42 KiB
5. LLM Architecture
LLM Architecture
{% hint style="success" %} इस पांचवे चरण का लक्ष्य बहुत सरल है: पूर्ण LLM की आर्किटेक्चर विकसित करना। सब कुछ एक साथ रखें, सभी परतों को लागू करें और पाठ उत्पन्न करने या पाठ को IDs में और पीछे की ओर बदलने के लिए सभी कार्यों को बनाएं।
यह आर्किटेक्चर प्रशिक्षण और भविष्यवाणी दोनों के लिए उपयोग किया जाएगा, जब इसे प्रशिक्षित किया गया हो। {% endhint %}
LLM आर्किटेक्चर का उदाहरण https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
एक उच्च स्तर का प्रतिनिधित्व देखा जा सकता है:
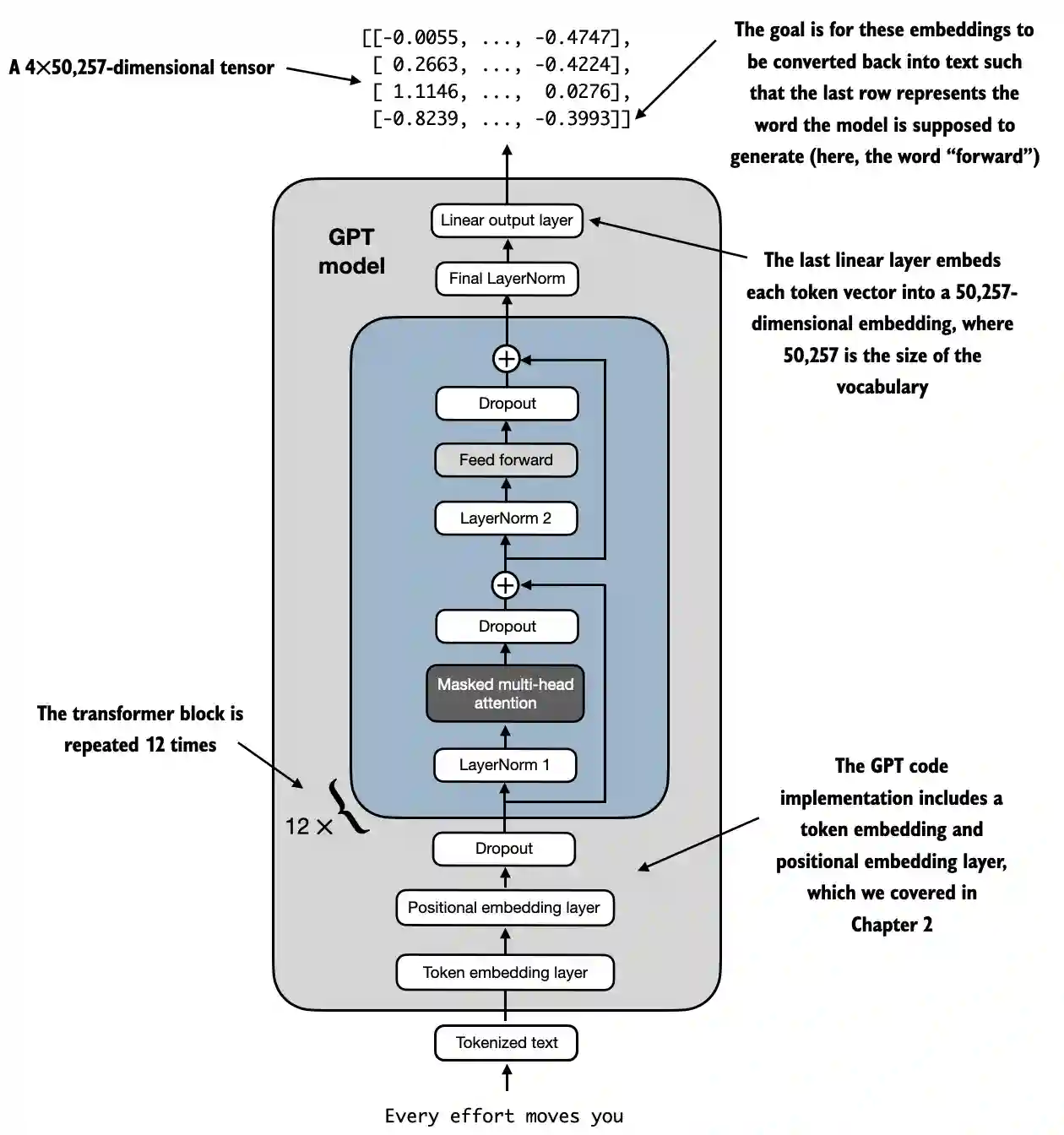
- Input (Tokenized Text): प्रक्रिया टोकनयुक्त पाठ के साथ शुरू होती है, जिसे संख्यात्मक प्रतिनिधित्व में परिवर्तित किया जाता है।
- Token Embedding and Positional Embedding Layer: टोकनयुक्त पाठ को टोकन एम्बेडिंग परत और पोजिशनल एम्बेडिंग परत के माध्यम से भेजा जाता है, जो अनुक्रम में टोकनों की स्थिति को कैप्चर करता है, जो शब्द क्रम को समझने के लिए महत्वपूर्ण है।
- Transformer Blocks: मॉडल में 12 ट्रांसफार्मर ब्लॉक्स होते हैं, प्रत्येक में कई परतें होती हैं। ये ब्लॉक्स निम्नलिखित अनुक्रम को दोहराते हैं:
- Masked Multi-Head Attention: मॉडल को एक बार में इनपुट पाठ के विभिन्न भागों पर ध्यान केंद्रित करने की अनुमति देता है।
- Layer Normalization: प्रशिक्षण को स्थिर और सुधारने के लिए एक सामान्यीकरण कदम।
- Feed Forward Layer: ध्यान परत से जानकारी को संसाधित करने और अगले टोकन के बारे में भविष्यवाणी करने के लिए जिम्मेदार।
- Dropout Layers: ये परतें प्रशिक्षण के दौरान यादृच्छिक रूप से इकाइयों को छोड़कर ओवरफिटिंग को रोकती हैं।
- Final Output Layer: मॉडल एक 4x50,257-आयामी टेन्सर आउटपुट करता है, जहाँ 50,257 शब्दावली के आकार का प्रतिनिधित्व करता है। इस टेन्सर में प्रत्येक पंक्ति एक वेक्टर के अनुरूप होती है जिसका उपयोग मॉडल अनुक्रम में अगले शब्द की भविष्यवाणी करने के लिए करता है।
- Goal: उद्देश्य इन एम्बेडिंग को लेना और उन्हें फिर से पाठ में परिवर्तित करना है। विशेष रूप से, आउटपुट की अंतिम पंक्ति का उपयोग अगले शब्द को उत्पन्न करने के लिए किया जाता है, जिसे इस आरेख में "आगे" के रूप में दर्शाया गया है।
Code representation
import torch
import torch.nn as nn
import tiktoken
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
def forward(self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x
x = self.norm1(x)
x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
# Shortcut connection for feed forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # Add the original input back
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input batch:\n", batch)
print("\nOutput shape:", out.shape)
print(out)
GELU सक्रियण फ़ंक्शन
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
उद्देश्य और कार्यक्षमता
- GELU (Gaussian Error Linear Unit): एक सक्रियण फ़ंक्शन जो मॉडल में गैर-रेखीयता को पेश करता है।
- स्मूद सक्रियण: ReLU के विपरीत, जो नकारात्मक इनपुट को शून्य कर देता है, GELU इनपुट को आउटपुट में स्मूद तरीके से मैप करता है, जिससे नकारात्मक इनपुट के लिए छोटे, गैर-शून्य मानों की अनुमति मिलती है।
- गणितीय परिभाषा:

{% hint style="info" %} इस फ़ंक्शन का उपयोग FeedForward लेयर के अंदर रेखीय परतों के बाद करने का लक्ष्य रेखीय डेटा को गैर-रेखीय में बदलना है ताकि मॉडल जटिल, गैर-रेखीय संबंधों को सीख सके। {% endhint %}
FeedForward न्यूरल नेटवर्क
आकृतियों को मैट्रिस के आकार को बेहतर समझने के लिए टिप्पणियों के रूप में जोड़ा गया है:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
x = self.layers[0](x)# x shape: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[1](x) # x shape remains: (batch_size, seq_len, 4 * emb_dim)
x = self.layers[2](x) # x shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
उद्देश्य और कार्यक्षमता
- पोजीशन-वाइज फीडफॉरवर्ड नेटवर्क: प्रत्येक पोजीशन पर अलग-अलग और समान रूप से दो-परतों वाला पूरी तरह से जुड़े नेटवर्क लागू करता है।
- परत विवरण:
- पहली रैखिक परत:
emb_dimसे4 * emb_dimतक आयाम का विस्तार करता है। - GELU सक्रियण: गैर-रेखीयता लागू करता है।
- दूसरी रैखिक परत: आयाम को फिर से
emb_dimतक कम करता है।
{% hint style="info" %} जैसा कि आप देख सकते हैं, फीड फॉरवर्ड नेटवर्क 3 परतों का उपयोग करता है। पहली एक रैखिक परत है जो रैखिक वजन (मॉडल के अंदर प्रशिक्षित करने के लिए पैरामीटर) का उपयोग करके आयामों को 4 से गुणा करेगी। फिर, GELU फ़ंक्शन का उपयोग उन सभी आयामों में गैर-रेखीय भिन्नताओं को लागू करने के लिए किया जाता है ताकि समृद्ध प्रतिनिधित्व को कैप्चर किया जा सके और अंततः एक और रैखिक परत का उपयोग करके मूल आयाम के आकार पर वापस लाया जाता है। {% endhint %}
मल्टी-हेड ध्यान तंत्र
यह पहले के खंड में पहले ही समझाया गया था।
उद्देश्य और कार्यक्षमता
- मल्टी-हेड सेल्फ-अटेंशन: मॉडल को टोकन को एन्कोड करते समय इनपुट अनुक्रम के भीतर विभिन्न पोजीशनों पर ध्यान केंद्रित करने की अनुमति देता है।
- मुख्य घटक:
- क्वेरी, की, वैल्यू: इनपुट के रैखिक प्रक्षिप्तियाँ, जो ध्यान स्कोर की गणना के लिए उपयोग की जाती हैं।
- हेड्स: समानांतर में चलने वाले कई ध्यान तंत्र (
num_heads), प्रत्येक के साथ एक कम आयाम (head_dim)। - ध्यान स्कोर: क्वेरी और कीज़ के डॉट उत्पाद के रूप में गणना की जाती है, स्केल और मास्क की जाती है।
- मास्किंग: भविष्य के टोकनों पर ध्यान केंद्रित करने से रोकने के लिए एक कारणात्मक मास्क लागू किया जाता है (GPT जैसे ऑटोरिग्रेसिव मॉडलों के लिए महत्वपूर्ण)।
- ध्यान वजन: मास्क किए गए और स्केल किए गए ध्यान स्कोर का सॉफ्टमैक्स।
- संदर्भ वेक्टर: ध्यान वजन के अनुसार मानों का भारित योग।
- आउटपुट प्रक्षिप्ति: सभी हेड्स के आउटपुट को संयोजित करने के लिए रैखिक परत।
{% hint style="info" %} इस नेटवर्क का लक्ष्य एक ही संदर्भ में टोकनों के बीच संबंधों को खोजना है। इसके अलावा, टोकनों को विभिन्न हेड्स में विभाजित किया जाता है ताकि ओवरफिटिंग को रोका जा सके, हालांकि प्रत्येक हेड में पाए गए अंतिम संबंधों को इस नेटवर्क के अंत में संयोजित किया जाता है।
इसके अलावा, प्रशिक्षण के दौरान एक कारणात्मक मास्क लागू किया जाता है ताकि बाद के टोकनों को एक टोकन के लिए विशिष्ट संबंधों को देखते समय ध्यान में न लिया जाए और कुछ ड्रॉपआउट भी लागू किया जाता है ताकि ओवरफिटिंग को रोका जा सके। {% endhint %}
परत सामान्यीकरण
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5 # Prevent division by zero during normalization.
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
उद्देश्य और कार्यक्षमता
- लेयर नॉर्मलाइजेशन: एक तकनीक जो बैच में प्रत्येक व्यक्तिगत उदाहरण के लिए विशेषताओं (एम्बेडिंग आयाम) के बीच इनपुट को सामान्य करने के लिए उपयोग की जाती है।
- घटक:
eps: एक छोटा स्थिरांक (1e-5) जो सामान्यीकरण के दौरान शून्य से विभाजन को रोकने के लिए वैरिएंस में जोड़ा जाता है।scaleऔरshift: सीखने योग्य पैरामीटर (nn.Parameter) जो मॉडल को सामान्यीकृत आउटपुट को स्केल और शिफ्ट करने की अनुमति देते हैं। इन्हें क्रमशः एक और शून्य से प्रारंभ किया जाता है।- सामान्यीकरण प्रक्रिया:
- मीन की गणना (
mean): एम्बेडिंग आयाम (dim=-1) के पार इनपुटxका औसत निकालता है, प्रसार के लिए आयाम को बनाए रखते हुए (keepdim=True)। - वैरिएंस की गणना (
var): एम्बेडिंग आयाम के पारxका वैरिएंस निकालता है, आयाम को भी बनाए रखते हुए।unbiased=Falseपैरामीटर यह सुनिश्चित करता है कि वैरिएंस पूर्वाग्रहित अनुमानक का उपयोग करके निकाला जाता है (N के बजाय N-1 से विभाजित करना), जो विशेषताओं के बजाय नमूनों के ऊपर सामान्यीकृत करते समय उपयुक्त है। - नॉर्मलाइज (
norm_x):xसे मीन घटाता है और वैरिएंस के वर्गमूल के साथepsको जोड़कर विभाजित करता है। - स्केल और शिफ्ट: सामान्यीकृत आउटपुट पर सीखने योग्य
scaleऔरshiftपैरामीटर लागू करता है।
{% hint style="info" %} लक्ष्य यह सुनिश्चित करना है कि एक ही टोकन के सभी आयामों में 0 का औसत और 1 का वैरिएंस हो। इसका लक्ष्य गहरे न्यूरल नेटवर्क के प्रशिक्षण को स्थिर करना है, जो प्रशिक्षण के दौरान पैरामीटर के अद्यतन के कारण नेटवर्क सक्रियण के वितरण में परिवर्तन को संदर्भित करता है। {% endhint %}
ट्रांसफार्मर ब्लॉक
आकृतियों को मैट्रिसेस के आकार को बेहतर समझने के लिए टिप्पणियों के रूप में जोड़ा गया है:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"]
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# x shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for attention block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm1(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.att(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
# Shortcut connection for feedforward block
shortcut = x # shape: (batch_size, seq_len, emb_dim)
x = self.norm2(x) # shape remains (batch_size, seq_len, emb_dim)
x = self.ff(x) # shape: (batch_size, seq_len, emb_dim)
x = self.drop_shortcut(x) # shape remains (batch_size, seq_len, emb_dim)
x = x + shortcut # shape: (batch_size, seq_len, emb_dim)
return x # Output shape: (batch_size, seq_len, emb_dim)
उद्देश्य और कार्यक्षमता
- परतों की संरचना: मल्टी-हेड ध्यान, फीडफॉरवर्ड नेटवर्क, परत सामान्यीकरण, और अवशिष्ट कनेक्शन को जोड़ता है।
- परत सामान्यीकरण: स्थिर प्रशिक्षण के लिए ध्यान और फीडफॉरवर्ड परतों से पहले लागू किया जाता है।
- अवशिष्ट कनेक्शन (शॉर्टकट): ग्रेडिएंट प्रवाह में सुधार करने और गहरे नेटवर्क के प्रशिक्षण को सक्षम करने के लिए एक परत के इनपुट को इसके आउटपुट में जोड़ता है।
- ड्रॉपआउट: नियमितीकरण के लिए ध्यान और फीडफॉरवर्ड परतों के बाद लागू किया जाता है।
चरण-दर-चरण कार्यक्षमता
- पहला अवशिष्ट पथ (सेल्फ-अटेंशन):
- इनपुट (
shortcut): अवशिष्ट कनेक्शन के लिए मूल इनपुट को सहेजें। - लेयर नॉर्म (
norm1): इनपुट को सामान्यीकृत करें। - मल्टी-हेड अटेंशन (
att): सेल्फ-अटेंशन लागू करें। - ड्रॉपआउट (
drop_shortcut): नियमितीकरण के लिए ड्रॉपआउट लागू करें। - अवशिष्ट जोड़ें (
x + shortcut): मूल इनपुट के साथ मिलाएं।
- दूसरा अवशिष्ट पथ (फीडफॉरवर्ड):
- इनपुट (
shortcut): अगले अवशिष्ट कनेक्शन के लिए अपडेटेड इनपुट को सहेजें। - लेयर नॉर्म (
norm2): इनपुट को सामान्यीकृत करें। - फीडफॉरवर्ड नेटवर्क (
ff): फीडफॉरवर्ड परिवर्तन लागू करें। - ड्रॉपआउट (
drop_shortcut): ड्रॉपआउट लागू करें। - अवशिष्ट जोड़ें (
x + shortcut): पहले अवशिष्ट पथ से इनपुट के साथ मिलाएं।
{% hint style="info" %}
ट्रांसफार्मर ब्लॉक सभी नेटवर्क को एक साथ समूहित करता है और प्रशिक्षण स्थिरता और परिणामों में सुधार के लिए कुछ सामान्यीकरण और ड्रॉपआउट लागू करता है।
ध्यान दें कि ड्रॉपआउट प्रत्येक नेटवर्क के उपयोग के बाद किया जाता है जबकि सामान्यीकरण पहले लागू किया जाता है।
इसके अलावा, यह शॉर्टकट का भी उपयोग करता है जिसमें एक नेटवर्क के आउटपुट को इसके इनपुट के साथ जोड़ना शामिल है। यह सुनिश्चित करके वैनिशिंग ग्रेडिएंट समस्या को रोकने में मदद करता है कि प्रारंभिक परतें "जितना" योगदान करती हैं जितना कि अंतिम परतें। {% endhint %}
GPTModel
आकृतियों को मैट्रिसेस के आकार को बेहतर समझने के लिए टिप्पणियों के रूप में जोड़ा गया है:
# From https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
# shape: (vocab_size, emb_dim)
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
# shape: (context_length, emb_dim)
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# Stack of TransformerBlocks
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
# shape: (emb_dim, vocab_size)
def forward(self, in_idx):
# in_idx shape: (batch_size, seq_len)
batch_size, seq_len = in_idx.shape
# Token embeddings
tok_embeds = self.tok_emb(in_idx)
# shape: (batch_size, seq_len, emb_dim)
# Positional embeddings
pos_indices = torch.arange(seq_len, device=in_idx.device)
# shape: (seq_len,)
pos_embeds = self.pos_emb(pos_indices)
# shape: (seq_len, emb_dim)
# Add token and positional embeddings
x = tok_embeds + pos_embeds # Broadcasting over batch dimension
# x shape: (batch_size, seq_len, emb_dim)
x = self.drop_emb(x) # Dropout applied
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.trf_blocks(x) # Pass through Transformer blocks
# x shape remains: (batch_size, seq_len, emb_dim)
x = self.final_norm(x) # Final LayerNorm
# x shape remains: (batch_size, seq_len, emb_dim)
logits = self.out_head(x) # Project to vocabulary size
# logits shape: (batch_size, seq_len, vocab_size)
return logits # Output shape: (batch_size, seq_len, vocab_size)
उद्देश्य और कार्यक्षमता
- Embedding Layers:
- Token Embeddings (
tok_emb): टोकन अनुक्रमांक को एम्बेडिंग में परिवर्तित करता है। याद दिलाने के लिए, ये शब्दावली में प्रत्येक टोकन के प्रत्येक आयाम को दिए गए वजन हैं। - Positional Embeddings (
pos_emb): एम्बेडिंग में स्थिति संबंधी जानकारी जोड़ता है ताकि टोकनों के क्रम को कैप्चर किया जा सके। याद दिलाने के लिए, ये टोकन को उसके पाठ में स्थिति के अनुसार दिए गए वजन हैं। - Dropout (
drop_emb): नियमितीकरण के लिए एम्बेडिंग पर लागू किया जाता है। - Transformer Blocks (
trf_blocks): एम्बेडिंग को प्रोसेस करने के लिएn_layersट्रांसफार्मर ब्लॉकों का स्टैक। - Final Normalization (
final_norm): आउटपुट लेयर से पहले लेयर नॉर्मलाइजेशन। - Output Layer (
out_head): अंतिम छिपे हुए राज्यों को शब्दावली के आकार में प्रक्षिप्त करता है ताकि भविष्यवाणी के लिए लॉजिट्स उत्पन्न हो सकें।
{% hint style="info" %} इस वर्ग का लक्ष्य अनुक्रम में अगले टोकन की भविष्यवाणी करने के लिए सभी अन्य उल्लेखित नेटवर्क का उपयोग करना है, जो पाठ निर्माण जैसे कार्यों के लिए मौलिक है।
ध्यान दें कि यह जितने ट्रांसफार्मर ब्लॉक निर्दिष्ट हैं उतने का उपयोग करेगा और प्रत्येक ट्रांसफार्मर ब्लॉक एक मल्टी-हेड अटेंशन नेट, एक फीड फॉरवर्ड नेट और कई नॉर्मलाइजेशन का उपयोग कर रहा है। इसलिए यदि 12 ट्रांसफार्मर ब्लॉक का उपयोग किया जाता है, तो इसे 12 से गुणा करें।
इसके अलावा, एक नॉर्मलाइजेशन लेयर आउटपुट से पहले जोड़ी जाती है और अंत में परिणामों को उचित आयामों के साथ प्राप्त करने के लिए एक अंतिम रैखिक लेयर लागू की जाती है। ध्यान दें कि प्रत्येक अंतिम वेक्टर का आकार उपयोग की गई शब्दावली के आकार के बराबर है। इसका कारण यह है कि यह शब्दावली के भीतर संभावित टोकन के लिए एक संभावना प्राप्त करने की कोशिश कर रहा है। {% endhint %}
प्रशिक्षित करने के लिए पैरामीटर की संख्या
GPT संरचना को परिभाषित करने के बाद, प्रशिक्षित करने के लिए पैरामीटर की संख्या पता लगाना संभव है:
GPT_CONFIG_124M = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"emb_dim": 768, # Embedding dimension
"n_heads": 12, # Number of attention heads
"n_layers": 12, # Number of layers
"drop_rate": 0.1, # Dropout rate
"qkv_bias": False # Query-Key-Value bias
}
model = GPTModel(GPT_CONFIG_124M)
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# Total number of parameters: 163,009,536
चरण-दर-चरण गणना
1. एम्बेडिंग परतें: टोकन एम्बेडिंग और स्थिति एम्बेडिंग
- परत:
nn.Embedding(vocab_size, emb_dim) - पैरामीटर:
vocab_size * emb_dim
token_embedding_params = 50257 * 768 = 38,597,376
- लेयर:
nn.Embedding(context_length, emb_dim) - पैरामीटर्स:
context_length * emb_dim
position_embedding_params = 1024 * 768 = 786,432
कुल एम्बेडिंग पैरामीटर
embedding_params = token_embedding_params + position_embedding_params
embedding_params = 38,597,376 + 786,432 = 39,383,808
2. Transformer Blocks
यहां 12 ट्रांसफार्मर ब्लॉक हैं, इसलिए हम एक ब्लॉक के लिए पैरामीटर की गणना करेंगे और फिर 12 से गुणा करेंगे।
प्रत्येक ट्रांसफार्मर ब्लॉक के लिए पैरामीटर
a. मल्टी-हेड अटेंशन
- घटक:
- क्वेरी लीनियर लेयर (
W_query):nn.Linear(emb_dim, emb_dim, bias=False) - की लीनियर लेयर (
W_key):nn.Linear(emb_dim, emb_dim, bias=False) - वैल्यू लीनियर लेयर (
W_value):nn.Linear(emb_dim, emb_dim, bias=False) - आउटपुट प्रोजेक्शन (
out_proj):nn.Linear(emb_dim, emb_dim) - गणनाएँ:
W_query,W_key,W_valueमें से प्रत्येक:
qkv_params = emb_dim * emb_dim = 768 * 768 = 589,824
चूंकि ऐसी तीन लेयर हैं:
total_qkv_params = 3 * qkv_params = 3 * 589,824 = 1,769,472
- आउटपुट प्रोजेक्शन (
out_proj):
out_proj_params = (emb_dim * emb_dim) + emb_dim = (768 * 768) + 768 = 589,824 + 768 = 590,592
- कुल मल्टी-हेड अटेंशन पैरामीटर:
mha_params = total_qkv_params + out_proj_params
mha_params = 1,769,472 + 590,592 = 2,360,064
b. फीडफॉरवर्ड नेटवर्क
- घटक:
- पहली लीनियर लेयर:
nn.Linear(emb_dim, 4 * emb_dim) - दूसरी लीनियर लेयर:
nn.Linear(4 * emb_dim, emb_dim) - गणनाएँ:
- पहली लीनियर लेयर:
ff_first_layer_params = (emb_dim * 4 * emb_dim) + (4 * emb_dim)
ff_first_layer_params = (768 * 3072) + 3072 = 2,359,296 + 3,072 = 2,362,368
- दूसरी लीनियर लेयर:
ff_second_layer_params = (4 * emb_dim * emb_dim) + emb_dim
ff_second_layer_params = (3072 * 768) + 768 = 2,359,296 + 768 = 2,360,064
- कुल फीडफॉरवर्ड पैरामीटर:
ff_params = ff_first_layer_params + ff_second_layer_params
ff_params = 2,362,368 + 2,360,064 = 4,722,432
c. लेयर नॉर्मलाइजेशन
- घटक:
- प्रत्येक ब्लॉक में दो
LayerNormउदाहरण। - प्रत्येक
LayerNormमें2 * emb_dimपैरामीटर होते हैं (स्केल और शिफ्ट)। - गणनाएँ:
layer_norm_params_per_block = 2 * (2 * emb_dim) = 2 * 768 * 2 = 3,072
d. प्रत्येक ट्रांसफार्मर ब्लॉक के लिए कुल पैरामीटर
pythonCopy codeparams_per_block = mha_params + ff_params + layer_norm_params_per_block
params_per_block = 2,360,064 + 4,722,432 + 3,072 = 7,085,568
सभी ट्रांसफार्मर ब्लॉक्स के लिए कुल पैरामीटर
pythonCopy codetotal_transformer_blocks_params = params_per_block * n_layers
total_transformer_blocks_params = 7,085,568 * 12 = 85,026,816
3. अंतिम परतें
क. अंतिम परत सामान्यीकरण
- पैरामीटर:
2 * emb_dim(स्केल और शिफ्ट)
pythonCopy codefinal_layer_norm_params = 2 * 768 = 1,536
b. आउटपुट प्रोजेक्शन लेयर (out_head)
- लेयर:
nn.Linear(emb_dim, vocab_size, bias=False) - पैरामीटर्स:
emb_dim * vocab_size
pythonCopy codeoutput_projection_params = 768 * 50257 = 38,597,376
4. सभी पैरामीटर का सारांश
pythonCopy codetotal_params = (
embedding_params +
total_transformer_blocks_params +
final_layer_norm_params +
output_projection_params
)
total_params = (
39,383,808 +
85,026,816 +
1,536 +
38,597,376
)
total_params = 163,009,536
Generate Text
एक ऐसा मॉडल होना जो अगले टोकन की भविष्यवाणी करता है जैसे कि पहले वाला, बस अंतिम टोकन मानों को आउटपुट से लेना आवश्यक है (क्योंकि वे भविष्यवाणी किए गए टोकन के होंगे), जो कि शब्दावली में प्रत्येक प्रविष्टि के लिए एक मान होगा और फिर softmax फ़ंक्शन का उपयोग करके आयामों को 1 के योग में संभावनाओं में सामान्यीकृत करना होगा और फिर सबसे बड़े प्रविष्टि का अनुक्रमांक प्राप्त करना होगा, जो कि शब्दावली के भीतर शब्द का अनुक्रमांक होगा।
Code from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch04/01_main-chapter-code/ch04.ipynb:
def generate_text_simple(model, idx, max_new_tokens, context_size):
# idx is (batch, n_tokens) array of indices in the current context
for _ in range(max_new_tokens):
# Crop current context if it exceeds the supported context size
# E.g., if LLM supports only 5 tokens, and the context size is 10
# then only the last 5 tokens are used as context
idx_cond = idx[:, -context_size:]
# Get the predictions
with torch.no_grad():
logits = model(idx_cond)
# Focus only on the last time step
# (batch, n_tokens, vocab_size) becomes (batch, vocab_size)
logits = logits[:, -1, :]
# Apply softmax to get probabilities
probas = torch.softmax(logits, dim=-1) # (batch, vocab_size)
# Get the idx of the vocab entry with the highest probability value
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # (batch, 1)
# Append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (batch, n_tokens+1)
return idx
start_context = "Hello, I am"
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0)
print("encoded_tensor.shape:", encoded_tensor.shape)
model.eval() # disable dropout
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", out)
print("Output length:", len(out[0]))