# Objective
To upgrade winit's dependency, it's useful to reuse SmolStr, which
replaces/improves the too restrictive Key letter enums.
As Input<Key> is a resource it should implement Reflect through all its
fields.
## Solution
Add smol_str to bevy_reflect supported types, behind a feature flag.
This PR blocks winit's upgrade PR:
https://github.com/bevyengine/bevy/pull/8745.
# Current state
- I'm discovering bevy_reflect, I appreciate all feedbacks, and send me
your nitpicks!
- Lacking more tests
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Followup to #7184
This makes `Reflect: DynamicTypePath` which allows us to remove
`Reflect::get_type_path`, reducing unnecessary codegen and simplifying
`Reflect` implementations.
# Objective
- Introduce a stable alternative to
[`std::any::type_name`](https://doc.rust-lang.org/std/any/fn.type_name.html).
- Rewrite of #5805 with heavy inspiration in design.
- On the path to #5830.
- Part of solving #3327.
## Solution
- Add a `TypePath` trait for static stable type path/name information.
- Add a `TypePath` derive macro.
- Add a `impl_type_path` macro for implementing internal and foreign
types in `bevy_reflect`.
---
## Changelog
- Added `TypePath` trait.
- Added `DynamicTypePath` trait and `get_type_path` method to `Reflect`.
- Added a `TypePath` derive macro.
- Added a `bevy_reflect::impl_type_path` for implementing `TypePath` on
internal and foreign types in `bevy_reflect`.
- Changed `bevy_reflect::utility::(Non)GenericTypeInfoCell` to
`(Non)GenericTypedCell<T>` which allows us to be generic over both
`TypeInfo` and `TypePath`.
- `TypePath` is now a supertrait of `Asset`, `Material` and
`Material2d`.
- `impl_reflect_struct` needs a `#[type_path = "..."]` attribute to be
specified.
- `impl_reflect_value` needs to either specify path starting with a
double colon (`::core::option::Option`) or an `in my_crate::foo`
declaration.
- Added `bevy_reflect_derive::ReflectTypePath`.
- Most uses of `Ident` in `bevy_reflect_derive` changed to use
`ReflectTypePath`.
## Migration Guide
- Implementors of `Asset`, `Material` and `Material2d` now also need to
derive `TypePath`.
- Manual implementors of `Reflect` will need to implement the new
`get_type_path` method.
## Open Questions
- [x] ~This PR currently does not migrate any usages of
`std::any::type_name` to use `bevy_reflect::TypePath` to ease the review
process. Should it?~ Migration will be left to a follow-up PR.
- [ ] This PR adds a lot of `#[derive(TypePath)]` and `T: TypePath` to
satisfy new bounds, mostly when deriving `TypeUuid`. Should we make
`TypePath` a supertrait of `TypeUuid`? [Should we remove `TypeUuid` in
favour of
`TypePath`?](2afbd85532 (r961067892))
# Objective
Fixes#8596
## Solution
Change interface of the trait Map. Adjust implementations of this trait
---
## Changelog
### Changed
- Interface of Map trait
### Added
- `Map::get_at_mut`
## Migration Guide
Every implementor of Map trait would need to implement `get_at_mut`.
Which, judging by changes in this PR, should be fairly trivial.
# Objective
Right now it's impossible to construct a MapIter outside of the
bevy_reflect crate, making it impossible to implement the Map trait for
custom map types.
## Solution
Addition of a pub constructor to MapIter.
# Objective
- Add Reflect and FromReflect for AssetPath
- Fixes#8458
## Solution
- Straightforward derive of `Reflect` and `FromReflect` for `AssetPath`
- Implement `Reflect` and `FromReflect` for `Cow<'static, Path>` as to
satisfy the 'static lifetime requierments of bevy_reflect.
Implementation is a direct copy of that for `Cow<'static, str>` so maybe
it begs the question that was already asked in #7429 - maybe it would be
benefitial to write a general implementation for `Reflect` for
`Cow<'static, T>`.
# Objective
> This PR is based on discussion from #6601
The Dynamic types (e.g. `DynamicStruct`, `DynamicList`, etc.) act as
both:
1. Dynamic containers which may hold any arbitrary data
2. Proxy types which may represent any other type
Currently, the only way we can represent the proxy-ness of a Dynamic is
by giving it a name.
```rust
// This is just a dynamic container
let mut data = DynamicStruct::default();
// This is a "proxy"
data.set_name(std::any::type_name::<Foo>());
```
This type name is the only way we check that the given Dynamic is a
proxy of some other type. When we need to "assert the type" of a `dyn
Reflect`, we call `Reflect::type_name` on it. However, because we're
only using a string to denote the type, we run into a few gotchas and
limitations.
For example, hashing a Dynamic proxy may work differently than the type
it proxies:
```rust
#[derive(Reflect, Hash)]
#[reflect(Hash)]
struct Foo(i32);
let concrete = Foo(123);
let dynamic = concrete.clone_dynamic();
let concrete_hash = concrete.reflect_hash();
let dynamic_hash = dynamic.reflect_hash();
// The hashes are not equal because `concrete` uses its own `Hash` impl
// while `dynamic` uses a reflection-based hashing algorithm
assert_ne!(concrete_hash, dynamic_hash);
```
Because the Dynamic proxy only knows about the name of the type, it's
unaware of any other information about it. This means it also differs on
`Reflect::reflect_partial_eq`, and may include ignored or skipped fields
in places the concrete type wouldn't.
## Solution
Rather than having Dynamics pass along just the type name of proxied
types, we can instead have them pass around the `TypeInfo`.
Now all Dynamic types contain an `Option<&'static TypeInfo>` rather than
a `String`:
```diff
pub struct DynamicTupleStruct {
- type_name: String,
+ represented_type: Option<&'static TypeInfo>,
fields: Vec<Box<dyn Reflect>>,
}
```
By changing `Reflect::get_type_info` to
`Reflect::represented_type_info`, hopefully we make this behavior a
little clearer. And to account for `None` values on these dynamic types,
`Reflect::represented_type_info` now returns `Option<&'static
TypeInfo>`.
```rust
let mut data = DynamicTupleStruct::default();
// Not proxying any specific type
assert!(dyn_tuple_struct.represented_type_info().is_none());
let type_info = <Foo as Typed>::type_info();
dyn_tuple_struct.set_represented_type(Some(type_info));
// Alternatively:
// let dyn_tuple_struct = foo.clone_dynamic();
// Now we're proxying `Foo`
assert!(dyn_tuple_struct.represented_type_info().is_some());
```
This means that we can have full access to all the static type
information for the proxied type. Future work would include
transitioning more static type information (trait impls, attributes,
etc.) over to the `TypeInfo` so it can actually be utilized by Dynamic
proxies.
### Alternatives & Rationale
> **Note**
> These alternatives were written when this PR was first made using a
`Proxy` trait. This trait has since been removed.
<details>
<summary>View</summary>
#### Alternative: The `Proxy<T>` Approach
I had considered adding something like a `Proxy<T>` type where `T` would
be the Dynamic and would contain the proxied type information.
This was nice in that it allows us to explicitly determine whether
something is a proxy or not at a type level. `Proxy<DynamicStruct>`
proxies a struct. Makes sense.
The reason I didn't go with this approach is because (1) tuples, (2)
complexity, and (3) `PartialReflect`.
The `DynamicTuple` struct allows us to represent tuples at runtime. It
also allows us to do something you normally can't with tuples: add new
fields. Because of this, adding a field immediately invalidates the
proxy (e.g. our info for `(i32, i32)` doesn't apply to `(i32, i32,
NewField)`). By going with this PR's approach, we can just remove the
type info on `DynamicTuple` when that happens. However, with the
`Proxy<T>` approach, it becomes difficult to represent this behavior—
we'd have to completely control how we access data for `T` for each `T`.
Secondly, it introduces some added complexities (aside from the manual
impls for each `T`). Does `Proxy<T>` impl `Reflect`? Likely yes, if we
want to represent it as `dyn Reflect`. What `TypeInfo` do we give it?
How would we forward reflection methods to the inner type (remember, we
don't have specialization)? How do we separate this from Dynamic types?
And finally, how do all this in a way that's both logical and intuitive
for users?
Lastly, introducing a `Proxy` trait rather than a `Proxy<T>` struct is
actually more inline with the [Unique Reflect
RFC](https://github.com/bevyengine/rfcs/pull/56). In a way, the `Proxy`
trait is really one part of the `PartialReflect` trait introduced in
that RFC (it's technically not in that RFC but it fits well with it),
where the `PartialReflect` serves as a way for proxies to work _like_
concrete types without having full access to everything a concrete
`Reflect` type can do. This would help bridge the gap between the
current state of the crate and the implementation of that RFC.
All that said, this is still a viable solution. If the community
believes this is the better path forward, then we can do that instead.
These were just my reasons for not initially going with it in this PR.
#### Alternative: The Type Registry Approach
The `Proxy` trait is great and all, but how does it solve the original
problem? Well, it doesn't— yet!
The goal would be to start moving information from the derive macro and
its attributes to the generated `TypeInfo` since these are known
statically and shouldn't change. For example, adding `ignored: bool` to
`[Un]NamedField` or a list of impls.
However, there is another way of storing this information. This is, of
course, one of the uses of the `TypeRegistry`. If we're worried about
Dynamic proxies not aligning with their concrete counterparts, we could
move more type information to the registry and require its usage.
For example, we could replace `Reflect::reflect_hash(&self)` with
`Reflect::reflect_hash(&self, registry: &TypeRegistry)`.
That's not the _worst_ thing in the world, but it is an ergonomics loss.
Additionally, other attributes may have their own requirements, further
restricting what's possible without the registry. The `Reflect::apply`
method will require the registry as well now. Why? Well because the
`map_apply` function used for the `Reflect::apply` impls on `Map` types
depends on `Map::insert_boxed`, which (at least for `DynamicMap`)
requires `Reflect::reflect_hash`. The same would apply when adding
support for reflection-based diffing, which will require
`Reflect::reflect_partial_eq`.
Again, this is a totally viable alternative. I just chose not to go with
it for the reasons above. If we want to go with it, then we can close
this PR and we can pursue this alternative instead.
#### Downsides
Just to highlight a quick potential downside (likely needs more
investigation): retrieving the `TypeInfo` requires acquiring a lock on
the `GenericTypeInfoCell` used by the `Typed` impls for generic types
(non-generic types use a `OnceBox which should be faster). I am not sure
how much of a performance hit that is and will need to run some
benchmarks to compare against.
</details>
### Open Questions
1. Should we use `Cow<'static, TypeInfo>` instead? I think that might be
easier for modding? Perhaps, in that case, we need to update
`Typed::type_info` and friends as well?
2. Are the alternatives better than the approach this PR takes? Are
there other alternatives?
---
## Changelog
### Changed
- `Reflect::get_type_info` has been renamed to
`Reflect::represented_type_info`
- This method now returns `Option<&'static TypeInfo>` rather than just
`&'static TypeInfo`
### Added
- Added `Reflect::is_dynamic` method to indicate when a type is dynamic
- Added a `set_represented_type` method on all dynamic types
### Removed
- Removed `TypeInfo::Dynamic` (use `Reflect::is_dynamic` instead)
- Removed `Typed` impls for all dynamic types
## Migration Guide
- The Dynamic types no longer take a string type name. Instead, they
require a static reference to `TypeInfo`:
```rust
#[derive(Reflect)]
struct MyTupleStruct(f32, f32);
let mut dyn_tuple_struct = DynamicTupleStruct::default();
dyn_tuple_struct.insert(1.23_f32);
dyn_tuple_struct.insert(3.21_f32);
// BEFORE:
let type_name = std::any::type_name::<MyTupleStruct>();
dyn_tuple_struct.set_name(type_name);
// AFTER:
let type_info = <MyTupleStruct as Typed>::type_info();
dyn_tuple_struct.set_represented_type(Some(type_info));
```
- `Reflect::get_type_info` has been renamed to
`Reflect::represented_type_info` and now also returns an
`Option<&'static TypeInfo>` (instead of just `&'static TypeInfo`):
```rust
// BEFORE:
let info: &'static TypeInfo = value.get_type_info();
// AFTER:
let info: &'static TypeInfo = value.represented_type_info().unwrap();
```
- `TypeInfo::Dynamic` and `DynamicInfo` has been removed. Use
`Reflect::is_dynamic` instead:
```rust
// BEFORE:
if matches!(value.get_type_info(), TypeInfo::Dynamic) {
// ...
}
// AFTER:
if value.is_dynamic() {
// ...
}
```
---------
Co-authored-by: radiish <cb.setho@gmail.com>
# Objective
- Fix the issue described in #8183: Box<dyn Reflect> structs with a
hashmap in them will panic when clone_value is called on it
- Fixes: #8183
## Solution
- Updates the implementation of Reflect for Hashmaps to make clone_value
call from_reflect on the key before inserting it into the new struct
# Objective
Implement `Reflect` for `std::collections::HashMap<K, V, S>` as well as `hashbrown::HashMap<K, V, S>` rather than just for `hashbrown::HashMap<K, V, RandomState>`. Fixes#7739.
## Solution
Rather than implementing on `HashMap<K, V>` I instead implemented most of the related traits on `HashMap<K, V, S> where S: BuildHasher + Send + Sync + 'static` and then `FromReflect` also needs the extra bound `S: Default` because it needs to use `with_capacity_and_hasher` so needs to be able to generate a default hasher.
As the API of `hashbrown::HashMap` is identical to `collections::HashMap` making them both work just required creating an `impl_reflect_for_hashmap` macro like the `impl_reflect_for_veclike` above and then applying this to both HashMaps.
---
## Changelog
`std::collections::HashMap` can now be reflected. Also more `State` generics than just `RandomState` can now be reflected for both `hashbrown::HashMap` and `collections::HashMap`
# Objective
- bevy_ggrs uses `reflect_hash` in order to produce checksums for its world snapshots. These checksums are sent between clients in order to detect desyncronization.
- However, since we currently use `async::AHasher` with the `std` feature, this means that hashes will always be different for different peers, even if the state is identical.
- This means bevy_ggrs needs a way to get a deterministic (fixed) hash.
## Solution
- ~~Add a feature to use `bevy_utils::FixedState` for the hasher used by bevy_reflect.~~
- Always use `bevy_utils::FixedState` for initializing the bevy_reflect hasher.
---
## Changelog
- bevy_reflect now uses a fixed state for its hasher, which means the output of `Reflect::reflect_hash` is now deterministic across processes.
# Objective
Resolves#7121
## Solution
Decouples `List` and `Array` by removing `Array` as a supertrait of `List`. Additionally, similar methods from `Array` have been added to `List` so that their usages can remain largely unchanged.
#### Possible Alternatives
##### `Sequence`
My guess for why we originally made `List` a subtrait of `Array` is that they share a lot of common operations. We could potentially move these overlapping methods to a `Sequence` (name taken from #7059) trait and make that a supertrait of both. This would allow functions to contain logic that simply operates on a sequence rather than "list vs array".
However, this means that we'd need to add methods for converting to a `dyn Sequence`. It also might be confusing since we wouldn't add a `ReflectRef::Sequence` or anything like that. Is such a trait worth adding (either in this PR or a followup one)?
---
## Changelog
- Removed `Array` as supertrait of `List`
- Added methods to `List` that were previously provided by `Array`
## Migration Guide
The `List` trait is no longer dependent on `Array`. Implementors of `List` can remove the `Array` impl and move its methods into the `List` impl (with only a couple tweaks).
```rust
// BEFORE
impl Array for Foo {
fn get(&self, index: usize) -> Option<&dyn Reflect> {/* ... */}
fn get_mut(&mut self, index: usize) -> Option<&mut dyn Reflect> {/* ... */}
fn len(&self) -> usize {/* ... */}
fn is_empty(&self) -> bool {/* ... */}
fn iter(&self) -> ArrayIter {/* ... */}
fn drain(self: Box<Self>) -> Vec<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicArray {/* ... */}
}
impl List for Foo {
fn insert(&mut self, index: usize, element: Box<dyn Reflect>) {/* ... */}
fn remove(&mut self, index: usize) -> Box<dyn Reflect> {/* ... */}
fn push(&mut self, value: Box<dyn Reflect>) {/* ... */}
fn pop(&mut self) -> Option<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicList {/* ... */}
}
// AFTER
impl List for Foo {
fn get(&self, index: usize) -> Option<&dyn Reflect> {/* ... */}
fn get_mut(&mut self, index: usize) -> Option<&mut dyn Reflect> {/* ... */}
fn insert(&mut self, index: usize, element: Box<dyn Reflect>) {/* ... */}
fn remove(&mut self, index: usize) -> Box<dyn Reflect> {/* ... */}
fn push(&mut self, value: Box<dyn Reflect>) {/* ... */}
fn pop(&mut self) -> Option<Box<dyn Reflect>> {/* ... */}
fn len(&self) -> usize {/* ... */}
fn is_empty(&self) -> bool {/* ... */}
fn iter(&self) -> ListIter {/* ... */}
fn drain(self: Box<Self>) -> Vec<Box<dyn Reflect>> {/* ... */}
fn clone_dynamic(&self) -> DynamicList {/* ... */}
}
```
Some other small tweaks that will need to be made include:
- Use `ListIter` for `List::iter` instead of `ArrayIter` (the return type from `Array::iter`)
- Replace `array_hash` with `list_hash` in `Reflect::reflect_hash` for implementors of `List`
Implementing GetTypeRegistration in macro impl_reflect_for_veclike! had typos!
It only implement GetTypeRegistration for Vec<T>, but not for VecDeque<T>.
This will cause serialization and deserialization failure.
# Objective
- Fixes#7430.
## Solution
- Changed fields of `ArrayIter` to be private.
- Add a constructor `new` to `ArrayIter`.
- Replace normal struct creation with `new`.
---
## Changelog
- Add a constructor `new` to `ArrayIter`.
Co-authored-by: Elbert Ronnie <103196773+elbertronnie@users.noreply.github.com>
# Objective
There are times where we want to simply take an owned `dyn Reflect` and cast it to a type `T`.
Currently, this involves doing:
```rust
let value = value.take::<T>().unwrap_or_else(|value| {
T::from_reflect(&*value).unwrap_or_else(|| {
panic!(
"expected value of type {} to convert to type {}.",
value.type_name(),
std::any::type_name::<T>()
)
})
});
```
This is a common operation that could be easily be simplified.
## Solution
Add the `FromReflect::take_from_reflect` method. This first tries to `take` the value, calling `from_reflect` iff that fails.
```rust
let value = T::take_from_reflect(value).unwrap_or_else(|value| {
panic!(
"expected value of type {} to convert to type {}.",
value.type_name(),
std::any::type_name::<T>()
)
});
```
Based on suggestion from @soqb on [Discord](https://discord.com/channels/691052431525675048/1002362493634629796/1041046880316043374).
---
## Changelog
- Add `FromReflect::take_from_reflect` method
# Objective
- Fixes#7061
## Solution
- Add and implement `insert` and `remove` methods for `List`.
---
## Changelog
- Added `insert` and `remove` methods to `List`.
- Changed the `push` and `pop` methods on `List` to have default implementations.
## Migration Guide
- Manual implementors of `List` need to implement the new methods `insert` and `remove` and
consider whether to use the new default implementation of `push` and `pop`.
Co-authored-by: radiish <thesethskigamer@gmail.com>
# Objective
This is an adoption of #5792. Fixes#5791.
## Solution
Implemented all the required reflection traits for `VecDeque`, taking from `Vec`'s impls.
---
## Changelog
Added: `std::collections::VecDeque` now implements `Reflect` and all relevant traits.
Co-authored-by: james7132 <contact@jamessliu.com>
# Objective
- Fixes#3004
## Solution
- Replaced all the types with their fully quallified names
- Replaced all trait methods and inherent methods on dyn traits with their fully qualified names
- Made a new file `fq_std.rs` that contains structs corresponding to commonly used Structs and Traits from `std`. These structs are replaced by their respective fully qualified names when used inside `quote!`
# Objective
> Followup to [this](https://github.com/bevyengine/bevy/pull/6755#discussion_r1032671178) comment
Rearrange the impls in the `impls/std.rs` file.
The issue was that I had accidentally misplaced the impl for `Option<T>` and put it between the `Cow<'static, str>` impls. This is just a slight annoyance and readability issue.
## Solution
Move the `Option<T>` and `&'static Path` impls around to be more readable.
# Objective
Fixes#6739
## Solution
Implement the required traits. They cannot be implemented for `Path` directly, since it is a dynamically-sized type.
# Objective
> Part of #6573
When serializing a `DynamicScene` we end up treating almost all non-value types as though their type data doesn't exist. This is because when creating the `DynamicScene` we call `Reflect::clone_value` on the components, which generates a Dynamic type for all non-value types.
What this means is that the `glam` types are treated as though their `ReflectSerialize` registrations don't exist. However, the deserializer _does_ pick up the registration and attempts to use that instead. This results in the deserializer trying to operate on "malformed" data, causing this error:
```
WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected float
```
## Solution
Ideally, we should better handle the serialization of possibly-Dynamic types. However, this runs into issues where the `ReflectSerialize` expects the concrete type and not a Dynamic representation, resulting in a panic:
0aa4147af6/crates/bevy_reflect/src/type_registry.rs (L402-L413)
Since glam types are so heavily used in Bevy (specifically in `Transform` and `GlobalTransform`), it makes sense to just a quick fix in that enables them to be used properly in scenes while a proper solution is found.
This PR simply removes all `ReflectSerialize` and `ReflectDeserialize` registrations from the glam types that are reflected as structs.
---
## Changelog
- Remove `ReflectSerialize` and `ReflectDeserialize` registrations from most glam types
## Migration Guide
This PR removes `ReflectSerialize` and `ReflectDeserialize` registrations from most glam types. This means any code relying on either of those type data existing for those glam types will need to not do that.
This also means that some serialized glam types will need to be updated. For example, here is `Affine3A`:
```rust
// BEFORE
(
"glam::f32::affine3a::Affine3A": (1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0),
// AFTER
"glam::f32::affine3a::Affine3A": (
matrix3: (
x_axis: (
x: 1.0,
y: 0.0,
z: 0.0,
),
y_axis: (
x: 0.0,
y: 1.0,
z: 0.0,
),
z_axis: (
x: 0.0,
y: 0.0,
z: 1.0,
),
),
translation: (
x: 0.0,
y: 0.0,
z: 0.0,
),
)
)
```
# Objective
- Implements removal of entries from a `dyn Map`
- Fixes#6563
## Solution
- Adds a `remove` method to the `Map` trait which takes in a `&dyn Reflect` key and returns the value removed if it was present.
---
## Changelog
- Added `Map::remove`
## Migration Guide
- Implementors of `Map` will need to implement the `remove` method.
Co-authored-by: radiish <thesethskigamer@gmail.com>
# Objective
Using `Reflect` we can easily switch between a specific reflection trait object, such as a `dyn Struct`, to a `dyn Reflect` object via `Reflect::as_reflect` or `Reflect::as_reflect_mut`.
```rust
fn do_something(value: &dyn Reflect) {/* ... */}
let foo: Box<dyn Struct> = Box::new(Foo::default());
do_something(foo.as_reflect());
```
However, there is no way to convert a _boxed_ reflection trait object to a `Box<dyn Reflect>`.
## Solution
Add a `Reflect::into_reflect` method which allows converting a boxed reflection trait object back into a boxed `Reflect` trait object.
```rust
fn do_something(value: Box<dyn Reflect>) {/* ... */}
let foo: Box<dyn Struct> = Box::new(Foo::default());
do_something(foo.into_reflect());
```
---
## Changelog
- Added `Reflect::into_reflect`
# Objective
There is no way to gen an owned value of `Reflect`.
## Solution
Add it! This was originally a part of #6421, but @MrGVSV asked me to create a separate for it to implement reflect diffing.
---
## Changelog
### Added
- `Reflect::reflect_owned` to get an owned version of `Reflect`.
# Objective
- `ReflectDefault` can be used to create default values for reflected types
- `std` primitives that are `Default`-constructable should register `ReflectDefault`
## Solution
- register `ReflectDefault`
> Note: This is rebased off #4561 and can be viewed as a competitor to that PR. See `Comparison with #4561` section for details.
# Objective
The current serialization format used by `bevy_reflect` is both verbose and error-prone. Taking the following structs[^1] for example:
```rust
// -- src/inventory.rs
#[derive(Reflect)]
struct Inventory {
id: String,
max_storage: usize,
items: Vec<Item>
}
#[derive(Reflect)]
struct Item {
name: String
}
```
Given an inventory of a single item, this would serialize to something like:
```rust
// -- assets/inventory.ron
{
"type": "my_game::inventory::Inventory",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "inv001",
},
"max_storage": {
"type": "usize",
"value": 10
},
"items": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "my_game::inventory::Item",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Pickaxe"
},
},
},
],
},
},
}
```
Aside from being really long and difficult to read, it also has a few "gotchas" that users need to be aware of if they want to edit the file manually. A major one is the requirement that you use the proper keys for a given type. For structs, you need `"struct"`. For lists, `"list"`. For tuple structs, `"tuple_struct"`. And so on.
It also ***requires*** that the `"type"` entry come before the actual data. Despite being a map— which in programming is almost always orderless by default— the entries need to be in a particular order. Failure to follow the ordering convention results in a failure to deserialize the data.
This makes it very prone to errors and annoyances.
## Solution
Using #4042, we can remove a lot of the boilerplate and metadata needed by this older system. Since we now have static access to type information, we can simplify our serialized data to look like:
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
name: "Pickaxe"
),
],
),
}
```
This is much more digestible and a lot less error-prone (no more key requirements and no more extra type names).
Additionally, it is a lot more familiar to users as it follows conventional serde mechanics. For example, the struct is represented with `(...)` when serialized to RON.
#### Custom Serialization
Additionally, this PR adds the opt-in ability to specify a custom serde implementation to be used rather than the one created via reflection. For example[^1]:
```rust
// -- src/inventory.rs
#[derive(Reflect, Serialize)]
#[reflect(Serialize)]
struct Item {
#[serde(alias = "id")]
name: String
}
```
```rust
// -- assets/inventory.ron
{
"my_game::inventory::Inventory": (
id: "inv001",
max_storage: 10,
items: [
(
id: "Pickaxe"
),
],
),
},
```
By allowing users to define their own serialization methods, we do two things:
1. We give more control over how data is serialized/deserialized to the end user
2. We avoid having to re-define serde's attributes and forcing users to apply both (e.g. we don't need a `#[reflect(alias)]` attribute).
### Improved Formats
One of the improvements this PR provides is the ability to represent data in ways that are more conventional and/or familiar to users. Many users are familiar with RON so here are some of the ways we can now represent data in RON:
###### Structs
```js
{
"my_crate::Foo": (
bar: 123
)
}
// OR
{
"my_crate::Foo": Foo(
bar: 123
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Foo",
"struct": {
"bar": {
"type": "usize",
"value": 123
}
}
}
```
</details>
###### Tuples
```js
{
"(f32, f32)": (1.0, 2.0)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "(f32, f32)",
"tuple": [
{
"type": "f32",
"value": 1.0
},
{
"type": "f32",
"value": 2.0
}
]
}
```
</details>
###### Tuple Structs
```js
{
"my_crate::Bar": ("Hello World!")
}
// OR
{
"my_crate::Bar": Bar("Hello World!")
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::Bar",
"tuple_struct": [
{
"type": "alloc::string::String",
"value": "Hello World!"
}
]
}
```
</details>
###### Arrays
It may be a bit surprising to some, but arrays now also use the tuple format. This is because they essentially _are_ tuples (a sequence of values with a fixed size), but only allow for homogenous types. Additionally, this is how RON handles them and is probably a result of the 32-capacity limit imposed on them (both by [serde](https://docs.rs/serde/latest/serde/trait.Serialize.html#impl-Serialize-for-%5BT%3B%2032%5D) and by [bevy_reflect](https://docs.rs/bevy/latest/bevy/reflect/trait.GetTypeRegistration.html#impl-GetTypeRegistration-for-%5BT%3B%2032%5D)).
```js
{
"[i32; 3]": (1, 2, 3)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "[i32; 3]",
"array": [
{
"type": "i32",
"value": 1
},
{
"type": "i32",
"value": 2
},
{
"type": "i32",
"value": 3
}
]
}
```
</details>
###### Enums
To make things simple, I'll just put a struct variant here, but the style applies to all variant types:
```js
{
"my_crate::ItemType": Consumable(
name: "Healing potion"
)
}
```
<details>
<summary>Old Format</summary>
```js
{
"type": "my_crate::ItemType",
"enum": {
"variant": "Consumable",
"struct": {
"name": {
"type": "alloc::string::String",
"value": "Healing potion"
}
}
}
}
```
</details>
### Comparison with #4561
This PR is a rebased version of #4561. The reason for the split between the two is because this PR creates a _very_ different scene format. You may notice that the PR descriptions for either PR are pretty similar. This was done to better convey the changes depending on which (if any) gets merged first. If #4561 makes it in first, I will update this PR description accordingly.
---
## Changelog
* Re-worked serialization/deserialization for reflected types
* Added `TypedReflectDeserializer` for deserializing data with known `TypeInfo`
* Renamed `ReflectDeserializer` to `UntypedReflectDeserializer`
* ~~Replaced usages of `deserialize_any` with `deserialize_map` for non-self-describing formats~~ Reverted this change since there are still some issues that need to be sorted out (in a separate PR). By reverting this, crates like `bincode` can throw an error when attempting to deserialize non-self-describing formats (`bincode` results in `DeserializeAnyNotSupported`)
* Structs, tuples, tuple structs, arrays, and enums are now all de/serialized using conventional serde methods
## Migration Guide
* This PR reduces the verbosity of the scene format. Scenes will need to be updated accordingly:
```js
// Old format
{
"type": "my_game::item::Item",
"struct": {
"id": {
"type": "alloc::string::String",
"value": "bevycraft:stone",
},
"tags": {
"type": "alloc::vec::Vec<alloc::string::String>",
"list": [
{
"type": "alloc::string::String",
"value": "material"
},
],
},
}
// New format
{
"my_game::item::Item": (
id: "bevycraft:stone",
tags: ["material"]
)
}
```
[^1]: Some derives omitted for brevity.
# Objective
Add traits to events in `bevy_input` and `bevy_windows`: `Copy`, `Serialize`/`Deserialize`, `PartialEq`, and `Eq`, as requested in https://github.com/bevyengine/bevy/issues/6022, https://github.com/bevyengine/bevy/issues/6023, https://github.com/bevyengine/bevy/issues/6024.
## Solution
Added the traits to events in `bevy_input` and `bevy_windows`. Added dependency of `serde` in `Cargo.toml` of `bevy_input`.
## Migration Guide
If one has been `.clone()`'ing `bevy_input` events, Clippy will now complain about that. Just remove `.clone()` to solve.
## Other Notes
Some events in `bevy_input` had `f32` fields, so `Eq` trait was not derived for them.
Some events in `bevy_windows` had `String` fields, so `Copy` trait was not derived for them.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
Promote the `Rect` utility of `sprite::Rect`, which defines a rectangle
by its minimum and maximum corners, to the `bevy_math` crate to make it
available as a general math type to all crates without the need to
depend on the `bevy_sprite` crate.
Fixes#5575
## Solution
Move `sprite::Rect` into `bevy_math` and fix all uses.
Implement `Reflect` for `Rect` directly into the `bevy_reflect` crate by
having `bevy_reflect` depend on `bevy_math`. This looks like a new
dependency, but the `bevy_reflect` was "cheating" for other math types
by directly depending on `glam` to reflect other math types, thereby
giving the illusion that there was no dependency on `bevy_math`. In
practice conceptually Bevy's math types are reflected into the
`bevy_reflect` crate to avoid a dependency of that crate to a "lower
level" utility crate like `bevy_math` (which in turn would make
`bevy_reflect` be a dependency of most other crates, and increase the
risk of circular dependencies). So this change simply formalizes that
dependency in `Cargo.toml`.
The `Rect` struct is also augmented in this change with a collection of
utility methods to improve its usability. A few uses cases are updated
to use those new methods, resulting is more clear and concise syntax.
---
## Changelog
### Changed
- Moved the `sprite::Rect` type into `bevy_math`.
### Added
- Added several utility methods to the `math::Rect` type.
## Migration Guide
The `bevy::sprite::Rect` type moved to the math utility crate as
`bevy::math::Rect`. You should change your imports from `use
bevy::sprite::Rect` to `use bevy::math::Rect`.
# Objective
Sometimes it's useful to be able to retrieve all the fields of a container type so that they may be processed separately. With reflection, however, we typically only have access to references.
The only alternative is to "clone" the value using `Reflect::clone_value`. This, however, returns a Dynamic type in most cases. The solution there would be to use `FromReflect` instead, but this also has a problem in that it means we need to add `FromReflect` as an additional bound.
## Solution
Add a `drain` method to all container traits. This returns a `Vec<Box<dyn Reflect>>` (except for `Map` which returns `Vec<(Box<dyn Reflect>, Box<dyn Reflect>)>`).
This allows us to do things a lot simpler. For example, if we finished processing a struct and just need a particular value:
```rust
// === OLD === //
/// May or may not return a Dynamic*** value (even if `container` wasn't a `DynamicStruct`)
fn get_output(container: Box<dyn Struct>, output_index: usize) -> Box<dyn Reflect> {
container.field_at(output_index).unwrap().clone_value()
}
// === NEW === //
/// Returns _exactly_ whatever was in the given struct
fn get_output(container: Box<dyn Struct>, output_index: usize) -> Box<dyn Reflect> {
container.drain().remove(output_index).unwrap()
}
```
### Discussion
* Is `drain` the best method name? It makes sense that it "drains" all the fields and that it consumes the container in the process, but I'm open to alternatives.
---
## Changelog
* Added a `drain` method to the following traits:
* `Struct`
* `TupleStruct`
* `Tuple`
* `Array`
* `List`
* `Map`
* `Enum`
# Objective
- The reflection `List` trait does not have a `pop` function.
- Popping elements off a list is a common use case and is almost always supported by `List`-like types.
## Solution
- Add the `pop()` method to the `List` trait and add the appropriate implementations of this function.
## Migration Guide
- Any custom type that implements the `List` trait will now need to implement the `pop` method.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Fixes#5763
## Solution
Implemented as reflect value like the current `Range`. Is there a benefit to changing everything to a reflect struct?
# Objective
Some of the reflection impls for container types had unnecessary `Clone` bounds on their generic arguments. These come from before `FromReflect` when types were instead bound by `Reflect + Clone`. With `FromReflect` this is no longer necessary.
## Solution
Removed all leftover `Clone` bounds from types that use `FromReflect` instead.
## Note
I skipped `Result<T, E>`, `HashSet<T>`, and `Range<T>` since those do not use `FromReflect`. This should probably be handled in a separate PR since it would be a breaking change.
---
## Changelog
- Remove unnecessary `Clone` bounds on reflected containers
# Objective
#5658 made it so that `FromReflect` was used as the bound for `T` in `Option<T>`. However, it did not use this change effectively for the implementation of `Reflect::apply` (it was still using `take`, which would fail for Dynamic types).
Additionally, the changes were not consistent with other methods within the file, such as the ones for `Vec<T>` and `HashMap<K, V>`.
## Solution
Update `Option<T>` to fallback on `FromReflect` if `take` fails, instead of wholly relying on one or the other.
I also chose to update the error messages, as they weren't all too descriptive before.
---
## Changelog
- Use `FromReflect::from_reflect` as a fallback in the `Reflect::apply` implementation for `Option<T>`
# Objective
`SmallVec<T>` was missing a `GetTypeRegistration` impl.
## Solution
Added a `GetTypeRegistration` impl.
---
## Changelog
* Added a `GetTypeRegistration` impl for `SmallVec<T>`
# Objective
The reflection impls on `Option<T>` have the bound `T: Reflect + Clone`. This means that using `FromReflect` requires `Clone` even though we can normally get away with just `FromReflect`.
## Solution
Update the bounds on `Option<T>` to match that of `Vec<T>`, where `T: FromReflect`.
This helps remove a `Clone` implementation that may be undesired but added for the sole purpose of getting the code to compile.
---
## Changelog
* Reflection on `Option<T>` now has `T` bound by `FromReflect` rather than `Reflect + Clone`
* Added a `FromReflect` impl for `Instant`
## Migration Guide
If using `Option<T>` with Bevy's reflection API, `T` now needs to implement `FromReflect` rather than just `Clone`. This can be achieved easily by simply deriving `FromReflect`:
```rust
// OLD
#[derive(Reflect, Clone)]
struct Foo;
let reflected: Box<dyn Reflect> = Box::new(Some(Foo));
// NEW
#[derive(Reflect, FromReflect)]
struct Foo;
let reflected: Box<dyn Reflect> = Box::new(Some(Foo));
```
> Note: You can still derive `Clone`, but it's not required in order to compile.
# Objective
Add reflect/from reflect impls for NonZero integer types. I'm guessing these haven't been added yet because no one has needed them as of yet.
# Objective
> This is a revival of #1347. Credit for the original PR should go to @Davier.
Currently, enums are treated as `ReflectRef::Value` types by `bevy_reflect`. Obviously, there needs to be better a better representation for enums using the reflection API.
## Solution
Based on prior work from @Davier, an `Enum` trait has been added as well as the ability to automatically implement it via the `Reflect` derive macro. This allows enums to be expressed dynamically:
```rust
#[derive(Reflect)]
enum Foo {
A,
B(usize),
C { value: f32 },
}
let mut foo = Foo::B(123);
assert_eq!("B", foo.variant_name());
assert_eq!(1, foo.field_len());
let new_value = DynamicEnum::from(Foo::C { value: 1.23 });
foo.apply(&new_value);
assert_eq!(Foo::C{value: 1.23}, foo);
```
### Features
#### Derive Macro
Use the `#[derive(Reflect)]` macro to automatically implement the `Enum` trait for enum definitions. Optionally, you can use `#[reflect(ignore)]` with both variants and variant fields, just like you can with structs. These ignored items will not be considered as part of the reflection and cannot be accessed via reflection.
```rust
#[derive(Reflect)]
enum TestEnum {
A,
// Uncomment to ignore all of `B`
// #[reflect(ignore)]
B(usize),
C {
// Uncomment to ignore only field `foo` of `C`
// #[reflect(ignore)]
foo: f32,
bar: bool,
},
}
```
#### Dynamic Enums
Enums may be created/represented dynamically via the `DynamicEnum` struct. The main purpose of this struct is to allow enums to be deserialized into a partial state and to allow dynamic patching. In order to ensure conversion from a `DynamicEnum` to a concrete enum type goes smoothly, be sure to add `FromReflect` to your derive macro.
```rust
let mut value = TestEnum::A;
// Create from a concrete instance
let dyn_enum = DynamicEnum::from(TestEnum::B(123));
value.apply(&dyn_enum);
assert_eq!(TestEnum::B(123), value);
// Create a purely dynamic instance
let dyn_enum = DynamicEnum::new("TestEnum", "A", ());
value.apply(&dyn_enum);
assert_eq!(TestEnum::A, value);
```
#### Variants
An enum value is always represented as one of its variants— never the enum in its entirety.
```rust
let value = TestEnum::A;
assert_eq!("A", value.variant_name());
// Since we are using the `A` variant, we cannot also be the `B` variant
assert_ne!("B", value.variant_name());
```
All variant types are representable within the `Enum` trait: unit, struct, and tuple.
You can get the current type like:
```rust
match value.variant_type() {
VariantType::Unit => println!("A unit variant!"),
VariantType::Struct => println!("A struct variant!"),
VariantType::Tuple => println!("A tuple variant!"),
}
```
> Notice that they don't contain any values representing the fields. These are purely tags.
If a variant has them, you can access the fields as well:
```rust
let mut value = TestEnum::C {
foo: 1.23,
bar: false
};
// Read/write specific fields
*value.field_mut("bar").unwrap() = true;
// Iterate over the entire collection of fields
for field in value.iter_fields() {
println!("{} = {:?}", field.name(), field.value());
}
```
#### Variant Swapping
It might seem odd to group all variant types under a single trait (why allow `iter_fields` on a unit variant?), but the reason this was done ~~is to easily allow *variant swapping*.~~ As I was recently drafting up the **Design Decisions** section, I discovered that other solutions could have been made to work with variant swapping. So while there are reasons to keep the all-in-one approach, variant swapping is _not_ one of them.
```rust
let mut value: Box<dyn Enum> = Box::new(TestEnum::A);
value.set(Box::new(TestEnum::B(123))).unwrap();
```
#### Serialization
Enums can be serialized and deserialized via reflection without needing to implement `Serialize` or `Deserialize` themselves (which can save thousands of lines of generated code). Below are the ways an enum can be serialized.
> Note, like the rest of reflection-based serialization, the order of the keys in these representations is important!
##### Unit
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "A"
}
}
```
##### Tuple
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "B",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
<details>
<summary>Effects on Option</summary>
This ends up making `Option` look a little ugly:
```json
{
"type": "core::option::Option<usize>",
"enum": {
"variant": "Some",
"tuple": [
{
"type": "usize",
"value": 123
}
]
}
}
```
</details>
##### Struct
```json
{
"type": "my_crate::TestEnum",
"enum": {
"variant": "C",
"struct": {
"foo": {
"type": "f32",
"value": 1.23
},
"bar": {
"type": "bool",
"value": false
}
}
}
}
```
## Design Decisions
<details>
<summary><strong>View Section</strong></summary>
This section is here to provide some context for why certain decisions were made for this PR, alternatives that could have been used instead, and what could be improved upon in the future.
### Variant Representation
One of the biggest decisions was to decide on how to represent variants. The current design uses a "all-in-one" design where unit, tuple, and struct variants are all simultaneously represented by the `Enum` trait. This is not the only way it could have been done, though.
#### Alternatives
##### 1. Variant Traits
One way of representing variants would be to define traits for each variant, implementing them whenever an enum featured at least one instance of them. This would allow us to define variants like:
```rust
pub trait Enum: Reflect {
fn variant(&self) -> Variant;
}
pub enum Variant<'a> {
Unit,
Tuple(&'a dyn TupleVariant),
Struct(&'a dyn StructVariant),
}
pub trait TupleVariant {
fn field_len(&self) -> usize;
// ...
}
```
And then do things like:
```rust
fn get_tuple_len(foo: &dyn Enum) -> usize {
match foo.variant() {
Variant::Tuple(tuple) => tuple.field_len(),
_ => panic!("not a tuple variant!")
}
}
```
The reason this PR does not go with this approach is because of the fact that variants are not separate types. In other words, we cannot implement traits on specific variants— these cover the *entire* enum. This means we offer an easy footgun:
```rust
let foo: Option<i32> = None;
let my_enum = Box::new(foo) as Box<dyn TupleVariant>;
```
Here, `my_enum` contains `foo`, which is a unit variant. However, since we need to implement `TupleVariant` for `Option` as a whole, it's possible to perform such a cast. This is obviously wrong, but could easily go unnoticed. So unfortunately, this makes it not a good candidate for representing variants.
##### 2. Variant Structs
To get around the issue of traits necessarily needing to apply to both the enum and its variants, we could instead use structs that are created on a per-variant basis. This was also considered but was ultimately [[removed](71d27ab3c6) due to concerns about allocations.
Each variant struct would probably look something like:
```rust
pub trait Enum: Reflect {
fn variant_mut(&self) -> VariantMut;
}
pub enum VariantMut<'a> {
Unit,
Tuple(TupleVariantMut),
Struct(StructVariantMut),
}
struct StructVariantMut<'a> {
fields: Vec<&'a mut dyn Reflect>,
field_indices: HashMap<Cow<'static, str>, usize>
}
```
This allows us to isolate struct variants into their own defined struct and define methods specifically for their use. It also prevents users from casting to it since it's not a trait. However, this is not an optimal solution. Both `field_indices` and `fields` will require an allocation (remember, a `Box<[T]>` still requires a `Vec<T>` in order to be constructed). This *might* be a problem if called frequently enough.
##### 3. Generated Structs
The original design, implemented by @Davier, instead generates structs specific for each variant. So if we had a variant path like `Foo::Bar`, we'd generate a struct named `FooBarWrapper`. This would be newtyped around the original enum and forward tuple or struct methods to the enum with the chosen variant.
Because it involved using the `Tuple` and `Struct` traits (which are also both bound on `Reflect`), this meant a bit more code had to be generated. For a single struct variant with one field, the generated code amounted to ~110LoC. However, each new field added to that variant only added ~6 more LoC.
In order to work properly, the enum had to be transmuted to the generated struct:
```rust
fn variant(&self) -> crate::EnumVariant<'_> {
match self {
Foo::Bar {value: i32} => {
let wrapper_ref = unsafe {
std::mem::transmute::<&Self, &FooBarWrapper>(self)
};
crate::EnumVariant::Struct(wrapper_ref as &dyn crate::Struct)
}
}
}
```
This works because `FooBarWrapper` is defined as `repr(transparent)`.
Out of all the alternatives, this would probably be the one most likely to be used again in the future. The reasons for why this PR did not continue to use it was because:
* To reduce generated code (which would hopefully speed up compile times)
* To avoid cluttering the code with generated structs not visible to the user
* To keep bevy_reflect simple and extensible (these generated structs act as proxies and might not play well with current or future systems)
* To avoid additional unsafe blocks
* My own misunderstanding of @Davier's code
That last point is obviously on me. I misjudged the code to be too unsafe and unable to handle variant swapping (which it probably could) when I was rebasing it. Looking over it again when writing up this whole section, I see that it was actually a pretty clever way of handling variant representation.
#### Benefits of All-in-One
As stated before, the current implementation uses an all-in-one approach. All variants are capable of containing fields as far as `Enum` is concerned. This provides a few benefits that the alternatives do not (reduced indirection, safer code, etc.).
The biggest benefit, though, is direct field access. Rather than forcing users to have to go through pattern matching, we grant direct access to the fields contained by the current variant. The reason we can do this is because all of the pattern matching happens internally. Getting the field at index `2` will automatically return `Some(...)` for the current variant if it has a field at that index or `None` if it doesn't (or can't).
This could be useful for scenarios where the variant has already been verified or just set/swapped (or even where the type of variant doesn't matter):
```rust
let dyn_enum: &mut dyn Enum = &mut Foo::Bar {value: 123};
// We know it's the `Bar` variant
let field = dyn_enum.field("value").unwrap();
```
Reflection is not a type-safe abstraction— almost every return value is wrapped in `Option<...>`. There are plenty of places to check and recheck that a value is what Reflect says it is. Forcing users to have to go through `match` each time they want to access a field might just be an extra step among dozens of other verification processes.
Some might disagree, but ultimately, my view is that the benefit here is an improvement to the ergonomics and usability of reflected enums.
</details>
---
## Changelog
### Added
* Added `Enum` trait
* Added `Enum` impl to `Reflect` derive macro
* Added `DynamicEnum` struct
* Added `DynamicVariant`
* Added `EnumInfo`
* Added `VariantInfo`
* Added `StructVariantInfo`
* Added `TupleVariantInfo`
* Added `UnitVariantInfo`
* Added serializtion/deserialization support for enums
* Added `EnumSerializer`
* Added `VariantType`
* Added `VariantFieldIter`
* Added `VariantField`
* Added `enum_partial_eq(...)`
* Added `enum_hash(...)`
### Changed
* `Option<T>` now implements `Enum`
* `bevy_window` now depends on `bevy_reflect`
* Implemented `Reflect` and `FromReflect` for `WindowId`
* Derive `FromReflect` on `PerspectiveProjection`
* Derive `FromReflect` on `OrthographicProjection`
* Derive `FromReflect` on `WindowOrigin`
* Derive `FromReflect` on `ScalingMode`
* Derive `FromReflect` on `DepthCalculation`
## Migration Guide
* Enums no longer need to be treated as values and usages of `#[reflect_value(...)]` can be removed or replaced by `#[reflect(...)]`
* Enums (including `Option<T>`) now take a different format when serializing. The format is described above, but this may cause issues for existing scenes that make use of enums.
---
Also shout out to @nicopap for helping clean up some of the code here! It's a big feature so help like this is really appreciated!
Co-authored-by: Gino Valente <gino.valente.code@gmail.com>
# Objective
Some generic types like `Option<T>`, `Vec<T>` and `HashMap<K, V>` implement `Reflect` when where their generic types `T`/`K`/`V` implement `Serialize + for<'de> Deserialize<'de>`.
This is so that in their `GetTypeRegistration` impl they can insert the `ReflectSerialize` and `ReflectDeserialize` type data structs.
This has the annoying side effect that if your struct contains a `Option<NonSerdeStruct>` you won't be able to derive reflect (https://github.com/bevyengine/bevy/issues/4054).
## Solution
- remove the `Serialize + Deserialize` bounds on wrapper types
- this means that `ReflectSerialize` and `ReflectDeserialize` will no longer be inserted even for `.register::<Option<DoesImplSerde>>()`
- add `register_type_data<T, D>` shorthand for `registry.get_mut(T).insert(D::from_type<T>())`
- require users to register their specific generic types **and the serde types** separately like
```rust
.register_type::<Option<String>>()
.register_type_data::<Option<String>, ReflectSerialize>()
.register_type_data::<Option<String>, ReflectDeserialize>()
```
I believe this is the best we can do for extensibility and convenience without specialization.
## Changelog
- `.register_type` for generic types like `Option<T>`, `Vec<T>`, `HashMap<K, V>` will no longer insert `ReflectSerialize` and `ReflectDeserialize` type data. Instead you need to register it separately for concrete generic types like so:
```rust
.register_type::<Option<String>>()
.register_type_data::<Option<String>, ReflectSerialize>()
.register_type_data::<Option<String>, ReflectDeserialize>()
```
TODO: more docs and tweaks to the scene example to demonstrate registering generic types.
# Objective
https://github.com/bevyengine/bevy/pull/4447 adds functions that can fetch resources/components as `*const ()` ptr by providing the `ComponentId`. This alone is not enough for them to be usable safely with reflection, because there is no general way to go from the raw pointer to a `&dyn Reflect` which is the pointer + a pointer to the VTable of the `Reflect` impl.
By adding a `ReflectFromPtr` type that is included in the type type registration when deriving `Reflect`, safe functions can be implemented in scripting languages that don't assume a type layout and can access the component data via reflection:
```rust
#[derive(Reflect)]
struct StringResource {
value: String
}
```
```lua
local res_id = world:resource_id_by_name("example::StringResource")
local res = world:resource(res_id)
print(res.value)
```
## Solution
1. add a `ReflectFromPtr` type with a `FromType<T: Reflect>` implementation and the following methods:
- ` pub unsafe fn as_reflect_ptr<'a>(&self, val: Ptr<'a>) -> &'a dyn Reflect`
- ` pub unsafe fn as_reflect_ptr_mut<'a>(&self, val: PtrMut<'a>) -> &'a mud dyn Reflect`
Safety requirements of the methods are that you need to check that the `ReflectFromPtr` was constructed for the correct type.
2. add that type to the `TypeRegistration` in the `GetTypeRegistration` impl generated by `#[derive(Reflect)]`.
This is different to other reflected traits because it doesn't need `#[reflect(ReflectReflectFromPtr)]` which IMO should be there by default.
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- To implement `Reflect` for more glam types.
## Solution
insert `impl_reflect_struct` invocations for more glam types. I am not sure about the boolean vectors, since none of them implement `Serde::Serialize/Deserialize`, and the SIMD versions don't have public fields.
I do still think implementing reflection is useful for BVec's since then they can be incorporated into `Reflect`'ed components and set dynamically even if as a whole + it's more consistent.
## Changelog
Implemented `Reflect` for the following types
- BVec2
- BVec3
- **BVec3A** (on simd supported platforms only)
- BVec4
- **BVec4A** (on simd supported platforms only)
- Mat2
- Mat3A
- DMat2
- Affine2
- Affine3A
- DAffine2
- DAffine3
- EulerRot
# Objective
This is a rebase of #3701 which is currently scheduled for 0.8 but is marked for adoption.
> Fixes https://github.com/bevyengine/bevy/discussions/3609
## Solution
> - add an `insert_boxed()` method on the `Map` trait
> - implement it for `HashMap` using a new `FromReflect` generic bound
> - add a `map_apply()` helper method to implement `Map::apply()`, that inserts new values instead of ignoring them
---
## Changelog
TODO
Co-authored-by: james7132 <contact@jamessliu.com>
# Objective
Currently, `Reflect` is unsafe to implement because of a contract in which `any` and `any_mut` must return `self`, or `downcast` will cause UB. This PR makes `Reflect` safe, makes `downcast` not use unsafe, and eliminates this contract.
## Solution
This PR adds a method to `Reflect`, `any`. It also renames the old `any` to `as_any`.
`any` now takes a `Box<Self>` and returns a `Box<dyn Any>`.
---
## Changelog
### Added:
- `any()` method
- `represents()` method
### Changed:
- `Reflect` is now a safe trait
- `downcast()` is now safe
- The old `any` is now called `as_any`, and `any_mut` is now `as_mut_any`
## Migration Guide
- Reflect derives should not have to change anything
- Manual reflect impls will need to remove the `unsafe` keyword, add `any()` implementations, and rename the old `any` and `any_mut` to `as_any` and `as_mut_any`.
- Calls to `any`/`any_mut` must be changed to `as_any`/`as_mut_any`
## Points of discussion:
- Should renaming `any` be avoided and instead name the new method `any_box`?
- ~~Could there be a performance regression from avoiding the unsafe? I doubt it, but this change does seem to introduce redundant checks.~~
- ~~Could/should `is` and `type_id()` be implemented differently? For example, moving `is` onto `Reflect` as an `fn(&self, TypeId) -> bool`~~
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
# Objective
> Resolves#4504
It can be helpful to have access to type information without requiring an instance of that type. Especially for `Reflect`, a lot of the gathered type information is known at compile-time and should not necessarily require an instance.
## Solution
Created a dedicated `TypeInfo` enum to store static type information. All types that derive `Reflect` now also implement the newly created `Typed` trait:
```rust
pub trait Typed: Reflect {
fn type_info() -> &'static TypeInfo;
}
```
> Note: This trait was made separate from `Reflect` due to `Sized` restrictions.
If you only have access to a `dyn Reflect`, just call `.get_type_info()` on it. This new trait method on `Reflect` should return the same value as if you had called it statically.
If all you have is a `TypeId` or type name, you can get the `TypeInfo` directly from the registry using the `TypeRegistry::get_type_info` method (assuming it was registered).
### Usage
Below is an example of working with `TypeInfo`. As you can see, we don't have to generate an instance of `MyTupleStruct` in order to get this information.
```rust
#[derive(Reflect)]
struct MyTupleStruct(usize, i32, MyStruct);
let info = MyTupleStruct::type_info();
if let TypeInfo::TupleStruct(info) = info {
assert!(info.is::<MyTupleStruct>());
assert_eq!(std::any::type_name::<MyTupleStruct>(), info.type_name());
assert!(info.field_at(1).unwrap().is::<i32>());
} else {
panic!("Expected `TypeInfo::TupleStruct`");
}
```
### Manual Implementations
It's not recommended to manually implement `Typed` yourself, but if you must, you can use the `TypeInfoCell` to automatically create and manage the static `TypeInfo`s for you (which is very helpful for blanket/generic impls):
```rust
use bevy_reflect::{Reflect, TupleStructInfo, TypeInfo, UnnamedField};
use bevy_reflect::utility::TypeInfoCell;
struct Foo<T: Reflect>(T);
impl<T: Reflect> Typed for Foo<T> {
fn type_info() -> &'static TypeInfo {
static CELL: TypeInfoCell = TypeInfoCell::generic();
CELL.get_or_insert::<Self, _>(|| {
let fields = [UnnamedField:🆕:<T>()];
let info = TupleStructInfo:🆕:<Self>(&fields);
TypeInfo::TupleStruct(info)
})
}
}
```
## Benefits
One major benefit is that this opens the door to other serialization methods. Since we can get all the type info at compile time, we can know how to properly deserialize something like:
```rust
#[derive(Reflect)]
struct MyType {
foo: usize,
bar: Vec<String>
}
// RON to be deserialized:
(
type: "my_crate::MyType", // <- We now know how to deserialize the rest of this object
value: {
// "foo" is a value type matching "usize"
"foo": 123,
// "bar" is a list type matching "Vec<String>" with item type "String"
"bar": ["a", "b", "c"]
}
)
```
Not only is this more compact, but it has better compatibility (we can change the type of `"foo"` to `i32` without having to update our serialized data).
Of course, serialization/deserialization strategies like this may need to be discussed and fully considered before possibly making a change. However, we will be better equipped to do that now that we can access type information right from the registry.
## Discussion
Some items to discuss:
1. Duplication. There's a bit of overlap with the existing traits/structs since they require an instance of the type while the type info structs do not (for example, `Struct::field_at(&self, index: usize)` and `StructInfo::field_at(&self, index: usize)`, though only `StructInfo` is accessible without an instance object). Is this okay, or do we want to handle it in another way?
2. Should `TypeInfo::Dynamic` be removed? Since the dynamic types don't have type information available at runtime, we could consider them `TypeInfo::Value`s (or just even just `TypeInfo::Struct`). The intention with `TypeInfo::Dynamic` was to keep the distinction from these dynamic types and actual structs/values since users might incorrectly believe the methods of the dynamic type's info struct would map to some contained data (which isn't possible statically).
4. General usefulness of this change, including missing/unnecessary parts.
5. Possible changes to the scene format? (One possible issue with changing it like in the example above might be that we'd have to be careful when handling generic or trait object types.)
## Compile Tests
I ran a few tests to compare compile times (as suggested [here](https://github.com/bevyengine/bevy/pull/4042#discussion_r876408143)). I toggled `Reflect` and `FromReflect` derive macros using `cfg_attr` for both this PR (aa5178e773) and main (c309acd432).
<details>
<summary>See More</summary>
The test project included 250 of the following structs (as well as a few other structs):
```rust
#[derive(Default)]
#[cfg_attr(feature = "reflect", derive(Reflect))]
#[cfg_attr(feature = "from_reflect", derive(FromReflect))]
pub struct Big001 {
inventory: Inventory,
foo: usize,
bar: String,
baz: ItemDescriptor,
items: [Item; 20],
hello: Option<String>,
world: HashMap<i32, String>,
okay: (isize, usize, /* wesize */),
nope: ((String, String), (f32, f32)),
blah: Cow<'static, str>,
}
```
> I don't know if the compiler can optimize all these duplicate structs away, but I think it's fine either way. We're comparing times, not finding the absolute worst-case time.
I only ran each build 3 times using `cargo build --timings` (thank you @devil-ira), each of which were preceeded by a `cargo clean --package bevy_reflect_compile_test`.
Here are the times I got:
| Test | Test 1 | Test 2 | Test 3 | Average |
| -------------------------------- | ------ | ------ | ------ | ------- |
| Main | 1.7s | 3.1s | 1.9s | 2.33s |
| Main + `Reflect` | 8.3s | 8.6s | 8.1s | 8.33s |
| Main + `Reflect` + `FromReflect` | 11.6s | 11.8s | 13.8s | 12.4s |
| PR | 3.5s | 1.8s | 1.9s | 2.4s |
| PR + `Reflect` | 9.2s | 8.8s | 9.3s | 9.1s |
| PR + `Reflect` + `FromReflect` | 12.9s | 12.3s | 12.5s | 12.56s |
</details>
---
## Future Work
Even though everything could probably be made `const`, we unfortunately can't. This is because `TypeId::of::<T>()` is not yet `const` (see https://github.com/rust-lang/rust/issues/77125). When it does get stabilized, it would probably be worth coming back and making things `const`.
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
`bevy_reflect` as different kinds of reflected types (each with their own trait), `trait Struct: Reflect`, `trait List: Reflect`, `trait Map: Reflect`, ...
Types that don't fit either of those are called reflect value types, they are opaque and can't be deconstructed further.
`bevy_reflect` can serialize `dyn Reflect` values. Any container types (struct, list, map) get deconstructed and their elements serialized separately, which can all happen without serde being involved ever (happens [here](https://github.com/bevyengine/bevy/blob/main/crates/bevy_reflect/src/serde/ser.rs#L50-L85=)).
The only point at which we require types to be serde-serializable is for *value types* (happens [here](https://github.com/bevyengine/bevy/blob/main/crates/bevy_reflect/src/serde/ser.rs#L104=)).
So reflect array serializing is solved, since arrays are container types which don't require serde.
#1213 also introduced added the `serialize` method and `Serialize` impls for `dyn Array` and `DynamicArray` which use their element's `Reflect::serializable` function. This is 1. unnecessary, because it is not used for array serialization, and 2. annoying for removing the `Serialize` bound on container types, because these impls don't have access to the `TypeRegistry`, so we can't move the serialization code there.
# Solution
Remove these impls and `fn serialize`. It's not used and annoying for other changes.
# Objective
Debugging reflected types can be somewhat frustrating since all `dyn Reflect` trait objects return something like `Reflect(core::option::Option<alloc::string::String>)`.
It would be much nicer to be able to see the actual value— or even use a custom `Debug` implementation.
## Solution
Added `Reflect::debug` which allows users to customize the debug output. It sets defaults for all `ReflectRef` subtraits and falls back to `Reflect(type_name)` if no `Debug` implementation was registered.
To register a custom `Debug` impl, users can add `#[reflect(Debug)]` like they can with other traits.
### Example
Using the following structs:
```rust
#[derive(Reflect)]
pub struct Foo {
a: usize,
nested: Bar,
#[reflect(ignore)]
_ignored: NonReflectedValue,
}
#[derive(Reflect)]
pub struct Bar {
value: Vec2,
tuple_value: (i32, String),
list_value: Vec<usize>,
// We can't determine debug formatting for Option<T> yet
unknown_value: Option<String>,
custom_debug: CustomDebug
}
#[derive(Reflect)]
#[reflect(Debug)]
struct CustomDebug;
impl Debug for CustomDebug {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
write!(f, "This is a custom debug!")
}
}
pub struct NonReflectedValue {
_a: usize,
}
```
We can do:
```rust
let value = Foo {
a: 1,
_ignored: NonReflectedValue { _a: 10 },
nested: Bar {
value: Vec2::new(1.23, 3.21),
tuple_value: (123, String::from("Hello")),
list_value: vec![1, 2, 3],
unknown_value: Some(String::from("World")),
custom_debug: CustomDebug
},
};
let reflected_value: &dyn Reflect = &value;
println!("{:#?}", reflected_value)
```
Which results in:
```rust
Foo {
a: 2,
nested: Bar {
value: Vec2(
1.23,
3.21,
),
tuple_value: (
123,
"Hello",
),
list_value: [
1,
2,
3,
],
unknown_value: Reflect(core::option::Option<alloc::string::String>),
custom_debug: This is a custom debug!,
},
}
```
Notice that neither `Foo` nor `Bar` implement `Debug`, yet we can still deduce it. This might be a concern if we're worried about leaking internal values. If it is, we might want to consider a way to exclude fields (possibly with a `#[reflect(hide)]` macro) or make it purely opt in (as opposed to the default implementation automatically handled by ReflectRef subtraits).
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
# Objective
Quick followup to #4712.
While updating some [other PRs](https://github.com/bevyengine/bevy/pull/4218), I realized the `ReflectTraits` struct could be improved. The issue with the current implementation is that `ReflectTraits::get_xxx_impl(...)` returns just the _logic_ to the corresponding `Reflect` trait method, rather than the entire function.
This makes it slightly more annoying to manage since the variable names need to be consistent across files. For example, `get_partial_eq_impl` uses a `value` variable. But the name "value" isn't defined in the `get_partial_eq_impl` method, it's defined in three other methods in a completely separate file.
It's not likely to cause any bugs if we keep it as it is since differing variable names will probably just result in a compile error (except in very particular cases). But it would be useful to someone who wanted to edit/add/remove a method.
## Solution
Made `get_hash_impl`, `get_partial_eq_impl` and `get_serialize_impl` return the entire method implementation for `reflect_hash`, `reflect_partial_eq`, and `serializable`, respectively.
As a result of this, those three `Reflect` methods were also given default implementations. This was fairly simple to do since all three could just be made to return `None`.
---
## Changelog
* Small cleanup/refactor to `ReflectTraits` in `bevy_reflect_derive`
* Gave `Reflect::reflect_hash`, `Reflect::reflect_partial_eq`, and `Reflect::serializable` default implementations
# Objective
> ℹ️ **Note**: This is a rebased version of #2383. A large portion of it has not been touched (only a few minor changes) so that any additional discussion may happen here. All credit should go to @NathanSWard for their work on the original PR.
- Currently reflection is not supported for arrays.
- Fixes#1213
## Solution
* Implement reflection for arrays via the `Array` trait.
* Note, `Array` is different from `List` in the way that you cannot push elements onto an array as they are statically sized.
* Now `List` is defined as a sub-trait of `Array`.
---
## Changelog
* Added the `Array` reflection trait
* Allows arrays up to length 32 to be reflected via the `Array` trait
## Migration Guide
* The `List` trait now has the `Array` supertrait. This means that `clone_dynamic` will need to specify which version to use:
```rust
// Before
let cloned = my_list.clone_dynamic();
// After
let cloned = List::clone_dynamic(&my_list);
```
* All implementers of `List` will now need to implement `Array` (this mostly involves moving the existing methods to the `Array` impl)
Co-authored-by: NathanW <nathansward@comcast.net>
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
Relevant issue: #4474
Currently glam types implement Reflect as a value, which is problematic for reflection, making scripting/editor work much more difficult. This PR re-implements them as structs.
## Solution
Added a new proc macro, `impl_reflect_struct`, which replaces `impl_reflect_value` and `impl_from_reflect_value` for glam types. This macro could also be used for other types, but I don't know of any that would require it. It's specifically useful for foreign types that cannot derive Reflect normally.
---
## Changelog
### Added
- `impl_reflect_struct` proc macro
### Changed
- Glam reflect impls have been replaced with `impl_reflect_struct`
- from_reflect's `impl_struct` altered to take an optional custom constructor, allowing non-default non-constructible foreign types to use it
- Calls to `impl_struct` altered to conform to new signature
- Altered glam types (All vec/mat combinations) have a different serialization structure, as they are reflected differently now.
## Migration Guide
This will break altered glam types serialized to RON scenes, as they will expect to be serialized/deserialized as structs rather than values now. A future PR to add custom serialization for non-value types is likely on the way to restore previous behavior. Additionally, calls to `impl_struct` must add a `None` parameter to the end of the call to restore previous behavior.
Co-authored-by: PROMETHIA-27 <42193387+PROMETHIA-27@users.noreply.github.com>
# Objective
Comparing two reflected floating points would always fail:
```rust
let a: &dyn Reflect = &1.23_f32;
let b: &dyn Reflect = &1.23_f32;
// Panics:
assert!(a.reflect_partial_eq(b).unwrap_or_default());
```
The comparison returns `None` since `f32` (and `f64`) does not have a reflected `PartialEq` implementation.
## Solution
Include `PartialEq` in the `impl_reflect_value!` macro call for both `f32` and `f64`.
`Hash` is still excluded since neither implement `Hash`.
Also added equality tests for some of the common types from `std` (including `f32`).
# Objective
Trait objects that have `Reflect` as a supertrait cannot be upcast to a `dyn Reflect`.
Attempting something like:
```rust
trait MyTrait: Reflect {
// ...
}
fn foo(value: &dyn MyTrait) {
let reflected = value as &dyn Reflect; // Error!
// ...
}
```
Results in `error[E0658]: trait upcasting coercion is experimental`.
The reason this is important is that a lot of `bevy_reflect` methods require a `&dyn Reflect`. This is trivial with concrete types, but if we don't know the concrete type (we only have the trait object), we can't use these methods. For example, we couldn't create a `ReflectSerializer` for the type since it expects a `&dyn Reflect` value— even though we should be able to.
## Solution
Add `as_reflect` and `as_reflect_mut` to `Reflect` to allow upcasting to a `dyn Reflect`:
```rust
trait MyTrait: Reflect {
// ...
}
fn foo(value: &dyn MyTrait) {
let reflected = value.as_reflect();
// ...
}
```
## Alternatives
We could defer this type of logic to the crate/user. They can add these methods to their trait in the same exact way we do here. The main benefit of doing it ourselves is it makes things convenient for them (especially when using the derive macro).
We could also create an `AsReflect` trait with a blanket impl over all reflected types, however, I could not get that to work for trait objects since they aren't sized.
---
## Changelog
- Added trait method `Reflect::as_reflect(&self)`
- Added trait method `Reflect::as_reflect_mut(&mut self)`
## Migration Guide
- Manual implementors of `Reflect` will need to add implementations for the methods above (this should be pretty easy as most cases just need to return `self`)
## Objective
A step towards `f64` `Transform`s (#1680). For now, I am rolling my own `Transform`. But in order to derive Reflect, I specifically need `DQuat` to be reflectable.
```rust
#[derive(Component, Reflect, Copy, Clone, PartialEq, Debug)]
#[reflect(Component, PartialEq)]
pub struct Transform {
pub translation: DVec3,
pub rotation: DQuat, // error: the trait `bevy::prelude::Reflect` is not implemented for `DQuat`
pub scale: DVec3,
}
```
## Solution
I have added a `DQuat` impl for `Reflect` alongside the other glam impls. I've also added impls for `DMat3` and `DMat4` to match.
# Objective
`Vec3A` is does not implement `Reflect`. This is generally useful for `Reflect` derives using `Vec3A` fields, and may speed up some animation blending use cases.
## Solution
Extend the existing macro uses to include `Vec3A`.
For some keys, it is too expensive to hash them on every lookup. Historically in Bevy, we have regrettably done the "wrong" thing in these cases (pre-computing hashes, then re-hashing them) because Rust's built in hashed collections don't give us the tools we need to do otherwise. Doing this is "wrong" because two different values can result in the same hash. Hashed collections generally get around this by falling back to equality checks on hash collisions. You can't do that if the key _is_ the hash. Additionally, re-hashing a hash increase the odds of collision!
#3959 needs pre-hashing to be viable, so I decided to finally properly solve the problem. The solution involves two different changes:
1. A new generalized "pre-hashing" solution in bevy_utils: `Hashed<T>` types, which store a value alongside a pre-computed hash. And `PreHashMap<K, V>` (which uses `Hashed<T>` internally) . `PreHashMap` is just an alias for a normal HashMap that uses `Hashed<T>` as the key and a new `PassHash` implementation as the Hasher.
2. Replacing the `std::collections` re-exports in `bevy_utils` with equivalent `hashbrown` impls. Avoiding re-hashes requires the `raw_entry_mut` api, which isn't stabilized yet (and may never be ... `entry_ref` has favor now, but also isn't available yet). If std's HashMap ever provides the tools we need, we can move back to that. The latest version of `hashbrown` adds support for the `entity_ref` api, so we can move to that in preparation for an std migration, if thats the direction they seem to be going in. Note that adding hashbrown doesn't increase our dependency count because it was already in our tree.
In addition to providing these core tools, I also ported the "table identity hashing" in `bevy_ecs` to `raw_entry_mut`, which was a particularly egregious case.
The biggest outstanding case is `AssetPathId`, which stores a pre-hash. We need AssetPathId to be cheaply clone-able (and ideally Copy), but `Hashed<AssetPath>` requires ownership of the AssetPath, which makes cloning ids way more expensive. We could consider doing `Hashed<Arc<AssetPath>>`, but cloning an arc is still a non-trivial expensive that needs to be considered. I would like to handle this in a separate PR. And given that we will be re-evaluating the Bevy Assets implementation in the very near future, I'd prefer to hold off until after that conversation is concluded.
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
Resolves#3277
Currenty if we try to serialize a scene that contains a `Duration` (which is very common, since `Timer` contains one), we get an error saying:
> Type 'core::time::Duration' does not support ReflectValue serialization
## Solution
Let `Duration` implement `SerializeValue`.
Co-authored-by: Jonathan Cornaz <jcornaz@users.noreply.github.com>
Dynamic types (`DynamicStruct`, `DynamicTupleStruct`, `DynamicTuple`, `DynamicList` and `DynamicMap`) are used when deserializing scenes, but currently they can only be applied to existing concrete types. This leads to issues when trying to spawn non trivial deserialized scene.
For components, the issue is avoided by requiring that reflected components implement ~~`FromResources`~~ `FromWorld` (or `Default`). When spawning, a new concrete type is created that way, and the dynamic type is applied to it. Unfortunately, some components don't have any valid implementation of these traits.
In addition, any `Vec` or `HashMap` inside a component will panic when a dynamic type is pushed into it (for instance, `Text` panics when adding a text section).
To solve this issue, this PR adds the `FromReflect` trait that creates a concrete type from a dynamic type that represent it, derives the trait alongside the `Reflect` trait, drops the ~~`FromResources`~~ `FromWorld` requirement on reflected components, ~~and enables reflection for UI and Text bundles~~. It also adds the requirement that fields ignored with `#[reflect(ignore)]` implement `Default`, since we need to initialize them somehow.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
Fixes#1100
Implementors must make sure that `Reflect::any` and `Reflect::any_mut` both return the `self` reference passed in (both for logical correctness and downcast safety).
This is an effort to provide the correct `#[reflect_value(...)]` attributes where they are needed.
Supersedes #1533 and resolves#1528.
---
I am working under the following assumptions (thanks to @bjorn3 and @Davier for advice here):
- Any `enum` that derives `Reflect` and one or more of { `Serialize`, `Deserialize`, `PartialEq`, `Hash` } needs a `#[reflect_value(...)]` attribute containing the same subset of { `Serialize`, `Deserialize`, `PartialEq`, `Hash` } that is present on the derive.
- Same as above for `struct` and `#[reflect(...)]`, respectively.
- If a `struct` is used as a component, it should also have `#[reflect(Component)]`
- All reflected types should be registered in their plugins
I treated the following as components (added `#[reflect(Component)]` if necessary):
- `bevy_render`
- `struct RenderLayers`
- `bevy_transform`
- `struct GlobalTransform`
- `struct Parent`
- `struct Transform`
- `bevy_ui`
- `struct Style`
Not treated as components:
- `bevy_math`
- `struct Size<T>`
- `struct Rect<T>`
- Note: The updates for `Size<T>` and `Rect<T>` in `bevy::math::geometry` required using @Davier's suggestion to add `+ PartialEq` to the trait bound. I then registered the specific types used over in `bevy_ui` such as `Size<Val>`, etc. in `bevy_ui`'s plugin, since `bevy::math` does not contain a plugin.
- `bevy_render`
- `struct Color`
- `struct PipelineSpecialization`
- `struct ShaderSpecialization`
- `enum PrimitiveTopology`
- `enum IndexFormat`
Not Addressed:
- I am not searching for components in Bevy that are _not_ reflected. So if there are components that are not reflected that should be reflected, that will need to be figured out in another PR.
- I only added `#[reflect(...)]` or `#[reflect_value(...)]` entries for the set of four traits { `Serialize`, `Deserialize`, `PartialEq`, `Hash` } _if they were derived via `#[derive(...)]`_. I did not look for manual trait implementations of the same set of four, nor did I consider any traits outside the four. Are those other possibilities something that needs to be looked into?
This pull request is following the discussion on the issue #1127. Additionally, it integrates the change proposed by #1112.
The list of change of this pull request:
* ✨ Add `Timer::times_finished` method that counts the number of wraps for repeating timers.
* ♻️ Refactored `Timer`
* 🐛 Fix a bug where 2 successive calls to `Timer::tick` which makes a repeating timer to finish makes `Timer::just_finished` to return `false` where it should return `true`. Minimal failing example:
```rust
use bevy::prelude::*;
let mut timer: Timer<()> = Timer::from_seconds(1.0, true);
timer.tick(1.5);
assert!(timer.finished());
assert!(timer.just_finished());
timer.tick(1.5);
assert!(timer.finished());
assert!(timer.just_finished()); // <- This fails where it should not
```
* 📚 Add extensive documentation for Timer with doc examples.
* ✨ Add a `Stopwatch` struct similar to `Timer` with extensive doc and tests.
Even if the type specialization is not retained for bevy, the doc, bugfix and added method are worth salvaging 😅.
This is my first PR for bevy, please be kind to me ❤️ .
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Bevy ECS V2
This is a rewrite of Bevy ECS (basically everything but the new executor/schedule, which are already awesome). The overall goal was to improve the performance and versatility of Bevy ECS. Here is a quick bulleted list of changes before we dive into the details:
* Complete World rewrite
* Multiple component storage types:
* Tables: fast cache friendly iteration, slower add/removes (previously called Archetypes)
* Sparse Sets: fast add/remove, slower iteration
* Stateful Queries (caches query results for faster iteration. fragmented iteration is _fast_ now)
* Stateful System Params (caches expensive operations. inspired by @DJMcNab's work in #1364)
* Configurable System Params (users can set configuration when they construct their systems. once again inspired by @DJMcNab's work)
* Archetypes are now "just metadata", component storage is separate
* Archetype Graph (for faster archetype changes)
* Component Metadata
* Configure component storage type
* Retrieve information about component size/type/name/layout/send-ness/etc
* Components are uniquely identified by a densely packed ComponentId
* TypeIds are now totally optional (which should make implementing scripting easier)
* Super fast "for_each" query iterators
* Merged Resources into World. Resources are now just a special type of component
* EntityRef/EntityMut builder apis (more efficient and more ergonomic)
* Fast bitset-backed `Access<T>` replaces old hashmap-based approach everywhere
* Query conflicts are determined by component access instead of archetype component access (to avoid random failures at runtime)
* With/Without are still taken into account for conflicts, so this should still be comfy to use
* Much simpler `IntoSystem` impl
* Significantly reduced the amount of hashing throughout the ecs in favor of Sparse Sets (indexed by densely packed ArchetypeId, ComponentId, BundleId, and TableId)
* Safety Improvements
* Entity reservation uses a normal world reference instead of unsafe transmute
* QuerySets no longer transmute lifetimes
* Made traits "unsafe" where relevant
* More thorough safety docs
* WorldCell
* Exposes safe mutable access to multiple resources at a time in a World
* Replaced "catch all" `System::update_archetypes(world: &World)` with `System::new_archetype(archetype: &Archetype)`
* Simpler Bundle implementation
* Replaced slow "remove_bundle_one_by_one" used as fallback for Commands::remove_bundle with fast "remove_bundle_intersection"
* Removed `Mut<T>` query impl. it is better to only support one way: `&mut T`
* Removed with() from `Flags<T>` in favor of `Option<Flags<T>>`, which allows querying for flags to be "filtered" by default
* Components now have is_send property (currently only resources support non-send)
* More granular module organization
* New `RemovedComponents<T>` SystemParam that replaces `query.removed::<T>()`
* `world.resource_scope()` for mutable access to resources and world at the same time
* WorldQuery and QueryFilter traits unified. FilterFetch trait added to enable "short circuit" filtering. Auto impled for cases that don't need it
* Significantly slimmed down SystemState in favor of individual SystemParam state
* System Commands changed from `commands: &mut Commands` back to `mut commands: Commands` (to allow Commands to have a World reference)
Fixes#1320
## `World` Rewrite
This is a from-scratch rewrite of `World` that fills the niche that `hecs` used to. Yes, this means Bevy ECS is no longer a "fork" of hecs. We're going out our own!
(the only shared code between the projects is the entity id allocator, which is already basically ideal)
A huge shout out to @SanderMertens (author of [flecs](https://github.com/SanderMertens/flecs)) for sharing some great ideas with me (specifically hybrid ecs storage and archetype graphs). He also helped advise on a number of implementation details.
## Component Storage (The Problem)
Two ECS storage paradigms have gained a lot of traction over the years:
* **Archetypal ECS**:
* Stores components in "tables" with static schemas. Each "column" stores components of a given type. Each "row" is an entity.
* Each "archetype" has its own table. Adding/removing an entity's component changes the archetype.
* Enables super-fast Query iteration due to its cache-friendly data layout
* Comes at the cost of more expensive add/remove operations for an Entity's components, because all components need to be copied to the new archetype's "table"
* **Sparse Set ECS**:
* Stores components of the same type in densely packed arrays, which are sparsely indexed by densely packed unsigned integers (Entity ids)
* Query iteration is slower than Archetypal ECS because each entity's component could be at any position in the sparse set. This "random access" pattern isn't cache friendly. Additionally, there is an extra layer of indirection because you must first map the entity id to an index in the component array.
* Adding/removing components is a cheap, constant time operation
Bevy ECS V1, hecs, legion, flec, and Unity DOTS are all "archetypal ecs-es". I personally think "archetypal" storage is a good default for game engines. An entity's archetype doesn't need to change frequently in general, and it creates "fast by default" query iteration (which is a much more common operation). It is also "self optimizing". Users don't need to think about optimizing component layouts for iteration performance. It "just works" without any extra boilerplate.
Shipyard and EnTT are "sparse set ecs-es". They employ "packing" as a way to work around the "suboptimal by default" iteration performance for specific sets of components. This helps, but I didn't think this was a good choice for a general purpose engine like Bevy because:
1. "packs" conflict with each other. If bevy decides to internally pack the Transform and GlobalTransform components, users are then blocked if they want to pack some custom component with Transform.
2. users need to take manual action to optimize
Developers selecting an ECS framework are stuck with a hard choice. Select an "archetypal" framework with "fast iteration everywhere" but without the ability to cheaply add/remove components, or select a "sparse set" framework to cheaply add/remove components but with slower iteration performance.
## Hybrid Component Storage (The Solution)
In Bevy ECS V2, we get to have our cake and eat it too. It now has _both_ of the component storage types above (and more can be added later if needed):
* **Tables** (aka "archetypal" storage)
* The default storage. If you don't configure anything, this is what you get
* Fast iteration by default
* Slower add/remove operations
* **Sparse Sets**
* Opt-in
* Slower iteration
* Faster add/remove operations
These storage types complement each other perfectly. By default Query iteration is fast. If developers know that they want to add/remove a component at high frequencies, they can set the storage to "sparse set":
```rust
world.register_component(
ComponentDescriptor:🆕:<MyComponent>(StorageType::SparseSet)
).unwrap();
```
## Archetypes
Archetypes are now "just metadata" ... they no longer store components directly. They do store:
* The `ComponentId`s of each of the Archetype's components (and that component's storage type)
* Archetypes are uniquely defined by their component layouts
* For example: entities with "table" components `[A, B, C]` _and_ "sparse set" components `[D, E]` will always be in the same archetype.
* The `TableId` associated with the archetype
* For now each archetype has exactly one table (which can have no components),
* There is a 1->Many relationship from Tables->Archetypes. A given table could have any number of archetype components stored in it:
* Ex: an entity with "table storage" components `[A, B, C]` and "sparse set" components `[D, E]` will share the same `[A, B, C]` table as an entity with `[A, B, C]` table component and `[F]` sparse set components.
* This 1->Many relationship is how we preserve fast "cache friendly" iteration performance when possible (more on this later)
* A list of entities that are in the archetype and the row id of the table they are in
* ArchetypeComponentIds
* unique densely packed identifiers for (ArchetypeId, ComponentId) pairs
* used by the schedule executor for cheap system access control
* "Archetype Graph Edges" (see the next section)
## The "Archetype Graph"
Archetype changes in Bevy (and a number of other archetypal ecs-es) have historically been expensive to compute. First, you need to allocate a new vector of the entity's current component ids, add or remove components based on the operation performed, sort it (to ensure it is order-independent), then hash it to find the archetype (if it exists). And thats all before we get to the _already_ expensive full copy of all components to the new table storage.
The solution is to build a "graph" of archetypes to cache these results. @SanderMertens first exposed me to the idea (and he got it from @gjroelofs, who came up with it). They propose adding directed edges between archetypes for add/remove component operations. If `ComponentId`s are densely packed, you can use sparse sets to cheaply jump between archetypes.
Bevy takes this one step further by using add/remove `Bundle` edges instead of `Component` edges. Bevy encourages the use of `Bundles` to group add/remove operations. This is largely for "clearer game logic" reasons, but it also helps cut down on the number of archetype changes required. `Bundles` now also have densely-packed `BundleId`s. This allows us to use a _single_ edge for each bundle operation (rather than needing to traverse N edges ... one for each component). Single component operations are also bundles, so this is strictly an improvement over a "component only" graph.
As a result, an operation that used to be _heavy_ (both for allocations and compute) is now two dirt-cheap array lookups and zero allocations.
## Stateful Queries
World queries are now stateful. This allows us to:
1. Cache archetype (and table) matches
* This resolves another issue with (naive) archetypal ECS: query performance getting worse as the number of archetypes goes up (and fragmentation occurs).
2. Cache Fetch and Filter state
* The expensive parts of fetch/filter operations (such as hashing the TypeId to find the ComponentId) now only happen once when the Query is first constructed
3. Incrementally build up state
* When new archetypes are added, we only process the new archetypes (no need to rebuild state for old archetypes)
As a result, the direct `World` query api now looks like this:
```rust
let mut query = world.query::<(&A, &mut B)>();
for (a, mut b) in query.iter_mut(&mut world) {
}
```
Requiring `World` to generate stateful queries (rather than letting the `QueryState` type be constructed separately) allows us to ensure that _all_ queries are properly initialized (and the relevant world state, such as ComponentIds). This enables QueryState to remove branches from its operations that check for initialization status (and also enables query.iter() to take an immutable world reference because it doesn't need to initialize anything in world).
However in systems, this is a non-breaking change. State management is done internally by the relevant SystemParam.
## Stateful SystemParams
Like Queries, `SystemParams` now also cache state. For example, `Query` system params store the "stateful query" state mentioned above. Commands store their internal `CommandQueue`. This means you can now safely use as many separate `Commands` parameters in your system as you want. `Local<T>` system params store their `T` value in their state (instead of in Resources).
SystemParam state also enabled a significant slim-down of SystemState. It is much nicer to look at now.
Per-SystemParam state naturally insulates us from an "aliased mut" class of errors we have hit in the past (ex: using multiple `Commands` system params).
(credit goes to @DJMcNab for the initial idea and draft pr here #1364)
## Configurable SystemParams
@DJMcNab also had the great idea to make SystemParams configurable. This allows users to provide some initial configuration / values for system parameters (when possible). Most SystemParams have no config (the config type is `()`), but the `Local<T>` param now supports user-provided parameters:
```rust
fn foo(value: Local<usize>) {
}
app.add_system(foo.system().config(|c| c.0 = Some(10)));
```
## Uber Fast "for_each" Query Iterators
Developers now have the choice to use a fast "for_each" iterator, which yields ~1.5-3x iteration speed improvements for "fragmented iteration", and minor ~1.2x iteration speed improvements for unfragmented iteration.
```rust
fn system(query: Query<(&A, &mut B)>) {
// you now have the option to do this for a speed boost
query.for_each_mut(|(a, mut b)| {
});
// however normal iterators are still available
for (a, mut b) in query.iter_mut() {
}
}
```
I think in most cases we should continue to encourage "normal" iterators as they are more flexible and more "rust idiomatic". But when that extra "oomf" is needed, it makes sense to use `for_each`.
We should also consider using `for_each` for internal bevy systems to give our users a nice speed boost (but that should be a separate pr).
## Component Metadata
`World` now has a `Components` collection, which is accessible via `world.components()`. This stores mappings from `ComponentId` to `ComponentInfo`, as well as `TypeId` to `ComponentId` mappings (where relevant). `ComponentInfo` stores information about the component, such as ComponentId, TypeId, memory layout, send-ness (currently limited to resources), and storage type.
## Significantly Cheaper `Access<T>`
We used to use `TypeAccess<TypeId>` to manage read/write component/archetype-component access. This was expensive because TypeIds must be hashed and compared individually. The parallel executor got around this by "condensing" type ids into bitset-backed access types. This worked, but it had to be re-generated from the `TypeAccess<TypeId>`sources every time archetypes changed.
This pr removes TypeAccess in favor of faster bitset access everywhere. We can do this thanks to the move to densely packed `ComponentId`s and `ArchetypeComponentId`s.
## Merged Resources into World
Resources had a lot of redundant functionality with Components. They stored typed data, they had access control, they had unique ids, they were queryable via SystemParams, etc. In fact the _only_ major difference between them was that they were unique (and didn't correlate to an entity).
Separate resources also had the downside of requiring a separate set of access controls, which meant the parallel executor needed to compare more bitsets per system and manage more state.
I initially got the "separate resources" idea from `legion`. I think that design was motivated by the fact that it made the direct world query/resource lifetime interactions more manageable. It certainly made our lives easier when using Resources alongside hecs/bevy_ecs. However we already have a construct for safely and ergonomically managing in-world lifetimes: systems (which use `Access<T>` internally).
This pr merges Resources into World:
```rust
world.insert_resource(1);
world.insert_resource(2.0);
let a = world.get_resource::<i32>().unwrap();
let mut b = world.get_resource_mut::<f64>().unwrap();
*b = 3.0;
```
Resources are now just a special kind of component. They have their own ComponentIds (and their own resource TypeId->ComponentId scope, so they don't conflict wit components of the same type). They are stored in a special "resource archetype", which stores components inside the archetype using a new `unique_components` sparse set (note that this sparse set could later be used to implement Tags). This allows us to keep the code size small by reusing existing datastructures (namely Column, Archetype, ComponentFlags, and ComponentInfo). This allows us the executor to use a single `Access<ArchetypeComponentId>` per system. It should also make scripting language integration easier.
_But_ this merge did create problems for people directly interacting with `World`. What if you need mutable access to multiple resources at the same time? `world.get_resource_mut()` borrows World mutably!
## WorldCell
WorldCell applies the `Access<ArchetypeComponentId>` concept to direct world access:
```rust
let world_cell = world.cell();
let a = world_cell.get_resource_mut::<i32>().unwrap();
let b = world_cell.get_resource_mut::<f64>().unwrap();
```
This adds cheap runtime checks (a sparse set lookup of `ArchetypeComponentId` and a counter) to ensure that world accesses do not conflict with each other. Each operation returns a `WorldBorrow<'w, T>` or `WorldBorrowMut<'w, T>` wrapper type, which will release the relevant ArchetypeComponentId resources when dropped.
World caches the access sparse set (and only one cell can exist at a time), so `world.cell()` is a cheap operation.
WorldCell does _not_ use atomic operations. It is non-send, does a mutable borrow of world to prevent other accesses, and uses a simple `Rc<RefCell<ArchetypeComponentAccess>>` wrapper in each WorldBorrow pointer.
The api is currently limited to resource access, but it can and should be extended to queries / entity component access.
## Resource Scopes
WorldCell does not yet support component queries, and even when it does there are sometimes legitimate reasons to want a mutable world ref _and_ a mutable resource ref (ex: bevy_render and bevy_scene both need this). In these cases we could always drop down to the unsafe `world.get_resource_unchecked_mut()`, but that is not ideal!
Instead developers can use a "resource scope"
```rust
world.resource_scope(|world: &mut World, a: &mut A| {
})
```
This temporarily removes the `A` resource from `World`, provides mutable pointers to both, and re-adds A to World when finished. Thanks to the move to ComponentIds/sparse sets, this is a cheap operation.
If multiple resources are required, scopes can be nested. We could also consider adding a "resource tuple" to the api if this pattern becomes common and the boilerplate gets nasty.
## Query Conflicts Use ComponentId Instead of ArchetypeComponentId
For safety reasons, systems cannot contain queries that conflict with each other without wrapping them in a QuerySet. On bevy `main`, we use ArchetypeComponentIds to determine conflicts. This is nice because it can take into account filters:
```rust
// these queries will never conflict due to their filters
fn filter_system(a: Query<&mut A, With<B>>, b: Query<&mut B, Without<B>>) {
}
```
But it also has a significant downside:
```rust
// these queries will not conflict _until_ an entity with A, B, and C is spawned
fn maybe_conflicts_system(a: Query<(&mut A, &C)>, b: Query<(&mut A, &B)>) {
}
```
The system above will panic at runtime if an entity with A, B, and C is spawned. This makes it hard to trust that your game logic will run without crashing.
In this pr, I switched to using `ComponentId` instead. This _is_ more constraining. `maybe_conflicts_system` will now always fail, but it will do it consistently at startup. Naively, it would also _disallow_ `filter_system`, which would be a significant downgrade in usability. Bevy has a number of internal systems that rely on disjoint queries and I expect it to be a common pattern in userspace.
To resolve this, I added a new `FilteredAccess<T>` type, which wraps `Access<T>` and adds with/without filters. If two `FilteredAccess` have with/without values that prove they are disjoint, they will no longer conflict.
## EntityRef / EntityMut
World entity operations on `main` require that the user passes in an `entity` id to each operation:
```rust
let entity = world.spawn((A, )); // create a new entity with A
world.get::<A>(entity);
world.insert(entity, (B, C));
world.insert_one(entity, D);
```
This means that each operation needs to look up the entity location / verify its validity. The initial spawn operation also requires a Bundle as input. This can be awkward when no components are required (or one component is required).
These operations have been replaced by `EntityRef` and `EntityMut`, which are "builder-style" wrappers around world that provide read and read/write operations on a single, pre-validated entity:
```rust
// spawn now takes no inputs and returns an EntityMut
let entity = world.spawn()
.insert(A) // insert a single component into the entity
.insert_bundle((B, C)) // insert a bundle of components into the entity
.id() // id returns the Entity id
// Returns EntityMut (or panics if the entity does not exist)
world.entity_mut(entity)
.insert(D)
.insert_bundle(SomeBundle::default());
{
// returns EntityRef (or panics if the entity does not exist)
let d = world.entity(entity)
.get::<D>() // gets the D component
.unwrap();
// world.get still exists for ergonomics
let d = world.get::<D>(entity).unwrap();
}
// These variants return Options if you want to check existence instead of panicing
world.get_entity_mut(entity)
.unwrap()
.insert(E);
if let Some(entity_ref) = world.get_entity(entity) {
let d = entity_ref.get::<D>().unwrap();
}
```
This _does not_ affect the current Commands api or terminology. I think that should be a separate conversation as that is a much larger breaking change.
## Safety Improvements
* Entity reservation in Commands uses a normal world borrow instead of an unsafe transmute
* QuerySets no longer transmutes lifetimes
* Made traits "unsafe" when implementing a trait incorrectly could cause unsafety
* More thorough safety docs
## RemovedComponents SystemParam
The old approach to querying removed components: `query.removed:<T>()` was confusing because it had no connection to the query itself. I replaced it with the following, which is both clearer and allows us to cache the ComponentId mapping in the SystemParamState:
```rust
fn system(removed: RemovedComponents<T>) {
for entity in removed.iter() {
}
}
```
## Simpler Bundle implementation
Bundles are no longer responsible for sorting (or deduping) TypeInfo. They are just a simple ordered list of component types / data. This makes the implementation smaller and opens the door to an easy "nested bundle" implementation in the future (which i might even add in this pr). Duplicate detection is now done once per bundle type by World the first time a bundle is used.
## Unified WorldQuery and QueryFilter types
(don't worry they are still separate type _parameters_ in Queries .. this is a non-breaking change)
WorldQuery and QueryFilter were already basically identical apis. With the addition of `FetchState` and more storage-specific fetch methods, the overlap was even clearer (and the redundancy more painful).
QueryFilters are now just `F: WorldQuery where F::Fetch: FilterFetch`. FilterFetch requires `Fetch<Item = bool>` and adds new "short circuit" variants of fetch methods. This enables a filter tuple like `(With<A>, Without<B>, Changed<C>)` to stop evaluating the filter after the first mismatch is encountered. FilterFetch is automatically implemented for `Fetch` implementations that return bool.
This forces fetch implementations that return things like `(bool, bool, bool)` (such as the filter above) to manually implement FilterFetch and decide whether or not to short-circuit.
## More Granular Modules
World no longer globs all of the internal modules together. It now exports `core`, `system`, and `schedule` separately. I'm also considering exporting `core` submodules directly as that is still pretty "glob-ey" and unorganized (feedback welcome here).
## Remaining Draft Work (to be done in this pr)
* ~~panic on conflicting WorldQuery fetches (&A, &mut A)~~
* ~~bevy `main` and hecs both currently allow this, but we should protect against it if possible~~
* ~~batch_iter / par_iter (currently stubbed out)~~
* ~~ChangedRes~~
* ~~I skipped this while we sort out #1313. This pr should be adapted to account for whatever we land on there~~.
* ~~The `Archetypes` and `Tables` collections use hashes of sorted lists of component ids to uniquely identify each archetype/table. This hash is then used as the key in a HashMap to look up the relevant ArchetypeId or TableId. (which doesn't handle hash collisions properly)~~
* ~~It is currently unsafe to generate a Query from "World A", then use it on "World B" (despite the api claiming it is safe). We should probably close this gap. This could be done by adding a randomly generated WorldId to each world, then storing that id in each Query. They could then be compared to each other on each `query.do_thing(&world)` operation. This _does_ add an extra branch to each query operation, so I'm open to other suggestions if people have them.~~
* ~~Nested Bundles (if i find time)~~
## Potential Future Work
* Expand WorldCell to support queries.
* Consider not allocating in the empty archetype on `world.spawn()`
* ex: return something like EntityMutUninit, which turns into EntityMut after an `insert` or `insert_bundle` op
* this actually regressed performance last time i tried it, but in theory it should be faster
* Optimize SparseSet::insert (see `PERF` comment on insert)
* Replace SparseArray `Option<T>` with T::MAX to cut down on branching
* would enable cheaper get_unchecked() operations
* upstream fixedbitset optimizations
* fixedbitset could be allocation free for small block counts (store blocks in a SmallVec)
* fixedbitset could have a const constructor
* Consider implementing Tags (archetype-specific by-value data that affects archetype identity)
* ex: ArchetypeA could have `[A, B, C]` table components and `[D(1)]` "tag" component. ArchetypeB could have `[A, B, C]` table components and a `[D(2)]` tag component. The archetypes are different, despite both having D tags because the value inside D is different.
* this could potentially build on top of the `archetype.unique_components` added in this pr for resource storage.
* Consider reverting `all_tuples` proc macro in favor of the old `macro_rules` implementation
* all_tuples is more flexible and produces cleaner documentation (the macro_rules version produces weird type parameter orders due to parser constraints)
* but unfortunately all_tuples also appears to make Rust Analyzer sad/slow when working inside of `bevy_ecs` (does not affect user code)
* Consider "resource queries" and/or "mixed resource and entity component queries" as an alternative to WorldCell
* this is basically just "systems" so maybe it's not worth it
* Add more world ops
* `world.clear()`
* `world.reserve<T: Bundle>(count: usize)`
* Try using the old archetype allocation strategy (allocate new memory on resize and copy everything over). I expect this to improve batch insertion performance at the cost of unbatched performance. But thats just a guess. I'm not an allocation perf pro :)
* Adapt Commands apis for consistency with new World apis
## Benchmarks
key:
* `bevy_old`: bevy `main` branch
* `bevy`: this branch
* `_foreach`: uses an optimized for_each iterator
* ` _sparse`: uses sparse set storage (if unspecified assume table storage)
* `_system`: runs inside a system (if unspecified assume test happens via direct world ops)
### Simple Insert (from ecs_bench_suite)
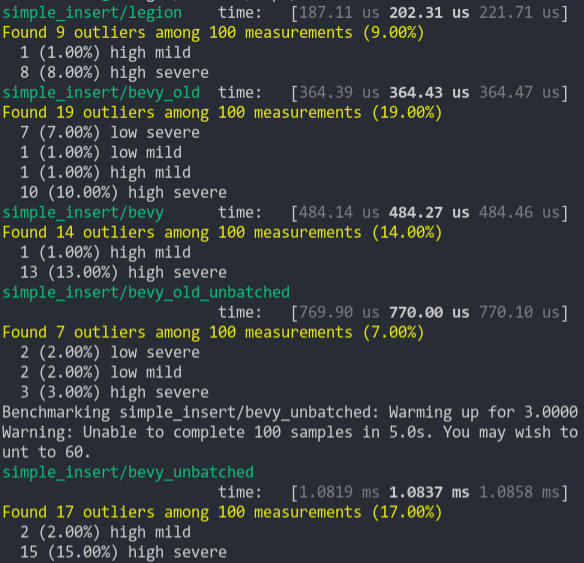
### Simpler Iter (from ecs_bench_suite)
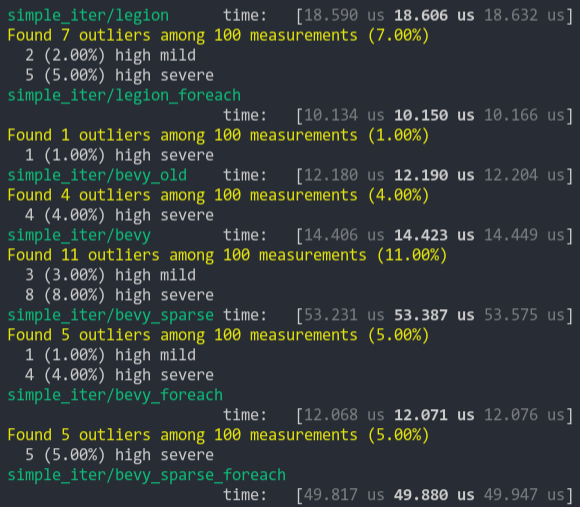
### Fragment Iter (from ecs_bench_suite)
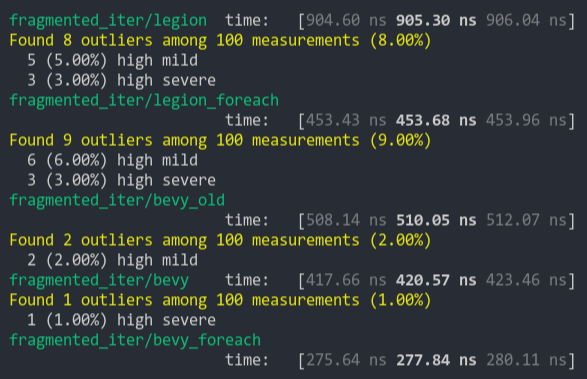
### Sparse Fragmented Iter
Iterate a query that matches 5 entities from a single matching archetype, but there are 100 unmatching archetypes
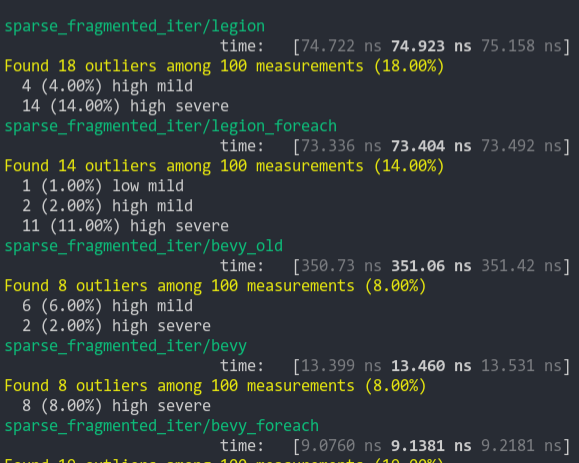
### Schedule (from ecs_bench_suite)
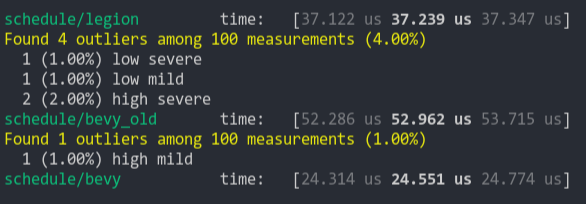
### Add Remove Component (from ecs_bench_suite)
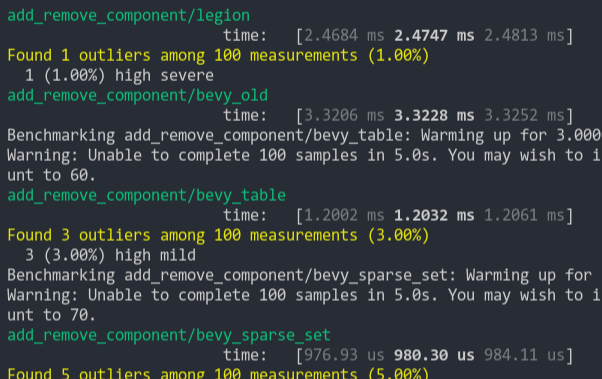
### Add Remove Component Big
Same as the test above, but each entity has 5 "large" matrix components and 1 "large" matrix component is added and removed
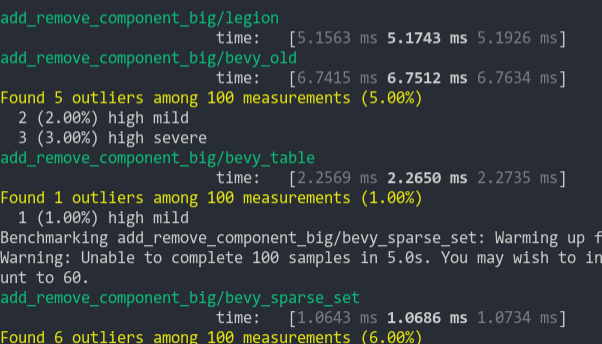
### Get Component
Looks up a single component value a large number of times
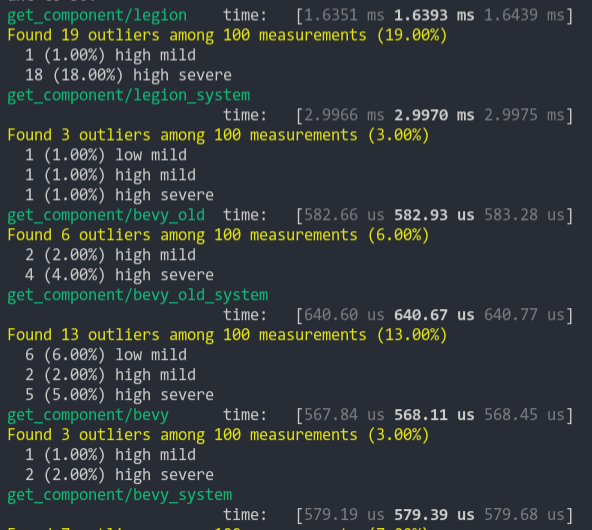
* Rename reflect 'hash' method to 'reflect_hash' to avoid colliding with std:#️⃣:Hash::hash to resolve#943.
* Rename partial_eq to reflect_partial_eq to avoid collisions with implementations of PartialEq on primitives.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}