This is a continuation of this PR: #8062
# Objective
- Reorder render schedule sets to allow data preparation when phase item
order is known to support improved batching
- Part of the batching/instancing etc plan from here:
https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074
- The original idea came from @inodentry and proved to be a good one.
Thanks!
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new
ordering
## Solution
- Move `Prepare` and `PrepareFlush` after `PhaseSortFlush`
- Add a `PrepareAssets` set that runs in parallel with other systems and
sets in the render schedule.
- Put prepare_assets systems in the `PrepareAssets` set
- If explicit dependencies are needed on Mesh or Material RenderAssets
then depend on the appropriate system.
- Add `ManageViews` and `ManageViewsFlush` sets between
`ExtractCommands` and Queue
- Move `queue_mesh*_bind_group` to the Prepare stage
- Rename them to `prepare_`
- Put systems that prepare resources (buffers, textures, etc.) into a
`PrepareResources` set inside `Prepare`
- Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set
after `PrepareResources`
- Move `prepare_lights` to the `ManageViews` set
- `prepare_lights` creates views and this must happen before `Queue`
- This system needs refactoring to stop handling all responsibilities
- Gather lights, sort, and create shadow map views. Store sorted light
entities in a resource
- Remove `BatchedPhaseItem`
- Replace `batch_range` with `batch_size` representing how many items to
skip after rendering the item or to skip the item entirely if
`batch_size` is 0.
- `queue_sprites` has been split into `queue_sprites` for queueing phase
items and `prepare_sprites` for batching after the `PhaseSort`
- `PhaseItem`s are still inserted in `queue_sprites`
- After sorting adjacent compatible sprite phase items are accumulated
into `SpriteBatch` components on the first entity of each batch,
containing a range of vertex indices. The associated `PhaseItem`'s
`batch_size` is updated appropriately.
- `SpriteBatch` items are then drawn skipping over the other items in
the batch based on the value in `batch_size`
- A very similar refactor was performed on `bevy_ui`
---
## Changelog
Changed:
- Reordered and reworked render app schedule sets. The main change is
that data is extracted, queued, sorted, and then prepared when the order
of data is known.
- Refactor `bevy_sprite` and `bevy_ui` to take advantage of the
reordering.
## Migration Guide
- Assets such as materials and meshes should now be created in
`PrepareAssets` e.g. `prepare_assets<Mesh>`
- Queueing entities to `RenderPhase`s continues to be done in `Queue`
e.g. `queue_sprites`
- Preparing resources (textures, buffers, etc.) should now be done in
`PrepareResources`, e.g. `prepare_prepass_textures`,
`prepare_mesh_uniforms`
- Prepare bind groups should now be done in `PrepareBindGroups` e.g.
`prepare_mesh_bind_group`
- Any batching or instancing can now be done in `Prepare` where the
order of the phase items is known e.g. `prepare_sprites`
## Next Steps
- Introduce some generic mechanism to ensure items that can be batched
are grouped in the phase item order, currently you could easily have
`[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching.
- Investigate improved orderings for building the MeshUniform buffer
- Implementing batching across the rest of bevy
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
[Rust 1.72.0](https://blog.rust-lang.org/2023/08/24/Rust-1.72.0.html) is
now stable.
# Notes
- `let-else` formatting has arrived!
- I chose to allow `explicit_iter_loop` due to
https://github.com/rust-lang/rust-clippy/issues/11074.
We didn't hit any of the false positives that prevent compilation, but
fixing this did produce a lot of the "symbol soup" mentioned, e.g. `for
image in &mut *image_events {`.
Happy to undo this if there's consensus the other way.
---------
Co-authored-by: François <mockersf@gmail.com>
If a line has one point behind the camera(near plane) then it would
deform or, if the `depth_bias` setting was set to a negative value,
disappear.
## Solution
The issue is that performing a perspective divide does not work
correctly for points behind the near plane and a perspective divide is
used inside the shader to define the line width in screen space.
The solution is to perform near plane clipping manually inside the
shader before the perspective divide is done.
# Objective
Fix#9089
## Solution
Don't try to draw lines with less than 2 vertices. These would not be
visible either way.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Repeat in `Gizmos` that they are drawned in immediate mode, which is
said at the module level but not here, and detail what it means.
- Clarify for every method of `Gizmos` that they should be called for
every frame.
- Clarify which methods belong to 3D or 2D space (kinda obvious for 2D
but still)
The first time I used gizmos I didn't understand how they work and was
confused as to why nothing showed up.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: SpecificProtagonist <vincentjunge@posteo.net>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- In bevy_polyline, we discovered an issue that happens when line width
is smaller than 1.0 and using perspective. It would sometimes end up
negative or NaN. I'm not entirely sure _why_ it happens.
## Solution
- Make sure the width doesn't go below 0 before multiplying it with the
alpha
# Notes
Here's a link to the bevy_polyline issue
https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline/issues/46
I'm not sure if the solution is correct but it solved the issue in my
testing.
Co-authored-by: François <mockersf@gmail.com>
# Objective
- #8960 isn't optimal for very distinct AABB colors, it can be improved
## Solution
We want a function that maps sequential values (entities concurrently
living in a scene _usually_ have ids that are sequential) into very
different colors (the hue component of the color, to be specific)
What we are looking for is a [so-called "low discrepancy"
sequence](https://en.wikipedia.org/wiki/Low-discrepancy_sequence). ie: a
function `f` such as for integers in a given range (eg: 101, 102, 103…),
`f(i)` returns a rational number in the [0..1] range, such as `|f(i) -
f(i±1)| ≈ 0.5` (maximum difference of images for neighboring preimages)
AHash is a good random hasher, but it has relatively high discrepancy,
so we need something else.
Known good low discrepancy sequences are:
#### The [Van Der Corput
sequence](https://en.wikipedia.org/wiki/Van_der_Corput_sequence)
<details><summary>Rust implementation</summary>
```rust
fn van_der_corput(bits: u64) -> f32 {
let leading_zeros = if bits == 0 { 0 } else { bits.leading_zeros() };
let nominator = bits.reverse_bits() >> leading_zeros;
let denominator = bits.next_power_of_two();
nominator as f32 / denominator as f32
}
```
</details>
#### The [Gold Kronecker
sequence](https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/)
<details><summary>Rust implementation</summary>
Note that the implementation suggested in the linked post assumes
floats, we have integers
```rust
fn gold_kronecker(bits: u64) -> f32 {
const U64_MAX_F: f32 = u64::MAX as f32;
// (u64::MAX / Φ) rounded down
const FRAC_U64MAX_GOLDEN_RATIO: u64 = 11400714819323198485;
bits.wrapping_mul(FRAC_U64MAX_GOLDEN_RATIO) as f32 / U64_MAX_F
}
```
</details>
### Comparison of the sequences
So they are both pretty good. Both only have a single (!) division and
two `u32 as f32` conversions.
- Kronecker is resilient to regular sequence (eg: 100, 102, 104, 106)
while this kills Van Der Corput (consider that potentially one entity
out of two spawned might be a mesh)
I made a small app to compare the two sequences, available at:
https://gist.github.com/nicopap/5dd9bd6700c6a9a9cf90c9199941883e
At the top, we have Van Der Corput, at the bottom we have the Gold
Kronecker. In the video, we spawn a vertical line at the position on
screen where the x coordinate is the image of the sequence. The
preimages are 1,2,3,4,… The ideal algorithm would always have the
largest possible gap between each line (imagine the screen x coordinate
as the color hue):
https://github.com/bevyengine/bevy/assets/26321040/349aa8f8-f669-43ba-9842-f9a46945e25c
Here, we repeat the experiment, but with with `entity.to_bits()` instead
of a sequence:
https://github.com/bevyengine/bevy/assets/26321040/516cea27-7135-4daa-a4e7-edfd1781d119
Notice how Van Der Corput tend to bunch the lines on a single side of
the screen. This is because we always skip odd-numbered entities.
Gold Kronecker seems always worse than Van Der Corput, but it is
resilient to finicky stuff like entity indices being multiples of a
number rather than purely sequential, so I prefer it over Van Der
Corput, since we can't really predict how distributed the entity indices
will be.
### Chosen implementation
You'll notice this PR's implementation is not the Golden ratio-based
Kronecker sequence as described in
[tueoqs](https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/).
Why?
tueoqs R function multiplies a rational/float and takes the fractional
part of the result `(x/Φ) % 1`. We start with an integer `u32`. So
instead of converting into float and dividing by Φ (mod 1) we directly
divide by Φ as integer (mod 2³²) both operations are equivalent, the
integer division (which is actually a multiplication by `u32::MAX / Φ`)
is probably faster.
## Acknowledgements
- `inspi` on discord linked me to
https://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/
and the wikipedia article.
- [this blog
post](https://probablydance.com/2018/06/16/fibonacci-hashing-the-optimization-that-the-world-forgot-or-a-better-alternative-to-integer-modulo/)
for the idea of multiplying the `u32` rather than the `f32`.
- `nakedible` for suggesting the `index()` over `to_bits()` which
considerably reduces generated code (goes from 50 to 11 instructions)
# Objective
Gizmos are intended to draw over everything but for some reason I set
the sort key to `0` during #8427 :v
I didn't catch this mistake because it still draws over sprites with a Z
translation of `0`.
## Solution
Set the sort key to `f32::INFINITY`.
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
The bounding box colors are from bevy_gizmo are randomized between app
runs. This can get confusing for users.
## Solution
Use a fixed seed with `RandomState::with_seeds` rather than initializing
a `AHash`.
The random number was chose so that the first few colors are clearly
distinct.
According to the `RandomState::hash_one` documentation, it's also
faster.

---
## Changelog
* bevy_gizmo: Keep a consistent color for AABBs of identical entities
between runs
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Added `GizmoConfig::render_layers`, which will ensure Gizmos are only
rendered on cameras that can see those `RenderLayers`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
`color_from_entity` uses the poor man's hash to get a fixed random color
for an entity.
While the poor man's hash is succinct, it has a tendency to clump. As a
result, bevy_gizmos has a tendency to re-use very similar colors for
different entities.
This is bad, we would want non-similar colors that take the whole range
of possible hues. This way, each bevy_gizmos aabb gizmo is easy to
identify.
## Solution
AHash is a nice and fast hash that just so happen to be available to
use, so we use it.
# Objective
Fix#8908.
## Solution
Assign the vertex buffers twice with a single item offset instead of
setting the array_stride lower than the vertex layout's size for
linestrips.
# Objective
- Better consistency with `add_systems`.
- Deprecating `add_plugin` in favor of a more powerful `add_plugins`.
- Allow passing `Plugin` to `add_plugins`.
- Allow passing tuples to `add_plugins`.
## Solution
- `App::add_plugins` now takes an `impl Plugins` parameter.
- `App::add_plugin` is deprecated.
- `Plugins` is a new sealed trait that is only implemented for `Plugin`,
`PluginGroup` and tuples over `Plugins`.
- All examples, benchmarks and tests are changed to use `add_plugins`,
using tuples where appropriate.
---
## Changelog
### Changed
- `App::add_plugins` now accepts all types that implement `Plugins`,
which is implemented for:
- Types that implement `Plugin`.
- Types that implement `PluginGroup`.
- Tuples (up to 16 elements) over types that implement `Plugins`.
- Deprecated `App::add_plugin` in favor of `App::add_plugins`.
## Migration Guide
- Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Support WebGPU
- alternative to #5027 that doesn't need any async / await
- fixes#8315
- Surprise fix#7318
## Solution
### For async renderer initialisation
- Update the plugin lifecycle:
- app builds the plugin
- calls `plugin.build`
- registers the plugin
- app starts the event loop
- event loop waits for `ready` of all registered plugins in the same
order
- returns `true` by default
- then call all `finish` then all `cleanup` in the same order as
registered
- then execute the schedule
In the case of the renderer, to avoid anything async:
- building the renderer plugin creates a detached task that will send
back the initialised renderer through a mutex in a resource
- `ready` will wait for the renderer to be present in the resource
- `finish` will take that renderer and place it in the expected
resources by other plugins
- other plugins (that expect the renderer to be available) `finish` are
called and they are able to set up their pipelines
- `cleanup` is called, only custom one is still for pipeline rendering
### For WebGPU support
- update the `build-wasm-example` script to support passing `--api
webgpu` that will build the example with WebGPU support
- feature for webgl2 was always enabled when building for wasm. it's now
in the default feature list and enabled on all platforms, so check for
this feature must also check that the target_arch is `wasm32`
---
## Migration Guide
- `Plugin::setup` has been renamed `Plugin::cleanup`
- `Plugin::finish` has been added, and plugins adding pipelines should
do it in this function instead of `Plugin::build`
```rust
// Before
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.insert_resource::<MyResource>
.add_systems(Update, my_system);
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<RenderResourceNeedingDevice>()
.init_resource::<OtherRenderResource>();
}
}
// After
impl Plugin for MyPlugin {
fn build(&self, app: &mut App) {
app.insert_resource::<MyResource>
.add_systems(Update, my_system);
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<OtherRenderResource>();
}
fn finish(&self, app: &mut App) {
let render_app = match app.get_sub_app_mut(RenderApp) {
Ok(render_app) => render_app,
Err(_) => return,
};
render_app
.init_resource::<RenderResourceNeedingDevice>();
}
}
```
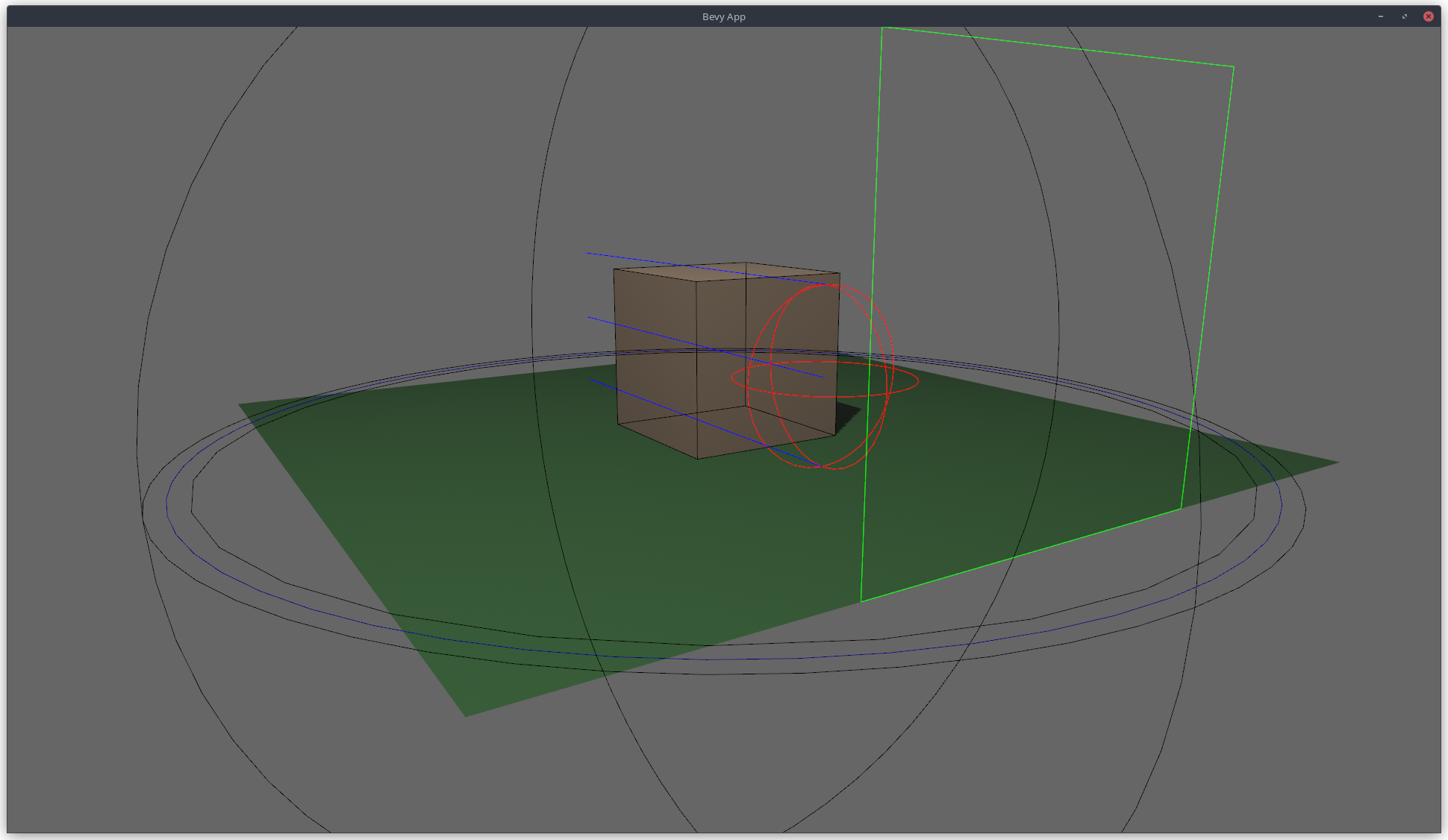
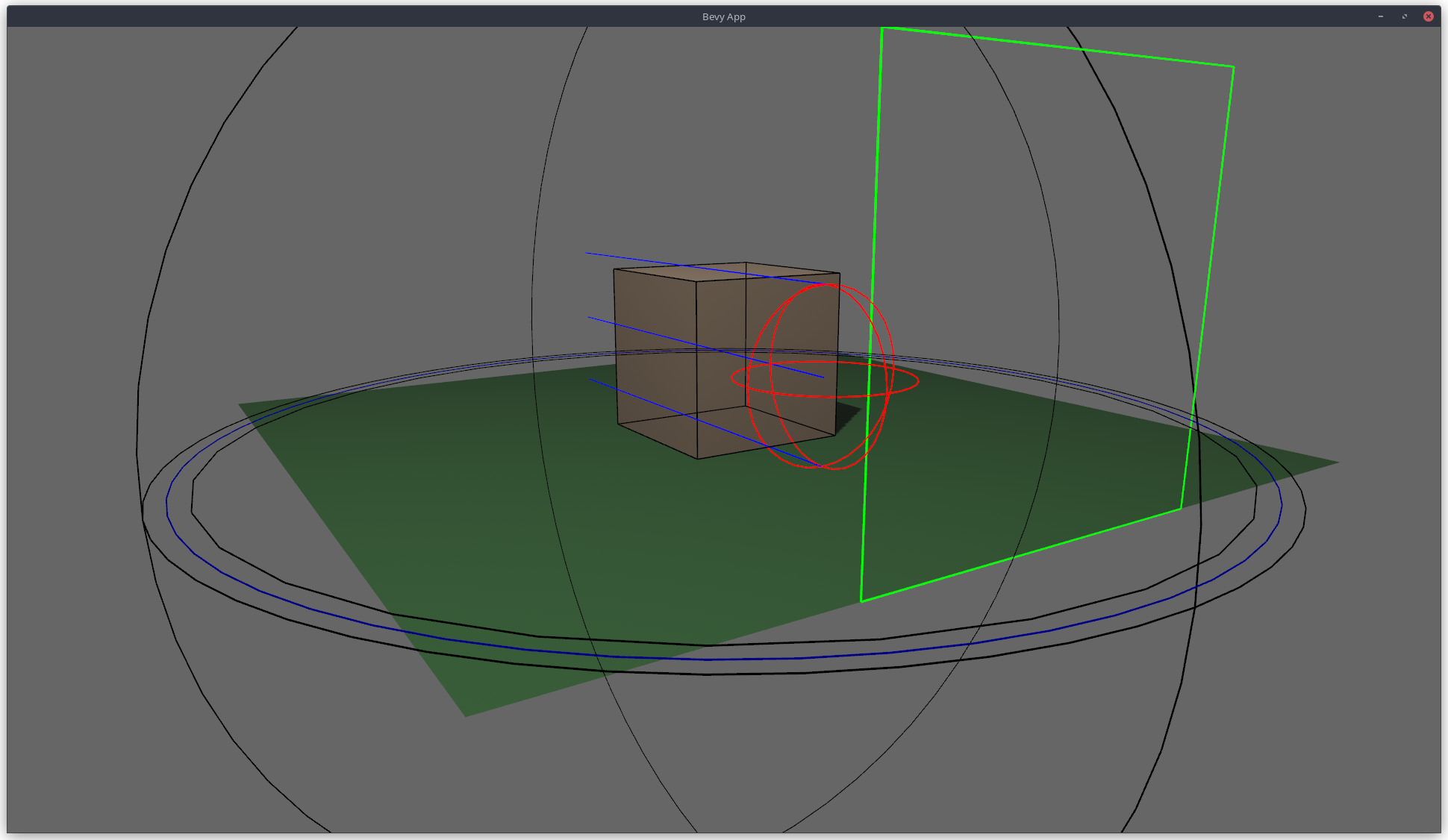
# Objective
Add a bounding box gizmo
## Changes
- Added the `AabbGizmo` component that will draw the `Aabb` component on
that entity.
- Added an option to draw all bounding boxes in a scene on the
`GizmoConfig` resource.
- Added `TransformPoint` trait to generalize over the point
transformation methods on various transform types (e.g `Transform` and
`GlobalTransform`).
- Changed the `Gizmos::cuboid` method to accept an `impl TransformPoint`
instead of separate translation, rotation, and scale.
# Objective
Added the possibility to draw arcs in 2d via gizmos
## Solution
- Added `arc_2d` function to `Gizmos`
- Added `arc_inner` function
- Added `Arc2dBuilder<'a, 's>`
- Updated `2d_gizmos.rs` example to draw an arc
---------
Co-authored-by: kjolnyr <kjolnyr@protonmail.ch>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: ira <JustTheCoolDude@gmail.com>
# Objective
Avoid queuing empty meshes for rendering.
Should prevent #8144 from triggering when no gizmos are in use. Not a
real fix, unfortunately.
## Solution
Add an `in_use` field to `GizmoStorage` and only set it to true when
there are gizmos to draw.
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
Fix#8179
## Solution
- Added `#![warn(missing_docs)]` and document all public items. All
methods on `Gizmos` have doc examples.
- Expanded the docs on the module/crate. Some unfortunate duplication
there :/
- Moved the methods from `GizmoBuffer` to be directly on `Gizmos` and
made `GizmoBuffer` private. This means the methods on `Gizmos` will show
up on its doc page.
---------
Co-authored-by: James Liu <contact@jamessliu.com>

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
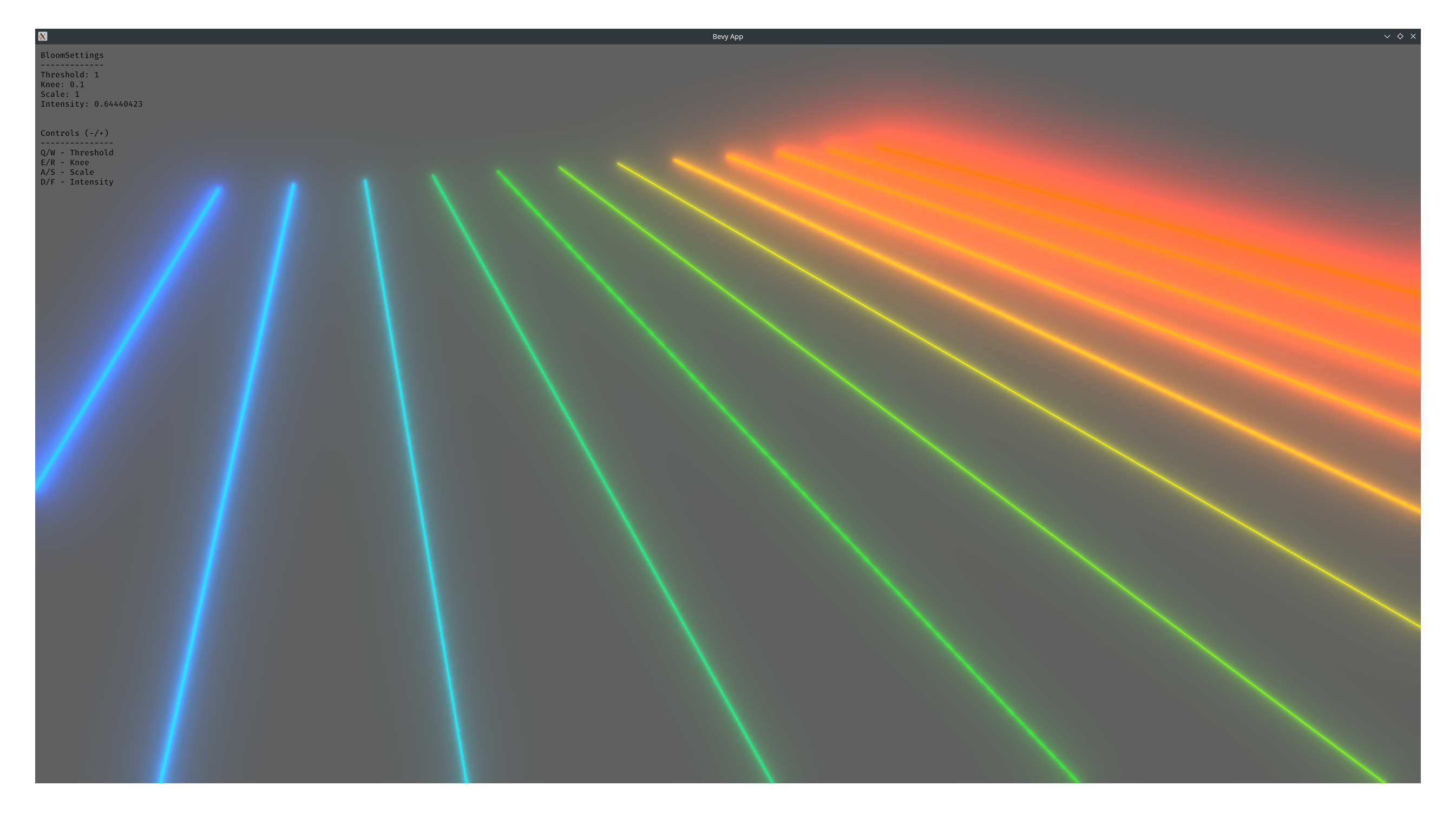
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}