10847: fix: derive attr path handling in `replace_derive_with_manual_impl` r=rainy-me a=rainy-me
partially fixes#10666
renaming issues mentioned in https://github.com/rust-analyzer/rust-analyzer/issues/10666#issuecomment-955671021 doesn't seem to be fixable at this moment since it's not searchable?(not recorded?) by name.
<del>I'm not sure if it's appropriate to move `parse_comma_sep_paths` function to a method in `ast/node_ext`, maybe `ide_db::helpers` also make sense.</del> put into `ide_db::` instead.
Co-authored-by: rainy-me <github@yue.coffee>
10631: fix: Fix postfix completions panicking r=Veykril a=Veykril
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/10243, I couldn't reproduce the panic with the given snippet, but this change should still guard against it.
bors r+
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
This renames `descend_into_macros` to `descend_into_macros_single` and `descend_into_macros_many` into `descend_into_macros`.
However, this does not touch a function in `SemanticsImpl` of same name.
10440: Fix Clippy warnings and replace some `if let`s with `match` r=Veykril a=arzg
I decided to try fixing a bunch of Clippy warnings. I am aware of this project’s opinion of Clippy (I have read both [rust-lang/clippy#5537](https://github.com/rust-lang/rust-clippy/issues/5537) and [rust-analyzer/rowan#57 (comment)](https://github.com/rust-analyzer/rowan/pull/57#discussion_r415676159)), so I totally understand if part of or the entirety of this PR is rejected. In particular, I can see how the semicolons and `if let` vs `match` commits provide comparatively little benefit when compared to the ensuing churn.
I tried to separate each kind of change into its own commit to make it easier to discard certain changes. I also only applied Clippy suggestions where I thought they provided a definite improvement to the code (apart from semicolons, which is IMO more of a formatting/consistency question than a linting question). In the end I accumulated a list of 28 Clippy lints I ignored entirely.
Sidenote: I should really have asked about this on Zulip before going through all 1,555 `if let`s in the codebase to decide which ones definitely look better as `match` :P
Co-authored-by: Aramis Razzaghipour <aramisnoah@gmail.com>
Consider these expples
{ 92 }
async { 92 }
'a: { 92 }
#[a] { 92 }
Previously the tree for them were
BLOCK_EXPR
{ ... }
EFFECT_EXPR
async
BLOCK_EXPR
{ ... }
EFFECT_EXPR
'a:
BLOCK_EXPR
{ ... }
BLOCK_EXPR
#[a]
{ ... }
As you see, it gets progressively worse :) The last two items are
especially odd. The last one even violates the balanced curleys
invariant we have (#10357) The new approach is to say that the stuff in
`{}` is stmt_list, and the block is stmt_list + optional modifiers
BLOCK_EXPR
STMT_LIST
{ ... }
BLOCK_EXPR
async
STMT_LIST
{ ... }
BLOCK_EXPR
'a:
STMT_LIST
{ ... }
BLOCK_EXPR
#[a]
STMT_LIST
{ ... }
10152: feat: Add completion for raw identifiers r=matklad a=nabakin

Adds support for valid Rust completion of raw identifiers.
Previously, code completion of fields made via raw identifiers would not re-insert those raw identifiers, resulting in invalid Rust code. Now, code completion of fields made via raw identifiers do re-insert those raw identifiers, resulting in valid Rust code.
The same is true for all code completion instances for fields and compatible Rust identifiers.
Co-authored-by: Blake Wyatt <894305+nabakin@users.noreply.github.com>
10154: feat: Complete `#![recursion_limit = "N"]` instead of `#![recursion_limit = N]` r=lnicola a=hkmatsumoto
Currently ra emits `#![recursion_limit = 128]`, but this should rather be `#![recursion_limit = "128"]`
Co-authored-by: Hirochika Matsumoto <git@hkmatsumoto.com>
Today, rust-analyzer (and rustc, and bat, and IntelliJ) fail badly on
some kinds of maliciously constructed code, like a deep sequence of
nested parenthesis.
"Who writes 100k nested parenthesis" you'd ask?
Well, in a language with macros, a run-away macro expansion might do
that (see the added tests)! Such expansion can be broad, rather than
deep, so it bypasses recursion check at the macro-expansion layer, but
triggers deep recursion in parser.
In the ideal world, the parser would just handle deeply nested structs
gracefully. We'll get there some day, but at the moment, let's try to be
simple, and just avoid expanding macros with unbalanced parenthesis in
the first place.
closes#9358
9808: fix: Look for enum variants and trait assoc functions when looking for lang items r=matklad a=Veykril
Examples for lang enum variants are the `Option` variants.
Assoc trait functions aren't being seen since they aren't declared in the direct module scope.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Fix ide_completion tests.
Move 'complete_record_literal' call to the main completion function.
Fix a rendering bug when snippet not available.
Checks if an expression is expected before adding completion for struct literal.
Move 'completion struct literal with private field' test to 'expressions.rs' test file.
Update 'expect' tests with new check in 'complete record literal'.
9764: fix: Don't use the module as the candidate node in fuzzy path flyimport r=Veykril a=Veykril
The problem was that the candidate node is whats being used for the scope, so using an inline module will yield the surrounding scope of the module instead of the scope of the module itself.
Also seems to fix the problem in this comment https://github.com/rust-analyzer/rust-analyzer/issues/9760#issuecomment-891125674, though I could not recreate that in a test for some reason.
Fixes#9760
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9453: Add first-class limits. r=matklad,lnicola a=rbartlensky
Partially fixes#9286.
This introduces a new `Limits` structure which is passed as an input
to `SourceDatabase`. This makes limits accessible almost everywhere in
the code, since most places have a database in scope.
One downside of this approach is that whenever you query limits, you
essentially do an `Arc::clone` which is less than ideal.
Let me know if I missed anything, or would like me to take a different approach!
Co-authored-by: Robert Bartlensky <bartlensky.robert@gmail.com>
9567: remove unneded special case r=matklad a=matklad
bors r+
🤖
9568: feat: add 'for' postfix completion r=lnicola a=mahdi-frms
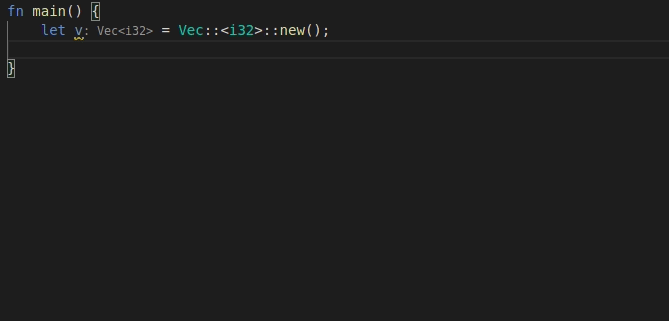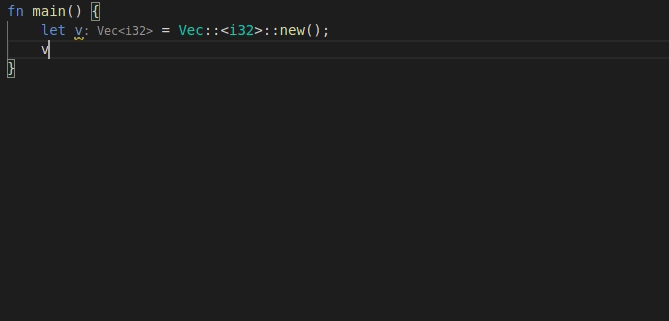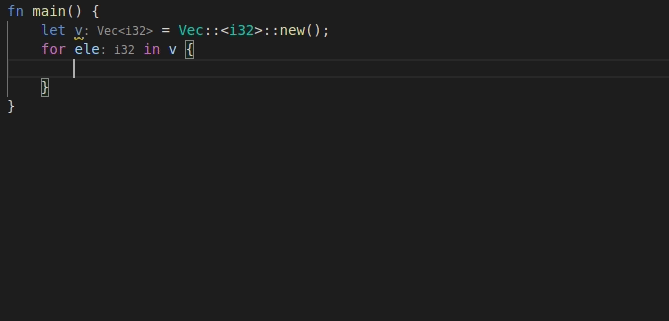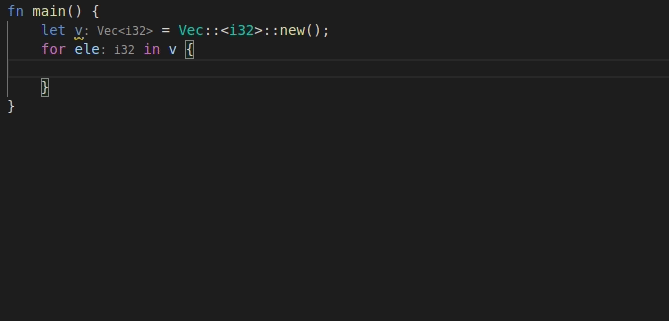
adds #9561
used ```ele``` as identifier for each element in the iteration
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
Co-authored-by: mahdi-frms <mahdif1380@outlook.com>
Note that, while we don't currently have a fuzzy-matching score, it
makes sense to special-case postfix templates -- it's very annoying when
`.not()` gets sorted before `.not`. We might want to move this infra to
fuzzy matching, once we have that!
Before this PR, SourceChange used a bool and CompletionItem used an enum
to signify if edit is a snippet. It makes sense to use the same pattern
in both cases. `bool` feels simpler, as there's only one consumer of
this API, and all producers are encapsulated anyway (we check the
capability at the production site).
* Keep codegen adjacent to the relevant crates.
* Remove codgen deps from xtask, speeding-up from-source installation.
This regresses the release process a bit, as it now needs to run the
tests (and, by extension, compile the code).
The completion of cfg will look at the enabled cfg keys when
performing completion.
It will also look crate features when completing a feature cfg
option. A fixed list of known values for some cfg options are
provided.
For unknown keys it will look at the enabled values for that cfg key,
which means that completion will only show enabled options for those.
9334: feat: Allow to disable import insertion on single path glob imports r=Veykril a=Veykril
On by default as I feel like this is something the majority would prefer.
Closes#8490
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
{kind=link}
{kind=link}
{kind=link}