Configuration is editor-independent. For this reason, we pick
JSON-schema as the repr of the source of truth. We do specify it using
rust-macros and some quick&dirty hackery though.
The idea for syncing truth with package.json is to just do that
manually, but there's a test to check that they are actually synced.
There's CLI to print config's json schema:
$ rust-analyzer --print-config-schema
We go with a CLI rather than LSP request/response to make it easier to
incorporate the thing into extension's static config. This is roughtly
how we put the thing in package.json.
6553: Auto imports in completion r=matklad a=SomeoneToIgnore

Closes https://github.com/rust-analyzer/rust-analyzer/issues/1062 but does not handle the completion order, since it's a separate task for https://github.com/rust-analyzer/rust-analyzer/issues/4922 , https://github.com/rust-analyzer/rust-analyzer/issues/4922 and maybe something else.
2 quirks in the current implementation:
* traits are not auto imported during method completion
If I understand the current situation right, we cannot search for traits by a **part** of a method name, we need a full name with correct case to get a trait for it.
* VSCode (?) autocompletion is not as rigid as in Intellij Rust as you can notice on the animation.
Intellij is able to refresh the completions on every new symbol added, yet VS Code does not query the completions on every symbol for me.
With a few debug prints placed in RA, I've observed the following behaviour: after the first set of completion suggestions is received, next symbol input does not trigger a server request, if the completions contain this symbol.
When more symbols added, the existing completion suggestions are filtered out until none are left and only then, on the next symbol it queries for completions.
It seems like the only alternative to get an updated set of results is to manually retrigger it with Esc and Ctrl + Space.
Despite the eerie latter bullet, the completion seems to work pretty fine and fast nontheless, but if you have any ideas on how to make it more smooth, I'll gladly try it out.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
6331: correct hover text for items with doc attribute with raw strings r=matklad a=JoshMcguigan
Fixes#6300 by improving the handling of raw string literals in attribute style doc comments.
This still has a bug where it could consume too many `"` at the start or end of the comment text, just as the original code had. Not sure if we want to fix that as part of this PR or not? If so, I think I'd prefer to add a unit test for either the `as_simple_key_value` function (I'm not exactly sure where this would belong / how to set this up) or create a `fn(&SmolStr) -> &SmolStr` to unit test by factoring out the `trim` operations from `as_simple_key_value`. Thoughts on this?
6342: Shorter dependency chain r=matklad a=popzxc
Continuing implementing suggestions from the `Completion refactoring` zulip thread.
This PR does the following:
- Removes dependency of `completions` on `assists` by moving required functionality into `ide_db`.
- Moves completely `call_info` crate into `ide_db` as it looks like it fits perfect there.
- Adds a bunch of new tests and docs.
- Adds the re-export of `base_db` to the `ide_db` and removes direct dependency on `base_db` from other crates.
The last point is controversial, I guess, but I noticed that in places where `ide_db` is used, `base_db` is also *always* used. Thus I think the dependency on the `base_db` is implied by the fact of `ide_db` interfaces, and thus it makes sense to just provide `base_db` out of the box.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Co-authored-by: Igor Aleksanov <popzxc@yandex.ru>
6251: Semantic Highlight: Add Callable modifier for variables r=matklad a=GrayJack
This PR added the `HighlightModifier::Callable` variant and assigned it to variables and parameters that are fn pointers, closures and implements FnOnce trait.
This allows to colorize these variables/parameters when used in call expression.
6310: Rewrite algo::diff to support insertion and deletion r=matklad a=Veykril
This in turn also makes `algo::diff` generate finer diffs(maybe even minimal diffs?) as insertions and deletions aren't always represented as as replacements of parent nodes now.
Required for #6287 to go on.
Co-authored-by: GrayJack <gr41.j4ck@gmail.com>
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
6324: Improve #[cfg] diagnostics r=jonas-schievink a=jonas-schievink
Unfortunately I ran into https://github.com/rust-analyzer/rust-analyzer/issues/4058 while testing this on https://github.com/nrf-rs/nrf-hal/, so I didn't see much of it in action yet, but it does seem to work.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
6207: Extract ImportAssets out of auto_import r=matklad a=Veykril
See https://github.com/rust-analyzer/rust-analyzer/pull/6172#issuecomment-707182140
I couldn't fully pull out `AssistContext` as `find_node_at_offset_with_descend`: 81fa00c5b5/crates/assists/src/assist_context.rs (L90-L92) requires the `SourceFile` which is private in it and I don't think making it public just for this is the right call?
6224: ⬆️ salsa r=matklad a=matklad
bors r+
🤖
6226: Add reminder to update lsp-extensions.md r=matklad a=matklad
bors r+
🤖
6227: Reduce bors timeout r=matklad a=matklad
bors r+
🤖
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
* Chalk very recently (like an hour ago) merged a fix that prevents rust analyzer from panicking. This allows it to be usable again for code that hits those situations. See #6134, #6145, Probably #6120
5930: Migrate to the latest Semantic Tokens Proposal for LSP 3.16 r=matklad a=kjeremy
This stabilizes call hierarchy and semantic tokens features on the client side and changes the server-side semantic tokens protocol to match the latest proposal for 3.16.
The server-side change will break clients depending on the earlier semantic tokens draft.
Fixes#4942
Co-authored-by: kjeremy <kjeremy@gmail.com>
`hir` should know nothing about URLs, markdown and html. It should
only be able to:
* resolve stringy path from documentation
* generate canonical stringy path for a def
In contrast, link rewriting should not care about semantics of paths
and names resolution, and should be concern only with text mangling
bits.
5758: SSR: Explicitly autoderef and ref placeholders as needed r=matklad a=davidlattimore
Structural search replace now inserts *, & and &mut in the replacement to match any auto[de]ref in the matched code.
e.g. `$a.foo() ==>> bar($a)` might convert `x.foo()` to `bar(&mut x)`
Co-authored-by: David Lattimore <dml@google.com>
The primary advantage of ungrammar is that it (eventually) allows one
to describe concrete syntax tree structure -- with alternatives and
specific sequence of tokens & nodes.
That should be re-usable for:
* generate `make` calls
* Rust reference
* Hypothetical parser's evented API
We loose doc comments for the time being unfortunately. I don't think
we should add support for doc comments to ungrammar -- they'll make
grammar file hard to read. We might supply docs as out-of band info,
or maybe just via a reference, but we'll think about that once things
are no longer in flux
5479: Allow gathering memory stats on non-jemalloc Linux r=matklad a=jonas-schievink
I could also parse `/proc/$PID/statm` to get the resident set size, but decided against that for now as it isn't terribly useful.
Note that `mallinfo()` is incredibly slow for some reason, and unfortunately this will be exposed to users via the "Memory Usage" command (even worse, the opened document will show the outdated values while the server is processing). So, not very ideal, but it keeps me from recompiling r-a with different feature sets all the time.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5451: Highlight more cases of SyntaxKind when it is a punctuation r=matklad a=GrayJack
This maybe closes#5406
Closes #5453
Separate what one expect to be a punctuation semantic token (like `,`, `;`, `(`, etc), and what is not (`&`, `::`, `+`, etc)
5463: Bump lexer r=matklad a=kjeremy
Since we're now on rust 1.45
5465: Bump chalk r=matklad a=kjeremy
5466: Do not show default types in function and closure return values r=matklad a=SomeoneToIgnore
Avoid things like
<img width="522" alt="image" src="https://user-images.githubusercontent.com/2690773/87985936-1bbe4f80-cae5-11ea-9b8a-5383d896c296.png">
Co-authored-by: GrayJack <gr41.j4ck@gmail.com>
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
5270: Add argument count mismatch diagnostic r=matklad a=jonas-schievink
Closes https://github.com/rust-analyzer/rust-analyzer/issues/4025.
This currently has one false positive on this line, where `max` is resolved to `Iterator::max` instead of `Ord::max`:
8aa10c00a4/crates/expect/src/lib.rs (L263)
(I have no idea why it thinks that `usize` is an `Iterator`)
TODO:
* [x] Tests
* [x] Improve diagnostic text for method calls
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Co-authored-by: bjorn3 <bjorn3@users.noreply.github.com>
Override miniz_oxide to build it with optimizations
Building this crate with optimizations decreases the gzipping
part of `cargo xtask dist` from `30-40s` down to `3s`,
the overhead for `rustc` to apply optimizations is miserable on this background
5142: analysis-stats: allow parallel type inference r=matklad a=jonas-schievink
This is mostly just for testing/fun, but it looks like type inference can be sped up massively with little to no effort (since it runs after the serial phases are already done).
Without `--parallel`:
```
Item Collection: 16.43597698s, 683mb allocated 720mb resident
Inference: 25.429774879s, 1720mb allocated 1781mb resident
Total: 41.865866352s, 1720mb allocated 1781mb resident
```
With `--parallel`:
```
Item Collection: 16.380369815s, 683mb allocated 735mb resident
Parallel Inference: 7.449166445s, 1721mb allocated 1812mb resident
Inference: 143.437157ms, 1721mb allocated 1812mb resident
Total: 23.973303611s, 1721mb allocated 1812mb resident
```
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5101: Add expect -- a light-weight alternative to insta r=matklad a=matklad
This PR implements a small snapshot-testing library. Snapshot updating is done by setting an env var, or by using editor feature (which runs a test with env-var set).
Here's workflow for updating a failing test:
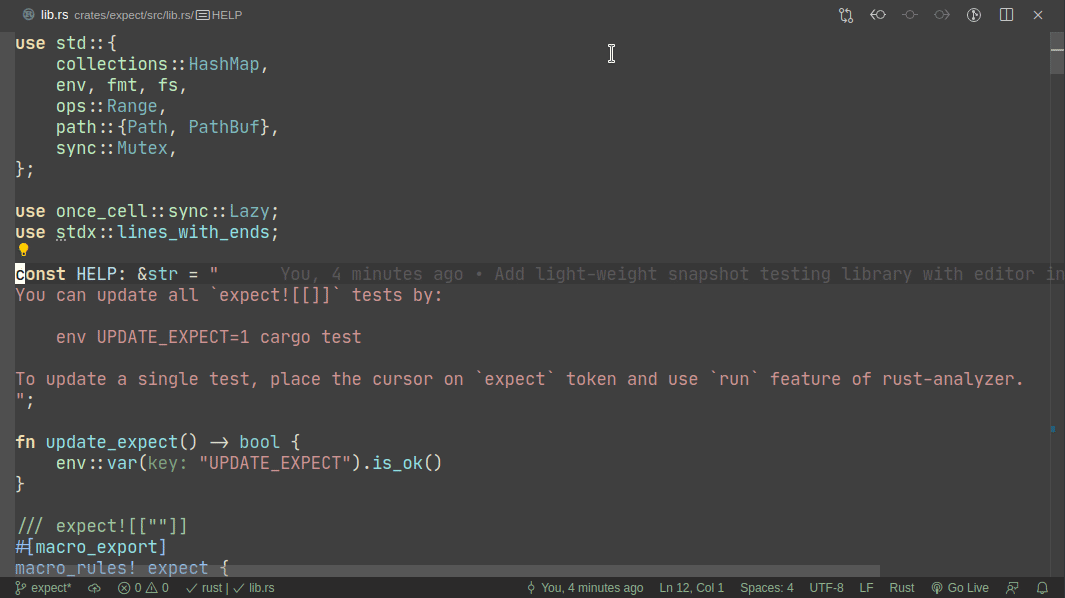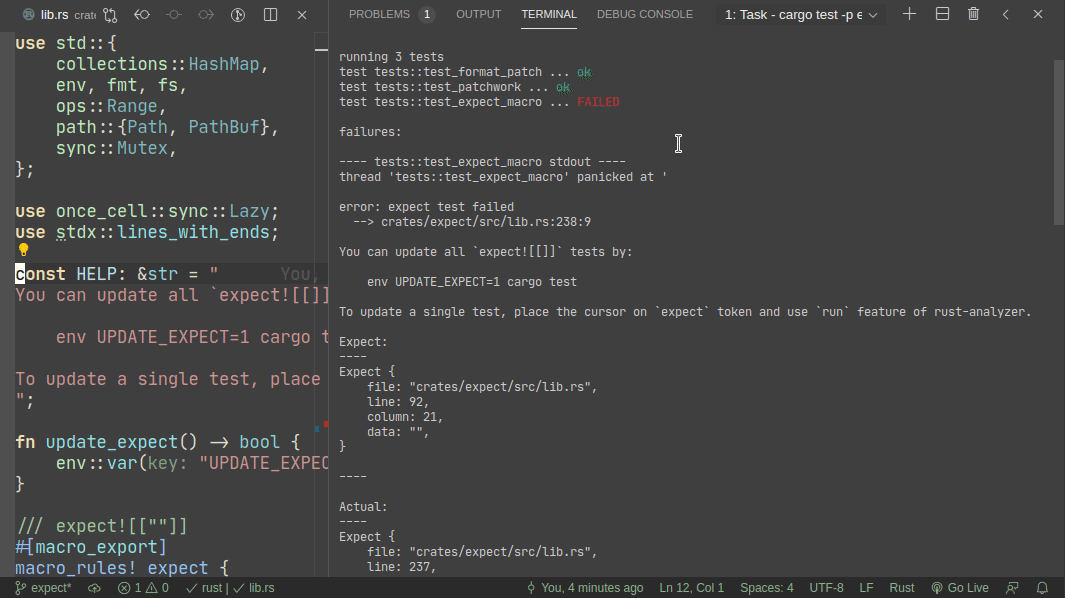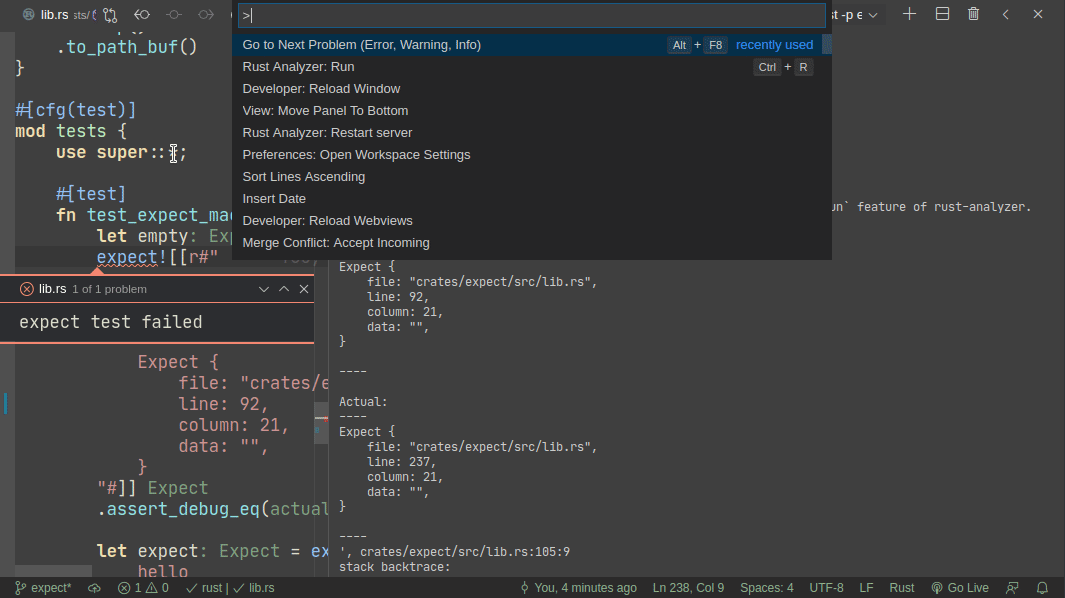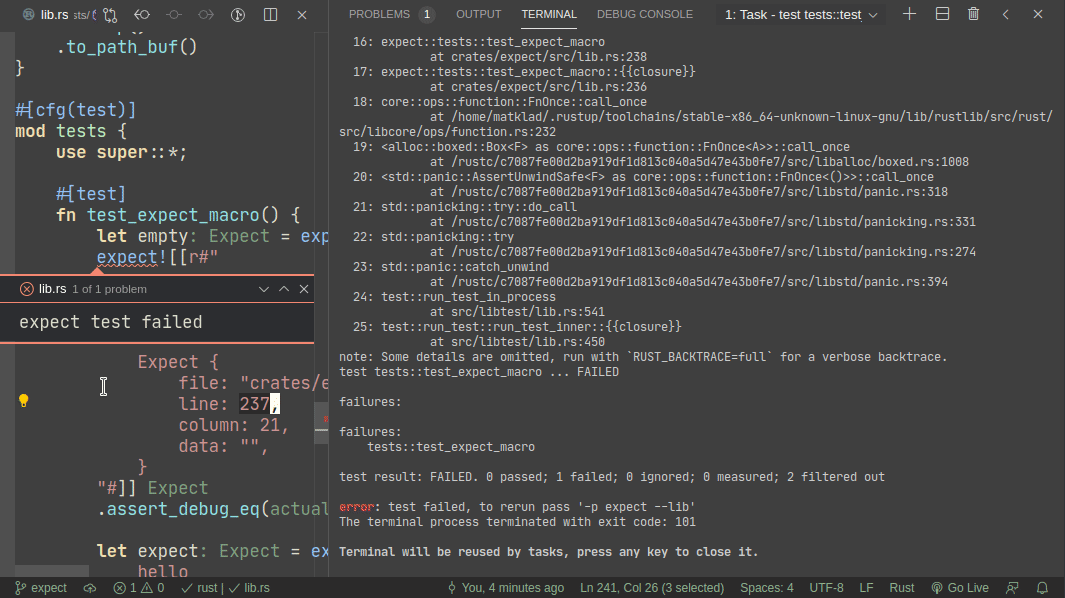
Here's workflow for adding a new test:
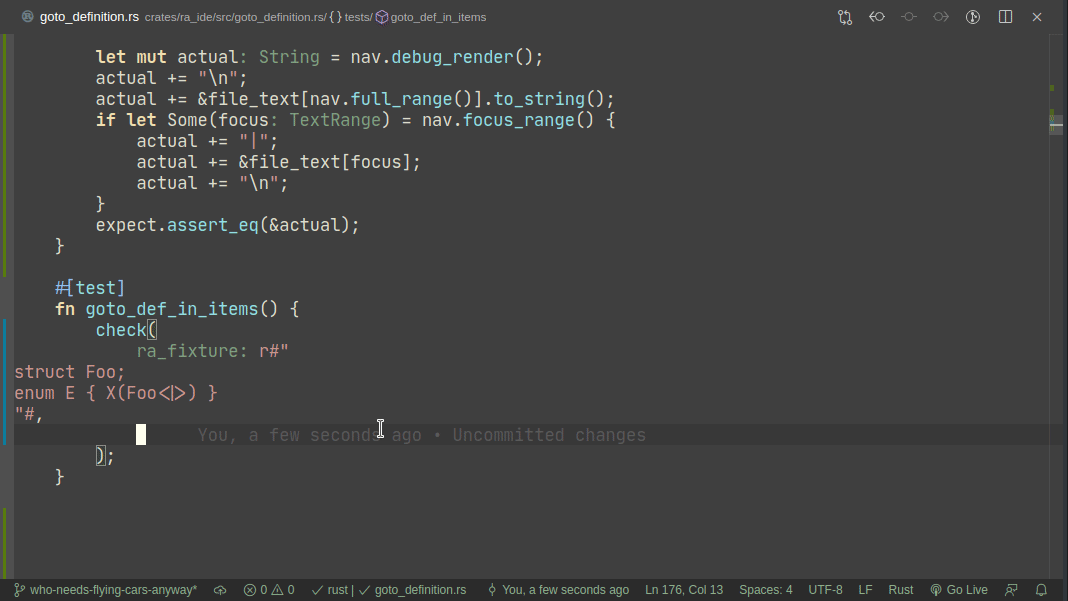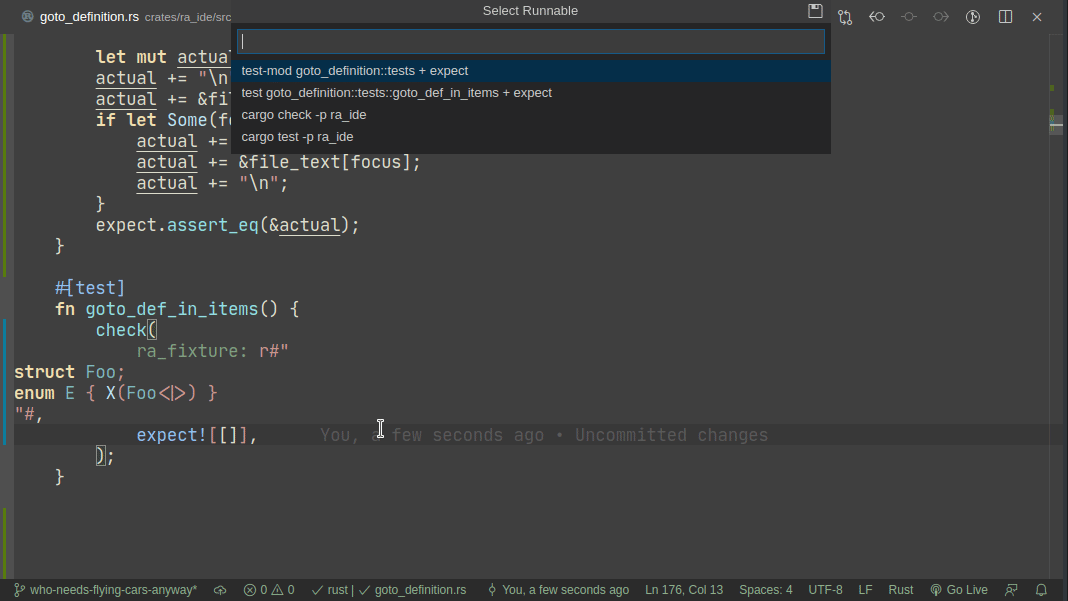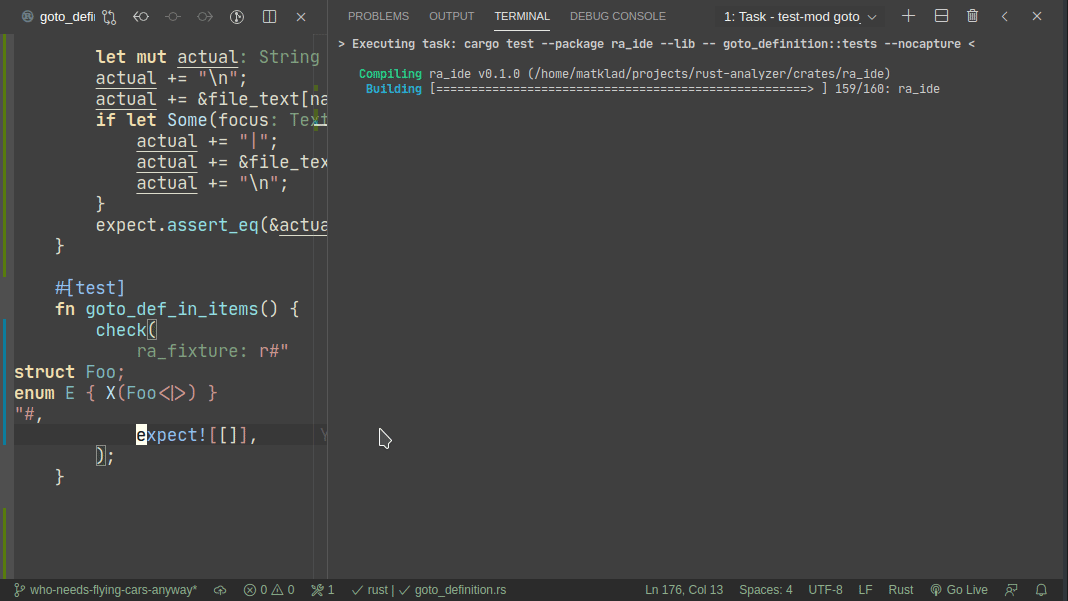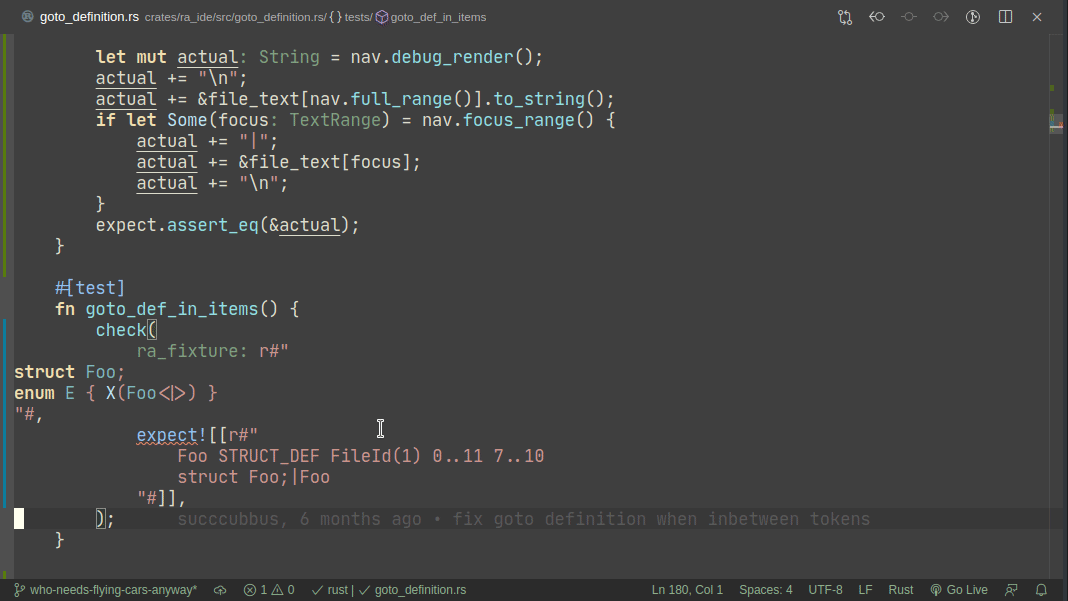
Note that colorized diffs are not implemented in this PR, but should be easy to add (we already use them in test_utils).
Main differences from insta (which is essential for rust-analyzer development, thanks @mitsuhiko!):
* self-updating tests, no need for a separate tool
* fewer features (only inline snapshots, no redactions)
* fewer deps (no yaml, no persistence)
* tighter integration with editor
* first-class snapshot object, which can be used to write test functions (as opposed to testing macros)
* trivial to tweak for rust-analyzer needs, by virtue of being a workspace member.
I think eventually we should converge to a single snapshot testing library, but I am not sure that `expect` is exactly right, so I suggest rolling with both insta and expect for some time (if folks agree that expect might be better in the first place!).
# Editor Integration Implementation
The thing I am most excited about is the ability to update a specific snapshot from the editor. I want this to be available to other snapshot-testing libraries (cc @mitsuhiko, @aaronabramov), so I want to document how this works.
The ideal UI here would be a code action (💡). Unfortunately, it seems like it is impossible to implement without some kind of persistence (if you save test failures into some kind of a database, like insta does, than you can read the database from the editor plugin). Note that it is possible to highlight error by outputing error message in rustc's format. Unfortunately, one can't use the same trick to implement a quick fix.
For this reason, expect makes use of another rust-analyzer feature -- ability to run a single test at the cursor position. This does need some expect-specific code in rust-analyzer unfortunately. Specifically, if rust-analyzer notices that the cursor is on `expect!` macro, it adds a special flag to runnable's JSON. However, given #5017 it is possible to approximate this well-enough without rust-analyzer integration. Specifically, an extension can register a special runner which checks (using regexes) if rust-anlyzer runnable covers text with specific macro invocation and do special magic in that case.
closes#3835
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}