# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
bevy-scene does not have a reason to depend on bevy-render except to
include the `Visibility` and `ComputedVisibility` components. Including
that in the dependency chain is unnecessary for people not using
`bevy_render`.
Also fixed a problem where compilation fails when the `serialize`
feature was not enabled.
## Solution
This was added in #5335 to address some of the problems caused by #5310.
Imo the user just always have to remember to include `VisibilityBundle`
when they spawn `SceneBundle` or `DynamicSceneBundle`, but that will be
a breaking change. This PR makes `bevy_render` an optional dependency of
`bevy_scene` instead to respect the existing behavior.
# Objective
While migrating the engine to use the `Tick` type in #7905, I forgot to
update `UnsafeWorldCell::increment_change_tick`.
## Solution
Update the function.
---
## Changelog
- The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
## Migration Guide
The function `UnsafeWorldCell::increment_change_tick` is now
strongly-typed, returning a value of type `Tick` instead of a raw `u32`.
# Objective
TAA, FXAA, and some other post processing effects can cause the image to
become blurry. Sharpening helps to counteract that.
## Solution
~~This is a port of AMD's Contrast Adaptive Sharpening (I ported it from
the
[SweetFX](https://github.com/CeeJayDK/SweetFX/blob/master/Shaders/CAS.fx)
version, which is still MIT licensed). CAS is a good sharpening
algorithm that is better at avoiding the full screen oversharpening
artifacts that simpler algorithms tend to create.~~
This is a port of AMD's Robust Contrast Adaptive Sharpening (RCAS) which
they developed for FSR 1 ([and continue to use in FSR
2](149cf26e12/src/ffx-fsr2-api/shaders/ffx_fsr1.h (L599))).
RCAS is a good sharpening algorithm that is better at avoiding the full
screen oversharpening artifacts that simpler algorithms tend to create.
---
## Future Work
- Consider porting this to a compute shader for potentially better
performance. (In my testing it is currently ridiculously cheap (0.01ms
in Bistro at 1440p where I'm GPU bound), so this wasn't a priority,
especially since it would increase complexity due to still needing the
non-compute version for webgl2 support).
---
## Changelog
- Added Contrast Adaptive Sharpening.
---------
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- Closes https://github.com/bevyengine/bevy/issues/8008
## Solution
- Add a skybox plugin that renders a fullscreen triangle, and then
modifies the vertices in a vertex shader to enforce that it renders as a
skybox background.
- Skybox is run at the end of MainOpaquePass3dNode.
- In the future, it would be nice to get something like bevy_atmosphere
built-in, and have a default skybox+environment map light.
---
## Changelog
- Added `Skybox`.
- `EnvironmentMapLight` now renders in the correct orientation.
## Migration Guide
- Flip `EnvironmentMapLight` maps if needed to match how they previously
rendered (which was backwards).
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Some examples still manually implement the States trait, even though
manual implementation is no longer needed as there is now the derive
macro for that.
---------
Signed-off-by: Natalia Asteria <fortressnordlys@outlook.com>
These traits are both implemented, but not reflected, requiring user
code to do `app.register_type_data::<BloomSettings,
ReflectDefault>().register_type_data::<BloomSettings,
ReflectComponent>()` to make these usable via reflection.
# Objective
The type `&World` is currently in an awkward place, since it has two
meanings:
1. Read-only access to the entire world.
2. Interior mutable access to the world; immutable and/or mutable access
to certain portions of world data.
This makes `&World` difficult to reason about, and surprising to see in
function signatures if one does not know about the interior mutable
property.
The type `UnsafeWorldCell` was added in #6404, which is meant to
alleviate this confusion by adding a dedicated type for interior mutable
world access. However, much of the engine still treats `&World` as an
interior mutable-ish type. One of those places is `SystemParam`.
## Solution
Modify `SystemParam::get_param` to accept `UnsafeWorldCell` instead of
`&World`. Simplify the safety invariants, since the `UnsafeWorldCell`
type encapsulates the concept of constrained world access.
---
## Changelog
`SystemParam::get_param` now accepts an `UnsafeWorldCell` instead of
`&World`. This type provides a high-level API for unsafe interior
mutable world access.
## Migration Guide
For manual implementers of `SystemParam`: the function `get_item` now
takes `UnsafeWorldCell` instead of `&World`. To access world data, use:
* `.get_entity()`, which returns an `UnsafeEntityCell` which can be used
to access component data.
* `get_resource()` and its variants, to access resource data.
# Objective
Fix typo in bevy_reflect README: `MyType` is a struct and not a trait,
so `&dyn MyType` is incorrect.
## Solution
Replace `&dyn MyType` with `&dyn DoThing`
# Objective
The function `SyncUnsafeCell::from_mut` returns `&SyncUnsafeCell<T>`,
even though it could return `&mut SyncUnsafeCell<T>`. This means it is
not possible to call `get_mut` on the returned value, so you need to use
unsafe code to get exclusive access back.
## Solution
Return `&mut Self` instead of `&Self` in `SyncUnsafeCell::from_mut`.
This is consistent with my proposal for `UnsafeCell::from_mut`:
https://github.com/rust-lang/libs-team/issues/198.
Replace an unsafe pointer dereference with a safe call to `get_mut`.
---
## Changelog
+ The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
## Migration Guide
The function `bevy_utils::SyncUnsafeCell::get_mut` now returns a value
of type `&mut SyncUnsafeCell<T>`. Previously, this returned an immutable
reference.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Fix `CubicCurve::iter_samples` iteration count.
## Solution
If I understand the function and the docs correctly, this should iterate
over `0..=subdivisions` instead of `0..subdivisions`.
For example: Now the iteration returns 3 points at `subdivisions = 2`,
as indicated in the documentation.
# Objective
Fix#7731. Add basic Event sending and iteration benchmarks to
bevy_ecs's benchmark suite.
## Solution
Add said benchmarks scaling from 100 to 50,000 events.
Not sure if I want to include a randomization of the events going in,
the current implementation might be too easy for the compiler to
optimize.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
Our regression tests for `SystemParam` currently consist of a bunch of
loosely dispersed struct definitions. This is messy, and doesn't fully
test their functionality.
## Solution
Group the struct definitions into functions annotated with `#[test]`.
This not only makes the module more organized, but it allows us to call
`assert_is_system`, which has the potential to catch some bugs that
would have been missed with the old approach. Also, this approach is
consistent with how `WorldQuery` regression tests are organized.
# Objective
- Fixes#7659
## Solution
The idea of anonymous system sets or "implicit hidden organizational
sets" was briefly mentioned by @cart here:
https://github.com/bevyengine/bevy/pull/7634#issuecomment-1428619449.
- `Schedule::add_systems` creates an implicit, anonymous system set of
all systems in `SystemConfigs`.
- All dependencies and conditions from the `SystemConfigs` are now
applied to the implicit system set, instead of being applied to each
individual system. This should not change the behavior, AFAIU, because
`before`, `after`, `run_if` and `ambiguous_with` are transitive
properties from a set to its members.
- The newly added `AnonymousSystemSet` stores the names of its members
to provide better error messages.
- The names are stored in a reference counted slice, allowing fast
clones of the `AnonymousSystemSet`.
- However, only the pointer of the slice is used for hash and equality
operations
- This ensures that two `AnonymousSystemSet` are not equal, even if they
have the same members / member names.
- So two identical `add_systems` calls will produce two different
`AnonymousSystemSet`s.
- Clones of the same `AnonymousSystemSet` will be equal.
## Drawbacks
If my assumptions are correct, the observed behavior should stay the
same. But the number of system sets in the `Schedule` will increase with
each `add_systems` call. If this has negative performance implications,
`add_systems` could be changed to only create the implicit system set if
necessary / when a run condition was added.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
With the removal of base sets, some variants of `ScheduleBuildError` can
never occur and should be removed.
## Solution
- Remove the obsolete variants of `ScheduleBuildError`.
- Also fix a doc comment which mentioned base sets.
---
## Changelog
### Removed
- Remove `ScheduleBuildError::SystemInMultipleBaseSets` and
`ScheduleBuildError::SetInMultipleBaseSets`.
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
The type `ThinSlicePtr` has a manual implementation of `Clone` that
manually clones each field. Since this type implements `Copy`, we can
change this implementation to simply dereference `&self`.
# Objective
I ran into a case where I need to create a `CommandQueue` and push
standard `Command` actions like `Insert` or `Remove` to it manually. I
saw that `Remove` looked as follows:
```rust
struct Remove<T> {
entity: Entity,
phantom: PhantomData<T>
}
```
so naturally, I tried to use `Remove::<Foo>::from(entity)` but it didn't
exist. We need to specify the `PhantomData` explicitly when creating
this command action. The same goes for `RemoveResource` and
`InitResource`
## Solution
This PR implements the following:
- `From<Entity>` for `Remove<T>`
- `Default` for `RemoveResource` and `InitResource`
- use these traits in the implementation of methods of `Commands`
- rename `phantom` field on the structs above to `_phantom` to have a
more uniform field naming scheme for the command actions
---
## Changelog
> This section is optional. If this was a trivial fix, or has no
externally-visible impact, you can delete this section.
- Added: implemented `From<Entity>` for `Remove<T>` and `Default` for
`RemoveResource` and `InitResource` for ergonomics
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- We support enabling a normal prepass, but the main pass never actually
uses it and recomputes the normals in the main pass. This isn't ideal
since it's doing redundant work.
## Solution
- Use the normal texture from the prepass in the main pass
## Notes
~~I used `NORMAL_PREPASS_ENABLED` as a shader_def because
`NORMAL_PREPASS` is currently used to signify that it is running in the
prepass while this shader_def need to indicate the prepass is done and
the normal prepass was ran before. I'm not sure if there's a better way
to name this.~~
# Objective
- Test mobile example on real devices
## Solution
- Use [BrowserStack](https://www.browserstack.com) to have access to
[real
devices](https://www.browserstack.com/list-of-browsers-and-platforms/app_automate)
- [App Automate](https://www.browserstack.com/app-automate) to run the
example
- [App Percy](https://www.browserstack.com/app-percy) to compare the
screenshot
- Added a daily/manual CI job that will build for iOS and Android, send
the apps to BrowserStack, run the app on one iOS device and one Android
device, capture a screenshot, send it for visual validation, and archive
it in the GitHub action
Example run: https://github.com/mockersf/bevy/actions/runs/4521883534
They currently have a bug with the settings to view snapshots, they
should be public. I'll raise it to them, and if they don't fix it in
time it's possible to work around for everyone to view the results
through their API.
@cart to get this to work, you'll need
- to set up an account on BrowserStack
- add the secrets `BROWSERSTACK_USERNAME` and `BROWSERSTACK_ACCESS_KEY`
to the Bevy repo
- create a project in Percy
- add the secret `PERCY_TOKEN` to the Bevy repo and modify the project
name line 122 in the `Daily.yml` file
# Objective
Fix#8179
## Solution
- Added `#![warn(missing_docs)]` and document all public items. All
methods on `Gizmos` have doc examples.
- Expanded the docs on the module/crate. Some unfortunate duplication
there :/
- Moved the methods from `GizmoBuffer` to be directly on `Gizmos` and
made `GizmoBuffer` private. This means the methods on `Gizmos` will show
up on its doc page.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Allow the use of the "glam _assert" feature to help catch runtime
errors and validate the arguments passed to glam.
e.g.
```rs
// Will panic if self is zero length when glam_assert is enabled.
pub fn normalize(self) -> Self {
let normalized = self.mul(self.length_recip());
glam_assert!(normalized.is_finite());
normalized
}
```
## Solution
- Re-export the optional feature glam_assert
---
## Changelog
Added: Optional feature "glam_assert"
# Objective
WebP is a modern image format developed by Google that offers a
significant reduction in file size compared to other image formats such
as PNG and JPEG, while still maintaining good image quality. This makes
it particularly useful for games with large numbers of images, such as
those with high-quality textures or detailed sprites, where file size
and loading times can have a significant impact on performance.
By adding support for WebP images in Bevy, game developers using this
engine can now take advantage of this modern image format and reduce the
memory usage and loading times of their games. This improvement can
ultimately result in a better gaming experience for players.
In summary, the objective of adding WebP image format support in Bevy is
to enable game developers to use a modern image format that provides
better compression rates and smaller file sizes, resulting in faster
loading times and reduced memory usage for their games.
## Solution
To add support for WebP images in Bevy, this pull request leverages the
existing `image` crate support for WebP. This implementation is easily
integrated into the existing Bevy asset-loading system. To maintain
compatibility with existing Bevy projects, WebP image support is
disabled by default, and developers can enable it by adding a feature
flag to their project's `Cargo.toml` file. With this feature, Bevy
becomes even more versatile for game developers and provides a valuable
addition to the game engine.
---
## Changelog
- Added support for WebP image format in Bevy game engine
## Migration Guide
To enable WebP image support in your Bevy project, add the following
line to your project's Cargo.toml file:
```toml
bevy = { version = "*", features = ["webp"]}
```
# Objective
Fixes#8089.
## Solution
Splits the MainPass3dNode into 2 nodes, one for the opaque + alpha
passes and one for the transparent pass.
---
## Changelog
- Split MainPass3dNode into MainOpaquePass3dNode and
MainTransparentPass3dNode
- Combine opaque and alpha phases in MainOpaquePass3dNode into one pass
- Create `START_MAIN_PASS` and `END_MAIN_PASS` empty nodes as labels
- Main pass becomes `START_MAIN_PASS -> MAIN_OPAQUE_PASS ->
MAIN_TRANSPARENT_PASS -> END_MAIN_PASS`
## Migration Guide
Nodes that previously added edges involving `MAIN_PASS` should now add
edges to or from `START_MAIN_PASS` or `END_MAIN_PASS` respectively.

# Objective
- Implement an alternative antialias technique
- TAA scales based off of view resolution, not geometry complexity
- TAA filters textures, firefly pixels, and other aliasing not covered
by MSAA
- TAA additionally will reduce noise / increase quality in future
stochastic rendering techniques
- Closes https://github.com/bevyengine/bevy/issues/3663
## Solution
- Add a temporal jitter component
- Add a motion vector prepass
- Add a TemporalAntialias component and plugin
- Combine existing MSAA and FXAA examples and add TAA
## Followup Work
- Prepass motion vector support for skinned meshes
- Move uniforms needed for motion vectors into a separate bind group,
instead of using different bind group layouts
- Reuse previous frame's GPU view buffer for motion vectors, instead of
recomputing
- Mip biasing for sharper textures, and or unjitter texture UVs
https://github.com/bevyengine/bevy/issues/7323
- Compute shader for better performance
- Investigate FSR techniques
- Historical depth based disocclusion tests, for geometry disocclusion
- Historical luminance/hue based tests, for shading disocclusion
- Pixel "locks" to reduce blending rate / revamp history confidence
mechanism
- Orthographic camera support for TemporalJitter
- Figure out COD's 1-tap bicubic filter
---
## Changelog
- Added MotionVectorPrepass and TemporalJitter
- Added TemporalAntialiasPlugin, TemporalAntialiasBundle, and
TemporalAntialiasSettings
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
Fix a bug with scene reload.
(This is a copy of #7570 but without the breaking API change, in order
to allow the bugfix to be introduced in 0.10.1)
When a scene was reloaded, it was corrupting components that weren't
native to the scene itself. In particular, when a DynamicScene was
created on Entity (A), all components in the scene without parents are
automatically added as children of Entity (A). But if that scene was
reloaded and the same ID of Entity (A) was a scene ID as well*, that
parent component was corrupted, causing the hierarchy to become
malformed and bevy to panic.
*For example, if Entity (A)'s ID was 3, and the scene contained an
entity with ID 3
This issue could affect any components that:
* Implemented `MapEntities`, basically components that contained
references to other entities
* Were added to entities from a scene file but weren't defined in the
scene file
- Fixes#7529
## Solution
The solution was to keep track of entities+components that had
`MapEntities` functionality during scene load, and only apply the entity
update behavior to them. They were tracked with a HashMap from the
component's TypeID to a vector of entity ID's. Then the
`ReflectMapEntities` struct was updated to hold a function that took a
list of entities to be applied to, instead of naively applying itself to
all values in the EntityMap.
(See this PR comment
https://github.com/bevyengine/bevy/pull/7570#issuecomment-1432302796 for
a story-based explanation of this bug and solution)
## Changelog
### Fixed
- Components that implement `MapEntities` added to scene entities after
load are not corrupted during scene reload.
# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/7990.
## Solution
- Register needed types, verified pasted code in issue works.
Do I need to register more `Option<T>` types?
# Objective
Fixes#7989
Based on #7991 by @CoffeeVampir3
## Solution
There were three parts to this issue:
1. `extend_where_clause` did not account for the optionality of a where
clause's trailing comma
```rust
// OKAY
struct Foo<T> where T: Asset, {/* ... */}
// ERROR
struct Foo<T> where T: Asset {/* ... */}
```
2. `FromReflect` derive logic was not actively using
`extend_where_clause` which led to some inconsistencies (enums weren't
adding _any_ additional bounds even)
3. Using `extend_where_clause` in the `FromReflect` derive logic meant
we had to optionally add `Default` bounds to ignored fields iff the
entire item itself was not already `Default` (otherwise the definition
for `Handle<T>` wouldn't compile since `HandleType` doesn't impl
`Default` but `Handle<T>` itself does)
---
## Changelog
- Fixed issue where a missing trailing comma could break the reflection
derives
- Fixes#7965
- Code quality improvements.
- Removes the unreferenced function `dither` in pbr_functions.wgsl
introduced in 72fbcc7, but made obsolete in c069c54.
- Makes the reference to `screen_space_dither` in pbr.wgsl conditional
on `#ifdef TONEMAP_IN_SHADER`, as the required import is conditional on
the same, as deband dithering can only occur if tonemapping is also
occurring.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- `Sprite` components are not included in scene (de)serialization.
- Fixes#8206
## Solution
- Add `#[reflect(Component, Default)]` to `Sprite`
- Add `#[derive(FromReflect)]` to `Sprite` and `Anchor`
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy with
```
default-features = false
features = [
"trace_tracy"
]
```
will fail due to `error: The platform you're compiling for is not
supported by winit`
## Solution
- Make bevy_winit/trace optional in trace feature
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
A `RegularPolygon` is described by the circumscribed radius, not the
inscribed radius.
## Objective
- Correct documentation for `RegularPolygon`
## Solution
- Use the correct term
---------
Co-authored-by: Paul Hüber <phueber@kernsp.in>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
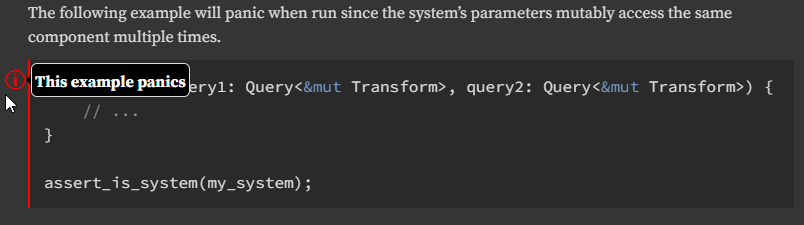
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
- Rename `text_layout` example to `flex_layout` to better reflect the
example purpose
- `AlignItems`/`JustifyContent` is not related to text layout, it's
about child nodes positioning
## Solution
- Rename the example
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
{kind=link}
{kind=link}