Make fields of mir::Terminator public
When trying to use the RA crate, I am unable to access the fields in `hir_def::mir::Terminator`.
I don't see any reason, why these should be private, especially as the fields of `hir_def::mir::Statement` are `pub`.
I am not sure if the fields in `hir_def::mir::SwitchTargets` should be made `pub` too, but at least they are read-accessible via some public methods..
Sorry if I missed something, this is my first PR.
Mark test for MIR execution limit as slow test
The test for MIR execution limit accounts for ~2/3 of total execution time of non-slow hir-ty tests. It significantly slows down edit-and-run-test type of workflow. Can we mark it as a slow test?
internal: Migrate assists to the structured snippet API, part 3
Continuing from #15231
Migrates the following assists:
- `add_missing_match_arms`
- `fix_visibility`
- `promote_local_to_const`
The `add_missing_match_arms` changes are best reviewed commit-by-commit since they're relatively big changes compared to the rest of the commits.
Structured snippets precisely track which text edits need to be marked
as snippet text edits, but the cases where structured snippets aren't
used but snippets are still present are for simple single text-edit
changes, so it's perfectly fine to mark all one of them as being a
snippet text edit
`clone_for_update` is relatively cheap in comparison, since making a
node require parsing an entire source text
Adds a test to make sure that it doesn't crash when multiple uses are
present.
Skip building subtrees for builtin derives
This is a waste of resources, we go from node to subtree just to go from subtree to node in the expander impl. We can skip the subtree building and only build the tokenmap instead.
internal: Migrate more assists to use the structured snippet API
Continuing from #14979
Migrates the following assists:
- `generate_derive`
- `wrap_return_type_in_result`
- `generate_delegate_methods`
As a bonus, `generate_delegate_methods` now generates the function and impl block at the correct indentation 🎉.
`does_not_fill_wildcard_with_wildcard`
and `does_not_fill_wildcard_with_partial_wildcard_and_wildcard`
both made no modifications to the code,
which is a problem for mutable ast porting as it generates a best-effort
minimal set of text edits,
and assists require at least one text edit.
# Overview
Extracting a match arm value that has type unit into a function, when a
comma already follows the match arm value, results in an invalid (syntax
error) semicolon added between the newly generated function's generated
call and the comma.
# Example
Running this extraction
```rust
fn main() {
match () {
_ => $0()$0,
};
}
```
would lead to
```rust
fn main() {
match () {
_ => fun_name();,
};
}
fn fun_name() {
}
```
# Issue / Fix details
This happens because when there is no comma, rust-analyzer would simply
add the comma and wouldn't even try to evaluate whether it needs to add
a semicolon. But when the comma is there, it proceeds to evaluate
whether it needs to add a semicolon and it looks like the evaluation
logic erroneously ignores the possibility that we're in a match arm.
IIUC it never makes sense to add a semicolon when we're extracting from
a match arm value, so I've adjusted the logic to always decide against
adding a semicolon when we're in a match arm
Can actually split out adding the functions from getting the impl to
update or create thanks to being able to refer to the impl ast node.
FIXME Context:
Unfortunately we can't adjust the indentation of the newly added function
inside of `ast::AssocItemList::add_item` since for some reason the `todo!()`
placeholder generated by `add_missing_impl_members` and
`replace_derive_with_manual_impl` gets indented weirdly.
Implement recursion in mir interpreter without recursion
This enables interpreting functions with deep stack + profiling. I also applied some changes to make it faster based on the profiling result.
Unify getter and setter assists
This PR combines what previously have been two different files into a single file. I want to talk about the reasons why I did this. The issue that prompted this PR ( and before I forget : this pr fixes#15080 ) mentions an interesting behavior. We combine these two assists into an assist group and the order in which the assists are listed in this group changes depending on the text range of the selected area. The reason for that is that VSCode prioritizes actions that have a bigger impact in a smaller area and until now generate setter assist was only possible to be invoked for a single field whereas you could generate multiple getters for the getter assist. So I used the latter's infra to make former applicable to multiple fields, hence the unification. So this PR solves in essence
1. Make `generate setter` applicable to multiple fields
2. Provide a consistent order of the said assists in listing.
Don't show `unresolved-field` diagnostic for missing names
I don't think reporting ``"no field `[missing name]` on type `SomeType`"`` makes much sense because it's a syntax error rather than a semantic error. We already report a syntax error for it and I find it sufficient.
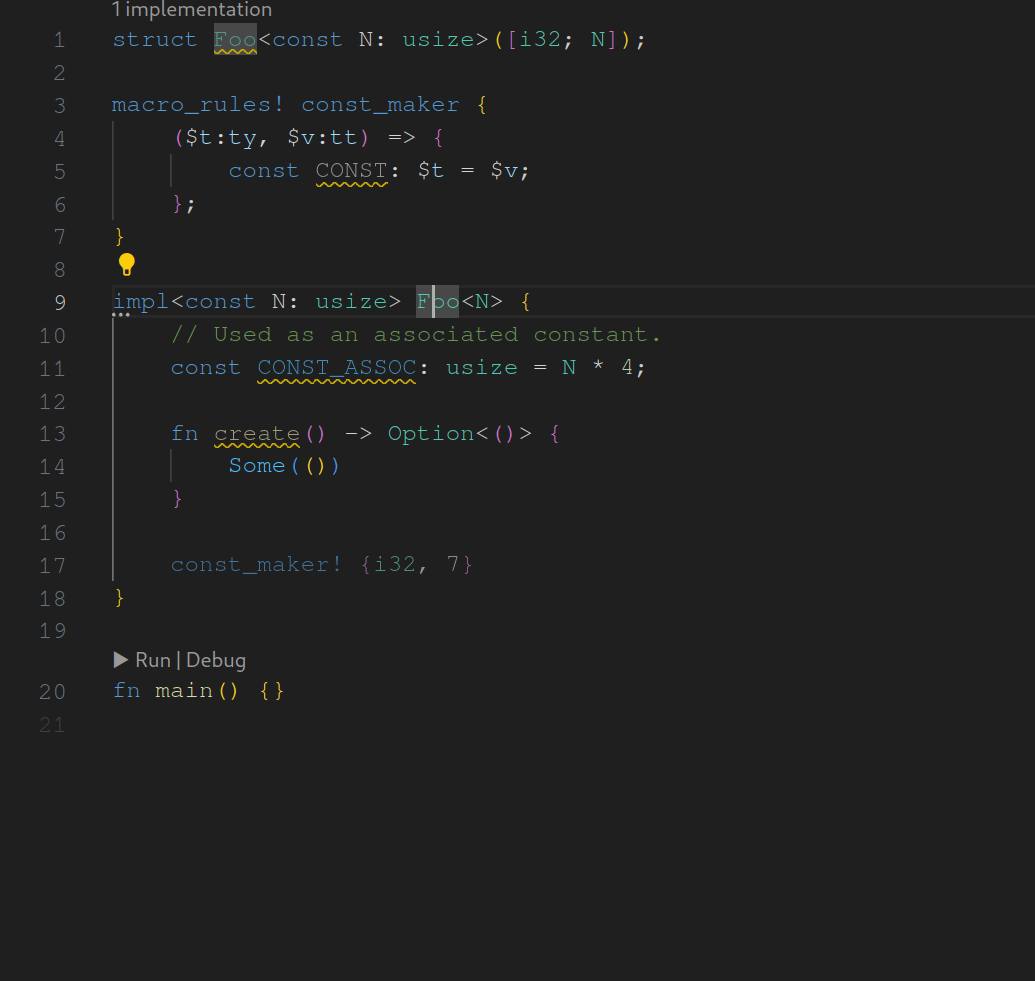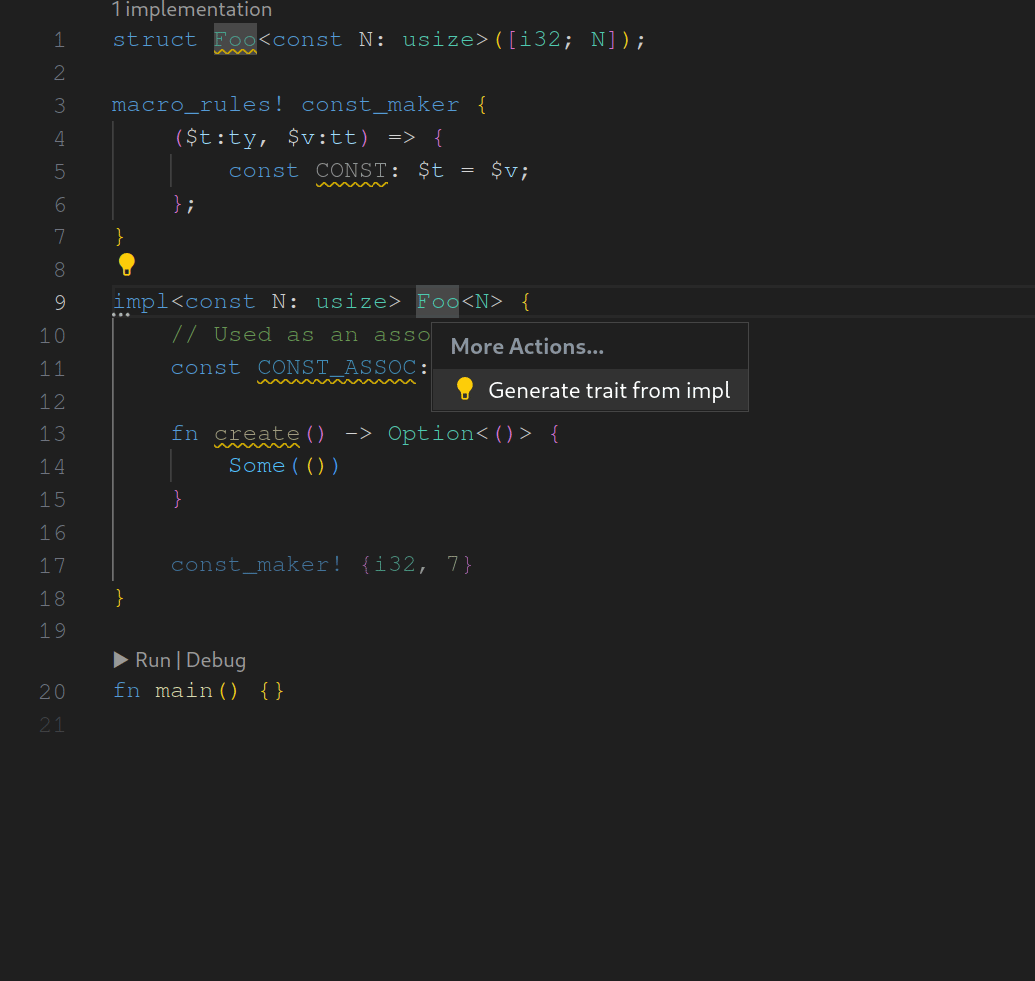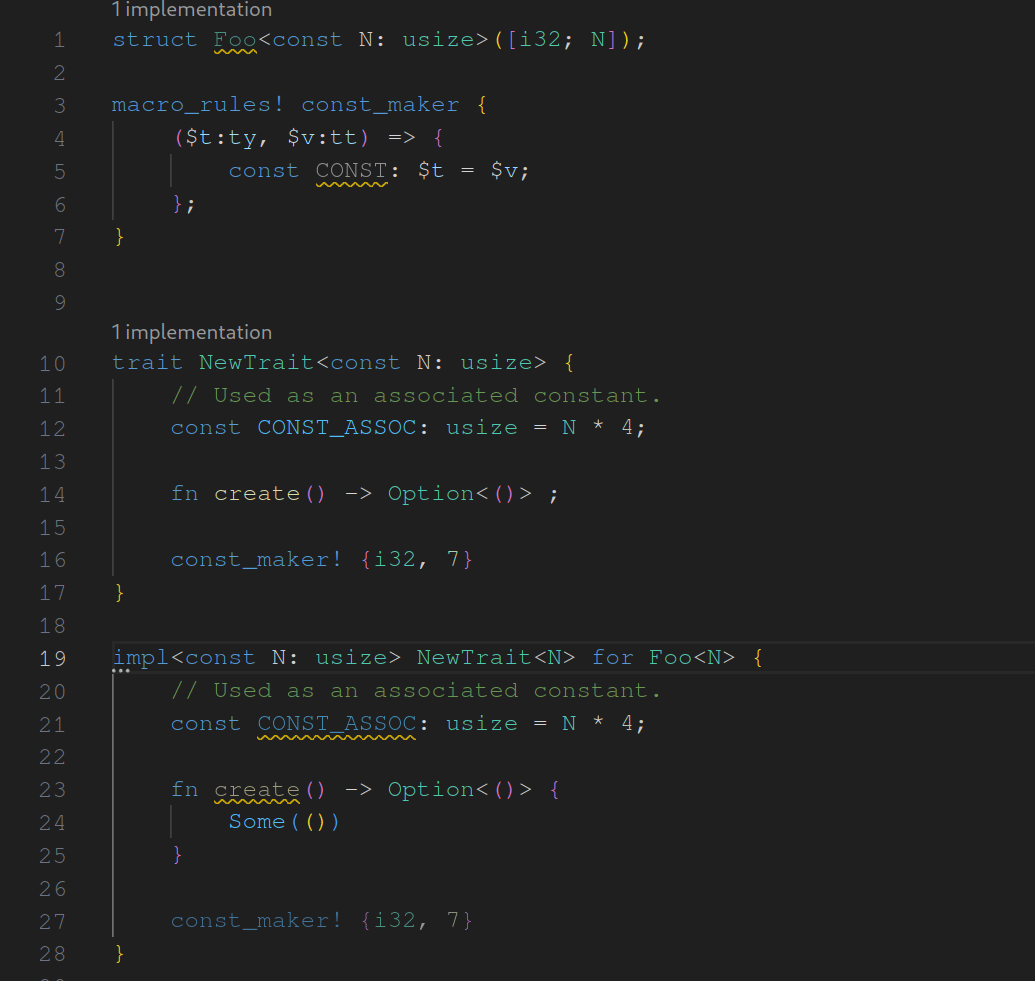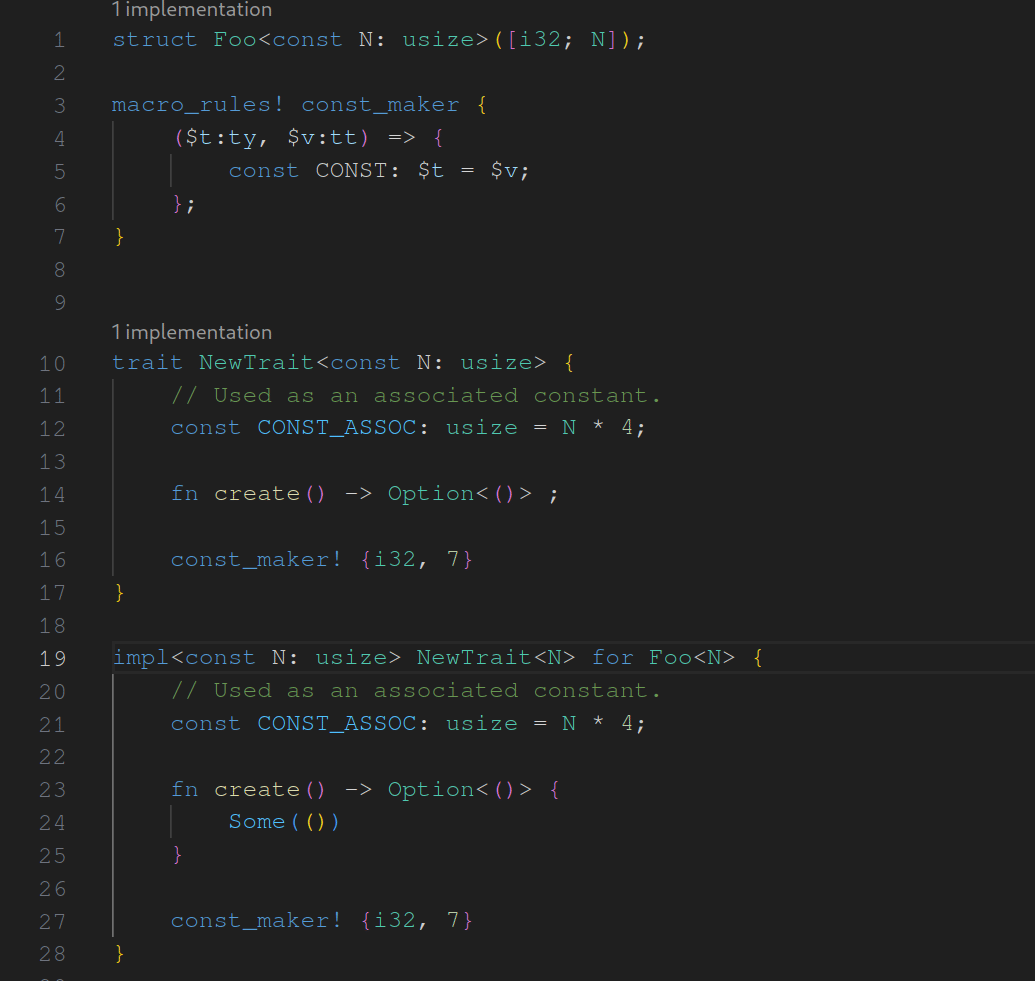
assist : generate trait from impl
fixes#14987 . As the name suggests this assist is used to generate traits from inherent impls while adapting the original impl to fit to the newly generated trait. I made some decisions regarding when the assist should be applicable. These are surely open to discussion. I looking forward to any feedback.
Disable remove unnecessary braces diagnotics for self imports
Disable `remove unnecessary braces` diagnostic if the there is a `self` inside the bracketed `use`
Fix#15191
Support GATs in bounds for associated types
Chalk has a dedicated IR for bounds on trait associated type: `rust_ir::InlineBound`. We have been failing to convert GATs inside those bounds from our IR to chalk IR. This PR provides an easy fix for it: properly take GATs into account during the conversion.
Map our diagnostics to rustc and clippy's ones
And control their severity by lint attributes `#[allow]`, `#[deny]` and ... .
It doesn't work with proc macros and I would like to fix that before merge but I don't know how to do it.
internal: Format let-else
As nightly finally got support for it I went ahead and formatted r-a with the latest nightly, then with the latest stable (in case other stuff changed)
Split out project loading capabilities from rust-analyzer crate
External tools currently depend on the entire lsp infra for no good reason so let's lift that out so those tools have something better to depend on
Clean up `ImportMap`
There are several things in `hir_def::import_map` that are never used. This PR removes them and restructures the code. Namely:
- Removes `Query::name_only`, because it's *always* true.
- Because of this, we never took advantage of storing items' full path. This PR removes `ImportPath` and changes `ImportInfo` to only store items' name, which should reduce the memory consumption to some extent.
- Removes `SearchMode::Contains` for `Query` because it's never used.
- Merges `Query::assoc_items_only` and `Query::exclude_import_kinds` into `Query::assoc_mode`, because the latter is never used besides filtering associated items out.
Best reviewed one commit at a time. I made sure each commit passes full test suite. I can squash the first three commits if needed.
Use anonymous lifetime where possible
Because anonymous lifetimes are *super* cool.
More seriously, I believe anonymous lifetimes, especially those in impl headers, reduce cognitive load to a certain extent because they usually signify that they are not relevant in the signature of the methods within (or that we can apply the usual lifetime elision rules even if they are relevant).
Fix runnable detection for `#[tokio::test]`
fix#15141
It is hacky, and it wouldn't work for e.g. this case:
```Rust
use ::core::prelude;
#[prelude::v1::test]
fn foo() {
}
```
But it works for the tokio case. We should use the name resolution here somehow, and after that we should probably also get rid of the ast based `test_related_attribute` function.
internal: add `library` fixture meta
Currently, there is no way to specify `CrateOrigin` of a file fixture ([this] might be a bug?). This PR adds `library` meta to explicitly specify the fixture to be `CrateOrigin::Library` and also makes sure crates that belong to a library source root are set `CrateOrigin::Library`.
(`library` isn't really the best name. It essentially means that the crate is outside workspace but `non_workspace_member` feels a bit too long. Suggestions for the better name would be appreciated)
Additionally:
- documents the fixture meta syntax as thoroughly as possible
- refactors relevant code
[this]: 4b06d3c595/crates/base-db/src/fixture.rs (L450)
Fix `self` and `super` path resolution in block modules
This PR fixes `self` and `super` path resolution with block modules involved.
Previously, we were just going up the module tree count-of-`super` times without considering block modules in the way, and then if we ended up in a block `DefMap`, we adjust "to the containing crate-rooted module". While this seems to work in most real-world cases, we failed to resolve them within peculiar module structures.
`self` and `super` should actually be resolved to the nearest non-block module, and the paths don't necessarily resolve to a crate-rooted module. This PR makes sure every `self` and `super` segment in paths are resolved to a non-block module.
internal: support `#[rustc_coinductive]`
rust-lang/rust#100386 changed the trait solver so that `Sized` is treated as coinductive trait, just like auto traits. This is now controlled by the perma-unstable `#[rustc_coinductive]` attribute (rust-lang/rust#108033), which this PR adds support for.
In practice, I don't think this matters much if at all. Currently we don't give chalk enough information so chalk cannot precisely (dis)prove `Sized` bounds.