26 KiB
4. Механізми уваги
Механізми уваги та самоувага в нейронних мережах
Механізми уваги дозволяють нейронним мережам зосереджуватися на конкретних частинах вхідних даних під час генерації кожної частини виходу. Вони призначають різні ваги різним вхідним даним, допомагаючи моделі вирішити, які вхідні дані є найбільш релевантними для поставленого завдання. Це є критично важливим у таких завданнях, як машинний переклад, де розуміння контексту всього речення необхідне для точного перекладу.
{% hint style="success" %}
Мета цього четвертого етапу дуже проста: застосувати деякі механізми уваги. Це будуть багато повторюваних шарів, які захоплюватимуть зв'язок слова у словнику з його сусідами в поточному реченні, що використовується для навчання LLM.
Для цього використовується багато шарів, тому багато навчальних параметрів будуть захоплювати цю інформацію.
{% endhint %}
Розуміння механізмів уваги
У традиційних моделях послідовність до послідовності, що використовуються для перекладу мов, модель кодує вхідну послідовність у вектор контексту фіксованого розміру. Однак цей підхід має труднощі з довгими реченнями, оскільки вектор контексту фіксованого розміру може не захоплювати всю необхідну інформацію. Механізми уваги вирішують це обмеження, дозволяючи моделі враховувати всі вхідні токени під час генерації кожного вихідного токена.
Приклад: Машинний переклад
Розглянемо переклад німецького речення "Kannst du mir helfen diesen Satz zu übersetzen" на англійську. Переклад слово за словом не дасть граматично правильного англійського речення через відмінності в граматичних структурах між мовами. Механізм уваги дозволяє моделі зосереджуватися на релевантних частинах вхідного речення під час генерації кожного слова вихідного речення, що призводить до більш точного та зв'язного перекладу.
Вступ до самоуваги
Самоувага, або внутрішня увага, є механізмом, де увага застосовується в межах однієї послідовності для обчислення представлення цієї послідовності. Це дозволяє кожному токену в послідовності звертатися до всіх інших токенів, допомагаючи моделі захоплювати залежності між токенами незалежно від їх відстані в послідовності.
Ключові концепції
- Токени: Окремі елементи вхідної послідовності (наприклад, слова в реченні).
- Векторні представлення: Векторні представлення токенів, що захоплюють семантичну інформацію.
- Ваги уваги: Значення, які визначають важливість кожного токена відносно інших.
Обчислення ваг уваги: покроковий приклад
Розглянемо речення "Hello shiny sun!" і представимо кожне слово з 3-вимірним векторним представленням:
- Hello:
[0.34, 0.22, 0.54] - shiny:
[0.53, 0.34, 0.98] - sun:
[0.29, 0.54, 0.93]
Наша мета - обчислити вектор контексту для слова "shiny" за допомогою самоуваги.
Крок 1: Обчислення оцінок уваги
{% hint style="success" %} Просто помножте кожне значення виміру запиту на відповідне значення кожного токена і додайте результати. Ви отримуєте 1 значення для кожної пари токенів. {% endhint %}
Для кожного слова в реченні обчисліть оцінку уваги відносно "shiny", обчислюючи скалярний добуток їх векторних представлень.
Оцінка уваги між "Hello" та "shiny"

Оцінка уваги між "shiny" та "shiny"
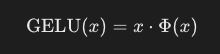
Оцінка уваги між "sun" та "shiny"

Крок 2: Нормалізація оцінок уваги для отримання ваг уваги
{% hint style="success" %} Не губіться в математичних термінах, мета цієї функції проста: нормалізувати всі ваги так, щоб вони в сумі давали 1.
Крім того, функція softmax використовується, оскільки вона підкреслює відмінності завдяки експоненціальній частині, що полегшує виявлення корисних значень. {% endhint %}
Застосуйте функцію softmax до оцінок уваги, щоб перетворити їх на ваги уваги, які в сумі дають 1.

Обчислення експонент:

Обчислення суми:

Обчислення ваг уваги:

Крок 3: Обчислення вектора контексту
{% hint style="success" %} Просто візьміть кожну вагу уваги і помножте її на відповідні виміри токена, а потім додайте всі виміри, щоб отримати лише 1 вектор (вектор контексту) {% endhint %}
Вектор контексту обчислюється як зважена сума векторних представлень усіх слів, використовуючи ваги уваги.

Обчислення кожного компонента:
- Зважене векторне представлення "Hello":



Сумування зважених векторних представлень:
вектор контексту=[0.0779+0.2156+0.1057, 0.0504+0.1382+0.1972, 0.1237+0.3983+0.3390]=[0.3992,0.3858,0.8610]
Цей вектор контексту представляє збагачене векторне представлення для слова "shiny", включаючи інформацію з усіх слів у реченні.
Підсумок процесу
- Обчисліть оцінки уваги: Використовуйте скалярний добуток між векторним представленням цільового слова та векторними представленнями всіх слів у послідовності.
- Нормалізуйте оцінки для отримання ваг уваги: Застосуйте функцію softmax до оцінок уваги, щоб отримати ваги, які в сумі дають 1.
- Обчисліть вектор контексту: Помножте векторне представлення кожного слова на його вагу уваги та підсумуйте результати.
Самоувага з навчальними вагами
На практиці механізми самоуваги використовують навчальні ваги для навчання найкращих представлень для запитів, ключів і значень. Це передбачає введення трьох матриць ваг:

Запит є даними, які використовуються, як і раніше, тоді як матриці ключів і значень - це просто випадкові навчальні матриці.
Крок 1: Обчислення запитів, ключів і значень
Кожен токен матиме свою власну матрицю запиту, ключа та значення, множачи свої значення вимірів на визначені матриці:

Ці матриці перетворюють оригінальні векторні представлення в новий простір, придатний для обчислення уваги.
Приклад
Припустимо:
- Вхідний розмір
din=3(розмір векторного представлення) - Вихідний розмір
dout=2(бажаний розмір для запитів, ключів і значень)
Ініціалізуйте матриці ваг:
import torch.nn as nn
d_in = 3
d_out = 2
W_query = nn.Parameter(torch.rand(d_in, d_out))
W_key = nn.Parameter(torch.rand(d_in, d_out))
W_value = nn.Parameter(torch.rand(d_in, d_out))
Обчисліть запити, ключі та значення:
queries = torch.matmul(inputs, W_query)
keys = torch.matmul(inputs, W_key)
values = torch.matmul(inputs, W_value)
Крок 2: Обчислення масштабованої уваги за допомогою скалярного добутку
Обчислення оцінок уваги
Схоже на попередній приклад, але цього разу, замість використання значень вимірів токенів, ми використовуємо матрицю ключів токена (яка вже була обчислена за допомогою вимірів):. Отже, для кожного запиту qi та ключа kj:

Масштабування оцінок
Щоб запобігти тому, щоб скалярні добутки ставали занадто великими, масштабуйте їх за квадратним коренем з розміру ключа dk:

{% hint style="success" %} Оцінка ділиться на квадратний корінь з вимірів, оскільки скалярні добутки можуть ставати дуже великими, і це допомагає їх регулювати. {% endhint %}
Застосування Softmax для отримання ваг уваги: Як у початковому прикладі, нормалізуйте всі значення так, щоб їхня сума дорівнювала 1.

Крок 3: Обчислення контекстних векторів
Як у початковому прикладі, просто складіть усі матриці значень, помноживши кожну з них на її вагу уваги:

Приклад коду
Взявши приклад з https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb, ви можете перевірити цей клас, який реалізує функціональність самостійної уваги, про яку ми говорили:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
import torch.nn as nn
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
d_in=3
d_out=2
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
{% hint style="info" %}
Зверніть увагу, що замість ініціалізації матриць випадковими значеннями, використовується nn.Linear, щоб позначити всі ваги як параметри для навчання.
{% endhint %}
Причинна Увага: Приховування Майбутніх Слів
Для LLM ми хочемо, щоб модель враховувала лише токени, які з'являються перед поточною позицією, щоб прогнозувати наступний токен. Причинна увага, також відома як замаскована увага, досягає цього, модифікуючи механізм уваги, щоб запобігти доступу до майбутніх токенів.
Застосування Маски Причинної Уваги
Щоб реалізувати причинну увагу, ми застосовуємо маску до оцінок уваги перед операцією softmax, щоб залишкові значення все ще складали 1. Ця маска встановлює оцінки уваги майбутніх токенів на негативну нескінченність, забезпечуючи, що після softmax їх ваги уваги дорівнюють нулю.
Кроки
- Обчислити Оцінки Уваги: Так само, як і раніше.
- Застосувати Маску: Використовуйте верхню трикутну матрицю, заповнену негативною нескінченністю вище діагоналі.
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) * float('-inf')
masked_scores = attention_scores + mask
- Застосувати Softmax: Обчисліть ваги уваги, використовуючи замасковані оцінки.
attention_weights = torch.softmax(masked_scores, dim=-1)
Маскування Додаткових Ваг Уваги з Допомогою Dropout
Щоб запобігти перенавчанню, ми можемо застосувати dropout до ваг уваги після операції softmax. Dropout випадковим чином обнуляє деякі з ваг уваги під час навчання.
dropout = nn.Dropout(p=0.5)
attention_weights = dropout(attention_weights)
Звичайний дроп-аут становить близько 10-20%.
Code Example
Code example from https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb:
import torch
import torch.nn as nn
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
batch = torch.stack((inputs, inputs), dim=0)
print(batch.shape)
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length,
dropout, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1)) # New
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # This generates the keys of the tokens
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.transpose(1, 2) # Moves the third dimension to the second one and the second one to the third one to be able to multiply
attn_scores.masked_fill_( # New, _ ops are in-place
self.mask.bool()[:num_tokens, :num_tokens], -torch.inf) # `:num_tokens` to account for cases where the number of tokens in the batch is smaller than the supported context_size
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
attn_weights = self.dropout(attn_weights)
context_vec = attn_weights @ values
return context_vec
torch.manual_seed(123)
context_length = batch.shape[1]
d_in = 3
d_out = 2
ca = CausalAttention(d_in, d_out, context_length, 0.0)
context_vecs = ca(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Розширення одноголової уваги до багатоголової уваги
Багатоголова увага на практиці полягає в виконанні декількох екземплярів функції самостійної уваги, кожен з яких має свої власні ваги, тому розраховуються різні фінальні вектори.
Приклад коду
Можливо, можна повторно використовувати попередній код і просто додати обгортку, яка запускає його кілька разів, але це більш оптимізована версія з https://github.com/rasbt/LLMs-from-scratch/blob/main/ch03/01_main-chapter-code/ch03.ipynb, яка обробляє всі голови одночасно (зменшуючи кількість витратних циклів). Як ви можете бачити в коді, розміри кожного токена діляться на різні розміри відповідно до кількості голів. Таким чином, якщо токен має 8 розмірів і ми хочемо використовувати 3 голови, розміри будуть поділені на 2 масиви по 4 розміри, і кожна голова використовуватиме один з них:
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape
# b is the num of batches
# num_tokens is the number of tokens per batch
# d_in is the dimensions er token
keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
queries = self.W_query(x)
values = self.W_value(x)
# We implicitly split the matrix by adding a `num_heads` dimension
# Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
# Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
# Compute scaled dot-product attention (aka self-attention) with a causal mask
attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
# Original mask truncated to the number of tokens and converted to boolean
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
# Use the mask to fill attention scores
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# Shape: (b, num_tokens, num_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2)
# Combine heads, where self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec) # optional projection
return context_vec
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
Для ще однієї компактної та ефективної реалізації ви можете використовувати клас torch.nn.MultiheadAttention у PyTorch.
{% hint style="success" %} Коротка відповідь ChatGPT про те, чому краще розділити виміри токенів між головами, замість того, щоб кожна голова перевіряла всі виміри всіх токенів:
Хоча дозволити кожній голові обробляти всі вимірювання вбудовування може здаватися вигідним, оскільки кожна голова матиме доступ до всієї інформації, стандартною практикою є розділення вимірів вбудовування між головами. Цей підхід забезпечує баланс між обчислювальною ефективністю та продуктивністю моделі та заохочує кожну голову вивчати різноманітні представлення. Тому розподіл вимірів вбудовування зазвичай є кращим, ніж надання кожній голові можливості перевіряти всі виміри. {% endhint %}