Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>No-std support and better dict API</h2>
<p>This release features no-std support with big thanks to <a
href="https://github.com/antangelo"><code>@antangelo</code></a>!</p>
<p>Also the API for dictionaries has been revised, which required some
breaking changes in that department</p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="fa7bd9c7b3"><code>fa7bd9c</code></a>
allow streaming decoder to also be used with a &mut FrameDecoder for
easier r...</li>
<li><a
href="3b6403b8e7"><code>3b6403b</code></a>
reenable forcing a different dict</li>
<li><a
href="2be7fbb01b"><code>2be7fbb</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/40">#40</a>
from KillingSpark/overhaul_dicts</li>
<li><a
href="343d69b339"><code>343d69b</code></a>
no need to check that the dict still matches at the start of each decode
call</li>
<li><a
href="d73f5e689a"><code>d73f5e6</code></a>
cargo fmt</li>
<li><a
href="f3f09c76f0"><code>f3f09c7</code></a>
improve initing the decoder from a dict</li>
<li><a
href="0b9331dd19"><code>0b9331d</code></a>
make clippy happy</li>
<li><a
href="06433dec34"><code>06433de</code></a>
start overhauling dict API</li>
<li><a
href="1256944604"><code>1256944</code></a>
Update ci.yml</li>
<li><a
href="3449d0a2bf"><code>3449d0a</code></a>
Merge pull request <a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/39">#39</a>
from antangelo/no_std</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.3.1...v0.4.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
- Update dependencies `ruzstd` and `basis-universal`
- Alternative to #5278 and #8133
## Solution
- Update the dependencies, fix the code
- Bevy now also depend on `syn@2` so it's not a blocker to update
`ruzstd` anymore
# Objective
Add support for the [Netpbm](https://en.wikipedia.org/wiki/Netpbm) image
formats, behind a `pnm` feature flag.
My personal use case for this was robotics applications, with `pgm`
being a popular format used in the field to represent world maps in
robots.
I chose the formats and feature name by checking the logic in
[image.rs](a35ed552fa/crates/bevy_render/src/texture/image.rs (L76))
## Solution
Quite straightforward, the `pnm` feature flag already exists in the
`image` crate so it's just creating and exposing a `pnm` feature flag in
the root `Cargo.toml` and forwarding it through `bevy_internal` and
`bevy_render` all the way to the `image` crate.
---
## Changelog
### Added
`pnm` feature to add support for `pam`, `pbm`, `pgm` and `ppm` image
formats.
---------
Signed-off-by: Luca Della Vedova <lucadv@intrinsic.ai>
# Objective
- I want to take screenshots of examples in CI to help with validation
of changes
## Solution
- Can override how much time is updated per frame
- Can specify on which frame to take a screenshots
- Save screenshots in CI
I reused the `TimeUpdateStrategy::ManualDuration` to be able to set the
time update strategy to a fixed duration every frame. Its previous
meaning didn't make much sense to me. This change makes it possible to
have screenshots that are exactly the same across runs.
If this gets merged, I'll add visual comparison of screenshots between
runs to ensure nothing gets broken
## Migration Guide
* `TimeUpdateStrategy::ManualDuration` meaning has changed. Instead of
setting time to `Instant::now()` plus the given duration, it sets time
to last update plus the given duration.
# Objective
- Enable taking a screenshot in wasm
- Followup on #7163
## Solution
- Create a blob from the image data, generate a url to that blob, add an
`a` element to the document linking to that url, click on that element,
then revoke the url
- This will automatically trigger a download of the screenshot file in
the browser
# Objective
- Updated to wgpu 0.16.0 and wgpu-hal 0.16.0
---
## Changelog
1. Upgrade wgpu to 0.16.0 and wgpu-hal to 0.16.0
2. Fix the error in native when using a filterable
`TextureSampleType::Float` on a multisample `BindingType::Texture`.
([https://github.com/gfx-rs/wgpu/pull/3686](https://github.com/gfx-rs/wgpu/pull/3686))
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Reduce compilation time
## Solution
- Make `spirv` and `glsl` shader format support optional. They are not
needed for Bevy shaders.
- on my mac (where shaders are compiled to `msl`), this reduces the
total build time by 2 to 5 seconds, improvement should be even better
with less cores
There is a big reduction in compile time for `naga`, and small
improvements on `wgpu` and `bevy_render`
This PR with optional shader formats enabled timings:
<img width="1478" alt="current main"
src="https://user-images.githubusercontent.com/8672791/234347032-cbd5c276-a9b0-49c3-b793-481677391c18.png">
This PR:
<img width="1479" alt="this pr"
src="https://user-images.githubusercontent.com/8672791/234347059-a67412a9-da8d-4356-91d8-7b0ae84ca100.png">
---
## Migration Guide
- If you want to use shaders in `spirv`, enable the
`shader_format_spirv` feature
- If you want to use shaders in `glsl`, enable the `shader_format_glsl`
feature
# Objective
WebP is a modern image format developed by Google that offers a
significant reduction in file size compared to other image formats such
as PNG and JPEG, while still maintaining good image quality. This makes
it particularly useful for games with large numbers of images, such as
those with high-quality textures or detailed sprites, where file size
and loading times can have a significant impact on performance.
By adding support for WebP images in Bevy, game developers using this
engine can now take advantage of this modern image format and reduce the
memory usage and loading times of their games. This improvement can
ultimately result in a better gaming experience for players.
In summary, the objective of adding WebP image format support in Bevy is
to enable game developers to use a modern image format that provides
better compression rates and smaller file sizes, resulting in faster
loading times and reduced memory usage for their games.
## Solution
To add support for WebP images in Bevy, this pull request leverages the
existing `image` crate support for WebP. This implementation is easily
integrated into the existing Bevy asset-loading system. To maintain
compatibility with existing Bevy projects, WebP image support is
disabled by default, and developers can enable it by adding a feature
flag to their project's `Cargo.toml` file. With this feature, Bevy
becomes even more versatile for game developers and provides a valuable
addition to the game engine.
---
## Changelog
- Added support for WebP image format in Bevy game engine
## Migration Guide
To enable WebP image support in your Bevy project, add the following
line to your project's Cargo.toml file:
```toml
bevy = { version = "*", features = ["webp"]}
```
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
Splits tone mapping from https://github.com/bevyengine/bevy/pull/6677 into a separate PR.
Address https://github.com/bevyengine/bevy/issues/2264.
Adds tone mapping options:
- None: Bypasses tonemapping for instances where users want colors output to match those set.
- Reinhard
- Reinhard Luminance: Bevy's exiting tonemapping
- [ACES](https://github.com/TheRealMJP/BakingLab/blob/master/BakingLab/ACES.hlsl) (Fitted version, based on the same implementation that Godot 4 uses) see https://github.com/bevyengine/bevy/issues/2264
- [AgX](https://github.com/sobotka/AgX)
- SomewhatBoringDisplayTransform
- TonyMcMapface
- Blender Filmic
This PR also adds support for EXR images so they can be used to compare tonemapping options with reference images.
## Migration Guide
- Tonemapping is now an enum with NONE and the various tonemappers.
- The DebandDither is now a separate component.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
Update Bevy to wgpu 0.15.
## Changelog
- Update to wgpu 0.15, wgpu-hal 0.15.1, and naga 0.11
- Users can now use the [DirectX Shader Compiler](https://github.com/microsoft/DirectXShaderCompiler) (DXC) on Windows with DX12 for faster shader compilation and ShaderModel 6.0+ support (requires `dxcompiler.dll` and `dxil.dll`, which are included in DXC downloads from [here](https://github.com/microsoft/DirectXShaderCompiler/releases/latest))
## Migration Guide
### WGSL Top-Level `let` is now `const`
All top level constants are now declared with `const`, catching up with the wgsl spec.
`let` is no longer allowed at the global scope, only within functions.
```diff
-let SOME_CONSTANT = 12.0;
+const SOME_CONSTANT = 12.0;
```
#### `TextureDescriptor` and `SurfaceConfiguration` now requires a `view_formats` field
The new `view_formats` field in the `TextureDescriptor` is used to specify a list of formats the texture can be re-interpreted to in a texture view. Currently only changing srgb-ness is allowed (ex. `Rgba8Unorm` <=> `Rgba8UnormSrgb`). You should set `view_formats` to `&[]` (empty) unless you have a specific reason not to.
#### The DirectX Shader Compiler (DXC) is now supported on DX12
DXC is now the default shader compiler when using the DX12 backend. DXC is Microsoft's replacement for their legacy FXC compiler, and is faster, less buggy, and allows for modern shader features to be used (ShaderModel 6.0+). DXC requires `dxcompiler.dll` and `dxil.dll` to be available, otherwise it will log a warning and fall back to FXC.
You can get `dxcompiler.dll` and `dxil.dll` by downloading the latest release from [Microsoft's DirectXShaderCompiler github repo](https://github.com/microsoft/DirectXShaderCompiler/releases/latest) and copying them into your project's root directory. These must be included when you distribute your Bevy game/app/etc if you plan on supporting the DX12 backend and are using DXC.
`WgpuSettings` now has a `dx12_shader_compiler` field which can be used to choose between either FXC or DXC (if you pass None for the paths for DXC, it will check for the .dlls in the working directory).
After #6503, bevy_render uses the `send_blocking` method introduced in async-channel 1.7, but depended only on ^1.4.
I saw this after pulling main without running cargo update.
# Objective
- Fix minimum dependency version of async-channel
## Solution
- Bump async-channel version constraint to ^1.8, which is currently the latest version.
NOTE: Both bevy_ecs and bevy_tasks also depend on async-channel but they didn't use any newer features.
# Objective
- Implement pipelined rendering
- Fixes#5082
- Fixes#4718
## User Facing Description
Bevy now implements piplelined rendering! Pipelined rendering allows the app logic and rendering logic to run on different threads leading to large gains in performance.

*tracy capture of many_foxes example*
To use pipelined rendering, you just need to add the `PipelinedRenderingPlugin`. If you're using `DefaultPlugins` then it will automatically be added for you on all platforms except wasm. Bevy does not currently support multithreading on wasm which is needed for this feature to work. If you aren't using `DefaultPlugins` you can add the plugin manually.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new()
// whatever other plugins you need
.add_plugin(RenderPlugin)
// needs to be added after RenderPlugin
.add_plugin(PipelinedRenderingPlugin)
.run();
}
```
If for some reason pipelined rendering needs to be removed. You can also disable the plugin the normal way.
```rust
use bevy::prelude::*;
use bevy::render::pipelined_rendering::PipelinedRenderingPlugin;
fn main() {
App::new.add_plugins(DefaultPlugins.build().disable::<PipelinedRenderingPlugin>());
}
```
### A setup function was added to plugins
A optional plugin lifecycle function was added to the `Plugin trait`. This function is called after all plugins have been built, but before the app runner is called. This allows for some final setup to be done. In the case of pipelined rendering, the function removes the sub app from the main app and sends it to the render thread.
```rust
struct MyPlugin;
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
}
// optional function
fn setup(&self, app: &mut App) {
// do some final setup before runner is called
}
}
```
### A Stage for Frame Pacing
In the `RenderExtractApp` there is a stage labelled `BeforeIoAfterRenderStart` that systems can be added to. The specific use case for this stage is for a frame pacing system that can delay the start of main app processing in render bound apps to reduce input latency i.e. "frame pacing". This is not currently built into bevy, but exists as `bevy`
```text
|-------------------------------------------------------------------|
| | BeforeIoAfterRenderStart | winit events | main schedule |
| extract |---------------------------------------------------------|
| | extract commands | rendering schedule |
|-------------------------------------------------------------------|
```
### Small API additions
* `Schedule::remove_stage`
* `App::insert_sub_app`
* `App::remove_sub_app`
* `TaskPool::scope_with_executor`
## Problems and Solutions
### Moving render app to another thread
Most of the hard bits for this were done with the render redo. This PR just sends the render app back and forth through channels which seems to work ok. I originally experimented with using a scope to run the render task. It was cuter, but that approach didn't allow render to start before i/o processing. So I switched to using channels. There is much complexity in the coordination that needs to be done, but it's worth it. By moving rendering during i/o processing the frame times should be much more consistent in render bound apps. See https://github.com/bevyengine/bevy/issues/4691.
### Unsoundness with Sending World with NonSend resources
Dropping !Send things on threads other than the thread they were spawned on is considered unsound. The render world doesn't have any nonsend resources. So if we tell the users to "pretty please don't spawn nonsend resource on the render world", we can avoid this problem.
More seriously there is this https://github.com/bevyengine/bevy/pull/6534 pr, which patches the unsoundness by aborting the app if a nonsend resource is dropped on the wrong thread. ~~That PR should probably be merged before this one.~~ For a longer term solution we have this discussion going https://github.com/bevyengine/bevy/discussions/6552.
### NonSend Systems in render world
The render world doesn't have any !Send resources, but it does have a non send system. While Window is Send, winit does have some API's that can only be accessed on the main thread. `prepare_windows` in the render schedule thus needs to be scheduled on the main thread. Currently we run nonsend systems by running them on the thread the TaskPool::scope runs on. When we move render to another thread this no longer works.
To fix this, a new `scope_with_executor` method was added that takes a optional `TheadExecutor` that can only be ticked on the thread it was initialized on. The render world then holds a `MainThreadExecutor` resource which can be passed to the scope in the parallel executor that it uses to spawn it's non send systems on.
### Scopes executors between render and main should not share tasks
Since the render world and the app world share the `ComputeTaskPool`. Because `scope` has executors for the ComputeTaskPool a system from the main world could run on the render thread or a render system could run on the main thread. This can cause performance problems because it can delay a stage from finishing. See https://github.com/bevyengine/bevy/pull/6503#issuecomment-1309791442 for more details.
To avoid this problem, `TaskPool::scope` has been changed to not tick the ComputeTaskPool when it's used by the parallel executor. In the future when we move closer to the 1 thread to 1 logical core model we may want to overprovide threads, because the render and main app threads don't do much when executing the schedule.
## Performance
My machine is Windows 11, AMD Ryzen 5600x, RX 6600
### Examples
#### This PR with pipelining vs Main
> Note that these were run on an older version of main and the performance profile has probably changed due to optimizations
Seeing a perf gain from 29% on many lights to 7% on many sprites.
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | 27.01% | 27.34% | -47.09% | 1.58 | 1.55 | -1.78 | 5.85 | 5.67 | 3.78 | 4.27 | 4.12 | 5.56
many lights | 29.35% | 29.94% | -10.84% | 3.02 | 3.03 | -0.57 | 10.29 | 10.12 | 5.26 | 7.27 | 7.09 | 5.83
many animated sprites | 13.97% | 15.69% | 14.20% | 3.79 | 4.17 | 1.41 | 27.12 | 26.57 | 9.93 | 23.33 | 22.4 | 8.52
3d scene | 25.79% | 26.78% | 7.46% | 0.49 | 0.49 | 0.15 | 1.9 | 1.83 | 2.01 | 1.41 | 1.34 | 1.86
many cubes | 11.97% | 11.28% | 14.51% | 1.93 | 1.78 | 1.31 | 16.13 | 15.78 | 9.03 | 14.2 | 14 | 7.72
many sprites | 7.14% | 9.42% | -85.42% | 1.72 | 2.23 | -6.15 | 24.09 | 23.68 | 7.2 | 22.37 | 21.45 | 13.35
<!--EndFragment-->
</body>
</html>
#### This PR with pipelining disabled vs Main
Mostly regressions here. I don't think this should be a problem as users that are disabling pipelined rendering are probably running single threaded and not using the parallel executor. The regression is probably mostly due to the switch to use `async_executor::run` instead of `try_tick` and also having one less thread to run systems on. I'll do a writeup on why switching to `run` causes regressions, so we can try to eventually fix it. Using try_tick causes issues when pipeline rendering is enable as seen [here](https://github.com/bevyengine/bevy/pull/6503#issuecomment-1380803518)
<html>
<body>
<!--StartFragment--><google-sheets-html-origin>
| percent | | | Diff | | | Main | | | PR no pipelining | |
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
tracy frame time | mean | median | sigma | mean | median | sigma | mean | median | sigma | mean | median | sigma
many foxes | -3.72% | -4.42% | -1.07% | -0.21 | -0.24 | -0.04 | 5.64 | 5.43 | 3.74 | 5.85 | 5.67 | 3.78
many lights | 0.29% | -0.30% | 4.75% | 0.03 | -0.03 | 0.25 | 10.29 | 10.12 | 5.26 | 10.26 | 10.15 | 5.01
many animated sprites | 0.22% | 1.81% | -2.72% | 0.06 | 0.48 | -0.27 | 27.12 | 26.57 | 9.93 | 27.06 | 26.09 | 10.2
3d scene | -15.79% | -14.75% | -31.34% | -0.3 | -0.27 | -0.63 | 1.9 | 1.83 | 2.01 | 2.2 | 2.1 | 2.64
many cubes | -2.85% | -3.30% | 0.00% | -0.46 | -0.52 | 0 | 16.13 | 15.78 | 9.03 | 16.59 | 16.3 | 9.03
many sprites | 2.49% | 2.41% | 0.69% | 0.6 | 0.57 | 0.05 | 24.09 | 23.68 | 7.2 | 23.49 | 23.11 | 7.15
<!--EndFragment-->
</body>
</html>
### Benchmarks
Mostly the same except empty_systems has got a touch slower. The maybe_pipelining+1 column has the compute task pool with an extra thread over default added. This is because pipelining loses one thread over main to execute systems on, since the main thread no longer runs normal systems.
<details>
<summary>Click Me</summary>
```text
group main maybe-pipelining+1
----- ------------------------- ------------------
busy_systems/01x_entities_03_systems 1.07 30.7±1.32µs ? ?/sec 1.00 28.6±1.35µs ? ?/sec
busy_systems/01x_entities_06_systems 1.10 52.1±1.10µs ? ?/sec 1.00 47.2±1.08µs ? ?/sec
busy_systems/01x_entities_09_systems 1.00 74.6±1.36µs ? ?/sec 1.00 75.0±1.93µs ? ?/sec
busy_systems/01x_entities_12_systems 1.03 100.6±6.68µs ? ?/sec 1.00 98.0±1.46µs ? ?/sec
busy_systems/01x_entities_15_systems 1.11 128.5±3.53µs ? ?/sec 1.00 115.5±1.02µs ? ?/sec
busy_systems/02x_entities_03_systems 1.16 50.4±2.56µs ? ?/sec 1.00 43.5±3.00µs ? ?/sec
busy_systems/02x_entities_06_systems 1.00 87.1±1.27µs ? ?/sec 1.05 91.5±7.15µs ? ?/sec
busy_systems/02x_entities_09_systems 1.04 139.9±6.37µs ? ?/sec 1.00 134.0±1.06µs ? ?/sec
busy_systems/02x_entities_12_systems 1.05 179.2±3.47µs ? ?/sec 1.00 170.1±3.17µs ? ?/sec
busy_systems/02x_entities_15_systems 1.01 219.6±3.75µs ? ?/sec 1.00 218.1±2.55µs ? ?/sec
busy_systems/03x_entities_03_systems 1.10 70.6±2.33µs ? ?/sec 1.00 64.3±0.69µs ? ?/sec
busy_systems/03x_entities_06_systems 1.02 130.2±3.11µs ? ?/sec 1.00 128.0±1.34µs ? ?/sec
busy_systems/03x_entities_09_systems 1.00 195.0±10.11µs ? ?/sec 1.00 194.8±1.41µs ? ?/sec
busy_systems/03x_entities_12_systems 1.01 261.7±4.05µs ? ?/sec 1.00 259.8±4.11µs ? ?/sec
busy_systems/03x_entities_15_systems 1.00 318.0±3.04µs ? ?/sec 1.06 338.3±20.25µs ? ?/sec
busy_systems/04x_entities_03_systems 1.00 82.9±0.63µs ? ?/sec 1.02 84.3±0.63µs ? ?/sec
busy_systems/04x_entities_06_systems 1.01 181.7±3.65µs ? ?/sec 1.00 179.8±1.76µs ? ?/sec
busy_systems/04x_entities_09_systems 1.04 265.0±4.68µs ? ?/sec 1.00 255.3±1.98µs ? ?/sec
busy_systems/04x_entities_12_systems 1.00 335.9±3.00µs ? ?/sec 1.05 352.6±15.84µs ? ?/sec
busy_systems/04x_entities_15_systems 1.00 418.6±10.26µs ? ?/sec 1.08 450.2±39.58µs ? ?/sec
busy_systems/05x_entities_03_systems 1.07 114.3±0.95µs ? ?/sec 1.00 106.9±1.52µs ? ?/sec
busy_systems/05x_entities_06_systems 1.08 229.8±2.90µs ? ?/sec 1.00 212.3±4.18µs ? ?/sec
busy_systems/05x_entities_09_systems 1.03 329.3±1.99µs ? ?/sec 1.00 319.2±2.43µs ? ?/sec
busy_systems/05x_entities_12_systems 1.06 454.7±6.77µs ? ?/sec 1.00 430.1±3.58µs ? ?/sec
busy_systems/05x_entities_15_systems 1.03 554.6±6.15µs ? ?/sec 1.00 538.4±23.87µs ? ?/sec
contrived/01x_entities_03_systems 1.00 14.0±0.15µs ? ?/sec 1.08 15.1±0.21µs ? ?/sec
contrived/01x_entities_06_systems 1.04 28.5±0.37µs ? ?/sec 1.00 27.4±0.44µs ? ?/sec
contrived/01x_entities_09_systems 1.00 41.5±4.38µs ? ?/sec 1.02 42.2±2.24µs ? ?/sec
contrived/01x_entities_12_systems 1.06 55.9±1.49µs ? ?/sec 1.00 52.6±1.36µs ? ?/sec
contrived/01x_entities_15_systems 1.02 68.0±2.00µs ? ?/sec 1.00 66.5±0.78µs ? ?/sec
contrived/02x_entities_03_systems 1.03 25.2±0.38µs ? ?/sec 1.00 24.6±0.52µs ? ?/sec
contrived/02x_entities_06_systems 1.00 46.3±0.49µs ? ?/sec 1.04 48.1±4.13µs ? ?/sec
contrived/02x_entities_09_systems 1.02 70.4±0.99µs ? ?/sec 1.00 68.8±1.04µs ? ?/sec
contrived/02x_entities_12_systems 1.06 96.8±1.49µs ? ?/sec 1.00 91.5±0.93µs ? ?/sec
contrived/02x_entities_15_systems 1.02 116.2±0.95µs ? ?/sec 1.00 114.2±1.42µs ? ?/sec
contrived/03x_entities_03_systems 1.00 33.2±0.38µs ? ?/sec 1.01 33.6±0.45µs ? ?/sec
contrived/03x_entities_06_systems 1.00 62.4±0.73µs ? ?/sec 1.01 63.3±1.05µs ? ?/sec
contrived/03x_entities_09_systems 1.02 96.4±0.85µs ? ?/sec 1.00 94.8±3.02µs ? ?/sec
contrived/03x_entities_12_systems 1.01 126.3±4.67µs ? ?/sec 1.00 125.6±2.27µs ? ?/sec
contrived/03x_entities_15_systems 1.03 160.2±9.37µs ? ?/sec 1.00 156.0±1.53µs ? ?/sec
contrived/04x_entities_03_systems 1.02 41.4±3.39µs ? ?/sec 1.00 40.5±0.52µs ? ?/sec
contrived/04x_entities_06_systems 1.00 78.9±1.61µs ? ?/sec 1.02 80.3±1.06µs ? ?/sec
contrived/04x_entities_09_systems 1.02 121.8±3.97µs ? ?/sec 1.00 119.2±1.46µs ? ?/sec
contrived/04x_entities_12_systems 1.00 157.8±1.48µs ? ?/sec 1.01 160.1±1.72µs ? ?/sec
contrived/04x_entities_15_systems 1.00 197.9±1.47µs ? ?/sec 1.08 214.2±34.61µs ? ?/sec
contrived/05x_entities_03_systems 1.00 49.1±0.33µs ? ?/sec 1.01 49.7±0.75µs ? ?/sec
contrived/05x_entities_06_systems 1.00 95.0±0.93µs ? ?/sec 1.00 94.6±0.94µs ? ?/sec
contrived/05x_entities_09_systems 1.01 143.2±1.68µs ? ?/sec 1.00 142.2±2.00µs ? ?/sec
contrived/05x_entities_12_systems 1.00 191.8±2.03µs ? ?/sec 1.01 192.7±7.88µs ? ?/sec
contrived/05x_entities_15_systems 1.02 239.7±3.71µs ? ?/sec 1.00 235.8±4.11µs ? ?/sec
empty_systems/000_systems 1.01 47.8±0.67ns ? ?/sec 1.00 47.5±2.02ns ? ?/sec
empty_systems/001_systems 1.00 1743.2±126.14ns ? ?/sec 1.01 1761.1±70.10ns ? ?/sec
empty_systems/002_systems 1.01 2.2±0.04µs ? ?/sec 1.00 2.2±0.02µs ? ?/sec
empty_systems/003_systems 1.02 2.7±0.09µs ? ?/sec 1.00 2.7±0.16µs ? ?/sec
empty_systems/004_systems 1.00 3.1±0.11µs ? ?/sec 1.00 3.1±0.24µs ? ?/sec
empty_systems/005_systems 1.00 3.5±0.05µs ? ?/sec 1.11 3.9±0.70µs ? ?/sec
empty_systems/010_systems 1.00 5.5±0.12µs ? ?/sec 1.03 5.7±0.17µs ? ?/sec
empty_systems/015_systems 1.00 7.9±0.19µs ? ?/sec 1.06 8.4±0.16µs ? ?/sec
empty_systems/020_systems 1.00 10.4±1.25µs ? ?/sec 1.02 10.6±0.18µs ? ?/sec
empty_systems/025_systems 1.00 12.4±0.39µs ? ?/sec 1.14 14.1±1.07µs ? ?/sec
empty_systems/030_systems 1.00 15.1±0.39µs ? ?/sec 1.05 15.8±0.62µs ? ?/sec
empty_systems/035_systems 1.00 16.9±0.47µs ? ?/sec 1.07 18.0±0.37µs ? ?/sec
empty_systems/040_systems 1.00 19.3±0.41µs ? ?/sec 1.05 20.3±0.39µs ? ?/sec
empty_systems/045_systems 1.00 22.4±1.67µs ? ?/sec 1.02 22.9±0.51µs ? ?/sec
empty_systems/050_systems 1.00 24.4±1.67µs ? ?/sec 1.01 24.7±0.40µs ? ?/sec
empty_systems/055_systems 1.05 28.6±5.27µs ? ?/sec 1.00 27.2±0.70µs ? ?/sec
empty_systems/060_systems 1.02 29.9±1.64µs ? ?/sec 1.00 29.3±0.66µs ? ?/sec
empty_systems/065_systems 1.02 32.7±3.15µs ? ?/sec 1.00 32.1±0.98µs ? ?/sec
empty_systems/070_systems 1.00 33.0±1.42µs ? ?/sec 1.03 34.1±1.44µs ? ?/sec
empty_systems/075_systems 1.00 34.8±0.89µs ? ?/sec 1.04 36.2±0.70µs ? ?/sec
empty_systems/080_systems 1.00 37.0±1.82µs ? ?/sec 1.05 38.7±1.37µs ? ?/sec
empty_systems/085_systems 1.00 38.7±0.76µs ? ?/sec 1.05 40.8±0.83µs ? ?/sec
empty_systems/090_systems 1.00 41.5±1.09µs ? ?/sec 1.04 43.2±0.82µs ? ?/sec
empty_systems/095_systems 1.00 43.6±1.10µs ? ?/sec 1.04 45.2±0.99µs ? ?/sec
empty_systems/100_systems 1.00 46.7±2.27µs ? ?/sec 1.03 48.1±1.25µs ? ?/sec
```
</details>
## Migration Guide
### App `runner` and SubApp `extract` functions are now required to be Send
This was changed to enable pipelined rendering. If this breaks your use case please report it as these new bounds might be able to be relaxed.
## ToDo
* [x] redo benchmarking
* [x] reinvestigate the perf of the try_tick -> run change for task pool scope
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
- Update `wgpu` to 0.14.0, `naga` to `0.10.0`, `winit` to 0.27.4, `raw-window-handle` to 0.5.0, `ndk` to 0.7.
## Solution
---
## Changelog
### Changed
- Changed `RawWindowHandleWrapper` to `RawHandleWrapper` which wraps both `RawWindowHandle` and `RawDisplayHandle`, which satisfies the `impl HasRawWindowHandle and HasRawDisplayHandle` that `wgpu` 0.14.0 requires.
- Changed `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, change its type from `bool` to `bevy_window::CursorGrabMode`.
## Migration Guide
- Adjust usage of `bevy_window::WindowDescriptor`'s `cursor_locked` to `cursor_grab_mode`, and adjust its type from `bool` to `bevy_window::CursorGrabMode`.
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- The time update is currently done in the wrong part of the schedule. For a single frame the current order of things is update input, update time (First stage), other stages, render stage (frame presentation). So when we update the time it includes the input processing of the current frame and the frame presentation of the previous frame. This is a problem when vsync is on. When input processing takes a longer amount of time for a frame, the vsync wait time gets shorter. So when these are not paired correctly we can potentially have a long input processing time added to the normal vsync wait time in the previous frame. This leads to inaccurate frame time reporting and more variance of the time than actually exists. For more details of why this is an issue see the linked issue below.
- Helps with https://github.com/bevyengine/bevy/issues/4669
- Supercedes https://github.com/bevyengine/bevy/pull/4728 and https://github.com/bevyengine/bevy/pull/4735. This PR should be less controversial than those because it doesn't add to the API surface.
## Solution
- The most accurate frame time would come from hardware. We currently don't have access to that for multiple reasons, so the next best thing we can do is measure the frame time as close to frame presentation as possible. This PR gets the Instant::now() for the time immediately after frame presentation in the render system and then sends that time to the app world through a channel.
- implements suggestion from @aevyrie from here https://github.com/bevyengine/bevy/pull/4728#discussion_r872010606
## Statistics
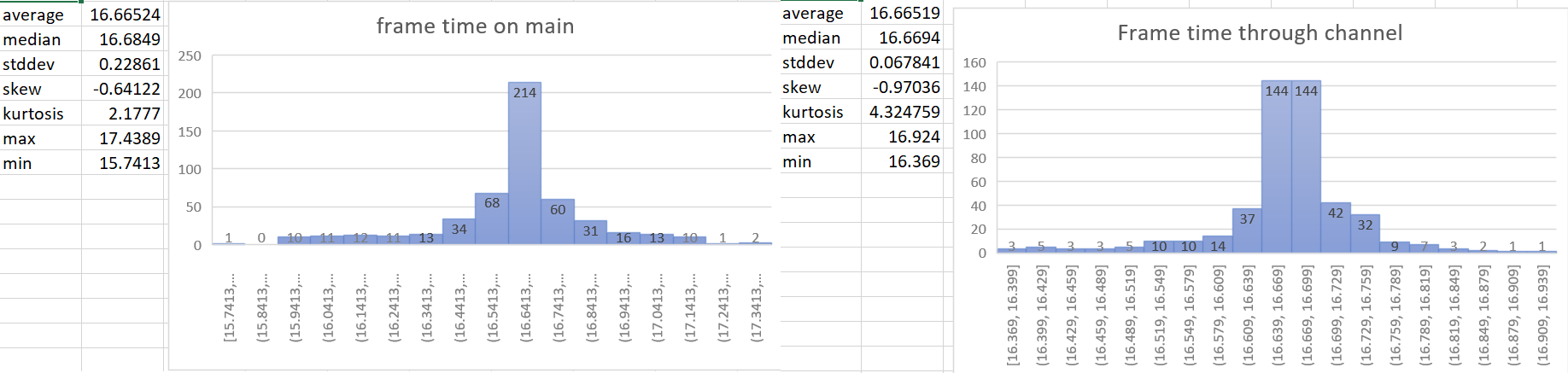
---
## Changelog
- Make frame time reporting more accurate.
## Migration Guide
`time.delta()` now reports zero for 2 frames on startup instead of 1 frame.
# Objective
- Extracting resources currently always uses commands, which requires *at least* one additional move of the extracted value, as well as dynamic dispatch.
- Addresses https://github.com/bevyengine/bevy/pull/4402#discussion_r911634931
## Solution
- Write the resource into a `ResMut<R>` directly.
- Fall-back to commands if the resource hasn't been added yet.
# Objective
- Enable `wgpu` profiling spans
## Solution
- `wgpu` uses the `profiling` crate to add profiling span instrumentation to their code
- `profiling` offers multiple 'backends' for profiling, including `tracing`
- When the `bevy` `trace` feature is used, add the `profiling` crate with its `profile-with-tracing` feature to enable appropriate profiling spans in `wgpu` using `tracing` which fits nicely into our infrastructure
- Bump our default `tracing` subscriber filter to `wgpu=info` from `wgpu=error` so that the profiling spans are not filtered out as they are created at the `info` level.
---
## Changelog
- Added: `tracing` profiling support for `wgpu` when using bevy's `trace` feature
- Changed: The default `tracing` filter statement for `wgpu` has been changed from the `error` level to the `info` level to not filter out the wgpu profiling spans
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
Further speed up visibility checking by removing the main sources of contention for the system.
## Solution
- ~~Make `ComputedVisibility` a resource wrapping a `FixedBitset`.~~
- ~~Remove `ComputedVisibility` as a component.~~
~~This adds a one-bit overhead to every entity in the app world. For a game with 100,000 entities, this is 12.5KB of memory. This is still small enough to fit entirely in most L1 caches. Also removes the need for a per-Entity change detection tick. This reduces the memory footprint of ComputedVisibility 72x.~~
~~The decreased memory usage and less fragmented memory locality should provide significant performance benefits.~~
~~Clearing visible entities should be significantly faster than before:~~
- ~~Setting one `u32` to 0 clears 32 entities per cycle.~~
- ~~No archetype fragmentation to contend with.~~
- ~~Change detection is applied to the resource, so there is no per-Entity update tick requirement.~~
~~The side benefit of this design is that it removes one more "computed component" from userspace. Though accessing the values within it are now less ergonomic.~~
This PR changes `crossbeam_channel` in `check_visibility` to use a `Local<ThreadLocal<Cell<Vec<Entity>>>` to mark down visible entities instead.
Co-Authored-By: TheRawMeatball <therawmeatball@gmail.com>
Co-Authored-By: Aevyrie <aevyrie@gmail.com>
# Objective
Working with a large number of entities with `Aabbs`, rendered with an instanced shader, I found the bottleneck became the frustum culling system. The goal of this PR is to significantly improve culling performance without any major changes. We should consider constructing a BVH for more substantial improvements.
## Solution
- Convert the inner entity query to a parallel iterator with `par_for_each_mut` using a batch size of 1,024.
- This outperforms single threaded culling when there are more than 1,000 entities.
- Below this they are approximately equal, with <= 10 microseconds of multithreading overhead.
- Above this, the multithreaded version is significantly faster, scaling linearly with core count.
- In my million-entity-workload, this PR improves my framerate by 200% - 300%.
## log-log of `check_visibility` time vs. entities for single/multithreaded
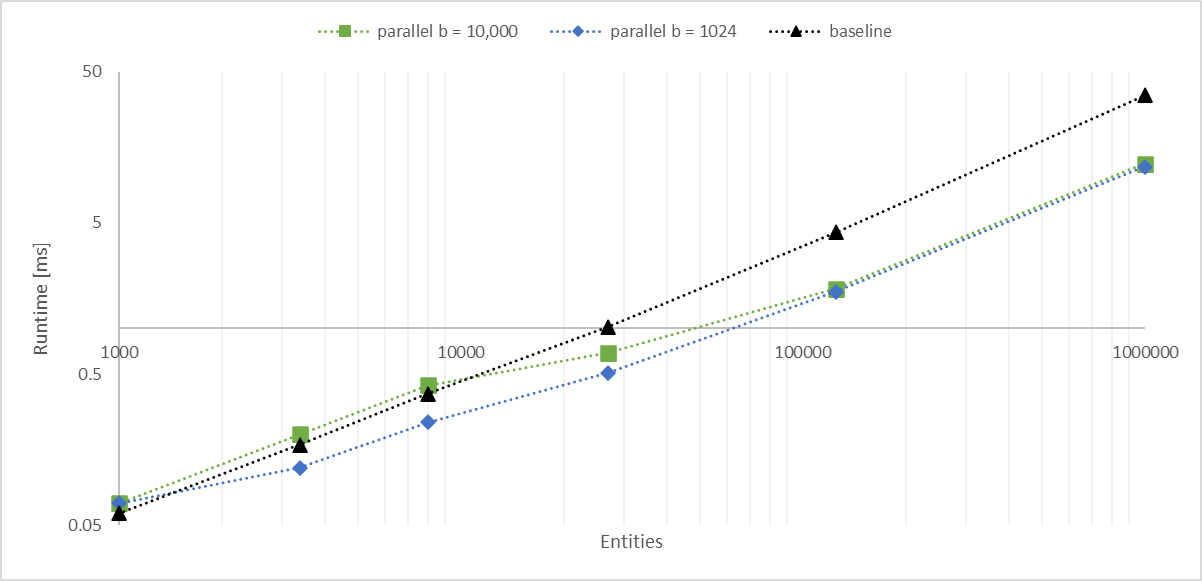
---
## Changelog
Frustum culling is now run with a parallel query. When culling more than a thousand entities, this is faster than the previous method, scaling proportionally with the number of available cores.
# Objective
Models can be produced that do not have vertex tangents but do have normal map textures. The tangents can be generated. There is a way that the vertex tangents can be generated to be exactly invertible to avoid introducing error when recreating the normals in the fragment shader.
## Solution
- After attempts to get https://github.com/gltf-rs/mikktspace to integrate simple glam changes and version bumps, and releases of that crate taking weeks / not being made (no offense intended to the authors/maintainers, bevy just has its own timelines and needs to take care of) it was decided to fork that repository. The following steps were taken:
- mikktspace was forked to https://github.com/bevyengine/mikktspace in order to preserve the repository's history in case the original is ever taken down
- The README in that repo was edited to add a note stating from where the repository was forked and explaining why
- The repo was locked for changes as its only purpose is historical
- The repo was integrated into the bevy repo using `git subtree add --prefix crates/bevy_mikktspace git@github.com:bevyengine/mikktspace.git master`
- In `bevy_mikktspace`:
- The travis configuration was removed
- `cargo fmt` was run
- The `Cargo.toml` was conformed to bevy's (just adding bevy to the keywords, changing the homepage and repository, changing the version to 0.7.0-dev - importantly the license is exactly the same)
- Remove the features, remove `nalgebra` entirely, only use `glam`, suppress clippy.
- This was necessary because our CI runs clippy with `--all-features` and the `nalgebra` and `glam` features are mutually exclusive, plus I don't want to modify this highly numerically-sensitive code just to appease clippy and diverge even more from upstream.
- Rebase https://github.com/bevyengine/bevy/pull/1795
- @jakobhellermann said it was fine to copy and paste but it ended up being almost exactly the same with just a couple of adjustments when validating correctness so I decided to actually rebase it and then build on top of it.
- Use the exact same fragment shader code to ensure correct normal mapping.
- Tested with both https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentMirrorTest which has vertex tangents and https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/NormalTangentTest which requires vertex tangent generation
Co-authored-by: alteous <alteous@outlook.com>
# Objective
- Add an `ExtractResourcePlugin` for convenience and consistency
## Solution
- Add an `ExtractResourcePlugin` similar to `ExtractComponentPlugin` but for ECS `Resource`s. The system that is executed simply clones the main world resource into a render world resource, if and only if the main world resource was either added or changed since the last execution of the system.
- Add an `ExtractResource` trait with a `fn extract_resource(res: &Self) -> Self` function. This is used by the `ExtractResourcePlugin` to extract the resource
- Add a derive macro for `ExtractResource` on a `Resource` with the `Clone` trait, that simply returns `res.clone()`
- Use `ExtractResourcePlugin` wherever both possible and appropriate
Currently `tracy` interprets the entire trace as one frame because the marker for frames isn't being recorded.
~~When an event with `tracy.trace_marker=true` is recorded, `tracing-tracy` will mark the frame as finished:
<aa0b96b2ae/tracing-tracy/src/lib.rs (L240)>~~
~~Unfortunately this leads to~~
```rs
INFO bevy_app:frame: bevy_app::app: finished frame tracy.frame_mark=true
```
~~being printed every frame (we can't use DEBUG because bevy_log sets `max_release_level_info`.~~
Instead of emitting an event that gets logged every frame, we can depend on tracy-client itself and call `finish_continuous_frame!();`
# Objective
- Support compressed textures including 'universal' formats (ETC1S, UASTC) and transcoding of them to
- Support `.dds`, `.ktx2`, and `.basis` files
## Solution
- Fixes https://github.com/bevyengine/bevy/issues/3608 Look there for more details.
- Note that the functionality is all enabled through non-default features. If it is desirable to enable some by default, I can do that.
- The `basis-universal` crate, used for `.basis` file support and for transcoding, is built on bindings against a C++ library. It's not feasible to rewrite in Rust in a short amount of time. There are no Rust alternatives of which I am aware and it's specialised code. In its current state it doesn't support the wasm target, but I don't know for sure. However, it is possible to build the upstream C++ library with emscripten, so there is perhaps a way to add support for web too with some shenanigans.
- There's no support for transcoding from BasisLZ/ETC1S in KTX2 files as it was quite non-trivial to implement and didn't feel important given people could use `.basis` files for ETC1S.
# Objective
The current 2d rendering is specialized to render sprites, we need a generic way to render 2d items, using meshes and materials like we have for 3d.
## Solution
I cloned a good part of `bevy_pbr` into `bevy_sprite/src/mesh2d`, removed lighting and pbr itself, adapted it to 2d rendering, added a `ColorMaterial`, and modified the sprite rendering to break batches around 2d meshes.
~~The PR is a bit crude; I tried to change as little as I could in both the parts copied from 3d and the current sprite rendering to make reviewing easier. In the future, I expect we could make the sprite rendering a normal 2d material, cleanly integrated with the rest.~~ _edit: see <https://github.com/bevyengine/bevy/pull/3460#issuecomment-1003605194>_
## Remaining work
- ~~don't require mesh normals~~ _out of scope_
- ~~add an example~~ _done_
- support 2d meshes & materials in the UI?
- bikeshed names (I didn't think hard about naming, please check if it's fine)
## Remaining questions
- ~~should we add a depth buffer to 2d now that there are 2d meshes?~~ _let's revisit that when we have an opaque render phase_
- ~~should we add MSAA support to the sprites, or remove it from the 2d meshes?~~ _I added MSAA to sprites since it's really needed for 2d meshes_
- ~~how to customize vertex attributes?~~ _#3120_
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Our crevice is still called "crevice", which we can't use for a release
- Users would need to use our "crevice" directly to be able to use the derive macro
## Solution
- Rename crevice to bevy_crevice, and crevice-derive to bevy-crevice-derive
- Re-export it from bevy_render, and use it from bevy_render everywhere
- Fix derive macro to work either from bevy_render, from bevy_crevice, or from bevy
## Remaining
- It is currently re-exported as `bevy::render::bevy_crevice`, is it the path we want?
- After a brief suggestion to Cart, I changed the version to follow Bevy version instead of crevice, do we want that?
- Crevice README.md need to be updated
- in the `Cargo.toml`, there are a few things to change. How do we want to change them? How do we keep attributions to original Crevice?
```
authors = ["Lucien Greathouse <me@lpghatguy.com>"]
documentation = "https://docs.rs/crevice"
homepage = "https://github.com/LPGhatguy/crevice"
repository = "https://github.com/LPGhatguy/crevice"
```
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
### Problem
- shader processing errors are not displayed
- during hot reloading when encountering a shader with errors, the whole app crashes
### Solution
- log `error!`s for shader processing errors
- when `cfg(debug_assertions)` is enabled (i.e. you're running in `debug` mode), parse shaders before passing them to wgpu. This lets us handle errors early.
# Objective
- 3d examples fail to run in webgl2 because of unsupported texture formats or texture too large
## Solution
- switch to supported formats if a feature is enabled. I choose a feature instead of a build target to not conflict with a potential webgpu support
Very inspired by 6813b2edc5, and need #3290 to work.
I named the feature `webgl2`, but it's only needed if one want to use PBR in webgl2. Examples using only 2D already work.
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
# Objective
Fixes#3352Fixes#3208
## Solution
- Update wgpu to 0.12
- Update naga to 0.8
- Resolve compilation errors
- Remove [[block]] from WGSL shaders (because it is depracated and now wgpu cant parse it)
- Replace `elseif` with `else if` in pbr.wgsl
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}