11 KiB
| description |
|---|
| source: https://infosecwriteups.com/simple-recon-methodology-920f5c5936d4 |
🔎 Simple Recon Methodology
Hey folks, here we back again with the most important topic in penetration testing or Bug Bounty Hunting “Recon” or “Information gathering”.

Content
- What’s Recon ?
- Recon based scope
- simple steps to collect all information in few time
- Recommended tools and automation frameworks
- Recommended blogs, streams to follow
What’s Recon ?
Before we start our talk, let’s know what’s the recon first?
Recon is the process by which you collect more information about your target, more information like subdomains, links, open ports, hidden directories, service information, etc.
To know more about recon, just see this pic to know where you're before and after recon…

informations Before Recon and After Recon
So the question of which in your mind now is how we will collect all this information, and what’s kind of tools we will use?
Actually, to collect all this information you need to follow methodology, I’ll show you my own methodology and after a few minutes you will know how it works.

My own methodology — 3klcon Automation framework — src: https://github.com/eslam3kl/3klCon/blob/v2.0/3klcon-MEthedology.png
{kind=link}
The Recon process should be based on scope, and I mean that you should collect information depending on your scope area (small, medium, or large). The difference will be in the amount and type of data you will collect, so let’s get started.
Recon based scope
We will divide the scopes into 3 types (Small, Medium and large scope)
A. Small Scope
In this type of scopes, you have the only subdomain which you are allowed to test on it like sub.domain.com and you don’t have any permission to test on any other subdomain, the information which you should collect will be like this…
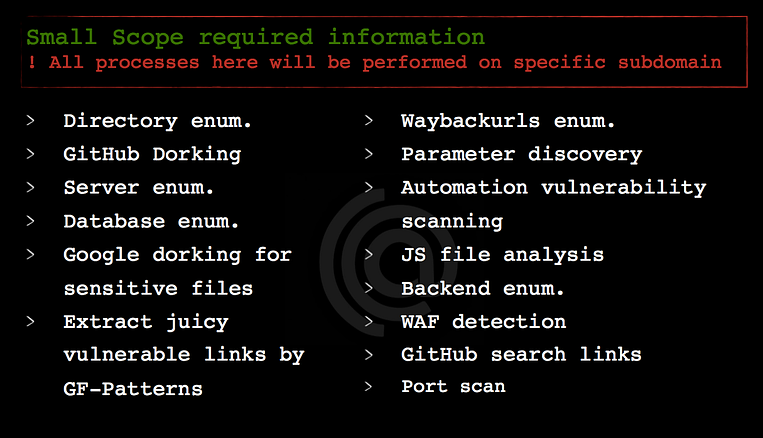
As you can see the information you should collect will be based on the subdomain you have permission to test on it only like directory discovery files, service information, JS files, GitHub dorks, waybackurls, etc
B. Medium scope
Here your testing area will be increased to contain all subdomains related to a specific domain, for example, you have a domain like example.com and on your program page, you’re allowed to test all subdomains like *.domain.com In this step the information which you should collect will be more than the small scope to contain for example all subdomains and treat every subdomain as small scope “we will talk more about this point”, just know the type of the information only.
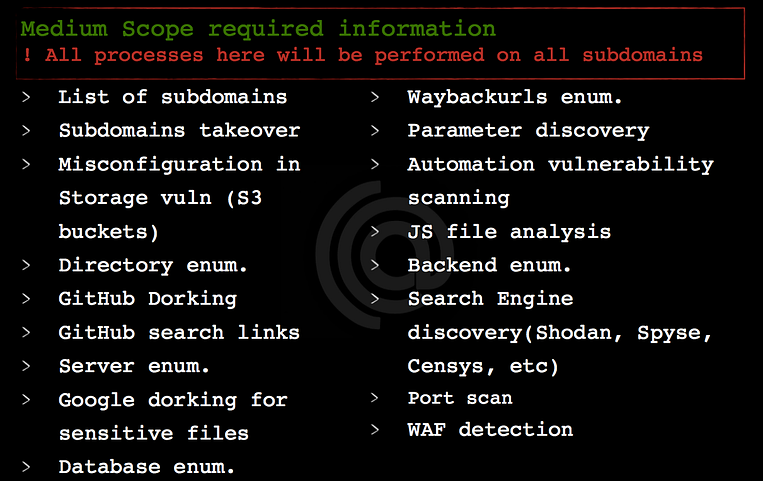
Medium scope required informations
C. Large scope
In this type of scopes, you have the permission to test all websites which belong to the main company, for example, you started to test on IBM company, so you need to collect all domains, subdomains, acquisitions, and ASN related to this company and treat every domain as medium scope. This type of scopes is the best scopes ever ❤
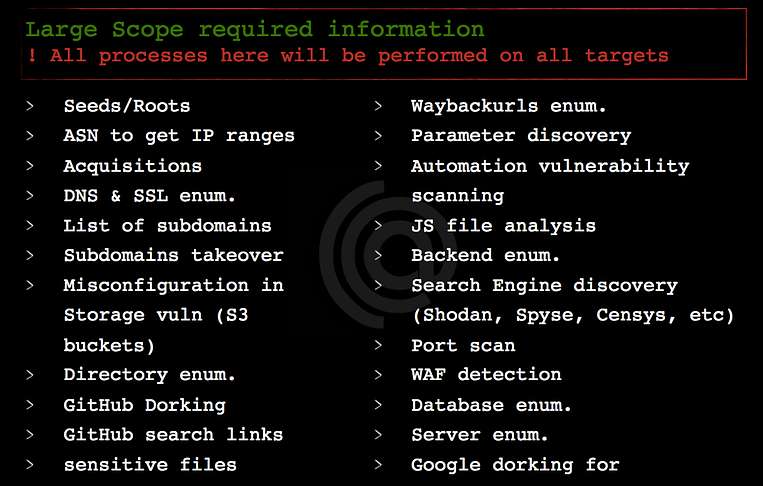
Large scope required informations
So here we know all the information which you need to collect for every scope, now let’s talk about how to collect all this info.
Let’s see how to collect this !

Ready ?
Simple steps to collect all information
we will work here as medium scope to be simple to understand
All the tools used here are free as open source on GitHub
- collect all subdomains from tools like
subfinder,amass,crtfinder,sublist3r(Use more than tool) - Use Google dorks for example
site:ibm.com -www - collect all these informations from
subdinder + amass + crtfinder + sublist3r + google_dorksand collect all of them into one text fileall_subdomains.txt
[*] Now we have 1 text file contains all subdomains all_subdomains.txt, let’s continue…
- Pass the text file over
httpxorhttprobe, these tools will filter all subdomains and return only live subdomains which works on ports 80 and 443 - take these live subdomains and collect them into separate file
live_subdomains.txt
[*] Now we have 2 text files all_subdomains.txt + live_subdomains.txt
- take the
live_subdomains.txtfile and pass it overwaybackurlstool to collect all links which related to all live subdomains - collect all these links into new file
waybackurls.txt
[*] Now we have 3 text files all_subdomains.txt + live_subdomains.txt+ waybackurls.txt
- take all subdomains text file and pass it over
dirsearchorffufto discover all hidden directories likehttps://community.ibm.com/database_conf.txt - collect and filter all the results to show only 2xx, 3xx, 403 response codes from the tool itself (use -h to know how to filter the results)
- collect all these informations into text file
hidden_directories.txtand try to discover the leakage data or the forbidden pages and try to bypass them
[*] Now we have 4 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt
- pass
all_subdomains.txttonmapormasscanto scan all ports and discover open ports + try to brute force this open ports if you see that this ports may be brute forced, usebrute-sprayto brute force this credentials - collect all the results into text file
nmap_results.txt
[*] Now we have 5 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt + nmap_results.txt
- use
live_subdomains.txtand search for credentials in GitHub by using automated tools likeGitHoundor by manual search (I’ll put pretty reference in the references section) - collect all these information into text file
GitHub_search.txt
[*] Now we have 6 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt + nmap_results.txt + GitHub_search.txt
- use
altdnsto collect subdomains from subdomains, for examplesub.sub.sub.domain.com - As usual :) collect all this info into text file
altdns_subdomain.txt
[*] Now we have 7 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt + nmap_results.txt + GitHub_search.txt + altdns_subdomain.txt
- pass
waybackurls.txtfile overgftool and usegf-patternsto filter the links to possible vulnerable links, for example if the link has parameter like?user_id=so this link may be vulnerable to sqli or idor, if the link has parameter like?page=so this link may be vulnerable to lfi - collect all this vulnerable links into directory
vulnerable_links.txtand into this directory have separated text files for all vulnerable linksgf_sqli.txt,gf_idor.txt,etc
[*] Now we have 7 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt + nmap_results.txt + GitHub_search.txt + altdns_subdomain.txt and one directory vulnerable_links.txt
- use
grepto collect all JS files formwaybackurls.txtascat waybackurls.txt | grep js > js_files.txt - you can analyze these files manually or use automation tools (I recommend manual scan, see references)
- save all the results to
js_files.txt
[*] Now we have 8 text files all_subdomains.txt + live_subdomains.txt + waybackurls.txt + hidden_directories.txt + nmap_results.txt + GitHub_search.txt + altdns_subdomain.txt + js_files.txt + one directory vulnerable_links.txt
- Pass
all_subdomain.txt + waybackurls.txt + vulnerable_links.txttonuclei“Automation scanner” to scan all of them.
Next step!! Don’t worry, No more steps :)

Congratulations, you have finished the biggest part of your recon ❤
Now I’m sure you know all this steps good, go to the upper methodology and check it again and see if you understand it or not!
Good ! Let’s move to the next step…
Recommended tools and automation frameworks
> For Automation frameworks, I recommend 2 frameworks
3klconhttps://github.com/eslam3kl/3klCon — My own framework and it depends on the upper methodologyBheemhttps://github.com/harsh-bothra/Bheem
> For the tools
3klectorhttps://github.com/eslam3kl/3klectorcrtfinderhttps://github.com/eslam3kl/crtfinderSubfinderhttps://github.com/projectdiscovery/subfinderAssetfinderhttps://github.com/tomnomnom/assetfinderAltdnshttps://github.com/infosec-au/altdnsDirsearchhttps://github.com/maurosoria/dirsearchHttpxhttps://github.com/projectdiscovery/httpxWaybackurlshttps://github.com/tomnomnom/waybackurlsGauhttps://github.com/lc/gauGit-houndhttps://github.com/tillson/git-houndGfhttps://github.com/tomnomnom/gfGf-patternhttps://github.com/1ndianl33t/Gf-PatternsNucleihttps://github.com/projectdiscovery/nucleiNuclei-templetshttps://github.com/projectdiscovery/nuclei-templatesSubjackhttps://github.com/haccer/subjack
Credits
Harsh Bothra “Recon based scope”
Jhaddix offensity