# Objective
- The functions added to utils.wgsl by the prepass assume that mesh_view_bindings are present, which isn't always the case
- Fixes https://github.com/bevyengine/bevy/issues/7353
## Solution
- Move these functions to their own `prepass_utils.wgsl` file
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
# Objective
Fixes#6931
Continues #6954 by squashing `Msaa` to a flat enum
Helps out #7215
# Solution
```
pub enum Msaa {
Off = 1,
#[default]
Sample4 = 4,
}
```
# Changelog
- Modified
- `Msaa` is now enum
- Defaults to 4 samples
- Uses `.samples()` method to get the sample number as `u32`
# Migration Guide
```
let multi = Msaa { samples: 4 }
// is now
let multi = Msaa::Sample4
multi.samples
// is now
multi.samples()
```
Co-authored-by: Sjael <jakeobrien44@gmail.com>
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Allow rendering queue systems to use a `Res<PipelineCache>` even for queueing up new rendering pipelines. This is part of unblocking parallel execution queue systems.
## Solution
- Make `PipelineCache` internally mutable w.r.t to queueing new pipelines. Pipelines are no longer immediately updated into the cache state, but rather queued into a Vec. The Vec of pending new pipelines is then later processed at the same time we actually create the queued pipelines on the GPU device.
---
## Changelog
`PipelineCache` no longer requires mutable access in order to queue render / compute pipelines.
## Migration Guide
* Most usages of `resource_mut::<PipelineCache>` and `ResMut<PipelineCache>` can be changed to `resource::<PipelineCache>` and `Res<PipelineCache>` as long as they don't use any methods requiring mutability - the only public method requiring it is `process_queue`.
# Objective
Pipelines can be customized by wrapping an existing pipeline in a newtype and adding custom logic to its implementation of `SpecializedMeshPipeline::specialize`. To make that easier, the wrapped pipeline type needs to implement `Clone`.
For example, the current non-cloneable pipelines require wrapper pipelines to pull apart the wrapped pipeline like this:
```rust
impl FromWorld for Wireframe2dPipeline {
fn from_world(world: &mut World) -> Self {
let p = &world.resource::<Material2dPipeline<ColorMaterial>>();
Self {
mesh2d_pipeline: p.mesh2d_pipeline.clone(),
material2d_layout: p.material2d_layout.clone(),
vertex_shader: p.vertex_shader.clone(),
fragment_shader: p.fragment_shader.clone(),
}
}
}
```
## Solution
Derive or implement `Clone` on all built-in pipeline types. This is easy to do since they mostly just contain cheaply clonable reference-counted types.
---
## Changelog
Implement `Clone` for all pipeline types.
# Objective
fix error with shadow shader's spotlight direction calculation when direction.y ~= 0
fixes#7152
## Solution
same as #6167: in shadows.wgsl, clamp 1-x^2-z^2 to >= 0 so that we can safely sqrt it
# Objective
Speed up the render phase for rendering.
## Solution
- Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality.
- Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s.
## Performance
This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.

---
## Changelog
Added: `RenderContext::begin_tracked_render_pass`.
Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction.
Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`.
## Migration Guide
TODO
# Objective
- Avoid slower than necessary first frame after spawning many entities due to them not having `Aabb`s and so being marked visible
- Avoids unnecessarily large system and VRAM allocations as a consequence
## Solution
- I noticed when debugging the `many_cubes` stress test in Xcode that the `MeshUniform` binding was much larger than it needed to be. I realised that this was because initially, all mesh entities are marked as being visible because they don't have `Aabb`s because `calculate_bounds` is being run in `PostUpdate` and there are no system commands applications before executing the visibility check systems that need the `Aabb`s. The solution then is to run the `calculate_bounds` system just before the previous system commands are applied which is at the end of the `Update` stage.
# Objective
Speed up the render phase of rendering. Simplify the trait structure for render commands.
## Solution
- Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`)
- Merge `EntityRenderCommand` into `RenderCommand`.
- Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`.
- Use the new associated types to construct two `QueryStates`s for `RenderCommandState`.
- Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once.
## Performance
`main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us)
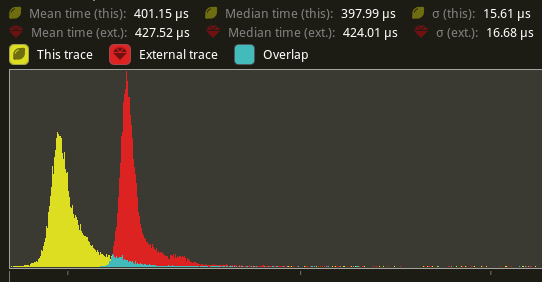
The shadow pass node is also slightly faster (344.52 -> 338.24us)
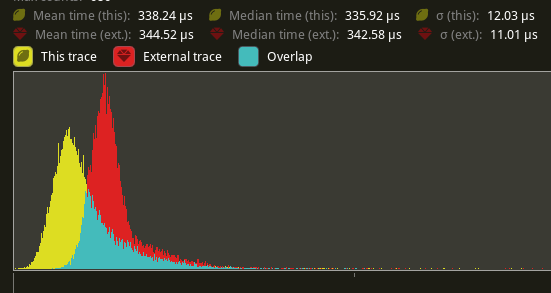
## Future Work
- Can we hoist the view level queries out of the core loop?
---
## Changelog
Added: `PhaseItem::entity`
Added: `RenderCommand::ViewWorldQuery` associated type.
Added: `RenderCommand::ItemorldQuery` associated type.
Added: `Draw<T>::prepare` optional trait function.
Removed: `EntityPhaseItem` trait
## Migration Guide
TODO
# Objective
- The #7064 PR had poor performance on an M1 Max in MacOS due to significant overuse of registers resulting in 'register spilling' where data that would normally be stored in registers on the GPU is instead stored in VRAM. The latency to read from/write to VRAM instead of registers incurs a significant performance penalty.
- Use of registers is a limiting factor in shader performance. Assignment of a struct from memory to a local variable can incur copies. Passing a variable that has struct type as an argument to a function can also incur copies. As such, these two cases can incur increased register usage and decreased performance.
## Solution
- Remove/avoid a number of assignments of light struct type data to local variables.
- Remove/avoid a number of passing light struct type variables/data as value arguments to shader functions.
# Objective
- The recently merged PR #7013 does not allow multiple `RenderPhase`s to share the same `RenderPass`.
- Due to the introduced overhead we want to minimize the number of `RenderPass`es recorded during each frame.
## Solution
- Take a constructed `TrackedRenderPass` instead of a `RenderPassDiscriptor` as a parameter to the `RenderPhase::render` method.
---
## Changelog
To enable multiple `RenderPhases` to share the same `TrackedRenderPass`,
the `RenderPhase::render` signature has changed.
```rust
pub fn render<'w>(
&self,
render_pass: &mut TrackedRenderPass<'w>,
world: &'w World,
view: Entity)
```
Co-authored-by: Kurt Kühnert <51823519+kurtkuehnert@users.noreply.github.com>
# Objective
All `RenderPhases` follow the same render procedure.
The same code is duplicated multiple times across the codebase.
## Solution
I simply extracted this code into a method on the `RenderPhase`.
This avoids code duplication and makes setting up new `RenderPhases` easier.
---
## Changelog
### Changed
You can now set up the rendering code of a `RenderPhase` directly using the `RenderPhase::render` method, instead of implementing it manually in your render graph node.
# Objective
Following #4402, extract systems run on the render world instead of the main world, and allow retained state operations on it's resources. We're currently extracting to `ExtractedJoints` and then copying it twice during Prepare. Once into `SkinnedMeshJoints` and again into the actual GPU buffer.
This makes #4902 obsolete.
## Solution
Cut out the middle copy and directly extract joints into `SkinnedMeshJoints` and remove `ExtractedJoints` entirely.
This also removes the per-frame allocation that is being made to send `ExtractedJoints` into the render world.
## Performance
On my local machine, this halves the time for `prepare_skinned _meshes` on `many_foxes` (195.75us -> 93.93us on average).
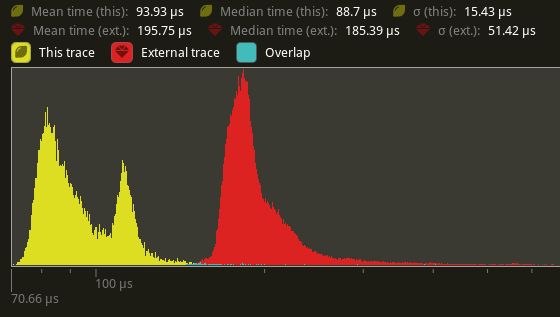
---
## Changelog
Added: `BufferVec::truncate`
Added: `BufferVec::extend`
Changed: `SkinnedMeshJoints::build` now takes a `&mut BufferVec` instead of a `&mut Vec` as a parameter.
Removed: `ExtractedJoints`.
## Migration Guide
`ExtractedJoints` has been removed. Read the bound bones from `SkinnedMeshJoints` instead.
# Objective
- Fixes#6841
- In some case, the number of maximum storage buffers is `u32::MAX` which doesn't fit in a `i32`
## Solution
- Add an option to have a `u32` in a `ShaderDefVal`
# Objective
- Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate.
## Solution
- Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible.
- I also took the opportunity to improve the error message a little in the case where it fails.
---
## Changelog
- Added `DrawFunctionsInternals::id()`
# Objective
- Reduce confusion around uniform bindings in materials. I've seen multiple people on discord get confused by it because it uses a struct that is named the same in the rust code and the wgsl code, but doesn't contain the same data. Also, the only reason this works is mostly by chance because the memory happens to align correctly.
## Solution
- Remove the confusing parts of the doc
## Notes
It's not super clear in the diff why this causes confusion, but essentially, the rust code defines a `CustomMaterial` struct with a color and a texture, but in the wgsl code the struct with the same name only contains the color. People are confused by it because the struct in wgsl doesn't need to be there.
You _can_ have complex structs on each side and the macro will even combine it for you if you reuse a binding index, but as it is now, this example seems to confuse more than help people.
# Objective
- shaders defs can now have a `bool` or `int` value
- `#if SHADER_DEF <operator> 3`
- ok if `SHADER_DEF` is defined, has the correct type and pass the comparison
- `==`, `!=`, `>=`, `>`, `<`, `<=` supported
- `#SHADER_DEF` or `#{SHADER_DEF}`
- will be replaced by the value in the shader code
---
## Migration Guide
- replace `shader_defs.push(String::from("NAME"));` by `shader_defs.push("NAME".into());`
- if you used shader def `NO_STORAGE_BUFFERS_SUPPORT`, check how `AVAILABLE_STORAGE_BUFFER_BINDINGS` is now used in Bevy default shaders
# Objective
`add_node_edge` and `add_slot_edge` are fallible methods, but are always used with `.unwrap()`.
`input_node` is often unwrapped as well.
This points to having an infallible behaviour as default, with an alternative fallible variant if needed.
Improves readability and ergonomics.
## Solution
- Change `add_node_edge` and `add_slot_edge` to panic on error.
- Change `input_node` to panic on `None`.
- Add `try_add_node_edge` and `try_add_slot_edge` in case fallible methods are needed.
- Add `get_input_node` to still be able to get an `Option`.
---
## Changelog
### Added
- `try_add_node_edge`
- `try_add_slot_edge`
- `get_input_node`
### Changed
- `add_node_edge` is now infallible (panics on error)
- `add_slot_edge` is now infallible (panics on error)
- `input_node` now panics on `None`
## Migration Guide
Remove `.unwrap()` from `add_node_edge` and `add_slot_edge`.
For cases where the error was handled, use `try_add_node_edge` and `try_add_slot_edge` instead.
Remove `.unwrap()` from `input_node`.
For cases where the option was handled, use `get_input_node` instead.
Co-authored-by: Torstein Grindvik <52322338+torsteingrindvik@users.noreply.github.com>
# Objective
- Closes#5262
- Fix color banding caused by quantization.
## Solution
- Adds dithering to the tonemapping node from #3425.
- This is inspired by Godot's default "debanding" shader: https://gist.github.com/belzecue/
- Unlike Godot:
- debanding happens after tonemapping. My understanding is that this is preferred, because we are running the debanding at the last moment before quantization (`[f32, f32, f32, f32]` -> `f32`). This ensures we aren't biasing the dithering strength by applying it in a different (linear) color space.
- This code instead uses and reference the origin source, Valve at GDC 2015


## Additional Notes
Real time rendering to standard dynamic range outputs is limited to 8 bits of depth per color channel. Internally we keep everything in full 32-bit precision (`vec4<f32>`) inside passes and 16-bit between passes until the image is ready to be displayed, at which point the GPU implicitly converts our `vec4<f32>` into a single 32bit value per pixel, with each channel (rgba) getting 8 of those 32 bits.
### The Problem
8 bits of color depth is simply not enough precision to make each step invisible - we only have 256 values per channel! Human vision can perceive steps in luma to about 14 bits of precision. When drawing a very slight gradient, the transition between steps become visible because with a gradient, neighboring pixels will all jump to the next "step" of precision at the same time.
### The Solution
One solution is to simply output in HDR - more bits of color data means the transition between bands will become smaller. However, not everyone has hardware that supports 10+ bit color depth. Additionally, 10 bit color doesn't even fully solve the issue, banding will result in coherent bands on shallow gradients, but the steps will be harder to perceive.
The solution in this PR adds noise to the signal before it is "quantized" or resampled from 32 to 8 bits. Done naively, it's easy to add unneeded noise to the image. To ensure dithering is correct and absolutely minimal, noise is adding *within* one step of the output color depth. When converting from the 32bit to 8bit signal, the value is rounded to the nearest 8 bit value (0 - 255). Banding occurs around the transition from one value to the next, let's say from 50-51. Dithering will never add more than +/-0.5 bits of noise, so the pixels near this transition might round to 50 instead of 51 but will never round more than one step. This means that the output image won't have excess variance:
- in a gradient from 49 to 51, there will be a step between each band at 49, 50, and 51.
- Done correctly, the modified image of this gradient will never have a adjacent pixels more than one step (0-255) from each other.
- I.e. when scanning across the gradient you should expect to see:
```
|-band-| |-band-| |-band-|
Baseline: 49 49 49 50 50 50 51 51 51
Dithered: 49 50 49 50 50 51 50 51 51
Dithered (wrong): 49 50 51 49 50 51 49 51 50
```


You can see from above how correct dithering "fuzzes" the transition between bands to reduce distinct steps in color, without adding excess noise.
### HDR
The previous section (and this PR) assumes the final output is to an 8-bit texture, however this is not always the case. When Bevy adds HDR support, the dithering code will need to take the per-channel depth into account instead of assuming it to be 0-255. Edit: I talked with Rob about this and it seems like the current solution is okay. We may need to revisit once we have actual HDR final image output.
---
## Changelog
### Added
- All pipelines now support deband dithering. This is enabled by default in 3D, and can be toggled in the `Tonemapping` component in camera bundles. Banding is a graphical artifact created when the rendered image is crunched from high precision (f32 per color channel) down to the final output (u8 per channel in SDR). This results in subtle gradients becoming blocky due to the reduced color precision. Deband dithering applies a small amount of noise to the signal before it is "crunched", which breaks up the hard edges of blocks (bands) of color. Note that this does not add excess noise to the image, as the amount of noise is less than a single step of a color channel - just enough to break up the transition between color blocks in a gradient.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make the many foxes not unnecessarily bright. Broken since #5666.
- Fixes#6528
## Solution
- In #5666 normalisation of normals was moved from the fragment stage to the vertex stage. However, it was not added to the vertex stage for skinned normals. The many foxes are skinned and their skinned normals were not unit normals. which made them brighter. Normalising the skinned normals fixes this.
---
## Changelog
- Fixed: Non-unit length skinned normals are now normalized.
# Objective
- it would be useful to inspect these structs using reflection
## Solution
- derive and register reflect
- Note that `#[reflect(Component)]` requires `Default` (or `FromWorld`) until #6060, so I implemented `Default` for `Tonemapping` with `is_enabled: false`
# Objective
Fixes#5393
## Solution
- Add padding to `GlobalsUniform` / `Globals` to make it 16-byte aligned.
Still not super clear on whether this is a `naga` thing or an `encase` thing or what. But now that we're offering `globals` up to users and #5393 is not just breaking an example, maybe we should do this sort of workaround?
# Objective
This PR fixes#5789, by enabling movable (and scalable) directional light shadow volumes.
## Solution
This PR changes `ExtractedDirectionalLight` to hold a copy of the `DirectionalLight` entity's `GlobalTransform`, instead of just a `direction` vector. This allows the shadow map volume (as defined by the light's `shadow_projection` field) to be transformed honoring translation _and_ scale transforms, and not just rotation.
It also augments the texel size calculation (used to determine the `shadow_normal_bias`) so that it now takes into account the upper bound of the x/y/z scale of the `GlobalTransform`.
This change makes the directional light extraction code more consistent with point and spot lights (that already use `transform`), and allows easily moving and scaling the shadow volume along with a player entity based on camera distance/angle, immediately enabling more real world use cases until we have a more sophisticated adaptive implementation, such as the one described in #3629.
**Note:** While it was previously possible to update the projection achieving a similar effect, depending on the light direction and distance to the origin, the fact that the shadow map camera was always positioned at the origin with a hardcoded `Vec3::Y` up value meant you would get sub-optimal or inconsistent/incorrect results.
---
## Changelog
### Changed
- `DirectionalLight` shadow volumes now honor translation and scale transforms
## Migration Guide
- If your directional lights were positioned at the origin and not scaled (the default, most common scenario) no changes are needed on your part; it just works as before;
- If you previously had a system for dynamically updating directional light shadow projections, you might now be able to simplify your code by updating the directional light entity's transform instead;
- In the unlikely scenario that a scene with directional lights that previously rendered shadows correctly has missing shadows, make sure your directional lights are positioned at (0, 0, 0) and are not scaled to a size that's too large or too small.
# Objective
- Adds a bloom pass for HDR-enabled Camera3ds.
- Supersedes (and all credit due to!) https://github.com/bevyengine/bevy/pull/3430 and https://github.com/bevyengine/bevy/pull/2876

## Solution
- A threshold is applied to isolate emissive samples, and then a series of downscale and upscaling passes are applied and composited together.
- Bloom is applied to 2d or 3d Cameras with hdr: true and a BloomSettings component.
---
## Changelog
- Added a `core_pipeline::bloom::BloomSettings` component.
- Added `BloomNode` that runs between the main pass and tonemapping.
- Added a `BloomPlugin` that is loaded as part of CorePipelinePlugin.
- Added a bloom example project.
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
# Objective
Currently we are limiting the amount of direction lights in a scene to one.
## Solution
Increase the amount of direction lights from 1 to 10.
This still is not a perfect solution, but should unblock many use cases.
We could probably just store the directional lights similar to the point lights in an storage buffer, allowing for an variable amount of directional lights.
Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com>
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
- Add post processing passes for FXAA (Fast Approximate Anti-Aliasing)
- Add example comparing MSAA and FXAA
## Solution
When the FXAA plugin is added, passes for FXAA are inserted between the main pass and the tonemapping pass. Supports using either HDR or LDR output from the main pass.
---
## Changelog
- Add a new FXAANode that runs after the main pass when the FXAA plugin is added.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
- Freeing unused memory held by visible entities
- Fixed comment style
# Objective
With Rust 1.56 it's possible to shrink vectors to a specified capacity. Visibility system had a comment before asking for that feature to free unused memory by a vector if its capacity is two times larger than the length.
## Solution
Shrinking the vector of visible entities to the nearest power of 2 elements next to `len()`, if capacity exceeds it more than two times.
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective

^ enable this
Concretely, I need to
- list all handle ids for an asset type
- fetch the asset as `dyn Reflect`, given a `HandleUntyped`
- when encountering a `Handle<T>`, find out what asset type that handle refers to (`T`'s type id) and turn the handle into a `HandleUntyped`
## Solution
- add `ReflectAsset` type containing function pointers for working with assets
```rust
pub struct ReflectAsset {
type_uuid: Uuid,
assets_resource_type_id: TypeId, // TypeId of the `Assets<T>` resource
get: fn(&World, HandleUntyped) -> Option<&dyn Reflect>,
get_mut: fn(&mut World, HandleUntyped) -> Option<&mut dyn Reflect>,
get_unchecked_mut: unsafe fn(&World, HandleUntyped) -> Option<&mut dyn Reflect>,
add: fn(&mut World, &dyn Reflect) -> HandleUntyped,
set: fn(&mut World, HandleUntyped, &dyn Reflect) -> HandleUntyped,
len: fn(&World) -> usize,
ids: for<'w> fn(&'w World) -> Box<dyn Iterator<Item = HandleId> + 'w>,
remove: fn(&mut World, HandleUntyped) -> Option<Box<dyn Reflect>>,
}
```
- add `ReflectHandle` type relating the handle back to the asset type and providing a way to create a `HandleUntyped`
```rust
pub struct ReflectHandle {
type_uuid: Uuid,
asset_type_id: TypeId,
downcast_handle_untyped: fn(&dyn Any) -> Option<HandleUntyped>,
}
```
- add the corresponding `FromType` impls
- add a function `app.register_asset_reflect` which is supposed to be called after `.add_asset` and registers `ReflectAsset` and `ReflectHandle` in the type registry
---
## Changelog
- add `ReflectAsset` and `ReflectHandle` types, which allow code to use reflection to manipulate arbitrary assets without knowing their types at compile time
# Objective
Bevy's internal plugins have lots of execution-order ambiguities, which makes the ambiguity detection tool very noisy for our users.
## Solution
Silence every last ambiguity that can currently be resolved.
Each time an ambiguity is silenced, it is accompanied by a comment describing why it is correct. This description should be based on the public API of the respective systems. Thus, I have added documentation to some systems describing how they use some resources.
# Future work
Some ambiguities remain, due to issues out of scope for this PR.
* The ambiguity checker does not respect `Without<>` filters, leading to false positives.
* Ambiguities between `bevy_ui` and `bevy_animation` cannot be resolved, since neither crate knows that the other exists. We will need a general solution to this problem.
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Improve ergonomics by passing on the `IntoIterator` impl of the underlying type to wrapper types.
## Solution
Implement `IntoIterator` for ECS wrapper types (Mut, Local, Res, etc.).
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Use saturate wgsl function now implemented in naga (version 0.10.0). There is now no need for one in utils.wgsl.
naga's version allows usage for not only scalars but vectors as well.
## Solution
Remove the utils.wgsl saturate function.
## Changelog
Remove saturate function from utils.wgsl in favor of saturate in naga v0.10.0.
# Objective
- It's possible to create a mesh without positions or normals, but currently bevy forces these attributes to be present on any mesh.
## Solution
- Don't assume these attributes are present and add a shader defs for each attributes
- I updated 2d and 3d meshes to use the same logic.
---
## Changelog
- Meshes don't require any attributes
# Notes
I didn't update the pbr.wgsl shader because I'm not sure how to handle it. It doesn't really make sense to use it without positions or normals.
# Objective
There is no Srgb support on some GPU and display protocols with `winit` (for example, Nvidia's GPUs with Wayland). Thus `TextureFormat::bevy_default()` which returns `Rgba8UnormSrgb` or `Bgra8UnormSrgb` will cause panics on such platforms. This patch will resolve this problem. Fix https://github.com/bevyengine/bevy/issues/3897.
## Solution
Make `initialize_renderer` expose `wgpu::Adapter` and `first_available_texture_format`, use the `first_available_texture_format` by default.
## Changelog
* Fixed https://github.com/bevyengine/bevy/issues/3897.
# Objective
fix error with pbr shader's spotlight direction calculation when direction.y ~= 0
## Solution
in pbr_lighting.wgsl, clamp `1-x^2-z^2` to `>= 0` so that we can safely `sqrt` it
# Objective
The `Wireframe` type implements `Reflect`, but is never registered, making its reflection inaccessible.
## Solution
Call `App::register_type::<Wireframe>()` in the `Plugin::build` implementation of `WireframePlugin`.
---
## Changelog
Fixed `Wireframe` type reflection not getting registered.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}