# Objective
- Fixes#10532
## Solution
I've updated the various `Event` send methods to return the sent
`EventId`(s). Since these methods previously returned nothing, and this
information is cheap to copy, there should be minimal negative
consequences to providing this additional information. In the case of
`send_batch`, an iterator is returned built from `Range` and `Map`,
which only consumes 16 bytes on the stack with no heap allocations for
all batch sizes. As such, the cost of this information is negligible.
These changes are reflected for `EventWriter` and `World`. For `World`,
the return types are optional to account for the possible lack of an
`Events` resource. Again, these methods previously returned no
information, so its inclusion should only be a benefit.
## Usage
Now when sending events, the IDs of those events is available for
immediate use:
```rust
// Example of a request-response system where the requester can track handled requests.
/// A system which can make and track requests
fn requester(
mut requests: EventWriter<Request>,
mut handled: EventReader<Handled>,
mut pending: Local<HashSet<EventId<Request>>>,
) {
// Check status of previous requests
for Handled(id) in handled.read() {
pending.remove(&id);
}
if !pending.is_empty() {
error!("Not all my requests were handled on the previous frame!");
pending.clear();
}
// Send a new request and remember its ID for later
let request_id = requests.send(Request::MyRequest { /* ... */ });
pending.insert(request_id);
}
/// A system which handles requests
fn responder(
mut requests: EventReader<Request>,
mut handled: EventWriter<Handled>,
) {
for (request, id) in requests.read_with_id() {
if handle(request).is_ok() {
handled.send(Handled(id));
}
}
}
```
In the above example, a `requester` system can send request events, and
keep track of which ones are currently pending by `EventId`. Then, a
`responder` system can act on that event, providing the ID as a
reference that the `requester` can use. Before this PR, it was not
trivial for a system sending events to keep track of events by ID. This
is unfortunate, since for a system reading events, it is trivial to
access the ID of a event.
---
## Changelog
- Updated `Events`:
- Added `send_batch`
- Modified `send` to return the sent `EventId`
- Modified `send_default` to return the sent `EventId`
- Updated `EventWriter`
- Modified `send_batch` to return all sent `EventId`s
- Modified `send` to return the sent `EventId`
- Modified `send_default` to return the sent `EventId`
- Updated `World`
- Modified `send_event` to return the sent `EventId` if sent, otherwise
`None`.
- Modified `send_event_default` to return the sent `EventId` if sent,
otherwise `None`.
- Modified `send_event_batch` to return all sent `EventId`s if sent,
otherwise `None`.
- Added unit test `test_send_events_ids` to ensure returned `EventId`s
match the sent `Event`s
- Updated uses of modified methods.
## Migration Guide
### `send` / `send_default` / `send_batch`
For the following methods:
- `Events::send`
- `Events::send_default`
- `Events::send_batch`
- `EventWriter::send`
- `EventWriter::send_default`
- `EventWriter::send_batch`
- `World::send_event`
- `World::send_event_default`
- `World::send_event_batch`
Ensure calls to these methods either handle the returned value, or
suppress the result with `;`.
```rust
// Now fails to compile due to mismatched return type
fn send_my_event(mut events: EventWriter<MyEvent>) {
events.send_default()
}
// Fix
fn send_my_event(mut events: EventWriter<MyEvent>) {
events.send_default();
}
```
This will most likely be noticed within `match` statements:
```rust
// Before
match is_pressed {
true => events.send(PlayerAction::Fire),
// ^--^ No longer returns ()
false => {}
}
// After
match is_pressed {
true => {
events.send(PlayerAction::Fire);
},
false => {}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
Allows chained systems taking an `In<_>` input parameter to be run as
one-shot systems. This API was mentioned in #8963.
In addition, `run_system(_with_input)` returns the system output, for
any `'static` output type.
## Solution
A new function, `World::run_system_with_input` allows a `SystemId<I, O>`
to be run by providing an `I` value as input and producing `O` as an
output.
`SystemId<I, O>` is now generic over the input type `I` and output type
`O`, along with the related functions and types `RegisteredSystem`,
`RemovedSystem`, `register_system`, `remove_system`, and
`RegisteredSystemError`. These default to `()`, preserving the existing
API, for all of the public types.
---
## Changelog
- Added `World::run_system_with_input` function to allow one-shot
systems that take `In<_>` input parameters
- Changed `World::run_system` and `World::register_system` to support
systems with return types beyond `()`
- Added `Commands::run_system_with_input` command that schedules a
one-shot system with an `In<_>` input parameter
(This is my first PR here, so I've probably missed some things. Please
let me know what else I should do to help you as a reviewer!)
# Objective
Due to https://github.com/rust-lang/rust/issues/117800, the `derive`'d
`PartialEq::eq` on `Entity` isn't as good as it could be. Since that's
used in hashtable lookup, let's improve it.
## Solution
The derived `PartialEq::eq` short-circuits if the generation doesn't
match. However, having a branch there is sub-optimal, especially on
64-bit systems like x64 that could just load the whole `Entity` in one
load anyway.
Due to complications around `poison` in LLVM and the exact details of
what unsafe code is allowed to do with reference in Rust
(https://github.com/rust-lang/unsafe-code-guidelines/issues/346), LLVM
isn't allowed to completely remove the short-circuiting. `&Entity` is
marked `dereferencable(8)` so LLVM knows it's allowed to *load* all 8
bytes -- and does so -- but it has to assume that the `index` might be
undef/poison if the `generation` doesn't match, and thus while it finds
a way to do it without needing a branch, it has to do something slightly
more complicated than optimal to combine the results. (LLVM is allowed
to change non-short-circuiting code to use branches, but not the other
way around.)
Here's a link showing the codegen today:
<https://rust.godbolt.org/z/9WzjxrY7c>
```rust
#[no_mangle]
pub fn demo_eq_ref(a: &Entity, b: &Entity) -> bool {
a == b
}
```
ends up generating the following assembly:
```asm
demo_eq_ref:
movq xmm0, qword ptr [rdi]
movq xmm1, qword ptr [rsi]
pcmpeqd xmm1, xmm0
pshufd xmm0, xmm1, 80
movmskpd eax, xmm0
cmp eax, 3
sete al
ret
```
(It's usually not this bad in real uses after inlining and LTO, but it
makes a strong demo.)
This PR manually implements `PartialEq::eq` *without* short-circuiting,
and because that tells LLVM that neither the generations nor the index
can be poison, it doesn't need to be so careful and can generate the
"just compare the two 64-bit values" code you'd have probably already
expected:
```asm
demo_eq_ref:
mov rax, qword ptr [rsi]
cmp qword ptr [rdi], rax
sete al
ret
```
Since this doesn't change the representation of `Entity`, if it's
instead passed by *value*, then each `Entity` is two `u32` registers,
and the old and the new code do exactly the same thing. (Other
approaches, like changing `Entity` to be `[u32; 2]` or `u64`, affect
this case.)
This should hopefully merge easily with changes like
https://github.com/bevyengine/bevy/pull/9907 that also want to change
`Entity`.
## Benchmarks
I'm not super-confident that I got my machine fully consistent for
benchmarking, but whether I run the old or the new one first I get
reasonably consistent results.
Here's a fairly typical example of the benchmarks I added in this PR:

Building the sets seems to be basically the same. It's usually reported
as noise, but sometimes I see a few percent slower or faster.
But lookup hits in particular -- since a hit checks that the key is
equal -- consistently shows around 10% improvement.
`cargo run --example many_cubes --features bevy/trace_tracy --release --
--benchmark` showed as slightly faster with this change, though if I had
to bet I'd probably say it's more noise than meaningful (but at least
it's not worse either):

This is my first PR here -- and my first time running Tracy -- so please
let me know what else I should run, or run things on your own more
reliable machines to double-check.
---
## Changelog
(probably not worth including)
Changed: micro-optimized `Entity::eq` to help LLVM slightly.
## Migration Guide
(I really hope nobody was using this on uninitialized entities where
sufficiently tortured `unsafe` could could technically notice that this
has changed.)
# Objective
- `CommandQueue::apply` calculates the address of the end of the
internal buffer as a `usize` rather than as a pointer, requiring two
casts of `cursor` to `usize`. Casting pointers to integers is generally
discouraged and may also prevent optimizations. It's also unnecessary
here.
## Solution
- Calculate the end address as a pointer rather than a `usize`.
Small note:
A trivial translation of the old code to use pointers would have
computed `end_addr` as `cursor.add(self.bytes.len())`, which is not
wrong but is an additional `unsafe` operation that also needs to be
properly documented and proven correct. However this operation is
already implemented in the form of the safe `as_mut_ptr_range`, so I
just used that.
# Objective
There is an if statement checking if a node is present in a graph
moments after it explicitly being added.
Unless the edge function has super weird side effects and the tests
don't pass, this is unnecessary.
## Solution
Removed it
# Objective
- Allow registration of one-shot systems when those systems have already
been `Box`ed.
- Needed for `bevy_eventlisteners` which allows adding event listeners
with callbacks in normal systems. The current one shot system
implementation requires systems be registered from an exclusive system,
and that those systems be passed in as types that implement
`IntoSystem`. However, the eventlistener callback crate allows users to
define their callbacks in normal systems, by boxing the system and
deferring initialization to an exclusive system.
## Solution
- Separate the registration of the system from the boxing of the system.
This is non-breaking, and adds a new method.
---
## Changelog
- Added `World::register_boxed_system` to allow registration of
already-boxed one shot systems.
# Objective
- There is a specialized hasher for entities:
[`EntityHashMap`](https://docs.rs/bevy/latest/bevy/utils/type.EntityHashMap.html)
- [`EntityMapper`] currently uses a normal `HashMap<Entity, Entity>`
- Fixes#10391
## Solution
- Replace the normal `HashMap` with the more performant `EntityHashMap`
## Questions
- This does change public API. Should a system be implemented to help
migrate code?
- Perhaps an `impl From<HashMap<K, V, S>> for EntityHashMap<K, V>`
- I updated to docs for each function that I changed, but I may have
missed something
---
## Changelog
- Changed `EntityMapper` to use `EntityHashMap` instead of normal
`HashMap`
## Migration Guide
If you are using the following types, update their listed methods to use
the new `EntityHashMap`. `EntityHashMap` has the same methods as the
normal `HashMap`, so you just need to replace the name.
### `EntityMapper`
- `get_map`
- `get_mut_map`
- `new`
- `world_scope`
### `ReflectMapEntities`
- `map_all_entities`
- `map_entities`
- `write_to_world`
### `InstanceInfo`
- `entity_map`
- This is a property, not a method.
---
This is my first time contributing in a while, and I'm not familiar with
the usage of `EntityMapper`. I changed the type definition and fixed all
errors, but there may have been things I've missed. Please keep an eye
out for me!
Preparing next release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Align all error-like types to implement `Error`.
Fixes #10176
## Solution
- Derive `Error` on more types
- Refactor instances of manual implementations that could be derived
This adds thiserror as a dependency to bevy_transform, which might
increase compilation time -- but I don't know of any situation where you
might only use that but not any other crate that pulls in bevy_utils.
The `contributors` example has a `LoadContributorsError` type, but as
it's an example I have not updated it. Doing that would mean either
having a `use bevy_internal::utils::thiserror::Error;` in an example
file, or adding `thiserror` as a dev-dependency to the main `bevy`
crate.
---
## Changelog
- All `…Error` types now implement the `Error` trait
# Objective
First of all, this PR took heavy inspiration from #7760 and #5715. It
intends to also fix#5569, but with a slightly different approach.
This also fixes#9335 by reexporting `DynEq`.
## Solution
The advantage of this API is that we can intern a value without
allocating for zero-sized-types and for enum variants that have no
fields. This PR does this automatically in the `SystemSet` and
`ScheduleLabel` derive macros for unit structs and fieldless enum
variants. So this should cover many internal and external use cases of
`SystemSet` and `ScheduleLabel`. In these optimal use cases, no memory
will be allocated.
- The interning returns a `Interned<dyn SystemSet>`, which is just a
wrapper around a `&'static dyn SystemSet`.
- `Hash` and `Eq` are implemented in terms of the pointer value of the
reference, similar to my first approach of anonymous system sets in
#7676.
- Therefore, `Interned<T>` does not implement `Borrow<T>`, only `Deref`.
- The debug output of `Interned<T>` is the same as the interned value.
Edit:
- `AppLabel` is now also interned and the old
`derive_label`/`define_label` macros were replaced with the new
interning implementation.
- Anonymous set ids are reused for different `Schedule`s, reducing the
amount of leaked memory.
### Pros
- `InternedSystemSet` and `InternedScheduleLabel` behave very similar to
the current `BoxedSystemSet` and `BoxedScheduleLabel`, but can be copied
without an allocation.
- Many use cases don't allocate at all.
- Very fast lookups and comparisons when using `InternedSystemSet` and
`InternedScheduleLabel`.
- The `intern` module might be usable in other areas.
- `Interned{ScheduleLabel, SystemSet, AppLabel}` does implement
`{ScheduleLabel, SystemSet, AppLabel}`, increasing ergonomics.
### Cons
- Implementors of `SystemSet` and `ScheduleLabel` still need to
implement `Hash` and `Eq` (and `Clone`) for it to work.
## Changelog
### Added
- Added `intern` module to `bevy_utils`.
- Added reexports of `DynEq` to `bevy_ecs` and `bevy_app`.
### Changed
- Replaced `BoxedSystemSet` and `BoxedScheduleLabel` with
`InternedSystemSet` and `InternedScheduleLabel`.
- Replaced `impl AsRef<dyn ScheduleLabel>` with `impl ScheduleLabel`.
- Replaced `AppLabelId` with `InternedAppLabel`.
- Changed `AppLabel` to use `Debug` for error messages.
- Changed `AppLabel` to use interning.
- Changed `define_label`/`derive_label` to use interning.
- Replaced `define_boxed_label`/`derive_boxed_label` with
`define_label`/`derive_label`.
- Changed anonymous set ids to be only unique inside a schedule, not
globally.
- Made interned label types implement their label trait.
### Removed
- Removed `define_boxed_label` and `derive_boxed_label`.
## Migration guide
- Replace `BoxedScheduleLabel` and `Box<dyn ScheduleLabel>` with
`InternedScheduleLabel` or `Interned<dyn ScheduleLabel>`.
- Replace `BoxedSystemSet` and `Box<dyn SystemSet>` with
`InternedSystemSet` or `Interned<dyn SystemSet>`.
- Replace `AppLabelId` with `InternedAppLabel` or `Interned<dyn
AppLabel>`.
- Types manually implementing `ScheduleLabel`, `AppLabel` or `SystemSet`
need to implement:
- `dyn_hash` directly instead of implementing `DynHash`
- `as_dyn_eq`
- Pass labels to `World::try_schedule_scope`, `World::schedule_scope`,
`World::try_run_schedule`. `World::run_schedule`, `Schedules::remove`,
`Schedules::remove_entry`, `Schedules::contains`, `Schedules::get` and
`Schedules::get_mut` by value instead of by reference.
---------
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Reduce code duplication and improve APIs of Bevy's [global
taskpools](https://github.com/bevyengine/bevy/blob/main/crates/bevy_tasks/src/usages.rs).
## Solution
- As all three of the global taskpools have identical implementations
and only differ in their identifiers, this PR moves the implementation
into a macro to reduce code duplication.
- The `init` method is renamed to `get_or_init` to more accurately
reflect what it really does.
- Add a new `try_get` method that just returns `None` when the pool is
uninitialized, to complement the other getter methods.
- Minor documentation improvements to accompany the above changes.
---
## Changelog
- Added a new `try_get` method to the global TaskPools
- The global TaskPools' `init` method has been renamed to `get_or_init`
for clarity
- Documentation improvements
## Migration Guide
- Uses of `ComputeTaskPool::init`, `AsyncComputeTaskPool::init` and
`IoTaskPool::init` should be changed to `::get_or_init`.
# Objective
Closes#9955.
Use the same interface for all "pure" builder types: taking and
returning `Self` (and not `&mut Self`).
## Solution
Changed `DynamicSceneBuilder`, `SceneFilter` and `TableBuilder` to take
and return `Self`.
## Changelog
### Changed
- `DynamicSceneBuilder` and `SceneBuilder` methods in `bevy_ecs` now
take and return `Self`.
## Migration guide
When using `bevy_ecs::DynamicSceneBuilder` and `bevy_ecs::SceneBuilder`,
instead of binding the builder to a variable, directly use it. Methods
on those types now consume `Self`, so you will need to re-bind the
builder if you don't `build` it immediately.
Before:
```rust
let mut scene_builder = DynamicSceneBuilder::from_world(&world);
let scene = scene_builder.extract_entity(a).extract_entity(b).build();
```
After:
```rust
let scene = DynamicSceneBuilder::from_world(&world)
.extract_entity(a)
.extract_entity(b)
.build();
```
# Objective
- Followup to #7184.
- ~Deprecate `TypeUuid` and remove its internal references.~ No longer
part of this PR.
- Use `TypePath` for the type registry, and (de)serialisation instead of
`std::any::type_name`.
- Allow accessing type path information behind proxies.
## Solution
- Introduce methods on `TypeInfo` and friends for dynamically querying
type path. These methods supersede the old `type_name` methods.
- Remove `Reflect::type_name` in favor of `DynamicTypePath::type_path`
and `TypeInfo::type_path_table`.
- Switch all uses of `std::any::type_name` in reflection, non-debugging
contexts to use `TypePath`.
---
## Changelog
- Added `TypePathTable` for dynamically accessing methods on `TypePath`
through `TypeInfo` and the type registry.
- Removed `type_name` from all `TypeInfo`-like structs.
- Added `type_path` and `type_path_table` methods to all `TypeInfo`-like
structs.
- Removed `Reflect::type_name` in favor of
`DynamicTypePath::reflect_type_path` and `TypeInfo::type_path`.
- Changed the signature of all `DynamicTypePath` methods to return
strings with a static lifetime.
## Migration Guide
- Rely on `TypePath` instead of `std::any::type_name` for all stability
guarantees and for use in all reflection contexts, this is used through
with one of the following APIs:
- `TypePath::type_path` if you have a concrete type and not a value.
- `DynamicTypePath::reflect_type_path` if you have an `dyn Reflect`
value without a concrete type.
- `TypeInfo::type_path` for use through the registry or if you want to
work with the represented type of a `DynamicFoo`.
- Remove `type_name` from manual `Reflect` implementations.
- Use `type_path` and `type_path_table` in place of `type_name` on
`TypeInfo`-like structs.
- Use `get_with_type_path(_mut)` over `get_with_type_name(_mut)`.
## Note to reviewers
I think if anything we were a little overzealous in merging #7184 and we
should take that extra care here.
In my mind, this is the "point of no return" for `TypePath` and while I
think we all agree on the design, we should carefully consider if the
finer details and current implementations are actually how we want them
moving forward.
For example [this incorrect `TypePath` implementation for
`String`](3fea3c6c0b/crates/bevy_reflect/src/impls/std.rs (L90))
(note that `String` is in the default Rust prelude) snuck in completely
under the radar.
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
- Fixes#9884
- Add API for ignoring ambiguities on certain resource or components.
## Solution
- Add a `IgnoreSchedulingAmbiguitiy` resource to the world which holds
the `ComponentIds` to be ignored
- Filter out ambiguities with those component id's.
## Changelog
- add `allow_ambiguous_component` and `allow_ambiguous_resource` apis
for ignoring ambiguities
---------
Co-authored-by: Ryan Johnson <ryanj00a@gmail.com>
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
Add a new method so you can do `set_if_neq` with dereferencing
components: `as_deref_mut()`!
## Solution
Added an as_deref_mut method so that we can use `set_if_neq()` without
having to wrap up types for derefencable components
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Joseph <21144246+JoJoJet@users.noreply.github.com>
# Objective
The `States::variants` method was once used to construct `OnExit` and
`OnEnter` schedules for every possible value of a given `States` type.
[Since the switch to lazily initialized
schedules](https://github.com/bevyengine/bevy/pull/8028/files#diff-b2fba3a0c86e496085ce7f0e3f1de5960cb754c7d215ed0f087aa556e529f97f),
we no longer need to track every possible value.
This also opens the door to `States` types that aren't enums.
## Solution
- Remove the unused `States::variants` method and its associated type.
- Remove the enum-only restriction on derived States types.
---
## Changelog
- Removed `States::variants` and its associated type.
- Derived `States` can now be datatypes other than enums.
## Migration Guide
- `States::variants` no longer exists. If you relied on this function,
consider using a library that provides enum iterators.
# Objective
- There were a few typos in the project.
- This PR fixes these typos.
## Solution
- Fixing the typos.
Signed-off-by: SADIK KUZU <sadikkuzu@hotmail.com>
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Scheduling low cost systems has significant overhead due to task pool
contention and the extra machinery to schedule and run them. Event
update systems are the prime example of a low cost system, requiring a
guaranteed O(1) operation, and there are a *lot* of them.
## Solution
Add a run condition to every event system so they only run when there is
an event in either of it's two internal Vecs.
---
## Changelog
Changed: Event update systems will not run if there are no events to
process.
## Migration Guide
`Events<T>::update_system` has been split off from the the type and can
be found at `bevy_ecs::event::event_update_system`.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
Improve code-gen for `QueryState::validate_world` and
`SystemState::validate_world`.
## Solution
* Move panics into separate, non-inlined functions, to reduce the code
size of the outer methods.
* Mark the panicking functions with `#[cold]` to help the compiler
optimize for the happy path.
* Mark the functions with `#[track_caller]` to make debugging easier.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Occasionally, it is useful to pull `ComponentInfo` or
`ComponentDescriptor` out of the `Components` collection so that they
can be inspected without borrowing the whole `World`.
## Solution
Make `ComponentInfo` and `ComponentDescriptor` `Clone`, so that
reflection-heavy code can store them in a side table.
---
## Changelog
- Implement `Clone` for `ComponentInfo` and `ComponentDescriptor`
# Objective
- I spoke with some users in the ECS channel of bevy discord today and
they suggested that I implement a fallible form of .insert for
components.
- In my opinion, it would be nice to have a fallible .insert like
.try_insert (or to just make insert be fallible!) because it was causing
a lot of panics in my game. In my game, I am spawning terrain chunks and
despawning them in the Update loop. However, this was causing bevy_xpbd
to panic because it was trying to .insert some physics components on my
chunks and a race condition meant that its check to see if the entity
exists would pass but then the next execution step it would not exist
and would do an .insert and then panic. This means that there is no way
to avoid a panic with conditionals.
Luckily, bevy_xpbd does not care about inserting these components if the
entity is being deleted and so if there were a .try_insert, like this PR
provides it could use that instead in order to NOT panic.
( My interim solution for my own game has been to run the entity despawn
events in the Last schedule but really this is just a hack and I should
not be expected to manage the scheduling of despawns like this - it
should just be easy and simple. IF it just so happened that bevy_xpbd
ran .inserts in the Last schedule also, this would be an untenable soln
overall )
## Solution
- Describe the solution used to achieve the objective above.
Add a new command named TryInsert (entitycommands.try_insert) which
functions exactly like .insert except if the entity does not exist it
will not panic. Instead, it will log to info. This way, crates that are
attaching components in ways which they do not mind that the entity no
longer exists can just use try_insert instead of insert.
---
## Changelog
## Additional Thoughts
In my opinion, NOT panicing should really be the default and having an
.insert that does panic should be the odd edgecase but removing the
panic! from .insert seems a bit above my paygrade -- although i would
love to see it. My other thought is it would be good for .insert to
return an Option AND not panic but it seems it uses an event bus right
now so that seems to be impossible w the current architecture.
# Objective
Currently, in bevy, it's valid to do `Query<&mut Foo, Changed<Foo>>`.
This assumes that `filter_fetch` and `fetch` are mutually exclusive,
because of the mutable reference to the tick that `Mut<Foo>` implies and
the reference that `Changed<Foo>` implies. However nothing guarantees
that.
## Solution
Documenting this assumption as a safety invariant is the least thing.
I'm adopting this ~~child~~ PR.
# Objective
- Working with exclusive world access is not always easy: in many cases,
a standard system or three is more ergonomic to write, and more
modularly maintainable.
- For small, one-off tasks (commonly handled with scripting), running an
event-reader system incurs a small but flat overhead cost and muddies
the schedule.
- Certain forms of logic (e.g. turn-based games) want very fine-grained
linear and/or branching control over logic.
- SystemState is not automatically cached, and so performance can suffer
and change detection breaks.
- Fixes https://github.com/bevyengine/bevy/issues/2192.
- Partial workaround for https://github.com/bevyengine/bevy/issues/279.
## Solution
- Adds a SystemRegistry resource to the World, which stores initialized
systems keyed by their SystemSet.
- Allows users to call world.run_system(my_system) and
commands.run_system(my_system), without re-initializing or losing state
(essential for change detection).
- Add a Callback type to enable convenient use of dynamic one shot
systems and reduce the mental overhead of working with Box<dyn
SystemSet>.
- Allow users to run systems based on their SystemSet, enabling more
complex user-made abstractions.
## Future work
- Parameterized one-shot systems would improve reusability and bring
them closer to events and commands. The API could be something like
run_system_with_input(my_system, my_input) and use the In SystemParam.
- We should evaluate the unification of commands and one-shot systems
since they are two different ways to run logic on demand over a World.
### Prior attempts
- https://github.com/bevyengine/bevy/pull/2234
- https://github.com/bevyengine/bevy/pull/2417
- https://github.com/bevyengine/bevy/pull/4090
- https://github.com/bevyengine/bevy/pull/7999
This PR continues the work done in
https://github.com/bevyengine/bevy/pull/7999.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Federico Rinaldi <gisquerin@gmail.com>
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
Co-authored-by: Alejandro Pascual Pozo <alejandro.pascual.pozo@gmail.com>
Co-authored-by: Rob Parrett <robparrett@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Dmytro Banin <banind@cs.washington.edu>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Replace instances of
```rust
for x in collection.iter{_mut}() {
```
with
```rust
for x in &{mut} collection {
```
This also changes CI to no longer suppress this lint. Note that since
this lint only shows up when using clippy in pedantic mode, it was
probably unnecessary to suppress this lint in the first place.
# Objective
- When reading API docs and seeing a reference to `ComponentId`, it
isn't immediately clear how to get one from your `Component`. It could
be made to be more clear.
## Solution
- Improve cross-linking of docs about `ComponentId`
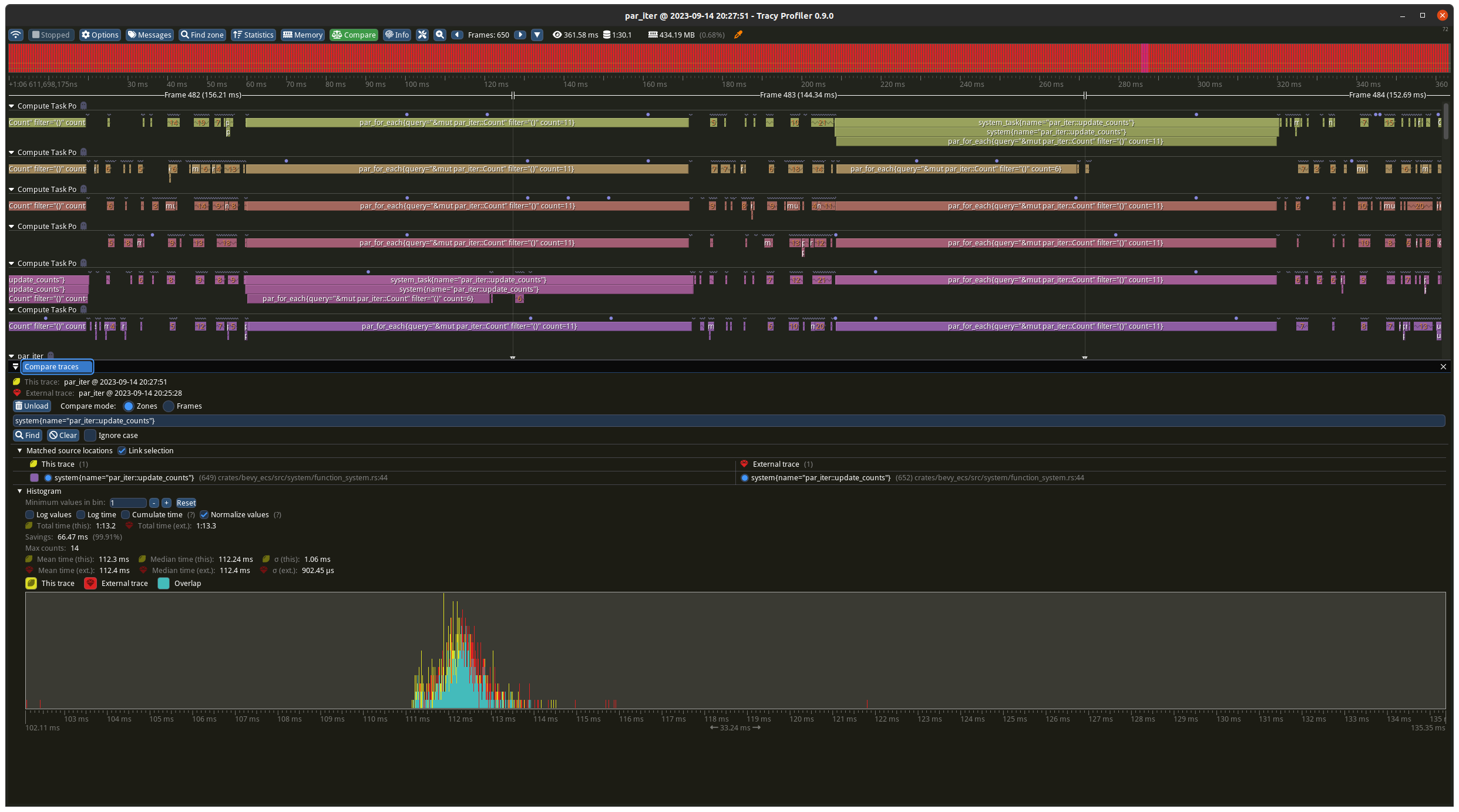
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
# Objective
The reasoning is similar to #8687.
I'm building a dynamic query. Currently, I store the ReflectFromPtr in
my dynamic `Fetch` type.
[See relevant
code](97ba68ae1e/src/fetches.rs (L14-L17))
However, `ReflectFromPtr` is:
- 16 bytes for TypeId
- 8 bytes for the non-mutable function pointer
- 8 bytes for the mutable function pointer
It's a lot, it adds 32 bytes to my base `Fetch` which is only
`ComponendId` (8 bytes) for a total of 40 bytes.
I only need one function per fetch, reducing the total dynamic fetch
size to 16 bytes.
Since I'm querying the components by the ComponendId associated with the
function pointer I'm using, I don't need the TypeId, it's a redundant
check.
In fact, I've difficulties coming up with situations where checking the
TypeId beforehand is relevant. So to me, if ReflectFromPtr makes sense
as a public API, exposing the function pointers also makes sense.
## Solution
- Make the fields public through methods.
---
## Changelog
- Add `from_ptr` and `from_ptr_mut` methods to `ReflectFromPtr` to
access the underlying function pointers
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
## Migration guide
- `ReflectFromPtr::as_reflect_ptr` is now `ReflectFromPtr::as_reflect`
- `ReflectFromPtr::as_reflect_ptr_mut` is now
`ReflectFromPtr::as_reflect_mut`
# Objective
Rename RemovedComponents::iter/iter_with_id to read/read_with_id to make
it clear that it consume the data
Fixes#9755.
(It's my first pull request, if i've made any mistake, please let me
know)
## Solution
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
## Changelog
Refactor RemovedComponents::iter/iter_with_id to read/read_with_id
Deprecate RemovedComponents::iter/iter_with_id
Remove IntoIterator implementation
Update removal_detection example accordingly
---
## Migration Guide
Rename calls of RemovedComponents::iter/iter_with_id to
read/read_with_id
Replace IntoIterator iteration (&mut <RemovedComponents>) with .read()
---------
Co-authored-by: denshi_ika <mojang2824@gmail.com>
# Objective
When using `set_if_neq`, sometimes you'd like to know if the new value
was different from the old value so that you can perform some additional
branching.
## Solution
Return a bool from this function, which indicates whether or not the
value was overwritten.
---
## Changelog
* `DetectChangesMut::set_if_neq` now returns a boolean indicating
whether or not the value was changed.
## Migration Guide
The trait method `DetectChangesMut::set_if_neq` now returns a boolean
value indicating whether or not the value was changed. If you were
implementing this function manually, you must now return `true` if the
value was overwritten and `false` if the value was not.
# Objective
- The tick access methods mention "ticks" (as in: plural). Yet, most of
them only access a single tick.
## Solution
- Rename those methods and fix docs to reflect the singular aspect of
the return values
---
## Migration Guide
The following method names were renamed, from `foo_ticks_bar` to
`foo_tick_bar` (`ticks` is now singular, `tick`):
- `ComponentSparseSet::get_added_ticks` → `get_added_tick`
- `ComponentSparseSet::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks` → `get_added_tick`
- `Column::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks_unchecked` → `get_added_tick_unchecked`
- `Column::get_changed_ticks_unchecked` → `get_changed_tick_unchecked`
# Objective
- Make it possible to snapshot/save states
- Useful for re-using parts of the state system for rollback safe states
- Or to save states with scenes/savegames
## Solution
- Conditionally add the derive if the `bevy_reflect` is enabled
---
## Changelog
- `NextState<S>` and `State<S>` now implement `Reflect` as long as `S`
does.
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
- Fixes#9244.
## Solution
- Changed the `(Into)SystemSetConfigs` traits and structs be more like
the `(Into)SystemConfigs` traits and structs.
- Replaced uses of `IntoSystemSetConfig` with `IntoSystemSetConfigs`
- Added generic `ItemConfig` and `ItemConfigs` types.
- Changed `SystemConfig(s)` and `SystemSetConfig(s)` to be type aliases
to `ItemConfig(s)`.
- Added generic `process_configs` to `ScheduleGraph`.
- Changed `configure_sets_inner` and `add_systems_inner` to reuse
`process_configs`.
---
## Changelog
- Added `run_if` to `IntoSystemSetConfigs`
- Deprecated `Schedule::configure_set` and `App::configure_set`
- Removed `IntoSystemSetConfig`
## Migration Guide
- Use `App::configure_sets` instead of `App::configure_set`
- Use `Schedule::configure_sets` instead of `Schedule::configure_set`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Currently we don't have panicking alternative for getting components
from `Query` like for resources. Partially addresses #9443.
## Solution
- Add these functions.
---
## Changelog
### Added
- `Query::component` and `Query::component_mut` to get specific
component from query and panic on error.
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.