# Objective
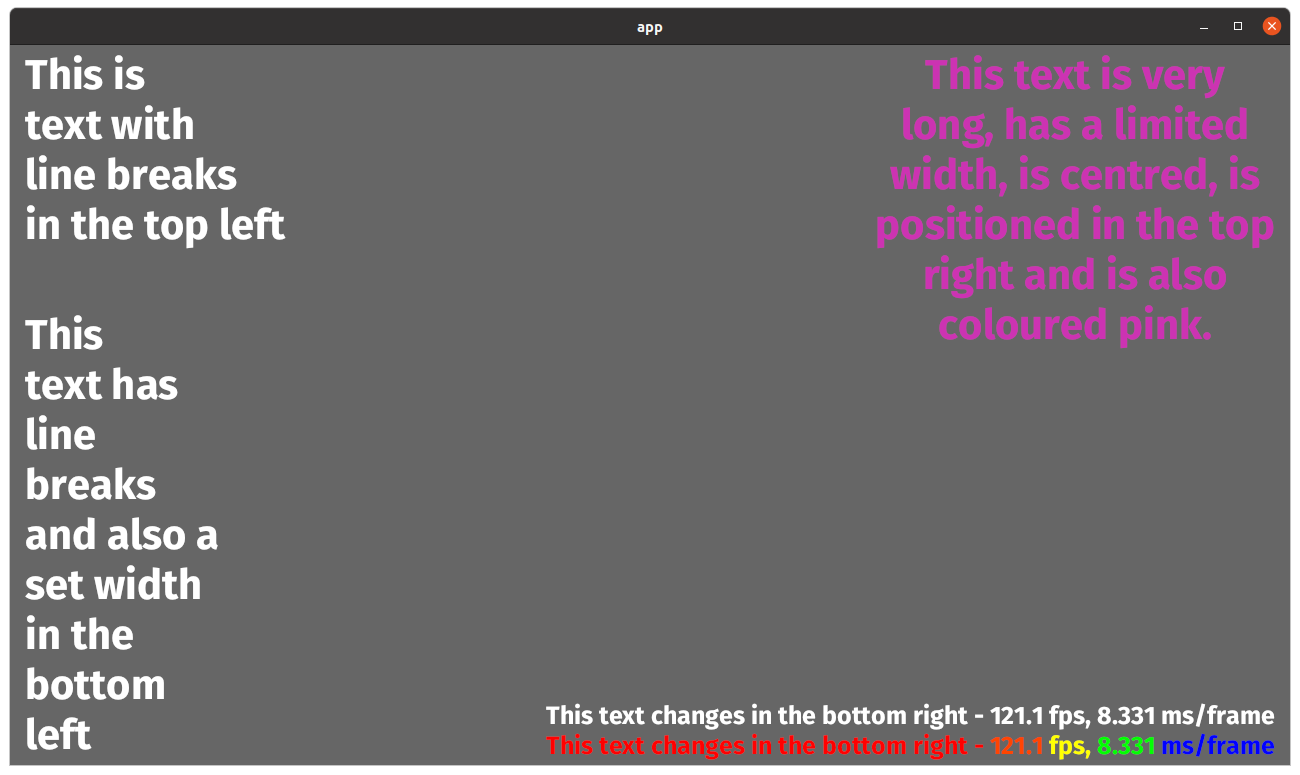
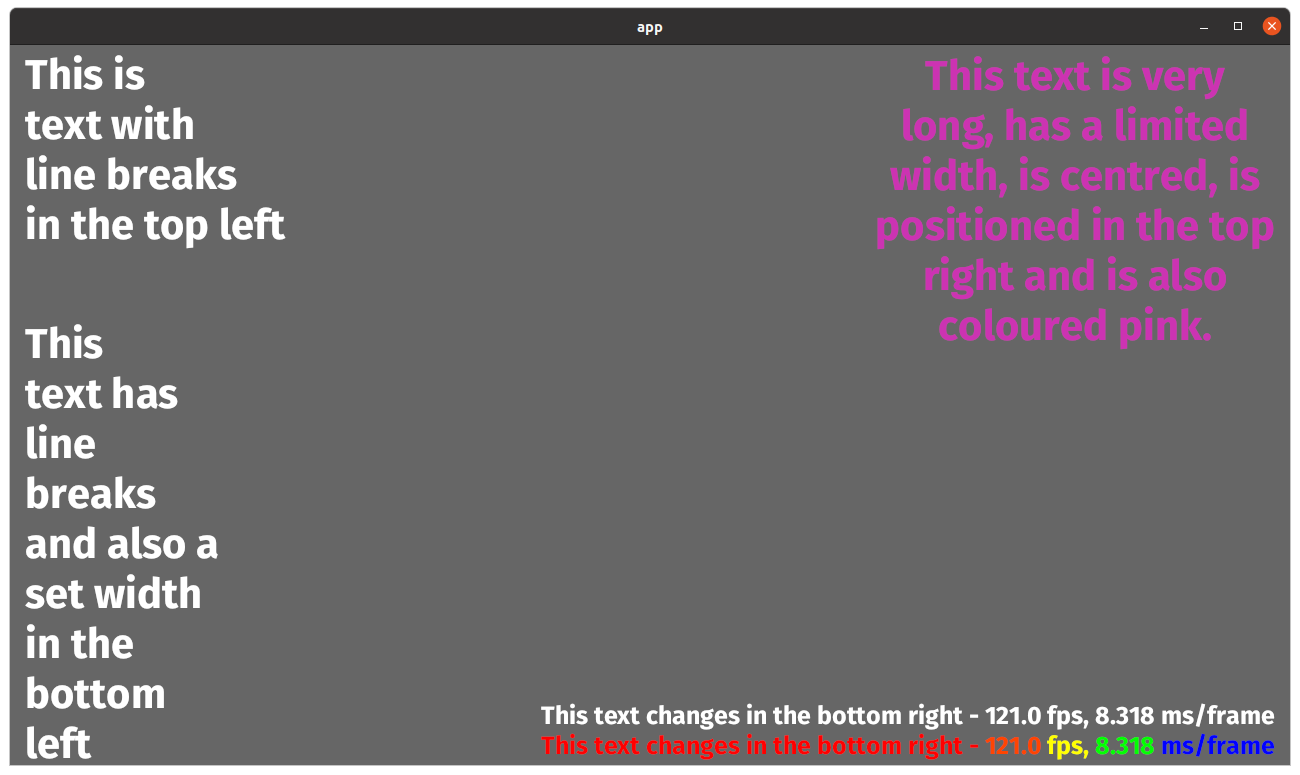
In both Text2d and Bevy UI text because of incorrect text size and
alignment calculations if a block of text has empty leading lines then
those lines are ignored. Also, depending on the font size when leading
empty lines are ignored the same number of lines of text can go missing
from the bottom of the text block.
## Example (from murtaugh on discord)
```rust
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.run();
}
fn setup(mut commands: Commands) {
commands.spawn(Camera2dBundle::default());
let text = "\nfirst line\nsecond line\nthird line\n";
commands.spawn(TextBundle {
text: Text::from_section(
text.to_string(),
TextStyle {
font_size: 60.0,
color: Color::YELLOW,
..Default::default()
},
),
style: Style {
position_type: PositionType::Absolute,
..Default::default()
},
background_color: BackgroundColor(Color::RED),
..Default::default()
});
}
```

## Solution
`TextPipeline::queue_text`,
`TextMeasureInfo::compute_size_from_section_texts` and
`GlyphBrush::process_glyphs` each have a nearly duplicate section of
code that calculates the minimum bounds around a list of text sections.
The first two functions don't apply any rounding, but `process_glyphs`
also floors all the values. It seems like this difference can cause
conflicts where the text gets incorrectly shaped.
Also when Bevy computes the text bounds it chooses the smallest possible
rect that fits all the glyphs, ignoring white space. The glyphs are then
realigned vertically so the first glyph is on the top line. Any empty
leading lines are missed.
This PR adds a function `compute_text_bounds` that replaces the
duplicate code, so the text bounds are rounded the same way by each
function. Also, since Bevy doesn't use `ab_glyph` to control vertical
alignment, the minimum y bound is just always set to 0 which ensures no
leading empty lines will be missed.
There is another problem in that trailing empty lines are also ignored,
but that's more difficult to deal with and much less important than the
other issues, so I'll leave it for another PR.
<img width="462" alt="fixed_text_align_bounds"
src="https://github.com/bevyengine/bevy/assets/27962798/85e32e2c-d68f-4677-8e87-38e27ade4487">
---
## Changelog
Added a new function `compute_text_bounds` to the `glyph_brush` module
that replaces the text size and bounds calculations in
`TextPipeline::queue_text`,
`TextMeasureInfo::compute_size_from_section_texts` and
`GlyphBrush::process_glyphs`. The text bounds are calculated identically
in each function and the minimum y bound is not derived from the glyphs
but is always set to 0.
CI-capable version of #9086
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
I created this manually as Github didn't want to run CI for the
workflow-generated PR. I'm guessing we didn't hit this in previous
releases because we used bors.
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
# Objective
**This implementation is based on
https://github.com/bevyengine/rfcs/pull/59.**
---
Resolves#4597
Full details and motivation can be found in the RFC, but here's a brief
summary.
`FromReflect` is a very powerful and important trait within the
reflection API. It allows Dynamic types (e.g., `DynamicList`, etc.) to
be formed into Real ones (e.g., `Vec<i32>`, etc.).
This mainly comes into play concerning deserialization, where the
reflection deserializers both return a `Box<dyn Reflect>` that almost
always contain one of these Dynamic representations of a Real type. To
convert this to our Real type, we need to use `FromReflect`.
It also sneaks up in other ways. For example, it's a required bound for
`T` in `Vec<T>` so that `Vec<T>` as a whole can be made `FromReflect`.
It's also required by all fields of an enum as it's used as part of the
`Reflect::apply` implementation.
So in other words, much like `GetTypeRegistration` and `Typed`, it is
very much a core reflection trait.
The problem is that it is not currently treated like a core trait and is
not automatically derived alongside `Reflect`. This makes using it a bit
cumbersome and easy to forget.
## Solution
Automatically derive `FromReflect` when deriving `Reflect`.
Users can then choose to opt-out if needed using the
`#[reflect(from_reflect = false)]` attribute.
```rust
#[derive(Reflect)]
struct Foo;
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Bar;
fn test<T: FromReflect>(value: T) {}
test(Foo); // <-- OK
test(Bar); // <-- Panic! Bar does not implement trait `FromReflect`
```
#### `ReflectFromReflect`
This PR also automatically adds the `ReflectFromReflect` (introduced in
#6245) registration to the derived `GetTypeRegistration` impl— if the
type hasn't opted out of `FromReflect` of course.
<details>
<summary><h4>Improved Deserialization</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
And since we can do all the above, we might as well improve
deserialization. We can now choose to deserialize into a Dynamic type or
automatically convert it using `FromReflect` under the hood.
`[Un]TypedReflectDeserializer::new` will now perform the conversion and
return the `Box`'d Real type.
`[Un]TypedReflectDeserializer::new_dynamic` will work like what we have
now and simply return the `Box`'d Dynamic type.
```rust
// Returns the Real type
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: SomeStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
// Returns the Dynamic type
let reflect_deserializer = UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
let output: DynamicStruct = reflect_deserializer.deserialize(&mut deserializer)?.take()?;
```
</details>
---
## Changelog
* `FromReflect` is now automatically derived within the `Reflect` derive
macro
* This includes auto-registering `ReflectFromReflect` in the derived
`GetTypeRegistration` impl
* ~~Renamed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic`, respectively~~ **Descoped**
* ~~Changed `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` to automatically convert the
deserialized output using `FromReflect`~~ **Descoped**
## Migration Guide
* `FromReflect` is now automatically derived within the `Reflect` derive
macro. Items with both derives will need to remove the `FromReflect`
one.
```rust
// OLD
#[derive(Reflect, FromReflect)]
struct Foo;
// NEW
#[derive(Reflect)]
struct Foo;
```
If using a manual implementation of `FromReflect` and the `Reflect`
derive, users will need to opt-out of the automatic implementation.
```rust
// OLD
#[derive(Reflect)]
struct Foo;
impl FromReflect for Foo {/* ... */}
// NEW
#[derive(Reflect)]
#[reflect(from_reflect = false)]
struct Foo;
impl FromReflect for Foo {/* ... */}
```
<details>
<summary><h4>Removed Migrations</h4></summary>
> **Warning**
> This section includes changes that have since been descoped from this
PR. They will likely be implemented again in a followup PR. I am mainly
leaving these details in for archival purposes, as well as for reference
when implementing this logic again.
* The reflect deserializers now perform a `FromReflect` conversion
internally. The expected output of `TypedReflectDeserializer::new` and
`UntypedReflectDeserializer::new` is no longer a Dynamic (e.g.,
`DynamicList`), but its Real counterpart (e.g., `Vec<i32>`).
```rust
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
let mut deserializer = ron:🇩🇪:Deserializer::from_str(input)?;
// OLD
let output: DynamicStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
// NEW
let output: SomeStruct = reflect_deserializer.deserialize(&mut
deserializer)?.take()?;
```
Alternatively, if this behavior isn't desired, use the
`TypedReflectDeserializer::new_dynamic` and
`UntypedReflectDeserializer::new_dynamic` methods instead:
```rust
// OLD
let reflect_deserializer = UntypedReflectDeserializer::new(®istry);
// NEW
let reflect_deserializer =
UntypedReflectDeserializer::new_dynamic(®istry);
```
</details>
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
operate on naga IR directly to improve handling of shader modules.
- give codespan reporting into imported modules
- allow glsl to be used from wgsl and vice-versa
the ultimate objective is to make it possible to
- provide user hooks for core shader functions (to modify light
behaviour within the standard pbr pipeline, for example)
- make automatic binding slot allocation possible
but ... since this is already big, adds some value and (i think) is at
feature parity with the existing code, i wanted to push this now.
## Solution
i made a crate called naga_oil (https://github.com/robtfm/naga_oil -
unpublished for now, could be part of bevy) which manages modules by
- building each module independantly to naga IR
- creating "header" files for each supported language, which are used to
build dependent modules/shaders
- make final shaders by combining the shader IR with the IR for imported
modules
then integrated this into bevy, replacing some of the existing shader
processing stuff. also reworked examples to reflect this.
## Migration Guide
shaders that don't use `#import` directives should work without changes.
the most notable user-facing difference is that imported
functions/variables/etc need to be qualified at point of use, and
there's no "leakage" of visible stuff into your shader scope from the
imports of your imports, so if you used things imported by your imports,
you now need to import them directly and qualify them.
the current strategy of including/'spreading' `mesh_vertex_output`
directly into a struct doesn't work any more, so these need to be
modified as per the examples (e.g. color_material.wgsl, or many others).
mesh data is assumed to be in bindgroup 2 by default, if mesh data is
bound into bindgroup 1 instead then the shader def `MESH_BINDGROUP_1`
needs to be added to the pipeline shader_defs.
# Objective
In Bevy 10.1 and before, the only way to enable text wrapping was to set
a local `Val::Px` width constraint on the text node itself.
`Val::Percent` constraints and constraints on the text node's ancestors
did nothing.
#7779 fixed those problems. But perversely displaying unwrapped text is
really difficult now, and requires users to nest each `TextBundle` in a
`NodeBundle` and apply `min_width` and `max_width` constraints. Some
constructions may even need more than one layer of nesting. I've seen
several people already who have really struggled with this when porting
their projects to main in advance of 0.11.
## Solution
Add a `NoWrap` variant to the `BreakLineOn` enum.
If `NoWrap` is set, ignore any constraints on the width for the text and
call `TextPipeline::queue_text` with a width bound of `f32::INFINITY`.
---
## Changelog
* Added a `NoWrap` variant to the `BreakLineOn` enum.
* If `NoWrap` is set, any constraints on the width for the text are
ignored and `TextPipeline::queue_text` is called with a width bound of
`f32::INFINITY`.
* Changed the `size` field of `FixedMeasure` to `pub`. This shouldn't
have been private, it was always intended to have `pub` visibility.
* Added a `with_no_wrap` method to `TextBundle`.
## Migration Guide
`bevy_text::text::BreakLineOn` has a new variant `NoWrap` that disables
text wrapping for the `Text`.
Text wrapping can also be disabled using the `with_no_wrap` method of
`TextBundle`.
# Objective
Discovered that PointLight did not implement FromReflect. Adding
FromReflect where Reflect is used. I overreached and applied this rule
everywhere there was a Reflect without a FromReflect, except from where
the compiler wouldn't allow me.
Based from question: https://github.com/bevyengine/bevy/discussions/8774
## Solution
- Adding FromReflect where Reflect was already derived
## Notes
First PR I do in this ecosystem, so not sure if this is the usual
approach, that is, to touch many files at once.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
- Fixes#8484
## Solution
Since #8445 fonts need to register a debug asset, otherwise the
`debug_asset_server` feature doesn't work. This adds the debug asset
registration
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
- Have a default font
## Solution
- Add a font based on FiraMono containing only ASCII characters and use
it as the default font
- It is behind a feature `default_font` enabled by default
- I also updated examples to use it, but not UI examples to still show
how to use a custom font
---
## Changelog
* If you display text without using the default handle provided by
`TextStyle`, the text will be displayed
# Objective
Fixes#8415.
## Solution
I simply added the missing types to the type registry.
## Changelog
Added `#[reflect(Component]` to `bevi_ui::ui_node::ZIndex`, since it
impls `Component` and `Reflect.`
The following types have been added to the type registry:
1. `bevy_ui::ZIndex`
2. `bevy_math::Rect`
3. `bevy_text::BreakLineOn`
4. `bevy_text::Text2dBounds`
# Objective
`text_system` runs before the UI layout is calculated and the size of
the text node is determined, so it cannot correctly shape the text to
fit the layout, and has no way of determining if the text needs to be
wrapped.
The function `text_constraint` attempts to determine the size of the
node from the local size constraints in the `Style` component. It can't
be made to work, you have to compute the whole layout to get the correct
size. A simple example of where this fails completely is a text node set
to stretch to fill the empty space adjacent to a node with size
constraints set to `Val::Percent(50.)`. The text node will take up half
the space, even though its size constraints are `Val::Auto`
Also because the `text_system` queries for changes to the `Style`
component, when a style value is changed that doesn't affect the node's
geometry the text is recomputed unnecessarily.
Querying on changes to `Node` is not much better. The UI layout is
changed to fit the `CalculatedSize` of the text, so the size of the node
is changed and so the text and UI layout get recalculated multiple times
from a single change to a `Text`.
Also, the `MeasureFunc` doesn't work at all, it doesn't have enough
information to fit the text correctly and makes no attempt.
Fixes#7663, #6717, #5834, #1490,
## Solution
Split the `text_system` into two functions:
* `measure_text_system` which calculates the size constraints for the
text node and runs before `UiSystem::Flex`
* `text_system` which runs after `UiSystem::Flex` and generates the
actual text.
* Fix the `MeasureFunc` calculations.
---
Text wrapping in main:
<img width="961" alt="Capturemain"
src="https://user-images.githubusercontent.com/27962798/220425740-4fe4bf46-24fb-4685-a1cf-bc01e139e72d.PNG">
With this PR:
<img width="961" alt="captured_wrap"
src="https://user-images.githubusercontent.com/27962798/220425807-949996b0-f127-4637-9f33-56a6da944fb0.PNG">
## Changelog
* Removed the previous fields from `CalculatedSize`. `CalculatedSize`
now contains a boxed `Measure`.
* Added `measurement` module to `bevy_ui`.
* Added the method `create_text_measure` to `TextPipeline`.
* Added a new system `measure_text_system` that runs before
`UiSystem::Flex` that creates a `MeasureFunc` for the text.
* Rescheduled `text_system` to run after `UiSystem::Flex`.
* Added a trait `Measure`. A `Measure` is used to compute the size of a
UI node when the size of that node is based on its content.
* Added `ImageMeasure` and `TextMeasure` which implement `Measure`.
* Added a new component `UiImageSize` which is used by
`update_image_calculated_size_system` to track image size changes.
* Added a `UiImageSize` component to `ImageBundle`.
## Migration Guide
`ImageBundle` has a new component `UiImageSize` which contains the size
of the image bundle's texture and is updated automatically by
`update_image_calculated_size_system`
---------
Co-authored-by: François <mockersf@gmail.com>
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
The clippy lint `type_complexity` is known not to play well with bevy.
It frequently triggers when writing complex queries, and taking the
lint's advice of using a type alias almost always just obfuscates the
code with no benefit. Because of this, this lint is currently ignored in
CI, but unfortunately it still shows up when viewing bevy code in an
IDE.
As someone who's made a fair amount of pull requests to this repo, I
will say that this issue has been a consistent thorn in my side. Since
bevy code is filled with spurious, ignorable warnings, it can be very
difficult to spot the *real* warnings that must be fixed -- most of the
time I just ignore all warnings, only to later find out that one of them
was real after I'm done when CI runs.
## Solution
Suppress this lint in all bevy crates. This was previously attempted in
#7050, but the review process ended up making it more complicated than
it needs to be and landed on a subpar solution.
The discussion in https://github.com/rust-lang/rust-clippy/pull/10571
explores some better long-term solutions to this problem. Since there is
no timeline on when these solutions may land, we should resolve this
issue in the meantime by locally suppressing these lints.
### Unresolved issues
Currently, these lints are not suppressed in our examples, since that
would require suppressing the lint in every single source file. They are
still ignored in CI.
# Objective
In the
[`Text`](3442a13d2c/crates/bevy_text/src/text.rs (L18))
struct the field is named: `linebreak_behaviour`, the British spelling
of _behavior_.
**Update**, also found:
- `FileDragAndDrop::HoveredFileCancelled`
- `TouchPhase::Cancelled`
- `Touches.just_cancelled`
The majority of all spelling is in the US but when you have a lot of
contributors across the world, sometimes
spelling differences can pop up in APIs such as in this case.
For consistency, I think it would be worth a while to ensure that the
API is persistent.
Some examples:
`from_reflect.rs` has `DefaultBehavior`
TextStyle has `color` and uses the `Color` struct.
In `bevy_input/src/Touch.rs` `TouchPhase::Cancelled` and _canceled_ are
used interchangeably in the documentation
I've found that there is also the same type of discrepancies in the
documentation, though this is a low priority but is worth checking.
**Update**: I've now checked the documentation (See #8291)
## Solution
I've only renamed the inconsistencies that have breaking changes and
documentation pertaining to them. The rest of the documentation will be
changed via #8291.
Do note that the winit API is written with UK spelling, thus this may be
a cause for confusion:
`winit::event::TouchPhase::Cancelled => TouchPhase::Canceled`
`winit::event::WindowEvent::HoveredFileCancelled` -> Related to
`FileDragAndDrop::HoveredFileCanceled`
But I'm hoping to maybe outline other spelling inconsistencies in the
API, and maybe an addition to the contribution guide.
---
## Changelog
- `Text` field `linebreak_behaviour` has been renamed to
`linebreak_behavior`.
- Event `FileDragAndDrop::HoveredFileCancelled` has been renamed to
`HoveredFileCanceled`
- Function `Touches.just_cancelled` has been renamed to
`Touches.just_canceled`
- Event `TouchPhase::Cancelled` has been renamed to
`TouchPhase::Canceled`
## Migration Guide
Update where `linebreak_behaviour` is used to `linebreak_behavior`
Updated the event `FileDragAndDrop::HoveredFileCancelled` where used to
`HoveredFileCanceled`
Update `Touches.just_cancelled` where used as `Touches.just_canceled`
The event `TouchPhase::Cancelled` is now called `TouchPhase::Canceled`
# Objective
Text2d entity's text needs to be recomputed when their bounds are changed, but it isn't.
# Solution
Change `update_text2d_layout` to query for `Ref<Text2dBounds>` and recompute the text if the bounds have changed.
# Objective
Support the following syntax for adding systems:
```rust
App::new()
.add_system(setup.on_startup())
.add_systems((
show_menu.in_schedule(OnEnter(GameState::Paused)),
menu_ssytem.in_set(OnUpdate(GameState::Paused)),
hide_menu.in_schedule(OnExit(GameState::Paused)),
))
```
## Solution
Add the traits `IntoSystemAppConfig{s}`, which provide the extension methods necessary for configuring which schedule a system belongs to. These extension methods return `IntoSystemAppConfig{s}`, which `App::add_system{s}` uses to choose which schedule to add systems to.
---
## Changelog
+ Added the extension methods `in_schedule(label)` and `on_startup()` for configuring the schedule a system belongs to.
## Future Work
* Replace all uses of `add_startup_system` in the engine.
* Deprecate this method
# Objective
Fix#7377Fix#7513
## Solution
Record the changes made to the Bevy `Window` from `winit` as 'canon' to avoid Bevy sending those changes back to `winit` again, causing a feedback loop.
## Changelog
* Removed `ModifiesWindows` system label.
Neither `despawn_window` nor `changed_window` actually modify the `Window` component so all the `.after(ModifiesWindows)` shouldn't be necessary.
* Moved `changed_window` and `despawn_window` systems to `CoreStage::Last` to avoid systems making changes to the `Window` between `changed_window` and the end of the frame as they would be ignored.
## Migration Guide
The `ModifiesWindows` system label was removed.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267.
"Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365).
## Solution
This adds "base sets" as a variant of `SystemSet`:
A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive:
```rust
#[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)]
#[system_set(base)]
enum MyBaseSet {
A,
B,
}
```
**Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build.
**Base sets cannot belong to other sets**: this is where the word "base" comes from
Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set.
```rust
app.add_system(foo.in_base_set(MyBaseSet::A))
// X must be a normal set ... base sets cannot be added to base sets
.configure_set(X.in_base_set(MyBaseSet::A))
```
Base sets can still be configured like normal sets:
```rust
app.add_system(MyBaseSet::B.after(MyBaseSet::Ap))
```
The primary use case for base sets is enabling a "default base set":
```rust
schedule.set_default_base_set(CoreSet::Update)
// this will belong to CoreSet::Update by default
.add_system(foo)
// this will override the default base set with PostUpdate
.add_system(bar.in_base_set(CoreSet::PostUpdate))
```
This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides.
---
## Changelog
- Added "base sets" and ported CoreSet to use them.
## Migration Guide
TODO
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR.
# Objective
- Followup #6587.
- Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45
## Solution
- [x] Remove old scheduling module
- [x] Migrate new methods to no longer use extension methods
- [x] Fix compiler errors
- [x] Fix benchmarks
- [x] Fix examples
- [x] Fix docs
- [x] Fix tests
## Changelog
### Added
- a large number of methods on `App` to work with schedules ergonomically
- the `CoreSchedule` enum
- `App::add_extract_system` via the `RenderingAppExtension` trait extension method
- the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms`
### Removed
- stages, and all code that mentions stages
- states have been dramatically simplified, and no longer use a stack
- `RunCriteriaLabel`
- `AsSystemLabel` trait
- `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition)
- systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world
- `RunCriteriaLabel`
- `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear.
### Changed
- `System::default_labels` is now `System::default_system_sets`.
- `App::add_default_labels` is now `App::add_default_sets`
- `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet`
- `App::add_system_set` was renamed to `App::add_systems`
- The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum
- `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)`
- `SystemLabel` trait was replaced by `SystemSet`
- `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>`
- The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq`
- Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria.
- Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied.
- `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`.
- `bevy_pbr::add_clusters` is no longer an exclusive system
- the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling`
- `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread.
## Migration Guide
- Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)`
- Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed.
- The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved.
- Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior.
- Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you.
- For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with
- `add_system(my_system.in_set(CoreSet::PostUpdate)`
- When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages
- Run criteria have been renamed to run conditions. These can now be combined with each other and with states.
- Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow.
- For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label.
- Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default.
- Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually.
- Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`.
- the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior.
- the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity
- `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl.
- Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings.
- `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds.
- `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool.
- States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set`
## TODO
- [x] remove dead methods on App and World
- [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule`
- [x] avoid adding the default system set at inappropriate times
- [x] remove any accidental cycles in the default plugins schedule
- [x] migrate benchmarks
- [x] expose explicit labels for the built-in command flush points
- [x] migrate engine code
- [x] remove all mentions of stages from the docs
- [x] verify docs for States
- [x] fix uses of exclusive systems that use .end / .at_start / .before_commands
- [x] migrate RenderStage and AssetStage
- [x] migrate examples
- [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub)
- [x] ensure that on_enter schedules are run at least once before the main app
- [x] re-enable opt-in to execution order ambiguities
- [x] revert change to `update_bounds` to ensure it runs in `PostUpdate`
- [x] test all examples
- [x] unbreak directional lights
- [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples)
- [x] game menu example shows loading screen and menu simultaneously
- [x] display settings menu is a blank screen
- [x] `without_winit` example panics
- [x] ensure all tests pass
- [x] SubApp doc test fails
- [x] runs_spawn_local tasks fails
- [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120)
## Points of Difficulty and Controversy
**Reviewers, please give feedback on these and look closely**
1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup.
2. The outer schedule controls which schedule is run when `App::update` is called.
3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes.
4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset.
5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order
6. Implemetnation strategy for fixed timesteps
7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks.
8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements.
## Future Work (ideally before 0.10)
- Rename schedule_v3 module to schedule or scheduling
- Add a derive macro to states, and likely a `EnumIter` trait of some form
- Figure out what exactly to do with the "systems added should basically work by default" problem
- Improve ergonomics for working with fixed timesteps and states
- Polish FixedTime API to match Time
- Rebase and merge #7415
- Resolve all internal ambiguities (blocked on better tools, especially #7442)
- Add "base sets" to replace the removed default sets.
# Objective
Currently, Text always uses the default linebreaking behaviour in glyph_brush_layout `BuiltInLineBreaker::Unicode` which breaks lines at word boundaries. However, glyph_brush_layout also supports breaking lines at any character by setting the linebreaker to `BuiltInLineBreaker::AnyChar`. Having text wrap character-by-character instead of at word boundaries is desirable in some cases - consider that consoles/terminals usually wrap this way.
As a side note, the default Unicode linebreaker does not seem to handle emergency cases, where there is no word boundary on a line to break at. In that case, the text runs out of bounds. Issue #1867 shows an example of this.
## Solution
Basically just copies how TextAlignment is exposed, but for a new enum TextLineBreakBehaviour.
This PR exposes glyph_brush_layout's two simple linebreaking options (Unicode, AnyChar) to users of Text via the enum TextLineBreakBehaviour (which just translates those 2 aforementioned options), plus a method 'with_linebreak_behaviour' on Text and TextBundle.
## Changelog
Added `Text::with_linebreak_behaviour`
Added `TextBundle::with_linebreak_behaviour`
`TextPipeline::queue_text` and `GlyphBrush::compute_glyphs` now need a TextLineBreakBehaviour argument, in order to pass through the new field.
Modified the `text2d` example to show both linebreaking behaviours.
## Example
Here's what the modified example looks like

# Objective
Fix https://github.com/bevyengine/bevy/issues/4530
- Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component.
- Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open)
## Solution
- Move all properties of window descriptor to ~components~ a component.
- Replace `WindowId` with `Entity`.
- ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~
Check each field individually to see what we need to update, events are still kept for user convenience.
---
## Changelog
- `WindowDescriptor` renamed to `Window`.
- Width/height consolidated into a `WindowResolution` component.
- Requesting maximization/minimization is done on the [`Window::state`] field.
- `WindowId` is now `Entity`.
## Migration Guide
- Replace `WindowDescriptor` with `Window`.
- Change `width` and `height` fields in a `WindowResolution`, either by doing
```rust
WindowResolution::new(width, height) // Explicitly
// or using From<_> for tuples for convenience
(1920., 1080.).into()
```
- Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so:
```rust
let window = commands.spawn(Window { ... }).id(); // open window
commands.entity(window).despawn(); // close window
```
## Unresolved
- ~How do we tell when a window is minimized by a user?~
~Currently using the `Resize(0, 0)` as an indicator of minimization.~
No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized.
## Future work
- Move `exit_on_close` functionality out from windowing and into app(?)
- https://github.com/bevyengine/bevy/issues/5621
- https://github.com/bevyengine/bevy/issues/7099
- https://github.com/bevyengine/bevy/issues/7098
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Remove the `VerticalAlign` enum.
Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree.
`Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform.
Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748
## Changelog
* Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants.
* Removed the `HorizontalAlign` and `VerticalAlign` types.
* Added an `Anchor` component to `Text2dBundle`
* Added `Component` derive to `Anchor`
* Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds
## Migration Guide
The `alignment` field of `Text` now only affects the text's internal alignment.
### Change `TextAlignment` to TextAlignment` which is now an enum. Replace:
* `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left`
* `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center`
* `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right`
### Changes for `Text2dBundle`
`Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform.
# Objective
Fixes#6642
In a way that doesn't create any breaking changes, as a possible way to fix the above in a patch release.
## Solution
Don't actually remove font atlases when `max_font_atlases` is exceeded. Add a warning instead.
Keep `TextError::ExceedMaxTextAtlases` and `TextSettings` as-is so we don't break anything.
This is a bit of a cop-out, but the problems revealed by #6642 seem very challenging to fix properly.
Maybe follow up later with something more like https://github.com/rparrett/bevy/commits/remove-max-font-atlases later, if this is the direction we want to go.
## Note
See previous attempt at a "simple fix" that only solved some of the issues: #6666
# Objective
Fixes: https://github.com/bevyengine/bevy/issues/6466
Summary: The UI Scaling example dynamically scales the UI which will dynamically allocate fonts to the font atlas surpassing the protective limit, throwing a panic.
## Solution
- Set TextSettings.allow_dynamic_font_size = true for the UI Scaling example. This is the ideal solution since the dynamic changes to the UI are not continuous yet still discrete.
- Update the panic text to reflect ui scaling as a potential cause
This reverts commit 53d387f340.
# Objective
Reverts #6448. This didn't have the intended effect: we're now getting bevy::prelude shown in the docs again.
Co-authored-by: Alejandro Pascual <alejandro.pascual.pozo@gmail.com>
# Objective
- Right now re-exports are completely hidden in prelude docs.
- Fixes#6433
## Solution
- We could show the re-exports without inlining their documentation.
# Objective
Following discussion on #3536 and #3522, `Handle::as_weak()` takes a type `U`, reinterpreting the handle as of another asset type while keeping the same ID. This is mainly used today in font atlas code. This PR does two things:
- Rename the method to `cast_weak()` to make its intent more clear
- Actually change the type uuid in the handle if it's not an asset path variant.
## Migration Guide
- Rename `Handle::as_weak` uses to `Handle::cast_weak`
The method now properly sets the associated type uuid if the handle is a direct reference (e.g. not a reference to an `AssetPath`), so adjust you code accordingly if you relied on the previous behavior.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Bevy's internal plugins have lots of execution-order ambiguities, which makes the ambiguity detection tool very noisy for our users.
## Solution
Silence every last ambiguity that can currently be resolved.
Each time an ambiguity is silenced, it is accompanied by a comment describing why it is correct. This description should be based on the public API of the respective systems. Thus, I have added documentation to some systems describing how they use some resources.
# Future work
Some ambiguities remain, due to issues out of scope for this PR.
* The ambiguity checker does not respect `Without<>` filters, leading to false positives.
* Ambiguities between `bevy_ui` and `bevy_animation` cannot be resolved, since neither crate knows that the other exists. We will need a general solution to this problem.
# Objective
- Proactive changing of code to comply with warnings generated by beta of rustlang version of cargo clippy.
## Solution
- Code changed as recommended by `rustup update`, `rustup default beta`, `cargo run -p ci -- clippy`.
- Tested using `beta` and `stable`. No clippy warnings in either after changes made.
---
## Changelog
- Warnings fixed were: `clippy::explicit-auto-deref` (present in 11 files), `clippy::needless-borrow` (present in 2 files), and `clippy::only-used-in-recursion` (only 1 file).
# Objective
Fixes#6272
## Solution
Revert to old way of positioning text for Text2D rendered text.
Co-authored-by: Michel van der Hulst <hulstmichel@gmail.com>
# Objective
- Field `id` of `Handle<T>` is public: https://docs.rs/bevy/latest/bevy/asset/struct.Handle.html#structfield.id
- Changing the value of this field doesn't make sense as it could mean changing the previous handle without dropping it, breaking asset cleanup detection for the old handle and the new one
## Solution
- Make the field private, and add a public getter
Opened after discussion in #6171. Pinging @zicklag
---
## Migration Guide
- If you were accessing the value `handle.id`, you can now do so with `handle.id()`
# Objective
The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move.
This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns).
## Solution
This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity).
This means you can remove all cases of `exclusive_system()`:
```rust
// before
commands.add_system(some_system.exclusive_system());
// after
commands.add_system(some_system);
```
I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems:
```rust
fn some_exclusive_system(
world: &mut World,
transforms: &mut QueryState<&Transform>,
state: &mut SystemState<(Res<Time>, Query<&Player>)>,
) {
for transform in transforms.iter(world) {
println!("{transform:?}");
}
let (time, players) = state.get(world);
for player in players.iter() {
println!("{player:?}");
}
}
```
Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system.
I added some targeted SystemParam `static` constraints, which removed the need for this:
``` rust
fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {}
```
## Related
- #2923
- #3001
- #3946
## Changelog
- `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait.
- `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems
- `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam`
- Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api.
## Migration Guide
Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems:
```rust
// Old (0.8)
app.add_system(some_exclusive_system.exclusive_system());
// New (0.9)
app.add_system(some_exclusive_system);
```
Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis:
```rust
// Old (0.8)
app.add_system(some_system.exclusive_system().at_end());
// New (0.9)
app.add_system(some_system.at_end());
```
Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons:
```rust
// Old (0.8)
fn some_system(world: &mut World) {
let mut transforms = world.query::<&Transform>();
for transform in transforms.iter(world) {
}
}
// New (0.9)
fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) {
for transform in transforms.iter(world) {
}
}
```
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}