FragmentKind played two roles:
* entry point to the parser
* syntactic category of a macro call
These are different use-cases, and warrant different types. For example,
macro can't expand to visibility, but we have such fragment today.
This PR introduces `ExpandsTo` enum to separate this two use-cases.
I suspect we might further split `FragmentKind` into `$x:specifier` enum
specific to MBE, and a general parser entry point, but that's for
another PR!
We generally avoid "syntax only" helper wrappers, which don't do much:
they make code easier to write, but harder to read. They also make
investigations harder, as "find_usages" needs to be invoked both for the
wrapped and unwrapped APIs
8560: Escape characters in doc comments in macros correctly r=jonas-schievink a=ChayimFriedman2
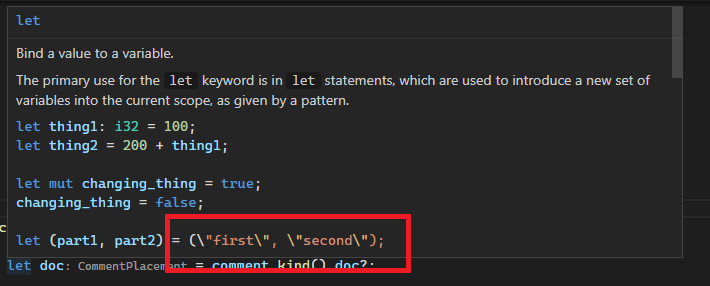
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
Example (the keyword and primitive docs are `include!()`d at https://doc.rust-lang.org/src/std/lib.rs.html#570-578, and thus originate from macro):
Before:
After:
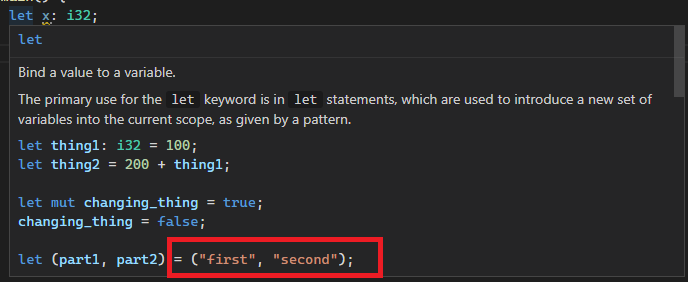
Co-authored-by: Chayim Refael Friedman <chayimfr@gmail.com>
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
{kind=link}
{kind=link}