7891: Improve handling of rustc_private r=matklad a=DJMcNab
This PR changes how `rust-analyzer` handles `rustc_private`. In particular, packages now must opt-in to using `rustc_private` in `Cargo.toml`, by adding:
```toml
[package.metadata.rust-analyzer]
rustc_private=true
```
This means that depending on crates which also use `rustc_private` will be significantly improved, since their dependencies on the `rustc_private` crates will be resolved properly.
A similar approach could be used in #6714 to allow annotating that your package uses the `test` crate, although I have not yet handled that in this PR.
Additionally, we now only index the crates which are transitive dependencies of `rustc_driver` in the `rustcSource` directory. This should not cause any change in behaviour when using `rustcSource: "discover"`, as the source used then will only be a partial clone. However, if `rustcSource` pointing at a local checkout of rustc, this should significantly improve the memory usage and lower indexing time. This is because we avoids indexing all crates in `src/tools/`, which includes `rust-analyzer` itself.
Furthermore, we also prefer named dependencies over dependencies from `rustcSource`. This ensures that feature resolution for crates which are depended on by both `rustc` and your crate uses the correct set for analysing your crate.
See also [introductory zulip stream](https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Fwg-rls-2.2E0/topic/Fixed.20crate.20graphs.20and.20optional.20builtin.20crates/near/229086673)
I have tested this in [priroda](https://github.com/oli-obk/priroda/), and it provides a significant improvement to the development experience (once I give `miri` the required data in `Cargo.toml`)
Todo:
- [ ] Documentation
This is ready to review, and I will add documentation if this would be accepted (or if I get time to do so anyway)
Co-authored-by: Daniel McNab <36049421+DJMcNab@users.noreply.github.com>
7892: Fix TokenStream::from_str for input consisting of a single group with delimiter r=edwin0cheng a=kevinmehall
TokenStream holds a `tt::Subtree` but assumes its `delimiter` is always `None`. In particular, the iterator implementation iterates over the inner `token_trees` and ignores the `delimiter`.
However, `TokenStream::from_str` violated this assumption when the input consists of a single group by producing a Subtree with an outer delimiter, which was ignored as seen by a procedural macro.
`tt::Subtree` is just `pub delimiter: Option<Delimiter>, pub token_trees: Vec<TokenTree>`, so a Subtree that is statically guaranteed not to have a delimiter is just `Vec<TokenTree>`.
Fixes#7810Fixes#7875
Co-authored-by: Kevin Mehall <km@kevinmehall.net>
7865: preserve escape sequences when replacing string with char r=Veykril a=jDomantas
Currently it replaces escape sequence with the actual value, which is very wrong for `"\n"`.
Co-authored-by: Domantas Jadenkus <djadenkus@gmail.com>
`TokenStream` assumes that its subtree's delimeter is `None`, and this
should be encoded in the type system instead of having a delimiter field
that is mostly ignored.
`tt::Subtree` is just `pub delimiter: Option<Delimiter>, pub
token_trees: Vec<TokenTree>`, so a Subtree that is statically guaranteed
not to have a delimiter is just Vec<TokenTree>.
TokenStream holds a `tt::Subtree` but assumes its `delimiter` is always
`None`. In particular, the iterator implementation iterates over the
inner `token_trees` and ignores the `delimiter`.
However, `TokenStream::from_str` violated this assumption when the input
consists of a single Group by producing a Subtree with an outer
delimiter, which was ignored as seen by a procedural macro.
In this case, wrap an extra level of Subtree around it.
Fixes#7810Fixes#7875
This is a hack to work around miri being included in
our analysis of rustc-dev
Really, we should probably use an include set of the actual root libraries
I'm not sure how those are determined however
7880: Honor snippet capability when using the extract function assist r=lnicola a=Arthamys
This fixes issue #7793
Co-authored-by: san <san@alien.parts>
7870: Use chalk_ir::AdtId r=Veykril a=Veykril
It's a bit unfortunate that we got two AdtId's now(technically 3 with the alias in the chalk module but that one won't allow pattern matching), one from hir_def and one from chalk_ir(hir_ty). But the hir_ty/chalk one doesn't leave hir so it shouldn't be that bad I suppose. Though if I see this right this will happen for almost all IDs.
I imagine most of the intermediate changes to using chalk ids will turn out not too nice until the refactor is over.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7795: Show docs on hover for keywords and primitives r=matklad a=Veykril
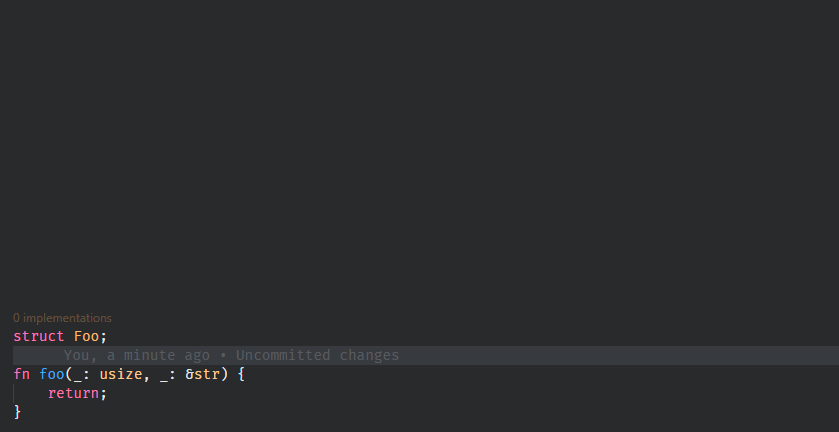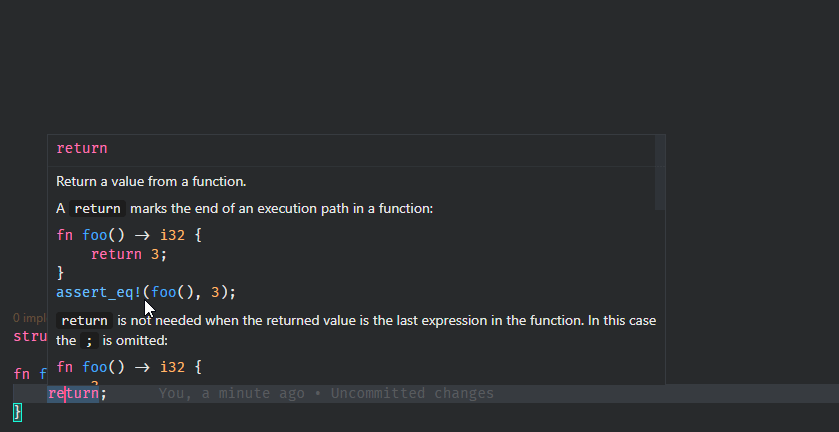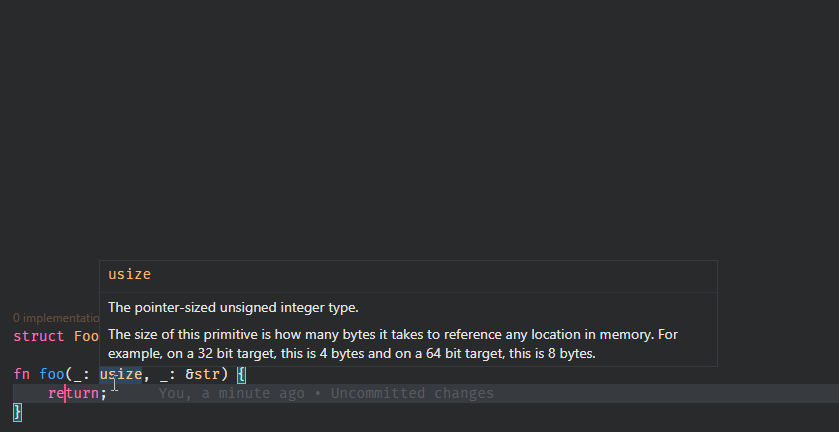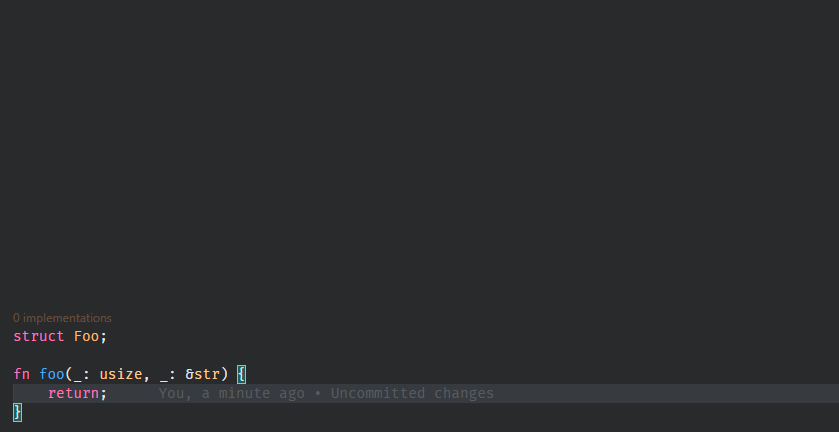
It's a bit annoying that this requires the `SyntaxNode` and `Semantics` to be pulled through `hover_for_definition` just so we can get the `std` crate but I couldn't think of a better way.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7335: added region folding r=matklad a=LucianoBestia
Regions of code that you'd like to be folded can be wrapped with `// #region` and `// #endregion` line comments.
This is called "Region Folding". It is originally available for many languages in VSCode. But Rust-analyzer has its own folding function and this is missing.
With this Pull Request I am suggesting a simple solution.
The regions are a special kind of comments, so I added a bit of code in the comment folding function.
The regex to match are: `^\s*//\s*#?region\b` and `^\s*//\s*#?endregion\b`.
The number of space characters is not important. There is an optional # character. The line can end with a name of the region.
Example:
```rust
// 1. some normal comment
// region: test
// 2. some normal comment
calling_function(x,y);
// endregion: test
```
I added a test for this new functionality in `folding_ranges.rs`.
Please, take a look and comment.
I found that these exact regexes are already present in the file `language-configuration.json`, but I don't find a way to read this configuration. So my regex is hardcoded in the code.
7691: Suggest name in extract variable r=matklad a=cpud36
Generate better default name in extract variable assist as was mentioned in issue #1587
# Currently supported
(in order of declining precedence)
1. Expr is argument to a function; use corresponding parameter name
2. Expr is result of a function or method call; use this function/method's name
3. Use expr type name (if possible)
4. Fallback to `var_name` otherwise
# Showcase


# Questions
* Should we more aggressively strip known types? E.g. we already strip `&T -> T`; should we strip `Option<T> -> T`, `Result<T, E> -> T`, and others?
* Integers and floats use `var_name` by default. Should we introduce a name, like `i`, `f` etc?
* Can we return a list and suggest a name when renaming(like IntelliJ does)?
* Should we add counters to remove duplicate variables? E.g. `type`, `type1`, type2`, etc.
Co-authored-by: Luciano Bestia <LucianoBestia@gmail.com>
Co-authored-by: Luciano <31509965+LucianoBestia@users.noreply.github.com>
Co-authored-by: Vladyslav Katasonov <cpud47@gmail.com>
7827: Fix proc macro TokenStream::from_str token ids r=vlad20012 a=vlad20012
To be honest, I don't know what it changes from a user perspective.
Internally, this fixes spans (token ids) of a `TokenStream` parsed from a string:
```rust
#[proc_macro_derive(FooDerive)]
pub fn foo_derive(item: TokenStream) -> TokenStream {
"fn foo() {}".parse().unwrap()
}
```
Previously, `TokenStream` was constructed from tokens with incremental ids (that conflicted with call-site tokens). Now they are `-1`.
Co-authored-by: vlad20012 <beskvlad@gmail.com>
7829: Bump deps r=matklad a=lnicola
Unfortunately, this brings a bunch of proc macros dep because `cargo-metadata` went full-in on `derive-builder`. I'm not sure what we can do here..
7833: Use chalk_ir::Mutability r=Veykril a=Veykril
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7778: Fix lowering trailing self paths in UseTrees r=Veykril a=Veykril
Noticed that hovering over `self` in a use tree like `use foo::bar::{self}` showing documentation and such for the current module instead of `bar`.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7819: Speedup heavy tests r=matklad a=matklad
bors r+
🤖
7820: Update vscode README with a small features list r=matklad a=Veykril
Nothing grande but I figured this is a bit better than showing almost nothing
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7813: Inline TypeCtor into Ty r=flodiebold a=Veykril
This removes the `ApplicationTy` variant from `Ty` bringing the representation a lot closer to chalk's `TyKind`.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7804: Introduce TypeCtor::Scalar r=lnicola a=Veykril
`TypeCtor::Int(..) | TypeCtor::Float(..) | TypeCtor::Char | TypeCtor::Bool` => `TypeCtor::Scalar(..)`, in this case we can actually just straight up use `chalk_ir::Scalar` already since its just a POD without any IDs or anything.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
7797: Format generated lints and features manually r=matklad a=lnicola
As `quote` and `rustfmt` leave them on a single line, which makes running `grep` in the repository quite annoying.
Also removes a dead `gen_features.rs` file (`gen_lint_completions.rs` does the same thing).
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
7566: Add benchmark tests for mbe r=matklad a=edwin0cheng
This PR add more real world tests dumped from `rust-analyzer analysis-stats .` to benchmark its performance.
cc #7513
r? @matklad
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
{kind=link}
{kind=link}
{kind=link}