> In draft until #4761 is merged. See the relevant commits [here](a85fe94a18).
---
# Objective
Update enums across Bevy to use the new enum reflection and get rid of `#[reflect_value(...)]` usages.
## Solution
Find and replace all[^1] instances of `#[reflect_value(...)]` on enum types.
---
## Changelog
- Updated all[^1] reflected enums to implement `Enum` (i.e. they are no longer `ReflectRef::Value`)
## Migration Guide
Bevy-defined enums have been updated to implement `Enum` and are not considered value types (`ReflectRef::Value`) anymore. This means that their serialized representations will need to be updated. For example, given the Bevy enum:
```rust
pub enum ScalingMode {
None,
WindowSize,
Auto { min_width: f32, min_height: f32 },
FixedVertical(f32),
FixedHorizontal(f32),
}
```
You will need to update the serialized versions accordingly.
```js
// OLD FORMAT
{
"type": "bevy_render:📷:projection::ScalingMode",
"value": FixedHorizontal(720),
},
// NEW FORMAT
{
"type": "bevy_render:📷:projection::ScalingMode",
"enum": {
"variant": "FixedHorizontal",
"tuple": [
{
"type": "f32",
"value": 720,
},
],
},
},
```
This may also have other smaller implications (such as `Debug` representation), but serialization is probably the most prominent.
[^1]: All enums except `HandleId` as neither `Uuid` nor `AssetPathId` implement the reflection traits
# Objective
> This is a revival of #1347. Credit for the original PR should go to @Davier.
Currently, enums are treated as `ReflectRef::Value` types by `bevy_reflect`. Obviously, there needs to be better a better representation for enums using the reflection API.
## Solution
Based on prior work from @Davier, an `Enum` trait has been added as well as the ability to automatically implement it via the `Reflect` derive macro. This allows enums to be expressed dynamically:
```rust
#[derive(Reflect)]
enum Foo {
A,
B(usize),
C { value: f32 },
}
let mut foo = Foo::B(123);
assert_eq!("B", foo.variant_name());
assert_eq!(1, foo.field_len());
let new_value = DynamicEnum::from(Foo::C { value: 1.23 });
foo.apply(&new_value);
assert_eq!(Foo::C{value: 1.23}, foo);
```
### Features
#### Derive Macro
Use the `#[derive(Reflect)]` macro to automatically implement the `Enum` trait for enum definitions. Optionally, you can use `#[reflect(ignore)]` with both variants and variant fields, just like you can with structs. These ignored items will not be considered as part of the reflection and cannot be accessed via reflection.
```rust
#[derive(Reflect)]
enum TestEnum {
A,
// Uncomment to ignore all of `B`
// #[reflect(ignore)]
B(usize),
C {
// Uncomment to ignore only field `foo` of `C`
// #[reflect(ignore)]
foo: f32,
bar: bool,
},
}
```
#### Dynamic Enums
Enums may be created/represented dynamically via the `DynamicEnum` struct. The main purpose of this struct is to allow enums to be deserialized into a partial state and to allow dynamic patching. In order to ensure conversion from a `DynamicEnum` to a concrete enum type goes smoothly, be sure to add `FromReflect` to your derive macro.
```rust
let mut value = TestEnum::A;
// Create from a concrete instance
let dyn_enum = DynamicEnum::from(TestEnum::B(123));
value.apply(&dyn_enum);
assert_eq!(TestEnum::B(123), value);
// Create a purely dynamic instance
let dyn_enum = DynamicEnum::new("TestEnum", "A", ());
value.apply(&dyn_enum);
assert_eq!(TestEnum::A, value);
```
#### Variants
An enum value is always represented as one of its variants— never the enum in its entirety.
```rust
let value = TestEnum::A;
assert_eq!("A", value.variant_name());
// Since we are using the `A` variant, we cannot also be the `B` variant
assert_ne!("B", value.variant_name());
```
All variant types are representable within the `Enum` trait: unit, struct, and tuple.
You can get the current type like:
```rust
match value.variant_type() {
VariantType::Unit => println!("A unit variant!"),
VariantType::Struct => println!("A struct variant!"),
VariantType::Tuple => println!("A tuple variant!"),
}
```
> Notice that they don't contain any values representing the fields. These are purely tags.
If a variant has them, you can access the fields as well:
```rust
let mut value = TestEnum::C {
foo: 1.23,
bar: false
};
// Read/write specific fields
*value.field_mut("bar").unwrap() = true;
// Iterate over the entire collection of fields
for field in value.iter_fields() {
println!("{} = {:?}", field.name(), field.value());
}
```
#### Variant Swapping
It might seem odd to group all variant types under a single trait (why allow `iter_fields` on a unit variant?), but the reason this was done ~~is to easily allow *variant swapping*.~~ As I was recently drafting up the **Design Decisions** section, I discovered that other solutions could have been made to work with variant swapping. So while there are reasons to keep the all-in-one approach, variant swapping is _not_ one of them.
```rust
let mut value: Box<dyn Enum> = Box::new(TestEnum::A);
value.set(Box::new(TestEnum::B(123))).unwrap();
```
#### Serialization
Enums can be serialized and deserialized via reflection without needing to implement `Serialize` or `Deserialize` themselves (which can save thousands of lines of generated code). Below are the ways an enum can be serialized.
> Note, like the rest of reflection-based serialization, the order of the keys in these representations is important!
##### Unit
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "A"
}
}
```
##### Tuple
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "B",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
<details>
<summary>Effects on Option</summary>
This ends up making `Option` look a little ugly:
```json
{
"type": "core::option::Option<usize>",
"enum": {
"variant": "Some",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
</details>
##### Struct
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "C",
"struct": {
"foo": {
"type": "f32",
"value": 1.23
},
"bar": {
"type": "bool",
"value": false
}
}
}
}
```
## Design Decisions
<details>
<summary><strong>View Section</strong></summary>
This section is here to provide some context for why certain decisions were made for this PR, alternatives that could have been used instead, and what could be improved upon in the future.
### Variant Representation
One of the biggest decisions was to decide on how to represent variants. The current design uses a "all-in-one" design where unit, tuple, and struct variants are all simultaneously represented by the `Enum` trait. This is not the only way it could have been done, though.
#### Alternatives
##### 1. Variant Traits
One way of representing variants would be to define traits for each variant, implementing them whenever an enum featured at least one instance of them. This would allow us to define variants like:
```rust
pub trait Enum: Reflect {
fn variant(&self) -> Variant;
}
pub enum Variant<'a> {
Unit,
Tuple(&'a dyn TupleVariant),
Struct(&'a dyn StructVariant),
}
pub trait TupleVariant {
fn field_len(&self) -> usize;
// ...
}
```
And then do things like:
```rust
fn get_tuple_len(foo: &dyn Enum) -> usize {
match foo.variant() {
Variant::Tuple(tuple) => tuple.field_len(),
_ => panic!("not a tuple variant!")
}
}
```
The reason this PR does not go with this approach is because of the fact that variants are not separate types. In other words, we cannot implement traits on specific variants— these cover the *entire* enum. This means we offer an easy footgun:
```rust
let foo: Option<i32> = None;
let my_enum = Box::new(foo) as Box<dyn TupleVariant>;
```
Here, `my_enum` contains `foo`, which is a unit variant. However, since we need to implement `TupleVariant` for `Option` as a whole, it's possible to perform such a cast. This is obviously wrong, but could easily go unnoticed. So unfortunately, this makes it not a good candidate for representing variants.
##### 2. Variant Structs
To get around the issue of traits necessarily needing to apply to both the enum and its variants, we could instead use structs that are created on a per-variant basis. This was also considered but was ultimately [[removed](71d27ab3c6) due to concerns about allocations.
Each variant struct would probably look something like:
```rust
pub trait Enum: Reflect {
fn variant_mut(&self) -> VariantMut;
}
pub enum VariantMut<'a> {
Unit,
Tuple(TupleVariantMut),
Struct(StructVariantMut),
}
struct StructVariantMut<'a> {
fields: Vec<&'a mut dyn Reflect>,
field_indices: HashMap<Cow<'static, str>, usize>
}
```
This allows us to isolate struct variants into their own defined struct and define methods specifically for their use. It also prevents users from casting to it since it's not a trait. However, this is not an optimal solution. Both `field_indices` and `fields` will require an allocation (remember, a `Box<[T]>` still requires a `Vec<T>` in order to be constructed). This *might* be a problem if called frequently enough.
##### 3. Generated Structs
The original design, implemented by @Davier, instead generates structs specific for each variant. So if we had a variant path like `Foo::Bar`, we'd generate a struct named `FooBarWrapper`. This would be newtyped around the original enum and forward tuple or struct methods to the enum with the chosen variant.
Because it involved using the `Tuple` and `Struct` traits (which are also both bound on `Reflect`), this meant a bit more code had to be generated. For a single struct variant with one field, the generated code amounted to ~110LoC. However, each new field added to that variant only added ~6 more LoC.
In order to work properly, the enum had to be transmuted to the generated struct:
```rust
fn variant(&self) -> crate::EnumVariant<'_> {
match self {
Foo::Bar {value: i32} => {
let wrapper_ref = unsafe {
std::mem::transmute::<&Self, &FooBarWrapper>(self)
};
crate::EnumVariant::Struct(wrapper_ref as &dyn crate::Struct)
}
}
}
```
This works because `FooBarWrapper` is defined as `repr(transparent)`.
Out of all the alternatives, this would probably be the one most likely to be used again in the future. The reasons for why this PR did not continue to use it was because:
* To reduce generated code (which would hopefully speed up compile times)
* To avoid cluttering the code with generated structs not visible to the user
* To keep bevy_reflect simple and extensible (these generated structs act as proxies and might not play well with current or future systems)
* To avoid additional unsafe blocks
* My own misunderstanding of @Davier's code
That last point is obviously on me. I misjudged the code to be too unsafe and unable to handle variant swapping (which it probably could) when I was rebasing it. Looking over it again when writing up this whole section, I see that it was actually a pretty clever way of handling variant representation.
#### Benefits of All-in-One
As stated before, the current implementation uses an all-in-one approach. All variants are capable of containing fields as far as `Enum` is concerned. This provides a few benefits that the alternatives do not (reduced indirection, safer code, etc.).
The biggest benefit, though, is direct field access. Rather than forcing users to have to go through pattern matching, we grant direct access to the fields contained by the current variant. The reason we can do this is because all of the pattern matching happens internally. Getting the field at index `2` will automatically return `Some(...)` for the current variant if it has a field at that index or `None` if it doesn't (or can't).
This could be useful for scenarios where the variant has already been verified or just set/swapped (or even where the type of variant doesn't matter):
```rust
let dyn_enum: &mut dyn Enum = &mut Foo::Bar {value: 123};
// We know it's the `Bar` variant
let field = dyn_enum.field("value").unwrap();
```
Reflection is not a type-safe abstraction— almost every return value is wrapped in `Option<...>`. There are plenty of places to check and recheck that a value is what Reflect says it is. Forcing users to have to go through `match` each time they want to access a field might just be an extra step among dozens of other verification processes.
Some might disagree, but ultimately, my view is that the benefit here is an improvement to the ergonomics and usability of reflected enums.
</details>
---
## Changelog
### Added
* Added `Enum` trait
* Added `Enum` impl to `Reflect` derive macro
* Added `DynamicEnum` struct
* Added `DynamicVariant`
* Added `EnumInfo`
* Added `VariantInfo`
* Added `StructVariantInfo`
* Added `TupleVariantInfo`
* Added `UnitVariantInfo`
* Added serializtion/deserialization support for enums
* Added `EnumSerializer`
* Added `VariantType`
* Added `VariantFieldIter`
* Added `VariantField`
* Added `enum_partial_eq(...)`
* Added `enum_hash(...)`
### Changed
* `Option<T>` now implements `Enum`
* `bevy_window` now depends on `bevy_reflect`
* Implemented `Reflect` and `FromReflect` for `WindowId`
* Derive `FromReflect` on `PerspectiveProjection`
* Derive `FromReflect` on `OrthographicProjection`
* Derive `FromReflect` on `WindowOrigin`
* Derive `FromReflect` on `ScalingMode`
* Derive `FromReflect` on `DepthCalculation`
## Migration Guide
* Enums no longer need to be treated as values and usages of `#[reflect_value(...)]` can be removed or replaced by `#[reflect(...)]`
* Enums (including `Option<T>`) now take a different format when serializing. The format is described above, but this may cause issues for existing scenes that make use of enums.
---
Also shout out to @nicopap for helping clean up some of the code here! It's a big feature so help like this is really appreciated!
Co-authored-by: Gino Valente <gino.valente.code@gmail.com>
# Objective
- Fix / support KTX2 array / cubemap / cubemap array textures
- Fixes#4495 . Supersedes #4514 .
## Solution
- Add `Option<TextureViewDescriptor>` to `Image` to enable configuration of the `TextureViewDimension` of a texture.
- This allows users to set `D2Array`, `D3`, `Cube`, `CubeArray` or whatever they need
- Automatically configure this when loading KTX2
- Transcode all layers and faces instead of just one
- Use the UASTC block size of 128 bits, and the number of blocks in x/y for a given mip level in order to determine the offset of the layer and face within the KTX2 mip level data
- `wgpu` wants data ordered as layer 0 mip 0..n, layer 1 mip 0..n, etc. See https://docs.rs/wgpu/latest/wgpu/util/trait.DeviceExt.html#tymethod.create_texture_with_data
- Reorder the data KTX2 mip X layer Y face Z to `wgpu` layer Y face Z mip X order
- Add a `skybox` example to demonstrate / test loading cubemaps from PNG and KTX2, including ASTC 4x4, BC7, and ETC2 compression for support everywhere. Note that you need to enable the `ktx2,zstd` features to be able to load the compressed textures.
---
## Changelog
- Fixed: KTX2 array / cubemap / cubemap array textures
- Fixes: Validation failure for compressed textures stored in KTX2 where the width/height are not a multiple of the block dimensions.
- Added: `Image` now has an `Option<TextureViewDescriptor>` field to enable configuration of the texture view. This is useful for configuring the `TextureViewDimension` when it is not just a plain 2D texture and the loader could/did not identify what it should be.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Sadly, #4944 introduces a serious exponential despawn behavior, which cannot be included in 0.8. [Handling AABBs properly is a controversial topic](https://github.com/bevyengine/bevy/pull/5423#issuecomment-1199995825) and one that deserves more time than the day we have left before release.
## Solution
This reverts commit c2b332f98a.
# Objective
- Expose the wgpu debug label on storage buffer types.
## Solution
🐄
- Add an optional cow static string and pass that to the label field of create_buffer_with_data
- This pattern is already used by Bevy for debug tags on bind group and layout descriptors.
---
Example Usage:
A buffer is given a label using the label function. Alternatively a buffer may be labeled when it is created if the default() convention is not used.
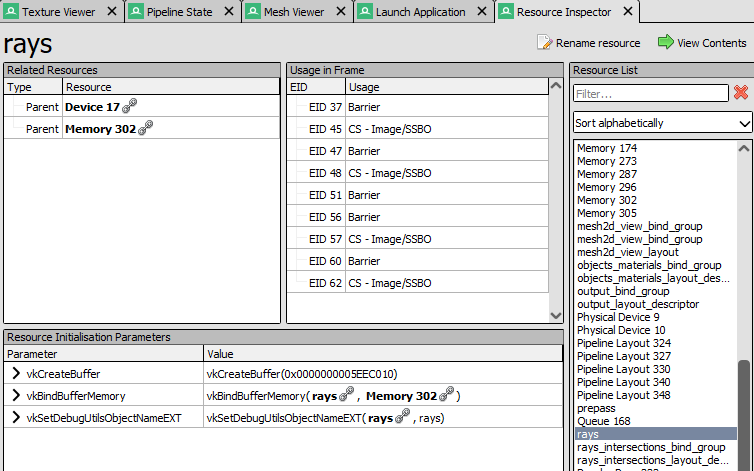
Here is the buffer appearing with the correct name in RenderDoc. Previously the buffer would have an anonymous name such as "Buffer223":
Co-authored-by: rebelroad-reinhart <reinhart@rebelroad.gg>
# Objective
I found this small ux hiccup when writing the 0.8 blog post:
```rust
image.sampler = ImageSampler::Descriptor(ImageSampler::nearest_descriptor());
```
Not good!
## Solution
```rust
image.sampler = ImageSampler::nearest();
```
(there are Good Reasons to keep around the nearest_descriptor() constructor and I think it belongs on this type)
# Objective
- wgpu 0.13 has validation to ensure that the width and height specified for a texture are both multiples of the respective block width and block height. This means validation fails for compressed textures with say a 4x4 block size, but non-modulo-4 image width/height.
## Solution
- Using `Extent3d`'s `physical_size()` method in the `dds` loader. It takes a `TextureFormat` argument and ensures the resolution is correct.
---
## Changelog
- Fixes: Validation failure for compressed textures stored in `dds` where the width/height are not a multiple of the block dimensions.
# Objective
Creating UI elements is very boilerplate-y with lots of indentation.
This PR aims to reduce boilerplate around creating text elements.
## Changelog
* Renamed `Text::with_section` to `from_section`.
It no longer takes a `TextAlignment` as argument, as the vast majority of cases left it `Default::default()`.
* Added `Text::from_sections` which creates a `Text` from a list of `TextSections`.
Reduces line-count and reduces indentation by one level.
* Added `Text::with_alignment`.
A builder style method for setting the `TextAlignment` of a `Text`.
* Added `TextSection::new`.
Does not reduce line count, but reduces character count and made it easier to read. No more `.to_string()` calls!
* Added `TextSection::from_style` which creates an empty `TextSection` with a style.
No more empty strings! Reduces indentation.
* Added `TextAlignment::CENTER` and friends.
* Added methods to `TextBundle`. `from_section`, `from_sections`, `with_text_alignment` and `with_style`.
## Note for reviewers.
Because of the nature of these changes I recommend setting diff view to 'split'.
~~Look for the book icon~~ cog in the top-left of the Files changed tab.
Have fun reviewing ❤️
<sup> >:D </sup>
## Migration Guide
`Text::with_section` was renamed to `from_section` and no longer takes a `TextAlignment` as argument.
Use `with_alignment` to set the alignment instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Update the `calculate_bounds` system to update `Aabb`s
for entities who've either:
- gotten a new mesh
- had their mesh mutated
Fixes https://github.com/bevyengine/bevy/issues/4294.
## Solution
There are two commits here to address the two issues above:
### Commit 1
**This Commit**
Updates the `calculate_bounds` system to operate not only on entities
without `Aabb`s but also on entities whose `Handle<Mesh>` has changed.
**Why?**
So if an entity gets a new mesh, its associated `Aabb` is properly
recalculated.
**Questions**
- This type is getting pretty gnarly - should I extract some types?
- This system is public - should I add some quick docs while I'm here?
### Commit 2
**This Commit**
Updates `calculate_bounds` to update `Aabb`s of entities whose meshes
have been directly mutated.
**Why?**
So if an entity's mesh gets updated, its associated `Aabb` is properly
recalculated.
**Questions**
- I think we should be using `ahash`. Do we want to do that with a
direct `hashbrown` dependency or an `ahash` dependency that we
configure the `HashMap` with?
- There is an edge case of duplicates with `Vec<Entity>` in the
`HashMap`. If an entity gets its mesh handle changed and changed back
again it'll be added to the list twice. Do we want to use a `HashSet`
to avoid that? Or do a check in the list first (assuming iterating
over the `Vec` is faster and this edge case is rare)?
- There is an edge case where, if an entity gets a new mesh handle and
then its old mesh is updated, we'll update the entity's `Aabb` to the
new geometry of the _old_ mesh. Do we want to remove items from the
`Local<HashMap>` when handles change? Does the `Changed` event give us
the old mesh handle? If not we might need to have a
`HashMap<Entity, Handle<Mesh>>` or something so we can unlink entities
from mesh handles when the handle changes.
- I did the `zip()` with the two `HashMap` gets assuming those would
be faster than calculating the Aabb of the mesh (otherwise we could do
`meshes.get(mesh_handle).and_then(Mesh::compute_aabb).zip(entity_mesh_map...)`
or something). Is that assumption way off?
## Testing
I originally tried testing this with `bevy_mod_raycast` as mentioned in the
original issue but it seemed to work (maybe they are currently manually
updating the Aabbs?). I then tried doing it in 2D but it looks like
`Handle<Mesh>` is just for 3D. So I took [this example](https://github.com/bevyengine/bevy/blob/main/examples/3d/pbr.rs)
and added some systems to mutate/assign meshes:
<details>
<summary>Test Script</summary>
```rust
use bevy::prelude::*;
use bevy::render:📷:ScalingMode;
use bevy::render::primitives::Aabb;
/// Make sure we only mutate one mesh once.
#[derive(Eq, PartialEq, Clone, Debug, Default)]
struct MutateMeshState(bool);
/// Let's have a few global meshes that we can cycle between.
/// This way we can be assigned a new mesh, mutate the old one, and then get the old one assigned.
#[derive(Eq, PartialEq, Clone, Debug, Default)]
struct Meshes(Vec<Handle<Mesh>>);
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.init_resource::<MutateMeshState>()
.init_resource::<Meshes>()
.add_startup_system(setup)
.add_system(assign_new_mesh)
.add_system(show_aabbs.after(assign_new_mesh))
.add_system(mutate_meshes.after(show_aabbs))
.run();
}
fn setup(
mut commands: Commands,
mut meshes: ResMut<Assets<Mesh>>,
mut global_meshes: ResMut<Meshes>,
mut materials: ResMut<Assets<StandardMaterial>>,
) {
let m1 = meshes.add(Mesh::from(shape::Icosphere::default()));
let m2 = meshes.add(Mesh::from(shape::Icosphere {
radius: 0.90,
..Default::default()
}));
let m3 = meshes.add(Mesh::from(shape::Icosphere {
radius: 0.80,
..Default::default()
}));
global_meshes.0.push(m1.clone());
global_meshes.0.push(m2);
global_meshes.0.push(m3);
// add entities to the world
// sphere
commands.spawn_bundle(PbrBundle {
mesh: m1,
material: materials.add(StandardMaterial {
base_color: Color::hex("ffd891").unwrap(),
..default()
}),
..default()
});
// new 3d camera
commands.spawn_bundle(Camera3dBundle {
projection: OrthographicProjection {
scale: 3.0,
scaling_mode: ScalingMode::FixedVertical(1.0),
..default()
}
.into(),
..default()
});
// old 3d camera
// commands.spawn_bundle(OrthographicCameraBundle {
// transform: Transform::from_xyz(0.0, 0.0, 8.0).looking_at(Vec3::default(), Vec3::Y),
// orthographic_projection: OrthographicProjection {
// scale: 0.01,
// ..default()
// },
// ..OrthographicCameraBundle::new_3d()
// });
}
fn show_aabbs(query: Query<(Entity, &Handle<Mesh>, &Aabb)>) {
for thing in query.iter() {
println!("{thing:?}");
}
}
/// For testing the second part - mutating a mesh.
///
/// Without the fix we should see this mutate an old mesh and it affects the new mesh that the
/// entity currently has.
/// With the fix, the mutation doesn't affect anything until the entity is reassigned the old mesh.
fn mutate_meshes(
mut meshes: ResMut<Assets<Mesh>>,
time: Res<Time>,
global_meshes: Res<Meshes>,
mut mutate_mesh_state: ResMut<MutateMeshState>,
) {
let mutated = mutate_mesh_state.0;
if time.seconds_since_startup() > 4.5 && !mutated {
println!("Mutating {:?}", global_meshes.0[0]);
let m = meshes.get_mut(&global_meshes.0[0]).unwrap();
let mut p = m.attribute(Mesh::ATTRIBUTE_POSITION).unwrap().clone();
use bevy::render::mesh::VertexAttributeValues;
match &mut p {
VertexAttributeValues::Float32x3(v) => {
v[0] = [10.0, 10.0, 10.0];
}
_ => unreachable!(),
}
m.insert_attribute(Mesh::ATTRIBUTE_POSITION, p);
mutate_mesh_state.0 = true;
}
}
/// For testing the first part - assigning a new handle.
fn assign_new_mesh(
mut query: Query<&mut Handle<Mesh>, With<Aabb>>,
time: Res<Time>,
global_meshes: Res<Meshes>,
) {
let s = time.seconds_since_startup() as usize;
let idx = s % global_meshes.0.len();
for mut handle in query.iter_mut() {
*handle = global_meshes.0[idx].clone_weak();
}
}
```
</details>
## Changelog
### Fixed
Entity `Aabb`s not updating when meshes are mutated or re-assigned.
# Objective
- Provide better compile-time errors and diagnostics.
- Add more options to allow more textures types and sampler types.
- Update array_texture example to use upgraded AsBindGroup derive macro.
## Solution
Split out the parsing of the inner struct/field attributes (the inside part of a `#[foo(...)]` attribute) for better clarity
Parse the binding index for all inner attributes, as it is part of all attributes (`#[foo(0, ...)`), then allow each attribute implementer to parse the rest of the attribute metadata as needed. This should make it very trivial to extend/change if needed in the future.
Replaced invocations of `panic!` with the `syn::Error` type, providing fine-grained errors that retains span information. This provides much nicer compile-time errors, and even better IDE errors.

Updated the array_texture example to demonstrate the new changes.
## New AsBindGroup attribute options
### `#[texture(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|-------------- |---------------------------------------------------------------- | ----------- |
| dimension = "..." | `"1d"`, `"2d"`, `"2d_array"`, `"3d"`, `"cube"`, `"cube_array"` | `"2d"` |
| sample_type = "..." | `"float"`, `"depth"`, `"s_int"` or `"u_int"` | `"float"` |
| filterable = ... | `true`, `false` | `true` |
| multisampled = ... | `true`, `false` | `false` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[texture(0, dimension = "2d_array", visibility(vertex, fragment))]`
### `#[sampler(u32, ...)]`
Where `...` is an optional list of arguments.
| Arguments | Values | Default |
|----------- |--------------------------------------------------- | ----------- |
| sampler_type = "..." | `"filtering"`, `"non_filtering"`, `"comparison"`. | `"filtering"` |
| visibility(...) | `all`, `none`, or a list-combination of `vertex`, `fragment`, `compute` | `vertex`, `fragment` |
Example: `#[sampler(0, sampler_type = "filtering", visibility(vertex, fragment)]`
## Changelog
- Added more options to `#[texture(...)]` and `#[sampler(...)]` attributes, supporting more kinds of materials. See above for details.
- Upgraded IDE and compile-time error messages.
- Updated array_texture example using the new options.
# Objective
- Help user when they need to add both a `TransformBundle` and a `VisibilityBundle`
## Solution
- Add a `SpatialBundle` adding all components
# Objective
- Add capability to use `Affine3A`s for some `GlobalTransform`s. This allows affine transformations that are not possible using a single `Transform` such as shear and non-uniform scaling along an arbitrary axis.
- Related to #1755 and #2026
## Solution
- `GlobalTransform` becomes an enum wrapping either a `Transform` or an `Affine3A`.
- The API of `GlobalTransform` is minimized to avoid inefficiency, and to make it clear that operations should be performed using the underlying data types.
- using `GlobalTransform::Affine3A` disables transform propagation, because the main use is for cases that `Transform`s cannot support.
---
## Changelog
- `GlobalTransform`s can optionally support any affine transformation using an `Affine3A`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#4907. Fixes#838. Fixes#5089.
Supersedes #5146. Supersedes #2087. Supersedes #865. Supersedes #5114
Visibility is currently entirely local. Set a parent entity to be invisible, and the children are still visible. This makes it hard for users to hide entire hierarchies of entities.
Additionally, the semantics of `Visibility` vs `ComputedVisibility` are inconsistent across entity types. 3D meshes use `ComputedVisibility` as the "definitive" visibility component, with `Visibility` being just one data source. Sprites just use `Visibility`, which means they can't feed off of `ComputedVisibility` data, such as culling information, RenderLayers, and (added in this pr) visibility inheritance information.
## Solution
Splits `ComputedVisibilty::is_visible` into `ComputedVisibilty::is_visible_in_view` and `ComputedVisibilty::is_visible_in_hierarchy`. For each visible entity, `is_visible_in_hierarchy` is computed by propagating visibility down the hierarchy. The `ComputedVisibility::is_visible()` function combines these two booleans for the canonical "is this entity visible" function.
Additionally, all entities that have `Visibility` now also have `ComputedVisibility`. Sprites, Lights, and UI entities now use `ComputedVisibility` when appropriate.
This means that in addition to visibility inheritance, everything using Visibility now also supports RenderLayers. Notably, Sprites (and other 2d objects) now support `RenderLayers` and work properly across multiple views.
Also note that this does increase the amount of work done per sprite. Bevymark with 100,000 sprites on `main` runs in `0.017612` seconds and this runs in `0.01902`. That is certainly a gap, but I believe the api consistency and extra functionality this buys us is worth it. See [this thread](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for more info. Note that #5146 in combination with #5114 _are_ a viable alternative to this PR and _would_ perform better, but that comes at the cost of api inconsistencies and doing visibility calculations in the "wrong" place. The current visibility system does have potential for performance improvements. I would prefer to evolve that one system as a whole rather than doing custom hacks / different behaviors for each feature slice.
Here is a "split screen" example where the left camera uses RenderLayers to filter out the blue sprite.

Note that this builds directly on #5146 and that @james7132 deserves the credit for the baseline visibility inheritance work. This pr moves the inherited visibility field into `ComputedVisibility`, then does the additional work of porting everything to `ComputedVisibility`. See my [comments here](https://github.com/bevyengine/bevy/pull/5146#issuecomment-1182783452) for rationale.
## Follow up work
* Now that lights use ComputedVisibility, VisibleEntities now includes "visible lights" in the entity list. Functionally not a problem as we use queries to filter the list down in the desired context. But we should consider splitting this out into a separate`VisibleLights` collection for both clarity and performance reasons. And _maybe_ even consider scoping `VisibleEntities` down to `VisibleMeshes`?.
* Investigate alternative sprite rendering impls (in combination with visibility system tweaks) that avoid re-generating a per-view fixedbitset of visible entities every frame, then checking each ExtractedEntity. This is where most of the performance overhead lives. Ex: we could generate ExtractedEntities per-view using the VisibleEntities list, avoiding the need for the bitset.
* Should ComputedVisibility use bitflags under the hood? This would cut down on the size of the component, potentially speed up the `is_visible()` function, and allow us to cheaply expand ComputedVisibility with more data (ex: split out local visibility and parent visibility, add more culling classes, etc).
---
## Changelog
* ComputedVisibility now takes hierarchy visibility into account.
* 2D, UI and Light entities now use the ComputedVisibility component.
## Migration Guide
If you were previously reading `Visibility::is_visible` as the "actual visibility" for sprites or lights, use `ComputedVisibilty::is_visible()` instead:
```rust
// before (0.7)
fn system(query: Query<&Visibility>) {
for visibility in query.iter() {
if visibility.is_visible {
log!("found visible entity");
}
}
}
// after (0.8)
fn system(query: Query<&ComputedVisibility>) {
for visibility in query.iter() {
if visibility.is_visible() {
log!("found visible entity");
}
}
}
```
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- There is a warning when building in release:
```
warning: unused import: `Local`
--> crates/bevy_render/src/extract_resource.rs:4:34
|
4 | use bevy_ecs::system::{Commands, Local, Res, ResMut, Resource};
| ^^^^^
|
= note: `#[warn(unused_imports)]` on by default
```
- It's used 814f8d1635/crates/bevy_render/src/extract_resource.rs (L45)
- Fix it
## Solution
- Gate the import
# Objective
Fixes#5304
## Solution
Instead of using a simple utility function for loading, which uses a default allocation limit of 512MB, we use a Reader object which can be configured ad hoc.
## Changelog
> This section is optional. If this was a trivial fix, or has no externally-visible impact, you can delete this section.
- Allows loading of textures larger than 512MB
# Objective
When someone searches in rustdoc for `world_to_screen`, they now will
find `world_to_viewport`. The method was renamed in 0.8, it would be
nice to allow users to find the new name more easily.
---
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
# Objective
- The time update is currently done in the wrong part of the schedule. For a single frame the current order of things is update input, update time (First stage), other stages, render stage (frame presentation). So when we update the time it includes the input processing of the current frame and the frame presentation of the previous frame. This is a problem when vsync is on. When input processing takes a longer amount of time for a frame, the vsync wait time gets shorter. So when these are not paired correctly we can potentially have a long input processing time added to the normal vsync wait time in the previous frame. This leads to inaccurate frame time reporting and more variance of the time than actually exists. For more details of why this is an issue see the linked issue below.
- Helps with https://github.com/bevyengine/bevy/issues/4669
- Supercedes https://github.com/bevyengine/bevy/pull/4728 and https://github.com/bevyengine/bevy/pull/4735. This PR should be less controversial than those because it doesn't add to the API surface.
## Solution
- The most accurate frame time would come from hardware. We currently don't have access to that for multiple reasons, so the next best thing we can do is measure the frame time as close to frame presentation as possible. This PR gets the Instant::now() for the time immediately after frame presentation in the render system and then sends that time to the app world through a channel.
- implements suggestion from @aevyrie from here https://github.com/bevyengine/bevy/pull/4728#discussion_r872010606
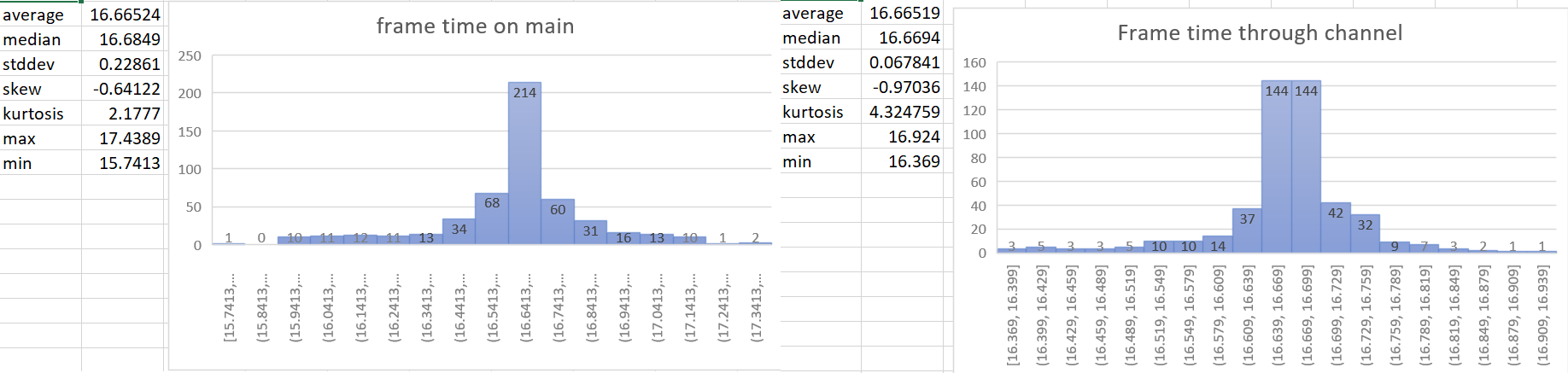
## Statistics
---
## Changelog
- Make frame time reporting more accurate.
## Migration Guide
`time.delta()` now reports zero for 2 frames on startup instead of 1 frame.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
- Validate the format of the values with the expected attribute format.
- Currently, if you pass the wrong format, it will crash somewhere unrelated with a very cryptic error message, so it's really hard to debug for beginners.
## Solution
- Compare the format and panic when unexpected format is passed
## Note
- I used a separate `error!()` for a human friendly message because the panic message is very noisy and hard to parse for beginners. I don't mind changing this to only a panic if people prefer that.
- This could potentially be something that runs only in debug mode, but I don't think inserting attributes is done often enough for this to be an issue.
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Small optimization. `.collect()` from arrays generates very nice code without reallocations: https://rust.godbolt.org/z/6E6c595bq
Co-authored-by: Kornel <kornel@geekhood.net>
# Objective
Currently some TextureFormats are not supported by the Image type.
The `TextureFormat::R16Unorm` format is useful for storing heightmaps.
This small change would unblock releasing my terrain plugin on bevy 0.8.
## Solution
Added `TextureFormat::R16Unorm` support to Image.
This is an alternative (short term solution) to the large texture format issue https://github.com/bevyengine/bevy/pull/4124.
# Objective
- Extracting resources currently always uses commands, which requires *at least* one additional move of the extracted value, as well as dynamic dispatch.
- Addresses https://github.com/bevyengine/bevy/pull/4402#discussion_r911634931
## Solution
- Write the resource into a `ResMut<R>` directly.
- Fall-back to commands if the resource hasn't been added yet.
# Objective
- Currently, the `Extract` `RenderStage` is executed on the main world, with the render world available as a resource.
- However, when needing access to resources in the render world (e.g. to mutate them), the only way to do so was to get exclusive access to the whole `RenderWorld` resource.
- This meant that effectively only one extract which wrote to resources could run at a time.
- We didn't previously make `Extract`ing writing to the world a non-happy path, even though we want to discourage that.
## Solution
- Move the extract stage to run on the render world.
- Add the main world as a `MainWorld` resource.
- Add an `Extract` `SystemParam` as a convenience to access a (read only) `SystemParam` in the main world during `Extract`.
## Future work
It should be possible to avoid needing to use `get_or_spawn` for the render commands, since now the `Commands`' `Entities` matches up with the world being executed on.
We need to determine how this interacts with https://github.com/bevyengine/bevy/pull/3519
It's theoretically possible to remove the need for the `value` method on `Extract`. However, that requires slightly changing the `SystemParam` interface, which would make it more complicated. That would probably mess up the `SystemState` api too.
## Todo
I still need to add doc comments to `Extract`.
---
## Changelog
### Changed
- The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase.
Resources on the render world can now be accessed using `ResMut` during extract.
### Removed
- `Commands::spawn_and_forget`. Use `Commands::get_or_spawn(e).insert_bundle(bundle)` instead
## Migration Guide
The `Extract` `RenderStage` now runs on the render world (instead of the main world as before).
You must use the `Extract` `SystemParam` to access the main world during the extract phase. `Extract` takes a single type parameter, which is any system parameter (such as `Res`, `Query` etc.). It will extract this from the main world, and returns the result of this extraction when `value` is called on it.
For example, if previously your extract system looked like:
```rust
fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
for cloud in clouds.iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
the new version would be:
```rust
fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
The diff is:
```diff
--- a/src/clouds.rs
+++ b/src/clouds.rs
@@ -1,5 +1,5 @@
-fn extract_clouds(mut commands: Commands, clouds: Query<Entity, With<Cloud>>) {
- for cloud in clouds.iter() {
+fn extract_clouds(mut commands: Commands, mut clouds: Extract<Query<Entity, With<Cloud>>>) {
+ for cloud in clouds.value().iter() {
commands.get_or_spawn(cloud).insert(Cloud);
}
}
```
You can now also access resources from the render world using the normal system parameters during `Extract`:
```rust
fn extract_assets(mut render_assets: ResMut<MyAssets>, source_assets: Extract<Res<MyAssets>>) {
*render_assets = source_assets.clone();
}
```
Please note that all existing extract systems need to be updated to match this new style; even if they currently compile they will not run as expected. A warning will be emitted on a best-effort basis if this is not met.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Support removing attributes from meshes. For an example use case, meshes created using the bevy::predule::shape types or loaded from external files may have attributes that are not needed for the materials they will be rendered with.
This was extracted from PR #5222.
## Solution
Implement Mesh::remove_attribute().
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
Reduce the boilerplate code needed to make draw order sorting work correctly when queuing items through new common functionality. Also fix several instances in the bevy code-base (mostly examples) where this boilerplate appears to be incorrect.
## Solution
- Moved the logic for handling back-to-front vs front-to-back draw ordering into the PhaseItems by inverting the sort key ordering of Opaque3d and AlphaMask3d. The means that all the standard 3d rendering phases measure distance in the same way. Clients of these structs no longer need to know to negate the distance.
- Added a new utility struct, ViewRangefinder3d, which encapsulates the maths needed to calculate a "distance" from an ExtractedView and a mesh's transform matrix.
- Converted all the occurrences of the distance calculations in Bevy and its examples to use ViewRangefinder3d. Several of these occurrences appear to be buggy because they don't invert the view matrix or don't negate the distance where appropriate. This leads me to the view that Bevy should expose a facility to correctly perform this calculation.
## Migration Guide
Code which creates Opaque3d, AlphaMask3d, or Transparent3d phase items _should_ use ViewRangefinder3d to calculate the distance value.
Code which manually calculated the distance for Opaque3d or AlphaMask3d phase items and correctly negated the z value will no longer depth sort correctly. However, incorrect depth sorting for these types will not impact the rendered output as sorting is only a performance optimisation when drawing with depth-testing enabled. Code which manually calculated the distance for Transparent3d phase items will continue to work as before.
# Objective
We don't have reflection for resources.
## Solution
Introduce reflection for resources.
Continues #3580 (by @Davier), related to #3576.
---
## Changelog
### Added
* Reflection on a resource type (by adding `ReflectResource`):
```rust
#[derive(Reflect)]
#[reflect(Resource)]
struct MyResourse;
```
### Changed
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component` for consistency.
## Migration Guide
* Rename `ReflectComponent::add_component` into `ReflectComponent::insert_component`.
# Objective
Transform screen-space coordinates into world space in shaders. (My use case is for generating rays for ray tracing with the same perspective as the 3d camera).
## Solution
Add `inverse_projection` and `inverse_view_proj` fields to shader view uniform
---
## Changelog
### Added
`inverse_projection` and `inverse_view_proj` fields to shader view uniform
## Note
It'd probably be good to double-check that I did the matrix multiplication in the right order for `inverse_proj_view`. Thanks!
# Objective
- Enable `wgpu` profiling spans
## Solution
- `wgpu` uses the `profiling` crate to add profiling span instrumentation to their code
- `profiling` offers multiple 'backends' for profiling, including `tracing`
- When the `bevy` `trace` feature is used, add the `profiling` crate with its `profile-with-tracing` feature to enable appropriate profiling spans in `wgpu` using `tracing` which fits nicely into our infrastructure
- Bump our default `tracing` subscriber filter to `wgpu=info` from `wgpu=error` so that the profiling spans are not filtered out as they are created at the `info` level.
---
## Changelog
- Added: `tracing` profiling support for `wgpu` when using bevy's `trace` feature
- Changed: The default `tracing` filter statement for `wgpu` has been changed from the `error` level to the `info` level to not filter out the wgpu profiling spans
Removed `const_vec2`/`const_vec3`
and replaced with equivalent `.from_array`.
# Objective
Fixes#5112
## Solution
- `encase` needs to update to `glam` as well. See teoxoy/encase#4 on progress on that.
- `hexasphere` also needs to be updated, see OptimisticPeach/hexasphere#12.
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
Fixes#5153
## Solution
Search for all enums and manually check if they have default impls that can use this new derive.
By my reckoning:
| enum | num |
|-|-|
| total | 159 |
| has default impl | 29 |
| default is unit variant | 23 |
# Objective
This PR reworks Bevy's Material system, making the user experience of defining Materials _much_ nicer. Bevy's previous material system leaves a lot to be desired:
* Materials require manually implementing the `RenderAsset` trait, which involves manually generating the bind group, handling gpu buffer data transfer, looking up image textures, etc. Even the simplest single-texture material involves writing ~80 unnecessary lines of code. This was never the long term plan.
* There are two material traits, which is confusing, hard to document, and often redundant: `Material` and `SpecializedMaterial`. `Material` implicitly implements `SpecializedMaterial`, and `SpecializedMaterial` is used in most high level apis to support both use cases. Most users shouldn't need to think about specialization at all (I consider it a "power-user tool"), so the fact that `SpecializedMaterial` is front-and-center in our apis is a miss.
* Implementing either material trait involves a lot of "type soup". The "prepared asset" parameter is particularly heinous: `&<Self as RenderAsset>::PreparedAsset`. Defining vertex and fragment shaders is also more verbose than it needs to be.
## Solution
Say hello to the new `Material` system:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
}
```
Thats it! This same material would have required [~80 lines of complicated "type heavy" code](https://github.com/bevyengine/bevy/blob/v0.7.0/examples/shader/shader_material.rs) in the old Material system. Now it is just 14 lines of simple, readable code.
This is thanks to a new consolidated `Material` trait and the new `AsBindGroup` trait / derive.
### The new `Material` trait
The old "split" `Material` and `SpecializedMaterial` traits have been removed in favor of a new consolidated `Material` trait. All of the functions on the trait are optional.
The difficulty of implementing `Material` has been reduced by simplifying dataflow and removing type complexity:
```rust
// Old
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn alpha_mode(render_asset: &<Self as RenderAsset>::PreparedAsset) -> AlphaMode {
render_asset.alpha_mode
}
}
// New
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn alpha_mode(&self) -> AlphaMode {
self.alpha_mode
}
}
```
Specialization is still supported, but it is hidden by default under the `specialize()` function (more on this later).
### The `AsBindGroup` trait / derive
The `Material` trait now requires the `AsBindGroup` derive. This can be implemented manually relatively easily, but deriving it will almost always be preferable.
Field attributes like `uniform` and `texture` are used to define which fields should be bindings,
what their binding type is, and what index they should be bound at:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
In WGSL shaders, the binding looks like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
[[group(1), binding(1)]]
var color_texture: texture_2d<f32>;
[[group(1), binding(2)]]
var color_sampler: sampler;
```
Note that the "group" index is determined by the usage context. It is not defined in `AsBindGroup`. Bevy material bind groups are bound to group 1.
The following field-level attributes are supported:
* `uniform(BINDING_INDEX)`
* The field will be converted to a shader-compatible type using the `ShaderType` trait, written to a `Buffer`, and bound as a uniform. It can also be derived for custom structs.
* `texture(BINDING_INDEX)`
* This field's `Handle<Image>` will be used to look up the matching `Texture` gpu resource, which will be bound as a texture in shaders. The field will be assumed to implement `Into<Option<Handle<Image>>>`. In practice, most fields should be a `Handle<Image>` or `Option<Handle<Image>>`. If the value of an `Option<Handle<Image>>` is `None`, the new `FallbackImage` resource will be used instead. This attribute can be used in conjunction with a `sampler` binding attribute (with a different binding index).
* `sampler(BINDING_INDEX)`
* Behaves exactly like the `texture` attribute, but sets the Image's sampler binding instead of the texture.
Note that fields without field-level binding attributes will be ignored.
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
this_field_is_ignored: String,
}
```
As mentioned above, `Option<Handle<Image>>` is also supported:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Option<Handle<Image>>,
}
```
This is useful if you want a texture to be optional. When the value is `None`, the `FallbackImage` will be used for the binding instead, which defaults to "pure white".
Field uniforms with the same binding index will be combined into a single binding:
```rust
#[derive(AsBindGroup)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
#[uniform(0)]
roughness: f32,
}
```
In WGSL shaders, the binding would look like this:
```wgsl
struct CoolMaterial {
color: vec4<f32>;
roughness: f32;
};
[[group(1), binding(0)]]
var<uniform> material: CoolMaterial;
```
Some less common scenarios will require "struct-level" attributes. These are the currently supported struct-level attributes:
* `uniform(BINDING_INDEX, ConvertedShaderType)`
* Similar to the field-level `uniform` attribute, but instead the entire `AsBindGroup` value is converted to `ConvertedShaderType`, which must implement `ShaderType`. This is useful if more complicated conversion logic is required.
* `bind_group_data(DataType)`
* The `AsBindGroup` type will be converted to some `DataType` using `Into<DataType>` and stored as `AsBindGroup::Data` as part of the `AsBindGroup::as_bind_group` call. This is useful if data needs to be stored alongside the generated bind group, such as a unique identifier for a material's bind group. The most common use case for this attribute is "shader pipeline specialization".
The previous `CoolMaterial` example illustrating "combining multiple field-level uniform attributes with the same binding index" can
also be equivalently represented with a single struct-level uniform attribute:
```rust
#[derive(AsBindGroup)]
#[uniform(0, CoolMaterialUniform)]
struct CoolMaterial {
color: Color,
roughness: f32,
}
#[derive(ShaderType)]
struct CoolMaterialUniform {
color: Color,
roughness: f32,
}
impl From<&CoolMaterial> for CoolMaterialUniform {
fn from(material: &CoolMaterial) -> CoolMaterialUniform {
CoolMaterialUniform {
color: material.color,
roughness: material.roughness,
}
}
}
```
### Material Specialization
Material shader specialization is now _much_ simpler:
```rust
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
#[bind_group_data(CoolMaterialKey)]
struct CoolMaterial {
#[uniform(0)]
color: Color,
is_red: bool,
}
#[derive(Copy, Clone, Hash, Eq, PartialEq)]
struct CoolMaterialKey {
is_red: bool,
}
impl From<&CoolMaterial> for CoolMaterialKey {
fn from(material: &CoolMaterial) -> CoolMaterialKey {
CoolMaterialKey {
is_red: material.is_red,
}
}
}
impl Material for CoolMaterial {
fn fragment_shader() -> ShaderRef {
"cool_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
if key.bind_group_data.is_red {
let fragment = descriptor.fragment.as_mut().unwrap();
fragment.shader_defs.push("IS_RED".to_string());
}
Ok(())
}
}
```
Setting `bind_group_data` is not required for specialization (it defaults to `()`). Scenarios like "custom vertex attributes" also benefit from this system:
```rust
impl Material for CustomMaterial {
fn vertex_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
fn specialize(
pipeline: &MaterialPipeline<Self>,
descriptor: &mut RenderPipelineDescriptor,
layout: &MeshVertexBufferLayout,
key: MaterialPipelineKey<Self>,
) -> Result<(), SpecializedMeshPipelineError> {
let vertex_layout = layout.get_layout(&[
Mesh::ATTRIBUTE_POSITION.at_shader_location(0),
ATTRIBUTE_BLEND_COLOR.at_shader_location(1),
])?;
descriptor.vertex.buffers = vec![vertex_layout];
Ok(())
}
}
```
### Ported `StandardMaterial` to the new `Material` system
Bevy's built-in PBR material uses the new Material system (including the AsBindGroup derive):
```rust
#[derive(AsBindGroup, Debug, Clone, TypeUuid)]
#[uuid = "7494888b-c082-457b-aacf-517228cc0c22"]
#[bind_group_data(StandardMaterialKey)]
#[uniform(0, StandardMaterialUniform)]
pub struct StandardMaterial {
pub base_color: Color,
#[texture(1)]
#[sampler(2)]
pub base_color_texture: Option<Handle<Image>>,
/* other fields omitted for brevity */
```
### Ported Bevy examples to the new `Material` system
The overall complexity of Bevy's "custom shader examples" has gone down significantly. Take a look at the diffs if you want a dopamine spike.
Please note that while this PR has a net increase in "lines of code", most of those extra lines come from added documentation. There is a significant reduction
in the overall complexity of the code (even accounting for the new derive logic).
---
## Changelog
### Added
* `AsBindGroup` trait and derive, which make it much easier to transfer data to the gpu and generate bind groups for a given type.
### Changed
* The old `Material` and `SpecializedMaterial` traits have been replaced by a consolidated (much simpler) `Material` trait. Materials no longer implement `RenderAsset`.
* `StandardMaterial` was ported to the new material system. There are no user-facing api changes to the `StandardMaterial` struct api, but it now implements `AsBindGroup` and `Material` instead of `RenderAsset` and `SpecializedMaterial`.
## Migration Guide
The Material system has been reworked to be much simpler. We've removed a lot of boilerplate with the new `AsBindGroup` derive and the `Material` trait is simpler as well!
### Bevy 0.7 (old)
```rust
#[derive(Debug, Clone, TypeUuid)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
color: Color,
color_texture: Handle<Image>,
}
#[derive(Clone)]
pub struct GpuCustomMaterial {
_buffer: Buffer,
bind_group: BindGroup,
}
impl RenderAsset for CustomMaterial {
type ExtractedAsset = CustomMaterial;
type PreparedAsset = GpuCustomMaterial;
type Param = (SRes<RenderDevice>, SRes<MaterialPipeline<Self>>);
fn extract_asset(&self) -> Self::ExtractedAsset {
self.clone()
}
fn prepare_asset(
extracted_asset: Self::ExtractedAsset,
(render_device, material_pipeline): &mut SystemParamItem<Self::Param>,
) -> Result<Self::PreparedAsset, PrepareAssetError<Self::ExtractedAsset>> {
let color = Vec4::from_slice(&extracted_asset.color.as_linear_rgba_f32());
let byte_buffer = [0u8; Vec4::SIZE.get() as usize];
let mut buffer = encase::UniformBuffer::new(byte_buffer);
buffer.write(&color).unwrap();
let buffer = render_device.create_buffer_with_data(&BufferInitDescriptor {
contents: buffer.as_ref(),
label: None,
usage: BufferUsages::UNIFORM | BufferUsages::COPY_DST,
});
let (texture_view, texture_sampler) = if let Some(result) = material_pipeline
.mesh_pipeline
.get_image_texture(gpu_images, &Some(extracted_asset.color_texture.clone()))
{
result
} else {
return Err(PrepareAssetError::RetryNextUpdate(extracted_asset));
};
let bind_group = render_device.create_bind_group(&BindGroupDescriptor {
entries: &[
BindGroupEntry {
binding: 0,
resource: buffer.as_entire_binding(),
},
BindGroupEntry {
binding: 0,
resource: BindingResource::TextureView(texture_view),
},
BindGroupEntry {
binding: 1,
resource: BindingResource::Sampler(texture_sampler),
},
],
label: None,
layout: &material_pipeline.material_layout,
});
Ok(GpuCustomMaterial {
_buffer: buffer,
bind_group,
})
}
}
impl Material for CustomMaterial {
fn fragment_shader(asset_server: &AssetServer) -> Option<Handle<Shader>> {
Some(asset_server.load("custom_material.wgsl"))
}
fn bind_group(render_asset: &<Self as RenderAsset>::PreparedAsset) -> &BindGroup {
&render_asset.bind_group
}
fn bind_group_layout(render_device: &RenderDevice) -> BindGroupLayout {
render_device.create_bind_group_layout(&BindGroupLayoutDescriptor {
entries: &[
BindGroupLayoutEntry {
binding: 0,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Buffer {
ty: BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: Some(Vec4::min_size()),
},
count: None,
},
BindGroupLayoutEntry {
binding: 1,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Texture {
multisampled: false,
sample_type: TextureSampleType::Float { filterable: true },
view_dimension: TextureViewDimension::D2Array,
},
count: None,
},
BindGroupLayoutEntry {
binding: 2,
visibility: ShaderStages::FRAGMENT,
ty: BindingType::Sampler(SamplerBindingType::Filtering),
count: None,
},
],
label: None,
})
}
}
```
### Bevy 0.8 (new)
```rust
impl Material for CustomMaterial {
fn fragment_shader() -> ShaderRef {
"custom_material.wgsl".into()
}
}
#[derive(AsBindGroup, TypeUuid, Debug, Clone)]
#[uuid = "f690fdae-d598-45ab-8225-97e2a3f056e0"]
pub struct CustomMaterial {
#[uniform(0)]
color: Color,
#[texture(1)]
#[sampler(2)]
color_texture: Handle<Image>,
}
```
## Future Work
* Add support for more binding types (cubemaps, buffers, etc). This PR intentionally includes a bare minimum number of binding types to keep "reviewability" in check.
* Consider optionally eliding binding indices using binding names. `AsBindGroup` could pass in (optional?) reflection info as a "hint".
* This would make it possible for the derive to do this:
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[uniform]
color: Color,
#[texture]
#[sampler]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or this
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
#[binding]
color: Color,
#[binding]
color_texture: Option<Handle<Image>>,
alpha_mode: AlphaMode,
}
```
* Or even this (if we flip to "include bindings by default")
```rust
#[derive(AsBindGroup)]
pub struct CustomMaterial {
color: Color,
color_texture: Option<Handle<Image>>,
#[binding(ignore)]
alpha_mode: AlphaMode,
}
```
* If we add the option to define custom draw functions for materials (which could be done in a type-erased way), I think that would be enough to support extra non-material bindings. Worth considering!
# Objective
Documents the `BufferVec` render resource.
`BufferVec` is a fairly low level object, that will likely be managed by a higher level API (e.g. through [`encase`](https://github.com/bevyengine/bevy/issues/4272)) in the future. For now, since it is still used by some simple
example crates (e.g. [bevy-vertex-pulling](https://github.com/superdump/bevy-vertex-pulling)), it will be helpful
to provide some simple documentation on what `BufferVec` does.
## Solution
I looked through Discord discussion on `BufferVec`, and found [a comment](https://discord.com/channels/691052431525675048/953222550568173580/956596218857918464 ) by @superdump to be particularly helpful, in the general discussion around `encase`.
I have taken care to clarify where the data is stored (host-side), when the device-side buffer is created (through calls to `reserve`), and when data writes from host to device are scheduled (using `write_buffer` calls).
---
## Changelog
- Added doc string for `BufferVec` and two of its methods: `reserve` and `write_buffer`.
Co-authored-by: Brian Merchant <bhmerchant@gmail.com>
# Objective
Attempt to more clearly document `ImageSettings` and setting a default sampler for new images, as per #5046
## Changelog
- Moved ImageSettings into image.rs, image::* is already exported. Makes it simpler for linking docs.
- Renamed "DefaultImageSampler" to "RenderDefaultImageSampler". Not a great name, but more consistent with other render resources.
- Added/updated related docs
# Objective
Partially addresses #4291.
Speed up the sort phase for unbatched render phases.
## Solution
Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass.
## Performance
This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change.
On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.

## Future Work
There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems.
Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`.
Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while.
---
## Changelog
Added: `PhaseItem::sort`
## Migration Guide
RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`).
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: colepoirier <colepoirier@gmail.com>
# Objective
Further speed up visibility checking by removing the main sources of contention for the system.
## Solution
- ~~Make `ComputedVisibility` a resource wrapping a `FixedBitset`.~~
- ~~Remove `ComputedVisibility` as a component.~~
~~This adds a one-bit overhead to every entity in the app world. For a game with 100,000 entities, this is 12.5KB of memory. This is still small enough to fit entirely in most L1 caches. Also removes the need for a per-Entity change detection tick. This reduces the memory footprint of ComputedVisibility 72x.~~
~~The decreased memory usage and less fragmented memory locality should provide significant performance benefits.~~
~~Clearing visible entities should be significantly faster than before:~~
- ~~Setting one `u32` to 0 clears 32 entities per cycle.~~
- ~~No archetype fragmentation to contend with.~~
- ~~Change detection is applied to the resource, so there is no per-Entity update tick requirement.~~
~~The side benefit of this design is that it removes one more "computed component" from userspace. Though accessing the values within it are now less ergonomic.~~
This PR changes `crossbeam_channel` in `check_visibility` to use a `Local<ThreadLocal<Cell<Vec<Entity>>>` to mark down visible entities instead.
Co-Authored-By: TheRawMeatball <therawmeatball@gmail.com>
Co-Authored-By: Aevyrie <aevyrie@gmail.com>
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
# Objective
- KTX2 UASTC format mapping was incorrect. For some reason I had written it to map to a set of data formats based on the count of KTX2 sample information blocks, but the mapping should be done based on the channel type in the sample information.
- This is a valid change pulled out from #4514 as the attempt to fix the array textures there was incorrect
## Solution
- Fix the KTX2 UASTC `DataFormat` enum to contain the correct formats based on the channel types in section 3.10.2 of https://github.khronos.org/KTX-Specification/ (search for "Basis Universal UASTC Format")
- Correctly map from the sample information channel type to `DataFormat`
- Correctly configure transcoding and the resulting texture format based on the `DataFormat`
---
## Changelog
- Fixed: KTX2 UASTC format handling
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}