9954: feat: Show try operator propogated types on ranged hover r=matklad a=Veykril
Basically this just shows the type of the inner expression of the `?` expression as well as the type of the expression that the `?` returns from:
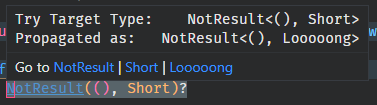
Unless both of these types are `core::result::Result` in which case we show the error types only.
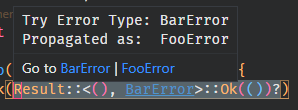
If both types are `core::option::Option` with different type params we do not show this special hover either as it would be pointless(instead fallback to default type hover)
Very much open to changes to the hover text here(I suppose we also want to show the actual type of the `?` expression, that is its output type?).
Fixes#9931
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
When dealing with proc macros, there are two very different kinds of
errors:
* first, usual errors of "proc macro panicked on this particular input"
* second, the proc macro server might day if the user, eg, kills it
First kind of errors are expected and are a normal output, while the
second kind are genuine IO-errors.
For this reason, we use a curious nested result here: `Result<Result<T,
E1>, E2>` pattern, which is 100% inspired by http://sled.rs/errors.html
10095: internal: Augment panic context when resolving path r=jonas-schievink a=jonas-schievink
Should help with debugging https://github.com/rust-analyzer/rust-analyzer/issues/10084 and similar issues.
Might have a perf impact since the string is created on every function call.
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
10097: fix: Allow inherent impls for arrays r=jonas-schievink a=jonas-schievink
Part of https://github.com/rust-analyzer/rust-analyzer/issues/9992 (method resolution of these methods still does not work)
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
10091: fix: fix "disjunction in conjunction" panic r=matklad a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/10073
The DNF construction code created expressions that were combined in a way that made us "forget" to make their contents valid DNF again. This PR fixes that by flattening nested `any(any())` and `all(all())` predicates. There was also a typo that led to a redundant call to `make_nnf` instead of the correct recursive call to `make_dnf` (but this didn't seem to break/fix anything).
This also adds some light property testing, though I'm not really sure this is the best way to do it.
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
10092: feat: Improve `extract_struct_from_enum_variant` output r=matklad a=DropDemBits
Improves the struct generated by `extract_struct_from_enum_variant`.
Summary of changes:
- Indent the generated struct and enum to the same indent level
- Preserve comments & attributes from the enum variant (something I missed when doing the same thing for the variant fields)
- Use enum's visibility for fields without any visibility, instead of filling it in with `pub`
Co-authored-by: DropDemBits <r3usrlnd@gmail.com>
10076: Use struct init shorthand when applicable in fill struct fields assist r=matklad a=nathanwhit
This PR tweaks the fill struct fields assist to use the struct init shorthand when a local variable with a matching name and type is in scope.
For example:
```rust
struct Foo {
a: usize,
b: i32,
c: char,
}
fn main() {
let a = 1;
let b = 2;
let c = 3;
let foo = Foo { <|> };
}
```
Before we would insert
```rust
Foo {
a: (),
b: (),
c: (),
}
```
now we would insert
```rust
Foo {
a,
b,
c: ()
}
```
Co-authored-by: nathan.whitaker <nathan.whitaker01@gmail.com>
closes#9922
Turned out to be trivial after preliminary refactor.
The intended behavior is that we schedule cache priming once ws become
quiescent (that is, we fully load cargo project), and we continue to
rschedule it until it completes (priming might get cancelled by user
typing into a file).
Group related stuff together, use only on path for parsing extern blocks
(they actually have modifiers).
Perhaps we should get rid of items_without_modifiers altogether? Better
to handle these kinds on diagnostics in validation layer...
10005: Extend `CargoConfig.unset_test_crates` r=matklad a=regexident
This is to allow for efficiently disabling `#[cfg(test)]` on all crates (by passing `unset_test_crates: UnsetTestCrates::All`) without having to first load the crate graph, when using rust-analyzer as a library.
(FYI: The change doesn't seem to be covered by any existing tests.)
Co-authored-by: Vincent Esche <regexident@gmail.com>
10080: internal: don't shut up the compiler when it says the code's buggy r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
10066: internal: improve compile times a bit r=matklad a=matklad
I wanted to *quickly* remove `smol_str = {features = "serde"}`, and figured out that the simplest way to do that is to replace our straightforward proc macro serialization with something significantly more obscure.
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
9970: feat: Implement attribute input token mapping, fix attribute item token mapping r=Veykril a=Veykril
The token mapping for items with attributes got overwritten partially by the attributes non-item input, since attributes have two different inputs, the item and the direct input both.
This PR gives attributes a second TokenMap for its direct input. We now shift all normal input IDs by the item input maximum(we maybe wanna swap this see below) similar to what we do for macro-rules/def. For mapping down we then have to figure out whether we are inside the direct attribute input or its item input to pick the appropriate mapping which can be done with some token range comparisons.
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/9867
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
10030: fix: Fix multiple derives in one attribute not expanding all in expand_macro r=Veykril a=Veykril
It's probably better to only expand the exact derive the cursor is on(if possible) instead of all derives in the attribute the cursor is one.
follow up to #10029
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
10029: internal: Improve expand_macro r=Veykril a=Veykril
- Adds a few more newlines to the output making it more readable
- Fixes a bug with multiple derives not being expandable
There seems to be an issue with multiple derives in one attribute only showing the expansion of the last derive which I'll have to investigate.
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9944: internal: introduce in-place indenting API r=matklad a=iDawer
Introduce `edit_in_place::Indent` that uses mutable tree API and intended to replace `edit::AstNodeEdit`.
Closes#9903
Co-authored-by: Dawer <7803845+iDawer@users.noreply.github.com>
10001: Sort enum variant r=Veykril a=vsrs
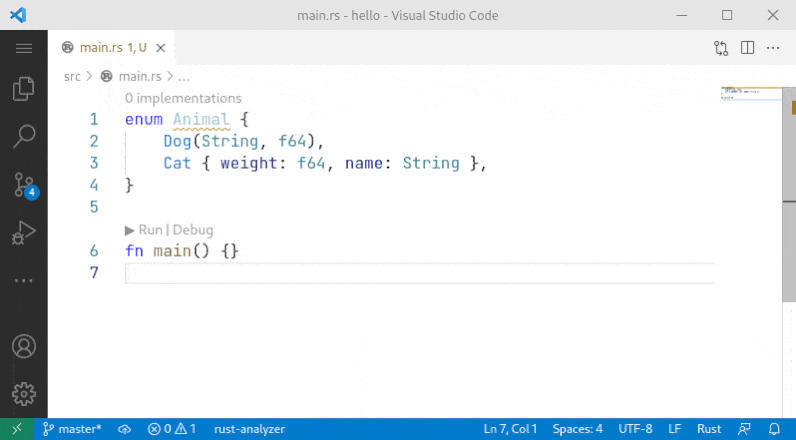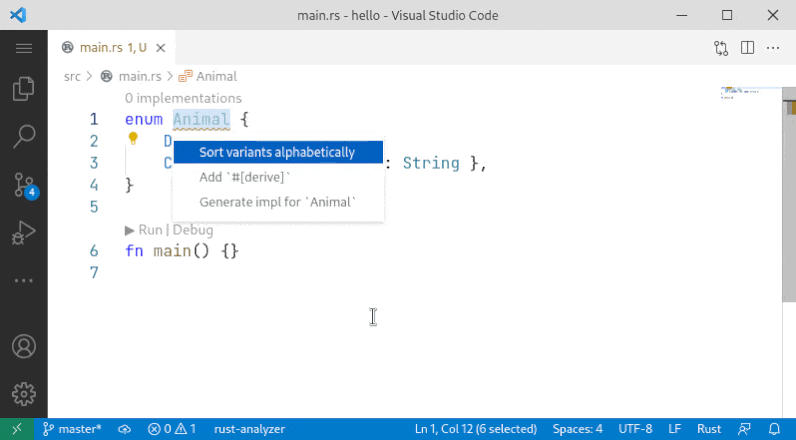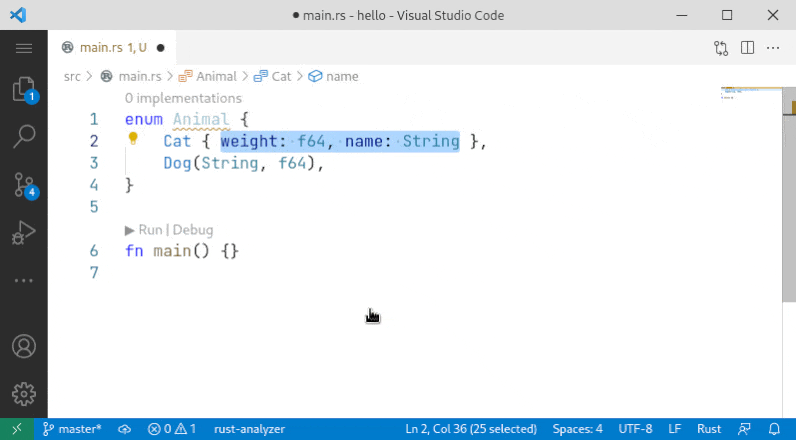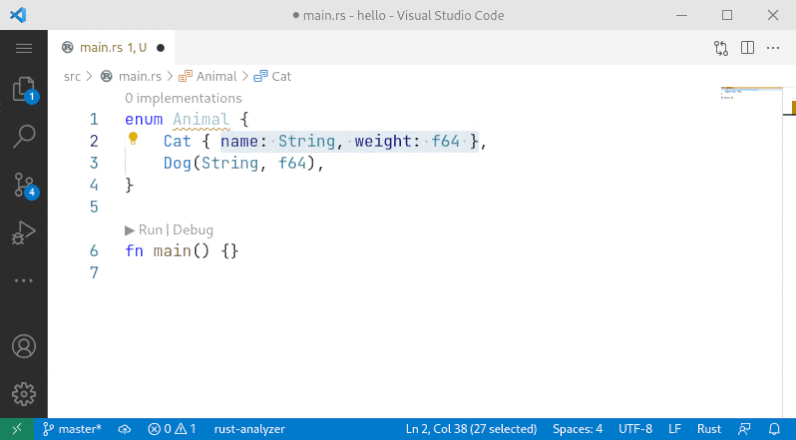
A small fix to the problem noted by `@lnicola` :
> 
>
> (note the slight inconsistency here: to sort the variants of `Animal` I have to select the enum name, but to sort the fields of `Cat` I have to select the fields themselves)
Co-authored-by: vsrs <vit@conrlab.com>
9989: Fix two more “a”/“an” typos (this time the other way) r=lnicola a=steffahn
Follow-up to #9987
you guys are still merging these fast 😅
_this time I thought – for sure – that I’d get this commit into #9987 before it’s merged…_
Co-authored-by: Frank Steffahn <frank.steffahn@stu.uni-kiel.de>
It's good that rust-analyzer doesn't belly-up on a panic in some random
assist.
It is less good that rust-analyzer devs only know that the assists are
buggy when they are actively looking at the logs.
9972: refactor : function generation assists r=Veykril a=mahdi-frms
Separated code generation from finding position for generated code. This will be ground work for introducing static associated function generation.
Co-authored-by: mahdi-frms <mahdif1380@outlook.com>
9979: fix: Incorrect up-mapping for tokens in derive attributes r=Veykril a=Veykril
Merely detaching the attributes causes incorrect spans to appear when mapping tokens up as the token ids resolve to the ranges of the stripped item so all the text ranges of its tokens are actually lower than the non-stripped ones.
Same fix as with attributes can be applied here, just replace the derive attribute with an equal amount of whitespace.
Fixes#9387
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
I don't think there's anything wrong with project_model depending on
proc_macro_api directly -- fundamentally, both are about gluing our pure
data model to the messy outside world.
However, it's easy enough to avoid the dependency, so why not.
As an additional consideration, `proc_macro_api` now pulls in `base_db`.
project_model should definitely not depend on that!
9975: minor: Fix panic caused by #9966 r=flodiebold a=flodiebold
Chalk can introduce new type variables when doing lazy normalization, so we have to do the proper 'fudging' after all.
Co-authored-by: Florian Diebold <flodiebold@gmail.com>
9965: minor: Don't ask for the builtin attribute input twice r=Veykril a=Veykril
`tt` and `item` here were the same, I misunderstood what the main input for attributes was in #9943
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9962: Add empty-body check to replace_match_with_if_let and re-prioritize choices r=elkowar a=elkowar
This PR changes some behaviour of the `replace_match_with_if_let` ide-assist.
Concretely, it makes two changes:
it introduces a check for empty expression bodies. This means that checks of the shape
```rs
match x {
A => {}
B => {
println!("hi");
}
}
```
will prefer to use the B branch as the first (and only) variant.
It also reprioritizes the importance of "happy" and "sad" patterns.
Concretely, if there are reasons to prefer having the sad pattern be the first (/only) pattern,
it will follow these.
This means that in the case of
```rs
match x {
Ok(_) => {
println!("Success");
}
Err(e) => {
println!("Failure: {}", e);
}
}
```
the `Err` variant will correctly be used as the first expression in the generated if.
Up until now, the generated code was actually invalid, as it would generate
```rs
if let Ok(_) = x {
println!("Success");
} else {
println!("Failure: {}", e);
}
```
where `e` in the else branch is not defined.
Co-authored-by: elkowar <5300871+elkowar@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}