# Objective
fix crash / misbehaviour when `DeferredPrepass` is used without
`DepthPrepass`.
- Deferred lighting requires the depth prepass texture to be present, so
that the depth texture is available for binding. without it the deferred
lighting pass will use 0 for depth of all meshes.
- When `DeferredPrepass` is used without other prepass markers, and with
any materials that use `OpaqueRenderMode::Forward`, those entities will
try to queue to the `Opaque3dPrepass` render phase, which doesn't exist,
causing a crash.
## Solution
- check if the prepass phases exist before queueing
- generate prepass textures if `Opaque3dDeferred` is present
- add a note to the DeferredPrepass marker to note that DepthPrepass is
also required by the default deferred lighting pass
- also changed some `With<T>.is_some()`s to `Has<T>`s
# Objective
I was working with forward rendering prepass fragment shaders and ran
into an issue of not being able to access vertex colors in the prepass.
I was able to access vertex colors in regular fragment shaders as well
as in deferred shaders.
## Solution
It seems like this `if` was nested unintentionally as moving it outside
of the `deferred` block works.
---
## Changelog
Enable vertex colors in forward rendering prepass fragment shaders
# Objective
<img width="1920" alt="Screenshot 2023-04-26 at 01 07 34"
src="https://user-images.githubusercontent.com/418473/234467578-0f34187b-5863-4ea1-88e9-7a6bb8ce8da3.png">
This PR adds both diffuse and specular light transmission capabilities
to the `StandardMaterial`, with support for screen space refractions.
This enables realistically representing a wide range of real-world
materials, such as:
- Glass; (Including frosted glass)
- Transparent and translucent plastics;
- Various liquids and gels;
- Gemstones;
- Marble;
- Wax;
- Paper;
- Leaves;
- Porcelain.
Unlike existing support for transparency, light transmission does not
rely on fixed function alpha blending, and therefore works with both
`AlphaMode::Opaque` and `AlphaMode::Mask` materials.
## Solution
- Introduces a number of transmission related fields in the
`StandardMaterial`;
- For specular transmission:
- Adds logic to take a view main texture snapshot after the opaque
phase; (in order to perform screen space refractions)
- Introduces a new `Transmissive3d` phase to the renderer, to which all
meshes with `transmission > 0.0` materials are sent.
- Calculates a light exit point (of the approximate mesh volume) using
`ior` and `thickness` properties
- Samples the snapshot texture with an adaptive number of taps across a
`roughness`-controlled radius enabling “blurry” refractions
- For diffuse transmission:
- Approximates transmitted diffuse light by using a second, flipped +
displaced, diffuse-only Lambertian lobe for each light source.
## To Do
- [x] Figure out where `fresnel_mix()` is taking place, if at all, and
where `dielectric_specular` is being calculated, if at all, and update
them to use the `ior` value (Not a blocker, just a nice-to-have for more
correct BSDF)
- To the _best of my knowledge, this is now taking place, after
964340cdd. The fresnel mix is actually "split" into two parts in our
implementation, one `(1 - fresnel(...))` in the transmission, and
`fresnel()` in the light implementations. A surface with more
reflectance now will produce slightly dimmer transmission towards the
grazing angle, as more of the light gets reflected.
- [x] Add `transmission_texture`
- [x] Add `diffuse_transmission_texture`
- [x] Add `thickness_texture`
- [x] Add `attenuation_distance` and `attenuation_color`
- [x] Connect values to glTF loader
- [x] `transmission` and `transmission_texture`
- [x] `thickness` and `thickness_texture`
- [x] `ior`
- [ ] `diffuse_transmission` and `diffuse_transmission_texture` (needs
upstream support in `gltf` crate, not a blocker)
- [x] Add support for multiple screen space refraction “steps”
- [x] Conditionally create no transmission snapshot texture at all if
`steps == 0`
- [x] Conditionally enable/disable screen space refraction transmission
snapshots
- [x] Read from depth pre-pass to prevent refracting pixels in front of
the light exit point
- [x] Use `interleaved_gradient_noise()` function for sampling blur in a
way that benefits from TAA
- [x] Drill down a TAA `#define`, tweak some aspects of the effect
conditionally based on it
- [x] Remove const array that's crashing under HLSL (unless a new `naga`
release with https://github.com/gfx-rs/naga/pull/2496 comes out before
we merge this)
- [ ] Look into alternatives to the `switch` hack for dynamically
indexing the const array (might not be needed, compilers seem to be
decent at expanding it)
- [ ] Add pipeline keys for gating transmission (do we really want/need
this?)
- [x] Tweak some material field/function names?
## A Note on Texture Packing
_This was originally added as a comment to the
`specular_transmission_texture`, `thickness_texture` and
`diffuse_transmission_texture` documentation, I removed it since it was
more confusing than helpful, and will likely be made redundant/will need
to be updated once we have a better infrastructure for preprocessing
assets_
Due to how channels are mapped, you can more efficiently use a single
shared texture image
for configuring the following:
- R - `specular_transmission_texture`
- G - `thickness_texture`
- B - _unused_
- A - `diffuse_transmission_texture`
The `KHR_materials_diffuse_transmission` glTF extension also defines a
`diffuseTransmissionColorTexture`,
that _we don't currently support_. One might choose to pack the
intensity and color textures together,
using RGB for the color and A for the intensity, in which case this
packing advice doesn't really apply.
---
## Changelog
- Added a new `Transmissive3d` render phase for rendering specular
transmissive materials with screen space refractions
- Added rendering support for transmitted environment map light on the
`StandardMaterial` as a fallback for screen space refractions
- Added `diffuse_transmission`, `specular_transmission`, `thickness`,
`ior`, `attenuation_distance` and `attenuation_color` to the
`StandardMaterial`
- Added `diffuse_transmission_texture`, `specular_transmission_texture`,
`thickness_texture` to the `StandardMaterial`, gated behind a new
`pbr_transmission_textures` cargo feature (off by default, for maximum
hardware compatibility)
- Added `Camera3d::screen_space_specular_transmission_steps` for
controlling the number of “layers of transparency” rendered for
transmissive objects
- Added a `TransmittedShadowReceiver` component for enabling shadows in
(diffusely) transmitted light. (disabled by default, as it requires
carefully setting up the `thickness` to avoid self-shadow artifacts)
- Added support for the `KHR_materials_transmission`,
`KHR_materials_ior` and `KHR_materials_volume` glTF extensions
- Renamed items related to temporal jitter for greater consistency
## Migration Guide
- `SsaoPipelineKey::temporal_noise` has been renamed to
`SsaoPipelineKey::temporal_jitter`
- The `TAA` shader def (controlled by the presence of the
`TemporalAntiAliasSettings` component in the camera) has been replaced
with the `TEMPORAL_JITTER` shader def (controlled by the presence of the
`TemporalJitter` component in the camera)
- `MeshPipelineKey::TAA` has been replaced by
`MeshPipelineKey::TEMPORAL_JITTER`
- The `TEMPORAL_NOISE` shader def has been consolidated with
`TEMPORAL_JITTER`
# Objective
Right now, we flip the `world_normal` in response to `double_sided &&
!is_front`, however when calculating `N` from tangents and the normal
map, we don't flip the normal read from the normal map, which produces
extremely weird results.
## Solution
- Pass `double_sided` and `is_front` flags to the
`apply_normal_mapping()` function and use them to conditionally flip
`Nt`
## Comparison
Note: These are from a custom scene running with the `transmission`
branch, (#8015) I noticed lighting got pretty weird for the back side of
translucent `double_sided` materials whenever I added a normal map.
### Before
<img width="1392" alt="Screenshot 2023-10-31 at 01 26 06"
src="https://github.com/bevyengine/bevy/assets/418473/d5f8c9c3-aca1-4c2f-854d-f0d0fd2fb19a">
### After
<img width="1392" alt="Screenshot 2023-10-31 at 01 25 42"
src="https://github.com/bevyengine/bevy/assets/418473/fa0e1aa2-19ad-4c27-bb08-37299d97971c">
---
## Changelog
- Fixed a bug where `StandardMaterial::double_sided` would interact
incorrectly with normal maps, producing broken results.
Extracted the easy stuff from #8974 .
# Problem
1. Commands from `update_previous_view_projections` would crash when
matching entities were despawned.
2. `TaaPipelineId` and `draw_3d_graph` module were not public.
3. When the motion vectors pointed to pixels that are now off screen, a
smearing artifact could occur.
# Solution
1. Use `try_insert` command instead.
2. Make them public, renaming to `TemporalAntiAliasPipelineId`.
3. Check for this case, and ignore history for pixels that are
off-screen.
# Objective
- `deferred_rendering` and `load_gltf` fail in WebGPU builds due to
textureSample() being called on the diffuse environment map texture
after non-uniform control flow
## Solution
- The diffuse environment map texture only has one mip, so use
`textureSampleLevel(..., 0.0)` to sample that mip and not require UV
gradient calculation.
# Objective
- Build on the changes in https://github.com/bevyengine/bevy/pull/9982
- Use `ImageSamplerDescriptor` as the "public image sampler descriptor"
interface in all places (for consistency)
- Make it possible to configure textures to use the "default" sampler
(as configured in the `DefaultImageSampler` resource)
- Fix a bug introduced in #9982 that prevents configured samplers from
being used in Basis, KTX2, and DDS textures
---
## Migration Guide
- When using the `Image` API, use `ImageSamplerDescriptor` instead of
`wgpu::SamplerDescriptor`
- If writing custom wgpu renderer features that work with `Image`, call
`&image_sampler.as_wgpu()` to convert to a wgpu descriptor.
# Objective
- the style of import used by bevy guarantees merge conflicts when any
file change
- This is especially true when import lists are large, such as in
`bevy_pbr`
- Merge conflicts are tricky to resolve. This bogs down rendering PRs
and makes contributing to bevy's rendering system more difficult than it
needs to
## Solution
- Use wildcard imports to replace multiline import list in `bevy_pbr`
I suspect this is controversial, but I'd like to hear alternatives.
Because this is one of many papercuts that makes developing render
features near impossible.
# Objective
- Fixes#10250
```
[Log] ERROR crates/bevy_render/src/render_resource/pipeline_cache.rs:823 failed to process shader: (wasm_example.js, line 376)
error: no definition in scope for identifier: 'bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_'
┌─ crates/bevy_pbr/src/deferred/deferred_lighting.wgsl:44:20
│
44 │ frag_coord.z = bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_(deferred_data.b).w;
│ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ unknown identifier
│
= no definition in scope for identifier: 'bevy_pbr::pbr_deferred_functions::unpack_unorm3x4_plus_unorm_20_'
```
## Solution
- Fix the import path
The "gray" issue is since #9258 on macOS
... at least they're not white anymore
<img width="1294" alt="Screenshot 2023-10-25 at 00 14 11"
src="https://github.com/bevyengine/bevy/assets/8672791/df1a1138-c26c-4417-9b49-a00fbb8561d7">
# Objective
A follow-up PR for https://github.com/bevyengine/bevy/pull/10221
## Changelog
Replaced usages of texture_descriptor.size with the helper methods of
`Image` through the entire engine codebase
# Objective
Fog color was passed to shaders without conversion from sRGB to linear
color space. Because shaders expect colors in linear space this resulted
in wrong color being used. This is most noticeable in open scenes with
dark fog color and clear color set to the same color. In such case
background/clear color (which is properly processed) is going to be
darker than very far objects.
Example:

[bevy-fog-color-bug.zip](https://github.com/bevyengine/bevy/files/13063718/bevy-fog-color-bug.zip)
## Solution
Add missing conversion of fog color to linear color space.
---
## Changelog
* Fixed conversion of fog color
## Migration Guide
- Colors in `FogSettings` struct (`color` and `directional_light_color`)
are now sent to the GPU in linear space. If you were using
`Color::rgb()`/`Color::rgba()` and would like to retain the previous
colors, you can quickly fix it by switching to
`Color::rgb_linear()`/`Color::rgba_linear()`.
# Objective
Even at `reflectance == 0.0`, our ambient and environment map light
implementations still produce fresnel/specular highlights.
Such a low `reflectance` value lies outside of the physically possible
range and is already used by our directional, point and spot light
implementations (via the `fresnel()` function) to enable artistic
control, effectively disabling the fresnel "look" for non-physically
realistic materials. Since ambient and environment lights use a
different formulation, they were not honoring this same principle.
This PR aims to bring consistency to all light types, offering the same
fresnel extinguishing control to ambient and environment lights.
Thanks to `@nathanf` for [pointing
out](https://discord.com/channels/691052431525675048/743663924229963868/1164083373514440744)
the [Filament docs section about
this](https://google.github.io/filament/Filament.md.html#lighting/occlusion/specularocclusion).
## Solution
- We use [the same
formulation](ffc572728f/crates/bevy_pbr/src/render/pbr_lighting.wgsl (L99))
already used by the `fresnel()` function in `bevy_pbr::lighting` to
modulate the F90, to modulate the specular component of Ambient and
Environment Map lights.
## Comparison
⚠️ **Modified version of the PBR example for demo purposes, that shows
reflectance (_NOT_ part of this PR)** ⚠️
Also, keep in mind this is a very subtle difference (look for the
fresnel highlights on the lower left spheres, you might need to zoom in.
### Before
<img width="1392" alt="Screenshot 2023-10-18 at 23 02 25"
src="https://github.com/bevyengine/bevy/assets/418473/ec0efb58-9a98-4377-87bc-726a1b0a3ff3">
### After
<img width="1392" alt="Screenshot 2023-10-18 at 23 01 43"
src="https://github.com/bevyengine/bevy/assets/418473/a2809325-5728-405e-af02-9b5779767843">
---
## Changelog
- Ambient and Environment Map lights will now honor values of
`reflectance` that are below the physically possible range (⪅ 0.35) by
extinguishing their fresnel highlights. (Just like point, directional
and spot lights already did.) This allows for more consistent artistic
control and for non-physically realistic looks with all light types.
## Migration Guide
- If Fresnel highlights from Ambient and Environment Map lights are no
longer visible in your materials, make sure you're using a higher,
physically plausible value of `reflectance` (⪆ 0.35).
# Objective
Simplify bind group creation code. alternative to (and based on) #9476
## Solution
- Add a `BindGroupEntries` struct that can transparently be used where
`&[BindGroupEntry<'b>]` is required in BindGroupDescriptors.
Allows constructing the descriptor's entries as:
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::with_indexes((
(2, &my_sampler),
(3, my_uniform),
)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 2,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 3,
resource: my_uniform,
},
],
);
```
or
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&BindGroupEntries::sequential((&my_sampler, my_uniform)),
);
```
instead of
```rust
render_device.create_bind_group(
"my_bind_group",
&my_layout,
&[
BindGroupEntry {
binding: 0,
resource: BindingResource::Sampler(&my_sampler),
},
BindGroupEntry {
binding: 1,
resource: my_uniform,
},
],
);
```
the structs has no user facing macros, is tuple-type-based so stack
allocated, and has no noticeable impact on compile time.
- Also adds a `DynamicBindGroupEntries` struct with a similar api that
uses a `Vec` under the hood and allows extending the entries.
- Modifies `RenderDevice::create_bind_group` to take separate arguments
`label`, `layout` and `entries` instead of a `BindGroupDescriptor`
struct. The struct can't be stored due to the internal references, and
with only 3 members arguably does not add enough context to justify
itself.
- Modify the codebase to use the new api and the `BindGroupEntries` /
`DynamicBindGroupEntries` structs where appropriate (whenever the
entries slice contains more than 1 member).
## Migration Guide
- Calls to `RenderDevice::create_bind_group({BindGroupDescriptor {
label, layout, entries })` must be amended to
`RenderDevice::create_bind_group(label, layout, entries)`.
- If `label`s have been specified as `"bind_group_name".into()`, they
need to change to just `"bind_group_name"`. `Some("bind_group_name")`
and `None` will still work, but `Some("bind_group_name")` can optionally
be simplified to just `"bind_group_name"`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- bump naga_oil to 0.10
- update shader imports to use rusty syntax
## Migration Guide
naga_oil 0.10 reworks the import mechanism to support more syntax to
make it more rusty, and test for item use before importing to determine
which imports are modules and which are items, which allows:
- use rust-style imports
```
#import bevy_pbr::{
pbr_functions::{alpha_discard as discard, apply_pbr_lighting},
mesh_bindings,
}
```
- import partial paths:
```
#import part::of::path
...
path::remainder::function();
```
which will call to `part::of::path::remainder::function`
- use fully qualified paths without importing:
```
// #import bevy_pbr::pbr_functions
bevy_pbr::pbr_functions::pbr()
```
- use imported items without qualifying
```
#import bevy_pbr::pbr_functions::pbr
// for backwards compatibility the old style is still supported:
// #import bevy_pbr::pbr_functions pbr
...
pbr()
```
- allows most imported items to end with `_` and numbers (naga_oil#30).
still doesn't allow struct members to end with `_` or numbers but it's
progress.
- the vast majority of existing shader code will work without changes,
but will emit "deprecated" warnings for old-style imports. these can be
suppressed with the `allow-deprecated` feature.
- partly breaks overrides (as far as i'm aware nobody uses these yet) -
now overrides will only be applied if the overriding module is added as
an additional import in the arguments to `Composer::make_naga_module` or
`Composer::add_composable_module`. this is necessary to support
determining whether imports are modules or items.
# Objective
This PR aims to make it so that we don't accidentally go over
`MAX_TEXTURE_IMAGE_UNITS` (in WebGL) or
`maxSampledTexturesPerShaderStage` (in WebGPU), giving us some extra
leeway to add more view bind group textures.
(This PR is extracted from—and unblocks—#8015)
## Solution
- We replace the existing `view_layout` and `view_layout_multisampled`
pair with an array of 32 bind group layouts, generated ahead of time;
- For now, these layouts cover all the possible combinations of:
`multisampled`, `depth_prepass`, `normal_prepass`,
`motion_vector_prepass` and `deferred_prepass`:
- In the future, as @JMS55 pointed out, we can likely take out
`motion_vector_prepass` and `deferred_prepass`, as these are not really
needed for the mesh pipeline and can use separate pipelines. This would
bring the possible combinations down to 8;
- We can also add more "optional" textures as they become needed,
allowing the engine to scale to a wider variety of use cases in lower
end/web environments (e.g. some apps might just want normal and depth
prepasses, others might only want light probes), while still keeping a
high ceiling for high end native environments where more textures are
supported.
- While preallocating bind group layouts is relatively cheap, the number
of combinations grows exponentially, so we should likely limit ourselves
to something like at most 256–1024 total layouts until we find a better
solution (like generating them lazily)
- To make this mechanism a little bit more explicit/discoverable, so
that compatibility with WebGPU/WebGL is not broken by accident, we add a
`MESH_PIPELINE_VIEW_LAYOUT_SAFE_MAX_TEXTURES` const and warn whenever
the number of textures in the layout crosses it.
- The warning is gated by `#[cfg(debug_assertions)]` and not issued in
release builds;
- We're counting the actual textures in the bind group layout instead of
using some roundabout metric so it should be accurate;
- Right now `MESH_PIPELINE_VIEW_LAYOUT_SAFE_MAX_TEXTURES` is set to 10
in order to leave 6 textures free for other groups;
- Currently there's no combination that would cause us to go over the
limit, but that will change once #8015 lands.
---
## Changelog
- `MeshPipeline` view bind group layouts now vary based on the current
multisampling and prepass states, saving a couple of texture binding
entries when prepasses are not in use.
## Migration Guide
- `MeshPipeline::view_layout` and
`MeshPipeline::view_layout_multisampled` have been replaced with a
private array to accomodate for variable view bind group layouts. To
obtain a view bind group layout for the current pipeline state, use the
new `MeshPipeline::get_view_layout()` or
`MeshPipeline::get_view_layout_from_key()` methods.
# Objective
allow extending `Material`s (including the built in `StandardMaterial`)
with custom vertex/fragment shaders and additional data, to easily get
pbr lighting with custom modifications, or otherwise extend a base
material.
# Solution
- added `ExtendedMaterial<B: Material, E: MaterialExtension>` which
contains a base material and a user-defined extension.
- added example `extended_material` showing how to use it
- modified AsBindGroup to have "unprepared" functions that return raw
resources / layout entries so that the extended material can combine
them
note: doesn't currently work with array resources, as i can't figure out
how to make the OwnedBindingResource::get_binding() work, as wgpu
requires a `&'a[&'a TextureView]` and i have a `Vec<TextureView>`.
# Migration Guide
manual implementations of `AsBindGroup` will need to be adjusted, the
changes are pretty straightforward and can be seen in the diff for e.g.
the `texture_binding_array` example.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
deferred doesn't currently run unless one of `DepthPrepass`,
`ForwardPrepass` or `MotionVectorPrepass` is also present on the camera.
## Solution
modify the `queue_prepass_material_meshes` view query to check for any
relevant phase, instead of requiring `Opaque3dPrepass` and
`AlphaMask3dPrepass` to be present
# Objective
- This PR aims to make the various `*_PREPASS` shader defs we have
(`NORMAL_PREPASS`, `DEPTH_PREPASS`, `MOTION_VECTORS_PREPASS` AND
`DEFERRED_PREPASS`) easier to use and understand:
- So that their meaning is now consistent across all contexts; (“prepass
X is enabled for the current view”)
- So that they're also consistently set across all contexts.
- It also aims to enable us to (with a follow up PR) to conditionally
gate the `BindGroupEntry` and `BindGroupLayoutEntry` items associated
with these prepasses, saving us up to 4 texture slots in WebGL
(currently globally limited to 16 per shader, regardless of bind groups)
## Solution
- We now consistently set these from `PrepassPipeline`, the
`MeshPipeline` and the `DeferredLightingPipeline`, we also set their
`MeshPipelineKey`s;
- We introduce `PREPASS_PIPELINE`, `MESH_PIPELINE` and
`DEFERRED_LIGHTING_PIPELINE` that can be used to detect where the code
is running, without overloading the meanings of the prepass shader defs;
- We also gate the WGSL functions in `bevy_pbr::prepass_utils` with
`#ifdef`s for their respective shader defs, so that shader code can
provide a fallback whenever they're not available.
- This allows us to conditionally include the bindings for these prepass
textures (My next PR, which will hopefully unblock #8015)
- @robtfm mentioned [these were being used to prevent accessing the same
binding as read/write in the
prepass](https://discord.com/channels/691052431525675048/743663924229963868/1163270458393759814),
however even after reversing the `#ifndef`s I had no issues running the
code, so perhaps the compiler is already smart enough even without tree
shaking to know they're not being used, thanks to `#ifdef
PREPASS_PIPELINE`?
## Comparison
### Before
| Shader Def | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | No | No |
| `DEPTH_PREPASS` | Yes | No | No |
| `MOTION_VECTORS_PREPASS` | Yes | No | No |
| `DEFERRED_PREPASS` | Yes | No | No |
| View Key | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | No |
| `DEPTH_PREPASS` | Yes | No | No |
| `MOTION_VECTORS_PREPASS` | Yes | No | No |
| `DEFERRED_PREPASS` | Yes | Yes\* | No |
\* Accidentally was being set twice, once with only
`deferred_prepass.is_some()` as a condition,
and once with `deferred_p repass.is_some() && !forward` as a condition.
### After
| Shader Def | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ---------------------------- | ----------------- | --------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | Yes |
| `DEPTH_PREPASS` | Yes | Yes | Yes |
| `MOTION_VECTORS_PREPASS` | Yes | Yes | Yes |
| `DEFERRED_PREPASS` | Yes | Yes | Unconditionally |
| `PREPASS_PIPELINE` | Unconditionally | No | No |
| `MESH_PIPELINE` | No | Unconditionally | No |
| `DEFERRED_LIGHTING_PIPELINE` | No | No | Unconditionally |
| View Key | `PrepassPipeline` | `MeshPipeline` |
`DeferredLightingPipeline` |
| ------------------------ | ----------------- | -------------- |
-------------------------- |
| `NORMAL_PREPASS` | Yes | Yes | Yes |
| `DEPTH_PREPASS` | Yes | Yes | Yes |
| `MOTION_VECTORS_PREPASS` | Yes | Yes | Yes |
| `DEFERRED_PREPASS` | Yes | Yes | Unconditionally |
---
## Changelog
- Cleaned up WGSL `*_PREPASS` shader defs so they're now consistently
used everywhere;
- Introduced `PREPASS_PIPELINE`, `MESH_PIPELINE` and
`DEFERRED_LIGHTING_PIPELINE` WGSL shader defs for conditionally
compiling logic based the current pipeline;
- WGSL functions from `bevy_pbr::prepass_utils` are now guarded with
`#ifdef` based on the currently enabled prepasses;
## Migration Guide
- When using functions from `bevy_pbr::prepass_utils`
(`prepass_depth()`, `prepass_normal()`, `prepass_motion_vector()`) in
contexts where these prepasses might be disabled, you should now wrap
your calls with the appropriate `#ifdef` guards, (`#ifdef
DEPTH_PREPASS`, `#ifdef NORMAL_PREPASS`, `#ifdef MOTION_VECTOR_PREPASS`)
providing fallback logic where applicable.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
#10105 changed the ssao input color from the material base color to
white. i can't actually see a difference in the example but there should
be one in some cases.
## Solution
change it back.
# Objective
cleanup some pbr shader code. improve shader stage io consistency and
make pbr.wgsl (probably many people's first foray into bevy shader code)
a little more human-readable. also fix a couple of small issues with
deferred rendering.
## Solution
mesh_vertex_output:
- rename to forward_io (to align with prepass_io)
- rename `MeshVertexOutput` to `VertexOutput` (to align with prepass_io)
- move `Vertex` from mesh.wgsl into here (to align with prepass_io)
prepass_io:
- remove `FragmentInput`, use `VertexOutput` directly (to align with
forward_io)
- rename `VertexOutput::clip_position` to `position` (to align with
forward_io)
pbr.wgsl:
- restructure so we don't need `#ifdefs` on the actual entrypoint, use
VertexOutput and FragmentOutput in all cases and use #ifdefs to import
the right struct definitions.
- rearrange to make the flow clearer
- move alpha_discard up from `pbr_functions::pbr` to avoid needing to
call it on some branches and not others
- add a bunch of comments
deferred_lighting:
- move ssao into the `!unlit` block to reflect forward behaviour
correctly
- fix compile error with deferred + premultiply_alpha
## Migration Guide
in custom material shaders:
- `pbr_functions::pbr` no longer calls to
`pbr_functions::alpha_discard`. if you were using the `pbr` function in
a custom shader with alpha mask mode you now also need to call
alpha_discard manually
- rename imports of `bevy_pbr::mesh_vertex_output` to
`bevy_pbr::forward_io`
- rename instances of `MeshVertexOutput` to `VertexOutput`
in custom material prepass shaders:
- rename instances of `VertexOutput::clip_position` to
`VertexOutput::position`
# Objective
Fixes [#10061]
## Solution
Renamed `RenderInstance` to `ExtractInstance`, `RenderInstances` to
`ExtractedInstances` and `RenderInstancePlugin` to
`ExtractInstancesPlugin`
# Objective
- Add a [Deferred
Renderer](https://en.wikipedia.org/wiki/Deferred_shading) to Bevy.
- This allows subsequent passes to access per pixel material information
before/during shading.
- Accessing this per pixel material information is needed for some
features, like GI. It also makes other features (ex. Decals) simpler to
implement and/or improves their capability. There are multiple
approaches to accomplishing this. The deferred shading approach works
well given the limitations of WebGPU and WebGL2.
Motivation: [I'm working on a GI solution for
Bevy](https://youtu.be/eH1AkL-mwhI)
# Solution
- The deferred renderer is implemented with a prepass and a deferred
lighting pass.
- The prepass renders opaque objects into the Gbuffer attachment
(`Rgba32Uint`). The PBR shader generates a `PbrInput` in mostly the same
way as the forward implementation and then [packs it into the
Gbuffer](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L168)).
- The deferred lighting pass unpacks the `PbrInput` and [feeds it into
the pbr()
function](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L65)),
then outputs the shaded color data.
- There is now a resource
[DefaultOpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L599))
that can be used to set the default render method for opaque materials.
If materials return `None` from
[opaque_render_method()](ec1465559f/crates/bevy_pbr/src/material.rs (L131))
the `DefaultOpaqueRendererMethod` will be used. Otherwise, custom
materials can also explicitly choose to only support Deferred or Forward
by returning the respective
[OpaqueRendererMethod](ec1465559f/crates/bevy_pbr/src/material.rs (L603))
- Deferred materials can be used seamlessly along with both opaque and
transparent forward rendered materials in the same scene. The [deferred
rendering
example](https://github.com/DGriffin91/bevy/blob/deferred/examples/3d/deferred_rendering.rs)
does this.
- The deferred renderer does not support MSAA. If any deferred materials
are used, MSAA must be disabled. Both TAA and FXAA are supported.
- Deferred rendering supports WebGL2/WebGPU.
## Custom deferred materials
- Custom materials can support both deferred and forward at the same
time. The
[StandardMaterial](ec1465559f/crates/bevy_pbr/src/render/pbr.wgsl (L166))
does this. So does [this
example](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56).
- Custom deferred materials that require PBR lighting can create a
`PbrInput`, write it to the deferred GBuffer and let it be rendered by
the `PBRDeferredLightingPlugin`.
- Custom deferred materials that require custom lighting have two
options:
1. Use the base_color channel of the `PbrInput` combined with the
`STANDARD_MATERIAL_FLAGS_UNLIT_BIT` flag.
[Example.](https://github.com/DGriffin91/bevy_glowy_orb_tutorial/blob/deferred/assets/shaders/glowy.wgsl#L56)
(If the unlit bit is set, the base_color is stored as RGB9E5 for extra
precision)
2. A Custom Deferred Lighting pass can be created, either overriding the
default, or running in addition. The a depth buffer is used to limit
rendering to only the required fragments for each deferred lighting
pass. Materials can set their respective depth id via the
[deferred_lighting_pass_id](b79182d2a3/crates/bevy_pbr/src/prepass/prepass_io.wgsl (L95))
attachment. The custom deferred lighting pass plugin can then set [its
corresponding
depth](ec1465559f/crates/bevy_pbr/src/deferred/deferred_lighting.wgsl (L37)).
Then with the lighting pass using
[CompareFunction::Equal](ec1465559f/crates/bevy_pbr/src/deferred/mod.rs (L335)),
only the fragments with a depth that equal the corresponding depth
written in the material will be rendered.
Custom deferred lighting plugins can also be created to render the
StandardMaterial. The default deferred lighting plugin can be bypassed
with `DefaultPlugins.set(PBRDeferredLightingPlugin { bypass: true })`
---------
Co-authored-by: nickrart <nickolas.g.russell@gmail.com>
# Objective
- The filter type on the `apply_global_wireframe_material` system had
duplicate filter code and the `clippy::type_complexity` attribute.
## Solution
- Extract the common part of the filter into a type alias
# Objective
- Use the `Material` abstraction for the Wireframes
- Right now this doesn't have many benefits other than simplifying some
of the rendering code
- We can reuse the default vertex shader and avoid rendering
inconsistencies
- The goal is to have a material with a color on each mesh so this
approach will make it easier to implement
- Originally done in https://github.com/bevyengine/bevy/pull/5303 but I
decided to split the Material part to it's own PR and then adding
per-entity colors and globally configurable colors will be a much
simpler diff.
## Solution
- Use the new `Material` abstraction for the Wireframes
## Notes
It's possible this isn't ideal since this adds a
`Handle<WireframeMaterial>` to all the meshes compared to the original
approach that didn't need anything. I didn't notice any performance
impact on my machine.
This might be a surprising usage of `Material` at first, because
intuitively you only have one material per mesh, but the way it's
implemented you can have as many different types of materials as you
want on a mesh.
## Migration Guide
`WireframePipeline` was removed. If you were using it directly, please
create an issue explaining your use case.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
~~Currently blocked on an upstream bug that causes crashes when
minimizing/resizing on dx12 https://github.com/gfx-rs/wgpu/issues/3967~~
wgpu 0.17.1 is out which fixes it
# Objective
Keep wgpu up to date.
## Solution
Update wgpu and naga_oil.
Currently this depends on an unreleased (and unmerged) branch of
naga_oil, and hasn't been properly tested yet.
The wgpu side of this seems to have been an extremely trivial upgrade
(all the upgrade work seems to be in naga_oil). This also lets us remove
the workarounds for pack/unpack4x8unorm in the SSAO shaders.
Lets us close the dx12 part of
https://github.com/bevyengine/bevy/issues/8888
related: https://github.com/bevyengine/bevy/issues/9304
---
## Changelog
Update to wgpu 0.17 and naga_oil 0.9
# Objective
- This PR aims to make creating meshes a little bit more ergonomic,
specifically by removing the need for intermediate mutable variables.
## Solution
- We add methods that consume the `Mesh` and return a mesh with the
specified changes, so that meshes can be entirely constructed via
builder-style calls, without intermediate variables;
- Methods are flagged with `#[must_use]` to ensure proper use;
- Examples are updated to use the new methods where applicable. Some
examples are kept with the mutating methods so that users can still
easily discover them, and also where the new methods wouldn't really be
an improvement.
## Examples
Before:
```rust
let mut mesh = Mesh::new(PrimitiveTopology::TriangleList);
mesh.insert_attribute(Mesh::ATTRIBUTE_POSITION, vs);
mesh.insert_attribute(Mesh::ATTRIBUTE_NORMAL, vns);
mesh.insert_attribute(Mesh::ATTRIBUTE_UV_0, vts);
mesh.set_indices(Some(Indices::U32(tris)));
mesh
```
After:
```rust
Mesh::new(PrimitiveTopology::TriangleList)
.with_inserted_attribute(Mesh::ATTRIBUTE_POSITION, vs)
.with_inserted_attribute(Mesh::ATTRIBUTE_NORMAL, vns)
.with_inserted_attribute(Mesh::ATTRIBUTE_UV_0, vts)
.with_indices(Some(Indices::U32(tris)))
```
Before:
```rust
let mut cube = Mesh::from(shape::Cube { size: 1.0 });
cube.generate_tangents().unwrap();
PbrBundle {
mesh: meshes.add(cube),
..default()
}
```
After:
```rust
PbrBundle {
mesh: meshes.add(
Mesh::from(shape::Cube { size: 1.0 })
.with_generated_tangents()
.unwrap(),
),
..default()
}
```
---
## Changelog
- Added consuming builder methods for more ergonomic `Mesh` creation:
`with_inserted_attribute()`, `with_removed_attribute()`,
`with_indices()`, `with_duplicated_vertices()`,
`with_computed_flat_normals()`, `with_generated_tangents()`,
`with_morph_targets()`, `with_morph_target_names()`.
# Objective
fix#9605
spotlight culling uses an incorrect cluster aabb for orthographic
projections: it does not take into account the near and far cluster
bounds at all.
## Solution
use z_near and z_far to determine cluster aabb in orthographic mode.
i'm not 100% sure this is the only change that's needed, but i am sure
this change is needed, and the example seems to work well now
(CLUSTERED_FORWARD_DEBUG_CLUSTER_LIGHT_COMPLEXITY shows good bounds
around the cone for a variety of orthographic setups).
# Objective
Webgl2 broke when pcf was merged.
Fixes#10048
## Solution
Change the `textureSampleCompareLevel` in shadow_sampling.wgsl to
`textureSampleCompare` to make it work again.
# Objective
Currently, the only way for custom components that participate in
rendering to opt into the higher-performance extraction method in #9903
is to implement the `RenderInstances` data structure and the extraction
logic manually. This is inconvenient compared to the `ExtractComponent`
API.
## Solution
This commit creates a new `RenderInstance` trait that mirrors the
existing `ExtractComponent` method but uses the higher-performance
approach that #9903 uses. Additionally, `RenderInstance` is more
flexible than `ExtractComponent`, because it can extract multiple
components at once. This makes high-performance rendering components
essentially as easy to write as the existing ones based on component
extraction.
---
## Changelog
### Added
A new `RenderInstance` trait is available mirroring `ExtractComponent`,
but using a higher-performance method to extract one or more components
to the render world. If you have custom components that rendering takes
into account, you may consider migration from `ExtractComponent` to
`RenderInstance` for higher performance.
# Objective
- Improve antialiasing for non-point light shadow edges.
- Very partially addresses
https://github.com/bevyengine/bevy/issues/3628.
## Solution
- Implements "The Witness"'s shadow map sampling technique.
- Ported from @superdump's old branch, all credit to them :)
- Implements "Call of Duty: Advanced Warfare"'s stochastic shadow map
sampling technique when the velocity prepass is enabled, for use with
TAA.
- Uses interleaved gradient noise to generate a random angle, and then
averages 8 samples in a spiral pattern, rotated by the random angle.
- I also tried spatiotemporal blue noise, but it was far too noisy to be
filtered by TAA alone. In the future, we should try spatiotemporal blue
noise + a specialized shadow denoiser such as
https://gpuopen.com/fidelityfx-denoiser/#shadow. This approach would
also be useful for hybrid rasterized applications with raytraced
shadows.
- The COD presentation has an interesting temporal dithering of the
noise for use with temporal supersampling that we should revisit when we
get DLSS/FSR/other TSR.
---
## Changelog
* Added `ShadowFilteringMethod`. Improved directional light and
spotlight shadow edges to be less aliased.
## Migration Guide
* Shadows cast by directional lights or spotlights now have smoother
edges. To revert to the old behavior, add
`ShadowFilteringMethod::Hardware2x2` to your cameras.
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/pull/7328 introduced an API to
override the global wireframe config. I believe it is flawed for a few
reasons.
This PR uses a non-breaking API. Instead of making the `Wireframe` an
enum I introduced the `NeverRenderWireframe` component. Here's the
reason why I think this is better:
- Easier to migrate since it doesn't change the old behaviour.
Essentially nothing to migrate. Right now this PR is a breaking change
but I don't think it has to be.
- It's similar to other "per mesh" rendering features like
NotShadowCaster/NotShadowReceiver
- It doesn't force new users to also think about global vs not global if
all they want is to render a wireframe
- This would also let you filter at the query definition level instead
of filtering when running the query
## Solution
- Introduce a `NeverRenderWireframe` component that ignores the global
config
---
## Changelog
- Added a `NeverRenderWireframe` component that ignores the global
`WireframeConfig`
# Objective
Allow the user to choose between "Add wireframes to these specific
entities" or "Add wireframes to everything _except_ these specific
entities".
Fixes#7309
# Solution
Make the `Wireframe` component act like an override to the global
configuration.
Having `global` set to `false`, and adding a `Wireframe` with `enable:
true` acts exactly as before.
But now the opposite is also possible: Set `global` to `true` and add a
`Wireframe` with `enable: false` will draw wireframes for everything
_except_ that entity.
Updated the example to show how overriding the global config works.
Conventionally, the second UV map (`TEXCOORD1`, `UV1`) is used for
lightmap UVs. This commit allows Bevy to import them, so that a custom
shader that applies lightmaps can use those UVs if desired.
Note that this doesn't actually apply lightmaps to Bevy meshes; that
will be a followup. It does, however, open the door to future Bevy
plugins that implement baked global illumination.
## Changelog
### Added
The Bevy glTF loader now imports a second UV channel (`TEXCOORD1`,
`UV1`) from meshes if present. This can be used by custom shaders to
implement lightmapping.
# Objective
`Has<T>` was added to bevy_ecs, but we're still using the
`Option<With<T>>` pattern in multiple locations.
## Solution
Replace them with `Has<T>`.
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
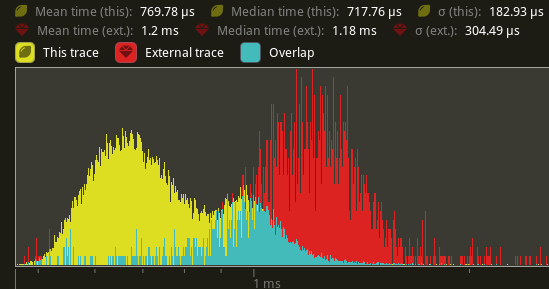
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
This is a minimally disruptive version of #8340. I attempted to update
it, but failed due to the scope of the changes added in #8204.
Fixes#8307. Partially addresses #4642. As seen in
https://github.com/bevyengine/bevy/issues/8284, we're actually copying
data twice in Prepare stage systems. Once into a CPU-side intermediate
scratch buffer, and once again into a mapped buffer. This is inefficient
and effectively doubles the time spent and memory allocated to run these
systems.
## Solution
Skip the scratch buffer entirely and use
`wgpu::Queue::write_buffer_with` to directly write data into mapped
buffers.
Separately, this also directly uses
`wgpu::Limits::min_uniform_buffer_offset_alignment` to set up the
alignment when writing to the buffers. Partially addressing the issue
raised in #4642.
Storage buffers and the abstractions built on top of
`DynamicUniformBuffer` will need to come in followup PRs.
This may not have a noticeable performance difference in this PR, as the
only first-party systems affected by this are view related, and likely
are not going to be particularly heavy.
---
## Changelog
Added: `DynamicUniformBuffer::get_writer`.
Added: `DynamicUniformBufferWriter`.
# Objective
mesh.rs is infamously large. We could split off unrelated code.
## Solution
Morph targets are very similar to skinning and have their own module. We
move skinned meshes to an independent module like morph targets and give
the systems similar names.
### Open questions
Should the skinning systems and structs stay public?
---
## Migration Guide
Renamed skinning systems, resources and components:
- extract_skinned_meshes -> extract_skins
- prepare_skinned_meshes -> prepare_skins
- SkinnedMeshUniform -> SkinUniform
- SkinnedMeshJoints -> SkinIndex
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
# Objective
- Implement the foundations of automatic batching/instancing of draw
commands as the next step from #89
- NOTE: More performance improvements will come when more data is
managed and bound in ways that do not require rebinding such as mesh,
material, and texture data.
## Solution
- The core idea for batching of draw commands is to check whether any of
the information that has to be passed when encoding a draw command
changes between two things that are being drawn according to the sorted
render phase order. These should be things like the pipeline, bind
groups and their dynamic offsets, index/vertex buffers, and so on.
- The following assumptions have been made:
- Only entities with prepared assets (pipelines, materials, meshes) are
queued to phases
- View bindings are constant across a phase for a given draw function as
phases are per-view
- `batch_and_prepare_render_phase` is the only system that performs this
batching and has sole responsibility for preparing the per-object data.
As such the mesh binding and dynamic offsets are assumed to only vary as
a result of the `batch_and_prepare_render_phase` system, e.g. due to
having to split data across separate uniform bindings within the same
buffer due to the maximum uniform buffer binding size.
- Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform
in arrays in GPU buffers rather than each one being at a dynamic offset
in a uniform buffer. This is the same optimisation that was made for 3D
not long ago.
- Change batch size for a range in `PhaseItem`, adding API for getting
or mutating the range. This is more flexible than a size as the length
of the range can be used in place of the size, but the start and end can
be otherwise whatever is needed.
- Add an optional mesh bind group dynamic offset to `PhaseItem`. This
avoids having to do a massive table move just to insert
`GpuArrayBufferIndex` components.
## Benchmarks
All tests have been run on an M1 Max on AC power. `bevymark` and
`many_cubes` were modified to use 1920x1080 with a scale factor of 1. I
run a script that runs a separate Tracy capture process, and then runs
the bevy example with `--features bevy_ci_testing,trace_tracy` and
`CI_TESTING_CONFIG=../benchmark.ron` with the contents of
`../benchmark.ron`:
```rust
(
exit_after: Some(1500)
)
```
...in order to run each test for 1500 frames.
The recent changes to `many_cubes` and `bevymark` added reproducible
random number generation so that with the same settings, the same rng
will occur. They also added benchmark modes that use a fixed delta time
for animations. Combined this means that the same frames should be
rendered both on main and on the branch.
The graphs compare main (yellow) to this PR (red).
### 3D Mesh `many_cubes --benchmark`
<img width="1411" alt="Screenshot 2023-09-03 at 23 42 10"
src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4">
The mesh and material are the same for all instances. This is basically
the best case for the initial batching implementation as it results in 1
draw for the ~11.7k visible meshes. It gives a ~30% reduction in median
frame time.
The 1000th frame is identical using the flip tool:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4615 seconds
```
### 3D Mesh `many_cubes --benchmark --material-texture-count 10`
<img width="1404" alt="Screenshot 2023-09-03 at 23 45 18"
src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf">
This run uses 10 different materials by varying their textures. The
materials are randomly selected, and there is no sorting by material
bind group for opaque 3D so any batching is 'random'. The PR produces a
~5% reduction in median frame time. If we were to sort the opaque phase
by the material bind group, then this should be a lot faster. This
produces about 10.5k draws for the 11.7k visible entities. This makes
sense as randomly selecting from 10 materials gives a chance that two
adjacent entities randomly select the same material and can be batched.
The 1000th frame is identical in flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4537 seconds
```
### 3D Mesh `many_cubes --benchmark --vary-per-instance`
<img width="1394" alt="Screenshot 2023-09-03 at 23 48 44"
src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f">
This run varies the material data per instance by randomly-generating
its colour. This is the worst case for batching and that it performs
about the same as `main` is a good thing as it demonstrates that the
batching has minimal overhead when dealing with ~11k visible mesh
entities.
The 1000th frame is identical according to flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4568 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d`
<img width="1412" alt="Screenshot 2023-09-03 at 23 59 56"
src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4">
This spawns 160 waves of 1000 quad meshes that are shaded with
ColorMaterial. Each wave has a different material so 160 waves currently
should result in 160 batches. This results in a 50% reduction in median
frame time.
Capturing a screenshot of the 1000th frame main vs PR gives:

```
Mean: 0.001222
Weighted median: 0.750432
1st weighted quartile: 0.453494
3rd weighted quartile: 0.969758
Min: 0.000000
Max: 0.990296
Evaluation time: 0.4255 seconds
```
So they seem to produce the same results. I also double-checked the
number of draws. `main` does 160000 draws, and the PR does 160, as
expected.
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --material-texture-count 10`
<img width="1392" alt="Screenshot 2023-09-04 at 00 09 22"
src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c">
This generates 10 textures and generates materials for each of those and
then selects one material per wave. The median frame time is reduced by
50%. Similar to the plain run above, this produces 160 draws on the PR
and 160000 on `main` and the 1000th frame is identical (ignoring the fps
counter text overlay).

```
Mean: 0.002877
Weighted median: 0.964980
1st weighted quartile: 0.668871
3rd weighted quartile: 0.982749
Min: 0.000000
Max: 0.992377
Evaluation time: 0.4301 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --vary-per-instance`
<img width="1396" alt="Screenshot 2023-09-04 at 00 13 53"
src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb">
This creates unique materials per instance by randomly-generating the
material's colour. This is the worst case for 2D batching. Somehow, this
PR manages a 7% reduction in median frame time. Both main and this PR
issue 160000 draws.
The 1000th frame is the same:

```
Mean: 0.001214
Weighted median: 0.937499
1st weighted quartile: 0.635467
3rd weighted quartile: 0.979085
Min: 0.000000
Max: 0.988971
Evaluation time: 0.4462 seconds
```
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite`
<img width="1396" alt="Screenshot 2023-09-04 at 12 21 12"
src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43">
This just spawns 160 waves of 1000 sprites. There should be and is no
notable difference between main and the PR.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --material-texture-count 10`
<img width="1389" alt="Screenshot 2023-09-04 at 12 36 08"
src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413">
This spawns the sprites selecting a texture at random per instance from
the 10 generated textures. This has no significant change vs main and
shouldn't.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --vary-per-instance`
<img width="1401" alt="Screenshot 2023-09-04 at 12 29 52"
src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6">
This sets the sprite colour as being unique per instance. This can still
all be drawn using one batch. There should be no difference but the PR
produces median frame times that are 4% higher. Investigation showed no
clear sources of cost, rather a mix of give and take that should not
happen. It seems like noise in the results.
### Summary
| Benchmark | % change in median frame time |
| ------------- | ------------- |
| many_cubes | 🟩 -30% |
| many_cubes 10 materials | 🟩 -5% |
| many_cubes unique materials | 🟩 ~0% |
| bevymark mesh2d | 🟩 -50% |
| bevymark mesh2d 10 materials | 🟩 -50% |
| bevymark mesh2d unique materials | 🟩 -7% |
| bevymark sprite | 🟥 2% |
| bevymark sprite 10 materials | 🟥 0.6% |
| bevymark sprite unique materials | 🟥 4.1% |
---
## Changelog
- Added: 2D and 3D mesh entities that share the same mesh and material
(same textures, same data) are now batched into the same draw command
for better performance.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective
Some rendering system did heavy use of `if let`, and could be improved
by using `let else`.
## Solution
- Reduce rightward drift by using let-else over if-let
- Extract value-to-key mappings to their own functions so that the
system is less bloated, easier to understand
- Use a `let` binding instead of untupling in closure argument to reduce
indentation
## Note to reviewers
Enable the "no white space diff" for easier viewing.
In the "Files changed" view, click on the little cog right of the "Jump
to" text, on the row where the "Review changes" button is. then enable
the "Hide whitespace" checkbox and click reload.
# Objective
Fix a typo introduced by #9497. While drafting the PR, the type was
originally called `VisibleInHierarchy` before I renamed it to
`InheritedVisibility`, but this field got left behind due to a typo.
# Objective
- When adding/removing bindings in large binding lists, git would
generate very difficult-to-read diffs
## Solution
- Move the `@group(X) @binding(Y)` into the same line as the binding
type declaration
{kind=link}