mirror of
https://github.com/bevyengine/bevy
synced 2025-02-19 15:38:36 +00:00
53 commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
23a77ca5eb
|
Rename push children to add children (#15196)
# Objective - Makes naming between add_child and add_children more consistent - Fixes #15101 ## Solution renamed push_children to add_children ## Testing - Did you test these changes? If so, how? Ran tests + grep search for any instance of `push_child` - Are there any parts that need more testing? - How can other people (reviewers) test your changes? Is there anything specific they need to know? - If relevant, what platforms did you test these changes on, and are there any important ones you can't test? ran tests on WSL2 --- ## Migration Guide > This section is optional. If there are no breaking changes, you can delete this section. - If this PR is a breaking change (relative to the last release of Bevy), describe how a user might need to migrate their code to support these changes rename any use of `push_children()` to the updated `add_children()` |
||
|
|
522d82b21a
|
Fixing text sizes for examples (#15190)
# Objective - Fixes #14265 ## Solution - Go through Pixel Eagle examples (and examples all in all) - If default size is used it is usually left there - If size of font is touched try dividing with 1.2 and round it to nearest whole number ## Testing - Run example before and after - Make sure examples text are readable or like before cosmic-text change --- ## Showcase Before:  After:  |
||
|
|
fa51e26052
|
Trim cosmic-text's shape run cache (#15037)
# Objective - Fixes https://github.com/bevyengine/bevy/pull/14991. The `cosmic-text` shape run cache requires manual cleanup for old text that no longer needs to be cached. ## Solution - Add a system to trim the cache. - Add an `average fps` indicator to the `text_debug` example. ## Testing Tested with `cargo run --example text_debug`. - **No shape run cache**: 82fps with ~1fps variance. - **Shape run cache no trim**: 90-100fps with ~2-4fps variance - **Shape run cache trim age = 1**: 90-100fps with ~2-8fps variance - **Shape run cache trim age = 2**: 90-100fps with ~2-4fps variance - **Shape run cache trim age = 2000**: 80-120fps with ~2-6fps variance The shape run cache seems to increase average FPS but also increases frame time variance (when there is dynamic text). |
||
|
|
5986d5d309
|
Cosmic text (#10193)
# Replace ab_glyph with the more capable cosmic-text Fixes #7616. Cosmic-text is a more mature text-rendering library that handles scripts and ligatures better than ab_glyph, it can also handle system fonts which can be implemented in bevy in the future Rebase of https://github.com/bevyengine/bevy/pull/8808 ## Changelog Replaces text renderer ab_glyph with cosmic-text The definition of the font size has changed with the migration to cosmic text. The behavior is now consistent with other platforms (e.g. the web), where the font size in pixels measures the height of the font (the distance between the top of the highest ascender and the bottom of the lowest descender). Font sizes in your app need to be rescaled to approximately 1.2x smaller; for example, if you were using a font size of 60.0, you should now use a font size of 50.0. ## Migration guide - `Text2dBounds` has been replaced with `TextBounds`, and it now accepts `Option`s to the bounds, instead of using `f32::INFINITY` to inidicate lack of bounds - Textsizes should be changed, dividing the current size with 1.2 will result in the same size as before. - `TextSettings` struct is removed - Feature `subpixel_alignment` has been removed since cosmic-text already does this automatically - TextBundles and things rendering texts requires the `CosmicBuffer` Component on them as well ## Suggested followups: - TextPipeline: reconstruct byte indices for keeping track of eventual cursors in text input - TextPipeline: (future work) split text entities into section entities - TextPipeline: (future work) text editing - Support line height as an option. Unitless `1.2` is the default used in browsers (1.2x font size). - Support System Fonts and font families - Example showing of animated text styles. Eg. throbbing hyperlinks --------- Co-authored-by: tigregalis <anak.harimau@gmail.com> Co-authored-by: Nico Burns <nico@nicoburns.com> Co-authored-by: sam edelsten <samedelsten1@gmail.com> Co-authored-by: Dimchikkk <velo.app1@gmail.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: Rob Parrett <robparrett@gmail.com> |
||
|
|
f237cf2441
|
Updates default Text font size to 24px (#13603)
# Objective - The default font size is too small to be useful in examples or for debug text. - Fixes #13587 ## Solution - Updated the default font size value in `TextStyle` from 12px to 24px. - Resorted to Text defaults in examples to use the default font size in most of them. ## Testing - WIP --- ## Migration Guide - The default font size has been increased to 24px from 12px. Make sure you set the font to the appropriate values in places you were using `Default` text style. |
||
|
|
84363f2fab
|
Remove redundant imports (#12817)
# Objective - There are several redundant imports in the tests and examples that are not caught by CI because additional flags need to be passed. ## Solution - Run `cargo check --workspace --tests` and `cargo check --workspace --examples`, then fix all warnings. - Add `test-check` to CI, which will be run in the check-compiles job. This should catch future warnings for tests. Examples are already checked, but I'm not yet sure why they weren't caught. ## Discussion - Should the `--tests` and `--examples` flags be added to CI, so this is caught in the future? - If so, #12818 will need to be merged first. It was also a warning raised by checking the examples, but I chose to split off into a separate PR. --------- Co-authored-by: François Mockers <francois.mockers@vleue.com> |
||
|
|
0746b8eb4c
|
Fix green colors becoming darker in various examples (#12328)
# Objective Fixes #12225 Prior to the `bevy_color` port, `GREEN` used to mean "full green." But it is now a much darker color matching the css1 spec. ## Solution Change usages of `basic::GREEN` or `css::GREEN` to `LIME` to restore the examples to their former colors. This also removes the duplicate definition of `GREEN` from `css`. (it was already re-exported from `basic`) ## Note A lot of these examples could use nicer colors. I'm not trying to do that here. "Dark Grey" will be tackled separately and has its own tracking issue. |
||
|
|
599e5e4e76
|
Migrate from LegacyColor to bevy_color::Color (#12163)
# Objective - As part of the migration process we need to a) see the end effect of the migration on user ergonomics b) check for serious perf regressions c) actually migrate the code - To accomplish this, I'm going to attempt to migrate all of the remaining user-facing usages of `LegacyColor` in one PR, being careful to keep a clean commit history. - Fixes #12056. ## Solution I've chosen to use the polymorphic `Color` type as our standard user-facing API. - [x] Migrate `bevy_gizmos`. - [x] Take `impl Into<Color>` in all `bevy_gizmos` APIs - [x] Migrate sprites - [x] Migrate UI - [x] Migrate `ColorMaterial` - [x] Migrate `MaterialMesh2D` - [x] Migrate fog - [x] Migrate lights - [x] Migrate StandardMaterial - [x] Migrate wireframes - [x] Migrate clear color - [x] Migrate text - [x] Migrate gltf loader - [x] Register color types for reflection - [x] Remove `LegacyColor` - [x] Make sure CI passes Incidental improvements to ease migration: - added `Color::srgba_u8`, `Color::srgba_from_array` and friends - added `set_alpha`, `is_fully_transparent` and `is_fully_opaque` to the `Alpha` trait - add and immediately deprecate (lol) `Color::rgb` and friends in favor of more explicit and consistent `Color::srgb` - standardized on white and black for most example text colors - added vector field traits to `LinearRgba`: ~~`Add`, `Sub`, `AddAssign`, `SubAssign`,~~ `Mul<f32>` and `Div<f32>`. Multiplications and divisions do not scale alpha. `Add` and `Sub` have been cut from this PR. - added `LinearRgba` and `Srgba` `RED/GREEN/BLUE` - added `LinearRgba_to_f32_array` and `LinearRgba::to_u32` ## Migration Guide Bevy's color types have changed! Wherever you used a `bevy::render::Color`, a `bevy::color::Color` is used instead. These are quite similar! Both are enums storing a color in a specific color space (or to be more precise, using a specific color model). However, each of the different color models now has its own type. TODO... - `Color::rgba`, `Color::rgb`, `Color::rbga_u8`, `Color::rgb_u8`, `Color::rgb_from_array` are now `Color::srgba`, `Color::srgb`, `Color::srgba_u8`, `Color::srgb_u8` and `Color::srgb_from_array`. - `Color::set_a` and `Color::a` is now `Color::set_alpha` and `Color::alpha`. These are part of the `Alpha` trait in `bevy_color`. - `Color::is_fully_transparent` is now part of the `Alpha` trait in `bevy_color` - `Color::r`, `Color::set_r`, `Color::with_r` and the equivalents for `g`, `b` `h`, `s` and `l` have been removed due to causing silent relatively expensive conversions. Convert your `Color` into the desired color space, perform your operations there, and then convert it back into a polymorphic `Color` enum. - `Color::hex` is now `Srgba::hex`. Call `.into` or construct a `Color::Srgba` variant manually to convert it. - `WireframeMaterial`, `ExtractedUiNode`, `ExtractedDirectionalLight`, `ExtractedPointLight`, `ExtractedSpotLight` and `ExtractedSprite` now store a `LinearRgba`, rather than a polymorphic `Color` - `Color::rgb_linear` and `Color::rgba_linear` are now `Color::linear_rgb` and `Color::linear_rgba` - The various CSS color constants are no longer stored directly on `Color`. Instead, they're defined in the `Srgba` color space, and accessed via `bevy::color::palettes::css`. Call `.into()` on them to convert them into a `Color` for quick debugging use, and consider using the much prettier `tailwind` palette for prototyping. - The `LIME_GREEN` color has been renamed to `LIMEGREEN` to comply with the standard naming. - Vector field arithmetic operations on `Color` (add, subtract, multiply and divide by a f32) have been removed. Instead, convert your colors into `LinearRgba` space, and perform your operations explicitly there. This is particularly relevant when working with emissive or HDR colors, whose color channel values are routinely outside of the ordinary 0 to 1 range. - `Color::as_linear_rgba_f32` has been removed. Call `LinearRgba::to_f32_array` instead, converting if needed. - `Color::as_linear_rgba_u32` has been removed. Call `LinearRgba::to_u32` instead, converting if needed. - Several other color conversion methods to transform LCH or HSL colors into float arrays or `Vec` types have been removed. Please reimplement these externally or open a PR to re-add them if you found them particularly useful. - Various methods on `Color` such as `rgb` or `hsl` to convert the color into a specific color space have been removed. Convert into `LinearRgba`, then to the color space of your choice. - Various implicitly-converting color value methods on `Color` such as `r`, `g`, `b` or `h` have been removed. Please convert it into the color space of your choice, then check these properties. - `Color` no longer implements `AsBindGroup`. Store a `LinearRgba` internally instead to avoid conversion costs. --------- Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com> Co-authored-by: Afonso Lage <lage.afonso@gmail.com> Co-authored-by: Rob Parrett <robparrett@gmail.com> Co-authored-by: Zachary Harrold <zac@harrold.com.au> |
||
|
|
de004da8d5
|
Rename bevy_render::Color to LegacyColor (#12069)
# Objective The migration process for `bevy_color` (#12013) will be fairly involved: there will be hundreds of affected files, and a large number of APIs. ## Solution To allow us to proceed granularly, we're going to keep both `bevy_color::Color` (new) and `bevy_render::Color` (old) around until the migration is complete. However, simply doing this directly is confusing! They're both called `Color`, making it very hard to tell when a portion of the code has been ported. As discussed in #12056, by renaming the old `Color` type, we can make it easier to gradually migrate over, one API at a time. ## Migration Guide THIS MIGRATION GUIDE INTENTIONALLY LEFT BLANK. This change should not be shipped to end users: delete this section in the final migration guide! --------- Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com> |
||
|
|
320ac65a9e
|
Replace DiagnosticId by DiagnosticPath (#9266)
# Objective Implements #9216 ## Solution - Replace `DiagnosticId` by `DiagnosticPath`. It's pre-hashed using `const-fnv1a-hash` crate, so it's possible to create path in const contexts. --- ## Changelog - Replaced `DiagnosticId` by `DiagnosticPath` - Set default history length to 120 measurements (2 seconds on 60 fps). I've noticed hardcoded constant 20 everywhere and decided to change it to `DEFAULT_MAX_HISTORY_LENGTH` , which is set to new diagnostics by default. To override it, use `with_max_history_length`. ## Migration Guide ```diff - const UNIQUE_DIAG_ID: DiagnosticId = DiagnosticId::from_u128(42); + const UNIQUE_DIAG_PATH: DiagnosticPath = DiagnosticPath::const_new("foo/bar"); - Diagnostic::new(UNIQUE_DIAG_ID, "example", 10) + Diagnostic::new(UNIQUE_DIAG_PATH).with_max_history_length(10) - diagnostics.add_measurement(UNIQUE_DIAG_ID, || 42); + diagnostics.add_measurement(&UNIQUE_DIAG_ID, || 42); ``` |
||
|
|
166686e0f2
|
Rename TextAlignment to JustifyText. (#10854)
# Objective The name `TextAlignment` is really deceptive and almost every new user gets confused about the differences between aligning text with `TextAlignment`, aligning text with `Style` and aligning text with anchor (when using `Text2d`). ## Solution * Rename `TextAlignment` to `JustifyText`. The associated helper methods are also renamed. * Improve the doc comments for text explaining explicitly how the `JustifyText` component affects the arrangement of text. * Add some extra cases to the `text_debug` example that demonstate the differences between alignment using `JustifyText` and alignment using `Style`. <img width="757" alt="text_debug_2" src="https://github.com/bevyengine/bevy/assets/27962798/9d53e647-93f9-4bc7-8a20-0d9f783304d2"> --- ## Changelog * `TextAlignment` has been renamed to `JustifyText` * `TextBundle::with_text_alignment` has been renamed to `TextBundle::with_text_justify` * `Text::with_alignment` has been renamed to `Text::with_justify` * The `text_alignment` field of `TextMeasureInfo` has been renamed to `justification` ## Migration Guide * `TextAlignment` has been renamed to `JustifyText` * `TextBundle::with_text_alignment` has been renamed to `TextBundle::with_text_justify` * `Text::with_alignment` has been renamed to `Text::with_justify` * The `text_alignment` field of `TextMeasureInfo` has been renamed to `justification` |
||
|
|
1918608b02
|
Update default ClearColor to better match Bevy's branding (#10339)
# Objective - Changes the default clear color to match the code block color on Bevy's website. ## Solution - Changed the clear color, updated text in examples to ensure adequate contrast. Inconsistent usage of white text color set to use the default color instead, which is already white. - Additionally, updated the `3d_scene` example to make it look a bit better, and use bevy's branding colors.  |
||
|
|
f18f28874a
|
Allow tuples and single plugins in add_plugins, deprecate add_plugin (#8097)
# Objective - Better consistency with `add_systems`. - Deprecating `add_plugin` in favor of a more powerful `add_plugins`. - Allow passing `Plugin` to `add_plugins`. - Allow passing tuples to `add_plugins`. ## Solution - `App::add_plugins` now takes an `impl Plugins` parameter. - `App::add_plugin` is deprecated. - `Plugins` is a new sealed trait that is only implemented for `Plugin`, `PluginGroup` and tuples over `Plugins`. - All examples, benchmarks and tests are changed to use `add_plugins`, using tuples where appropriate. --- ## Changelog ### Changed - `App::add_plugins` now accepts all types that implement `Plugins`, which is implemented for: - Types that implement `Plugin`. - Types that implement `PluginGroup`. - Tuples (up to 16 elements) over types that implement `Plugins`. - Deprecated `App::add_plugin` in favor of `App::add_plugins`. ## Migration Guide - Replace `app.add_plugin(plugin)` calls with `app.add_plugins(plugin)`. --------- Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
3507b21dce
|
Allow systems using Diagnostics to run in parallel (#8677)
# Objective
I was trying to add some `Diagnostics` to have a better break down of
performance but I noticed that the current implementation uses a
`ResMut` which forces the functions to all run sequentially whereas
before they could run in parallel. This created too great a performance
penalty to be usable.
## Solution
This PR reworks how the diagnostics work with a couple of breaking
changes. The idea is to change how `Diagnostics` works by changing it to
a `SystemParam`. This allows us to hold a `Deferred` buffer of
measurements that can be applied later, avoiding the need for multiple
mutable references to the hashmap. This means we can run systems that
write diagnostic measurements in parallel.
Firstly, we rename the old `Diagnostics` to `DiagnosticsStore`. This
clears up the original name for the new interface while allowing us to
preserve more closely the original API.
Then we create a new `Diagnostics` struct which implements `SystemParam`
and contains a deferred `SystemBuffer`. This can be used very similar to
the old `Diagnostics` for writing new measurements.
```rust
fn system(diagnostics: ResMut<Diagnostics>) { diagnostics.new_measurement(ID, || 10.0)}
// changes to
fn system(mut diagnostics: Diagnostics) { diagnostics.new_measurement(ID, || 10.0)}
```
For reading the diagnostics, the user needs to change from `Diagnostics`
to `DiagnosticsStore` but otherwise the function calls are the same.
Finally, we add a new method to the `App` for registering diagnostics.
This replaces the old method of creating a startup system and adding it
manually.
Testing it, this PR does indeed allow Diagnostic systems to be run in
parallel.
## Changelog
- Change `Diagnostics` to implement `SystemParam` which allows
diagnostic systems to run in parallel.
## Migration Guide
- Register `Diagnostic`'s using the new
`app.register_diagnostic(Diagnostic::new(DIAGNOSTIC_ID,
"diagnostic_name", 10));`
- In systems for writing new measurements, change `mut diagnostics:
ResMut<Diagnostics>` to `mut diagnostics: Diagnostics` to allow the
systems to run in parallel.
- In systems for reading measurements, change `diagnostics:
Res<Diagnostics>` to `diagnostics: Res<DiagnosticsStore>`.
|
||
|
|
08bf1a6c2e
|
Flatten UI Style properties that use Size + remove Size (#8548)
# Objective - Simplify API and make authoring styles easier See: https://github.com/bevyengine/bevy/issues/8540#issuecomment-1536177102 ## Solution - The `size`, `min_size`, `max_size`, and `gap` properties have been replaced by `width`, `height`, `min_width`, `min_height`, `max_width`, `max_height`, `row_gap`, and `column_gap` properties --- ## Changelog - Flattened `Style` properties that have a `Size` value directly into `Style` ## Migration Guide - The `size`, `min_size`, `max_size`, and `gap` properties have been replaced by the `width`, `height`, `min_width`, `min_height`, `max_width`, `max_height`, `row_gap`, and `column_gap` properties. Use the new properties instead. --------- Co-authored-by: ickshonpe <david.curthoys@googlemail.com> |
||
|
|
e9312254d8
|
Non-breaking change* from UK spellings to US (#8291)
Fixes issue mentioned in PR #8285. _Note: By mistake, this is currently dependent on #8285_ # Objective Ensure consistency in the spelling of the documentation. Exceptions: `crates/bevy_mikktspace/src/generated.rs` - Has not been changed from licence to license as it is part of a licensing agreement. Maybe for further consistency, https://github.com/bevyengine/bevy-website should also be given a look. ## Solution ### Changed the spelling of the current words (UK/CN/AU -> US) : cancelled -> canceled (Breaking API changes in #8285) behaviour -> behavior (Breaking API changes in #8285) neighbour -> neighbor grey -> gray recognise -> recognize centre -> center metres -> meters colour -> color ### ~~Update [`engine_style_guide.md`]~~ Moved to #8324 --- ## Changelog Changed UK spellings in documentation to US ## Migration Guide Non-breaking changes* \* If merged after #8285 |
||
|
|
aefe1f0739
|
Schedule-First: the new and improved add_systems (#8079)
Co-authored-by: Mike <mike.hsu@gmail.com> |
||
|
|
87dda354dd
|
Remove Val::Undefined (#7485)
|
||
|
|
fd1af7c8b8
|
Replace multiple calls to add_system with add_systems (#8001)
|
||
|
|
dcc03724a5 |
Base Sets (#7466)
# Objective NOTE: This depends on #7267 and should not be merged until #7267 is merged. If you are reviewing this before that is merged, I highly recommend viewing the Base Sets commit instead of trying to find my changes amongst those from #7267. "Default sets" as described by the [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) have some [unfortunate consequences](https://github.com/bevyengine/bevy/discussions/7365). ## Solution This adds "base sets" as a variant of `SystemSet`: A set is a "base set" if `SystemSet::is_base` returns `true`. Typically this will be opted-in to using the `SystemSet` derive: ```rust #[derive(SystemSet, Clone, Hash, Debug, PartialEq, Eq)] #[system_set(base)] enum MyBaseSet { A, B, } ``` **Base sets are exclusive**: a system can belong to at most one "base set". Adding a system to more than one will result in an error. When possible we fail immediately during system-config-time with a nice file + line number. For the more nested graph-ey cases, this will fail at the final schedule build. **Base sets cannot belong to other sets**: this is where the word "base" comes from Systems and Sets can only be added to base sets using `in_base_set`. Calling `in_set` with a base set will fail. As will calling `in_base_set` with a normal set. ```rust app.add_system(foo.in_base_set(MyBaseSet::A)) // X must be a normal set ... base sets cannot be added to base sets .configure_set(X.in_base_set(MyBaseSet::A)) ``` Base sets can still be configured like normal sets: ```rust app.add_system(MyBaseSet::B.after(MyBaseSet::Ap)) ``` The primary use case for base sets is enabling a "default base set": ```rust schedule.set_default_base_set(CoreSet::Update) // this will belong to CoreSet::Update by default .add_system(foo) // this will override the default base set with PostUpdate .add_system(bar.in_base_set(CoreSet::PostUpdate)) ``` This allows us to build apis that work by default in the standard Bevy style. This is a rough analog to the "default stage" model, but it use the new "stageless sets" model instead, with all of the ordering flexibility (including exclusive systems) that it provides. --- ## Changelog - Added "base sets" and ported CoreSet to use them. ## Migration Guide TODO |
||
|
|
206c7ce219 |
Migrate engine to Schedule v3 (#7267)
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR. # Objective - Followup #6587. - Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45 ## Solution - [x] Remove old scheduling module - [x] Migrate new methods to no longer use extension methods - [x] Fix compiler errors - [x] Fix benchmarks - [x] Fix examples - [x] Fix docs - [x] Fix tests ## Changelog ### Added - a large number of methods on `App` to work with schedules ergonomically - the `CoreSchedule` enum - `App::add_extract_system` via the `RenderingAppExtension` trait extension method - the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms` ### Removed - stages, and all code that mentions stages - states have been dramatically simplified, and no longer use a stack - `RunCriteriaLabel` - `AsSystemLabel` trait - `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition) - systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world - `RunCriteriaLabel` - `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear. ### Changed - `System::default_labels` is now `System::default_system_sets`. - `App::add_default_labels` is now `App::add_default_sets` - `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet` - `App::add_system_set` was renamed to `App::add_systems` - The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum - `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)` - `SystemLabel` trait was replaced by `SystemSet` - `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>` - The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq` - Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria. - Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. - `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`. - `bevy_pbr::add_clusters` is no longer an exclusive system - the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling` - `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread. ## Migration Guide - Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)` - Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed. - The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved. - Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior. - Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you. - For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with - `add_system(my_system.in_set(CoreSet::PostUpdate)` - When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages - Run criteria have been renamed to run conditions. These can now be combined with each other and with states. - Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow. - For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label. - Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default. - Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually. - Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior. - the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity - `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl. - Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings. - `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds. - `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool. - States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set` ## TODO - [x] remove dead methods on App and World - [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule` - [x] avoid adding the default system set at inappropriate times - [x] remove any accidental cycles in the default plugins schedule - [x] migrate benchmarks - [x] expose explicit labels for the built-in command flush points - [x] migrate engine code - [x] remove all mentions of stages from the docs - [x] verify docs for States - [x] fix uses of exclusive systems that use .end / .at_start / .before_commands - [x] migrate RenderStage and AssetStage - [x] migrate examples - [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub) - [x] ensure that on_enter schedules are run at least once before the main app - [x] re-enable opt-in to execution order ambiguities - [x] revert change to `update_bounds` to ensure it runs in `PostUpdate` - [x] test all examples - [x] unbreak directional lights - [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples) - [x] game menu example shows loading screen and menu simultaneously - [x] display settings menu is a blank screen - [x] `without_winit` example panics - [x] ensure all tests pass - [x] SubApp doc test fails - [x] runs_spawn_local tasks fails - [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120) ## Points of Difficulty and Controversy **Reviewers, please give feedback on these and look closely** 1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup. 2. The outer schedule controls which schedule is run when `App::update` is called. 3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes. 4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset. 5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order 6. Implemetnation strategy for fixed timesteps 7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks. 8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements. ## Future Work (ideally before 0.10) - Rename schedule_v3 module to schedule or scheduling - Add a derive macro to states, and likely a `EnumIter` trait of some form - Figure out what exactly to do with the "systems added should basically work by default" problem - Improve ergonomics for working with fixed timesteps and states - Polish FixedTime API to match Time - Rebase and merge #7415 - Resolve all internal ambiguities (blocked on better tools, especially #7442) - Add "base sets" to replace the removed default sets. |
||
|
|
ddfafab971 |
Windows as Entities (#5589)
# Objective Fix https://github.com/bevyengine/bevy/issues/4530 - Make it easier to open/close/modify windows by setting them up as `Entity`s with a `Window` component. - Make multiple windows very simple to set up. (just add a `Window` component to an entity and it should open) ## Solution - Move all properties of window descriptor to ~components~ a component. - Replace `WindowId` with `Entity`. - ~Use change detection for components to update backend rather than events/commands. (The `CursorMoved`/`WindowResized`/... events are kept for user convenience.~ Check each field individually to see what we need to update, events are still kept for user convenience. --- ## Changelog - `WindowDescriptor` renamed to `Window`. - Width/height consolidated into a `WindowResolution` component. - Requesting maximization/minimization is done on the [`Window::state`] field. - `WindowId` is now `Entity`. ## Migration Guide - Replace `WindowDescriptor` with `Window`. - Change `width` and `height` fields in a `WindowResolution`, either by doing ```rust WindowResolution::new(width, height) // Explicitly // or using From<_> for tuples for convenience (1920., 1080.).into() ``` - Replace any `WindowCommand` code to just modify the `Window`'s fields directly and creating/closing windows is now by spawning/despawning an entity with a `Window` component like so: ```rust let window = commands.spawn(Window { ... }).id(); // open window commands.entity(window).despawn(); // close window ``` ## Unresolved - ~How do we tell when a window is minimized by a user?~ ~Currently using the `Resize(0, 0)` as an indicator of minimization.~ No longer attempting to tell given how finnicky this was across platforms, now the user can only request that a window be maximized/minimized. ## Future work - Move `exit_on_close` functionality out from windowing and into app(?) - https://github.com/bevyengine/bevy/issues/5621 - https://github.com/bevyengine/bevy/issues/7099 - https://github.com/bevyengine/bevy/issues/7098 Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
9eefd7c022 |
Remove VerticalAlign from TextAlignment (#6807)
# Objective Remove the `VerticalAlign` enum. Text's alignment field should only affect the text's internal text alignment, not its position. The only way to control a `TextBundle`'s position and bounds should be through the manipulation of the constraints in the `Style` components of the nodes in the Bevy UI's layout tree. `Text2dBundle` should have a separate `Anchor` component that sets its position relative to its transform. Related issues: #676, #1490, #5502, #5513, #5834, #6717, #6724, #6741, #6748 ## Changelog * Changed `TextAlignment` into an enum with `Left`, `Center`, and `Right` variants. * Removed the `HorizontalAlign` and `VerticalAlign` types. * Added an `Anchor` component to `Text2dBundle` * Added `Component` derive to `Anchor` * Use `f32::INFINITY` instead of `f32::MAX` to represent unbounded text in Text2dBounds ## Migration Guide The `alignment` field of `Text` now only affects the text's internal alignment. ### Change `TextAlignment` to TextAlignment` which is now an enum. Replace: * `TextAlignment::TOP_LEFT`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_LEFT` with `TextAlignment::Left` * `TextAlignment::TOP_CENTER`, `TextAlignment::CENTER_LEFT`, `TextAlignment::BOTTOM_CENTER` with `TextAlignment::Center` * `TextAlignment::TOP_RIGHT`, `TextAlignment::CENTER_RIGHT`, `TextAlignment::BOTTOM_RIGHT` with `TextAlignment::Right` ### Changes for `Text2dBundle` `Text2dBundle` has a new field 'text_anchor' that takes an `Anchor` component that controls its position relative to its transform. |
||
|
|
0d2cdb450d |
Fix beta clippy lints (#7154)
# Objective - When I run `cargo run -p ci` for my pr locally using latest beta toolchain, the ci failed due to [uninlined_format_args](https://rust-lang.github.io/rust-clippy/master/index.html#uninlined_format_args) and [needless_lifetimes](https://rust-lang.github.io/rust-clippy/master/index.html#needless_lifetimes) lints ## Solution - Fix lints according to clippy suggestions. |
||
|
|
e71c4d2802 |
fix nightly clippy warnings (#6395)
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
|
||
|
|
1bb751cb8d |
Plugins own their settings. Rework PluginGroup trait. (#6336)
# Objective Fixes #5884 #2879 Alternative to #2988 #5885 #2886 "Immutable" Plugin settings are currently represented as normal ECS resources, which are read as part of plugin init. This presents a number of problems: 1. If a user inserts the plugin settings resource after the plugin is initialized, it will be silently ignored (and use the defaults instead) 2. Users can modify the plugin settings resource after the plugin has been initialized. This creates a false sense of control over settings that can no longer be changed. (1) and (2) are especially problematic and confusing for the `WindowDescriptor` resource, but this is a general problem. ## Solution Immutable Plugin settings now live on each Plugin struct (ex: `WindowPlugin`). PluginGroups have been reworked to support overriding plugin values. This also removes the need for the `add_plugins_with` api, as the `add_plugins` api can use the builder pattern directly. Settings that can be used at runtime continue to be represented as ECS resources. Plugins are now configured like this: ```rust app.add_plugin(AssetPlugin { watch_for_changes: true, ..default() }) ``` PluginGroups are now configured like this: ```rust app.add_plugins(DefaultPlugins .set(AssetPlugin { watch_for_changes: true, ..default() }) ) ``` This is an alternative to #2988, which is similar. But I personally prefer this solution for a couple of reasons: * ~~#2988 doesn't solve (1)~~ #2988 does solve (1) and will panic in that case. I was wrong! * This PR directly ties plugin settings to Plugin types in a 1:1 relationship, rather than a loose "setup resource" <-> plugin coupling (where the setup resource is consumed by the first plugin that uses it). * I'm not a huge fan of overloading the ECS resource concept and implementation for something that has very different use cases and constraints. ## Changelog - PluginGroups can now be configured directly using the builder pattern. Individual plugin values can be overridden by using `plugin_group.set(SomePlugin {})`, which enables overriding default plugin values. - `WindowDescriptor` plugin settings have been moved to `WindowPlugin` and `AssetServerSettings` have been moved to `AssetPlugin` - `app.add_plugins_with` has been replaced by using `add_plugins` with the builder pattern. ## Migration Guide The `WindowDescriptor` settings have been moved from a resource to `WindowPlugin::window`: ```rust // Old (Bevy 0.8) app .insert_resource(WindowDescriptor { width: 400.0, ..default() }) .add_plugins(DefaultPlugins) // New (Bevy 0.9) app.add_plugins(DefaultPlugins.set(WindowPlugin { window: WindowDescriptor { width: 400.0, ..default() }, ..default() })) ``` The `AssetServerSettings` resource has been removed in favor of direct `AssetPlugin` configuration: ```rust // Old (Bevy 0.8) app .insert_resource(AssetServerSettings { watch_for_changes: true, ..default() }) .add_plugins(DefaultPlugins) // New (Bevy 0.9) app.add_plugins(DefaultPlugins.set(AssetPlugin { watch_for_changes: true, ..default() })) ``` `add_plugins_with` has been replaced by `add_plugins` in combination with the builder pattern: ```rust // Old (Bevy 0.8) app.add_plugins_with(DefaultPlugins, |group| group.disable::<AssetPlugin>()); // New (Bevy 0.9) app.add_plugins(DefaultPlugins.build().disable::<AssetPlugin>()); ``` |
||
|
|
c19aa5939d |
Add Exponential Moving Average into diagnostics (#4992)
# Objective - Add Time-Adjusted Rolling EMA-based smoothing to diagnostics. - Closes #4983; see that issue for more more information. ## Terms - EMA - [Exponential Moving Average](https://en.wikipedia.org/wiki/Moving_average#Exponential_moving_average) - SMA - [Simple Moving Average](https://en.wikipedia.org/wiki/Moving_average#Simple_moving_average) ## Solution - We use a fairly standard approximation of a true EMA where $EMA_{\text{frame}} = EMA_{\text{previous}} + \alpha \left( x_{\text{frame}} - EMA_{\text{previous}} \right)$ where $\alpha = \Delta t / \tau$ and $\tau$ is an arbitrary smoothness factor. (See #4983 for more discussion of the math.) - The smoothness factor is here defaulted to $2 / 21$; this was chosen fairly arbitrarily as supposedly related to the existing 20-bucket SMA. - The smoothness factor can be set on a per-diagnostic basis via `Diagnostic::with_smoothing_factor`. --- ## Changelog ### Added - `Diagnostic::smoothed` - provides an exponentially smoothed view of a recorded diagnostic, to e.g. reduce jitter in frametime readings. ### Changed - `LogDiagnosticsPlugin` now records the smoothed value rather than the raw value. - For diagnostics recorded less often than every 0.1 seconds, this change to defaults will have no visible effect. - For discrete diagnostics where this smoothing is not desirable, set a smoothing factor of 0 to disable smoothing. - The average of the recent history is still shown when available. |
||
|
|
6ce7ce208e |
Change UI coordinate system to have origin at top left corner (#6000)
# Objective Fixes #5572 ## Solution Approach is to invert the Y-axis of the UI Camera by changing the UI projection matrix to render the UI upside down. After that I'm trying to fix all issues, that pop up: - interaction expected the "old" position - images and text were displayed upside-down - baseline of text was based on the top of the glyph instead of bottom ... probably a lot more. --- Result when running examples: <details> <summary>Button example</summary> main branch:  this pr:  </details> <details> <summary>Text example</summary> m  ain branch: this pr:  </details> <details> <summary>Text debug example</summary> main branch: 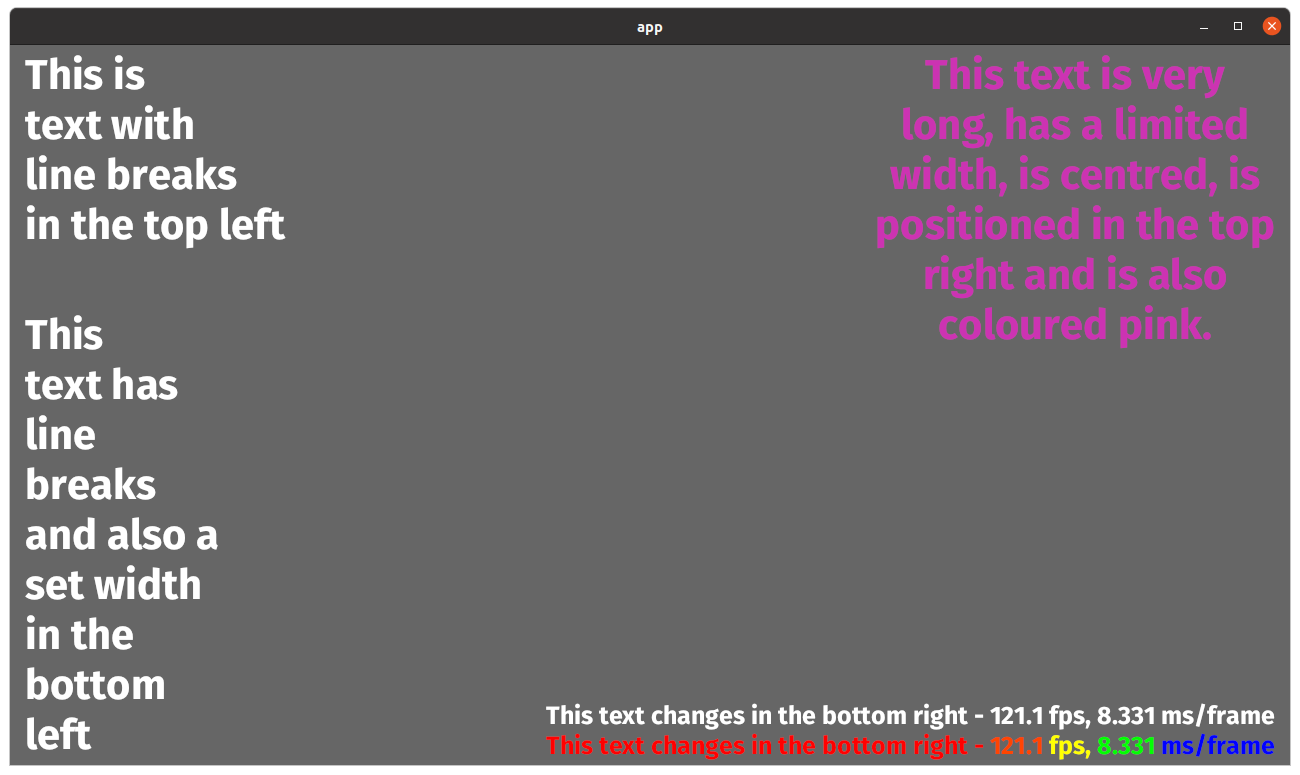 this pr: 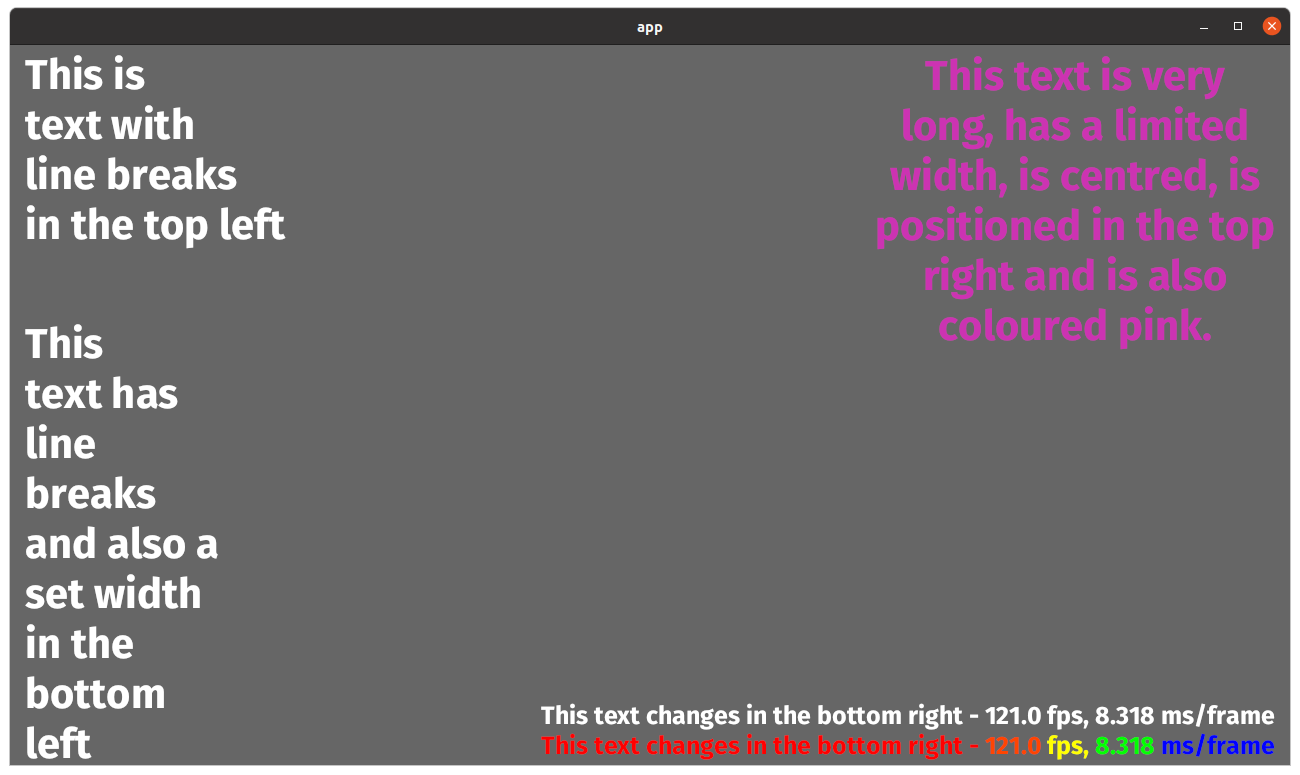 </details> <details> <summary>Transparency UI example</summary> main branch:  this pr:  </details> <details> <summary>UI example</summary> **ui example** main branch:  this pr:  </details> ## Changelog UI coordinate system and cursor position was changed from bottom left origin, y+ up to top left origin, y+ down. ## Migration Guide All flex layout should be inverted (ColumnReverse => Column, FlexStart => FlexEnd, WrapReverse => Wrap) System where dealing with cursor position should be changed to account for cursor position being based on the top left instead of bottom left |
||
|
|
01aedc8431 |
Spawn now takes a Bundle (#6054)
# Objective Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands). ## Solution All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input: ```rust // before: commands .spawn() .insert((A, B, C)); world .spawn() .insert((A, B, C); // after commands.spawn((A, B, C)); world.spawn((A, B, C)); ``` All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api. By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`). This improves spawn performance by over 10%:  To take this measurement, I added a new `world_spawn` benchmark. Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main. **Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).** --- ## Changelog - All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input - All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api - World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior. ## Migration Guide ```rust // Old (0.8): commands .spawn() .insert_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): commands.spawn_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): let entity = commands.spawn().id(); // New (0.9) let entity = commands.spawn_empty().id(); // Old (0.8) let entity = world.spawn().id(); // New (0.9) let entity = world.spawn_empty(); ``` |
||
|
|
0ffb5441c3 |
changed diagnostics from seconds to milliseconds (#5554)
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> # Objective Change frametimediagnostic from seconds to milliseconds because this will always be less than one seconds and is the common diagnostic display unit for game engines. ## Solution - multiplied the existing value by 1000 --- ## Changelog Frametimes are now reported in milliseconds Co-authored-by: Syama Mishra <38512086+SyamaMishra@users.noreply.github.com> Co-authored-by: McSpidey <mcspidey@gmail.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
9f906fdc8b |
Improve ergonomics and reduce boilerplate around creating text elements. (#5343)
# Objective
Creating UI elements is very boilerplate-y with lots of indentation.
This PR aims to reduce boilerplate around creating text elements.
## Changelog
* Renamed `Text::with_section` to `from_section`.
It no longer takes a `TextAlignment` as argument, as the vast majority of cases left it `Default::default()`.
* Added `Text::from_sections` which creates a `Text` from a list of `TextSections`.
Reduces line-count and reduces indentation by one level.
* Added `Text::with_alignment`.
A builder style method for setting the `TextAlignment` of a `Text`.
* Added `TextSection::new`.
Does not reduce line count, but reduces character count and made it easier to read. No more `.to_string()` calls!
* Added `TextSection::from_style` which creates an empty `TextSection` with a style.
No more empty strings! Reduces indentation.
* Added `TextAlignment::CENTER` and friends.
* Added methods to `TextBundle`. `from_section`, `from_sections`, `with_text_alignment` and `with_style`.
## Note for reviewers.
Because of the nature of these changes I recommend setting diff view to 'split'.
~~Look for the book icon~~ cog in the top-left of the Files changed tab.
Have fun reviewing ❤️
<sup> >:D </sup>
## Migration Guide
`Text::with_section` was renamed to `from_section` and no longer takes a `TextAlignment` as argument.
Use `with_alignment` to set the alignment instead.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
814f8d1635 |
update wgpu to 0.13 (#5168)
# Objective - Update wgpu to 0.13 - ~~Wait, is wgpu 0.13 released? No, but I had most of the changes already ready since playing with webgpu~~ well it has been released now - Also update parking_lot to 0.12 and naga to 0.9 ## Solution - Update syntax for wgsl shaders https://github.com/gfx-rs/wgpu/blob/master/CHANGELOG.md#wgsl-syntax - Add a few options, remove some references: https://github.com/gfx-rs/wgpu/blob/master/CHANGELOG.md#other-breaking-changes - fragment inputs should now exactly match vertex outputs for locations, so I added exports for those to be able to reuse them https://github.com/gfx-rs/wgpu/pull/2704 |
||
|
|
4847f7e3ad |
Update codebase to use IntoIterator where possible. (#5269)
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
f487407e07 |
Camera Driven Rendering (#4745)
This adds "high level camera driven rendering" to Bevy. The goal is to give users more control over what gets rendered (and where) without needing to deal with render logic. This will make scenarios like "render to texture", "multiple windows", "split screen", "2d on 3d", "3d on 2d", "pass layering", and more significantly easier. Here is an [example of a 2d render sandwiched between two 3d renders (each from a different perspective)](https://gist.github.com/cart/4fe56874b2e53bc5594a182fc76f4915):  Users can now spawn a camera, point it at a RenderTarget (a texture or a window), and it will "just work". Rendering to a second window is as simple as spawning a second camera and assigning it to a specific window id: ```rust // main camera (main window) commands.spawn_bundle(Camera2dBundle::default()); // second camera (other window) commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Window(window_id), ..default() }, ..default() }); ``` Rendering to a texture is as simple as pointing the camera at a texture: ```rust commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Texture(image_handle), ..default() }, ..default() }); ``` Cameras now have a "render priority", which controls the order they are drawn in. If you want to use a camera's output texture as a texture in the main pass, just set the priority to a number lower than the main pass camera (which defaults to `0`). ```rust // main pass camera with a default priority of 0 commands.spawn_bundle(Camera2dBundle::default()); commands.spawn_bundle(Camera2dBundle { camera: Camera { target: RenderTarget::Texture(image_handle.clone()), priority: -1, ..default() }, ..default() }); commands.spawn_bundle(SpriteBundle { texture: image_handle, ..default() }) ``` Priority can also be used to layer to cameras on top of each other for the same RenderTarget. This is what "2d on top of 3d" looks like in the new system: ```rust commands.spawn_bundle(Camera3dBundle::default()); commands.spawn_bundle(Camera2dBundle { camera: Camera { // this will render 2d entities "on top" of the default 3d camera's render priority: 1, ..default() }, ..default() }); ``` There is no longer the concept of a global "active camera". Resources like `ActiveCamera<Camera2d>` and `ActiveCamera<Camera3d>` have been replaced with the camera-specific `Camera::is_active` field. This does put the onus on users to manage which cameras should be active. Cameras are now assigned a single render graph as an "entry point", which is configured on each camera entity using the new `CameraRenderGraph` component. The old `PerspectiveCameraBundle` and `OrthographicCameraBundle` (generic on camera marker components like Camera2d and Camera3d) have been replaced by `Camera3dBundle` and `Camera2dBundle`, which set 3d and 2d default values for the `CameraRenderGraph` and projections. ```rust // old 3d perspective camera commands.spawn_bundle(PerspectiveCameraBundle::default()) // new 3d perspective camera commands.spawn_bundle(Camera3dBundle::default()) ``` ```rust // old 2d orthographic camera commands.spawn_bundle(OrthographicCameraBundle::new_2d()) // new 2d orthographic camera commands.spawn_bundle(Camera2dBundle::default()) ``` ```rust // old 3d orthographic camera commands.spawn_bundle(OrthographicCameraBundle::new_3d()) // new 3d orthographic camera commands.spawn_bundle(Camera3dBundle { projection: OrthographicProjection { scale: 3.0, scaling_mode: ScalingMode::FixedVertical, ..default() }.into(), ..default() }) ``` Note that `Camera3dBundle` now uses a new `Projection` enum instead of hard coding the projection into the type. There are a number of motivators for this change: the render graph is now a part of the bundle, the way "generic bundles" work in the rust type system prevents nice `..default()` syntax, and changing projections at runtime is much easier with an enum (ex for editor scenarios). I'm open to discussing this choice, but I'm relatively certain we will all come to the same conclusion here. Camera2dBundle and Camera3dBundle are much clearer than being generic on marker components / using non-default constructors. If you want to run a custom render graph on a camera, just set the `CameraRenderGraph` component: ```rust commands.spawn_bundle(Camera3dBundle { camera_render_graph: CameraRenderGraph::new(some_render_graph_name), ..default() }) ``` Just note that if the graph requires data from specific components to work (such as `Camera3d` config, which is provided in the `Camera3dBundle`), make sure the relevant components have been added. Speaking of using components to configure graphs / passes, there are a number of new configuration options: ```rust commands.spawn_bundle(Camera3dBundle { camera_3d: Camera3d { // overrides the default global clear color clear_color: ClearColorConfig::Custom(Color::RED), ..default() }, ..default() }) commands.spawn_bundle(Camera3dBundle { camera_3d: Camera3d { // disables clearing clear_color: ClearColorConfig::None, ..default() }, ..default() }) ``` Expect to see more of the "graph configuration Components on Cameras" pattern in the future. By popular demand, UI no longer requires a dedicated camera. `UiCameraBundle` has been removed. `Camera2dBundle` and `Camera3dBundle` now both default to rendering UI as part of their own render graphs. To disable UI rendering for a camera, disable it using the CameraUi component: ```rust commands .spawn_bundle(Camera3dBundle::default()) .insert(CameraUi { is_enabled: false, ..default() }) ``` ## Other Changes * The separate clear pass has been removed. We should revisit this for things like sky rendering, but I think this PR should "keep it simple" until we're ready to properly support that (for code complexity and performance reasons). We can come up with the right design for a modular clear pass in a followup pr. * I reorganized bevy_core_pipeline into Core2dPlugin and Core3dPlugin (and core_2d / core_3d modules). Everything is pretty much the same as before, just logically separate. I've moved relevant types (like Camera2d, Camera3d, Camera3dBundle, Camera2dBundle) into their relevant modules, which is what motivated this reorganization. * I adapted the `scene_viewer` example (which relied on the ActiveCameras behavior) to the new system. I also refactored bits and pieces to be a bit simpler. * All of the examples have been ported to the new camera approach. `render_to_texture` and `multiple_windows` are now _much_ simpler. I removed `two_passes` because it is less relevant with the new approach. If someone wants to add a new "layered custom pass with CameraRenderGraph" example, that might fill a similar niche. But I don't feel much pressure to add that in this pr. * Cameras now have `target_logical_size` and `target_physical_size` fields, which makes finding the size of a camera's render target _much_ simpler. As a result, the `Assets<Image>` and `Windows` parameters were removed from `Camera::world_to_screen`, making that operation much more ergonomic. * Render order ambiguities between cameras with the same target and the same priority now produce a warning. This accomplishes two goals: 1. Now that there is no "global" active camera, by default spawning two cameras will result in two renders (one covering the other). This would be a silent performance killer that would be hard to detect after the fact. By detecting ambiguities, we can provide a helpful warning when this occurs. 2. Render order ambiguities could result in unexpected / unpredictable render results. Resolving them makes sense. ## Follow Up Work * Per-Camera viewports, which will make it possible to render to a smaller area inside of a RenderTarget (great for something like splitscreen) * Camera-specific MSAA config (should use the same "overriding" pattern used for ClearColor) * Graph Based Camera Ordering: priorities are simple, but they make complicated ordering constraints harder to express. We should consider adopting a "graph based" camera ordering model with "before" and "after" relationships to other cameras (or build it "on top" of the priority system). * Consider allowing graphs to run subgraphs from any nest level (aka a global namespace for graphs). Right now the 2d and 3d graphs each need their own UI subgraph, which feels "fine" in the short term. But being able to share subgraphs between other subgraphs seems valuable. * Consider splitting `bevy_core_pipeline` into `bevy_core_2d` and `bevy_core_3d` packages. Theres a shared "clear color" dependency here, which would need a new home. |
||
|
|
1ba7429371 |
Doc/module style doc blocks for examples (#4438)
# Objective Provide a starting point for #3951, or a partial solution. Providing a few comment blocks to discuss, and hopefully find better one in the process. ## Solution Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less. ## Changelog - Moved some existing comments from main() functions in the 2d examples to the file header level - Wrote some more comment blocks for most other 2d examples TODO: - [x] 2d/sprite_sheet, wasnt able to come up with something good yet - [x] all other example groups... Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed. I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please. |
||
|
|
989fb8a78d |
Move Rect to bevy_ui and rename it to UiRect (#4276)
# Objective - Closes #335. - Related #4285. - Part of the splitting process of #3503. ## Solution - Move `Rect` to `bevy_ui` and rename it to `UiRect`. ## Reasons - `Rect` is only used in `bevy_ui` and therefore calling it `UiRect` makes the intent clearer. - We have two types that are called `Rect` currently and it's missleading (see `bevy_sprite::Rect` and #335). - Discussion in #3503. ## Changelog ### Changed - The `Rect` type got moved from `bevy_math` to `bevy_ui` and renamed to `UiRect`. ## Migration Guide - The `Rect` type got renamed to `UiRect`. To migrate you just have to change every occurrence of `Rect` to `UiRect`. Co-authored-by: KDecay <KDecayMusic@protonmail.com> |
||
|
|
b6a647cc01 |
default() shorthand (#4071)
Adds a `default()` shorthand for `Default::default()` ... because life is too short to constantly type `Default::default()`.
```rust
use bevy::prelude::*;
#[derive(Default)]
struct Foo {
bar: usize,
baz: usize,
}
// Normally you would do this:
let foo = Foo {
bar: 10,
..Default::default()
};
// But now you can do this:
let foo = Foo {
bar: 10,
..default()
};
```
The examples have been adapted to use `..default()`. I've left internal crates as-is for now because they don't pull in the bevy prelude, and the ergonomics of each case should be considered individually.
|
||
|
|
1477765f62 |
Replace VSync with PresentMode (#3812)
# Objective Enable the user to specify any presentation modes (including `Mailbox`). Fixes #3807 ## Solution I've added a new `PresentMode` enum in `bevy_window` that mirrors the `wgpu` enum 1:1. Alternatively, I could add a new dependency on `wgpu-types` if that would be preferred. |
||
|
|
07ed1d053e |
Implement and require #[derive(Component)] on all component structs (#2254)
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection. In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users. This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them. One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error. Co-authored-by: = <=> Co-authored-by: TheRawMeatball <therawmeatball@gmail.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
b724a0f586 |
Down with the system! (#2496)
# Objective - Remove all the `.system()` possible. - Check for remaining missing cases. ## Solution - Remove all `.system()`, fix compile errors - 32 calls to `.system()` remains, mostly internals, the few others should be removed after #2446 |
||
|
|
6d6bc2a8b4 |
Merge AppBuilder into App (#2531)
This is extracted out of eb8f973646476b4a4926ba644a77e2b3a5772159 and includes some additional changes to remove all references to AppBuilder and fix examples that still used App::build() instead of App::new(). In addition I didn't extract the sub app feature as it isn't ready yet. You can use `git diff --diff-filter=M eb8f973646476b4a4926ba644a77e2b3a5772159` to find all differences in this PR. The `--diff-filtered=M` filters all files added in the original commit but not in this commit away. Co-Authored-By: Carter Anderson <mcanders1@gmail.com> |
||
|
|
81b53d15d4 |
Make Commands and World apis consistent (#1703)
Resolves #1253 #1562 This makes the Commands apis consistent with World apis. This moves to a "type state" pattern (like World) where the "current entity" is stored in an `EntityCommands` builder. In general this tends to cuts down on indentation and line count. It comes at the cost of needing to type `commands` more and adding more semicolons to terminate expressions. I also added `spawn_bundle` to Commands because this is a common enough operation that I think its worth providing a shorthand. |
||
|
|
3a2a68852c |
Bevy ECS V2 (#1525)
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes #1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
### Simple Insert (from ecs_bench_suite)
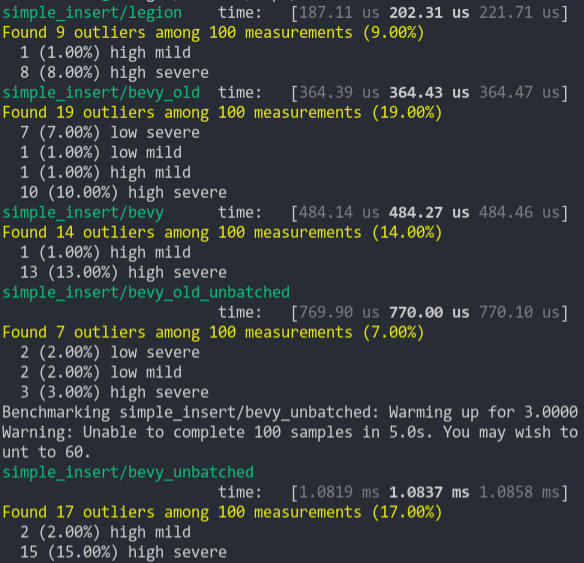
### Simpler Iter (from ecs_bench_suite)
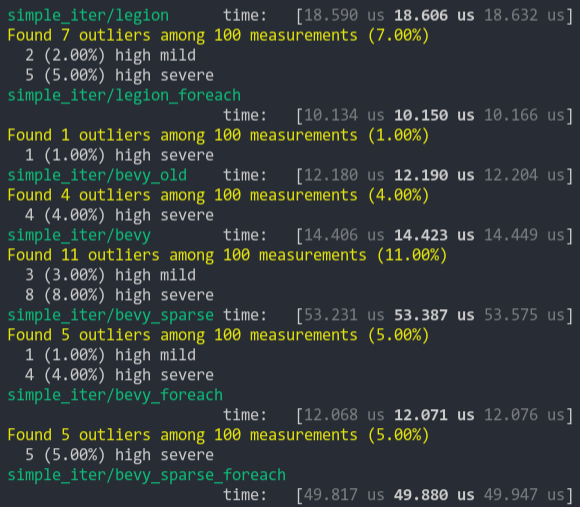
### Fragment Iter (from ecs_bench_suite)
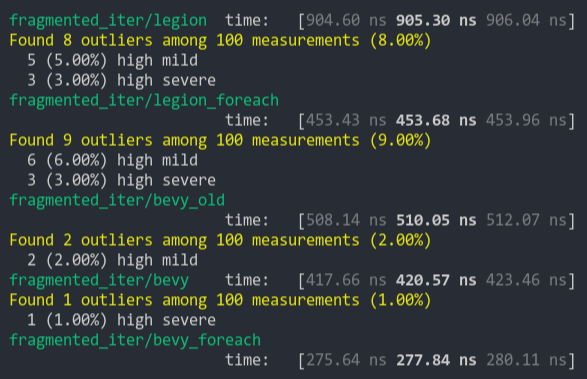
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
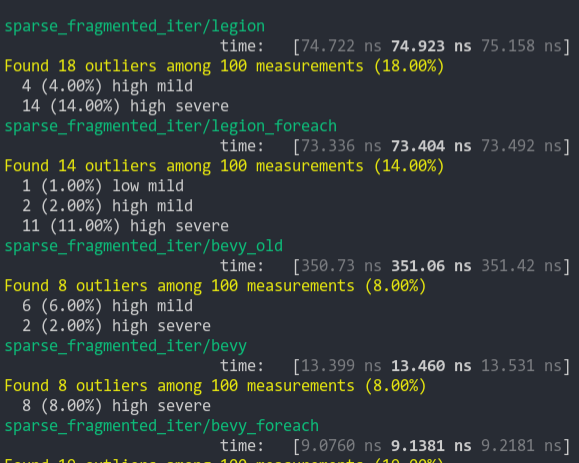
### Schedule (from ecs_bench_suite)
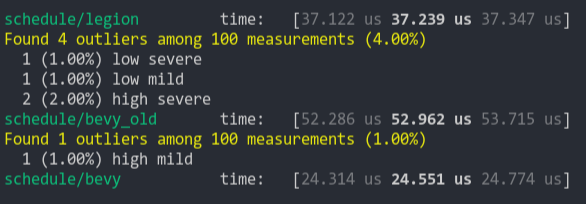
### Add Remove Component (from ecs_bench_suite)
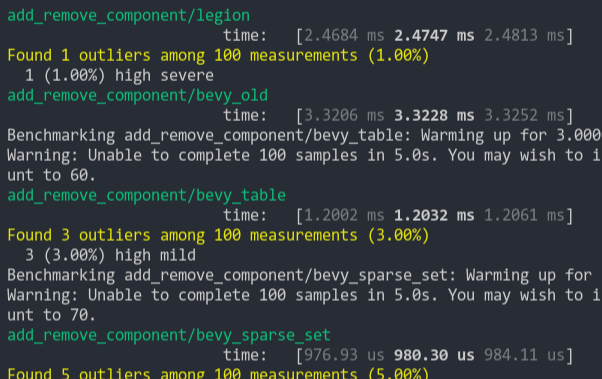
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
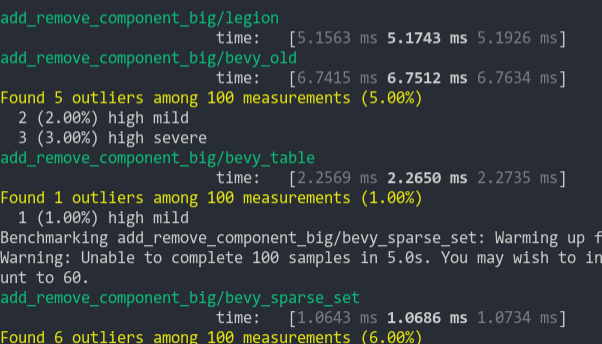
### Get Component
Looks up a single component value a large number of times
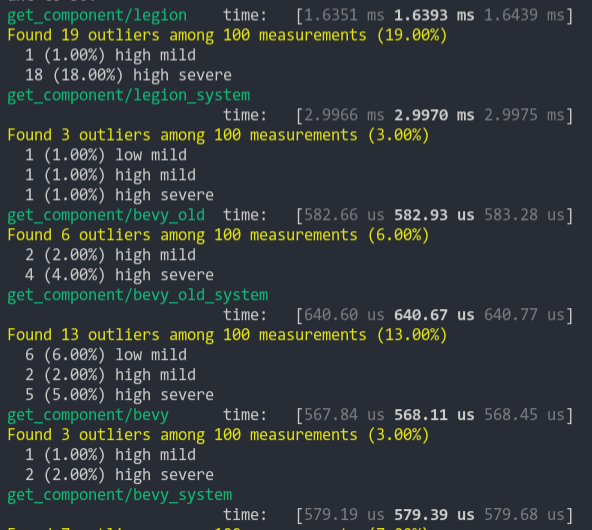
|
||
|
|
6f5a4d9deb
|
Rename add_resource to insert_resource (#1356)
* Renamed add_resource to insert_resource * Changed usage of add_resource to insert_resource * Renamed add_thread_local_resource |
||
|
|
57f9ac18d7
|
OrthographicProjection scaling mode + camera bundle refactoring (#400)
* add normalized orthographic projection * custom scale for ScaledOrthographicProjection * allow choosing base axis for ScaledOrthographicProjection * cargo fmt * add general (scaled) orthographic camera bundle FIXME: does the same "far" trick from Camera2DBundle make any sense here? * fixes * camera bundles: rename and new ortho constructors * unify orthographic projections * give PerspectiveCameraBundle constructors like those of OrthographicCameraBundle * update examples with new camera bundle syntax * rename CameraUiBundle to UiCameraBundle * update examples * ScalingMode::None * remove extra blank lines * sane default bounds for orthographic projection * fix alien_cake_addict example * reorder ScalingMode enum variants * ios example fix |
||
|
|
40b5bbd028
|
Rich text (#1245)
Rich text support (different fonts / styles within the same text section) |
||
|
|
841755aaf2
|
Adopt a Fetch pattern for SystemParams (#1074) | ||
|
|
fd3706b8de
|
Just spawn one CameraUiBundle (not 4) (#1047) | ||
|
|
59d98de194
|
naming coherence for cameras (#995)
naming coherence for cameras |
||
|
|
71e2c7f4e4
|
Debug text example: render fps and frame time (#978)
Display fps and frame time in text_debug example |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}