Rename `checkOnSave` settings to `check`
Now that flychecks can be triggered without saving the setting name doesn't make that much sense anymore. This PR renames it to just `check`, but keeps `checkOnSave` as the enabling setting.
Add action to expand a declarative macro once, inline. Fixes#13598
This commit adds a new r-a method, `expandMacroInline`, which expands the macro that's currently selected. See #13598 for the most applicable issue; though I suspect it'll resolve part of #5949 and make #11888 significantly easier).
The macro works like this:
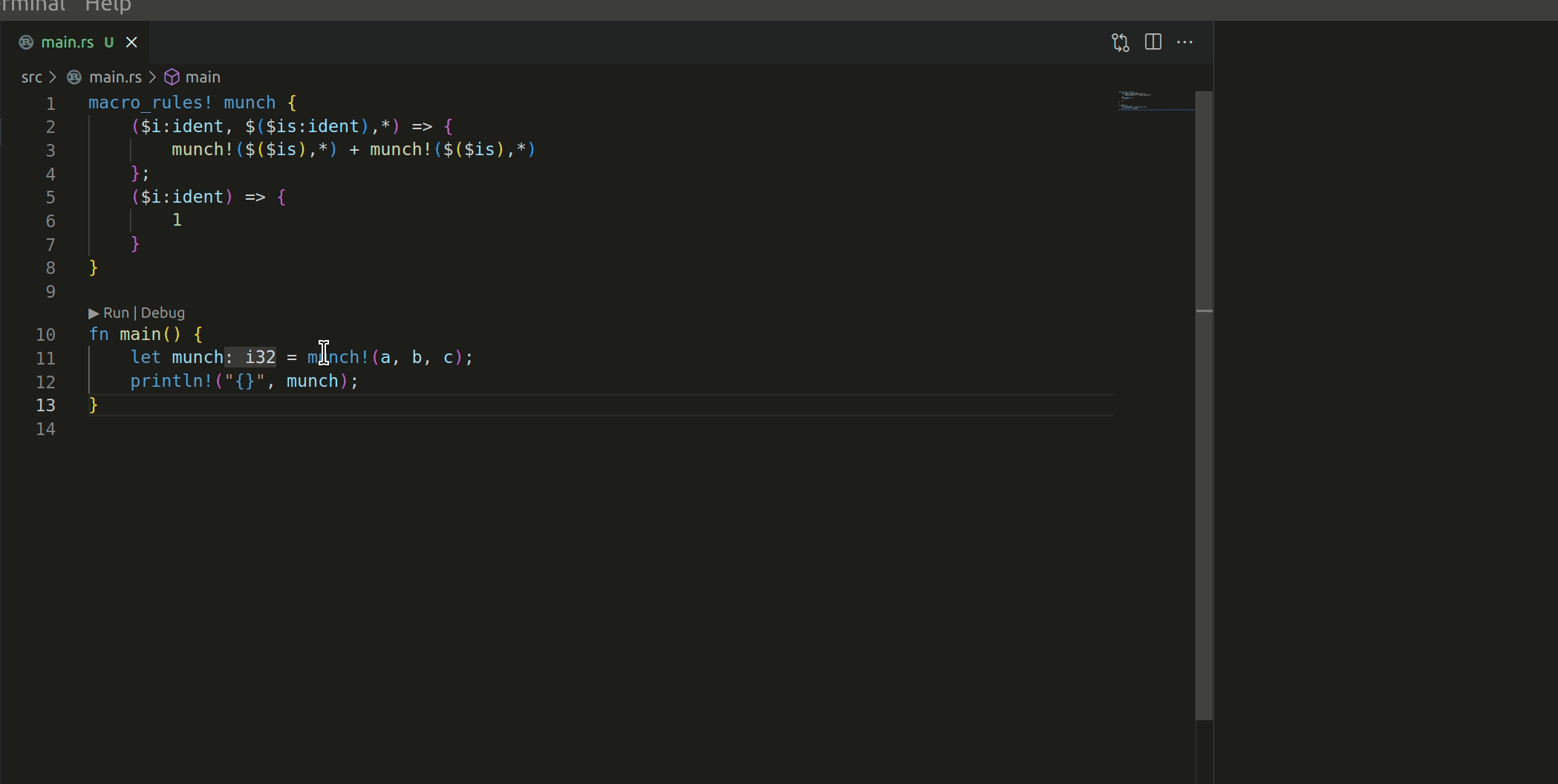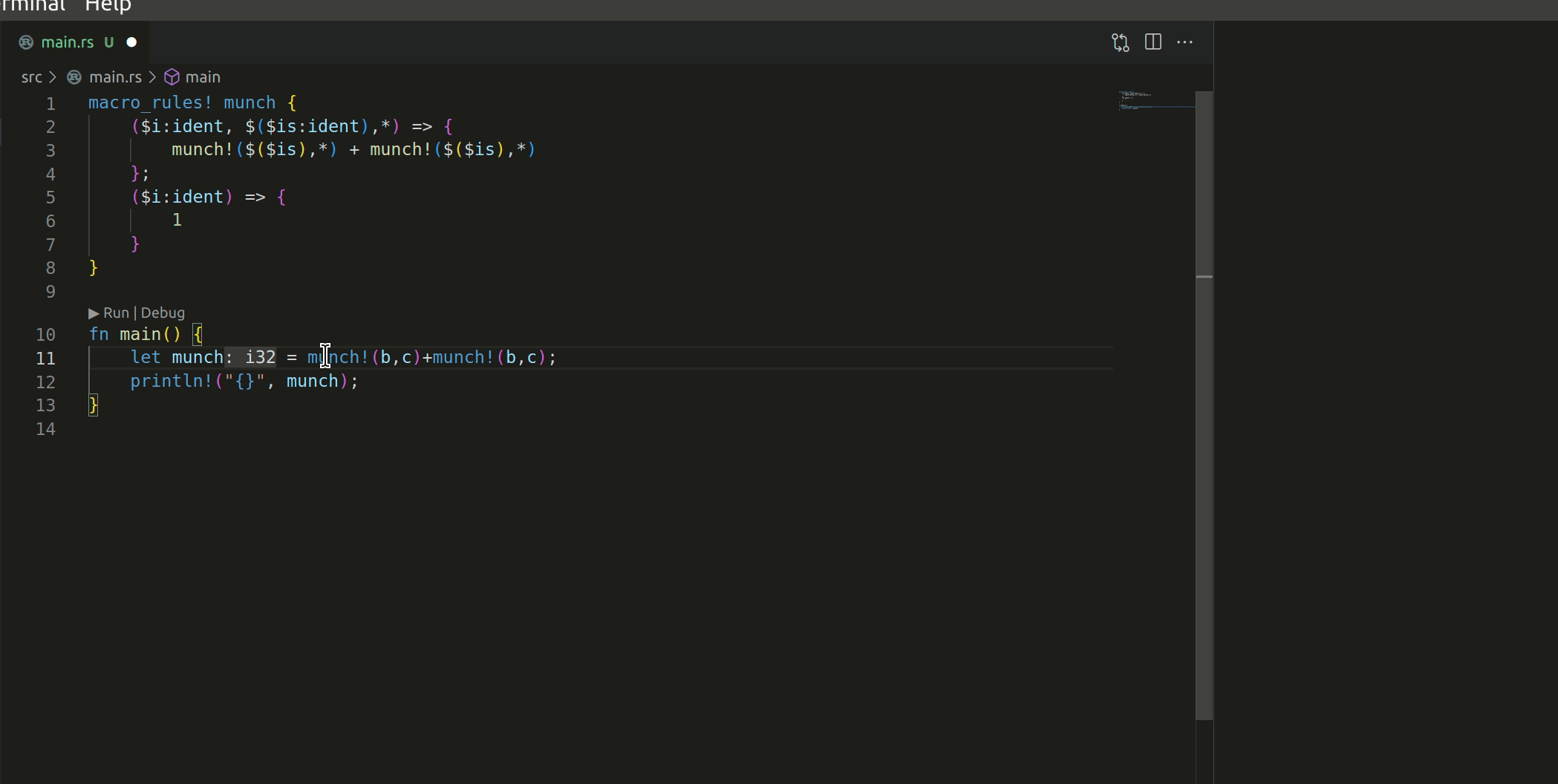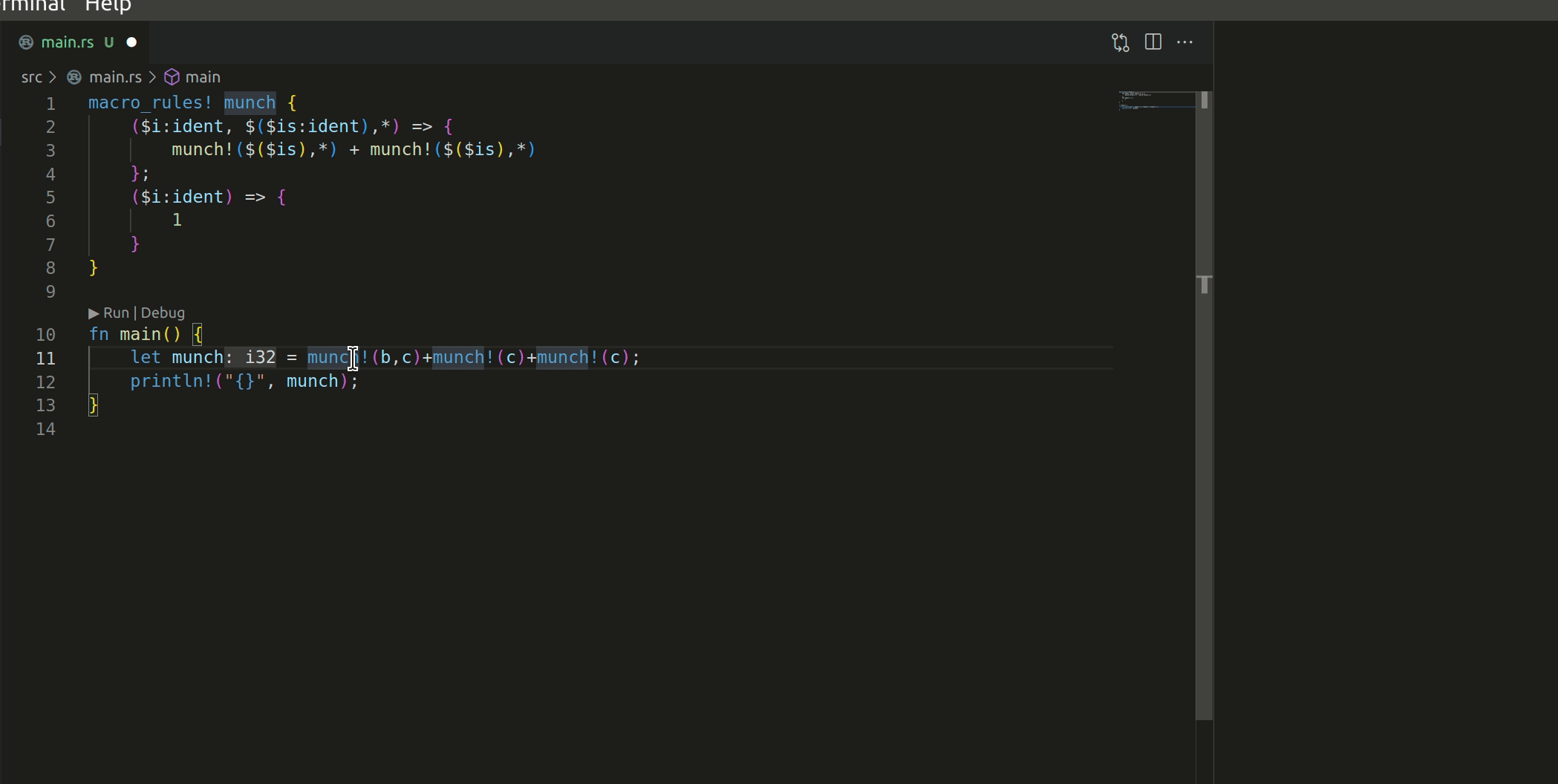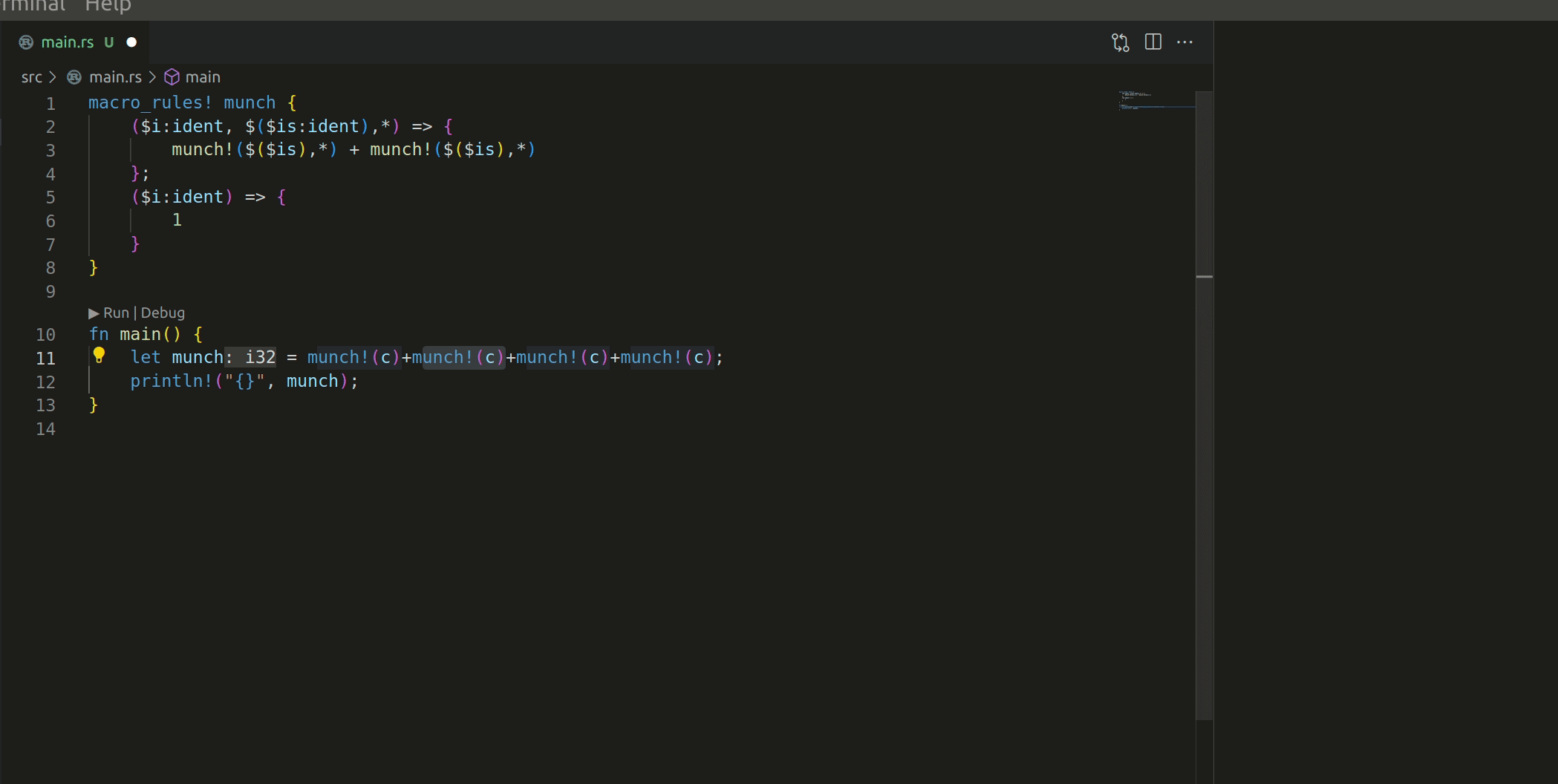
I have 2 questions before this PR can be merged:
1. **Should we rustfmt the output?** The advantage of doing this is neater code. The disadvantages are we'd have to format the whole expr/stmt/block (since there's no point just formatting one part, especially over multiple lines), and maybe it moves the code around more in weird ways. My suggestion here is to start off by not doing any formatting; and if it appears useful we can decide to do formatting in a later release.
2. **Is it worth solving the `$crate` hygiene issue now?** -- I think this PR is usable as of right now for some use-cases; but it is annoying that many common macros (i.e. `println!()`, `format!()`) can't be expanded further unless the user guesses the correct `$crate` value. The trouble with solving that issue is that I think it's complicated and imperfect. If we do solve it; we'd also need to either change the existing `expandMacro`/`expandMacroInline` commands; provide some option to allow/disallow `$crate` expanding; or come to some other compromise.
fix: generate async delegate methods
Fixes a bug where the generated async method doesn't await the result before returning it.
This is an example of what the output looked like:
```rust
struct Age<T>(T);
impl<T> Age<T> {
pub(crate) async fn age<J, 'a>(&'a mut self, ty: T, arg: J) -> T {
self.0
}
}
struct Person<T> {
age: Age<T>,
}
impl<T> Person<T> {
pub(crate) async fn age<J, 'a>(&'a mut self, ty: T, arg: J) -> T {
self.age.age(ty, arg) // .await is missing
}
}
```
The `.await` is missing, so the return type is `impl Future<Output = T>` instead of `T`
feat: add the ability to limit the number of threads launched by `main_loop`
## Motivation
`main_loop` defaults to launch as many threads as cpus in one machine. When developing on multi-core remote servers on multiple projects, this will lead to thousands of idle threads being created. This is very annoying when one wants check whether his program under developing is running correctly via `htop`.
<img width="756" alt="image" src="https://user-images.githubusercontent.com/41831480/206656419-fa3f0dd2-e554-4f36-be1b-29d54739930c.png">
## Contribution
This patch introduce the configuration option `rust-analyzer.numThreads` to set the desired thread number used by the main thread pool.
This should have no effects on the performance as not all threads are actually used.
<img width="1325" alt="image" src="https://user-images.githubusercontent.com/41831480/206656834-fe625c4c-b993-4771-8a82-7427c297fd41.png">
## Demonstration
The following is a snippet of `lunarvim` configuration using my own build.
```lua
vim.list_extend(lvim.lsp.automatic_configuration.skipped_servers, { "rust_analyzer" })
require("lvim.lsp.manager").setup("rust_analyzer", {
cmd = { "env", "RA_LOG=debug", "RA_LOG_FILE=/tmp/ra-test.log",
"/home/jlhu/Projects/rust-analyzer/target/debug/rust-analyzer",
},
init_options = {
numThreads = 4,
},
settings = {
cachePriming = {
numThreads = 8,
},
},
})
```
## Limitations
The `numThreads` can only be modified via `initializationOptions` in early initialisation because everything has to wait until the thread pool starts including the dynamic settings modification support.
The `numThreads` also does not reflect the end results of how many threads is actually created, because I have not yet tracked down everything that spawns threads.
add wrapping/checked/saturating assist
This addresses #13452
I'm not sure about the structure of the code. I'm not sure if it needs to be 3 separate assists, and if that means it needs to be in 3 separate files as well.
Most of the logic is in `util.rs`, which feels funny to me, but there seems to be a pattern of 1 assist per file, and this seems better than duplicating the logic.
Let me know if anything needs changes 😁
fix a bunch of clippy lints
fixes a bunch of clippy lints for fun and profit
i'm aware of this repo's position on clippy. The changes are split into separate commits so they can be reviewed separately
feat: Package Windows release artifacts as ZIP and add symbols file
Closes#13872Closes#7747
CC #10371
This allows us to ship a format that's easier to handle on Windows. As a bonus, we can also include the PDB, to get useful stack traces. Unfortunately, it adds a couple of dependencies to `xtask`, increasing the debug build times from 1.28 to 1.58 s (release from 1.60s to 2.20s) on my system.
Apply fallback before final obligation resolution
Fixes#13249Fixes#13518
We've been applying fallback to type variables independently even when there are some unresolved obligations that associate them. This PR applies fallback to unresolved scalar type variables before the final attempt of resolving obligations, which enables us to infer more.
Unlike rustc, which has separate storages for each kind of type variables, we currently don't have a way to retrieve only integer/float type variables without folding/visiting every single type we've inferred. I've repurposed `TypeVariableData` as bitflags that also hold the kind of the type variable it's referring to so that we can "reconstruct" scalar type variables from their indices.
This PR increases the number of ??ty for rust-analyzer repo not because we regress and fail to infer the existing code but because we fail to infer the new code. It seems we have problems inferring some functions bitflags produces.
Support multi-character punct tokens in MBE
Fixes#11497
In the context of MBE, consecutive puncts are parsed as multi-character punct tokens whenever possible. For example, `:::` is parsed as ``[Punct(`::`), Punct(`:`)]`` and shouldn't get matched to patterns like `: : :` or `: ::`.
We have implemented this behavior only for when we match puncts against `tt` fragments, but not when we match puncts literally. This PR extracts the multi-character punct handling procedure into a separate method and extends its support for literal matching.
For good measure, this PR adds support for `<-` token, which is still [considered as one token in rustc](e396186407/compiler/rustc_ast/src/token.rs (L249)) despite the placement syntax having been removed.
fix: merge multiple intersecting ranges
Fixes#13791
In `check_intersection_and_push()`, there may exist two ranges we should merge with the new one. We've been assuming there should be only one range that intersects, which lead to [this assertion](da15d92a32/crates/text-edit/src/lib.rs (L192)) to fail under specific circumstances.
Use `rustc_safe_intrinsic` attribute to check for intrinsic safety
Instead of maintaining a list that is poorly kept in sync we can just use the attribute.
This will make new RA versions unusable with old toolchains that don't have the attribute yet. Should we keep maintaining the list as a fallback or just don't care?
derive 'Hash'
clippy doesn't like that `PartialEq` is derived, and `Hash` is manually implemented. This PR resolves that by deriving the `Hash` implementation.
Moar linting: needless_borrow, let_unit_value, ...
* There are a few needless borrows that don't seem to be needed. I even did a quick assembly comparison and posted a q to stackoveflow on it. See [here](https://stackoverflow.com/questions/74910196/advantages-of-pass-by-ref-val-with-impl-intoiteratoritem-impl-asrefstr)
* removed several `let _ = ...` when they don't look necessary (even a few ones that were not suggested by clippy (?))
* some unneeded assignment+return - keep the code a bit leaner
* a few `writeln!` instead of `write!`, or even consolidate write!
* a nice optimization to use `ch.is_ascii_digit` instead of `ch.is_digit(10)`
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}