity and in second option both client and server verify each other’s identity. Certificates establish the identity of a server. For an example of both options check this page.
Container image security
Container images are stored either in private repository or public repository. Following are the options that Docker provides for storing Container images:
- Docker hub – This is a public registry service provided by Docker
- Docker registry – This is an open source project that users can use to host their own registry.
- Docker trusted registry – This is Docker’s commercial implementation of Docker registry and it provides role based user authentication along with LDAP directory service integration.
Image Scanning
Containers can have security vulnerabilities either because of the base image or because of the software installed on top of the base image. Docker is working on a project called Nautilus that does security scan of Containers and lists the vulnerabilities. Nautilus works by comparing the each Container image layer with vulnerability repository to identify security holes.
For more information read this.
docker scan
The docker scan command allows you to scan existing Docker images using the image name or ID. For example, run the following command to scan the hello-world image:
docker scan hello-world
Testing hello-world...
Organization: docker-desktop-test
Package manager: linux
Project name: docker-image|hello-world
Docker image: hello-world
Licenses: enabled
✓ Tested 0 dependencies for known issues, no vulnerable paths found.
Note that we do not currently have vulnerability data for your image.
trivy -q -f json <ontainer_name>:<tag>
snyk container test <image> --json-file-output=<output file> --severity-threshold=high
clair-scanner -w example-alpine.yaml --ip YOUR_LOCAL_IP alpine:3.5
Docker Image Signing
Docker Container images can be stored either in public or private registry. It is needed to sign Container images to be able to confirm images haven't being tampered. Content publisher takes care of signing Container image and pushing it into the registry.
Following are some details on Docker content trust:
- The Docker content trust is an implementation of the Notary open source project. The Notary open source project is based on The Update Framework (TUF) project.
- Docker content trust is enabled with
export DOCKER_CONTENT_TRUST=1. As of Docker version 1.10, content trust is not enabled by default. - When content trust is enabled, we can pull only signed images. When image is pushed, we need to enter tagging key.
- When the publisher pushes the image for the first time using docker push, there is a need to enter a passphrase for the root key and tagging key. Other keys are generated automatically.
- Docker has also added support for hardware keys using Yubikey and details are available here.
Following is the error we get when content trust is enabled and image is not signed.
$ docker pull smakam/mybusybox
Using default tag: latest
No trust data for latest
Following output shows Container image being pushed to Docker hub with signing enabled. Since this is not the first time, user is requested to enter only the passphrase for repository key.
$ docker push smakam/mybusybox:v2
The push refers to a repository [docker.io/smakam/mybusybox]
a7022f99b0cc: Layer already exists
5f70bf18a086: Layer already exists
9508eff2c687: Layer already exists
v2: digest: sha256:8509fa814029e1c1baf7696b36f0b273492b87f59554a33589e1bd6283557fc9 size: 2205
Signing and pushing trust metadata
Enter passphrase for repository key with ID 001986b (docker.io/smakam/mybusybox):
It is needed to store root key, repository key as well as passphrase in a safe place. Following command can be used to take backup of private keys:
tar -zcvf private_keys_backup.tar.gz ~/.docker/trust/private
When I changed Docker host, I had to move the root keys and repository keys to operate from the new host.
Use Trickest to easily build and automate workflows powered by the world's most advanced community tools.
Get Access Today:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
Containers Security Features
Summary of Container Security Features
Namespaces
Namespaces are useful to isolate a project from the other ones, isolating process communications, network, mounts... It's useful to isolate the docker process from other processes (and even the /proc folder) so it cannot escape abusing other processes.
It could be possible "escape" or more exactly create new namespaces using the binary unshare (that uses the unshare syscall). Docker by default prevents it, but kubernetes doesn't (at the time of this writtiing).
Ayway, this is helpful to create new namespaces, but not to get back to the host defaults namespaces (unless you have access to some /proc inside the host namespaces, where you could use nsenter to enter in the host namespaces.).
CGroups
This allows to limit resources and doesn't affect the security of the isolation of the process (except for the release_agent that could be used to escape).
Capabilities Drop
I find this to be one of the most important features regarding the process isolation security. This is because without the capabilities, even if the process is running as root you won't be able to do some privileged actions (because the called syscall will return permission error because the process doesn't have the needed capabilities).
These are the remaining capabilities after the process drop the others:
{% code overflow="wrap" %}
Current: cap_chown,cap_dac_override,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_net_bind_service,cap_net_raw,cap_sys_chroot,cap_mknod,cap_audit_write,cap_setfcap=ep
{% endcode %}
Seccomp
It's enabled by default in Docker. It helps to limit even more the syscalls that the process can call.
The default Docker Seccomp profile can be found in https://github.com/moby/moby/blob/master/profiles/seccomp/default.json
AppArmor
Docker has a template that you can activate: https://github.com/moby/moby/tree/master/profiles/apparmor
This will allow to reduce capabilities, syscalls, access to files and folders...
Namespaces
Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources. The feature works by having the same namespace for a set of resources and processes, but those namespaces refer to distinct resources. Resources may exist in multiple spaces.
Docker makes use of the following Linux kernel Namespaces to achieve Container isolation:
- pid namespace
- mount namespace
- network namespace
- ipc namespace
- UTS namespace
For more information about the namespaces check the following page:
{% content-ref url="namespaces/" %} namespaces {% endcontent-ref %}
cgroups
Linux kernel feature cgroups provides capability to restrict resources like cpu, memory, io, network bandwidth among a set of processes. Docker allows to create Containers using cgroup feature which allows for resource control for the specific Container.
Following is a Container created with user space memory limited to 500m, kernel memory limited to 50m, cpu share to 512, blkioweight to 400. CPU share is a ratio that controls Container’s CPU usage. It has a default value of 1024 and range between 0 and 1024. If three Containers have the same CPU share of 1024, each Container can take upto 33% of CPU in case of CPU resource contention. blkio-weight is a ratio that controls Container’s IO. It has a default value of 500 and range between 10 and 1000.
docker run -it -m 500M --kernel-memory 50M --cpu-shares 512 --blkio-weight 400 --name ubuntu1 ubuntu bash
To get the cgroup of a container you can do:
docker run -dt --rm denial sleep 1234 #Run a large sleep inside a Debian container
ps -ef | grep 1234 #Get info about the sleep process
ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the hosts and some may be shred with it)
For more information check:
{% content-ref url="cgroups.md" %} cgroups.md {% endcontent-ref %}
Capabilities
Capabilities allow finer control for the capabilities that can be allowed for root user. Docker uses the Linux kernel capability feature to limit the operations that can be done inside a Container irrespective of the type of user.
When a docker container is run, the process drops sensitive capabilities that the proccess could use to escape from the isolation. This try to assure that the proccess won't be able to perform sensitive actions and escape:
{% content-ref url="../linux-capabilities.md" %} linux-capabilities.md {% endcontent-ref %}
Seccomp in Docker
This is a security feature that allows Docker to limit the syscalls that can be used inside the container:
{% content-ref url="seccomp.md" %} seccomp.md {% endcontent-ref %}
AppArmor in Docker
AppArmor is a kernel enhancement to confine containers to a limited set of resources with per-program profiles.:
{% content-ref url="apparmor.md" %} apparmor.md {% endcontent-ref %}
SELinux in Docker
SELinux is a labeling system. Every process and every file system object has a label. SELinux policies define rules about what a process label is allowed to do with all of the other labels on the system.
Container engines launch container processes with a single confined SELinux label, usually container_t, and then set the container inside of the container to be labeled container_file_t. The SELinux policy rules basically say that the container_t processes can only read/write/execute files labeled container_file_t.
{% content-ref url="../selinux.md" %} selinux.md {% endcontent-ref %}
AuthZ & AuthN
An authorization plugin approves or denies requests to the Docker daemon based on both the current authentication context and the command context. The authentication context contains all user details and the authentication method. The command context contains all the relevant request data.
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
DoS from a container
If you are not properly limiting the resources a container can use, a compromised container could DoS the host where it's running.
- CPU DoS
# stress-ng
sudo apt-get install -y stress-ng && stress-ng --vm 1 --vm-bytes 1G --verify -t 5m
# While loop
docker run -d --name malicious-container -c 512 busybox sh -c 'while true; do :; done'
- Bandwidth DoS
nc -lvp 4444 >/dev/null & while true; do cat /dev/urandom | nc <target IP> 4444; done
Interesting Docker Flags
--privileged flag
In the following page you can learn what does the --privileged flag imply:
{% content-ref url="docker-privileged.md" %} docker-privileged.md {% endcontent-ref %}
--security-opt
no-new-privileges
If you are running a container where an attacker manages to get access as a low privilege user. If you have a miss-configured suid binary, the attacker may abuse it and escalate privileges inside the container. Which, may allow him to escape from it.
Running the container with the no-new-privileges option enabled will prevent this kind of privilege escalation.
docker run -it --security-opt=no-new-privileges:true nonewpriv
Other
#You can manually add/drop capabilities with
--cap-add
--cap-drop
# You can manually disable seccomp in docker with
--security-opt seccomp=unconfined
# You can manually disable seccomp in docker with
--security-opt apparmor=unconfined
# You can manually disable selinux in docker with
--security-opt label:disable
For more --security-opt options check: https://docs.docker.com/engine/reference/run/#security-configuration
Other Security Considerations
Managing Secrets
First of all, do not put them inside your image!
Also, don’t use environment variables for your sensitive info, either. Anyone who can run docker inspect or exec into the container can find your secret.
Docker volumes are better. They are the recommended way to access your sensitive info in the Docker docs. You can use a volume as temporary file system held in memory. Volumes remove the docker inspect and the logging risk. However, root users could still see the secret, as could anyone who can exec into the container.
Even better than volumes, use Docker secrets.
If you just need the secret in your image, you can use BuildKit. BuildKit cuts build time significantly and has other nice features, including build-time secrets support.
There are three ways to specify the BuildKit backend so you can use its features now.:
- Set it as an environment variable with
export DOCKER_BUILDKIT=1. - Start your
buildorruncommand withDOCKER_BUILDKIT=1. - Enable BuildKit by default. Set the configuration in /etc/docker/daemon.json to true with:
{ "features": { "buildkit": true } }. Then restart Docker. - Then you can use secrets at build time with the
--secretflag like this:
docker build --secret my_key=my_value ,src=path/to/my_secret_file .
Where your file specifies your secrets as key-value pair.
These secrets are excluded from the image build cache. and from the final image.
If you need your secret in your running container, and not just when building your image, use Docker Compose or Kubernetes.
With Docker Compose, add the secrets key-value pair to a service and specify the secret file. Hat tip to Stack Exchange answer for the Docker Compose secrets tip that the example below is adapted from.
Example docker-compose.yml with secrets:
version: "3.7"
services:
my_service:
image: centos:7
entrypoint: "cat /run/secrets/my_secret"
secrets:
- my_secret
secrets:
my_secret:
file: ./my_secret_file.txt
Then start Compose as usual with docker-compose up --build my_service.
If you’re using Kubernetes, it has support for secrets. Helm-Secrets can help make secrets management in K8s easier. Additionally, K8s has Role Based Access Controls (RBAC) — as does Docker Enterprise. RBAC makes access Secrets management more manageable and more secure for teams.
gVisor
gVisor is an application kernel, written in Go, that implements a substantial portion of the Linux system surface. It includes an Open Container Initiative (OCI) runtime called runsc that provides an isolation boundary between the application and the host kernel. The runsc runtime integrates with Docker and Kubernetes, making it simple to run sandboxed containers.
{% embed url="https://github.com/google/gvisor" %}
Kata Containers
Kata Containers is an open source community working to build a secure container runtime with lightweight virtual machines that feel and perform like containers, but provide stronger workload isolation using hardware virtualization technology as a second layer of defense.
{% embed url="https://katacontainers.io/" %}
Summary Tips
- Do not use the
--privilegedflag or mount a Docker socket inside the container. The docker socket allows for spawning containers, so it is an easy way to take full control of the host, for example, by running another container with the--privilegedflag. - Do not run as root inside the container. Use a different user and user namespaces. The root in the container is the same as on host unless remapped with user namespaces. It is only lightly restricted by, primarily, Linux namespaces, capabilities, and cgroups.
- Drop all capabilities (
--cap-drop=all) and enable only those that are required (--cap-add=...). Many of workloads don’t need any capabilities and adding them increases the scope of a potential attack. - Use the “no-new-privileges” security option to prevent processes from gaining more privileges, for example through suid binaries.
- Limit resources available to the container. Resource limits can protect the machine from denial of service attacks.
- Adjust seccomp, AppArmor (or SELinux) profiles to restrict the actions and syscalls available for the container to the minimum required.
- Use official docker images and require signatures or build your own based on them. Don’t inherit or use backdoored images. Also store root keys, passphrase in a safe place. Docker has plans to manage keys with UCP.
- Regularly rebuild your images to apply security patches to the host an images.
- Manage your secrets wisely so it's difficult to the attacker to access them.
- If you exposes the docker daemon use HTTPS with client & server authentication.
- In your Dockerfile, favor COPY instead of ADD. ADD automatically extracts zipped files and can copy files from URLs. COPY doesn’t have these capabilities. Whenever possible, avoid using ADD so you aren’t susceptible to attacks through remote URLs and Zip files.
- Have separate containers for each micro-service
- Don’t put ssh inside container, “docker exec” can be used to ssh to Container.
- Have smaller container images
Docker Breakout / Privilege Escalation
If you are inside a docker container or you have access to a user in the docker group, you could try to escape and escalate privileges:
{% content-ref url="docker-breakout-privilege-escalation/" %} docker-breakout-privilege-escalation {% endcontent-ref %}
Docker Authentication Plugin Bypass
If you have access to the docker socket or have access to a user in the docker group but your actions are being limited by a docker auth plugin, check if you can bypass it:
{% content-ref url="authz-and-authn-docker-access-authorization-plugin.md" %} authz-and-authn-docker-access-authorization-plugin.md {% endcontent-ref %}
Hardening Docker
- The tool docker-bench-security is a script that checks for dozens of common best-practices around deploying Docker containers in production. The tests are all automated, and are based on the CIS Docker Benchmark v1.3.1.
You need to run the tool from the host running docker or from a container with enough privileges. Find out how to run it in the README: https://github.com/docker/docker-bench-security.
References
- https://blog.trailofbits.com/2019/07/19/understanding-docker-container-escapes/
- https://twitter.com/_fel1x/status/1151487051986087936
- https://ajxchapman.github.io/containers/2020/11/19/privileged-container-escape.html
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-1overview/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-2docker-engine/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-3engine-access/
- https://sreeninet.wordpress.com/2016/03/06/docker-security-part-4container-image/
- https://en.wikipedia.org/wiki/Linux_namespaces
- https://towardsdatascience.com/top-20-docker-security-tips-81c41dd06f57
Use Trickest to easily build and automate workflows powered by the world's most advanced community tools.
Get Access Today:
{% embed url="https://trickest.com/?utm_campaign=hacktrics&utm_medium=banner&utm_source=hacktricks" %}
☁️ HackTricks Cloud ☁️ -🐦 Twitter 🐦 - 🎙️ Twitch 🎙️ - 🎥 Youtube 🎥
- Do you work in a cybersecurity company? Do you want to see your company advertised in HackTricks? or do you want to have access to the latest version of the PEASS or download HackTricks in PDF? Check the SUBSCRIPTION PLANS!
- Discover The PEASS Family, our collection of exclusive NFTs
- Get the official PEASS & HackTricks swag
- Join the 💬 Discord group or the telegram group or follow me on Twitter 🐦@carlospolopm.
- Share your hacking tricks by submitting PRs to the hacktricks repo and hacktricks-cloud repo.