# Objective
This PR reorganizes majority of the scene viewer example into a module of plugins which then allows reuse of functionality among new or existing examples. In addition, this enables the scene viewer to be more succinct and showcase the distinct cases of camera control and scene control.
This work is to support future work in organization and future examples. A more complicated 3D scene example has been requested by the community (#6551) which requests functionality currently included in scene_viewer, but previously inaccessible. The future example can now just utilize the two plugins created here. The existing example [animated_fox example] can utilize the scene creation and animation control functionality of `SceneViewerPlugin`.
## Solution
- Created a `scene_viewer` module inside the `tools` example folder.
- Created two plugins: `SceneViewerPlugin` (gltf scene loading, animation control, camera tracking control, light control) and `CameraControllerPlugin` (controllable camera).
- Original `scene_viewer.rs` moved to `scene_viewer/main.rs` and now utilizes the two plugins.
# Objective
[Rust 1.66](https://blog.rust-lang.org/inside-rust/2022/12/12/1.66.0-prerelease.html) is coming in a few days, and bevy doesn't build with it.
Fix that.
## Solution
Replace output from a trybuild test, and fix a few new instances of `needless_borrow` and `unnecessary_cast` that are now caught.
## Note
Due to the trybuild test, this can't be merged until 1.66 is released.
# Objective
- Fixes#6630, fixes#6679
- Improve scene viewer in cases where there are more than one scene in a gltf file
## Solution
- Can select which scene to display using `#SceneN`, defaults to scene 0 if not present
- Display the number of scenes available if there are more than one
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Fixes#5884#2879
Alternative to #2988#5885#2886
"Immutable" Plugin settings are currently represented as normal ECS resources, which are read as part of plugin init. This presents a number of problems:
1. If a user inserts the plugin settings resource after the plugin is initialized, it will be silently ignored (and use the defaults instead)
2. Users can modify the plugin settings resource after the plugin has been initialized. This creates a false sense of control over settings that can no longer be changed.
(1) and (2) are especially problematic and confusing for the `WindowDescriptor` resource, but this is a general problem.
## Solution
Immutable Plugin settings now live on each Plugin struct (ex: `WindowPlugin`). PluginGroups have been reworked to support overriding plugin values. This also removes the need for the `add_plugins_with` api, as the `add_plugins` api can use the builder pattern directly. Settings that can be used at runtime continue to be represented as ECS resources.
Plugins are now configured like this:
```rust
app.add_plugin(AssetPlugin {
watch_for_changes: true,
..default()
})
```
PluginGroups are now configured like this:
```rust
app.add_plugins(DefaultPlugins
.set(AssetPlugin {
watch_for_changes: true,
..default()
})
)
```
This is an alternative to #2988, which is similar. But I personally prefer this solution for a couple of reasons:
* ~~#2988 doesn't solve (1)~~ #2988 does solve (1) and will panic in that case. I was wrong!
* This PR directly ties plugin settings to Plugin types in a 1:1 relationship, rather than a loose "setup resource" <-> plugin coupling (where the setup resource is consumed by the first plugin that uses it).
* I'm not a huge fan of overloading the ECS resource concept and implementation for something that has very different use cases and constraints.
## Changelog
- PluginGroups can now be configured directly using the builder pattern. Individual plugin values can be overridden by using `plugin_group.set(SomePlugin {})`, which enables overriding default plugin values.
- `WindowDescriptor` plugin settings have been moved to `WindowPlugin` and `AssetServerSettings` have been moved to `AssetPlugin`
- `app.add_plugins_with` has been replaced by using `add_plugins` with the builder pattern.
## Migration Guide
The `WindowDescriptor` settings have been moved from a resource to `WindowPlugin::window`:
```rust
// Old (Bevy 0.8)
app
.insert_resource(WindowDescriptor {
width: 400.0,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(WindowPlugin {
window: WindowDescriptor {
width: 400.0,
..default()
},
..default()
}))
```
The `AssetServerSettings` resource has been removed in favor of direct `AssetPlugin` configuration:
```rust
// Old (Bevy 0.8)
app
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
.add_plugins(DefaultPlugins)
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.set(AssetPlugin {
watch_for_changes: true,
..default()
}))
```
`add_plugins_with` has been replaced by `add_plugins` in combination with the builder pattern:
```rust
// Old (Bevy 0.8)
app.add_plugins_with(DefaultPlugins, |group| group.disable::<AssetPlugin>());
// New (Bevy 0.9)
app.add_plugins(DefaultPlugins.build().disable::<AssetPlugin>());
```
# Objective
Fixes#6339.
## Solution
This PR adds a new type, `GamepadInfo`, which holds metadata associated with a particular `Gamepad`. The `Gamepads` resource now holds a `HashMap<Gamepad, GamepadInfo>`. The `GamepadInfo` is created when the gamepad backend (by default `bevy_gilrs`) emits a "gamepad connected" event.
The `gamepad_viewer` example has been updated to showcase the new functionality.
Before:

After:

---
## Changelog
### Added
- Added `GamepadInfo`.
- Added `Gamepads::name()`, which returns the name of the specified gamepad if it exists.
### Changed
- `GamepadEventType::Connected` is now a tuple variant with a single field of type `GamepadInfo`.
- Since `GamepadInfo` is not `Copy`, `GamepadEventType` is no longer `Copy`. The same is true of `GamepadEvent` and `GamepadEventRaw`.
## Migration Guide
- Pattern matches on `GamepadEventType::Connected` will need to be updated, as the form of the variant has changed.
- Code that requires `GamepadEvent`, `GamepadEventRaw` or `GamepadEventType` to be `Copy` will need to be updated.
# Objective
- Make `Time` API more consistent.
- Support time accel/decel/pause.
## Solution
This is just the `Time` half of #3002. I was told that part isn't controversial.
- Give the "delta time" and "total elapsed time" methods `f32`, `f64`, and `Duration` variants with consistent naming.
- Implement accelerating / decelerating the passage of time.
- Implement stopping time.
---
## Changelog
- Changed `time_since_startup` to `elapsed` because `time.time_*` is just silly.
- Added `relative_speed` and `set_relative_speed` methods.
- Added `is_paused`, `pause`, `unpause` , and methods. (I'd prefer `resume`, but `unpause` matches `Timer` API.)
- Added `raw_*` variants of the "delta time" and "total elapsed time" methods.
- Added `first_update` method because there's a non-zero duration between startup and the first update.
## Migration Guide
- `time.time_since_startup()` -> `time.elapsed()`
- `time.seconds_since_startup()` -> `time.elapsed_seconds_f64()`
- `time.seconds_since_startup_wrapped_f32()` -> `time.elapsed_seconds_wrapped()`
If you aren't sure which to use, most systems should continue to use "scaled" time (e.g. `time.delta_seconds()`). The realtime "unscaled" time measurements (e.g. `time.raw_delta_seconds()`) are mostly for debugging and profiling.
# Objective
Fixes https://github.com/bevyengine/bevy/issues/3418
## Solution
Originally a rebase of https://github.com/bevyengine/bevy/pull/3446. Work was originally done by mfdorst, who should receive considerable credit. Then the error types were extensively reworked by targrub.
## Migration Guide
`AxisSettings` now has a `new()`, which may return an `AxisSettingsError`.
`AxisSettings` fields made private; now must be accessed through getters and setters. There's a dead zone, from `.deadzone_upperbound()` to `.deadzone_lowerbound()`, and a live zone, from `.deadzone_upperbound()` to `.livezone_upperbound()` and from `.deadzone_lowerbound()` to `.livezone_lowerbound()`.
`AxisSettings` setters no longer panic.
`ButtonSettings` fields made private; now must be accessed through getters and setters.
`ButtonSettings` now has a `new()`, which may return a `ButtonSettingsError`.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
The docs ended up quite verbose :v
Also added a missing `#[inline]` to `GlobalTransform::mul_transform`.
I'd say this resolves#5500
# Migration Guide
`Transform::mul_vec3` has been renamed to `transform_point`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Reduce code duplication in the `gamepad_viewer` example.
- Fixes#6164
## Solution
- Added a custom Bundle called `GamepadButtonBundle` to avoid repeating similar code throughout the example.
- Created a `new()` method on `GamepadButtonBundle`.
Co-authored-by: Alvin Philips <alvinphilips257@gmail.com>
# Objective
Scene viewer example has switch camera keys defined, but only one camera was instantiated on the scene.
## Solution
More explicit help how to cycle the cameras, explaining that more cameras must be present in loaded scene.
Co-authored-by: Fanda Vacek <fvacek@elektroline.cz>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
`AssetServer::watch_for_changes()` is racy and redundant with `AssetServerSettings`.
Closes#5964.
## Changelog
* Remove `AssetServer::watch_for_changes()`
* Add `AssetServerSettings` to the prelude.
* Minor cleanup.
## Migration Guide
`AssetServer::watch_for_changes()` was removed.
Instead, use the `AssetServerSettings` resource.
```rust
app // AssetServerSettings must be inserted before adding the AssetPlugin or DefaultPlugins.
.insert_resource(AssetServerSettings {
watch_for_changes: true,
..default()
})
```
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Examples inconsistently use either `TAU`, `PI`, `FRAC_PI_2` or `FRAC_PI_4`.
Often in odd ways and without `use`ing the constants, making it difficult to parse.
* Use `PI` to specify angles.
* General code-quality improvements.
* Fix borked `hierarchy` example.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
*This PR description is an edited copy of #5007, written by @alice-i-cecile.*
# Objective
Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds.
While ergonomic, this results in several drawbacks:
* it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource
* it is challenging to discover if a type is intended to be used as a resource
* we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component).
* dependencies can use the same Rust type as a resource in invisibly conflicting ways
* raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values
* we cannot capture a definitive list of possible resources to display to users in an editor
## Notes to reviewers
* Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits.
*ira: My commits are not as well organized :')*
* I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does.
* I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981.
## Changelog
`Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro.
## Migration Guide
Add `#[derive(Resource)]` to all types you are using as a resource.
If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics.
`ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing.
Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead.
Co-authored-by: Alice <alice.i.cecile@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Users often ask for help with rotations as they struggle with `Quat`s.
`Quat` is rather complex and has a ton of verbose methods.
## Solution
Add rotation helper methods to `Transform`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier.
Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):

Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work".
Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id:
```rust
// main camera (main window)
commands.spawn_bundle(Camera2dBundle::default());
// second camera (other window)
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Window(window_id),
..default()
},
..default()
});
```
Rendering to a texture is as simple as pointing the camera at a texture:
```rust
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle),
..default()
},
..default()
});
```
Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`).
```rust
// main pass camera with a default priority of 0
commands.spawn_bundle(Camera2dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
target: RenderTarget::Texture(image_handle.clone()),
priority: -1,
..default()
},
..default()
});
commands.spawn_bundle(SpriteBundle {
texture: image_handle,
..default()
})
```
Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system:
```rust
commands.spawn_bundle(Camera3dBundle::default());
commands.spawn_bundle(Camera2dBundle {
camera: Camera {
// this will render 2d entities "on top" of the default 3d camera's render
priority: 1,
..default()
},
..default()
});
```
There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active.
Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections.
```rust
// old 3d perspective camera
commands.spawn_bundle(PerspectiveCameraBundle::default())
// new 3d perspective camera
commands.spawn_bundle(Camera3dBundle::default())
```
```rust
// old 2d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_2d())
// new 2d orthographic camera
commands.spawn_bundle(Camera2dBundle::default())
```
```rust
// old 3d orthographic camera
commands.spawn_bundle(OrthographicCameraBundle::new_3d())
// new 3d orthographic camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical,
..default()
}.into(),
..default()
})
```
Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors.
If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_render_graph: CameraRenderGraph::new(some_render_graph_name),
..default()
})
```
Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added.
Speaking of using components to configure graphs / passes, there are a number of new configuration options:
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// overrides the default global clear color
clear_color: ClearColorConfig::Custom(Color::RED),
..default()
},
..default()
})
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
// disables clearing
clear_color: ClearColorConfig::None,
..default()
},
..default()
})
```
Expect to see more of the "graph configuration Components on Cameras" pattern in the future.
By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component:
```rust
commands
.spawn_bundle(Camera3dBundle::default())
.insert(CameraUi {
is_enabled: false,
..default()
})
```
## Other Changes
* The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr.
* I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization.
* I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler.
* All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr.
* Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic.
* Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals:
1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs.
2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense.
## Follow Up Work
* Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen)
* Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor)
* Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system).
* Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable.
* Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home.
# Objective
- The `scene_viewer` example assumes the `animation` feature is enabled, which it is by default. However, animations may have a performance cost that is undesirable when testing performance, for example. Then it is useful to be able to disable the `animation` feature and one would still like the `scene_viewer` example to work.
## Solution
- Gate animation code in `scene_viewer` on the `animation` feature being enabled.
# Objective
- Sometimes, people might load an asset as one type, then use it with an `Asset`s for a different type.
- See e.g. #4784.
- This is especially likely with the Gltf types, since users may not have a clear conceptual model of what types the assets will be.
- We had an instance of this ourselves, in the `scene_viewer` example
## Solution
- Make `Assets::get` require a type safe handle.
---
## Changelog
### Changed
- `Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles.
### Added
- `HandleUntyped::typed_weak`, a helper function for creating a weak typed version of an exisitng `HandleUntyped`.
## Migration Guide
`Assets::<T>::get` and `Assets::<T>::get_mut` now require that the passed handles are `Handle<T>`, improving the type safety of handles. If you were previously passing in:
- a `HandleId`, use `&Handle::weak(id)` instead, to create a weak handle. You may have been able to store a type safe `Handle` instead.
- a `HandleUntyped`, use `&handle_untyped.typed_weak()` to create a weak handle of the specified type. This is most likely to be the useful when using [load_folder](https://docs.rs/bevy_asset/latest/bevy_asset/struct.AssetServer.html#method.load_folder)
- a `Handle<U>` of of a different type, consider whether this is the correct handle type to store. If it is (i.e. the same handle id is used for multiple different Asset types) use `Handle::weak(handle.id)` to cast to a different type.
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
glTF files can contain cameras. Currently the scene viewer example uses _a_ camera defined in the file if possible, otherwise it spawns a new one. It would be nice if instead it could load all the cameras and cycle through them, while also having a separate user-controller camera.
## Solution
- instead of just a camera that is already defined, always spawn a new separate user-controller camera
- maintain a list of loaded cameras and cycle through them (wrapping to the user-controller camera) when pressing `C`
This matches the behavious that https://github.khronos.org/glTF-Sample-Viewer-Release/ has.
## Implementation notes
- The gltf scene asset loader just spawns the cameras into the world, but does not return a mapping of camera index to bevy entity. So instead the scene_viewer example just collects all spawned cameras with a good old `query.iter().collect()`, so the order is unspecified and may change between runs.
## Demo
https://user-images.githubusercontent.com/22177966/161826637-40161482-5b3b-4df5-aae8-1d5e9b918393.mp4
using the virtual city glTF sample file: https://github.com/KhronosGroup/glTF-Sample-Models/tree/master/2.0/VC
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Several examples are useful for qualitative tests of Bevy's performance
- By contrast, these are less useful for learning material: they are often relatively complex and have large amounts of setup and are performance optimized.
## Solution
- Move bevymark, many_sprites and many_cubes into the new stress_tests example folder
- Move contributors into the games folder: unlike the remaining examples in the 2d folder, it is not focused on demonstrating a clear feature.
# Objective
- Changing animation mid animation can leave the model not in its original position
- ~~The movement speed is fixed, no matter the size of the model~~
## Solution
- when changing animation, set it to its initial state and wait for one frame before changing the animation
- ~~when settings the camera controller, use the camera transform to know how far it is from the origin and use the distance for the speed~~
The scene viewer example doesn't run on wasm because it sets the asset folder to `std::env::var("CARGO_MANIFEST_DIR").unwrap()`, which isn't supported on the web.
Solution: set the asset folder to `"."` instead.
# Objective
- Only move the camera when explicitly wanted, otherwise the camera goes crazy if the cursor isn't already in the middle of the window when it opens.
## Solution
- Check if the Left mouse button is pressed before updating the mouse delta
- Input is configurable
# Objective
- Since #4224, using labels which only refer to one system doesn't make sense.
## Solution
- Remove some of those.
## Future work
- We should remove the ability to use strings as system labels entirely. I haven't in this PR because there are tests which use this, and that's a lot of code to change.
- The only use cases for labels are either intra-crate, which use #4224, or inter-crate, which should either use #4224 or explicit types. Neither of those should use strings.
# Objective
A common pattern in Rust is the [newtype](https://doc.rust-lang.org/rust-by-example/generics/new_types.html). This is an especially useful pattern in Bevy as it allows us to give common/foreign types different semantics (such as allowing it to implement `Component` or `FromWorld`) or to simply treat them as a "new type" (clever). For example, it allows us to wrap a common `Vec<String>` and do things like:
```rust
#[derive(Component)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().0.push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
> We could then define another struct that wraps `Vec<String>` without anything clashing in the query.
However, one of the worst parts of this pattern is the ugly `.0` we have to write in order to access the type we actually care about. This is why people often implement `Deref` and `DerefMut` in order to get around this.
Since it's such a common pattern, especially for Bevy, it makes sense to add a derive macro to automatically add those implementations.
## Solution
Added a derive macro for `Deref` and another for `DerefMut` (both exported into the prelude). This works on all structs (including tuple structs) as long as they only contain a single field:
```rust
#[derive(Deref)]
struct Foo(String);
#[derive(Deref, DerefMut)]
struct Bar {
name: String,
}
```
This allows us to then remove that pesky `.0`:
```rust
#[derive(Component, Deref, DerefMut)]
struct Items(Vec<String>);
fn give_sword(query: Query<&mut Items>) {
query.single_mut().push(String::from("Flaming Poisoning Raging Sword of Doom"));
}
```
### Alternatives
There are other alternatives to this such as by using the [`derive_more`](https://crates.io/crates/derive_more) crate. However, it doesn't seem like we need an entire crate just yet since we only need `Deref` and `DerefMut` (for now).
### Considerations
One thing to consider is that the Rust std library recommends _not_ using `Deref` and `DerefMut` for things like this: "`Deref` should only be implemented for smart pointers to avoid confusion" ([reference](https://doc.rust-lang.org/std/ops/trait.Deref.html)). Personally, I believe it makes sense to use it in the way described above, but others may disagree.
### Additional Context
Discord: https://discord.com/channels/691052431525675048/692572690833473578/956648422163746827 (controversiality discussed [here](https://discord.com/channels/691052431525675048/692572690833473578/956711911481835630))
---
## Changelog
- Add `Deref` derive macro (exported to prelude)
- Add `DerefMut` derive macro (exported to prelude)
- Updated most newtypes in examples to use one or both derives
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Allow quick and easy testing of scenes
## Solution
- Add a `scene-viewer` tool based on `load_gltf`.
- Run it with e.g. `cargo run --release --example scene_viewer --features jpeg -- ../some/path/assets/models/Sponza/glTF/Sponza.gltf#Scene0`
- Configure the asset path as pointing to the repo root for convenience (paths specified relative to current working directory)
- Copy over the camera controller from the `shadow_biases` example
- Support toggling the light animation
- Support toggling shadows
- Support adjusting the directional light shadow projection (cascaded shadow maps will remove the need for this later)
I don't want to do too much on it up-front. Rather we can add features over time as we need them.
# Objective
- Improve documentation.
- Provide helper functions for common uses of `Windows` relating to getting the primary `Window`.
- Reduce repeated `Window` code.
# Solution
- Adds infallible `primary()` and `primary_mut()` functions with standard error text. This replaces the commonly used `get_primary().unwrap()` seen throughout bevy which has inconsistent or nonexistent error messages.
- Adds `scale_factor(WindowId)` to replace repeated code blocks throughout.
# Considerations
- The added functions can panic if the primary window does not exist.
- It is very uncommon for the primary window to not exist, as seen by the regular use of `get_primary().unwrap()`. Most users will have a single window and will need to reference the primary window in their code multiple times.
- The panic provides a consistent error message to make this class of error easy to spot from the panic text.
- This follows the established standard of short names for infallible-but-unlikely-to-panic functions in bevy.
- Removes line noise for common usage of `Windows`.
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
# Objective
Enable the user to specify any presentation modes (including `Mailbox`).
Fixes#3807
## Solution
I've added a new `PresentMode` enum in `bevy_window` that mirrors the `wgpu` enum 1:1. Alternatively, I could add a new dependency on `wgpu-types` if that would be preferred.
# Objective
Have the bird spawning/collision systems in bevymark use the proper window size, instead of the size set in WindowDescriptor which isn't updated when the window is resized.
## Solution
Use the Windows resource to grab the width/height from the primary window. This is consistent with the other examples.
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
This implements the following:
* **Sprite Batching**: Collects sprites in a vertex buffer to draw many sprites with a single draw call. Sprites are batched by their `Handle<Image>` within a specific z-level. When possible, sprites are opportunistically batched _across_ z-levels (when no sprites with a different texture exist between two sprites with the same texture on different z levels). With these changes, I can now get ~130,000 sprites at 60fps on the `bevymark_pipelined` example.
* **Sprite Color Tints**: The `Sprite` type now has a `color` field. Non-white color tints result in a specialized render pipeline that passes the color in as a vertex attribute. I chose to specialize this because passing vertex colors has a measurable price (without colors I get ~130,000 sprites on bevymark, with colors I get ~100,000 sprites). "Colored" sprites cannot be batched with "uncolored" sprites, but I think this is fine because the chance of a "colored" sprite needing to batch with other "colored" sprites is generally probably way higher than an "uncolored" sprite needing to batch with a "colored" sprite.
* **Sprite Flipping**: Sprites can be flipped on their x or y axis using `Sprite::flip_x` and `Sprite::flip_y`. This is also true for `TextureAtlasSprite`.
* **Simpler BufferVec/UniformVec/DynamicUniformVec Clearing**: improved the clearing interface by removing the need to know the size of the final buffer at the initial clear.
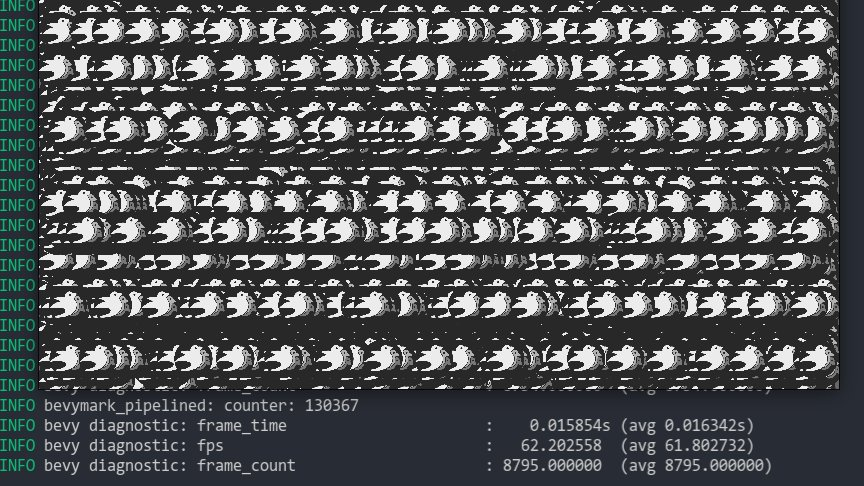
Note that this moves sprites away from entity-driven rendering and back to extracted lists. We _could_ use entities here, but it necessitates that an intermediate list is allocated / populated to collect and sort extracted sprites. This redundant copy, combined with the normal overhead of spawning extracted sprite entities, brings bevymark down to ~80,000 sprites at 60fps. I think making sprites a bit more fixed (by default) is worth it. I view this as acceptable because batching makes normal entity-driven rendering pretty useless anyway (and we would want to batch most custom materials too). We can still support custom shaders with custom bindings, we'll just need to define a specific interface for it.
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This changes how render logic is composed to make it much more modular. Previously, all extraction logic was centralized for a given "type" of rendered thing. For example, we extracted meshes into a vector of ExtractedMesh, which contained the mesh and material asset handles, the transform, etc. We looked up bindings for "drawn things" using their index in the `Vec<ExtractedMesh>`. This worked fine for built in rendering, but made it hard to reuse logic for "custom" rendering. It also prevented us from reusing things like "extracted transforms" across contexts.
To make rendering more modular, I made a number of changes:
* Entities now drive rendering:
* We extract "render components" from "app components" and store them _on_ entities. No more centralized uber lists! We now have true "ECS-driven rendering"
* To make this perform well, I implemented #2673 in upstream Bevy for fast batch insertions into specific entities. This was merged into the `pipelined-rendering` branch here: #2815
* Reworked the `Draw` abstraction:
* Generic `PhaseItems`: each draw phase can define its own type of "rendered thing", which can define its own "sort key"
* Ported the 2d, 3d, and shadow phases to the new PhaseItem impl (currently Transparent2d, Transparent3d, and Shadow PhaseItems)
* `Draw` trait and and `DrawFunctions` are now generic on PhaseItem
* Modular / Ergonomic `DrawFunctions` via `RenderCommands`
* RenderCommand is a trait that runs an ECS query and produces one or more RenderPass calls. Types implementing this trait can be composed to create a final DrawFunction. For example the DrawPbr DrawFunction is created from the following DrawCommand tuple. Const generics are used to set specific bind group locations:
```rust
pub type DrawPbr = (
SetPbrPipeline,
SetMeshViewBindGroup<0>,
SetStandardMaterialBindGroup<1>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* The new `custom_shader_pipelined` example illustrates how the commands above can be reused to create a custom draw function:
```rust
type DrawCustom = (
SetCustomMaterialPipeline,
SetMeshViewBindGroup<0>,
SetTransformBindGroup<2>,
DrawMesh,
);
```
* ExtractComponentPlugin and UniformComponentPlugin:
* Simple, standardized ways to easily extract individual components and write them to GPU buffers
* Ported PBR and Sprite rendering to the new primitives above.
* Removed staging buffer from UniformVec in favor of direct Queue usage
* Makes UniformVec much easier to use and more ergonomic. Completely removes the need for custom render graph nodes in these contexts (see the PbrNode and view Node removals and the much simpler call patterns in the relevant Prepare systems).
* Added a many_cubes_pipelined example to benchmark baseline 3d rendering performance and ensure there were no major regressions during this port. Avoiding regressions was challenging given that the old approach of extracting into centralized vectors is basically the "optimal" approach. However thanks to a various ECS optimizations and render logic rephrasing, we pretty much break even on this benchmark!
* Lifetimeless SystemParams: this will be a bit divisive, but as we continue to embrace "trait driven systems" (ex: ExtractComponentPlugin, UniformComponentPlugin, DrawCommand), the ergonomics of `(Query<'static, 'static, (&'static A, &'static B, &'static)>, Res<'static, C>)` were getting very hard to bear. As a compromise, I added "static type aliases" for the relevant SystemParams. The previous example can now be expressed like this: `(SQuery<(Read<A>, Read<B>)>, SRes<C>)`. If anyone has better ideas / conflicting opinions, please let me know!
* RunSystem trait: a way to define Systems via a trait with a SystemParam associated type. This is used to implement the various plugins mentioned above. I also added SystemParamItem and QueryItem type aliases to make "trait stye" ecs interactions nicer on the eyes (and fingers).
* RenderAsset retrying: ensures that render assets are only created when they are "ready" and allows us to create bind groups directly inside render assets (which significantly simplified the StandardMaterial code). I think ultimately we should swap this out on "asset dependency" events to wait for dependencies to load, but this will require significant asset system changes.
* Updated some built in shaders to account for missing MeshUniform fields
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
- Prevent the need to have a system that synchronizes sprite sizes with their images
## Solution
- Read the sprite size from the image asset when rendering the sprite
- Replace the `size` and `resize_mode` fields of `Sprite` with a `custom_size: Option<Vec2>` that will modify the sprite's rendered size to be different than the image size, but only if it is `Some(Vec2)`
# Objective
- Remove all the `.system()` possible.
- Check for remaining missing cases.
## Solution
- Remove all `.system()`, fix compile errors
- 32 calls to `.system()` remains, mostly internals, the few others should be removed after #2446
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet.
You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away.
Co-Authored-By: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}