# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
This is an attempt to implement a new `Value::LazyRecord` variant for
performance reasons.
`LazyRecord` is like a regular `Record`, but it's possible to access
individual columns without evaluating other columns. I've implemented
`LazyRecord` for the special `$nu` variable; accessing `$nu` is
relatively slow because of all the information in `scope`, and [`$nu`
accounts for about 2/3 of Nu's startup time on
Linux](https://github.com/nushell/nushell/issues/6677#issuecomment-1364618122).
### Benchmarks
I ran some benchmarks on my desktop (Linux, 12900K) and the results are
very pleasing.
Nu's time to start up and run a command (`cargo build --release;
hyperfine 'target/release/nu -c "echo \"Hello, world!\""' --shell=none
--warmup 10`) goes from **8.8ms to 3.2ms, about 2.8x faster**.
Tests are also much faster! Running `cargo nextest` (with our very slow
`proptest` tests disabled) goes from **7.2s to 4.4s (1.6x faster)**,
because most tests involve launching a new instance of Nu.
### Design (updated)
I've added a new `LazyRecord` trait and added a `Value` variant wrapping
those trait objects, much like `CustomValue`. `LazyRecord`
implementations must implement these 2 functions:
```rust
// All column names
fn column_names(&self) -> Vec<&'static str>;
// Get 1 specific column value
fn get_column_value(&self, column: &str) -> Result<Value, ShellError>;
```
### Serializability
`Value` variants must implement `Serializable` and `Deserializable`, which poses some problems because I want to use unserializable things like `EngineState` in `LazyRecord`s. To work around this, I basically lie to the type system:
1. Add `#[typetag::serde(tag = "type")]` to `LazyRecord` to make it serializable
2. Any unserializable fields in `LazyRecord` implementations get marked with `#[serde(skip)]`
3. At the point where a `LazyRecord` normally would get serialized and sent to a plugin, I instead collect it into a regular `Value::Record` (which can be serialized)
# Description
* I was dismayed to discover recently that UnsupportedInput and
TypeMismatch are used *extremely* inconsistently across the codebase.
UnsupportedInput is sometimes used for input type-checks (as per the
name!!), but *also* used for argument type-checks. TypeMismatch is also
used for both.
I thus devised the following standard: input type-checking *only* uses
UnsupportedInput, and argument type-checking *only* uses TypeMismatch.
Moreover, to differentiate them, UnsupportedInput now has *two* error
arrows (spans), one pointing at the command and the other at the input
origin, while TypeMismatch only has the one (because the command should
always be nearby)
* In order to apply that standard, a very large number of
UnsupportedInput uses were changed so that the input's span could be
retrieved and delivered to it.
* Additionally, I noticed many places where **errors are not propagated
correctly**: there are lots of `match` sites which take a Value::Error,
then throw it away and replace it with a new Value::Error with
less/misleading information (such as reporting the error as an
"incorrect type"). I believe that the earliest errors are the most
important, and should always be propagated where possible.
* Also, to standardise one broad subset of UnsupportedInput error
messages, who all used slightly different wordings of "expected
`<type>`, got `<type>`", I created OnlySupportsThisInputType as a
variant of it.
* Finally, a bunch of error sites that had "repeated spans" - i.e. where
an error expected two spans, but `call.head` was given for both - were
fixed to use different spans.
# Example
BEFORE
```
〉20b | str starts-with 'a'
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #31:1:1]
1 │ 20b | str starts-with 'a'
· ┬
· ╰── Input's type is filesize. This command only works with strings.
╰────
〉'a' | math cos
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #33:1:1]
1 │ 'a' | math cos
· ─┬─
· ╰── Only numerical values are supported, input type: String
╰────
〉0x[12] | encode utf8
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #38:1:1]
1 │ 0x[12] | encode utf8
· ───┬──
· ╰── non-string input
╰────
```
AFTER
```
〉20b | str starts-with 'a'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ 20b | str starts-with 'a'
· ┬ ───────┬───────
· │ ╰── only string input data is supported
· ╰── input type: filesize
╰────
〉'a' | math cos
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #2:1:1]
1 │ 'a' | math cos
· ─┬─ ────┬───
· │ ╰── only numeric input data is supported
· ╰── input type: string
╰────
〉0x[12] | encode utf8
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #3:1:1]
1 │ 0x[12] | encode utf8
· ───┬── ───┬──
· │ ╰── only string input data is supported
· ╰── input type: binary
╰────
```
# User-Facing Changes
Various error messages suddenly make more sense (i.e. have two arrows
instead of one).
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This PR changes the `schema` command for viewing the schema of a SQLite
database file. It removes 1 level of nesting (intended to handle
multiple databases in the same connection) that I believe is
unnecessary.
### Before
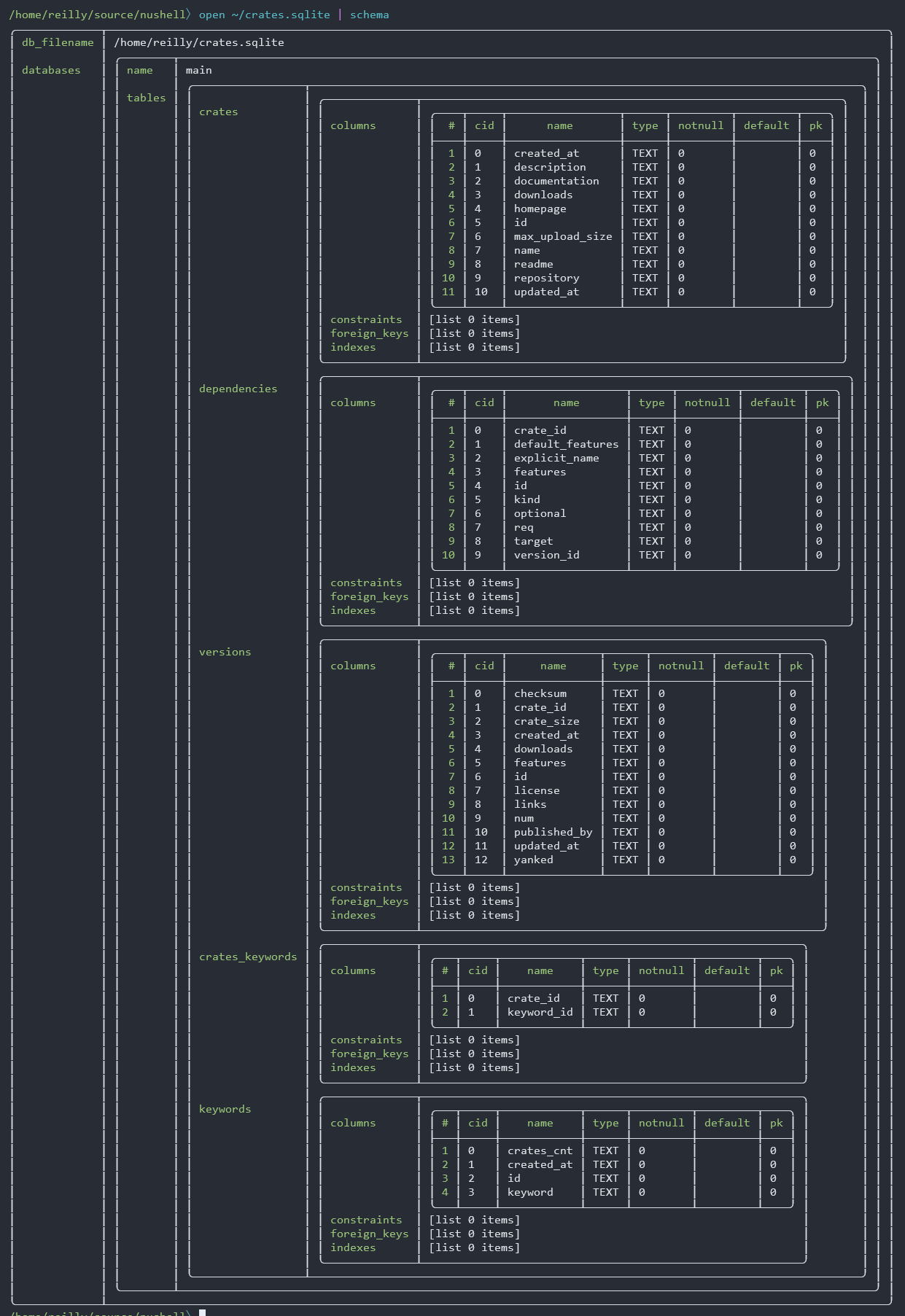
### After

## Rationale
A SQLite database connection can technically be associated with multiple
non-temporary databases using [the ATTACH DATABASE
command](https://www.sqlite.org/lang_attach.html). But it's not possible
to do that _in the context of Nushell_, and so I believe that there is
no benefit to displaying the schema as if there could be multiple
databases.
I initially raised this concern back in April, but we decided to keep
the database nesting because at the time we were still looking into more
generalized database functionality (i.e. not just SQLite). I believe
that rationale no longer applies.
Also, the existing code would not have worked correctly even if a
connection had multiple databases; for every database, it was looking up
tables without filtering them by database:
6295b20545/crates/nu-command/src/database/values/sqlite.rs (L104-L118)
## Future Work
I'd like to add information on views+triggers to the `schema` output.
I'm also working on making it possible to `ctrl+c` reading from a
database (which is turning into a massive yak shave).
# Description
rust 1.65.0 has been released for a while, this pr applies lint
suggestions from rust 1.65.0.
# User-Facing Changes
N/A
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Allows use of slightly optimized variants that check if they have to use
the heavier vte parser. Tries to avoid unnnecessary allocations. Initial
performance characteristics proven out in #4378.
Also reduces boilerplate with right-ward drift.
* Test commands for proper names and search terms
Assert that the `Command.name()` is equal to `Signature.name`
Check that search terms are not just substrings of the command name as
they would not help finding the command.
* Clean up search terms
Remove redundant terms that just replicate the command name.
Try to eliminate substring between search terms, clean up where
necessary.
* dabase access commands
* select expression
* select using expressions
* cargo fmt
* alias for database
* database where command
* expression operations
* and and or operators
* limit and sort by commands
* database commands
* db commands
* filesystem opens sqlite file
* clippy error
* corrected error in ci file
* removes matrix flag from ci
* flax matrix for clippy
* add conditional compile for tests
* add conditional compile for tests
* correct order of command
* correct error msg
* correct typo
{kind=link}
{kind=link}