builds on top of #4780
# Objective
`Reflect` and `Serialize` are currently very tied together because `Reflect` has a `fn serialize(&self) -> Option<Serializable<'_>>` method. Because of that, we can either implement `Reflect` for types like `Option<T>` with `T: Serialize` and have `fn serialize` be implemented, or without the bound but having `fn serialize` return `None`.
By separating `ReflectSerialize` into a separate type (like how it already is for `ReflectDeserialize`, `ReflectDefault`), we could separately `.register::<Option<T>>()` and `.register_data::<Option<T>, ReflectSerialize>()` only if the type `T: Serialize`.
This PR does not change the registration but allows it to be changed in a future PR.
## Solution
- add the type
```rust
struct ReflectSerialize { .. }
impl<T: Reflect + Serialize> FromType<T> for ReflectSerialize { .. }
```
- remove `#[reflect(Serialize)]` special casing.
- when serializing reflect value types, look for `ReflectSerialize` in the `TypeRegistry` instead of calling `value.serialize()`
- changed `EntityCountDiagnosticsPlugin` to not use an exclusive system to get its entity count
- removed mention of `WgpuResourceDiagnosticsPlugin` in example `log_diagnostics` as it doesn't exist anymore
- added ability to enable, disable ~~or toggle~~ a diagnostic (fix#3767)
- made diagnostic values lazy, so they are only computed if the diagnostic is enabled
- do not log an average for diagnostics with only one value
- removed `sum` function from diagnostic as it isn't really useful
- ~~do not keep an average of the FPS diagnostic. it is already an average on the last 20 frames, so the average FPS was an average of the last 20 frames over the last 20 frames~~
- do not compute the FPS value as an average over the last 20 frames but give the actual "instant FPS"
- updated log format to use variable capture
- added some doc
- the frame counter diagnostic value can be reseted to 0
# Objective
- Optional dependencies were enabled by some features as a side effect. for example, enabling the `webgl` feature enables the `bevy_pbr` optional dependency
## Solution
- Use the syntax introduced in rust 1.60 to specify weak dependency features: https://blog.rust-lang.org/2022/04/07/Rust-1.60.0.html#new-syntax-for-cargo-features
> Weak dependency features tackle the second issue where the `"optional-dependency/feature-name"` syntax would always enable `optional-dependency`. However, often you want to enable the feature on the optional dependency only if some other feature has enabled the optional dependency. Starting in 1.60, you can add a ? as in `"package-name?/feature-name"` which will only enable the given feature if something else has enabled the optional dependency.
# Objective
- `.x` is not the correct syntax to access a column in a matrix in WGSL: https://www.w3.org/TR/WGSL/#matrix-access-expr
- naga accepts it and translates it correctly, but it's not valid when shaders are kept as is and used directly in WGSL
## Solution
- Use the correct syntax
# Objective
- Update hashbrown to 0.12
## Solution
- Replace #4004
- As the 0.12 is already in Bevy dependency tree, it shouldn't be an issue to update
- The exception for the 0.11 should be removed once https://github.com/zakarumych/gpu-descriptor/pull/21 is merged and released
- Also removed a few exceptions that weren't needed anymore
# Objective
- KTX2 UASTC format mapping was incorrect. For some reason I had written it to map to a set of data formats based on the count of KTX2 sample information blocks, but the mapping should be done based on the channel type in the sample information.
- This is a valid change pulled out from #4514 as the attempt to fix the array textures there was incorrect
## Solution
- Fix the KTX2 UASTC `DataFormat` enum to contain the correct formats based on the channel types in section 3.10.2 of https://github.khronos.org/KTX-Specification/ (search for "Basis Universal UASTC Format")
- Correctly map from the sample information channel type to `DataFormat`
- Correctly configure transcoding and the resulting texture format based on the `DataFormat`
---
## Changelog
- Fixed: KTX2 UASTC format handling
# Use Case
Seems generally useful, but specifically motivated by my work on the [`bevy_datasize`](https://github.com/BGR360/bevy_datasize) crate.
For that project, I'm implementing "heap size estimators" for all of the Bevy internal types. To do this accurately for `Mesh`, I need to get the lengths of all of the mesh's attribute vectors.
Currently, in order to accomplish this, I am doing the following:
* Checking all of the attributes that are mentioned in the `Mesh` class ([see here](0531ec2d02/src/builtins/render/mesh.rs (L46-L54)))
* Providing the user with an option to configure additional attributes to check ([see here](0531ec2d02/src/config.rs (L7-L21)))
This is both overly complicated and a bit wasteful (since I have to check every attribute name that I know about in case there are attributes set for it).
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
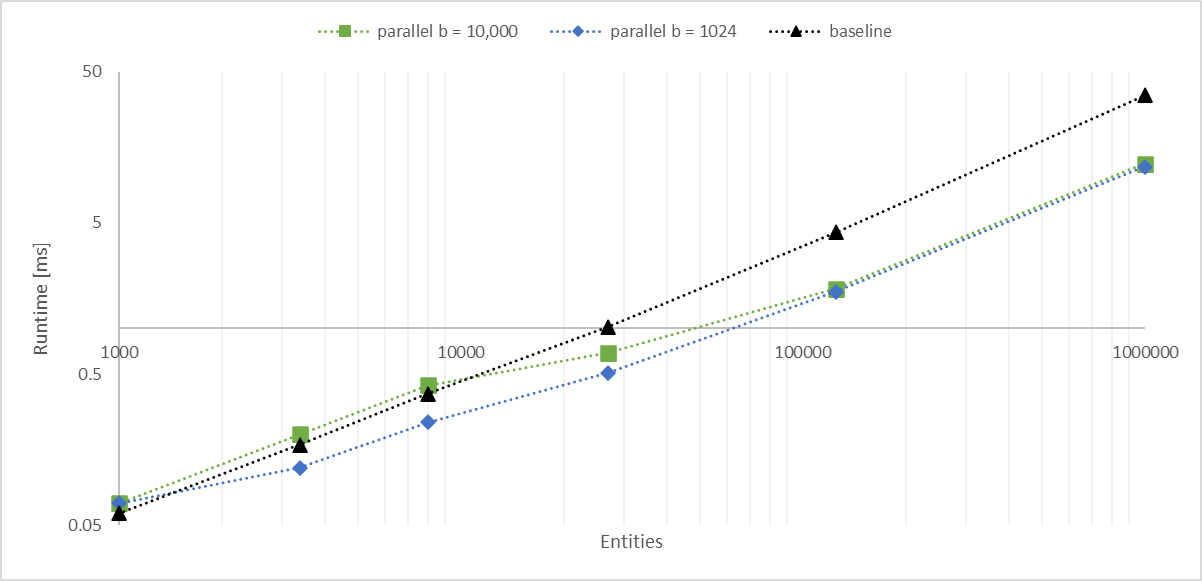
# Objective
Working with a large number of entities with `Aabbs`, rendered with an instanced shader, I found the bottleneck became the frustum culling system. The goal of this PR is to significantly improve culling performance without any major changes. We should consider constructing a BVH for more substantial improvements.
## Solution
- Convert the inner entity query to a parallel iterator with `par_for_each_mut` using a batch size of 1,024.
- This outperforms single threaded culling when there are more than 1,000 entities.
- Below this they are approximately equal, with <= 10 microseconds of multithreading overhead.
- Above this, the multithreaded version is significantly faster, scaling linearly with core count.
- In my million-entity-workload, this PR improves my framerate by 200% - 300%.
## log-log of `check_visibility` time vs. entities for single/multithreaded
---
## Changelog
Frustum culling is now run with a parallel query. When culling more than a thousand entities, this is faster than the previous method, scaling proportionally with the number of available cores.
# Objective
- Builds on top of #4901
- Separate out PBR lighting, shadows, clustered forward, and utils from `pbr.wgsl` as part of making the PBR code more reusable and extensible.
- See #3969 for details.
## Solution
- Add `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
---
## Changelog
- Added: `bevy_pbr::utils`, `bevy_pbr::clustered_forward`, `bevy_pbr::lighting`, `bevy_pbr::shadows` shader imports exposing many shader functions for external use
- Split `PI`, `saturate()`, `hsv2rgb()`, and `random1D()` into `bevy_pbr::utils`
- Split clustered-forward-specific functions into `bevy_pbr::clustered_forward`, including moving the debug visualization code into a `cluster_debug_visualization()` function in that import
- Split PBR lighting functions into `bevy_pbr::lighting`
- Split shadow functions into `bevy_pbr::shadows`
# Objective
- Add reusable shader functions for transforming positions / normals / tangents between local and world / clip space for 2D and 3D so that they are done in a simple and correct way
- The next step in #3969 so check there for more details.
## Solution
- Add `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports
- These contain `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
- Use them everywhere where it is appropriate
- Notably not in the sprite and UI shaders where `mesh2d_position_world_to_clip` could have been used, but including all the functions depends on the mesh binding so I chose to not use the function there
- NOTE: The `mesh_` and `mesh2d_` functions are currently identical. However, if I had defined only `bevy_pbr::mesh_functions` and used that in bevy_sprite, then bevy_sprite would have a runtime dependency on bevy_pbr, which seems undesirable. I also expect that when we have a proper 2D rendering API, these functions will diverge between 2D and 3D.
---
## Changelog
- Added: `bevy_pbr::mesh_functions` and `bevy_sprite::mesh2d_functions` shader imports containing `mesh_` and `mesh2d_` versions of the following functions:
- `mesh_position_local_to_world`
- `mesh_position_world_to_clip`
- `mesh_position_local_to_clip`
- `mesh_normal_local_to_world`
- `mesh_tangent_local_to_world`
## Migration Guide
- The `skin_tangents` function from the `bevy_pbr::skinning` shader import has been replaced with the `mesh_tangent_local_to_world` function from the `bevy_pbr::mesh_functions` shader import
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
This upgrade should bring some significant performance improvements to
instrumentation. These are mostly achieved by disabling features (by
default) that are likely not widely used by default – collection of
callstacks and support for fibers that wasn't used for anything in
particular yet. For callstack collection it might be worthwhile to
provide a mechanism to enable this at runtime by calling
`TracyLayer::with_stackdepth`.
These should bring the cost of a single span down from 30+µs per span to
a more reasonable 1.5µs or so and down to the ns scale for events (on my
1st gen Ryzen machine, anyway.) There is still a fair amount of overhead
over plain tracy_client instrumentation in formatting and such, but
dealing with it requires significant effort and this is a
straightforward improvement to have for the time being.
Co-authored-by: Simonas Kazlauskas <git@kazlauskas.me>
# Objective
- Fix CI
- relevant clap issue https://github.com/clap-rs/clap/issues/3822
## Solution
- slap `value_parser` on all the clap derives. This tells clap to use the default parser for the type.
# Objective
- Fixes#4271
## Solution
- Check for a pending transition in addition to a scheduled operation.
- I don't see a valid reason for updating the state unless both `scheduled` and `transition` are empty.
# Objective
Overflow::Hidden doesn't work correctly with scale_factor_override.
If you run the Bevy UI example with scale_factor_override 3 you'll see half clipped text around the edges of the scrolling listbox.
The problem seems to be that the corners of the node are transformed before the amount of clipping required is calculated. But then that transformed clip is compared to the original untransformed size of the node rect to see if it should be culled or not. With a higher scale factor the relative size of the untransformed node rect is going to be really big, so the overflow isn't culled.
# Solution
Multiply the size of the node rect by extracted_uinode.transform before the cull test.
# Objective
Fix#4958
There was 4 issues:
- this is not true in WASM and on macOS: f28b921209/examples/3d/split_screen.rs (L90)
- ~~I made sure the system was running at least once~~
- I'm sending the event on window creation
- in webgl, setting a viewport has impacts on other render passes
- only in webgl and when there is a custom viewport, I added a render pass without a custom viewport
- shaderdef NO_ARRAY_TEXTURES_SUPPORT was not used by the 2d pipeline
- webgl feature was used but not declared in bevy_sprite, I added it to the Cargo.toml
- shaderdef NO_STORAGE_BUFFERS_SUPPORT was not used by the 2d pipeline
- I added it based on the BufferBindingType
The last commit changes the two last fixes to add the shaderdefs in the shader cache directly instead of needing to do it in each pipeline
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Closes#4464
## Solution
- Specify default mag and min filter types for `Image` instead of using `wgpu`'s defaults.
---
## Changelog
### Changed
- Default `Image` filtering changed from `Nearest` to `Linear`.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fix timeout in miri
## Solution
- Use a nightly version from before the issue happened: 2022-06-08
- To be checked after https://github.com/rust-lang/miri/issues/2223 is fixed
# Objective
- CONTRIBUTING.md references wrong issue label, making it potentially confusing for new contributors.
## Solution
- Update CONTRIBUTING.md.
---
I assume the label was changed recently.
# Objective
> Resolves#4504
It can be helpful to have access to type information without requiring an instance of that type. Especially for `Reflect`, a lot of the gathered type information is known at compile-time and should not necessarily require an instance.
## Solution
Created a dedicated `TypeInfo` enum to store static type information. All types that derive `Reflect` now also implement the newly created `Typed` trait:
```rust
pub trait Typed: Reflect {
fn type_info() -> &'static TypeInfo;
}
```
> Note: This trait was made separate from `Reflect` due to `Sized` restrictions.
If you only have access to a `dyn Reflect`, just call `.get_type_info()` on it. This new trait method on `Reflect` should return the same value as if you had called it statically.
If all you have is a `TypeId` or type name, you can get the `TypeInfo` directly from the registry using the `TypeRegistry::get_type_info` method (assuming it was registered).
### Usage
Below is an example of working with `TypeInfo`. As you can see, we don't have to generate an instance of `MyTupleStruct` in order to get this information.
```rust
#[derive(Reflect)]
struct MyTupleStruct(usize, i32, MyStruct);
let info = MyTupleStruct::type_info();
if let TypeInfo::TupleStruct(info) = info {
assert!(info.is::<MyTupleStruct>());
assert_eq!(std::any::type_name::<MyTupleStruct>(), info.type_name());
assert!(info.field_at(1).unwrap().is::<i32>());
} else {
panic!("Expected `TypeInfo::TupleStruct`");
}
```
### Manual Implementations
It's not recommended to manually implement `Typed` yourself, but if you must, you can use the `TypeInfoCell` to automatically create and manage the static `TypeInfo`s for you (which is very helpful for blanket/generic impls):
```rust
use bevy_reflect::{Reflect, TupleStructInfo, TypeInfo, UnnamedField};
use bevy_reflect::utility::TypeInfoCell;
struct Foo<T: Reflect>(T);
impl<T: Reflect> Typed for Foo<T> {
fn type_info() -> &'static TypeInfo {
static CELL: TypeInfoCell = TypeInfoCell::generic();
CELL.get_or_insert::<Self, _>(|| {
let fields = [UnnamedField:🆕:<T>()];
let info = TupleStructInfo:🆕:<Self>(&fields);
TypeInfo::TupleStruct(info)
})
}
}
```
## Benefits
One major benefit is that this opens the door to other serialization methods. Since we can get all the type info at compile time, we can know how to properly deserialize something like:
```rust
#[derive(Reflect)]
struct MyType {
foo: usize,
bar: Vec<String>
}
// RON to be deserialized:
(
type: "my_crate::MyType", // <- We now know how to deserialize the rest of this object
value: {
// "foo" is a value type matching "usize"
"foo": 123,
// "bar" is a list type matching "Vec<String>" with item type "String"
"bar": ["a", "b", "c"]
}
)
```
Not only is this more compact, but it has better compatibility (we can change the type of `"foo"` to `i32` without having to update our serialized data).
Of course, serialization/deserialization strategies like this may need to be discussed and fully considered before possibly making a change. However, we will be better equipped to do that now that we can access type information right from the registry.
## Discussion
Some items to discuss:
1. Duplication. There's a bit of overlap with the existing traits/structs since they require an instance of the type while the type info structs do not (for example, `Struct::field_at(&self, index: usize)` and `StructInfo::field_at(&self, index: usize)`, though only `StructInfo` is accessible without an instance object). Is this okay, or do we want to handle it in another way?
2. Should `TypeInfo::Dynamic` be removed? Since the dynamic types don't have type information available at runtime, we could consider them `TypeInfo::Value`s (or just even just `TypeInfo::Struct`). The intention with `TypeInfo::Dynamic` was to keep the distinction from these dynamic types and actual structs/values since users might incorrectly believe the methods of the dynamic type's info struct would map to some contained data (which isn't possible statically).
4. General usefulness of this change, including missing/unnecessary parts.
5. Possible changes to the scene format? (One possible issue with changing it like in the example above might be that we'd have to be careful when handling generic or trait object types.)
## Compile Tests
I ran a few tests to compare compile times (as suggested [here](https://github.com/bevyengine/bevy/pull/4042#discussion_r876408143)). I toggled `Reflect` and `FromReflect` derive macros using `cfg_attr` for both this PR (aa5178e773) and main (c309acd432).
<details>
<summary>See More</summary>
The test project included 250 of the following structs (as well as a few other structs):
```rust
#[derive(Default)]
#[cfg_attr(feature = "reflect", derive(Reflect))]
#[cfg_attr(feature = "from_reflect", derive(FromReflect))]
pub struct Big001 {
inventory: Inventory,
foo: usize,
bar: String,
baz: ItemDescriptor,
items: [Item; 20],
hello: Option<String>,
world: HashMap<i32, String>,
okay: (isize, usize, /* wesize */),
nope: ((String, String), (f32, f32)),
blah: Cow<'static, str>,
}
```
> I don't know if the compiler can optimize all these duplicate structs away, but I think it's fine either way. We're comparing times, not finding the absolute worst-case time.
I only ran each build 3 times using `cargo build --timings` (thank you @devil-ira), each of which were preceeded by a `cargo clean --package bevy_reflect_compile_test`.
Here are the times I got:
| Test | Test 1 | Test 2 | Test 3 | Average |
| -------------------------------- | ------ | ------ | ------ | ------- |
| Main | 1.7s | 3.1s | 1.9s | 2.33s |
| Main + `Reflect` | 8.3s | 8.6s | 8.1s | 8.33s |
| Main + `Reflect` + `FromReflect` | 11.6s | 11.8s | 13.8s | 12.4s |
| PR | 3.5s | 1.8s | 1.9s | 2.4s |
| PR + `Reflect` | 9.2s | 8.8s | 9.3s | 9.1s |
| PR + `Reflect` + `FromReflect` | 12.9s | 12.3s | 12.5s | 12.56s |
</details>
---
## Future Work
Even though everything could probably be made `const`, we unfortunately can't. This is because `TypeId::of::<T>()` is not yet `const` (see https://github.com/rust-lang/rust/issues/77125). When it does get stabilized, it would probably be worth coming back and making things `const`.
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- Spawning a scene is handled as a special case with a command `spawn_scene` that takes an handle but doesn't let you specify anything else. This is the only handle that works that way.
- Workaround for this have been to add the `spawn_scene` on `ChildBuilder` to be able to specify transform of parent, or to make the `SceneSpawner` available to be able to select entities from a scene by their instance id
## Solution
Add a bundle
```rust
pub struct SceneBundle {
pub scene: Handle<Scene>,
pub transform: Transform,
pub global_transform: GlobalTransform,
pub instance_id: Option<InstanceId>,
}
```
and instead of
```rust
commands.spawn_scene(asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"));
```
you can do
```rust
commands.spawn_bundle(SceneBundle {
scene: asset_server.load("models/FlightHelmet/FlightHelmet.gltf#Scene0"),
..Default::default()
});
```
The scene will be spawned as a child of the entity with the `SceneBundle`
~I would like to remove the command `spawn_scene` in favor of this bundle but didn't do it yet to get feedback first~
Co-authored-by: François <8672791+mockersf@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Following #4855, `Column` is just a parallel `BlobVec`/`Vec<UnsafeCell<ComponentTicks>>` pair, which is identical to the dense and ticks vecs in `ComponentSparseSet`, which has some code duplication with `Column`.
## Solution
Replace dense and ticks in `ComponentSparseSet` with a `Column`.
# Objective
Most of our `Iterator` impls satisfy the requirements of `std::iter::FusedIterator`, which has internal specialization that optimizes `Interator::fuse`. The std lib iterator combinators do have a few that rely on `fuse`, so this could optimize those use cases. I don't think we're using any of them in the engine itself, but beyond a light increase in compile time, it doesn't hurt to implement the trait.
## Solution
Implement the trait for all eligible iterators in first party crates. Also add a missing `ExactSizeIterator` on an iterator that could use it.
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
Change _LICENSE-APACHE_ and _LICENSE-MIT_ file location
Delete _LICENSE_
You can make the license in about on bevy's GitHub page display as **Apache-2.0, MIT licenses found** instead of **View license**
# Objective
Users should be able to configure depth load operations on cameras. Currently every camera clears depth when it is rendered. But sometimes later passes need to rely on depth from previous passes.
## Solution
This adds the `Camera3d::depth_load_op` field with a new `Camera3dDepthLoadOp` value. This is a custom type because Camera3d uses "reverse-z depth" and this helps us record and document that in a discoverable way. It also gives us more control over reflection + other trait impls, whereas `LoadOp` is owned by the `wgpu` crate.
```rust
commands.spawn_bundle(Camera3dBundle {
camera_3d: Camera3d {
depth_load_op: Camera3dDepthLoadOp::Load,
..default()
},
..default()
});
```
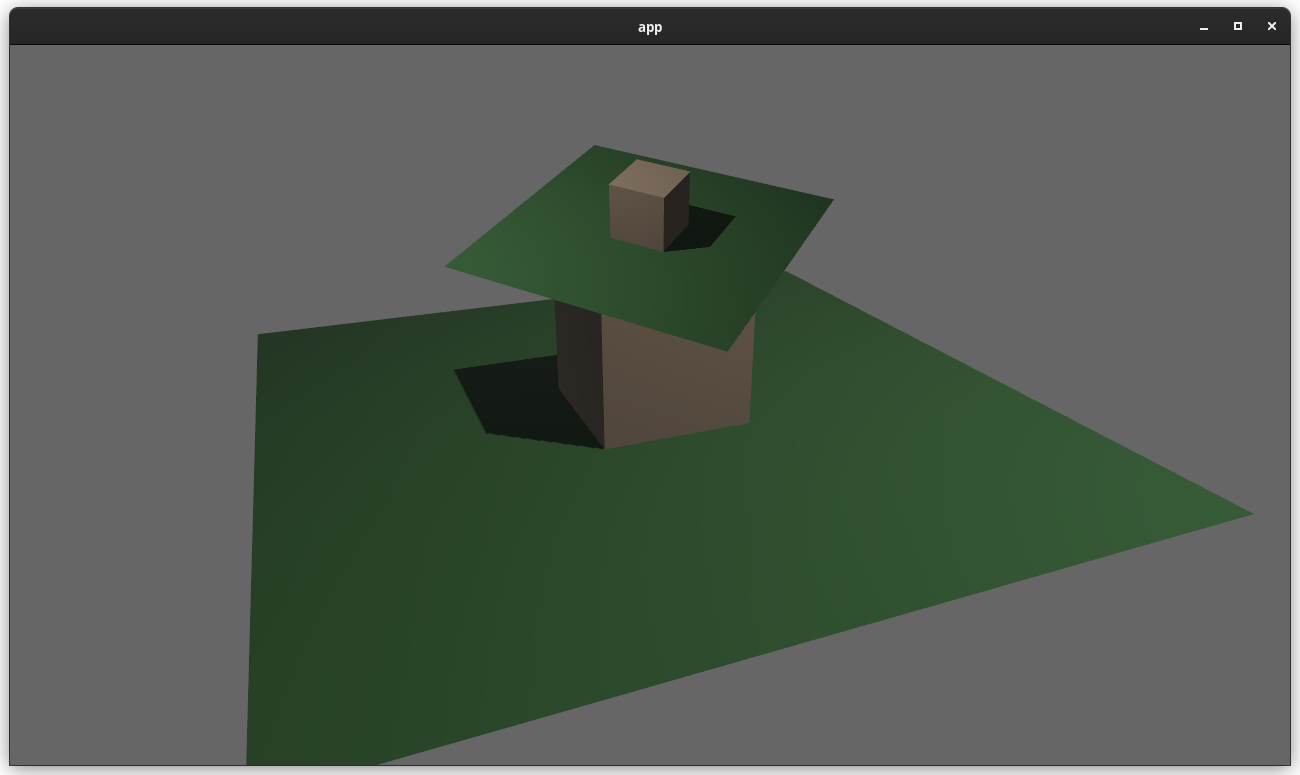
### two_passes example with the "second pass" camera configured to the default (clear depth to 0.0)
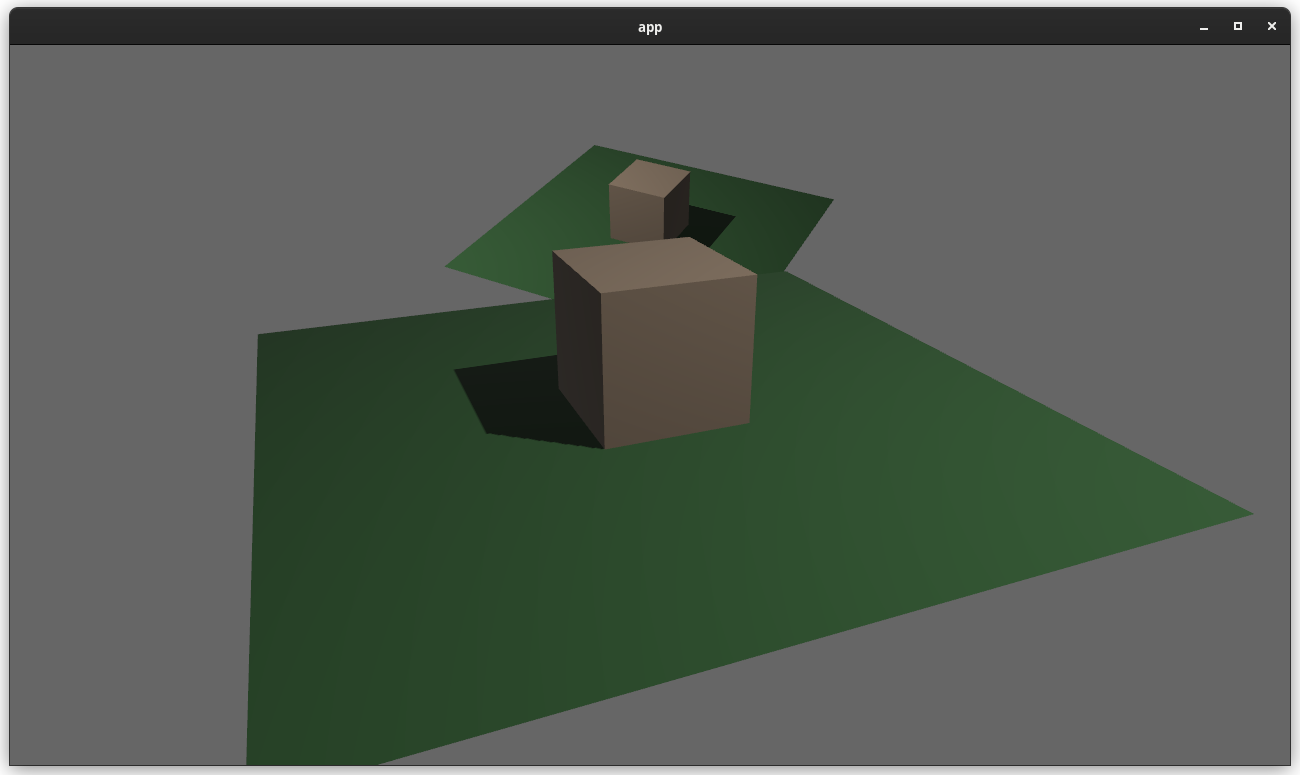
### two_passes example with the "second pass" camera configured to "load" the depth
---
## Changelog
### Added
* `Camera3d` now has a `depth_load_op` field, which can configure the Camera's main 3d pass depth loading behavior.
While working on a refactor of `bevy_mod_picking` to include viewport-awareness, I found myself writing these functions to test if a cursor coordinate was inside the camera's rendered area.
# Objective
- Simplify conversion from physical to logical pixels
- Add methods that returns the dimensions of the viewport as a min-max rect
---
## Changelog
- Added `Camera::to_logical`
- Added `Camera::physical_viewport_rect`
- Added `Camera::logical_viewport_rect`
# Objective
- Guide people to the right discord channel to post about their new plugin. #showcase was split into multiple channels.
## Solution
- recommend posting in #crates
# Objective
- Adds an example of testing systems that handle events. I had a hard time figuring out how to do it a couple days ago so figured an official example could be useful.
- Fixes#4936
## Solution
- Adds a `Score` resource and an `EnemyDied` event. An `update_score` system updates the score when a new event comes through. I'm not sure the example is great, as this probably isn't how you'd do it in a real game, but I didn't want to change the existing example too much.
# Objective
- Run examples in WASM in CI
- Fix#4817
## Solution
- on feature `bevy_ci_testing`
- add an extra log message before exiting
- when building for wasm, read CI config file at compile time
- add a simple [playwright](https://playwright.dev) test script that opens the browser then waits for the success log, and takes a screenshot
- add a CI job that runs the playwright test for Chromium and Firefox on one example (lighting) and save the screenshots
- Firefox screenshot is good (with some clusters visible)
- Chromium screenshot is gray, I don't know why but it's logging `GPU stall due to ReadPixels`
- Webkit is not enabled for now, to revisit once https://bugs.webkit.org/show_bug.cgi?id=234926 is fixed or worked around
- the CI job only runs on bors validation
example run: https://github.com/mockersf/bevy/actions/runs/2361673465. The screenshots can be downloaded
# Objective
- fix#4946
- fix running 3d in wasm
## Solution
- since #4867, the imports are splitter differently, and this shader def was not always set correctly depending on the shader used
- add it when needed
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864Fixes#1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Currently, providing the wrong number of inputs to a render graph node triggers this assertion:
```
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `1`,
right: `2`', /[redacted]/bevy/crates/bevy_render/src/renderer/graph_runner.rs:164:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
This does not provide the user any context.
## Solution
Add a new `RenderGraphRunnerError` variant to handle this case. The new message looks like this:
```
ERROR bevy_render::renderer: Error running render graph:
ERROR bevy_render::renderer: > node (name: 'Some("outline_pass")') has 2 input slots, but was provided 1 values
```
---
## Changelog
### Changed
`RenderGraphRunnerError` now has a new variant, `MismatchedInputCount`.
## Migration Guide
Exhaustive matches on `RenderGraphRunnerError` will need to add a branch to handle the new `MismatchedInputCount` variant.
# Objective
While playing with the code, I found some problems in the recently merged version-bumping workflow:
- Most importantly, now that we are using `0.8.0-dev` in development, the workflow will try to bump it to `0.9.0` 😭
- The crate filter is outdated now that we have more crates in `tools`.
- We are using `bevy@users.noreply.github.com`, but according to [Github help](https://docs.github.com/en/account-and-profile/setting-up-and-managing-your-personal-account-on-github/managing-email-preferences/setting-your-commit-email-address#about-commit-email-addresses), that email address means "old no-reply email format for the user `bevy`". It is currently not associated with any account, but I feel this is still not appropriate here.
## Solution
- Create a new workflow, `Post-release version bump`, that should be run after a release and bumps version from `0.X.0` to `0.X+1.0-dev`. Unfortunately, cargo-release doesn't have a builtin way to do this, so we need to parse and increment the version manually.
- Add the new crates in `tools` to exclusion list. Also removes the dependency version specifier from `bevy_ecs_compile_fail_tests`. It is not in the workspace so the dependency version will not get automatically updated by cargo-release.
- Change the author email to `41898282+github-actions[bot]@users.noreply.github.com`. According to the discussion [here](https://github.com/actions/checkout/issues/13#issuecomment-724415212) and [here](https://github.community/t/github-actions-bot-email-address/17204/6), this is the email address associated with the github-actions bot account.
- Also add the workflows to our release checklist.
See infmagic2047#5 and infmagic2047#6 for examples of release and post-release PRs.
(follow-up to #4423)
# Objective
Currently, it isn't possible to easily fire commands from within par_for_each blocks. This PR allows for issuing commands from within parallel scopes.
# Objective
In the `queue_custom` system in `shader_instancing` example, the query of `material_meshes` has a redundant `With<Handle<Mesh>>` query filter because `Handle<Mesh>` is included in the component access.
## Solution
Remove the `With<Handle<Mesh>>` filter
# Objective
- Add an example showing a custom post processing effect, done after the first rendering pass.
## Solution
- A simple post processing "chromatic aberration" effect. I mixed together examples `3d/render_to_texture`, and `shader/shader_material_screenspace_texture`
- Reading a bit how https://github.com/bevyengine/bevy/pull/3430 was done gave me pointers to apply the main pass to the 2d render rather than using a 3d quad.
This work might be or not be relevant to https://github.com/bevyengine/bevy/issues/2724
<details>
<summary> ⚠️ Click for a video of the render ⚠️ I’ve been told it might hurt the eyes 👀 , maybe we should choose another effect just in case ?</summary>
https://user-images.githubusercontent.com/2290685/169138830-a6dc8a9f-8798-44b9-8d9e-449e60614916.mp4
</details>
# Request for feedbacks
- [ ] Is chromatic aberration effect ok ? (Correct term, not a danger for the eyes ?) I'm open to suggestion to make something different.
- [ ] Is the code idiomatic ? I preferred a "main camera -> **new camera with post processing applied to a quad**" approach to emulate minimum modification to existing code wanting to add global post processing.
---
## Changelog
- Add a full screen post processing shader example
# Objective
Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc.
Builds on the new Camera Driven Rendering added here: #4745Fixes: #202
Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering)
## Solution
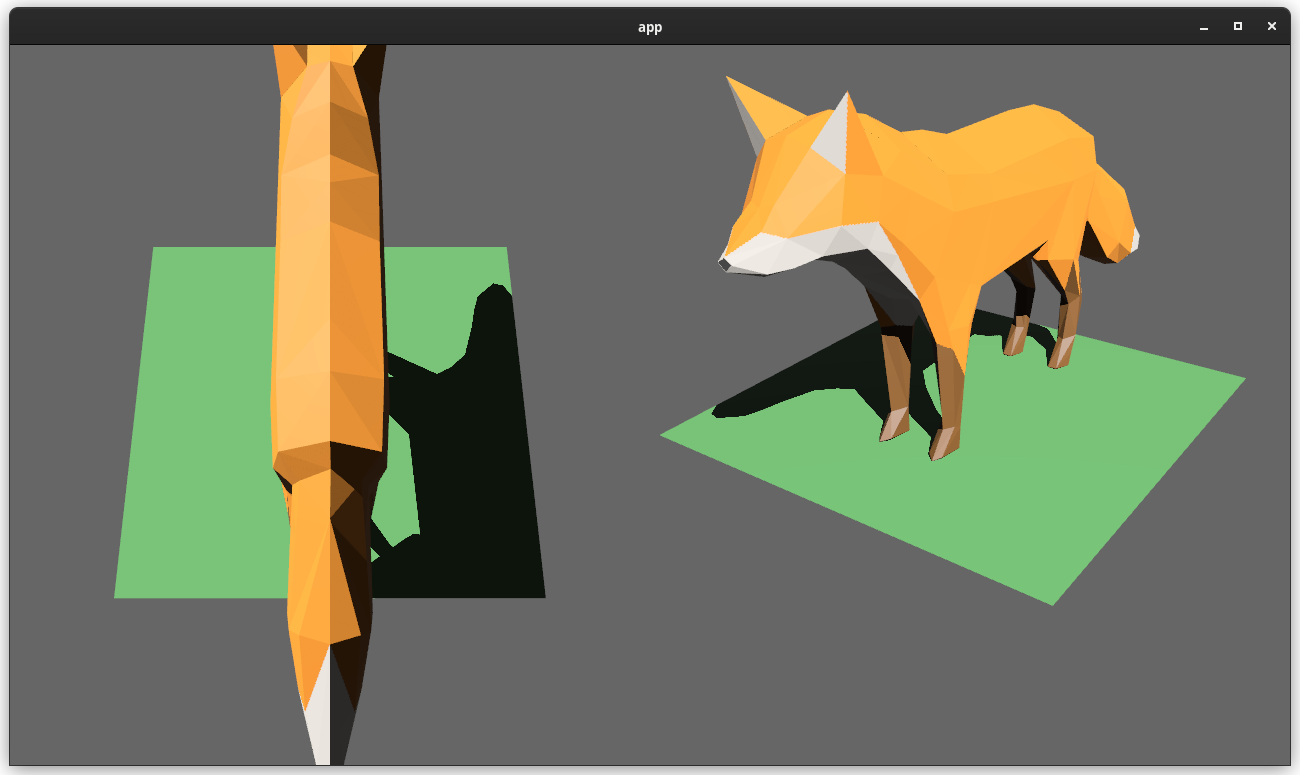
Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target.
```rust
// This camera will render to the first half of the primary window (on the left side).
commands.spawn_bundle(Camera3dBundle {
camera: Camera {
viewport: Some(Viewport {
physical_position: UVec2::new(0, 0),
physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()),
depth: 0.0..1.0,
}),
..default()
},
..default()
});
```
To account for this, the `Camera` component has received a few adjustments:
* `Camera` now has some new getter functions:
* `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix`
* All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue.
---
## Changelog
### Added
* `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target.
* `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix`
* Added a new split_screen example illustrating how to render two cameras to the same scene
## Migration Guide
`Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead:
```rust
// Bevy 0.7
let projection = camera.projection_matrix;
// Bevy 0.8
let projection = camera.projection_matrix();
```
# Objective
- To fix the broken commented code in `examples/shader/compute_shader_game_of_life.rs` for disabling frame throttling
## Solution
- Change the commented code from using the old `WindowDescriptor::vsync` to the new `WindowDescriptor::present_mode`
### Note
I chose to use the fully qualified scope `bevy:🪟:PresentWindow::Immediate` rather than explicitly including `PresentWindow` to avoid an unused import when the code is commented.
# Objective
- Upgrading ndk-glue (our Android interop layer) desynchronized us from winit
- This further broke Android builds, see #4905 (oops...)
- Reverting to 0.5 should help with this, until the new `winit` version releases
- Fixes#4774 and closes#4529
# Objective
At the moment all extra capabilities are disabled when validating shaders with naga:
c7c08f95cb/crates/bevy_render/src/render_resource/shader.rs (L146-L149)
This means these features can't be used even if the corresponding wgpu features are active.
## Solution
With these changes capabilities are now set corresponding to `RenderDevice::features`.
---
I have validated these changes for push constants with a project I am currently working on. Though bevy does not support creating pipelines with push constants yet, so I was only able to see that shaders are validated and compiled as expected.
{kind=link}
{kind=link}
{kind=link}
{kind=link}