8524: Fix extract function with partial block selection r=matklad a=brandondong
**Reproduction:**
```rust
fn foo() {
let n = 1;
let mut v = $0n * n;$0
v += 1;
}
```
1. Select the snippet ($0) and use the "Extract into function" assist.
2. Extracted function is incorrect and does not compile:
```rust
fn foo() {
let n = 1;
let mut v = fun_name(n);
v += 1;
}
fn fun_name(n: i32) {}
```
3. Omitting the ending semicolon from the selection fixes the extracted function:
```rust
fn fun_name(n: i32) -> i32 {
n * n
}
```
**Cause:**
- When `extraction_target` uses a block extraction (semicolon case) instead of an expression extraction (no semicolon case), the user selection is directly used as the TextRange.
- However, the existing function extraction logic for blocks requires that the TextRange spans from start to end of complete statements to work correctly.
- For example:
```rust
fn foo() {
let m = 2;
let n = 1;
let mut v = m $0* n;
let mut w = 3;$0
v += 1;
w += 1;
}
```
produces
```rust
fn foo() {
let m = 2;
let n = 1;
let mut v = m let mut w = fun_name(n);
v += 1;
w += 1;
}
fn fun_name(n: i32) -> i32 {
let mut w = 3;
w
}
```
- The user selected TextRange is directly replaced by the function call which is now in the middle of another statement. The extracted function body only contains statements that were fully covered by the TextRange and so the `* n` code is deleted. The logic for calculating variable usage and outlived variables for the function parameters and return type respectively search within the TextRange and so do not include `m` or `v`.
**Fix:**
- Only extract full statements when using block extraction. If a user selected part of a statement, extract that full statement.
8527: Switch introduce_named_lifetime assist to use mutable syntax tree r=matklad a=iDawer
This extends `GenericParamsOwnerEdit` trait with `get_or_create_generic_param_list` method
Co-authored-by: Brandon <brandondong604@hotmail.com>
Co-authored-by: Dawer <7803845+iDawer@users.noreply.github.com>
8565: Fill match arms assist: add remaining arms for tuple of enums r=iDawer a=iDawer
Fix for #8493
However, the assist is still flaky and does not use `hir_ty::diagnostics::match_check`
Co-authored-by: Dawer <7803845+iDawer@users.noreply.github.com>
8540: Prevent being able to rename items that are not part of the workspace r=Veykril a=Veykril
This change causes renames that happen on items coming from crates outside the workspace to fail. I believe this should be the right approach, but usage of cargo's workspace might not be entirely correct for preventing these kinds of refactoring from touching things they shouldn't. I'm not entirely sure?
cc #6623, this is one of the bigger footguns when it comes to refactoring, especially in combination with import aliases people tend to rename items coming from a crates dependency which this prevents.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8467: Adds impl Deref assist r=jhgg a=jhgg
This PR adds a new `generate_deref` assist that automatically generates a deref impl for a given struct field.
Check out this gif:

--
I have a few Q's:
- [x] Should I write more tests, if so, what precisely should I test for?
- [x] I have an inline question on line 65, can someone provide guidance? :)
- [x] I can implement this for `ast::TupleField` too. But should it be a separate assist fn, or should I try and jam both into the `generate_deref`?
- [x] I want to follow this up with an assist on `impl $0Deref for T {` which would automatically generate a `DerefMut` impl that mirrors the Deref as well, however, I could probably use some pointers on how to do that, since I'll have to reach into the ast of `fn deref` to grab the field that it's referencing for the `DerefMut` impl.
Co-authored-by: jake <jh@discordapp.com>
8560: Escape characters in doc comments in macros correctly r=jonas-schievink a=ChayimFriedman2
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
Example (the keyword and primitive docs are `include!()`d at https://doc.rust-lang.org/src/std/lib.rs.html#570-578, and thus originate from macro):
Before:
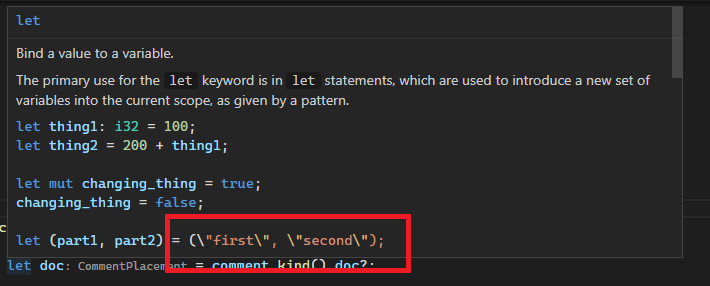
After:
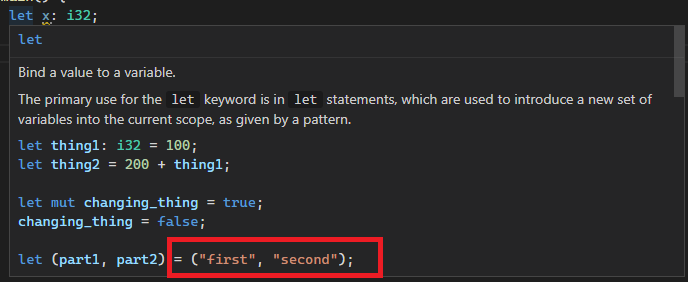
Co-authored-by: Chayim Refael Friedman <chayimfr@gmail.com>
Previously they were escaped twice, both by `.escape_default()` and the debug view of strings (`{:?}`). This leads to things like newlines or tabs in documentation comments being `\\n`, but we unescape literals only once, ending up with `\n`.
This was hard to spot because CMark unescaped them (at least for `'` and `"`), but it did not do so in code blocks.
This also was the root cause of #7781. This issue was solved by using `.escape_debug()` instead of `.escape_default()`, but the real issue remained.
We can bring the `.escape_default()` back by now, however I didn't do it because it is probably slower than `.escape_debug()` (more work to do), and also in order to change the code the least.
{kind=link}
{kind=link}
{kind=link}