# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add a section to the example's README on how
to reduce generated wasm executable size.
Add a `wasm-release` profile to bevy's `Cargo.toml`
in order to use it when building bevy-website.
Notes:
- We do not recommend `strip = "symbols"` since it breaks bindgen
- see https://github.com/bevyengine/bevy-website/pull/402
# Objective
Bevy need a way to benchmark UI rendering code,
this PR adds a stress test that spawns a lot of buttons.
## Solution
- Add the `many_buttons` stress test.
---
## Changelog
- Add the `many_buttons` stress test.
If users try to implement a custom asset loader, they must manually import anyhow::error as it's used by the asset loader trait but not exported.
2b93ab5812/examples/asset/custom_asset.rs (L25)Fixes#3138
Co-authored-by: sark <sarkahn@hotmail.com>
# Objective
Creating UI elements is very boilerplate-y with lots of indentation.
This PR aims to reduce boilerplate around creating text elements.
## Changelog
* Renamed `Text::with_section` to `from_section`.
It no longer takes a `TextAlignment` as argument, as the vast majority of cases left it `Default::default()`.
* Added `Text::from_sections` which creates a `Text` from a list of `TextSections`.
Reduces line-count and reduces indentation by one level.
* Added `Text::with_alignment`.
A builder style method for setting the `TextAlignment` of a `Text`.
* Added `TextSection::new`.
Does not reduce line count, but reduces character count and made it easier to read. No more `.to_string()` calls!
* Added `TextSection::from_style` which creates an empty `TextSection` with a style.
No more empty strings! Reduces indentation.
* Added `TextAlignment::CENTER` and friends.
* Added methods to `TextBundle`. `from_section`, `from_sections`, `with_text_alignment` and `with_style`.
## Note for reviewers.
Because of the nature of these changes I recommend setting diff view to 'split'.
~~Look for the book icon~~ cog in the top-left of the Files changed tab.
Have fun reviewing ❤️
<sup> >:D </sup>
## Migration Guide
`Text::with_section` was renamed to `from_section` and no longer takes a `TextAlignment` as argument.
Use `with_alignment` to set the alignment instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Provide better compile-time errors and diagnostics.
- Add more options to allow more textures types and sampler types.
- Update array_texture example to use upgraded AsBindGroup derive macro.
## Solution
Split out the parsing of the inner struct/field attributes (the inside part of a `#[foo(...)]` attribute) for better clarity
Parse the binding index for all inner attributes, as it is part of all attributes (`#[foo(0, ...)`), then allow each attribute implementer to parse the rest of the attribute metadata as needed. This should make it very trivial to extend/change if needed in the future.
Replaced invocations of `panic!` with the `syn::Error` type, providing fine-grained errors that retains span information. This provides much nicer compile-time errors, and even better IDE errors.

Updated the array_texture example to demonstrate the new changes.
## New AsBindGroup attribute options
### `#[texture(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|-------------- |---------------------------------------------------------------- | ----------- |
| dimension = "..." | `"1d"`, `"2d"`, `"2d_array"`, `"3d"`, `"cube"`, `"cube_array"` | `"2d"` |
| sample_type = "..." | `"float"`, `"depth"`, `"s_int"` or `"u_int"` | `"float"` |
| filterable = ... | `true`, `false` | `true` |
| multisampled = ... | `true`, `false` | `false` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[texture(0, dimension = "2d_array", visibility(vertex, fragment))]`
### `#[sampler(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|----------- |--------------------------------------------------- | ----------- |
| sampler_type = "..." | `"filtering"`, `"non_filtering"`, `"comparison"`. | `"filtering"` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[sampler(0, sampler_type = "filtering", visibility(vertex, fragment)]`
## Changelog
- Added more options to `#[texture(...)]` and `#[sampler(...)]` attributes, supporting more kinds of materials. See above for details.
- Upgraded IDE and compile-time error messages.
- Updated array_texture example using the new options.
# Objective
- Help user when they need to add both a `TransformBundle` and a `VisibilityBundle`
## Solution
- Add a `SpatialBundle` adding all components
Birbs no longer bounce too low, not coming close to their true bouncy potential.
Birbs also no longer bonk head when window is smaller. (Will still bonk head when window is made smaller too fast! pls no)
*cough cough*
Make the height of the birb-bounces dependent on the window size so they always bounce elegantly towards the top of the window.
Also no longer panics when closing the window q:
~~Might put a video here if I figure out how to.~~
<sup> rendering video is hard. birbrate go brr
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Port changes made to Material in #5053 to Material2d as well.
This is more or less an exact copy of the implementation in bevy_pbr; I
simply pretended the API existed, then copied stuff over until it
started building and the shapes example was working again.
# Objective
The changes in #5053 makes it possible to add custom materials with a lot less boiler plate. However, the implementation isn't shared with Material 2d as it's a kind of fork of the bevy_pbr version. It should be possible to use AsBindGroup on the 2d version as well.
## Solution
This makes the same kind of changes in Material2d in bevy_sprite.
This makes the following work:
```rust
//! Draws a circular purple bevy in the middle of the screen using a custom shader
use bevy::{
prelude::*,
reflect::TypeUuid,
render::render_resource::{AsBindGroup, ShaderRef},
sprite::{Material2d, Material2dPlugin, MaterialMesh2dBundle},
};
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_plugin(Material2dPlugin::<CustomMaterial>::default())
.add_startup_system(setup)
.run();
}
/// set up a simple 2D scene
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut materials: ResMut<Assets<CustomMaterial>>,
asset_server: Res<AssetServer>,
) {
commands.spawn_bundle(MaterialMesh2dBundle {
mesh: meshes.add(shape::Circle::new(50.).into()).into(),
material: materials.add(CustomMaterial {
color: Color::PURPLE,
color_texture: Some(asset_server.load("branding/icon.png")),
}),
transform: Transform::from_translation(Vec3::new(-100., 0., 0.)),
..default()
});
commands.spawn_bundle(Camera2dBundle::default());
}
/// The Material2d trait is very configurable, but comes with sensible defaults for all methods.
/// You only need to implement functions for features that need non-default behavior. See the Material api docs for details!
impl Material2d for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"shaders/custom_material.wgsl".into()
}
}
// This is the struct that will be passed to your shader
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Showcase how to use a `Material` and `Mesh` to spawn 3d lines
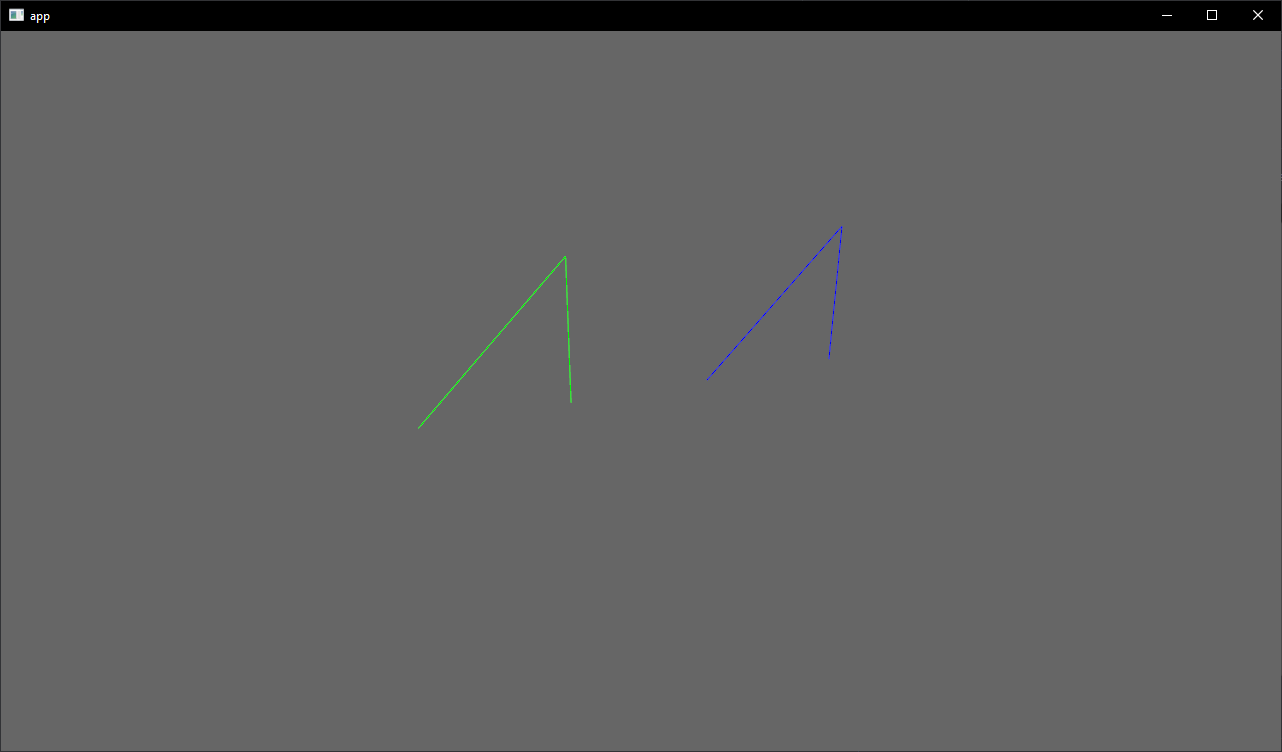
## Solution
- Add an example using a simple `Material` and `Mesh` definition to draw a 3d line
- Shows how to use `LineList` and `LineStrip` in combination with a specialized `Material`
## Notes
This isn't just a primitive shape because it needs a special Material, but I think it's a good showcase of the power of the `Material` and `AsBindGroup` abstractions. All of this is easy to figure out when you know these options are a thing, but I think they are hard to discover which is why I think this should be an example and not shipped with bevy.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Reduce confusion as the example opens a window and isn't truly "headless"
- Fixes https://github.com/bevyengine/bevy/issues/5260.
## Solution
- Rename the example and add to the docs that the window is expected.
## Objective
Implement absolute minimum viable product for the changes proposed in bevyengine/rfcs#53.
## Solution
- Remove public mutative access to `Parent` (Children is already publicly read-only). This includes public construction methods like `Copy`, `Clone`, and `Default`.
- Remove `PreviousParent`
- Remove `parent_update_system`
- Update all hierarchy related commands to immediately update both `Parent` and `Children` references.
## Remaining TODOs
- [ ] Update documentation for both `Parent` and `Children`. Discourage using `EntityCommands::remove`
- [x] Add `HierarchyEvent` to notify listeners of hierarchy updates. This is meant to replace listening on `PreviousParent`
## Followup
- These changes should be best moved to the hooks mentioned in #3742.
- Backing storage for both might be best moved to indexes mentioned in the same relations.
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Add texture sampling to the GLSL shader example, as naga does not support the commonly used sampler2d type.
Fixes#5059
## Solution
- Align the shader_material_glsl example behaviour with the shader_material example, as the later includes texture sampling.
- Update the GLSL shader to do texture sampling the way naga supports it, and document the way naga does not support it.
## Changelog
- The shader_material_glsl example has been updated to demonstrate texture sampling using the GLSL shading language.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
Intended to close#5073
## Solution
Adds a stress test that use TextureAtlas based on the existing many_sprites test using the animated sprite implementation from the sprite_sheet example.
In order to satisfy the goals described in #5073 the animations are all slightly offset.
Of note is that the original stress test was designed to test fullstrum culling. I kept this test similar as to facilitate easy comparisons between the use of TextureAtlas and without.
# Objective
Currently stress tests are vsynced. This is undesirable for a stress test, as you want to run them with uncapped framerates.
## Solution
Ensure all stress tests are using PresentMode::Immediate if they render anything.
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
- Make Bevy work on android
## Solution
- Update android metadata and add a few more
- Set the target sdk to 31 as it will soon (in august) be the minimum sdk level for play store
- Remove the custom code to create an activity and use ndk-glue macro instead
- Delay window creation event on android
- Set the example with compatibility settings for wgpu. Those are needed for Bevy to work on my 2019 android tablet
- Add a few details on how to debug in case of failures
- Fix running the example on emulator. This was failing because of the name of the example
Bevy still doesn't work on android with this, audio features need to be disabled because of an ndk-glue version mismatch: rodio depends on 0.6.2, winit on 0.5.2. You can test with:
```
cargo apk run --release --example android_example --no-default-features --features "bevy_winit,render"
```
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Small bug in the example game given in examples/ecs/ecs_guide
Currently, if there are 2 players in this example game, the function exclusive_player_system can add a player with the name "Player 2". However, the name should be "Player 3". This PR fixes this. I also add a message to inform that a new player has arrived in the mock game.
Co-authored-by: Dilyan Kostov <dilyanks@amazon.com>
# Objective
- Have information about examples only in one place that can be used for the repo and for the website (and remove the need to keep a list of example to build for wasm in the website 75acb73040/generate-wasm-examples/generate_wasm_examples.sh (L92-L99))
## Solution
- Add metadata about examples in `Cargo.toml`
- Build the `examples/README.md` from a template using those metadata. I used tera as the template engine to use the same tech as the website.
- Make CI fail if an example is missing metadata, or if the readme file needs to be updated (the command to update it is displayed in the failed step in CI)
## Remaining To Do
- After the next release with this merged in, the website will be able to be updated to use those metadata too
- I would like to build the examples in wasm and make them available at http://dev-docs.bevyengine.org/ but that will require more design
- https://github.com/bevyengine/bevy-website/issues/299 for other ToDos
Co-authored-by: Readme <github-actions@github.com>
# Objective
`bevy_ui` doesn't support correctly touch inputs because of two problems in the focus system:
- It attempts to retrieve touch input with a specific `0` id
- It doesn't retrieve touch positions and bases its focus solely on mouse position, absent from mobile devices
## Solution
I added a few methods to the `Touches` resource, allowing to check if **any** touch input was pressed, released or cancelled and to retrieve the *position* of the first pressed touch input and adapted the focus system.
I added a test button to the *iOS* example and it works correclty on emulator. I did not test on a real touch device as:
- Android is not working (https://github.com/bevyengine/bevy/issues/3249)
- I don't have an iOS device
- changed `EntityCountDiagnosticsPlugin` to not use an exclusive system to get its entity count
- removed mention of `WgpuResourceDiagnosticsPlugin` in example `log_diagnostics` as it doesn't exist anymore
- added ability to enable, disable ~~or toggle~~ a diagnostic (fix#3767)
- made diagnostic values lazy, so they are only computed if the diagnostic is enabled
- do not log an average for diagnostics with only one value
- removed `sum` function from diagnostic as it isn't really useful
- ~~do not keep an average of the FPS diagnostic. it is already an average on the last 20 frames, so the average FPS was an average of the last 20 frames over the last 20 frames~~
- do not compute the FPS value as an average over the last 20 frames but give the actual "instant FPS"
- updated log format to use variable capture
- added some doc
- the frame counter diagnostic value can be reseted to 0
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
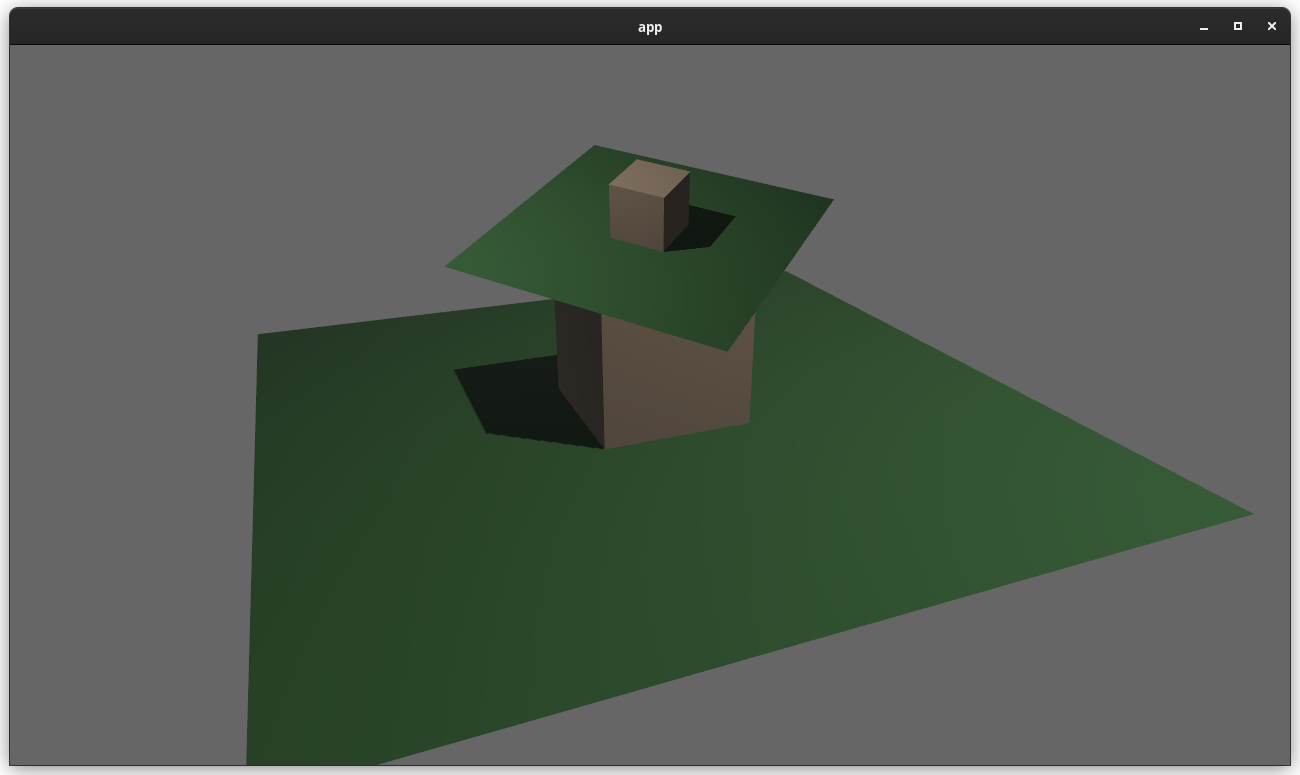
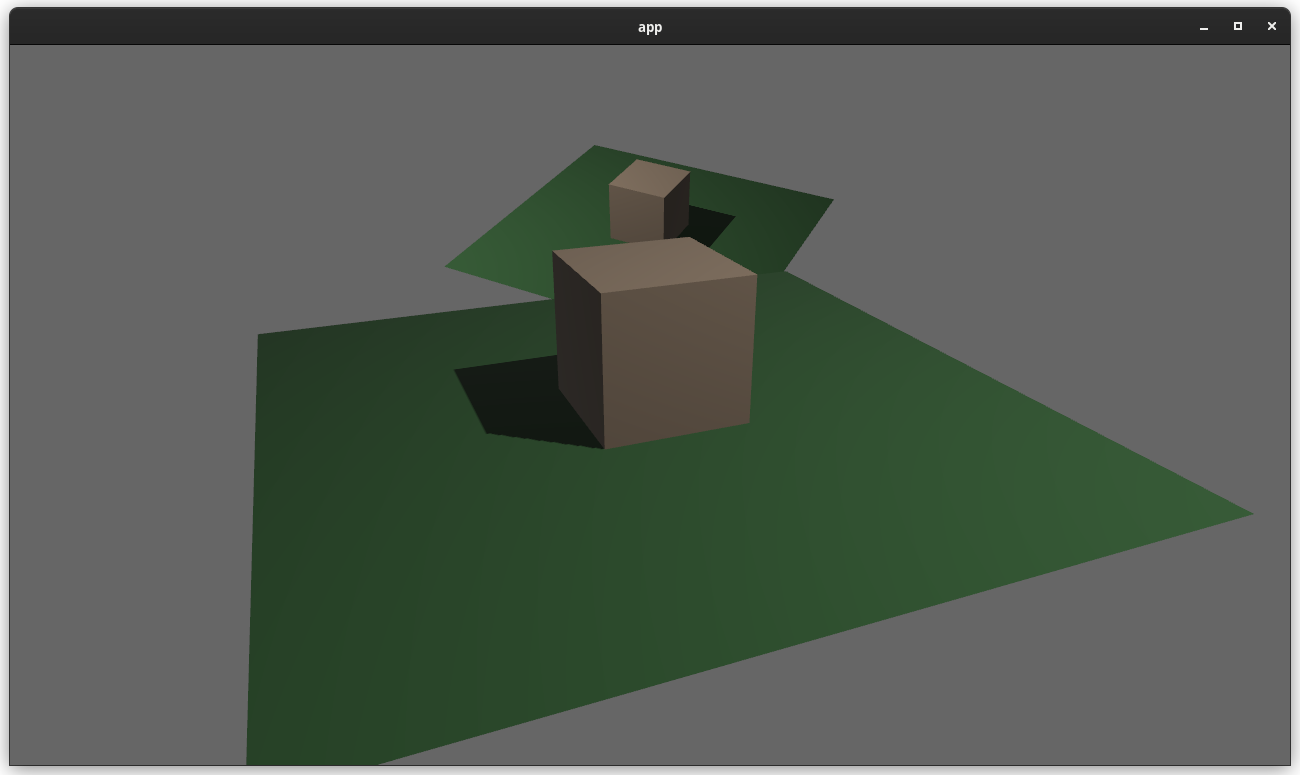
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
### two_passes example with the "second pass" camera configured to "load" the depth
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
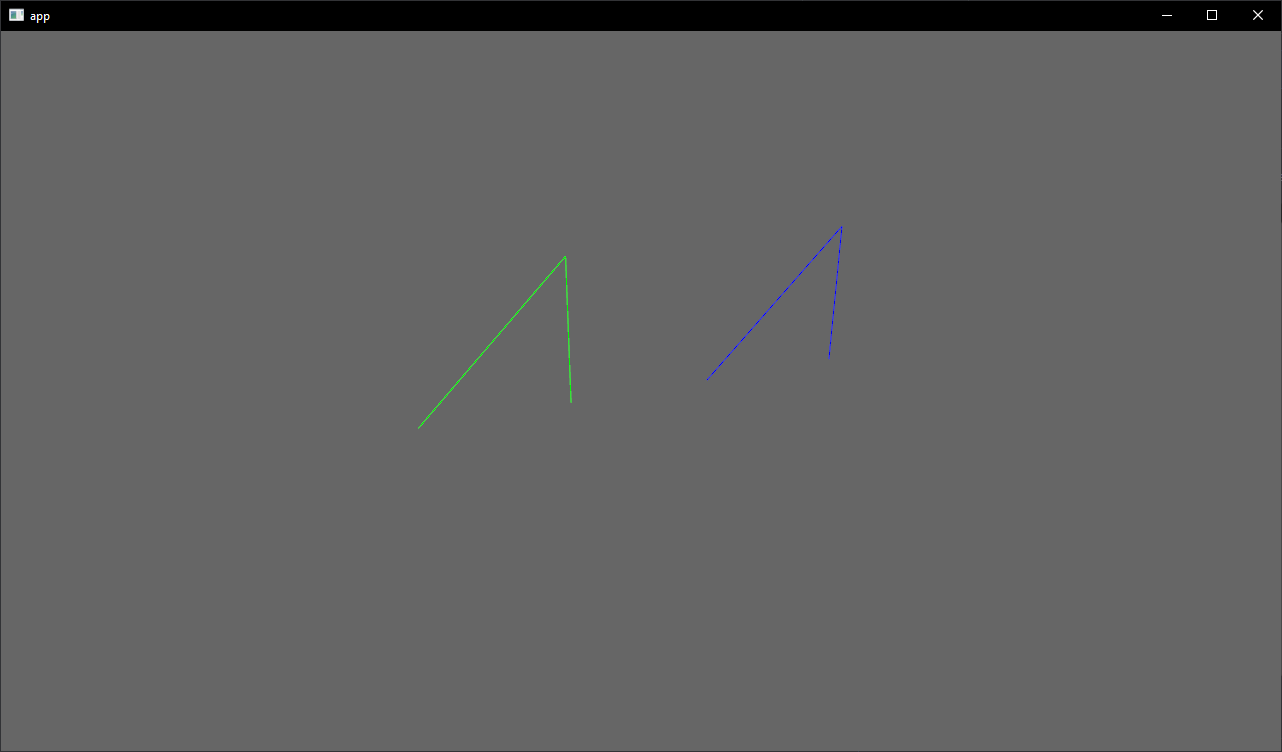{kind=link}
{kind=link}
{kind=link}
{kind=link}