# Objective
- Make the implementation order consistent between all sources to fit
the order in the trait.
## Solution
- Change the implementation order.
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
Enables warning on `clippy::undocumented_unsafe_blocks` across the
workspace rather than only in `bevy_ecs`, `bevy_transform` and
`bevy_utils`. This adds a little awkwardness in a few areas of code that
have trivial safety or explain safety for multiple unsafe blocks with
one comment however automatically prevents these comments from being
missed.
## Solution
This adds `undocumented_unsafe_blocks = "warn"` to the workspace
`Cargo.toml` and fixes / adds a few missed safety comments. I also added
`#[allow(clippy::undocumented_unsafe_blocks)]` where the safety is
explained somewhere above.
There are a couple of safety comments I added I'm not 100% sure about in
`bevy_animation` and `bevy_render/src/view` and I'm not sure about the
use of `#[allow(clippy::undocumented_unsafe_blocks)]` compared to adding
comments like `// SAFETY: See above`.
# Objective
- Standardize fmt for toml files
## Solution
- Add [taplo](https://taplo.tamasfe.dev/) to CI (check for fmt and diff
for toml files), for context taplo is used by the most popular extension
in VScode [Even Better
TOML](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml
- Add contribution section to explain toml fmt with taplo.
Now to pass CI you need to run `taplo fmt --option indent_string=" "` or
if you use vscode have the `Even Better TOML` extension with 4 spaces
for indent
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Sometimes it's very useful to know if a `Transform` contains any `NaN`
or infinite values. It's a bit boiler-plate heavy to check translation,
rotation and scale individually.
## Solution
- Add a new method `is_finite` that returns true if, and only if
translation, rotation and scale all are finite.
- It's a natural extension of `Quat::is_finite`, and `Vec3::is_finite`,
which return true if, and only if all their components' `is_finite()`
returns true.
---
## Changelog
- Added `Transform::is_finite`
# Objective
- Fix adding `#![allow(clippy::type_complexity)]` everywhere. like #9796
## Solution
- Use the new [lints] table that will land in 1.74
(https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#lints)
- inherit lint to the workspace, crates and examples.
```
[lints]
workspace = true
```
## Changelog
- Bump rust version to 1.74
- Enable lints table for the workspace
```toml
[workspace.lints.clippy]
type_complexity = "allow"
```
- Allow type complexity for all crates and examples
```toml
[lints]
workspace = true
```
---------
Co-authored-by: Martín Maita <47983254+mnmaita@users.noreply.github.com>
Preparing next release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Align all error-like types to implement `Error`.
Fixes #10176
## Solution
- Derive `Error` on more types
- Refactor instances of manual implementations that could be derived
This adds thiserror as a dependency to bevy_transform, which might
increase compilation time -- but I don't know of any situation where you
might only use that but not any other crate that pulls in bevy_utils.
The `contributors` example has a `LoadContributorsError` type, but as
it's an example I have not updated it. Doing that would mean either
having a `use bevy_internal::utils::thiserror::Error;` in an example
file, or adding `thiserror` as a dev-dependency to the main `bevy`
crate.
---
## Changelog
- All `…Error` types now implement the `Error` trait
# Objective
Reduce code duplication and improve APIs of Bevy's [global
taskpools](https://github.com/bevyengine/bevy/blob/main/crates/bevy_tasks/src/usages.rs).
## Solution
- As all three of the global taskpools have identical implementations
and only differ in their identifiers, this PR moves the implementation
into a macro to reduce code duplication.
- The `init` method is renamed to `get_or_init` to more accurately
reflect what it really does.
- Add a new `try_get` method that just returns `None` when the pool is
uninitialized, to complement the other getter methods.
- Minor documentation improvements to accompany the above changes.
---
## Changelog
- Added a new `try_get` method to the global TaskPools
- The global TaskPools' `init` method has been renamed to `get_or_init`
for clarity
- Documentation improvements
## Migration Guide
- Uses of `ComputeTaskPool::init`, `AsyncComputeTaskPool::init` and
`IoTaskPool::init` should be changed to `::get_or_init`.
# Objective
Add a way to easily compute the up-to-date `GlobalTransform` of an
entity.
## Solution
Add the `TransformHelper`(Name pending) system parameter with the
`compute_global_transform` method that takes an `Entity` and returns a
`GlobalTransform` if successful.
## Changelog
- Added the `TransformHelper` system parameter for computing the
up-to-date `GlobalTransform` of an entity.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Noah <noahshomette@gmail.com>
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
Rename RemovedComponents::iter/iter_with_id to read/read_with_id to make
it clear that it consume the data
Fixes#9755.
(It's my first pull request, if i've made any mistake, please let me
know)
## Solution
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
## Changelog
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
Deprecate RemovedComponents::iter/iter_with_id
Remove IntoIterator implementation
Update removal_detection example accordingly
---
## Migration Guide
Rename calls of RemovedComponents::iter/iter_with_id to
read/read_with_id
Replace IntoIterator iteration (&mut <RemovedComponents>) with .read()
---------
Co-authored-by: denshi_ika <mojang2824@gmail.com>
# Objective
- Fixes#9244.
## Solution
- Changed the `(Into)SystemSetConfigs` traits and structs be more like
the `(Into)SystemConfigs` traits and structs.
- Replaced uses of `IntoSystemSetConfig` with `IntoSystemSetConfigs`
- Added generic `ItemConfig` and `ItemConfigs` types.
- Changed `SystemConfig(s)` and `SystemSetConfig(s)` to be type aliases
to `ItemConfig(s)`.
- Added generic `process_configs` to `ScheduleGraph`.
- Changed `configure_sets_inner` and `add_systems_inner` to reuse
`process_configs`.
---
## Changelog
- Added `run_if` to `IntoSystemSetConfigs`
- Deprecated `Schedule::configure_set` and `App::configure_set`
- Removed `IntoSystemSetConfig`
## Migration Guide
- Use `App::configure_sets` instead of `App::configure_set`
- Use `Schedule::configure_sets` instead of `Schedule::configure_set`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
I've been collecting some mistakes in the documentation and fixed them
---------
Co-authored-by: Emi <emanuel.boehm@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
- Move schedule name into `Schedule` to allow the schedule name to be
used for errors and tracing in Schedule methods
- Fixes#9510
## Solution
- Move label onto `Schedule` and adjust api's on `World` and `Schedule`
to not pass explicit label where it makes sense to.
- add name to errors and tracing.
- `Schedule::new` now takes a label so either add the label or use
`Schedule::default` which uses a default label. `default` is mostly used
in doc examples and tests.
---
## Changelog
- move label onto `Schedule` to improve error message and logging for
schedules.
## Migration Guide
`Schedule::new` and `App::add_schedule`
```rust
// old
let schedule = Schedule::new();
app.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
app.add_schedule(schedule);
```
if you aren't using a label and are using the schedule struct directly
you can use the default constructor.
```rust
// old
let schedule = Schedule::new();
schedule.run(world);
// new
let schedule = Schedule::default();
schedule.run(world);
```
`Schedules:insert`
```rust
// old
let schedule = Schedule::new();
schedules.insert(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
schedules.insert(schedule);
```
`World::add_schedule`
```rust
// old
let schedule = Schedule::new();
world.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
world.add_schedule(schedule);
```
# Objective
`sync_simple_transforms` only checks for removed parents and doesn't
filter for `Without<Parent>`, so it overwrites the `GlobalTransform` of
non-orphan entities that were orphaned and then reparented since the
last update.
Introduced by #7264
## Solution
Filter for `Without<Parent>`.
Fixes#9517, #9492
## Changelog
`sync_simple_transforms`:
* Added a `Without<Parent>` filter to the orphaned entities query.
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
`GlobalTransform` after insertion will be updated only on `Transform` or
hierarchy change.
Fixes#9075
## Solution
Update `GlobalTransform` after insertion too.
---
## Changelog
- `GlobalTransform` is now updated not only on `Transform` or hierarchy
change, but also on insertion.
# Objective
Fix typos throughout the project.
## Solution
[`typos`](https://github.com/crate-ci/typos) project was used for
scanning, but no automatic corrections were applied. I checked
everything by hand before fixing.
Most of the changes are documentation/comments corrections. Also, there
are few trivial changes to code (variable name, pub(crate) function name
and a few error/panic messages).
## Unsolved
`bevy_reflect_derive` has
[typo](1b51053f19/crates/bevy_reflect/bevy_reflect_derive/src/type_path.rs (L76))
in enum variant name that I didn't fix. Enum is `pub(crate)`, so there
shouldn't be any trouble if fixed. However, code is tightly coupled with
macro usage, so I decided to leave it for more experienced contributor
just in case.
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Better consistency with `add_systems`.
- Deprecating `add_plugin` in favor of a more powerful `add_plugins`.
- Allow passing `Plugin` to `add_plugins`.
- Allow passing tuples to `add_plugins`.
## Solution
- `App::add_plugins` now takes an `impl Plugins` parameter.
- `App::add_plugin` is deprecated.
- `Plugins` is a new sealed trait that is only implemented for `Plugin`,
`PluginGroup` and tuples over `Plugins`.
- All examples, benchmarks and tests are changed to use `add_plugins`,
using tuples where appropriate.
---
## Changelog
### Changed
- `App::add_plugins` now accepts all types that implement `Plugins`,
which is implemented for:
- Types that implement `Plugin`.
- Types that implement `PluginGroup`.
- Tuples (up to 16 elements) over types that implement `Plugins`.
- Deprecated `App::add_plugin` in favor of `App::add_plugins`.
## Migration Guide
- Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Discovered that PointLight did not implement FromReflect. Adding
FromReflect where Reflect is used. I overreached and applied this rule
everywhere there was a Reflect without a FromReflect, except from where
the compiler wouldn't allow me.
Based from question: https://github.com/bevyengine/bevy/discussions/8774
## Solution
- Adding FromReflect where Reflect was already derived
## Notes
First PR I do in this ecosystem, so not sure if this is the usual
approach, that is, to touch many files at once.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#8811 .
## Solution
- Rename "write" method to "apply" in Command trait definition.
- Rename other implementations of command trait throughout bevy's code
base.
---
## Changelog
- Changed: `Command::write` has been changed to `Command::apply`
- Changed: `EntityCommand::write` has been changed to
`EntityCommand::apply`
## Migration Guide
- `Command::write` implementations need to be changed to implement
`Command::apply` instead. This is a mere name change, with no further
actions needed.
- `EntityCommand::write` implementations need to be changed to implement
`EntityCommand::apply` instead. This is a mere name change, with no
further actions needed.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- `apply_system_buffers` is an unhelpful name: it introduces a new
internal-only concept
- this is particularly rough for beginners as reasoning about how
commands work is a critical stumbling block
## Solution
- rename `apply_system_buffers` to the more descriptive `apply_deferred`
- rename related fields, arguments and methods in the internals fo
bevy_ecs for consistency
- update the docs
## Changelog
`apply_system_buffers` has been renamed to `apply_deferred`, to more
clearly communicate its intent and relation to `Deferred` system
parameters like `Commands`.
## Migration Guide
- `apply_system_buffers` has been renamed to `apply_deferred`
- the `apply_system_buffers` method on the `System` trait has been
renamed to `apply_deferred`
- the `is_apply_system_buffers` function has been replaced by
`is_apply_deferred`
- `Executor::set_apply_final_buffers` is now
`Executor::set_apply_final_deferred`
- `Schedule::apply_system_buffers` is now `Schedule::apply_deferred`
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
- If I understand correctly, forward points in `direction`, so the
negative of `direction` should be back.
## Migration Guide
- `Transform::look_to` method changed default value of
`direction.try_normalize()` from `Vec3::Z` to `Vec3::NEG_Z`
# Objective
Add a bounding box gizmo
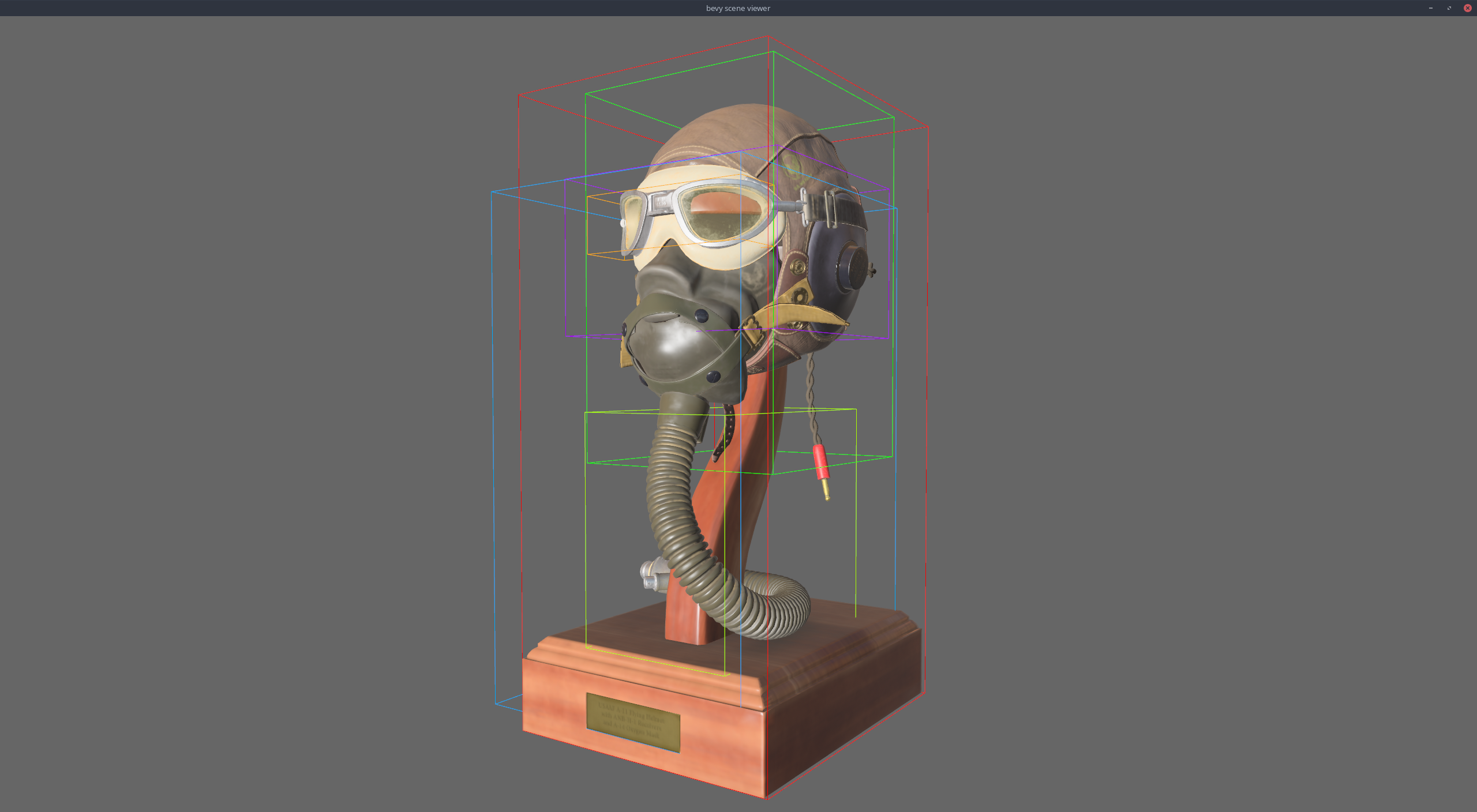
## Changes
- Added the `AabbGizmo` component that will draw the `Aabb` component on
that entity.
- Added an option to draw all bounding boxes in a scene on the
`GizmoConfig` resource.
- Added `TransformPoint` trait to generalize over the point
transformation methods on various transform types (e.g `Transform` and
`GlobalTransform`).
- Changed the `Gizmos::cuboid` method to accept an `impl TransformPoint`
instead of separate translation, rotation, and scale.
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Fix#7263
This has nothing to do with #7024. This is for the case where the
user opted to **not** keep the same global transform on update.
## Solution
- Add a `RemovedComponent<Parent>` to `propagate_transforms`
- Add a `RemovedComponent<Parent>` and `Local<Vec<Entity>>` to
`sync_simple_transforms`
- Add test to make sure all of this works.
### Performance note
This should only incur a cost in cases where a parent is removed.
A minimal overhead (one look up in the `removed_components`
sparse set) per root entities without children which transform didn't
change. A `Vec` the size of the largest number of entities removed
with a `Parent` component in a single frame, and a binary search on
a `Vec` per root entities.
It could slow up considerably in situations where a lot of entities are
orphaned consistently during every frame, since
`sync_simple_transforms` is not parallel. But in this situation,
it is likely that the overhead of archetype updates overwhelms
everything.
---
## Changelog
- Fix the `GlobalTransform` not getting updated when `Parent` is removed
## Migration Guide
- If you called `bevy_transform::systems::sync_simple_transforms` and
`bevy_transform::systems::propagate_transforms` (which is not
re-exported by bevy) you need to account for the additional
`RemovedComponents<Parent>` parameter.
---------
Co-authored-by: vyb <vyb@users.noreply.github.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
Alternative to #7804
Allows other instances of the `sync_simple_transforms` and `propagate_transforms` systems to be added.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Closes#7573
- Make `StartupSet` a base set
## Solution
- Add `#[system_set(base)]` to the enum declaration
- Replace `.in_set(StartupSet::...)` with `.in_base_set(StartupSet::...)`
**Note**: I don't really know what I'm doing and what exactly the difference between base and non-base sets are. I mostly opened this PR based on discussion in Discord. I also don't really know how to test that I didn't break everything. Your reviews are appreciated!
---
## Changelog
- `StartupSet` is now a base set
## Migration Guide
`StartupSet` is now a base set. This means that you have to use `.in_base_set` instead of `.in_set`:
### Before
```rs
app.add_system(foo.in_set(StartupSet::PreStartup))
```
### After
```rs
app.add_system(foo.in_base_set(StartupSet::PreStartup))
```
# Objective
We have a few old system labels that are now system sets but are still named or documented as labels. Documentation also generally mentioned system labels in some places.
## Solution
- Clean up naming and documentation regarding system sets
## Migration Guide
`PrepareAssetLabel` is now called `PrepareAssetSet`
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
- Bevy should not have any "internal" execution order ambiguities. These clutter the output of user-facing error reporting, and can result in nasty, nondetermistic, very difficult to solve bugs.
- Verifying this currently involves repeated non-trivial manual work.
## Solution
- [x] add an example to quickly check this
- ~~[ ] ensure that this example panics if there are any unresolved ambiguities~~
- ~~[ ] run the example in CI 😈~~
There's one tricky ambiguity left, between UI and animation. I don't have the tools to fix this without system set configuration, so the remaining work is going to be left to #7267 or another PR after that.
```
2023-01-27T18:38:42.989405Z INFO bevy_ecs::schedule::ambiguity_detection: Execution order ambiguities detected, you might want to add an explicit dependency relation between some of these systems:
* Parallel systems:
-- "bevy_animation::animation_player" and "bevy_ui::flex::flex_node_system"
conflicts: ["bevy_transform::components::transform::Transform"]
```
## Changelog
Resolved internal execution order ambiguities for:
1. Transform propagation (ignored, we need smarter filter checking).
2. Gamepad processing (fixed).
3. bevy_winit's window handling (fixed).
4. Cascaded shadow maps and perspectives (fixed).
Also fixed a desynchronized state bug that could occur when the `Window` component is removed and then added to the same entity in a single frame.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
Fix#4647. If any child is changed, or even reordered, `Changed<Children>` is true, which causes transform propagation to propagate changes to all siblings of a changed child, even if they don't need to be.
## Solution
As `Parent` and `Children` are updated in tandem in hierarchy commands after #4800. `Changed<Parent>` is true on the child when `Changed<Children>` is true on the parent. However, unlike checking children, checking `Changed<Parent>` is only localized to the current entity and will not force propagation to the siblings.
Also took the opportunity to change propagation to use `Query::iter_many` instead of repeated `Query::get` calls. Should cut a bit of the overhead out of propagation. This means we won't panic when there isn't a `Parent` on the child, just skip over it.
The tests from #4608 still pass, so the change detection here still works just fine under this approach.
{kind=link}
{kind=link}
{kind=link}