mirror of
https://github.com/rust-lang/rust-analyzer
synced 2024-12-25 20:43:21 +00:00
Make architecture more informative
Call out boundaries and invariants
This commit is contained in:
parent
7e66cde764
commit
1008aaae58
2 changed files with 317 additions and 201 deletions
|
|
@ -9,8 +9,9 @@ $ cargo test
|
|||
|
||||
should be enough to get you started!
|
||||
|
||||
To learn more about how rust-analyzer works, see
|
||||
[./architecture.md](./architecture.md) document.
|
||||
To learn more about how rust-analyzer works, see [./architecture.md](./architecture.md) document.
|
||||
It also explains the high-level layout of the source code.
|
||||
Do skim through that document.
|
||||
|
||||
We also publish rustdoc docs to pages:
|
||||
|
||||
|
|
@ -99,25 +100,6 @@ I don't have a specific workflow for this case.
|
|||
Additionally, I use `cargo run --release -p rust-analyzer -- analysis-stats path/to/some/rust/crate` to run a batch analysis.
|
||||
This is primarily useful for performance optimizations, or for bug minimization.
|
||||
|
||||
## Parser Tests
|
||||
|
||||
Tests for the parser (`parser`) live in the `syntax` crate (see `test_data` directory).
|
||||
There are two kinds of tests:
|
||||
|
||||
* Manually written test cases in `parser/ok` and `parser/err`
|
||||
* "Inline" tests in `parser/inline` (these are generated) from comments in `parser` crate.
|
||||
|
||||
The purpose of inline tests is not to achieve full coverage by test cases, but to explain to the reader of the code what each particular `if` and `match` is responsible for.
|
||||
If you are tempted to add a large inline test, it might be a good idea to leave only the simplest example in place, and move the test to a manual `parser/ok` test.
|
||||
|
||||
To update test data, run with `UPDATE_EXPECT` variable:
|
||||
|
||||
```bash
|
||||
env UPDATE_EXPECT=1 cargo qt
|
||||
```
|
||||
|
||||
After adding a new inline test you need to run `cargo xtest codegen` and also update the test data as described above.
|
||||
|
||||
## TypeScript Tests
|
||||
|
||||
If you change files under `editors/code` and would like to run the tests and linter, install npm and run:
|
||||
|
|
@ -128,73 +110,6 @@ npm ci
|
|||
npm run lint
|
||||
```
|
||||
|
||||
# Code organization
|
||||
|
||||
All Rust code lives in the `crates` top-level directory, and is organized as a single Cargo workspace.
|
||||
The `editors` top-level directory contains code for integrating with editors.
|
||||
Currently, it contains the plugin for VS Code (in TypeScript).
|
||||
The `docs` top-level directory contains both developer and user documentation.
|
||||
|
||||
We have some automation infra in Rust in the `xtask` package.
|
||||
It contains stuff like formatting checking, code generation and powers `cargo xtask install`.
|
||||
The latter syntax is achieved with the help of cargo aliases (see `.cargo` directory).
|
||||
|
||||
# Architecture Invariants
|
||||
|
||||
This section tries to document high-level design constraints, which are not
|
||||
always obvious from the low-level code.
|
||||
|
||||
## Incomplete syntax trees
|
||||
|
||||
Syntax trees are by design incomplete and do not enforce well-formedness.
|
||||
If an AST method returns an `Option`, it *can* be `None` at runtime, even if this is forbidden by the grammar.
|
||||
|
||||
## LSP independence
|
||||
|
||||
rust-analyzer is independent from LSP.
|
||||
It provides features for a hypothetical perfect Rust-specific IDE client.
|
||||
Internal representations are lowered to LSP in the `rust-analyzer` crate (the only crate which is allowed to use LSP types).
|
||||
|
||||
## IDE/Compiler split
|
||||
|
||||
There's a semi-hard split between "compiler" and "IDE", at the `hir` crate.
|
||||
Compiler derives new facts about source code.
|
||||
It explicitly acknowledges that not all info is available (i.e. you can't look at types during name resolution).
|
||||
|
||||
IDE assumes that all information is available at all times.
|
||||
|
||||
IDE should use only types from `hir`, and should not depend on the underling compiler types.
|
||||
`hir` is a facade.
|
||||
|
||||
## IDE API
|
||||
|
||||
The main IDE crate (`ide`) uses "Plain Old Data" for the API.
|
||||
Rather than talking in definitions and references, it talks in Strings and textual offsets.
|
||||
In general, API is centered around UI concerns -- the result of the call is what the user sees in the editor, and not what the compiler sees underneath.
|
||||
The results are 100% Rust specific though.
|
||||
Shout outs to LSP developers for popularizing the idea that "UI" is a good place to draw a boundary at.
|
||||
|
||||
## LSP is stateless
|
||||
|
||||
The protocol is implemented in the mostly stateless way.
|
||||
A good mental model is HTTP, which doesn't store per-client state, and instead relies on devices like cookies to maintain an illusion of state.
|
||||
If some action requires multi-step protocol, each step should be self-contained.
|
||||
|
||||
A good example here is code action resolving process.
|
||||
TO display the lightbulb, we compute the list of code actions without computing edits.
|
||||
Figuring out the edit is done in a separate `codeAction/resolve` call.
|
||||
Rather than storing some `lazy_edit: Box<dyn FnOnce() -> Edit>` somewhere, we use a string ID of action to re-compute the list of actions during the resolve process.
|
||||
(See [this post](https://rust-analyzer.github.io/blog/2020/09/28/how-to-make-a-light-bulb.html) for more details.)
|
||||
The benefit here is that, generally speaking, the state of the world might change between `codeAction` and `codeAction` resolve requests, so any closure we store might become invalid.
|
||||
|
||||
While we don't currently implement any complicated refactors with complex GUI, I imagine we'd use the same techniques for refactors.
|
||||
After clicking each "Next" button during refactor, the client would send all the info which server needs to re-recreate the context from scratch.
|
||||
|
||||
## CI
|
||||
|
||||
CI does not test rust-analyzer, CI is a core part of rust-analyzer, and is maintained with above average standard of quality.
|
||||
CI is reproducible -- it can only be broken by changes to files in this repository, any dependence on externalities is a bug.
|
||||
|
||||
# Code Style & Review Process
|
||||
|
||||
Do see [./style.md](./style.md).
|
||||
|
|
|
|||
|
|
@ -1,174 +1,375 @@
|
|||
# Architecture
|
||||
|
||||
This document describes the high-level architecture of rust-analyzer.
|
||||
If you want to familiarize yourself with the code base, you are just
|
||||
in the right place!
|
||||
If you want to familiarize yourself with the code base, you are just in the right place!
|
||||
|
||||
See also the [guide](./guide.md), which walks through a particular snapshot of
|
||||
rust-analyzer code base.
|
||||
See also the [guide](./guide.md), which walks through a particular snapshot of rust-analyzer code base.
|
||||
|
||||
Yet another resource is this playlist with videos about various parts of the
|
||||
analyzer:
|
||||
Yet another resource is this playlist with videos about various parts of the analyzer:
|
||||
|
||||
https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE
|
||||
|
||||
Note that the guide and videos are pretty dated, this document should be in
|
||||
generally fresher.
|
||||
Note that the guide and videos are pretty dated, this document should be in generally fresher.
|
||||
|
||||
## The Big Picture
|
||||
See also this implementation-oriented blog posts:
|
||||
|
||||
* https://rust-analyzer.github.io/blog/2019/11/13/find-usages.html
|
||||
* https://rust-analyzer.github.io/blog/2020/07/20/three-architectures-for-responsive-ide.html
|
||||
* https://rust-analyzer.github.io/blog/2020/09/16/challeging-LR-parsing.html
|
||||
* https://rust-analyzer.github.io/blog/2020/09/28/how-to-make-a-light-bulb.html
|
||||
* https://rust-analyzer.github.io/blog/2020/10/24/introducing-ungrammar.html
|
||||
|
||||
## Bird's Eye View
|
||||
|
||||
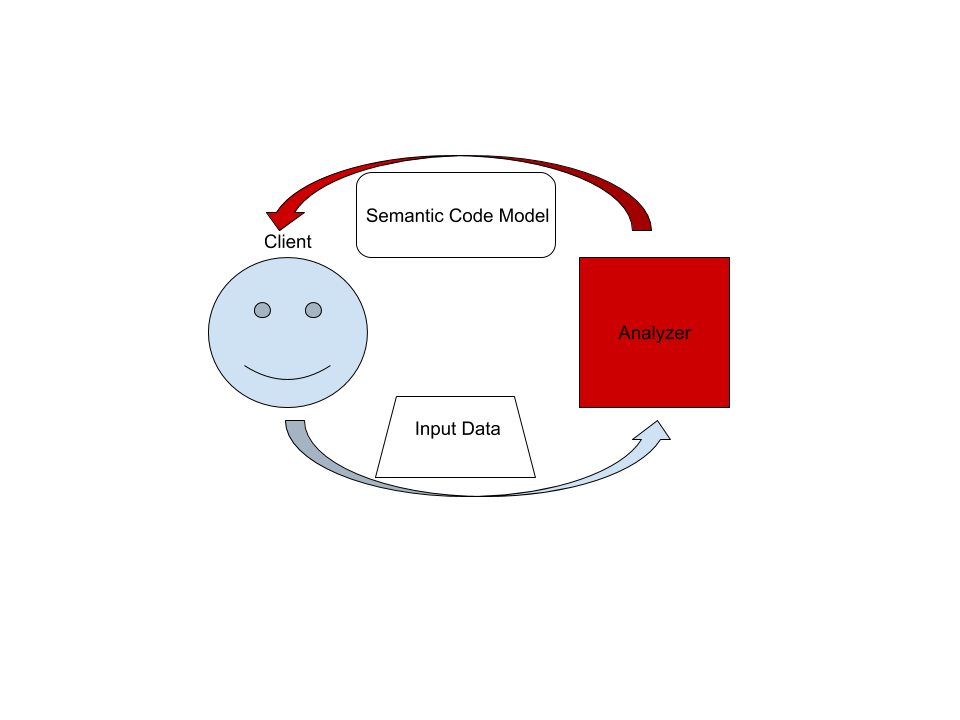
|
||||
|
||||
On the highest level, rust-analyzer is a thing which accepts input source code
|
||||
from the client and produces a structured semantic model of the code.
|
||||
On the highest level, rust-analyzer is a thing which accepts input source code from the client and produces a structured semantic model of the code.
|
||||
|
||||
More specifically, input data consists of a set of test files (`(PathBuf,
|
||||
String)` pairs) and information about project structure, captured in the so
|
||||
called `CrateGraph`. The crate graph specifies which files are crate roots,
|
||||
which cfg flags are specified for each crate and what dependencies exist between
|
||||
the crates. The analyzer keeps all this input data in memory and never does any
|
||||
IO. Because the input data are source code, which typically measures in tens of
|
||||
megabytes at most, keeping everything in memory is OK.
|
||||
More specifically, input data consists of a set of test files (`(PathBuf, String)` pairs) and information about project structure, captured in the so called `CrateGraph`.
|
||||
The crate graph specifies which files are crate roots, which cfg flags are specified for each crate and what dependencies exist between the crates.
|
||||
This the input (ground) state.
|
||||
The analyzer keeps all this input data in memory and never does any IO.
|
||||
Because the input data are source code, which typically measures in tens of megabytes at most, keeping everything in memory is OK.
|
||||
|
||||
A "structured semantic model" is basically an object-oriented representation of
|
||||
modules, functions and types which appear in the source code. This representation
|
||||
is fully "resolved": all expressions have types, all references are bound to
|
||||
declarations, etc.
|
||||
A "structured semantic model" is basically an object-oriented representation of modules, functions and types which appear in the source code.
|
||||
This representation is fully "resolved": all expressions have types, all references are bound to declarations, etc.
|
||||
This is derived state.
|
||||
|
||||
The client can submit a small delta of input data (typically, a change to a
|
||||
single file) and get a fresh code model which accounts for changes.
|
||||
The client can submit a small delta of input data (typically, a change to a single file) and get a fresh code model which accounts for changes.
|
||||
|
||||
The underlying engine makes sure that model is computed lazily (on-demand) and
|
||||
can be quickly updated for small modifications.
|
||||
The underlying engine makes sure that model is computed lazily (on-demand) and can be quickly updated for small modifications.
|
||||
|
||||
|
||||
## Code generation
|
||||
## Code Map
|
||||
|
||||
Some of the components of this repository are generated through automatic
|
||||
processes. `cargo xtask codegen` runs all generation tasks. Generated code is
|
||||
committed to the git repository.
|
||||
This section talks briefly about various important directories an data structures.
|
||||
Pay attention to the **Architecture Invariant** sections.
|
||||
They often talk about things which are deliberately absent in the source code.
|
||||
|
||||
In particular, `cargo xtask codegen` generates:
|
||||
Note also which crates are **API Boundaries**.
|
||||
Remember, [rules at the boundary are different](https://www.tedinski.com/2018/02/06/system-boundaries.html).
|
||||
|
||||
1. [`syntax_kind/generated`](https://github.com/rust-analyzer/rust-analyzer/blob/a0be39296d2925972cacd9fbf8b5fb258fad6947/crates/ra_parser/src/syntax_kind/generated.rs)
|
||||
-- the set of terminals and non-terminals of rust grammar.
|
||||
### `xtask`
|
||||
|
||||
2. [`ast/generated`](https://github.com/rust-analyzer/rust-analyzer/blob/a0be39296d2925972cacd9fbf8b5fb258fad6947/crates/ra_syntax/src/ast/generated.rs)
|
||||
-- AST data structure.
|
||||
This is rust-analyzer's "build system".
|
||||
We use cargo to compile rust code, but there are also various other tasks, like release management or local installation.
|
||||
They are handled by Rust code in the xtask directory.
|
||||
|
||||
3. [`doc_tests/generated`](https://github.com/rust-analyzer/rust-analyzer/blob/a0be39296d2925972cacd9fbf8b5fb258fad6947/crates/assists/src/doc_tests/generated.rs),
|
||||
[`test_data/parser/inline`](https://github.com/rust-analyzer/rust-analyzer/tree/a0be39296d2925972cacd9fbf8b5fb258fad6947/crates/ra_syntax/test_data/parser/inline)
|
||||
-- tests for assists and the parser.
|
||||
### `editors/code`
|
||||
|
||||
The source for 1 and 2 is in [`ast_src.rs`](https://github.com/rust-analyzer/rust-analyzer/blob/a0be39296d2925972cacd9fbf8b5fb258fad6947/xtask/src/ast_src.rs).
|
||||
VS Code plugin.
|
||||
|
||||
## Code Walk-Through
|
||||
### `libs/`
|
||||
|
||||
### `crates/ra_syntax`, `crates/parser`
|
||||
rust-analyzer independent libraries which we publish to crates.io.
|
||||
It not heavily utilized at the moment.
|
||||
|
||||
Rust syntax tree structure and parser. See
|
||||
[RFC](https://github.com/rust-lang/rfcs/pull/2256) and [./syntax.md](./syntax.md) for some design notes.
|
||||
### `crates/parser`
|
||||
|
||||
It is a hand-written recursive descent parser, which produces a sequence of events like "start node X", "finish node Y".
|
||||
It works similarly to
|
||||
[kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java),
|
||||
which is a good source of inspiration for dealing with syntax errors and incomplete input.
|
||||
Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs) is what we use for the definition of the Rust language.
|
||||
`TreeSink` and `TokenSource` traits bridge the tree-agnostic parser from `grammar` with `rowan` trees.
|
||||
|
||||
**Architecture Invariant:** the parser is independent of the particular tree structure and particular representation of the tokens.
|
||||
It transforms one flat stream of events into another flat stream of events.
|
||||
Token independence allows us to pares out both text-based source code and `tt`-based macro input.
|
||||
Tree independence allows us to more easily vary the syntax tree implementation.
|
||||
It should also unlock efficient light-parsing approaches.
|
||||
For example, you can extract the set of names defined in a file (for typo correction) without building a syntax tree.
|
||||
|
||||
**Architecture Invariant:** parsing never fails, the parser produces `(T, Vec<Error>)` rather than `Result<T, Error>`.
|
||||
|
||||
### `crates/syntax`
|
||||
|
||||
Rust syntax tree structure and parser.
|
||||
See [RFC](https://github.com/rust-lang/rfcs/pull/2256) and [./syntax.md](./syntax.md) for some design notes.
|
||||
|
||||
- [rowan](https://github.com/rust-analyzer/rowan) library is used for constructing syntax trees.
|
||||
- `grammar` module is the actual parser. It is a hand-written recursive descent parser, which
|
||||
produces a sequence of events like "start node X", "finish node Y". It works similarly to [kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java),
|
||||
which is a good source of inspiration for dealing with syntax errors and incomplete input. Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs)
|
||||
is what we use for the definition of the Rust language.
|
||||
- `TreeSink` and `TokenSource` traits bridge the tree-agnostic parser from `grammar` with `rowan` trees.
|
||||
- `ast` provides a type safe API on top of the raw `rowan` tree.
|
||||
- `ast_src` description of the grammar, which is used to generate `syntax_kinds`
|
||||
and `ast` modules, using `cargo xtask codegen` command.
|
||||
- `ungrammar` description of the grammar, which is used to generate `syntax_kinds` and `ast` modules, using `cargo xtask codegen` command.
|
||||
|
||||
Tests for ra_syntax are mostly data-driven: `test_data/parser` contains subdirectories with a bunch of `.rs`
|
||||
(test vectors) and `.txt` files with corresponding syntax trees. During testing, we check
|
||||
`.rs` against `.txt`. If the `.txt` file is missing, it is created (this is how you update
|
||||
tests). Additionally, running `cargo xtask codegen` will walk the grammar module and collect
|
||||
all `// test test_name` comments into files inside `test_data/parser/inline` directory.
|
||||
Tests for ra_syntax are mostly data-driven.
|
||||
`test_data/parser` contains subdirectories with a bunch of `.rs` (test vectors) and `.txt` files with corresponding syntax trees.
|
||||
During testing, we check `.rs` against `.txt`.
|
||||
If the `.txt` file is missing, it is created (this is how you update tests).
|
||||
Additionally, running `cargo xtask codegen` will walk the grammar module and collect all `// test test_name` comments into files inside `test_data/parser/inline` directory.
|
||||
|
||||
Note
|
||||
[`api_walkthrough`](https://github.com/rust-analyzer/rust-analyzer/blob/2fb6af89eb794f775de60b82afe56b6f986c2a40/crates/ra_syntax/src/lib.rs#L190-L348)
|
||||
To update test data, run with `UPDATE_EXPECT` variable:
|
||||
|
||||
```bash
|
||||
env UPDATE_EXPECT=1 cargo qt
|
||||
```
|
||||
|
||||
After adding a new inline test you need to run `cargo xtest codegen` and also update the test data as described above.
|
||||
|
||||
Note [`api_walkthrough`](https://github.com/rust-analyzer/rust-analyzer/blob/2fb6af89eb794f775de60b82afe56b6f986c2a40/crates/ra_syntax/src/lib.rs#L190-L348)
|
||||
in particular: it shows off various methods of working with syntax tree.
|
||||
|
||||
See [#93](https://github.com/rust-analyzer/rust-analyzer/pull/93) for an example PR which
|
||||
fixes a bug in the grammar.
|
||||
See [#93](https://github.com/rust-analyzer/rust-analyzer/pull/93) for an example PR which fixes a bug in the grammar.
|
||||
|
||||
**Architecture Invariant:** `syntax` crate is completely independent from the rest of rust-analyzer, it knows nothing about salsa or LSP.
|
||||
This is important because it is possible to useful tooling using only syntax tree.
|
||||
Without semantic information, you don't need to be able to _build_ code, which makes the tooling more robust.
|
||||
See also https://web.stanford.edu/~mlfbrown/paper.pdf.
|
||||
You can view the `syntax` crate as an entry point to rust-analyzer.
|
||||
`sytax` crate is an **API Boundary**.
|
||||
|
||||
**Architecture Invariant:** syntax tree is a value type.
|
||||
The tree is fully determined by the contents of its syntax nodes, it doesn't need global context (like an interner) and doesn't store semantic info.
|
||||
Using the tree as a store for semantic info is convenient in traditional compilers, but doesn't work nicely in the IDE.
|
||||
Specifically, assists and refactors require transforming syntax trees, and that becomes awkward if you need to do something with the semantic info.
|
||||
|
||||
**Architecture Invariant:** syntax tree is build for a single file.
|
||||
This is to enable parallel parsing of all files.
|
||||
|
||||
**Architecture Invariant:** Syntax trees are by design incomplete and do not enforce well-formedness.
|
||||
If an AST method returns an `Option`, it *can* be `None` at runtime, even if this is forbidden by the grammar.
|
||||
|
||||
### `crates/base_db`
|
||||
|
||||
We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and
|
||||
on-demand computation. Roughly, you can think of salsa as a key-value store, but
|
||||
it also can compute derived values using specified functions. The `base_db` crate
|
||||
provides basic infrastructure for interacting with salsa. Crucially, it
|
||||
defines most of the "input" queries: facts supplied by the client of the
|
||||
analyzer. Reading the docs of the `base_db::input` module should be useful:
|
||||
everything else is strictly derived from those inputs.
|
||||
We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and on-demand computation.
|
||||
Roughly, you can think of salsa as a key-value store, but it also can compute derived values using specified functions. The `base_db` crate provides basic infrastructure for interacting with salsa.
|
||||
Crucially, it defines most of the "input" queries: facts supplied by the client of the analyzer.
|
||||
Reading the docs of the `base_db::input` module should be useful: everything else is strictly derived from those inputs.
|
||||
|
||||
### `crates/hir*` crates
|
||||
**Architecture Invariant:** particularities of the build system are *not* the part of the ground state.
|
||||
In particular, `base_db` knows nothing about cargo.
|
||||
The `CrateGraph` structure is used to represent the dependencies between the crates abstractly.
|
||||
|
||||
HIR provides high-level "object oriented" access to Rust code.
|
||||
**Architecture Invariant:** `base_db` doesn't know about file system and file paths.
|
||||
Files are represented with opaque `FileId`, there's no operation to get an `std::path::Path` out of the `FileId`.
|
||||
|
||||
The principal difference between HIR and syntax trees is that HIR is bound to a
|
||||
particular crate instance. That is, it has cfg flags and features applied. So,
|
||||
the relation between syntax and HIR is many-to-one. The `source_binder` module
|
||||
is responsible for guessing a HIR for a particular source position.
|
||||
### `crates/hir_expand`, `crates/hir_def`, `crates/hir_ty`
|
||||
|
||||
Underneath, HIR works on top of salsa, using a `HirDatabase` trait.
|
||||
These crates are the *brain* of rust-analyzer.
|
||||
This is the compiler part of the IDE.
|
||||
|
||||
`hir_xxx` crates have a strong ECS flavor, in that they work with raw ids and
|
||||
directly query the database.
|
||||
`hir_xxx` crates have a strong ECS flavor, in that they work with raw ids and directly query the database.
|
||||
There's little abstraction here.
|
||||
These crates integrate deeply with salsa and chalk.
|
||||
|
||||
The top-level `hir` façade crate wraps ids into a more OO-flavored API.
|
||||
Name resolution, macro expansion and type inference all happen here.
|
||||
These crates also define various intermediate representations of the core.
|
||||
|
||||
`ItemTree` condenses a single `SyntaxTree` into a "summary" data structure, which is stable over modifications to function bodies.
|
||||
|
||||
`DefMap` contains the module tree of a crate and stores module scopes.
|
||||
|
||||
`Body` stores information about expressions.
|
||||
|
||||
**Architecture Invariant:** this crates are not, and will never be, an api boundary.
|
||||
|
||||
**Architecture Invariant:** these creates explicitly care about being incremental.
|
||||
The core invariant we maintain is "typing inside a function's body never invalidates global derived data".
|
||||
Ie, if you change body of `foo`, all facts about `bar` should remain intact.
|
||||
|
||||
**Architecture Invariant:** hir exists only in context of particular crate instance with specific CFG flags.
|
||||
The same syntax may produce several instances of HIR if the crate participates in the crate graph more than once.
|
||||
|
||||
### `crates/hir`
|
||||
|
||||
The top-level `hir` crate is an **API Boundary**.
|
||||
If you think about "using rust-analyzer as a library", `hir` crate is most likely the façade you'll be talking to.
|
||||
|
||||
It wraps ECS-style internal API into a more OO-flavored API (with an extra `db` argument for each call).
|
||||
|
||||
**Architecture Invariant:** `hir` provides a static, fully resolved view of the code.
|
||||
While internal `hir_*` crates _compute_ things, `hir`, from the outside, looks like an inert data structure.
|
||||
|
||||
`hir` also handles the delicate task of going from syntax to the corresponding `hir`.
|
||||
Remember that the mapping here is one-to-many.
|
||||
See `Semantics` type and `source_to_def` module.
|
||||
|
||||
Note in particular a curious recursive structure in `source_to_def`.
|
||||
We first resolve the parent _syntax_ node to the parent _hir_ element.
|
||||
Then we ask the _hir_ parent what _syntax_ children does it have.
|
||||
Then we look for our node in the set of children.
|
||||
|
||||
This is the heart of many IDE features, like goto definition, which start with figuring out a hir node at the cursor.
|
||||
This is some kind of (yet unnamed) uber-IDE pattern, as it is present in Roslyn and Kotlin as well.
|
||||
|
||||
### `crates/ide`
|
||||
|
||||
A stateful library for analyzing many Rust files as they change. `AnalysisHost`
|
||||
is a mutable entity (clojure's atom) which holds the current state, incorporates
|
||||
changes and hands out `Analysis` --- an immutable and consistent snapshot of
|
||||
the world state at a point in time, which actually powers analysis.
|
||||
The `ide` crate build's on top of `hir` semantic model to provide high-level IDE features like completion or goto definition.
|
||||
It is an **API Boundary**.
|
||||
If you want to use IDE parts of rust-analyzer via LSP, custom flatbuffers-based protocol or just as a library in your text editor, this is the right API.
|
||||
|
||||
One interesting aspect of analysis is its support for cancellation. When a
|
||||
change is applied to `AnalysisHost`, first all currently active snapshots are
|
||||
canceled. Only after all snapshots are dropped the change actually affects the
|
||||
database.
|
||||
**Architecture Invariant:** `ide` crate's API is build out of POD types with public fields.
|
||||
The API uses editor's terminology, it talks about offsets and string labels rathe than in terms of definitions or types.
|
||||
It is effectively the view in MVC and viewmodel in [MVVM](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel).
|
||||
All arguments and return types are conceptually serializable.
|
||||
In particular, syntax tress and and hir types are generally absent from the API (but are used heavily in the implementation).
|
||||
Shout outs to LSP developers for popularizing the idea that "UI" is a good place to draw a boundary at.
|
||||
|
||||
APIs in this crate are IDE centric: they take text offsets as input and produce
|
||||
offsets and strings as output. This works on top of rich code model powered by
|
||||
`hir`.
|
||||
`ide` is also the first crate which has the notion of change over time.
|
||||
`AnalysisHost` is a state to which you can transactonally `apply_change`.
|
||||
`Analysis` is an immutable snapshot of the state.
|
||||
|
||||
Internally, `ide` is split across several crates. `ide_assists`, `ide_completion` and `ide_ssr` implement large isolated features.
|
||||
`ide_db` implements common IDE functionality (notably, reference search is implemented here).
|
||||
The `ide` contains a public API/façade, as well as implementation for a plethora of smaller features.
|
||||
|
||||
**Architecture Invariant:** `ide` crate strives to provide a _perfect_ API.
|
||||
Although at the moment it has only one consumer, the LSP server, LSP *does not* influence it's API design.
|
||||
Instead, we keep in mind a hypothetical _ideal_ client -- an IDE tailored specifically for rust, every nook and cranny of which is packed with Rust-specific goodies.
|
||||
|
||||
### `crates/rust-analyzer`
|
||||
|
||||
An LSP implementation which wraps `ide` into a language server protocol.
|
||||
This crate defines the `rust-analyzer` binary, so it is the **entry point**.
|
||||
It implements the language server.
|
||||
|
||||
### `crates/vfs`
|
||||
**Architecture Invariant:** `rust-analyzer` is the only crate that knows about LSP and JSON serialization.
|
||||
If you want to expose a datastructure `X` from ide to LSP, don't make it serializable.
|
||||
Instead, create a serializable counterpart in `rust-analyzer` crate and manually convert between the two.
|
||||
|
||||
Although `hir` and `ide` don't do any IO, we need to be able to read
|
||||
files from disk at the end of the day. This is what `vfs` does. It also
|
||||
manages overlays: "dirty" files in the editor, whose "true" contents is
|
||||
different from data on disk.
|
||||
`GlobalState` is the state of the server.
|
||||
The `main_loop` defines the server event loop which accepts requests and sends responses.
|
||||
Requests that modify the state or might block user's typing are handled on the main thread.
|
||||
All other requests are processed in background.
|
||||
|
||||
## Testing Infrastructure
|
||||
**Architecture Invariant:** the server is stateless, a-la HTTP.
|
||||
Sometimes state needs to be preserved between requests.
|
||||
For example, "what is the `edit` for the fifth's completion item of the last completion edit?".
|
||||
For this, the second request should include enough info to re-create the context from scratch.
|
||||
This generally means including all the parameters of the original request.
|
||||
|
||||
Rust Analyzer has three interesting [systems
|
||||
boundaries](https://www.tedinski.com/2018/04/10/making-tests-a-positive-influence-on-design.html)
|
||||
to concentrate tests on.
|
||||
`reload` module contains the code that handles configuration and Cargo.toml changes.
|
||||
This is a tricky business.
|
||||
|
||||
The outermost boundary is the `rust-analyzer` crate, which defines an LSP
|
||||
interface in terms of stdio. We do integration testing of this component, by
|
||||
feeding it with a stream of LSP requests and checking responses. These tests are
|
||||
known as "heavy", because they interact with Cargo and read real files from
|
||||
disk. For this reason, we try to avoid writing too many tests on this boundary:
|
||||
in a statically typed language, it's hard to make an error in the protocol
|
||||
itself if messages are themselves typed.
|
||||
**Architecture Invariant:** `rust-analyzer` should be partially available even when the build is broken.
|
||||
Reloading process should not prevent IDE features from working.
|
||||
|
||||
The middle, and most important, boundary is `ide`. Unlike
|
||||
`rust-analyzer`, which exposes API, `ide` uses Rust API and is intended to
|
||||
use by various tools. Typical test creates an `AnalysisHost`, calls some
|
||||
`Analysis` functions and compares the results against expectation.
|
||||
### `crates/toolchain`, `crates/project_model`, `crates/flycheck`
|
||||
|
||||
The innermost and most elaborate boundary is `hir`. It has a much richer
|
||||
vocabulary of types than `ide`, but the basic testing setup is the same: we
|
||||
create a database, run some queries, assert result.
|
||||
These crates deal with invoking `cargo` to learn about project structure and get compiler errors for the "check on save" feature.
|
||||
|
||||
They use `crates/path` heavily instead of `std::path`.
|
||||
A single `rust-analyzer` process can serve many projects, so it is important that server's current directory does not leak.
|
||||
|
||||
### `crates/mbe`, `crated/tt`, `crates/proc_macro_api`, `crates/proc_macro_srv`
|
||||
|
||||
These crates implement macros as token tree -> token tree transforms.
|
||||
They are independent from the rest of the code.
|
||||
|
||||
### `crates/vfs`, `crates/vfs-notify`
|
||||
|
||||
These crates implement a virtual fils system.
|
||||
They provide consistent snapshots of the underlying file system and insulate messy OS paths.
|
||||
|
||||
**Architecture Invariant:** vfs doesn't assume a single unified file system.
|
||||
IE, a single rust-analyzer process can act as a remote server for two different machines, where the same `/tmp/foo.rs` path points to different files.
|
||||
For this reason, all path APIs generally take some existing path as a "file system witness".
|
||||
|
||||
### `crates/stdx`
|
||||
|
||||
This crate contains various non-rust-analyzer specific utils, which could have been in std.
|
||||
|
||||
### `crates/profile`
|
||||
|
||||
This crate contains utilities for CPU and memory profiling.
|
||||
|
||||
|
||||
## Cross-Cutting Concerns
|
||||
|
||||
This sections talks about the things which are everywhere and nowhere in particular.
|
||||
|
||||
### Code generation
|
||||
|
||||
Some of the components of this repository are generated through automatic processes.
|
||||
`cargo xtask codegen` runs all generation tasks.
|
||||
Generated code is generally committed to the git repository.
|
||||
There are tests to check that the generated code is fresh.
|
||||
|
||||
In particular, we generate:
|
||||
|
||||
* API for working with syntax trees (`syntax::ast`, the `ungrammar` crate).
|
||||
* Various sections of the manual:
|
||||
|
||||
* features
|
||||
* assists
|
||||
* config
|
||||
|
||||
* Documentation tests for assists
|
||||
|
||||
**Architecture Invariant:** we avoid bootstrapping.
|
||||
For codegen we need to parse Rust code.
|
||||
Using rust-analyzer for that would work and would be fun, but it would also complicate the build process a lot.
|
||||
For that reason, we use syn and manual string parsing.
|
||||
|
||||
### Cancellation
|
||||
|
||||
Let's say that the IDE is in the process of computing syntax highlighting, when the user types `foo`.
|
||||
What should happen?
|
||||
`rust-analyzer`s answer is that the highlighting process should be cancelled -- its results are now stale, and it also blocks modification of the inputs.
|
||||
|
||||
The salsa database maintains a global revision counter.
|
||||
When applying a change, salsa bumps this counter and waits until all other threads using salsa finish.
|
||||
If a thread does salsa-based computation and notices that the counter is incremented, it panics with a special value (see `Canceled::throw`).
|
||||
That is, rust-analyzer requires unwinding.
|
||||
|
||||
`ide` is the boundary where the panic is caught and transformed into a `Result<T, Cancelled>`.
|
||||
|
||||
### Testing
|
||||
|
||||
Rust Analyzer has three interesting [systems boundaries](https://www.tedinski.com/2018/04/10/making-tests-a-positive-influence-on-design.html) to concentrate tests on.
|
||||
|
||||
The outermost boundary is the `rust-analyzer` crate, which defines an LSP interface in terms of stdio.
|
||||
We do integration testing of this component, by feeding it with a stream of LSP requests and checking responses.
|
||||
These tests are known as "heavy", because they interact with Cargo and read real files from disk.
|
||||
For this reason, we try to avoid writing too many tests on this boundary: in a statically typed language, it's hard to make an error in the protocol itself if messages are themselves typed.
|
||||
Heavy tests are only run when `RUN_SLOW_TESTS` env var is set.
|
||||
|
||||
The middle, and most important, boundary is `ide`.
|
||||
Unlike `rust-analyzer`, which exposes API, `ide` uses Rust API and is intended to use by various tools.
|
||||
Typical test creates an `AnalysisHost`, calls some `Analysis` functions and compares the results against expectation.
|
||||
|
||||
The innermost and most elaborate boundary is `hir`.
|
||||
It has a much richer vocabulary of types than `ide`, but the basic testing setup is the same: we create a database, run some queries, assert result.
|
||||
|
||||
For comparisons, we use the `expect` crate for snapshot testing.
|
||||
|
||||
To test various analysis corner cases and avoid forgetting about old tests, we
|
||||
use so-called marks. See the `marks` module in the `test_utils` crate for more.
|
||||
To test various analysis corner cases and avoid forgetting about old tests, we use so-called marks.
|
||||
See the `marks` module in the `test_utils` crate for more.
|
||||
|
||||
**Architecture Invariant:** rust-analyzer tests do not use libcore or libstd.
|
||||
All required library code must be a part of the tests.
|
||||
This ensures fast test execution.
|
||||
|
||||
**Architecture Invariant:** tests are data driven and do not test API.
|
||||
Tests which directly call various API functions are a liability, because they make refactoring the API significantly more complicated.
|
||||
So most of the tests look like this:
|
||||
|
||||
```rust
|
||||
fn check(input: &str, expect: expect_test::Expect) {
|
||||
// The single place that actually exercises a particular API
|
||||
}
|
||||
|
||||
|
||||
#[test]
|
||||
fn foo() {
|
||||
check("foo", expect![["bar"]]);
|
||||
}
|
||||
|
||||
#[test]
|
||||
fn spam() {
|
||||
check("spam", expect![["eggs"]]);
|
||||
}
|
||||
// ...and a hundred more tests that don't care about the specific API at all.
|
||||
```
|
||||
|
||||
To specify input data, we use a single string literal in a special format, which can describe a set of rust files.
|
||||
See the `Fixture` type.
|
||||
|
||||
**Architecture Invariant:** all code invariants are tested by `#[test]` tests.
|
||||
There's no additional checks in CI, formatting and tidy tests are run with `cargo test`.
|
||||
|
||||
**Architecture Invariant:** tests do not depend on any kind of external resources, they are perfectly reproducible.
|
||||
|
||||
### Observability
|
||||
|
||||
I've run out of steam here :)
|
||||
rust-analyzer is a long-running process, so its important to understand what's going on inside.
|
||||
We have hierarchical profiler (`RA_PROFILER=1`) and object counting (`RA_COUNT=1`).
|
||||
|
|
|
|||
Loading…
Reference in a new issue