8065: Better handling of block doc comments r=Veykril a=Veykril
Moves doc string processing to `Attrs::docs`, as we need the indent info from all comments before being able to know how much to strip
Closes#7774
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8063: couple clippy::complexity fixes r=matklad a=matthiaskrgr
avoid redundant `.into()` calls to convert T into identical T (`let x: String = String::from("hello").into();`)
use `if let Some(x)` instead of `.is_some()` + `.unwrap()`
don't clone Copy types
remove redundant wrapped ?s: `Some(Some(3)?)` can just be `Some(3)`
use `.map(|x| y)` instead of `and_then(|x| Some(y)` on `Option`s
Co-authored-by: Matthias Krüger <matthias.krueger@famsik.de>
8052: minor style fixes per feedback on #8036 r=JoshMcguigan a=JoshMcguigan
cc @matklad - this PR addresses your comments in #8036.
changelog fixup #8036
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
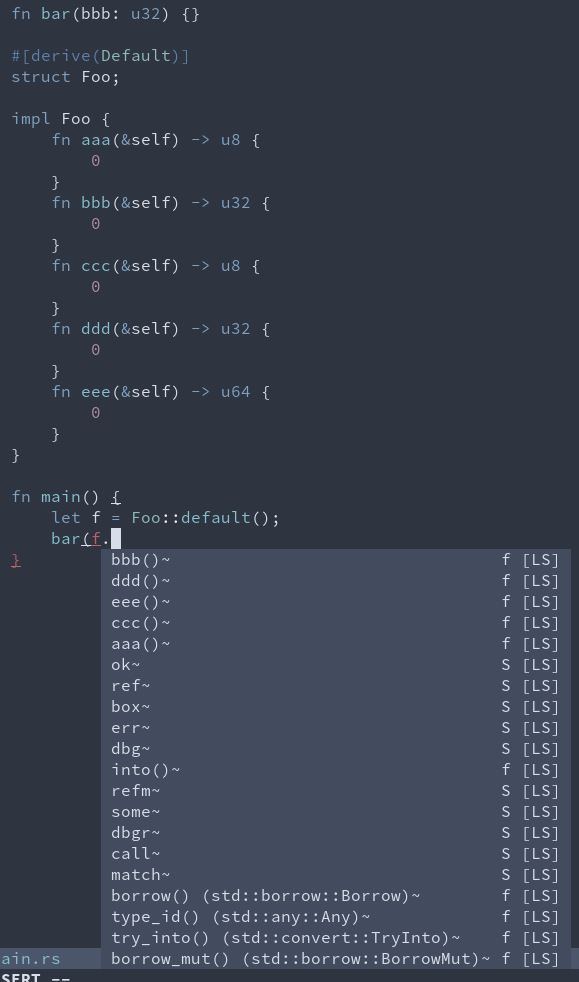
7900: show function params in completion detail r=matklad a=JoshMcguigan
This resolves#7842 by updating the detail for function completions from `-> T` to `fn(T, U) -> V`. I added an expicit unit test for this, `ide_completion::render::fn_detail_includes_args_and_return_type`, which passes.
Lots of other unit tests fail (~60 of them) due to this change, although I believe the failures are purely cosmetic (they were testing the exact format of this output). I'm happy to go update those tests, but before I do that I'd like to make sure this is in fact the format we want for the detail?
edit - I realized `UPDATE_EXPECT=1 cargo test` automatically updates `expect!` tests. Big 👍 to whoever worked on that! So I'll go ahead and update all these tests soon. But I still would like to confirm `fn(T, U) -> V` is the desired content in the `detail` field.
8000: Use hir formatter for hover text r=matklad a=oxalica
Fix#2765 , (should) fix#4665
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Co-authored-by: oxalica <oxalicc@pm.me>
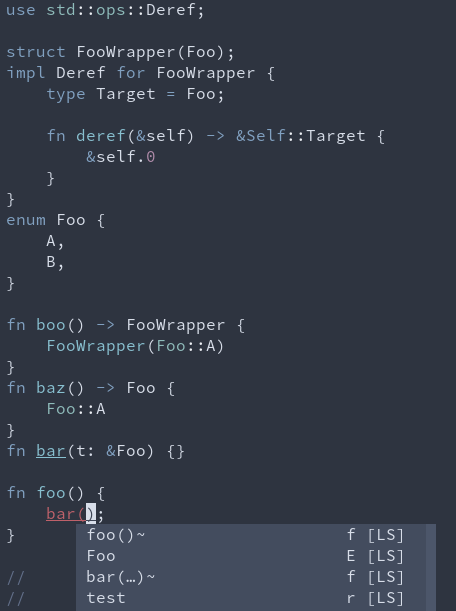
8036: completions: provide relevance bonus for enum types, and suggest ref matches for fn and enum r=matklad a=JoshMcguigan
This PR makes several improvements to completions and completion sorting:
1. Provide exact match type relevance score bonus for enum variants
2. Suggest `&Foo` (ref_match) for enums if that is an exact type match
3. Suggest `&foo()` (ref_match) if `foo` returns a type which would be an exact match either with the reference or due to a `Deref` impl
### Before
### After
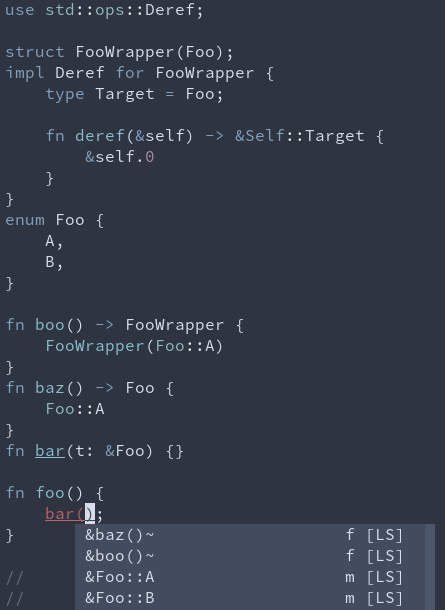
### Caveats
I think generic types will require some kind of fancier logic when testing for `exact_type_match`, so for now `Option`/`Result`/etc unfortunately still don't have great completions.
### Implementation
I implemented this in a way that I think makes it most likely for each completion type to be handled consistently. Just replace `CompletionItem::new` with `CompletionItem::new_with_type_info` and `exact_type_match`/`exact_name_match`/`ref_match` are all handled for you, in a way which is sure to be consistent across completion types.
This approach does introduce some coupling/plumbing that didn't exist before. Notice for example `set_is_local` on the builder, because `set_relevance` was removed from the builder to enforce that the relevance was built "properly" with `CompletionItem::new_with_type_info`. But I think there are benefits to this approach, like `CompletionRelevance` should probably consider deprecation status, and we already tell the builder about that, so in the (likely near term) future we can just pass that information along to `CompletionRelevance` when the user calls `set_deprecated` rather than the user having to manually set it in two places. This basically just hides `CompletionRelevance` from the individual completions, so they only worry about the `CompletionItem` interface. At the moment this seems like a cleaner approach to me, but I'm open to feedback here.
edit - I've reimplemented this in a simpler way, per feedback below.
8046: Prefer match to if let else r=matklad a=matklad
bors r+
🤖
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
7970: Fix incorrect diagnostics for failing built in macros r=jonas-schievink a=brandondong
**Reproduction:**
1. Use a built in macro in such a way that rust-analyzer fails to expand it. For example:
**lib.rs**
```
include!("<valid file but without a .rs extension so it is not indexed by rust-analyzer>");
```
2. rust-analyzer highlights the macro call and says the macro itself cannot be resolved even though include! is in the standard library (unresolved-macro-call diagnostic).
3. No macro-error diagnostic is raised.
**Root cause for incorrect unresolved-macro-call diagnostic:**
1. collector:collect_macro_call is able to resolve include! in legacy scope but the expansion fails. Therefore, it's pushed into unexpanded_macros to be retried with module scope.
2. include! fails at the resolution step in collector:resolve_macros now that it's using module scope. Therefore, it's retained in unexpanded_macros.
3. Finally, collector:finish tries resolving the remaining unexpanded macros but only with module scope. include! again fails at the resolution step so a diagnostic is created.
**Root cause for missing macro-error diagnostic:**
1. In collector:resolve_macros, directive.legacy is None since eager expansion failed in collector:collect_macro_call. The macro_call_as_call_id fails to resolve since we're retrying in module scope. Therefore, collect_macro_expansion is not called for the macro and no macro-error diagnostic is generated.
**Fix:**
- In collector:collect_macro_call, do not add failing built-in macros to the unexpanded_macros list and immediately raise the macro-error diagnostic. This is in contrast to lazy macros which are resolved in collector::resolve_macros and later expanded in collect_macro_expansion where a macro-error diagnostic may be raised.
Co-authored-by: Brandon <brandondong604@hotmail.com>
Co-authored-by: brandondong <brandondong604@hotmail.com>
8037: Assist is empty 7709 r=Veykril a=chetankhilosiya
Updated the implementation to get the function from implementation
Co-authored-by: Chetan Khilosiya <chetan.khilosiya@gmail.com>
8020: Power up goto_implementation r=matklad a=Veykril
by allowing it to be invoked on references of names, now showing all (trait)
implementations of the given type in all crates instead of just the defining
crate as well as including support for builtin types
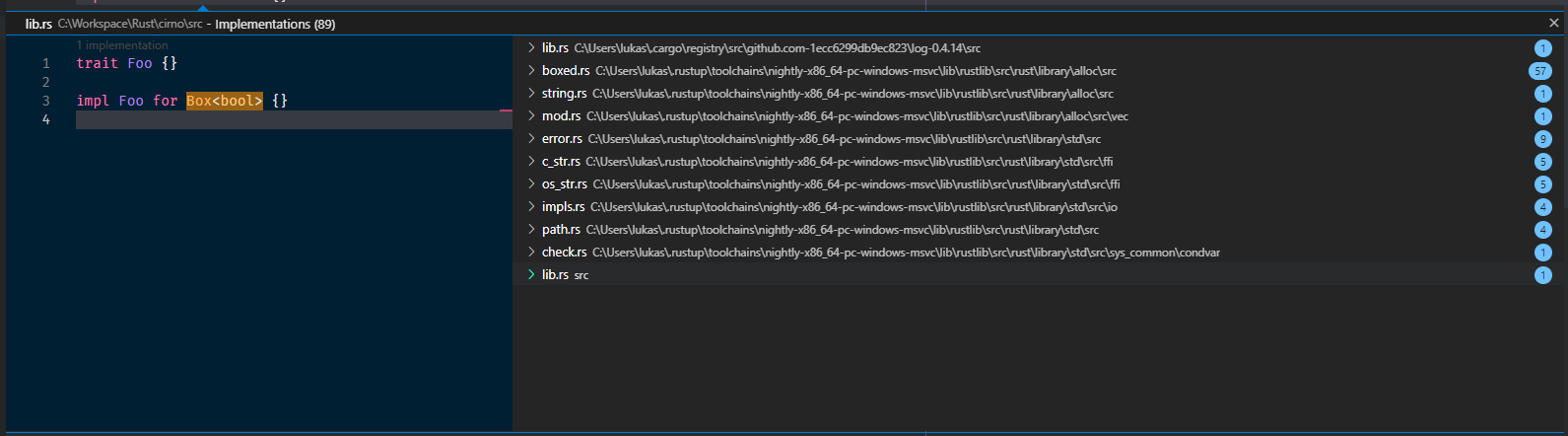
Example screenshot of `impl`s of Box in `log`, `alloc`, `std` and the current crate. Before you had to invoke it on the definition where it would only show the `impls` in `alloc`.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8027: Completion context remove exact match method in favor of fields r=JoshMcguigan a=JoshMcguigan
This is a minor cleanup PR following #8008. It removes the `expected_name_and_type` method on completion context in favor of using the fields.
I thought this method was used in more places, or else it may have just made sense to make this change directly in #8008🤷
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
8008: Completion context expected type r=matklad a=JoshMcguigan
Currently there are two ways completions use to determine the expected type. There is the `expected_type` field on the `CompletionContext`, as well as the `expected_name_and_type` method on the `RenderContext`. These two things returned slightly different results, and their results were only valid if you had pre-checked some (undocumented) invariants. A simple combination of the two approaches doesn't work because they are both too willing to go far up the syntax tree to find something that fits what they are looking for.
This PR makes the following changes:
1. Updates the algorithm that sets `expected_type` on `CompletionContext`
2. Adds `expected_name` field to `CompletionContext`
3. Re-writes the `expected_name_and_type` method to simply return the underlying fields from `CompletionContext` (I'd like to save actually removing this method for a follow up PR just to keep the scope of the changes down)
4. Adds unit tests for the `expected_type`/`expected_name` fields
All the existing unit tests still pass (unmodified), but this new algorithm certainly has some gaps (although I believe all the `FIXME` introduced in this PR are also flaws in the current code). I wanted to stop here and get some feedback though - is this approach fundamentally sound?
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
8018: Make Ty wrap TyKind in an Arc r=flodiebold a=flodiebold
... to further move towards Chalk.
This is a bit of a slowdown (218ginstr vs 213ginstr for inference on RA), even though it allows us to unwrap the Substs in `TyKind::Ref` etc..
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
What happens here is that we lower `: ` to a missing expression, and
then correctly record that the corresponding field expression resolves
to a specific field. Where we fail is in the mapping of syntax to this
missing expression. Doing it via `ast_field.expr()` fails, as that
expression is `None`. Instead, we go in the opposite direcition and ask
each lowered field about its source.
This works, but has wrong complexity `O(N)` and, really, the
implementation is just too complex. We need some better management of
data here.
8021: Enable searching for builtin types r=matklad a=Veykril
Not too sure how useful this is for reference search overall, but for completeness sake it should be there
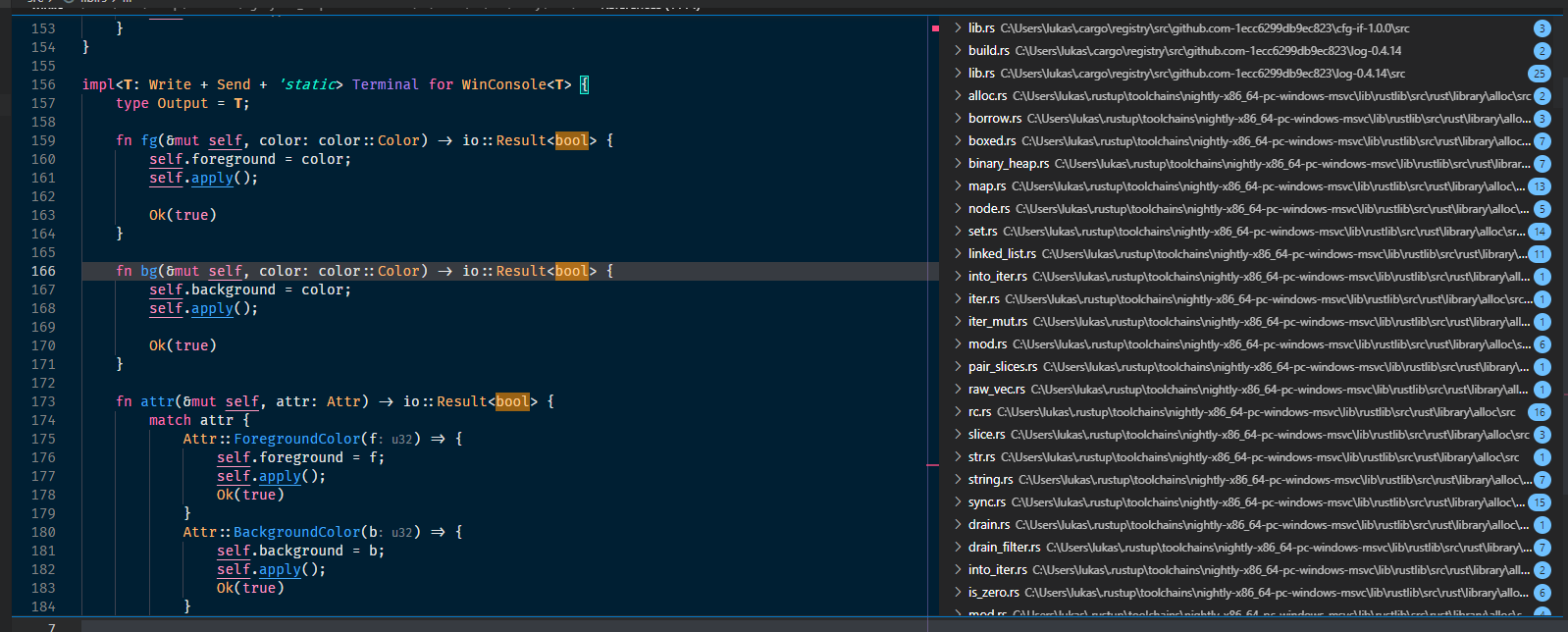
Also enables document highlighting for them.
8022: some clippy::performance fixes r=matklad a=matthiaskrgr
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unnecessary resizing
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Co-authored-by: Matthias Krüger <matthias.krueger@famsik.de>
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
7966: Diagnose files that aren't in the module tree r=jonas-schievink a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/6377
I'm not sure if this is the best way to do this. It will cause false positives for all `include!`d files (though I'm not sure how much IDE functionality we have for these).
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
... like it will be in Chalk. We still keep `interned_mut` and
`into_inner` methods that will probably not exist with Chalk.
This worsens performance slightly (5ginstr inference on RA), but doesn't
include other simplifications we can do yet.
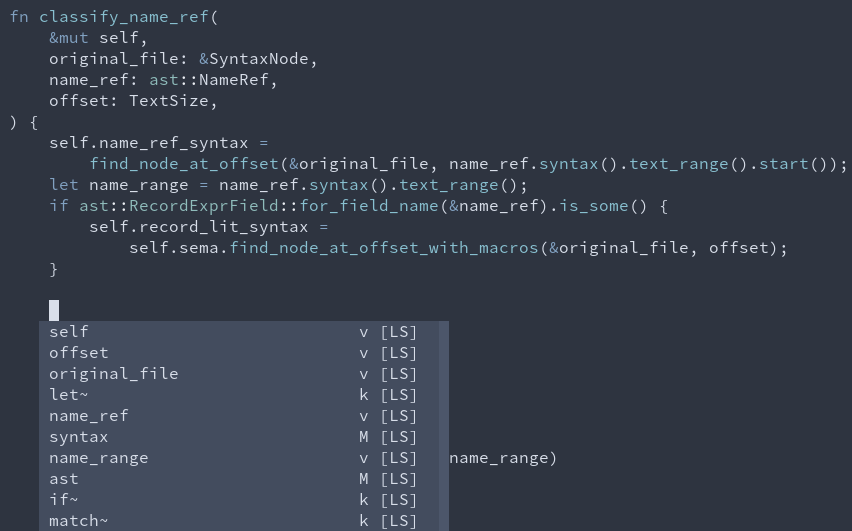
8014: increase completion relevance for items in local scope r=matklad a=JoshMcguigan
This PR provides a small completion relevance score bonus for items in local scope. The changes here are relatively minimal, since `coc` by default pre-sorts by position in file. But as we move toward fully server side sorting #7935 I think we'll want some relevance score bump for items in local scope.
### Before
Note `let~` and `syntax` are both ahead of locals. Ultimately we may decide that `let~` is a high relevance completion given my cursor position here, but that should be done with some explicit scoring on the server side, rather than being caused by (I think) `coc` preferring shorter completions.
### After
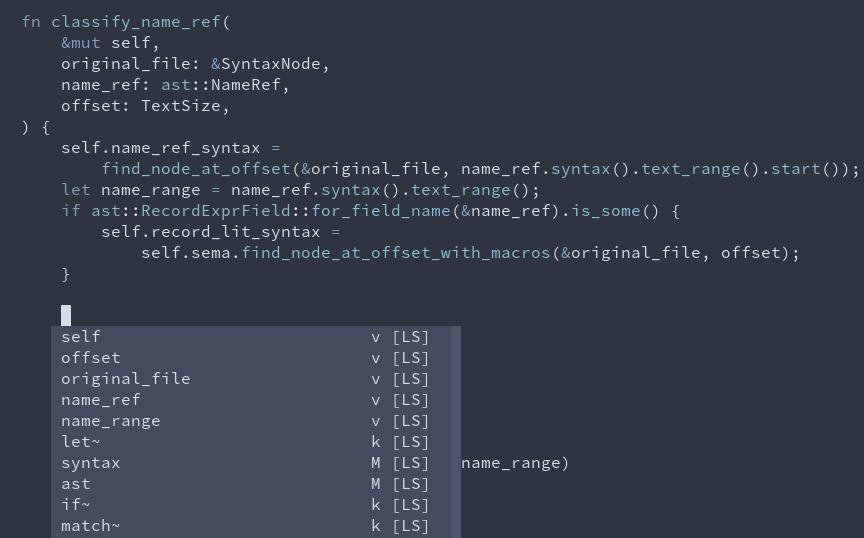
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
8011: Add no-sysroot flag for analysis-stats r=edwin0cheng a=edwin0cheng
Add `no-sysroot` flag for `rust-analyzer analysis-stats`. It is very useful for debugging propose.
bors r+
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7984: Improve version display r=matklad a=lnicola
Maybe closes#7854
The version string for unreleased builds looks like this now:
```
$ rust-analyzer --version
rust-analyzer 2021-03-08-159-gc0459c535
```
Release builds should only have the tag name (`2021-03-15`).
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
7994: Speed up mbe matching in heavy recursive cases r=edwin0cheng a=edwin0cheng
In some cases (e.g. #4186), mbe matching is very slow due to a lot of copy and allocation for bindings, this PR try to solve this problem by introduce a semi "link-list" approach for bindings building.
I used this [test case](https://github.com/weiznich/minimal_example_for_rust_81262) (for `features(32-column-tables)`) to run following command to benchmark:
```
time rust-analyzer analysis-stats --load-output-dirs ./
```
Before this PR : 2 mins
After this PR: 3 seconds.
However, for 64-column-tables cases, we still need 4 mins to complete.
I will try to investigate in the following weeks.
bors r+
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7904: Improved completion sorting r=JoshMcguigan a=JoshMcguigan
I was working on extending #3954 to apply completion scores in more places (I'll have another PR open for that soon) when I discovered that actually completion sorting was not working for me at all in `coc.nvim`. This led me down a bit of a rabbit hole of how coc and vs code each sort completion items.
Before this PR, rust-analyzer was setting the `sortText` field on completion items to `None` if we hadn't applied any completion score for that item, or to the label of the item with a leading whitespace character if we had applied any completion score. Completion score is defined in rust-analyzer as an enum with two variants, `TypeMatch` and `TypeAndNameMatch`.
In vs code the above strategy works, because if `sortText` isn't set [they default it to the label](b4ead4ed66). However, coc [does not do this](e211e36147/src/completion/complete.ts (L245)).
I was going to file a bug report against coc, but I read the [LSP spec for the `sortText` field](https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion) and I feel like it is ambiguous and coc could claim what they do is a valid interpretation of the spec.
Further, the existing rust-analyzer behavior of prepending a leading whitespace character for completion items with any completion score does not handle sorting `TypeAndNameMatch` completions above `TypeMatch` completions. They were both being treated the same.
The first change this PR makes is to set the `sortText` field to either "1" for `TypeAndNameMatch` completions, "2" for `TypeMatch` completions, or "3" for completions which are neither of those. This change works around the potential ambiguity in the LSP spec and fixes completion sorting for users of coc. It also allows `TypeAndNameMatch` items to be sorted above just `TypeMatch` items (of course both of these will be sorted above completion items without a score).
The second change this PR makes is to use the actual completion scores for ref matches. The existing code ignored the actual score and always assumed these would be a high priority completion item.
#### Before
Here coc just sorts based on how close the items are in the file.

#### After
Here we correctly get `zzz` first, since that is both a type and name match. Then we get `ccc` which is just a type match.
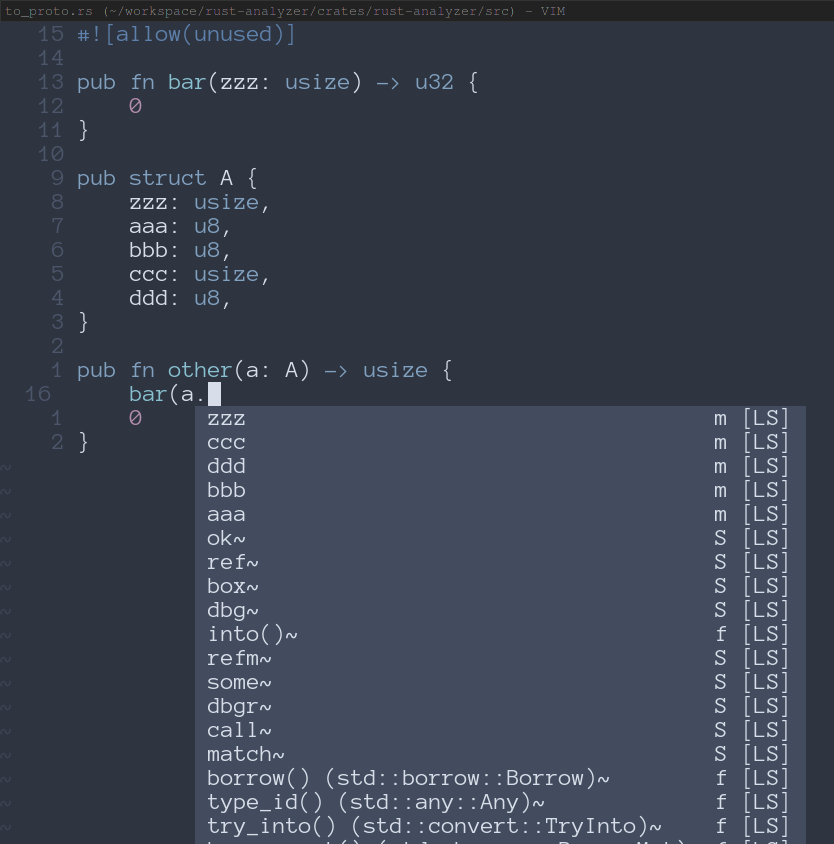
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
7961: add user docs for ssr assist r=JoshMcguigan a=JoshMcguigan
@matklad
This is a small follow up on #7874, adding user docs for the SSR assist functionality. Since most other assists aren't handled this way I wasn't sure exactly how we wanted to document this, so feel free to suggest alternatives.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
6822: Read version of rustc that compiled proc macro r=edwin0cheng a=jsomedon
Signed-off-by: Jay Somedon <jay.somedon@outlook.com>
This PR is to fix#6174.
I basically
* added two methods, `read_version` and `read_section`(used by `read_version`)
* two new crates `snap` and `object` to be used by those two methods
I just noticed that some part of code were auto-reformatted by rust-analyzer on file save. Does it matter?
Co-authored-by: Jay Somedon <jay.somedon@outlook.com>
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
7878: Remove `item_scope` field from `Body` r=jonas-schievink a=jonas-schievink
Closes https://github.com/rust-analyzer/rust-analyzer/issues/7632
Instead of storing an `ItemScope` filled with inner items, we store the list of `BlockId`s for all block expressions that are part of a `Body`. Code can then query the `block_def_map` for those.
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
7873: Consider unresolved qualifiers during flyimport r=matklad a=SomeoneToIgnore
Closes https://github.com/rust-analyzer/rust-analyzer/issues/7679
Takes unresolved qualifiers into account, providing better completions (or none, if the path is resolved or do not match).
Does not handle cases when both path qualifier and some trait has to be imported: there are many extra issues with those (such as overlapping imports, for instance) that will require large diffs to address.
Also does not do a fuzzy search on qualifier, that requires some adjustments in `import_map` for better queries and changes to the default replace range which also seems relatively big to include here.
7933: Improve compilation speed r=matklad a=matklad
bors r+
🤖
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
7898: generate_function assist: infer return type r=JoshMcguigan a=JoshMcguigan
This PR makes two changes to the generate function assist:
1. Attempt to infer an appropriate return type for the generated function
2. If a return type is inferred, and that return type is not unit, don't render the snippet
```rust
fn main() {
let x: u32 = foo$0();
// ^^^ trigger the assist to generate this function
}
// BEFORE
fn foo() ${0:-> ()} {
todo!()
}
// AFTER (only change 1)
fn foo() ${0:-> u32} {
todo!()
}
// AFTER (change 1 and 2, note the lack of snippet around the return type)
fn foo() -> u32 {
todo!()
}
```
These changes are made as two commits, in case we want to omit change 2. I personally feel like it is a nice change, but I could understand there being some opposition.
#### Pros of change 2
If we are able to infer a return type, and especially if that return type is not the unit type, the return type is almost as likely to be correct as the argument names/types. I think this becomes even more true as people learn how this feature works.
#### Cons of change 2
We could never be as confident about the return type as we are about the function argument types, so it is more likely a user will want to change that. Plus it is a confusing UX to sometimes have the cursor highlight the return type after triggering this assist and sometimes not have that happen.
#### Why omit unit type?
The assumption is that if we infer the return type as unit, it is likely just because of the current structure of the code rather than that actually being the desired return type. However, this is obviously just a heuristic and will sometimes be wrong. But being wrong here just means falling back to the exact behavior that existed before this PR.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}