# Description
Does some misc changes to `ListStream`:
- Moves it into its own module/file separate from `RawStream`.
- `ListStream`s now have an associated `Span`.
- This required changes to `ListStreamInfo` in `nu-plugin`. Note sure if
this is a breaking change for the plugin protocol.
- Hides the internals of `ListStream` but also adds a few more methods.
- This includes two functions to more easily alter a stream (these take
a `ListStream` and return a `ListStream` instead of having to go through
the whole `into_pipeline_data(..)` route).
- `map`: takes a `FnMut(Value) -> Value`
- `modify`: takes a function to modify the inner stream.
# Description
Spaces were causing an issue with into_sqlite when they appeared in
column names.
This is because the column names were not properly wrapped with
backticks that allow sqlite to properly interpret the column.
The issue has been addressed by adding backticks to the column names of
into sqlite. The output of the column names when using open is
unchanged, and the column names appear without backticks as expected.
fixes#12700
# User-Facing Changes
N/A
# Tests + Formatting
Formatting has been respected.
Repro steps from the issue have been done, and ran multiple times. New
values get added to the correct columns as expected.
# Description
Continuing from #12568, this PR further reduces the size of `Expr` from
64 to 40 bytes. It also reduces `Expression` from 128 to 96 bytes and
`Type` from 32 to 24 bytes.
This was accomplished by:
- for `Expr` with multiple fields (e.g., `Expr::Thing(A, B, C)`),
merging the fields into new AST struct types and then boxing this struct
(e.g. `Expr::Thing(Box<ABC>)`).
- replacing `Vec<T>` with `Box<[T]>` in multiple places. `Expr`s and
`Expression`s should rarely be mutated, if at all, so this optimization
makes sense.
By reducing the size of these types, I didn't notice a large performance
improvement (at least compared to #12568). But this PR does reduce the
memory usage of nushell. My config is somewhat light so I only noticed a
difference of 1.4MiB (38.9MiB vs 37.5MiB).
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
This adds a `SharedCow` type as a transparent copy-on-write pointer that
clones to unique on mutate.
As an initial test, the `Record` within `Value::Record` is shared.
There are some pretty big wins for performance. I'll post benchmark
results in a comment. The biggest winner is nested access, as that would
have cloned the records for each cell path follow before and it doesn't
have to anymore.
The reusability of the `SharedCow` type is nice and I think it could be
used to clean up the previous work I did with `Arc` in `EngineState`.
It's meant to be a mostly transparent clone-on-write that just clones on
`.to_mut()` or `.into_owned()` if there are actually multiple
references, but avoids cloning if the reference is unique.
# User-Facing Changes
- `Value::Record` field is a different type (plugin authors)
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] use for `EngineState`
- [ ] use for `Value::List`
# Description
In #10232, the allowed input types were changed to be stricter, only
allowing records with types that can easily map onto sqlite equivalents.
Unfortunately, null was left out of the accepted input types, which
makes inserting rows with null values impossible.
This change fixes that by accepting null values as input.
One caveat of this is that when the command is creating a new table, it
uses the first row to infer an appropriate sqlite schema. If the first
row contains a null value, then it is impossible to tell which type this
column is supposed to have.
Throwing a hard error seems undesirable from a UX perspective, but
guessing can lead to a potentially useless database if we guess wrong.
So as a compromise, for null columns, we will assume the sqlite type is
TEXT and print a warning so the user knows. For the time being, if users
can't avoid a first row with null values, but also wants the right
schema, they are advised to create their table before running `into
sqlite`.
A future PR can add the ability to explicitly specify a schema.
Fixes#12225
# Tests + Formatting
* Tests added to cover expected behavior around insertion of null values
# Description
Again avoid uses of the `Record` internals, so we are free to change the
data layout
- **Don't use internals of `Record` in `into sqlite`**
- **Don't use internals of `Record` in `to xml`**
Remaining: `rename`
# User-Facing Changes
None
# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
# Description
This PR adds a `--params` param to `query db`. This closes#11643.
You can't combine both named and positional parameters, I think this
might be a limitation with rusqlite itself. I tried using named
parameters with indices like `{ ':named': 123, '1': "positional" }` but
that always failed with a rusqlite error. On the flip side, the other
way around works: for something like `VALUES (:named, ?)`, you can treat
both as positional: `-p [hello 123]`.
This PR introduces some very gnarly code repetition in
`prepared_statement_to_nu_list`. I tried, I swear; the compiler wasn't
having any of it, it kept telling me to box my closures and then it said
that the reference lifetimes were incompatible in the match arms. I gave
up and put the mapping code in the match itself, but I'm still not
happy.
Another thing I'm unhappy about: I don't like how you have to put the
`:colon` in named parameters. I think nushell should insert it if it's
[missing](https://www.sqlite.org/lang_expr.html#parameters). But this is
the way [rusqlite
works](https://docs.rs/rusqlite/latest/rusqlite/trait.Params.html#example-named),
so for now, I'll let it be consistent. Just know that it's not really a
blocker, and it isn't a compatibility change to later make `{ colon: 123
}` work, without the quotes and `:`. This would require allocating and
turning our pretty little `&str` into a `String`, though
# User-Facing Changes
Less incentive to leave yourself open to SQL injection with statements
like `query db $"INSERT INTO x VALUES \($unsafe_user_input)"`.
Additionally, the `$""` syntax being annoying with parentheses plays in
our favor, making users even more likely to use ? with `--params`.
# Tests + Formatting
Hehe
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
- fixes#12126
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This pr improves the error message for issue #12126
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
I noticed that ctrl+C handling wasn't fully wired up in `into sqlite`,
for some data types we were ignoring ctrl+C presses.
I fixed that up and also made sure we roll back the current transaction
when cancelling (without that, I think we leak memory and database
locks).
# Description
This PR fixes the typo in the parameter `--table-name` instead of
`--table_name` in the `into sqlite` command.
fixes#12067
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This is a follow up to
https://github.com/nushell/nushell/pull/11621#issuecomment-1937484322
Also Fixes: #11838
## About the code change
It applys the same logic when we pass variables to external commands:
0487e9ffcb/crates/nu-command/src/system/run_external.rs (L162-L170)
That is: if user input dynamic things(like variables, sub-expression, or
string interpolation), it returns a quoted `NuPath`, then user input
won't be globbed
# User-Facing Changes
Given two input files: `a*c.txt`, `abc.txt`
* `let f = "a*c.txt"; rm $f` will remove one file: `a*c.txt`.
~* `let f = "a*c.txt"; rm --glob $f` will remove `a*c.txt` and
`abc.txt`~
* `let f: glob = "a*c.txt"; rm $f` will remove `a*c.txt` and `abc.txt`
## Rules about globbing with *variable*
Given two files: `a*c.txt`, `abc.txt`
| Cmd Type | example | Result |
| ----- | ------------------ | ------ |
| builtin | let f = "a*c.txt"; rm $f | remove `a*c.txt` |
| builtin | let f: glob = "a*c.txt"; rm $f | remove `a*c.txt` and
`abc.txt`
| builtin | let f = "a*c.txt"; rm ($f \| into glob) | remove `a*c.txt`
and `abc.txt`
| custom | def crm [f: glob] { rm $f }; let f = "a*c.txt"; crm $f |
remove `a*c.txt` and `abc.txt`
| custom | def crm [f: glob] { rm ($f \| into string) }; let f =
"a*c.txt"; crm $f | remove `a*c.txt`
| custom | def crm [f: string] { rm $f }; let f = "a*c.txt"; crm $f |
remove `a*c.txt`
| custom | def crm [f: string] { rm $f }; let f = "a*c.txt"; crm ($f \|
into glob) | remove `a*c.txt` and `abc.txt`
In general, if a variable is annotated with `glob` type, nushell will
expand glob pattern. Or else, we need to use `into | glob` to expand
glob pattern
# Tests + Formatting
Done
# After Submitting
I think `str glob-escape` command will be no-longer required. We can
remove it.
# Description
Currently, the `into sqlite` command collects the entire input stream
into a single Value, which soaks up the entire input into memory, before
it ever tries to write anything to the DB. This is very problematic for
large inputs; for example, I tried transforming a multi-gigabyte CSV
file into SQLite, and before I knew what was happening, my system's
memory was completely exhausted, and I had to hard reboot to recover.
This PR fixes this problem by working directly with the pipeline stream,
inserting into the DB as values are read from the stream.
In order to facilitate working with the stream directly, I introduced a
new `Table` struct to store the connection and a few configuration
parameters, as well as to make it easier to lazily create the table on
the first read value.
In addition to the purely functional fixes, a few other changes were
made to the serialization and user facing behavior.
### Serialization
Much of the preexisting code was focused on generating the exact text
needed for a SQL statement. This is unneeded and less safe than using
the `rusqlite` crate's serialization for native Rust types along with
prepared statements.
### User-Facing Changes
Currently, the command is very liberal in the input types it accepts.
The strategy is basically if it is a record, try to follow its structure
and make an analogous SQL row, which is pretty reasonable. However, when
it's not a record, it basically tries to guess what the user wanted and
just makes a single column table and serializes the value into that one
column, whatever type it may be.
This has been changed so that it only accepts records as input. If the
user wants to serialize non-record types into SQL, then they must
explicitly opt into doing this by constructing a record or table with it
first. For a utility for inserting data into SQL, I think it makes more
sense to let the user choose how to convert their data, rather than make
a choice for them that may surprise them.
However, I understand this may be a controversial change. If the
maintainers don't agree, I can change this back.
#### Long switch names
The `file_name` and `table_name` long form switches are currently
snake_case and expect to be as such at the command line. These have been
changed to kebab-case to be more conventional.
# Tests + Formatting
To test the memory consumption, I used [this publicly available index of
all Wikipedia articles](https://dumps.wikimedia.org/enwiki/20230820/),
using the first 10,000, 100,000, and 1,000,000 entries, in that order. I
ran the following script to benchmark the changes against the current
stable release:
```nu
#!/usr/bin/nu
# let shellbin = $"($env.HOME)/src/nushell/target/aarch64-linux-android/release/nu"
let shellbin = "nu"
const dbpath = 'enwiki-index.db'
[10000, 100000, 1000000]
| each {|rows|
rm -f $dbpath;
do { time -f '%M %e %U %S' $shellbin -c (
$"bzip2 -cdk ~/enwiki-20230820-pages-articles-multistream-index.txt.bz2
| head -n ($rows)
| lines
| parse '{offset}:{id}:{title}'
| update cells -c [offset, id] { into int }
| into sqlite ($dbpath)"
)
}
| complete
| get stderr
| str trim
| parse '{rss_max} {real} {user} {kernel}'
| update cells -c [rss_max] { $"($in)kb" | into filesize }
| update cells -c [real, user, kernel] { $"($in)sec" | into duration }
| insert rows $rows
| roll right
}
| flatten
| to nuon
```
This yields the following results
Current stable release:
|rows|rss_max|real|user|kernel|
|-|-|-|-|-|
|10000|53.6 MiB|770ms|460ms|420ms|
|100000|209.6 MiB|6sec 940ms|3sec 740ms|4sec 380ms|
|1000000|1.7 GiB|1min 8sec 810ms|38sec 690ms|42sec 550ms|
This PR:
|rows|rss_max|real|user|kernel|
|-|-|-|-|-|
|10000|38.2 MiB|780ms|440ms|410ms|
|100000|39.8 MiB|6sec 450ms|3sec 530ms|4sec 160ms|
|1000000|39.8 MiB|1min 3sec 230ms|37sec 440ms|40sec 180ms|
# Note
I started this branch kind of at the same time as my others, but I
understand the feedback that smaller PRs are preferred. Let me know if
it would be better to split this up.
I do think the scope of the changes are on the bigger side even without
the behavior changes I mentioned, so I'm not sure if that will help this
particular PR very much, but I'm happy to oblige on request.
# Description
`Value::MatchPattern` implies that `MatchPattern`s are first-class
values. This PR removes this case, and commands must now instead use
`Expr::MatchPattern` to extract `MatchPattern`s just like how the
`match` command does using `Expr::MatchBlock`.
# User-Facing Changes
Breaking API change for `nu_protocol` crate.
# Description
This updates all the positional arguments (except with
`--features=dataframe` or `--features=extra`) to start with an uppercase
letter and end with a period.
Part of #5066, specifically [this
comment](/nushell/nushell/issues/5066#issuecomment-1421528910)
Some arguments had example data removed from them because it also
appears in the examples.
There are other inconsistencies in positional arguments I noticed while
making the tests pass which I will bring up in #5066.
# User-Facing Changes
Positional arguments are now consistent
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
Automatic documentation updates
# Description
Replace `.to_string()` used in `GenericError` with `.into()` as
`.into()` seems more popular
Replace `Vec::new()` used in `GenericError` with `vec![]` as `vec![]`
seems more popular
(There are so, so many)
# Description
Since #10841 the goal is to remove the implementation details of
`Record` outside of core operations.
To this end use Record iterators and map-like accessors in a bunch of
places. In this PR I try to collect the boring cases where I don't
expect any dramatic performance impacts or don't have doubts about the
correctness afterwards
- Use checked record construction in `nu_plugin_example`
- Use `Record::into_iter` in `columns`
- Use `Record` iterators in `headers` cmd
- Use explicit record iterators in `split-by`
- Use `Record::into_iter` in variable completions
- Use `Record::values` iterator in `into sqlite`
- Use `Record::iter_mut` for-loop in `default`
- Change `nu_engine::nonexistent_column` to use iterator
- Use `Record::columns` iter in `nu-cmd-base`
- Use `Record::get_index` in `nu-command/network/http`
- Use `Record.insert()` in `merge`
- Refactor `move` to use encapsulated record API
- Use `Record.insert()` in `explore`
- Use proper `Record` API in `explore`
- Remove defensiveness around record in `explore`
- Use encapsulated record API in more `nu-command`s
# User-Facing Changes
None intentional
# Tests + Formatting
(-)
# Description
Reuses the existing `Closure` type in `Value::Closure`. This will help
with the span refactoring for `Value`. Additionally, this allows us to
more easily box or unbox the `Closure` case should we chose to do so in
the future.
# User-Facing Changes
Breaking API change for `nu_protocol`.
# Description
As part of the refactor to split spans off of Value, this moves to using
helper functions to create values, and using `.span()` instead of
matching span out of Value directly.
Hoping to get a few more helping hands to finish this, as there are a
lot of commands to update :)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <windsoilder@outlook.com>
# Description
This doesn't really do much that the user could see, but it helps get us
ready to do the steps of the refactor to split the span off of Value, so
that values can be spanless. This allows us to have top-level values
that can hold both a Value and a Span, without requiring that all values
have them.
We expect to see significant memory reduction by removing so many
unnecessary spans from values. For example, a table of 100,000 rows and
5 columns would have a savings of ~8megs in just spans that are almost
always duplicated.
# User-Facing Changes
Nothing yet
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR creates a new `Record` type to reduce duplicate code and
possibly bugs as well. (This is an edited version of #9648.)
- `Record` implements `FromIterator` and `IntoIterator` and so can be
iterated over or collected into. For example, this helps with
conversions to and from (hash)maps. (Also, no more
`cols.iter().zip(vals)`!)
- `Record` has a `push(col, val)` function to help insure that the
number of columns is equal to the number of values. I caught a few
potential bugs thanks to this (e.g. in the `ls` command).
- Finally, this PR also adds a `record!` macro that helps simplify
record creation. It is used like so:
```rust
record! {
"key1" => some_value,
"key2" => Value::string("text", span),
"key3" => Value::int(optional_int.unwrap_or(0), span),
"key4" => Value::bool(config.setting, span),
}
```
Since macros hinder formatting, etc., the right hand side values should
be relatively short and sweet like the examples above.
Where possible, prefer `record!` or `.collect()` on an iterator instead
of multiple `Record::push`s, since the first two automatically set the
record capacity and do less work overall.
# User-Facing Changes
Besides the changes in `nu-protocol` the only other breaking changes are
to `nu-table::{ExpandedTable::build_map, JustTable::kv_table}`.
# Description
This PR helps the sqlite handling better by surrounding table names with
brackets. This makes it easier to have table names with spaces like
`Basin / profile`.
Closes#9751
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR does a few things to help improve type hovers and, in the
process, fixes a few outstanding issues in the type system. Here's a
list of the changes:
* `for` now will try to infer the type of the iteration variable based
on the expression it's given. This fixes things like `for x in [1, 2, 3]
{ }` where `x` now properly gets the int type.
* Removed old input/output type fields from the signature, focuses on
the vec of signatures. Updated a bunch of dataframe commands that hadn't
moved over. This helps tie things together a bit better
* Fixed inference of types from subexpressions to use the last
expression in the block
* Fixed handling of explicit types in `let` and `mut` calls, so we now
respect that as the authoritative type
I also tried to add `def` input/output type inference, but unfortunately
we only know the predecl types universally, which means we won't have
enough information to properly know what the types of the custom
commands are.
# User-Facing Changes
Script typechecking will get tighter in some cases
Hovers should be more accurate in some cases that previously resorted to
any.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- crates/nu-std/tests/run.nu` to run the tests for the
standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
# Description
This adds `match` and basic pattern matching.
An example:
```
match $x {
1..10 => { print "Value is between 1 and 10" }
{ foo: $bar } => { print $"Value has a 'foo' field with value ($bar)" }
[$a, $b] => { print $"Value is a list with two items: ($a) and ($b)" }
_ => { print "Value is none of the above" }
}
```
Like the recent changes to `if` to allow it to be used as an expression,
`match` can also be used as an expression. This allows you to assign the
result to a variable, eg) `let xyz = match ...`
I've also included a short-hand pattern for matching records, as I think
it might help when doing a lot of record patterns: `{$foo}` which is
equivalent to `{foo: $foo}`.
There are still missing components, so consider this the first step in
full pattern matching support. Currently missing:
* Patterns for strings
* Or-patterns (like the `|` in Rust)
* Patterns for tables (unclear how we want to match a table, so it'll
need some design)
* Patterns for binary values
* And much more
# User-Facing Changes
[see above]
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
The "CREATE TABLE" statement in `into sqlite` does not add quotes to the
column names, reproduction steps are below:
```
/home/xxx〉[[name,y/n];[a,y]] | into sqlite test.db
Error:
× Failed to prepare SQLite statement
╭─[entry #1:1:1]
1 │ [[name,y/n];[a,y]] | into sqlite test.db
· ───┬───
· ╰── near "/": syntax error in CREATE TABLE IF NOT EXISTS main (name TEXT,y/n TEXT) at offset 44
╰────
```
# User-Facing Changes
None
---------
Co-authored-by: Reilly Wood <reilly.wood@icloud.com>
# Description
Our `ShellError` at the moment has a `std::mem::size_of<ShellError>` of
136 bytes (on AMD64). As a result `Value` directly storing the struct
also required 136 bytes (thanks to alignment requirements).
This change stores the `Value::Error` `ShellError` on the heap.
Pro:
- Value now needs just 80 bytes
- Should be 1 cacheline less (still at least 2 cachelines)
Con:
- More small heap allocations when dealing with `Value::Error`
- More heap fragmentation
- Potential for additional required memcopies
# Further code changes
Includes a small refactor of `try` due to a type mismatch in its large
match.
# User-Facing Changes
None for regular users.
Plugin authors may have to update their matches on `Value` if they use
`nu-protocol`
Needs benchmarking to see if there is a benefit in real world workloads.
**Update** small improvements in runtime for workloads with high volume
of values. Significant reduction in maximum resident set size, when many
values are held in memory.
# Tests + Formatting
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
Feel free to add review comments if you spot inconsistent use of
`ShellError` variants.
- Name fields on `ShellError::OperatorOverflow`
- Name fields on `ShellError::PipelineMismatch`
- Add doc to `ShellError::OnlySupportsThisInputType`
- Name `ShellError::OnlySupportsThisInputType`
- Name field on `ShellError::PipelineEmpty`
- Comment about issues with `TypeMismatch*`
- Fix a few `exp_input_type`s
- Name fields on `ShellError::InvalidRange`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
Working on uniformizing the ending messages regarding methods usage()
and extra_usage(). This is related to the issue
https://github.com/nushell/nushell/issues/5066 after discussing it with
@jntrnr
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
This is an attempt to implement a new `Value::LazyRecord` variant for
performance reasons.
`LazyRecord` is like a regular `Record`, but it's possible to access
individual columns without evaluating other columns. I've implemented
`LazyRecord` for the special `$nu` variable; accessing `$nu` is
relatively slow because of all the information in `scope`, and [`$nu`
accounts for about 2/3 of Nu's startup time on
Linux](https://github.com/nushell/nushell/issues/6677#issuecomment-1364618122).
### Benchmarks
I ran some benchmarks on my desktop (Linux, 12900K) and the results are
very pleasing.
Nu's time to start up and run a command (`cargo build --release;
hyperfine 'target/release/nu -c "echo \"Hello, world!\""' --shell=none
--warmup 10`) goes from **8.8ms to 3.2ms, about 2.8x faster**.
Tests are also much faster! Running `cargo nextest` (with our very slow
`proptest` tests disabled) goes from **7.2s to 4.4s (1.6x faster)**,
because most tests involve launching a new instance of Nu.
### Design (updated)
I've added a new `LazyRecord` trait and added a `Value` variant wrapping
those trait objects, much like `CustomValue`. `LazyRecord`
implementations must implement these 2 functions:
```rust
// All column names
fn column_names(&self) -> Vec<&'static str>;
// Get 1 specific column value
fn get_column_value(&self, column: &str) -> Result<Value, ShellError>;
```
### Serializability
`Value` variants must implement `Serializable` and `Deserializable`, which poses some problems because I want to use unserializable things like `EngineState` in `LazyRecord`s. To work around this, I basically lie to the type system:
1. Add `#[typetag::serde(tag = "type")]` to `LazyRecord` to make it serializable
2. Any unserializable fields in `LazyRecord` implementations get marked with `#[serde(skip)]`
3. At the point where a `LazyRecord` normally would get serialized and sent to a plugin, I instead collect it into a regular `Value::Record` (which can be serialized)
# Description
* I was dismayed to discover recently that UnsupportedInput and
TypeMismatch are used *extremely* inconsistently across the codebase.
UnsupportedInput is sometimes used for input type-checks (as per the
name!!), but *also* used for argument type-checks. TypeMismatch is also
used for both.
I thus devised the following standard: input type-checking *only* uses
UnsupportedInput, and argument type-checking *only* uses TypeMismatch.
Moreover, to differentiate them, UnsupportedInput now has *two* error
arrows (spans), one pointing at the command and the other at the input
origin, while TypeMismatch only has the one (because the command should
always be nearby)
* In order to apply that standard, a very large number of
UnsupportedInput uses were changed so that the input's span could be
retrieved and delivered to it.
* Additionally, I noticed many places where **errors are not propagated
correctly**: there are lots of `match` sites which take a Value::Error,
then throw it away and replace it with a new Value::Error with
less/misleading information (such as reporting the error as an
"incorrect type"). I believe that the earliest errors are the most
important, and should always be propagated where possible.
* Also, to standardise one broad subset of UnsupportedInput error
messages, who all used slightly different wordings of "expected
`<type>`, got `<type>`", I created OnlySupportsThisInputType as a
variant of it.
* Finally, a bunch of error sites that had "repeated spans" - i.e. where
an error expected two spans, but `call.head` was given for both - were
fixed to use different spans.
# Example
BEFORE
```
〉20b | str starts-with 'a'
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #31:1:1]
1 │ 20b | str starts-with 'a'
· ┬
· ╰── Input's type is filesize. This command only works with strings.
╰────
〉'a' | math cos
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #33:1:1]
1 │ 'a' | math cos
· ─┬─
· ╰── Only numerical values are supported, input type: String
╰────
〉0x[12] | encode utf8
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #38:1:1]
1 │ 0x[12] | encode utf8
· ───┬──
· ╰── non-string input
╰────
```
AFTER
```
〉20b | str starts-with 'a'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ 20b | str starts-with 'a'
· ┬ ───────┬───────
· │ ╰── only string input data is supported
· ╰── input type: filesize
╰────
〉'a' | math cos
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #2:1:1]
1 │ 'a' | math cos
· ─┬─ ────┬───
· │ ╰── only numeric input data is supported
· ╰── input type: string
╰────
〉0x[12] | encode utf8
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #3:1:1]
1 │ 0x[12] | encode utf8
· ───┬── ───┬──
· │ ╰── only string input data is supported
· ╰── input type: binary
╰────
```
# User-Facing Changes
Various error messages suddenly make more sense (i.e. have two arrows
instead of one).
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This PR changes the `schema` command for viewing the schema of a SQLite
database file. It removes 1 level of nesting (intended to handle
multiple databases in the same connection) that I believe is
unnecessary.
### Before
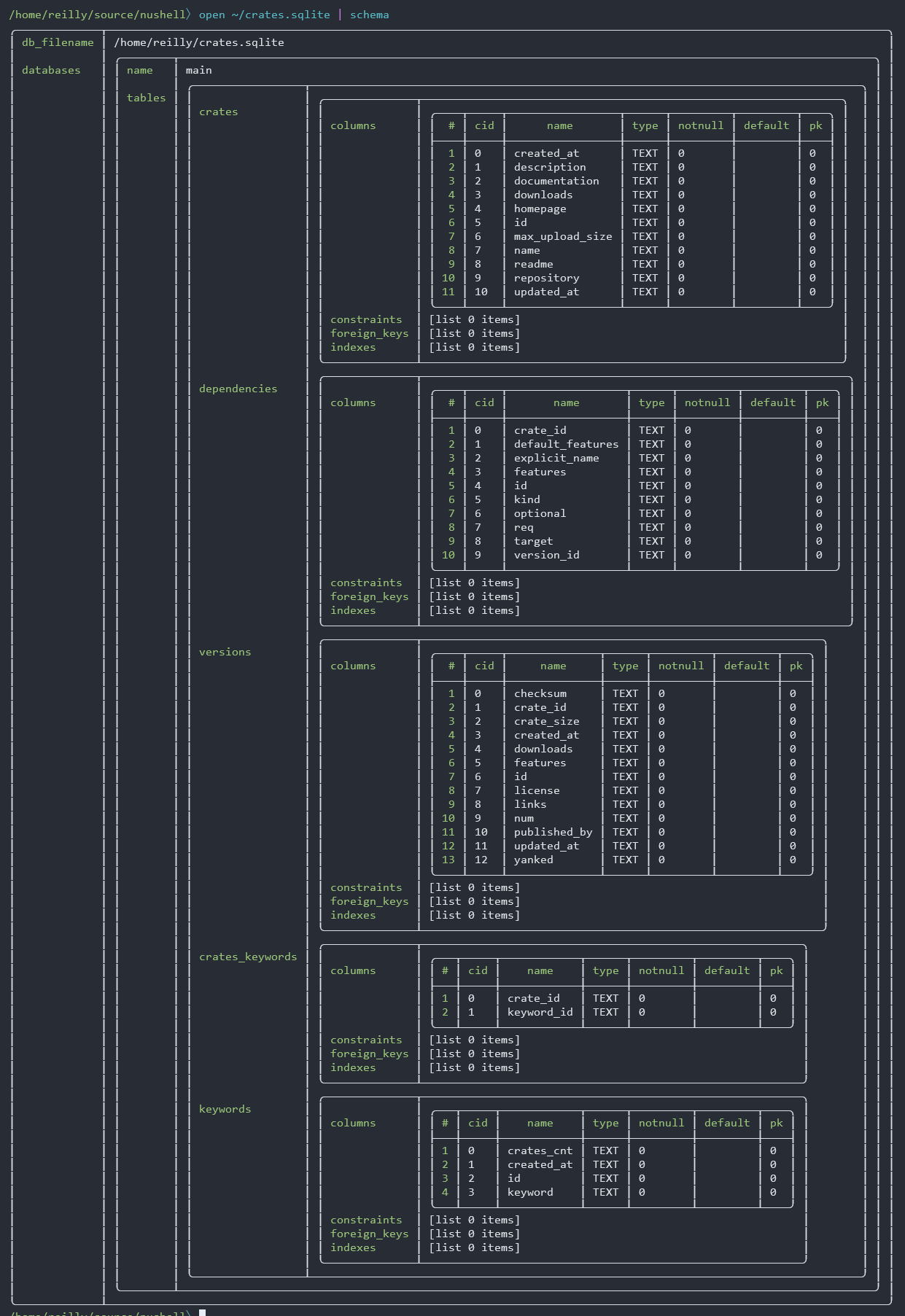
### After

## Rationale
A SQLite database connection can technically be associated with multiple
non-temporary databases using [the ATTACH DATABASE
command](https://www.sqlite.org/lang_attach.html). But it's not possible
to do that _in the context of Nushell_, and so I believe that there is
no benefit to displaying the schema as if there could be multiple
databases.
I initially raised this concern back in April, but we decided to keep
the database nesting because at the time we were still looking into more
generalized database functionality (i.e. not just SQLite). I believe
that rationale no longer applies.
Also, the existing code would not have worked correctly even if a
connection had multiple databases; for every database, it was looking up
tables without filtering them by database:
6295b20545/crates/nu-command/src/database/values/sqlite.rs (L104-L118)
## Future Work
I'd like to add information on views+triggers to the `schema` output.
I'm also working on making it possible to `ctrl+c` reading from a
database (which is turning into a massive yak shave).
# Description
rust 1.65.0 has been released for a while, this pr applies lint
suggestions from rust 1.65.0.
# User-Facing Changes
N/A
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Allows use of slightly optimized variants that check if they have to use
the heavier vte parser. Tries to avoid unnnecessary allocations. Initial
performance characteristics proven out in #4378.
Also reduces boilerplate with right-ward drift.
* Test commands for proper names and search terms
Assert that the `Command.name()` is equal to `Signature.name`
Check that search terms are not just substrings of the command name as
they would not help finding the command.
* Clean up search terms
Remove redundant terms that just replicate the command name.
Try to eliminate substring between search terms, clean up where
necessary.
{kind=link}
{kind=link}