# Description
The `zstd` team released a version that breaks dataframe compilation.
This change pins to `zstd-sys = "=2.0.1+zstd.1.5.2"` in order to prevent
the required `+nightly` build flag.
_(Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.)_
_(Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.)_
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
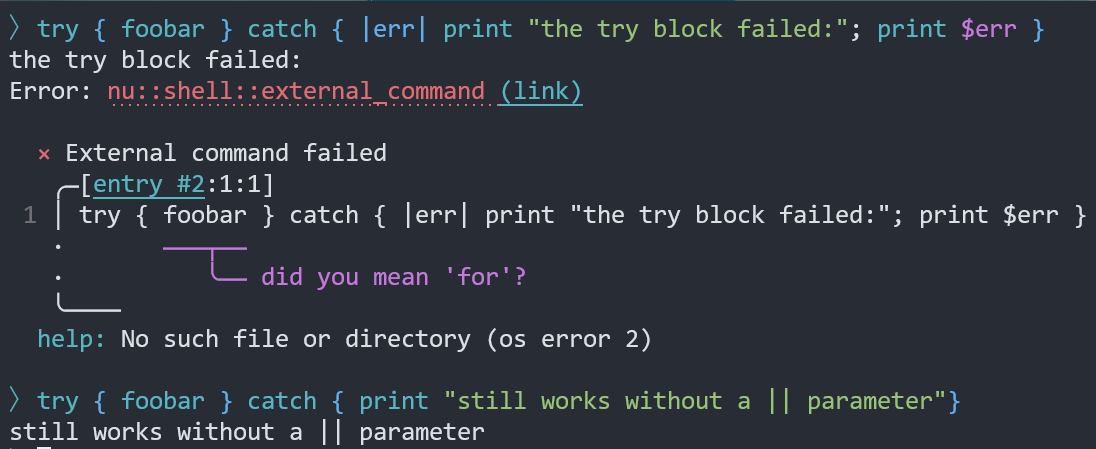
A small follow-up to #7221. This changes the `catch` block from a block
to a closure, so that it can access the error returned from the `try`
block. This helps with a common scenario: "the `try` block failed, and I
want to log why it failed."
### Example
### Future Work
Nu's closure syntax is a little awkward here; it might be nicer to allow
something like `catch err { print $err }`. We discussed this on Discord
and it will require special parser code similar to what's already done
for `for`.
I'm not feeling confident enough in my parser knowledge to make that
change; I will spend some more time looking at the `for` code but I
doubt I will be able to implement anything in the next few days.
Volunteers welcome.
# Description
This adds `try` (with an optional `catch` piece). Much like other
languages, `try` will try to run a block. If the block fails to run
successfully, the optional `catch` block will run if it is available.
# User-Facing Changes
This adds the `try` command.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
This is a set of fixes to `err>` to make it work a bit more predictably.
I've also revised the tests, which accidentally tested the wrong thing
for redirection, but should be more correct now.
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
`uniq -i` does not convert output strings to lowercase.
Also, `uniq -i` did not ignore case in strings below the first level of
Tables and Records. Now all strings case are ignored for all children
Values for tables, Records, and List.
Fixes https://github.com/nushell/nushell/issues/7192
# Tests + Formatting
About the issue https://github.com/nushell/nushell/issues/7192, the
output will be:
```
〉[AAA BBB CCC] | uniq -i
╭───┬─────╮
│ 0 │ AAA │
│ 1 │ BBB │
│ 2 │ CCC │
╰───┴─────╯
```
About ignoring case for all children string, I expect this to be true:
```
([[origin, people];
[World, (
[[name, meal];
['Geremias', {plate: 'bitoque', carbs: 100}]
]
)],
[World, (
[[name, meal];
['Martin', {plate: 'bitoque', carbs: 100}]
]
)],
[World, (
[[name, meal];
['Geremias', {plate: 'Bitoque', carbs: 100}]
]
)],
] | uniq -i
) == ([[origin, people];
[World, (
[[name, meal];
['Geremias', {plate: 'bitoque', carbs: 100}]
]
)],
[World, (
[[name, meal];
['Martin', {plate: 'bitoque', carbs: 100}]
]
)]
])
```
# Description
Closes#6803.
You can look at the code and see this was always supposed to work this
way, but was broken due to 1 line (per file).
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
While trying to add a new `uniq-by` command I refactored the `uniq`
command code to understand it and try to reuse. I think this is more
compact and easier to understand.
The part that I think it's a little confusing in this refactor is the
conditions inside `.filters()`, for example: `!flag_show_repeated ||
(value.1 > 1)`. I could use `if (flag_show_repeated) {value.1 > 1} else
{true}` but it is more verbose, what do you think?
PS: Not sure if you like this kind of PR, sorry if not.
# Tests + Formatting
I also added a test where the `uniq` has a table as input.
# Description
BEFORE:
```
〉ls | size
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #22:1:1]
1 │ ls | size
· ──┬─
· │╰── value originates from here
· ╰── expected: string
╰────
〉ls | sort-by SIZE
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #17:1:1]
1 │ ls | sort-by SIZE
· ───┬───
· │╰── value originates here
· ╰── cannot find column
╰────
〉[4kb] | path join 'b'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #6:1:1]
1 │ [4kb] | path join 'b'
· ──┬──
· │╰── value originates from here
· ╰── expected: string or record
╰────
```
AFTER:
```
〉ls | size
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ ls | size
· ─┬ ──┬─
· │ ╰── expected: string
· ╰── value originates from here
╰────
〉ls | get 0 | sort-by SIZE
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #2:1:1]
1 │ ls | get 0 | sort-by SIZE
· ─┬ ───┬───
· │ ╰── cannot find column 'SIZE'
· ╰── value originates here
╰────
〉[4kb] | path join 'b'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ [4kb] | path join 'b'
· ──┬── ────┬────
· │ ╰── expected: string or record
· ╰── value originates from here
╰────
```
(Hey, anyone noticed that there's TWO wordings of "value originates from
here" in this codebase………?)
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Fixes a two's complement underflow/overflow when given a negative arg.
Breaking change as it is throwing an error instead of most likely
returning most of the output.
Same behavior as #7184
# Tests + Formatting
+ 1 failure test
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
- Error on negative argument to `last`
- Add test for negative value in last
Follow-up for #7178
# User-Facing Changes
Breaking change:
even before #7178 `last` returned an empty `list<any>` when given
negative indices.
Now this is an
[error](https://docs.rs/nu-protocol/latest/nu_protocol/enum.ShellError.html#variant.NeedsPositiveValue)
Note:
In #7136 we are considering supporting negative indexing
# Tests + Formatting
+ 1 failure test
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Closes: #6937
# User-Facing Changes
N/A
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
I noticed that some json values are not parsed at the top level, for
example: `null`, `true`, `false`. Although this is a valid json.
```
> "null" | from json
Error:
× Error while parsing JSON text
╭─[entry #12:1:1]
1 │ "null" | from json
· ────┬────
· ╰── error parsing JSON text
╰────
Error:
× Error while parsing JSON text
╭────
1 │ null
╰────
```
I tried to fix it and it seems to work fine.
# User-Facing Changes
It should give fewer errors.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: sholderbach <sholderbach@users.noreply.github.com>
# Description
rust 1.65.0 has been released for a while, this pr applies lint
suggestions from rust 1.65.0.
# User-Facing Changes
N/A
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
BEFORE (notice Windows paths look wrong):
```
〉mv 8 9
Error:
× Destination file already exists
╭─[entry #22:1:1]
1 │ mv 8 9
· ┬
· ╰── you can use -f, --force to force overwriting the destination
╰────
〉mv d1 tmp
Error:
× Can't move "C:\\Users\\Leon\\TODO\\d1" to "C:\\Users\\Leon\\TODO\\tmp\\d1"
╭─[entry #19:1:1]
1 │ mv d1 tmp
· ─┬─
· ╰── Directory not empty
╰────
```
AFTER (full paths are now included in the arrows' messages to make lines
like `mv $foo` entirely unambiguous):
```
〉mv 8 9
Error:
× Destination file already exists
╭─[entry #4:1:1]
1 │ mv 8 9
· ┬
· ╰── Destination file 'C:\Users\Leon\TODO\tmp\9' already exists
╰────
help: you can use -f, --force to force overwriting the destination
〉mv d1 tmp
Error:
× Can't move 'C:\Users\Leon\TODO\d1' to 'C:\Users\Leon\TODO\tmp\d1'
╭─[entry #3:1:1]
1 │ mv d1 tmp
· ─┬─
· ╰── Directory 'C:\Users\Leon\TODO\tmp' is not empty
╰────
```
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
As title, when execute external sub command, auto-trimming end
new-lines, like how fish shell does.
And if the command is executed directly like: `cat tmp`, the result
won't change.
Fixes: #6816Fixes: #3980
Note that although nushell works correctly by directly replace output of
external command to variable(or other places like string interpolation),
it's not friendly to user, and users almost want to use `str trim` to
trim trailing newline, I think that's why fish shell do this
automatically.
If the pr is ok, as a result, no more `str trim -r` is required when
user is writing scripts which using external commands.
# User-Facing Changes
Before:
<img width="523" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468810-86b04dbb-c147-459a-96a5-e0095eeaab3d.png">
After:
<img width="505" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468599-7b537488-3d6b-458e-9d75-d85780826db0.png">
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Following up on #7180 with some feature cleanup:
- Move the `database` feature from `plugin` to `default`
- Rename the `database` feature to `sqlite`
- Remove `--features=extra` from a lot of scripts etc.
- No need to specify this, the `extra` feature is now the same as the
default feature set
- Remove the now-redundant 2nd Ubuntu test run
# Description
Support for this breaking change was raised in #7191. This affects
`sort`, `sort-by`, `str contains` and `find`. `--ignore-case` is used by
a few POSIX programs such as `less` and `grep`, as well as a few other
popular utils like `tree` and `wget`. Since long names aren't especially
popular (existing primarily for self-documentation purposes), I consider
this on the shallow end of the compat-break scale.
Note that the `-i` short flag is not affected.
# User-Facing Changes
See above.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This adds new pipeline connectors called out> and err> which redirect either stdout or stderr to a file. You can also use out+err> (or err+out>) to redirect both streams into a file.
Currently `last n` memory use is O(input), while it should be O(n). This
patch replaces code collecting all of last's input into a Vec<_> with
collecting into a bounded VecDeque<_>. UI/UX remain are unchanged.
Alters `all`, `any`, `each while`, `each`, `insert`, `par-each`, `reduce`, `update`, `upsert` and `where`,
so that their blocks take an optional parameter containing the index.
* Make json require string and pass around metadata
The json deserializer was accepting any inputs by coercing non-strings
into strings. As an example, if the input was `[1, 2]` the coercion
would turn into `[12]` and deserialize as a list containing number
twelve instead of a list of two numbers, one and two. This could lead
to silent data corruption.
Aside from that pipeline metadata wasn't passed aroud.
This commit fixes the type issue by adding a strict conversion
function that errors if the input type is not a string or external
stream. It then uses this function instead of the original
`collect_string()`. In addition, this function returns the pipeline
metadata so it can be passed along.
* Make other formats require string
The problem with json coercing non-string types to string was present in
all other text formats. This reuses the `collect_string_strict` function
to fix them.
* `IntoPipelineData` cleanup
The method `into_pipeline_data_with_metadata` can now be conveniently
used.
* add signature information when help on one command
* tell user that one command support operated on cell paths
Also, make type output to be more friendly, like `record<>` should just be `record`
And the same to `table<>`, which should be `table`
* simplify code
* don't show signatures for parser keyword
* update comment
* output arg syntax shape as type, so it's the same as describe command
* fix string when no positional args
* update signature body
* update
* add help signature test
* fix arg output format for composed data type like list or record
* fix clippy
* add comment
* Grouped config commands better
* Tweaked test slightly
* Fix merge conflict(?)
* Remove recently-added test case
* Revert rm.always_trash default
* Untweak rm help messages
* Formatting
* Remove example
* Add deprecation warning
* Remove deprecation timeline
Not sure we want to commit to a specific timeline just yet
Co-authored-by: Reilly Wood <26268125+rgwood@users.noreply.github.com>
* removes unused features.
* Adds back multithreading feature to sysinfo.
* Adds back alloc for percent-encoding
* Adds updated lock file.
* Missed one sysinfo.
* `indexmap` just defaults
* Revert `miette``default-features=false`
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
This adds support for (limited) mutable variables. Mutable variables are created with mut much the same way immutable variables are made with let.
Mutable variables allow mutation via the assignment operator (=).
❯ mut x = 100
❯ $x = 200
❯ print $x
200
Mutable variables are limited in that they're only tended to be used in the local code block. Trying to capture a local variable will result in an error:
❯ mut x = 123; {|| $x }
Error: nu::parser::expected_keyword (link)
× Capture of mutable variable.
The intent of this limitation is to reduce some of the issues with mutable variables in general: namely they make code that's harder to reason about. By reducing the scope that a mutable variable can be used it, we can help create local reasoning about them.
Mutation can occur with fields as well, as in this case:
❯ mut y = {abc: 123}
❯ $y.abc = 456
❯ $y
On a historical note: mutable variables are something that we resisted for quite a long time, leaning as much as we could on the functional style of pipelines and dataflow. That said, we've watched folks struggle to work with reduce as an approximation for patterns that would be trivial to express with local mutation. With that in mind, we're leaning towards the happy path.
{kind=link}
{kind=link}
{kind=link}