# Objective - Make it easier to understand how to profile things. - Talk about CPU vs GPU work for graphics. ## Solution - Add a section on GPU profiling and CPU vs GPU work. - Rearrange some sections so Tracy is the first backend mentioned. ## Issues I did this as a very quick fix to clear some things up, but the overall guide still flows poorly and has too much extraneous info distracting from the use case of "I just want to figure out why my app is slow", where the advice should be "use tracy, and if GPU bottlenecked, do this". Someone should do a full rewrite at some point. I chose to omit talking about RenderDiagnosticsPlugin, but it's definitely worth a mention as a way to easily check GPU + GPU time for graphics work, although it's not hooked up in a lot of the engine, iirc only shadows and the main passes. Again someone else should write about it in the future. Similarly it might've been useful to have a section describing how to use NSight/RGP/IGA/Xcode for GPU profiling, as they're far from intuitive tools.
11 KiB
Profiling
Table of Contents
CPU runtime
Overview
Bevy has built-in tracing spans to make it cheap and easy to profile Bevy ECS systems, render logic, engine internals, and user app code. Enable the trace cargo feature to enable Bevy's built-in spans.
If you also want to include wgpu tracing spans when profiling, they are emitted at the tracing info level so you will need to make sure they are not filtered out by the LogSettings resource's filter member which defaults to wgpu=error. You can do this by setting the RUST_LOG=info environment variable when running your application.
You also need to select a tracing backend using one of the cargo features described in the below sections.
Note
When your app is bottlenecked by the GPU, you may encounter frames that have multiple prepare-set systems all taking an unusually long time to complete, and all finishing at about the same time.
See the section on GPU profiling for determining what GPU work is the bottleneck.
You can find more details in the docs for
prepare_windows.
Adding your own spans
Add spans to your app like this (these are in bevy::prelude::* and bevy::log::*, just like the normal logging macros).
{
// creates a span and starts the timer
let my_span = info_span!("span_name", name = "span_name").entered();
do_something_here();
} // my_span is dropped here ... this stops the timer
// You can also "manually" enter the span if you need more control over when the timer starts
// Prefer the previous, simpler syntax unless you need the extra control.
let my_span = info_span!("span_name", name = "span_name");
{
// starts the span's timer
let guard = my_span.enter();
do_something_here();
} // guard is dropped here ... this stops the timer
Search for info_span! in this repo for some real-world examples.
For more details, check out the tracing span docs.
Tracy profiler
The Tracy profiling tool is:
A real time, nanosecond resolution, remote telemetry, hybrid frame and sampling profiler for games and other applications.
There are binaries available for Windows, and installation / build instructions for other operating systems can be found in the Tracy documentation PDF.
It has a command line capture tool that can record the execution of graphical applications, saving it as a profile file. Tracy has a GUI to inspect these profile files. The GUI app also supports live capture, showing you in real time the trace of your app. The version of tracy must be matched to the version of tracing-tracy used in bevy. A compatibility table can be found on crates.io and the version used can be found here.
On macOS, Tracy can be installed through Homebrew by running brew install tracy, and the GUI client can be launched by running tracy.
In one terminal, run:
./capture-release -o my_capture.tracy
This will sit and wait for a tracy-instrumented application to start, and when it does, it will automatically connect and start capturing.
The name and location of the Tracy command line tool will vary depending on how you installed it - the default executable names are capture-release on Linux, tracy on macOS and capture.exe on Windows. In one terminal, run this tool: ./capture-release -o my_capture.tracy. This will sit and wait for a tracy-instrumented application to start, and when it does, it will automatically connect and start capturing.
Then run your application, enabling the trace_tracy feature: cargo run --release --features bevy/trace_tracy. If you also want to track memory allocations, at the cost of increased runtime overhead, then enable the trace_tracy_memory feature instead: cargo run --release --features bevy/trace_tracy_memory.
After running your app, you can open the captured profile file (my_capture.tracy in the example above) in the Tracy GUI application to see a timeline of the executed spans.
Alternatively, directly run the tracy GUI and then run your application, for live capture. However, beware that running the live capture on the same machine will be a competing graphical application, which may impact results. Pre-recording the profile data through the CLI tool is recommended for more accurate traces.
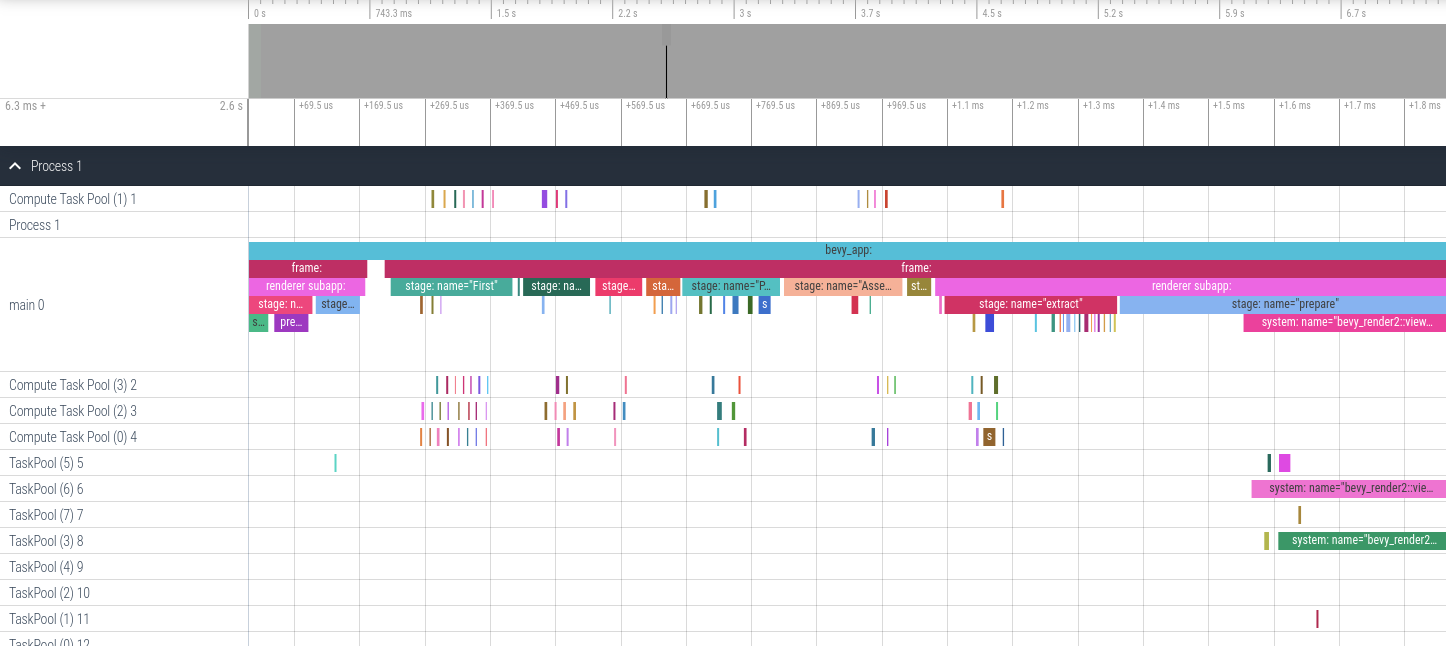
In any case, you'll see your trace in the GUI window:
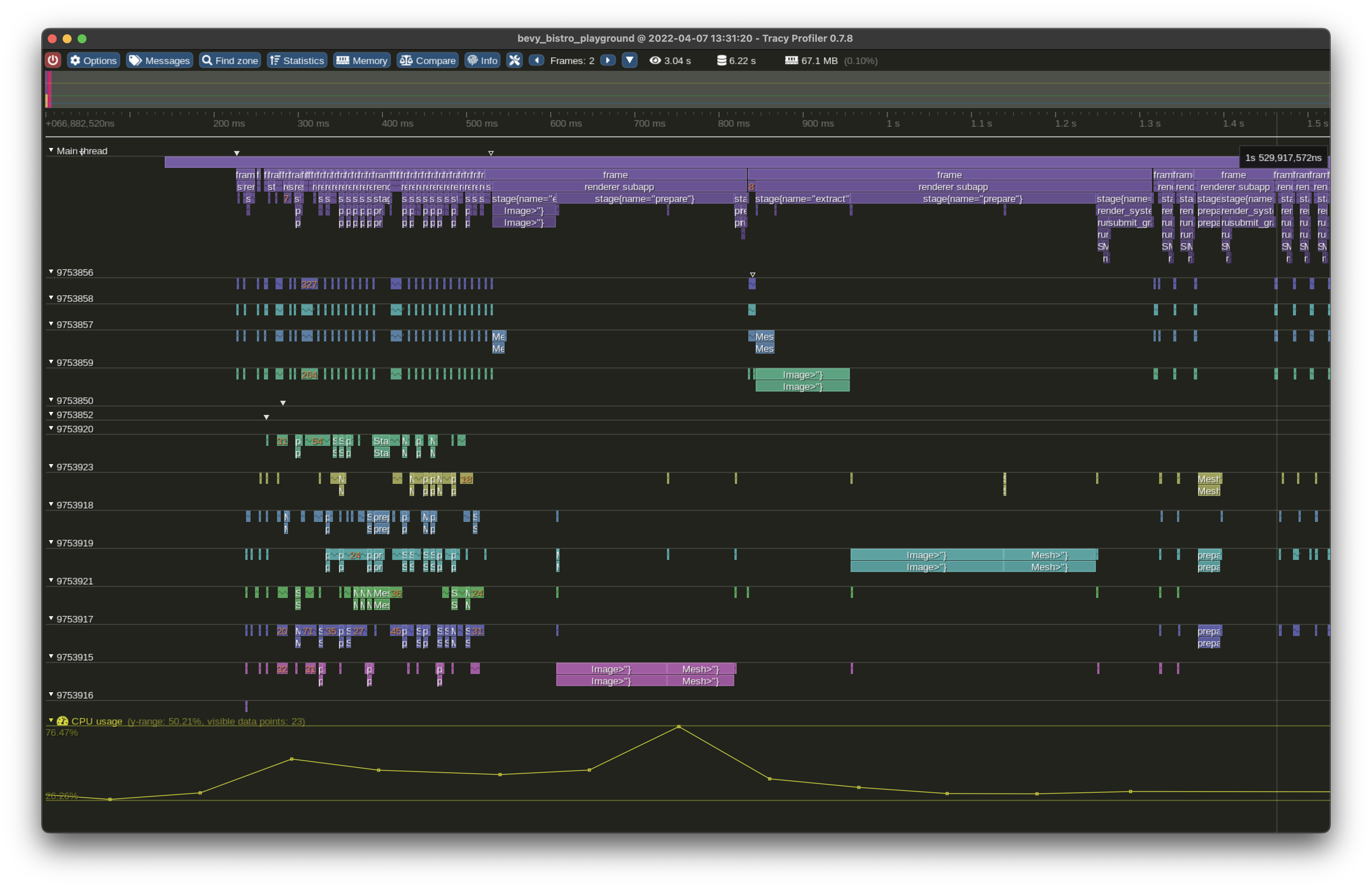
There is a button to display statistics of mean time per call (MTPC) for all systems:
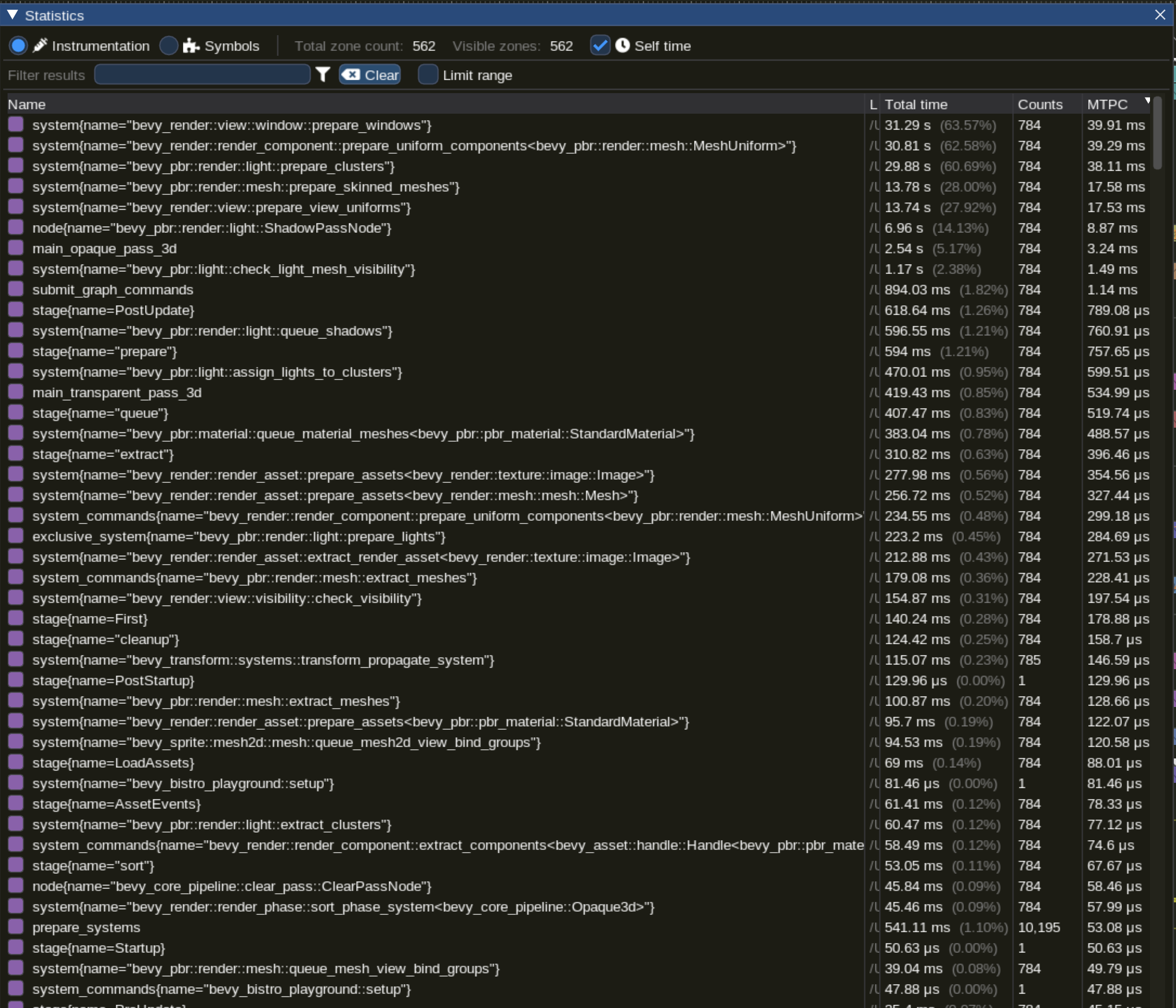
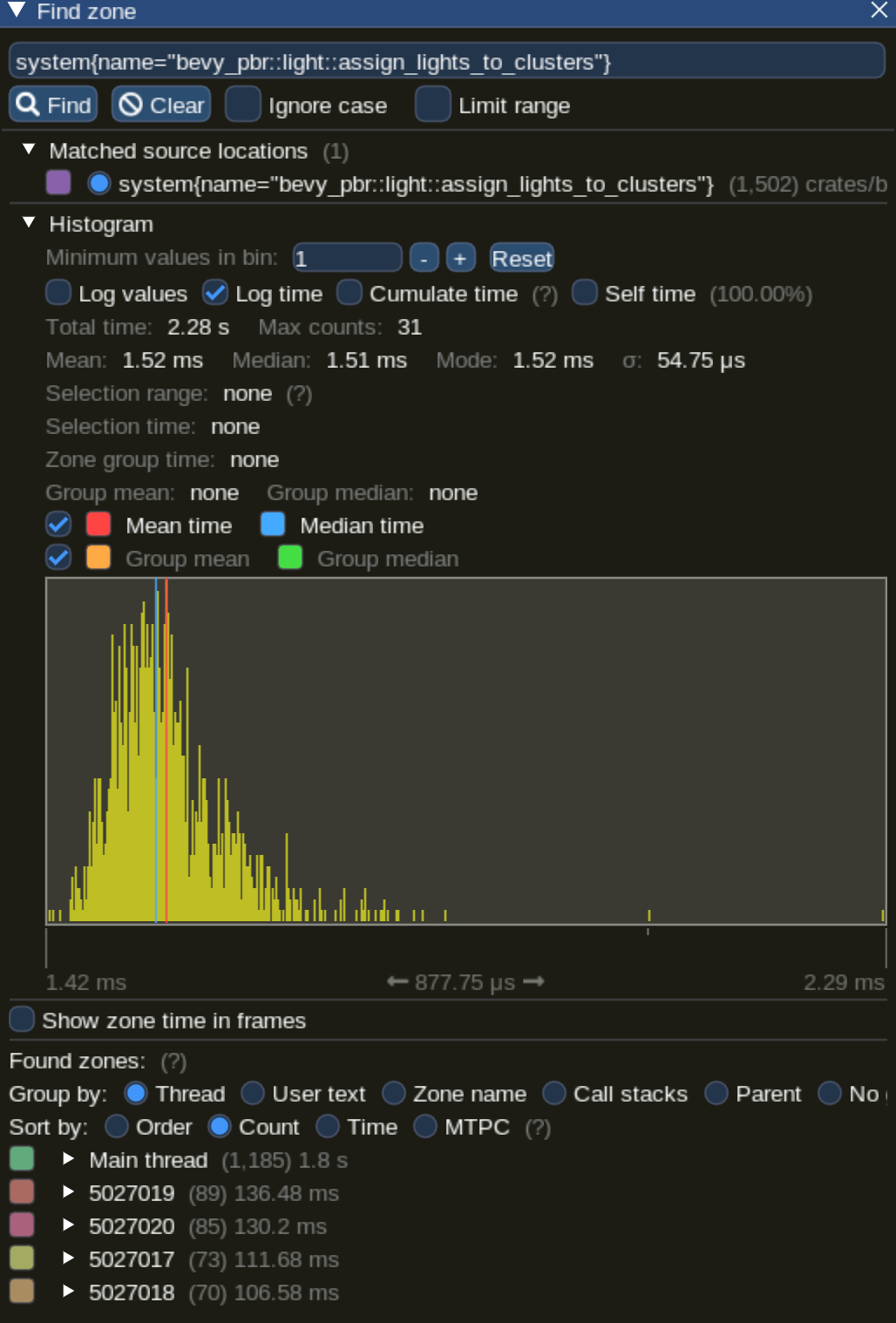
Or you can select an individual system and inspect its statistics (available through the "statistics" button in the top menu) to see things like the distribution of execution times in a graph, or statistical aggregates such as mean, median, standard deviation, etc. It will look something like this:
If you enabled memory tracing then the Zone Info window will also show the allocation events which occurred during a span:
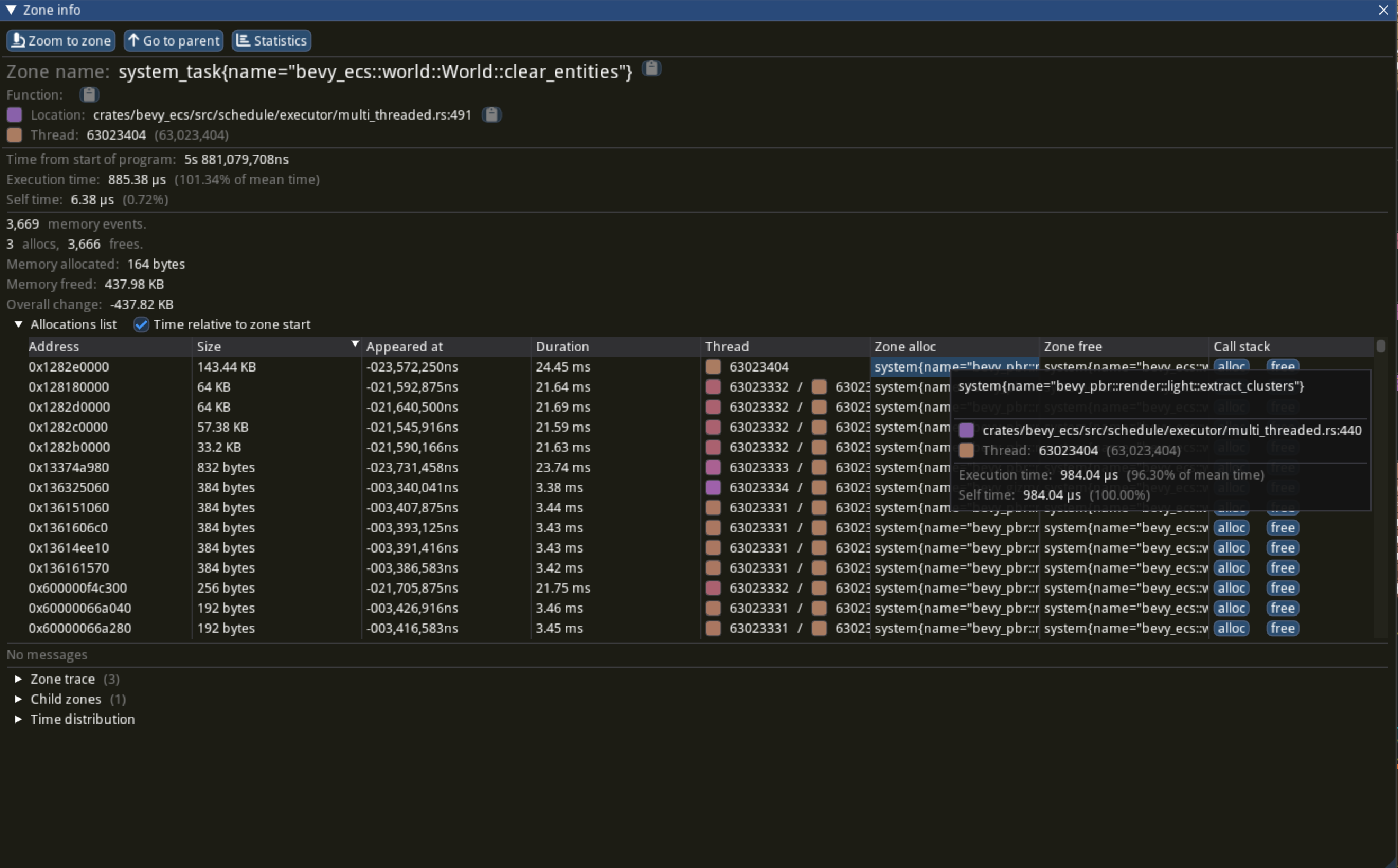
Note that the Bottom-up call stack tree and Top-down call stack tree views reached by clicking the Memory button at the top of the UI will not show a usable backtrace even if memory tracking is enabled, as backtraces are not fully supported yet.
If you save more than one trace, you can compare the spans between both of them by clicking the Compare button at the top of the UI. This will open a dialog box asking to load a second trace. From there, it's possible to select any family of spans to more closely compare the timing and distribution of a particular span.
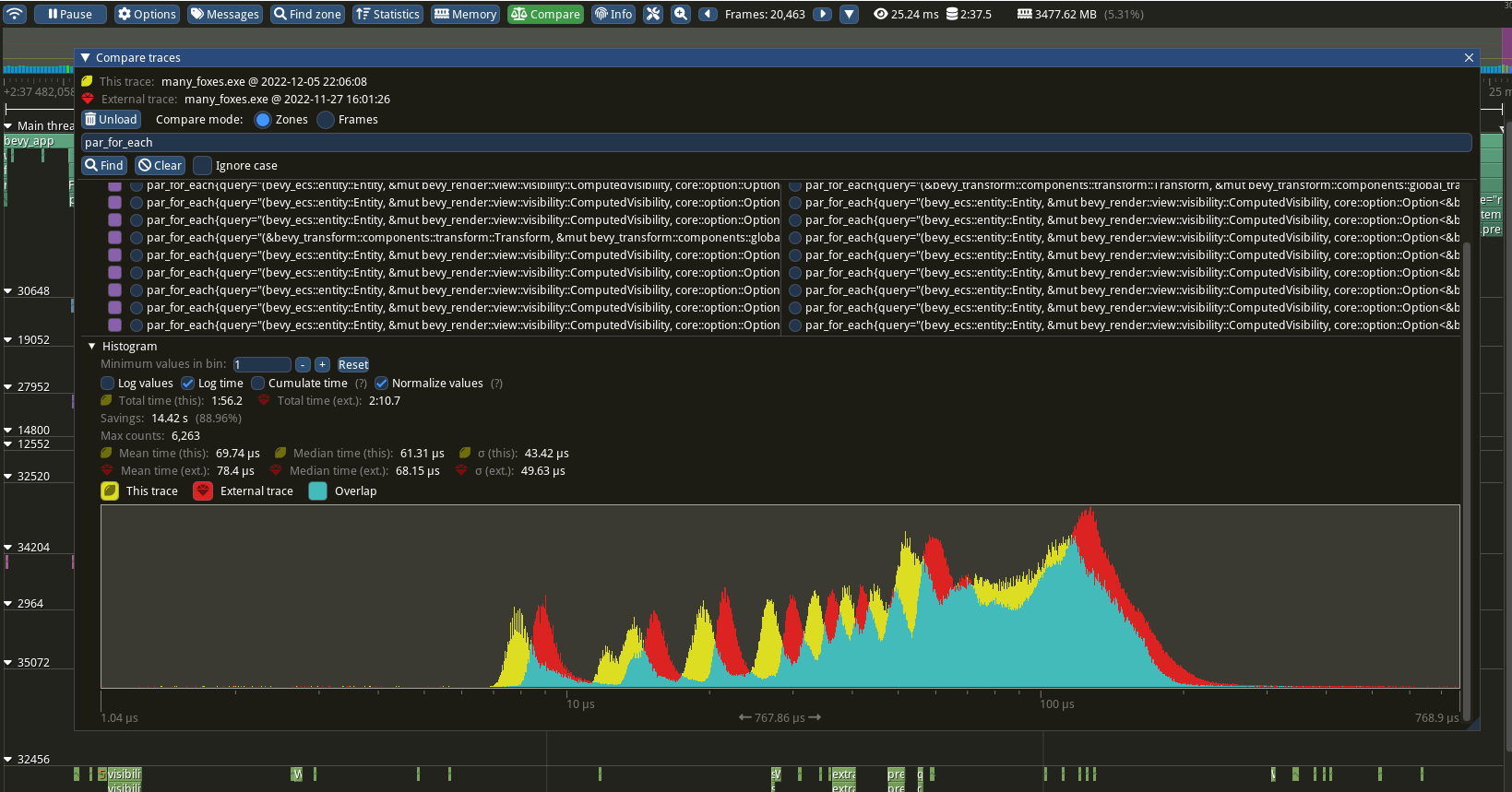
Chrome tracing format
cargo run --release --features bevy/trace_chrome
After running your app a json file in the "chrome tracing format" will be produced. You can open this file in your browser using https://ui.perfetto.dev. It will look something like this:
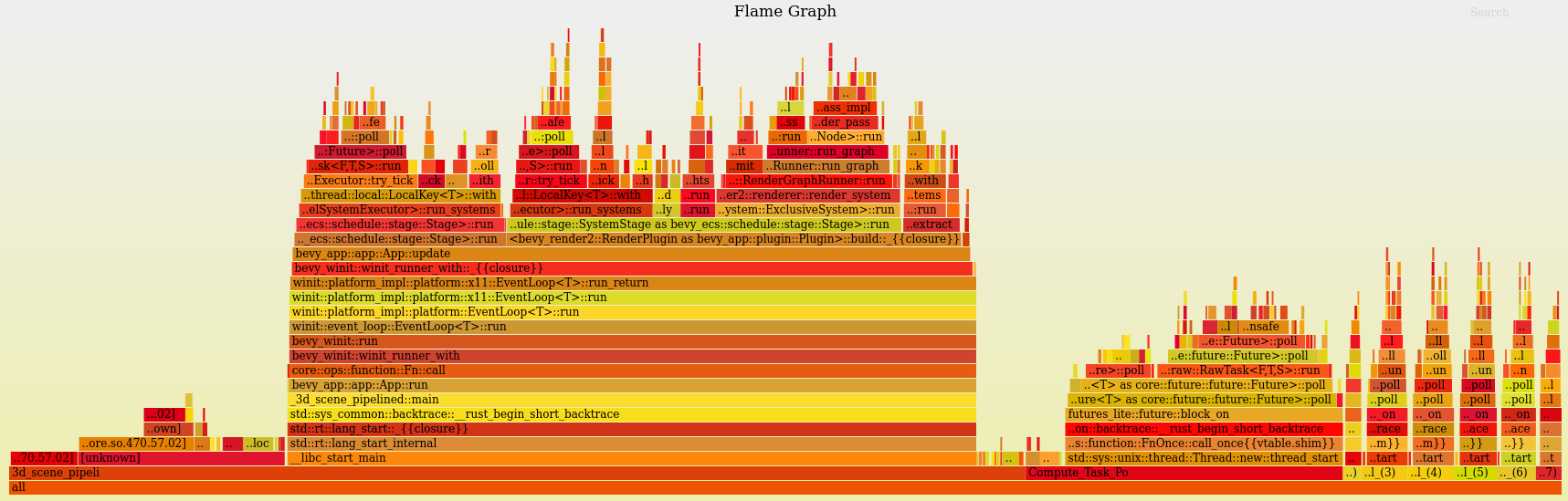
perf Flame Graph
This approach requires no extra instrumentation and shows finer-grained flame graphs of actual code call trees. This is useful when you want to identify the specific function of a "hot spot". The downside is that it has higher overhead, so your app will run slower than it normally does.
Install cargo-flamegraph, enable debug symbols in your release build, then run your app using one of the following commands. Note that cargo-flamegraph forwards arguments to cargo. You should treat the cargo-flamegraph command as a replacement for cargo run --release. The commands below include --example EXAMPLE_NAME to illustrate, but you can remove those arguments in favor of whatever you use to run your app:
- Graph-Like Flame Graph:
RUSTFLAGS='-C force-frame-pointers=y' cargo flamegraph -c "record -g" --example EXAMPLE_NAME - Flat-ish Flame Graph:
RUSTFLAGS='-C force-frame-pointers=y' cargo flamegraph --example EXAMPLE_NAME
After closing your app, an interactive svg file will be produced:
GPU runtime
If CPU profiling has shown that GPU work is the bottleneck, it's time to profile the GPU.
For profiling GPU work, you should use the tool corresponding to your GPU's vendor:
- NVIDIA - Nsight Graphics
- AMD - Radeon GPU Profiler
- Intel - Graphics Frame Analyzer
- Apple - Xcode
Note that while RenderDoc is a great debugging tool, it is not a profiler, and should not be used for this purpose.
Graphics work
Finally, a quick note on how GPU programming works. GPUs are essentially separate computers with their own compiler, scheduler, memory (for discrete GPUs), etc. You do not simply call functions to have the GPU perform work - instead, you communicate with them by sending data back and forth over the PCIe bus, via the GPU driver.
Specifically, you record a list of tasks (commands) for the GPU to perform into a CommandBuffer, and then submit that on a Queue to the GPU. At some point in the future, the GPU will receive the commands and execute them.
In terms of where your app is spending time doing graphics work, it might manifest as a CPU bottleneck (extracting to the render world, wgpu resource tracking, recording commands to a CommandBuffer, or GPU driver code), or it might manifest as a GPU bottleneck (the GPU actually running your commands).
Graphics related work is not all CPU work or all GPU work, but a mix of both, and you should find the bottleneck and profile using the appropriate tool for each case.
Compile time
Append --timings to your app's cargo command (ex: cargo build --timings).
If you want a "full" profile, make sure you run cargo clean first (note: this will clear previously generated reports).
The command will tell you where it saved the report, which will be in your target directory under cargo-timings/.
The report is a .html file and can be opened and viewed in your browser.
This will show how much time each crate in your app's dependency tree took to build.
